
Методы кодирования данных, основные понятия
Содержание:

Введение
Цель курсовой работы – рассмотреть методы кодирования данных, дать их подробную характеристику, а также сформулировать выводы по намеченным задачам.
Задачей курсовой работы является рассмотрение цели на основе: основных понятий кодирования и методов кодирования – регистрационных и классификационных; методов кодирования – сжатие или упаковка данных; кодирования как средства защиты информации от несанкционированного доступа; помехоустойчивого кодирования; способов кодирования информации.
Цели и задачи работы определили ее структуру.
Курсовая работа состоит из теоретической части, в которой излагается материал учебных и методических пособий. Актуальность темы «Методы кодирования данных» обосновываем в теоретической части на понятиях: коды, кодировка, кодирование данных, кодирование и методы кодирования; порядковый, серийно-порядковый, последовательный и параллельный методы кодирования данных; методов кодирования, позволяющих построить (без потери информации) коды сообщений, которые имеют меньшую длину по соотношению с исходным сообщением, т.е. методов сжатия или упаковки данных; алгоритма Шеннона-Фано и алгоритма Хаффмена; шифра простой подстановки, шифров перестановки, шифра Виженера и шифрования гаммированием; помехоустойчивого кодирования; способов кодирования информации.
Глава 1. Кодирование. Методы кодирования данных.
Основные понятия
Компьютер с точки зрения пользователя работает с самой разной информацией: числовой, графической, звуковой, текстовой и пр. Чтобы работать с данными различных видов, необходимо унифицировать форму их представления. Это можно сделать с помощью кодирования.3
Различные методы кодирования широко используются в практической деятельности человека с незапамятных времён. Например, десятичная позиционная система счисления – это способ кодирования натуральных чисел. Другой способ кодирования натуральных чисел – римские цифры, причем этот метод более наглядный и естественный, действительно, палец – I, пятерня – V, две пятерни – X. Однако при этом способе кодирования труднее выполнять арифметические операции над большими числами, поэтому он был вытеснен способом кодирования основанном на позиционной десятичной системой счисления. Из этого примера можно заключить, что различные способы кодирования обладают присущими только им специфическими особенностями, которые в зависимости от целей кодирования могут быть как достоинством конкретного способа кодирования, так и его недостатком.11
В процессе кодирования объектам классификации и их группам присваивают цифровые, буквенные или цифро-буквенные обозначения – так называемые коды. Итак, код – это знак или совокупность знаков, применяемых для обозначения объектов классификации и их классификационных группировок. Совокупность методов и правил кодирования классификационных группировок и объектов классификации данного множества составляет коди-
ровку.12
___________________
3 Задохина Н.В. Математика и информатика. Решение логико-познавательных задач: Учебное пособие для студентов вузов / Н.В. Задохина. – М.: ЮНИТИ-ДАНА, 2015. – 5 с.
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 26 с.
12 Информационные системы в финансово-кредитных учреждениях: Учебное пособие [2-изд, перераб. и доп.] / И.Ф. Рогач, М.А. Сендзюк, В.А. Антонюк; Под ред. И.Ф. Рогач. – М.: Финансы, 2001. – 38 с.
Кодирование данных – это процесс формирования определенного представления информации.
В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Также стоит отметить, что кодирование представляет собой процесс перевода информации из одной системы знаков в другую, т.е. перевод записи на естественном языке в запись с помощью кодов.
Любой способ кодирования характеризуется наличием основы, в которую входит алфавит, система координат, основание системы счисления, а также правил конструирования информационных образов на этой основе.9
К методам кодирования предъявляются такие требования, соблюдение которых способствует повышению качества классификатора. Рассмотрим основные аспекты для метода кодирования:
- код метода должен содержать нужную информацию об объекте и проводить в пределах заданного множества объектов классификации его идентификацию;
- код метода должен предусматривать использование кода десятичных цифр и букв в качестве алфавита;
- код метода должен обеспечивать минимальную длину кода и достаточный резерв незанятых позиций для кодирования новых объектов без нарушения структуры классификатора;
- код метода должен быть максимально ориентирован на автоматизированную обработку информации.8
Методы кодирования технико-экономической и социальной информации (ТЭСИ далее по тексту) очень тесно взаимосвязаны с методами классификации, так каждому методу классификации соответствует один или не
_________________
9 Федин Л.Н. Кодирование данных / Л.Н. Федин. – М.: ИНФРА-М, 2008. – 17 с.
8 Титоренко Г.А. Информационные технологии управления / Г.А. Титоренко. – М.: ЮНИТИ-ДАНА, 2002. – 48 с.
сколько методов кодирования.
В классификаторах ТЭСИ используются четыре метода кодирования информации. Полная классификация методов кодирования данных представлена на рис. 1. Если охарактеризовать два основных метода кодирования данных, то регистрационный метод кодирования – это метод кодирования, который носит самостоятельный характер, а классификационный метод кодирования – основан на предварительной классификации объектов.
Далее рассмотрим подробнее регистрационный и классификационный методы кодирования.6
Методы кодирования
Классификационные
Регистрационные
Параллель-ный
Последова-тельный
Серийно-порядковый
Порядковый
Рис. 1. Классификация методов кодирования данных
1.1. Регистрационные методы кодирования данных
Регистрационные методы кодирования – это методы, при которых кодовыми обозначениями служат числа натурального цифрового ряда или числа натурального цифрового ряда с закреплением отдельных диапазонов (серий) этих чисел за элементами классификации с одинаковыми признаками. Они полностью идентифицируют объект, но не отражают существенную призначную информацию о нем в коде.
__________________
6 Минаева И.Б. Информационное обеспечение деятельности / И.Б. Минаева. – М.: Секретарское дело, 2006. – 124 с.
Необычностью регистрационных систем кодирования служит их незави-
симость от применяемых систем классификации. Регистрационные коды используются для идентификации объектов и передачи информации об объектах на расстояние, поэтому они должны удовлетворять следующим условиям:
- минимальность длины кода;
- однозначность соответствия наименования объекта и его кода в течение длительного периода времени;
- защищенность кода от помех и ошибок.
Регистрационные коды состоят из двух частей – информационной и контрольной, последняя предназначена для защиты передаваемой информации от ошибок, существуют различные алгоритмы ее просчета, например, наиболее употребляемыми являются последующие две формулы расчета:
K = M - [∑Xi / M]
K = M - [∑xi×B / M]
где М – модуль (простое число, делящееся на единицу и на само себя)
i – номер разряда
Хi – информационные разряды
В – вес информационного разряда
Регистрационный метод по большей части прост – каждый объект исходного кодируемого множества обозначается с помощью текущего номера, символы, которые использованы для образования текущего номера (кода), образуют алфавит кода, в котором число различных символов называют основанием кода. Например, при кодировании с помощью десятичных чисел основание кода равно 10, т.к. используется 10 различных цифр.
Недостатками данного метода кодирования данных являются отсутствие дополнительной информации об объекте и трудность проведения поиска закодированной информации в базе данных. Поэтому данный метод применяют только для кодирования существенно небольших объемов информации, к
примеру – нумерация анкет.13
В свою очередь, регистрационные методы кодирование бывают двух видов: порядковый и серийно-порядковый.5
Далее рассмотрим подробнее порядковый и серийно-порядковый методы кодирования.
1.1.1. Порядковый метод кодирования
Порядковый метод кодирования – предполагает использование в качестве кодов чисел натурального ряда (например, номера страниц в книге). Это – негибкая система, поскольку каждый новый объект можно записать лишь после ранее закодированного, что приводит к нарушению логического расположения классифицируемых объектов.5 В этом случае каждый из объектов классифицируемого множества кодируется таким образом, что ему присваивается порядкового номер без какого-либо пропуска номеров. Новые элементы получают номера в конце имеющегося перечня. Здесь не требуется предварительной классификации. Последовательность присвоения кодов определяется в большинстве случаев хронологией возникновения информации. Примером использования порядкового метода кодирования может служить систематизация домов на улице, квартир в доме.
Порядковый метод является наиболее простым, он заключается в сквоз-
ной последовательности порядковой регистрации объектов. Чаще всего для удобства обработки информации используется равномерный код, в котором число разрядов в каждом кодовом обозначении одинаково. Число объектов, которое можно закодировать при применении этого метода, зависит от основания кода и числа разрядов в кодовом обозначении.
