
Операции, производимые с данными
Содержание:

ВВЕДЕНИЕ
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
Поэтому в данной курсовой работе будут рассмотрены наиболее возможные операции с данными так и основные с которыми приходится сталкиваться практически в любой сфере человеческой деятельности, связанной с информационными технологиями.
Из возможных операций над данными можно выделить следующие:
- Получение - или сбор информации с целью обеспечения достаточной полноты для принятия решений.
- Формализация - приведение данных к одному виду для повешения уровня доступности к ним.
- Сортировка - упорядочение данных по заданному признаку с целью их удобного использования и дальнейшей обработки.
- Фильтрация – отбрасывание лишних данных которые не несут никакой ценной информации.
- Защита - меры, направленные на то чтобы запретить несанкционированное изменение, удаление и добавление данных в системе.
- Архивация - организация хранения данных, служит для снижения экономические затраты и повышает общую надежность информационного процесса в целом.
- Перемещение - прием и передача данных между удаленными участками информационного процесса.
- Преобразование – перевод данных из одной формы в другую что довольно часто связано с изменением типа носителя, например, видеоряд может хранится как в виде кассеты, так и в электронном виде в памяти компьютера.
Список приведенных здесь операций является далеко не полным и вполне, может быть пополнен ещё какой-либо операций, но в данном случае будут рассмотрены именно они.
Так как операций в таком списке достаточно обширное множество, то для того, чтобы в той или иной мере раскрыть каждую будет использоваться язык программирования высокого уровня C++ (также в некоторых случаях будут приведены блок-схемы) и веб технологии. Можно было использовать Pascal или скажем Python, но в первом случае язык является слишком формальным для реализации, а во втором довольно простым.
Для рассмотрения основных операций над данными будут приведены упрощенные блок-схемы, по которым также будет частично написан код на языке C++.
Список таких операций:
- Добавление
- Удаление
- Изменение
- Просмотр
- Обработка
Все эти операции можно считать фундаментальными которые выполнимы как для реляционных баз данных, так и скажем структур данных.
1. СПИСОК ВОЗМОЖНЫХ ОПЕРАЦИЙ НАД ДАННЫМИ
1.1 Получение
Данные можно получать откуда угодно, это может быть, как тестовый файл или ввод со стороны пользователя, так и данные пришедшие из интернета.
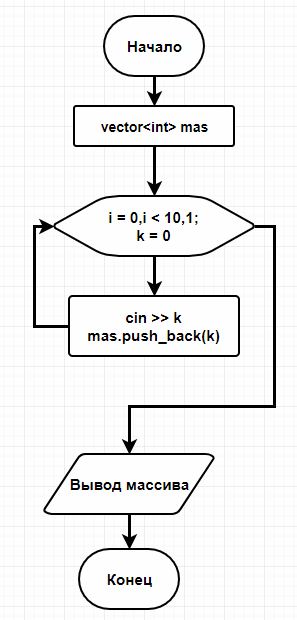
Блок-схема 1. Получение информации от пользователя
Листинг 1. Ввод данных пользователем
vector<int> mas;
//ввод данных
for (int i = 0,k = 0; i < 10; i++) {
cin >> k;
mas.push_back(k);
}
//вывод массива
for (auto& i : mas) {
cout << i << ' ';
}
В листинге 1 отображен ввод элементов со стороны пользователя, который заканчивается, когда нарушается условие в цикле, после чего выводится массив, который был введен.
Так же данные можно брать из файла.

Блок-схема 2. Получение данных из файла
Листинг 2. Ввод данных из файла
vector<int> mas;
//открываем файл для чтения
ifstream ios("file.txt");
//если открыли то
if (ios.is_open()) {
int k = 0;
//считываем все до конца файла
while (ios >> k) {
mas.push_back(k);
}
}
else {
cout << "Ошибка открытия файла" << endl;
}
ios.close();
//вывод массива
for (auto& i : mas) {
cout << i << ' ';
}
Здесь происходит считывание данных из файла пока не будет достигнуть конец (eof).
Ещё есть возможность получения данные по сети как пример взаимодействия клиент-серверного приложения, где клиент получает от сервера запрашиваемою страничку, которая в свою очередь передается ему с откомпилированными скриптами (если имеется компилятор php на сервере) и прочими стилями. Или ajax взаимодействие которое будет рассматриваться в пункте 1.7. данной курсовой работы.
В итоге все сущности участвующие в информационном процесс рано или поздно получают какие-либо данные выполняют над нами определенные действия и отправляют дальше.
1.2 Формализация
Иногда требуется привести данные к одинаковому виду, чтобы сделать их сопоставимыми между собой тем самым повысив их уровень доступности.
В качестве примера допустим имеется два канала связи (два файла) по одному из которых передаются целые числа, а по-другому двоичные, и чтобы не запутаться в таком случае следует перевести двоичные числа в десятичные и хранить их вмести как одно целое (или хранить все в двоичной записи).
