
Методы кодирования данных (позволяющие выполнять шифрование)
Содержание:

ВВЕДЕНИЕ
Информация (данные) в общем смысле – это сведения, представленные в различной форме, которая может быть распознана человеком и/или специальными устройствами. С течением времени понятие информации, используемое в повседневной речи, претерпело значительные изменения. Главным образом это произошло из-за распространения технологий, связанных с коммуникацией. В середине XX в. появилась информатика – наука, отделившаяся от кибернетики, занимающаяся исследованиями способов получения, хранения, передачи и обработки информации. В промышленно развитых западных обществах информация стала чем-то необходимым, главным и незаменимым компонентом общества. Таким образом, актуальность использования методов передачи и обработки информации (данных) возрастает.
Кодирование – это процесс формирования представления информации, как правило, в удобном для хранения и передачи виде. В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач, в том числе имеющих отношение к программированию. Преобразование информации в дискретную (набор логических нулей и единиц) или при помощи кодирования может подразумевать:
- Представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
- Обеспечение помехоустойчивости при передаче данных по каналам связи;
- Шифрование данных;
- Сжатие информации.
Информация, кодирование которой необходимо осуществить, как правило, доступна в виде файлов данных.
Файл данных – это компьютерный файл (именованная область внешней памяти, выделенная для хранения), в котором хранятся данные, используемые компьютерным приложением или системой, включая входные и выходные данные [3.]. Файл данных обычно не содержит инструкций или кода для выполнения (то есть компьютерной программы). Большинство компьютерных программ работают с файлами данных.
Файлы данных могут храниться двумя способами:
- Текстовые файлы;
- Бинарные файлы.
Текстовые файлы (часто называемые ASCII-файлами) хранят информацию в символах кодировки ASCII. Текстовый файл содержит удобочитаемые символы. Пользователь может читать содержимое текстового файла или редактировать его с помощью текстового редактора. В текстовых файлах каждая строка текста заканчивается (разделяется) специальным символов, известным от EOL (от англ. End Of Line – конец строки). Примером текстового файла может служить текстовый документ – файл с расширением .txt.
Бинарные (двоичные) файлы содержат информацию в том же формате, в котором она хранится в памяти, то есть в двоичной форме. В двоичном файле нет разделителей строк и символов перевода. Это позволяет проще и быстрее осуществлять операции чтения и записи, чем при работе с текстовыми файлами [3.]. До тех пор, пока файл не нужно переносить в другую операционную систему либо читать при помощи текстового редактора, двоичные файлы являются лучшим способом хранения информации. Примером бинарного файла может служить изображение в формате JPEG.
Цель данной работы – изучить методы кодирования информации, позволяющие выполнять шифрование и сжатие файлов данных, а также выявление ошибок в файлах.
Для достижения цели в курсовой работе были поставлены следующие задачи:
- изучить методы кодирования, предназначенные для шифрования и дешифрования данных;
- изучить методы кодирования, предназначенные для сжатия файлов данных;
- ознакомиться с теорией циклических избыточных кодов для выявления искажений в сообщениях;
- выбрать язык программирования высокого уровня для программной реализации алгоритмов кодирования с возможностью использования графического пользовательского интерфейса;
- реализовать программы на выбранном языке программирования, а также выполнить тестирование и отладку разработанных программ.
В процессе выполнения работы все поставленные задачи были успешно выполнены.
Методы шифрования данных
Теоретические основы шифрования данных
Актуальность использования криптографических методов обусловлена быстрым развитием сетевых технологий и мощностей вычислительных устройств, а также широким использованием компьютерных сетей, в том числе и глобальной сети Интернет, по которым передаются большие объемы информации государственного, военного, коммерческого и частного характера, не допускающего возможность доступа к ней посторонних лиц. Потребность в криптографии возникла с появлением письменности. Так, например, еще до нашей эры встречались первые криптосистемы – в секретной переписке римского полководца Цезаря был использован шифр подстановки, впоследствии названный его именем. Тем не менее, до появления алгоритма RSA (аббревиатура от фамилий его создателей – Rivest, Shamir и Adleman) все существующие криптосистемы основывались на том факте, что как передающая сообщение сторона, так и принимающая его должны разбираться в принципах работы самого метода шифрования и обладать знанием о единственном ключе для декодирования шифра.
Алгоритм RSA, разработанный в 1977 году Ривестом, Шамиром и Адлеманом, предложил новую модель шифрования – шифрование с открытым ключом. Создатели алгоритма исходили из предпосылки о том, что отправитель сообщения не обязательно должен уметь его расшифровывать. В этой парадигме для шифрования используется так называемый открытый ключ, который может быть опубликован для всех, кто хочет получить доступ к результату шифрования. Для дешифрования используется закрытый ключ, доступный только получателю. Обеспечение конфиденциальности в криптосистеме с открытым ключом состоит в том, что чрезвычайно трудно получить ключ дешифрования из общедоступного ключа шифрования [6.]. Алгоритм работает, используя понятия теории чисел, в том числе теорему Ферма.
Метод Диффи-Хеллмана
Общим слабым местом криптографических систем, существовавших до второй половины XX века, была проблема распределения ключей. Для того, чтобы обмен информацией между двумя сторонами был конфиденциальным, используемый для этого обмена ключ должен быть сгенерирован одной из сторон, а затем безопасно передан другой. Таким образом, даже для передачи самого ключа требовалось использование какой-то криптосистемы. Как передающая сообщение сторона, так и принимающая его должны были разбираться в принципах работы самого метода шифрования и обладать знанием о единственном ключе для декодирования шифра [5.].
Впервые эта проблема была решена Уитфилдом Диффи, работающим в сотрудничестве с Мартином Хеллманом [6.]. Шифр, предложенный Диффи, содержал асимметричный ключ (пару «открытый ключ, закрытый ключ»). В других криптосистемах дешифрование было просто противоположным шифрованию; эти системы использовали симметричный ключ, потому что дешифрование и шифрование симметричны. Несмотря на то, что Диффи разработал общую концепцию асимметричного шифра, у него фактически не было определенной односторонней функции, которая отвечала бы необходимым требованиям. Тем не менее, его статья, опубликованная в 1975 году, вызвала интерес среди других математиков и ученых. Диффи и Хеллман, однако, не смогли продвинуться дальше в разработке нового шифра. Это открытие было сделано группой других исследователей: Ривестом, Шамиром и Адлеманом в 1977-м году [6.].
Пример алгоритма Диффи-Хеллмана.
1 шаг: Алиса и Боб договариваются о значениях для некоторой математической односторонней функции. Значения не являются секретными. Допустим, что эти значения 9 и 14. Функция будет иметь вид 9х (mod 14)
2 шаг: Алиса и Боб выбирают свои случайные числа, которые хранят в секрете. Пусть Алиса выбрала число 5, а Боб – 7. Эти числа обозначаются А и В соответственно.
3 шаг: Алиса и Боб подставляют свои секретные числа в функцию и вычисляют значение. 95 (mod 14) = 59 049 mod 14 = 11. 97 (mod 14) = 4782969 (mod 14) = 9. Эти числа обозначаются С и Е соответственно.
4 шаг: Алиса и Боб обмениваются вычисленными значениями и вычисляют значение функции со своим и полученным числом в качестве аргумента, т.е. Алиса вычисляет ЕА (mod 14), Боб, соответственно, вычисляет СВ (mod 14). 95 (mod 14) = 59 049 mod 14 = 11. 117 (mod 14) = 19487171 mod 14 = 11. Полученное в результате всех операций число 11 будет секретным ключом для шифрования передаваемых данных.
При работе алгоритма Диффи-Хеллмана [5.] каждая сторона:
- Генерирует случайное натуральное число a – закрытый ключ, затем совместно с удалённой стороной устанавливает открытые параметры p и g (обычно значения p и g генерируются на одной стороне и передаются другой), где p является случайным простым числом, g является первообразным корнем по модулю p
- Вычисляет открытый ключ A, используя преобразование над закрытым ключом по формуле (1):
 , (1)
, (1)
- Обменивается открытыми ключами с удалённой стороной и вычисляет общий секретный ключ K, используя открытый ключ удаленной стороны B и свой закрытый ключ a, формула (2):
 (2)
(2)
К получается равным с обоих сторон, потому что
 (3)
(3)
Алгоритм [5.] проиллюстрирован на рисунке 1.

