
Методы кодирования данных (Кодирование аудиоданных в формате WAV)
Содержание:

Введение
Актуальность данной темы заключается в том, что изначально вычислительная техника появилась в качестве кандидата на роль средства автоматизации вычислений, где сразу же встал вопрос о формате представления данных.
В первую очередь, возник вопрос представления простых типов данных: ими являлись обыкновенные десятичные числа. За числами последовала текстовая информация. Сначала тексты просто поясняли труднообозримые столбики цифр, но затем машины все более существенным образом стали преобразовывать текстовую информацию. Оформление текстов достаточно быстро вызвали у людей стремление дополнить их графиками и рисунками. Делались попытки частично решить эти проблемы в рамках символьного подхода: вводились специальные символы для рисования таблиц и диаграммам. Но практические потребности людей в графике делали ее появление среди видов компьютерной информации неизбежной. Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи. Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Объектом изучения, представленным в теоретической части являются данные в компьютере.
Цель работы – рассмотреть форматы данных и методы кодирования данных в вычислительной технике.
Для достижения цели необходимо решить следующие задачи:
- рассмотреть существующие форматы данных;
- рассмотреть представление различных форматов данных в вычислительной технике и описать способы кодирования информации.
Понятие информации и формата данных
Информация. Представление данных в вычислительной технике
Информация – это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состояниях, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний[1].
В процессе обработки информация может менять структуру и форму. Признаком структуры являются элементы информации и их взаимосвязь. Формы представления информации могут быть различны. Основными из них являются: символьная; текстовая; графическая; световых или звуковых сигналов; радиоволн; электрических и нервных импульсов; магнитных записей; жестов и мимики; запахов и вкусовых ощущений и так далее.
В повседневной практике такие понятия, как информация и данные, часто рассматриваются как синонимы. На самом деле между ними имеются существенные различия.
Данными называется информация, представленная в удобном для обработки виде. Данные могут быть представлены в виде текста, графики, аудиовизуального ряда. Представление данных называется языком, представляющим собой совокупность символов, соглашений и правил, используемых для общения, отображения, передачи информации в электронном виде.
Среди форматов данных стоит выделить несколько категорий, которые будут рассматриваться далее.
Цифровой звук — результат преобразования аналогового сигнала звукового диапазона в цифровой аудиоформат.
Наиболее простой метод преобразования звука из аналогового в цифровой – метод импульсно-кодовой модуляции. Его суть заключается в представлении идущих последовательно моментальных величин уровня сигнала, который измеряется при помощи аналого-цифрового преобразователя, через определенные временные интервалы.
Сам по себе формат представления звуковых данных в цифровой форме зависит от метода квантования аналогово-цифровым преобразователем (АЦП). Кроме импульсно-кодовой модуляции также существует другой способ: сигма-дельта-модуляция. Разрядность квантования, равно как и частота дискретизации, по своей сути определяет формат файла и качество звука, к примеру, звук кодируется с глубиной 16 бит и частотой 48000 Гц.
Аудиофайл — компьютерный файл, который содержит информацию об основных характеристиках звука, а именно – частоте и амплитуде, созданный для проигрывания на специализированных устройствах или на компьютере [2].
Расширение (формат) файла включает в себя описание особенностей представления аудиоданных и спецификацию хранения последовательности данных во внутренней памяти компьютера или другого устройства.
Для устранения избыточности аудиоданных используются аудиокодеки, при помощи которых производится сжатие аудиоданных.
Цифровое представление видеоданных
Видеоданные также являются одним из наиболее распространенных форм представления информации. По своей сути, видеоданные представляют собой последовательность изображений, которым задан четкий порядок и скорость смены.
Помимо этого, видеоданные как правило сопровождаются звуковой дорожкой, которая также кодируется в определенном формате. В целом, видеофайл характеризуется видеопотоком, стандартом разложения и цветовой субстракцией.
