
Технология клиент- сервер
Содержание:

ВВЕДЕНИЕ
Известно, что основой современного общества являются информационные технологии.
Информация, циркулирующая в обществе, по праву считается ценнейшим ресурсом.
Для обработки больших объемов данных люди уже давно используют компьютеры с различными приложениями, установленными на них. При этом, чем больший объем данных необходимо обработать, тем большее количество ресурсов на это будет затрачено.
Технология клиент-сервер позволила людям ускорить процесс обработки данных за счет использования более мощного вычислителя – сервера. Благодаря этому даже слабые компьютеры могли быстро получить результат обработки данных путем подключения к серверу.
Все вышесказанное объясняет актуальность рассматриваемой темы.
Цель данной работы – изучить технологию клиент-сервер.
Для достижения поставленной цели необходимо решить ряд задач:
- изучить литературу по заданной теме;
- изучить историю возникновения технологии;
- описать идею технологии;
- рассмотреть возможные варианты архитектуры;
- изучить развитие технологии.
Структурно работа состоит из трех глав. В первой приводится общее описание технологии, во второй рассматриваются варианты архитектуры клиент-сервер, третья глава посвящена развитию технологии.
1. Основные понятия
1.1. История
Архитектура информационной системы (ИС) представляет собой концепцию, характеризующую модель, структуру, выполняемые функции и взаимосвязь элементов ИС.
Клиент-сервер (Client-server) – это вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределяются между поставщиками услуг (сервисов), называемых серверами, и заказчиками услуг - клиентами.
Сервер представляет собой программу, которая предоставляет какие-либо услуги другим программам, а также обслуживает клиентские запросы на получение ресурсов определенного типа.
Клиентом называется программа, которая использует услуги сервера [2].
Чаще всего под терминами «клиент» и «сервер» люди понимают компьютер, на котором функционирует какая-либо из этих программ. В действительности, клиент и сервер — это всего лишь роли, исполняемые программами.
С физической точки зрения клиенты и серверы могут размещаться на одном компьютере. Более того, даже одна и та же программа одновременно может играть роль и клиента, и сервера.
Известно, что основными недостатками персонального компьютера являются его достаточно невысокая вычислительная мощность и надежность, а также необходимость приобретения дополнительных аппаратных средств с целью устранения изолированности отдельных персональных компьютеров друг от друга.
В большинстве случаев пользователям компьютеров требуется высокая вычислительная мощность, поэтому там, где для выполнения сложных вычислений используются мощные изолированные центральные компьютеры с терминалами, их пользователям периодически приходится ходить на персональные компьютеры для редактирования текстов или выполнения задач, использующих электронные таблицы. Данный факт заставляет пользователей освоить две различные операционные системы (на больших машинах обычно установлены OC MVS, VMS, VM, UNIX, а на персональных - MS DOS/MS Windows, OS/2 или Mac) и не решает задачи совместного использования данных.
В результате опроса представителей трехсот крупнейших компаний США, использующих персональные компьютеры, выяснилось, что для 81% опрошенных необходим доступ к данным более чем одного компьютера.
Для решения этой задачи персональные компьютеры стали объединять в локальные сети и устанавливать на них специальные операционные системы, например, NetWare. Данная ОС реализует операции совместного использования компьютерами сети файлов, размещенных в различных узлах. Подобная технология получила название «файл-сервер».
Однако файл-серверы обладают рядом недостатков. Так, например, данная архитектура не позволяет в полной мере обеспечить целостность и конфиденциальность данных. В рамках сети файлы передаются целиком, независимо от того, какая часть содержащихся в них данных действительно необходима пользователю. Такой подход серьезно загружает сеть и оказывает негативное влияние на быстродействие системы. Также невысока и надежность этих систем – сбой, произошедший на одной из рабочих станций в момент записи файла, является причиной утраты или искажения данных.
Для обеспечения непротиворечивости данных в подобных системах необходимо блокировать файлы, что также сказывается на скорости работы. Естественное желание специалистов в области информатики и вычислительной техники - объединить преимущества персональных компьютеров и мощных центральных компьютеров.
Первым шагом в этом направлении стало использование персональных компьютеров в качестве интеллектуальных терминалов. В этом случае в персональном компьютере, соединенным с центральным компьютером, запускается специальное программное обеспечение, которое позволяет ему работать в режиме эмуляции терминала. Так получается архитектура, реализующая все преимущества архитектуры с мощным центральным компьютером, но, за исключением того, что персональный компьютер может использоваться самостоятельно. При этом пропадает необходимость двух дисплеев, однако большинство недостатков, присущих архитектуре с центральным компьютером, все еще сохраняется. Кроме того, даже персональные компьютеры, имеющие дисплеи с картой VGA, и предоставляющие возможность работы с графикой, не могут использоваться в качестве графических терминалов большой центральной машины. Эта задача реализуется непосредственно центральным компьютером, в результате чего графические образы экрана передаются по проводам. Стоит отметить, что эти образы достаточно велики и скорость смены изображений на экране может быть очень низкой.
Следующим шагом в решении проблемы, описанной выше, стало использование клиент-серверной архитектуры. При таком подходе все компьютеры сети делятся на две группы: клиенты и серверы.
Компьютер-сервер представляет собой мощный компьютер с большим объемом оперативной памяти и жесткого диска. На нем хранится база данных, а также реализуется сложная обработка, требующая больших вычислительных ресурсов. Клиентские компьютеры выполняют первичную обработку данных при вводе, форматирование данных, а также окончательную обработку данных, полученных от сервера. В качестве клиентских компьютеров чаще всего используются персональные компьютеры типа IBM PC или Macintosh.
Достоинства описанного подхода очевидны. Каждый тип компьютера используется строго по своему назначению, за счет чего достигается более полное использование возможностей компьютеров.
