
Методы кодирования данных (Теоретические основы теории кодирования данных)
Содержание:

Введение
Необходимость кодирования информации возникла задолго до появления компьютеров. Речь, азбука и цифры – есть не что иное, как система моделирования мыслей, речевых звуков и числовой информации. В технике потребность кодирования возникла сразу после создания телеграфа, но особенно важной она стала с изобретением компьютеров.
Современный мир немыслим без интенсивного информационного обмена, поэтому год от года количество передаваемой между абонентами информации растёт. В настоящий момент около 70% всего объёма информации проходит через волоконно-оптические линии связи. Это, несомненно, определяет важность как теоретических, так и прикладных исследований, направленных как на совершенствование существующих линий волоконно-оптической связи, так и на разработку новых технологий, необходимых для ещё большего увеличения пропускной способности телекоммуникационных каналов.
Целью курсовой работы является анализ методов кодирования данных.
Достижение поставленной цели предполагает решение следующих задач:
- определить теоретические основы теории кодирования данных;
- рассмотреть прикладные аспекты методов кодирования;
- изучить применение специальных методов кодирования информации при передаче данных по волоконно-оптическим линям связи.
Объектом исследования в курсовой работе являются направления использования кодирования данных.
Предмет исследования – методы кодирования.
Методологической основой исследования являются учебники и учебные пособия по информатике, статьи в периодической печати и Интернет-ресурсы.
Глава 1. Теоретические основы теории кодирования данных
1.1. Основоположники теории кодирования
С необходимостью кодирования данных впервые столкнулись более полутораста лет назад, вскоре после изобретения телеграфа. Каналы были дороги и ненадежны, что сделало актуальной задачу минимизации стоимости и повышения надёжности передачи телеграмм.
Проблема ещё более обострилась в связи с прокладкой трансатлантических кабелей. С 1845 вошли в употребление специальные кодовые книги; с их помощью телеграфисты вручную выполняли «компрессию» сообщений, заменяя распространенные последовательности слов более короткими кодами. Тогда же для проверки правильности передачи стали использовать контроль чётности, метод, который применялся для проверки правильности ввода перфокарт ещё и в компьютерах первых поколений.
Для этого во вводимую колоду последней вкладывали специально подготовленную карту с контрольной суммой. Если устройство ввода было не слишком надежным (или колода - слишком большой), то могла возникнуть ошибка. Чтобы исправить её, процедуру ввода повторяли до тех пор, пока подсчитанная контрольная сумма не совпадала с суммой, сохраненной на карте. Эта схема неудобна, и к тому же пропускает двойные ошибки.
С развитием каналов связи потребовался более эффективный механизм контроля. Первым теоретическое решение проблемы передачи данных по зашумленным каналам предложил Клод Шеннон, основоположник статистической теории информации. Работая в Bell Labs, Шеннон написал работу «Математическая теория передачи сообщений» (1948), где показал, что если пропускная способность канала выше энтропии источника сообщений, то сообщение можно закодировать так, что оно будет передано без излишних задержек. В одной из теорем Шеннон доказал, что при наличии канала с достаточной пропускной способностью сообщение может быть передано с некоторыми временными задержками.
Кроме того, он показал возможность достоверной передачи при наличии шума в канале. Формула C = W log ((P+N)/N), высечена на скромном памятнике Шеннону, установленном в его родном городе в штате Мичиган. Труды Шеннона дали пищу для множества дальнейших исследований в области теории информации, но практического инженерного приложения они не имели.
Переход от теории к практике стал возможен благодаря усилиям Ричарда Хэмминга, коллеги Шеннона по Bell Labs, получившего известность за открытие класса кодов «коды Хэмминга». Существует легенда, что к изобретению своих кодов Хэмминга подтолкнуло неудобство в работе с перфокартами на релейной счетной машине Bell Model V в середине 40-х годов. Ему давали время для работы на машине в выходные дни, когда не было операторов, и ему самому приходилось возиться с вводом. Хэмминг предложил коды, способные корректировать ошибки в каналах связи, в том числе и в магистралях передачи данных в компьютерах, прежде всего между процессором и памятью.
Коды Хэмминга показали, как можно практически реализовать возможности теоремы Шеннона. Хэмминг опубликовал свою статью в 1950, хотя во внутренних отчетах его теория кодирования датируется 1947.
Поэтому некоторые считают, что отцом теории кодирования следует считать Хэмминга, а не Шеннона. Ричард Хэмминг (1915 - 1998) получил степень бакалавра в Чикагском университете в 1937. В 1939 он получил степень магистра в Университете Небраски, а степень доктора по математике – в Университете Иллинойса. В 1945 Хэмминг начал работать в рамках Манхэттенского проекта. В1946 поступил на работу в Bell Telephone Laboratories, где работал с Шенноном. В 1976 получил кафедру в военно-морской аспирантуре в Монтерей в Калифорнии. Труд, сделавший его знаменитым, фундаментальное исследование кодов обнаружения и исправления ошибок, Хэмминг опубликовал в 1950. В 1956 он принимал участие в работе над IBM 650. Его работы заложили основу языка программирования, который позднее эволюционировал в языки программирования высокого уровня.