К наиболее распространенным относятся форматы AVI, WMV, MKV, DVD-VIDEO и некоторые другие.
Цифровое видео может существовать во многих разных форматах - каждый со специфическими переменными, такими как видео-контейнеры (.MOV, .FLV, .MP4, .OGG, .WMV, WebM), кодеки (H264, VP6, ProRes) и битрейты (в мегабитах или килобитах в секунду). Различные устройства и браузеры имеют разные спецификации, большинство из которых связаны с одной или несколькими из этих переменных - и другими переменными.
Реальная разница между большинством видеофайлов меньше зависит от используемого контейнера, но больше от видео или аудио кодека – в контейнере. Видеокодек определяет, как обрабатывается информация.
Различные кодеки обеспечивают различное качество звука или изображения.
Цифровое представление визуальной информации
Изображения и видеозаписи – крайне важные формы представления информации. Разумеется, для работы вычислительной техники с графическими данными, их также требуется грамотно представить.
В первую очередь следует учесть то, что графическая информация может занимать очень большие объёмы памяти запоминающих устройств. Наиболее остро вопрос встает при представлении видеоданных в высоком качестве: даже на сегодняшний день файлы видеозаписей в формате BluRay занимают колоссальный объём дискового пространства, а объёма накопителя в 1 Тб хватит всего на 30 фильмов в таком качестве.
Далее очень важны вопросы представления графических данных для редактирования и масштабирования. Далеко не все форматы графики позволяют добиться масштабирования без потерь, так же как и не все форматы просто поддаются редактированию и корректировке.
Рассмотрим понятие графического формата. Графическим форматом — это способ записи графической информации. Графические форматы файлов предназначены для хранения изображений, таких как фотографии и рисунки. Форматы можно классифицировать различным образом, но в первую очередь используется разделение на векторные и растровые.
Само собой, различные графические форматы предоставляют разнообразные возможности: некоторые предназначены для хранения высококачественных изображений, другие используются исключительно для графической информации малого размера, третьи – поддерживают прозрачность и могут быть растянуты или уменьшены без потери качества, тем самым находя применение в той или иной области. Но для всех графических форматов основным моментом является то, каким образом производится определение цвета в каждой точке изображения[3].
Для представления цветов в изображениях используются различные методы и кодировки: на основе сочетания трёх или четырёх базовых цветов и их процентного соотношения, на основе шестнадцатеричных кодов и другие. Наиболее часто для определения цвета используются модели RGB, CMYK. Сам цвет представляется в форме соотношений базовых цветов, прозрачности, насыщенности и другими способами.
Строковые данные. Символы и текст
Набор литералов, применяющихся в качестве инструмента визуального представления строковых, символьных и текстовых данных, называют алфавитом[4]. Одним из ключевых свойств алфавита является его мощность, т.е. количество знаков в алфавите. Для представления текстовых данных используются различные кодировки, которые отличаются кодами символов и их набором.
Для представления текстовых данных применяются алфавиты, которые содержат определенное количество знаков. Количество знаков, которое включает в себя алфавит, называется мощностью. Каждый знак содержит 8 бит информации, сами символы имеют порядковые номера и содержат восьмиразрядный код в двоичной системе счисления. На данный момент такая мощность для специфического алфавита является весьма ограниченным набором, поэтому в определенный момент времени возникла идея увеличить количество бит для хранения символа в два раза, тем самым предоставив возможность хранить чуть более чем 65 тысяч символов.
Графическая информация. Кодировка цвета HSV, RGB. Формат TIFF
Кодирование изображения подразумевает процесс его дискретизации, т.е. разбиения на отдельные составляющие. Таким образом, графическое изображение представляет собой мозаику, каждому элементу которой соответствует определенный цвет. Качество изображения напрямую зависит от кодирования, а именно – от размера точки и размера применяемой палитры цветов. Чем меньше размер точки – тем выше качество изображения, а чем богаче палитра – тем более натуральным оно является.
