
Технология «клиент-сервер »
Содержание:

ВВЕДЕНИЕ
Согласно данным аналитиков, количество используемых в настоящее время компьютеров превысило отметку в 2,5 млрд. По оценкам, ежегодное количество компьютеров в мире увеличивается на 12%, из них 85% соединены в информационно-вычислительные сети, начиная от локальных сетей в офисах до глобальных сетей типа Интернет. Мировая тенденция к объединению компьютеров в сети вызвана такими причинами, как скоростное получение и передача информации непосредственно на рабочем месте из любой точки земного шара. Применение на практике таких больших потенциальных возможностей, какие несут в себе информационно-вычислительные сети, значительно улучшает производственные процессы[1].
Всемирная тенденция к объединению компьютеров в сети обусловлена рядом важных причин, таких как ускорение передачи информационных сообщений, возможность быстрого обмена информацией между пользователями, получение и передача сообщений не отходя от рабочего места, возможность мгновенного получения любой информации из любой точки земного шара, а так же обмен информацией между компьютерами разных фирм производителей работающих под разным программным обеспечением. В связи с чем данная работа является актуальной. Такие огромные потенциальные возможности, которые несет в себе вычислительная сеть и тот новый потенциальный подъем, который при этом испытывает информационный комплекс, а так же значительное ускорение производственного процесса не дают нам право не принимать это к разработке и не применять их на практике.
В данной работе рассматривается проблема технологий взаимодействия клиентских персональных компьютеров с серверами.
Объект исследования – сеть архитектуры клиент-сервер. Предметом исследования курсовой работы является практическое применение данной технологии. Целью данной работы является описание основных принципов построения и работы локальных вычислительных сетей и организация архитектур взаимодействия.
Для достижения этих целей решались следующие задачи:
- рассмотреть общие понятие об архитектуре вычислительных систем;
- рассмотреть архитектуру «файл-сервер»;
- рассмотреть архитектуру «клиент-сервер»;
- изучить практическое применение многоуровневого «клиент-сервера»
- изучить практическое применение технологии «клиент-сервер» при проектировании распределенных систем;
- изучить практическое применение технологии «клиент-сервер» при проектировании Веб-приложений.
При написании данной работы были использованы научная и учебно-методическая литература Российской Федерации. Основными источниками, раскрывающими теоретические основы технологии «клиент-сервер», явились работы современных авторов В.В. Бойко, Т Конноли, Л.В. Рудиковой, В.Ю. Шишмарева. В данных источниках подробно рассмотрено понятие архитектуры, технологий «файл-сервер» и «клиент-сервер». На основе работ Р Фрост, «Базы данных. Проектирование и разработка», И.М. Промахина «Интерфейсы сетевой СУБД (ПЭВМ) с языками высокого уровня» подробно рассмотрены технологии взаимодействия клиентских персональных компьютеров с серверами. Данные источники использовались в работе так как их авторы являются авторитетными специалистами в области исследований архитектуры сетевого взаимодействия персональных компьютеров с серверами. Надежность источников подтверждается многочисленными использованиями данных работ многими авторами и практической ценностью материала истояников.
Работа состоит из введения, заключения, двух глав и списка использованных источников.
ГЛАВА 1. АРХИТЕКТУРА ИНФОРМАЦИОННЫХ СИСТЕМ
Современные программные приложения и информационные системы достигли такого уровня развития, что термин «архитектура» в применении к ним уже давно не удивляет. Грамотно построить информационную систему, эффективно и надежно функционирующую не проще, чем сконструировать и возвести современное многофункциональное здание.
Архитектура - это «организационная структура системы». Архитектура – это «набор значимых решений по поводу организации системы программного обеспечения, набор структурных элементов и их интерфейсов, при помощи которых компонуется система, вместе с их поведением, определяемым во взаимодействии между этими элементами, компоновка элементов в постепенно укрупняющиеся подсистемы, а также стиль архитектуры, который направляет эту организацию – элементы и их интерфейсы, взаимодействия и компоновку»[2]. Архитектура программы или компьютерной системы – это «структура или структуры системы, которые включают элементы программы, видимые извне свойства этих элементов и связи между ними»[3]. Архитектуру можно рекурсивно разобрать на части, взаимодействующие посредством интерфейсов, связи, которые соединяют части, и условия сборки частей. Части, которые взаимодействуют через интерфейсы, включают классы, компоненты и подсистемы. Архитектура программного обеспечения системы или набора систем состоит из всех важных проектных решений по поводу структур программы и взаимодействий между этими структурами, которые составляют системы[4]. Проектные решения обеспечивают необходимый набор свойств, которые система должна поддерживать для успеха. Проектные решения обеспечивают концептуальную основу для разработки, поддержки и обслуживания системы[5].
