
Основные структуры алгоритмов: сравнительный анализ и примеры их использования
Содержание:

Введение
За последние годы работа с информацией без помощи вычислительной техники становится практически немыслимой. Овладение навыками программирования на одном из языков высокого уровня является обязательным элементом образования и культуры каждого инженера.
Созданием языков программирования занимаются в большинстве случаев очень квалифицированные специалисты, часто группы программистов, а иногда даже международные коллективы. Однако подавляющее большинство языков программирования умирало, едва родившись. Лишь к немногим из них был проявлен интерес, и буквально единицы получили действительно широкое распространение. К таким «счастливым» языкам принадлежит язык Паскаль, разработанный Никлаусом Виртом в 1968-1971гг. в Цюрихском Институте информатики (Швейцария). Первоначальная цель разработки языка диктовалась необходимостью инструмента «для обучения программированию как системной дисциплине». Однако очень скоро обнаружилась чрезвычайная эффективность языка Паскаль в самых разнообразных приложениях: от решения небольших задач численного характера до разработки сложных программных систем – компиляторов, баз данных, операционных систем и т.д. Существуют многочисленные реализации языка практически для всех машинных архитектур; разработаны десятки диалектов и проблемно-ориентированных расширений языка Паскаль; обучение программированию и научно-технические публикации часто базируются на этом языке.
В курсовой работе рассматриваются основные структуры алгоритмов: сравнительный анализ и примеры их использования. Алгоритмические структуры, такие как следование, ветвление и цикл являются основой любой программы на языке программирования высокого уровня.
Объектом исследования являются основные алгоритмические структуры.
Предметом исследования являются особенности алгоритмических структур.
Цель работы — провести сравнительный анализ основных алгоритмических структур и их реализации на языках программирования высокого уровня.
Задачи курсовой работы:
-раскрыть понятие, способы описания алгоритмов;
-дать анализ алгоритмов;
-раскрыть примеры использования программ.
В работе используются только работы широко известных авторов, информация из официальных сайтов. Поэтому использованную литературу можно считать надежной.
Глава 1. Понятие алгоритмов
1.1 Понятие алгоритма
Понятие алгоритм [1] является основным для всей области компьютерного программирования, поэтому начать мы должны с тщательного анализа этого термина. Слово "алгоритм" (algorithm) уже само по себе представляет большой интерес. На первый взгляд может показаться, будто кто-то собирался написать слово "логарифм" (logarithm), но случайно переставил первые четыре буквы. Этого слова еще не было в издании словаря 'VeЬster's New World Dictionary, вышедшем в 1957 году. Мы находим там только устаревшую форму "algorism" – старинное слово, которое означает "выполнение арифметических действий с помощью арабских цифр". В средние века абакисты считали на абаках (счетных досках), а алгоритмики использовали "algorism". Наконец историки математики обнаружили истинное происхождение слова "algorism": оно берет начало от имени автора знаменитого персидского учебника по математике – Абу Абд Аллах Мухаммед ибн Муса аль-Хорезми (ок. 825 г.), означающего буквально "Отец Абдуллы, Мухаммед, сын Мусы, уроженец Хо-резма". Аральское море в Центральной Азии когда-то называлось озе-ром Хорезм, и район Хорезма (Khwarizm) расположен в бассейне реки Амударьи южнее этого моря. Аль-Хорезми написал знаменитую книгу Китаб альджебр вальмукабала – "Книга о восстановлении и противопоставлении". От названия этой книги, которая была посвящена решению линейных и квадратных уравнений, произошло еще одно слово – "алгебра".
К 1950 году слово "алгоритм" чаще всего ассоциировалось с алгоритмом Евклида, который представляет собой процесс нахождения наибольшего общего делителя двух чисел. Данный алгоритм был впервые описан в книге Евклида "Начала" (около 300 г. до н.э.) и является наиболее цитируемым при рассмотрении введение в алгоритмизацию и программирование.
Современное значение слова "алгоритм" во многом аналогично таким понятиям, как рецепт, процесс, метод, способ, процедура, программа, но всетаки слово "algorithm" имеет дополнительный смысловой оттенок.
Алгоритм – это не просто набор конечного числа правил, задающих последовательность выполнения операций для решения задачи определенного типа. Помимо этого, он имеет пять важных особенностей [1].
1) Конечность. Алгоритм всегда должен заканчиваться после вы-полнения конечного числа шагов. Количество шагов может быть сколь угодно большим; выбор слишком больших значений m и n в алгоритме Евклида приведет к тому, что некоторые шаги будет выполняться более миллиона раз (неважно какая модификация алгоритма будет использована, циклическая или рекурсивная).
Процедура, обладающая всеми характеристиками алгоритма, за исключением, возможно, конечности, называется методом вычислений. Евклид предложил не только алгоритм нахождения наибольшего общего делителя, но и аналогичное ему геометрическое построение "наибольшей общей меры" длин двух отрезков прямой; это уже метод вычислений, выполнение которого не заканчивается, если заданные длины оказываются несоизмеримыми
2) Определенность. Каждый шаг алгоритма должен быть точно определен. Действия, которые нужно выполнить, должны быть строго и недвусмысленно определены для каждого возможного случая. На практике алгоритмы могут описываться и на обычном языке, и на формализованных псевдоязыках так и на языках программирования. Метод вычислений, выраженный на языке программирования, называется программой.
3) Ввод. Алгоритм имеет некоторое (возможно, равное нулю) число входных данных, т. е. величин, которые задаются до начала его работы или определяются динамически во время его работы. Эти входные данные берутся из определенного набора объектов. Например, в алгоритме есть два входных значения, а именно m и n, которые принадлежат множеству целых положительных чисел.
4) Вывод. У алгоритма есть одно или несколько выходных данных, т. е. величин, имеющих вполне определенную связь с входными данными. У алгоритма Евклида имеется только одно выходное значение, а именно – наибольший общий делитель двух входных значений.
5) Эффективность. Алгоритм обычно считается эффективным, если все его операторы достаточно просты для того, чтобы их можно было точно выполнить в течение конечного промежутка времени с помощью карандаша и бумаги. В алгоритме Евклида используются только следующие операции: деление одного целого положительного числа на другое, сравнение с нулем и присвоение одной переменной значения другой. Эти операции являются эффективными, так как целые числа можно представить на бумаге с помощью конечного числа знаков и так как существует, по меньшей мере, один способ ("алгоритм деления") деления одного целого числа на другое. Но те же самые операции были бы неэффективными, если бы они выполнялись над действительными числами, представляющими собой бесконечные десятичные дроби, либо над величинами, выражающими длины физических отрезков прямой, которые нельзя измерить абсолютно точно.