Текущий метод кодирования данных обеспечивает достаточно большую
____________________________________
13 Проектирование автоматизированных систем обработки информации и управления: Учебное пособие / Д.В. Гайчук, М.В. Самус, А.П. Жук; Под ред. Д.В. Гайчук. – Ставрополь.: СВИС РВ, 2009. – 56-57 с.
5 Ларьков Н.С. Документоведение: 3-е издание. Учебник / Н.С. Ларьков. – ООО «Проспект», 2015. – 291 с.
5 Ларьков Н.С. Документоведение: 3-е издание. Учебник / Н.С. Ларьков. – ООО «Проспект», 2015. – 291-292 с.
долговечность классификатора при невесомой избыточности кода. Также метод обладает предельной простотой, использует преимущественно короткие
коды и вернее обеспечивает однозначность каждого объекта классификации.
Существенными недостатками порядкового метода кодирования данных служат отсутствие в коде конкретной информации о свойствах объекта, а также сложность машинной обработки информации при получении итогов по группе объектов классификации с одинаковыми признаками. Данный метод кодирования не обеспечивает возможности размещения вновь появившихся объектов классификации в необходимом месте классификатора, т.к. резервные коды располагаются в конце ряда. Поэтому этот метод кодирования рекомендуется использовать для небольших, преимущественно простых и постоянных множеств, например, таких как – категории работающих, виды образования, национальность, единицы измерения.
По этим же причинам порядковый метод самостоятельно редко применяется при создании классификаторов, а напротив чаще всего он применяет-
ся в сочетании с другими методами кодирования.1
1.1.2. Серийно-порядковый метод кодирования
Серийно-порядковый метод кодирования – это метод, при котором кодами служат также числа натурального ряда, однако отдельные серии этих чисел закрепляются за объектами классификации с одинаковыми признаками. Иначе говоря, на каждую крупную классификационную рубрику отводится серия порядковых номеров, например, от 1 до 100 (первая серия), от 101 до 200 (вторая серия) и т.д.5
В каждой серии, за исключением кодов имеющихся объектов классифи-
кации, предусматривается определенное количество кодов для резерва, кото-
___________________
1 Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Питер, 2011. – 126-128 с.
5 Ларьков Н.С. Документоведение: 3-е издание. Учебник / Н.С. Ларьков. – ООО «Проспект», 2015. – 292 с.
рый располагается в середине или в конце кода. Это, несомненно, является
немалым преимуществом данного метода по сравнению с порядковым методом кодирования данных. Серийно-порядковый метод характеризуется назначением конкретной серии порядковых номеров для кодирования группы сходных объектов с выделением одного, возможно, и нескольких отдельных разрядов (при основании кода, как правило, равным 10 или кратным ему), т.е. ступенчатым использованием нескольких порядковых перечислений объектов, которые соподчинены друг другу. Впрочем, и при таком условии в коде отсутствует определенная информация о существенных признаках, которые характеризуют свойства особливых объектов классификации, что создает трудность для автоматизированной обработки информации при суммировании итогов по группе объектов.
Серийно-порядковый метод кодирования предполагает, что информацию можно разделить по тому или иному признаку на отдельные части (серии), которым отводится своя группа условных обозначений. В данном случае номера единиц информации будущих серий не продолжают точно последовательно номера имеющихся единиц информации предыдущей серии, а напротив, между ними возникает разрыв. Примером данного метода служит кодирование цехов на предприятиях, так, если имеется 10 основных цехов и 3 вспомогательных, то их можно закодировать следующим образом: 01, 02, ..., 10 и 25, 26, 27.
Данный метод кодирования обладает теми же преимуществами и недостатками, какими обладает порядковый метод кодирования данных. Несмотря на наличие в кодах определенных элементов классификации, созданных по этому же методу кодирования, они зачастую используются для идентификации объектов в сочетании с классификационными методами кодирования данных.
Серийно-порядковый метод используется для множеств, которые имеют
классификацию по двум признакам: старшему признаку назначается своя
группа номеров, в которой все элементы младшего признака кодируются по
порядку. Стоит отметить, что поэтому данный метод и называется серийно-порядковым методом кодирования данных. Размер серии устанавливается с учетом количества элементов младшего признака и необходимого резерва свободных номеров на момент расширения. Для новых номеров выделяются кодовые обозначения из резерва свободных номеров серии, которая соответствует.
Исходя и этого, данный метод разумно применять для объектов, имеющих два или больше порядковых признака. Точнее говоря, этот метод рассматривается как использование иерархического метода классификации с серийно-порядковым методом кодирования.1
В дополнение к описанному выше виду серийно-порядкового метода кодирования часто используется его разновидность, которая заключается в выделении серии порядковых номеров, в пределах которых объекты кодируются в регистрационном порядке. При этом количество выделенных номеров в серии не соответствует постоянному десятичному или кратному ему основанию кода. Данное количество чаще всего не подчиняется определенному закону и содержит переменное значение в зависимости от количества объектов в данной серии, что не дает возможность закрепить за серией постоянный разряд или группу разрядов кодового обозначения. Символично можно сказать, что при данном кодировании используется переменный алфавит и основание кода. Например, с 1-го номера по 5-й закодирована одна группа объектов, с 6-го по 12-й другая, с 13-го по 25-й третья и т.д.10
Серийно-порядковый метод кодирования данных гарантирует получение итогов по сериям, но только по одному классификационному признаку, а также позволяет сохранять принцип при расширении номенклатуры. Но т.к. предвидеть запас кодов трудно, то на практике серийность иногда нарушается, поэтому к недостаткам этого метода можно отнести то, что размер серии
____________________
1 Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Питер, 2011. – 129 с.
10 Харитонов Г.Б. Технологии программирования в сфере услуг: Учебник / Г.Б. Харитонов. – М.: Научный Мир, 2009. – 227 с.
не всегда предусматривается. Данный метод удобен для относительно устойчивых номенклатур, так, его рекомендуется использовать для кодирования цехов, видов оплат и удержаний.13
1.2. Классификационные методы кодирования данных
Классификационные методы кодирования – это методы, при которых в кодовом обозначении последовательно указываются зависимые или наоборот независимые признаки классификации. Они дают важную призначную информацию об объектах, но, однако, обладают ограниченными возможностями идентифицировать их.
Данные методы основаны на предварительной классификации объектов ориентированы на проведение предварительной классификации объектов на основе иерархической или фасетной классификации.
Классификационные методы кодирования в свою очередь бывают двух видов и строятся на основе разрядной (позиционной) или комбинированной систем кодирования:
• последовательный;
• параллельный.1
Далее рассмотрим подробнее последовательный и параллельный методы кодирования.
1.2.1. Последовательный метод кодирования
Последовательный метод кодирования – метод, при котором код классификационной группировки и (или) объекта классификации образуется с использованием кодов последовательно расположенных подчиненных груп-
___________________
13 Проектирование автоматизированных систем обработки информации и управления: Учебное пособие / Д.В. Гайчук, М.В. Самус, А.П. Жук; Под ред. Д.В. Гайчук. – Ставрополь.: СВИС РВ, 2009. – 64 с.
1 Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Пи-тер, 2011. – 131 с.
пировок, полученных при иерархическом методе кодирования. В данном случае код нижестоящей группировки образуется с помощью добавления определенного количества разрядов к коду вышестоящей группировки. Последовательный метод кодирования обычно используют при иерархическом методе классификации.10
Чтобы понять последовательный метод кодирования данных наглядно рассмотрим и изобразим, как присваиваются кодовые обозначения наименованиям материалов по укрупненной номенклатуре. Для этого материалы делят на классы, каждый класс соответственно на подклассы, подкласс – на группы, группы – на подгруппы, а каждая подгруппа содержит четкое число наименований, сортов и размеров материалов.
Пример:
- класс – основные и вспомогательные материалы;
- подкласс – черные, цветные металлы и т.д.;
- группа для черных металлов – чугун, сталь и т.д.;
- подгруппа для стали – круглая, листовая и т.п.
И конечно же, подытожив, всякий материал имеет сорт и размер.1
Преимуществами последовательного метода кодирования данных являются логичность построения кода, большая емкость при высокой информативности и возможность получения итогов по старшим разрядам.
Несмотря на все преимущества, данный метод влечет за собой большую значимость и сложность построения кода, а также обладает урезанными возможностями распознавания объектов. Использование этого метода кодирования связано с трудностями, которые обусловлены тем, что в итоге зависимости последующих разрядов кода от предыдущих применять этот код по частям нельзя, также очень сложно группировать объекты по различным сочетаниям имеющихся признаков, очевидно, что практически невозможно
___________________
10 Харитонов Г.Б. Технологии программирования в сфере услуг: Учебник / Г.Б. Харитонов. – М.: Научный Мир, 2009. – 229 с.