Хотя определения несколько различаются, существует значительная степень сходства. Например, большинство определений указывают на то, что архитектура связана со структурой и поведением, а также только со значимыми решениями, может соответствовать определенному архитектурному стилю, на нее влияют ее заинтересованные стороны и ее окружение, она воплощает решения, основанные на логических рассуждениях[6].
Под архитектурой программных систем будем понимать совокупность решений относительно:
- организации программной системы;
- выбора структурных элементов, составляющих систему и их интерфейсов;
- поведения этих элементов во взаимодействии с другими элементами;
- объединение этих элементов в подсистемы;
- архитектурного стиля, определяющего логическую и физическую организацию системы: статические и динамические элементы, их интерфейсы и способы их объединения.
Архитектура программной системы охватывает не только ее структурные и поведенческие аспекты, но и правила ее использования и интеграции с другими системами, функциональность, производительность, гибкость, надежность, повторного применения, полноту, экономические и технологические ограничения, а также проблемы пользовательского интерфейса[7].
С развитием программных систем все большее значение приобретает их интеграция друг с другом в целях построения единого информационного пространства предприятия. Как видно из приведенных выше определений, интеграция является важным элементом архитектуры[8].
Для того чтобы построить правильную и надежную архитектуру и грамотно спроектировать интеграцию программных систем, необходимо следовать современным стандартам в этих областях. Без этого он, скорее всего, создаст архитектуру, которая не сможет развиваться и удовлетворять растущие потребности пользователей информационных технологий[9].
Законодателями стандартов в этой области выступают такие международные организации, как SEI (Software Engineering Institute), WWW (консорциум World Wide Web), OMG (Object Management Group), организация разработчиков Java – JCP (Java Community Process), IEEE (Institute of Electrical and Electronics Engineers) и другие[10].
Рассмотрим классификацию программных систем по их архитектуре (рисунок 1):
Рисунок 1 – Классификация программных систем по архитектуре[11]
Следует заметить, что, как и любая классификация, данная классификация архитектур информационных систем не является абсолютно жесткой. В архитектуре любой конкретной информационной системы часто можно найти влияния нескольких общих архитектурных решений[12].
Далее подробно рассмотрим особенности каждой архитектуры.
Централизованная архитектура вычислительных систем была распространена в 70-х и 80-х годах и реализовывалась на базе мейнфреймов (например, IBM-360/370 или их отечественных аналогов серии ЕС ЭВМ), либо на базе мини-ЭВМ (например, PDP-11 или их отечественного аналога СМ-4). Характерная особенность такой архитектуры – полная «неинтеллектуальность» терминалов. Их работой управляет хост-ЭВМ (рисунок 2)[13].
Рисунок 2 – Достоинства и недостатки централизованной архитектуры[14]
Использование такой архитектуры является оправданным, если хост-ЭВМ очень дорогая, например, супер-ЭВМ.
Классическое представление централизованной архитектуры показано на рисунке 3.
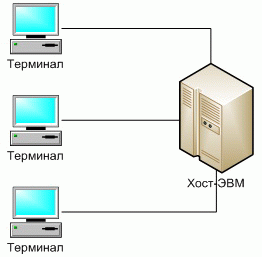
Рисунок 3 - Классическое представление централизованной архитектуры[15]
Таким образом, хост-ЭВМ должен иметь большую память и высокую производительность для обеспечения комфортной работы большого количества пользователей. Все приложения, работающие в этой архитектуре, полностью находятся в основной памяти хост-ЭВМ. Терминалы являются лишь устройствами ввода-вывода и таким образом в минимальной степени поддерживают интерфейс пользователя.
Архитектура «файл-сервер»
Файл-серверные приложения – приложения, схожие по своей структуре с локальными приложениями и использующие сетевой ресурс для хранения программы и данных. Функции сервера заключаются в хранения данных и кода программы. Функции клиента в обработке данных, которая происходит исключительно на стороне клиента[16].
Классическое представление информационной системы в архитектуре «файл-сервер» представлено на рисунке 4.
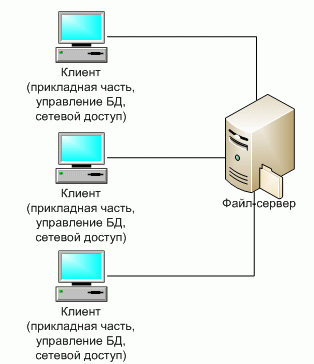
Рисунок 4 - Классическое представление архитектуры «файл-сервер»[17]
Организация информационных систем на основе использования выделенных файл-серверов все еще является распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания персональных компьютеров и локальных сетей[18].
Конечно, основным достоинством данной архитектуры является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях в операционной системе, Windows или какого-либо облегченного варианта Windows Server[19]. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных или систем управления базами данных (рисунок 5)[20].
