
Операции, производимые с данными (Сущность данных)
Содержание:

ВВЕДЕНИЕ
Данные — диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) характера химических связей, изменение состояния электронной системы и многое другое.
Понятие данных, их классификация и операции, которые производятся с ними, исследованы в работах таких авторов, как Астафьева Н.Е., Васильев А.Н., Гагарина Л.Г., Калягина Л.В., Кёнег Э., Коломейченко А.С., Мельников В.П., Перри Г., Плотникова Н.Г., Тельнова Ю.Ф. и др.
Целью данной курсовой работы является исследование операций, производимых с данными.
Достижение поставленной цели обуславливает решение следующих задач:
- изучить сущность данных
- рассмотреть типы данных
- определить задачи управления данными
- рассмотреть подходы к анализу данных
- исследовать операции с данными
- охарактеризовать модели данных
Объектом исследования данной курсовой работы являются данные.
Предметом исследования данной курсовой работы являются операции, производимые с данными.
Теоретическую базу исследования составили учебные пособия, монографии.
Глава 1. Сущность и типы данных
Данные - представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
Синонимами термина «данные» являются слова: информация, сведения. Антонимами - параметры, код.
К определению значения термина «данные» существует несколько подходов:
- совокупность сведений, информация;
- совокупность свойств, способностей как условие для достижения какой-либо цели или выполнения какой-либо работы, например: «У него неплохие данные для бокса»;
- пассивная часть программного обеспечения, совокупность значений определенных ячеек памяти, преобразование которых осуществляет код [5, с.68].
Термин «данные» в широком смысле означает фактический материал, являющийся основой для обсуждения или принятия решений; в статистике - это информация, пригодная для анализа и интерпретации.
К базовым понятиям, которые используются в экономической информатике, относятся: данные, информация и знания. Хотя эти понятия используются как синонимы, между ними существуют принципиальные различия.
Считается, что термин «данные» происходит от слова data - факт, а «информация» (informatio) означает разъяснение, изложение, т.е. сведения или сообщение.
Рассмотрим следующие определения:
- Данные - это совокупность сведений, зафиксированных на определенном носителе в форме, пригодной для постоянного хранения, передачи и обработки. Преобразование и обработка данных позволяют получить информацию [10, с.44].
- Информация - это результат преобразования и анализа данных. Отличие информации от данных состоит в том, что данные - это фиксированные сведения о событиях и явлениях, которые хранятся на определенных носителях, а информация появляется в результате обработки данных при решении конкретных задач. Например, в базах данных хранятся различные данные, а по определенному запросу система управления базой данных выдает требуемую информацию [2, с.18].
Существуют и другие определения информации, например: информация - это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний.
Знания - это зафиксированная и проверенная практикой обработанная информация, которая использовалась и может многократно использоваться для принятия решений. Знания - это вид информации, которая хранится в базе знаний и отображает знания специалиста в конкретной предметной области. Знания - это интеллектуальный капитал.
Формальные знания могут быть в виде документов (стандартов, нормативов), регламентирующих принятие решений или учебников, инструкций с описанием решения задач. Неформальные знания - это знания и опыт специалистов в определенной предметной области.
Необходимо отметить, что универсальных определений этих понятий (данных, информации, знаний) нет, они трактуются по-разному.
В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов. Самым распространённым носителем данных, хотя и не самым экономичным, по-видимому, является бумага. На бумаге данные регистрируются путём изменения оптических характеристик её поверхности. Изменение оптических свойств (изменение коэффициента отражения поверхности в определённом диапазоне длин волн) используется также в устройствах, осуществляющих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD-ROM).
В качестве носителей, использующих изменение магнитных свойств, можно назвать магнитные ленты и диски. Регистрация данных путём изменения химического состава поверхностных веществ носителя широко используется в фотографии. На биохимическом уровне происходит накопление и передача данных в живой природе. Любой носитель можно характеризовать параметром разрешающей способности (количеством данных, записанных в принятой для носителя единице измерения) и динамическим диапазоном (логарифмическим отношением интенсивности амплитуд максимального и минимального регистрируемого сигналов). От этих свойств носителя нередко зависят такие свойства информации, как полнота, доступность и достоверность. Так, например, мы можем рассчитывать на то, что в базе данных, размещаемой на компакт-диске, проще обеспечить полноту информации, чем в аналогичной по назначению базе данных, размещённой на гибком магнитном диске, поскольку в первом случае плотность записи данных на единице длины дорожки намного выше [8, с.92].