В знак признания заслуг Хэмминга в области информатики институт IEEE учредил медаль за выдающиеся заслуги в развитии информатики и теории систем, которую назвал его именем. Хэмминг первым предложил «коды с исправлением ошибок» (Error-Correcting Code, ECC).
Современные модификации этих кодов используются во всех системах хранения данных и для обмена между процессором и оперативной памятью. Один из их вариантов, коды Рида-Соломона применяются в компакт-дисках, позволяя воспроизводить записи без скрипов и шумов, вызванных царапинами и пылинками. Существует множество версий кодов, построенных «по мотивам» Хэмминга, они различаются алгоритмами кодирования и количеством проверочных битов.
Особое значение подобные коды приобрели в связи с развитием дальней космической связи с межпланетными станциями. Среди новейших кодов ECC следует назвать коды LDPC (Low-Density Parity-check Code). Вообще-то они известны лет тридцать, но особый интерес к ним обнаружился именно в последние годы, когда стало развиваться телевидение высокой чёткости. Коды LDPC не обладают 100-процентной достоверностью, но вероятность ошибки может быть доведена до желаемой, и при этом с максимальной полнотой используется пропускная способность канала. К ним близки «турбокоды» (Turbo Code), они эффективны при работе с объектами, находящимися в условиях далекого космоса и ограниченной пропускной способности канала.
В историю теории кодирования прочно вписано имя В. А. Котельникова. В 1933 в «Материалах по радиосвязи к I Всесоюзному съезду по вопросам технической реконструкции связи» он опубликовал работу «О пропускной способности «эфира» и «проволоки». Имя Котельникова входит в название одной из важнейших теорем теории кодирования, определяющей условия, при которых переданный сигнал может быть восстановлен без потери информации. Эту теорему называют по-разному, в том числе «теоремой WKS» (аббревиатура WKS взята от Whittaker, Kotelnikov, Shannon). В некоторых источниках используют и Nyquist-Shannon sampling theorem, и Whittaker-Shannon sampling theorem, а в отечественных вузовских учебниках чаще всего встречается просто «теорема Котельникова».
На самом же деле теорема имеет более долгую историю. Ее первую часть в 1897 доказал французский математик Э. Борель. Свой вклад в 1915 внес Э. Уиттекер. В1920 японец К. Огура опубликовал поправки к исследованиям Уиттекера, а в 1928 американец Гарри Найквист уточнил принципы оцифровки и восстановления аналогового сигнала.
1.2. Сущность теории кодирования, ее цели и задачи
Кодирование информации - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки (цифровое кодирование, аналоговое кодирование, таблично-символьное кодирование, числовое кодирование). Процесс преобразования сообщения в комбинацию символов в соответствии с кодом называется кодированием, процесс восстановления сообщения из комбинации символов называется декодированием Информацию необходимо представлять в какой- либо форме, т.е. кодировать.
Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации. Алфавит, с помощью которого представляется информация до преобразования называется первичным; алфавит конечного представления – вторичным.
Код это:
– правило, описывающее соответствие знаков или их сочетаний одного алфавита знакам или их сочетаниям другого алфавита;
- знаки вторичного алфавита, используемые для представления знаков или их сочетаний первичного алфавита.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо её потерь. Примером обратимого кодирования является представление знаков в телеграфном коде и их восстановление после передачи. Примером кодирования необратимого может служить перевод с одного естественного языка на другой – обратный перевод, вообще говоря, не восстанавливает исходного текста. Безусловно, для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применения кода, поэтому в дальнейшем изложении ограничим себя рассмотрением только обратимого кодирования. Таким образом, кодирование предшествует передаче и хранению информации. При этом хранение связано с фиксацией некоторого состояния носителя информации, а передача – с изменением состояния с течением времени (т.е. процессом). Эти состояния или сигналы будем называть элементарными сигналами – именно их совокупность и составляет вторичный алфавит.
Любой код должен обеспечивать однозначное чтение сообщения (надежность), так и, желательно, быть экономным (использовать в среднем поменьше символов на сообщение). Возможность восстановить текст означает, что в языке имеется определенная избыточность, за счет которой мы восстанавливаем отсутствующие элементы по оставшимся. Ясно, что избыточность находится в вероятностях букв и их комбинациях, их знание позволяет подобрать наиболее вероятный ответ. Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. С помощью компьютерных программ можно преобразовывать полученную информацию, в том числе - текстовую. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов. Как правило, все числа в компьютере представляются с помощью нулей и единиц, т.е. словами, компьютеры работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Кодер - программист, специализирующийся на кодировании - написании исходного кода по заданным спецификациям. Кодер - одна из двух компонент кодека (пары кодер – декодер). Декодер - некоторое звено, которое преобразует информацию из внешнего вида в вид, применяемый внутри узла. В программном обеспечении: модуль программы или самостоятельное приложение, которое преобразует файл или информационный поток из внешнего вида в вид, который поддерживает другое программное обеспечение. В процессе преобразования информации из одной формы представления (знаковой системы) в другую осуществляется кодирование. Средством кодирования служит таблица соответствия, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем. В процессе обмена информацией часто приходится производить операции кодирования и декодирования информации.