Рисунок 5 – Достоинства и недостатки архитектуры «файл-сервер»[21]
Таким образом, для упрощения работы с небольшим объемом информации, которая будет использоваться в однопользовательском режиме возможно использование архитектуры «файл-сервер». Очень часто небольшие компании ведут, например, кадровый учет в изолированной системе, работающей на автономном персональном компьютере. Однако в некоторых более сложных случаях (например, при организации информационной системы поддержки проекта, реализуемого группой) файл-серверные архитектуры становятся недостаточными.
Архитектура «клиент-сервер»
Клиент-сервер (Client-server) – вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг (сервисов), называемых серверами, и заказчиками услуг, называемых клиентами. Нередко клиенты и серверы взаимодействуют через компьютерную сеть и могут быть как различными физическими устройствами, так и программным обеспечением[22].
Первоначально системы такого уровня базировались на классической двухуровневой клиент-серверной архитектуре (Two-tier architecture). Под клиент-серверным приложением в этом случае понимается информационная система, основанная на использовании серверов баз данных. Схематически такую архитектуру можно представить, как показано на рисунке 6.
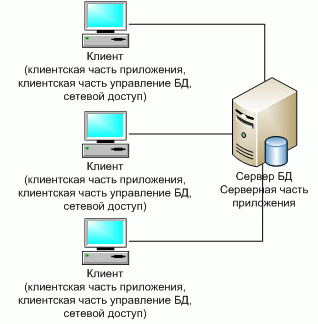
Рисунок 6 - Классическое представление архитектуры «клиент-сервер»[23]
На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции[24]. Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая, фактически, является индивидуальным представителем СУБД для приложения.
Интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения[25].
Разработчики и пользователи информационных систем, основанных на архитектуре «клиент-сервер», часто бывают неудовлетворены постоянно существующими сетевыми «накладными расходами», которые вытекают из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента[26].
Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных баз данных. Как и в целом, для поддержки локального кэша базы данных программное обеспечение рабочей станции должно включать компонент управления базой данных-упрощенную версию сервера базы данных, которая, например, может не обеспечивать многопользовательский доступ. Отдельной проблемой является согласованность (слаженность) кэшей и общей базы данных. Существуют различные решения – от автоматической поддержки согласованности за счет средств базового управления базами данных, программного обеспечения до полного перекладывания этой задачи на прикладной уровень (рисунок 7)[27].
Рисунок 7 – Достоинства и недостатки архитектуры «клиент-сервер»[28]
При проектировании информационной системы, основанной на архитектуре «клиент-сервер», большее внимание следует обращать на грамотность общих решений[29]. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике[30].
Таким образом, увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы.
2. ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ ТЕХНОЛОГИИ «КЛИЕНТ-СЕРВЕР»
Многоуровневая архитектура клиент-сервер (Multitier architecture) – разновидность архитектуры клиент-сервер, в которой функция обработки данных вынесена на один или несколько отдельных серверов. Это позволяет разделить функции хранения, обработки и представления данных для более эффективного использования возможностей серверов и клиентов. Среди многоуровневой архитектуры клиент-сервер наиболее распространена трехуровневая архитектура, предполагающая наличие следующих компонентов приложения: клиентское приложение (обычно говорят «тонкий клиент» или терминал), подключенное к серверу приложений, который в свою очередь подключен к серверу базы данных. Схематически такую архитектуру можно представить, как показано на рисунке 8[31].
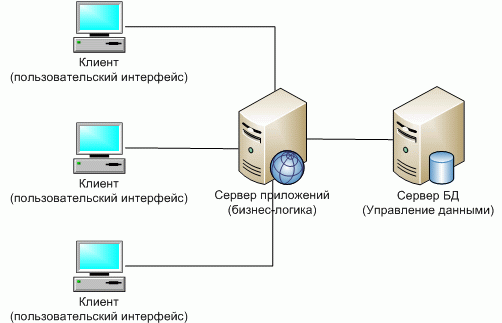
Рисунок 8 - Представление многоуровневой архитектуры «клиент-сервер»[32]
Терминал - это интерфейсный (обычно графический) компонент, представляющий первый уровень, само приложение конечному пользователю. Первый уровень не должен иметь прямых связей с базой данных (по требованиям безопасности), быть нагруженным основной бизнес-логикой (по требованиям масштабируемости) и хранить состояние приложения (по требованиям надежности). На первом уровне можно сделать и обычно самая простая бизнес-логика: интерфейс авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и соответствие формату, несложные операции (сортировка, группировка, подсчет значений) с данными, уже загруженными на терминал[33].
Сервер приложений располагается на втором уровне. На втором уровне сосредоточена большая часть бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы, а также погруженные в третий уровень хранимые процедуры и триггеры[34].
