
"Методы кодирования данных. Пример"
Содержание:

Введение
Для автоматизации работы с данными, относящимися к различным типам очень важно унифицировать их форму представления - для этого обычно используется приём кодирования, т.е. выражение данных одного типа через данные другого типа. Естественные человеческие языки - системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки - системы кодирования компонентов языка с помощью графических символов.
Своя системы существует и в вычислительной технике - она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называют двоичными цифрами, по-английски - binary digit или сокращённо bit (бит). Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, чёрное или белое, истина или ложь и т.п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия. Тремя битами можно закодировать восемь различных значений.
Цель данной работы – ознакомиться с понятием кодирования и изучить методы кодирования данных.
С учетом поставленной цели будут решены следующие задачи:
- рассмотрены теоретические основы кодирования: дано понятие, классификация;
- проанализированы методы кодирования данных и примеры их применения.
Курсовая работа состоит из введения, двух глав, заключения и библиографии.
Глава 1 Теоретические основы кодирования данных
1.1 Понятие кодирования данных
В ЭВМ применяется двоичная система счисления, т.е. все числа в компьютере представляются с помощью нулей и единиц, поэтому компьютер может обрабатывать только информацию, представленную в цифровой форме.
Для преобразования числовой, текстовой, графической, звуковой информации в цифровую необходимо применить кодирование.
Кодирование – это преобразование данных одного типа через данные другого типа. В ЭВМ применяется система двоичного кодирования, основанная на представлении данных последовательностью двух знаков: 1 и 0, которые называются двоичными цифрами (binary digit – сокращенно bit)[1].
Целые числа кодируются двоичным кодом довольно просто (путем деления числа на два). Для кодирования нечисловой информации используется следующий алгоритм: все возможные значения кодируемой информации нумеруются и эти номера кодируются с помощью двоичного кода[2].
Кодирование чисел
Есть два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Кодирование целых чисел производится через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак "плюс", единицей – "минус").
Кодирование координат
Закодировать можно не только числа, но и другую информацию, например, о том, где находится некоторый объект. Величины, определяющие положение объекта в пространстве, называются координатами. В любой системе координат есть начало отсчёта, единица измерения, масштаб, направление отсчёта, или оси координат. Примеры систем координат – декартовы координаты, полярная система координат, шахматы, географические координаты.
Кодирование текста
Для представления текстовой информации используется таблица нумерации символов или таблица кодировки символов, в которой каждому символу соответствует целое число (порядковый номер). Восемь двоичных разрядов могут закодировать 256 различных символов.
Существующий стандарт ASCII (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией; 8 – разрядная система кодирования) содержит две таблицы кодирования – базовую и расширенную. Первая таблица содержит 128 основных символов, в ней размещены коды символов английского алфавита, а во второй таблице кодирования содержатся 128 расширенных символов.
Так как в этот стандарт не входят символы национальных алфавитов других стран, то в каждой стране 128 кодов расширенных символов заменяются символами национального алфавита. В настоящее время существует множество таблиц кодировки символов, в которых 128 кодов расширенных символов заменены символами национального алфавита.
Так, например, кодировка символов русского языка Widows – 1251 используется для компьютеров, работающих под ОС Windows. Другая кодировка для русского языка – это КОИ – 8, которая также широко используется в компьютерных сетях и российском секторе Интернет.
В настоящее время существует универсальная система UNICODE, основанная на 16 – разрядном кодировании символов. Эта 16 – разрядная система обеспечивает универсальные коды для 65536 различных символов, т.е. в этой таблице могут разместиться символы языков большинства стран мира.
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие группы – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. picture element). Код пикселя содержит информации о его цвете.
Для описания черно-белых изображений используются оттенки серого цвета, то есть при кодировании учитывается только яркость. Она описывается одним числом, поэтому для кодирования одного пикселя требуется от 1 до 8 бит: чёрный цвет – 0, белый цвет – N = 2k-l, где k – число разрядов, которые отводятся для кодирования цвета. Например, при длине ячейки в 8 бит это 256-1 = 255. Человеческий глаз в состоянии различить от 100 до 200 оттенков серого цвета, поэтому восьми разрядов для этого вполне хватает.
