
Методы кодирования данных (Виды кодирование данных)
Содержание:

Введение
Основная задача программиста - принять решение о форме представления данных и выборе алгоритмов, применяемых к этим данным. Только тогда выбранная структура программы и данных реализуется на конкретном языке программирования. В связи с этим знание классических методов и приемов обработки данных позволяет избежать ошибок, которые могут возникнуть при разработке программного обеспечения [1].
Объект исследования: классические и современные методы кодирования данных.
Предмет исследования: алгоритм и реализация методов кодирования информации.
Цель: анализ некоторых методов кодирования информации.
Задачи работы:
- дать строгое определение кодирования информации;
- описать процесс сжатия;
- описать общий принцип действия современных методов адаптивного кодирования;
- описать принцип действия алгоритма Хаффмана;
- описать принцип действия алгоритма Гуаццо;
- описать принцип действия алгоритма Гуаццо, примененного к марковским цепям.
Методы исследования: изучение литературных источников, нормативно-правовой базы, изучение технической документации средств кодирования информации.
Виды кодирование данных
Определение кодирования информации
Теория кодирования, как и теория сжатия информации, возникли в начале двадцатого века. Начало развития этих теорий служит цикл научных работ К. Шеннона, вышедших в 1948 году статей. Они заложили основу для дальнейших исследований в этой области [2].
Кодирование - это способ представления информации в удобной для хранения и передачи форме [3]. В связи с развитием информационных технологий кодирование стало основной проблемой при решении различных задач программирования, например, представление данных любой структуры в памяти компьютера, обеспечение помехоустойчивости при передаче данных по каналам связи, сжатие информации в базах данных и других.
Основной моделью, которую изучает теория информации, является модель системы передачи сигнала. В ней: исследуемая информация поступает в кодер источника, от кодера источника проходит в кодер канала, далее – в декодер канала, затем – в декодер источника и, наконец, в приемник передаваемой информации [4]. При этом, при передаче информации из кодер канала к декодеру информация, как правило, зашумляется. Шум может быть довольно разной природы: от лишних, либо неправильно закодированных данных, добавленных алгоритмом кодирования (зависит от выбора метода) до помех, связанных с аппаратными средствами ЭВМ.
В дискретных источниках без памяти на выходе получается последовательность символов фиксированного алфавита. Набор всех различных символов, сгенерированных некоторым источником, называется исходным алфавитом, а количество символов в этом наборе - размером алфавита [5]. К примеру, текст на русском языке генерируется источником с алфавитом из 33 букв, пробелов, знаков препинания и некоторых других специальных символов, используемых при хранения текста.
Кодирование дискретного источника состоит в том, чтобы сопоставить символы некоторого заданного алфавита с исходными символами другого алфавита. Обычно символ исходного алфавита представляет собой не один, а группу символов алфавита результирующего, которая называется кодовым словом. Кодовый алфавит – это совокупность символов, используемых для написания кодовых слов. Код - это коллекция всех кодовых слов, используемых для представления символов, сгенерированных источником.
В качестве примера, можно привести азбуку Морзе. Это известный код из символов телеграфного алфавита, в котором буквы языка соответствуют кодовым словам, то есть последовательностям, «точек» и «тире».
Большой интерес представляет двоичное кодирование, то есть кодирование, размер кодового алфавита которого равен 2. В нем, конечная последовательность битов называется кодовым словом, а количество битов в этой последовательности является длиной кодового слова. Одним из самых распространенных примеров является код ASCII (американский стандартный код для обмена информацией), где каждому символу ставит в однозначное соответствие кодовое слово длиной 8 бит.
Дадим строгое определение кодирования. Пусть даны алфавит источника , , и кодовый алфавит . Обозначим через множество всех возможных последовательностей в алфавите . Множество сообщений в алфавите обозначим через . Тогда отображение , которое преобразует множество сообщений в кодовые слова в алфавите , называется кодированием.
Если , то – кодовое слово. Обратное отображение (если оно существует) называется декодированием.
Задача кодирования сообщения ставится следующим образом. Необходимо, при заданных алфавитах и , и множестве сообщений найти такое кодирование , которое обладает определенными свойствами и оптимально в некотором заданном алгоритмом кодирования смысле.
Свойства, которые требуются от кодирования, могут быть довольно различными. Вот лишь некоторые из них:
существование декодирования;
помехоустойчивость или исправление ошибок при кодировании;
обладает заданной трудоемкостью (например, ограничения на время или объем памяти) и т.д.
Существует два класса методов кодирования дискретных источников информации: равномерное и неравномерное кодирование. Под равномерным кодированием понимается использование кодов со словами постоянной длины. Для того чтобы декодирование равномерного кода было возможным, разным символам алфавита источника должны соответствовать разные кодовые слова. При этом длина кодового слова должна быть не меньше символов, где – размер исходного алфавита, – размер закодированного алфавита. Например, для кодирования источника, состоящего из 26 букв латинского алфавита, равномерным двоичным кодом могут быть построены кодовые слова, длиной не меньше бит.
При неравномерном кодировании источника используются кодовые слова разной длины. Причем кодовые слова обычно строятся так, что часто встречающиеся символы кодируются более короткими кодовыми словами, а редкие символы – более длинными (за счет этого и достигается «сжатие» данных).
1.2 Сжатие данных
Сжатие данных — это алгоритмическое преобразование данных, которое производится с целью уменьшения занимаемого объёма. Сжатие данных относится к компактному представлению данных, достигаемому избыточностью информации, содержащейся в сообщениях. Большое значение для практического использования имеет неискажающее сжатие, которое позволяет полностью восстановить исходное сообщение. Неискажающее сжатие кодирует сообщение перед передачей или хранением, и после окончания процесса сообщение однозначно декодируется. Это соответствует модели канала без шума (помех).