Сервер базы данных обеспечивает хранение данных и выносится на третий уровень. Обычно это стандартная реляционная или объектно-ориентированная СУБД. Если третий уровень представляет собой базу данных вместе с хранимыми процедурами, триггерами и схемой, описывающей приложение в терминах реляционной модели, то второй уровень строится как программный интерфейс, связывающий клиентские компоненты с прикладной логикой базы данных.
В простейшей конфигурации физически сервер приложений может быть совмещен с сервером базы данных на одном компьютере, к которому по сети подключается один или несколько терминалов.
В «правильной» (с точки зрения безопасности, надежности, масштабирования) конфигурации сервер базы данных находится на выделенном компьютере (или кластере), к которому по сети подключены один или несколько серверов приложений, к которым, в свою очередь, по сети подключаются терминалы (рисунок 9)[35].
Рисунок 9 – Преимущества и недостатки многозвенной архитектуры[36]
Некоторые авторы (например, Мартин Фаулер) представляют многозвенную архитектуру (трехзвенную) в виде пяти уровней (рисунок 10)[37]:
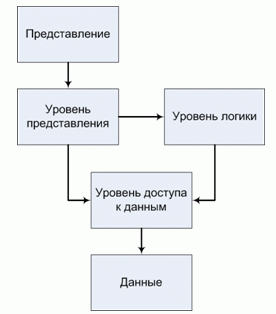
Рисунок 10 - Пять уровней многозвенной архитектуры «клиент-сервер»
Представление включает в себя всю информацию, непосредственно отображаемую пользователю: сгенерированные html-страницы, таблицы стилей, изображения[38].
Уровень представления охватывает все, что имеет отношение к общению пользователя с системой. Основными функциями уровня представления являются отображение информации и интерпретация введенных пользователем команд, преобразование их в соответствующие операции в контексте логики и данных.
Уровень логики содержит основные функции системы, предназначенные для достижения ее цели. К этим функциям относятся вычисления на основе вводимых и хранимых данных, проверка всех элементов данных и обработка команд от слоя представления, а также передача информации на уровне данных[39].
Уровень доступа к данным - это подмножество функций, обеспечивающих взаимодействие со сторонними системами, выполняющими задачи от имени приложения. Данные обычно хранятся в базе данных[40].
Таким образом, многозвенные архитектуры клиент-сервер являются прямым продолжением разделения приложений на уровни пользовательского интерфейса, компонентов обработки и данных. Различные звенья взаимодействуют в соответствии с логической организацией приложения. Во множестве бизнес-приложений распределенная обработка эквивалентна организации многозвенной архитектуры приложений клиент-сервер.
ГЛАВА 3. ПРИМЕНЕНИЕ ТЕХНОЛОГИИ «КЛИЕНТ-СЕРВЕР» ПРИ ПРОЕКТИРОВАНИИ ИНФОРМАЦИОННЫХ СИСТЕМ
Проектирование распределенных систем
Такой тип систем является более сложным с точки зрения организации системы. Суть распределенной системы заключается в том, чтобы хранить локальные копии важных данных. Схематически такую архитектуру можно представить, как показано на рисунке 11.
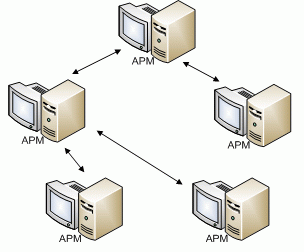
Рисунок 11 - Архитектура распределенных систем[41]
Более 95 % данных, используемых в управлении предприятием могут быть размещены на одном персональном компьютере, обеспечив возможность его независимой работы[42].
Поток исправлений и дополнений, созданных на этом компьютере, незначителен по сравнению с объемом данных, используемых в этом процессе. Поэтому, если хранить непрерывно используемые данные на самих компьютерах, и организовать обмен между ними исправлениями и дополнениями к хранящимся данным, то суммарный передаваемый трафик резко снизиться.
Это позволяет снизить требования к каналам связи между компьютерами и чаще использовать асинхронную связь, а значит создать надежно функционирующие распределенные информационные системы, использующие нестабильную связь, такую как Интернет, мобильная связь, коммерческие спутниковые каналы для связи отдельных элементов. А минимизация трафика между элементами сделает стоимость эксплуатации такого соединения вполне доступной. Конечно, реализация такой системы не элементарна, и требует решения ряда проблем, одна из которых своевременная синхронизация данных[43].
Каждый АРМ независим, содержит только ту информацию, с которой можно работать, а актуальность данных во всей системе обеспечивается благодаря непрерывному обмену сообщениями с другими АРМами.
Обмен сообщениями между АРМами может быть реализован различными способами, от отправки данных по электронной почте до передачи данных по сетям.
Еще одно преимущество такой схемы эксплуатации и архитектуры системы является возможность персональной ответственности за сохранность данных. Поскольку данные, доступные на конкретном рабочем месте, находятся только на этом компьютере, использование шифрования и персональных аппаратных ключей исключает доступ к данным третьих лиц, в том числе ИТ-администраторов[44].