Рисунок 1. Алгоритм Диффи-Хеллмана
Алгоритм RSA
Алгоритм RSA получения открытого и закрытого ключей выглядит следующим образом [5.]:
- Выбрать два простых числа
 и
и  .
. - Найти их произведение

 , которое называется модулем.
, которое называется модулем. - Найти значение функции Эйлера от числа
 :
:  .
. - Выбрать целое число
 :
:  , взаимно простое со значением функции
, взаимно простое со значением функции  .
. - Найти линейное представление наибольшего общего делителя этих двух чисел:
 и вычислить число
и вычислить число  (например, при помощи расширенного алгоритма Евклида).
(например, при помощи расширенного алгоритма Евклида).
Пара чисел  публикуется в качестве открытого ключа RSA.
публикуется в качестве открытого ключа RSA.
Пара чисел  играет роль закрытого ключа RSA и не публикуется. Делители
играет роль закрытого ключа RSA и не публикуется. Делители  и
и  могут быть как уничтожены, так и сохранены вместе с секретным ключом.
могут быть как уничтожены, так и сохранены вместе с секретным ключом.
В схеме RSA сообщением являются целые числа, лежащие от  до
до  . Перед началом шифрования шифруемый текст должен быть переведен в числовую форму (символы строк кодируются набором байтов). В результате этого текст может быть представлен в виде одного большого числа, которое затем разбивается на части (блоки) так, чтобы каждая его часть располагалась в промежутке от
. Перед началом шифрования шифруемый текст должен быть переведен в числовую форму (символы строк кодируются набором байтов). В результате этого текст может быть представлен в виде одного большого числа, которое затем разбивается на части (блоки) так, чтобы каждая его часть располагалась в промежутке от  до
до  . Процесс шифрования одинаков для каждого блока, поэтому для записи алгоритма можно считать, что блок исходного текста представлен числом a.
. Процесс шифрования одинаков для каждого блока, поэтому для записи алгоритма можно считать, что блок исходного текста представлен числом a.
Алгоритм шифрования RSA [3.]:
- Взять открытый ключ