Существует несколько различных моделей представления цвета в изображениях. Они условно разделяются на субтрактивные и аддитивные. Субтрактивные модели используют методику вычитания определенного количества цвета из базового представления. Аддитивные модели используют принцип добавления цветов к палитре с целью получения нового оттенка. Наиболее распространены 2 модели кодирования информации о цвете: HSV и RGB. Рассмотрим эти модели более подробно.
RGB основана на строении человеческого глаза. Она идеально удобна для светящихся поверхностей (мониторы, телевизоры, цветные лампы и т.п.)[4]. В основе ее лежат три цвета: Red- красный, Green- зеленый и Blue- синий. Еще Ломоносов заметил, что с помощью этих трех основных цветов можно получить почти весь видимый спектр. Например, желтый цвет- это сложение красного и зеленого. Поэтому RGB называют аддитивной системой смешения цветов. Чаще всего данную модель представляют в виде единичного куба с ортами: (1;0;0)- красный, (0;1;0)- зеленый, (0;0;1)- синий и началом (0;0;0)- черный.
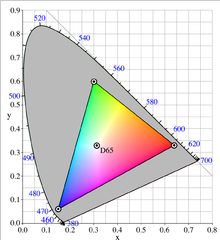
Рисунок 1 – цветовая модель RGB и ограничение по передаче цвета.
HSV - более интересная модель. Она построена на трёх базовых понятиях:
- Hue — цветовой тон, (например, красный, зелёный или сине-голубой). Варьируется в пределах 0—360°, однако иногда приводится к диапазону 0—100 или 0—1.
- Saturation — насыщенность. Варьируется в пределах 0—100 или 0—1. Чем больше этот параметр, тем «чище» цвет, поэтому этот параметр иногда называют чистотой цвета. А чем ближе этот параметр к нулю, тем ближе цвет к нейтральному серому.
- Value (значение цвета) или Brightness — яркость. Также задаётся в пределах 0—100 или 0—1.
Данная модель оперирует более сложными понятиями, но по своей сути она также представляет полноцветную палитру. Шкала оттенков приведена на рисунке.
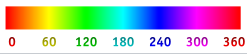
Рисунок 2 – шкала оттенков по HSV.
Далее стоит рассмотреть классификацию по типу изображений. Форматы подразделяются на две большие группы: растровые и векторные.
Растровое изображение представляет собой сетку из пикселей, каждому из которых соответствует определенная позиция и цвет[5]. Подавляющее большинство изображений являются растровыми.
Векторная графика — методика представления графической информации, базирующаяся на математическом описании различных геометрических единиц (примитивов), таких как: точки, отрезки, кривые, различные геометрические фигуры и другие[6].
Рассмотрим кодирование растрового изображения на примере формата TIFF. Это один из наиболее распространенных форматов изображений. Файлы данного формата представляют собой последовательность так называемых тегов, которые начинаются с сервисных байтов – указателей формата и определения порядка байтов в графическом файле. Отдельные теги состоят только из этих маркеров, однако есть те, которые включают в себя различные дополнительные данные, которые состоят из двухбайтового поля с длинной информационной части маркера. Эта форма организации хранения данных позволяет быстро найти маркер с требуемыми данными (например, с длиной строки, числом строк и числом цветовых компонентов сжатого изображения)[7]. Рассмотрим основные теги TIFF – таблица 1.