1 Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Пи-тер, 2011. – 132 с.
вносить новые признаки и производить изменения в коде без исконной перестройки классификатора. Поэтому можно сделать вывод, что применять последовательный метод кодирования данных рационально в случаях, когда набор признаков классификации и их последовательность стабильны в течение длительного времени.13
1.2.2. Параллельный метод кодирования данных
Параллельный метод кодирования – образование кода классификационной группировки и (или) объекта классификации с использованием кодов независимых группировок, полученных при фасетном методе классификации. При данном методе кодирования данных признаки объекта кодируются автономно друг от друга. Для параллельного метода кодирования данных возможны два варианта записи кодов объекта:
- каждый фасет и признак внутри него имеют свои коды, включающиеся в состав кода объекта – данный способ записи удобно применять в том случае, когда объекты характеризуются неодинаковым набором признаков и различны их числом. При формировании кода любого объекта берутся исключительно необходимые признаки;
- для определения групп объектов выделяется фиксированный набор признаков и устанавливается стабильный порядок их следования, то есть устанавливается фасетная формула. В этом случае не нужно всякий раз указывать значение какого признака приведено в тех или иных разрядах кода объекта.
В качестве примера рассмотрим классификацию сотрудников предприятия. Здесь учитываются следующие классификационные признаки: пол, возраст, образование, семейное положение и др. Бесспорно все эти признаки не
___________________
13 Проектирование автоматизированных систем обработки информации и управления: Учебное пособие / Д.В. Гайчук, М.В. Самус, А.П. Жук; Под ред. Д.В. Гайчук. – Ставрополь.: СВИС РВ, 2009. – 66 с.
зависят друг от друга.1
Рассмотрим еще один пример применения параллельного метода кодирования и отразим его в Таблице 1. Исходными данными служат: на предприятии имеются 6 видов материалов и 99 их наименований, которые могут располагаться на 3 складах, требуется найти код масляной краски.10
Таблица 1.
Применение параллельного метода кодирования
на основе данных предприятия
|
Вид материала |
Код |
Склад |
Код |
Материал |
Код |
|
Сырье |
1 |
Сырья и материалов |
1 |
Краска масляная |
01 |
|
Полуфабрикаты |
2 |
ГСМ |
2 |
Гвозди обойные |
02 |
|
Топливо |
3 |
Стройматериалов |
3 |
Белила цинковые |
03 |
|
Запчасти |
4 |
Мазут |
04 |
||
|
Тара |
5 |
Ящики упаковочные |
05 |
||
|
Стройматериалы |
6 |
… |
Искомый код масляной краски составляет 6301.
К преимуществам параллельного метода кодирования данных относится гибкость структуры кода, обусловленная самостоятельностью признаков, из кодов которых строится код объекта классификации. Данный метод позволяет использовать при решении ТЭСИ те коды и тех признаков объектов, которые существенно важны, что при этом дает возможность работать в каждом индивидуальном случае с кодами небольшой длины. При этом методе кодирования данных целиком и полностью можно осуществлять группировку
___________________
1 Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Питер, 2011. – 133-134 с.
10 Харитонов Г.Б. Технологии программирования в сфере услуг: Учебник / Г.Б. Харитонов. – М.: Научный Мир, 2009. – 231 с.
объектов по абсолютно каждому сочетанию признаков. Этот метод кодирования прекрасно приспособлен для машинной обработки информации – по конкретной кодовой комбинации легко узнать, набором каких характеристик обладает рассматриваемый объект. В результате чего из небольшого числа признаков можно образовать большое число кодовых комбинаций. Набор признаков при необходимости может легко пополняться присоединением кода нового признака – это свойство параллельного метода кодирования особенно важно при решении технико-экономических задач, состав которых часто меняется.
Параллельный метод кодирования уместно использовать для кодирования однородных объектов, т.к. в противном случае реальной становится лишь малосущественная часть сочетаний признаков, а емкость классификатора будет использоваться не полностью, что является большим недостатком данного метода кодирования данных.1
Рассмотрев главу 1 можно сделать вывод, что приведенные классификационные методы кодирования данных (последовательный и параллельный) характеризуются тем, что при глубокой классификации объектов код несет информацию о классификационной группировке, но не всегда опознает конкретный объект, а коды, полученные на основе регистрационных методов кодирования данных (порядковый и серийно-порядковый) при том, что хорошо выполняют функцию идентификации объектов, на деле почти не несут информацию об их свойствах. Поэтому регистрационные и классификационные методы кодирования данных чаще всего применяются в классификаторах в сочетании друг с другом.
___________________
1 Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Питер, 2011. – 136 с.
Глава 2. Методы кодирования - сжатие или упаковка данных
Довольно часто в отдельный класс выделяют методы кодирования, которые позволяют построить (без потери информации) коды сообщений, имеющие меньшую длину по сравнению с исходным сообщением. Такие методы кодирования называют методами сжатия или упаковки данных. Качество сжатия определяется коэффициентом сжатия, который обычно измеряется в процентах и который показывает на сколько процентов кодированное сообщение короче исходного.11
Сжатие данных (data compression) – технический прием сокращения объема (размеров) записи данных на их носителе (жестком магнитном диске, дискете, магнитной ленте), реализуется разными методами, предпочтительно использующими кодирование (повторяющихся слов, фраз, символов). Выделяют две группы режимов сжатия данных – статическую и динамическую. Различают также виды сжатий:
- физическое и логическое;
- симметричное и асимметричное;
- адаптивное, полуадаптивное и неадаптивное кодирование;
- сжатие без потерь, с потерями и минимизацией потерь.7
Алгоритм Шеннона-Фано – один из первых алгоритмов сжатия, который впервые сформулировали американские ученые Шеннон и Роберт Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже и является логическим продолжением алгоритма Шеннона.14
Далее рассмотрим подробнее алгоритмы Шеннона-Фано и Хаффмана.
___________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 28 с.
7 Русанов К.Л. Приемы сокращения объемов информации / К.Л. Русанов. – М.: ЮНИТИ-ДАНА, 2013. – 58 с.
14 https://ru.wikipedia.org/wiki/
2.1. Алгоритм Шеннона-Фано
Суть алгоритма Шенона-Фано заключается в том, что все символы алфавита источника сообщений ранжируют, т.е. располагают в порядке убывания вероятностей их появления и при использовании двоичного кода объем алфавита элементов символов кода равен 2. Впоследствии символы алфавита делятся на две группы примерно равной суммарной вероятности их появления. Все символы первой группы в качестве первого элемента кодового символа получают «0», а все символы второй группы – «1». Дальше группы делятся на подгруппы, по тому же правилу примерно равных суммарных вероятностей, и в каждой подгруппе присваивается вторая позиция кодовых символов. Процесс повторяется до закодирования всех символов алфавита кодируемого источника сообщений. В кодовый символ, который соответствует последней группе, добавляется в качестве последнего элемента «0» для того, чтобы начальный элемент символов кода не совпадал с конечным, что позволяет исключить разделительные элементы между символами кода (см. Таблицу 2 – построения кода Шеннона-Фано на примере источника сообщений, алфавит которого состоит из восьми символов).
Таблица 2
Процесс построения кода Шеннона-Фано
|
Номер |
Символы |
Вероятности |
Номера разбиений |
Кодовые символы |
|
символа (i) |
алфавита (mi) |
(Рi) |
символы |
|
|
1 |
m1 |
1/2 |
I |
0 |
|
2 |
m2 |
1/4 |
II |
10 |
|
3 |
m3 |
1/8 |
III |
110 |
|
4 |
m4 |
1/16 |
IV |
1110 |
|
5 |
m5 |
1/32 |
V |
11110 |
|
6 |
m6 |
1/64 |
VI |
111110 |
Продолжение Таблицы 2
|
7 |
m7 |
1/128 |
VII |
1111110 |
|
8 |
m8 |
1/256 |
11111110 |
На рис. 2 представлен граф кодирования (кодовое дерево), показывающий, как «расщепляется» ранжированная последовательность символов кодируемого источника сообщений на группы и отдельные символы и какие кодовые символы присваиваются группам и отдельным символам алфавита источника сообщений на каждом шаге разбиения.