При вводе знака алфавита в компьютер путем нажатия соответствующей клавиши на клавиатуре выполняется его кодирование, т. е. преобразование в компьютерный код. При выводе знака на экран монитора или принтер происходит обратный процесс - декодирование, когда из компьютерного кода знак преобразуется в графическое изображение. Кодирование информации распадается на этапы:
1) Определение объёма информации, подлежащей кодированию.
2) Классификация и систематизация информации.
3) Выбор системы кодирования и разработка кодовых обозначений.
4) Непосредственное кодирование
1.3. Классификация методов кодирования
Одним из видов кодирования является арифметическое кодирование.
Пусть задано конечное множество A = {a1, a2 … an}, которое называется алфавитом [1].
Элементы алфавита называются буквами. Последовательность букв называется словом. Множество слов в алфавите А обозначается А*. Если слово α = a1, a2 ... ак, то k - длина слова.
Если а = a1, a2 , то a1 называется началом или префиксом слова, а a2 -концом или постфиксом слова.
Алфавитное, или побуквенное, кодирование задается схемой (таблицей кодов),δ:

Приведем следующий пример. Рассмотрим алфавиты А:={0,1,2,3,4,5,6,7,8,9}, B:={0,1} и таблицу кодов δ:
|
0–0 |
5–101 |
Эта схема однозначна, но декодирование не является однозначным, например Fδ (333) = 111111 = = Fδ (77), и, значит, невозможно однозначное декодирование. |
|
1–1 |
6–110 |
|
|
2–10 |
7–111 |
|
|
3–11 |
8–1000 |
|
|
4–100 |
9–1001. |
С другой стороны, таблица кодов δ, известная как двоично-десятичное кодирование, допускает однозначное декодирование.
|
0–0000 |
5–0101 |
|
1–0001 |
6–0110 |
|
2–0010 |
7–0111 |
|
3–0011 |
8–1000 |
|
4–0100 |
9–1001 |
Таким образом, очевидно, что не всякое кодирование дает возможность восстановить исходную информацию.
Введем следующие два понятия. Разделимое кодирование – такое, что любое слово, состоящее из элементарных кодов, единственным образом разлагается на элементарные коды. Очевидно, что двоично-десятичный код является разделимым.
Префиксное кодирование – такое, что элементарный код одной буквы не является префиксом элементарного кода другой буквы. Например, разделимая, но не префиксная схема кодирования может быть представлена следующим образом:
A = {a,b}, B = {0,1}, δ = {a – 0, b – 01}.
Следовательно, свойство быть префиксной является достаточным, но не является необходимым для разделимости кода (хотя префиксная схема всегда является разделимой).
Для получения разделимой схемы алфавитного кодирования необходимо, чтобы длины элементарных кодов удовлетворяли определенному соотношению, известному как неравенство Макмиллана:
Если числа l1 ,l2, …, ln , соответствующие длинам элементарных кодов β1, β2, …, βn , удовлетворяют неравенству:

то существует разделимая схема алфавитного кодирования

Примером является азбука Морзе, которая задается таблицей алфавитного кодирования, где 0 называется точкой, а 1 - тире.
|
A – 01 |
H – 0000 |
O – 111 |
V – 0001 |
|
B – 1000 |
I – 00 |
P – 0110 |
W – 011 |
|
C – 1010 |
J – 0111 |
Q – 1101 |
X – 1001 |
|
D – 100 |
K – 101 |
R – 010 |
Y – 1011 |
|
E – 0 |
L – 0100 |
S – 000 |
Z – 1100 |
|
F – 0010 |
M – 11 |
T – 1 |
|
|
G – 110 |
N – 10 |
U – 001 |
Проверим выполнение неравенства Макмиллана для азбуки Морзе:
4 · (1/4) + 12 · (1/16) + 8 · (1/8) + 2 · (1/2) = 3 + 6/8 > 1.
Эта схема кодирования не является разделимой, так как неравенство Макмиллана для нее не выполнено. Заметим, что в азбуке Морзе имеются дополнительные элементы - паузы между буквами и словами, что все же позволяет разделить текст для декодирования. Манчестерское кодирование
Рассмотрим асинхронное и синхронное кодирование. Для правильного распознавания позиций символов в передаваемом сообщении получатель должен знать границы передаваемых элементов сообщения. Для этого необходима синхронизация передатчика и приемника. Использование специального дополнительного канала для сигналов синхронизации слишком дорого, поэтому в современных средствах передачи данных используют другие способы синхронизации.