Листинг 3. Пример задачи формализации
vector<string> dmas;
vector<int> imas;
//открываем файлы для чтения
ifstream ios("file.txt");
ifstream ios_d("dfile.txt");
//получаем информацию из файлов
get_info(dmas, ios_d);
get_info(imas, ios);
ios.close();
ios_d.close();
merge(imas, dmas);
//вывод массива
for (auto& i : imas) {
cout << i << ' ';
}
Метод get_info выполняет считывание информации с файла в массив аналогичный блок-схеме 2.
Процедура merge принимает два разнотипных массива и переводит все двоичные числа из массива dmas в десятичные после чего добавляет каждое в imas.
Более подробно данный процесс представлен на Блок-схеме 3.
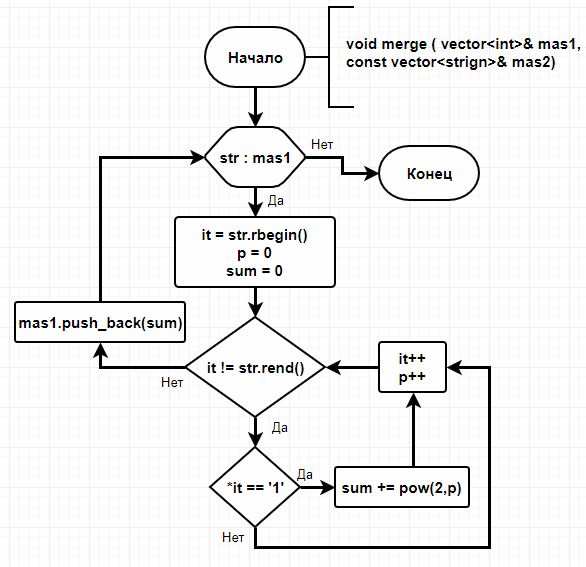
Блок-схема 3. Процедура merge (перевод чисел из двоичной систему в десятичную)
Рассматривая данную операцию с более широкой позиции, то практически все разрозненные данные так или иначе можно представить в виде одного целого которыми в дальнейшем можно будет легко манипулировать.
Довольно часто операция формализации применяется специалистами по большим данным для которых представление данных в одном каком-то виде существенно упрощает решение задачи.
1.3 Сортировка
Сортировка является достаточно важной операцией над данными способная мгновенно (зависит от сортировки) упорядочить данные как по возрастанию, так и по убыванию.
Рассмотрим, как пример сортировку пузырьком написанную на языке C++.
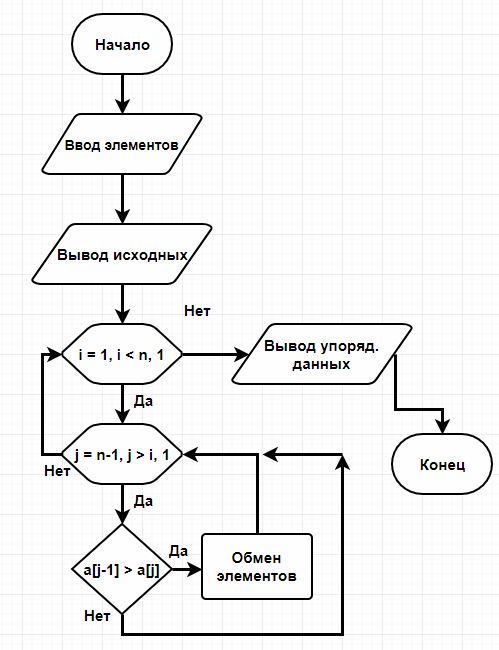
Блок-схема 4. Алгоритм сортировки пузырьком
Листинг 4. Программная реализация алгоритма сортировки
vector<int> a;
int n = 10;
//ввод
for (int i = 0,k = 0; i < n; i++) {
cin >> k;
a.push_back(k);
}
//вывод
cout << "Исходный массив : ";
for (auto& i : a) {
cout << i << ' ';
}
//сортировка пузырьком
for (int i = 0; i < n; i++) {
for (int j = n-1; j > i; j--) {
if (a[j - 1] > a[j]) {
int t = a[j];
a[j] = a[j-1];
a[j - 1] = t;
}
}
}
//вывод
cout << endl << "Упорядоченный : ";
for (auto& i : a) {
cout << i << ' ';
}
Таким образом можно упорядочивать любые данные для которых определен оператор сравнения.
Даже если нужно к примеру, отсортировать какую-то довольно сложную структуру содержащую информацию о пользователе и его возраст, то по полю возраст такая сортировка вполне может пригодится.
Конечно уже мало где используется такая сортировку если только в плане научить основам алгоритмизации (субъективный взгляд), а в довольно серьезных проектах может использоваться, например, быстрая сортировка или TimSort сортировка, которая совмещает в себе сразу и сортировку слиянием, и сортировку вставками, что на деле показывает довольно хорошие результаты.
