
Понятие компьютерных данных и информации
Содержание:

Введение
Теоретической основой информатики является группа фундаментальных наук таких как: теория информации, теория алгоритмов, математическая логика, теория формальных языков и грамматик, комбинаторный анализ и т. д. Кроме них информатика включает такие разделы, как архитектура ЭВМ, операционные системы, теория баз данных, технология программирования и многие другие. Важным в определении информатики как науки является то, что с одной стороны, она занимается изучением устройств и принципов действия средств вычислительной техники, а с другой — систематизацией приемов и методов работы с программами, управляющими этой техникой.
Информационная технология — это совокупность конкретных технических и программных средств, с помощью которых выполняются разнообразные операции по обработке информации во всех сферах нашей жизни и деятельности. Иногда информационную технологию называют компьютерной технологией или прикладной информатикой.
Информация аналоговая и цифровая. Термин «информация» восходит к латинскому informatio — разъяснение, изложение, осведомленность.
Информацию можно классифицировать разными способами, и разные науки это делают по-разному. Например, в философии различают информацию объективную и субъективную. Объективная информация отражает явления природы и человеческого общества. Субъективная информация создается людьми и отражает их взгляд на объективные явления.
В информатике отдельно рассматривается аналоговая информация и цифровая. Это важно, поскольку человек благодаря своим органам чувств, привык иметь дело с аналоговой информацией, а вычислительная техника, наоборот, в основном, работает с цифровой информацией.
Объектом исследования в данном работе является информация, фиксируемая в компьютерах.
Предмет исследования — методы кодирования информации в ЭВМ.
Цель написания курсовой работы — изучить теорию информации и кодирования, а также рассмотреть алгоритмы кодирования информации.
Для достижения цели были поставлены следующие задачи:
- сформировать представление о базовых логических элементах, объяснять работу основных логических элементов;
- развитие логического и комбинационного мышления, памяти, внимательности, формирование элементов графической культуры;
- изучения логических основ ЭВМ.
Методологическую основу данной работы составили такие методы как анализ, синтез, сравнение, обобщение, выделение, интерпретация, классификация, статистические и другие методы научного познания.
Структура работы. Данная работа состоит из введения, двух глав, заключения и списка использованной литературы.
Глава 1. Основы кодирования данных
1.1. Понятие компьютерных данных и информации
Понятие информации часто встречается в деятельности людей. Можно сказать, что, сколько существует человечество, столько времени оно пользуется информацией. Жизнь каждого человека, так или иначе, связана с получением, накоплением и обработкой информации. Все профессиональные навыки и секреты мастерства отдельных специалистов по получению каких-либо материалов или изготовлению изделий представляют ни что иное как информацию, которая в течение нескольких поколений, бережно накапливалась, строго охранялась и передавалась, сохраняя секреты профессии. Информация имеет большое значение в современном мире. С каждым годом растет объем информации и величина информационных потоков. Особенно это характерно для науки, производственной деятельности и управления. Помимо увеличения объема информации, имеет место резкое увеличение скорости ее возрастания. Общая сумма человеческих знаний в XVIII веке удваивалась каждые 50 лет, к 1950 г. — каждые 10 лет, к 1970 г. — 5 лет, к 1990 г. — каждые 2-3 года, а к началу XXI века 1-2 года. Оценки показывают, что в настоящее время ежеминутно в мире делается от 15 до 20 изобретений [1].
До XX века основным предметом труда были материальные объекты. Экономическая мощь государства измерялась, прежде всего, его материальными и энергетическими ресурсами, а также средствами материального производства. В последнюю очередь экономическая мощь государства определялась наличием научно-технического потенциала. В настоящее время, одним из основных показателем становится информационные технологии, и мощь государства определяется теперь, в большей степени, наличием высококвалифицированных работников — ученых, инженеров, рабочих. Проведенная оценка сфер человеческой деятельности показывает, что более половины человечества в своей профессиональной деятельности, в настоящее время, занимается непосредственно работой, связанной с той или иной обработкой информации. Одной из важнейших проблем человечества является лавинообразный поток информации практически в любой отрасли его жизнедеятельности. Подсчитано, например, что в настоящее время специалист должен тратить до 80% своего рабочего времени, чтобы уследить за всеми новыми печатными работами в его области деятельности [4, с. 41]. Во всех областях человеческой деятельности приходится накапливать, собирать, обрабатывать и пользовать информацию. Разнообразие и огромное количество информации, и также растущий спрос на нее, вызывает необходимость прибегать к разработке автоматизированных систем хранения, обработки и передачи информации.
При работе с информацией производятся самые разнообразные действия. Информация собирается, хранится, передается, анализируется, обобщается. Информация также распространяется, при этом она может перерабатываться и преобразовываться по форме и виду (например, кодируется или декодируется, текст озвучивается, звуковая или видеоинформация преобразуется в радиоволны, передается на соответствующий приемник и опять преобразуется в звуковую или видеоинформацию) и т. п. Достаточно специфическими действиями с информацией являются получение новой информации, а также продажа и покупка информации.
В понятие информации может быть вложен различный смысл. Существует несколько определений информации. Это обусловлено сложностью, специфичностью и многообразием подходов к толкованию сущности этого понятия. В бытовом смысле под информацией понимается сообщение, любые данные или знания, которые кого-либо интересуют. Практически, до середины XX века под информацией понимались сведения, передаваемые друг другу. Такое понимание информации основано на логико-семантическом подходе (семантика — изучение сообщения с точки зрения смысла), при котором информация трактуется как знание, причем не любое знание, а только та его часть, которая используется для принятия решений, активных действий и управления. В дальнейшем понятие информации получило более широкое толкование — это сведения, обмениваемые тем или иным способом между людьми, обмен сигналами между животными и растениями, передача сведений в живом мире на клеточном и генном уровне и т. п. Такое понимание информации рассматривает информацию как свойство (атрибут) материи. В производственной и научной деятельности под информацией также понимают сведения, которыми обмениваются люди между собой, человек и компьютер. Появление понятия информации связано с развитием кибернетики и основано на утверждении, что информацию содержат любые сообщения, воспринимаемые человеком или приборами. Можно сказать, что сейчас, в широком смысле, информация — это отражение реального мира. В узком смысле информация — это любые сведения, являющиеся объектом хранения, передачи и преобразования. С точки зрения фундаментальных наук понятие информации является настолько общим и глубоким понятием, что оно не может быть определено через более простые — первичные понятия. Поэтому понятие информации является одним из фундаментальных основных понятий многих современных научных дисциплин (в философии существует даже такая философская категория как информация).