В асинхронном режиме применяют коды, в которых явно выделены границы каждого символа (байта) специальными стартовым и стоповым символами. Подобные побайтно выделенные коды называют байт-ориентированными, а способ передачи – байтовой синхронизацией. Однако при использовании асинхронного способа кодирования значительно увеличивается объем данных, не относящихся собственно к сообщению.
В синхронном режиме синхронизм поддерживается во время передачи всего информационного блока без обрамления каждого байта. Такие коды называют бит-ориентированными. Для входа в синхронизм нужно обозначать лишь границы всего передаваемого блока информации с помощью специальных начальной и конечной комбинаций байтов (обычно это двухбайтовые комбинации). В этом случае синхронизация называется блочной (фреймовой).
Асинхронные методы передачи данных представляют собой наиболее старый способ связи. Они оперируют не с фреймами, а с отдельными символами, которые представлены байтами со стартстоповыми символами (рис.1).

Рис.1. Асинхронная передача на уровне байтов
При использовании асинхронных методов передачи применяются стандартные наборы символов, например широко известная кодировка ASCII (American Standard Code for Information Interchange), так как первые 32 кода этого набора являются специальными, которые не отображаются на дисплее или принтере, то они могут использоваться для управления режимом обмена данными (рис.2). В самих пользовательских данных, которые представляют собой буквы, цифры, а также такие знаки, как @, #, $ и подобные, специальные символы не встречаются, так что проблема их отделения от пользовательских данных решается достаточно тривиально.
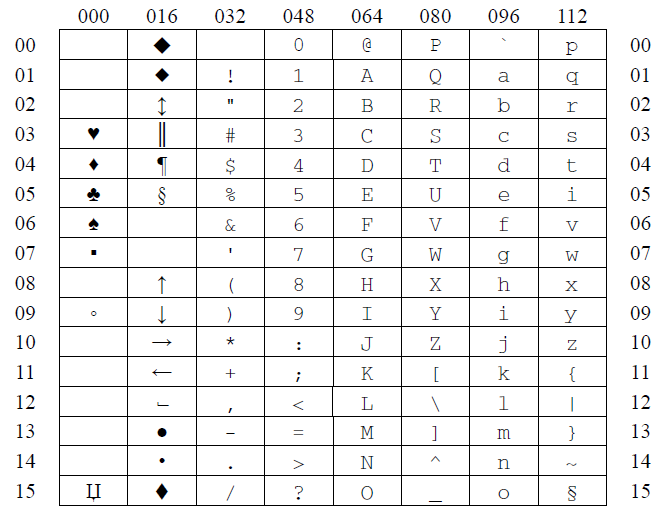
Рис.2. Код ASCII (American Standard Code for Information Interchange)
В синхронных методах передачи данных между пересылаемыми символами (байтами) нет стартовых и стоповых сигналов, поэтому отдельные символы в этих случаях пересылать нельзя. Все обмены данными осуществляются фреймами (кадрами), которые имеют в общем случае заголовок, поле данных и концевик. Все биты кадра передаются непрерывным синхронным потоком, что значительно ускоряет передачу данных. Пример структуры кадра приведен на рис.3.
|
Синхробиты |
Служебная информация |
Данные |
Контрольная сумма |
Рис.3. Структура кадра при использовании синхронных методов передачи
Так как байты в кадре не отделяются друг от друга служебными символами, то одной из первых задач приемника является распознавание границы байтов. Затем приемник должен найти начало и конец кадра, а также определить границы каждого поля кадра – адреса назначения, адреса источника, других служебных полей заголовка, поля данных и контрольной суммы, если она имеется.
Современные способы передачи данных в телекоммуникационных сетях используют два основных метода синхронизации:
- символьно-ориентированный (байт-ориентированный);
- бит-ориентированный.
Главное различие между ними заключается в методе синхронизации символов и кадров.
Глава 2. Прикладные аспекты методов кодирования
2.1. Применение специальных методов кодирования информации при передаче данных по волоконно-оптическим линям связи
Специфика природы сигнала в волоконном световоде начинает проявляться на скоростях передачи данных порядка 10 Гбит/с в одном частотном канале. В этом случае на передачу данных начинают оказывать значительное воздействие так называемые нелинейные эффекты. Их отличительной особенностью является то, что сила их воздействия увеличивается с ростом мощности сигнала, что отличает их от других, «линейных», эффектов. В информационном плане канальные нелинейности проявляются зависимостью количества ошибок при передаче информации от вида самой информации – так называемым паттерн-эффектом (patterning effect). В этом случае в канале наблюдается неравномерность статистики ошибок по элементарным битовым последовательностям – паттернам.