Для обычного потребителя доступность информации в книге заметно выше, чем той же информации на компакт-диске, поскольку не все потребители обладают необходимым оборудованием. И, наконец, известно, что визуальный эффект от просмотра слайда в проекторе намного больше, чем от просмотра аналогичной иллюстрации, напечатанной на бумаге, поскольку диапазон яркостных сигналов в проходящем свете на два-три порядка больше, чем в отражённом.
Информация, поступающая в компьютер, состоит из определенного множества данных, относящихся к какой-то проблеме, — это именно те данные, которые относятся к конкретной задаче и из которых требуется получить желаемый ответ. В математике классифицируют данные в соответствии с некоторыми важными характеристиками. Принято различать целые, вещественные и логические данные, множества, последовательности, векторы, матрицы (таблицы) и т.д. В обработке данных на компьютере классификация играет даже большую роль.
Любая константа, переменная, выражение или функция относятся к некоторому типу. Тип данных определяет диапазон допустимых значений и операций, которые могут быть применены к этим значениям. Кроме того, тип данных задает формат представления объектов в памяти компьютера, ведь в конце концов любые данные будут представлены в виде последовательности двоичных цифр (нулей и единиц). Тип данных указывает, каким образом следует интерпретировать эту информацию. Тип любой величины может быть установлен при ее описании, а в некоторых языках может выводиться компилятором по ее виду [7, с.46].
Например, если переменная имеет целочисленный тип данных, то таким образом определен диапазон значений, которые могут быть сохранены в этой переменной (целые числа) и определены операции, которые могут быть применены к этой переменной (арифметические, логические, возможность ввода и вывода значений этой переменной). Каждый язык программирования поддерживает один или несколько типов данных. Наличие в языке программирования типизации означает жесткую связку операций и типов объектов, над которыми их можно выполнять. Не все языки обладают таким свойством. Например, в языке С практически любые операции можно выполнять над любыми данными (например, складывать два символа или число с логическим значением, но в большинстве случаев такие операции бессмысленны и соответствуют ошибке в программе, на которую компилятор указать не сможет).
Любые данные могут быть отнесены к одному из двух типов: простому (основному), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач. Данные простого типа — это символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из таких элементарных данных формируются структуры (сложные типы) данных.
Принято различать следующие типы данных (рис.1).
Рисунок 1 - Типы данных [1, с.24]
Рассмотрим простые типы данных:
Числовые типы. Значениями переменных таких типов являются числа. К ним могут применяться обычные арифметические операции, операции сравнения (в результате получается логическое значение). Принципиально различны в компьютерном представлении целые и вещественные типы.
Целочисленные типы данных делятся, в свою очередь, на знаковые и беззнаковые. Целочисленные со знаком могут принимать как положительные, так и отрицательные значения, а беззнаковые — только неотрицательные значения. Диапазон значений при этом определяется количеством разрядов, отводимых на представление конкретного типа в памяти компьютера.
Вещественные типы бывают: с фиксированной точкой, то есть хранятся знак и цифры целой и дробной частей (в настоящее время в языках программирования реализуются редко), и с плавающей точкой, то есть число приводится к виду m х 2e, где m — мантисса, а e — порядок числа, причем 1/2 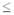 m
m 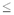 1, e — целое число. В данном случае хранятся знак, число e и двоичные цифры дробной части числа m, которые умещаются в отведенную для этого память. Говорят, что вещественные числа представимы с некоторой точностью.
1, e — целое число. В данном случае хранятся знак, число e и двоичные цифры дробной части числа m, которые умещаются в отведенную для этого память. Говорят, что вещественные числа представимы с некоторой точностью.
Символьный тип. Элемент этого типа хранит один символ. При этом могут использоваться различные кодировки, которые определяют, какому коду (двоичному числу) какой символ (знак) соответствует. К значениям этого типа могут применяться операции сравнения (в результате получается логическое значение). Символы считаются упорядоченными согласно своим кодам (номерам в кодовой таблице) [9, с.32].
Логический тип. Данные этого типа имеют два значения: истина (true) и ложь (false). К ним могут применяться логические операции. Используется в условных выражениях, операторах ветвления и циклах. В некоторых языках, например С, является подтипом числового типа, при этом ложь = 0, истина = 1 (или истинным считается любое значение, отличное от нуля).
