
Системы с распределенной разделяемой памятью (Классификация архитектур вычислительных систем)
Содержание:

ВВЕДЕНИЕ
Актуальность темы исследования. В существующих условиях весьма широкое распространение имеют многопроцессорные вычислительные системы. При решении задач, связанных с увеличение производительности подобных систем можно использовать два подхода.
В первом из них повышают тактовую частоту процессоров, во втором ориентируются на то, что параллельным образом выполняют программы. При осуществлении процессов компиляции для исходных последовательных программ для многопроцессорных систем активным образом применяют процедуры выявления информационно-независимых операторов при их дальнейшем распараллеливании.
Многопроцессорная техника развивается, что определяет возрастание числа процессоров в подобных системах, что ведет к необходимости того, чтобы происходила загрузка каждого из процессоров на основе информационно независимых задачам и требуется, чтобы происходило распараллеливание последовательных программ для того, чтобы они выполнялись одновременным образом на нескольких процессорах.
Действующие способы и алгоритмы, которые направлены на выявление информационно-независимых участков в программах большей частью – программные, и проблемы, связанные с распараллеливанием циклических участков по последовательным программам с точки зрения использования в системах высокой готовности рассмотрены в них в недостаточно.
Цель исследования – рассмотреть и проанализировать системы с распределенной разделяемой памятью.
В соответствии с поставленными целями решались следующие основные задачи:
- рассмотреть классификацию архитектур вычислительных систем;
- дать понятие и выявить сущность вычислительной системы с распределенной памятью (distributed memory);
- рассмотреть мультипроцессоры CC-NUMA;
- дать характеристику мультипроцессорам NC-NUMA с координатными коммутаторами;
- изучить особенности мультипроцессор Stanford DASH;
- рассмотреть мультипроцессор Sequent NUMA-Q;
- выявить особенности мультипроцессора СОМА.Методы исследования:
-обработка, анализ научных источников;
-анализ научной литературы, учебников и пособий по исследуемой проблеме.
Объект исследования – системы с распределенной разделяемой памятью
Предмет исследования – архитектура и способы построения систем с распределенной разделяемой памятью
Теоретическую основу курсовой работы составляют труды таких авторов, Бос Х., Вялова Е.П., Данилова А.В., Карташевский И.В., Лавлинская О.Ю., Лукашенко В. В., Малахов С.В., Преображенский А.П., Романчук В.А., Ручкин В.Н., Савельев В.А., Таненбаум Э., Фулин В.А., Хюбнер М., Цилькер Б.Я., Штейнберг Б.Я., Яцутин С.В. , Ящук А.М.
Одним из самых надежных источников является Цилькер Б.Я. Организация ЭВМ и систем. Учебник посвящен систематическому изложению вопросов организации структуры и функционирования вычислительных машин и систем, при этом большое внимание уделяется вопросам эффективности традиционных и перспективных решений в области компьютерной техники. Рассмотрены структура и функционирование классических фон-неймановских машин, принципы организации шин, внутренней и внешней памяти, операционных устройств и устройств управления, систем ввода-вывода. Изложены основные тенденции в архитектуре современных процессоров. Значительная часть материала посвящена идеологии построения и функционирования параллельных и распределенных вычислительных систем самых разнообразных классов. Показаны наиболее перспективные направления в области организации и архитектуры вычислительных машин и систем
Курсовая работа состоит из введения, двух глав, заключения и списка использованных источников.
1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ И КЛАССИФИКАЦИЯ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
1.1 Классификация архитектур вычислительных систем
Бурное развитие микропроцессорных технологий в конце 20-го века привело к колоссальному росту производительности настольных вычислительных систем. Это породило ожидания, что большие вычислительные системы скоро навсегда уйдут в прошлое. Однако, этого не произошло. Персональные компьютеры, ставшие незаменимыми помощниками в повседневной деятельности громадного числа людей, не смогли заменить большие вычислительные системы в той сфере деятельности, для которой компьютеры изначально и создавались, а именно, для решения сложных вычислительных задач.
Потребности развития науки и технологий постоянно диктуют необходимость создания вычислительных систем в тысячи раз превосходящие возможности персональных компьютеров. Такие вычислительные системы называют суперкомпьютерами, а развитие суперкомпьютерных технологий объявлено приоритетным направлением во всех ведущих странах мира. В настоящее время, без применения суперкомпьютеров невозможно проведение исследований ни в фундаментальных, ни в прикладных науках. [3, с. 18].
Большое разнообразие многопроцессорных вычислительных систем породило естественное желание ввести для них какую-то классификацию. Эта классификация должна однозначно относить ту или иную вычислительную систему к определенному классу. С другой стороны, принадлежность вычислительной системы к некоторому классу должна достаточно определенно и полно характеризовать ее. Одна из первых классификаций была предложена Флинном еще в конце 60-х годов. [23, с. 1901] На нее до сих пор наиболее часто ссылаются в литературе. Она базируется на понятии двух потоков: потока команд и потока данных.
В классической вычислительной системе единственный центральный процессор через шину памяти имеет прямой доступ ко всей оперативной памяти. В современных компьютерах частота, на которой работает оперативная память и, соответственно, шина памяти существенно отстала от частоты работы процессора. В самом деле, частота работы процессора составляет сегодня порядка 3 Ггц, а частота шины памяти едва превысила 1 Ггц. [1, с. 105]
Для преодоления этого разрыва современные микропроцессоры снабжаются скоростной кэш-памятью, работающей на частоте процессора. Поскольку увеличение частоты работы оперативной памяти поддается с большим трудом, то увеличение объема кэш-памяти стало одним из основных резервов увеличения скорости работы вычислительной системы в целом. За последние два десятилетия объем кэш-памяти вырос от нескольких килобайт до нескольких мегабайт. [6, с. 59]. Таким образом, схема современной однопроцессорной вычислительной системы выглядит следующим образом (Рис. 1.1.).
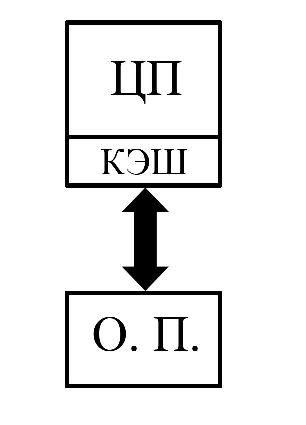
Рис.1.1. Архитектура традиционной вычислительной системы
Задача, связанная с распараллеливанием в многопроцессорных системах, когда ее решают программным способом, выполняется при помощи хост–процессора, который решает множество задач: маршрутизацию, проведение назначения и перераспределения задач, проведение реконфигурации и исполнение функций, которые требуются для того, чтобы управлять системой, что ведет к дополнительной нагрузке на хост-процессор.