Сжатие данных применяется для рационального использования устройств хранения и передачи данных, также оно устраняет избыточность, содержащуюся в исходных данных. Например, избыточностью является наличие в тексте повторяющихся фрагментов. Такая избыточность, как правило, может быть устранена путем замены повторяющейся последовательности ссылкой на уже закодированный фрагмент кода с указанием его положения. Другой вид избыточности связан с тем, что некоторые значения закодированных данных появляются чаще других. Популярным способом сокращения объёма данных является энтропийное кодирование, которое достигается за счёт замены часто встречающихся данных короткими кодовыми словами, а редких — длинными. Сжатие данных, не обладающих свойством избыточности, таких как случайный сигнал, белый шум или зашифрованные сообщения принципиально невозможно без потерь.
В основе большинства способов сжатия данных лежит модель источника данных или модель избыточности. Другими словами, для сжатия данных используются предварительные сведения о сжимаемости данных. В противном случае невозможно сделать каких-либо предположений о преобразованиях, уменьшающих объём. Таким образом, модель избыточности может быть неизменной для всего сжимаемого сообщения, статической или параметризуемой на этапах сжатия и восстановления.
Методы, которые позволяют, используя входные данные, изменить модель избыточности заданной информации, называются адаптивными. Неадаптивными назовем узконаправленные методы, применяемые для работы с информацией, обладающей достаточно определёнными статичными характеристиками.
Современные методы сжатия данных основаны на априорных предположениях о структуре исходных данных. Например, кодирование Хаффмана предполагает, что исходные данные состоят из случайно выбранных символов потока, в соответствии с некоторыми статистическими вероятностями [6]. Для определенности, в дальнейшем будем предполагать, что исходные данные будут являться некоторым потоком битов, которые сгенерированы с помощью дискретных цепей Маркова [7]. Подобная модель будет являться довольно общей для того чтобы описать предположения, данные в модели кодирования Хаффмана, модели кодирования по длине прогона и некоторых других часто используемых методов сжатия. В методах Зива-Лемпеля и Клири-Виттена также сделано предположение о том, что для исходных данных существует базовая марковская модель. Было доказано, что кодирование методом Зав-Лемпеля стремится к оптимальному коэффициенту сжатия для достаточно длинных сообщений, задаваемых моделью Маркова [8, 9].
Однако, одним из популярных направлений в моделировании сжатия данных – это построение Марковской цепной модели, построенной из первых частей сообщения, которую можно использовать для предсказания предполагаемых двоичных символов.
Каждое звено в цепи Маркова представляет собой вероятность того, что следующий символ будет нулем или единицей. После использования оценки этой вероятности в описываемой схеме кодирования данных, можно использовать фактический символ для перехода к следующему звену цепи. Это новое звено будет предсказывать, какой будет следующий бит сообщения и так далее. Если оценки вероятности для каждого звена цепи Маркова отклоняются от ½, то их можно считать достаточно точными и их можно использовать как основу для метода сжатия данных. Такой подход, в котором оценки вероятностей используются для управления методом кодирования с минимальной избыточностью, называется арифметическим кодированием [10].
В работах Гуаццо [11] был получен достаточно мощный метод сжатия данных, который является модификацией метода арифметического кодирования и сочетает в себе генерацию цепной модели Маркова. Несмотря на то, что результаты производительности модификации метода сжатия данных Гуаццо похожи на результаты производительности, достижимые с помощью метода Клири и Виттена, метод Гуаццо гораздо проще реализуется, а также требует меньше памяти ЭВМ и потребляет меньше времени процессора.
Методы сжатия данных можно разделить на две группы: статические методы и адаптивные методы. Методы сжатия статических данных предназначены для кодирования определенных источников информации с известной статистической структурой, которая генерирует определенный набор сообщений. Эти методы основаны на знании статистической структуры исходных данных. Наиболее известные методы статического сжатия включают коды Хаффмана, Шеннона, Фано, Гилберта-Мура, арифметический код и другие методы, которые используют известную информацию о вероятностях источника, создающего различные символы или их комбинации.
Если статистика источника информации неизвестна или изменяется со временем, то для кодирования сообщений такого источника используются методы адаптивного сжатия. Адаптивные методы используют информацию о ранее закодированной части сообщения для оценки вероятности следующего символа при кодировании следующего символа текста. В процессе кодирования адаптивные методы «настраиваются» на статистическую структуру закодированных сообщений, то есть коды символов меняются в зависимости от статистики накопленных данных. Это позволяет адаптивным методам эффективно и быстро кодировать сообщение в одном представлении.
Существует много различных адаптивных методов сжатия данных. Самым известным из них является адаптивный код Хаффмана, код «стопки книг», интервальные и частотные коды, а также методы из класса Лемпеля-Зива.
Адаптивные методы кодирования
Кодирование Хаффмана
Алгоритм кодирования Гуаццо генерирует коды минимальной избыточности, подходящие для дискретных источников сообщений с памятью. Термин «источник сообщений с памятью» используется для описания сообщений, которые были сгенерированы моделью цепей Маркова. На практике сообщения почти всегда демонстрируют некоторую степень совпадения между соседними символами.
Для того чтобы показать, что кодирование Гуаццо достигает почти оптимальных кодов, сравним его работу с довольно популярным кодированием Хаффмана [6].
Рассмотрим пример кодирования Хаффмана сообщений, генерируемых цепной моделью Маркова, приведенной на рисунке 1.