Перечислимый тип. Отражает самый прямолинейный способ описания простого типа — перечисление всех значений, относящихся к этому типу. Каждая константа такого типа получает свой порядковый номер, что позволяет реализовать ряд простых операций над этим типом, таких, как получить следующее по порядку значение данного типа.
Множество как тип данных в основном совпадает с обычным математическим понятием множества. Допустимы стандартные операции с множествами и проверка на принадлежность элемента множеству. В некоторых языках рассматривается как составной тип (массив логических значений, i-й элемент которого указывает, находится ли i в множестве), однако эффективней реализовывать множество как машинное слово (или несколько слов), каждый бит которого характеризует наличие соответствующего элемента в множестве.
Указатель (тип данных). Если описанные выше типы данных представляли какие-либо объекты реального мира, то указатели представляют объекты компьютерного мира, то есть являются исключительно компьютерными терминами. Переменная-указатель хранит адрес в памяти компьютера, указывающий на какую-либо информацию, как правило — на другую переменную.
Составные типы формируются на основе комбинаций простых типов.
Массив является индексированным набором элементов одного типа, простого или составного (см. “Операции с массивами”). Одномерный массив предназначен для компьютерной реализации такой структуры, как вектор, двухмерный массив — таблицы.
Строковый тип. Хранит строку символов. Вообще говоря, может рассматриваться как массив символов, но иногда рассматривается в качестве простого типа. Часто используется для хранения фамилий людей, названий предметов и т.п. К элементам этого типа может применяться операция конкатенации (сложения) строк. Обычно реализованы также операции сравнения над строками, в том числе операции “<” и “>”, которые интерпретируются как сравнение строк согласно алфавитному порядку (алфавитом здесь является набор символов соответствующей кодовой таблицы). Во многих языках реализованы и специальные операции над строками: поиск заданного символа (подстроки), вставка символа, удаление символа, замена символа.
Запись. Наиболее общий метод получения составных типов из простых заключается в объединении элементов произвольных типов. Причем сами эти элементы могут быть, в свою очередь, составными. Так, человек описывается с помощью нескольких различных характеристик, таких, как имя, фамилия, дата рождения, пол, и т.д. Записью (в языке С — структурой) называется набор различных элементов (полей записи), хранимый как единое целое. При этом возможен доступ к отдельным полям записи. К полю записи применимы те же операции, что и к базовому типу, к которому это поле относится (тип каждого поля указывается при описании записи).
Последовательность. Данный тип можно рассматривать как массив бесконечного размера (память для него может выделяться в процессе выполнения программы по мере роста последовательности). Зачастую такой тип данных обладает лишь последовательным доступом к элементам. Под этим подразумевается, что последовательность просматривается от одного элемента строго к следующему, формируется же она путем добавления элементов в ее конец. В языке Pascal подобному типу соответствуют файловые типы данных [3, с.37].
1.3. Задачи управления данными
Современные программные средства обработки информации в большем числе случаев эффективны лишь тогда, когда они способны с приемлемой скоростью обрабатывать большие объемы данных. Даже при высокой скорости современных аппаратных средств, процессоров, которые способны производить миллионы операций в секунду, это не всегда достижимо. Причины этого следующие:
- ограниченность объема быстродействующих полупроводниковых устройств памяти (ОЗУ), не позволяющая держать в ОЗУ все данные;
- хранение информации на внешних носителях (дисках) вызывает большие задержки в обработке данных, так как диски имеют механические считывающие головки, позиционирование которых занимает время порядка 10 миллисекунд;
- последовательный характер работы центральных процессоров, когда практически все действия осуществляются последовательно, выстраиваясь в длинную очередь [6, с.28].
Для решения задачи скоростной обработки больших объемов информации были найдены мощные методы поиска и упорядочения данных:
- многоступенчатость поиска;
- препроцессорность поиска;
- структурирование данных.
Многоступенчатость проявляется в том, что прикладная программа работает не напрямую с большими базами данных, но только с так называемыми индексами или ключами, то есть малой частью объема информации, которая является указателем, где искать целевые данные.
Препроцессорность поиска проявляется в том, что такая малая часть информации подготавливается в виде специальных индексных таблиц или файлов, в которых хранятся не сами данные, но только указатели на них.