На клиентских компьютерах функционируют знакомые пользователям PC пакеты, которые позволяют предоставлять результаты работы всей системы в виде, удобном для понимания и анализа. На этих компьютерах можно легко реализовать интуитивно понятный пользовательский интерфейс приложения при помощи графики, цвета, звука, работы с окнами и мышью и т.д. Компьютер-клиент способен быстро выполнять ввод и первичный контроль данных. Для финальной обработки данных могут использоваться те редакторы или пакеты электронных таблиц, которые наиболее удобны пользователю. В качестве клиентских компьютеров могут одновременно применяться компьютеры разных типов с различными операционными системами.
Стоит отметить, что клиент-серверная архитектура также способна реализовать распределенную обработку, поскольку часть работы (интерфейс с пользователем, финальная обработка) выполняется на компьютере-клиенте, а часть - на компьютере-сервере. Подобный подход позволяет сократить загрузку сервера и оптимизировать его работу, а также увеличить число клиентов, одновременно работающих с сервером.
Наиболее часто клиент-серверная архитектура используется для приложений, созданных с применением систем управления базами данных (СУБД) [5].
1.2. Архитектура
В настоящее время проблема выбора между распределенной и централизованной моделями предоставления вычислительных ресурсов считается одной из ключевых проблем организации вычислительных систем в целом.
В качестве подтверждения данного факта можно рассмотреть статью Джона Лесли Кинга «Централизованные и децентрализованные вычислительные системы: организационные соображения и варианты управления» 1983 г. До середины 70-х годов XX века по причине высокой стоимости телекоммуникационного оборудования и относительно невысокой мощности вычислительных систем преобладала централизованная модель. В конце 70-х годов в результате возникновения клиент-серверной архитектуры, обеспечивающей предоставление ресурсов мейнфреймов конечным пользователям посредством удаленного соединения, появились системы разделения времени и удаленных терминалов. Дальнейшее развитие телекоммуникационных систем и появление персональных компьютеров послужило развитием клиент-серверной парадигмы обработки данных.
Клиент-серверная архитектура предполагает ситуацию, при которой один или несколько клиентов и один или несколько серверов совместно с базовой операционной системой и средой взаимодействия образуют единую систему, реализующую распределенные вычисления, а также анализ и представление данных. Использование этого подхода позволяет конечному пользователю персонального компьютера получить доступ к различным ресурсам удаленных серверов, например, файлам, принтерам, базам данных, процессорному времени и т.п.
В базовой модели клиент-сервер все процессы в распределенных системах делятся на две пересекающиеся группы:
- процессы, реализующие некоторую службу, например, службу файловой системы или базы данных. Эти процессы принято называть серверами;
- процессы, запрашивающие службы у серверов посредством посылки запроса и последующего ожидания ответа от сервера - клиенты.
Взаимодействие между клиентом и сервером предполагает режим работы запрос-ответ, представленный на рисунке 1.
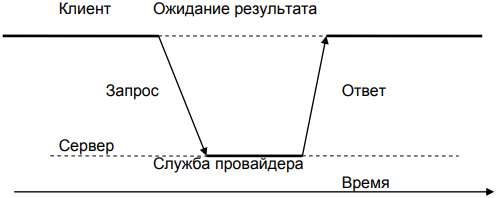
Рисунок 1 - Обобщенное взаимодействие между клиентом и сервером
Если базовая сеть так же надежна, как локальные сети, то взаимодействие между клиентом и сервером может быть реализовано без дополнительной установки соединения. В этом случае клиент, запрашивая службу, формирует запрос в виде сообщения, указав в нем службы, которыми он желает воспользоваться, а также данные, необходимые для этого. Сформированное сообщение отправляется на сервер, который, в свою очередь, находится в постоянном ожидании входящих сообщений. Получив сообщение, сервер его обрабатывает, а результат обработки упаковывает в ответное сообщение и отправляет клиенту.
Использование протокола, не требующего соединения, дает существенный выигрыш в плане эффективности. Такой подход может успешно использоваться до тех пор, пока сообщения не начнут повреждаться или пропадать. Однако, создать протокол, устойчивый к случайным сбоям связи, практически невозможно. Самым простым решением этой проблемы является предоставление клиенту возможности повторного отправления запроса, на который он не получил ответ.
Однако, при этом возникает еще одна проблема - клиент не способен самостоятельно понять, действительно ли первоначальное сообщение с запросом было потеряно или ошибка произошла уже в процессе передачи ответа. В том случае, когда потерялся ответ, повторная посылка запроса может привести к повторному выполнению операции. Если операция представляла собой что-то важное, например, «снять тысячу рублей с моего банковского счета», понятно, что было бы гораздо лучше, если бы вместо повторного выполнения операции клиент получал уведомление о случившейся ошибке. С другой стороны, если операция была «сообщите мне, сколько денег у меня осталось», запрос можно было бы послать повторно. Нетрудно заметить, что однозначного решения у этой проблемы нет.
В качестве альтернативы во многих системах клиент-сервер используется надежный протокол с установкой соединения. Хотя данное решение по причине его относительно низкой производительности не слишком хорошо подходит для локальных сетей, оно прекрасно зарекомендовало себя в глобальных системах, где ненадежность является «врожденным» свойством соединений. Так, практически все прикладные протоколы сети Интернет основаны на надежных соединениях по протоколу TCP/IP. В этих случаях всякий раз, когда клиент запрашивает службу, он сперва должен установить соединение с сервером. Сервер обычно использует для посылки ответного сообщения то же самое соединение, после чего оно разрывается. В данном случае основной проблемой является то, что установка и разрыв соединения в смысле затрачиваемого времени и ресурсов относительно дороги, особенно если сообщения с запросом и ответом невелики [7].