На практике нам нужны не просто алгоритмы, а хорошие алгоритмы в широком смысле этого слова. Одним из критериев качества алгоритма является время, необходимое для его выполнения; данную характеристику можно оценить по тому, сколько раз выполняется каждый шаг. Другими критериями являются адаптируемость алгоритма к различным компьютерам, его простота, изящество и т. д.
Часто решить одну и ту же проблему можно с помощью нескольких алгоритмов и нужно выбрать наилучший из них. Таким образом, возникает чрезвычайно интересная и крайне важная область анализа алгоритмов. Предмет этой области состоит в том, чтобы для заданного алгоритма определить рабочие характеристики. Как правило, это среднее число операций, необходимых для выполнения алгоритма – Tn, где n – параметр, характеризующий каким-то образом исходные данные, например число входных данных.
Для обозначения области подобных исследований используется термин анализ алгоритмов, Основная идея заключается в том, чтобы взять конкретный алгоритм и определить его количественные характеристики. Можно выяснять, является ли алгоритм оптимальным в некотором смысле. Теория алгоритмов – это совершенно другая область, в которой, в первую очередь, рассматриваются вопросы существования или не существования эффективных алгоритмов вычисления определенных величин.
Алгоритмы, как и аппаратное обеспечение компьютера, представляют собой технологию. Общая производительность системы настолько же зависит от эффективности алгоритма, как и от мощности применяющегося аппаратного обеспечения. В области разработки алгоритмов происходит такое же быстрое развитие, как и в других компьютерных технологиях.
Возникает вопрос, действительно ли так важны алгоритмы, работающие на современных компьютерах, если и так достигнуты выдающиеся успехи в других областях высоких технологий, таких как:
• аппаратное обеспечение с высокими тактовыми частотами, конвейерной обработкой и суперскалярной архитектурой;
• легкодоступные, интуитивно понятные графические интерфейсы (GUI);
• объектно-ориентированные системы;
• локальные и глобальные сети.
Ответ – да, безусловно. Несмотря на то, что иногда встречаются приложения, – которые не требуют алгоритмического наполнения (например, некоторые простые Web-приложения), для большинства приложений определенное алгоритмическое наполнение необходимо. Например, рассмотрим Web-службу, определяющую, как добраться из одного места в другое. В основе ее реализации лежит высокопроизводительное аппаратное обеспечение, графический интерфейс пользователя, глобальная сеть и, возможно , объектно-ориентированный подход. Кроме того, для определенных операций, выполняемых дан-ной Web-службой, необходимо использование алгоритмов – напри-мер, таких как вычисление квадратных корней (что может потребоваться для определения кратчайшего пути), визуализации карт и интерполяции адресов.
Более того, даже приложение, не требующее алгоритмического наполнения на высоком уровне, сильно зависит от алгоритмов. Известно, что работа приложения зависит от производительности аппаратного обеспечения, а при его разработке применяются разнообразные алгоритмы. Все мы также знаем, что приложение тесно связано с графическим интерфейсом пользователя, а для разработки любого графического интерфейса пользователя требуются алгоритмы.
Вспомним приложения, работающие в сети. Чтобы они могли функционировать, необходимо осуществлять маршрутизацию, которая, как уже говорилось, основана на ряде алгоритмов. Чаще всего приложения составляются на языке, отличном от машинного. Их код обрабатывается компилятором или интерпретатором, которые интенсивно используют различные алгоритмы. И таким примерам нет числа. Кроме того, ввиду постоянного роста вычислительных возможностей компьютеров, они применяются для решения все более сложных задач. Как мы уже убедились на примере сравнительного анализа двух методов сортировки, с ростом сложности решаемой задачи различия в эффективности алгоритмов проявляются все значительнее. Знание основных алгоритмов и методов их разработки – одна из характеристик, отличающих умелого программиста от новичка. Располагая современными компьютерными технологиями, некоторые задачи можно решить и без основательного знания алгоритмов, однако знания в этой области позволяют достичь намного большего.
1.2. Способы описания алгоритмов
Одним из самых трудоемких этапов решения задачи на ЭВМ является разработка алгоритма. Человечество разработало эффективный алгоритм завязывания шнурков на ботинках. Многие дети с пятилетнего возраста могут это делать. Но дать чисто словесное описание этого алгоритма без картинок и демонстрации - очень трудно.
При разработке алгоритмов чаще всего используют следующие способы их описания: словесный, графический, с помощью языков программирования.
Рассмотрим два способа: графический и с помощью языков программирования.
Графический способ записи алгоритмов наиболее наглядный и распространенный. Он основан на использовании геометрических фигур (блоков), каждая из которых отображает конкретный этап процесса обработки данных, соединяемых между собой прямыми линиями, называемыми линиями потока. Обозначение и назначение элементов графических схем алгоритмов приведено в табл.1. В поле каждого блочного символа указывают выполняемую функцию. При необходимости справа можно поместить комментарии, относящиеся к данному блоку или направлению потока. Каждый блочный символ (кроме начального и конечного) помечается порядковым номером. Для отличия ситуаций пересечения и слияния потоков последняя изображается точкой. Линии потока, имеющие направление вверх или направо, дополняются стрелками.
Таблица 1
|
Геометрическая фигура |
Назначение |
|
1 |
2 |
|
|
Начало и завершение алгоритма, прерывание процесса обработки данных или выполнения программы. a выбирается из ряда 5,10,15мм и т.д. ,а b=1,5a или 2a |
|
|
Выполнение операции или группы операций, в результате которых изменяются значение, форма представления или расположение данных |
|
|
Выбор направления выполнения алгоритма или программы в зависимости от некоторых переменных условий |
|
|
Ввод-вывод − преобразование данных в форму, пригодную для обработки или регистрации результатов обработки |
|
|
Вызов подпрограммы: функции или процедуры |
|
|
Текст, поясняющий выполняемую операцию или группу операций. Располагается справа от геометрической фигуры |
|
|
Внутристраничный соединитель, указывающий связь между прерванными линиями потока |
|
|
Межстраничный соединитель, указывающий связь между прерванными линиями потока, помещенными на разных листах |
|
Указания последовательности связей между элементами схемы алгоритма |








По своей структуре различают следующие типы алгоритмов: линейные, разветвляющиеся и циклические. В линейных схемах алгоритмов все предписания выполняются одно за другим. Например, алгоритм вычисления длины окружности по известной площади круга (рис.1). В разветвляющихся схемах алгоритмов для конкретных исходных данных выполняются не все заданные предписания. Однако какие именно предписания будут выполняться, конкретно определяется в процессе выполнения алгоритма в результате проверки некоторых условий. Разветвляющийся алгоритм всегда избыточен. Примером разветвляющегося алгоритма является алгоритм, приведенный на рис.2 и определяющий, пройдет ли график функции y=3x+4 через точку с координатами x1,y1.