Есть процессоры, в которых существуют встроенные дополнительные устройства по распараллеливанию, дающие возможности для повышения эффективности вычислительной системы, это ведет к тому, что будет функциональная разгрузка хост-процессора. [12, с. 96].
Но, процессы распараллеливания в таких системах выполняются лишь для уровня команд, в то время как проведение распараллеливания на уровне данных или участков программ дает возможности для увеличения быстродействия всей системы. [6, с. 109].
Так как в программах большая часть времени при их выполнении относится к циклам, то проведение их распараллеливания ведет к тому, что будет увеличение быстродействия в системе. Весьма заметно это будет для циклов, имеющих большое количество итераций, когда происходит распараллеливание для систем высокой готовности. Важная роль принадлежит использованию соответствующих алгоритмов управления компьютерной сетью.
В любой вычислительной системе можно выделить два важнейших компонента - центральный процессор, выполняющий вычисления, и оперативную память, в которой хранится выполняемая программа совместно с обрабатываемыми данными. В классической однопроцессорной вычислительной системе единый поток инструкций, генерируемый программой, обрабатывает единый поток данных.
Сейчас среди способов, связанных с классификацией ЭВМ довольно большое распространение имеет систематика Флинна. [23, с. 1903] В таком методе классификации систем основное внимание уделяют подходам, описывающим взаимодействие потоков команд и потоков данных. Указанная классификация выделяет такие типы систем:
SISD (Single Instruction, Single Data) – системы, имеющие одиночный поток команд и одиночный поток данных. К этому классу относят обычные последовательные ЭВМ. [16, с. 205].
SIMD (Single Instruction, Multiple Data) – системы, имеющие одиночный поток команд и множественный поток данных. В качестве примера можно привести многопроцессорные системы, имеющие единое устройство управления (ILLIAC IV, CM-1). SIMD системы (Single Instruction stream - Multiple Data stream) позволяют организовать выполнение на всех процессорах одной и той же команды над различными данными. При этом в классических SIMD архитектурах выполнение каждой команды программы во всех процессорах осуществляется синхронно под управлением единого блока интерпретации команд единственного экземпляра программы, что избавляет от необходимости использования специальных средств синхронизации программ для обеспечения одновременности выполнения команд межпроцессорных коммуникаций. Поэтому SIMD системы часто называют также системами с синхронным параллелизмом. [20, с. 544].
MISD (Multiple Instruction, Single Data) – системы, имеющие множественный поток команд и одиночный поток данных. В качестве примера можно привести систолические вычислительные системы или системы, в которых происходит конвейерная обработка данных; [6, с. 85].
Более общим случаем, являются MIMD системы (Multiple Instruction stream - Multiple Data stream), в которых каждый процессор может выполнять свой поток инструкций над отдельным потоком данных. MIMD (Multiple Instruction, Multiple Data) – системы, имеющие классу относятся большинство из параллельных многопроцессорных вычислительных систем. Отметим, что для программирования многопроцессорных систем с архитектурой типа MIMD может использоваться принцип программирования SPMD (Single Program - Multiple Data), реализуемый путем клонирования экземпляров одной программы во все процессоры системы с архитектурой типа MIMD. При этом, однако, выполнение различных экземпляров такой программы в различных процессорах осуществляется асинхронно и, поэтому, выполнение межпроцессорных коммуникаций должно синхронизироваться с использованием соответствующих средств. Как правило, многопроцессорные системы с архитектурой типа MIMD и развитым системным программным обеспечением кроме режима MIMD (который без всякого изменения смысла может быть назван MPMD) поддерживают также режим SPMD выполнения параллельной программы. Например, оба режима работы поддерживала многопроцессорная вычислительная система nCUBE 2S. [1, с. 125]
Хотя классификация Флинна вплоть до настоящего времени является самой упоминаемой при характеристике того или иного компьютера, однако она уже плохо отражает состояние развития суперкомпьютерных технологий. На сегодняшний день классические системы SIMD архитектуры (ILLIAC IV, ICL DAP и др.) остались в прошлом, а класс MIMD оказался перегруженным, поскольку к нему можно отнести любую современную многопроцессорную систему. Теоретически возможная архитектура MISD (Multiple Instruction stream - Single Data stream) так и не получила ни какого реального воплощения. [22, с. 10].
Даже при широком распространении систематики Флинна, которая позволяет проводить классификацию вычислительных систем, в ней отмечают один существенный недостаток. В этой классификации к группе MIMD относят почти все параллельные вычислительные системы, хотя при этом они являются весьма разнородными. [20, с. 546].
В этой связи для MIMD систем есть предложения по своей отдельной классификации. При этом многопроцессорные системы подразделяют по тому, как организована оперативная память в таких системах. Классификацию многопроцессорных вычислительных систем можем увидеть на рисунке 1.2

Рис.1.2. Проведение классификации по многопроцессорным вычислительным системам
В этой классификации происходит выделение двух основных классов многопроцессорных вычислительных систем – мультипроцессоров (говорят о системах с общей памятью) и мультикомпьютеров (говорят о системах с распределенной памятью).
Происходит подразделение мультипроцессоров, в свою очередь, по способам организации общей памяти: рассматривают системы, имеющие однородную общую память (uniform memory access, UMA) и системы, имеющие неоднородную общую память (non-uniform memory access, NUMA). [10].