Таблица 1 – основные теги в файле TIFF.
|
Код |
HEX |
Название |
Описание |
|
|
254 |
0x00FE |
NewSubfileType |
Тип данных, хранящихся в этом файле. Эта метка является заменой метке SubfileType, и является очень полезным, когда в одном TIFF файле хранится несколько изображений. |
|
|
255 |
0x00FF |
SubfileType |
Тип данных, хранящихся в этом файле (старый). |
|
|
256 |
0x0100 |
ImageWidth |
Количество столбцов в изображении. |
|
|
257 |
0x0101 |
ImageLength |
Количество строк в изображении. |
|
|
258 |
0x0102 |
BitsPerSample |
Количество бит в компоненте. Эта метка предполагает различное число битов в каждом компоненте (хотя в большинстве случаев оно одинаковое). Например, для RGB может быть 8 для всех компонентов — красного, зелёного и голубого, или 8,8,8 для каждого из компонентов. |
|
|
259 |
0x0103 |
Compression |
Используемый вид компрессии. |
|
|
262 |
0x0106 |
PhotometricInterpretation |
Используемая цветовая модель. |
|
|
263 |
0x0107 |
Threshholding |
Вид преобразования серого в чёрное и белое для черно-белых изображений. |
|
|
264 |
0x0108 |
CellWidth |
Количество колонок в матрице преобразования из серого в чёрное и белое. |
|
|
265 |
0x0109 |
CellHeight |
Количество строк в матрице преобразования из серого в чёрное и белое. |
|
|
266 |
0x010A |
FillOrder |
Логический порядок битов в байте. |
|
|
270 |
0x010E |
ImageDescription |
Описание изображения. |
|
|
271 |
0x010F |
Make |
Производитель изображения. |
|
|
272 |
0x0110 |
Model |
Модель или серийный номер. |
|
|
273 |
0x0111 |
StripOffsets |
Смещение для каждой полосы изображения в байтах. |
|
|
274 |
0x0112 |
Orientation |
Ориентация изображения. |
|
|
277 |
0x0115 |
SamplesPerPixel |
Количество компонентов на пиксель. |
|
|
278 |
0x0116 |
RowsPerStrip |
Количество строк на полосу. |
|
|
279 |
0x0117 |
StripByteCounts |
Количество байт на полосу после компрессии. |
|
|
280 |
0x0118 |
MinSampleValue |
Минимальное значение, используемое компонентом. |
|
|
281 |
0x0119 |
MaxSampleValue |
Максимальное значение, используемое компонентом. |
|
|
282 |
0x011A |
XResolution |
Количество пикселей в ResolutionUnit строки. |
|
|
283 |
0x011B |
YResolution |
Количество пикселей в ResolutionUnit столбца. |
|
|
284 |
0x011C |
PlanarConfiguration |
Метод хранения компонентов каждого пикселя. |
|
|
288 |
0x0120 |
FreeOffsets |
Смещение в байтах к строке неиспользуемых байтов. |
|
|
289 |
0x0121 |
FreeByteCounts |
Количество байтов в строке неиспользуемых байтов. |
|
|
290 |
0x0122 |
GrayResponseUnit |
Разрешение данных, хранящихся в GrayResponseCurve. |
|
|
291 |
0x0123 |
GrayResponseCurve |
Величина плотности серого. |
|
|
296 |
0x0128 |
ResolutionUnit |
Разрешение данных, хранящихся в XResolution, YResolution. |
|
|
305 |
0x0131 |
Software |
Имя и версия программного продукта. |
|
|
306 |
0x0132 |
DateTime |
Дата и время создания изображения. |
|
|
315 |
0x013B |
HostComputer |
Компьютер и операционная система, использованные при создании изображения. |
|
|
316 |
0x013C |
Artist |
Имя создателя изображения. |
|
|
320 |
0x0140 |
ColorMap |
Цветовая таблица для изображений, использующих палитру цветов. |
|
|
338 |
0x0152 |
ExtraSamples |
Описание дополнительных компонентов. |
|
|
33432 |
0x8298 |
Copyright |
Имя владельца прав на хранимое изображение. |
|
Таким образом, в целом графическая информация кодируется при помощи различных методологий, а главной информацией в файле можно считать координаты участков определенного цвета.