Рис. 3
 Рис. 2
Рис. 2

Рис. 1
Циклическим алгоритмом называется такой алгоритм, в котором можно выделить многократно повторяющуюся последовательность предписаний, называемую циклом. Для таких алгоритмов характерно наличие параметра цикла, которое перед входом в цикл имеет начальное значение, а затем изменяется внутри цикла. Имеется также предписание о проверке условия окончания цикла. Применение циклов сокращает текст алгоритма и, в конечном итоге, длину программы. Примером циклического алгоритма может служить алгоритм, приведенный на рис.3 и определяющий факториал натурального числа n. В этом алгоритме введена дополнительная переменная i, которая является параметром цикла и изменяется от начального значения 1 до конечного значения n c шагом 1. На каждом шаге итерации искомая величина f умножается на переменную цикла. В реальных задачах, как правило, сочетаются все три типа алгоритмов. Способ описания алгоритма с помощью алгоритмического языка подробно рассматривается в следующем разделе.
1.3 Анализ алгоритмов
Время выполнения алгоритма или операции над структурой данных зависит, как правило, от целого ряда факторов, вследствие чего возникает вопрос – как следует проводить его измерение. При реализации алгоритма можно определить затраты времени, регистрируя действительное время, затраченное на выполнение алгоритма в каждом отдельном случае запуска с различными исходными данными [8]. Подобные измерения должны проводиться с достаточной точностью с помощью системных вызовов, встроенных в язык или операционную систему, для которой написан данный алгоритм (например, метод System.currentTimeMillis() в Java или вызовом исполняющей среды с возможностью профилирования). В общем, требуется определить, каким образом время выполнения программы зависит от количества исходных данных. Для решения этой задачи можно провести ряд экспериментов, в которых будет использовано различное количество исходных данных . Далее полученные результаты наглядно представляются с помощью графика, где каждый случай выполнения алгоритма обозначается с помощью точки, координата х которой равна размеру исходных данных n, а координата у – времени выполнения алгоритма t ( рис. 1.1). Чтобы сделать определенные выводы на основе полученных экспериментов, необходимо использовать качественные образцы исходных данных и провести достаточно большое число экспериментов, что позволит определить некоторые статистические характеристики в отношении времени выполнения алгоритма.
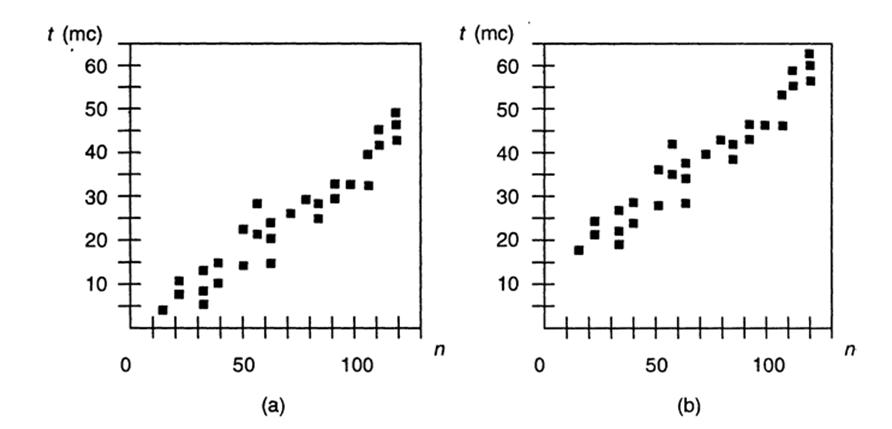
Рис.1.1
Результаты экспериментального исследования времени выполнения алгоритма. Точка с координатами (n, t) обозначает, что при размере
исходных данных n время выполнения алгоритма составило t миллисекунд (мс).
На рис. 1.1, а представлены результаты выполнения алгоритма на компьютере с быстрым процессором, на рис. 1.1, b представлены результаты выполнения алгоритма на компьютере с медленным процессором. В целом можно сказать, что время выполнения алгоритма или ме-тода доступа к полям структуры данных возрастает по мере увеличения размера исходных данных, хотя оно зависит и от типа данных, даже при равном размере. Кроме того, время выполнения зависит от аппаратного обеспечения ( процессора, тактовой частоты, размера памяти, места на диске и др .) и программ программного обеспечения (операционной среды, языка программирования, компилятора, интерпретатора и др.), с помощью которых осуществляется реализация, компиляция и выполнение алгоритма. Например, при всех прочих равных условиях время выполнения алгоритма определенного количества исходных данных будет меньше при использовании более мощного компьютера или при записи алгоритма в виде программы на машинном коде по сравнению с его исполнением виртуальной машиной, проводящей интерпретацию в байт-коды.
Экспериментальные исследования, безусловно, очень полезны, однако при их проведении существуют три основных ограничения:
- эксперименты могут проводиться лишь с использованием ограниченного набора исходных данных; результаты, полученные с использованием другого набора, не учитываются;
- для сравнения эффективности двух алгоритмов необходимо, чтобы эксперименты по определению времени их выполнения проводились на одинаковом аппаратном и программном обеспечении;
- для экспериментального изучения времени выполнения алгоритма необходимо провести его реализацию и выполнение.
Обычно для сравнительного анализа рассматривается, так называемая общая методология анализа времени выполнения алгоритмов, кото-рая:
- учитывает различные типы входных данных;
- позволяет производить оценку относительной эффективности любых двух алгоритмов независимо от аппаратного и программного обеспечения;
- может проводиться по описанию алгоритма без его – непосредственной реализации или экспериментов.
Сущность такой методологии состоит в том, что каждому алгоритму соответствует функция, которая представляет время выполнения алгоритма как функцию размера исходных данных n. Наиболее распространенными являются функции n и n2. Например, можно записать следующее утверждение: «Время выполнения алгоритма А пропорционально n». В этом случае, в результате проведения экспериментов, окажется, что время выполнения алгоритма А при любом размере входных данных n не превышает значения cn, где с является константой, определяемой условиями используемого аппаратного и программного обеспечения. Если имеются два алгоритма А и В, причем время выполнения алгоритма А пропорционально n, а время выполнения В пропорционально n2, то предпочтительнее использовать алгоритм А, так как функция n возрастает медленнее, чем функция n 2. Выводы о скорости возрастания этих функций являются, безусловно, очевидными, однако предлагаемая методология содержит точные определения данных понятий. Прежде чем перейти к описанию общей методики, определим понятие псевдокод и области его применения.