К примеру, если мы имеем громадный файл с данными переписи населения страны (это десятки гигабайт), в котором мы собираемся искать данные о конкретном человеке, то на препроцессорном этапе, то есть этапе подготовки базы к последующему многократному поиску создается индексный файл, представляющий собой таблицу с двумя полями: первое – кодовое значение искомой записи, второе – адрес (смещение записи от начала базового файла данных). Эта операция осуществляется один раз для всей следующей за ней серии поисков по базе данных индексированной информации.
Кодовым значением может быть сочетание фамилия + имя + отчество + дата рождения, а в реальных случаях более компактная кодовая величина, вычисляемая из этого сочетания, так называемый “хэш”, однозначно определяемая данным сочетанием.
В процессе индексирования базы находится и записывается во второе поле адрес-смещение или иначе – положение записи в базовом файле соответствующее данному сочетанию, то есть человеку для приводимого примера [4, с.11].
Таким образом на этапе поиска производятся лишь три быстрых операции:
- определение индекса или вычисление хэша для искомой записи;
- поиск в индексном файле записи с соответствующим значением индекса или хэша и выборка из этой записи в индексном файле адреса целевой записи в базовом файле;
- обращение к базовому файлу методом прямого доступа к искомой записи.
Каждая из этих операций занимает ничтожное время по сравнению с прямым перебором записей базового файла. Таким образом, процесс поиска данных ускоряется на много порядков.
Глава 2. Процедуры и операции с данными
При интенсивно развивающихся информационных технологиях в настоящее время появилось множество разновидностей в подходах к анализу данных. Перечислим основные из них:
1) Интеллектуальный анализ данных - это особый метод анализа данных, который фокусируется на моделировании и открытии данных, а не на их описании.
2) Бизнес-аналитика охватывает анализ данных, который полагается на агрегацию.
3) В статистическом смысле некоторые разделяют анализ данных на описательную статистику, исследовательский анализ данных и проверку статистических гипотез.
4) Исследовательский анализ данных занимается открытием новых характеристик данных, а проверка статистических гипотез - подтверждением или опровержением существующих гипотез [10, с.61].
5) Прогнозный анализ фокусируется на применении статистических или структурных моделей для предсказания или классификации, а анализ текста применяет статистические, лингвистические и структурные методы для извлечения и классификации информации из текстовых источников, принадлежащих к неструктурированным данным.
6) Data Mining (рус. добыча данных, интеллектуальный анализ данных, глубинный анализ данных) - собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Термин введён Григорием Пятецким-Шапиро в 1989 году.
Английское словосочетание «Data Mining» пока не имеет устоявшегося перевода на русский язык. Поэтому при переводе используются следующие словосочетания: просев информации, добыча данных, извлечение данных, а также интеллектуальный анализ данных. Более полным и точным является словосочетание обнаружение знаний в базах данных (англ. knowledge discovering in databases, KDD).
Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечеткой логики. К методам Data Mining нередко относят статистические методы (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов, анализ выживаемости, анализ связей). Такие методы, однако, предполагают некоторые априорные представления об анализируемых данных, что несколько расходится с целями Data Mining (обнаружение ранее неизвестных нетривиальных и практически полезных знаний).
Одно из важнейших назначений методов Data Mining состоит в наглядном представлении результатов вычислений (визуализация), что позволяет использовать инструментарий Data Mining людьми, не имеющими специальной математической подготовки. В то же время применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой [1, с.105].
7) Интеграция данных - это предшественник анализа данных, а сам анализ данных считается связанным с визуализацией данных и распространением данных. Интеграция данных включает объединение данных, находящихся в различных источниках, и предоставление данных пользователям в унифицированном виде. Этот процесс становится существенным как в коммерческих задачах (когда двум похожим компаниям необходимо объединить их базы данных), так и в научных (комбинирование результатов исследования из различных биоинформационных репозиториев - для примера). Роль интеграции данных возрастает, когда увеличивается объём и необходимость совместного использования данных. Это стало фокусом обширной теоретической работы, а многочисленные проблемы остаются нерешенными.
Разнообразные задачи анализа данных занимают центральное место при проведении экспериментальных исследований в любой области знаний. Вместе с тем в ряде случаев попытки использования широко известных статистических процедур обработки данных заканчиваются неудачно, так как возможности статистических методов в большинстве случаев не оправдывают требования исследователей. Это обусловлено прежде всего формализованным подходом к применению методов, относительно поверхностным знанием предпосылок их применения. С другой стороны, исследование детерминированных объектов выдвигает задачи анализа данных при неполном знании механизма явлений, происходящих в изучаемом объекте.