С практической точки зрения информация всегда представляется в виде какого-либо сообщения. Любое информационное сообщение обязательно связано с источником информации, приемником информации и каналом передачи сообщения. Процесс, который происходит при установлении связи между источником информации (генератором информации) и приемником информации (получателем), называется информационным процессом. Обмен информацией происходит по каналам передачи сообщений посредством сигнала. Сообщение от источника к приемнику передается в материально-энергетической форме (электрической, магнитной, электромагнитной или световой, акустической, тепловой, химической реакции или веществом и т.п.). Физическая среда, в которой может фиксироваться или накапливаться информация для последующей обработки или передачи и анализа называется носителем информации. Чаще всего информация существует в форме электромагнитных волн различной частоты (световых или радиоволн), акустических волн (звуков), электрического тока или напряжения, в форме магнитных полей или, что для нас более привычно, в виде каких-либо знаков на бумаге, жестов, поз и мимики (в животном мире), наличия определенных веществ. Сигнал — это материальный носитель информации (предмет, символ, физический или химический процесс, явление), распространяющийся в пространстве и времени [7, с. 38]. Полученный сигнал, каким-либо образом, перерабатывается получателем информации и воспринимается в смысловом значении для дальнейшего его использования, учета, обработки или передаче к другим получателям. В принципе, информацию может переносить любая материальная структура или поток энергии.
Таким образом, любой информационный процесс может происходить только в такой системе, в которой упорядочены и определенным образом связаны между собой ее элементы: источник, приемник, переработчик информации, а также каналы передачи информации или сообщений между ними. Упорядоченную совокупность таких элементов системы в дальнейшем будем называть информационной системой.
1.2. Понятие и сущность кодирования данных
Начиная с древних времен, вся жизнь человека в той или иной степени была связана с использованием какого-либо рода информации. Количество обрабатываемых данных изо дня в день увеличивался. В связи с этим информация стала определяться как товар и начала иметь цену. Ценность обрабатываемой и передаваемой информации с каждым днем возрастала, и поэтому же возникла проблема «засекречивания» данных. Ни для кого не секрет, что успех любого вида деятельности, организации сильно зависит от обладания конкретными сведениями (тайнами, секретами), а также их отсутствия у конкурентов. Чем сильнее, эффективнее защита информация, тем меньше потенциальные убытки организации от злоумышленников в информационной сфере. Одним словом, использование методов криптографии актуально по сей день. Неудивительно, что в связи с этим возникла целая наука, называемая криптографией.
Под криптографией понимается наука, которая изучает методы обеспечения конфиденциальности (невозможности прочтения информации лицами, которым она не предназначена), целостности данных (невозможности незаконной модификации данных, а также повреждения при передаче), аутентификации (проверки подлинности авторства или иных свойств объекта), а также невозможности отказа от авторства. Она занимается построением и исследованием математических методов преобразования информации.
Существует обратная сторона криптографии — криптоанализ — наука о методах расшифровки зашифрованной информации без предназначенного для такой расшифровки ключа и сам процесс такой расшифровки. Два данных понятия составляют основу науки криптологии, которая занимается вопросами защиты и скрытия информации. Можно заметить такую особенность, что до начала 90-х годов криптография в основном использовалась только в интересах государства, а с появлением интернета ею активно начали пользоваться как частные лица, так и хакеры для шифрования той или иной информации в сети. Это связано с переходом от промышленного общества к информационному [11. с. 27].
Следует заметить, что криптография одна из старейших наук и насчитывает несколько тысяч лет, однако активно используется и применяется в современном мире. Клод Шеннон был одним из первых, кто подошел к криптографии с научной точки зрения, он первым сформулировал ее теоретические основы и ввел в рассмотрение многие основные понятия. Термин «криптография» произошел от греческих слов: криптос — тайна и грофейн — писать. Таким образом, это тайнопись, система перекодировки сообщения с целью сделать его непонятным для непосвященных лиц и дисциплина, изучающая общие свойства и принципы систем тайнописи [2]. В рамках этой науки выделяются два понятия, которые многие путают, такте как кодирование и шифрование.
Для того чтобы дать определение кодированию, сначала необходимо вести понятие код, который подразумевает под собой правила соответствия набора знаков одного множества Х знакам другого множества Y. Говоря обычными словами, если каждому символу Х при кодировании соответствует отдельный знак Y, то это называется кодированием. Следует отметить, что обратный процесс, когда для каждого символа из Y однозначно можно отыскать по некоторому правилу его прообраз в X, называется декодированием. Многие знают, что кодирование сообщений в ЭВМ в байтах. Банальным примером служит следующее: если каждый цвет кодировать двумя битами, то можно закодировать не более 4 цветов, тремя — 8 цветов, восемью битами (байтом) — 256 цветов [1].
Чтобы в полной мере понять термин шифрование, сообщение, которое мы хотим передать адресату, назовем открытым (А), которое однозначно определено над некоторым алфавитом. Зашифрованное сообщение может быть построено над другим алфавитом. Назовем его закрытым сообщением (В). Процесс преобразования открытого сообщения в закрытое сообщение и есть шифрование f(A) = B, где f — правило шифрования. Главная особенность в данном случае заключается в том, чтобы зашифрованное сообщение можно было расшифровать. Он, как правило, секретный и сообщается лишь тому, кто должен прочесть зашифрованное сообщение (обладателю ключа).
Важно обратить внимание, что при кодировании нет такого ключа, поскольку главной целью его является предоставление информации в более сжатом, компактном виде. В качестве элементов кодируемой информации могут выступать буквы, слова; различные символы, числа; ситуации и явления; аудиовизуальные образы и т.д. Если k — ключ, то можно записать f(k(A)) = B. Для каждого ключа k, преобразование f(k) должно быть обратимым, то есть f(k(B)) = A. Совокупность преобразования f(k) и соответствия множества k называется шифром. Как правило, любой шифр должен обладать таким свойством как надежность, который предполагает способность противостоять взлому, так называемый стойкость шифра. По аналогии с кодированием, в данном случае также существует обратный процесс шифрованию, называемый дешифрованием.
Следует учесть тот факт, что при дешифровании мы можем получить несколько осмысленных текстов. На основе вышесказанного приходим к мысли, что кодирование и шифрование два разных понятия в криптографии. Кодирование — это представление информации в альтернативном виде, то есть замена символов чем-либо, которое используется для удобства обработки информации. А шифрование представляет собой метод защиты информации от несанкционированного доступа, от попытки его изменения, а также для передачи сообщения через незащищенный канал [3].