Глава 2. Анализ алгоритмов
2.1. Псевдокод
Зачастую программистам требуется создать описание алгоритма, предназначаемое только для человека. Подобные описания не являются программами, но вместе с тем они более структурированы, чем обычный текст. В частности, «высокоуровневые» описания сочетают естественный язык и распространенные структуры языка программирования, что делает их доступными и вместе с тем информативными. Такие описания способствуют проведению высокоуровневого анализа структуры данных или алгоритма. Подобные описания принято называть псевдокодом.
Проблема «максимума в массиве» является простой задачей поиска элемента с максимальным значением в массиве А, содержащем n целых чисел. Для решения этой задачи можно использовать алгоритм аггауМах, который осуществляет просмотр массива А с использованием цикла for.
Псевдокод алгоритма аггауМах представлен во фрагменте кода, а полная реализация программы Java представлена в следующем фрагменте кода.
Input: массив А, содержащий п целых чисел (n > 1).
Output: элемент с максимальным значением в массиве A.
1 currentMax ←А [0] выполняется один раз
2 for i ←1 to n - 1 do выполняется от 1 до n, n-1 раз соответственно
- if currentMax < A[i] then выполняется n-1 раз
- currentMax ← А [i] выполняется максимально n-1 раз
- return currentMax выполняется один раз
Фрагмент кода Алгоритм аггауМах
- Тестируем программу алгоритма поиска максимального элемента массива.
public class ArrayMaxProgram {
- находит элемент с максимальным значением в массиве А, содержащем n целых //чисел.
static int arrayMax(int[ ] A, int n) {
int currentMax = A[0]; // выполняется один раз
for (int i = l; i < N; i++) /* выполняется от 1 до n, n-1 раз соответ-ственно. */
if (currentMax < A[i]) // выполняется n-1 раз currentMax = A[i]; // выполняется максимально n-1 раз return currentMax; // выполняется один раз
}
- Тестирующий метод, вызываемый после выполнения программы. public static void main(String args[ ]) {
int[ ] num = { 10, 15, 3, 5, 56, 107, 22, 16, 85 }; int n = num.length; System.out.print("Array:");
for (int j = 0; i < n; i++) System.out.print("" + num[i]); System.out.println(".");
System.out.println("The maximum elementis" + arrayMax(num,n) +
".");
}
}
Фрагмент кода Алгоритм arrayMax внутри законченной Java-программы.
Как можно заметить, псевдокод выглядит компактнее Java-кода, и его легче читать и понимать. При анализе псевдокода можно поспорить
- правильности алгоритма arrayMax c простым аргументом. Переменная currentMax первоначально принимает значение первого элемента массива А. Можно утверждать, что перед началом итерации по номеру i значение currentMax равно максимальному значению среди первых i элементов массива А. Так как при повторении I значение currentMax сравнивается с A[i], то, если это утверждение верно перед данной итерацией, оно будет верно и после нее для i + 1 (которое является следующим значением счетчика i).Таким образом, после количества итераций n - 1 значение currentMax будет равно элементу массива А, содержащему максимальное значение.
Псевдокод является сочетанием естественного языка и конструкций языка программирования, которые используются для описания основных идей, заложенных в реализацию структуры данных или алгоритма. Точного определения языка псевдокода не существует, так как в нем все же преобладает естественный язык. В то же время для обеспечения четкости и ясности в псевдокоде наряду с естественным языком используются стандартные конструкции языка программирования, такие как [8]:
-
- Выражения. Для написания числовых и логических выражений используются стандартные математические символы. Знак стрелки применяется в качестве оператора присваивания в командах присваивания (равнозначен оператору «=» языка Java). Знак «=» используется для передачи отношения равенства в логических выражениях (что соответствует оператору «= =» языка Java).
- Объявление метода. Имя алгоритма (paraml, param2,...) объявляет «имя» нового метода и его параметры.
- Структуры принятия решений. Условие if, then – действия, если условие верно [else – если условие не верно]. Отступы используются для обозначения выполняемых в том или другом случае действий.
- Цикл while, while – условие, do - действия. Отступ обозначает действия, выполняемые внутри цикла.
- Цикл repeat, repeat – действия, которые выполняются, пока выполняется условие until. Отступ обозначает действия, выполняемые внутри цикла.
- Цикл for. for – описание переменной и инкремента, do – действия. Отступ обозначает действия, выполняемые внутри цикла
- Индексирование массива. A[i] обозначает i-ую ячейку массива А. Ячейки массива А с количеством ячеек n индексируются от A[0] до A[n
- 1] (как в Java).
- Обращения к методам, object.method (args) (часть object необязательна, если она очевидна).
- Возвращаемое методом значение. Значение return. Данный оператор возвращает значение, указанное в методе, вызывающим данный метод.
При записи псевдокода следует помнить, что он записывается для анализа человеком, а не компьютером, и необходимо выразить основные глобальные идеи, а не базовые детали реализации структуры. В то же время не следует упускать из виду важные этапы. Таким образом, как при любом типе человеческого общения, написание псевдокода состоит в поиске баланса между общим и частным; такое умение вырабатывается в ходе практической деятельности. Дополнительно, для лучшей передачи сущности алгоритма или структуры данных, описание алгоритма должно начинаться с краткого абстрактного объяснения характера входного и выходного потока данных, а также основных действий и используемых идей алгоритма.
2.2. Простейшие операции
После изложения высокоуровневого способа описания алгоритмов приступим к рассмотрению различных способов анализа алгоритмов.
Как уже отмечалось, экспериментальный анализ может быть очень полезен, но обладает рядом ограничений. Чтобы провести анализ алгоритма без экспериментов, связанных с изучением времени его выполнения, используем аналитический подход, который состоит из следующих операций:
-
- Записать алгоритм в виде кода одного из развитых языков программирования (например, Java).
- Перевести программу в последовательность машинных команд (например, байт-коды, используемые в виртуальной машине Java).
- Определить для каждой машинной команды i время ti, необходимое для ее выполнения.
- Определить для каждой машинной команды i количество повторений команды ni за время выполнения алгоритма.
- Определить произведение ti*ni всех машинных команд, что и будет составлять время выполнения алгоритма.
Данный подход позволяет точно определить время выполнения алгоритма, однако он очень сложен и трудоемок, поскольку требуется доскональное знание машинных команд, создаваемых компилятором и средой, в которой выполняется алгоритм.
- силу этого удобнее проводить анализ непосредственно программы, написанной на языке высокого уровня, или псевдокода. Выделим ряд простейших операций высокого уровня, которые в целом не зависят от используемого языка программирования и могут использоваться в псевдокоде:
• присваивание переменной значения,
• вызов метода,
• выполнение арифметической операции (например, сложение двух чисел),
• сравнение двух чисел,
• индексация массива,
• переход по ссылке на объект,
• возвращение из метода.