Такой характер искажений сигнала позволяет в качестве средств кодирования использовать не только корректирующие коды (forward error correction, FEC-коды), но также и коды с ограничениями (constrained codes), направленные на снижение в сообщении количества наиболее подверженных ошибкам паттернов. Данный вид кодов было предложено применять в оптике. И хотя набор паттернов, подлежащих подавлению, варьируется в зависимости от конкретной статистики ошибок, в большинстве случаев в бинарных каналах максимальную вероятность ошибки имеют паттерны 101 и 010. Ниже будет рассмотрен более общий, адаптивный подход, учитывающий сложную статистику ошибок; также будет проведён анализ того, при каких условиях использование предложенного кода улучшает качество работы телекоммуникационной системы.
Адаптивным блочным кодом называется ограниченный код, удаляющий из сообщения паттерны, наиболее подверженные возникновению в них ошибок во время передачи по каналу с паттерн-эффектом. Набор паттернов определяется исходя из статистики ошибок в канале связи.
Для подавления паттернинга в этом случае определим для каждого возможного двоичного кодового слова длины n величину:
где Ti – элементарные паттерны, из которых состоит данное кодовое слово.
Например кодовое слово 0110010 состоит из элементарных триплетов 011, 110, 100, 001 и 010. Данная величина фактически является вероятностью того, что внутренние биты кодового слова будут переданы без ошибок. Такая величина определяется для каждого кодового слова, количество которых равно, очевидно, 2n. Получается совокупность пар (i; Pne(i)), которая упорядочивается в порядке убывания величины Pne(i). Такой подход позволяет получить кодовую таблицу W, первые элементы которой являются наиболее пригодными кодовыми словами для передачи по линии, поскольку обладают максимальной вероятностью безошибочной передачи.
Перед тем как начать кодирование, определяется, код с какой кодовой скоростью m/n необходимо получить. В данном случае m – количество битов исходного сообщения, соответствующих одному кодовому слову длины n в закодированном сообщении. Далее будем обозначать за A(m,n) адаптивный код со скоростью m/n. Чем ниже кодовая скорость (и, соответственно, больше кодовая избыточность), тем меньше кодовых слов из таблицы W будет задействовано в кодировании а, значит, будут задействованы только самые надёжные кодовые слова, порождающие минимум ошибок при их трансмиссии по оптоволоконному каналу связи. Кодирование ведётся путём поиска по таблице (table lookup), в результате чего из исходных кодовых слов размера m получаются кодовые слова, каждое из которых лежит среди первых 2m элементов таблицы W.
Декодируется сообщение путём поиска по обратной таблице W-1, ставящей в соответствие кодовому слову его индекс в «прямой» таблице W.
Код был применён к результатам моделирования линии в 5 каналов каждый по 40 Гбит/с WDM RZ-OOK SMF/DCF с гибридным усилением. Статистика ошибок в сигнале после прохождения им 4500 км по линии имеет вид, показанный гистограммой на рис.4.
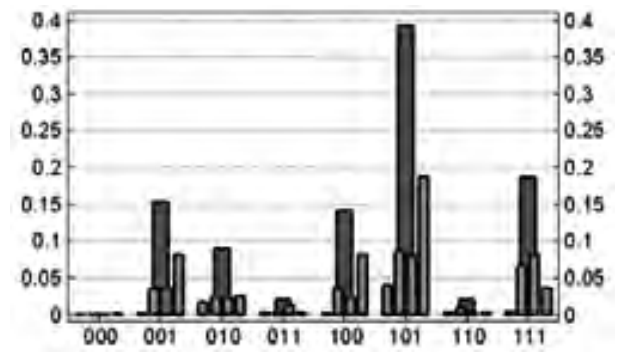
Рис.4. Гистограмма статистики ошибок
Красные столбцы представляют собой триплетную частоту ошибок, а голубые – частоту ошибок по квинтуплетам. Например, голубые столбцы, окружающие столбец 101, соответствуют квинтуплетам 01010, 01011, 11010, 11011, если их просматривать слева направо.
В ходе эксперимента были построены 16- и 24-битные адаптивные коды, результаты для расстояния в 3400 км и в 6400 км приведены на рис.5.
Начальные уровни значений частоты ошибок BER=10-2 и BER=10-1 соответственно могут быть уменьшены до 10-3, что показывает эффективность использованного метода кодирования.
