
Методы математической статистики в психолого-педагогических исследованиях
Содержание:

ВВЕДЕНИЕ
Актуальность темы. Современная математическая статистика представляет собой большую и сложную систему знаний. Статистика — это область науки, имеющая дело со сбором, анализом и интерпретацией данных. Массовые социально-экономические явления и процессы измерения однородных объектов, обладающие качественной общностью, обнаруживают определенные закономерности, математическая статистика создает методы выявления этих закономерностей.
Статистические методы применяются при обработке материалов психологических исследований для того, чтобы извлечь из тех количественных данных, которые получены в экспериментах, при опросе и наблюдениях, возможно больше полезной информации. В частности, в обработке данных, получаемых, при испытаниях по психологической диагностике, это будет информация об индивидуально-психологических особенностях испытуемых. Вообще психологические исследования обычно строятся с опорой на количественные данные.
Нельзя рассчитывать на то, что каждый психолог, сделавший диагностику своей специальностью, овладеет этими знаниями. Между тем, статистика нужна психологу постоянно в его повседневной работе. Специалисты статистики разработали целый комплекс простых методов, которые совершенно доступны любому человеку, не забывшему то, что он выучил еще в средней школе.
Уместное грамотное применение этих методов позволит практику и исследователю, во всяком случае, проведя начальную обработку, получить общую картину того, что дают количественные результаты его исследований, оперативно проконтролировать ход исследований.
Теоретическую базу для решения проблем проведения научно-исследовательской деятельности создали многие работы в этой области Бусыгина A.JI., Ведерникова Л.В., Горностаев П.В., Дайв Р, Кнепер К., Левитская Е.Ю., Легран П., Матушанский Г.У., Менг Т.В., Соломко Л.И. и др. Вопрос о системном подходе к исследовательской подготовке, включающей обработку результатов психолого-педагогических исследований, впервые поставили, Архангельский С.И., Данилов М.А., Королев Ф.Ф., Юдан Э.Г. В последующих исследованиях этот подход к анализу исследовательской деятельности применили Андреев В.И., Вяткин Л.Г., Ильин B.C., Кузьмина Н.В., Леднев В.С., Махмутов М.И., Поляков В.А., Сластенин В.А., Талызина Н.Ф. др. Однако, малоразработанным направлением остается применение методов математической статистики в психолого-педагогических исследованиях. Поэтому современное науковедение сосредотачивает на этой проблеме особое внимание (Греков А.А., Загвязинский В.И., Кузьмина Н.В., Мамчур Е.А., Степин B.C., Швырев B.C., и др.). Следует отметить, что наряду с возрастающей актуальностью и значимостью, практически не изученным является аспект особенностей и проблем применения методов математической статистики при проведении психолого-педагогических исследований.
При рассмотрении сущности и возможностей применения методов математической статистики обработки информации, полученной в результате психолого-педагогического исследования, следует опираться на ученых, разрабатывающих методологические основы психологии и педагогики (Гмурман В.Е., Загвязинский В.И., Ильин B.C., Краевский В.В., Новиков Д.А., Скаткин М.Н., Щукина Г.И.), которые установили новую тенденцию использования методов математической статистики в психолого-педагогических исследованиях.
Целью данной работе является рассмотрение основных методов математической статистики, которые наиболее часто используются в обработке результатов психологических и педагогических исследований.
Объект исследования — процесс психолого-педагогических исследований с использованием методов математической статистики.
Предмет исследования — роль, место и способы применения методов математической статистики при проведении психолого-педагогического эксперимента.
Цель определила постановку следующих задач исследования:
- изучить теоретические основы и сущность применения математической статистики при проведении психолого-педагогических изысканий;
- раскрыть базовые термины математической статистики и анализа данных;
- привести примеры применения методов математической статистики в психолого-педагогическом исследовании.
Для проверки выдвинутой цели и решения поставленных задач использовались следующие методы исследования: теоретический - изучение и анализ научно-педагогической, науковедческой и статистической литературы по проблеме исследования; эмпирический - изучение и анализ типичных наиболее распространенных методов математической статистики, применяемых при проведении экспериментальной части психолого-педагогических исследований; аналитический - анализ, сравнение и обобщение полученных результатов,
Структура курсовой работы состоит из введения, трех глав, включающих в себя шесть параграфов, заключения и списка использованной литературы.
ГЛАВА 1. БАЗОВЫЕ ТЕРМИНЫ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ И АНАЛИЗА ДАННЫХ
1.1. Использование методов математической статистики в психолого-педагогических исследованиях
От педагога-исследователя требуются сейчас хорошие знания информатики, основных статистических методов, а также умение ставить и решать исследовательские задачи с использованием ЭВМ.
Широкому внедрению методов анализа данных в 60-х и 70-х годах нашего века немало способствовало появление компьютеров, а начиная с 80-х годов — персональных компьютеров. Статистические программные пакеты сделали методы анализа данных более доступными и наглядными. Теперь уже не требуется вручную выполнять трудоемкие расчеты по сложным формулам, строить вручную сложные диаграммы и графики — всю эту черновую работу взял на себя компьютер, а исследователю осталась главным образом творческая работа: постановка задач исследования, выбор методов педагогического исследования и грамотная интерпретация результатов.
Приведем несколько примеров применения методов анализа данных в практических задачах.
Пример 1. Рассмотрим довольно часто встречающуюся задачу. Предположим, что Вы изобрели важное нововведение: изменили систему оплаты труда, перешли на выпуск новой продукции, использовали новую технологию, методику. Вам кажется, что это дало положительный эффект, но действительно ли это так? А может быть этот кажущийся эффект определен вовсе не вашим нововведением, а естественной случайностью, и уже завтра Вы можете получить прямо противоположный, но столь же случайный эффект? Для решения этой задачи надо сформировать два набора чисел, каждый из которых содержит значения интересующего вас показателя эффективности до и после нововведения. Статистические критерии сравнения двух выборок покажут Вам, случайны или неслучайны различия этих двух рядов чисел.
Пример 2. Другая важная задача состоит в прогнозировании будущего поведения некоторого временного ряда: изменения курса доллара, цен и спроса на продукцию или сырье. Для такого временного ряда с помощью статистических методов подбирают некоторое аналитическое уравнение – строят регрессионную модель. Если мы предполагаем, что на интересующий нас показатель влияют некоторые другие факторы, их тоже можно включить в модель, предварительно проверив значимость этого влияния. Затем на основе построенной модели можно сделать прогноз и указать его точность.
Пример 3. Еще одна интересная и часто встречающаяся задача связана с классификацией объектов. Пусть, например, Вы являетесь начальником кредитного отдела банка. Столкнувшись с невозвратом кредитов, Вы решаетесь впредь выдавать кредиты лишь фирмам, которые «схожи» с теми, которые себя хорошо зарекомендовали, и не выдавать тем, которые «схожи» с неплательщиками или мошенниками. Для классификации фирм можно собрать показатели их деятельности (размер основных фондов, валюту баланса, вид деятельности, объем реализации и т.д.), и провести кластерный анализ (многомерное шкалирование) этих данных. Во многих случаях имеющиеся объекты удается сгруппировать в несколько групп (кластеров), и Вы сможете увидеть, не принадлежит ли запрашивающая кредит фирма к группе неплательщиков[1].