Следует отметить, что простейшие операции соответствуют машинным командам, время выполнения которых зависит от аппаратного и программного обеспечения, но тем не менее является постоянной известной величиной. Вместо попыток определения времени выполнения отдельной простейшей операции достаточно просто подсчитать - количество таких операций и использовать полученное значение в качестве критерия оценки времени выполнения алгоритма. Такой подсчет количества операций можно соотнести со временем выполнения алгоритма в условиях определенного аппаратного и программного обеспечения, так как каждая простейшая операция соответствует машинной команде, время выполнения которой есть величина постоянная, а число простейших операций известно и неизменно. Данный метод основан на неявном предположении о том, что время выполнения различных простейших операций приблизительно одинаково. Таким образом, число t простейших операций, выполняемых внутри алгоритма, пропорционально действительному времени выполнения данного алгоритма.
Рассмотрим процесс подсчета числа простейших операций, выполняемых внутри алгоритма, на примере алгоритма аггауМах. Псевдокод и Java-реализация этого алгоритма представлены во фрагментах кодов
3.1 и 3.2 соответственно. Данный анализ может проводиться как на ос-новании псевдокода, так и Java-реализации.
-
- На этапе инициализации переменной currentMax и присваивания ей значения A[0] выполняются две простейшие операции (индексация массива и присваивание переменной значения), которые однократно выполняются в начале алгоритма. Таким образом, счетчик операций равен 2.
- В начале выполнения цикла for счетчик i получает значение 1. Это соответствует одной простейшей операции (присваивание значения переменной).
- Перед выполнением тела цикла проверяется условие i<n. В данном случае выполняется простейшая операция сравнения чисел. Так как первоначальное значение счетчика i равно 0, а затем его значение увеличивается на 1 в конце каждой итерации цикла, сравнение i<n проверяется n раз. Таким образом, в счетчик простейших операций добавляется еще n единиц.
- Тело цикла for выполняется n ≥ 1 раз (для значений счетчика 1, 2,..., n- 1). При каждой итерации A[i] сравнивается с currentMax (две простейшие операции – индексирование и сравнение), значение A[i], возможно, присваивается currentMax (две простейшие операции – индексирование и присваивание значения), а счетчик i увеличивается на 1 (две простейшие операции – сложение и присваивание значения). Таким
образом, при каждой итерации цикла выполняется 4 или 6 простейших операций, в зависимости от того A[i] ≤ currentMax или A[i] > currentMax. Таким образом, при выполнении тела цикла в счетчик простейших операций добавляется
4(n - 1) или 6(n - 1) единиц.
- При возвращений значения переменной currentMax однократно в выполняется одна простейшая операция.
Итак, число простейших операций t(n), выполняемых алгоритмом arrayMax, минимально равно
2+ 1 + n + 4(n -1) + 1 = 5n,
а максимально
2+ 1 + n + 6(n -1) + 1 = 7n - 2.
Число выполняемых операций равно минимально (t(n) = 5 n) в том случае, если A[0] является максимальным элементом массива, то есть переменной currentMax не присваивается нового значения. Число выполняемых операций максимально равно ( t(n)= = 7n - 2) в том случае, если элементы массива отсортированы по возрастанию, и переменной currentMax присваивается новое значение при каждой очередной итерации цикла.
2.3. Анализ средних и худших показателей
На примере метода аггауМах можно убедиться, что при определенном типе исходных данных алгоритм выполняется быстрее, чем при других. В данном случае можно попытаться выразить время выполнения алгоритма как среднее, взятое на основе результатов, полученных при всех возможных исходных данных. К сожалению, проведение анализа с точки зрения средних показателей является весьма проблематичным, так как в этом случае требуется определить вероятностное распре-деление входящего потока. На рис. 3.3 схематично представлена зависимость времени выполнения алгоритма от распределения входного потока данных. Например, если исходные данные только типа «А» или «D».
При анализе средних показателей необходимо определить предположительное время выполнения алгоритма при некотором распределении входного потока данных. Для проведения подобных вычислений зачастую требуется применение понятий высшей математики и теории вероятности.
- связи с этим в дальнейшем будем по умолчанию указывать худший показатель времени выполнения алгоритма (если не будет оговоре-но другое условие). Можно сказать, что в худшем случае алгоритм arrayMax выполняет t(n) = 7n - 2 простейших операций, то есть максимальное число простейших операций, выполняемых алгоритмом при использовании всех исходных данных размера n, составляет 7n - 2.
Подобный тип анализа намного проще анализа средних показателей, так как не требует использования теории вероятности; для него просто необходимо определить, при каком типе исходных данных время выполнения алгоритма будет максимальным, что зачастую является вполне очевидным. Кроме того, использование такого подхода может способствовать совершенствованию алгоритмов. Другими словами, если создаваемый алгоритм должен успешно работать при худших исходных данных, предполагается, что он будет работать при любом типе исходных данных.
Таким образом, проектирование алгоритма на основании худших показателей приводит к созданию более устойчивой «сущности» алгоритма, аналогично ситуации, когда чемпион по бегу во время тренировок бегает только в гору.
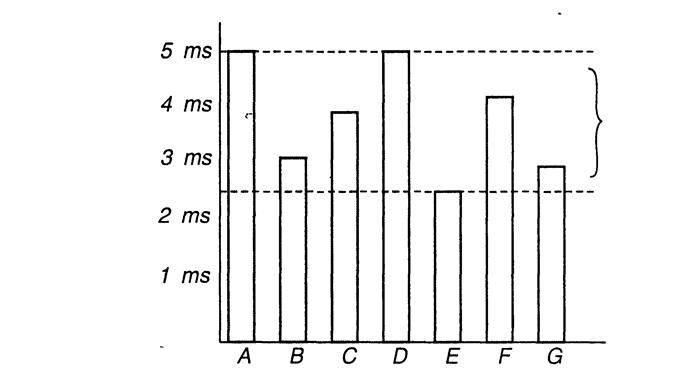
Рис. 1.2. Различие между наилучшим и наихудшим показателями времени выполнения алгоритма
Каждый прямоугольник соответствует времени выполнения алгоритма при различных типах исходных данных
2.4. Асимптотическая нотация
Очевидно, что анализ времени выполнения такого простого алгоритма, как arrayMax, проведен слишком глубоко. В ходе анализа возникает несколько вопросов:
- Действительно ли необходим такой уровень детализации?
- Действительно ли так важно установить точное число простейших операций, выполняемых алгоритмом?