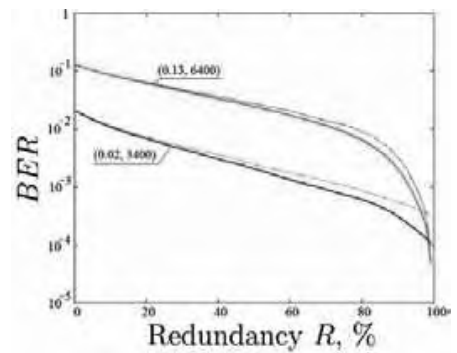
Рис.5. Уменьшение частоты ошибок в зависимости от избыточности кода
Особо стоит отметить специальные свойства ограниченных кодов, по сравнению с корректирующими кодами, действующими в одних и тех же условиях. Обозначим за BER’ частоту ошибок после декодирования сигнала, а за BERL – максимальную частоту ошибок в канале, при которой корректирующий код способен удовлетворительно работать (выше этой частоты коррекция ошибок не способна их уменьшить, вне зависимости от избыточности кода). Последнее значение можно найти экспериментально для всякого известного корректирующего кода; как правило, оно заключено между 510-2 и 10-1. Хотя некоторые корректирующие коды способны немного превзойти величину 10-1, в силу своей сложности они не могут быть использованы в быстрых оптических линиях. Далее полагаем, что при BER<BERL корректирующая схема работает идеально и число ошибок на выходе схемы равно нулю, а при частоте ошибок больше предельного значения корректирующий код не уменьшает количество ошибок. Это соответствует действительности, так как качество работы корректирующих кодов носит пороговый характер.
Именно на границе возможностей корректирующего кода применение ограниченных кодов является наиболее эффективным, поскольку они, хотя и не способны скорректировать ошибки, могут уменьшить их общее количество прежде, чем сообщение будет декодировано FEC-кодом. Уменьшение ошибок, как было показано выше, связано с наличием в канале неравномерной статистики передачи информации, обусловленной наличием внутриканальных нелинейностей. В рассмотренном случае с помощью ограниченного кода с избыточностью 5% можно уменьшить частоту ошибок на 30%, как показано на рис.5. Учитывая, что методы сочетания ограниченных кодов с корректирующими хорошо разработаны [4], объединённый код сможет сделать работу корректирующего кода более эффективной.
2.2. Применение алгоритма дельта-кодирования при обработке радиолокационных данных
При испытании бортовых радиолокационных комплексов специальной контрольно - записывающей аппаратурой (КЗА) выполняется регистрация реализаций эхо-сигнала и результатов его обработки в трактах РЛС для последующего пост-полетного анализа с целью оценки эффективности работы комплекса [5]. Объем регистрируемых данных составляет несколько десятком Мбайт на каждую секунду работы комплекса, что предъявляет очень высокие требования к производительности КЗА. Естественно стремление сжимать регистрируемые данные «на лету» и без потерь [4]. Однако предложенные методы сжатие требуют значительных аппаратурных и временных затрат. Авторами ставится задача предложить алгоритм сжатия, обладающий простатой аппаратной реализации, что особо важно для бортовой системы.
Исходные данные получены в результате регистрации потоков данных контрольно-записывающей аппаратурой импульсно-доплеровской радиолокационной станции. Зарегистрированная информация, формируемая радиолокационной станцией, разбита на кадры. Кадр представляет совокупность m строк дальности, каждая строка содержит d элементов дальности (рис.6).
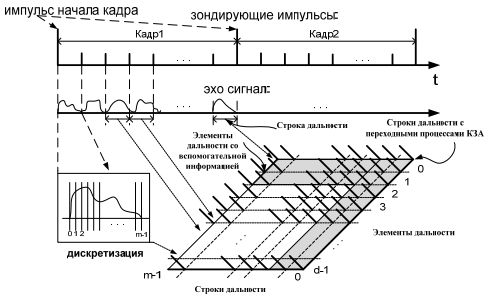
Рис.6. Обработка входного потока данных
Файл с исходными данными содержит в квадратурном представлении отсчеты на каждом элементе дальности (рис.7). Отсчет представляет собой пару значений (синус и косинус) размерностью по 2 байта каждое. Двадцать первых отсчетов в начале каждой дальности представляют собой вспомогательную информацию (рис.7), эти отсчеты будут исключены при выполнении сжатия сигнала.
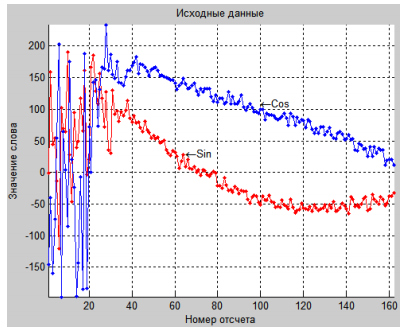
Рис. 7. Визуализация исходных данных
После получения отсчетов из исходного файла выполнили визуализацию сигнала на первой дальности (рис.7). В дальнейшем все рисунки будут представлены для этой дальности. Далее была выполнена фильтрация сигнала с помощью средств MATLAB. Был использован фильтр Баттерворта 5-го порядка с частотой среза 0,05. Эти параметры были вы- браны путем подбора. Была использована функция пакета Signal Processing Toolbox filtfilt [2]. Эта функция позволяет компенсировать фазовый сдвиг, вносимый при обычной фильтрации. Осуществляется это путем двунаправленной обработки сигнала. Этот метод фильтрации предусмотрен только в рамках проводимого эксперимента, так как аппаратно двунаправленную обработку сигнала реализовать нельзя. Аппаратная фильтрация в режиме реального времени – тема для дальнейших разработок. Сигнал после фильтрации представлен на рис.8.