1.3. Разделение приложений по уровням
Модель клиент-сервер изначально была предметом множества споров. Один из главных вопросов заключался в том, как именно делить клиенты и серверы. Рассматривая множество приложений типа клиент-сервер, предназначенных для организации доступа пользователей к базам данных, многие рекомендовали использовать три уровня:
- уровень пользовательского интерфейса (представления) – включает в себя все необходимое для непосредственного общения с пользователем, например, для управления дисплеем. Обычно данный уровень реализуется на стороне клиента. К нему относятся программы, посредством которых пользователь может взаимодействовать с приложением. Сложность программ, входящих в пользовательский интерфейс, весьма различна. Простейший вариант программы пользовательского интерфейса представляет собой символьный дисплей. Чаще всего такие интерфейсы используются при работе с мэйнфреймами. В том случае, когда мэйнфрейм контролирует все взаимодействия (в том числе работу с клавиатурой и монитором), нельзя говорить о модели клиент-сервер. Однако в большинстве случаев пользовательские терминалы реализуют некоторую локальную обработку, осуществляя, например, эхо-печать вводимых строк или предоставляя интерфейс форм, где можно редактировать введенные данные до их пересылки на главный компьютер. Стоит отметить, что современные пользовательские интерфейсы гораздо более функциональны;
- уровень обработки (бизнес-логики) - содержит непосредственно приложения. Под бизнес-логикой здесь понимается совокупность принципов, правил и зависимостей поведения объектов предметной области системы. В качестве синонима данного понятия может использоваться термин «логика предметной области» (Domain Logic). Бизнес-логика является реализацией предметной области (например, бухгалтерского учета, методов управления предприятием и т.п.) в пределах информационной системы. Сюда относятся, например, формулы расчета ежемесячных выплат по ссудам (в финансовой индустрии), автоматизированная отправка сообщений электронной почты руководителю проекта по окончании выполнения частей задания всеми подчиненными (в системах управления проектами), отказ от отеля при отмене рейса авиакомпанией (в туристическом бизнесе) и т. д.
- уровень данных - данные, с которыми происходит работа. Уровень данных включает в себя программы, отвечающие за предоставление данных обрабатывающим их приложениям. Отличительной чертой этого уровня является требование сохранности. Оно говорит о том, что когда приложение не работает, данные по-прежнему должны сохраняться в определенном месте с расчетом на дальнейшее использование. В простейшем варианте уровень данных реализуется файловой системой, но чаще всего для его реализации используется база данных. В модели клиент-сервер уровень данных обычно находится на стороне сервера. Кроме простого хранения информации также данный уровень отвечает за поддержание целостности данных для различных приложений. Для базы данных поддержание целостности говорит о том, что метаданные, например, описания таблиц, ограничения и специфические метаданные приложений, также должны храниться на этом уровне. Обычно в деловой среде уровень данных представляет собой реляционную базу данных. Ключевым моментом здесь является независимость данных. Данные организуются независимо от приложений таким образом, чтобы изменения в их организации никак не влияли на приложения, а приложения не влияли на организацию данных. Использование реляционных баз данных в модели клиент-сервер помогает отделить уровень обработки от уровня данных, рассматривая обработку и данные независимо друг от друга. Стоит отметить, что существует широкий класс приложений, для которых реляционные базы данных не являются лучшим решением. Характерной чертой этих приложений является работа со сложными типами данных, которые проще моделировать в понятиях объектов, а не отношений. Примеры таких типов данных – от простых наборов прямоугольников и окружностей до проекта самолета в случае систем автоматизированного проектирования. Также и мультимедийным системам гораздо проще работать с видео- и аудиопотоками, используя специфичные для них операции, чем с моделями этих потоков в виде реляционных таблиц. В тех случаях, когда операции с данными гораздо проще выразить в понятиях работы с объектами, имеет смысл реализовать уровень данных средствами объектно-ориентированных баз данных. Подобные базы данных не только поддерживают организацию сложных данных в форме объектов, но и хранят реализации операций над этими объектами. Таким образом, часть функциональности, приходившейся на уровень обработки, в этом случае переносится на уровень данных [10].
2. Архитектура клиент-сервер
2.1. Двухуровневая
Первый вариант клиент-серверной архитектуры принято называть одноуровневой (однозвенной) архитектурой. В этом случае клиент отвечает исключительно за отображение информации, предоставляемой со стороны сервера. В качестве примера такой архитектуры можно назвать терминальный доступ к удаленному серверу или удаленный рабочий стол. При этом весь объем вычислительной нагрузки приходится на сервер.
Следующий шаг в развитии клиент-серверной архитектуры - появление двухуровневой архитектуры, представленной на рисунке 2.
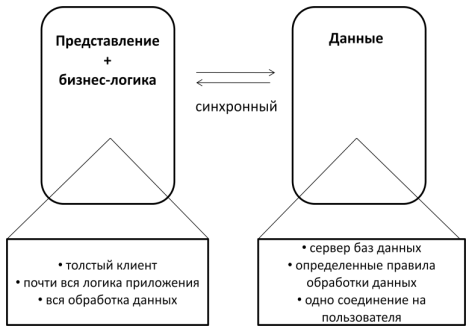
Рисунок 2 - Двухуровневая клиент-серверная архитектура
Особенностью этого подхода стало использование «толстых» клиентов, отвечающих за реализацию основных задач по отображению информации пользователю и обработке всех данных. Центральный сервер при этом выполнял лишь функции хранения и предоставления данных.
Подобный подход считался наиболее удобным решением для корпоративных распределенных вычислительных систем вплоть до начала 2000-х годов.