- Взять открытый текст

- Получить криптограмму
 :
: 
- Передать шифрованное сообщение

Алгоритм дешифрования [5.]:
- Принять зашифрованное сообщение
 .
. - Применить закрытый ключ
 для расшифровки сообщения
для расшифровки сообщения  .
.
Одним из наиболее известных протоколов аутентификации является протокол на основе алгоритма RSA, который состоит из этапов генерации (получения открытого и закрытого ключей) и аутентификации:
-
-
-
- Принимающая сторона выбирает случайное число
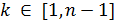 , вычисляет
, вычисляет 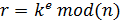 и посылает
и посылает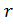 отправляющей стороне;
отправляющей стороне; - Отправляющая сторона вычисляет
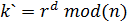 и отправляет
и отправляет 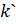 принимающей стороне;
принимающей стороне; - Принимающая сторона проверяет соотношение
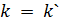 : если оно истинно, то сторона принимает доказательство.
: если оно истинно, то сторона принимает доказательство.
- Принимающая сторона выбирает случайное число
-
-
До появления Интернета шифрование во многих отношениях считалось проблемой только для государственных учреждений. Алгоритм RSA был введен в то время, когда потенциальная популярность Интернета впервые стала очевидной. С этой популярностью пришел высокий спрос на безопасную и надежную возможность передачи информации. Алгоритм RSA, воспринимаемый как почти неразрушимая криптосистема с открытым ключом, быстро стал ключевым методом выбора для приложений криптографии в Интернете, включая, например, шифрование электронной почты. Сегодня RSA также продолжает использоваться внутри протокола Secure Socket Layer (SSL), используемого в большинстве случаев обмена данными в интернете [1.]. Это позволяет сделать вывод о том, что алгоритм RSA является очень надежной криптосистемой, которая используется в течение последних тридцати лет для обеспечения безопасности в миллионах приложений в Интернете.
Вместе с тем алгоритм был подвергнут ряду криптографических атак, то есть попыток найти и использовать слабые стороны алгоритма. Некоторые из них рассматриваются в следующем разделе. Основа безопасности алгоритма RSA состоит в том, что при заданном  невозможно разложить
невозможно разложить  на соответствующие значения
на соответствующие значения  и
и  за полиномиальное время. Однако это основное предположение до сих пор не было ни доказано, ни опровергнуто. Если бы существовал алгоритм для факторизации больших чисел, работающий за полиномиальное время, безопасность Интернета была бы поставлена под угрозу.
за полиномиальное время. Однако это основное предположение до сих пор не было ни доказано, ни опровергнуто. Если бы существовал алгоритм для факторизации больших чисел, работающий за полиномиальное время, безопасность Интернета была бы поставлена под угрозу.
Методы сжатия данных
Основы сжатия данных
Объемы регулярно производимых цифровых данных растут день ото дня. По данным всемирной консалтинговой организации International Data Corporation, общий объем новых данных будет увеличиваться с ежегодным приростом 57%, что опережает ожидаемый рост емкости носителей информации. Поскольку необходимо сохранять большую часть этих данных, всегда существует экономически целесообразная потребность в эффективных цифровых архивах. Наиболее популярные их них используют принцип сжатия данных. Сжатие представляет собой процесс преобразования входного потока данных (исходного потока, или исходных необработанных данных) в другой поток данных (выходной поток, поток битов, или сжатый поток), который имеет меньший размер [14.]. Поток – это файл или буфер в памяти.
Для конечного пользователя потребность сжатия файлов и каталогов на компьютере обусловлена целым рядом причин. Некоторые из них экономят место на диске и используют минимальную пропускную способность для сетевого взаимодействия с передачей файлов. Как правило, архивирование данных означает создание резервной копии и ее сохранение в безопасном месте, которое находится в сжатом формате. Архивный файл состоит из одного или нескольких файлов, включая метаданные в дополнительных полях, таких как имя файла, разрешение и так далее. Архивные файлы обычно используются для объединения нескольких файлов данных в один с целью добиться переносимости и меньшего пространства для хранения [11.].
Предметную область сжатия данных часто называют кодированием для сжатия. Легко представить себе, что входные символы (такие как биты, коды ASCII, байты, аудиосэмплы или значения пикселей) генерируются определенным источником информации и должны быть закодированы перед их отправкой по назначению. Источник может быть без внутренней памяти, но может также иметь память. В первом случае каждый символ не зависит от предшествующих ему, во втором – зависит от некоторых ему предшествующих и, возможно, также от следующих за ним символов, поэтому они взаимосвязаны. Источник данных без памяти также называется «независимым и одинаково распределенным». Сжатие данных достигло своего пика за последние 20 лет. Количество и качество литературы в этой области являются достаточным доказательством.
Существует много известных способов сжатия данных [14.]. Они основаны на разных идеях, подходят для разных типов данных и дают разные результаты, но в основе каждого из них лежит один и тот же принцип – они сжимают данные, удаляя избыточность из исходных данных в исходном файле. Любые неслучайные данные имеют некоторую структуру, и эта структура может быть использована для достижения меньшего представления данных, представления, где структура не различима. Термины «избыточность» и «структура» используются в профессиональной литературе, равно как и «гладкость», «согласованность» и «корреляция»; все они относятся к одному и тому же понятию. Таким образом, избыточность является ключевым понятием в любой дискуссии о сжатии данных.
Идея сжатия путем уменьшения избыточности формулирует общий закон сжатия данных, который заключается в том, чтобы «присваивать короткие коды общим событиям (символы или фразы) и длинные коды редким событиям». Существует много способов реализации этого закона, и анализ любого метода сжатия демонстрирует, что в своей фундаментальной реализации он работает, подчиняясь общему закону.
Сжатие данных осуществляется путем изменения их представления с неэффективного (то есть длинного) на эффективное (короткое). Следовательно, сжатие возможно только потому, что данные обычно представлены на компьютере в формате, который длиннее, чем это в целом требуется. Причина того, что неэффективные (длинные) представления данных используются постоянно, состоит в том, что эти представления облегчают их обработку, а обработка данных является более распространенной практикой и более важной, чем сжатие. Кодировка ASCII для символов является хорошим примером представления данных, которое длиннее, чем это необходимо. Она использует 7-битные коды, потому что с кодами фиксированного размера легко работать. Однако коды переменного размера были бы более эффективными, поскольку некоторые символы используются чаще других, и поэтому им могут быть назначены более короткие коды. В мире, где информация всегда представлена в кратчайшем формате, невозможно будет сжимать данные.
Принцип сжатия путем удаления избыточности [15.] также отвечает на следующий вопрос: «Почему уже сжатый файл не может быть сжат в дальнейшем?» Ответ, конечно же, заключается в том, что такой файл имеет небольшую избыточность или не имеет ее вообще, поэтому из него уже ничего нельзя удалить. Примером такого файла является случайный текст. В случайном тексте каждая буква встречается с равной вероятностью, поэтому присвоение символам кодов фиксированного размера не добавляет избыточности. Когда такой файл сжимается, избыточность для удаления отсутствует. Другой ответ на вопрос заключается в том, что если бы можно было сжимать уже сжатый файл, то последовательные сжатия уменьшали бы размер файла до тех пор, пока он не станет занимать всего лишь один байт или даже один бит в памяти компьютера. Это, конечно, невозможно, поскольку один байт не может содержать информацию, представленную в сколь угодно большом файле.
Как правило, файлы со случайными данными встречаются редко, но есть еще один хороший пример с ранее сжатым файлом. Владелец сжатого файла, как правило, знает, что он уже сжат, и не будет пытаться сжимать его дальше, но существует одно исключение при передаче данных модемами. Современные модемы содержат оборудование для автоматического сжатия отправляемых данных, и, если эти данные уже сжаты, дальнейшего сжатия не будет. Возможно даже расширение данных. Вот почему модем обязан отслеживать степень сжатия «на лету», а если она низкая, он должен прекратить сжатие и передавать оставшиеся данные без него.
Методы сжатия без потерь создают файл меньшего размера, чем исходный, который можно использовать для восстановления исходного файла. Эти методы используют некоторые алгоритмы для определения повторяющихся частей внутри файла, где всегда создается список переменных, которые определяют блоки данных. Фактически все методы сжатия без потерь используют двухэтапный процесс: сначала сопоставляют сильно повторяющиеся значения с чем-то менее повторяющимся, на что можно легко ссылаться, а затем изменяют вхождения всех этих значений с помощью ссылок.
Кроме того, современные методы сжатия без потерь [11.] являются адаптивными, поскольку они не просматривают весь входной файл и не создают словарь ссылок, который должен быть заменен. Вместо этого они анализируют файл, когда начинают его читать, и воссоздают словарь, основываясь на том, какие данные в действительности повторяются. Словарь становится более информативным и объемным по мере продолжения процесса.
Архивы и форматы архивных файлов
Архивный файл (архив) – это файл, который состоит из одного или нескольких компьютерных файлов вместе с метаданными (метаинформацией). Архивные файлы используются для объединения нескольких файлов данных в один с целью облегчить переносимость и хранение этих файлов, или просто для сжатия файлов с целью уменьшения места для их хранения. Архивы часто хранят структуры каталогов, информацию об обнаружении и исправлении ошибок (как правило, контрольные суммы), произвольные комментарии, а иногда используют встроенное шифрование (шифруя данные при помощи пароля).
Некоторые архивы могут быть оформлены в виде программ [17.]. Они являются самораспаковывающимися – для распаковки содержимого такого архива не требуется иметь совместимую с ним программу-архиватор.
Использование архивов имеет ряд преимуществ:
- удобство ориентации в файловом пространстве;
- экономия места;
- надежность хранения информации.
При создании многофайлового архива можно добавить специальную информацию для восстановления данных и указать пароль для ограничения доступа. Если произойдет повреждение какого-либо файла (из-за технических проблем устройства или по другим причинам), то открыть его будет почти невозможно. Добавив в архив информацию для восстановления, с большой вероятностью можно восстановить данные в архиве. Наличие пароля также обеспечивает приватность хранимой информации.
Кроме того, многие интернет-сервисы ограничивают разрешенные для загрузки типы файлов. Оптимальным решением в данных случаях будет архив информации. В нем может храниться как один файл, так и папка с множеством подкаталогов и файлов. Использование архивов для обмена информацией в интернете является стандартом де-факто.
Формат архива – это файловый формат архивного файла. Существует множество форматов для различных архивных файлов, но лишь некоторые из них получили широкое признание и поддержку со стороны поставщиков программного обеспечения и пользовательских сообществ.