1.4 Фильтрация
Очищение данных от “шума” есть довольно важная операция способная не только правильно классифицировать данные (если требуется), но и улучшить их общую информативность.
Здесь можно рассмотреть такую задачу:
Допустим передается исходная последовательность символов (со стороны пользователя), содержащая в себе как буквы английского алфавита, так и любые другие знаки включая цифры и требуется составить из этой строки массив, который будет содержать только цифры.
Листинг 5. Выявление чисел из переданной строки
vector<int> a;
string ss;
string num;
cout << "Введите строку : ";
cin >> ss;
//берем только цифры
for (int i = 0; i < ss.size(); i++) {
//если дошли до конца
if (i == (ss.size() - 1) && num.size()) {
if (isdigit(ss[i])) {
num.push_back(ss[i]);
}
a.push_back(atoi(num.c_str()));
num.clear();
break;
}
//если это цифра
if (isdigit(ss[i])) {
num.push_back(ss[i]);
}
else {
if (num.size()) {
a.push_back(atoi(num.c_str()));
num = "";
}
}
}
Таким образом последовательность: dsdu78v^(Db83b0s8xv&D759IN902
после фильтрации будет такой: 78, 83, 0, 8, 759, 902;
1.5 Защита
Наряду с другими операциями является не столько нужной как сама собой разумеющейся.
Например, C++ в основном является объектно-ориентированным языком программирования, который включает в себя такие принципы как инкапсуляция, полиморфизм и наследование. Из этого списка к операции защита более относится инкапсуляция, которая накладывает на класс права доступа в следствии чего не каждый пользователь может получить данные которые относятся к закрытой части или к защищенной.
Листинг 6. Класс Point
class Point {
private:
double x, y;
public:
Point(double _x,double _y):x(_x),y(_y){}
double get_x()const {
return x;
}
double get_y()const {
return y;
}
void set_x(double _x) {
x = _x;
}
void set_y(double _y) {
y = _y;
}
friend ostream& operator<<(ostream& os, Point& k) {
os << "x : " << k.x << " ; y : " << k.y;
return os;
}
};
В приведенном классе точка определены координаты на плоскости и геттеры, сеттеры для манипуляции ими, что дает нам доступ к закрытой части класса.
В таком случае если пользователь захочет напрямую обратится к закрытой части класса Point.x, то компилятор выдаст ошибку доступа, что дает уже хоть какую -то защищенность от внешнего вмешательства.
Ещё один пример можно привести на основе хеш-функции, которая преобразовывает массив входных данных произвольный длины в (выходную) битовую строку фиксированной длины, выполняемое определенным алгоритмом. Существует огромное множество хеш-функций, одни из которых работают на отлично ну а другие не очень (выдают один и тот же хеш при различных данных). Но большое внимание хотелось бы уделить хеш-таблице, которая будет хранить данные посредством вычисления хеш-функции.
Хеш-таблицу можно представить в следующем виде:
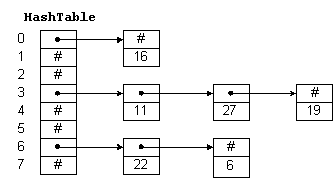
Рис 1. Хеш-таблица на основе метода цепочек
На рис 1. Можно видеть таблицу где каждый элемент такой таблицы представим в виде односвязного списка, это сделано для того чтобы разрешить ситуацию, при которой хеш-функция вычисляет один и тот же номер строки (хеш). Иначе говоря, такая ситуация называется коллизией и для того чтобы ещё разрешить используется односвязный список, но может также использоваться и метод открытой адресации, который основан на том что если возникнет коллизия, то будет производится поиск свободного места для вставки, после того элемента на который указывала вычисленная хеш-функция. Что касается защиты, то в обычном массиве пользователь может сразу обратится к несуществующему элементу и тем самым поймать out of range (выход за пределы массива) или ещё хуже получить какое-то немыслимое число, ну а в случае с хеш-таблицей такой ситуации не возникнет так-как введенная последовательность будет однозначно отображаться на отрезок допустимых значений массива.
1.6 Архивация
Организовать хранение данных можно по-разному, рассмотрим основные виды организации:
- Иерархический – представляет из себя древовидную структуру
- Объектно-ориентированный – данные представимы в виде объектов, имеющих свои атрибуты-свойства и методы.
- Реляционный – данные хранятся в виде таблиц, имеющих различные поля.
Вот наиболее часто используемые виды хранения и организации данных которые также находят свое применение и сегодня.
Рассмотрим для начала Объектно-ориентированный вид организации данных на примере диаграммы классов UML (undefined modeling language).