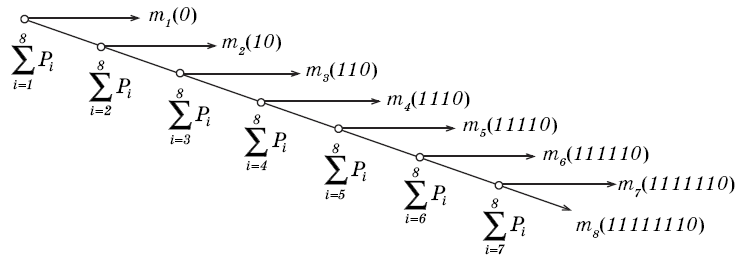
Рис. 2. Граф кодирования по алгоритму Шеннона-Фано
Алгоритм Шеннона-Фано применим и при иных числовых основаниях кода (k > 2). В этом случае алгоритм получения кода аналогичен рассмотренному примеру, только алфавит кодируемого источника сообщений разбивается на k групп и подгрупп примерно одинаковой суммарной вероятности.
Представляет интерес сравнение эффективного кодирования равномерным кодом и неравномерным кодом по алгоритму Шеннона-Фано.
В качестве примера рассмотрим предложенный выше (Табл. 2) источник сообщений с объемом алфавита равным 8 и соответствующими вероятностями появления отдельных символов (Pi). Для кодирования используем двоичный код ( k = 2).
Энтропия рассмотренного источника сообщений (Hи) определяется по формуле Шеннона-Фано:

Максимально же возможное значение энтропии источника сообщений
(Hu.max), при условии равновероятного и взаимно независимого появления символов, находится по формуле Хартли:

Следовательно, избыточность рассматриваемого источника сообщений (Rи) может быть найдена из соотношения:

Используя формулу для эффективного равномерного кода, при k = 2,
получим значность равномерного двоичного кода (пр):

и избыточность равномерного кода (Rрк):

Энтропия элементов символов равномерного кода  , то есть количество информации, приходящееся на один элемент символа кода, будет равна:
, то есть количество информации, приходящееся на один элемент символа кода, будет равна:

При использовании эффективного кодирования по алгоритму Шеннона-Фано соответствующие информационные параметры кода будут следующие.
Средняя длина неравномерного кода (пН) определяется выражением:
 (1)
(1)
где пi – значность i - го кодового символа, соответствующего символу алфавита mi.
Избыточность неравномерного кода (RНК) определим из соотношения:
 (2)
(2)
Энтропия элементов символов эффективного неравномерного кода
 может быть легко найдена:
может быть легко найдена:
 (3)
(3)
Сравнивая выражения (1) и (3) видно, что, при использовании эффективного кодирования по алгоритму Шеннона-Фано, энтропия элементов символов такого неравномерного кода на 50% выше, чем энтропия элементов символов в случае использования равномерного кода. Предполагая, что скорость передачи по каналу элементов символов кода (W) одинакова для равномерного и неравномерного кода, то скорость передачи информации (V), определяемая выражением:

где Н – энтропия элементов символа кода, также будет на 50% выше при
использовании эффективного кодирования по алгоритму Шеннона-Фано по
сравнению с равномерным кодированием.
Алгоритм Шеннона-Фано часто применяют также и для блочного кодирования, где также существенно повышается эффективность кодирования. Для иллюстрации данного кодирования рассмотрим процедуру эффективного кодирования двоичным числовым кодом сообщений, генерируемых источником сообщений с объемом алфавита равным 2 (m = 2), то есть с алфавитом, который состоит только из двух символов m1 и m2 с вероятностями появления P(m1) = 0,9 и P(m2) = 0,1 и, следовательно, с энтропией Н = 0,47.
При посимвольном кодировании по алгоритму Шеннона-Фано эффект отсутствует, т.к. на каждый символ сообщения будет приходиться один символ кода, который состоит из одного элемента.
Осуществим кодирование блоков по алгоритму Шеннона-Фано, которые состоят из комбинаций двух символов источника сообщений, считая
символы взаимнонезависимыми. Результат приведен в Таблице 3.
Таблица 3
Кодирование блоков по алгоритму Шеннона-Фано
|
Блоки |
Вероятности |
Номера разбиений |
Кодовые комбинации |
|
m1m1 |
0,81 |
I |
1 |
|
m1m2 |
0,09 |
II |
01 |
|
m2m1 |
0,09 |
III |
001 |
|
m2m2 |
0,01 |
0001 |
Среднее число элементов символов кода на один символ исходного сообщения, вычисленное по формуле (2), равно 0,645, что значительно ниже, чем при посимвольном кодировании.
Кодирование блоков, соответствующих комбинациям из трех символов
источника сообщений, дает еще больший эффект. Результат приведен в Таблице 4.
Таблица 4
Кодирование блоков, соответствующих комбинациям
из трех символов источника сообщений
|
Блоки |
Вероятности |
Номера разбиений |
Кодовые комбинации |
|
m1 m1 m1 |
0,729 |
I |
1 |
|
m2 m1 m1 |
0,081 |
III |
011 |
|
m1 m2 m1 |
0,081 |
II |
010 |
|
m1 m1 m2 |
0,081 |
IV |
001 |
|
m2 m2 m1 |
0,009 |
VI |
00011 |
|
m2 m1 m2 |
0,009 |
V |
00010 |
Продолжение Таблицы 4
|
m1 m2 m2 |
0,009 |
VII |
00001 |
|
m2 m2 m2 |
0,001 |
00000 |
В этом случае среднее число элементов символов кода на один символ исходного источника сообщений равно 0,53.
Теоретический минимум Н = 0,47 может быть достигнут при кодировании блоков неограниченной длины.
Алгоритм Шеннона-Фано не всегда приводит к однозначному построению кода, т.к. если разбивать группы на подгруппы, то можно сделать большей по суммарной вероятности как верхнюю, так и нижнюю подгруппы. Такого недостатка нет в алгоритме Хаффмена, гарантирующим однозначное построение эффективного кода.11
2.2. Алгоритм Хаффмена
Алгоритм Хаффмана – скупой алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Он был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. Данный алгоритм в настоящее время используется в многочисленных программах сжатия данных.
Алгоритм Хаффмана остается всегда оптимальным и для вторичных алфавитов m2 с более чем двумя символами, в отличие от алгоритма Шеннона-Фано.
Данный метод кодирования состоит из двух наиболее важных этапов:
- построение оптимального кодового дерева;
- построение отображения код-символ на основе построенного дерева.
___________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 34-37 с.
В чем же состоит суть данного алгоритма? При использовании двоичного кода все символы алфавита источника сообщений ранжируют, т.е. выписывают в столбец в порядке убывания вероятностей их появления. Два же последних символа консолидируют в один символ, так называемый вспомогательный, которому далее приписывают суммарную вероятность.
Не участвовавшие в объединении вероятности символов и вероятность вспомогательного символа снова ранжируют, т.е. размещают в порядке убывания вероятностей в дополнительном столбце, а два последних символа группируются. Такого рода процесс продлевают до тех пор, пока не получат единичный вспомогательный символ с вероятностью, которая будет равна 1. Пример того, как кодируют по алгоритму Хаффмена приведен в Таблице 5.