Все приведенные примеры имеют одну общую черту: непредсказуемость результатов для действий, которые проводятся в неизменных условиях. Еще одной особенностью приведенных примеров является сравнительно малый объем исходных данных (объем выборки). Причина этого состоит в том, что для большинства прикладных исследований, особенно в гуманитарных областях, характерны именно небольшие объемы данных (исключение здесь составляет лишь демография и отдельные области медицинской статистики)[2].
Математическая статистика — раздел математики, посвященный математическим методам систематизации, обработки и использования статистических данных для научных и практических выводов[3].
Математическая статистика исходит из предположения, что наблюдаемая изменчивость окружающего мира имеет два источника:
– действие известных причин и факторов. Они порождают изменчивость, закономерно объяснимую.
- действие случайных причин и факторов. Большинство природных и общественных явлений обнаруживают изменчивость, которая не может быть целиком объяснена закономерными причинами. В таком случае прибегают к концепции случайной изменчивости. Выражение «случайный» в данном контексте означает «подчиняющийся законам теории вероятности».
Проверка психолого-педагогических гипотез и моделей является тоже случайным событием, так как результаты педагогического исследования определяются очень большим количеством заранее непредсказуемых факторов. Определенные закономерности можно выявить только в случае массовых наблюдений вследствие закона больших чисел. Закон больших чисел – это объективный математический закон, согласно которому совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая[4].
Отсюда совершенно очевидным является факт, что педагогические измерения однозначно связаны со статистическими измерениями.
Статистический подход — это выявление закономерной изменчивости на фоне случайных факторов и причин. Методы математической статистики позволяют оценить параметры имеющихся закономерностей, проверить те или иные гипотезы об этих закономерностях[5].
Аппарат математической статистики является изумительным по мощности и гибкости инструментом для отсеивания закономерностей от случайностей. Педагогу-исследователю обязательно необходимо накапливать информацию об окружающем мире, пытаясь выделить закономерности из случайностей.
1.2. Генеральная и выборочная совокупности
Исходным понятием статистики является понятие совокупность, объединяющее обычно какое-либо множество испытуемых (учащихся) по одному или нескольким интересующим признакам. Главное требование к выделению изучаемой совокупности — это ее качественная однородность, например, по уровню знаний, росту, весу и другим признакам. Члены совокупности могут сравниваться между собой в отношении только того качества, которое становится предметом исследования. При этом обычно абстрагируются от других неинтересующих качеств[6]. Так, если педагога интересует успеваемость учащихся, то он не принимает во внимание, как правило, их рост, вес и другие параметры, не относящиеся непосредственно к изучаемому вопросу.
Применение большинства статистических методов основано на идее использования небольшой случайной совокупности испытуемых из общего числа тех, на которых можно было бы распространить (генерализовать) выводы, полученные в результате изучения совокупности. Эта небольшая совокупность в статистике называется выборочной совокупностью (или короче — выборкой). Главный принцип формирования выборки — это случайный отбор испытуемых из мыслимого множества учащихся, называемого генеральной совокупностью или популяцией объектов или явлений. Как по анализу элементов, содержащихся в капле крови, медики нередко судят о составе всей крови человека, так и по выборочной совокупности учащихся изучаются явления, характерные для всей генеральной совокупности.
Когда для каждого объекта в выборке измерено значение одной переменной, популяция и выборка называются одномерными. Если же для каждого объекта регистрируются значения двух или нескольких переменных, такие данные называются многомерными.
Одной из основных задач статистического анализа является получение по имеющейся выборке достоверных сведений об интересующих исследователя характеристиках генеральной совокупности. Поэтому важным требованием к выборке является ее репрезентативность, то есть правильная представимость в ней пропорций генеральной совокупности. Достижению репрезентативности может способствовать такая организация эксперимента, при которой элементы выборки извлекаются из генеральной совокупности случайным образом.
Обычно в статистике различают три типа значений переменных: количественные, номинальные и ранговые.
Значения количественных переменных являются числовыми, могут быть упорядочены и для них имеют смысл различные вычисления (например, среднее значение). На обработку количественных переменных ориентировано подавляющее большинство статистических методов[7].
Значения номинальных переменных (например: пол, вид, цвет) являются нечисловыми, они означают принадлежность к некоторым классам и не могут быть упорядочены или непосредственно использованы в вычислениях. Для анализа номинальных переменных специально предназначены лишь избранные разделы математической статистики, например, категориальный анализ. Однако в ряде случаев для этой цели могут быть использованы и некоторые ранговые и количественные методы, если номинальные значения предварительно заменить на числа, обозначающие их условные коды[8].
Ранговые или порядковые переменные занимают промежуточное положение: их значения упорядочены (состояние больного, степень предпочтения), но не могут быть с уверенностью измерены и сопоставлены количественно. К анализу ранговых переменных применимы так называемые ранговые методы.
Ранг наблюдения — это тот номер, который получит данное наблюдение в упорядоченной совокупности всех данных — после их упорядочивания по определенному правилу (например, от большего значения к меньшим)[9]. Процедура перехода от совокупности наблюдений к последовательности их рангов называется ранжированием.
Ранговые и номинальные значения при вводе данных следует обозначать целыми числами.
1.3. Типы данных психолого-педагогического исследования
В целях классификации применимости статистических методов будем различать следующие типы исходных данных:
1. одна выборка — совокупность измерений одной количественной, номинальной или ранговой переменной, произведенных в ходе эксперимента, опроса или наблюдения[10]. Для одной выборки используются статистические методы описательной статистики.
Выборка может быть: неупорядоченная и структурированная (упорядоченная).
2. несколько выборок — совокупность измерений нескольких количественных, номинальных или ранговых переменных, произведенных в ходе эксперимента[11]. Выборки могут быть:
- независимые — получены в эксперименте независимо друг от друга;
- зависимые — значения данных переменных каким-то образом согласованы (связаны) друг с другом в имеющихся наблюдениях[12].
Приведем типичные примеры зависимых переменных: рост человека связан с весом, потому что обычно высокие индивиды тяжелее низких; IQ (коэффициент интеллекта) связан с количеством ошибок в тесте, так как люди с высоким IQ, как правило, делают меньше ошибок, цена винчестера связана с его объемом и т.д.
Для экспериментальной педагогики характерна постановка исследований, преследующих цель выявления эффективности педагогических средств путем сравнения достижений или свойств одной и той же группы учащихся в разные периоды времени (такие группы получили название зависимых выборок) или разных групп учащихся (независимые выборки).
3. временной ряд или процесс — представляет собой значение количественной переменной (отклика), измеренные через равные интервалы значений другой количественной переменной (параметра)[13]. Например, время измерения. В качестве исходных данных рассматриваются, как правило, значения переменной отклика.
4. связные временные ряды — синхронные по времени измерения одной переменной в разных точках (объектах) или же измерения нескольких переменных в одной точке (объекте)[14];
5. многомерные данные — представляются для статистического анализа в виде прямоугольной матрицы. Это могут быть измерения значений переменных у нескольких объектов или в нескольких точках, или же это могут быть измерения значений переменных у одного объекта в различные моменты времени или при различных состояниях[15].