Кроме того, сам по себе цвет часто кодируется при помощи шестнадцатиричного кода[8]. Каждому цвету соответствует шестиразрядный код в шестнадацтиричной системе счисления. Он делится на три секции по два разряда: #RRGGBB, где RR – доля красного цвета, GG – доля зеленого цвета, BB – доля голубого цвета. В качестве примера можно рассмотреть часть таблицы веб-цветов (безопасных цветов). Она приведена на рисунке 4.
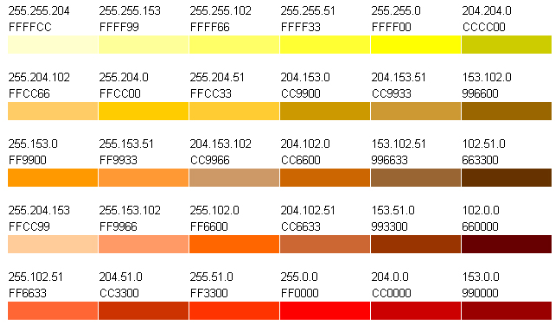
Рисунок 3 – часть таблицы безопасных цветов.
Кодирование аудиоданных в формате WAV
Для представления звука в цифровых форматах, в каждый единичный интервал времени производится измерение амплитуды сигнала. В силу того, что сам по себе звук имеет волновую природу, для точного представления его в цифровом виде, необходимо также непрерывно измерять амплитуду колебаний. В действительности, количество измерений в секунду, называемое частотой дискретизации, варьируется от 10000 до 96000. Наиболее часто применяется частоты 44100 и 48000 Гц. В качестве амплитудной градации (разрешения) применяют 28, 216 и 224 бита. Само собой, при оцифровке аудиосигнала возникают искажения и отклонения, которые напрямую зависят от частоты дискретизации и разрешения. Высокочастотные искажения могут подавляться при помощи специальных фильтров, которые размещаются на выходе цифро-аналогового преобразователя[9].
Звук в цифровом формате занимает достаточно большой объём памяти. Для примера возьмём аудиофайл, длительность которого составляет 60 секунд, частота дискретизации равна 44100 Герц, а разрешение – 16 бит. Такой файл занимает чуть более 10 мегабайт дискового пространства.
Звуковые файлы плохо сжимаются в архивы стандартными средствами, но существуют различные форматы, которые позволяют сократить объём используемого пространства памяти, однако в связи с этим возникают потери качества, поэтому для профессиональной работы со звуком не применяются форматы со сжатием.
Рассмотрим кодирование звука в формате WAV. Для данного формата характерно 2 строго отделенных друг от друга области: это заголовок файла, содержащий техническую информацию, и аудиоданные, представляющие звук.
Заголовок файла содержит информацию о:
- размере аудиофайла;
- каналах;
- частоте дискретизации;
- глубине звучания.
Эти термины уже были озвучены ранее, и их определение было дано, поэтому перейдем к структуре файла WAV, а именно - к заголовку. Его структура описана в таблице 2.
Таблица 2 – структура файла WAV.
|
0-3 |
chunkId |
Содержит символы «RIFF» в ASCII кодировке 0x52494646. Является началом RIFF-цепочки. |
|
4-7 |
chunkSize |
Это оставшийся размер цепочки, начиная с этой позиции. Иначе говоря, это размер файла минус 8, то есть, исключены поля chunkId и chunkSize. |
|
8-11 |
format |
Содержит символы «WAVE» 0x57415645 |
|
12-15 |
subchunk1Id |
Содержит символы "fmt " 0x666d7420 |
|
16-19 |
subchunk1Size |
16 для формата PCM. Это оставшийся размер подцепочки, начиная с этой позиции. |
|
20-21 |
audioFormat |
Аудио формат, список допустипых форматов. Для PCM= 1 (то есть, Линейное квантование). Значения, отличающиеся от 1, обозначают некоторый формат сжатия. |
|
22-23 |
numChannels |
Количество каналов. Моно = 1, Стерео = 2 и т.д. |
|
24-27 |
sampleRate |
Частота дискретизации. 8000 Гц, 44100 Гц и т.д. |
|
28-31 |
byteRate |
Количество байт, переданных за секунду воспроизведения. |
|
32-33 |
blockAlign |
Количество байт для одного сэмпла, включая все каналы. |
|
34-35 |
bitsPerSample |
Количество бит в сэмпле. Так называемая «глубина» или точность звучания. 8 бит, 16 бит и т.д. |
|
36-39 |
subchunk2Id |
Содержит символы «data» 0x64617461 |
|
40-43 |
subchunk2Size |
Количество байт в области данных. |
|
44- |
data |
Непосредственно WAV-данные. |
Методы кодирования символьных данных. Кодировка Unicode и ASCII
Unicode – одна из наиболее популярных кроссплатформенных мультиязычных кодировок, которая используется для описания различных текстовых символов. В Unicode есть большое количество символов и национальных литералов.