Таблица 5
Кодирование по алгоритму Хаффмена
|
Символы |
Вероятности |
Вспомогательные столбцы |
||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
||
|
m1 |
0,22 |
0,22 |
0,22 |
0,26 |
0,32 |
0,42 |
0,52 |
1 |
|
m2 |
0,20 |
0,20 |
0,20 |
0,22 |
0,26 |
0,32 |
0,42 |
|
|
m3 |
0,16 |
0,16 |
0,16 |
0,20 |
0,22 |
0,26 |
||
|
m4 |
0,16 |
0,16 |
0,16 |
0,16 |
0,20 |
|||
|
m5 |
0,10 |
0,10 |
0,16 |
0,16 |
||||
|
m6 |
0,10 |
0,10 |
0,10 |
|||||
|
m7 |
0,04 |
0,06 |
||||||
|
m8 |
0,02 |
|||||||
Граф кодирования (кодовое дерево) представлен на рис. 3, он иллюстрирует выстраивание символов на группы и отдельные символы, причем из точки, которой соответствует вероятность 1, направлены две ветви: одной из них (с большей вероятностью) присваиваем символ 1, а второй – символ 0.
|
|
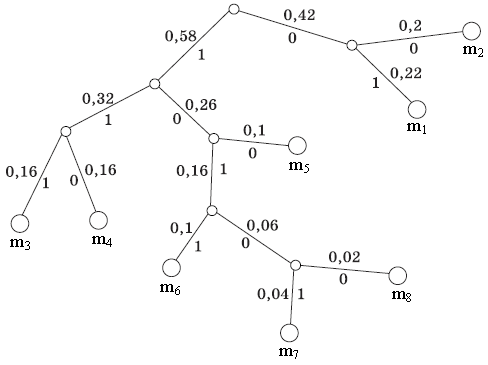
Рис. 3. Граф кодирования по алгоритму Хаффмена
Данное ветвление шаг за шагом будем делать до тех пор, пока не дойдем до вероятности каждого символа. Спускаясь по кодовому дереву сверху вниз, легко записать для каждого символа источника сообщений соразмеримую ему комбинацию (кодовый символ): m1 = 01, m2 = 00, m3 = 111, m4 = 110, m5 = 100, m6 = 1011, m7 = 10101, m8 = 10100
Этот алгоритм можно использовать и при ином числовом основании кода, а также использовать блоки, как это рассмотрено в алгоритме Шеннона-Фано.11
Рассмотрев главу 2 можно сделать вывод, что эффективность данных алгоритмов осуществляется в результате присвоения более коротких кодовых комбинаций (кодовых символов) символам источника сообщений, с более высокой вероятностью, и более длинных кодовых комбинаций – символам источника сообщений с малой вероятностью. Все это сводится к тому, что
___________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 37-40 с.
появляются различия в длине кодовых символов и трудности при их расшифровки. Чтобы разделить отдельные кодовые символы разрешено применять особый разделительный элемент, хотя при этом значительно снижается эффективность кода, т.к. средняя длина кодового символа реально увеличивается на один элемент символа кода. Разумней осуществить декодирование без введения дополнительных элементов символов, что можно добиться, если в эффективном коде ни одна кодовая комбинация не будет совпадать с началом более длинной кодовой комбинации.
Главным недостатком рассмотренных алгоритмов по праву считается нестандартное влияние помех на достоверность декодирования, проявляющееся в одиночной ошибке в кодовой комбинации, которая переведет ее в другую кодовую комбинацию, где та будет не равна ей по длительности. Все это не исключено, что приведет к неправильному декодированию ряда следующих комбинаций (трек ошибки), хотя есть такие методы, которые позволят свести трек ошибки к минимуму. К одному из существенных недостатков также можно отнести сложность технической реализации систем эффективного кодирования, включающих в себя буферные устройства, а также устройства накопления. Применение данных устройств вызвано тем, что длина кодовых комбинаций различна, а каналы связи при этом плодотворно работают только в случае, если символы поступают на них с непрерывной скоростью. Помимо всего прочего, при кодировании блоками неизбежно накапливать символы, прежде чем присвоить их совокупности любую кодовую комбинацию.
Глава 3. Кодирование как средство защиты информации от несанкционированного доступа
Отдельно стоящей задачей кодирования является защита сообщений от несанкционированного доступа, искажения и уничтожения их. При этом виде кодирования кодирование сообщений осуществляется таким образом, чтобы, даже получив их, злоумышленник не смог бы их раскодировать. Процесс такого вида кодирования сообщений называется шифрованием (или зашифровкой), а процесс декодирования – расшифрованием (или расшифровкой). Само кодированное сообщение называют шифрованным (или просто шифровкой), а применяемый метод кодирования – шифром.
На кодировании основывался один из способов защиты информации, где исходные сообщения становятся открытыми, если есть наличие у получателя некоторой специфической информации, т.е. ключа, которая позволяет осуществить обратное преобразование и обрести исходное сообщение. Данный вид защиты информации – криптографическая защита информации, которую исполняют нестандартными операциями кодирования и декодирования, носящими названия шифрование и дешифрование. Сообщение, которое зашифровано, называется криптограммой, область знаний о шифрах, методах их создания и раскрытия – криптографией. Свойство шифра, которое противостоит противостоять раскрытию называется криптостойкостью, оно измеряется сложностью алгоритма дешифрирования.11
Обеспечение неосуществимости доступа к информации при условии того, что вероятный противник обладает всяким техническим оборудованием, которое способно перехватить, записать криптограммы или ему известны кое-какие фрагменты криптограмм и подходящие им части исходного сообщения является важнейшей задачей криптографической защиты.4
___________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 27-53 с.
4 Кретова Л.М. Методы и средства защиты информации: 2-е издание. Учебное пособие для студентов вузов / Л.М. Кретова. – М.: АГРАФ, 2012. – 34 с.
Реализация для методов криптографического закрытия может быть программная и аппаратная:
- программная реализовывается на основе вычислительных процессов, причем и на этапе шифрования, и на этапе дешифрирования;
- аппаратная реализация создана на использовании специализированной аппаратуры.
Использование криптографии идет с глубокой древности и с тех же пор известно огромное количество совершенно разных методов криптографического закрытия (шифров), как информационных, так и механических, имеющих разные степени сложности и надежности защиты.11
Далее рассмотрим подробнее метода криптографического закрытия на примере шифрования текстов.
3.1. Шифр простой подстановки
Данный метод шифрования заключается в том, что при нем все символы алфавита однозначно заменяют другими символами того же самого или другого алфавита. Например, если объем алфавита исходного сообщения берем за n, а замена происходит из того же алфавита, то в таком случае существует n! способов замены символов отправного сообщения, т.е. имеется n! многообразных ключей.4
Рассмотрим несколько примеров шифра подстановки:
1. Эпохальный шифр Цезаря (I век до н.э.), который если применять к тексту на русском языке заключается в том, что выписывается алфавит, а затем этажом ниже выписывается тот же алфавит, но буквы при этом сдвигаются, например на 3 позиции:
________________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 54 с.
4 Кретова Л.М. Методы и средства защиты информации: 2-е издание. Учебное пособие для студентов вузов / Л.М. Кретова. – М.: АГРАФ, 2012. – 36 с.
а б в г д ………. ъ э ю я
г д е ё ж ………. я а б в
Таким образом видно, что при шифровании буква А заменяется буквой
Г, буква Б заменяется буквой Д и т.д. Ключом в шифре Цезаря служит мера
сдвига алфавита в нижней строке, на деле являющаяся любой.
Когда получателю данного сообщения доставляли такое послание, то он выполнял обратную хронологию операций и воссоздавал изначальное сообщение.
2. Шифр «пляшущие человечки» К.Дойля, широко применимый в художественной литературе, он заключается в том, что каким-то неощутимым методом помечают буквы засекреченного сообщения в тексте книги или в каком-либо другом печатном издании. Так, во времена первой мировой войны немецкие шпионы использовали данный шифр, они наносили симпатическими чернилами точки на букве газетного текста. В настоящее время книжный шифр имеет немного другой вид, его суть – в замене на номер строки и номер этой буквы на заранее условленной странице определенной книги. Ключ данного шифра – книга, а главное используемая страница в ней. Такой шифр применялся также во времена второй мировой войны.
3. Квадрат Полибия, шифрование в данном случае заключается в том, что в квадратную матрицу с числом элементов, которое равно или больше объема алфавита на место каждого элемента в хаотическом порядке вписываются все буквы алфавита, та буква, которая зашифрована, заменяется ее координатами в матрице. При расшифровке такого сообщения каждая пара чисел определяла соответствующую букву сообщения. Ключом в таком шифровании служит расположение букв в исходной матрице, но стоит отметить, что при свободном от порядка расположении букв в исходной матрице возникает определенное затруднение, т.к. отправителю и получателю данного сообщения необходимо помнить заданное расположение букв (ключ шифра), что весьма трудно делать, а если либо иметь при себе записанный ключ, то это опасно, т.к. что посторонние лица могут с ним ознакомиться. Чтобы устранить данные неудобства иногда ключ представляют дальнейшим образом – берут за основу любое «ключевое слово», преимущественно легкозапоминающееся, выдергивают из него повторы букв, а потом записывают его в начальных элементах матрицы, на место же других элементов записывают остальные буквы алфавита в естественном порядке. Широко применяемым примером данного шифра служит в народе называемый «тюремный шифр», в котором матрица заполняется буквами в порядке их расстановки в алфавите.11
3.2. Шифры перестановки
Данный метод шифрования заключается в том, что берется определенное число n и записывается в строку ряд чисел 1, 2, …, n затем под ними записываются те же цифры, но уже в произвольном порядке, к примеру, для n = 5:
1 2 3 4 5
4 3 2 5 1
Далее записывается шифруемое сообщение без пропусков и дробится на группы по n букв, н стоит отметить, что если число букв до n не кратно n, то последняя группа дополняется до n любыми буквами. Впоследствии буквы каждой группы передвигаются в соответствии с выбранной двухстрочной таблицей: 1-ая буква становится 4-ой, 2-ая – 3-ей и т.д. После того, как выполнили перестановку в каждой группе, полученный текст записывается без пропусков. Для данного шифра ключом служит таблица перестановок. При дешифрировании криптограмма разбивается на группы по n букв и буквы перестанавливаются в противоположном порядке.11
____________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 54-55 с.
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 55-56 с.