Программистам UNIX-подобных систем хорошо известна стандартная утилита ar, так как она широко используется даже сегодня для создания статических библиотек, которые являются не чем иным, как архивами скомпилированных файлов. Утилита ar может использоваться для создания архивов всех видов. Как правило, файлы пакетов .deb в системах Debian – это не что иное, как ar-архивы. А пакеты mpkg в MacOS X – это сжатые gzip-архивы cpio. Формат tar более популярен среди пользователей, чем thanar и cpio, поскольку команда tar была действительно хорошей и простой в использовании [11.].
RAR – это хорошо известный формат архивных файлов, который используется для сжатия данных, восстановления после ошибок и охвата файлов [11.]. Структурно файл RAR состоит из блоков переменной длины обязательных и необязательных данных. Точность создания блоков со временем развивалась от версии к версии. Первоначально файл RAR состоял из маркера или вводного блока, архивного блока, который состоял из заголовка архива и заголовка файла, и закрывающего блока, который состоял из дополнительных комментариев или другой информации, необходимой для правильной обработки файла. Порядок этих блоков мог варьироваться, но первый блок должен быть вводным блоком, за которым следует блок заголовка архива. Блок архива очень сложен, потому что он содержит заголовки своих архивов, а также заголовки файлов [18.].
Формат файла ZIP был введен в конце 1980-х годов для утилиты PKZIP. Он обновлялся из года в год, и теперь включает в себя различные алгоритмы сжатия. Не всегда случается так, что ZIP-алгоритмы являются наиболее эффективными или действенными – у них есть много других конкурентов, которые могут работать лучше во многих ситуациях, но общая производительность этих алгоритмов хорошая. Формат файла ZIP используется во многих продуктах, таких как файлы JAR Java, файлы проекта SAS Enterprise Guide и т.д. Формат ZIP поддерживается Windows, поэтому он специально используется в кроссплатформенных средах [14.].
После десятилетия внедрения tar формат ZIP также появился в мире MS-DOS в качестве формата архива, поддерживающего сжатие. Самым распространенным методом сжатия, используемым в ZIP, является deflate, который представляет собой не что иное, как реализацию алгоритма LZ77. Но формат ZIP-файла, разработанный PKWARE для коммерческих целей, годами сталкивался с препятствиями для патентов. Формат gzip был создан для реализации алгоритма LZ77 в свободном программном обеспечении без нарушения каких-либо патентов PKWARE, который использовался только для сжатия файлов. Таким образом, чтобы создать сжатый архивный файл, сначала необходимо создать архивный файл, используя, например, утилиту tar, затем сжать этот архивный файл и получить файл tar.gz (иногда сокращенно .tgz).
tar-файл – это обычный архивный файл, в котором данные находятся не в сжатом виде. Другими словами, при создании tar из 100 файлов размером 50 КБ можно получить архив, размер которого составит около 5000 КБ. Единственный выигрыш, который можно ожидать при использовании только формата tar, – это предотвращение потери используемой памяти файловой системой, поскольку большинство из них выделяют пространство с определенной степенью детализации (например, в некоторых системах однобайтовый файл использует 4 КБ дискового пространства, 1000 из них потребуют 4 МБ, но соответствующий архив tar просто требует 1 МБ) [17.].
По мере развития компьютерных наук было разработано еще несколько алгоритмов для достижения более высокой степени сжатия. Например, алгоритм Барроуза-Уилера, используемый в bzip2 (сокращение с tar.bz2 архива), или популярный в последнее время Timesxz, который реализует алгоритм LZMA, используемый в утилите 7zip.
Tar поддерживает множество программ сжатия, таких как gzip, bzip2, lzip, lzma, lzop, xz. Из них gzip, вероятно, наиболее широко используемый инструмент хранения, используемый в системах Unix и Linux. Для сжатия данных используется алгоритм Лемпеля-Зива (LZ77).
Формат gzip использует технику сжатия, известную как Deflate. Этот алгоритм также используется в некоторых других популярных технологиях, таких как формат файла изображения PNG, веб-протокол HTTP и протокол защищенной оболочки SSH. Одним из главных его преимуществ является скорость. Он может сжимать, а также распаковывать данные с гораздо большей скоростью, чем другие конкурирующие технологии, особенно при сравнении самых компактных форматов сжатия этих утилит. Он также очень эффективен с точки зрения использования памяти во время сжатия и распаковки, и не требует памяти при оптимизации для наилучшего сжатия. В то время как gzip использует алгоритм Deflate, bzip2 является реализацией алгоритма Берроуза-Уилера.
Важный момент для пользователей – большее сжатие за счет более длительного времени сжатия. bzip2 может создавать более компактные файлы, чем gzip, но для достижения результатов требуется много времени из-за более сложного алгоритма. Требуемое время распаковки меньше по сравнению со временем сжатия, поэтому может быть преимуществом использование формата файла bzip2, так как в этом случае нужно только понести временные потери во время сжатия и иметь возможность использовать сжатые файлы меньшего размера, которые можно распаковать в сравнительно короткие сроки. Время, необходимое для распаковки, все еще намного больше, чем gzip, но не оказывает такого большого влияния, как операция сжатия. Также следует отметить, что требования к памяти у bzip2 больше, чем у gzip.
Утилиты сжатия xz влияют на алгоритм сжатия [11.], известный как LZMA2. Этот алгоритм имеет большую степень сжатия по сравнению с двумя приведенными выше примерами, и это предпочтительный формат, когда требуется хранить данные на ограниченном дисковом пространстве. Он дает сравнительно меньшие файлы, что снова приводит к тем же нюансам, которые есть у bzip2. В то время как сжатые файлы, которые создает xz, меньше, чем у других инструментов, для сжатия требуется значительно больше времени. У утилиты сжатия xz также больше требований к памяти, иногда она на порядок выше, чем у других утилит. При работе в системе с достаточным объемом памяти, это может не быть значительной проблемой, но стоит подумать над этим нюансом.
Основное отличие между этими форматами состоит в том, что bzip2 использует алгоритм сжатия текста с сортировкой блоков алгоритмом Берроуза-Уилера в сочетании с кодированием Хаффмана вместо алгоритма LZ77, который используется в gzip. Техника сжатия bzip2 дает более эффективное сжатие, чем gzip, однако метод сжатия bzip2 обычно является более сложным и занимает больше времени (т.е. использует больше циклов ЦП), чем сжатие gzip [17.].
Формат RAR использует необязательное шифрование AES, которое является типом блочного шифра и задействует алгоритм, который шифрует данные в каждом блоке. Существуют различные типы стандартов AES и реализаций, используемых RAR, которые меняются в зависимости от версии. RAR5 (текущая версия) использует AES-256, а не AES-128, используемый в RAR4 [18.]. Формат RAR стал более популярным с годами по сравнению с конкурирующими форматами архивов, такими как 7Z, zip и т. д., поскольку он имеет более высокую скорость сжатия данных, чем ZIP, и использует метод сжатия без потерь [19.].
Что касается .jpg, .mp3, .mp4 и подобных им форматов, то практически общеизвестно, что это сжатые файлы данных. Менее известным является тот факт, что все они используют деструктивное сжатие. Это означает, что невозможно воспроизвести точно такое же изображение после технологии сжатия JPEG. Из-за этого обстоятельства сжатие изображений JPEG или файлов MP3 / MP4 не принесет значительных результатов.
На сегодняшний день есть возможность свободно использовать любой формат файла архива как в Linux, так и в Windows. Но формат файла zip имеет встроенную поддержку в Windows, и это особенно используется в кроссплатформенных средах. Также можно обнаружить формат файла zip в разных местах. Например, он также использовался Sun для JAR-архивов при распространении скомпилированных программ Java или для файлов Open Document (.odf, .odp и т.д.), используемых LibreOffice и некоторыми другими офисными пакетами. Все эти форматы файлов являются ничем иным, как zip-архивами.
Все еще в пользу формата архива tar говорит тот факт, что формат файла zip в полной мере не поддерживает все метаданные файловой системы Unix. По некоторым причинам следует иметь в виду, что формат файла ZIP определяет только ограниченный набор обязательных атрибутов файла: имя файла, дата изменения, разрешения [19.]. Помимо этих основных атрибутов, архиватор может хранить некоторые дополнительные метаданные в дополнительных полях заголовка ZIP-файла, но эти дополнительные поля зависят от реализации, и даже у эффективных архиваторов нет гарантий хранения или извлечения одного и того же набора метаданных.
Алгоритмы сжатия данных
Алгоритм RLE (Run Length Encoding). Основная идея алгоритма RLE состоит в выявления повторяющихся последовательностей данных и замены их более простой структурой, в которой указывается код данных и коэффициент повторения. Несмотря на то, что кодер RLE, как правило, дает очень незначительное сжатие, он может работать очень быстро. А скорость работы декодера RLE вообще близка к скорости простого копирования блока информации. К положительным сторонам алгоритма, можно отнести то, что он не требует дополнительной памяти при работе, и быстро выполняется. Алгоритм применяется в форматах РСХ, TIFF, ВМР. Интересная особенность группового кодирования в PCX заключается в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.
Алгоритмы группы KWE (KeyWord Encoding). В основу алгоритма сжатия по ключевым словам положен принцип кодирования лексических единиц группами байт фиксированной длины. Примером лексической единицы может быть обычное слово. На практике на роль лексических единиц выбираются повторяющиеся последовательности символов, которые кодируются цепочкой символов (кодом) меньшей длины. Результат кодирования помещается в таблице, образовывая так называемый словарь. Алгоритмы сжатия этой группы наиболее эффективны для текстовых данных больших объемов и малоэффективны для файлов небольших размеров (за счет необходимости сохранение словаря).
Алгоритм Хаффмана. В основе алгоритма Хаффмана лежит идея кодирования битовыми группами. Сначала проводится частотный анализ входной последовательности данных, то есть устанавливается частота вхождения каждого символа, встречающегося в ней. После этого, символы сортируются по уменьшению частоты вхождения.
Основная идея состоит в следующем: чем чаще встречается символ, тем меньшим количеством бит он кодируется. Результат кодирования заносится в словарь, необходимый для декодирования.
Сравнение алгоритмов приведено в таблице ниже.
Сравнение алгоритмов сжатия данных
|
Название |
Выходная структура |
Сфера применения |
Явные плюсы |
Явные минусы |
|
RLE |
Список |
Графические данные |
1. Не требует дополнительной памяти при работе 2. Эффективность не зависит от объема 3. Высокая скорость работы |
1.Ограниченный круг применения. 2. Низкая степень сжатия |
Сравнение алгоритмов сжатия данных (продолжение таблицы)
|
Название |
Выходная структура |
Сфера применения |
Явные плюсы |
Явные минусы |
|
KWE |
Таблица словаря |
Текстовые данные |
2. Хорошая скорость работы. |
1.Ограниченный круг применения 2.Малоэффективны при работе с маленькими объемами данных |
|
Алгоритм Хаффмана |
Дерево кодировки |
Любые данные |
1.Универсальность 2. Не увеличивает объем при неудаче (не считая таблицы) |
1. Эффективен для большого объема данных. 2. Двухэтапная обработка |
Теория циклических избыточных кодов
Основные положения
Теория циклических избыточных кодов, несмотря на свое давнее появление (конец 60-х годов XX столетия) по-прежнему остается актуальной. Циклические избыточные коды широко использовались на протяжении десятилетий в компьютерной индустрии для того, чтобы можно было гарантировать правильную запись блоков на дисках и магнитных лентах. Они также широко используются для кодирования и декодирования пакетных ошибок канала связи, где временный сбой может вызвать сразу несколько смежных ошибок данных. Кроме того, циклические избыточные коды принимают участие в механизме встроенного самотестирования (англ. built-in self-testing – BIST) и для тестирования ПЗУ памяти.