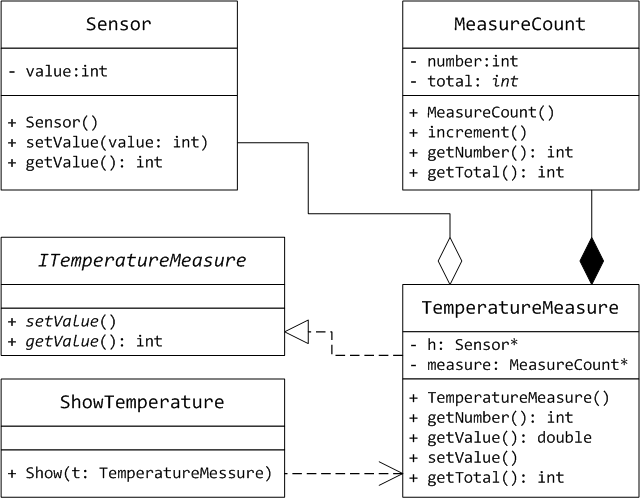
Рис 2. UML диаграмма классов
На рис 2 показана организация датчика температуры, который наследует интерфейс простого измерителя и использует дополнительные классы для своей работы. Такая структура организации данных свойственна языкам имеющих ООП парадигму: C++, С#, Java и тд.
В случае с реляционной организацией, рассмотрим следующую структуру:
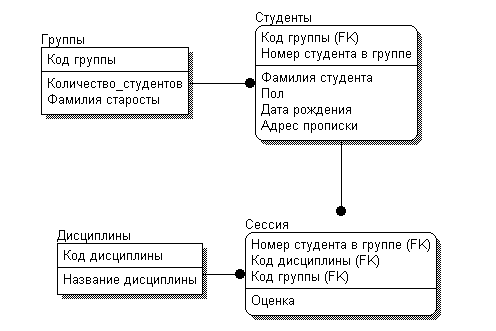
Рис 3. Пример реляционной базы данных
Как видно здесь используются как первичные ключи, так и внешние (FK) по которым можно однозначно обратится к определенному полю в другой таблице данных. Такой подход хранения и организации данных свойственен реляционным базам данных и СУБД для их использования как например: MS Access, MySQL,Oracle и др.
В результате были рассмотрены основные хотя и не последние виды организации хранения данных.
1.7 Перемещение или транспортировка
Получение и отправление данных между участниками информационного процесса есть процесс повсеместный и обычно источником данных в информатике принято называть сервер, а сторону принимающую данные клиент.
Рассмотрим клиент-серверное взаимодействие на простой html форме которая после заполнения будет отправляться на сервер для дальнейшей обработки и возвращать ответ:
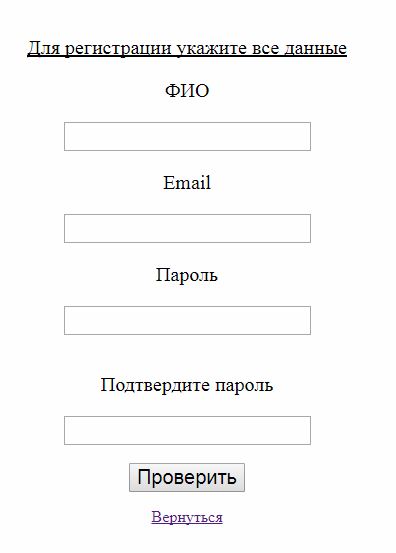
Рис 4. Форма регистрации
Пользователю предлагается заполнить форму регистрации, а после чего нажать “Проверить”. После нажатия на кнопку “Проверить” все данные введенные пользователем собираются в “кучу” и отправляются на сторону сервера, который в свою очередь их обрабатывает и если что-то не так то дает нам знать об этом см Рис 5.

Рис 5. Забыли ввести mail
Тем самым все что введено правильно подсвечивается зеленым, а остальное красным. Чтобы исправить эту ситуацию напишем наконец mail.
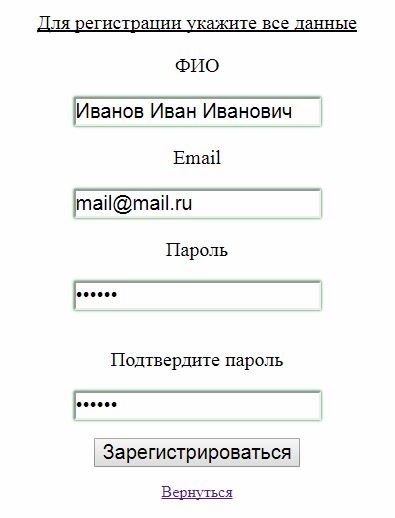
Рис 6. Правильно заполненная форма
Теперь на рис 6. Стала доступна регистрация нового пользователя в системе.
В данном случае применяется технология ajax и чтобы понять как она работает можно рассмотреть рисунок 7.