Данными между различными рабочими станциями и централизованным хранилищем данных, передаются репликацией (рисунок 12). При вводе информации на рабочих станциях – данные также записываются в локальную базу данных, а лишь затем синхронизируются.
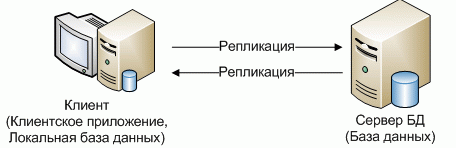
Рисунок 12 - Архитектура распределенных систем с репликацией[45]
Распределенные системы с элементами удаленного исполнения
Существуют определенные особенности, которые невозможно качественно реализовать на обычной распределенной системе репликативного типа. К этим особенностям можно отнести:
- использование данных из сущностей, которые хранятся на удаленном сервере (узле);
- использование данных из сущностей, хранящихся на разных серверах (узлах) частично;
- использование обособленного функционала, на выделенном сервере (узле).
У каждого из описанных типов используется общий принцип: программа клиент или обращается к выделенному (удаленному) серверу непосредственно или обращается к локальной базе, которая инкапсулирует в себе обращение к удаленному серверу (рисунок 13).
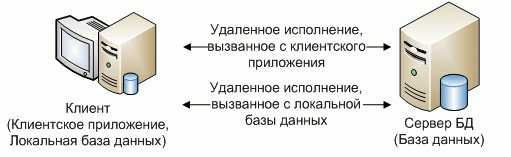
Рисунок 13 - Архитектура распределенных систем с удаленным исполнением[46]
Таким образом, такая архитектура системы также позволяет распределенные вычисления между клиентскими машинами. Например, вычисление задачи, требующей больших вычислений, может быть распределено между соседними АРМами из-за того, что они обычно имеют одинаковую информацию в своих базах данных и тем самым достигают максимальной производительности системы.
Проектирование Веб-приложений
Обычно Веб-приложения создаются как приложения в архитектуре «клиент-сервер», но серверная часть имеет различные архитектурные решения.
Изначально World Wide Web (WWW) представлялась ее создателям как «пространство для обмена информацией, в котором люди и компьютеры могут общаться между собой». Поэтому первые Веб-приложения представляли собой примитивные файловые серверы, которые возвращали статические HTML-страницы запросившим их клиентам. Таким образом, Веб начиналась как документо-ориентированная[47].
Следующим этапом развития Веб стало появление понятия приложений, которые базировались на таких интерфейсах, как CGI (или FastCGI), а в дальнейшем – на ISAPI. Common Gateway Interface (CGI) – это стандартный интерфейс работы с серверами, позволяющий выполнять серверные приложения, вызываемые через URL. Входной информацией для таких приложений служило содержимое HTTP-заголовка (и тело запроса при использовании протокола POST). CGI-приложения генерировали HTML-код, который возвращался браузеру. Основной проблемой CGI-приложений было то, что при каждом клиентском запросе сервер выполнял CGI-программу в реальном времени, загружая ее в отдельное адресное пространство[48].
Появление Internet Server API (ISAPI) позволило не только решить проблемы производительности, которые возникали с CGI-приложениями, но и предоставить в распоряжение разработчиков более богатый программный интерфейс. ISAPI DLL можно было ассоциировать с расширениями имен файлов через специальную мета-базу. Эти два механизма (CGI и ISAPI) послужили основой создания первого типа Веб-приложений, в которых, в зависимости от каких-либо клиентских действий, выполнялся серверный код. Таким образом, стала возможной динамическая генерация содержимого Веб-страниц и наполнение Веб перестало быть чисто статическим.
Интерфейс ISAPI является функцией Microsoft Internet Information Server. Приложения ISAPI это динамически загружаемые библиотеки (DLL), которые выполняются в адресном пространстве веб-сервера. Другие веб-серверы через некоторое время также имеют возможность запускать приложения, реализованные в виде библиотек. В случае веб-серверов Netscape этот программный интерфейс назывался NSAPI (Netscape Server API). Довольно популярный веб-сервер Apache также имеет возможность запускать веб-приложения, реализованные в виде библиотек; эти библиотеки называются Apache DSO (динамические общие объекты).
Естественно, что при использовании как CGI, так и ISAPI-приложений разработчики в основном решали одни и те же задачи, поэтому естественным шагом стало появление нового, высокоуровневого интерфейса, который упростил задачу генерации HTML-кода, позволил получить доступ к компонентам и использовать базы данных. Этот интерфейс является объектной моделью active Server Pages (ASP) на основе фильтра ISAPI.
Схематически такую архитектуру (в трехзвенном варианте) можно представить, как показано на рисунке 14[49].