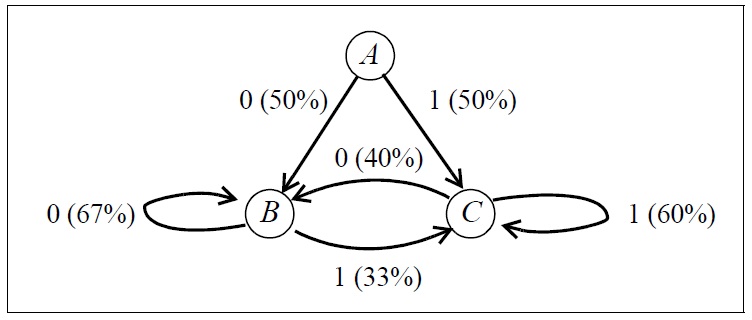
Рис. 1 Пример модели цепи Маркова.
Кодирование Хаффмана не может быть непосредственно применено к двоичному исходному алфавиту. Необходимость предоставления отдельных кодов для нулевого бита и одного бита означает, что сжатие невозможно. Обычным способом решения этой проблемы является создание довольно большого исходного алфавита. Это легко сделать, сгруппировав символы сообщения вместе. Например, мы можем выбрать работу с группами из трех битов, получая алфавит размером 8. Посредством анализа модели Маркова на рис. 1, включающей вычисление вероятностей состояния равновесия, мы вычислили вероятность возникновения для каждого символа в новом исходном алфавите. Эти вероятности могут быть использованы для получения кодов Хаффмана.
Если кодирование тройками Хаффмана используется для кодирования длинного сообщения, генерируемого моделью цепи Маркова, тогда достигается умеренная степень сжатия. Фактически, длинное сообщение будет в среднем сжато примерно до 90,3% от его первоначального размера. Однако это число значительно больше, чем теоретико-информационная нижняя граница. Простой расчет энтропии в источнике информации показывает, что сжатие до 81,9% от исходного размера может быть достижимым.
Есть две причины, по которым кодирование Хаффмана не достигает конкретной нижней границы. Первая причина заключается в том, что кодирование Хаффмана может быть свободно от избыточности, только если частоты появления символов в исходном алфавите имеет целочисленные степени 2. Вторая причина заключается в том, что кодирование Хаффмана использует совпадение только между битами, которые были сгруппированы вместе. Однако этот факт игнорирует совпадение между последним битом первой группы и первым битом второй группы. Таким образом, вторая группа кодируется неоптимальным образом.
Эти две проблемы со схемой Хаффмана улучшаются только путем выбора больших групп битов для построения исходного алфавита. Если выбираются группы большего размера, эффективность кодирования приближается к нижней границе, но размер алфавита растет в геометрической прогрессии. Размер таблиц, необходимых для хранения кодировок Хаффмана, также растет в геометрической прогрессии, в то время как вычислительные затраты на создание этих таблиц становятся неосуществимыми.
Альтернативой неосторожному расширению размера алфавита является использование нескольких наборов кодирования Хаффмана. Выбор набора кодирования для использования в следующем символе сообщения определяется предыдущими символами. Такой подход может быть реализован для достижения компромисса между производительностью сжатия данных и используемым объемом памяти, необходимых для хранения таблиц кодов Хаффмана [12].
2.2. Кодирование Гуаццо, примененное к модели Маркова
У метода Гуаццо нет недостатков, отмеченных ранее для кодирования Хаффмана. Для достаточно длинных сообщений метод может генерировать кодировки, сколь угодно близкие к теоретико-информационной нижней границе. Первым шагом в обосновании работы двоичной версии метода Гуаццо является рассмотрение выходной кодировки в виде двоичной дроби. Например, если кодирование вывода начинается с цифр «0 1 1 0 1 ...», то это двоичное число рассматривается как число, начинающееся с цифр «0.01101...». Это число имеет значение, близкое к выраженному в десятичной дроби. Задача алгоритма кодирования состоит в выборе дробного числа в диапазоне от нуля до единицы, которое кодирует все исходное сообщение.
Учитывая, что алгоритм Гуаццо имеет доступ к цепной модели Маркова, например, в виде, изображенном на рис. 1, можно проследить, как алгоритм кодирования будет выбирать из достаточно длинного источника сообщение, начинающееся с заданной последовательности цифр «0 1 1 1 0 0 1 ...». Изначально алгоритм кодирования Гуаццо выбирает двоичные дроби, лежащие в диапазоне от «0.000...» до «0.111...» включительно, произвольно. Алгоритм Гуаццо определяет по цепной модели Маркова, что первая цифра исходного сообщения с одинаковой вероятностью равна нулю или единице. Поэтому эта цифра делит пространство двоичных дробей на две половины: если дробь начинается с «0», то она находится в замкнутом интервале [0.000..., 0.0111...], если же начинается с «1», то она находится в замкнутом интервале [0.1000..., 0.111...]. В приведенном примере, исходное сообщение начинается с нуля, поэтому алгоритм выберет интервал [0.000..., 0.0111...].
Первая цифра источника данных приводит к состоянию, обозначенному на рисунке 1 через «B». В этом состоянии вероятность того, что следующая цифра будет нулем, в два раза больше, чем если бы она была единицей. Вследствие этого, алгоритм Гуаццо определяет диапазон доступных двоичных дробей и делит их на две части в соотношении 2:1. Далее алгоритм получает два интервала: подинтервал [0.000... , 0.010101...], который представляет собой исходные сообщения, начинающиеся с «0.00...», и подинтервал [0.010101... , 0.0111... ], представляющий собой сообщения, начинающиеся с «0.01». Первый из этих подинтервалов имеет вдвое больший диапазон, чем второй. Т.к. вторая цифра исходного сообщения равна единице, то ограничиваемся вторым подинтервалом. Поскольку эта цифра исходных данных приводит нас к состоянию C в цепной модели Маркова (рис. 1), то доступный диапазон кодировок сообщений в дальнейшем делится в соотношении 3:2.