3.3. Шифр Виженера
Данный метод шифрования заключается в том, что каждая буква алфавита нумеруется, например, для русского языка ставятся в соответствие цифры от 1 (А = 1) до 33 (Я = 33).
В данном методе шифрования в качестве ключа употребляется любое
слово или вообще определенная последовательность букв, где этот самый ключ подписывается с повторением под сообщением, которое шифруется, да так, чтобы под каждой буквой начального сообщения находилась одна буква ключа. Криптограмма создается в виде последовательности цифр, которые получаются в итоге суммирования числовых эквивалентов, соответствующих букве исходного сообщения, а также букве стоящего под ней ключа и созданной по модулю 33 (что означает объем алфавита).
При таком шифровании степень безопасности закрытия сообщений весьма высока, т.к. данный шифр ломает статистическое распределение вероятностей появления отдельных букв в сообщении. Для того, чтобы обеспечить довольно большую надежность закрытия нужно использовать очень длинные ключи, а это уже сопряжено с некоторыми трудностями.11
3.4. Шифрование гаммированием
Данный метод шифрования заключается в том, что цифровые эквиваленты символов сообщения, т.е. букв, складываются с псевдослучайной последовательностью чисел, которая именуется гаммой, и приводятся по модулю k, где k – объем алфавита источника сообщений. Следовательно, ключом в этом способе шифрования служит псевдослучайная последовательность чисел.
Данную псевдослучайную последовательность формируют на основе ре-
___________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 56 с.
гистров сдвига с обратными связями. Подходящим выбором обратных связей добиваются генерирования последовательностей с периодом повторения  символов, где n – число разрядов регистра. В результате чего такие последовательности чисел являются псевдослучайными, т.к. соответствуют ряду ключевых тестов на случайность, что, конечно же, очень сильно затрудняет раскрытие данного ключа, но в то же время такие последовательности являются также детерминированными, а это уже позволяет обеспечить конкретность дешифрирования сообщений.
символов, где n – число разрядов регистра. В результате чего такие последовательности чисел являются псевдослучайными, т.к. соответствуют ряду ключевых тестов на случайность, что, конечно же, очень сильно затрудняет раскрытие данного ключа, но в то же время такие последовательности являются также детерминированными, а это уже позволяет обеспечить конкретность дешифрирования сообщений.
Высоконадежность криптографического закрытия методом гаммирования, чаще всего, подчиняется длине периода единичной части гаммы и, в том случае, если длина периода превосходит длину сообщения, которое шифруется, то раскрыть криптограмму, если только базироваться на статистических результатах обработки, теоретически невозможно. Но следует отметить, что если известно некое число цифровых эквивалентов символов сообщения и символы криптограммы, которые соответствуют им, то дешифрирование весьма просто осуществить, т.к. преобразование, которое воплощается при гаммировании, является линейным. Чтобы всеобъемно раскрыть криптограммы хватит всего 2n соответствующих пар символов исходного сообщения и символов криптограммы.11
Рассмотрев главу 3 следует отметить, что методы шифрования простой подстановкой довольно просты, но также не гарантируют высокую степень защиты, т.к. буквы абсолютно любого языка мира владеют той или иной вероятностью появления. В зашифрованном по такому методу кодирования данных тексте статистические свойства начального сообщения сохраняются,
поэтому, анализируя криптограммы обильной длительности, можно их де-
шифрировать исходя из их статистических свойств. При шифровании методом перестановки символы текста, который шифруется, перемещаются по
___________________
11 Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 56-57 с.
некоторому правилу в пределах блока этого текста, поэтому шифры перестановки – самые простые, а, может быть, и древние в мире. Что касается шифра Виженера, то по современным стандартам он является весьма ненадежным, не стоит использовать его для чего-то действительно секретного. Ну и пару слов о шифровании гаммированием – на деле гамма данного шифра должна изменяться непроизвольным образом для каждого шифруемого блока, а если период гаммы больше длины всего текста, который шифруется и покусителю неизвестна ни одна часть исходного текста, то, чтобы раскрыть такой шифр
нужно осуществить перебор всех вариантов ключа.
Глава 4. Помехоустойчивое кодирование
Теория о помехоустойчивом кодировании основывается на исследованиях, которые проводил Шеннон, а точнее на их результатах, которые он выразил в виде основной теоремы для дискретного канала с шумом – при любой скорости передачи двоичных символов R, меньшей чем С, вероятность ошибки на символ можно сделать произвольно малой путем надлежащего конструирования кодера и декодера канала, и обратно, вероятность ошибки не может быть сделана произвольно малой, когда К больше чем С.4
Кодирование должно реализовываться так, чтобы сигнал, который соответствует утвержденной последовательности символов, после того, как на него было выполнено воздействие предполагаемой в канале помехи, был ближе к сигналу, уместному конкретной переданной последовательности символов, чем к сигналам, которые соответствуют другим вероятным последовательностям. Все это осуществляется с помощью цены впуска при кодировании избыточности, позволяющей выбрать передаваемые последовательности символов таким образом, чтобы они угождали дополнительным условиям, которые проверяются на приемной стороне, и после проверки которых, дается возможность обнаружить, а далее исправить ошибки. Коды, которые обладают таким свойством, впоследствии получили название помехоустойчивые, используемые для исправления ошибок (корректирующие) и для их обнаружения.7
В настоящее время у огромного количества помехоустойчивых кодов перечисленные выше условия – это следствие их алгебраической структуры, поэтому их стали называть алгебраическими кодами, которые делятся на два класса: блоковые и непрерывные:
- При блоковых кодах порядок кодирования состоит в сравнении каж-
___________________
4 Кретова Л.М. Методы и средства защиты информации: 2-е издание. Учебное пособие для студентов вузов / Л.М. Кретова. – М.: АГРАФ, 2012. – 46 с.
7 Русанов К.Л. Приемы сокращения объемов информации / К.Л. Русанов. – М.: ЮНИТИ-ДАНА, 2013. – 252 с.
дой буквы сообщения (последовательности из k символов, которая соответствует данной букве) блока из n символов, вдобавок стоит обратить внимание на то, что в операциях по преобразованию участвуют исключительно указанные k символы и конечная последовательность не зависит от других символов в передаваемом сообщении. Блоковый код будет называться равномерным, если n остается константой для всех букв сообщения. Существуют также разделимые и неразделимые блоковые коды: в результате кодирования разделимыми кодами конечные последовательности состоят из символов, отчетливо разграниченных по роли – это информационные символы, которые идентичны символам последовательности, поступающей на вход кодера канала, и избыточные (проверочные) символы, которые вводятся в начальную последовательность кодером канала и работают для обнаружения и исправления ошибок; в результате же кодирования неразделимыми кодами раздробить символы выходной последовательности на информационные и проверочные вероятность отсутствует.
- Коды, в которых введение избыточных символов в кодируемую последовательность информационных символов осуществляется непрерывно, без разделения ее на независимые блоки называются непрерывными. Существуют также разделимые и неразделимые непрерывные коды.4
В случае обоюдно свободных ошибках, скорее всего, вероятен переход в кодовую комбинацию, которая отличается от данной в наименьшем числе символов. Величина расхождения всяких двух кодовых комбинаций обуславливается расстоянием между ними или, проще говоря, кодовым расстоянием, которое изображается числом символов с комбинациями, отличающимися одна от другой, и обозначается через d.
Для расчета кодового расстояния между двумя комбинациями двоичного кода, достаточно произвести подсчет числа единиц в сумме этих комбинаций по модулю 2.
___________________
4 Кретова Л.М. Методы и средства защиты информации: 2-е издание. Учебное пособие для студентов вузов / Л.М. Кретова. – М.: АГРАФ, 2012. – 48-53 с.