ГЛАВА 2. ПРИМЕРЫ ПРИМЕНЕНИЯ МЕТОДОВ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ В ПСИХОЛОГО-ПЕДАГОГИЧЕСКОМ ИССЛЕДОВАНИИ
2.1. Статистические гипотезы и уровни статистической значимости
Полученные в результате психолого-педагогического эксперимента, проведенного на конкретной выборке, данные призваны послужить основанием для выводов о возможности распространения выявленных связей и зависимостей между компонентами предмета исследования на всю генеральную совокупность. Вместе с тем психолого-педагогические измерения, проведенные с помощью методов диагностики, всегда сопровождаются некоторой ошибкой, связанной с тем, что изучаемый предмет никогда точно не отражает своей сущности. Количественные данные представлены в виде случайных чисел, а результаты измерений имеют вероятностный характер[16]. Отсюда появляется необходимость доказательства статистической достоверности (статистической значимости) полученных результатов. При наличии указанных характеристик данные, полученные при исследовании малой выборочной совокупности, можно распространять на всю генеральную совокупность (или признать выборку репрезентативной неотъемлемой частью генеральной совокупности).
Процедура признания свойств малой выборочной совокупности принадлежностью генеральной совокупности осуществляется при помощи статистических гипотез. Под статистической гипотезой понимается предположение о том, что различие (сходство) отдельных характеристик психолого-педагогического явления, измеренного на связанных или несвязанных выборках, является случайным (неслучайным)[17].
В практике статистических расчетов применяется два вида гипотез: нулевая Н0 и альтернативная (рабочая) Н1. Принято считать, что Н0 — это гипотеза о сходстве (формулируется как отсутствие различий), а Н1 — гипотеза о различии. Например, пусть в двух уравновешенных выборках, извлеченных из генеральной совокупности всех второклассников достаточно большой городской школы (2 «А» и 2 «Б» классы), средняя арифметическая показателей уровня развития невербального интеллекта (методика Е. Векслера) — М1 и М2 соответственно. Нулевая гипотеза исходит из предположения, что М1 = М2, то есть М1 — М2 = 0, что и определяет ее название – нулевая, альтернативная же гипотеза призвана прогнозировать обратное: М1 ≠ М2, то есть│М1 – М2│> 0.
Нулевая гипотеза определяет позицию исследователя, где он заявляет о вероятной несостоятельности своей ведущей идеи — нетрадиционного метода решения проблемы: различия между новым и традиционным методом объявляются равными нулю, в то время как в альтернативной гипотезе Н1 делается предположение о преимуществе нового метода[18].
Сущность проверки гипотез заключается в том, чтобы попытаться опровергнуть нулевую гипотезу и тем самым подтвердить альтернативную. Для этого при помощи статистического анализа необходимо установить, согласуются ли экспериментальные данные и выдвинутая гипотеза Н, допустимо ли отнести расхождение между гипотезой и этими данными за счет случайных причин? Ответы на поставленные вопросы осуществляются на основе понятия уровня значимости. Уровень значимости — это вероятность ошибочного отклонения гипотезы, хотя в действительности она оказывается верной. В гуманитарных науках используются в основном два уровня статистической значимости р ≤ 0,05 и p ≤ 0,01. Случайные события, вероятность которых определяется данными неравенствами, считаются практически невозможными, но если они происходят, то наступление этого рода событий следует рассматривать как неслучайное. Уровень значимости показывает, в скольких случаях из ста мы можем ошибиться, объявив изучаемое событие неслучайным. Так, при первом уровне, пятипроцентном (р = 0,05), допускается риск ошибки в выводе в пяти и меньше случаях из ста теоретически возможных таких экспериментов при случайном отборе испытуемых. При втором уровне, однопроцентном (р = 0,01), соответственно допуск составляет один случай из ста.
Для получения статистического вывода необходимо руководствоваться следующими правилами.
1. На основе эмпирических количественных данных находится эмпирическое значение, которое называется статистическим критерием, или статистикой (обозначим его условно Сэмп). Алгоритм для нахождения количественного показателя критерия определяется типом психолого-педагогической задачи (см. ниже).
2. Критерий Сэмп сравнивается с табличными критическими величинами, которые соответствуют уровням в 5 и 1% для выбранного статистического метода. Эти величины принято обозначать С0,05 и С0,01. Например, при решении задачи по определению статистической значимости сдвига с помощью алгоритма Вилкоксона (символическое обозначение критерия Т) табличные значения для двенадцати испытуемых будут следующими: Т0,05 = 17 и Т0,01 = 9.
3. Сравнение проводится при помощи «оси значимости», которая представляет собой прямую в виде оси абсцисс декартовой системы координат (нулевая точка подразумевается, но не отмечается). На числовой прямой откладываются табличные значения критерия, в результате получаются три зоны: зона значимости, зона неопределенности, зона незначимости[19].

Тэмп попадет в одну из трех указанных зон. Рассмотрим последовательно все варианты.
Вариант 1. Если, к примеру, Тэмп = 7, то соответствующая ей точка на прямой попадает в зону значимости. В этом случае гипотеза Н0 отклоняется, принимается гипотеза Н1 – сдвиги являются статистическими значимыми при p ≤ 0,01, преимущество нового метода перед старым, традиционным, доказано.
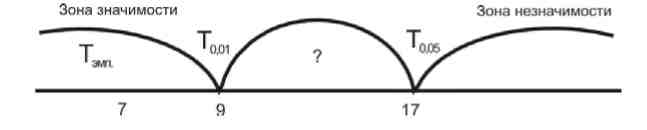
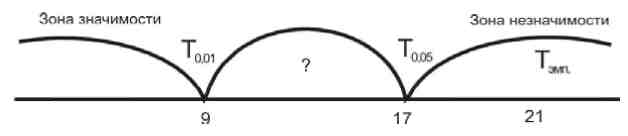
Вариант 2. Если Тэмп = 21, соответствующая ей точка попадает в зону незначимости. Принимается гипотеза Н0 – сдвиги не обладают статистической значимостью при p≤0,01, нам не удалось доказать преимущества старого метода перед новым.
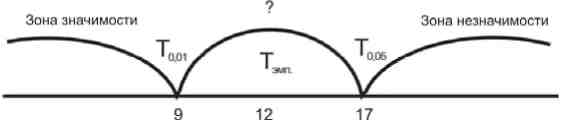
Вариант 3. Если Тэмп = 12, соответствующая ей точка попадает в зону неопределенности. Здесь возможно принятие одного из двух решений:
а) исследователь может отклонить гипотезу Н0 и принять альтернативную Н1, считая полученную оценку достоверной на уровне р ≤ 0,05;
б) возможно принятие гипотезы Н0 на уровне статистической достоверности р ≤ 0,01.
Формулировка вывода осуществляется с учетом вопроса в условии психолого-педагогической задачи (ситуации) или результирующей части общей гипотезы исследования.
2.2. Коэффициент ранговой корреляции rs Спирмена
Метод ранговой корреляции Спирмена позволяет определить тесноту (силу) и направление корреляционной связи между двумя признаками или двумя профилями (иерархиями) признаков[20].
Пример формулировки гипотез:
Вариант 1:
Н0: корреляция между переменными А и Б не отличается от нуля.
Н1: корреляция между переменными А и Б достоверно отличается от нуля.
Вариант 2:
Н0: корреляция между иерархиями А и Б не отличается от нуля.
Н1: корреляция между иерархиями А и Б достоверно отличается от нуля.
Ограничения критерия:
1. По каждой переменной должно быть представлено не менее пяти наблюдений. Верхняя граница выборки определяется имеющимися таблицами критических значений (табл. I, приложение), а именно N≤40.
2. Коэффициент ранговой корреляции Спирмена rs при большом количестве одинаковых рангов по одной или обеим сопоставляемым переменным дает огрубленные значения. В идеале оба коррелируемых ряда должны представлять собой две последовательности несовпадающих значений. В случае, если это условие не соблюдается, внести поправку на одинаковые ранги.