В конечном итоге, алгоритм Гуаццо определит, что наше исходное сообщение, начинающееся с «0111001», должно быть представлено некоторой двоичной дробью в интервале [0.011100110101... , 0.01110100101111...]. Поскольку нижняя и верхняя границы интервала начинаются с одних и тех же пяти цифр, алгоритм кодирования определит последовательность символов передаваемого сообщения, как «0 1 1 1 0».
Если рассматривать требования к практической компьютерной реализации, то очевидно, что интервальные границы не должны вычисляться как дроби, содержащие неограниченное количество цифр. Необходимо, чтобы только нужное количество битов было сохранено в вычислениях интервальных границ. Способ, которым доступное пространство двоичных кодировок разделяется на каждом шаге алгоритма, распределяет закодированные сообщения максимально равномерно по всему исходному пространству. Важно распределить кодировки равномерно, иначе некоторые кодировки будут излишне близки друг к другу, как следствие, два значения, которые почти одинаковы, потребуют больше битов, чтобы различать их, чем два значения, которые находятся дальше друг от друга.
Описанный процесс кодирования легко обратим. Алгоритм декодирования имеет доступ к той же марковской цепной модели источника информации, которая использовалась в процессе кодирования. Он начинается с построения того же интервала [0.000..., 0.111...] возможных кодировок и разделяет его таким же образом, как при кодировании. Затем, проверка ведущего бита в закодированном сообщении определяет, какой из двух разделов должен был использоваться и, следовательно, какой должна быть первая исходная цифра. Как только эта первая цифра известна, алгоритм декодирования может выбрать соответствующий подинтервал и повторить дальнейшее деление на две части. Затем определяется вторая цифра закодированного сообщения и так далее.
2.3 Адаптивное кодирование
Сжатие данных обычно реализовывается в виде двухэтапного метода. Начальный этап выполняется для обнаружения характеристик исходного сообщения. Затем, используя эти характеристики, реализуется второй этап для выполнения сжатия. Например, если мы используем кодировку Хаффмана, то на первом этапе будем считать частоты появления каждого символа. Данные, полученные с использованием кодирования Хаффмана, могут быть построены до того, как второй этап выполнит кодирование. Чтобы обеспечить возможность декодирования сжатых данных, необходимо использовать фиксированную схему кодирования или включить сведения о схеме сжатия в сжатые данные. Хотя двухэтапную реализацию метода сжатия данных несложно разработать, на практике обычно применяют одноэтапный алгоритм адаптивной реализации сжатия данных. Также одноэтапные реализации предпочтительны, поскольку они не требуют сохранения всего сообщения в оперативной памяти компьютера перед кодированием.
Существует одноэтапный метод сжатия данных, который на практике обеспечивает сжатие, очень близкое к полученному с помощью двухэтапного методов. Основная идея этого метода заключается в том, что схема кодирования динамически изменяется во время кодирования сообщения. Схема кодирования, используемая для k-го символа сообщения (), основана на характеристиках предыдущих k-1 символов в сообщении. Этот метод известен как адаптивное кодирование. На практике адаптивное кодирование Хаффмана обеспечивает сжатие данных, которое незначительно отличается от обычного двухэтапного кодирования Хаффмана, но затрачивает большее количество ресурсов ЭВМ [13, 14].
Методы Зив-Лемпеля и Клири-Виттена также являются адаптивными методами кодирования. Основная идея кодирования метода Зив-Лемпеля состоит в том, что группа символов в сообщении может быть заменена указателем на более раннее появление этой группы символов в сообщении [17]. После короткого периода обучения эти указатели будут последовательно занимать меньше битов, чем группы символов, которые они заменяют. Программно этот алгоритм может быть реализован таким образом, чтобы быть намного быстрее, чем адаптивное кодирование Хаффмана, при этом достигается гораздо лучшее сжатие данных. Тем не менее, алгоритм Зив-Лемпеля использует только совпадение между исходными символами, которые группируются вместе: весь контекст отбрасывается между такими группами. Таким образом, схема страдает тем же дефектом, что и описанная в разделе 2.1; потеря контекста улучшается только за счет использования более длинных групп с соответствующим потреблением ресурсов памяти.
Метод Клири и Виттена использует предыдущие k символов в сообщении для предсказания вероятностей появления текущего символа сообщения и использует эти вероятности для управления арифметической схемой кодирования [15]. С этой целью сохраняется таблица всех предыдущих вхождений строк длины k, а также количество символов, следующих за строкой. Однако, если определенная комбинация из k символов не появилась ранее в сообщении, мы не сможем оценить вероятности появления символа. В этом случае метод Клири и Виттена пропускает предыдущие k-1 символов, которые смогут лишь оценить вероятности. Если комбинация предшествующих k-l символов также ранее не определялась алгоритмом, произойдет другой пропуск кода и оценивание вероятностей и так далее. Каждый набо k строк может рассматриваться как представление достаточно большой модели марковской цепи k-го порядка. Вероятности, используемые в цепных Марковских моделях, изучаются по мере обработки сообщения. А так как декодер может быть запрограммирован так же, как и кодировщик, то легко построить адаптивный алгоритм сжатия.