- Насколько досконально следует определять количество простейших операций? Например, сколько простейших операций выполняется в команде у = a*x + b? (Можно определить, что выполняются две арифметические операции и одна операция присваивания, но , с другой стороны, в этом случае не учитывается еще одна «скрытая» операция присваивания результата произведения a*x временной переменной перед выполнением операции сложения.)
- целом каждый этап псевдокода или команда программы на языке программирования содержит небольшое число простейших операций, которое не зависит от размера исходных данных. Таким образом, можно проводить упрощенный анализ, при котором число простейших операций определяется применением некоторой константы, путем подсчета выполненных шагов псевдокода или команд программы. Возвращаясь к алгоритму arrayMax, упрощенный анализ даст следующий результат: алгоритм выполняет от 5n до 7n - 2 шагов при размере исходных данных n.
При анализе алгоритмов следует рассматривать увеличение времени его выполнения как функцию исходных данных n, уделяя основное внимание глобальным аспектам и не вдаваясь в отдельные мелкие детали. Зачастую достаточно просто знать, что время выполнения алгоритма, например, arrayMax, увеличивается пропорционально n. Это означает, что действительное время выполнения алгоритма является произведением n на некий постоянный множитель, который определяется условиями аппаратного и программного обеспечения, и может колебаться в определенных пределах в зависимости от особенностей исходных данных.
Формализуем приведенный метод анализа структур данных и алгоритмов, используя математическую систему функций, в которой не учитываются постоянные факторы. В частности, будем описывать время выполнения и требования к памяти с помощью функций, которые преобразуют целые числа в действительные, обращая внимание на глобальные характеристики функции времени выполнения алгоритма или ограничения дискового пространства.
Рассмотрим основные понятия так называемой нотация большого
- [6].
Пусть f(n) и g(n) являются функциями, которые преобразуют неотрицательные целые числа в действительные. Докажем, что f(n) есть O(g(n)), если существует действительная константа с > 0 и целочисленная константа n0 > 1, такие, что f(n) < cg (n) для любого целого числа n
- n0. Такое определение функции зачастую называется нотацией большого О, так как иногда говорят, что f(n) является большим O функции g(n). Другими словами, можно сказать, что f(n) есть порядковая функция g(n) (определение показано на рис. 3.4).
Пример: 7n - 2 есть O(n).
Доказательство: по определению нотации большого О необходимо найти действительную константу с > 0, а также целочисленную константу n0 ≥1, так, что 7n-2n0 ≤ сn для любого целого числа, n≥n0. Одним из очевидных вариантов является с = 7, а n0 = 1. Безусловно, это один из бесконечного множества вариантов; с в данном случае может принимать значение любого действительного числа, равного или большего 7, а n0 - любое целочисленное значение, большее или равное 1.
Нотация большого О позволяет выразить, что функция n «меньше или равна» другой функции (в определении это выражается знаком «≤ ») до определенного постоянного значения (константа с в определении) и по мере того, как n стремится к бесконечности (условие «n ≥ n0» в определении).
Зачастую нотация большого O используется для характеристики времени выполнения и использования памяти на основании некоего параметра n, который может различаться в конкретных ситуациях, однако, как правило, зависит от целей анализа.
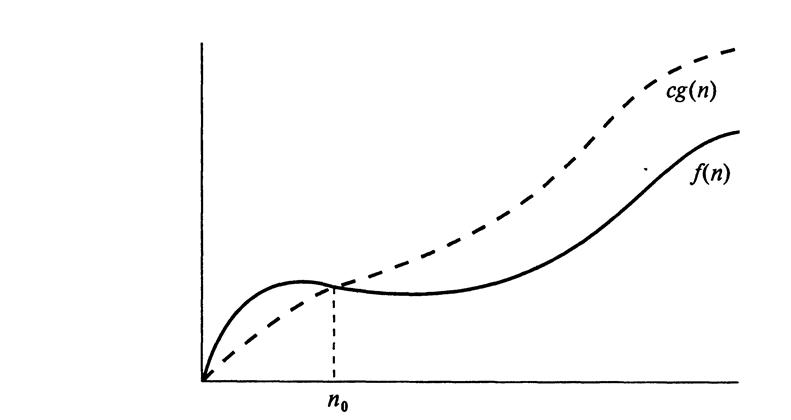
Рис. 1.3. Наглядное изображение нотации большого О. Функция f(n) есть O(g(n)), так как f(n)≤ cg(n) при n ≥ n0
Например, если требуется найти наибольший элемент массива целых чисел (см. аггауМах, представленный во фрагментах кодов), то вполне естественно использовать n для обозначения числа элементов массива. Нотация большого О позволяет не учитывать постоянные множители и частные детали, а сосредоточиться только на основных компонентах функции, определяющих ее возрастание.
Используя нотацию большого О, можно представить математически точное определение времени выполнения алгоритма аггауМах независимо от применяемых аппаратного и программного обеспечения.
Утверждение. Время выполнения алгоритма аггауМах, определяющего максимальный элемент массива целых чисел, есть функция O(n).
Доказательство. Как было отмечено, максимальное число простейших операций, выполняемых алгоритмом аггауМах, равно 7n - 2. Таким образом, существует положительная константа a, которая определяется единицами измерения времени, а также применяемым при реализации, компиляции и исполнении аппаратным и программным обеспечениями, при которой время выполнения алгоритма аггауМах для размера исходных данных n равно максимально a(7n - 2) . Используя нотацию большого О для с = 7a,a n 0= 1, можно сделать вывод, что время выполнения алгоритма аггауМах является O(n).
Рассмотрим еще несколько примеров, демонстрирующих использование нотации большого О.
Рассмотрим еще несколько примеров, демонстрирующих использование нотации большого О.
Пример: 20n3+ 10n log n + 5 есть О(n3).
Доказательство: 20n3+ 10n log n + 5 < 35n3 для n≥1.
-
- сущности, любой многочлен (полином) aknk + ak-1+ …+0 является
О(nk).
Пример: 2100 есть O(1)
Доказательство: 2100 ≤ 2100 • 1 для n ≥ 1. Заметьте, что переменная n не присутствует в неравенстве, так как в данном случае рассматриваются постоянные функции.
Пример: 5 / n есть O(1/n)
Доказательство: 5 / n ≤ 5(1/n) для n ≥1 (на самом деле это убывающая функция).
-
- целом можно сказать, что нотация большого О используется для максимально точного описания функции. Если верно, что функция F(n)
- 4n3 + Зn4/3 есть О (n5) или даже O (n3 log n), то более точно будет сказать, что f(n) есть O(n3). Рассмотрим следующую аналогию. Голодный путешественник долго едет по пустынной проселочной дороге и встречает местного фермера, который возвращается домой с рынка. Если путешественник спросит фермера, сколько ему нужно ехать, чтобы добраться до ближайшего места, где он может поесть, фермер может вполне правдиво ответить: «Не более 12 часов», но более точным (и полезным) будет, если он скажет: «Всего в нескольких минутах езды отсюда находится рынок».