Расположение табличных значений признака:
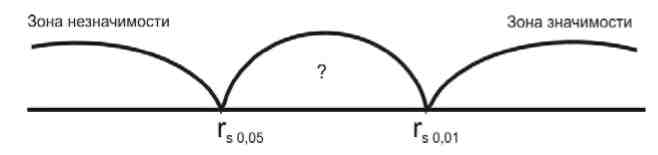
Алгоритм
Расчет коэффициента ранговой корреляции Спирмена rs
1. Определить, какие два признака или две иерархии признаков будут участвовать в сопоставлении как переменные А и В.
2. Проранжировать значения переменной А, начисляя ранг 1 наименьшему (или наибольшему) значению в соответствии с правилами ранжирования (см. Приложение 5). Занести ранги в первый столбец таблицы по порядку номеров испытуемых или признаков.
3. Проранжировать значения переменной В в соответствии с теми же правилами. Занести ранги во второй столбец таблицы по порядку номеров испытуемых или признаков.
4. Подсчитать разности d между рангами А и В по каждой строке таблицы и занести в третий столбец таблицы.
5. Возвести каждую разность в квадрат: d2. Эти значения занести в четвертый столбец таблицы.
6. Подсчитать сумму квадратов ∑d2.
7. При наличии одинаковых рангов рассчитать поправки:
Та = _∑(a3-a)
12
Т b = _∑(b3-b)
12
где
a — объем каждой группы одинаковых рангов в ранговом ряду А;
b — объем каждой группы одинаковых рангов в ранговом ряду В.
8. Рассчитать коэффициент ранговой корреляции гs по формуле:
а) при отсутствии одинаковых рангов:
rs = 1 – 6 • __∑d2___
N •(N2 -1)
б) при наличии одинаковых рангов:
rs = 1 – 6 • __∑d2 + Ta +Tb__
N •(N2 -1)
где ∑d2—- сумма квадратов разностей между рангами;
Та и Tb — поправки на одинаковые ранги;
N — количество испытуемых или признаков, участвовавших в ранжировании.
9. Определить по табл. I (Приложение) критические значения rs для данного N. Руководствуясь указаниями, данными в п. 6.1, сформулировать ответ и сделать вывод[21].
Пример решения задачи
У учащихся одиннадцатого класса (выборка в десять человек) было подсчитано количество ошибок, допущенных во всех контрольных работах по математике за учебный год.
В этой же группе проведен тест на определение уровня общего интеллекта. Данные занесены в таблицу.
Связано ли количество ошибок, допущенных учащимися, с уровнем их общего интеллекта?
Таблица 2.1.
Данные о количестве ошибок и показатели общего интеллекта испытуемых
|
№ п/п |
Количество ошибок |
Показатели уровня общего интеллекта |
|
1. |
29 |
85 |
|
2. |
17 |
90 |
|
3. |
13 |
95 |
|
4. |
8 |
117 |
|
5. |
4 |
118 |
|
6. |
24 |
87 |
|
7. |
9 |
117 |
|
8. |
17 |
102 |
|
9. |
2 |
119 |
|
10. |
17 |
99 |
Решение
Сформулируем гипотезы:
Н0: корреляция между количеством ошибок, допущенных учащимися в контрольных работах, и показателями их общего интеллекта не отличается от нуля.
Н1: корреляция между количеством ошибок, допущенных учащимися в контрольных работах, и показателями их общего интеллекта отличается от нуля.
Определим эмпирическое значение r s эмп по формуле:
rs = 1 – 6 • __∑d2 + Ta +Tb__
N •(N2 — 1)
Для нахождения ∑d2 составим вспомогательную таблицу, в которой проведем ранжирование каждого ряда значений, вычислим разность соответствующих рангов, квадрат разности.
Таблица 2.2
Вспомогательная таблица для расчета «суммы d-квадрат»
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
|
1 ряд |
29 |
17 |
13 |
8 |
4 |
24 |
9 |
17 |
2 |
17 |
|
2 ряд |
85 |
90 |
95 |
117 |
118 |
87 |
117 |
102 |
119 |
99 |
|
1 р.-р. |
1 |
4 |
6 |
8 |
9 |
2 |
7 |
4 |
10 |
4 |
|
2 р.-р. |
10 |
8 |
7 |
3,5 |
2 |
9 |
3,5 |
5 |
1 |
6 |
|
d |
9 |
4 |
1 |
-4,5 |
-7 |
7 |
-3,5 |
1 |
-9 |
2 |
|
d2 |
81 |
16 |
1 |
20,25 |
49 |
49 |
12,25 |
1 |
81 |
4 |
∑d2 = 314,5. Выполним поправку на одинаковые ранги:
Ta = ∑(a3-a) = (33-3) = (27-3) = 2
12 12 12
Tb = ∑(b3-b) = (23-2) = (8-2) = 0,5
12 12 12
Подставим полученные данные в формулу.
rs = 1 – 6 • 314,5 + 2 + 0,5 = 1 – 6 • 317 = 1 – 6 = -0,9
N •(N2 — 1) 990
Табличные значения для n =10 rS 0,05 = 0,64; rS 0,01= 0,79.
Сравним эмпирическое значение критерия с табличными значениями.
Представим данные на числовой прямой (в соответствии с алгоритмом Спирмена на оси откладывается абсолютное значение критерия rS эмп = │- 0,9│ = 0,9).
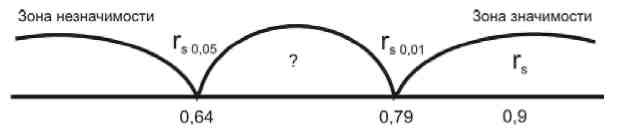
Эмпирическое значение расположено в зоне значимости (rs эмп >rs таб.).
Ответ: Н0 – отклоняется, принимается Н1: корреляция между количеством ошибок, допущенных учащимися в контрольных работах, и показателями их общего интеллекта отличается от нуля на статистически значимом уровне (при p≤0,01).
С учетом отрицательного значения rSэмп доказано, что между исследуемыми психолого-педагогическими явлениями существует связь, выраженная обратно пропорциональной зависимостью.
Вывод: по данной выборке учащихся количество ошибок, допущенных ими в контрольных работах по математике, связано с уровнем развития общего интеллекта. Просматривается следующая закономерность: чем выше показатели уровня развития интеллекта, тем меньше ошибок допустил ученик в контрольных работах по математике.
2.3. Т-критерий Вилкоксона
Критерий применяется для сопоставления показателей, измеренных в двух разных условиях на одной и той же выборке испытуемых.
Он позволяет установить не только направленность изменений, но и их выраженность. С его помощью можно определить, является ли сдвиг показателей в каком-то одном направлении более интенсивным, чем в другом[22].
Пример формулировки гипотез:
Вариант 1.
Н0: сдвиг в сторону увеличения (уменьшения) показателей признака не является статистически значимым.
Н1: сдвиг в сторону увеличения (уменьшения) показателей признака является статистически значимым.
Вариант 2.
Н0: интенсивность сдвигов в типичном направлении не превышает интенсивности сдвигов в нетипичном направлении.
Н1: интенсивность сдвигов в типичном направлении превышает интенсивность сдвигов в нетипичном направлении.
Ограничения критерия:
Минимальное количество испытуемых в группе с отсроченной диагностикой — 5 человек. Максимальное количество испытуемых — 50 человек.