Подводя итог, можем сказать, что на сегодняшний день наука, как криптография, достаточно хорошо изучена представителями разных стран как США, Россия, Англия, Франция, Германия, но она, как и другая наука не стоит на месте, а продолжает развиваться. Важно также подчеркнуть актуальность применения разных методов криптографической защиты информации, которая возрастает изо дня в день благодаря специалистам в этой области. Таким образом, шифрование и кодирование является важным аспектом при соблюдении информационной безопасности технических средств, ПК и операционной системы.
Глава 2. Формы и особенности кодирования информации
2.1. Формы помехоустойчивого кодирования данных
В последние годы происходит бурный рост телекоммуникационной отрасли, в связи с научно-техническим прогрессом, разрабатываются новые способы передачи информации, увеличиваются скорость и объем передачи данных. Но вместе с тем происходит и нежелательное явление в виде повышенной зашумленности каналов связи, связанное с повышением возникновения различных ошибок и помех в передаваемых фалах. Бороться с данной проблемой призвано помехоустойчивое кодирование, и в связи с возникшими сложностями данное направление также переживает бурный подъём, а именно, разрабатываются новые кодовые алгоритмы, которые призваны повысить помехозащищенность, а также модернизируются старые образцы кодов.
В данной статье представлен большой обзор помехоустойчивых кодов, которые существуют в настоящее время, будут рассмотрены как уже давно известные и зарекомендовавшие себя с лучшей стороны коды, так и перспективные разработки в помехоустойчивом кодировании.
Сначала рассмотрим самые простые помехоустойчивые коды, данные алгоритмы отличают простота реализации, ограниченность обнаружения и исправления ошибок, а также тот факт, что данные коды в современном помехоустойчивом кодировании используются в составе других более сложных кодов (например, в составе кодов Рида-Соломона, Турбокодов, Каскадных кодов и т. п.). К ним относятся следующие коды [17].
Коды с проверкой на чётность, являются самими простыми и самыми распространенными в помехоустойчивом кодировании. Данные коды построены с помощью одной общей проверки на чётность, в которой проверочным разрядом является результат суммирования по модулю на два всех бит пакета информации. С помощью данных кодов можно обнаруживать одиночную ошибку, но восстановить поврежденные файлы он не в состоянии. Главным достоинством кодов с проверкой на чётность является простота реализации. В настоящее время данные коды используются в составе более сложных кодов, например в составе каскадных кодов.
Код Хэмминга, как и коды с проверкой на четность, позволяет обнаруживать одиночные ошибки, но в отличии от них имеет более совершенную структуру, а именно: в данном коде для каждого числа проверенных символов используется специальная маркировка, которая состоит из двух составляющих, а именно, количества символов в сообщении и количества информационных символов в сообщении.
Данный код также используется в составе более сложных кодов.
Код Боуза-Чаудхури-Хоквингхема или же, как его ещё называют, код БЧХ, данный код, в своё время, активно использовался в аппаратуре передачи данных, но в последнее время был вытеснен более совершенными кодовыми алгоритмами. Данный код отличается специальным выбором образующего циклический код полинома, что позволяет более просто декодировать передаваемую информацию, также данный код обладает нечётными значениями минимального кодового расстояния, всё это позволяет превосходно обнаруживать и исправлять ошибки с учётом группирования.
Блочные неравномерные коды, особенностью этих кодов является то, что в данных алгоритмах все кодовые комбинации содержат разное число разрядов с постоянной длительностью импульсов. Данный вид кодов не является корректирующим и способен только обнаруживать ошибки в передаваемой информации благодаря большой избыточности. Примерами таких кодов являются код Морзе, который в настоящее время используется как специализированный код передачи информации в военной сфере, и код Хафмена, который применяется для компрессии информации и в настоящий момент используется в составе некоторых Каскадных кодов.
Циклический избыточный код (CRC код) — это еще один код, который занимается обнаружением ошибок, данный код используется наравне с кодом Хэмминга и с кодами с проверкой на чётность. Отличительной особенностью данного кода является его способ кодирования информации, основанный на свойстве деления с остатком двоичных многочленов, что позволяет с хорошей точность определять ошибки в передаваемых сообщениях.
Другими алгоритмами помехоустойчивого кодирования являются более сложные коды, которые зарекомендовали себя в поиске и исправлении ошибок, а также в защите от помех, в связи с чем, данные коды в настоящий момент используются повсеместно в телекоммуникационной отрасли. К ним относятся:
Код SMPTE, обладает возможностью самосинхронизации и, как следствие, восстановления поврежденных данных. Также данный код имеет и второе название, а именно: двухфазный код со скачком фазы при передаче нуля, данное название является профессиональным и полностью отражает всю суть кодирования информации этим кодом. Код SMPTE является профессиональным кодом и применяется для синхронизации носителей звуковой и видеоинформации [14].
Потенциальное кодирование или же NRZ код является цифровым двоичным кодом, особенностью которого является то, что при передаче цифрового нуля данный код передает потенциал, который был установлен на предыдущем такте, а при передаче единицы потенциал инвертируется на противоположный. Благодаря этому данный код может с хорошей точностью распознавать ошибки в передаваемой информации. Из недостатков можно выделить тот факт, что этот код не обладает свойством самосинхронизации, а также имеет низкочастотную составляющую.
Манчестерское кодирование, особенностью данного кода является его способ кодирования информации, а именно, передаваемая информация кодируется перепадами потенциала в середине каждого такта, единица кодируется перепадом от низкого уровня к высокому, а ноль — наоборот. В связи с этим данный код обладает хорошей самосинхронизацией, а также в нём отсутствует постоянная составляющая. Манчестерское кодирование применяется в стандарте передачи цифровой информации IEEE802.3.
Код Рида-Соломона — это блочный недвоичный циклический код, символы которого представляют собой m-битовые последовательности. Данный код предназначен для исправления одиночных и групповых ошибок, кроме исправления ошибок код Рида-Соломона может также восстанавливать стёртые или же неразборчивые символы. Всё это позволило коду Рида- Соломона занять обширную нишу в телекоммуникационных системах, например, данные коды используются в таких стандартах связи, как IEEE802.16, Internet, CCSDS и т.п.