Таким образом, даже используя нотацию большого O, следует стремиться сообщать все возможные подробности.
При анализе алгоритмов и структур данных часто применяются некоторые функции, имеющие особые названия. Например, термин «линейная функция» обозначает функции вида O(n). В табл. 3.1 представлены функции, часто используемые при анализе алгоритмов.
Нотация большого О позволяет проводить асимптотический анализ, то есть определять, что функция «меньше или равна» другой функции. Существуют типы нотаций, которые позволяют проводить асимптотические сравнения других типов: Ω- и Θ- нотации, которые асимптотически задают ограничения на функцию снизу или снизу и сверху одновременно (рис 1.4)
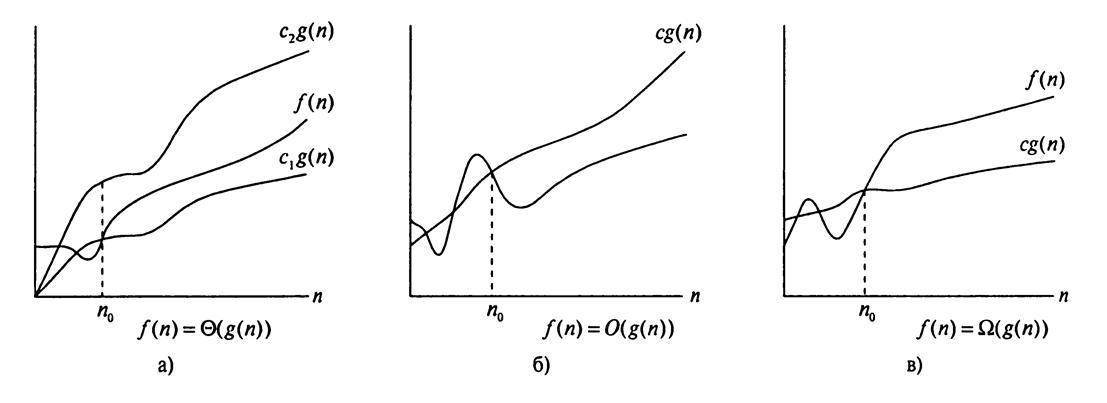
Рис. 1.4. Графические примеры Θ, О и Ω, обозначений; в каждой части рисунка в качестве n0 используется минимально возможное значение, т.е. любое большее значение также сможет выполнить роль n0
Выскажем некоторые предостережения в отношении использования асимптотических нотаций. Во-первых, следует отметить, что нотация большого О и аналогичные ей могут привести к ошибочным результатам, если «скрываемые» ими постоянные множители достаточно велики. Например, хотя функция 10100n есть Θ(n), если она обозначает время выполнения алгоритма, сравниваемого с алгоритмом, время выполнения которого равно 10n log n, следует выбрать алгоритм со временем Θ(n logn), даже несмотря на то, что асимптотически время выполнения, выраженное линейной функцией, меньше. Данный выбор обусловлен тем, что постоянный множитель 10100, называемый «hiding», считается верхним пределом числа атомов в наблюдаемой части вселенной. Таким образом, маловероятно, что алгоритму придется решать задачу реального мира с таким размером исходных данных. Таким образом, при использовании нотации большого О следует обращать внимание на постоянные множители и элементы низшего порядка, которые могут «скрываться» за ними.
- целом нотации большого O, большой омеги и большой теты являются удобным средством анализа структур данных и алгоритмов. Как упоминалось ранее, удобство данных нотаций состоит в том, что они позволяют сосредоточиться на основных составляющих, влияющих на время выполнения алгоритмов без учета частных деталей.
Глава 3. Примеры программ
3.1 Линейные программы
Теперь, когда мы познакомились с операторами, необходимыми для составления линейной программы, рассмотрим еще один пример такой программы. Пусть дано два числа a и b − длины сторон прямоугольника. Найти площадь s и периметр p прямоугольника. На рис.6 представлена графическая схема алгоритма решения данной задачи, а программа приведена в примере pr2.

Рис. 3
program pr2 ;
var
a,b,s,p:real;
begin
writeln('Введите длины стоpон пpямоугольника:');
read(a,b);
s:=a*b;
p:=(a+b)*2;
writeln('Площадь = ',s:5:3);
writeln('Пеpиметp = ',p:5:3);
end.
В этой программе все операторы выполняются последовательно друг за другом. Выполнение программы начинается с вызова процедуры вывода writeln, которая выводит на экран подсказку "Введите длины сторон прямоугольника:", что обеспечивает удобный интерфейс с пользователем. Вызов процедуры read приводит к прерыванию программы до тех пор, пока пользователь не введет два числа. Далее вычисляются площадь и периметр прямоугольника и выводятся результаты на экран.
3.2 Программы с использованием ветвлений
К разветвляющимся программам приводят задачи, в которых, в зависимости от некоторого условия, вычисления производятся тем или иным путем. Пусть нам необходимо вычислить значение y по формуле:

На рис.4 приведена графическая схема алгоритма, а программа − в примере pr3.

Рис. 4
program pr3;
var
x,y:real;
begin
writeln('Введите x:');
readln(x);
if x>0
then
y:=x*x*x+3
else
y:=x*sin(x);
writeln(y);
end.
В этой программе впервые встречается условный оператор и служит для выбора формулы вычисления y в зависимости от введенного значения x.
3.3 Программы с использования циклов
К циклическим программам приводят задачи, в которых часть действий выполняется многократно.
Пусть необходимо протабулировать функцию F(x) на интервале [a,b] c шагом h (где, F(x)=x*sin(x), a<b, h>0 ) и вывести полученные значения функции и аргумента.
Протабулировать функцию – это значит вычислить значения функции F(x) на отрезке [a,b] в точках a, a+h, a+2h и т.д.
Графическая схема алгоритма приведена на рис.5, а программа – в примере pr9.
Program pr9;
var a, b, h, x, y: real;
begin
writeln('Введите a,b,h:');
read(a,b,h);
x:=a;
repeat
y:=x*sin(x);
writeln('x = ',x:5, ' y= ',y:5);
x:=x+h; {К "старому" значению х добавляется
h и результат пересылается снова в х}
until x>b;
end.

Рис. 5
В этой программе оператор цикла используется для многократного выполнения группы операторов, расположенных между словами repeat, until. Каждый раз в цикле вычисляется значение y, выводятся x и y, задается новое значение х и проверяется, не выходит ли х за пределы интервала. В результате работы этой программы будут напечатаны в два столбика значения x и y.