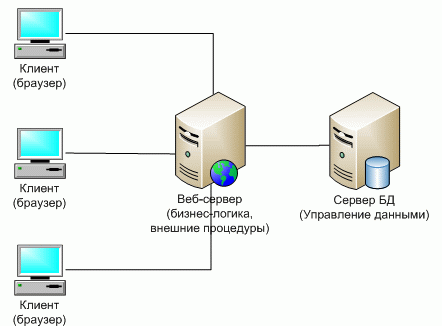
Рисунок 14 - Архитектура Веб-приложений
Другим способом поддержки различных типов клиентов является создание «разумных» серверных компонентов, которые способны генерировать различный код в зависимости от типа клиента. Такой подход, в частности, реализован в Microsoft ASP .NET. Другим направлением развития клиентских частей Веб-приложений стало размещение некоторой части логики приложения (такой как проверка корректности вводимых данных) в самом Веб-браузере. В частности, современные Веб-браузеры способны интерпретировать скриптовые языки (VBScript, JavaScript), код на которых, как и ASP-код, внедряется в Веб-страницу, но интерпретируется не Веб-сервером, а браузером и соответственно выполняется на клиентском устройстве. Кроме того, современные браузеры способны отображать и выполнять Java-аплеты – специальные Java-приложения, которые пользователь получает в составе Веб-страницы, а некоторые из браузеров могут также служить контейнерами для элементов управления ActiveX – выполняющихся в адресном пространстве браузера специальных COM-серверов, также получаемых в составе Веб-страницы. И в Java-аплетах, и в элементах управления ActiveX можно реализовать практически любую функциональность[50].
Отметим, что, будучи составной частью подобного решения, Веб-сервер должен уметь не только выполнять приложения и взаимодействовать с сервером приложений, но и использовать сервисы интеграции, сервисы управления приложениями и данными, а также сервисы для разработчиков[51].
Таким образом, следующим шагом эволюции Веб-приложений, помимо доступа к корпоративным данным и данным партнеров, стало получение доступа к корпоративным приложениям. Для решения этой задачи интеграции Веб-приложений с внутренними информационными системами предприятий и с приложениями, обеспечивающими взаимодействие с клиентами и партнерами, используются специальные решения, называемые корпоративными порталами.
Нередко частью портального решения являются средства управления информационным наполнением Веб-сайта – ведь объем данных, доступных пользователям с помощью сайтов крупных компаний и порталов, сейчас таков, что управление этими данными «вручную» не представляется возможным.
ЗАКЛЮЧЕНИЕ
Таким образом, клиент-серверная архитектура имеет ряд существенных преимуществ перед традиционной архитектуры информационных систем на основе сетевых версий настольных баз данных: более высокая производительность, низкий сетевой трафик, повышенная безопасность и целостность данных.
Рассмотрены последние достижения в области управления базами данных и информационной архитектуры клиент-сервер, в частности стандартизированное программное обеспечение промежуточного уровня. Если в будущем типичная компания будет поддерживать среду, которая следует принципу «любой клиент может подключиться к любому серверу», ключом к такой взаимозаменяемости будут стандарты.
Существование нескольких стандартов не должно вызывать озабоченности по ряду причин. Соединение может быть реализовано через мини-шлюз или через использование клиентов и серверов с двойными возможностями промежуточного уровня на основе обоих стандартов. Даже соединение между несовместимыми системами промежуточного программного обеспечения, такими, будет тривиальной задачей, такой как использование промежуточного программного обеспечения или клиентов и серверов, поддерживающих несколько стандартов.
Независимо от направления, в котором будет развиваться архитектура клиент-сервер, Эта технология окажет значительное влияние на все области, от хранилищ данных до систем с несколькими базами данных.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Бакаревич, Ю.Б., Пушкина Н.В. Самоучитель Microsoft Access 2010. – СПб.: БХВ-Петербург, 2012 – 153с.
- Бойко, В.В., Савинков, В.М. Проектирование баз данных информационных систем. – М.: Финансы и статистика, 2018. – 256с.
- Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с.
- Бондарева Г.А., Сахарова Е.В., Королькова Л.Н., Информатика. Методические указания. Ставрополь.: СТИС, 2016. – 312с.
- Борри, Х. Firebird: руководство работника баз данных [Текст]: пер. с англ. / Х. Бори. - СПб.: БХВ - Петербург, 2014. - 1104с.
- Броневщук, Е.С. Система управления базами данных [Текст] / Е.С. Броневщук, В.И. Бурдаков, Л.И. Гуков. - М.: Финансы и статистика, 2018. - 634с.
- Гончаров, А.Ю. Access 2010. Самоучитель с примерами. –М.:, 2014г.
- Гончаров, А.Ю. Access 2007. Справочник с примерами [Текст] / А.Ю. Гончаров. - М.: КУДИЦ - ПРЕСС, 2017. - 296с.