Системы, имеющие однородную общую память, рассматриваются в качестве основы для того, чтобы строить векторные параллельные процессоры (PVP) и симметричные мультипроцессоры (SMP). Векторный параллельный процессор – это суперкомпьютер Cray T90, симметричный - HP Superdome, IBM eServer и другие. [3, с. 105]
Первые мультипроцессорные вычислительные системы были получены из однопроцессорных систем подключением к шине памяти одного или нескольких дополнительных процессоров без радикального изменения базовой архитектуры. В самом деле, если у 2-х процессорной системы оставить только один процессор, то компьютер будет работать как обычная однопроцессорная система, если же установить оба процессора, то получится мультипроцессорная вычислительная система с общей памятью, поскольку оба процессора имеют равноправный доступ к общей шине памяти. Поэтому системы с общей памятью еще называют симметричными мультипроцессорными системам (Symmetric MultiProcessing - SMP). [1, с. 139]
Упрощенная схема системы с общей памятью представлена на Рис. 1.3. 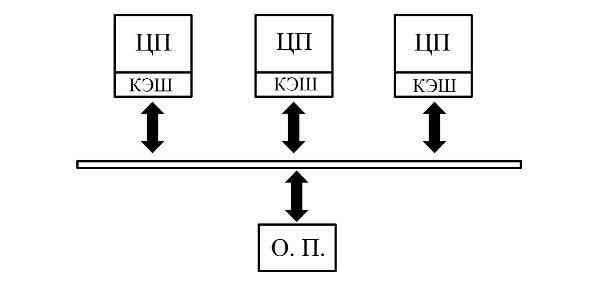
Рис.1.3. Архитектура параллельной вычислительной системы с общей памятью
Разумеется, в реальности все сложнее, поскольку сама архитектура процессоров, допускающих использование их в многопроцессорных системах значительно сложнее, чем у процессоров, используемых в однопроцессорных системах. С этим связана непропорционально высокая стоимость SMP систем по сравнению с обычными персональными компьютерами. Как компромиссный вариант некоторые производители процессоров стали выпускать специализированные процессоры для 2-х, 4-х и 8-ми процессорных систем. [6, с. 102].
Второй способ создания многопроцессорной вычислительной системы состоит в объединении в единую вычислительную систему множества традиционных однопроцессорных вычислительных систем с помощью коммуникационного оборудования. [16, с. 221].
Таким образом, в системах этого типа каждый процессор имеет прямой доступ только к собственной оперативной памяти, а обмен с памятью других процессоров возможен только через коммуникационные каналы посредством передачи сообщений. Вычислительные системы этого типа получили название систем с массовым параллелизмом (Massively-Parallel Processing - MPP). Поскольку память распределена между процессорами, то системы этого типа называют системами с распределенной памятью. Архитектура вычислительных систем с распределенной памятью представлена на Рис. 1.4.
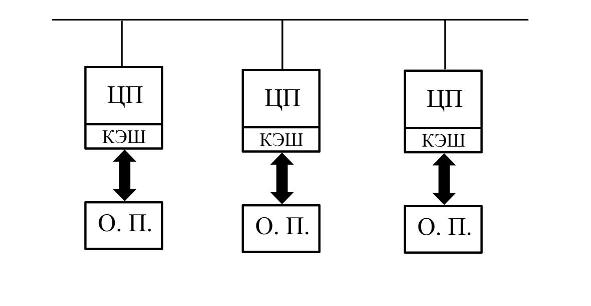
Рис.1.4. Архитектура параллельной вычислительной системы с распределенной памятью
Первоначально системы MPP типа тоже строились с использованием специальных процессоров, со встроенным коммуникационным оборудованием, однако, с появлением высокоскоростного коммуникационного оборудования общего назначения, надобность в этом отпала и в настоящее время такие системы создаются на базе общедоступного серийного коммуникационного оборудования. [13 с. 68].
Следует отметить, что в последнее время, особенно с появлением многоядерных процессоров, все более популярными становятся гибридные системы, в которых коммуникационное оборудование объединяет многопроцессорные (многоядерные) узлы с общей памятью.
Каждая из архитектур - с общей и с распределенной памятью, имеют свои достоинства и недостатки.
1.2 Понятие и сущность вычислительной системы с распределенной памятью (distributed memory)
Вычислительная система с распределенной памятью (distributed memory) – система, в которой каждый процессор обладает собственной локальной памятью, а общая память отсутствует. Обмен информацией между составляющими системы обеспечивается с помощью коммуникационной сети посредством обмена сообщениями. [14 с. 71].
Системы с распределенной памятью изначально конструировались как системы, призванные преодолеть ограничения свойственные системам с общей памятью. Было предложено строить многопроцессорные вычислительные системы как набор независимых вычислительных узлов, состоящих из процессора, локальной оперативной памяти, и коммуникационного оборудования для взаимодействия узлов. Такая архитектура вычислительной системы снимала проблемы, связанные с пропускной способность шины памяти и с необходимостью поддержки когерентности кэш-памяти всех процессоров. Это значительно расширило возможности по наращиванию числа процессоров в вычислительной системе, которое ограничивалось теперь только возможностями коммуникационного оборудования. [3, с. 122]
Системы с общей (разделяемой) оперативной памятью образуют современный класс ВС — многопроцессорных супер-ЭВМ. Одинаковый доступ всех процессоров к программам и данным представляет широкие возможности организации параллельного вычислительного процесса (параллельных вычислений). Отсутствуют потери реальной производительности на межпроцессорный (между задачами, процессами и т.д.) обмен данными (рис. 1.5a).
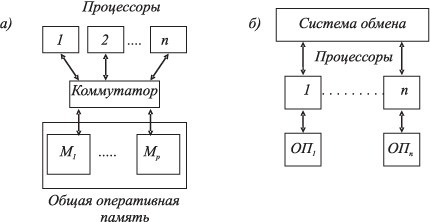
Рис. 1.5. ВС с общей (а) и распределённой (б) памятью
Системы с распределенной памятью образуют вычислительные комплексы (ВК) — коллективы ЭВМ с межмашинным обменом для совместного решения задач (рис. 1.5б). В ВК объединяются вычислительные средства систем управления, решающие специальные наборы задач, взаимосвязанных по данным. Принято говорить, что такие ВК выполняют распределенные вычисления, а сами ВК называют распределенными ВК. [16, с. 117].
В настоящее время функционируют вычислительные системы с распределенной памятью, состоящие из нескольких сотен тысяч процессоров (IBM Blue Gene/L). При построении таких систем используются высокоскоростные коммутаторы, соединяемые в топологию «толстого дерева». [3, с. 122]
Первоначально, системы с распределенной памятью появились как дорогие специализированные вычислительные системы. Однако, с появлением недорого высокоскоростного коммуникационного оборудования, вычислительные системы с распределенной памятью стали создавать на базе стандартных системных блоков. Это значительно снизило стоимость многопроцессорных вычислительных систем и сделало их общедоступными. Такие вычислительные системы получили название вычислительных кластеров. Не составляет большого труда создать вычислительный кластер из компьютеров учебного класса или лаборатории. Законченные, хорошо сбалансированные решения предлагаются сегодня практически всеми фирмами - производителями компьютерного оборудования. [1, с. 189]
Отсутствие общей памяти улучшило масштабируемость вычислительных систем, но значительно усложнило взаимодействие между процессорами и, соответственно, программирование для них. Как правило, на каждом узле функционирует своя копия операционной системы, в которой запускается отдельная копия параллельной программы.