Разница между исходным сигналом и гладкой составляющей – шум, который был выделен для хранения и последующего восстановления исходного сигнала.
После фильтрации сигнала к гладкой составляющей был применен алгоритм дельта-кодирования [6].
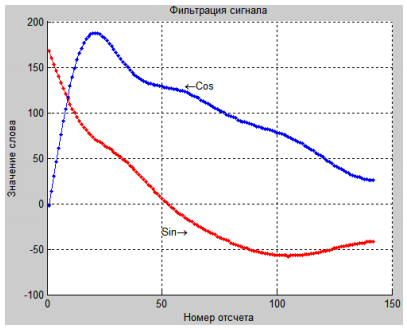
Рис. 8. Фильтрация сигнала
Первый отсчет хранится неизменным в файле с шумом. Это делается для уменьшения алфавита при последующем применении алгоритма арифметического кодирования Хаффмана. Все дальнейшие значения представляются в виде разницы между предыдущим и данным отсчетом (рис.9).
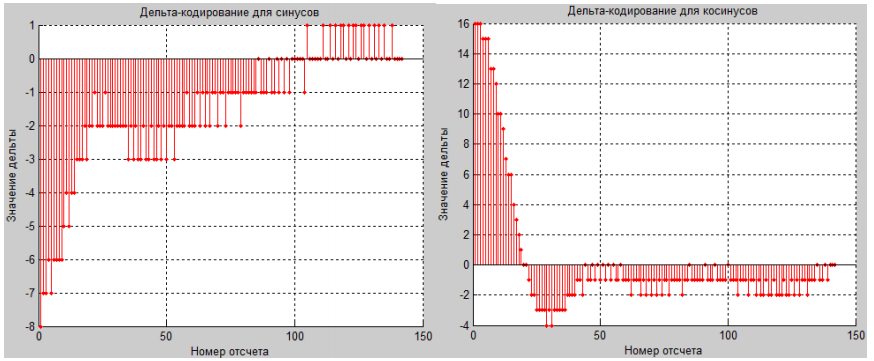
Рис. 9. Результаты применения алгоритма дельта-кодирования
Разница была взята по модулю. Использование абсолютных значений позволит в дальнейшем сократить алфавит для арифметического кодирования. В результате существенно снизилась размерность данных: с 2 байт до 6 бит.
Было составлено два алфавита: для синусов, который содержит 26 символов, и для косинусов, который содержит 43 символа. Для составления алфавитов в матрице с данными, полученными в результате применения дельта-кодирования, производится поиск уникальных значений, которые заносятся в массив с последующим подсчетом количества повторений каждого из этих значений.
Затем, используя эти данные, был построен словарь Хаффмана [3], который и использовался при сжатии сигнала, с помощью функции huffmandict.
Само кодирование выполняется средствами функции huffmanenco, входными параметрами которой являются словарь Хаффмана и сигнал, который требуется закодировать. В начале выполнения работы планировалось получить коэффициент, приблизительно равный 4, после применения к файлу с данными алгоритмов дельта-кодирования и арифметического сжатия. В ходе выполнения работы были получены следующие результаты:
1. Эффективность алгоритма дельта-кодирования определяется коэффициентом сжатия, равным 2,8. Это значение получено из отношения размера несжатого файла с исходным зашумленным сигналом к суммарному размеру файлов, полученных в результате применения этого алгоритма.
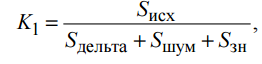
где Sисх – размер исходного файла,
Sдельта – размер закодированного файла,
Sшум –размер файла с шумовой компонентой,
Sзн –размер файла с матрицами знаков,
K1 – коэффициент сжатия после дельта-кодирования.
2. Чтобы оценить эффективность алгоритма арифметического кодирования, было вычислено отношение размера файлов, полученных на предыдущем этапе, к суммарному размеру файлов, полученных в результате сжатия методом Хаффмана. Коэффициент сжатия в этом случае составил 1,3.
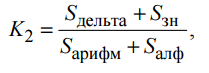
где Sарифм –размер файла после применения арифметического кода,
Sалф –размер файла со словарем Хаффмана,
K2 – коэффициент сжатия после применения арифметического кодирования.
3. Также в процессе выполнения работы была произведена попытка сжатия шумовой компоненты методом арифметического кодирования без предварительной обработки дельта-кодированием. Коэффициент сжатия для шума составил 0,8, то есть на выходе получили файл большего размера, чем исходный. Отсюда можно сделать вывод, что применение алгоритма Хаффмана для шумовой компоненты нецелесообразно.
4. Суммарный коэффициент сжатия, показывающий отношение размера исходного несжатого файла к размеру набора выходных файлов, составил 3,6. Этот коэффициент немного меньше ожидаемого, что объясняется потребностью хранения дополнительной информации. Однако он является приемлемым.