Цветные изображения воспринимаются нами как сумма трёх основных цветов – красного, зелёного и синего. Например, сиреневый = красный + синий; жёлтый = красный + зелёный; оранжевый = красный + зелёный, но в другой пропорции. Поэтому достаточно закодировать цвет тремя числами – яркостью его красной, зелёной и синей составляющих. Этот способ кодирования называется RGB (Red – Green – Blue). Его используют в устройствах, способных излучать свет (мониторы). При рисовании на бумаге действуют другие правила, так как краски сами по себе не испускают свет, а только поглощают некоторые цвета спектра. Если смешать красную и зелёную краски, то получится коричневый, а не жёлтый цвет. Поэтому при печати цветных изображений используют метод CMY (Cyan – Magenta – Yellow) – голубой, сиреневый, жёлтый цвета. При таком кодировании красный = сиреневый + жёлтый; зелёный = голубой + жёлтый.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент такого изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пиксели которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
Кодирование черно-белых изображений
Теперь - о цвете: как же его закодировать? Если говорить о чернобелой (монохроматической) гамме, то характеристика цвета сводится к яркости. Она описывается одним числом. Для кодирования яркости пикселов отводятся ячейки фиксированного размера, чаще всего от 1 до 8 бит. Черный цвет кодируется нулем, а белый - максимальным числом N, которое может быть записано в ячейку. Для одноразрядной ячейки N=1, для 8-разрядной - N=255. Для практического применения 8-разрядных ячеек вполне достаточно, потому что как раз не более 200 оттенков серого цвета способен различить человеческий глаз. Если же N=1, то оттенки серого цвета при достаточно маленьких размерах пикселов нетрудно имитировать. Здесь можно использовать частоту чередования черных и белых пикселов. Например, серый цвет можно получить, если из каждых двух соседних пикселов сделаем один белый, а другой черный. Глазу будет казаться, что эта часть картинки имеет серый цвет. Если количество черных пикселей в таком чередовании уменьшить, то получится серый цвет более светлого оттенка:
Кодирование цветных изображений
С цветными изображениями дело обстоит сложнее. Человеческий глаз различает огромное количество оттенков разных цветов. Здесь кодирование осуществляется так. Известно, что каждый цвет - это сумма 3-х основных цветов: красного, зеленого и синего. Поэтому цвет пикселя можно закодировать тремя числами: яркостью красной, зеленой и синей составляющих. Этот способ называется RGB (red - красный, green - зеленый, blue - синий).
При рисовании на бумаге действуют другие законы (краски не испускают света, а только поглощают некоторые цвета из падающего на них света). Если смешать красную и зеленую краски, то получится не желтый цвет, а коричневый. Поэтому на печатающих устройствах обычно используется в качестве основных голубой, сиреневый и желтый цвета (такой метод кодировки называется CМY). Эти способы просты в реализации, но неудобны работе. Поэтому все чаще используется другая схема кодирования: цветовой тон / насыщенность / яркость (HSV). При этом цвет каждого пикселя кодируется тремя числами, но их значения уже не те, что в методах кодирования RGB и CMY.
Кодирование звукового сигнала
Звук - это колебания воздуха, амплитуда которых непрерывно изменяется со временем. Звук - это непрерывный сигнал, для кодирования необходимо превратить в последовательность из нулей и единиц. Как это сделать? Звук через микрофон можно превратить в колебания электрического тока. Если измерять амплитуду колебаний через равные промежутки времени (на практике - несколько десятков тысяч раз в секунду), каждое измерение сделать с ограниченной точностью и записать в двоичном виде, то мы осуществим так называемую дискретизацию непрерывного сигнала, каковым является звук.
Для этого существует устройство, которое называется аналого-цифровым преобразователем (АЦП). АЦП измеряет электрическое напряжение в определенном диапазоне и выдает ответ в виде многоразрядного двоичного числа. Например, 8-разрядный АЦП преобразует напряжения в диапазоне [-500мВ, 500мВ] в 8-битовые двоичные числа в диапазоне [-128, 127].
Воспроизведение закодированного таким образом звука осуществляется при помощи цифро-аналогового преобразователя (ЦАП). Двоичные числа, кодирующие звук, подаются на вход с точно такой частотой, как и при дискретизации, и ЦАП преобразует их электрические напряжения обратно тому, как это делал АЦП. Ступенчатый сигнал, выходящий их ЦАП, сглаживается при прохождении через аналоговый фильтр, а затем преобразуется в звук с помощью усилителя и динамика.