5≤ n≤50
Расположение табличных значений признака:
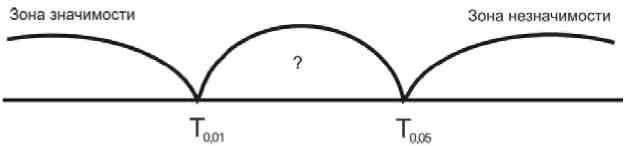
Алгоритм
Подсчет критерия Т. Вилкоксона
1. Внести данные во вспомогательную таблицу (образец таблицы см. ниже).
2. Вычислить разность (сдвиг) между индивидуальными значениями во втором и первом замерах («после» — «до»). Подсчитать количество положительных и отрицательных сдвигов. (Нулевые сдвиги во внимание не принимаются.)
3. Определить, какие сдвиги будут считаться типичными, и сформулировать гипотезы.
4. Записать абсолютные величины сдвигов отдельным столбцом.
5. Провести ранжирование абсолютных величин сдвигов. Проверить совпадение полученной суммы рангов с расчетной.
6. Выделить (например, маркером) ранги, соответствующие сдвигам в «нетипичном» направлении.
7. Подсчитать сумму этих рангов по формуле:
Т=∑Ri,
где Ri — ранговые значения сдвигов с более редким знаком. Полученное число служит эмпирическим значением критерия.
8. Определить критические значения Т для данного n по табл. II (Приложение). Сравнение табличных значений с эмпирическим провести на числовой прямой.
9. Руководствуясь указаниями, данными в п. 6.1, сформулировать ответ и сделать вывод[23].
Пример решения задачи
Психолог поставил задачу: определить эффективность проведения тренинга по снижению ситуативной тревожности у спортсменов перед соревнованиями. До и после занятия состоялось тестирование. Данные приведены в таблице. Дайте оценку эффективности тренинговых занятий.
Сравним показатели ситуативной тревожности спортсменов до и после учебного занятия.
Для этого используем статистический критерий Вилкоксона.
Составим вспомогательную таблицу, в которую занесем полученные результаты двух замеров экспериментальной группы и их разность. Подсчитаем количество сдвигов:
– положительных 0;
– отрицательных 15;
– нулевых 0.
Типичные сдвиги – отрицательные.
Составим гипотезы:
H0: сдвиг в сторону уменьшения показателей ситуативной тревожности у спортсменов перед соревнованиями не является статистически значимым.
Н1: сдвиг в сторону уменьшения показателей ситуативной тревожности у спортсменов перед соревнованиями является статистически значимым.
Далее переведем разности в абсолютные величины, проранжируем абсолютные величины разностей, начисляя большему значению меньший ранг.
Таблица 2.3
Вспомогательная таблица для расчета статистической значимости сдвига Т-критерия Вилкоксона
|
Код имени испытуемого |
Показатели ситуативной тревожности |
Разность |
Абсолютное значение разности |
Ранговый номер разности |
||
|
до |
после |
|||||
|
1 |
А. Н. |
37 |
25 |
-9 |
9 |
12 |
|
2 |
Б. Е. |
24 |
24 |
0 |
0 |
0 |
|
3 |
В. В. |
36 |
20 |
- 16 |
16 |
7,5 |
|
4 |
Г. Н. |
44 |
30 |
-14 |
14 |
10 |
|
5 |
Е. Ю. |
34 |
17 |
-17 |
17 |
4 |
|
6 |
З. М. |
43 |
35 |
-8 |
8 |
13 |
|
7 |
К. Е. |
36 |
19 |
-17 |
17 |
4 |
|
8 |
К. В. |
41 |
24 |
-17 |
17 |
4 |
|
9 |
К. Т. |
39 |
42 |
+3 |
3 |
14 |
|
10 |
Л. Ю. |
34 |
16 |
-18 |
18 |
1 |
|
11 |
М. П. |
38 |
21 |
-17 |
17 |
4 |
|
12 |
М. Е. |
45 |
31 |
-14 |
14 |
10 |
|
13 |
Н. А. |
32 |
16 |
-16 |
16 |
7,5 |
|
14 |
О. Т. |
45 |
28 |
-17 |
17 |
4 |
|
15 |
П. Е. |
30 |
44 |
+14 |
14 |
10 |
|
Сумма |
105 |
|||||
Проверим правильность ранжирования:
∑Ri = N •(N + 1)
2
∑Ri = 14 •(14 + 1) = 105
2
Найдем Tэмп
Tэмп = ∑Ri
где Ri – ранговые значения нетипичных сдвигов.
Tэмп = 14 + 10 = 24.
Определим критическое (табличное) значение для n = 14;
T0,05 = 30,
T0,01 = 19.
Представим данные на числовой прямой:
Эмпирическое значение расположено в зоне неопределенности.
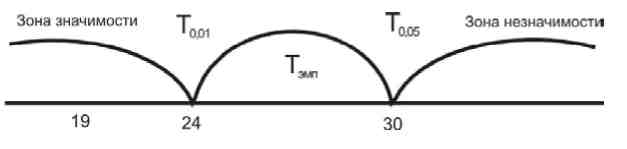
Ответ: Н0 – отклоняется, принимается Н1: сдвиг в сторону уменьшения показателей ситуативной тревожности у спортсменов перед соревнованиями является статистически значимым при p ≤ 0,05.
Вывод: тренинг проведен достаточно эффективно.
2.4. U-критерий Манна–Уитни
Критерий предназначен для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. Он позволяет выявлять различия между малыми выборками, когда n1, n2 > 3 или n1 = 2, n2 > 5[24].
Пример формулировки гипотез:
Вариант 1.
Н0: различия в значениях уровня признака в группе 1 и в группе 2 не являются статистически значимыми.
Н1: различия в значениях уровня признака в группе 1 и в группе 2 являются статистически значимыми.
Вариант 2.
Н0: уровень признака в группе 2 не ниже уровня признака в группе 1.
Н1: уровень признака в группе 2 ниже уровня признака в группе 1.
Ограничения критерия:
1. В каждой выборке должно быть не менее трех наблюдений: n1,n 2> 3.
2. Допускается, чтобы в одной выборке было два наблюдения, но тогда во второй их должно быть не менее пяти; n1=2, n2 > 5.
3. В каждой выборке должно быть не более 60 наблюдений: n1,n2 > 60.
Расположение табличных значений признака:
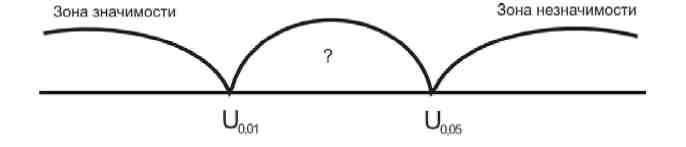
Алгоритм
Подсчет критерия U Манна-Уитни
1. Упорядочить значения в обеих выборках при помощи вспомогательной таблицы (образец таблицы см. ниже).
2. Проранжировать значения с учетом левого и правого столбцов таблицы. Количество рангов определяется суммой членов числовых рядов (n1 + n2).
3. Подсчитать сумму рангов отдельно по каждому столбцу (группе испытуемых).
4. Проверить, совпадает ли общая сумма рангов с расчетной.
5. Определить большую из двух ранговых сумм.
6. Определить значение U по формуле:
U = (n1 • n2) + nx •(nx + 1) – Tx
2
где n1 - количество испытуемых в выборке 1;
n2 - количество испытуемых в выборке 2;
Т - большая из двух ранговых сумм;
n - количество испытуемых в группе с большей суммой рангов.
7. Определить критические значения U по табл. III (Приложение).