Однако в силу того, что большинство логики клиент-серверного приложения располагается в клиентской части, клиентская рабочая станция отвечает за большую часть обработки. Для оценки разделения объемов работ часто используется соотношение 80/20: на сервер базы данных приходится порядка двадцати процентов всей работы. Несмотря на это, база данных зачастую является узким местом производительности в таких средах.
Двухуровневая клиент-серверная система требует, чтобы каждый клиент устанавливал собственные соединения с базой данных. Постоянная поддержка подобного множества соединений является очень дорогой. Кроме того, необходимость ресурсов иногда может являться причиной перегрузки сервера баз данных и задержки обработки запросов пользователей.
Одной из ключевых причин отказа от двухуровнего подхода стал постоянный рост расходов, связанных с поддержкой логики работы приложения на пользовательских рабочих станциях. Поскольку код приложения реализуется каждым клиентом, каждое обновление приложения требует переустановки клиентского программного обеспечения на всех рабочих станциях, что является серьезной проблемой администрирования в больших сетях.
Кроме того, возникает ряд вопросов по поддержанию работоспособности клиентских частей, поскольку рабочие станции могут иметь различный набор установленного ПО или, возможно, были приобретены у различных поставщиков оборудования. Отдельно стоит отметить, что при расширении возможностей клиентской программы, устаревший парк пользовательских рабочих станций может стать препятствием для обновления до новой версии системы [1].
2.2. Трехуровневая
Кроме описанного ранее варианта разделения двухуровневой архитектуры, также существует множество других подходов распределения программ, находящихся на уровне приложений по различным машинам, как это представлено на рисунке 3 [4].
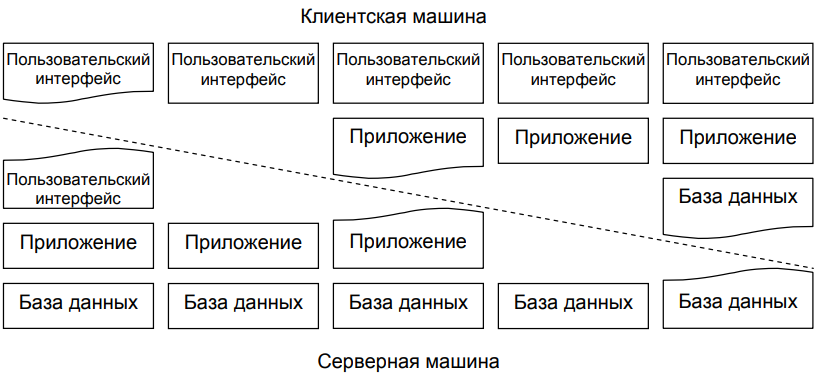
Рисунок 3 - Альтернативные формы организации двухуровневой архитектуры клиент-сервер
В ответ на ограничения и затраты, вызванные двухуровневой архитектурой, была сформулирована концепция компонентно-ориентированной разработки приложений.
Многоуровневая клиент-серверная архитектура обеспечила переход к объектно-ориентированному подходу в рамках задачи построения распределенных вычислительных систем.
Применение такого подхода позволило распределить уровень бизнес-логики среди нескольких компонентов (часть – на клиенте, часть – на сервере) и сократить количество проблем, возникающих при развертывании системы за счет централизации большего количества логики на серверах. Серверные компоненты, перешедшие на выделенные сервера приложений, обеспечили возможность управления пулами соединений с базой данных. За счет этого сократилось число одновременных соединений к базе, так как одно соединение в таком случае способно обеспечить работу нескольким клиентам (см. рисунок 4).
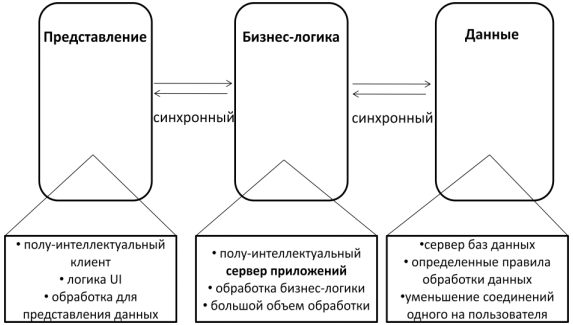
Рисунок 4 - Обобщенная организация трехуровневой архитектуры
В качестве примера описывается поисковая машина в Интернете, представленная на рисунке 5.
Пользовательский интерфейс поисковой машины очень прост: пользователь вводит строку, представляющую собой набор ключевых слов, а в ответ получает список заголовков web-страниц. Результат формируется из огромной базы проиндексированных web-страниц. Ядром поисковой машины является программа, трансформирующая введенную пользователем строку в один или несколько запросов к базе данных. После этого она помещает результаты запроса в список, преобразуя его в набор HTML-страниц. В рамках модели клиент-сервер часть, отвечающая за выборку информации, обычно располагается на уровне обработки [3].
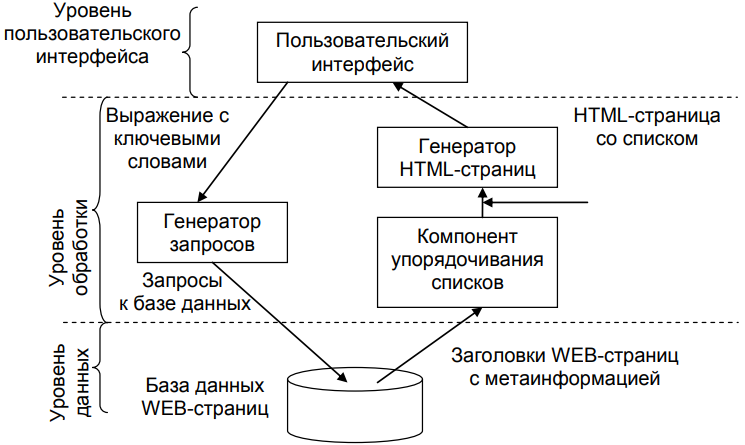
Рисунок 5 - Обобщенная организация трехуровневой поисковой машины для Интернета
2.3. Многоуровневая
Многоуровневые архитектуры являются непосредственным продолжением разделения приложений на уровни пользовательского интерфейса, компонентов обработки и данных.