Циклический избыточный код (англ. Cyclic Redundancy Check, CRC) – это код проверки ошибок, который широко используется в системах передачи данных и других системах последовательной передачи. CRC представляет собой алгоритм нахождения контрольной суммы, проверяющий целостность данных. Он основан на полиномиальных манипуляциях с использованием модульной арифметики. Некоторыми из распространенных стандартов проверки циклическим избыточным кодом являются CRC-8, CRC-12, CRC-16, CRC-32 и CRC-CCIT.
Методы обнаружения ошибок предназначены для выявления искажений в сообщениях при их передаче по зашумленным каналам. Для этого передающее устройство вычисляет некоторое число, называемое контрольной суммой и являющееся функцией сообщения, и добавляет его к этому сообщению. Приемное устройство, используя тот же самый алгоритм, рассчитывает контрольную сумму принятого сообщения и сравнивает ее с переданным значением [15.].
Под контрольной суммой CRC (Cyclic Redundancy Check) понимается некоторое значение, рассчитанное по набору данных путем применения математических алгоритмов, обеспечивающих устойчивость к хэш-коллизиям [7.]. Под хэш-коллизией понимается равенство контрольных сумм для различных входных данных. Контрольные суммы широко применяются для осуществления контроля правильности хранимой и передаваемой информации.
Логической предпосылкой использования контрольной суммы этого типа явилось то, что размер контрольной суммы значительно меньше формата преобразуемых чисел/сообщений, следовательно, вероятность искажения контрольной суммы (при передаче информации по какому-либо каналу или при ее хранении на носителе) значительно ниже вероятности искажения массива информации.
Циклические избыточные коды (CRC) являются подклассом блочных кодов и применяются в протоколах HDLC, Token Ring, Token Bus, в семействах протоколов Ethernet и других протоколах канального уровня. Популярность CRC-кодов обусловлена тем, что процедуры кодирования и декодирования достаточно просты и не требуют больших вычислительных ресурсов.
В сетевых системах значительная роль уровня канала передачи данных заключается в преобразовании потенциально ненадежного физического канала между двумя компьютерами в максимально надежный канал. Это достигается путем включения избыточной информации в каждый передаваемый фрейм данных. В зависимости от характера канала и данных, можно включить достаточно избыточности, чтобы можно было обнаружить ошибки и затем организовать повторную передачу поврежденных кадров. Проверка при помощи CRC является широко используемой схемой обнаружения ошибок на основе битов четности в приложениях последовательной передачи данных. Этот код основан на полиномиальной арифметике. Биты данных, которые должны быть переданы, являются коэффициентами полинома. В качестве примера, битовый поток 1101011011 имеет 10 битов, представляющих полином десятой степени:
 (4)
(4)
Для того, чтобы вычислить CRC сообщения, выбирается другой многочлен, называемый порождающим полиномом G(x). G(x) должен иметь степень больше нуля и меньше, чем у многочлена M(x). Другое требование для G(x) – это ненулевой коэффициент члена x0. Это приводит к нескольким возможным вариантам полинома-генератора и, следовательно, к необходимости стандартизации. CRC-16 является одним из таких стандартов, который использует генерирующий полином:
 (5)
(5)
CRC-16 обнаруживает все единичные и двойные ошибки, все ошибки с нечетным числом битов, все пакетные ошибки длиной 16 или менее и большинство ошибок для более длинных пакетов.
CRC-32 использует другой генераторный полином:
 (6)
(6)
В общем случае n-битный CRC вычисляется путем представления потока данных в виде полинома M(x), умножения M(x) на xn (где n – степень полинома G(x)) и деления результата на порождающий полином G(x). Полученный остаток добавляется к многочлену M(x) и передается по каналу. Полный переданный полином затем делится на этот же порождающий полином на стороне получателя. Если результат этого деления не имеет остатка, это означает, что нет ошибок передачи. Математически это можно представить так:
 (7)
(7)
Выбор порождающего полинома является одной из важнейших задач построения CRC-кодов. Как правило, этот выбор обусловлен рекомендациями и стандартами реально существующих организаций, которые используют те или иные спецификации алгоритмов CRC.
Самый популярный и рекомендуемый IEEE полином для CRC-32 используется в Ethernet, FDDI; также этот многочлен является генератором кода Хемминга [8.]. Использование другого полинома – CRC-32C – позволяет достичь такой же производительности при длине исходного сообщения от 58 бит до 131 кбит, а в некоторых диапазонах длины входного сообщения может быть даже выше – поэтому в наши дни он тоже пользуется популярностью [13.]. К примеру, стандарт ITU-T G.hn использует CRC-32C с целью обнаружения ошибок в полезной нагрузке.
Полином (3) в шестнадцатеричном виде выглядит как 0x04C11DB7 – этот многочлен является рекомендованным для стандарта IEEE 802 с подгруппой 802.3. Эта подгруппа является основой семейства технологий пакетной передачи данных Ethernet. IEEE 802.3 определяет многочлен M(x) как адрес назначения, адрес источника, длину / тип и данные фрейма с добавлением первых 32-битных данных. Остаток от вычисления CRC выше дополняется, и в результате получается 32-битный CRC IEEE 802.3, называемый полем Frame Check Sequence (FCS). FCS добавляется в конец кадра Ethernet и передается первым битом высшего порядка (x31, x30, …, x1, x0).
Одним из основных условий для выбора многочлена является то, что коэффициенты в старшем и младшем битах равны единице. Математическая модель нахождения контрольной суммы может быть записана следующим образом:
 (8)
(8)
где
R(x) – полином, представляющий значение CRC;
P(x) – полином, коэффициенты которого представляют входные данные;
G(x) – порождающий полином;
N – степень порождающего полинома (1 ≤ N ≤ 256).
Алгоритмы вычисления циклических избыточных кодов
Прямой алгоритм вычисления CRC определяет контрольную CRC побитно [9.], его можно описать следующим образом в соответствии с (5):
1) дополнить исходное сообщение нулями для выравнивания (количество нулей обусловливается степенью порождающего полинома). P(x)´ = P(x)000…N;
2) выполнять операцию сдвига влево последовательности бит сообщения P(x)´ до тех пор, пока бит в ячейке не станет равным единице или количество бит станет меньше, чем в делителе;
3) если старший бит станет равным единице, то произвести операцию XOR между сообщением и порождающим полиномом и повторить шаг 2;
4) конечный остаток от последовательности P(x)´ является CRC-остатком.
В приведенном описании G(x) – полином, N – степень полинома, P(x) – исходное сообщение, а P(x)´ – дополненное исходное сообщение.
Необходимость выполнения множества итераций при генерации контрольной суммы CRC приводит к значительным временным затратам.
Табличный алгоритм вычисления CRC используется для ускорения расчета контрольной суммы CRC [10.].
Ускорение осуществляется за счет замены восьми операций сдвига одной операцией поиска по таблице, которая содержит 256 значений. Поэтому при расчете контрольной суммы CRC выполняется цикл по 256 значениям.
Предпосылкой появления таблицы явилось то, что при выполнении операции XOR содержимого с постоянной величиной при различных ее сдвигах всегда будет существовать некоторое значение, которое при применении операции XOR с исходным содержимым даст тот же самый результат [2.]. Следовательно, можно составить таблицу таких величин, где индексом является исходное содержимое [15.].
Алгоритм составления таблицы:
1) вычислить значение в таблице для каждого байта от 0x00 до 0xff:
а) выполнять 8 раз операцию «сдвиг вправо», причем, если младший бит равен 1, то выполняется операция XOR с полиномом G;
б) все что осталось от двух байт, становится значением в таблице.
Алгоритм вычисления контрольной суммы CRC по таблице:
1) просматривается каждый байт сообщения P(x):
а) над младшим байтом текущего значения CRC и текущим байтом сообщения проводится операция XOR – это индекс в таблице;
б) старший байт текущего значения CRC сдвигается вправо на 8 и становится младшим, затем объединяется по XOR со значением таблицы – это будет новое значение CRC;
2) в результате получено значение CRC.
Практическая реализация алгоритмов
Выбор языка и среды разработки
Данный раздел посвящен разработке простых прикладных программ с графическим интерфейсом пользователя. Учитывая цели данной курсовой работы, в качестве языка программирования был выбран язык высокого уровня C# версии 7.0 как один из наиболее популярных среди современных языков программирования, предназначенных для обучения. В качестве среды разработки выбрана Visual Studio 2019 Community. Выбор среды разработки для реализации программного приложения был мотивирован тем, что выбираемая среда должна быть простой в использовании, чтобы позволить сосредоточиться на изучении концепций программирования, а также многофункциональной для того, чтобы научиться создавать простые программы для решения прикладных задач [16.].
В качестве проектируемых приложений рассматриваются две программы с графическим пользовательским интерфейсом. Первая из рассматриваемых программ позволяет вычислять контрольные суммы файлов, выбранных пользователем, при помощи алгоритма CRC-32, вторая – выполнять шифрование и дешифрование текста, заданного пользователем, при помощи алгоритма RSA. Для реализации был выбран интерфейс программирования приложений Windows.Forms, являющийся частью Microsoft .NET Framework. С помощью Windows.Forms можно создавать приложения с полнофункциональным графическим интерфейсом, в то же время простые в использовании и обновлении [4.]. Выбранный язык программирования вместе со средой разработки позволяет полностью реализовать программу, отвечающую всем предъявленным ей требованиям [12.].
Разработка программного кода для алгоритма CRC-32
При разработке приложения учитывалась специфика алгоритма; его основные принципы легли в основу поставленной задачи. Пользователь имеет возможность выбрать входной файл (один или несколько) для того, чтобы получить результат вычисления его контрольной суммы. Файл передается на вход программе в виде байтового потока.
Вычисление контрольной суммы производится в соответствии с алгоритмами, рассмотренными в подразделе 3.2. В листинге 1 приведен фрагмент программы, выполняющий построение таблицы, в листинге 2 – фрагмент программы, выполняющий вычисление CRC в соответствии с построенной таблицей.
Листинг 1. Исходный код для реализации алгоритма построения таблицы CRC-32
for (int i = 0; i< 256; i++)
{
Crc32 = (uint) i;
for (int j = 8; j > 0; j--)
if ((Crc32 & 1) == 1)
Crc32 = (Crc32 >> 1) ^ POLYNOMIAL;
else
Crc32 >>= 1;
table_CRC32[i] = Crc32;
}
Листинг 2. Исходный код для реализации вычисления контрольной суммы в соответствии с таблицей CRC-32
int count = stream.Read(buffer, 0, buffer_size);
while (count > 0)
{
for (int i = 0; i < count; i++)
result = ((result) >> 8) ^ table_CRC32[(buffer[i]) ^ ((result) & 0x000000FF)];
count = stream.Read(buffer, 0, buffer_size);
}
Полный исходный код программы приведен в приложении 1.
Тестовый пример, приведенный в данном подразделе, можно рассматривать как руководство пользователя. Для запуска программы достаточно запустить файл CRC32List.exe. Программа корректно работает в MS Windows 7/8/10. Установка не требуется.
Пример работы программы после запуска и перетаскивания файлов в область экрана (в список на форме приложения) приведен на рисунке 2. Для проверки были взяты файлы текущего проекта программы.
На рисунке 3 приведен результат вычисления контрольных сумм при помощи программы WinRAR (проект приложения был архивирован в формате .zip). Как следует из рисунка 3, контрольные суммы всех файлов одинаковы. Таким образом, программа работает корректно.