- Григорьев, В.А., Ревунков В.И. Банки данных. Учебник для вузов. – М.:, МГТУ им.Баумана, 2016. – 216с.
- Дейт, К. Введение в системы баз данных [Текст] / К. Дейт 7-е изд. - М.: СПб.: Вильямс, 2013. - 325с.
- Каленик, А. Использование новых возможностей MS SQL Server 2005 [Текст] / А. Каленик. - СПб.: Питер, 2013. - 334с.
- Конноли, Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика [Текст] / Т. Конноли, Л Бегг, А. Страган 2-е изд. - М.: Вильямс, 2012. - 476с.
- Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с.
- Мотев, А.А. Уроки My SQL. Самоучитель [Текст] / А.А. Мотев. - СПб.: БХВ - Петербург, 2018. - 208с.
- Оппель, Э. Раскрытие тайны SQL [Текст]: пер. с англ. / Э. Опель, Джим Киу, Д. А. Терентьева. - М.: НТ Пресс, 2016. - 320с.
- Промахина, И.М. Интерфейсы сетевой СУБД (ПЭВМ) с языками высокого уровня [Текст] / И. М. Промахина - М.: ВЦ РАН, 2017.- 874с.
- Рудикова, Л.В. Базы данных. Разработка приложений. - Москва, БХВ-Петербург, 2016 г.- 496 с.
- Симонович, С.В., Евсеев, Г.А., Алексеев, А.Г. Специальная информатика: Учебное пособие. – М.: АСТ-ПРЕСС: Инфорком-Пресс, 2014. – 290с.
- Фаронов, В.В. Программирование баз данных. – СПб.: Питер, 2016. – 351с.
- Фрост, Р. Базы данных. Проектирование и разработка [Текст]: пер. с англ. / Р. Фрост, Д. Дей, К. Ван Слайк, А. Ю. Кухаренко. - М.: НТ Пресс, 2017. - 592с.
- Фуфаев, Э.В., Базы данных; [Текст] / Э.В. Фуфаев, Д.Э. Фуфаев - Академия - Москва, 2013. - 320 c.
- Хаббард, Дж. Автоматизированное проектирование баз данных. – М.: Мир, 2014. - 560с.
- Фролмов, А.В. Локальные свезти персональных компьютеров. Работка с сервером / А.В. Фролов, Г.В. Фролов. - М.: Диалогизм-Мифи, 2015. - 1655 c.
- Фролов А.В. Бразды данных в Интернете. Праклтическое руководство под созданию Web-приложений с базабми данных / А.В. Фролов, Г.В. Фролмов. - М.: Microsoft Press. Руссткая Редакция, 2015. - 1401 c.
- Шишмарев, В.Ю. Учеб. пособие для студ. сред. проф. образования / В.Ю. Шишмарев. – М.: Академия, 2017. – 304 с.
- Шишмарев, В.Ю. Автоматизация технологических процессов: учеб. пособие для студ. сред. проф. образования / В.Ю. Шишмарев. – М.: Академия, 2009. – 352 с.
-
Конноли, Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика [Текст] / Т. Конноли, Л Бегг, А. Страган 2-е изд. - М.: Вильямс, 2012. - 476с. ↑
-
Рудикова, Л.В. Базы данных. Разработка приложений. - Москва, БХВ-Петербург, 2016 г.- 496 с. ↑
-
Бойко, В.В., Савинков, В.М. Проектирование баз данных информационных систем. – М.: Финансы и статистика, 2018. – 256с. ↑
-
Григорьев, В.А., Ревунков В.И. Банки данных. Учебник для вузов. – М.:, МГТУ им.Баумана, 2016. – 216с. ↑
-
Там же ↑
-
Бойко, В.В., Савинков, В.М. Проектирование баз данных информационных систем. – М.: Финансы и статистика, 2018. – 256с. ↑
-
Промахина, И.М. Интерфейсы сетевой СУБД (ПЭВМ) с языками высокого уровня [Текст] / И. М. Промахина - М.: ВЦ РАН, 2017.- 874с. ↑
-
Фролов А.В. Бразды данных в Интернете. Праклтическое руководство под созданию Web-приложений с базабми данных / А.В. Фролов, Г.В. Фролмов. - М.: Microsoft Press. Руссткая Редакция, 2015. - 1401 c. ↑
-
Промахина, И.М. Интерфейсы сетевой СУБД (ПЭВМ) с языками высокого уровня [Текст] / И. М. Промахина - М.: ВЦ РАН, 2017.- 874с. ↑
-
Каленик, А. Использование новых возможностей MS SQL Server 2005 [Текст] / А. Каленик. - СПб.: Питер, 2013. - 334с. ↑
-
Бойко, В.В., Савинков, В.М. Проектирование баз данных информационных систем. – М.: Финансы и статистика, 2018. – 256с. ↑
-
Григорьев, В.А., Ревунков В.И. Банки данных. Учебник для вузов. – М.:, МГТУ им.Баумана, 2016. – 216с. ↑
-
Там же ↑
-
Фаронов, В.В. Программирование баз данных. – СПб.: Питер, 2016. – 351с. ↑
-
Фролов А.В. Базы данных в Интернете. Практическое руководство под созданию Web-приложений с базами данных / А.В. Фролов, Г.В. Фролмов. - М.: Microsoft Press. Русская Редакция, 2015. - 1401 c. ↑
