
Технология «клиент-сервер»
Содержание:

Введение
В настоящее время в связи с усложнением процесса принятия решений в бизнесе успех предприятия напрямую зависит от того, как быстро и слаженно взаимодействуют его структуры. В наш век обмен информацией немыслим без современных средств связи. Одно из таких средств – современные глобальные компьютерные сети. Сети - важная часть группового взаимодействия, так как они позволяют быстро и эффективно обмениваться информацией.
Обычно решение вопроса создания корпоративной ИС ищется в уже достаточно освоенной и всем знакомой плоскости клиент-сервер на базе локальной сети с централизованной базой данных.
Выбирается одна из популярных многопользовательских СУБД и доступные средства для быстрой разработки приложений (как правило, это пара Interbase/Delphi). Создается система, включающая в себя одну или несколько баз данных, а также набор обращающихся к ней (к ним) приложений, реализующих прикладные функции, необходимые конечному пользователю. Данная технология весьма неплохо работает в ограниченном масштабе, например, в рамках одного офиса или нескольких удаленных рабочих групп-филиалов, связанных с головным предприятием.
Одним из основных вопросов при создании клиент-серверных систем остается метод реализации требуемого функционала. От правильного ответа на этот вопрос, правильного распределения функциональной нагрузки зависят самые важные показатели разрабатываемых систем.
В данной курсовой работе будет рассмотрена разработка многоуровневого клиент-серверного приложения в визуальной среде разработки Delphi на основе системы управления базами данных InterBase.
В процессе разработки планируется реализовать основную часть бизнес-логики проекта на сервере приложений.
Глава 1. Теоретическая часть
Определение клиент-серверной системы
«Клиент-сервер» - это модель взаимодействия компьютеров в сети. Как правило, компьютеры не являются равноправными. Каждый из них имеет свое, отличное от других, назначение, играет определенную роль. Некоторые компьютеры в сети владеют и распоряжаются информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных. Другие имеют возможность обращаться к этим службам, пользуясь услугами первых. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться - клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого - обслуживать запросы клиентов, связанные с обработкой данных; если ресурс - это файловая система, то говорят о файловом сервере или файл-сервере и т.д.
В сети один и тот же компьютер может выполнять как роль клиента, так и роль сервера. Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа рассматривается в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами. Так, ядро реляционной SQL-ориентированной СУБД часто называют сервером базы данных или SQL-сервером, а программу, обращающуюся к нему за услугами по обработке данных - SQL-клиентом.
Первоначально СУБД имели централизованную архитектуру. В ней сама СУБД и прикладные программы, которые работали с базами данных, функционировали на центральном компьютере (большая ЭВМ или мини-компьютер). Там же располагались базы данных. К центральному компьютеру были подключены терминалы, выступавшие в качестве рабочих мест пользователей. Все процессы, связанные с обработкой данных: поддержка ввода, осуществляемого пользователем, формирование, оптимизация и выполнение запросов, обмен с устройствами внешней памяти и т.д., выполнялись на центральном компьютере, что предъявляло жесткие требования к его производительности. Особенности СУБД первого поколения напрямую связаны с архитектурой больших ЭВМ и мини-компьютеров и адекватно отражают все их преимущества и недостатки.
В настоящее время фактическим стандартом для многопользовательских СУБД, стала архитектура «клиент-сервер».
Если предполагается, что проектируемая информационная система (ИС) будет построена по технологии «клиент-сервер», то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер. Иными словами, часть функций прикладной программы (или, проще, приложения) будет реализована в программе-клиенте, другая - в программе-сервере, причем для их взаимодействия будет определен некоторый протокол.
Основной принцип технологии «клиент-сервер» заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу.
Первая группа - это функции ввода и отображения данных. Вторая группа объединяет чисто прикладные функции, характерные для данной предметной области. К третьей группе относятся фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.). Наконец, функции четвертой группы - служебные, играющие роль связок между функциями первых трех групп. В соответствии с этим в любом приложении выделяются следующие логические компоненты:
- компонент представления, реализующий функции первой группы;
- прикладной компонент, поддерживающий функции второй группы;
- компонент доступа к информационным ресурсам, поддерживающий функции третьей группы;
- протокол взаимодействия.
Модели клиент-серверных систем
Различия в реализациях технологии «клиент-сервер» определяются четырьмя факторами. Во-первых, тем, в какие виды программного обеспечения интегрирован каждый из этих компонентов. Во-вторых, тем, какие механизмы программного обеспечения используются для реализации функций всех четырех групп. В-третьих - как логические компоненты распределяются между компьютерами в сети. В-четвертых, какие механизмы используются для связи компонентов между собой.
Выделяются четыре подхода, реализованные в следующих моделях:
- модель файлового сервера (File Server - FS);
- модель доступа к удаленным данным (Remote Data Access - RDA);
- модель севера базы данных (DataBase Server - DBS);
- модель сервера приложений (Application Server - AS).
FS-модель является базовой для локальных сетей персональных компьютеров. В соответствии с этой моделью один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (то есть к файлам). На других компьютерах в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент. Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.

Рисунок 1.1 – Модель файлового сервера.
FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере. Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипулирования данными («данные - это файлы»), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д. Все перечисленные недостатки - следствие внутренне присущих FS-модели ограничений, определяемых ее характером.
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, если речь идет о базах данных) или вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования - API).