Различные звенья взаимодействуют в соответствии с логической организацией приложения. В большинстве бизнес-приложений распределенная обработка аналогична организации многоуровневой архитектуры. Такой тип распределения также принято называть вертикальным распределением. Характерной чертой вертикального распределения является то, что оно достигается благодаря размещению логически различных компонентов на разных машинах. Данное понятие принято связывать с концепцией вертикального разбиения, используемой в распределенных реляционных базах данных, где под этим термином понимается разбиение таблиц по столбцам для их последующего хранения на различных машинах.
Однако вертикальное распределение – это лишь один из возможных способов организации приложений клиент-сервер. В современных архитектурах распределение на клиенты и серверы происходит способом, известным как горизонтальное распределение. В этом случае клиент или сервер могут содержать физически разделенные части логически однородного модуля, причем работа с каждой из частей может происходить независимо - это сделано для выравнивания загрузки.
В качестве распространенного примера горизонтального распределения рассматривается web-сервер, реплицированный на несколько машин локальной сети (см. рисунок 6).
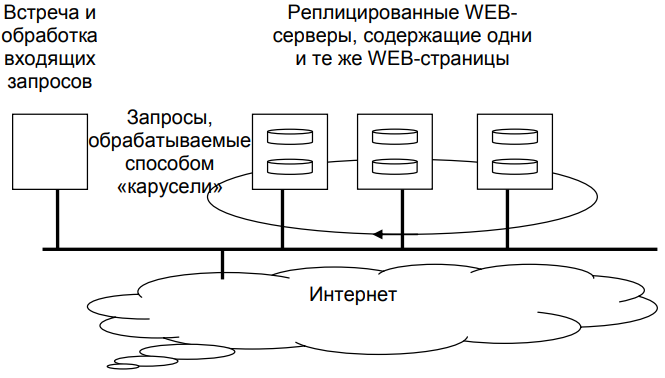
Рисунок 6 - Пример горизонтального распределения WEB-службы
Каждый сервер в этом случае содержит один и тот же набор web-страниц, и всякий раз, когда одна из web-страниц обновляется, ее копии незамедлительно рассылаются на все серверы.
Сервер, которому будет передан входящий запрос, выбирается по правилу «карусели». Эта форма горизонтального распределения достаточно успешно используется для выравнивания нагрузки на серверы популярных web-сайтов.
Таким же образом могут распределяться и клиенты. Для несложного приложения, предназначенного для коллективной работы, можно вообще не использовать сервер - это одноранговое распределение. Подобное происходит, например, если пользователь хочет связаться с другим пользователем. Они оба должны запустить одно и то же приложение для начала сеанса. Третий клиент может общаться с одним из них или с обоими сразу, для чего ему нужно запустить то же самое приложение [9].
3. Развитие технологии
70-е и 80-е годы XX века по традиции принято считать эпохой централизованных вычислений на мэйнфреймах IBM, которые в то время составляли более 70% мирового компьютерного бизнеса.
Бизнес-транзакции, базы данных, запросы и техническое обслуживание - все это реализовывалось посредством мэйнфреймов IBM. Этап перехода к клиент-серверным вычислениям представил совершенно новую концепцию и технологию организации всего делового мира. Эту парадигму называли «волной будущего».
Обычно клиентская машина управляет интерфейсами процессов, таких как графический интерфейс, отправкой запросов на сервер программ, проверкой данных, введенных пользователем, а также управляет местными ресурсами. При этом конечный пользователь только взаимодействует с устройствами - монитором, клавиатурой и т.п. За само выполнение клиентских запросов отвечает сервер.
Задача клиент-серверных вычислений - позволить каждой клиентской станции и серверу быть доступными, по мере необходимости приложения, а так же обеспечивать доступ к существующему программному обеспечению и аппаратным компонентам от различных поставщиков для совместного использования. Если эти два условия выполнены, преимущества клиент-серверной архитектуры очевидны - она позволяет экономить средства, а также увеличивать гибкость и производительность использования ресурсов.
В состав клиент-серверных архитектур входят три компонента:
- клиент - пользовательская станция, реализующая интерфейс приложения, проверку данных и отправку запросов на сервер. Кроме того, клиентский процесс также управляет локальными ресурсами;
- сервер - выполняет служебные запросы клиента. Сервер представляет собой программное обеспечение двигателя, управляющего общими ресурсами, таким как базы данных, принтеры, линии связи, или процессоры высокой мощности. Основная цель серверного процесса - выполнение фоновых задач, общих для приложений. Простейшие формы серверов - это дисковый и файл-сервер. Если клиент передает запросы на файл или группы файлов по сети на файловый сервер, такая форма обслуживания данных требует большой пропускной способности и способна замедлить сеть с большим количеством пользователей. Более продвинутые формы серверов - это серверы баз данных, сервер транзакций и сервер приложений;
- Middleware - промежуточный уровень, позволяющий приложениям прозрачно взаимодействовать с другими программами или процессами независимо от распоположения. Ключевым элемент Middleware является NOS (Network Operating System) - сетевая операционная система. Она необходима для предоставления таких услуг, как маршрутизация, распределение, обмен сообщениями и управления сервисной сети. NOS полагается на коммуникацию протоколов предоставления конкретных услуг. Прежде чем пользователь получит доступ к услугам сети, клиент-серверный протокол потребует от него установки физического соединения и выбора транспортных протоколов. Клиент-серверный протокол диктует, каким образом клиенты запрашивают информацию и услуги от сервера, а также как именно сервер должен отвечать на эту просьбу [8].