Взаимосвязь между узлами осуществляется с помощью механизма передачи сообщений. Этот механизм реализуется в виде прикладных библиотек, которые должны подключаться к параллельной программе. Каждый производитель многопроцессорных систем с распределенной памятью поставлял такие библиотеки в составе системного программного обеспечения своих компьютеров. Например, среда параллельного программирования (PSE) многопроцессорной системы nCUBE2 включала в себя 5 встроенных функций и небольшую вспомогательную библиотеку. [18, с. 136].
В настоящее время в качестве стандарта коммуникационной библиотеки принята платформенно-независимая библиотека MPI. Эта библиотека предоставляет широкий набор средств для создания параллельных программ, однако программирование на уровне вызовов коммуникационных библиотечных функций остается довольно трудоемким. [19, с. 88].
Предпринимаются попытки создания средств для автоматического и полуавтоматического распараллеливания программ. Одним из наиболее законченных решений такого рода является язык HPF (High Performance Fortran). Имеются как коммерческие версии компиляторов (PGHPF - Portland Group Inc., xlhpf - IBM, Absoft Pro Fortran - Absoft Corporation), так и открытые продукты (Adaptor - GMD-SCAI, DVM - ИПМ им Келдыша РАН).
Таким образом, можно сделать следующий вывод.
Вычислительные системы бывают двух видов
1.Компьютерные с общей памятью (мультипроцессорные системы)
2.Компьютерные с распределенной памятью (мультикомпьютерные системы) классы архитектур параллельных систем: с распределенной памятью (MPP) и с общей памятью (SMP).
Приведенная классификация вычислительных систем дает возможности говорить о том, что существует множество подходов, связанных с построением многопроцессорных систем, в каждом из них есть свои преимущества и недостатки. В качестве особого класса вычислительных систем можно считать системы высокой готовности, для которых идет предъявление особых требований по характеристикам надежности и доступности систем.
2. АНАЛИЗ СПОСОБОВ ПОСТРОЕНИЯ МИКРОПРОЦЕССОРОВ NUMA
2.1 Мультипроцессоры CC-NUMA
Архитектура неоднородного доступа к памяти с обеспечением когерентности кэшей ccNUMA (Cache Coherent Non-Uniform Memory) реализуется на базе шины. Аппаратные средства следят за процессами на шине, главным образом, относящимися к операциям записи в кэш-память. При попытке какого-то процессора модифицировать содержимое в одном из блоков своей кэш-памяти, эти аппаратные средства либо таким же образом обновляют содержимое аналогичных блоков в кэш-памяти других процессоров, либо помечают эти блоки как недостоверные. Примерами ВС с архитектурой системы памяти типа ccNUMA являются: SGI Origin 2000, Origin 3000, Cray ТЗЕ, HP Exemplar, IBM/Sequent NUMA-Q 2000. [16, с. 224].
Рассмотрим широко распространенный способ построения больших мультипроцессоров CC-NUMA (Cache Coherent NUMA – NUMA с согласованной кэш-памятью) на основе каталога. [18, с. 142].
Каталог представляет собой базу данных, которая содержит информацию о том, где именно находится каждая строка кэш-памяти и каково ее состояние (см. рис. 2.1). При каждом обращении к кэш-памяти все необходимые данные о затребованной строке выводятся из базы данных. Для взаимодействия с базой данных используются высокоскоростные аппаратные средства, способные выдавать ответ на запрос за долю цикла шины.
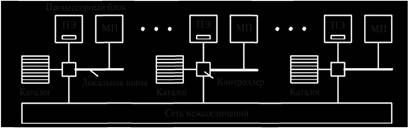
Рис. 2.1 Мультипроцессор CC-NUMA
Состав. Для понимания сути и особенностей мультипроцессоров на основе каталога рассмотрим систему (рис. 2.1) из 256 процессорных блоков, которые связаны через сеть межсоединений в виде решетки, гиперкуба или другой топологии. Каждый процессорный блок состоит из процессорного элемента ПЭ, модуля памяти МП, связанного с ПЭ через локальную шину, контроллера и каталога. Модуль памяти размером 224 = 16М байт используется в качестве кэша, содержащего 218 строк по 64 байта каждая. Таким образом, общий объем памяти ОЗУ, составляющий 256×224 = 232 байта, разделен на 226 строк кэш-памяти по 26 (64) байта каждая. Каталог каждого процессорного блока содержит 218 элементов длиной в 9 бит с записями для каждой строки кэша, т.е. объем памяти каталога равен 9×218 бит, что составляет 1,76% от объема памяти одного процессорного блока. [3, с. 136]
Принцип работы. Рассмотрим, как работает мультипроцессор на основе каталога, предполагая, что:
- процессорный блок обращается к памяти с помощью команды load;
- затребованная строка может содержаться только в одной кэш-памяти, т.е. других ее копий не существует.
В этом случае выполняется следующая последовательность действий: [16, с. 251].
- процессорный блок (исходный узел А1) передает команду load в контроллер;
- контроллер переводит команду в физический адрес, разделяя его на три части – адресуемый узел А2 (8 бит), адресуемая строка S1 (18 бит) и смещение С (6 бит);
- поскольку в исходном узле А1 строка отсутствует, то узлу А2 через сеть направляется запрос;
- запрос поступает в каталог, аппаратные средства которого индексируют таблицу из 218 элементов;
- если строка S1 отсутствует в кэш-памяти, то аппаратное обеспечение вызывает строку S1 из локального ОЗУ, отправляет в исходный узел А1 и обновляет элемент каталога S1, чтобы показать, что эта строка находится в кэш-памяти узла А1.