Рисунок 1.2 – Модель доступа к удаленным данным
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия и возвращает клиенту результат, оформленный как блок данных. При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль - обслуживание запросов и обработка данных.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Прежде всего, перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД, минимизируя общее число процессов операционной системы. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на ввод-вывод (как в системах с файловым сервером), а запросы на языке SQL, а их объем существенно меньше.
Основное достоинство RDA-модели заключается в унификации интерфейса «клиент-сервер» в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обеим сторонам. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором речь шла выше. Поэтому было бы целесообразно использовать его не только в качестве средства доступа к данным, но и как стандарта общения клиента и сервера.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные функции).
Наряду с RDA-моделью все большую популярность приобретает перспективная DBS-модель. Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle, InterBase). Ее основу составляет механизм хранимых процедур - средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры (SQL/PTL), представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД.
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, то есть ядро СУБД. Достоинства DBS-модели: возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), возможность разделения процедуры между несколькими приложениями, экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по функциональным возможностям с языками третьего поколения, такими как C или Pascal. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.

Рисунок 1.3 – Модель сервера баз данных
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции выполняются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая работает на компьютере-клиенте (RDA-модель). Так или иначе, современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей, либо их разумное сочетание.
В AS-модели процесс, выполняющийся на компьютере-клиенте, отвечает, как обычно, за интерфейс с пользователем (то есть реализует функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client - AC). Прикладной компонент реализован как группа процессов, выполняющих прикладные функции и называется сервером приложения (Application Server - AS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов - базы данных, очереди, почтовые службы и др.

Рисунок 1.4 – Модель сервера приложений
RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во втором - интегрируется в компонент доступа к информационным ресурсам. В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. AS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitors - TPM), или, проще, мониторов транзакций, которые выделяются как особый вид программного обеспечения.
В период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия такого типа, в современных же системах он жизненно необходим.
Чтобы понять проблему, рассмотрим эволюцию серверов баз данных. Первое время доминировала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Затем функции управления данными были выделены в самостоятельную группу - сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один-к-одному», то есть сервер обслуживал запросы ровно одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу - революционный шаг, позволяющий, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем - на другую, осуществляя взаимодействие между ними по сети. Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Проблемы, возникающие в модели «один-к-одному», решаются в архитектуре систем с выделенным сервером, способным обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами. Логически каждый клиент связан с сервером отдельной нитью (thread) или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой (multi-threaded).
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей. С другой стороны, возможность взаимодействия с одним сервером многих клиентов позволяет в полной степени использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что сильно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один-к-одному» будет создано 50 копий процессов СУБД для 50 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобиться только один сервер.
Однако такое решение создает новую проблему. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается заменой выделенного сервера на диспетчер или виртуальный сервер (virtual server), который теряет право монопольно распоряжаться данными, выполняя только функции диспетчеризации запросов к актуальным серверам. Таким образом, в архитектуру системы добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки (load balancing) и ограничивает возможности управления взаимодействием «клиент-сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными - невозможно устанавливать приоритеты для обслуживания запросов.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если два эти условия выполнены, то есть основание говорить о многопотоковой архитектуре с несколькими серверами (multi-threaded, multi-server architecture).
Высокопроизводительный, экономичный, многоплатформенный сервер баз данных InterBase представляет собой экономичную СУБД с обработкой транзакций, которую используют миллионы пользователей во всем мире. Сочетая легкость установки, автоматическое восстановление после аварийных отказов и минимальные требования к администрированию, InterBase является наиболее подходящим решением для встраивания в тиражируемые приложения. Обладая поддержкой многопроцессорного режима и сложной архитектурой, InterBase идеально подходит для многофункциональных бизнес приложений, обслуживающих большое количество пользователей. Графический пользовательский интерфейс IBConsole включает монитор производительности, одновременно отслеживающий состояние нескольких серверов и баз данных InterBase.
В основе InterBase находится многоуровневая архитектура управления несколькими версиями, предлагающая весомые преимущества в надежности, производительности, эффективности труда разработчиков и постоянном сопровождении. InterBase освобождает разработчиков от решения проблем совместимости и задач памятью, и наряду с этим обеспечивает немедленное восстановление после аварийных отказов.
InterBase представляет собой идеальное решение для установки в условиях отсутствия администратора баз данных или IT поддержки. Автоматическое восстановление после аварийных сбоев и автоматизированные процессы управления учетными записями пользователей, оперативное резервное копирование и автоматизация других задач сопровождения позволяют существенно уменьшить потребность в администрировании. Функции автоматической настройки включают оптимизацию запросов на основе затрат и автоматическую «сборку мусора». Динамическая перестройка структур индекса улучшает производительность и уменьшает потребность в администрировании.
СУБД InterBase не привязывает разработчиков к определенному языку программирования или к какой-либо платформе. InterBase обеспечивает межплатформенную совместимость систем Windows, Linux, Solaris и Java, при этом не требуется перекодирование и поддержка нескольких серверных частей СУБД.
Высокая экономичность и универсальность мощной встраиваемой СУБД Borland InterBase – это широко распространенная СУБД для потребительских приложений, используемых тысячами конечных пользователей.
Клиент-серверные компоненты среды Delphi
Разработка распределенных корпоративных систем доступа к данным – одна из наиболее высокотехнологических и динамично развивающихся областей современной индустрии ПО. Именно здесь сосредоточены усилия разработчиков прикладного ПО.
Мощные серверы должны обеспечивать бесперебойный доступ к данным сотен клиентов одновременно. При этом клиентское ПО установлено на разных аппаратных платформах и работает под управлением разных ОС. Пользователи могут находится в корпоративной сети, обращаться к серверу через Internet, intranet или по радиоканалу.