Мартин Батлер, председатель Butler Group, предложил новый способ реализации клиент-серверной стратегии - пятислойную модель под названием VAL (Value Added Layers). Данная структура по форме напоминает пирамиду.
Далее представлены характеристики каждого слоя:
- Уровень 1 - Инфраструктура слоя - данный слой содержит все те компоненты, которые являются пассивными и не выполняют бизнес-логику;
- Уровень 2 - Middleware - позволяет приложениям взаимодействовать с другими программами или процессами. Это средство отображения приложений используемых ими ресурсов. Middleware является ключом к интеграции гетерогенных программных и аппаратных сред, реализуя тот уровень интеграции, который необходим большинству организаций;
- Уровень 3 - Программы - непосредственно приложения, выступающие в роли активных компонентов, выполняющие задачи по организации данных;
- Уровень 4 - Хранилище - предназначено для изоляции бизнес-модели и спецификации от технологических инструментов, используемых для ее реализации;
- Уровень 5 - Бизнес-модели - набор независимых моделей, необходимых для того, чтобы все технологии, используемые для их реализации были применимы к программной и аппаратной среде в зависимости от того, что является наиболее подходящим [6].
Технология перехода к клиент-серверным вычислениям проявляется, главным образом, за счет более сложной ситуации в бизнесе в последние годы, такие как глобальный маркетинг, дистанционные он-лайн продажи распределения, децентрализованной корпоративной стратегии и т.д. Все это требует быстрого реагирования, легкого доступа к данным, а также более эффективной координации между людьми на всех уровнях как внутри, так и вне организации. Клиент-серверные вычисления позволяют решать все эти проблемы и, следовательно, являются одним из приоритетных вопросов в умах управления ИТ.
Известно, что клиент-серверная технология дает бизнесу много преимуществ, а также расширение возможностей для конкуренции. К сожалению, все это может достигаться исключительно за счет более высокой стоимости сооружений и более сложной совместимости систем.
Клиент-сервер не единственный способ решения бизнес-проблем, он также обладает своими ограничениями, одним из которых считается дороговизна. Но пока клиент-сервер осуществляется мудро, он может принести конкурентные преимущества.
В настоящее время клиент-серверная архитектура обладает гибкой модульной структурой - она может изменяться и дополняться.
Различные подходы могут комбинироваться в различных последовательностях, удовлетворяющих практически любые вычислительные потребности. Поскольку Интернет является важным фактором в вычислительных средах клиент-серверных приложений, то технология, поддерживающая работу через Интернет станет основой нового типа распределенных вычислений.
Интернет расширяет охват и мощь клиент-серверной архитектуры. С помощью общепринятых стандартов, это позволяет упростить и расширить клиент-серверную архитектуру как внутри, так и между компаниями. Так же из-за Интернета происходят изменения в языках программирования и технологии распределенных объектов.
Клиент-серверная архитектура по-прежнему остается единственной и лучшей архитектурой с точки зрения использования Интернета и других новых технологий. Но, независимо от развитий других архитектурных подходов, клиент-серверная архитектура, вероятно, останется основой большинства вычислительных событий в течение следующего десятилетия.
Конечно, с появлением большого числа людей, соединенных посредством компьютерной сети, пошло бурное развитие клиент-серверных приложений. Однако сервер в этом случае используется крайне экономно – это лишь средство для хранения данных и выполнения несложных операций. Основную вычислительную роль при этом выполняет именно клиент, присоединенный к сети. Такая архитектура позволяет максимально использовать ресурсы компьютера, предоставляет богатый пользовательский интерфейс, а также гарантирует, что все важные данные пользователя хранятся на компьютере дома, а не на сервере неизвестно какой страны.
При этом возникает несколько проблем – заставить человека установить какое-либо приложение можно лишь действительно предоставив ему это приложение в качестве средства решения проблемы. А как же быть тому числу предпринимателей, которые любыми способами хотят привлечь человека своим выгодным товаром? Пока что клиент-серверная архитектура не сильно им в этом помогает. Приложения пишутся для определенной платформы и версии операционной системы, что напрочь лишает взаимодействия пользователей разных операционных систем.
Однако прогресс не стоит на месте, и в 1989 году была предложена концепция всемирной паутины. А уже через четыре года появился первый браузер Mosaic. При этом в мире приложений начинает вырисоваться два класса приложений – тонкие клиенты, примером этого может служить тот же браузер Mosaic, и толстые клиенты, которые по-прежнему берут на себя значительную часть обработки информации и используют сервер для хранения и взаимодействия.
Клиентские приложения не сдают позиций, потому что все на что способен первый браузер - это отображать информацию. Динамика отсутствует. Одно лишь значительное преимущество – сайты становятся визитной картой с оригинальным дизайном, расположением меню, цветовой гаммой и т.п. Это не распространялось на клиентские приложения. Они по-прежнему создавались на основе стандартных вариантов, стандартного места расположения меню, стандартных цветов и шрифтов. С одной стороны простота и функциональность, с другой стороны – красота и изящество.
Конечно же, красота и изящество не могла не найти своих сторонников.
Также это позволило пользователям разных операционных систем просматривать одни и те же сайты. При этом были возможны некоторые несоответствия в отображении информации.