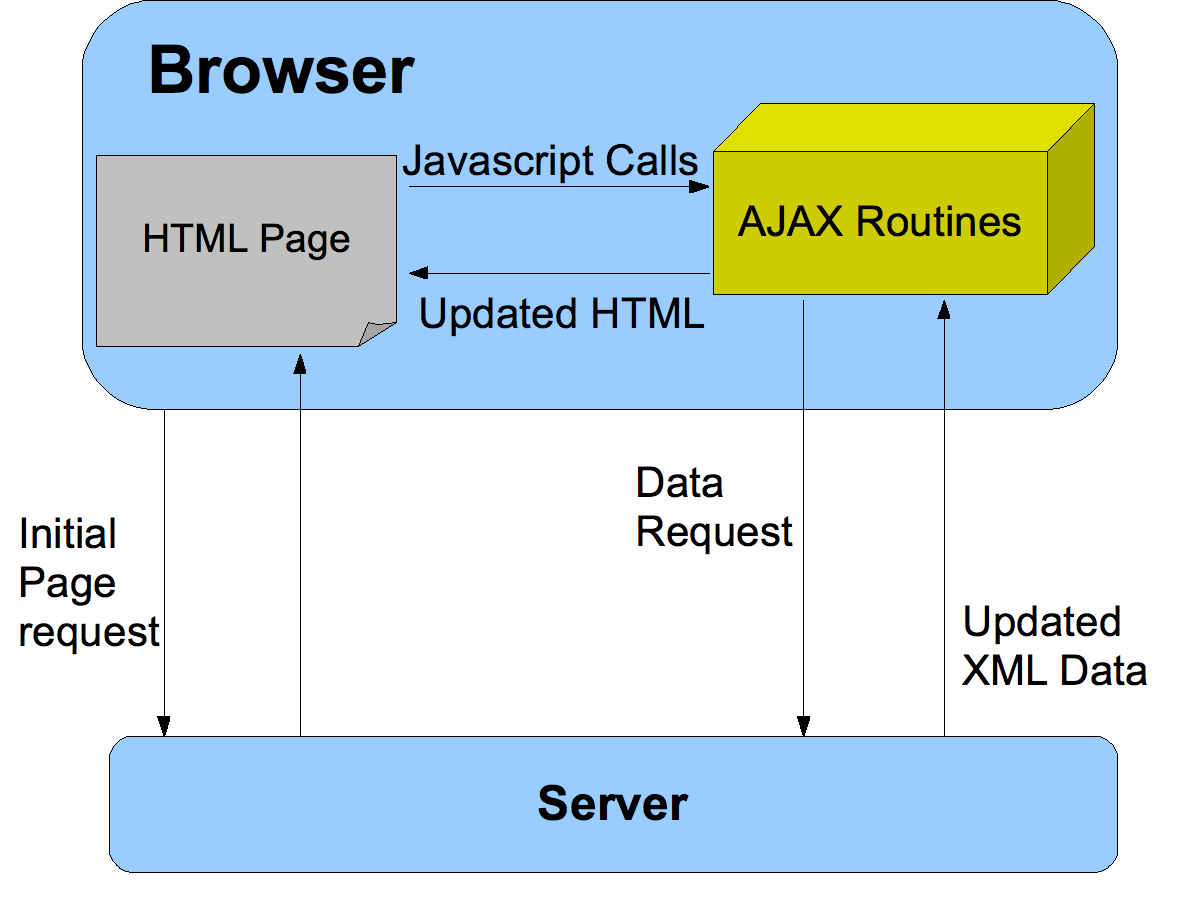
Рис 7. Взаимодействие технологии ajax с сервером
Таким образом данные от пользователя попадают сначала на сервер, там проходят проверку и по завершению отправляется ответ обратно на сторону пользователя как например на рис 6. Была заменена кнопка, нажав по которой пользователя может зарегистрироваться в системе.
Конечно в качестве примера все выглядит довольно просто и в реальных системах может не использоваться, но для объяснения операции транспортировки данных в интернете вполне приемлемо.
1.8 Преобразование
Перевод данных из одной формы в другую иногда бывает полезен в случае их транспортировки если принимающая часть ( сервер к примеру ) работает только с одним видом данных и больше не с каким.
На рисунке 6 ясно показано что пользователь ввел все данные потом нажал на кнопку “Проверить” и далее эти данные должны быть переданы на сервер, но для начала их нужно взять с формы поместить в переменные и только потом отправить одним пакетом на сервер, а уже там получить к ним доступ в зависимости от того каким запросом были переданы эти данные.
Ещё в качестве примера можно привести следующий рисунок, который также отвечает на вопрос преобразования данных.

Рис 8. Преобразования данных с бумажных носителей в
электронный (ноутбук)
Конечно в таком случае данные должны быть как минимум отсканированы, а уже потом производить их обработку чтобы в дальнейшем с ними можно было работать. Или как вариант поместить все в формат djvu.