Для создания распределенных систем разработаны подходы на основе ряда технологических решений. Используются технологии COM, OLEnterprise, сокеты TCP\IP, Microsoft Transaction Server, CORBA.
Для работы с корпоративными БД используются многоуровневые приложения, т.к. эффективное взаимодействие с БД многих пользователей может обеспечить только ПО промежуточного уровня. Серверы приложений решают задачи управления запросами клиентов и результатами запросов, разграничения доступа, сохранения целостности данных т.д. Причем и в этой сфере существуют готовые решения на основе вышеперечисленных технологий.
В Delphi можно создавать приложения для распределенных систем на основе всех перечисленных подходов. Для этого предназначена специальная технология MIDAS (Multi-tired Distributed Application Service) – Службы многоуровневых распределенных приложений. Она обеспечивает создание приложений для распределенных систем баз данных на основе единого подхода.
MIDAS – это технология компании Borland, разработанная для создания многоуровневых приложений баз данных. Применение данной архитектуры позволяет быстро разрабатывать простые в сопровождении и установке, надежные распределенные БД. Трехуровневое приложение баз данных содержит несколько компонентов (слоев):
а) Слой БД. Хранит данные. Выполняет функции хранения информации, обеспечения целостности и непротиворечивости данных. Пример – локальные (dBase, Paradox) и серверные БД (Oracle, Sybase, MS SQL), текстовые файлы и т.д. В нашем случае это InterBase.
б) Слой бизнес логики (сервер приложений) - это программа, обеспечивающая доступ клиентов к информации. На этом слое вводится понятие сервиса, как некоей услуги, поставляемой клиенту (например, получение данных об остатке денег на счете, как частный случай из реляционной БД). В этом слое реализуются правила и алгоритмы обработки информации, отражающие поведение реального моделируемого объекта (бизнес правила). Например, проверка остатка денег на не отрицательность, перевод денег со счета на счет.
в) Презентационный слой (тонкий клиент). Задача этого слоя, используя сервисы слоя бизнес логики, предоставлять пользователям запрошенную информацию в удобной и приятной во всех отношениях форме. Может быть выполнен в виде традиционного exe-файла. Также в качестве тонкого клиента можно использовать Web-браузер.
Применение данной схемы позволяет создать клиентское приложение, которое практически не требует настройки и сопровождения, вся логика работы с БД сосредоточена в среднем слое (сервере приложений). Соответственно при доработке алгоритмов доступа к БД необходимо лишь переустановить сервер приложений.
MIDAS предназначен для обеспечения связи между слоем бизнес логики и презентационным слоем. Он позволяет организовать взаимодействие тонкого клиента с сервером приложений. При этом сервер приложений взаимодействует с реляционной БД (чаще всего данные хранятся именно в этой форме) как и обычные приложения работы с БД, разработанные в Delphi.
Тонкий клиент для конечного пользователя ничем не отличается от обычного (толстого) клиента БД. Разница в том, что толстый клиент через BDE, ADO, компоненты прямого доступа к серверам БД и другие библиотеки работает с БД, а тонкий клиент взаимодействует с сервером приложений, используя MIDAS. Сервер приложений скрывает от клиента детали доступа и обработки БД. На компьютере с тонким клиентом не нужно устанавливать и настраивать BDE, ADO, клиентскую часть сервера БД. Необходимо лишь иметь небольшие по объему dll, которые легко переносить вместе с exe файлом тонкого клиента. В качестве тонкого клиента может использоваться и Web-браузер.
Структурированный язык запросов – SQL
На рубеже 70-х годов XX века Е.Ф. Кодд опубликовал базовую концепцию реляционной модели хранения данных, в которой было предусмотрено создание реляционных языков, осуществляющих управление данными. Одной из ключевых реализаций реляционных языков стал структурированный язык запросов (SQL, Structured Query Language). Впервые о языке SQL заговорили в 1974 году благодаря Д. Чамберлине, работавшему вместе с Коддом в лаборатории IBM. Первоначально язык назывался несколько иначе – SEQUEL (Structured English Query Language), поэтому от программистов, стоявших у истоков SQL, и сейчас можно услышать сокращение «СИКвЕЛ» вместо «ЭсКюЭль». SEQUEL был переименован в SQL по юридическим соображениям; видимо, аббревиатура SEQUEL была уже кем-то захвачена.
На данный момент общепризнанным считается стандарт SQL-92, принятый в 1992 году и имеющий официальное название: ISO (1992). Database Language SQL (ISO 9075:1992(E)). International Organization for Standardization. Практически любая серьезная компания, разрабатывающая СУБД, поддерживает требования SQL-92. К наиболее известным клиент–серверным СУБД стоит отнести Oracle, INGRES, Informix, Sybase, SQLbase, Microsoft SQL Server, DB2 и Interbase.
В первоначальной минимальной нотации SQL был нацелен на решение трех базовых задач:
- Создание БД и таблиц с исчерпывающим описанием их структуры.
- Запрос от БД информации и представление ее в удобном для пользователя виде.
- Манипуляции с данными: добавление, редактирование и удаление данных.
Несколько позже SQL был обучен:
- Обработке транзакций.
- Управлению курсором.
- Определению прав пользователей.
Если классифицировать команды SQL в соответствии с их функциональным назначением, то можно выделить шесть подмножеств языка:
- Язык запросов – DQL (Data Query Language) предназначен для извлечения данных из таблиц и в своей основе опирается на инструкцию SELECT.