Алгоритм кодирования Гуаццо в высшей степени подходит для использования в адаптивных схемах кодирования. Единственным аспектом алгоритма, который нуждается в динамическом изменении, является источник вероятностных оценок для символов сообщения. На каждом этапе процесса кодирования алгоритм требует оценки вероятности каждого из возможных символов последующего сообщения. Для алгоритма кодирования Гуаццо не имеет значения, получены ли эти оценки вероятности из статической марковской модели или из динамически изменяющейся. В такой динамической модели, как набор состояний, так и вероятности перехода могут измениться, на основе символов сообщения, видимых до текущего шага алгоритма.
Декодирование сообщения, полученного с помощью адаптивной реализации кодирования алгоритма Гуаццо, также достаточно просто реализуется на практике. Все, что нужно сделать алгоритму декодирования, это воссоздать ту же последовательность изменений в динамически изменяющейся марковской модели, что и алгоритм кодирования. Поскольку алгоритм декодирования видит точно такую же последовательность незакодированных цифр, как и алгоритм кодирования, особых в реализации трудностей не возникает.
3.1. Выбор вероятностей
Модель Марковской цепи можно охарактеризовать как ориентированный граф с вероятностями, прикрепленными к ребрам графа. Можно выделить два различных аспекта проблемы автоматического создания такой цепной марковской модели. Одна часть - это определение подходящих вероятностей для размещения на ребрах графа. Другая часть - это определение структуры самого графа.
Предположим, что существуют корреляции между символом сообщения и непосредственно предшествующими символами. Если бы считывать двоичные цифры из исходного сообщения, то можно отследить соответствующие переходы в модели и подсчитать, сколько раз каждый переход был принят в модели. Эти подсчеты дают адекватные оценки вероятностей для переходов, которые были сделаны много раз. Точнее, если переход из состояния A к цифре «0» был выполнен раз, а переход к цифре «1» был выполнен раз, то справедливы следующие оценки вероятностей: в состоянии A при переходе к цифре «0» оценка вероятности не превосходит значение , а в состоянии A при переходе к цифре «1» - [16]. При это, чем чаще осуществлялся переход в состояние A, тем точнее вероятностные оценки.
Для применения метода адаптивного кодирования требуется определение вероятностных оценок до того, как количество переходов будет достаточно большим. Кроме того, вышеприведенные значения оценок вероятностей не определены для первого нахождения в состоянии A и дают вероятности перехода 0% и 100% в течение следующих нескольких попаданий в это состояние. Необходимо следить, чтобы переход в алгоритме Гуаццо в следующее состояние не осуществлялся с вероятностью 0% для любого бита, т.к. генерируемая кодировка может иметь бесконечную длину. Существует много способов корректировки вероятностных формул для учета этой проблемы. Один из вариантов – это незначительно варьировать значение оценок. Тогда получим скорректированные оценки: в состоянии A при переходе к цифре «0» оценка вероятности не превосходит значение , а в состоянии A при переходе к цифре «1» - . Здесь - некоторая положительная константа. Использование малых значений для делает вероятностные оценки, основанные на малых размерах выборки, более надежными в практической реализации алгоритма, тогда как большие значения делают их оценки менее точными. С другой стороны, адаптивный алгоритм быстрее распознает характеристики исходного файла, если используются небольшие значения для , но чаще делает плохие прогнозы. Однако, при сжатии большого объема данных, выбор константы становится в неуместным.
3.2 Построение графа состояний перехода
Рассмотрим частично построенную модель, которая включает в себя состояния A, B, ... , E (рис. 2a). На рисунке показаны переходы от A и B к C, а также переходы от C к D и E. Теперь, когда модель переходит в состояние C, некоторая контекстуальная информация теряется. По сути, теряется информация достигли ли мы состояния C из A или из B. Но вполне возможно, что выбор следующего состояния, D или E, совпадает с предыдущим состоянием, A или B. Самый простой способ узнать, существует ли такая корреляция, - это дублировать состояние C, создавая новое состояние C'. Для определенности, назовем этот процесс «клонированием». Это создает новую Марковскую модель (рис. 2b). После этого изменения модели, количество переходов от состояния C к состояниям D или E будет обновляться только когда в состояние C переходим из состояния A, в то время как количество переходов из C в D или Е будет обновляться когда C' переходит из состояния B. Таким образом, теперь модель хранит информацию о корреляции между состояниями A, B и D, E.
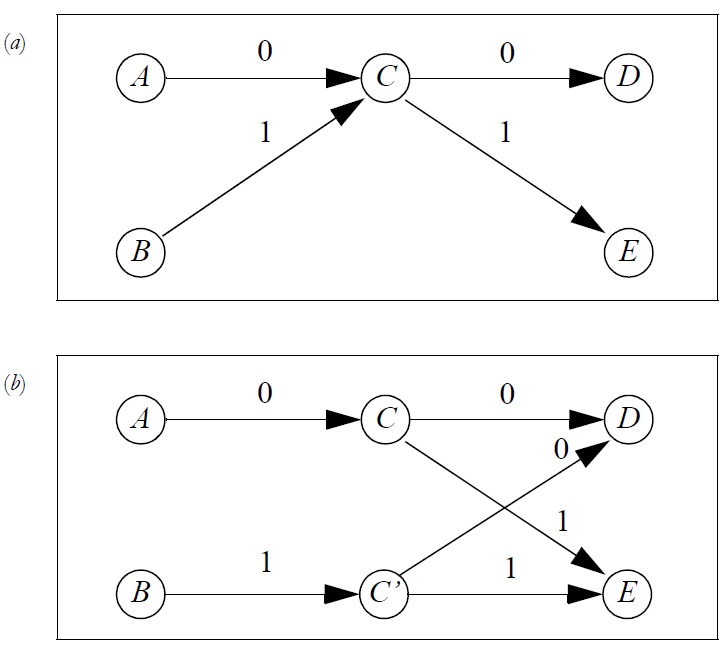
Рис. 2 (a) Часть марковской модели; (b) Марковская модель после процесса «клонирования»
Если вышеупомянутый процесс «клонирования» выполняется, когда на самом деле нет корреляции между предыдущим состоянием и следующим состоянием, то можно считать количество потерянных данных достаточно малым. Таким образом, модель стала содержать больше состояний и оценки вероятностей стали более восприимчивыми к статистическим колебаниям (т.к. каждое состояние посещается реже). Если такие корреляции существуют, улучшения в вероятностных оценках могут быть не удовлетворительными. В модели (рис. 2b), вполне возможно, что выбор следующего состояния D или E не может быть соотнесен с предыдущим состоянием A или B, но коррелирует с состоянием, находящимся непосредственно перед состоянием A или В. Если это так, то «клонирование» состояний A, B, и C' и пересмотр состояния C позволит модели обнаружить совпадения. Как правило, чем больше процессов «клонирования» выполняется, тем больше диапазон совпадений, которые могут быть обнаружены и использованы в целях прогнозирования.