8. Сравнение табличных значений с эмпирическим провести на числовой прямой.
9. Руководствуясь указаниями, данными в п. 6.1, сформулировать ответ и сделать вывод[25].
Пример решения задачи
У учащихся художественной школы были проведены измерения уровня развития художественного воображения. Данные занесены в таблицу. Можно ли утверждать, что группа учащихся, занимающаяся графикой, превосходит группу учащихся, занимающихся живописью, по исследуемому признаку?
Таблица 2.4.
Показатели уровня развития художественного воображения у учащихся
|
№ п/п |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
«Графики» |
46 |
54 |
34 |
22 |
54 |
30 |
48 |
28 |
30 |
26 |
42 |
||
|
«Живописцы» |
28 |
50 |
21 |
18 |
28 |
30 |
33 |
35 |
37 |
18 |
22 |
41 |
33 |
Сформулируем статистические гипотезы.
Н0: группа учащихся, занимающихся графикой, не превосходит группу учащихся, занимающихся живописью, по уровню развития художественного воображения.
Н1: группа учащихся, занимающихся графикой, превосходит группу учащихся, занимающихся живописью, по уровню развития художественного воображения.
Определим эмпирическое значение Uэмп по формуле:
U = (n1 • n2) + nx •(nx + 1) – Tx
2
Для нахождения необходимых данных составим вспомогательную таблицу, где упорядочим по убыванию индивидуальные показатели уровня развития художественного воображения[26].
Таблица 2.5
Определение ранговых сумм
|
Показатель художественного воображения в группе «графиков» |
Ранг |
Показатель художественного воображения в группе «живописцев» |
Ранг |
|
54 54 48 46 42 34 30 30 28 26 22 |
1,5 1,5 4 5 6 10 14 14 17 19 20,5 |
50 41 37 35 33 33 30 28 28 22 21 18 18 |
3 7 8 9 11,5 11,5 14 17 17 20,5 22 23,5 23,5 |
|
Суммы: |
112,5 |
187,5 |
После ранжирования проведем его проверку:
∑Ri = N •(N + 1)
2
∑Ri = 24 •(24+ 1) = 300
2
Ранжирование проведено правильно. Вычислим:
U = (n1 • n2) + nx •(nx + 1) – T = (11 • 13) + 13 •(13 + 1) – 1875 = 46,5
2 2
Определим критическое (табличное) значение для n = 11 и n =13:
U0,05 = 42,
U0,01 = 31.
Представим данные на числовой прямой:
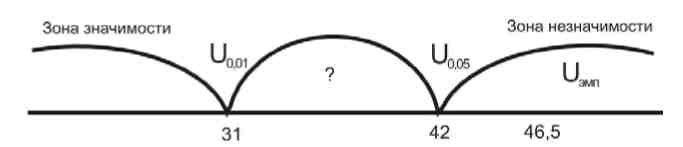
Эмпирическое значение расположено в зоне незначимости (Uэмп> Uкр.).
Ответ: Н0 принимается: группа учащихся, занимающихся графикой, не превосходит группу учащихся, занимающихся живописью, по уровню развития художественного воображения при p ≤ 0,01.
Вывод: нельзя утверждать, что группа учащихся, занимающаяся графикой, превосходит группу учащихся, занимающихся живописью, по уровню развития художественного воображения.
ЗАКЛЮЧЕНИЕ
Мы рассмотрели основные статистические понятия и методы математической обработки результатов психолого-педагогических исследований. Приведенные статистические критерии не являются единственными при количественном анализе эмпирического материала. Разумеется, что современная наука в области математической статистики создала большой арсенал методов, которыми может пользоваться психолог-исследователь. Однако описание других, более сложных статистических методов, требующих глубокой математической подготовки и умении в использовании компьютерных программ, не входило в нашу задачу.
Использование методов математической статистики в психолого-педагогических исследованиях позволяет не только существенно повысить достоверность и надежность полученных результатов, но и доказать формулируемые в ходе исследования статистические гипотезы. А ведь именно исследования в сфере социальных наук отличаются недостаточной степенью доказанности гипотез, выдвинутых авторами. Но «нельзя говорить о доказанности гипотезы, об эффективности разработанных и предлагаемых рекомендаций, программ, тренингов и т.п., о выявленных различиях или произошедших изменениях в уровне исследуемого признака без использования методов математической статистики»[27].
Применение методов математической статистики играет важную роль в обосновании результатов исследования. Как отмечает, например, Е.В. Сидоренко, многие психологические концепции (не говоря уже об отдельной студенческой научной работе) «в настоящее время подвергаются сомнениям именно потому, что в своё время не были подтверждены статистически»[28].
Список литературы
1. Глас, Дж. Статистические методы в педагогике и психологии / Дж. Гласс, Дж. Стенли; под общ. ред. Ю.П. Адлера; пер. с англ. Л.И. Хайрусовой. – М.: Прогресс, 1976. – 496 с.
2. Граничина, О.А. Математико-статистические методы психолого-педагогических исследований / О.А. Граничина. – СПб.: Издательство ВВМ, 2012. – 115 с.
3. Донелли Р.А. Статистика / Р.А. Донелли; пер. с англ. Н.А. Ворониной. – М.: Астрель: АСТ, 2007. – 367 с.
4. Калинин, С.И. Компьютерная обработка данных для психологов / С.И. Калинин; под ред. А.Л. Тулупьева. – 2-е изд. – СПб.: Речь, 2004. – 134 с.
5. Морозов Е.А. Пошаговый алгоритм действий при использовании методов математической статистики в психолого-педагогических исследованиях / Е. А. Морозов // Научный диалог. – 2014. – № 3. – С. 29–45.
6. Морозов, Е.А. Возможности автоматизированных систем обработки результатов психодиагностических исследований в сфере социального взаимодействия / Е.А. Морозов // Социальное взаимодействие субъектов в образовательном пространстве: коллективная монография / отв. ред. З.И. Колычева. – Тобольск: ТГСПА им. Д. И. Менделеева, 2013. – С. 137–154.
7. Морозов, Е.А. Псевдоисследования, или как мы готовим псевдоучёных (к проблеме использования методов математической статистики в социальных и психолого-педагогических исследованиях) / Е.А. Морозов // Молодежь и образование XXI века: материалы Всероссийской научно-практической конференции аспирантов, студентов и учащихся. — Тобольск: ТГСПА им. Д.И. Менделеева, 2010. – С. 132–139.
8. Морозов Е.А. Использование Microsoft Excel при проведении психолого-педагогических исследований как элемент модернизации системы профессионального педагогического образования / Е.А. Морозов // Модернизация системы профессионального образования на основе регулируемого эволюционирования: материалы Всероссийской научно-практической конференции: в 2 частях. Ч. 1 / Отв. ред. Д.Ф. Ильясов. – Челябинск: Образование, 2002. – С. 237–239.
9. Наследов, А.Д. SPSS: компьютерный анализ данных в психологии и социальных науках / А.Д. Наследов. — СПб.: Питер, 2016. – 416 с.
10. Наследов, А.Д. Математические методы психологического исследования / А.Д. Наследов. – СПб.: Речь, 2014. – 392 с.
11. Немов, Р.С. Психология: учебник для студентов высших педагогических учебных заведений: в 3 книгах. Книга 3: Психодиагностика: введение в научное психологическое исследование с элементами математической статистики / Р.С. Немов. – М.: Владос, 2011. –– 640 с.