Биполярный код AMI, особенность кодирования информации данным кодом заключается в том, что цифровой ноль в данном коде представляется нулевым напряжением, а цифровая единица представляется остальными значениями отличными от нуля. Благодаря этому код обладает хорошей синхронизацией, а также довольно прост в реализации, из недостатков можно выделить низкую скорость передачи данных. Данный код используется в телефонной связи.
Улучшенной версией кода AMI является код HDB3, отличающийся от AMI тем, что для представления цифрового нуля или единицы используется четыре значения в место одного. Данный код также используется в телефонной связи.
Код MLT-3 основывается на циклическом переключении уровней напряжения, где единице соответствует переход с одного уровня сигнала на другой. Данный код обладает хорошей синхронизацией и применяется в сетях FDDI, а также в FAST Ethernet 100BASE-TX.
Свёрточные коды с применением декодера Витерби являются оптимальными и достаточно легко реализуемыми для коротких сверточных кодов. Из недостатков можно выделить тот факт, что данный способ применяется только для декодирования коротких кодов, т. к. с ростом длины кода возрастает и его сложность реализации. Данный вид кодирования применяется в беспроводных сетях IEEE802.11, IEEE802.16 дальней космической связи CCSDS, спутниковой связи TIA-1008 и т. п.
Свёрточные коды с применением последовательного декодера, данный способ помехоустойчивого кодирования применяется в отношении свёрточных кодов с большой конструктивной длинной. Из недостатков следует выделить, что данный способ кодирования работоспособен только в области меньшей, чем вычислительная скорость канала, что накладывает серьёзные ограничения на использование этого алгоритма. В частности, последовательное декодирование применяется в стандарте TIA-10008.
Каскадные коды, в основе которых лежит идея совместного использования нескольких составляющих кодов, например код Рида- Соломона, код Хэмминга, код с проверкой на чётность и т. п., широко применяются в таких стандартах связи, как CCSDS, DVB-H/T/S, IEEE802.16 и т. п.
Многопороговый декодер самоортогональных кодов (МПДСОК), с помощью данного декодера возможно декодировать очень длинные коды с линейной от длины кода сложностью реализации. При этом МПДСОК способен вплотную приближаться к решению оптимального декодера в достаточно широком диапазоне кодовых скоростей и уровней шума в канале передачи данных. Более подробно МПДСОК рассматриваются в [4], данные алгоритмы используются в таких стандартах связи, как CCSDS, IEEE802.16 и т. п.
Турбокоды, образующиеся путём каскадирования двух или более составляющих кодов, данные коды могут получаться как при последовательном, так и при параллельном соединении кодов, разделяемых перемежителем.
Так, данные коды подразделяются на два подтипа, к первому относятся свёрточные турбокоды (Turbo Convolutional Code — TCC), данный вид алгоритмов образуется путём параллельного каскадирования двух кодов через перемежитель. Применяются такие алгоритмы в основном беспроводной связи в таких стандартах, как CCSDS, TIA-1008, CDMA2000, UMTS.
Ко второму подтипу относятся так называемые турбокоды произведения (Turbo Product Code — TPC), они образуются путём последовательного каскадирования алгоритмов и применяются в таких стандартах связи, как INTELSAT, IEEE 802.16.
Низкоплотностные коды (LDPC-коды), также данные коды называют кодами с малой плотностью проверок на чётность. LDPC-коды представляют собой линейные блоковые коды, задаваемые с помощью проверочной матрицы Н, характеризуемой относительно малым числом единиц в строках и в столбцах. Проверочной матрице кода ставится в соответствие граф Тоннера, в котором для представления столбцов проверочной матрицы используются определённым образом связанные между собой битовые и проверочные узлы. Всё это позволяет практически вплотную приблизиться к пропускной способности канала при относительно небольшой сложности реализации. Данные коды применяются в таких стандартах связи, как DVB-S2, 802.11n, 802.16e.
Последняя группа кодов, которые будут рассмотрены в данной статье, это коды, в настоящее время не используемые в стандартах связи, но при этом они являются очень перспективными разработками в помехоустойчивом кодировании и в скором времени могут войти в стандарты связи. К ним относятся:
Стеганографический алгоритм, особенностью данного алгоритма является способ кодирования информации. Для более простого понимания кодировки стеганографического алгоритма представлена схема:
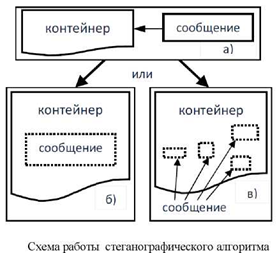
Рис.1 – Схема работы стеганографического алгоритма
Согласно схеме, первоначально кодируемая информация записывается в открытый и при этом значительно больший по размеру и не чувствительный к малым искажениям поток данных (контейнер). Дальнейшая передача информации может происходить по нескольким путям, либо данный пакет информации остаётся единым, либо информация в конверте подразделяется на несколько подфайлов. Выбор пути передачи зависит от объёма передаваемой информации. Преимуществом данного метода является полная защита от внешних шумов и ошибок, к минусам можно отнести очень сложную реализацию алгоритма на практике.
Алгоритм Кловкого-Николаева (АКН) является перспективной разработкой кафедры ТОРС ПГАТЦ, который в настоящее время активно модернизируется и дорабатывается. АКН является алгоритмом с ограниченным расстоянием, то есть данный алгоритм помехоустойчивого кодирования исправляет все комбинации из n и менее ошибок, но при этом не исправляет ни одну из комбинаций большего веса. Данный факт открывает большие перспективы развития алгоритма [17].
Коды повторения — накопления (Repeat-Accumulate — RA) являются одной из разновидностей каскадных кодов, данные алгоритмы сочетают в себе свойства турбо- и LDPC-кодов, в своей основе состоят из повторителя, перемежителя и аккумулятора.
Улучшенной версией кодов повторения — накопления являются нерегулярные коды повторения — накопления (Irregular Repeat Accumulate — IRA). Как было отмечено выше, коды RA сочетают в себе свойства как турбокодов, так и кодов Галагера, благодаря свойствам последних в структуру кодов повторения — накопления можно внести нерегулярность и тем самым улучшить характеристики алгоритмов.
Коды произведения — накопления (Product Accumulate — PA) являются еще одной разновидностью каскадных кодов, отличительной особенностью которых является то, что в их структуре в качестве основных кодов используется турбокод произведения и рекурсивный свёрточный код, применение данных алгоритмов с последовательной схемой каскадирования позволяет получить наилучшие характеристики.
Ниже приведены две таблицы, в первой представлено, в каких стандартах связи и в каких областях применяются вышеописанные коды.