При работе со стереозвуком процесс дискретизации производится для левого и правого каналов отдельно и независимо. На качество воспроизведения закодированного звука влияют два параметра: частота дискретизации и ее разрешение - размер ячейки, отводимый под запись амплитуды. Например, при записи на СD-диски используются 16-разрядные значения, а частота дискретизации около 44 КГц. Отсюда превосходное качество звучания речи и музыки. Но во многих случаях качество CD не требуется: для записи и воспроизведения звуков речи достаточно частоты 8 КГц. Основным достоинством работы компьютера со звуком является то, что закодированный звук можно не только хранить, но и обрабатывать его. Чем сложнее обработка, тем, естественно, сложнее алгоритм обработки. Простой же алгоритм, например, нарастания звука, сделать очень нетрудно:
алг нарастание_звука
арг | в i запис. звук с частотой дискр. 22016 КГц
рез | в o запис. этот звук, плавно нараст. в 1-ю сек.
нач цел i,x
| начать чтение("in.xxx"); начать запись("out.xxx")
| i:=1
| нц пока не конец файла
| | ввод x
| | если i<22016
| | | то x:=x+i/22016
| | все
| | вывод x; i:=i+1
| кц
| кончить запись; кончить чтение
кон
При работе этого алгоритма первые 22016 значений звука умножаются на множитель i/22016, который в течение 1-й секунды возрастает от 0 до 1.
Кодирование музыкального звука
Существует, по крайней мере, два способа кодирования музыкального звука: 1-й - кодирование по описанной выше схеме (так как музыка - это звук, т.е. может кодироваться как и любой другой звук). Но этот способ неудобен по многим веским причинам: достаточно сложно, например, изменить тембр звука или тональность мелодии.
К счастью, человечество уже давно придумало способ компактной записи музыкальных произведений - нотную запись. Она-то и положена в основу второго способа кодирования музыки.
Такой объект, как музыкальный звук, имеет 2 свойства:
1)высота звучания. Это свойство кодируется положением нотного значка на нотных линейках. В физическом смысле это - частота колебаний звука.
2)долгота (длительность) звучания. Она кодируется видом ноты (пустая/закрашенная, без штиля/со штилем, без флажка/ с флажками). Это временная характеристика музыкального звука.
Кроме того, есть дополнительные коды: нотный ключ, указывающий, что обозначают ноты на линейках, дополнительные линейки снизу и сверху и т.д.
В некоторых случаях, например, при пении под гитару для записи аккомпанимента используется система аккордов-созвучий. Партия записывается в строку последовательными названиями аккордов, например: Аm Dm E7 Am и т.д.
В силу особенностей человеческого восприятия те звуки, частоты которых отличаются в два раза, кажутся "похожими", как бы повторяют друг друга, но выше или ниже. Отсюда - деление музыкальных звуков по высоте (то есть по частоте) на октавы: интервал от 262 Гц до 2*262 Гц=524 Гц - это 12 нот 1-й октавы; если удвоить частоты еще раз, то получатся ноты 2-й октавы. В компьютерных программах для простых мелодий используется такой способ кодирования: указываются частота и длительность каждого звука мелодии: нота(цел f,t), где f - частота в Гц, а t - сотые доли секунды. Для паузы, например, используется частота f=0: нота(0,5) - пауза в 0.05 доли секунды.
В некоторых других языках программирования команда "исполнить музыкальный звук" записывается проще: латинская буква, соответствующая данной ноте (ноты от "ля" малой октавы до "соль" 1-й октавы обозначены латинскими буквами от "А" до "G") и длительность, записанная соответствующим числом (1 - целая, 2 - половинная, 4 - четверть, 8 - восьмая и т.д.). Также перед буквой ставится номер октавы, например, четвертная нота "ми" 1-й октавы будет записана так: 1Е4.
Если посмотреть на нотную запись музыкального произведения с точки зрения исполняющего это произведение, то можно представить ее как последовательность команд этому исполнителю: нажать такую-то клавишу с определенной силой и держать ее столько-то времени, нажать одновременно несколько клавиш, отпустить удерживаемую клавишу, и т.д. Выписав эти всевозможные команды, получим систему команд воображаемого исполнителя Музыкант. Аналогичные системы команд можно выписать и для других музыкальных инструментов.