12. Оценка качества подготовки будущих учителей / Отв. ред. Н.К. Новиков. — Тула: Изд-во Тул. гос. пед. ун-та, 2002. – 164 с.
13. Применение статистических методов в психолого-педагогических исследованиях: Учебное пособие / Сост. С.В. Нужнова. — Троицк: Троицкий филиал ГОУ ВПО «ЧелГУ», 2015. – 120 c.
14. Сапегин, А.Г. Психологический анализ в среде Excel: математические методы и инструментальные средства / А. Г. Сапегин. – М.: Ось-89, 2011. – 144 с.
15. Середенко, П.В. Психолого-педагогическое исследование: методология и методы: учебное пособие для студ. высш. учеб. заведений / П. В. Середенко. – Южно-Сахалинск: СахГУ, 2010. – 188 с.
16. Середенко, П.В. Методы математической статистики в психолого-педагогических исследованиях: учебное пособие / П.В. Середенко, А.В. Должикова. – 2-е изд. – Южно-Сахалинск: изд-во СахГУ, 2009. – 126 с.
17. Сидоренко, Е. В. Методы математической обработки в психологии : практическое руководство / Е.В. Сидоренко. – СПб.: Речь, 2012. – 350 с.
18. Суходольский, Г.В. Основы математической статистики для психологов / Г.В. Суходольский. — СПб.: Изд-во Санкт-Петербургского университета, 1998. – 439 с.
Таблица 1.
Критические значения выборочного коэффициента корреляции рангов
Связь достоверна, если r sэмп ≥ rs 0,05, и тем более достоверна, если rs эмп ≥ rs 0,01.
|
n |
p |
n |
p |
n |
p |
||||||
|
0,05 |
0,01 |
0,05 |
0,01 |
0,05 |
0,01 |
||||||
|
5 |
0,94 |
– |
17 |
0,48 |
0,62 |
29 |
0,37 |
0,48 |
|||
|
6 |
0,85 |
– |
18 |
0,47 |
0,60 |
30 |
0,36 |
0,47 |
|||
|
7 |
0,78 |
0,94 |
19 |
0,46 |
0,58 |
21 |
0,36 |
0,46 |
|||
|
8 |
0,72 |
0,88 |
20 |
0,45 |
0,57 |
32 |
0,36 |
0,45 |
|||
|
9 |
0,68 |
0,83 |
21 |
0,44 |
0,56 |
33 |
0,34 |
0,45 |
|||
|
10 |
0,64 |
0,79 |
22 |
0,43 |
0,54 |
34 |
0,34 |
0,44 |
|||
|
11 |
0,61 |
0,76 |
23 |
0,42 |
0,53 |
35 |
0,33 |
0,43 |
|||
|
12 |
0,58 |
0,73 |
24 |
0,41 |
0,52 |
36 |
0,33 |
0,43 |
|||
|
13 |
0,56 |
0,70 |
25 |
0,49 |
0,51 |
37 |
0,33 |
0,43 |
|||
|
14 |
0,54 |
0,68 |
26 |
0,39 |
0,50 |
38 |
0,32 |
0,41 |
|||
|
15 |
0,52 |
0,66 |
27 |
0,38 |
0,49 |
39 |
0,32 |
0,41 |
|||
|
16 |
0,50 |
0,64 |
28 |
0,38 |
0,48 |
40 |
0,31 |
0,40 |
|||
Таблица 2.
Критические значения критерия T Вилкоксона для уровней статистической значимости р ≤ 0,05 и p ≤ 0,01
«Типичный» сдвиг является достоверно преобладающим по интенсивности, если Tэмп ниже или равен Tэмп и тем более достоверно преобладающим, если T0,05 ниже или равен T0,01.
|
P |
P |
|||||
|
n |
0,05 |
0,01 |
n |
0,05 |
0,01 |
|
|
5 |
0 |
- |
28 |
130 |
101 |
|
|
6 |
2 |
- |
29 |
140 |
110 |
|
|
7 |
3 |
0 |
30 |
151 |
120 |
|
|
8 |
5 |
1 |
31 |
163 |
130 |
|
|
9 |
8 |
3 |
32 |
175 |
140 |
|
|
10 |
10 |
5 |
33 |
187 |
151 |
|
|
11 |
13 |
7 |
34 |
200 |
162 |
|
|
12 |
17 |
9 |
35 |
213 |
173 |
|
|
13 |
21 |
12 |
36 |
227 |
185 |
|
|
14 |
25 |
15 |
37 |
241 |
198 |
|
|
15 |
30 |
19 |
38 |
256 |
211 |
|
|
16 |
35 |
23 |
39 |
271 |
224 |
|
|
17 |
41 |
27 |
40 |
286 |
238 |
|
Продолжение таблицы 2
|
P |
P |
|||||
|
n |
0,05 |
0,01 |
n |
0,05 |
0,01 |
|
|
18 |
47 |
32 |
41 |
302 |
252 |
|
|
19 |
53 |
37 |
42 |
319 |
266 |
|
|
20 |
60 |
43 |
43 |
336 |
281 |
|
|
21 |
67 |
49 |
44 |
353 |
296 |
|
|
22 |
75 |
55 |
45 |
371 |
312 |
|
|
23 |
83 |
62 |
46 |
389 |
328 |
|
|
24 |
91 |
69 |
47 |
407 |
345 |
|
|
25 |
100 |
76 |
48 |
426 |
362 |
|
|
26 |
110 |
84 |
49 |
446 |
379 |
|
|
27 |
119 |
92 |
50 |
466 |
397 |
|
Таблица 3.
Критические значения критерия U Манна-Уитни для уровней статистической значимости
р < 0,05 и р < 0,01
Различия между двумя выборками можно считать значимыми (р<0,05), если Uэмп ниже или равен U005, и тем более достоверными (р<0,01), если Uэмпниже или равен U001.