- Язык определения данных – DDL (Data Definition Language) в первую очередь нацелен на решение вопросов создания (CREATE) и удаления (DROP) различных объектов БД (таблиц, представлений, индексов, курсоров, определений доменов).
- Язык манипулирования данными – DML (Data Manipulation Language) осуществляет операции вставки, редактирования и удаления данных и базируется на инструкциях INSERT, UPDATE и DELETE.
- Язык управления доступом к данным – DCL (Data Control Language) устанавливает ограничения на права пользователей при работе с объектами базы данных. Характерными представителями инструкций этой категории выступают GRANT и REVOKE.
- Язык обработки транзакций – TPL (Transaction Processing Language) включает инструкции BEGIN TRANSACTION, COMMIT и ROLLBACK. Язык позволяет объединять несколько команд SQL в группу, называемую транзакцией. Если хотя бы одна из команд, входящих в транзакцию, не будет выполнена, осуществляется откат и всех других команд.
- Язык управления курсором – CCL (Cursor Control Language) выбирает для обработки одну строку результирующего множества запроса.
глава 2.Практическая часть
2.1 Анализ предметной области
В качестве предметной области для автоматизации процессов выбран абстрактный магазин пищевых товаров. Допустим, в его состав входит несколько складов и несколько торговых точек. Магазин небольшой, но имеет потенциал к расширению. На каждом складе за погрузкой и отгрузкой товара следит кладовщик, в каждой торговой точке есть кассовые аппараты, работу с которыми осуществляют продавцы. Также в магазине есть офис, где располагается вся бухгалтерия.
Исходя из описания предметной области, можно выделить несколько процессов, требующих автоматизации:
- работа со складом, документирование приема и отгрузки товара;
- работа по отпуску товара на кассах;
- формирование смен кассиров и кладовщиков, начисление заработной платы сотрудникам;
- работа с денежными средствами – прибылью и налогами;
- менеджмент продукции, организация заказов товара у поставщиков.
По территориальному признаку вышеописанные процессы реализуются в трех местах: на кассах, на складах и в офисе. Соответственно для каждого из этих мест необходимо разработать собственное средство автоматизации. Очевидно, что все средства автоматизации, несмотря на их развернутую структуру, работают с одним и тем же набором данных - списком товаров. Отсюда вытекает необходимость клиент-серверной реализации настоящей разработки с централизованным управлением транзакциями доступа к базе данных.
2.2 Разработка структуры базы данных
Для успешной реализации программного средства автоматизации необходимо разработать базу данных, способную отразить все процессы, протекающие в рассматриваемой предметной области.
Так как СУБД InterBase не поддерживает русского языка, в дальнейшем при описании объектов базы данных будет использоваться совместно русскоязычное название и англоязычный код, который в последующем будет использоваться при формировании физической модели базы данных.
Основными объектами любой реляционной базы данных являются таблицы. В СУБД InterBase каждое поле таблицы должно иметь определенный тип данных, основанный на встроенных типах данных InterBase.
Исходя из списка объектов предметной области, а также процессов, требующих автоматизации разработаем структуры таблиц базы данных (Таблица 2.1 – Таблица 2.22).
Таблица 2.1 – Структура таблицы «Выплаты»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Операция |
Operation |
INTEGER |
|
Работник |
Person |
INTEGER |
|
Период |
Start |
DATE |
|
Конец |
Ending |
DATE |
|
Сумма |
Cash |
DECIMAL(10,4) |
Таблица 2.2 – Структура таблицы «Заказ»
|
Поле |
Код |
Тип |
|
Заказ |
Order |
INTEGER |
|
Товар |
Good |
INTEGER |
|
Количество |
Amount |
INTEGER |
Таблица 2.3 – Структура таблицы «Заказы»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Поставщик |
Supplier |
INTEGER |
|
Дата |
Date |
DATE |
|
Сотрудник |
Employee |
INTEGER |
Таблица 2.4 – Структура таблицы «Занятость»
|
Поле |
Код |
Тип |
|
Поставщик |
Supplier |
INTEGER |
|
Подкатегория |
Subcategory |
INTEGER |
Таблица 2.5 – Структура таблицы «Кассы»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Сумма |
Cash |
DECIMAL(10,4) |
|
Разменные |
Trifle |
DECIMAL(10,4) |
|
Обслуживание |
Service |
DATE |
Таблица 2.6 – Структура таблицы «Категории»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Название |
Name |
VARCHAR(15) |
Таблица 2.7 – Структура таблицы «Кладовщики»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Работник |