Рассмотрим другую ситуацию, когда из узла А1 запрашивается строка S2, а в каталоге узла А2 указано, что строка S2 находится в кэш-памяти узла А3. В этом случае выполняются следующие действия:
- из узла А2 посылается сообщение в узел А3, чтобы строка S2 из него была передана в узел А1;
- затребованная строка S2 передается в А1;
- строка S2 в кэш-памяти узла А3 объявляется недействительной;
- обновляется элемент каталога S2 узла А3, чтобы зафиксировать, что строка уже находится в узле А1.
Недостатком рассмотренного мультипроцессора является то, что строка может быть кэширована только в одном процессорном блоке (узле). Для его устранения предлагается: [18, с. 152].
- предоставить каждому элементу каталога k полей для определения других процессорных блоков;
- заменить номер процессорного блока битовым отображением: один бит на процессорный блок;
- хранить в каждом элементе каталога 8-битное поле, чтобы связать все копии строки всех кэшей.
На практике используются все три возможности, хотя каждая из них имеет свои достоинства и недостатки. [17, с. 596].
Контроль состояния строк кэш-памяти и операции с обновленными строками. Запрос на считывание строки кэш-памяти, которая не изменилась, может быть удовлетворен из основной памяти, поэтому его можно не направлять в кэш-память. [3, с. 147]
Запрос на считывание строки кэш-памяти, которая была изменена, направляется в тот процессорный блок (узел), в котором находится ее действительная копия. Если разрешается иметь только одну копию строки кэш-памяти, то отсутствует необходимость в отслеживании изменений в строках кэш-памяти. Это обусловлено тем, что любой новый запрос должен пересылаться к существующей копии, чтобы объявить ее недействительной. [1, с. 195]
Об изменении строки необходимо сообщить в исходный процессорный блок даже в том случае, когда в кэш-памяти существует только одна копия строки. При наличии нескольких копий изменение одной из них требует объявления всех остальных копий недействительными.
2.2 Мультипроцессоры NC-NUMA с координатными коммутаторами
Характерная особенность мультипроцессоров NUМA (Non Uniform Memory Access – с неоднородным доступом к памяти) проявляется в следующем:
- имеется одно адресное пространство, видимое для всех процессорных элементов (ПЭ);
- обращение к удаленной памяти производится с использованием команд load и store;
- доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти.
Рассмотрим два типа мультипроцессоров: без кэш-памяти и с кэш-памятью.
Мультипроцессоры NC-NUMA (No Caching NUMA). На рис. 2.2 приведена упрощенная схема одного из первых мультипроцессоров этого типа – Carnegie-Mellon Cm, построенного на основе процессорных блоков, каждый из которых состоит из процессорного элемента ПЭ, модуля памяти МП и контроллера управления памятью, связанных локальной шиной. Процессорные блоки связаны друг с другом системной шиной. [21, с. 158].
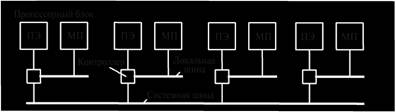
Рис. 2.2. Мультипроцессор NC-NUMA
Запрос чтения/записи поступает в контроллер управления памятью, который выявляет наличие нужного слова в локальной памяти: [3, с. 169]
- при наличии слова запрос отправляется по локальной шине;
- при отсутствии слова запрос направляется по системной шине к процессорному блоку, который содержит данное слово. Эта операция занимает гораздо больше времени, чем первая.
В связи с отсутствием кэш-памяти каждое слово находится в определенном (фиксированном) месте памяти, поэтому устаревших данных здесь нет. Однако обращения к удаленной памяти (при отсутствии запрашиваемого слова в локальной памяти) снижают производительность системы. [20, с. 559]. При расширении (добавлении новых процессорных блоков) мультипроцессора этот недостаток усугубляется. Для создания мультипроцессоров большей размерности используются другие способы.
2.3 Мультипроцессор Stanford DASH
Состав. Этот мультипроцессор, созданный в Стэнфордском университете, служит примером конкретной реализации систем CC-NUMA на основе каталога. Система состоит из 16 кластеров, каждый из которых содержит (рис. 2.3,а):
- 4 процессорных элемента ПЭ (MIPS R3000), при этом каждый ПЭ отслеживает только свою локальную шину;
- модуль памяти МП объемом 16 Мбайт, который выполняет функции кэша, содержащего 1М = 220 строк длиной 16 байт. Общий объем памяти равен 16x16 = 256 Мбайт;
- каталог из 1М элементов (рис. 2.3,б), который следит за тем, какие кластеры имеют копии своих строк. Каждый элемент содержит:
- 16 бит (биты 0–15), по одному биту на кластер. Биты показывают, имеется ли в данный момент строка данного кластера в кэш-памяти;
- 2-битное поле, которое сообщает о состоянии строки (Uncachcd – U, Shared – S, Modified – М).
Память всех каталогов 18×1М×16 несколько превышает 36 Мбайт, что составляет около 14% от 256 Мбайт. [6, с. 59].
Принцип функционирования. Кластеры в Stanford DASH имеют возможность обмениваться информацией друг с другом через межкластерный интерфейс по межкластерным каналам (рис. 2.3).
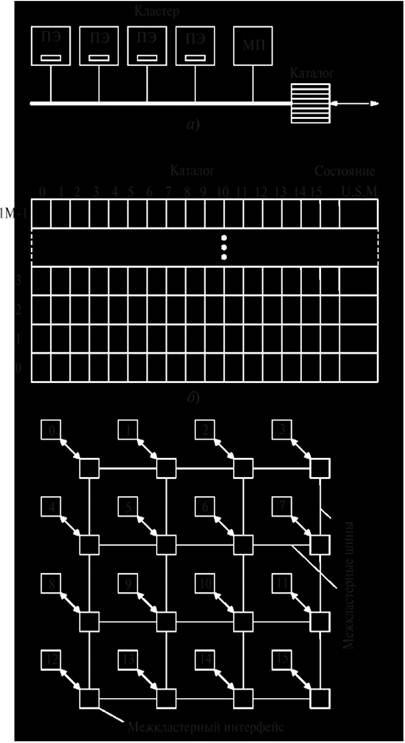
Рис. 2.3. Кластерный блок (а), каталог (б) и структура (в) DASH
Каждая строка кэш-памяти может находиться в одном из трех следующих состояний:
- Uncached (некэшированная) – строка находится только в памяти;
- Shared (совместно используемая) – строка в памяти содержит новейшие данные; строка может находиться в нескольких блоках кэшпамяти;
- Modified (измененная) – строка, содержащаяся в памяти, неправильная; строка находится только в одной кэш-памяти.