Возможность «клонирования» конкретного состояния зависит от того, заходил ли алгоритм в это состояние не большое количество раз от каждого из двух (или более) различных состояний-предшественников. Ссылаясь на рис. 2(а), опять-таки, предположим, что текущее состояние-это и переход будет сделан, чтобы государство С. Далее предположим (рис. 2a), что текущим состоянием является состояние A и переход осуществляется в состояние B. Необходимость «клонирования» состояния C зависит от того, являются ли значения переходов AC и BC достаточно большими. Если, количество переходов BC равно нулю или мало по сравнению с количеством переходов AC, то вероятности, связанные с переходами, выходящими из C, будут отражать корреляцию с предшественником, являющимся A. «Клонирование» состояния C позволит выявить корреляции с состоянием B, однако, будет бесполезным, если переход BC используется редко.
3.3. Запуск и остановка построения модели
Начинать построение цепной марковской модели необходимо с любой минимальной модели, содержащей только одно состояние, способной генерировать любую последовательность сообщений. Оба перехода из этого состояния (для цифр 0 и 1) возвращаются в это состояние. Пример такой модели изображен на рисунке. 3a. После работы алгоритма «клонирования» эта модель с исходным состоянием быстро переходит в сложную модель с довольно большим количеством состояний.
На практике, некоторые преимущества можно получить, начав с менее тривиальной начальной модели. Так как, почти все компьютерные данные выровнены по байтам или словам, то корреляции, как правило, происходят между соседними байтами чаще, чем между соседними битами. Если начать с модели, которая соответствует структуре байтов, то процесс изучения характеристик исходного сообщения происходит быстрее, что приводит к лучшему сжатию данных. Простая модель байтовой структуры имеет 255 состояний, расположенных в виде двоичного дерева, с переходами от каждого конечного узла к корню дерева. Общая форма этого дерева, но с меньшим количеством узлов, изображенная на рис. 3b.
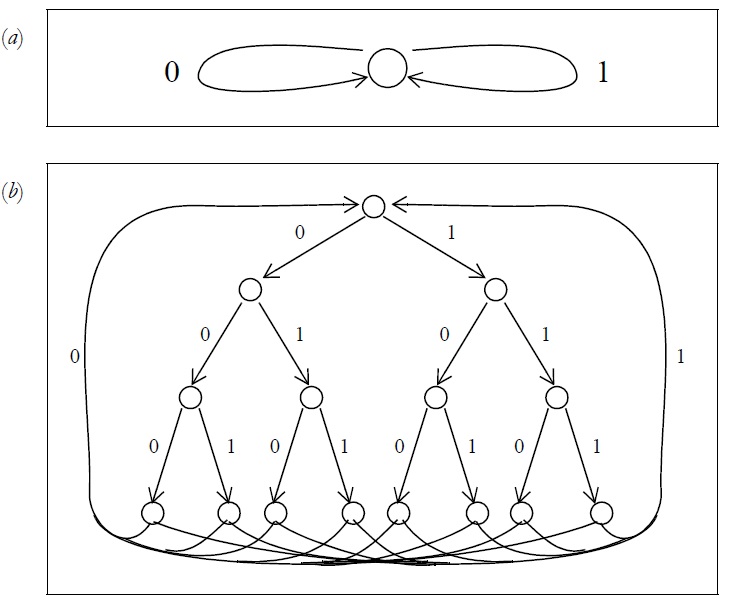
Рис. 3 (a) Исходное состояние Марковской цепи. (b) Первоначальная модель цепи Маркова для 4-битных символов.
Хотя древовидный начальный граф работает стабильно, его можно сделать еще лучше. Когда счетчики переходов достигают достаточных значений, они могут отображать корреляции между отдельными битами байта. Например, если третий бит в байте, являющийся нулем, подразумевает, что седьмой бит всегда является единицей, то древовидная модель сможет описать эту корреляцию. В общем случае состояние на k-ом уровне дерева () представляет собой корреляции с предыдущими k-1 битами. Объем левого контекста, который коррелирует с текущим состоянием, увеличивается от 0 бит до 7 бит, а затем корреляция отбрасывается при переходе к вершине (корню) дерева. Более удовлетворительной является модель, которая сохраняет постоянный объем левого контекста. Помимо эстетической привлекательности, такая модель имеет возможность изучать корреляции между последними несколькими битами одного байта и первыми битами следующего байта. Модель, которая сохраняет объем левого контекста постоянным, к сожалению, трудно показать на диаграмме. Проще всего ее изобразить на поверхности тора.