К примеру, заданы две кодовые комбинации А и В, требуется определить кодовое расстояние.
Если складывать по модулю 2 каждый разряд А и В, получим на выходе некоторую комбинацию С.
А: 1 0 0 1 1 1 1 1 0 1 (А) = 7 ϖ
+
В: 1 1 0 0 0 0 1 0 1 0 (В) = 4 ϖ
С: 0 1 0 1 1 1 0 1 1 1 (С) = 7
где С – кодовая комбинация;
(С) – вес, который определяет непосредственный подсчет единиц;
ϖ – равен кодовому расстоянию d.
Значит можно сделать вывод, что расстояние для данных кодовых комбинаций d=7.
Взятое по всем парам кодовых комбинаций данного кода минимальное расстояние – минимальное кодовое расстояние.7
Рассмотрев главу 4 следует отметить, что сильно уменьшить избыточность в сообщениях, которые передаются, осуществляет помехоустойчивое кодирование. Вцелом данное кодирование понимают в виде кодирования сообщений, при котором элементы связаны конкретной зависимостью, которая позволяет при ее нарушении указать ошибки и воссоздать информацию. Помехоустойчивые коды рассчитаны на определенные ошибки, что означает, что при других ошибках они могут оказаться недостаточно эффективными.
___________________
7 Русанов К.Л. Приемы сокращения объемов информации / К.Л. Русанов. – М.: ЮНИТИ-ДАНА, 2013. – 254 с.
Глава 5. Способы кодирования информации
В настоящее время существует 2 наиболее важных способа кодирования информации в штрих-коде:
1. Для снижения трудозатрат в процессе кодирования и ускорения этого процесса выбирают направление снижения с помощью использования штриховых (линейных) кодов, основными достоинствами которых служат:
- энергичное снижение числа ошибок при вводе информации в виде штриховых кодов по сравнению с вводом информации с клавиатуры на естественном языке;
- несложное считывание штриховых кодов электронными оптическими системами относительно считывания буквенно-цифровых символов;
- заоблачная экономическая действенность применения систем на основе штриховых кодов в результате резкого спада стоимости ввода данных в систему.
Штриховой (линейный) код – это комбинация вертикальных полосок разной ширины и пробелов между ними. Базовой считается ширина узкого элемента (полоски) кода, широкие же полоски должны быть аликвотны им по ширине или находиться с ними в определенных пропорциях. Основой данного кода является цифровой код.
Если говорить о разных странах и их применении штриховых кодов, то в каждом из них принято конкретное соотношение между широкими и узкими полосками, а также между полосками и интервалами между ними. Например, в коде «39» каждому знаку цифрового кода уместна комбинация из 9 элементов (3 широких полоски, 6 узких) и из них 5 штрихов и 4 интервала между ними.
Создание штриховых кодов исполняет Международная ассоциация по нумерации (ЕАН далее по тексту), чьи коды являются самыми распространенными в Европе. Наша страна с 1987 г. тоже стала членом ЕАН.
В 1988 г. Госстандарт СССР утвердил РД 50-666-88 «Методические
указания. Присвоение цифровых кодов товарам народного потребления». Данным документом утверждались правила присвоения товарам народного потребления цифровых (торговых) кодов, которые являются основой для штриховых кодов, наносимых, например, на ярлыки, упаковку или этикетки товаров народного потребления. Такого рода код строится в целом соответствии с кодом ЕАН-13 и состоит из 13 разрядов, а также имеет структуру:
- 2 знака – идентификатор страны-изготовителя товара;
- 5 знаков – идентификатор фирмы-изготовителя товара;
- 5 знаков – идентификатор товара;
- 1 знак – контрольное число.
Если рассматривать на примере стран, то США и Канада имеют идентификаторы с 00 до 09, Франция – с 30 до 37, ФРГ – с 40 до 43, СНГ – 46, Япония – 49, Италия – с 80 до 83, Корея – 88 и т.д.
В штриховом коде, который построен на основе ЕАН-13, каждому знаку цифрового кода созвучна комбинация из 7 элементов – штрихов и пробелов между ними.
Штриховой (линейный) код имеет следующий вид, показанный на рис. 4.

Рис.4. Штриховой (линейный) код
Штриховые коды могут использоваться кроме торговли также в таких областях, как медицина, банковское дело, промышленность и других. При этом в качестве цифровых кодов для них могут использоваться коды классификаторов ТЭСИ.
2. Двухмерное кодирование – новейшее направление в мире штриховых
кодов, это, своего рода, символики, которые разработаны для кодирования большого объема данных. Распознавание данного кода осуществляется по горизонтали и по вертикали.
Двухмерное кодирование имеет следующий вид, показанный на рис. 5
 .
.
Рис.4. Двухмерное кодирование
В настоящее время активно используются следующие виды двухмерных
штриховых кодов:
- Aztec Code – штрих-код, в каждом символе которого выделяют область данных и мишени, которая выступает в роли набора концентрических квадратов, а также предназначена для определения геометрического центра символа в момент его декодирования. Есть два основных формата символа этого кода: «Compact» (компактный) символ с мишенью из 2-х квадратов и «Full-Range» (полный) символ с мишенью из 3-х квадратов;
- DataMatrix – штрих-код, который является двумерным матричным и содержит чёрно-белые элементы или может содержать элементы двух разных величин яркости в форме квадрата, которые размещены в прямоугольной или квадратной группе. Данным методом кодирования можно закодировать текст или строковые данные с объемом информации от нескольких байтов до 2 килобайтов. Применимостью этого кода служат маркировки в электронике, автомобилестроении и энергетическом машиностроении, пищевой промышленности, авиакосмической и оборонной промышленности;
- MaxiCode – штрих-код, который создан для нужд сортировки товара, он элементарно сканируется, а также может быть нанесен на криволинейные поверхности. Данный код запросто диагностируется по 6-ти угольным элементам, которые являются его основой;
- Datamatrix – штрих-код, который целиком и полностью отвечает требованиям к емкости штриховых кодов и гарантирует коррекцию ошибок. Данный код наносится не только на этикетки небольшого размера, но и непосредственно на товар, если последний обладает плотностью;
- PDF417 (Portable Data File – на русский Переносимый Файл Данных) – штрих-код, который поддерживает кодирование до 2 710 знаков. Данный код в настоящее время обширно применяется в распознавании личности, а также в учете товаров и во многих других областях. Он обладает открытым форматом для общего использования и может охватывать до 90 строк, которые состоят из стартового и стопового шаблона и характеризуют код, как PDF417. Каждое ключевое слово этого кода состоит из 4 штрихов и 4 пробелов, а ширина ключевых слов в 17 раз больше минимального штриха или пробела – отсюда числовой суффикс в обозначении формата PDF417. Он поддерживает 3 типа данных: текст (ASCII), байты и числа;
- QR – это 2D штрих-код, т.е. двухмерный, который расшифровывается как «Quick Response» (быстрый отклик). Главное достоинство данного кода это простая идентификация сканирующим оборудованием, например фотокамерой мобильного телефона, что дает возможность использования в торговле, производстве, логистике.
Рассмотрев главу 5 следует отметить, что если провести аналогию двухмерного кодирования с линейными символиками штриховых кодов, позволяющими представлять в символе штрихового кода короткую последовательность данных, которая является, зачастую, ключом к записи во внешней базе данных, то многострочные символики позволяют кодировать информацию в полном объеме. Помимо этого, многострочные символики вбирают в себя особые механизмы по сжатию данных, т.е. защите их от повреждения, а также связыванию информации, которые представлены в нескольких симво-
___________________
2 Грифанова М.Ю. Штриховое кодирование. Виды и области применения: Учебник / М.Ю. Грифанова. – М.: Парад, 2008. – 47-59 с.
лах, в один большой файл. В условиях конкурентной среды большая часть информации должна быть оперативной и в то же время недоступной для ее использования нерегламентированным пользователем. Данную возможность нам целиком и полностью дает именно штриховое кодирование, которое в большей степени упрощает учет и контроль материальных средств, а также получило всеобъемлющее распространение в разных странах мира.