В начале 80-х годов появились электронные музыкальные инструменты - синтезаторы, способные воспроизводить звуки многих существующих и несуществующих инструментов. В 1983 году производители синтезаторов и компьютеров договорились о системе команд универсального синтезатора, об электрических сигналах, с помощью которых будут подаваться эти команды и даже о разъемах и кабелях, соединяющих синтезатор с компьютером. Это соглашение назвали стандарт MIDI (англ. Musical Instrument Digital Interface - описание цифрового музыкального инструмента). Этот стандарт удобно кодирует музыку. Запись музыкального произведения в формате MIDI - это программа игры на воображаемом музыкальном инструменте - синтезаторе. Состоит она из последовательности закодированных сообщений, разделенных закодированными паузами. Примеры таких сообщений:
- команды синтезатору (нажать или отпустить клавишу, изменить тембр звучания);
- описание параметров воспроизведения (значение силы давления на клавишу и др.);
- управляющее сообщение (например, включение полифонического режима.
Но при таком кодировании нельзя записать вокальное произведение, так как звуки, издаваемые певцом или хором, не входят в систему команд этого исполнителя. Но менять инструмент, тональность или вид синтезатора очень легко.
Кодирование фильмов
Кодирование движущихся изображений благодаря тому, что человеческий глаз несовершенен, представляется не очень сложной задачей. Для создания иллюзии движения достаточно показывать быстро сменяющиеся картинки, на которых изображены последовательные стадии движения. На этом принципе основаны кино и телевидение, а также компьютерное кодирование фильмов.
Так как принципы кодирования отдельных картинок уже известны (см. кодирование графических изображений), то можно закодировать и последовательность таких кадров.
Для "озвучивания" фильма звук записывается отдельно от изображения (как в кино).
В заголовке компьютерного фильма содержится описание следующих параметров:
- размер кадра в пикселях и количество используемых цветов;
- параметры звука (частота и разрешение);
- способ записи звука (отдельный звук для каждого кадра или непрерывная запись для всего фильма).
После заголовка идет последовательность закодированных картинок которые соответствуют кадрам фильма, и закодированных звуковых фрагментов.
Коды можно классифицировать по различным признакам[3]:
1. По основанию (количеству символов в алфавите): бинарные (двоичные m=2) и не бинарные (m № 2).
2. По длине кодовых комбинаций (слов):
равномерные - если все кодовые комбинации имеют одинаковую длину;
неравномерные - если длина кодовой комбинации не постоянна.
3. По способу передачи:
последовательные и параллельные;
блочные - данные сначала помещаются в буфер, а потом передаются в канал и бинарные непрерывные.
4. По помехоустойчивости:
простые (примитивные, полные) - для передачи информации используют все возможные кодовые комбинации (без избыточности);
корректирующие (помехозащищенные) - для передачи сообщений используют не все, а только часть (разрешенных) кодовых комбинаций.
5. В зависимости от назначения и применения условно можно выделить следующие типы кодов:
Внутренние коды - это коды, используемые внутри устройств. Это машинные коды, а также коды, базирующиеся на использовании позиционных систем счисления (двоичный, десятичный, двоично-десятичный, восьмеричный, шестнадцатеричный и др.). Наиболее распространенным кодом в ЭВМ является двоичный код, который позволяет просто реализовать аппаратно устройства для хранения, обработки и передачи данных в двоичном коде. Он обеспечивает высокую надежность устройств и простоту выполнения операций над данными в двоичном коде. Двоичные данные, объединенные в группы по 4, образуют шестнадцатеричный код, который хорошо согласуется с архитектурой ЭВМ, работающей с данными кратными байту (8 бит).
Коды для обмена данными и их передачи по каналам связи. Широкое распространение в ПК получил код ASCII (American Standard Code for Information Interchange). ASCII - это 7-битный код буквенно-цифровых и других символов. Поскольку ЭВМ работают с байтами, то 8-й разряд используется для синхронизации или проверки на четность, или расширения кода. В ЭВМ фирмы IBM используется расширенный двоично-десятичный код для обмена информацией EBCDIC (Extended Binary Coded Decimal Interchange Code).
В каналах связи широко используется телетайпный код МККТТ (международный консультативный комитет по телефонии и телеграфии) и его модификации (МТК и др.).