Таблица 1 – применение помехоустойчивых кодов
|
Название алгоритма |
Стандарт |
Применение |
||
|
Код БЧХ |
Ethernet 10BASE-T, Ethernet 100BASE-T |
Локальные сети |
||
|
Код Хэмминга |
RAID2, ECC |
Последовательный интерфейс ПК |
||
|
Код SMPTE |
DCP |
Последовательный интерфейс, наземное телевидение |
||
|
CRC код |
MPEG-2, ANSIX 3.28 |
Наземное телевидение, последовательный интерфейс USB |
||
|
NRZ код |
RS232-C, RS- 485, ATM155 |
Последовательный порт ПК, последовательный интерфейс |
||
|
Манчестерское кодирование |
IEEE 802.3, IEEE 802.4, IEEE 802.5 |
Локальные сети |
||
|
Код Рида- Соломона |
Ethernet 100BASE-T, IEEE 802.16 |
Локальные сети |
||
|
Код АМ1 |
IEEE 802.4, Ethernet 100BASE-TX |
Локальные сети |
||
|
Код HDB3 |
IEEE 802.5, FDDI |
Локальные сети |
||
|
Код MLT- 3 |
FDDI, Fast Ethernet 100BASE-TX |
Локальные сети |
||
|
Декодер Витерби СК |
IEEE 802.11, IEEE 802.16, CCSDS, TIA- 1008 |
Беспроводные сети, дальняя космическая связь, спутниковая связь |
||
|
Последо вательный декодер СК |
TIA-1008 |
Спутниковая связь |
||
|
Каскадный код |
CCSDS, DVB H/T/S, IEEE 802.16, TIA- 1008 |
Дальняя космическая связь, спутниковая связь, наземное телевидение, беспроводные сети, |
||
|
МПДСОК |
CCSDS, TIA- 1008, DVB- S2, IEEE 802.16 |
Дальняя космическая связь, спутниковая связь, беспроводные сети |
||
|
Турбокод TCC |
CDMA2000, DVB-S, IEEE 802.16, CCSDS, TIA- 1008, UMTS |
3 G, спутниковая связь, беспроводные сети, дальняя космическая связь |
||
|
Турбокод TPC |
INTELSAT, IEEE 802.16. |
Спутниковая связь, беспроводные сети |
||
|
LDPC-код |
DVB-S2, IEEE 802.16е, IEEE 802.11n, DVB - Т2 |
Спутниковая связь, беспроводные сети, локальные сети, наземное телевидение |
||
|
Стеганографический алгоритм |
F5, FAT32, StegFS, Rei- serFS, HICCUPS |
Наземное телевидение, локальные сети, беспроводные сети |
||
|
АКН |
IEEE 802.11, IEEE 802.16, |
Беспроводные сети, |
||
|
Код RA |
IEEE 802.16, TIA-1008 |
Спутниковая связь, беспроводные сети |
||
|
Код IRA |
IEEE 802.16 |
Беспроводные сети |
||
|
Код РА |
IEEE 802.16, IEEE 802.11 |
Беспроводные сети |
||
В результате анализа таблицы можно прийти к выводу, что самыми распространенными областями применения помехоустойчивых кодов являются локальные сети, беспроводная радио и сотовая связь, спутниковая передача данных и наземное телевиденье, что соответствует таким стандартам связи, как IEEE 802.4, IEEE 802.11, IEEE 802.16, TIA- 1008, DVB - Т2.
В табл. 2 сравниваются технические характеристики алгоритмов, такие как тактовая частота, количество итераций кода, пропускная способность и т. п.
Таблица 2 – Характеристика помехоустойчивых кодов
|
Название алгоритма |
Тактовая частота, МГц |
Число итераций |
Длина блока, бит |
Кодовая скорость |
Eb /N0 дБ |
|
Код БЧХ |
150 |
4 |
127 |
1/3 |
6,5 |
|
150 |
4 |
63 |
2/3 |
7,5 |
|
|
150 |
4 |
31 |
1/2 |
8 |
|
|
150 |
6 |
63 |
1/2 |
7 |
|
|
150 |
4 |
1023 |
1/2 |
5 |
|
|
150 |
6 |
31 |
1/3 |
8,5 |
|
|
Код Рида- |
160 |
5 |
255 |
0,7 |
6,3 |
|
Соломона |
160 |
10 |
255 |
0,48 |
6,8 |
|
160 |
5 |
255 |
0,9 |
7,3 |
|
|
160 |
10 |
255 |
0,35 |
7,5 |
|
|
Декодер |
220 |
14 |
7 |
1/2 |
4,5 |
|
Витерби |
200 |
10 |
7 |
1/2 |
4 |
|
СК |
200 |
5 |
7 |
1/2 |
3 |
|
150 |
10 |
7 |
1/3 |
3,5 |
|
|
220 |
5 |
11 |
1/2 |
2 |
|
|
200 |
10 |
15 |
1/2 |
2 |
|
|
Последовательный |
140 |
34 |
41 |
1/2 |
3 |
|
160 |
40 |
41 |
1/3 |
2,3 |
|
|
декодер СК |
160 |
40 |
41 |
1/2 |
2,7 |
|
Каскадный код |
160 |
12 |
16000 |
1/2 |
2,5 |
|
150 |
12 |
16000 |
0,87 |
2,9 |
|
|
160 |
12 |
20000 |
0,4 |
2,9 |
|
|
150 |
12 |
20000 |
0,35 |
2,1 |
|
|
МПД- |
190 |
40 |
94100 |
1/2 |
2 |
|
СОК |
200 |
40 |
40000 |
0,85 |
1,5 |
|
220 |
60 |
94100 |
1/2 |
1,6 |
|
|
200 |
220 |
94100 |
1/2 |
0,6 |
|
|
200 |
192 |
94100 |
1/2 |
1,2 |
|
|
Турбокод |
180 |
10 |
3060 |
1/2 |
1,5 |
|
180 |
25 |
16000 |
0,87 |
4,7 |
|
|
TCC |
250 |
10 |
848 |
1/2 |
2,5 |
|
220 |
25 |
3060 |
1/2 |
1,3 |
|
|
200 |
30 |
1524 |
1/2 |
1,5 |
|
|
250 |
15 |
756 |
1/2 |
2 |
|
|
200 |
15 |
380 |
1/2 |
2.3 |
|
|
Турбокод |
200 |
10 |
4096 |
1/2 |
2 |
|
220 |
10 |
16000 |
0,88 |
1 |
|
|
TPC |
200 |
10 |
16000 |
1/2 |
0,6 |
|
200 |
10 |
10000 |
1/2 |
1,7 |
|
|
200 |
10 |
1024 |
0,43 |
2,4 |
|
|
220 |
10 |
1024 |
0,66 |
3,4 |
|
|
200 |
10 |
4096 |
0,64 |
2,6 |
|
|
200 |
10 |
4096 |
0,79 |
3,4 |
Как видно из таблицы, лучшие характеристики по пропускной способности показывают турбокоды ТРС, LDPC-коды и МПДСОК, что обуславливает их повсеместное применение во многих стандартах связи.