2. СПИСОК ОСНОВНЫХ ОПЕРАЦИЙ НАД ДАННЫМИ
В данном разделе будут представлены основные операции над данными с которыми чаще всего приходится иметь дело.
Как известно процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
И чтобы лучше понять данные операции будет реализована структура данных на языке C++ которая обычно называется, как односвязный список или просто связный список.
Ниже приведен рисунок такого списка.
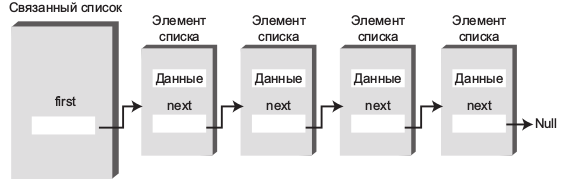
Рис 9. Односвязный список (структура данных)
Для такой структуры будут реализованы все основные операции, которые представлены выше.
Все блок-схемы будут выполнены в абстрактной форме, а примеры реализованы конкретно на языке C++.
2.1 Добавление
С операцией добавления можно также сравнить и получение, которое в какой-то мере выполняет туже работу по сбору информации из вне.
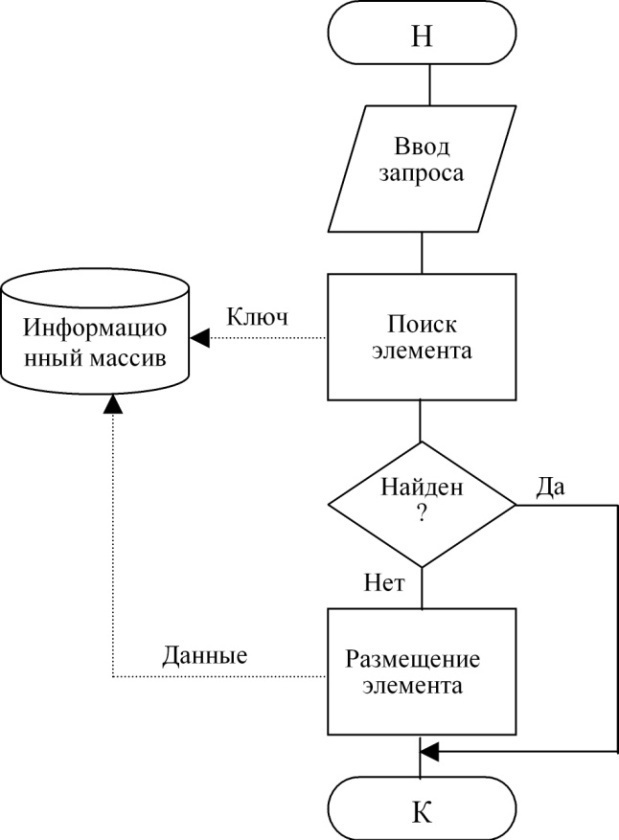
Блок-схема 5. Технология добавления элемента
Для односвязного списка данную операцию можно представить в следующем виде:
Листинг 7. Добавление элемента в односвязный список
void push(t item) {
shared_ptr<node> ptr(new node(item));
if (head == nullptr) {
head = move(ptr);
return;
}
else {
ptr->next = head;
head = ptr;
}
}
Отличие от схемы лишь в том, что не нужно проверять наличие элемента в таком списке так как хранится могут и одинаковые элементы.
2.2 Удаление
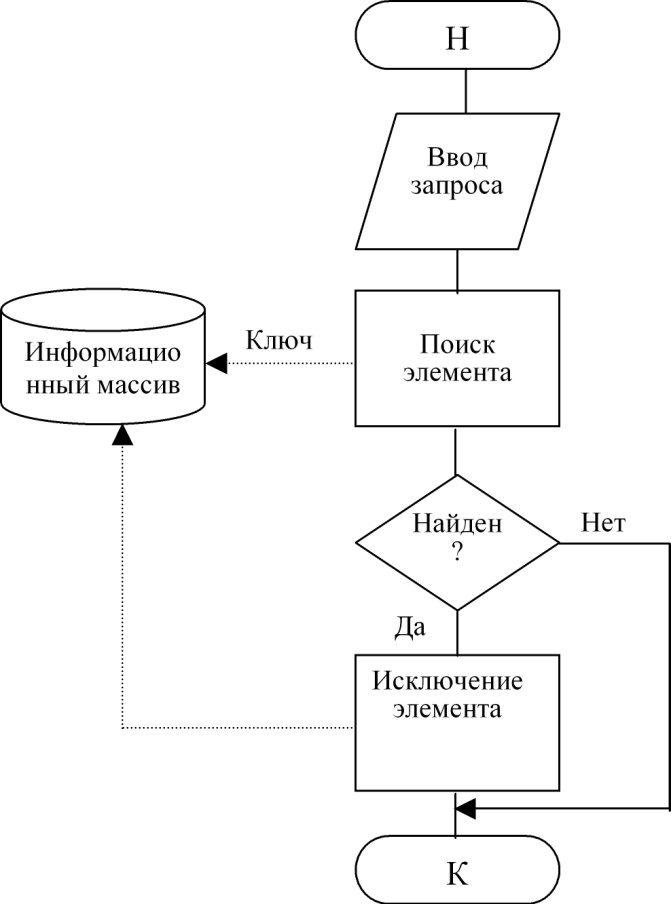
Блок-схема 6. Технология удаления элемента
Листинг 8. Удаление элемента в односвязном списке
void pop(t item) {
shared_ptr<node> ptr = head;
if (ptr->item == item) {
head = head->next;
return;
}
while (ptr->next != nullptr) {
if (ptr->next->item == item) {
ptr->next = ptr->next->next;
return;
}
ptr = ptr->next;
}
}
В случае с удалением схема 6 практически полностью соответствует листингу 8 с удалением элемента из списка.