При кодировании информации для передачи по каналам связи, в том числе внутри аппаратным трактам, используются коды, обеспечивающие максимальную скорость передачи информации, за счет ее сжатия и устранения избыточности (например: коды Хаффмана и Шеннона-Фано), и коды обеспечивающие достоверность передачи данных, за счет введения избыточности в передаваемые сообщения (например: групповые коды, Хэмминга, циклические и их разновидности).
Коды для специальных применений - это коды, предназначенные для решения специальных задач передачи и обработки данных. Примерами таких кодов является циклический код Грея, который широко используется в АЦП угловых и линейных перемещений. Коды Фибоначчи используются для построения быстродействующих и помехоустойчивых АЦП.
Глава 2 Методы кодирования данных
Используется для представления равномерных n - значных кодов. Для примитивного (полного и равномерного) кода матрица содержит n - столбцов и 2n - строк, т.е. код использует все сочетания. Для помехоустойчивых (корректирующих, обнаруживающих и исправляющих ошибки) матрица содержит n - столбцов (n = k+m, где k-число информационных, а m - число проверочных разрядов) и 2k - строк (где 2k - число разрешенных кодовых комбинаций). При больших значениях n и k матрица будет слишком громоздкой, при этом код записывается в сокращенном виде. Матричное представление кодов используется, например, в линейных групповых кодах, кодах Хэмминга и т.д.
Пример
a1 1 1000 111 011 Необходимо закодировать
a2 0 0100 110 101информационную комбинацию:
a31 0010 101 110 1011
a41 0001 011 111
Полученное значение проверочных
1011 001 разрядов.
В общем случае: a1, a2, a3, a4 – информационная кодовая комбинация в общем виде:
a1 a2 a3 a4 b1 b2 b3 b1 = a1 a2 a3 Для заданной образующей матрицы
b2 = a1 a2 a4
b3 = a1 a3 a4
В самом общем случае алгоритм образования проверочных символов b1…b2 по известной информационной частиa1, a2, … ak может быть записан следующем образом:
k
b1 = p11a1 p21a2 p … k1ak p= i1ai
i=1
k
b2 = p12a1 p22a2 p … k2ak p= i2ai
i=1
----------------------------------------------
k
bj = p1ja1 p2ja2 p … kjak p= ijai
i=1
----------------------------------------------
k
br = p1ra1 p2ra2 p … krak p= irai
i
Рассмотрим теперь метод построения образующей матрицы
Из свойств группового следует, что
dW min
С другой стороны Wi = Wнi d+ Wпi min
Wп dmin – Wн
Т.к. вес всех сторон ||Н||:W11=1, то имеем
dWп min – 1, dmin d t+1min t–1
dWп min t Wп t – 1
Необходимые и Отсюда: для кодов, обнаруживающихt– кратные ошибки:
достаточные требования Wп (строки) t
для построения проверочной для кодов, исправляющих t – кратные ошибки :
матрицы Wп (строки) 2t
Рассмотрим частные случаи:
1.) Коды, обнаруживающие одиночную ошибку.
dmin= 2 ( N=15, t=1 )
Wп 1
Единая матрица для dmin2
100…0 1 k k
010…0 1 b1 a=ip1i a=i Не что иное, как
001…0 1 i=1 i=1 проверка на четность.
000…1 1
И П
Во всех комбинациях построенного кода – четное.
Для dmin 3 проверочная матрица не может быть представлена в общей (единой) форме, т.к. дляdmin r зависит отk. 3
Построение кодовой комбинацииEв матричной форме имеет вид:
образующая матрица
E = IGn,k , гдеI– вектор длиныk, компонентами которой являются
информационные разряды.
кодовый вектор информационный
вектор
2.2 Представление кодов в виде кодовых деревьев
Кодовое дерево - связной граф, не содержащий циклов. Связной граф - граф, в котором для любой пары вершин существует путь, соединяющий эти вершины. Граф состоит из узлов (вершин) и ребер (ветвей), соединяющих узлы, расположенные на разных уровнях[4]. Для построения дерева равномерного двоичного кода выбирают вершину называемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
Пример кодового дерева для полного кода приведен на рис.1.