-
Броневщук, Е.С. Система управления базами данных [Текст] / Е.С. Броневщук, В.И. Бурдаков, Л.И. Гуков. - М.: Финансы и статистика, 2018. - 634с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Мотев, А.А. Уроки My SQL. Самоучитель [Текст] / А.А. Мотев. - СПб.: БХВ - Петербург, 2018. - 208с. ↑
-
Конноли, Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика [Текст] / Т. Конноли, Л Бегг, А. Страган 2-е изд. - М.: Вильямс, 2012. - 476с. ↑
-
Броневщук, Е.С. Система управления базами данных [Текст] / Е.С. Броневщук, В.И. Бурдаков, Л.И. Гуков. - М.: Финансы и статистика, 2018. - 634с. ↑
-
Фаронов, В.В. Программирование баз данных. – СПб.: Питер, 2016. – 351с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Бойко, В.В., Савинков, В.М. Проектирование баз данных информационных систем. – М.: Финансы и статистика, 2018. – 256с. ↑
-
Фролов А.В. Базы данных в Интернете. Практическое руководство под созданию Web-приложений с базами данных / А.В. Фролов, Г.В. Фролмов. - М.: Microsoft Press. Русская Редакция, 2015. - 1401 c. ↑
-
Каленик, А. Использование новых возможностей MS SQL Server 2005 [Текст] / А. Каленик. - СПб.: Питер, 2013. - 334с. ↑
-
Мотев, А.А. Уроки My SQL. Самоучитель [Текст] / А.А. Мотев. - СПб.: БХВ - Петербург, 2018. - 208с. ↑
-
Мотев, А.А. Уроки My SQL. Самоучитель [Текст] / А.А. Мотев. - СПб.: БХВ - Петербург, 2018. - 208с. ↑
-
Фаронов, В.В. Программирование баз данных. – СПб.: Питер, 2016. – 351с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Рудикова, Л.В. Базы данных. Разработка приложений. - Москва, БХВ-Петербург, 2016 г.- 496 с. ↑
-
Каленик, А. Использование новых возможностей MS SQL Server 2005 [Текст] / А. Каленик. - СПб.: Питер, 2013. - 334с. ↑
-
Фуфаев, Э.В., Базы данных; [Текст] / Э.В. Фуфаев, Д.Э. Фуфаев - Академия - Москва, 2013. - 320 c. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Фаронов, В.В. Программирование баз данных. – СПб.: Питер, 2016. – 351с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Фаронов, В.В. Программирование баз данных. – СПб.: Питер, 2016. – 351с. ↑
-
Конноли, Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика [Текст] / Т. Конноли, Л Бегг, А. Страган 2-е изд. - М.: Вильямс, 2012. - 476с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Фуфаев, Э.В., Базы данных; [Текст] / Э.В. Фуфаев, Д.Э. Фуфаев - Академия - Москва, 2013. - 320 c. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Конноли, Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика [Текст] / Т. Конноли, Л Бегг, А. Страган 2-е изд. - М.: Вильямс, 2012. - 476с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑
-
Мейер, М. Теория реляционных баз данных. – М.: Мир, 2015. - 184с. ↑
-
Бойченко, И.А. Проектирование компонентов доверенной среды реляционной СУБД на основе CASE-технологий [Текст] / И.А. Бойченко - Воронеж, 2016. - 251с. ↑

- Применение объектно-ориентированного подхода при проектировании информационной системы (ОАО «УМПО »)
- Понятие эффективности менеджмента
- Особенности управления организациями в современных условиях и пути его совершенствования (ООО «Марс» )
- Интернет- маркетинговые решения для службы курьерской доставки
- Налоговая система РФ и проблемы ее совершенствования
- Курсовая работСтимулирование и его значение в процессе мотивации трудовой деятельности персонала
- Проблемы комплексного исследования при подборе персонала (Технологический цикл подбора персонала)
- Аналитический обзор зарубежных подходов к исследованию личности (Личность и уровни общения)
- Формы международных расчетов и перспективы их изменения (Виды международных расчетов)
- Обзор языков программирования высокого уровня (Обзор Delphi.)
- Субъекты малого предпринимательства (Понятие субъектов малого предпринимательства в законодательстве Российской Федерации)
- Понятие субъектов малого предпринимательства в законодательстве Российской Федерации