Рисунок 2 – Результат работы программы

Рисунок 3 – Результат вычисления контрольных сумм при помощи программы WinRAR
Разработка программного кода для алгоритма RSA
При разработке приложения учитывалась специфика алгоритма; его основные принципы легли в основу поставленной задачи. Пользователь имеет возможность дешифровать введенный текст, используя закрытый ключ  , в то время как для шифрования введенного текста достаточно знать открытый ключ
, в то время как для шифрования введенного текста достаточно знать открытый ключ  , который можно получить используя как заданные вручную значения простых чисел
, который можно получить используя как заданные вручную значения простых чисел  и
и  , так и значения, сгенерированные внутри самой программы (в последнем случае пользователь не вводит ничего, кроме шифруемого текста). Генерация усложняет попытку атаки на алгоритм, поскольку значения получены независимо.
, так и значения, сгенерированные внутри самой программы (в последнем случае пользователь не вводит ничего, кроме шифруемого текста). Генерация усложняет попытку атаки на алгоритм, поскольку значения получены независимо.
При вводе чисел  и
и  пользователем необходимо выполнить их проверку на простоту. Для проверки простоты числа, заданного пользователем, в программе используется алгоритм Миллера-Рабина с 10 раундами. Исходный код функции, реализующей алгоритм, с комментариями к коду приведен в листинге 3.
пользователем необходимо выполнить их проверку на простоту. Для проверки простоты числа, заданного пользователем, в программе используется алгоритм Миллера-Рабина с 10 раундами. Исходный код функции, реализующей алгоритм, с комментариями к коду приведен в листинге 3.
Листинг 3. Исходный код функции Миллера-Рабина
public static bool MillerRabin(int n, int k)
{
for (int i = 0; i < k; i++) // цикл по количеству раундов
{
// проверка элементарных случаев:
if (n % 2 == 0)
return false;
if (n == 2)
return true;
if (n <= 1)
return false;
// представление n - 1 как 2 ^ s * m
int s = 0;
int m = n - 1;
while (m % 2 == 0)
{
s++;
m = m / 2;
}
// выбор случ. целого числа a в отрезке [2, n − 2]
Random r = new Random();
int a = r.Next(n - 1) + 1;
// поиск mod = a ^ m % n
int temp = m;
long mod = 1;
for (int j = 0; j < temp; j++)
mod = (mod * a) % n;
// вычислить в цикле mod как mod ^ 2 % n
while (temp != n - 1 && mod != 1 && mod != n - 1)
{
mod = (mod * mod) % n;
temp *= 2;
}
// если mod = 1, то составное
// если mod != n - 1, то составное
if (mod != n - 1 && temp % 2 == 0)
return false;
}
return true; // вернуть "вероятно простое"
}
В основной программе для реализации шифрования и дешифрования используется две основных функции – getEncryptedText и getDecryptedText соответственно. Каждая из них является методом класса RSA, в котором реализована основная логика приложения. В зависимости от способа задания значений  и
и  – случайным образом или вручную – каждый из методов вызывается с тремя параметрами (исходный или шифрованный текст в виде строки; пара значений
– случайным образом или вручную – каждый из методов вызывается с тремя параметрами (исходный или шифрованный текст в виде строки; пара значений  и
и  или пара значений закрытого ключа) либо с одним (исходный или шифрованный текст в виде строки). Для шифрования текста с заданными значениями
или пара значений закрытого ключа) либо с одним (исходный или шифрованный текст в виде строки). Для шифрования текста с заданными значениями  и
и  вычисление необходимых значений открытого ключа осуществляется внутри метода класса в соответствии с описанием алгоритма. Шифрование и дешифрование текста с известными значениями открытого и закрытого ключа осуществляются при помощи методов textEncrypt и textDecrypt соответственно. Каждый из этих методов осуществляет посимвольное преобразование, используя механизм возведения в степень по модулю (см. раздел 1). Исходный код методов приведен в листинге 4. Блоки байтов при шифровании отделяются друг от друга символом «*».
вычисление необходимых значений открытого ключа осуществляется внутри метода класса в соответствии с описанием алгоритма. Шифрование и дешифрование текста с известными значениями открытого и закрытого ключа осуществляются при помощи методов textEncrypt и textDecrypt соответственно. Каждый из этих методов осуществляет посимвольное преобразование, используя механизм возведения в степень по модулю (см. раздел 1). Исходный код методов приведен в листинге 4. Блоки байтов при шифровании отделяются друг от друга символом «*».
Листинг 4. Исходный код методов шифрования и дешифрования
private string encrypt(int symbol, BigInteger keyE, BigInteger keyN)
{
return BigInteger.ModPow(symbol, keyE, keyN).ToString();
}
private int decrypt(int symbol, BigInteger keyD, BigInteger keyN)
{
return (int)(BigInteger.ModPow(symbol, keyD, keyN));
}
private string textEncrypt(string text, BigInteger e, BigInteger n)
{
string eText = "";
foreach (var symbol in text)
eText += encrypt(symbol, e, n) + this.blockSep;
return eText;
}
private string textDecrypt(string text, BigInteger d, BigInteger n)
{
string[] arr = text.Split(this.blockSep);
string dText = "";
foreach (var symbol in arr)
if (symbol != string.Empty)
dText += Convert.ToChar(decrypt(int.Parse(symbol), d, n));
return dText;
}
Для работы с длинными числами здесь используется тип данных BigInteger. Этот целочисленный тип данных отображается на тип System.Numerics.BigInteger библиотеки Microsoft .NET Framework, позволяющий записывать и обрабатывать целые числа практически неограниченной длины. Для данных типа BigInteger реализованы арифметические операции сложения, вычитания, умножения и деления. Операция деления, в отличие от других целочисленных типов данных, возвращает не вещественное значение, а результат целочисленного деления, имеющий тип BigInteger. Метод класса BigInteger.ModPow(p, q, k) возвращает остаток от целочисленного деления на k значения p в степени q.
Функция generatePQ генерирует значения  и
и  , а также вычисляет соответствующие значения функции Эйлера, открытого и закрытого ключей.
, а также вычисляет соответствующие значения функции Эйлера, открытого и закрытого ключей.
Простые числа выбираются из диапазона (10000, 20000) – генерируется пара чисел, каждое из которых проверяется на простоту при помощи алгоритма Миллера-Рабина с 10 раундами до тех пор, пока оба выбранных числа не окажутся простыми. Исходный код функции представлен в листинге 5.
Листинг 5. Исходный код функции генерации p и q
private void getPrimeNum(Random rnd, out int n1, out int n2)
{
int firstNumber;
int secondNumber;
do
{
firstNumber = rnd.Next(10000, 20000);
secondNumber = rnd.Next(10000, 20000);
}
while (!Utilities.MillerRabin(firstNumber, 10) || !Utilities.MillerRabin(secondNumber, 10));
n1 = firstNumber;
n2 = secondNumber;
}
Набор методов для алгоритма RSA получения открытого и закрытого ключей, описанного в разделе 1, приводится в листинге 6. Функция NOD вычисляет НОД (Наибольший Общий Делитель) для проверки взаимной простоты в методе нахождения числа e. Вызов методов осуществляется внутри функции generatePQ, которая инициализирует поля класса RSA значениями для открытого и закрытого ключей.
Листинг 6. Набор методов для получения открытого и закрытого ключей в соответствии с алгоритмом RSA
// 2. найти модуль
private BigInteger getN(int p, int q)
{
return p * q;
}
// 3. найти значение функции Эйлера fi
private BigInteger getFi(int p, int q)
{
return (p - 1) * (q - 1);
}
// 4. выбрать число е, взаимное простое с fi
private BigInteger getPrime(Random rnd, BigInteger fi)
{
BigInteger e = rnd.Next(1, Math.Abs((int)fi));
do
{
if (NOD(e, fi) == 1)
break;
else e++;
} while (true);
if (e >= fi)
{
e--;
do
{
if (NOD(e, fi) == 1)
break;
else e--;
} while (true);
}
return e;
}
// 5. найти d при помощи расширенного алгоритма Евклида
private BigInteger getD(BigInteger e, BigInteger fi)
{
BigInteger i = fi, v = 0, d = 1;
while (e > 0)
{
BigInteger t = i / e, x = e;
e = i % x;
i = x;
x = d;
d = v - t * x;
v = x;
}
v %= fi;
if (v < 0)
v = (v + fi) % fi;
return v;
}
Полный исходный код программы приведен в приложении 1.
Тестовый пример, приведенный в данном подразделе, можно рассматривать как руководство пользователя. Для запуска программы достаточно запустить файл RSAForm.exe. Программа корректно работает в MS Windows 7/8/10. Установка не требуется.
Пример шифрования при помощи ввода текста в верхнее текстовое и нажатия кнопки «Зашифровать» приведен на рисунке 4.

Рисунок 4 – Шифрование текста с генерацией p и q
При выборе ручного ввода значений  и
и  программа проверяет числа на простоту, и в случае ошибки выдает сообщение (рисунок 5).
программа проверяет числа на простоту, и в случае ошибки выдает сообщение (рисунок 5).

Рисунок 5 – Сообщение об ошибке при попытке ручного ввода чисел
Функции приложения могут быть проверены без ввода секретного ключа. Для этого необходимо, не меняя результат шифрования текста в нижнем текстовом поле, нажать кнопку «Расшифровать» в левой верхней части окна (рисунок 6). Результат представлен на рисунке 7.