Характеризуя с этих позиций весь арсенал статистических методов, можно видеть, что практически ни один раздел статистики не дает прямого решения задачи анализа данных в такой ее постановке. Так, раздел описательных статистик позволяет с помощью моментов в сжатой форме представить данные, но не затрагивает вопрос о структуре данных. Раздел статистических выводов дает процедуры для проверки статистических гипотез, но в рамках заданной модели структуры данных. Методы идентификации и многомерной статистики позволяют выбрать наиболее пригодную модель для описания выборочных данных. Вопрос о пригодности выбранной модели для отображения общей структуры данных нередко остается открытым [8, с.42].
Отсутствие полностью определенной заранее модели приводит к организации процессов анализа данных в виде последовательностей процедур, позволяющей получить информацию о структуре данных. Именно грамотная организация работы человека, который не является специалистом по анализу данных, может помочь в решении поставленной задачи. Основные этапы решения задачи анализа данных показаны в левой части рисунка 2.
В правой части каждый из них разбит на более мелкие стадии.
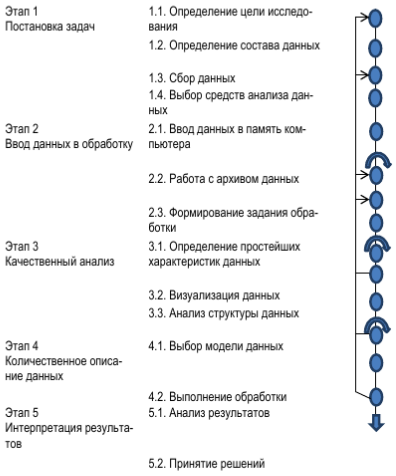
Рисунок 2 - Основные типы решения задачи анализа данных и их взаимосвязи [8, с.27]
При построении таких последовательностей необходимо уделять большое значение сбору данных, приемам накопления однородных данных, схемам классификации и группировки однородных данных, планам для выделения источников различного типа неоднородностей. Перечисленные приемы и методы развиваются в различных аспектах теории решающих функций, методов обработки данных, планирования эксперимента. Неформализованным в анализе данных остается выбор критерия для отбора в некотором смысле наилучшей последовательности процедур, раскрывающих структуру данных. Следует отметить, что никакие методы и программы обработки данных не помогут дилетанту извлечь из данных (и хороших, и плохих) информацию. Определяющим фактором всегда является профессионализм исследователей.
Создание данных, как процесс обработки, предусматривает их образование в результате выполнения некоторого алгоритма и дальнейшее использование для преобразований на более высоком уровне.
Модификация данных связана с отображением изменений в реальной предметной области, осуществляемых путем включения новых данных и удаления ненужных.
Контроль, безопасность и целостность направлены на адекватное отображение реального состояния предметной области в информационной модели и обеспечивают защиту информации от несанкционированного доступа (безопасность) и от сбоев и повреждений технических и программных средств.
Поиск информации, хранимой в памяти компьютера, осуществляется как самостоятельное действие при выполнении ответов на различные запросы и как вспомогательная операция при обработке информации [3, с.52].
Поддержка принятия решения является наиболее важным действием, выполняемым при обработке информации. Широкая альтернатива принимаемых решений приводит к необходимости использования разнообразных математических моделей.
Создание документов, сводок, отчетов заключается в преобразовании информации в формы, пригодные для восприятия как человеком, так и компьютером. С этим действием связаны и такие операции, как обработка, считывание, сканирование и сортировка документов.
При преобразовании информации осуществляется ее перевод из одной формы представления или существования в другую, что определяется потребностями, возникающими в процессе реализации информационных технологий.
Реализация всех действий, выполняемых в процессе обработки информации, осуществляется с помощью разнообразных программных средств.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
- сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
- формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
- фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
- сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
- архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
- защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя - клиентом;
- преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства - телефонные модемы [8, с.116].
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление, наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой [1, с.127].
Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее можно выделить нечто общее в этих определениях.
Модель данных - это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
На рисунке 3 представлена классификация моделей данных.