Самыми же простыми кодами в реализации (по числу итераций) являются такие коды, как БЧХ и коды Рида-Соломона, эти коды обладают простой структурой, но из-за этого неудовлетворяющей пропускной способностью, в связи с этим данные коды в настоящее время используются исключительно для обучения студентов или же в специализированных локальных сетях закрытого характера.
Новейшие коды, такие как стеганографический алгоритм и алгоритм Кловкого-Николаева, показывают средние показатели по пропускной способности, но этого недостаточно, особенно если сравнивать их с LDPC- кодом или же с МПДСОК. Также их техническая реализация в настоящее время достаточно сложна и требует доработки.
Наилучшими показателями по пропускной способности в сравнении с кодами Галагера показывают коды повторения — накопления и их модернизированная версия IRA. Данные коды в скором будущем могут составить полноценную конкуренцию LDPC-кодам и МПДСОК, единственным ограничением использования данных алгоритмов в настоящее время является их сложная структура, которая не позволяет использовать данные алгоритмы во многих стандартах связи.
Таким образом, нами были рассмотрены алгоритмы помехоустойчивого кодирования, образцы кодов, которые уже давно существуют и зарекомендовали себя с наилучшей стороны, так и коды, которые в настоящий момент только разрабатываются. Из всего вышеописанного можно сделать вывод, что отрасль помехоустойчивого кодирования не стоит на месте и бурно развивается, и что в ближайшее время на рынке могут появиться новые виды помехоустойчивых алгоритмов, которые могут поменять в лучшую сторону стандарты связи.
2.2. Способы кодирования текстовой и числовой информации в компьютере
Кодирование информации имеет огромное значение в современном мире вследствие широкой эксплуатации компьютеров и вычислительных сетей не только как средств обработки информации, но также как оперативных средств коммуникации. И поскольку, при передаче информации часть ее неизбежно теряется, проблемы помехоустойчивости информационных вычислительных систем весьма актуальны.
Набор условных обозначений для записи или передачи данных называется кодом. Кодирование информации понимают, как процесс формирования определенного представления информации, а в узком смысле — переход от одной формы представления информации к другой, более удобной для обработки, передачи и хранения.
Любые типы информации в компьютере представляются с помощью двоичной системы счисления, поскольку элементы технических устройств могут находиться в двух различных состояниях, которые обозначили цифрами 0 и 1. Ввод и вывод данных осуществляется в привычной для людей форме: текст в виде символов, числа в десятичной системе счисления. Такое возможно благодаря специальным программам, которые выполняют преобразования данных.
При вводе в компьютер каждая буква кодируется определенным набором двоичных цифр, а при выводе на внешние устройства для восприятия человеком по двоичному коду формируется изображение каждого символа. Соответствие между буквой и двоичным кодом называется кодировкой символов.
В начальном образовании учащихся знакомят с элементами, входящими в состав компьютера, их функциями, знакомят с некоторыми обучающими программами, которые соответствуют уровню развития детей. Знания из области представление, измерение и кодирование информации формируются у школьников в среднем звене. Так в материалах ГИА по информатике встречаются задачи на темы: оценка информационного объема данных; кодирование и декодирование данных; двоичное кодирование данных; скорость передачи данных.
В век информационных технологий огромная часть пользователей обрабатывает текстовую информацию на компьютерах и других устройствах. Для кодирования данных используются специальные кодовые таблицы. Первой таблицей кодировки стала ASCII — American Standard Code for Information Interchange. В этой таблице каждому символу (букве, цифре, знаку препинания и др.) соответствует определенный двоичный код.
Позднее появились и другие кодовые таблицы. Для кодировки русских букв сейчас используют различные кодовые таблицы: КОИ-8, СР1251, СР866, Unicode, Мас, ISO и др. В восьмибитных кодовых таблицах содержится 256 символов. Первые 33 кода (с 0 по 32) отведены под управляющие клавиши и специальные команды. Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания. Коды с 128 по 255 служат для национальных алфавитов.
Для определения информационного объема сообщения нужно знать единицы измерения информации: бит, байт, Кбайт и более крупные, а также правила перевода объема данных из одних единиц в другие. Кроме того, нужно иметь представление о способах определения длины кода одного символа i — по мощности алфавита — N. Мощность алфавита — это количество различных символов в нем. Формула, которая их связывает: мощность алфавита N=2i, длина кода i=log2 N. Информационный объем сообщения — I можно определить, умножив количество символов K в сообщении на длину кода: I = i • K. Рассмотрим особенности решения некоторых задач, в которых требуется определить информационный объем сообщения.
Задача № 1. Оцените информационный объем следующего предложения в байтах, считая, что каждый символ кодируется одним байтом:
«Скажи-ка, дядя, ведь не даром
Москва, спаленная пожаром,
Французу отдана?
Ведь были ж схватки боевые,
Да, говорят, еще какие!
Недаром помнит вся Россия про день Бородина!»
Решение: учитывая кавычки, знаки препинания и пробелы в данной цитате содержится 175 символов (K); длина кода каждой буквы 8 бит (i).
I = i • K =175*8=1400 бит=1400/8=175 байт. Ответ: информационный объем предложения 175 байт.
Задача № 2. Лазерный принтер EPSON печатает со средней скоростью 7,1 Кбит в секунду. Сколько времени будет затрачено для распечатки документа из 7 страниц, если в условии сказано, что на одной странице в среднем по 52 строк, а в каждой строке 65 символов (1 символ — 1 байт).
Решение: определим информационный объем документа. Количество информации, содержащейся на 1 странице: 52 * 65 * 7*8 бит = 189280 бит.
Найдем время печати: информационный объем разделим на скорость печати: t=I/v.
Переведем скорость печати из Кбит в биты в секунду: 7,1 Кбит/c =7,1*1024 =7270бит/с. t=189280/7270 = 26 секунд. Ответ: время печати документа 26 секунд.