Рисунок 6 – Выбор дешифрования только что зашифрованного текста

Рисунок 7 – Результат дешифрования только что зашифрованного текста
На рисунке 8 приведен результат шифрования при помощи значений p и q, заданных вручную.

Рисунок 8 – Шифрование текста при помощи заданных вручную значений p и q
Для дешифрования этого текста необходимо использовать закрытый ключ. Результат такого дешифрования приведен на рисунке 9.

Рисунок 9 – Результат дешифрования при помощи закрытого ключа
ЗАКЛЮЧЕНИЕ
В работе были изучены методы кодирования данных, среди которых подробно рассмотрены сжатие данных и шифрование информации. Получено представление о теории циклических избыточных кодов.
Сжатие и архивация данных являются удобными способами использовать связанные между собой файлы вместе, позволяя при этом значительно сэкономить занимаемое пространство. Однако при работе с различными форматами архивов важно осознавать недостатки производительности и проблемы совместимости, которые могут встречаться в каждом из этих решений. Насколько большое внимание конечные пользователи должны уделять этим деталям, полностью зависит от устройств, на которых они работают.
Сжатие файлов экономит место для хранения и ускоряет передачу данных, но оно также может занять много времени. Сжатие данных требует значительных ресурсов процессора, а сжатие набора данных в несколько терабайт может потребовать огромных вычислительных мощностей.
В ходе выполнения работой было выполнено ознакомление с понятием шифрования с открытым ключом и подробно рассмотрены алгоритмы RSA и Диффи-Хеллмана. Также было выполнено ознакомление с ключевыми понятиями теории циклических избыточных кодов, подробно рассмотрен алгоритм CRC, сформулированы алгоритмы построения таблицы и вычисления контрольной суммы по этому алгоритму. Также было выполнено обоснование выбора языка программирования и среды разработки, итогом которого стала реализация алгоритмов RSA и CRC на языке высокого уровня C# в виде оконных приложений Windows.Forms в среде Visual Studio 2019.
Разработанные программы имеют понятный графический интерфейс, выводят все необходимые пояснения и подсказки, являются законченными и удобными для использования. Таким образом, цели и задачи курсовой работы выполнены в полном объеме.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Аршинов М. Н. Коды и математика / М.: Наука, 1983. – 257 с.
- Буркатовская Ю. Б. Быстродействующие алгоритмы деления полиномов в арифметике по модулю два / Ю. Б. Буркатовская, А. Н. Мальчуков, А. Н. Осокин // Изв. Томск. политехн. ун-та. – 2006. – № 1 (309). – с. 19–24.
- Демидович, Е.М. Основы алгоритмизации и программирования. Учебное пособие / Е. М. Демидович. - 2-е изд., испр. и доп. - СПб. : БХВ - Петербург, 2008. - 440 с.
- Документация по семейству продуктов Visual Studio [Электронный ресурс]. – Режим доступа: https://docs.microsoft.com/ru-ru/visualstudio/?view=vs-2019 – (Дата обращения – 25.04.2020).
- Коробейников А. Г, Ю.А.Гатчин. Математические основы криптологии. Учебное пособие / СПб: СПб ГУ ИТМО, 2004. – 106 с.
- Коутинхо С. Введение в теорию чисел. Алгоритм RSA / М.: Постчаркет, 2001. – 328 с.
- Мыцко Е. А. Особенности программной реализации вычисления контрольной суммы CRC32 на примере PKZIP, WINZIP, ETHERNET / Е. А. Мыцко, А. Н. Мальчуков // Вестн. науки Сибири. – 2011. – № 1 (1). – с. 279–282.
- Олифер В. Г. Компьютерные сети. Принципы, технологии, протоколы / В. Г. Олифер, Н. А. Олифер. ‒ СПб.: Питер, 2008. ‒ 958 с.
- Темников Ф. Е. Теоретические основы информационной техники: учеб. пособие. – 2-е изд., испр. и доп. / Ф. Е. Темников, В. А. Афонин, В. И. Дмитриев. – М.: Энергия, 1979. – 512 с.
- Яковлев В. В. Оценка влияния помех на производительность протоколов канального уровня / В. В. Яковлев, Ф. И. Кушназаров // Изв. Петерб. гос. ун-та путей сообщения. – СПб.: ПГУПС, 2015. – Вып. 1 (42). – с. 133–138.
- Arthur-Durett K. The Weakness Of Winrar Encrypted Archives To Compression Side-channel Attack, Open Access Theses, Purdue University, 2014
- C# docs [Электронный ресурс]. – Режим доступа: https://docs.microsoft.com/ru-ru/dotnet/csharp/ – (Дата обращения – 19.04.2020).
- Halsall F. Data communications, computer networks and open systems / F. Halsall. – Addison-Wesley: Pearson Education, 1996. ‒ 907 р.
- Hamilton J. Creating ZIP Files with ODS, Division of Research, Kaiser Permanente, Oakland, California, Paper 131-2013, SAS Global Forum 2013
- Ross N. W. A Painless guide to CRC error detection algorithms / N. W. Ross. – 16 Lerwick Avenue, Hazelwood Park, 5066. – Australia, 1993. – URL: http://www.ross.net/crc/download/crc_v3.txt (дата обращения: 18.04.2020).
- Systems Engineering and Software Development Life Cycle Framework [Электронный ресурс]. – Режим доступа: http://opensdlc.org/mediawiki/index.php?title=Main_Page – (Дата обращения – 25.04.2020).
- Tar Vs Zip VsGz: Difference And Efficiency [Электронный ресурс] / URL: https://itsfoss.com/category/linux/ (Дата обращения: 22.04.2020)
- WinRAR Download and Support [Электронный ресурс] / URL: http://www.win-rar.com/rarproducts.html (Дата обращения: 24.04.2020)
- ZIP Format Specification [Электронный ресурс] / URL: http://www.pkware.com/documents/casestudies/APPNOTE.TXT (Дата обращения: 23.04.2020)
Приложение 1. Исходные коды программ
Листинг А1. RSA.cs
using System;
using System.Collections.Generic;
using System.Numerics;
namespace RSAForm
{
public class RSA
{
private char blockSep = '*';
private static Random rnd;
private BigInteger e;
private BigInteger d;
private BigInteger n;
public RSA()
{
this.initParams();
}
public RSA(char blockSep)
{
this.blockSep = blockSep;
this.initParams();
}
private void initParams()
{
rnd = new Random();
int p = 0, q = 0;
generatePQ(out p, out q);
}
private void getPrimeNum(Random rnd, out int n1, out int n2)
{
int firstNumber;
int secondNumber;
do
{
firstNumber = rnd.Next(10000, 20000);
secondNumber = rnd.Next(10000, 20000);
}
while (!Utilities.MillerRabin(firstNumber, 10) || !Utilities.MillerRabin(secondNumber, 10));
n1 = firstNumber;
n2 = secondNumber;
}
private BigInteger NOD(BigInteger a, BigInteger b)
{
while (a != 0 && b != 0)
{
if (a > b)
a %= b;
else
b %= a;
}
return a == 0 ? b : a;
}
// 2. найти модуль
private BigInteger getN(int p, int q)
{
return p * q;
}
// 3. найти значение функции Эйлера fi
private BigInteger getFi(int p, int q)
{
return (p - 1) * (q - 1);
}
// 4. выбрать число е, взаимное простое с fi
private BigInteger getPrime(Random rnd, BigInteger fi)
{
BigInteger e = rnd.Next(1, Math.Abs((int)fi));
do
{
if (NOD(e, fi) == 1)
break;
else e++;
} while (true);
if (e >= fi)
{
e--;
do
{
if (NOD(e, fi) == 1)
break;
else e--;
} while (true);
}
return e;
}
// 5. найти d при помощи расширенного алгоритма Евклида
private BigInteger getD(BigInteger e, BigInteger fi)
{
BigInteger i = fi, v = 0, d = 1;
while (e > 0)
{
BigInteger t = i / e, x = e;
e = i % x;
i = x;
x = d;
d = v - t * x;
v = x;
}
v %= fi;
if (v < 0)
v = (v + fi) % fi;
return v;
}
private string encrypt(int symbol, BigInteger keyE, BigInteger keyN)
{
return BigInteger.ModPow(symbol, keyE, keyN).ToString();
}
private int decrypt(int symbol, BigInteger keyD, BigInteger keyN)
{
return (int)(BigInteger.ModPow(symbol, keyD, keyN));
}
private string textEncrypt(string text, BigInteger e, BigInteger n)
{
string eText = "";
foreach (var symbol in text)
eText += encrypt(symbol, e, n) + this.blockSep;
return eText;
}
private string textDecrypt(string text, BigInteger d, BigInteger n)
{
string[] arr = text.Split(this.blockSep);
string dText = "";
foreach (var symbol in arr)
if (symbol != string.Empty)
dText += Convert.ToChar(decrypt(int.Parse(symbol), d, n));
return dText;
}
public string getEncryptedText(string originalText)
{
return textEncrypt(originalText, this.e, this.n);
}
public string getEncryptedText(string originalText, int p, int q)