2.3 Изменение
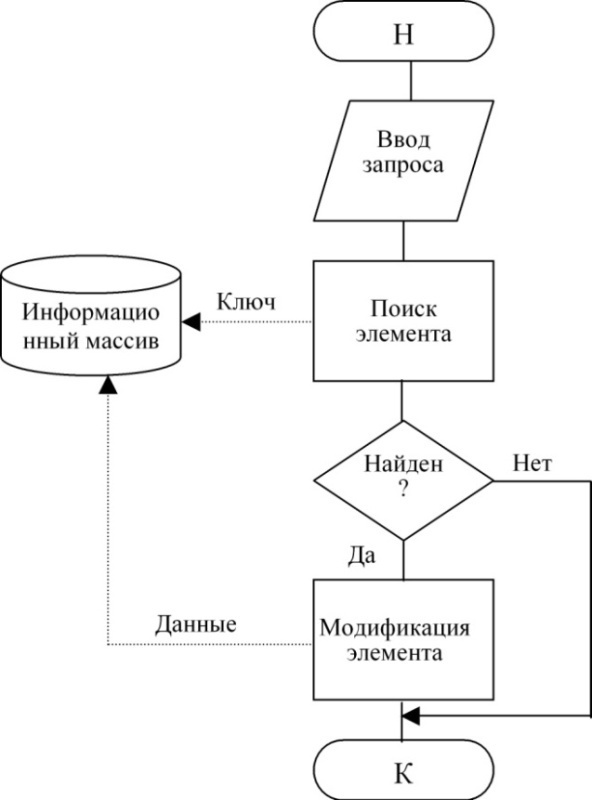
Блок-схема 7. Технология изменения элемента
Листинг 9. Модификация указанного элемента
shared_ptr<node> find(t item) {
shared_ptr<node> ptr = head;
while (ptr != nullptr) {
if (ptr->item == item) return ptr;
ptr = ptr->next;
}
return nullptr;
}
Таким образом если элемент для изменения найден, то его можно изменить, например, так:
auto ptr = indef.find(23);
ptr->item = 512;
При условии, что для node определен член класса item и шаблон класса инстанцирован числовым типом.
-
- Просмотр
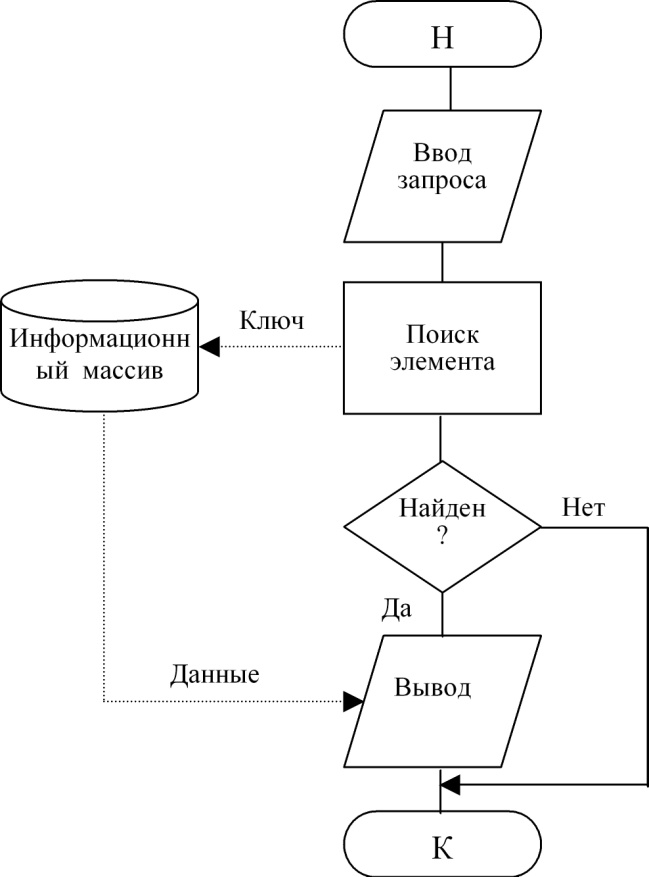
Блок-схема 8. Технология просмотра элемента(ов)
Листинг 10. Вывод элементов связного списка
void print()const {
shared_ptr<node> root = head;
while (root != nullptr) {
cout << root->item << ' ';
root = root->next;
}
cout << endl;
}
Тут происходит вывод всех элементов от начала и до конца связного списка и поиск здесь не нужен.