Владельцем строки в состоянии Uncached или Shared является собственный кластер, а в состоянии Modified – тот кластер, в котором содержится единственная копия этой строки. Прежде чем записать что-либо в строку в состоянии Shared, нужно найти и объявить недействительными все существующие копии. [3, с. 196]
Как уже отмечалось, состояние U, S или М каждой строки кэш-памяти фиксируется в поле "Состояние" в соответствующем элементе каталога (рис. 2.3,б).
Считывание из памяти. Рассмотрим выполняемые действия при считывании строки. В каждый момент у каждой строки имеется собственный (уникальный) владелец. [17, с. 625].
Сначала процессорный элемент ПЭ данного кластера проверяет свою кэш-память. Если там строки нет, на локальную шину кластера передается запрос для выявления, содержит ли какой-нибудь другой ПЭ этого же кластера нужную строку. [20, с. 557]. При наличии строки происходит передача ее из одной кэш-памяти в другую, при этом:
- если строка находится в состоянии Shared, то создается ее копия;
- если строка находится в состоянии Modified, нужно проинформировать исходный каталог, что строка перешла в состояние Shared.
В обоих случаях строка берется из какой-то кэш-памяти. Отметим, что каталог содержит 1 бит на кластер, а не 1 бит на каждый ПЭ, поэтому битовое отображение каталогов остается неизменным. [6, с. 122].
Если нужная строка не присутствует ни в одной кэш-памяти данного кластера, то пакет с запросом отправляется в исходный кластер, содержащий данную строку. Аппаратные средства в исходном кластере проверяют свои таблицы, выясняют, в каком состоянии находится строка, после чего предпринимают соответствующие действия:
- если нужная строка находится в состоянии Uncached или Shared, то аппаратные средства вызывают эту строку из глобальной памяти и посылают обратно в запрашивающий кластер. Затем обновляют свой каталог, помечая данную строку как сохраненную в кэш-памяти кластера запрашивающей стороны; [17, с. 652].
- если нужная строка находится в состоянии Modified, аппаратные средства находят кластер, который содержит эту строку, и посылают в этот кластер запрос. Получив запрос, кластер посылает данную строку в запрашивающий кластер и помечает ее копию как Shared, поскольку теперь эта строка находится более чем в одной кэш-памяти. Он также посылает копию обратно в исходный кластер, чтобы обновить память и изменить состояние строки на Shared.
Запись в память. Перед тем как осуществить запись, процессорный элемент ПЭ должен выявить единственного обладателя данной строки кэш-памяти в системе. [16, с. 285].
При наличии в кэш-памяти данного ПЭ этой строки действия зависят от ее состояния:
- если строка находится в состоянии Modified, то можно сразу же осуществить запись;
- если строка находится в состоянии Shared, то предварительно в исходный кластер посылается пакет, чтобы объявить все остальные копии недействительными.
При отсутствии нужной строки в кэш-памяти данного ПЭ он посылает запрос на локальную шину, чтобы узнать, нет ли этой строки в соседних ПЭ: [21, с. 185].
- если данная строка там есть, то она передается из одной кэш-памяти в другую. Если эта строка в состоянии Shared, то все остальные копии должны быть объявлены недействительными;
- если строка находится в других кластерах, в исходный кластер посылается пакет. При этом возможно три варианта:
- если строка находится в состоянии Uncached, она помечается как Modified и отправляется к запрашивающему процессору;
- если строка находится в состоянии Shared, все копии объявляются недействительными и после этого над строкой совершается та же процедура, что и над Uncached строкой;
- если строка находится в состоянии Modified, то запрос направляется в тот кластер, в котором строка содержится в данный момент. Этот кластер удовлетворяет запрос, а затем объявляет недействительной свою собственную копию.
2.4 Мультипроцессор Sequent NUMA-Q
Особенностью этой системы является то, что в ней реализован масштабируемый когерентный интерфейс (Scalable Coherent Interface – SCI) со стандартным протоколом когерентности кэширования, который используется в ряде других компьютерных систем CC-NUMA. [17, с. 668].
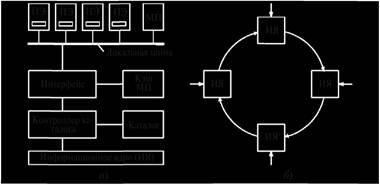
Рис. 2.4. Мультипроцессор NUMA-Q
Состав и структура мультипроцессора. Основой системы служит процессорный блок, содержащий (рис. 2.4,а):
- 4 процессорных элемента ПЭ, в качестве которых используются процессоры Pentium Pro. Каждый процессор содержит два уровня кэш-памяти. Размер строки кэш-памяти равен 64 байтам. Непротиворечивость кэшей поддерживается путем отслеживания локальной шины;
- модуль памяти МП емкостью до 4 Гбайт;
- сетевой контроллер, поддерживающий протокол MESI. В его состав входят:
- кэш-память емкостью 32 Мбайт;
- каталог, который следит за тем, что находится в кэш-памяти;
- интерфейс с локальной шиной;
- информационное ядро (ИЯ) для соединения двух процессорных блоков. Оно передает данные от входа к выходу, оставляя те данные, которые предназначены для своего процессорного блока. [18, с. 352].
Конструктивно процессорный блок состоит из стандартной платы quad board (с ПЭ и МП) и платы сетевого контроллера IQ-Link. Для объединения процессорных блоков в систему плата quad board имеет гнездо, предназначенное для установки контроллеров сети. Все платы 1Q-Link микроконтроллера с помощью ИЯ соединяются друг с другом, образуя кольцевую структуру (рис. 2.4,б). [21, с. 195].
В рассматриваемом микроконтроллере реализуется два уровня протокола когерентности кэширования с использованием протокола MES1:
- поддержка непротиворечивости кэшей всех плат IQ-Link в кольце;
- сохранение непротиворечивости в каждом процессорном блоке между кэшами четырьмя ПЭ и кэш-памятью на 32 Мбайт сетевого контроллера.