Задача №3. Автоматическое устройство выполнило перекодировку информационного сообщения на русском языке, первоначально зафиксированного в 16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом информационный объем сообщения уменьшился на 560 бит. Какова длина сообщения в символах?
Решение: количество символов в сообщении обозначим K. Информационный объем сообщения в 16-битной кодировке равен I1=16K бит. После перекодировки сообщения в 8битный код, его объем стал b=8-K бит. Объем информационного сообщения уменьшился на 560 бит, значит: I1-560= U16K - 560 = 8K; 8K = 560; K = 70. Ответ: длина сообщения 70 символов.
В наше время человек не может представить себя без компьютера, технических устройств и различных гаджетов. Однако, не каждый пользователь знает, каким образом представляется и хранится информация в компьютере, как она передается по каналам связи. Сведения об информации, системах счисления, о двоичном кодировании входят в Федеральный государственный образовательный стандарт школьного курса информатики. Представления об обработке данных на компьютере и навыки кодирования информации имеют принципиальное значение для уровня образованности современного человека. Задачи из этой области знаний позволяют выработать у учащихся важнейшие понятия информатики, освоить способы представления данных, алгоритмы кодирования и декодирования, развивать логическое мышление и формировать информационную культуру школьников.
Чтобы кодировать информацию в компьютере используют определенную, конкретизированную систему кодировки информации. Всю информацию, компьютер обрабатывает с помощью машинного кода, который содержит два символа. Такой код принято называть двоичным или бинарным. Он похож на азбуку Морзе, в которой двумя символами (точка и тире) кодируются текст. Для формирования общей культуры личности каждый современный человек должен иметь представление о принципах представления и кодирования информации в компьютерных устройствах.
Перед выводом информации на экран, компьютер преобразует ее в понятную для человека форму, но в компьютере она храниться только в виде двоичного кода. Для понимания основ работы и функционирования компьютера достаточно разобраться с данным вопросом хотя бы в общих чертах.
Идея использования бинарного кода принадлежит немецкому математику Г. Лейбницу. Он разработал двоичную арифметику и даже сделал чертеж двоичной вычислительной машины, но не сумел ее построить. Многие ученые трудились над созданием универсальной машины, которая бы могла выполнять сложные вычисления, понимать команды человека, выполнять различные программы: Б. Паскаль (Паскалина), Г. Лейбниц (арифмометр), Ч. Бэббидж (программно-управляемая машина), Г. Холлерит (табулятор), К. Цузе (электромеханическая машина на основе двоичного кода) Д. Мочли и П. Экерт (ЭВМ Эниак) и др. Инженерам оказалось легче изобрести устройство, которое принимает одно из двух состояний. И намного тяжелее, заставить устройство понимать и воспроизводить нескольких различных состояний. В компьютере двоичный код применяется для упрощения конструкции, учитывая тот факт, что "мозг" процессора состоит из транзисторов, которые, в свою очередь, имеют всего два состояния - вкл. и выкл., что легко можно передать двоичной системой. Логические операции имеют всего два состоянию - истина и ложь. В технике намного удобнее иметь дело с целым рядом несложных элементов, чем с невеликим объемом витиеватых. Чтобы иметь шанс хранить и обрабатывать информацию техническими средствами, люди решили переводить ее на максимально простой "язык" — так называемый двоичный или бинарный код.
Современные дети знакомятся с десятичной системой счисления в начальной школе. Они изучают правила записи чисел, сложения, вычитания, умножения и деления. Тем самым, получают навыки представления и выполнения математических операций с любыми, даже самыми большими числами.
Изучение принципов представления и кодирования информации в компьютере школьники осваивают в среднем звене. В 8 классе учащиеся осваивают двоичное кодирование числовой информации, правила перевода чисел из десятичной системы в двоичную и наоборот. Когда считываем в двоичной системе подставляем разряды чаще чем в десятичной. В этом и состоит главная трудность, так как мы привыкли к меньшему количеству разрядов.
Человек, привыкший к десятичной системе счисления, плохо воспринимает систему двоичную. Несмотря на то, что правила записи, математические операции выполняются также как и в десятичной системе. Разница лишь в том, что в двоичной системе: 12+12=102, 102-12=12. Главный недостаток двоичной системы - большое число разрядов.
Наибольшее десятичное число, которое можно показать в 8 разрядах двоичной системы — 255, в 16 разрядах — 65535, в 24 разрядах — 16777215.
Рассмотрим двоичное представление положительных целых чисел, меньших 256. Чтобы записать такое число в памяти ПК обычно выделяется 8 бит. Для такого представления достаточно перевести десятичное число в двоичную систему счисления. Целые десятичные числа без знака в памяти компьютера выглядят примерно так (рис. 1).
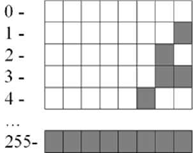
Рис.2 - Целые положительные числа меньшие 256 в двоичном коде
Чтобы записать большое целое число со знаком требуется 2-байтный код или 16 бит. Старший бит блока (крайний слева) отводится для записи знака числа. Если число со знаком положительное, то этот бит равен 0, если со знаком отрицательное — в него записывается единица. Само число записывается в оставшихся 15 битах.
Пример, алгоритм кодирования числа +3424 будет следующим:
1. Перевести число 3424 из десятичной системы счисления в двоичную. В итоге получится 1101 0110 0000;
2. Записать полученное двоичное число в 15 бит 16-битного блока. Получится число 3424 в двоичном коде на запоминающем устройстве будет изображено так:
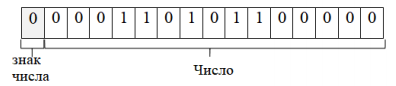
Рис. 3 – представление числа со знаком в машинном коде
Заметим, что в двоичном коде присвоение числу отрицательного значения предусматривает не только изменение старшего бита. Осуществляется также перевод числа сначала в обратный, а потом и в дополнительный коды. Для этого нужно выполнить алгоритм: перевести число 3424 из десятичной системы счисления в двоичную, получим двоичное число 110101100000; затем инвертировать, то есть, изменить на противоположное, значение каждого из 15 битов и получить обратный код (рис.4);

Рис.4 – обратный код числа
Запись отрицательных чисел в инвертированной форме позволяет заменить все операции вычитания, в которых они участвуют, операциями сложения. Это необходимо для нормальной работы процессора.