Заключение
Мы рассмотрели общие принципы построения алгоритмов, основные алгоритмические структуры и их реализацию на языках программирования высокого уровня. Мы описали общие принципы построения алгоритмов, сравнили основные алгоритмические структуры, выявили особенности построения основных алгоритмических структур, их достоинства и недостатки, сравнение реализации основных алгоритмических структур на различных языках программирования высокого уровня.
Мы ввели понятие алгоритмов, указали, что алгоритм должен отвечать требованиям детерминированности, результативности, массовости, дискретности и конечность для того, чтобы они могли быть эффективно использованы для решения вычислительных, прикладных и системных задач. Затем мы рассмотрели основные используемые формы записи алгоритмов, указали основные достоинства и недостатки каждой из них. Чаще всего для записи алгоритмов до этапа кодирования используются блок-схемы. Для разработки программ на компьютере чаще всего используются языки программирования высокого уровня. Затем мы проанализировали основные алгоритмические структуры, такие как линейный алгоритм, ветвление и цикл.
Ветвление позволяет реализовывать нелинейную логику выполнения программ[1-3]. При использовании полного ветвления необходимо учитывать, что оператор, стоящий сразу после выхода из ветвления будет выполнен в любом случае. При использовании неполного ветвления необходимо учитывать, что в ветвлении явно не указывается, что будет сделано в случае, если условие не выполняется (ложно). Цикл с предусловием стоит использовать в случае, если неизвестно точное количество повторений. Цикл с постусловием стоит использовать в случае, если необходимо, чтобы цикл был выполнен хотя бы один раз. Цикл с параметром является самым компактным способом записи циклической структуры.
Список использованных источников
- Ахо А., Хопкрофт Д., Ульман Д. Структуры данных и алгоритмы: пер. с англ. – М.: Вильямс, 2017.
- Агальцов, В. П. Математические методы в программировании / В.П. Агальцов. - М.: Форум, 2018. - 240 c.
- Абрамов, В.Г.; Трифонов, Н.П. и др. Введение в язык Паскаль; Наука, 2017. - 320 c.
- Акулов О.А. Информатика: учебник / О.А. Акулов, Н.В. Медведев. – М.: Омега-П, 2017. –270 с.
- Алексеев А.П. Информатика 2007 / А.П. Алексеев. – М.: СОЛОН-ПРЕСС, 2017. – 608 с.
- Баженова, И.Ю. Языки программирования: Учебник для студентов учреждений высш. проф. образования / И.Ю. Баженова; Под ред. В.А. Сухомлин. — М.: ИЦ Академия, 2018. — 368 с.
- Вирт Н. Алгоритмы + структуры данных = программы: пер. с англ. –М.: Мир, 2016.
- Вирт Н. Алгоритмы и структуры данных: пер. с англ. – М.: Мир, 2018.
- Информатика: Учебник для вузов. Стандарт третьего поколения / Макарова Н.В, Волков В.Б.-СПб.:Питер, 2017.
- Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. Алгоритмы: построение и анализ, 3-е издание — М.: Вильямс, 2017.
- Стариченко, Б.Е. Теоретические основы информатики : учебник для вузов / Б.Е.Стариченко .— 3-е изд., перераб. и доп. — М. : Горячая линия – Телеком, 2016 .— 401 с.
- Дж. Макконелл, Основы современных алгоритмов, М.: «Техносфера», 2016, С. 10-11
- КуМир [Электронный ресурс]. URL: https://www.niisi.ru/kumir/(Дата обращения 15.02.2019)
- Лукин С.М., Турбо-Паскаль 7.0. Самоучитель для начинающих // ¶М:Диалог-МИФИ, 2018.
- Епанешников, А.М.; Епанешников, В.А. Программирование в среде Turbo Pascal 7.0; М.: ДИАЛОГ-МИФИ; Издание 4-е, испр., 2018. - 367 c
- Учебник по паскалю [Электронный ресурс]. URL: http://pcfu.ru/stati/programmirovanie/uchebnik-po-paskalyu-oglavlenie//(Дата обращения 15.02.2019)
- Доусон М. Программируем на Python / М.Доусон,. – СПб.: Питер, 2018. – 416 с.
- Лутц М. Программирование на Python/М. Лутц- том II, 4-е издание. Пер. с англ. – СПб.: Символ-Плюс, 2017. – 992 с.
- Грин, Д. Математические методы анализа алгоритмов / Д. Грин, Д. Кнут. - М., 2018. – 496 c.
- Кнут Д. Искусство программирования для ЭВМ. Т.3. Сортировка и поиск: пер. с англ. – М.: Вильямс, 2017.
- Гудман С., Хидетниеми С. Введение в разработку и анализ алгоритмов. – М.: Мир, 2016.
- Кормен Т. и др. Алгоритмы. Построение и анализ: пер. с англ. -М.: Вильямс, 2017.
- Гудрич M.T., Тамассия Р. Структуры данных и алгоритмы в Java: пер. с англ. – Мн.: Новое знание, 2017.
- Гасфилд Д. Строки, деревья и последовательности в алгоритмах: пер. с англ. – СПб.: Невский Диалект; БХВ-Петербург, 2016.
- Седжвик Р. Фундаментальные алгоритмы на C++. Ана-лиз/Структуры данных/Сортировка/Поиск: пер. с англ. – К.: Диа-Софт, 2018.
- Топп У., Форд У. Структуры данных в С++. М.: Бином", 2017.
- Ключарев А. А., Матьяш В. А., Щекин С. В. Структуры и алгорит-мы обработки данных: учеб. пособие/СПбГУАП. СПб., 2017.

- Бренд как конкурентное преимущество компании (Бренд в понятийном аппарате маркетинга)
- « Проблема детской лжи в детском возрасте»
- Организационная культура и ее роль в современных организациях(Понятие организационной культуры)
- Понятие и виды правосознания (Правосознание: понятие и место в системе форм общественного сознания)
- Понятие и границы суверенитета государства (Понятие государственного суверенитета)
- Курсовая работа (Анализ макросреды деятельности организации)
- Управление процессом реализации изменений и нововведений (Теоретические основы процесса изменений и нововведений в организации).
- Понятие менеджмента. Менеджер и предприниматель (Понятие и сущность менеджмента как системы управления)
- Субъекты и объекты коммерческой деятельности в торговле (Сущность и задачи коммерческой деятельности)
- Влияние режимов труда и отдыха на работоспособность человека .
- Повышения производительности труда в компании: совершенствование мотивации работников (Понятие мотивации, её функции)
- Гендерные различия проявлений профессионального стресса (Теоретическое обоснование проблемы стресса в отечественной и зарубежной психологии)