1 0
1 0 1 0
1 0 1 0 1 0 1 0
111 110 101 100 011 010 001 000
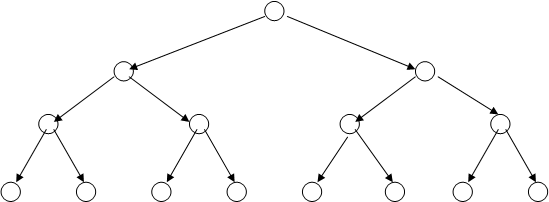
Рисунок 1 - Дерево для полного двоичного кода при n = 3
Дерево помехоустойчивого кода строится на основе дерева полного кода путем вычеркивания запрещенных кодовых комбинаций. Для дерева неравномерного кода используется взвешенный граф, при этом на ребрах дерева указываются вероятность переходов. Представление кода в виде кодового дерева используется, например, в кодах Хаффмена.
2.3 Представление кодов в виде многочленов
Описание циклических кодов и их построение удобно проводить с помощью многочленов (или полиномов). Запись комбинации в виде полинома понадобилась для того, чтобы отобразить формализованным способом операцию циклического сдвига исходной кодовой комбинации. Так, n-элементную кодовую комбинацию можно описать полиномом (n − 1) степени, в виде[5]:
An−1(x) = an−1 xn−1 + an−2 xn−2 + … + a1 x + a0,
где ai = {0, 1}, причем ai = 0 соответствуют нулевым элементам комбинации, ai = 1 — ненулевым.
Запишем полиномы для конкретных 4-элементных комбинаций:
1101 ⇔ A1(x) = x3 + x2 + 1
1010 ⇔ A2(x) = x3 + x
Операции сложения и вычитания выполняются по модулю 2. Они являются эквивалентными и ассоциативными:
- G1(x) + G2(x) ⇒ G3(x)
- G1(x) − G2(x) ⇒ G3(x)
- G2(x) + G1(x) ⇒ G3(x)
Примеры
- G1(x) = x5 + x3 + x
- G2(x) = x4 + x3 + 1
- G3(x) = G1(x) ⊕ G2(x) = x5 + x4 + x + 1
Операция деления является обычным делением многочленов, только вместо вычитания используется сложение по модулю 2:
- G1(x) = x6 + x4 + x3
- G2(x) = x3 + x2 + 1
x6 + x4 + x3 | x3 + x2 + 1
+------------
x6 + x5 + x3 | x3 + x2
------------
x5 + x4
x5 + x4 + x2
------------
x2
2.4 Геометрическое представление кодов
Числовая информация может быть представлена геометрически. Например, на различных приборах с циферблатом: часах, спидометре числовое значение времени (скорости) кодируется положением стрелки на круговой шкале (или на линейной). Геометрическое представление числовой информации - это также и различные диаграммы: круговые, столбчатые. Такое представление информации является очень удобным и наглядным.
Примером кодирования информации является условное обозначение силы подземных толчков при землетрясениях. Здесь рисунки со степенями разрушения здания занумерованы от 1 до 10 (вспомните учебник по географии). При указании на силу подземных толчков называют количество баллов по выбранной 10-бальной шкале. А на географической карте зоны землетрясений обозначаются концентрическими окружностями, где эпицентр бедствия является их центром[6]. Здесь отношение "сильнее" закодировано отношением "содержать".
Любая комбинация n - разрядного двоичного кода может быть представлена как вершина n - мерного единичного куба, т.е. куба с длиной ребра равной 1. Для двухэлементного кода (n = 2) кодовые комбинации располагаются в вершинах квадрата. Для трехэлементного кода
(n = 3) - в вершинах единичного куба (рис.2).
В общем случае n мерный куб имеет 2n вершин, что соответствует набору кодовых комбинаций 2n.
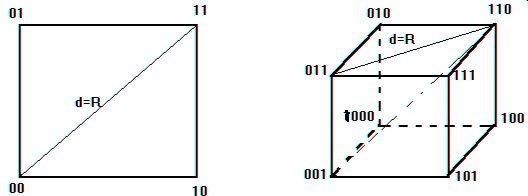
n = 2 n = 3
Рисунок 2 - Геометрическая модель двоичного кода
Геометрическая интерпретация кодового расстояния. Кодовое расстояние - минимальное число ребер, которое необходимо пройти, чтобы попасть из одной кодовой комбинации в другую. Кодовое расстояние характеризует помехоустойчивость кода[7].
Заключение
В данной работе были рассмотрены вопросы понятия кодирования данных, изучены типы кодов, рассмотрены методы кодирования данных.