Person |
INTEGER |
|
Оклад |
Salary |
DECIMAL(10,4) |
|
Премия |
Bonus |
DECIMAL(10,4) |
|
Отпускные |
Travel |
DECIMAL(10,4) |
|
Устройство |
Inauguration |
DATE |
|
Увольнение |
Dismissal |
DATE |
Таблица 2.8 – Структура таблицы «Налоги»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Операция |
Operation |
INTEGER |
|
Период |
Date |
DATE |
|
Конец |
Ending |
DATE |
|
Сумма |
Tax |
DECIMAL(10,4) |
Таблица 2.9 – Структура таблицы «Операции»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Касса |
Till |
INTEGER |
|
Дата |
Date |
DATE |
|
Остаток |
Balance |
DECIMAL(10,4) |
|
Плюс |
Plus |
DECIMAL(10,4) |
|
Минус |
Minus |
DECIMAL(10,4) |
|
Итог |
Total |
DECIMAL(10,4) |
Таблица 2.10 – Структура таблицы «Подкатегории»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Название |
Name |
VARCHAR(15) |
|
Категория |
Category |
INTEGER |
Таблица 2.11 – Структура таблицы «Поставки»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Поставщик |
Supplier |
INTEGER |
|
Заказ |
Order |
INTEGER |
|
Дата |
Date |
DATE |
Таблица 2.12 – Структура таблицы «Поставщики»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Организация |
Organization |
VARCHAR(50) |
|
ИНН |
Taxpayer |
VARCHAR(15) |
|
Адресс |
Adress |
VARCHAR(50) |
|
Телефон |
Phone |
VARCHAR(15) |
Таблица 2.13 – Структура таблицы «Продавцы»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Работник |
Person |
INTEGER |
|
Оклад |
Salary |
DECIMAL(10,4) |
|
Премия |
Bonus |
DECIMAL(10,4) |
|
Отпускные |
Travel |
DECIMAL(10,4) |
|
Устройство |
Inauguration |
DATE |
|
Увольнение |
Dismissal |
DATE |
Таблица 2.14 – Структура таблицы «Продажи»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Товар |
Product |
INTEGER |
|
Чек |
Ticket |
INTEGER |
|
Цена |
Price |
DECIMAL(10,4) |
|
Количество |
Counts |
INTEGER |
Таблица 2.15 – Структура таблицы «Продукты»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Товар |
Good |
INTEGER |
|
Годен до |
Expiration |
DATE |
|
Закупочная цена |
Purchase |
DECIMAL(10,4) |
|
Наценка |
Differential |
DECIMAL(10,4) |
|
НДС |
VAT |
DECIMAL(10,4) |
|
Скидка |
Discount |
DECIMAL(10,4) |
|
Цена |
Price |
DECIMAL(10,4) |
|
Количество |
Counts |
INTEGER |
|
Поставка |
Supply |
INTEGER |
|
Склад |
Stock |
INTEGER |
Таблица 2.16 – Структура таблицы «Работники»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Фамилия |
Surname |
VARCHAR(25) |
|
Имя |
Name |
VARCHAR(25) |
|
Отчество |
Patronymic |
VARCHAR(25) |
|
Дата рождения |
Birthday |
DATE |
|
Фотография |
Photo |
BLOB |
|
Счет |
Account |
VARCHAR(20) |
|
ИНН |
Taxpayer |
VARCHAR(15) |
|
Полис |
Policy |
VARCHAR(15) |
|
Пенсионный |
Pension |
VARCHAR(15) |
|
Должность |
Job |
VARCHAR(20) |
|
Доступ |
Access |
INTEGER |
|
Принят |
Inauguration |
DATE |
|
Уволен |
Dismissal |
DATE |
|
Отпуск |
Vacation |
DATE |
Таблица 2.17 – Структура таблицы «Склады»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Название |
Name |
VARCHAR(30) |
|
Адрес |
Adress |
VARCHAR(50) |
|
Телефон |
Phone |
VARCHAR(15) |
|
Описание |
Description |
VARCHAR(100) |
Таблица 2.18 – Структура таблицы «Смены кладовщиков»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Кладовщик |
Stockman |
INTEGER |
|
Склад |
Stock |
INTEGER |
|
Начало |
Start |
DATE |
|
Конец |
Ending |
DATE |
Таблица 2.19 – Структура таблицы «Смены продавцов»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Продавец |
Seller |
INTEGER |
|
Касса |
Till |
INTEGER |
|
Начало |
Start |
DATE |
|
Конец |
Ending |
DATE |
Таблица 2.20 – Структура таблицы «Сотрудники»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Работник |
Person |
INTEGER |
|
Оклад |
Salary |
DECIMAL(10,4) |
|
Премия |
Bonus |
DECIMAL(10,4) |
|
Отпускные |
Travel |
DECIMAL(10,4) |
|
Устройство |
Inauguration |
DATE |
|
Увольнение |
Dismissal |
DATE |
Таблица 2.21 – Структура таблицы «Товары»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Название |
Name |
VARCHAR(50) |
|
Производитель |
Maker |
VARCHAR(30) |
|
Подкатегория |
Subcategory |
INTEGER |
|
Ед. измерения |
Units |
VARCHAR(10) |
Таблица 2.22 – Структура таблицы «Чеки»
|
Поле |
Код |
Тип |
|
Номер |
Number |
INTEGER |
|
Дата |
Date |
DATE |
|
Касса |
Till |
INTEGER |
|
Наличные |
Cash |
DECIMAL(10,4) |
|
Сдача |
Submit |
DECIMAL(10,4) |
|
Итог |
Total |
DECIMAL(10,4) |
|
Отменен |
Canceled |
SMALLINT |
Определим коды названий таблиц для корректного физического проектирования базы данных в системе InterBase (Таблица 2.23).