Кольцо, соединяющее платы IQ-Link, можно представить как отдельные двухточечные кабели. Ширина кабеля составляет 18 бит: 1 бит синхронизации, 1 флаговый бит и 16 бит данных. Все биты передаются параллельно. Каналы синхронизируются с тактовой частотой 500 МГц, при этом скорость передачи данных составляет 1 Гбайт/с. По каналам передаются пакеты. Каждый пакет содержит заголовок из 14 байт; 0, 16, 64 или 256 байт данных и контрольную сумму на 2 байта. Трафик состоит из запросов и ответов. [3, с. 201]
Каждая плата quad board содержит 226 строк кэш-памяти по 64 байта. Неиспользуемая строка всегда находится в собственной памяти. Так как строки могут находиться в разных кэшах, для каждого процессорного блока существует таблица локальной памяти из 226 элементов, по которой можно находить местоположение строк. Для этого все копии строки кэш-памяти собираются в дважды связанный список. Элемент в таблице локальной памяти исходного процессорного блока показывает, в каком процессорном блоке содержится головная часть списка. [17, с. 685].
В машине NUMA-Q 2000 используется 6-битный номер, поскольку в ней может быть максимум 63 узла. Для системы SCI максимального размера достаточно будет 16-битного номера. Такая схема подходит для больших систем гораздо лучше, чем битовое отображение. Именно это свойство делает SCI более расширяемой по сравнению с системой DASH. [12, с. 98].
Поскольку размер кэш-памяти составляет 32 Мбайт (225), а строка кэш-памяти включает 64 байта (26), каждая плата 1Q-Link может содержать до 219 строк кэш-памяти. Поэтому каждый каталог также содержит 219 элементов, по одному элементу на каждую строку кэш-памяти. [14, с. 72].
Протокол SCI имеет три варианта сложности. Протокол минимальной степени сложности разрешает иметь только одну копию каждой строки в кэш-памяти. В соответствии с протоколом средней степени сложности каждая строка может кэшироваться в неограниченном количестве узлов. Полный протокол включает различные особенности для увеличения производительности. В системе NUMA-Q используется протокол средней степени сложности.
2.5 Мультипроцессоры СОМА
Основной недостаток компьютерных систем NUMA и CC-NUMA состоит в том, что обращения к удаленной памяти (которые происходят гораздо медленнее, чем обращения к локальной памяти) снижают производительность и препятствуют расширению системы. [21, с. 125].
В системах СОМА (Cache Only Memory Access – архитектура с доступом только к кэш-памяти) основная память каждого процессора используется как кэш-память. В ней физическое адресное пространство делится на строки (а не на страницы, как в системах NUMA и CC-NUMA), которые при необходимости перемещаются по системе. Память, которая привлекает строки, называется attraction memory. Использование основной памяти в качестве кэш-памяти большой емкости увеличивает частоту успешных к ней обращений, что сопутствует повышению производительности. [20, с. 560].
Однако с расширением кэша появляется две проблемы:
- как размещать строки кэш-памяти;
- во-первых, если при трансляции виртуального адреса нужной строки в кэш-памяти не оказалось, как определить, есть ли вообще эта строка в основной памяти? Такая ситуация обусловлена тем, что каждая страница состоит из большого количества отдельных строк кэш-памяти, которые перемещаются в системе независимо друг от друга;
- во-вторых, если даже известно, что строка отсутствует в основной памяти, как определить, где она находится?
- как действовать при удалении из памяти последней копии строки? Проблема состоит в том, что строка кэш-памяти может находиться одновременно в нескольких узлах. При вызове строки (при промахе кэша) из другого узла вызываемая строка отбрасывается. Если выбранная строка является последней копией, ее отбрасывать нельзя.
Возможные пути решения первой проблемы: [17, с. 596].
- введение дополнительных аппаратных средств оря слежения за тегом каждой строки кэш-памяти. В этом случае блок управления памятью может сравнивать тег нужной строки с тегами всех строк кэшпамяти, пока не обнаружит совпадение;
- использование полного (битового) отображения страницы, не требуя при этом присутствия всех строк кэш-памяти. В этом случае один бит для каждой строки указывает на присутствие или отсутствие этой строки:
- если строка присутствует, то она должна находиться в правильной позиции на этой странице;
- если строка отсутствует, то любая попытка использовать ее вызовет прерывание, что позволит программному обеспечению найти нужную строку и ввести ее.
Таким образом, система будет искать только те строки, которые действительно находятся в удаленной памяти. При этом можно организовать память в виде дерева и осуществлять поиск по направлению вверх, пока не будет обнаружена требующаяся строка. [21, с. 152].
Возможные пути решения второй проблемы:
- возврат к каталогу для проверки существования других копий:
- если копии существуют, то строку можно отбрасывать;
- если нет ни одной копии, то ее нужно переместить в какое-либо место памяти;
- размещение одной из копий каждой строки кэш-памяти в качестве главной копии, при этом никогда ее не удалять. Этот подход не требует проверки каталога.
В любом случае COMA-машинапотенциально должна иметь более высокую производительность, чем CC-NUMA, но пока было создано. [12, с. 99].
Таким образом, можно сделать следующий вывод.
CC-NUMA-системы относятся к классу NUMA-систем. В CC-NUMA-системах аппаратно обеспечивается когерентность локальной КЭШ памяти разных процессоров (cache-coherent NUMA - CC-NUMA).
NCC-NUMA-системы относятся к классу NUMA-систем/ В NCC-NUMA-системе аппаратно не поддерживается когерентность локальной кэш-памяти разных процессоров (non-cache coherent NUMA - NCC-NUMA).
COMA-системы относятся к классу NUMA-систем. В COMA-системах в качестве оперативной памяти используется только локальная КЭШ память процессоров (cache-only memory architecture - COMA).
ЗАКЛЮЧЕНИЕ
Таким образом, в результате проведенного исследования, можно сделать следующие выводы. Вычислительные системы бывают двух видов: компьютерные с общей памятью и компьютерные с распределенной памятью.
Вычислительная система с распределенной памятью (distributed memory) – система, в которой каждый процессор обладает собственной локальной памятью, а общая память отсутствует. Обмен информацией между составляющими системы обеспечивается с помощью коммуникационной сети посредством обмена сообщениями.
Часто такие системы объединяют отдельные ВМ. Данный вид ВС называют слабо связанными (loosely coupled systems). Слабо связанные системы встречаются как в классе SIMD, так и в классе MIMD. Подобное построение ВС снимает ограничения, свойственные для общей шины, но приводит к дополнительным издержкам на пересылку сообщений между процессорами или машинами. Многопроцессорность ВС приводит еще к одной проблеме - проблеме одновременного доступа к памяти со стороны нескольких процессоров.