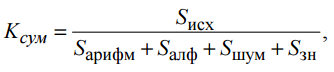
где Kсум – итоговый коэффициент сжатия.
Данный метод сжатия позволяет восстановить исходный сигнал без потерь, однако коэффициент сжатия снижается за счет хранения вспомогательной информации для восстановления сигнала. В дальнейшем планируется протестировать метод сжатия, рассмотренный в этой работе, на кадрах другой структуры и содержания для выявления его универсальности и эффективности.
Заключение
Все данные и команды в ЭВМ циркулируют в виде двоичных чисел. Информацию можно кодировать числами в различных системах счисления. Особая значимость двоичной системы счисления в информатике определяется тем, что с технической точки зрения разработчикам компьютерной техники такое представление информации казалось самым простым. Требовалось различать только два устойчивых состояния устройства: включено и выключено. Достаточно сложно создать устройство, которое могло бы обеспечить десять устойчивых состояний, да еще и быстрый переход из одного в другое. Поэтому вся сложная начинка микропроцессора сводится к поддержке двух легкоразличимых состояний: высокий сигнал – 1, низкий сигнал – 0.
Наиболее распространены две системы кодирования – ASCII и Unicode. ASCII (American Standart Information Interchange) была создана в 1963 г. В своей первоначальной версии это система семибитного кодирования. В следующей версии фирма IBM перешла на 8-битную кодировку символов. В ней первые 128 кодов отданы под буквы английского алфавита, цифры и некоторые специальные символы.
Остальные коды отданы под буквы некоторых европейских языков, греческие буквы, математические символы и символы псевдографики. Всего расширенный код ASCII позволяет кодировать 256 различных символов. Из сказанного выше следует, что 8-битная кодировка недостаточна для кодирования всех символов, которые хотелось бы иметь в расширенном алфавите.
В системе Unix используется 16-битная кодировка символов – Unicode. Unicode – 16-битное расширение 8-битной кодировки ASCII. Она допускает 65 536 кодовых комбинаций и практически включает все алфавиты мира.
Список литературы
1. Гагарина Л.Г. Информационные технологии: Учебное пособие / Л.Г. Гагарина, Я.О. Теплова, Е.Л. Румянцева и др.; Под ред. Л.Г. Гагариной - М.: ИД ФОРУМ: НИЦ ИНФРА-М, 2015. - 320 с.
2. Гвоздева В.А. Базовые и прикладные информационные технологии: Учебник / Гвоздева В. А. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2015. - 384 с.
3. Гвоздева В.А. Информатика, автоматизированные информационные технологии и системы: Учебник / В.А. Гвоздева. - М.: ИД ФОРУМ: ИНФРА-М, 2014. - 544 с.
4. Голицына О.Л. Информационные технологии: Учебник / О.Л. Голицына, Н.В. Максимов, Т.Л. Партыка, И.И. Попов. - 2-e изд., перераб. и доп. - М.: Форум: ИНФРА-М, 2017. - 608 с.
5. Гришин В.Н. Информационные технологии в профессиональной деятельности: Учебник / В.Н. Гришин, Е.Е. Панфилова. - М.: ИД ФОРУМ: НИЦ ИНФРА-М, 2017. - 416 с.
6. Киселев, Г.М. Информационные технологии: Учебник для бакалавров / Г. М. Киселев. - М.: Дашков и К, 2017. - 308 с.
7. Максимов Н.В. Современные информационные технологии: Учебное пособие / Н.В. Максимов, Т.Л. Партыка, И.И. Попов. - М.: Форум, 2017. - 512 с.
8. Румянцева Е.Л. Информационные технологии: Учебное пособие / Е.Л. Румянцева, В.В. Слюсарь; Под ред. Л.Г. Гагариной. - М.: ИД ФОРУМ: НИЦ Инфра-М, 2017. - 256 с.
9. Синаторов С.В. Информационные технологии: Учебное пособие / С.В. Синаторов. - М.: Альфа-М: ИНФРА-М, 2014. - 336 с.

- Хранение данных на разных языках программирования
- Подхода к управлению организацией ООО «Сальва»
- Международные стандарты гостиничного обслуживания (Понятие стандартов качества обслуживания)
- Управление поведением в конфликтных ситуациях (Основные причины конфликтов в современных организациях)
- Планирование финансового результата деятельности организации с учетом эффекта операционного левериджа
- Защита права собственности
- Алгоритмизация как обязательный этап разработки программы
- Ценообразование на услуги фитнес-клубов
- Анализ эффективности формирования портфеля ценных бумаг коммерческого банка ПАО «Московский Индустриальный банк»
- Налоговая система РФ и проблемы еe совершенствования (Сущность налоговой системы государства)
- Применение процессного подхода для оптимизации бизнес-процессов (Теоретические основы применения процессного подхода для оптимизации бизнес-процессов)
- Защита внутренней сети и сотрудников компании от атак