Таблица 2.23 – Коды таблиц базы данных
|
Название таблицы |
Код таблицы |
|
Выплаты |
Salaries |
|
Заказ |
Items |
|
Заказы |
Orders |
|
Занятость |
Busyness |
|
Кассы |
Tills |
|
Категории |
Categories |
|
Кладовщики |
Stockmen |
|
Налоги |
Taxes |
|
Операции |
Operations |
|
Подкатегории |
Subcategories |
|
Поставки |
Delivery |
|
Поставщики |
Suppliers |
|
Продавцы |
Sellers |
|
Продажи |
Sales |
|
Продукты |
Products |
|
Работники |
People |
|
Склады |
Stocks |
|
Смены кладовщиков |
Stockmen shift |
|
Смены продавцов |
Cellers shift |
|
Сотрудники |
Employees |
|
Товары |
Goods |
|
Чеки |
Tickets |
Таблицы разрабатываемой базы данных являются взаимосвязанными. Так как при физической реализации связей необходимо указывать имя связи, которое не несет никакой смысловой нагрузки, при описании связей в базе данных ограничимся только кодом связи, связующим полем, исходной и конечной таблицей. В качестве кода будем использовать английское слово «Reference», знак подчеркивания и порядковый номер связи (Таблица 2.24).
Таблица 2.24 – Связи между таблицами базы данных
|
Код связи |
Исходная таблица |
Конечная таблица |
Поле связи |
|
Reference_1 |
Категории |
Подкатегории |
Категория |
|
Reference_2 |
Подкатегории |
Занятость |
Подкатегория |
|
Reference_3 |
Поставщики |
Занятость |
Поставщик |
|
Reference_4 |
Поставщики |
Поставки |
Поставщик |
|
Reference_5 |
Заказы |
Поставки |
Заказ |
|
Reference_6 |
Заказы |
Заказ |
Заказ |
|
Reference_7 |
Товары |
Заказ |
Товар |
|
Reference_8 |
Подкатегории |
Товары |
Подкатегория |
|
Reference_9 |
Товары |
Продукты |
Товар |
|
Reference_10 |
Поставки |
Продукты |
Поставка |
|
Reference_11 |
Склады |
Продукты |
Склад |
|
Reference_12 |
Продукты |
Продажи |
Товар |
|
Reference_13 |
Чеки |
Продажи |
Чек |
|
Reference_14 |
Кассы |
Чеки |
Касса |
|
Reference_15 |
Кассы |
Смены продавцов |
Касса |
|
Reference_16 |
Продавцы |
Смены продавцов |
Продавец |
|
Reference_17 |
Работники |
Продавцы |
Работник |
|
Reference_18 |
Работники |
Кладовщики |
Работник |
|
Reference_19 |
Работники |
Сотрудники |
Работник |
|
Reference_20 |
Кладовщики |
Смены кладовщиков |
Кладовщик |
|
Reference_21 |
Склады |
Смены кладовщиков |
Склад |
|
Reference_22 |
Кассы |
Операции |
Касса |
|
Reference_23 |
Операции |
Налоги |
Операция |
|
Reference_24 |
Операции |
Выплаты |
Операция |
|
Reference_25 |
Работники |
Выплаты |
Работник |
Так как для первичных ключей в базе данных InterBase условие уникальности накладывается только в пределах таблицы, в качестве имени первичных ключей всех таблиц будем использовать «Key_1».
Для реализации структуры базы данных воспользуемся CASE-средством PowerDesigner версии 15.3, разработанным компанией Sybase. Данное средство позволяет разрабатывать физические модели баз данных, оптимизированные для дальнейшей реализации на конкретной платформе с учетом её особенностей.

Рисунок 2.1 – Структурная схема БД в PowerDesigner 15.3
2.3 Реализация БД на языке SQL
Для создания базы данных в InterBase прежде всего необходимо определиться с местоположением базы данных, размером страниц памяти, диалектом языка SQL и используемой кодировкой символов.
В данном случае разумно использовать третий диалект языка SQL, так как данная его реализация значительно дополнена и исправлена. Для наглядной иерархии каталогов в программной системе выберем подкаталог «Data» главного каталога программы. Имя файла базы данных выберем соответствующее разрабатываемому проекту: «Shop.gdb». Размер страниц памяти логичнее выбирать в соответствии с размером страниц памяти, используемом на компьютерах конечного пользователя. В данном случае выберем размер равный 4Кб. При создании файла базы данных необходимо иметь права доступа администратора в системе InterBase, такими правами доступа в этой системе обладает стандартная учетная запись «sysdba», имеющая стандартный пароль для входа в систему «masterkey».
Конечный фрагмент кода создания файла базы данных выглядит следующим образом:
SET SQL DIALECT 3;
CREATE DATABASE '\Data\Shop.gdb'
PAGE_SIZE 4096
USER 'sysdba' PASSWORD 'masterkey'
DEFAULT CHARACTER SET WIN1251;
В соответствии с описаниями, приведенными выше, разработаем коды формирования таблиц и связей между ними в созданной базе данных на языке SQL. При этом будем использовать оговоренные ранее англоязычные коды таблиц и полей вместо их русскоязычных имен.
2.4Архитектура клиент-серверной системы
Для дальнейшей реализации приложения необходимо определить каким образом разрабатываемые приложения будут располагаться относительно друг друга физически и как будут связаны (Рисунок 2.2).

Рисунок 2.2 – Схема физических каналов связи
Как видно из схемы, в локальной сети располагается один сервер и три вида терминалов, получающих к нему доступ.
Программная взаимосвязь (Рисунок 2.3) должна учитывать не только физическое расположение программных средств, но и архитектуру доступа к данным.

Рисунок 2.3 – Схема программных каналов связи
2.5 Реализация серверной части приложения
Для реализации комплекса программных средств воспользуемся менеджером проектов Delphi и создадим группу проектов «Shop». Назовем проект сервера соответственно «Server».
Добавим в проект сервера удаленный модуль данных и назовем его «rdm». Далее организуем его следующим образом (Рисунок 2.4).