Мультипроцессоры NUMA (Non Uniform Memory Access – с неоднородным доступом к памяти). Как и мультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным. Следовательно, все программы UMA будут работать без изменений на машинах NUMA, но производительность будет хуже, чем на машинах UMA с той же тактовой частотой.
Характерная особенность мультипроцессоров NUМA (Non Uniform Memory Access – с неоднородным доступом к памяти) проявляется в следующем:
• имеется одно адресное пространство, видимое для всех процессорных элементов (ПЭ);
• обращение к удаленной памяти производится с использованием команд load и store;
• доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти.
Отметим, что большинство современных процессоров относятся к представителям NUMA-архитектуры, где у каждого CPU существует собственная локальная память.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Божко, В.П. Информатика: данные, технология, маркетинг / В.П. Божко, В.В. Брага, Н.Г. Бубнова. - М.: Финансы и статистика, 2014. - 224 c.
- Вялова Е.П. Адаптивный алгоритм маршрутизации в компьютерной сети / Е.П.Вялова // Вестник Воронежского института высоких технологий. 2016. № 2 (17). С. 97-100
- Гейн, А.Г. Основы информатики и вычислительной техники / А.Г. Гейн, В.Г. Житомирский, Е.В. Линецкий, и др.. - М.: Просвещение, 2013. - 254 c
- Данилова А.В. Методы измерения нагрузки сети / А.В. Данилова, А.Г.Юрочкин, О.В. Шадымова // Вестник Воронежского института высоких технологий. 2016. № 2 (17). С. 73-76.
- Данилова А.В. Разработка локальной компьютерной сети предприятия / А.В. Данилова, А.Г.Юрочкин // Вестник Воронежского института высоких технологий. 2016. № 2 (17). С. 66-69.
- Карташевский И.В., Малахов С.В. Архитектура вычислительных систем. Конспект лекций. - Самара.: ФГОБУ ВПО ПГУТИ, 2013. - 234 с
- Лавлинская О.Ю. Технологии облачных вычислений и их применение в решении практических задач / О.Ю.Лавлинская, Т.М.Янкис // Вестник Воронежского института высоких технологий. 2016. № 1 (16). С. 33-36.
- Лукашенко В. В. Математическая модель реструктуризуемого под классы задач, виртуализуемого кластера вычислительной grid-системы на базе нейропроцессоров // Наука, техника, инновации, сборник статей Международной научно-технической конференции. 2014, с. 232-236.
- Лукашенко В. В., Романчук В.А. Разработка математической модели реструктуризуемого под классы задач, виртуализуемого кластера вычислительной grid-системы на базе нейропроцессоров //Вестник Рязанского государственного университета имени С. А. Есенина. Научный журнал. –2014. -№ 1/42 С. 176-181.
- Лукашенко В.В. Анализ основных вопросов классификаций распределенных вычислительных систем // Современная техника и технологии. 2015. № 4 [Электронный ресурс]. URL: http://technology.snauka.ru/2015/04/6452 (дата обращения: 22.11.2017).
- Лукашенко В.В. Формализация модели нейропроцессорной системы, как grid-системы // Информатика и прикладная математика, межвузовский сборник научных трудов, Рязань, 2013, №19, с. 048-052.
- Мартышкин А.И. Реализация аппаратного буфера памяти многопроцессорной системы // В сборнике: Новые информационные технологии и системы сборник научных статей XII Международной научно-технической конференции. 2015. С. 96-99.
- Преображенский А.П. О возможностях ускорения вычислений при решении задач / А.П.Преображенский // Вестник Воронежского института высоких технологий. 2014. № 12. С. 67-68.
- Романчук В.А., Ручкин В.Н., Фулин В.А. Разработка модели сложной нейропроцессорной системы // Цифровая обработка сигналов. – Рязань: Информационные технологии, 2012. – №4. – С.70–74.
- Савельев В.А. Об оптимизации распараллеливания вычислений типа прямого метода в задаче теплопроводности для систем с распределенной памятью. // Известия ВУЗов. Северо-Кавказский регион. Естественные науки. ― 2012, № 4. ― С. 12–14.
- Симонович, С.В. Общая информатика / С.В. Симонович. - М.: СПб: Питер, 2011. - 428 c.
- Таненбаум Э., Бос Х. Современные операционные системы. 4-е изд. — СПб.: Питер, 2015. — 1120 с
- Угринович, Н. Информатика и информационные технологии / Н. Угринович. - М.: Бином. Лаборатория знаний, 2017. - 512 c.
- Хюбнер М. Многопроцессорные системы на одном кристалле. Разработка аппаратных средств и интеграция инструментов. / М.Хюбнер, Ю.Бекер // М.: Техносфера, 2011. 304 с.
- Цилькер Б.Я. Организация ЭВМ и систем : Учебник для вузов / Б.Я. Цилькер, С.А. Орлов. - 2-е изд. - СПб.: Питер, 2011. - 688 с.
- Штейнберг Б.Я. Оптимизация размещения данных в параллельной памяти. Ростов н/Д.: Изд-во ЮФУ, 2010. 256 с.:
- Ящук А.М., Яцутин С.В. Свойства параллельных вычислительных систем // Моделирование, оптимизация и информационные технологии. Научный журнал №4(15) – 13 с.
- Flynn M. Very high-speed computing system // Proc. IEEE. 1966. # 54. P. 1901-1909.

- Обзор языков программирования высокого уровня (Понятие языка программирования)
- Проведение маркетингового исследования реально существующей организации (Цели, задачи и основные понятия маркетинговых исследований)
- Процесс построения модели управленческого решения (Определение организационного решения как процесса)
- Проектирование организации (Элементы и этапы организационного проектирования)
- Особенности политики мотивации персонала малых предприятий (Мотивации и оплата труда в малых предприятиях )
- Коммуникации в организациях (Сущность и способы коммуникации)
- Проектирование маршрутизации в двух трёхуровневых сетях с использованием протокола EIGRP
- Менеджмент как организационно-целевое управление (Функции, понятие и содержание менеджмента)
- Тенденция развития спортивных услуг в России
- Индустрия спорта в России: современное состояние и перспективы развития (Сущность понятия «индустрия спорта»)
- Управление финансовой устойчивостью организации (Понятие и виды финансовой устойчивости)
- Банки развития в национальной банковской системе (Цели и задачи банков развития в современной экономике)