2.4 Обработка данных
В качестве обработки данных можно привести пример с расчетом суммы элементов в заданном диапазоне связного списка.
Листинг 11. Метод расчета суммы элементов с указанным диапазоном
t obr(t left, t right) {
shared_ptr<node> ptr = head;
t sum = 0;
while (ptr != nullptr) {
if (ptr->item >= left && ptr->item <= right) {
sum += ptr->item;
}
ptr = ptr->next;
}
return sum;
}
Таким образом были рассмотрены основные операции с данными как в виде блок-схем, так и на примере кода.
Листинг включающий в себя программу целиком вы можете найти в Приложении А.
ЗАКЛЮЧЕНИЕ
В результате выполнения курсовой работы были рассмотрены как наиболее возможные операции над данными, так и основные которые в итоге раскрывают выбранную тему. Все из рассмотренных операций были в той или иной мере подкреплены языком программирования C++ для того чтобы лучше понять смысл приведенных операций. Список всех операций, который был здесь представлен не является всеобъемлющем и может в зависимости от задачи быть дополнен какой-либо сторонней операцией.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Язык программирования С++ Бьерн Страуструп Издательство: «Бином» 2012 г.
- Роберт Седжвик: Фундаментальные алгоритмы C++. Издательство «Диасофт» Год издания: 2001 г.
- Информатика: Учебник для вузов/ А.С. Грошев – Архангельск, Арханг.гос.техн.ун-т 2010.-470с https://narfu.ru/university/library/books/0690.pdf
- Технология программирования/ Г.С. Иванова - Москва Издательство МГТУ имени Н.Э. Баумана 2002 г.
- Информатика. Базовый курс/ С.В. Симонович. Год издания: 2013. Издательство: Питер.
- Технология программирования на C++. Начальный курс
Автор: Н. А. Литвиненко. Год издания 2005г.
- HTML и CSS. Разработка и дизайн веб-сайтов. Автор: Джон Даккет. Год выпуска: 2017. Издательство: Эксмо.
Приложение А.
Листинг кода на языке С++ реализующий связный список
template<typename t>
class spisok {
private:
class node {
public:
t item;
shared_ptr<node> next;
node(t it) :item(it) {}
friend spisok;
};
shared_ptr<node> head;
public:
spisok() {
head = nullptr;
}
spisok(t item) {
head = make_shared<node>(node(item));
}
void push(t item) {
shared_ptr<node> ptr(new node(item));
if (head == nullptr) {
head = move(ptr);
return;
}
else {
ptr->next = head;
head = ptr;
}
}
void pop(t item) {
shared_ptr<node> ptr = head;
if (ptr->item == item) {
head = head->next;
return;
}
while (ptr->next != nullptr) {
if (ptr->next->item == item) {
ptr->next = ptr->next->next;
return;
}
ptr = ptr->next;
}
}
shared_ptr<node> find(t item) {
shared_ptr<node> ptr = head;
while (ptr != nullptr) {
if (ptr->item == item) return ptr;
ptr = ptr->next;
}
return nullptr;
}
t obr(t left, t right) {
shared_ptr<node> ptr = head;
t sum = 0;
while (ptr != nullptr) {
if (ptr->item >= left && ptr->item <= right) {
sum += ptr->item;
}
ptr = ptr->next;
}
return sum;
}
void clear() {
while (head != nullptr) {
head = head->next;
}
}
void print()const {
shared_ptr<node> root = head;
while (root != nullptr) {
cout << root->item << ' ';
root = root->next;
}
cout << endl;
}
~spisok() {
clear();
}
};

- Разработка регламента выполнения процесса «Реализация билетов через розничные кассы»
- Понятие социального обслуживания (на примере города Минусинска)
- Роль мотивации в поведении организации (ООО «ДСК»)
- Затраты как объект управленческого учета
- Бухгалтерский баланс организации: порядок составления и аналитические возможности
- Понятие и виды наследования
- Управление поведением в конфликтных ситуациях( общее)
- Управление конфликтами в сфере органов государственной региональной власти
- Менеджмент человеческих ресурсов (ООО "ВАЛ")
- Кадровое обеспечение органов местного самоуправления: состояние и пути оптимизации (Основные понятия кадрового обеспечения в органах местного самоуправления)
- Особенности коммуникаций в организации («Евросеть»)
- Средства разработки COM-приложений