Рисунок 2.4 – Удаленный модуль данных
На главной оконной форме (Рисунок 2.5) серверной части разрабатываемой системы организуем системное меню, позволяющее получать информацию о подключенной базе данных, о клиентских программах, а также справочную информацию по работе системы.
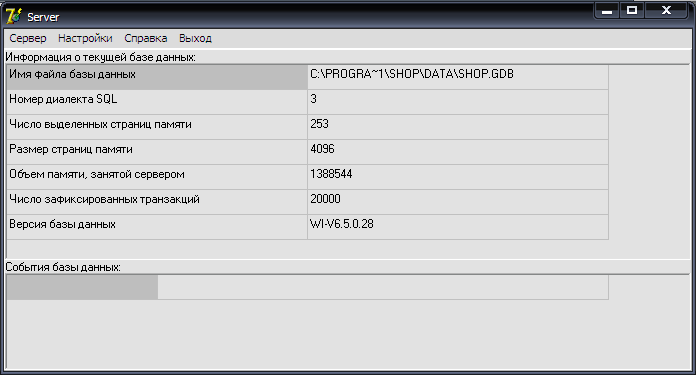
Рисунок 2.5 – Главная форма сервера приложений
Для указания местонахождения файла базы данных создадим форму настройки подключения базы данных (Рисунок 2.6).
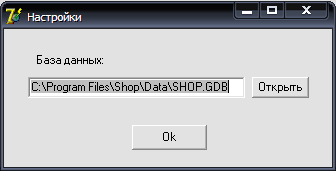
Рисунок 2.6 – Форма настройки адреса базы данных
Информацию о подключенных клиентских программах также отобразим на отдельной форме (Рисунок 2.7).
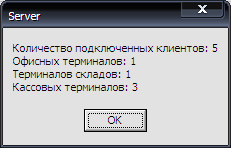
Рисунок 2.7 – Форма вывода информации о количестве подключений
2.6 Реализация клиентских частей приложения
В приложении «Cash» на главной форме создадим меню, позволяющее оперировать таблицами, устанавливать настройки соединения и вызывать справочные материалы (Рисунок 2.8).
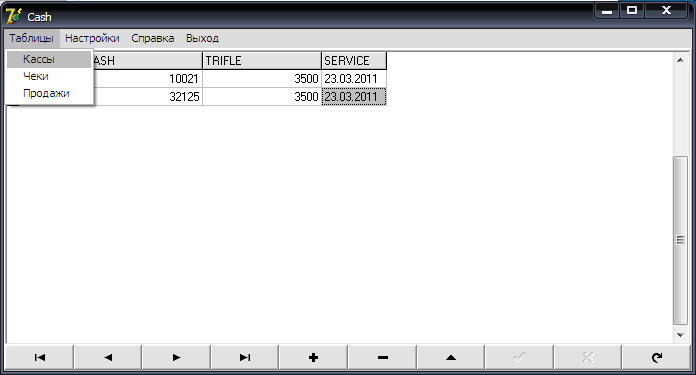
Рисунок 2.8 – Главная форма приложения «Cash»
Для удобства и экономии времени создадим отдельную форму «Соединение», которую будем вызывать из всех клиентских программ для настройки соединения с сервером (Рисунок 2.9).
Рисунок 2.9 – Форма настройки соединения с сервером приложений
Меню главной формы клиентских приложений «Stock» (Рисунок 2.10) и «Office» (Рисунок 2.11) создадим аналогичными приложению «Cash».
Рисунок 2.10 – Главная форма приложения «Stock»
Наполнению функционалом всех созданных форм предшествует размещение на них специальных компонентов отображения и управления данными, TDBGrid и TDBNavigator соответственно.
Рисунок 2.11 – Главная форма приложения «Office»
Заключение
В процессе выполнения курсовой работы был изучен теоретический материал по следующим темам:
- архитектура клиент-серверных приложений;
- технологии создания клиент-серверных приложений в Delphi 7;
- особенности системы управления базами данных InterBase;
- создание баз данных с помощью case-средства PowerDesigner 15;
- использование технологии сокетов при создании многоуровневых приложений в Delphi;
- обеспечение своевременности применения транзакций в технологии MIDAS Delphi.
После изучения теории была проведена следующая работа:
- создана физическая модель базы данных в PowerDesigner 15;
- сгенерирован sql-код для создания реальной базы данных;
- реализована разрабатываемая база данных в IBConsole;
- разработано и реализовано серверное приложение «Server»;
- разработаны и реализованы клиентские приложения «Cash», «Stock» и «Office»;
- создана инструкция пользователя для каждого приложения;
- оформлена пояснительная записка к курсовой работе.
Курсовая работа выполнена в полном объеме в соответствии с заданием.
Список литературы
- Сенов А.В. Access 2003. Практическая разработка баз данных / А.В. Сенов. СПб.: Питер, 2005.
- Барановская Т.П. Информационные системы и технологии в экономике: учебник / Т.П. Барановская, В.И. Лойко. М.: Финансы и статистика, 2003. – 416 с.
- Гайдамакин Н.А. Автоматизированные информационные системы, базы и банки данных. Вводный курс / Н.А. Гайдамакин. М.: Гелиос АРВ, 2002. – 412 с.
- Голицина О.Л. Основы алгоритмизации и программирования: учебное пособие. / О.Л. Голицина, И.И. Попов. М.Форум: Инфра-М, 2004. – 432 с.
- Кириллов В.В. Структурированный язык запросов (SQL): учебное пособие / В.В. Кириллов, Г.Ю. Громов. СПб.: ИТМО, 2004. – 71 с.