Любая информация, с которой работает современная вычислительная техника, преобразуется в числа в двоичной системе счисления.
Дело в том, что физические устройства (регистры, ячейки памяти) могут находиться в двух состояниях, которым соотносят 0 или 1. Используя ряд подобных физических устройств, можно хранить в памяти компьютера почти любое число в двоичной системе счисления. Сколько физических ячеек используемых для записи числа, столько и разрядное число можно записать. Если ячеек 8, то и число может состоять из 8 цифр.
Кодирование в компьютере целых чисел, дробных и отрицательных, а также символов (букв и др.) имеет свои особенности для каждого вида. Например, для хранения целых чисел выделяется меньше памяти (меньше ячеек), чем для хранения дробных независимо от их значения.
Однако, всегда следует помнить, что любая информация (числовая, текстовая, графическая, звуковая и др.) в памяти компьютера представляется в виде чисел в двоичной системе счисления (почти всегда).
В общем смысле кодирование информации можно определить как перевод информации, представленной сообщением в первичном алфавите, в последовательность кодов.
Надо понимать, что любые данные - это так или иначе закодированная информация. Информация может быть представлена в разных формах: в виде чисел, текста, рисунка и др. Перевод из одной формы в другую - это кодирование.
Список использованной литературы
1. Артамонов В.С., Серебряков Е.С. «Персональный компьютер для начинающих». - М. -СПб., 2000 – 315с.
2. Дмитриев В.И. Прикладная теория информации. М.: Высшая школа. Электронный учебник
3. Информатика: Учебник для вузов. Под ред. Симоновича.- СПб., 2000- 640с.
4. Информатика: Учебник Под ред Н.В. Макаровой.- М., 2000 – 768с.
5. Кловский Д.Д. Теория передачи сигналов. -М.: Связь, 1984. – 288с.
6. Колесник В.Д., Полтырев Г.Ш. Курс теории информации. М.: Наука, 2006. – 345с.
7. Кудряшов Б.Д. Теория информации. Учебник для вузов Изд-во ПИТЕР, 2008. - 320с.
8. Семенюк В.В. Экономное кодирование дискретной информации. - СПб.: СПбГИТМО (ТУ), 2001 – 434с.
10.Рябко Б.Я., Фионов А.Н. Эффективный метод адаптивного арифметического кодирования для источников с большими алфавитами // Проблемы передачи информации. - 1999. - Т.35, Вып. - С.95 - 108.
-
Артамонов В.С., Серебряков Е.С. «Персональный компьютер для начинающих». - М. -СПб., 2000 – С. 12. ↑
-
Информатика: Учебник для вузов. Под ред. Симоновича.- СПб., 2000- С. 24-25. ↑
-
Дмитриев В.И. Прикладная теория информации. М.: Высшая школа. Электронный учебник ↑
-
. Информатика: Учебник Под ред Н.В. Макаровой.- М., 2000 – С. 56-57. ↑
-
Кловский Д.Д. Теория передачи сигналов. -М.: Связь, 1984. – С. 67. ↑
-
Рябко Б.Я., Фионов А.Н. Эффективный метод адаптивного арифметического кодирования для источников с большими алфавитами // Проблемы передачи информации. - 1999. - Т.35, Вып. - С.95 - 108 ↑
-
Семенюк В.В. Экономное кодирование дискретной информации. - СПб.: СПбГИТМО (ТУ), 2001 – С. 110. ↑

- Влияние на потребительское поведение пользователей рекламы в социальной сети инстаграмм
- Разработка сайта стоматологической клиники (Анализ исходных данных)
- Соотношения системы права и системы законодательства
- Франчайзинг, как особый вид вертикальных ограничений
- АНАЛИЗ ДЕНЕЖНЫХ СРЕДСТВ ПРЕДПРИЯТИЯ (Теоретические аспекты денежных средств предприятия: понятие, методика анализа)
- Причина и история возникновения и развития кредитных отношений. Их эволюция
- "Адаптация персонала в организациях разных типов"
- "Основные виды валютных рисков и их источники"
- Мотивация в управлении на примере реально существующей организации (Мотивация как процесс воздействия на профессиональную деятельность)
- Выбор управленческого решения методом анализа иерархий. Оценить корректность метода (на примере КОАО «Прибор»)
- Различные способы представления данных в информационных системах (Кодирование графической информации)
- Методы кодирования данных. Пример"