В 1996 году с появлением JavaScript html-страницы получили небывалую динамику и немного начали походить на обычные клиентские приложения. Конечно, до полноценных клиентских приложений им, скорее всего, не дойти никогда, но страницы стали оживать. Это послужило переворотом в интернете, и дало бурное развитие скриптовой технологии, что привело к рождению в 2005 году AJAX - идеи асинхронного обращения к серверу для получения лишь необходимой части страницы, а не всей страницы. Инновационные решения, основанные на AJAX, типа карт Windows Live Local, приблизили веб-приложения к уровню удобства обычных клиентских программ.
На данном этапе веб-страницу уже можно было спутать с обычным клиентским приложением. Однако, выглядеть как в клиентском приложении, и работать как клиентское приложение – это разные вещи. Доступ к ресурсам по-прежнему оставался ограничен, соединение между клиентом и сервером одноразовое – уже просмотренные страницы при следующем обращении приходилось загружать повторно. Однако, эти проблемы могли быть решены появлением нового http-протокола.
В свое время толстые клиенты, работающие на пользовательской стороне, при грандиозном развитии веб-технологий стали в прямом смысле толстыми – они сложны для клиента при обновлении версии, прихотливы к семействам операционных систем, плохо взаимодействуют с веб-серверами, потому что чаще всего построены с использованием клиент-серверной структуры. При этом требовалось срочное решение данной ситуации.
Корпорация Microsoft не задержалась с предложением и выпустила на рынок программную технологию Microsoft .NET Framework, призванную объединить множество различных служб, написанных на разных языках, для общей совместимости. Эта виртуальная машина может быть установлена на разных семействах Windows, а также на других операционных системах, что позволяет использовать любой из языков .NET-семейства для написания работоспособных приложений для всех операционных систем, на которых установлен данный framework. Так частично была одна из проблем, которая так долго преследовала клиентские приложения.
В результате гонка клиентских и веб-приложений находится на той стадии, когда веб просто физически не способен проникнуть глубже в пользовательские ресурсы, чтобы увеличить быстродействие. Возможности в реализации отдельных техник еще не доступны по сравнению с клиентскими приложениями и есть проблема постоянного обращения к серверу, потому что технология по-прежнему работает с обычным html-кодом.
Клиентские же приложения со своим богатством и простотой реализации сложнейших техник веба слишком неохотно потребляются пользователями, привыкшими к этому времени с помощью браузера решать
самые сложные задачи. К тому же, клиентские приложения по-прежнему привязаны к определенным протоколам передачи данных для обмена информацией, что влечет за собой дублирование определенных сервисов.
Так мы плавно перешли от истории к сегодняшним дням и видим, что бесспорного лидера нет, и каждая из технологий имеет свои преимущества и недостатки.
После долгих блужданий возле клиентского компьютера интернет-гиганты все же готовы смирится с тем, что для увеличения быстродействия отдельных сервисов, для последующего усложнения систем придется рассчитывать на мощности своих серверов, а не пытаться максимально глубоко лезть в ресурсы пользователей. В связи с этим последнее время очень интенсивно пошло развитие сервисов, построенных для использования облачных вычислений (cloud computing).
Облачными вычислениями принято называть технологию обработки данных, в которой программное обеспечение предоставляется пользователю в качестве Интернет-сервиса. При этом пользователь не заботится об архитектуре облака, а лишь получает необходимые ему мощности от целых кластеров.
Такие сервисы в настоящее время уже предоставляют Microsoft и Amazon (Elastic Compute Cloud).
Таким образом вся необходимая пользователю функциональность перемещается на сервера тех фирм, которые ее предоставляют. Доступ осуществляет посредством браузера, а, следовательно, отсутствует привязанность к разным семействам операционных систем.
Ярким примером такой технологии может служить Gmail - почтовый клиент Google, предоставляющий богатый инструментарий для работы с почтой прямо из браузера.
Тем же временем продолжается совершенствование способов приблизить веб к клиентским приложениям. В 2006 году корпорация Microsoft выпустила плагин к IE – Silverlight, позволяющий запускать приложения, содержащие анимацию, векторную графику и аудио-видео ролики, что характерно для RIA (Rich Internet application).
Производители приложений имеют другую позицию – они видят будущее в smart client-ах – локальных приложениях, которые всецело ориентированы на потребление всевозможных сервисов извне.
Smart Client — это легко устанавливаемое и управляемое клиентское приложение, предоставляющее пользователю адаптивный, отзывчивый и богатый пользовательский интерфейс, полностью использующее возможности локальных ресурсов компьютера и интеллектуально управляющее взаимодействием с распределенными источниками данных.
Ключевыми особенностями Smart Client, являются:
- богатый пользовательский интерфейс. Чтобы называться «умным», клиентское приложение должно иметь удобный пользовательский интерфейс, подстраиваясь под нужды пользователя, допуская персонализацию и предоставляя все современные способы управления (drag’n’drop, контекстные меню, дочерние окна, нотификации и т.д.);
- простая установка, не требующая пользовательского участия. Приложение должно предлагать пользователю автоматическую установку, не требующую перезагрузки, долгого ожидания или большого объема закачиваемых файлов;
- автоматическая установка обновлений. Появление новых версий приложения должно автоматически проверяться, их установка также должна происходить в автоматическом режиме;
- возможность работы при отсутствии соединения с сервером. Если приложение в своей работе взаимодействует с удаленными источниками данных, оно также должно работать и предоставлять максимум возможной функциональности и при «отсоединенной» (оффлайн) работе.
Примерами существующих смарт-клиентов могут быть:
- IssueVision - help desk management application;
- TaskVision – клиентское приложение, которое позволяет подключенным пользователям создавать задачи, проекты и распределять их между другими пользователями. Взаимодействие между пользователями построено с использованием веб-сервисов.