Если процесс «клонирования» не остановлен, то память ЭВМ будет использоваться неограниченно. С другой стороны, если алгоритм полностью остановлен, то теряется способность алгоритма «адаптироваться», в случае если некоторые характеристики исходного сообщения изменяются. Одним из возможных решений является установление ограничения на количество состояний. Когда предел достигнут, текущая Марковская модель отбрасывается, и алгоритм начинается с начальной модели. На практике это радикальное решение более эффективно, чем может показаться [17]. Однако менее радикальный вариант подхода легче реализовать. Можно сохранить последние k байт исходного сообщения, которые были прочитаны в буфер. При достижении предельного числа состояний модель отбрасывается, как и раньше. Затем, создается новая модель путем обработки k байтов в буфере, без добавления к закодированному сообщению. Это приведет к созданию новой модели с относительно небольшим числом состояний, соответствующих характеристикам последних k байтов сообщения. Несмотря на некоторую потерю производительности сжатия данных при этих рекламациях хранилища, потеря не очень велика и алгоритм сжатия сохраняет свою «адаптивность».
3.4 Практическое использование алгоритма Гуаццо
Кодирование Гуаццо ранее обсуждалось без особого учета проблем, связанных с практической реализацией. Есть две основные проблемные области, которые необходимо решить. Первая проблема заключается в том, что нижняя и верхняя границы интервала являются рациональными числами, которые по мере выполнения алгоритма должны вычисляться с еще большей точностью. Решение, принятое Гуаццо, заключается в ослаблении требования о том, чтобы эти границы были точно рассчитаны.
На каждом шаге алгоритма кодирования, интервал делится на две части. Если деление не выполняется точно в тех же пропорциях, что и отношение вероятностей того, что следующая цифра источника равна нулю или единице, то больших потерь нет. Метод кодирования продолжает работать, в том смысле, что декодирование может быть выполнено единственным образом. Все, что теряется, это небольшая эффективность кодирования. Поэтому Гуаццо предложил использовать критерий для определения того, насколько точно должна быть рассчитана точка деления между двумя поддиапазонами. Чем жестче этот критерий, тем лучше кодировка сообщения, но за счет вычислений приходится искать точку деления более точно.
Для реализации алгоритма выбирается более практичный подход - сохранение в вычислении точки деления столько значащих битов, сколько удобно поместить в одном компьютерном слове. И, как только биты сообщения генерируются (когда обе границы интервала имеют одну или более идентичных ведущих цифр), они удаляются из обеих переменных, которые записывают границы интервала. Они могут быть удалены логическими операциями сдвига влево. Таким образом, такая реализация поддерживает постоянную степень точности (около 30 значащих битов). При этом декодер не создает избыточный выходной бит. Алгоритм также должен гарантировать, что декодер сможет воспроизвести все исходное сообщение, не потеряв ни одного из последних битов. Таким образом, в конце алгоритма должен быть выведен только самый правый бит алгоритма. Максимизация количества битов, выводимых кодировщиком, устраняет неоднозначность любых ожидающих выбора интервальных разделов в декодере. Алгоритм декодирования точно отражает алгоритм кодирования. Действительно, за исключением некоторых задержек, когда он не может сразу решить, выбрать верхнюю или нижнюю половину раздела диапазона, его расчеты идут почти одинаково с расчетами кодировщика.
Заключение
Словарные коды класса Лив-Земпеля широко используются в практических задачах. На их основе реализовано множество программ-архиваторов. Эти методы также используются при сжатии изображений в модемах и других цифровых устройствах передачи и хранения информации.
Словарные методы сжатия данных позволяют эффективно кодировать источники с неизвестной или меняющейся статистикой. Важными свойствами этих методов являются высокая скорость кодирования и декодирования, а также относительно небольшая сложность реализации. Кроме того, описанные методы обладают способностью быстро адаптироваться к изменению статистической структуры сообщений.
При декодировании по принятому коду определяется закодированное слово. В случае получения специального символа, сигнализирующего о передаче нового слова, принятое слово запоминается, и ему присваивается такой же, как и при кодировании, код. Таким образом, декодирование является однозначным, т. к. каждому слову соответствует свой собственный код.
Динамическое марковское сжатие (Dinamic Markov Compression, сокращенно DMC) - это общий алгоритм сжатия данных, который достигает лучших результатов сжатия, описанных в литературе. Например, текстовые файлы сжимаются до такой степени, что для каждого символа требуется в среднем чуть больше двух битов. В работе [17] приводятся результаты сравнения различных алгоритмов сжатия данных. Метод Зив-Лемпеля является самым быстрым алгоритмом, тогда как метод Клири-Виттена – самым медленным. С точки зрения требований к хранению, адаптивный алгоритм Хаффмана использует наименьший объем памяти, а метод Клири-Виттена обычно использует больше всех остальных алгоритмов. Однако это наблюдение должно быть квалифицировано фактом, что хранилище, используемое алгоритмами Зив-Лемпеля и Клири-Виттена, увеличивается безгранично, поскольку обрабатывается исходное сообщение. В качестве практического требования, объем хранилища, доступный для использования методов Зив-Лемпеля и Клири-Виттена, должен быть искусственно ограничен.
Хотя DMC составляет сильную конкуренцию методам Зив-Лемпеля и Клири-Виттена, алгоритм DMC является более общим подходом, который имеет несколько преимуществ. Оба метода Зив-Лемпеля и Клири-Виттена для практических целей ориентированы на байты. Действительно, можно реализовать бит-ориентированные версии Зив-Лемпеля и Клири-Виттена, но в случае Зив-Лемпеля результаты являются неудовлетворительными потому, что период обучения для метода Зив-Лемпеля становится намного дольше, чем для достижения сжатия типичных файлов. Бит-ориентированная версия Клири-Виттена непрактична по другой причине: если требуется достичь того же эффекта, что и Марковская модель четвертого порядка для байтов, необходимо использовать Марковскую модель 32-го порядка для битов. Объем памяти, необходимый для хранения таблиц расчетов, будет слишком большим.