- Кузин А.В. Базы данных: учебное пособие / А.В. Кузин, С.В. Левонисова. М.: Изд.центр «Академия», 2005. – 250 с.
- Послед Б.С. Access 2000 Базы данных и приложения: лекции / Б.С. Послед. М.: Изд.центр «Академия», 2005. – 250 с.
Инструкция пользователя программы-сервера
На главной оконной форме серверной части системы основным элементом управления является системное меню, позволяющее получать информацию о подключенной базе данных, о клиентских программах, а также справочную информацию по работе системы.

Для начала работы необходимо указать местонахождение файла базы данных, необходимо открыть форму настройки подключения базы данных Настройки-База данных.
Информацию о подключенных клиентских программах можно отобразить на отдельной форме после перехода Сервер-Подключения.
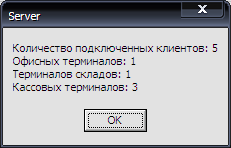
Для отображения информации о базе данных и событиях, происходящих в ней существует пункт меню Сервер-Мониторинг.
Инструкция пользователя для клиентских программ
Запуск приложения осуществляется двойным кликом мыши по ярлыку cash.exe. Для подключения к серверу нужно выбрать в меню «Настройки» пункт «Соединение» и в строку «Адрес» внести сетевой адрес сервера, или в строке «Хостинг» отобразить локальное имя сервера. После нажатия кнопки «Ok» программа попытается соединиться с указанным сервером .
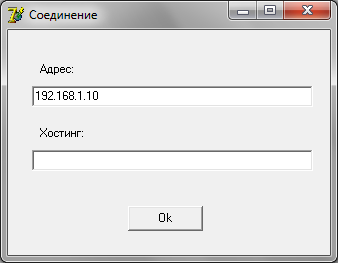
Соединение может занимать до 1 минуты. После подключения к серверу следует выбрать таблицу, которая будет нужна для работы. Для этого нажимаем: Меню – Таблицы и выбираем необходимую таблицу.
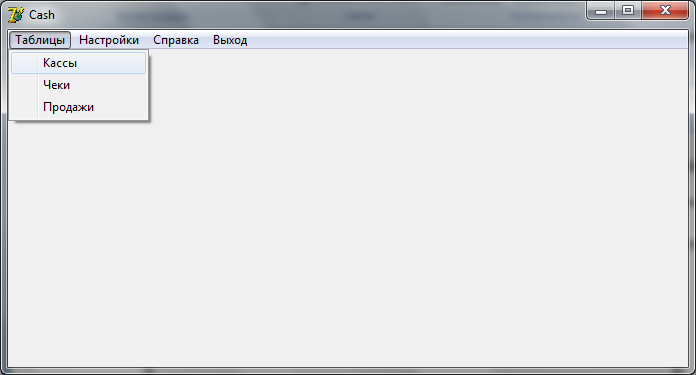
Для примера рассмотрим работу с таблицей Кассы. Работа с другими таблицами аналогична.
Для ввода данных в таблицу устанавливаем курсом на нужное поле для ввода и вносим данные. После ввода всех данных нажимаем на кнопку √ .
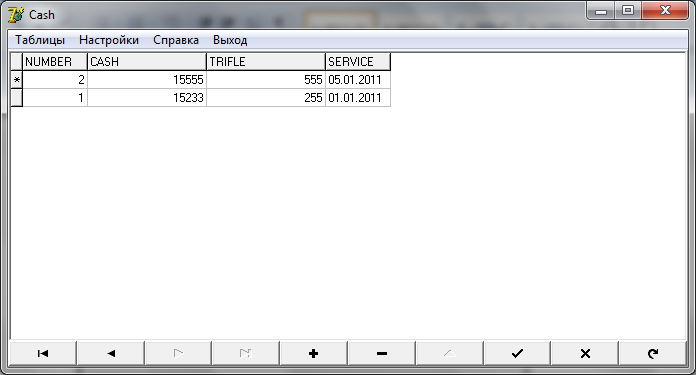
Для ввода новой строки с данными нажимаем на кнопку +
Для удаления строки с данными нажимаем на кнопку -
Для обновления данных всей таблицы нажимаем на кнопку 
Так же есть кнопки для перемещения между строками.
Для выхода из формы в основном меню нажимаем кнопку Выход.

- Рынок ценных бумаг
- Нотариат в Российской Федерации (Основные положения о нотариате и его деятельности)
- Управление эффективностью организации гостиничного (ресторанного) бизнеса (Анализ рынка и организации работы в пиццерии «American Hot Pizza» ООО «ЮНИВЕРФУД»)
- БРЕНД КАК КОНКУРЕНТНОЕ ПРЕИМУЩЕСТВО КОМПАНИИ
- Понятие и задачи экономического анализа (Предмет экономического анализа и его научный аппарат)
- Управление доходами организации индустрии гостеприимства (на примере гостиницы «МАРИЯ»)
- Понятие и виды ценных бумаг
- ГРАЖДАНСКО-ПРАВОВЫЕ СПОСОБЫ ЗАЩИТЫ ПРАВА СОБСТВЕННОСТИ
- Понятие и виды наследования
- Банковские риски и основы управления ими (на примере ОАО "Газпромбанк").
- Порядок отражения в бухгалтерском учете кассовых операций, операций с наличной иностранной валютой.
- История возникновения и развития языка программирования Си (С++) и Java (Возникновение и эволюция языка Си и С++)