Самым большим десятичным числом, которое можно закодировать в 15 битах накопителя, является 32767. Иногда для записи чисел по этому алгоритму выделяются 4-байтные блоки. В таком случае для кодирования каждого числа будет использоваться 31 бит плюс 1 бит для кодирования знака числа. Тогда максимальным десятичным числом, сохраняемым в каждую ячейку, будет 2147483647 (со знаком плюс или минус).
Раздел «Кодирование числовой информации» является важной частью базового курса информатики и ИКТ и относится к содержательной линии «Информационные технологии». Несмотря на сложность и большой объем знаний по теме «Кодирование числовой информации», в школьном курсе информатики ей уделено недостаточно времени. Поэтому приходится даже в профильных классах сжимать большой объем знаний в несколько алгоритмов и методов кодирования данных, что негативно отражается на освоении данной темы школьниками.
Двадцать первый век — век компьютеризации и глобальной сети Интернет. Проблема передачи, обработки и хранения любой информации без проблем решается современным человеком с помощью алгоритмов кодирования и декодирования. В наше время необходимо знать и применять искусство двоичного кода, но для начала каждый должен овладеть хотя бы простейшими его основами.
Заключение
Наиболее удобной для построения ЭВМ оказалась двоичная система счисления, т. е. система счисления, в которой используются только две цифры: 0 и 1, т. к. с технической точки зрения создать устройство с двумя состояниями проще, также упрощается различение этих состояний.
Для представления этих состояний в цифровых системах достаточно иметь электронные схемы, которые могут принимать два состояния, четко различающиеся значением какой-либо электрической величины — потенциала или тока. Одному из значений этой величины соответствует цифра 0, другому — 1. Относительная простота создания электронных схем с двумя электрическими состояниями и привела к тому, что двоичное представление чисел доминирует в современной цифровой технике. При этом 0 обычно представляется низким уровнем потенциала, а 1 — высоким уровнем. Такой способ представления называется положительной логикой.
Кодирование информации — это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью компьютерных программ можно преобразовывать полученную информацию, например «наложить» друг на друга звуки от разных источников.
Аналогично на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми.
Список использованной литературы
1. Королев А.И. Коды и устройства помехоустойчивого кодирования информации. Минск: 2002. 286 с.
2. Асотов Д.В., Матвеев Б.В., Панычев С.Н. Применение стеганографических алгоритмов для повышения степени защиты конфиденциальности данных в цифровых системах передачи информации // Вестник Воронежского государственного технического университета. 2012. Т. 8. № 12.1. С. 63 - 65.
3. Верификация LDPC-кодов / Н.В. Астахов, А.В. Башкиров, А.С. Костюков, М.В. Хорошайлова, О.Н. Чирков // Вестник Воронежского государственного технического университета. 2017. Т. 13. № 1. С. 74 - 77.
4. Зубарев Ю.Б., Овечкин Г.В. Помехоустойчивое кодирование в цифровых системах передачи данных // Электросвязь. 2008. № 12. С. 58 - 61.
5. Багдасарян Д.А. Повышение помехоустойчивости передачи дискретных сообщений по радиоканалам в системах сотовой связи стандарта GSM при мягком декодировании: дис. канд. техн. наук: 05.12.13; Поволжская государственная академия телекоммуникаций и информатики. Самара, 2005. 161 с.
6. Наконечный Б.М. Помехоустойчивые алгоритмы и процедуры отображения и передачи цифровой информации в телекоммуникационных системах с ограниченными энергетическими и частотными ресурсами: дис. ... канд. техн. наук: 05.12.13; МОУ «Институт инженерной физики». Серпухов, 2012. 142 с.
7. Гринченко Н.Н., Овечкин Г.В. Помехоустойчивое кодирование для цифровых систем связи // Известия ТРТУ. 2006. № 15(70). С. 5 - 10.
8. Гусева Е.Н. Основы математической обработки информации: учеб.-методич. пособ. Электронное издание / Магнитогорск, 2018.
9. Гусева Е.Н. Математика и информатика: практикум / Е.Н. Гусева, И.Ю. Ефимова, И.И.Боброва, И.Н. Мовчан, Л.А Савельева. - М.: Флинта, 2015.- 197 с.
10. Гусева Е.Н. Информатика: учеб. пособие/ Е.Н. Гусева, И.Ю. Ефимова, И.Н. Мовчан, Р. И. Коробков, Л.А. Савельева. - Магнитогорск: МаГУ, 2008. - 215 с.
11. Гусева Е.Н. Математическое и имитационное моделирование.- Электронное издание / Магнитогорск, 2017.
12. Гусева Е.Н. Задачи на измерение количества информации с использованием понятия вероятности //Информатика и образование. 2008. № 2. С. 61-64.
13. Гусева Е. Н. Основы имитационного моделирования экономических процессов: учеб. пособие/ Е.Н. Гусева. - Магнитогорск: МаГУ, 2008. - 100с.
14. Гусева Е.Н. Дидактические условия использования педагогических программных средств в процессе профессиональной подготовки будущих учителей: дис. канд. пед. наук.- Магнитогорск, 1999. - 168 с.
15. Павлушкина А.В., Гусева Е.Н. Решение логических задач из школьного курса информатики Вестник современных исследований. 2017. № 6-1 (9). С. 71-74.
16. Гусева Е.Н. Теория вероятностей и математическая статистика: учеб. пособие / Е.Н. Гусева. - М.: Флинта, 2011.- 220 с.
17. Поляков К.Ю., Еремин Е.А. Информатика и ИКТ, 10 класс, Профильный уровень. - М.: БИНОМ. Лаборатория знаний, 2018. - 704 с.
18. Семакин И. Г., Информатика: Базовый курс для 7 - 9 кл. - М.: Лаборатория базовых знаний, 2004.
19. Угринович Н. Д., Информатика и ИКТ. 11 класс. - М. БИНОМ. Лаборатория знаний, 2014. - 187 с.

- Характеристика понятия прикладных протоколов
- .Управление поведением в конфликтных ситуациях.
- Технико-экономическая характеристика предметной области.
- Сущность коммерческой деятельности торгового предприятия
- Теоретические аспекты организации рекламной деятельности предприятия
- Адаптация ребенка к школе (Теоретические основы исследования проблем адаптации детей младшего школьного возраста к школе)
- Правовое регулирование биржевых правоотношений
- Теоретические основы организации биржевой торговли
- Теоретические основы коммерческой деятельности спортивной организации
- Принципы и основания наследования
- Влияние процесса коммуникаций на эффективность управления организацией (Коммуникация - определение понятия)
- Основные проблемы и задачи защиты информации в компьютерных сетях