Поскольку обмен структурированными данными между клиентом и сервисом реализуется посредством стандартного языка XML – приложение способно взаимодействовать с большинством существующих сервисов, не зависимо от языка реализации. Однако даже с этими решениями у «smart» клиентов в случае прерывания связи с Internet только один выбор - отключаться, поэтому для устранения этого неудобства в Microsoft предложили технологию Live Mesh, позволяющую локально запускать веб приложения. Звучит немного парадоксально – имеется в виду, что приложение может работать с данными и при следующем подключении уже синхронизировать их с сервером.
Такая возможность (работать оффлайн) также будет включена в последний Silverlight, что позволит даже с веб-страницами работать в оффлайн режиме.
В ближайшее время, как и последние много лет, основной средой обмена информацией останется интернет. Судя по тенденциям, клиентские и веб приложения будут развиваться параллельно, только немного другим путем – теперь это будут не монолитные порталы, написанные одной командой и использующие ресурсы одной эко-системы. Это будут наряженные елки – один костяк и множество подключенных сервисов, возможно даже разработанные разными фирмами. Это приведет к тому, что основное внимание и львиная доля времени будет расходоваться на разработку сложных сервисов, но потом они легко будут подключаться к всевозможным порталам, приложениям и другим сервисам. Тем самым в скором будущем мы будем находиться не только во всемирной паутине, но еще и каждая ниточка этой паутины будет состоять из такого же сложного смешения различных сервисов, потребляемых различными устройствами. Но это огромное разнообразие сервисов будет полезно после окончательного внедрения нового протокола IPV6, что позволит подключать к интернету даже микроволновые печи, холодильники и т.д. Именно управление таким огромным количеством устройств в сети приведет к созданию множества сервисов и порталов, которые в онлайн режиме помогут управлять вашими электроприборами [11].
ЗАКЛЮЧЕНИЕ
В рамках выполнения данной работы была рассмотрена тема «Варианты архитектуры клиент-сервер».
Первая глава работы обзорная. В ней дается понятие термину «клиент-сервер» - это вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределяются между поставщиками услуг (сервисов), которые называются серверами, и заказчиками услуг - клиентами.
Сервер представляет собой программу, реализующую какие-либо услуги другим программам и обслуживающую клиентские запросы на получение ресурсов определенного типа.
Клиент — это программа, которая пользуется услугами, представляемыми сервером.
Во второй главе представлены существующие варианты архитектуры клиент-сервер.
Первый вариантом архитектуры клиент-сервер принято называть одноуровневой (однозвенной) архитектурой. В данном случае клиент отвечал исключительно за отображение информации, предоставляемой со стороны сервера.
Следующим шагом в развитии клиент-серверной архитектуры стало появление двухуровневой архитектуры. Особенностью этого подхода стало использование «толстых» клиентов, которые отвечали за реализацию основных задач по отображению информации пользователю и обработке всех данных. Центральный сервер выполняли лишь функции хранения и предоставления данных.
В ответ на затраты и ограничения, вызванные двухуровневой архитектурой, сформировалась концепция компонентно-ориентированной разработки приложений.
Многоуровневая клиент-серверная архитектура обеспечила переход к объектно-ориентированному подходу в рамках задачи построения распределенных вычислительных систем.
Третья глава работы посвящена описанию развития технологии, в результате которого можно сделать вывод о том, что клиент-сервер продолжит свое существование и в будущем.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Вишневский В.М. Теоретические основы проектирования компьютерных сетей. – М.: Техноосфера, 2013. – 512 с.
- Дубаков А.А. Сетевое программирование. – СПб.: НИУ ИТМО, 2015. – 248 с.
- Елизаров И.А. Интегрированные системы проектирования и управления. – Тамбов: Изд-во ФГБОУ ВПО «ТГТУ» 2015. – 160 с.
- Карпов А.Е. Архитектура распределенных систем программного обеспечения. – М.: МАКС Пресс, 2017. – 130 с.
- Когаловский М.Р. Перспективные технологии информационных систем. – М.: ДМК Пресс, 2013. – 288 с.
- Левин Л.И. Основы информационных технологий. – М.: Бином, 2012. – 336 с.
- Рогозов Ю.И. Архитектура информационных систем / Ю.И. Рогозов, А.С. Свиридов, С.А. Кучеров. – Ростов-на-Дону: Изд-во ЮФУ, 2014. – 117 с.
- Романчева Н.И. Базовые Интернет-технологии. – М.: МТУ ГА, 2014. – 96 с.
- Рябов В.А. Современные веб-технологии. – М.: Интуит, 2010. – 475 с.
- Советов Б.Я. Архитектура информационных систем. – М.: «Академия», 2012. – 288 с.
- Таненбаум Э. Распределенные системы. Принципы и парадигмы. – СПб.: Питер, 2011. – 368 с.

- Основные характеристики процессоров
- Учет ремонтных работ жилищно-коммунального хозяйства
- Анализ внешней и внутренней среды организации (ООО «Новая Логистика» )
- Понятие права, возникновение и его основные характеристики
- Нулевой артикль в английском языке (Употребление артикля)
- Понятие пенсии по инвалидности (Анализ динамики и структуры пенсионных поступлений)
- Менеджмент человеческих ресурсов (АО "Мотор-Супер")
- Налоговая оценка и учет объектов налогообложения. Формы и порядок ведения налоговой отчетности»
- Менеджмент как организационно – целевое управление (ОАО «Березовские минеральные воды»)
- Языки гипертекстовой разметки ( Общие сведения о языке разметки гипертекста)
- Налоги с физических лиц и их экономическое значение (Порядок исчисления, уплаты и отчетность по НДФЛ в ООО «ОАЗИС»)
- Налоги с физических лиц и их экономическое значение (Анализ механизма исчисления и взимания налога на доходы с физических лиц в ООО «Оазис»)