|
n1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
n2 |
Р=0,05 |
||||||||||||||||||
|
3 |
- |
0 |
|||||||||||||||||
|
4 |
- |
0 |
1 |
||||||||||||||||
|
5 |
0 |
1 |
2 |
4 |
|||||||||||||||
|
6 |
0 |
2 |
3 |
5 |
7 |
||||||||||||||
|
7 |
0 |
2 |
4 |
6 |
8 |
11 |
|||||||||||||
|
8 |
1 |
3 |
5 |
8 |
10 |
13 |
15 |
||||||||||||
|
9 |
1 |
4 |
6 |
9 |
12 |
15 |
18 |
21 |
|||||||||||
|
10 |
1 |
4 |
7 |
11 |
14 |
17 |
20 |
24 |
27 |
||||||||||
|
11 |
1 |
5 |
8 |
12 |
16 |
19 |
23 |
27 |
31 |
34 |
|||||||||
|
12 |
2 |
5 |
9 |
13 |
17 |
21 |
26 |
30 |
34 |
38 |
42 |
||||||||
|
13 |
2 |
6 |
10 |
15 |
19 |
24 |
28 |
33 |
37 |
42 |
47 |
51 |
|||||||
|
14 |
3 |
7 |
11 |
16 |
21 |
26 |
31 |
36 |
41 |
46 |
51 |
56 |
61 |
||||||
|
15 |
3 |
7 |
12 |
18 |
23 |
28 |
33 |
39 |
44 |
50 |
55 |
61 |
66 |
72 |
|||||
|
16 |
3 |
8 |
14 |
19 |
25 |
30 |
36 |
42 |
48 |
54 |
60 |
65 |
71 |
77 |
83 |
||||
|
17 |
3 |
9 |
15 |
20 |
26 |
33 |
39 |
45 |
51 |
57 |
64 |
70 |
77 |
83 |
89 |
96 |
|||
|
18 |
4 |
9 |
16 |
22 |
28 |
35 |
41 |
48 |
55 |
61 |
68 |
75 |
82 |
88 |
95 |
102 |
109 |
||
|
19 |
4 |
10 |
17 |
23 |
30 |
37 |
44 |
51 |
58 |
65 |
72 |
80 |
87 |
94 |
101 |
109 |
116 |
123 |
|
|
20 |
4 |
11 |
18 |
25 |
32 |
39 |
47 |
54 |
62 |
69 |
77 |
84 |
92 |
100 |
107 |
115 |
123 |
130 |
138 |
-
Граничина, О.А. Математико-статистические методы психолого-педагогических исследований / О.А. Граничина. – СПб.: Издательство ВВМ, 2012. С. 12. ↑
-
Глас, Дж. Статистические методы в педагогике и психологии / Дж. Гласс, Дж. Стенли; под общ. ред. Ю.П. Адлера; пер. с англ. Л.И. Хайрусовой. – М.: Прогресс, 1976. С. 21. ↑
-
Наследов, А.Д. Математические методы психологического исследования / А.Д. Наследов. – СПб.: Речь, 2014. С. 34. ↑
-
Оценка качества подготовки будущих учителей / Отв. ред. Н.К. Новиков. – Тула: Изд-во Тул. гос. пед. ун-та, 2002. С. 40. ↑
-
Середенко, П.В. Психолого-педагогическое исследование: методология и методы: учебное пособие для студ. высш. учеб. заведений / П. В. Середенко. – Южно-Сахалинск: СахГУ, 2010. С. 67. ↑
-
Середенко, П.В. Методы математической статистики в психолого-педагогических исследованиях: учебное пособие / П.В. Середенко, А.В. Должикова. – 2-е изд. – Южно-Сахалинск: изд-во СахГУ, 2009. С. 27. ↑
-
Сидоренко, Е. В. Методы математической обработки в психологии: практическое руководство / Е.В. Сидоренко. – СПб.: Речь, 2012. С. 111. ↑
-
Сидоренко, Е. В. Методы математической обработки в психологии: практическое руководство / Е.В. Сидоренко. – СПб.: Речь, 2012. С. 111. ↑
-
Суходольский, Г.В. Основы математической статистики для психологов / Г.В. Суходольский. — СПб.: Изд-во Санкт-Петербургского университета, 1998. С. 98. ↑
-
Немов, Р.С. Психология: учебник для студентов высших педагогических учебных заведений: в 3 книгах. Книга 3: Психодиагностика: введение в научное психологическое исследование с элементами математической статистики / Р.С. Немов. – М.: Владос, 2011. С. 112. ↑
-
Глас, Дж. Статистические методы в педагогике и психологии / Дж. Гласс, Дж. Стенли; под общ. ред. Ю.П. Адлера; пер. с англ. Л.И. Хайрусовой. – М.: Прогресс, 1976. С. 87. ↑
-
Донелли Р.А. Статистика / Р.А. Донелли; пер. с англ. Н.А. Ворониной. – М.: Астрель: АСТ, 2007. С. 144. ↑
-
Наследов, А.Д. Математические методы психологического исследования / А.Д. Наследов. – СПб.: Речь, 2014. С. 87. ↑
-
Морозов, Е.А. Возможности автоматизированных систем обработки результатов психодиагностических исследований в сфере социального взаимодействия / Е.А. Морозов // Социальное взаимодействие субъектов в образовательном пространстве: коллективная монография / отв. ред. З.И. Колычева. – Тобольск: ТГСПА им. Д. И. Менделеева, 2013. – С. 139. ↑
-
Граничина, О.А. Математико-статистические методы психолого-педагогических исследований / О.А. Граничина. – СПб.: Издательство ВВМ, 2012. С. 31. ↑
-
Морозов Е.А. Пошаговый алгоритм действий при использовании методов математической статистики в психолого-педагогических исследованиях / Е. А. Морозов // Научный диалог. – 2014. – № 3. – С. 30. ↑
-
Там же. ↑
-
Применение статистических методов в психолого-педагогических исследованиях: Учебное пособие / Сост. С.В. Нужнова. — Троицк: Троицкий филиал ГОУ ВПО «ЧелГУ», 2015. С. 56. ↑
-
Середенко, П.В. Психолого-педагогическое исследование: методология и методы: учебное пособие для студ. высш. учеб. заведений / П. В. Середенко. – Южно-Сахалинск: СахГУ, 2010. С. 91. ↑
-
Сидоренко, Е. В. Методы математической обработки в психологии: практическое руководство / Е.В. Сидоренко. – СПб.: Речь, 2012. С. 188. ↑
-
Суходольский, Г.В. Основы математической статистики для психологов / Г.В. Суходольский. — СПб.: Изд-во Санкт-Петербургского университета, 1998. С. 211. ↑
-
Немов, Р.С. Психология: учебник для студентов высших педагогических учебных заведений: в 3 книгах. Книга 3: Психодиагностика: введение в научное психологическое исследование с элементами математической статистики / Р.С. Немов. – М.: Владос, 2011. С. 311.. ↑
-
Донелли Р.А. Статистика / Р.А. Донелли; пер. с англ. Н.А. Ворониной. – М.: Астрель: АСТ, 2007. С. 214. ↑
-
Граничина, О.А. Математико-статистические методы психолого-педагогических исследований / О.А. Граничина. – СПб.: Издательство ВВМ, 2012. С. 87. ↑
-
Морозов Е.А. Пошаговый алгоритм действий при использовании методов математической статистики в психолого-педагогических исследованиях / Е. А. Морозов // Научный диалог. – 2014. – № 3. – С. 34. ↑
-
Морозов, Е.А. Возможности автоматизированных систем обработки результатов психодиагностических исследований в сфере социального взаимодействия / Е.А. Морозов // Социальное взаимодействие субъектов в образовательном пространстве: коллективная монография / отв. ред. З.И. Колычева. – Тобольск: ТГСПА им. Д. И. Менделеева, 2013. – С. 143. ↑
-
Морозов, Е.А. Псевдоисследования, или как мы готовим псевдоучёных (к проблеме использования методов математической статистики в социальных и психолого-педагогических исследованиях) / Е.А. Морозов // Молодежь и образование XXI века: материалы Всероссийской научно-практической конференции аспирантов, студентов и учащихся. – Тобольск: ТГСПА им. Д.И. Менделеева, 2010. – С. 132. ↑
-
Сидоренко, Е. В. Методы математической обработки в психологии : практическое руководство / Е.В. Сидоренко. – СПб.: Речь, 2012. С. 5. ↑

- Методология исследования личностного развития детей
- Разработка проекта информационной системы автотранспортного предприятия («TO-BE»)
- Критерии выбора средств разработки мобильных приложений
- Модель «клиент - сервер»
- Средства разработки клиентских программ
- Средства разработки клиентских программ
- Государственная служба в России: опыт, современное состояние и направления совершенствования
- Организационная культура и ее роль в современных организациях (на примере ООО «Dolce Vita»)
- Стресс на рабочем месте: причины, диагностика, создание системы профилактических мероприятий
- Влияние личностных особенностей на профессиональный выбор
- Создание и разработка индивидуального (фирменного) стиля для компании (для предприятий промышленности, торговли или сферы обслуживания)
- Проектирование интерьера