Заключение
По результатам курсовой работы можно сделать выводы:
В классификаторах ТЭСИ используются 4 метода кодирования информации: порядковый, серийно-порядковый (регистрационные методы кодирования, которые носят самостоятельный характер), последовательный, параллельный (классификационные методы кодирования – основаны на предварительной классификации объектов). Классификационные методы кодирования данных (последовательный и параллельный) характеризуются тем, что при глубокой классификации объектов код несет информацию о классификационной группировке, но не всегда опознает конкретный объект, а коды, полученные на основе регистрационных методов кодирования данных (порядковый и серийно-порядковый) при том, что хорошо выполняют функцию идентификации объектов, на деле почти не несут информацию об их свойствах. Поэтому регистрационные и классификационные методы кодирования данных чаще всего применяются в классификаторах в сочетании друг с другом.
Очень часто в отдельный класс выделяют методы кодирования, позволяющие построить (без потери информации) коды сообщений, которые имеют меньшую длину по соотношению с исходным сообщением. Данные методы кодирования призваны называть методами сжатия или упаковки данных, где качество данного сжатия определяется его коэффициентом, измеряющимся в процентах и который показывает, на сколько процентов кодирован-
ное сообщение короче исходного. Алгоритм Шеннона-Фано – один из первых алгоритмов сжатия, его впервые сформулировали американские ученые Шеннон и Роберт Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, появившегося на несколько лет позже и являющегося логическим продолжением алгоритма Шеннона-Фано. Эффективность данных алгоритмов осуществляется в результате присвоения более коротких кодовых комбинаций (кодовых символов) символам источника сообщений, с более высокой вероятностью, и более длинных кодовых комбинаций – символам источника сообщений с малой вероятностью. Все это сводится к тому, что появляются различия в длине кодовых символов и трудности при их расшифровки. Чтобы разделить отдельные кодовые символы разрешено применять особый разделительный элемент, хотя при этом значительно снижается эффективность кода, т.к. средняя длина кодового символа реально увеличивается на один элемент символа кода. Разумней осуществить декодирование без введения дополнительных элементов символов, что можно добиться, если в эффективном коде ни одна кодовая комбинация не будет совпадать с началом более длинной кодовой комбинации. Главным недостатком рассмотренных алгоритмов по праву считается нестандартное влияние помех на достоверность декодирования, проявляющееся в одиночной ошибке в кодовой комбинации, которая переведет ее в другую кодовую комбинацию, где та будет не равна ей по длительности. Все это не исключено, что приведет к неправильному декодированию ряда следующих комбинаций (трек ошибки), хотя есть такие методы, которые позволят свести трек ошибки к минимуму. К одному из существенных недостатков также можно отнести сложность технической реализации систем эффективного кодирования, включающих в себя буферные устройства, а также устройства накопления. Применение данных устройств вызвано тем, что длина кодовых комбинаций различна, а каналы связи при этом плодотворно работают только в случае, если символы поступают на них с непрерывной скоростью. Помимо всего прочего, при кодировании блоками неизбежно накапливать символы, прежде чем присвоить их совокупности любую кодовую комбинацию.
Рассмотрев кодирование, как средство защиты информации от несанкционированного доступа следует отметить, что методы шифрования простой подстановкой довольно просты, но также не гарантируют высокую степень защиты, т.к. буквы абсолютно любого языка мира владеют той или иной вероятностью появления. В зашифрованном по такому методу кодирования данных тексте статистические свойства начального сообщения сохраняются, поэтому, анализируя криптограммы обильной длительности, можно их де-
шифрировать исходя из их статистических свойств. При шифровании методом перестановки символы текста, который шифруется, перемещаются по некоторому правилу в пределах блока этого текста, поэтому шифры перестановки – самые простые, а, может быть, и древние в мире. Что касается шифра Виженера, то по современным стандартам он является весьма ненадежным, не стоит использовать его для чего-то действительно секретного. Ну и пару слов о шифровании гаммированием – на деле гамма данного шифра должна изменяться непроизвольным образом для каждого шифруемого блока, а если период гаммы больше длины всего текста, который шифруется и покусителю неизвестна ни одна часть исходного текста, то, чтобы раскрыть такой шифр нужно осуществить перебор всех вариантов ключа.
Рассмотрев помехоустойчивое кодирование следует отметить, что сильно уменьшить избыточность в сообщениях, которые передаются, осуществляет помехоустойчивое кодирование. Вцелом данное кодирование понимают в виде кодирования сообщений, при котором элементы связаны конкретной зависимостью, которая позволяет при ее нарушении указать ошибки и воссоздать информацию. Помехоустойчивые коды рассчитаны на определенные ошибки, что означает, что при других ошибках они могут оказаться недостаточно эффективными.
Рассмотрев способы кодирования информации на основе штриховых (линейных кодов) и двухмерного кодирования следует отметить, что если провести аналогию двухмерного кодирования с линейными символиками штриховых кодов, позволяющими представлять в символе штрихового кода короткую последовательность данных, которая является, зачастую, ключом к записи во внешней базе данных, то многострочные символики позволяют кодировать информацию в полном объеме. Помимо этого, многострочные символики вбирают в себя особые механизмы по сжатию данных, т.е. защите их от повреждения, а также связыванию информации, которые представлены в нескольких символах, в один большой файл. В условиях конкурентной среды большая часть информации должна быть оперативной и в то же время недоступной для ее использования нерегламентированным пользователем. Данную возможность нам целиком и полностью дает именно штриховое кодирование, которое в большей степени упрощает учет и контроль материальных средств, а также получило всеобъемлющее распространение в разных странах мира.
Список использованных источников
- Герасеймчук К.А. Кодирование. Основа кодирования: Учебник для вузов / К.А. Герасеймчук – СПб.: Питер, 2011. – 364 с.
- Грифанова М.Ю. Штриховое кодирование. Виды и области применения: Учебник / М.Ю. Грифанова. – М.: Парад, 2008. – 347 с.
- Задохина Н.В. Математика и информатика. Решение логико-познавательных задач: Учебное пособие для студентов вузов / Н.В. Задохина. – М.: ЮНИТИ-ДАНА, 2015. – 127 с.
- Кретова Л.М. Методы и средства защиты информации: 2-е издание. Учебное пособие для студентов вузов / Л.М. Кретова. – М.: АГРАФ, 2012. – 348 с.
- Ларьков Н.С. Документоведение: 3-е издание. Учебник / Н.С. Ларьков. – ООО «Проспект», 2015. – 387 с.
- Минаева И.Б. Информационное обеспечение деятельности / И.Б. Минаева. – М.: Секретарское дело, 2006. – 340 с.
- Русанов К.Л. Приемы сокращения объемов информации / К.Л. Русанов. – М.: ЮНИТИ-ДАНА, 2013. – 247 с.
- Титоренко Г.А. Информационные технологии управления / Г.А. Титоренко. – М.: ЮНИТИ-ДАНА, 2002. – 280 с.
- Федин Л.Н. Кодирование данных / Л.Н. Федин. – М.: ИНФРА-М, 2008. – 168 с.
- Харитонов Г.Б. Технологии программирования в сфере услуг: Учебник / Г.Б. Харитонов. – М.: Научный Мир, 2009. – 227 с.
- Шавенько Н.К. Основы теории информации и кодирования / Н.К. Шавенько. – М.: МИИГАиК, 2012. – 125 с.
- Информационные системы в финансово-кредитных учреждениях: Учебное пособие [2-изд, перераб. и доп.] / И.Ф. Рогач, М.А. Сендзюк, В.А. Антонюк; Под ред. И.Ф. Рогач. – М.: Финансы, 2001. – 239 с.
- Проектирование автоматизированных систем обработки информации и управления: Учебное пособие / Д.В. Гайчук, М.В. Самус, А.П. Жук; Под ред. Д.В. Гайчук. – Ставрополь.: СВИС РВ, 2009. – 136 с.
- https://ru.wikipedia.org/wiki/

- Особенности политики мотивации персонала организаций бюджетной сферы (ОГАПОУ «БТСИиЭ»)
- Технологии создания управленческих команд, АО «ОТП Банк»
- Психология мимики и жестов
- Кадровая стратегия в системе стратегического управления организации.
- Кадровая стратегия в системе стратегического управления организации, выбор стратегии
- Теоретические основы деятельности юридических лиц как субъектов предпринимательского права
- "Особенности кадровой стратегии кредитных организаций"
- Понятие, признаки и правовое регулирование несостоятельности ( Признаки банкротства)
- Опекунство (общая характеристика), проблемы и вопросы
- «Влияние информационных сетей на становление современного общества.»
- Цель и назначение создания или модернизации модулей или сервисов информационной системы
- Разработка инновационного проекта в социальной сфере.