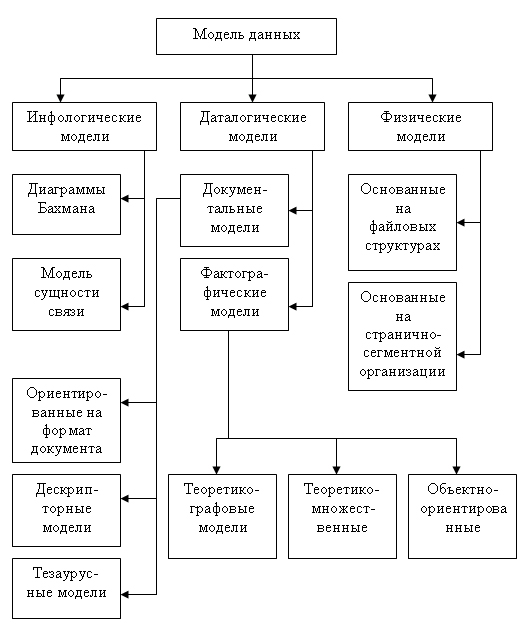
Рисунок 3 - Классификация моделей данных [5, с.73]
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими.
Инфологические модели данных - отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а дата-логические модели уже поддерживаются конкретной СУБД.
Документальные модели данных - соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Тезаурусные модели - это модели, которые основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели - самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента [9, с.84].
ЗАКЛЮЧЕНИЕ
Данные - представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе. Синонимами термина «данные» являются слова: информация, сведения. Антонимами - параметры, код.
Термин «данные» в широком смысле означает фактический материал, являющийся основой для обсуждения или принятия решений; в статистике - это информация, пригодная для анализа и интерпретации.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие: сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений; формализация - приведение данных, поступающих из разных источников, к одинаковой форме; фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; сортировка - упорядочение данных по заданному признаку с целью удобства использования; архивация - организация хранения данных в удобной и легкодоступной форме; защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных; транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Астафьева Н.Е. Информатика и ИКТ: Практикум для профессий и специальностей технического и социально-экономического профилей / Н.Е. Астафьева. - М.: Academia, 2019. - 384 c.
- Васильев А.Н. Программирование на C# для начинающих. Особенности языка / А.Н. Васильев. - М.: ЭКСМО, 2017. - 128 c.
- Гагарина Л.Г. Информационные технологии: Учебное пособие / Л.Г. Гагарина, Я.О. Теплова, Е.Л. Румянцева и др. - М.: Форум, 2018. - 144 c.
- Калягина Л.В. Категория «данные»: понятие, сущность, подходы к анализу // Вестник Красноярского государственного аграрного университета, 2014. - №4. – С.11
- Кёнег Э Эффективное программирование на C++. Практическое программирование на примерах. Серия "C++ In-Depth" / Э Кёнег, Б. Му. - М.: Диалектика, 2019. - 368 c.
- Коломейченко А.С. Информационные технологии: Учебное пособие / А.С. Коломейченко, Н.В. Польшакова, О.В. Чеха. - СПб.: Лань, 2018. - 228 c.
- Мельников В.П. Информационные технологии: Учебник / В.П. Мельников. - М.: Академия, 2018. - 176 c.
- Перри Г. Программирование на C для начинающих / Г. Перри, Д. Миллер. - М.: ЭКСМО, 2016. - 192 c.
- Плотникова Н.Г. Информатика и информационно-коммуникационные технологии (ИКТ): Учебное пособие / Н.Г. Плотникова. - М.: Риор, 2018. - 132 c.
- Тельнова Ю.Ф. Информационные системы и технологии / Под ред. Тельнова Ю.Ф.. - М.: Юнити, 2017. - 544 c.

- Основы программирования на языке HTML ( Язык HTML)
- Финансы в макроэкономической системе.
- Классификация языков программирования.Критерии выбора среды и языка разработки программ
- Судебная власть государства: организация и полномочия (Роль и место судебной власти в правовой жизни общества)
- Органы местного самоуправления (Правовая основа местного самоуправления)
- Органы местного самоуправления (Полномочия субъектов РФ)
- ПУБЛИЧНАЯ ВЛАСТЬ ( ПОНЯТИЕ ГОСУДАРСТВЕННОЙ ВЛАСТИ)
- Понятие, признаки и правовое регулирование несостоятельности (банкротства) (Состав отношений)
- Состав и свойства вычислительных систем, информационное и математическое обеспечение вычислительных систем
- Эффективность менеджмента организации (на примере розничного предприятия «Северный Градус»)
- Роль мотивации в поведении организации ( Классические теории мотивации персонала)
- Особенности управления организациями в современных условиях и пути его совершенствования (Оценка эффективности управления организацией на примере ООО «Универсам «Зебра»)