{
BigInteger fi = getFi(p, q);
this.n = getN(p, q);
this.e = getPrime(rnd, fi);
this.d = getD(e, fi);
Console.WriteLine("d = {0}, n = {1}", this.d.ToString(), this.n.ToString());
return textEncrypt(originalText, this.e, this.n);
}
public string getDecryptedText(string encryptedText)
{
return textDecrypt(encryptedText, this.d, this.n);
}
public string getDecryptedText(string encryptedText, BigInteger d, BigInteger n)
{
this.d = d;
this.n = n;
return textDecrypt(encryptedText, this.d, this.n);
}
public void generatePQ(out int p, out int q)
{
getPrimeNum(rnd, out q, out p);
BigInteger fi = getFi(p, q);
this.n = getN(p, q);
this.e = getPrime(rnd, fi);
this.d = getD(e, fi);
}
}
}
Листинг А2. Utilities.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Numerics;
using System.Text;
namespace RSAForm
{
public class Utilities
{
public static bool MillerRabin(int n, int k)
{
for (int i = 0; i < k; i++) // цикл по количеству раундов
{
// проверка элементарных случаев:
if (n % 2 == 0)
return false;
if (n == 2)
return true;
if (n <= 1)
return false;
// представление n - 1 как 2 ^ s * m
int s = 0;
int m = n - 1;
while (m % 2 == 0)
{
s++;
m = m / 2;
}
// выбор случ. целого числа a в отрезке [2, n − 2]
Random r = new Random();
int a = r.Next(n - 1) + 1;
// поиск mod = a ^ m % n
int temp = m;
long mod = 1;
for (int j = 0; j < temp; j++)
mod = (mod * a) % n;
// вычислить в цикле mod как mod ^ 2 % n
while (temp != n - 1 && mod != 1 && mod != n - 1)
{
mod = (mod * mod) % n;
temp *= 2;
}
// если mod = 1, то составное
// если mod != n - 1, то составное
if (mod != n - 1 && temp % 2 == 0)
return false;
}
return true; // вернуть "вероятно простое"
}
}
}
Листинг А3. Form1.cs
using System;
using System.Windows.Forms;
namespace RSAForm
{
public partial class Form1 : Form
{
RSA rsa;
public Form1()
{
InitializeComponent();
rsa = new RSA();
}
private void TextBox_p_KeyPress(object sender, KeyPressEventArgs e)
{
if (!char.IsControl(e.KeyChar) && !char.IsDigit(e.KeyChar))
{
e.Handled = true;
}
}
private void ButtonEncrypt_Click(object sender, EventArgs e)
{
string plaintext = textBox_plaintext.Text;
int p, q;
if (!generatePQ.Checked)
{
if (!int.TryParse(textBox_p.Text, out p) || !Utilities.MillerRabin(p, 10))
{
MessageBox.Show("Не удалось считать простое число p!", "Ошибка", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
if (!int.TryParse(textBox_q.Text, out q) || !Utilities.MillerRabin(q, 10))
{
MessageBox.Show("Не удалось считать простое число q!", "Ошибка", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
textBox_ciphertext.Text = rsa.getEncryptedText(plaintext, p, q);
}
else
{
rsa.generatePQ(out p, out q);
textBox_p.Text = p.ToString();
textBox_q.Text = q.ToString();
textBox_ciphertext.Text = rsa.getEncryptedText(plaintext);
}
sameDecipherButton.Enabled = true;
}
private void ButtonDecipher_Click(object sender, EventArgs e)
{
string cipherText = textBox_ciphertext.Text;
int d, n;
if (!int.TryParse(textBox_d.Text, out d))
{
MessageBox.Show("Не удалось считать число d!", "Ошибка", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
if (!int.TryParse(textBox_n.Text, out n))
{
MessageBox.Show("Не удалось считать число n!", "Ошибка", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
textBox_plaintext.Text = rsa.getDecryptedText(cipherText, d, n);
}
private void SameDecipherButton_Click(object sender, EventArgs e)
{
string cipherText = textBox_ciphertext.Text;
textBox_plaintext.Text = rsa.getDecryptedText(cipherText);
sameDecipherButton.Enabled = false;
}
private void TextBox_ciphertext_TextChanged(object sender, EventArgs e)
{
sameDecipherButton.Enabled = false;
}
}
}
Листинг B1. Form1.cs
using System;
using System.Collections.Generic;
using System.Drawing;
using System.IO;
using System.Windows.Forms;
namespace CRC32List
{
public partial class FormMain : Form
{
List<string> files = new List<string>(); // список имен файлов
string folder = null; // директория с файлами
int mouseWindowX = 0;
int mouseWindowY = 0;
public FormMain()
{
InitializeComponent();
}
// открытие файла(-ов):
private void button1_Click(object sender, EventArgs e)
{
// выбор начальной директории:
if (folder != null)
{
if (Directory.Exists(folder))
openFileDialog1.InitialDirectory = folder;
}
else
openFileDialog1.InitialDirectory = Environment.GetFolderPath(Environment.SpecialFolder.Desktop);
// открытие файлов при помощи файлового диалога:
DialogResult result = openFileDialog1.ShowDialog();
if (result == DialogResult.OK)
{
folder = Path.GetDirectoryName(openFileDialog1.FileName);
listView2.Items.Clear();
files.Clear();
files.AddRange(openFileDialog1.FileNames);
funcGet();
}
}
// получение списка контрольных сумм и добавление его на форму рядом со списком файлов:
private void funcGet()
{
int count = 0;
foreach (string file in files)
if (File.Exists(file))
{
string[] row = { Path.GetFileName(file), getCRC(file) };
var listViewItem = new ListViewItem(row);
listView2.Items.Add(listViewItem);
count++;
}
filesName.Text = "Файлы (" + count.ToString() + "):";
}
// получение контрольной суммы для переданного файла:
private string getCRC(string file)
{
FileStream streamFile = File.OpenRead(file);
string record = string.Format("{0:X}", calculateCRC(streamFile));
streamFile.Close();
while (record.Length != 8)
record = "0" + record;
return record;
}
// вычисление контрольной суммы:
private uint calculateCRC(Stream stream)
{
const int buffer_size = 1024;
const uint POLYNOMIAL = 0xEDB88320;
uint result = 0xFFFFFFFF;
uint Crc32;
byte[] buffer = new byte[buffer_size];
uint[] table_CRC32 = new uint[256];
unchecked
{
for (int i = 0; i < 256; i++)
{
Crc32 = (uint)i;
for (int j = 8; j > 0; j--)
if ((Crc32 & 1) == 1)
Crc32 = (Crc32 >> 1) ^ POLYNOMIAL;
else
Crc32 >>= 1;
table_CRC32[i] = Crc32;
}
int count = stream.Read(buffer, 0, buffer_size);
while (count > 0)
{
for (int i = 0; i < count; i++)
result = ((result) >> 8) ^ table_CRC32[(buffer[i]) ^ ((result) & 0x000000FF)];
count = stream.Read(buffer, 0, buffer_size);
}
}
stream.Close();
return ~result;
}
private void listView2_DragDrop(object sender, DragEventArgs e)
{
listView2.Items.Clear();
files.Clear();
files.AddRange((string[])e.Data.GetData(DataFormats.FileDrop));
funcGet();
}
private void listView2_DragEnter(object sender, DragEventArgs e)
{
if (e.Data.GetDataPresent(DataFormats.FileDrop, false))
e.Effect = DragDropEffects.All;
}
private void button2_Click(object sender, EventArgs e)
{
Application.Exit();
}
private void pictureBox1_MouseDown(object sender, MouseEventArgs e)
{
mouseWindowX = e.X + 147;
mouseWindowY = e.Y + 344;
pictureBox1.MouseMove += pictureBox1_MouseMove;
}
private void pictureBox1_MouseMove(object sender, MouseEventArgs e)
{
Location = new Point(Cursor.Position.X - mouseWindowX, Cursor.Position.Y - mouseWindowY);
}
private void pictureBox1_MouseUp(object sender, MouseEventArgs e)
{
pictureBox1.MouseMove -= pictureBox1_MouseMove;
}
}
}

- Процессы принятия решений в организации ООО «Компания «Омская Недвижимость»
- Основы работы с операционной системой Windows 7.(История ОС Windows. Семейства 4)
- Интеллектуальная собственность как объект правовой охраны
- Организационное проектирование
- Моделирование предметной области «Управление домашними финансами» с помощью UML
- Основы алгоритмизации и программирования (рассмотрение критериев выбора средств разработки)
- Основные понятия объектно-ориентированного программирования
- Роль мотивации в поведении организации АО ’’Концерн ”НПО ”Аврора”
- Потребительские свойства и показатели качества товаров (Расчет комплексных показателей)
- Коммерческая деятельность розничного торгового предприятия и ее совершенствование (на примере конкретной организации)
- Функция менеджмента (ЗАО "Ваша мебель")
- Кадровая стратегия в системе стратегического управления организацией (ООО «СЕРВИС»)