С другой стороны, DMC лучше обрабатывает байт-ориентированные данные в сравнении с битовыми данными. Использование байт-ориентированной начальной модели не приводит к тому, что DMC работает плохо, если данные на самом деле не ориентированы на байты. Поэтому можно сказать, что DMC является более общим методом и может применяться к данным, которые уже подверглись некоторой форме сжатия, не сохраняющих выравнивание байтов. В некоторой степени, это также объясняет, почему DMC превосходит другие методы сжатия данных объектного кода.
Несколько иное направление современных исследований заключается в обобщении алгоритма сжатия двумерных изображений, например, создаваемых для устройств растрового типа. Проблема здесь в том, что необходимо, чтобы модель учитывала корреляции между смежными линиями сканирования, а также между смежными точками на одной и той же линии сканирования. Также метод динамического Марковского моделирования применим к задачам, отличным от сжатия данных. Например, компьютерная система может использовать этот метод для прогнозирования доступа к записям в базе данных и использовать эти прогнозы для предварительной выборки записей. Еще одно возможное применение метода моделирования - в игровых программах для моделирования стратегии игры человеческого противника. Эта идея была использована в программе для детской игры «Камень, Ножницы, Бумага» [18].
Список использованных источников
- Акулов Л. Г. Хранение и защита компьютерной информации : учебное пособие / Л.Г. Акулов, В.Ю. Наумов. - Волгоград : ВолгГТУ, 2015. - 62 с.
- Андрианов В.В., Зефиров С.Л., Голованов В.Б., Голдуев Н.А. Обеспечение информационной безопасности бизнеса. – М.: Альпина Паблишерз, 2011 – 338 с.
- Ожиганов А.А. Криптография: учебное пособие / А.А. Ожиганов. - Санкт-Петербург : Университет ИТМО, 2016. - 142 c.
- Радько, Н.М. Основы криптографической защиты информации [Электронный ресурс]: учебное пособие / Н. М. Радько, А. Н. Мокроусов; Воронеж. гос. техн. ун-т. - Воронеж : ВГТУ, 2014.
- Герасименко В.А., Малюк А.А. Основы защиты информации. – СПб.: Питер, 2010. – 320с
- D.A. Huffman, A method for the construction of minimum redundancy codes. Proceedings of the IRE 40, vol. 40, issue 9, 1952, pp. 1098-1101.
- K.S. Trivedi, Probability and Statistics with Reliability, Queuing and Computer Science Applications. Prentice-Hall, Englewood Cliffs, N.J., 1982, 624 p.
- J. Ziv and A. Lempel, A universal algorithm for sequential data compression. IEEE Transactions on Information Theory, vol. IT-23 (3), 1977, pp. 337-343.
- J. Ziv and A. Lempel, Compression of individual sequences via variable-rate encoding. IEEE Transactions on Information Theory, vol. IT-24 (5), 1978, pp. 530-536.
- J. Rissanen and G.G. Langdon Jr., Arithmetic coding. IBM Journal of Research and Development, vol. 23, no. 2, 1979, pp. 149–162.
- M. Guazzo, A general minimum-redundancy source coding algorithm. IEEE Transactions on Information Theory, vol. IT-26 (1), 1980, pp. 15-25.
- G.V. Cormack, Data compression for a data base system. Communications of the ACM, vol. 28 (12), 1985, pp. 1336-1342.
- G. V. Cormack and R.N. Horspool, Algorithms for adaptive Huffman codes. Inf.Process.Lett. vol. 18, issue 3, 1984, pp. 159-166.
- R. Gallager, Variations on a theme by Huffman. IEEE Transactions on Information Theory, vol. IT-24 (6), 1978, pp. 668-674.
- T.A. Welch, A technique for high-performance data compression. IEEE Computer, vol. 17 (6), 1984, pp. 8-19.
- J.G. Cleary and I.H. Witten, Data compression using adaptive coding and partial string matching. IEEE Transactions on Communications, vol. COM-32 (4), 1984, pp. 396-402.
- G.V. Cormack and R.N.S. Horspool, Data compression Using dynamic Marcov modeling. The Computer Journal, vol. 30, no. 6, 1987, pp. 541-550.
- R.N. Horspool and G. V. Cormack, Dynamic Markov modelling – a prediction technique. Proceedings of the 19th Hawaii International Conference on the System Sciences, Honolulu, 1986, pp. 700-707.

- Разработка регламента выполнения процесса «Складской учет
- «Защита внутренней сети и сотрудников компании от атак»
- Проектирование реализации операций бизнес-процесса «Контроль поставок товара
- Система защиты коммерческой тайны малого коммерческого предприятия
- Программные и аппаратные средства ограничения доступа к ресурсам ПК и сетей
- Стратегия управления персоналом (Формирование кадровой политики в современной организации)
- Понятие и значение приватизации (Общая характеристика приватизации как основания возникновения права собственности)
- Правоспособность и дееспособность граждан: понятие и содержание (Понятие, содержание, проблемы правового регулирования гражданской правоспособность физических лиц)
- Индустрия спорта в России: современное состояние и перспективы развития (История развития индустрии спорта в России)
- Шрифт в рекламе. Фирменный стиль и рекламное объявление
- НАВИГАЦИЯ ТУРИСТИЧЕСКОГО САЙТА
- Формирование кадровой политики в современной организации