В Unicode для кодирования символов предоставляется 31 бит (4 байта за вычетом одного бита). Количество возможных комбинаций дает запредельное число: 231 = 2 147 483 684 (т.е. более двух миллиардов). Поэтому Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и иные специальные символы. Однако информационная емкость 31-битового Unicode все равно остается слишком большой. Поэтому чаще используется сокращенная 16-битовая версия (216 = 65 536 значений), где кодируются все современные алфавиты. Данная кодировка частично совпадает с ASCII (одинаковые коды имеют первые 128 символов).
Рассмотрим методику наложения символов в Unicode для получения специальных литералов. Это происходит с использованием различных методологий. На рисунке 4 представлен пример получения некоторых символов путем совмещения в формате NFD – рекурсивного сложения.

Рисунок 4 – сложение символов Unicode в методологии NFD.
Методология NFKD позволяет получить совмещенные символы в форме совместной декомпозиции. Пример использования данной методологии приведен на рисунке 5.

Рисунок 5 – сложение символов с использованием NFKD.
Также существуют и другие методологии для сложения символов в данной кодировке.
Далее следует рассмотреть кодировку символов в машинном представлении – UTF-8, одной из базовых составляющих Unicode.
Схема кодирования состоит из трёх последовательных процедур. В первую очередь определяется количество байт для представления символа, при этом номер символа берется из Unicode-таблицы. Пример представлен на рисунке 6.
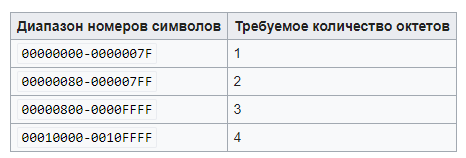
Рисунок 6 – соответствие диапазона номеров символов количеству байт в Unicode.
Далее производится установка старших битов:
- 0, если требуется 1 байт;
- 110, если требуется 2 байта;
- 1110, если требуется 3 байта;
- 11110, если требуется 4 байта.
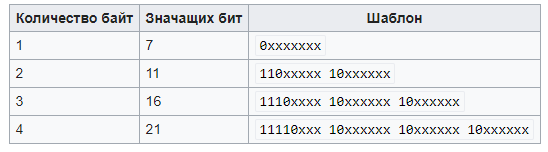
Рисунок 7 – шаблон кодирования символов.
Затем производится установка необходимых значений в младших байтах, которые непосредственно определяют символ. Примеры кодирования приведены на рисунке 8.

Рисунок 8 – примеры кодирования символов.
Чтобы указать на то, что файл содержит символы в кодировке Unicode, в заголовке файла выставляются преамбулы – маркеры последовательности. Они показаны на рисунке 9.

Рисунок 9 – маркеры последовательности в Unicode.
ASCII (American standard code for information interchange) — одна из наиболее распространенных и самая поддерживаемая из существующих на данный момент кодировка для представления распространенных символов, разработанная в Соединенных Штатах Америки в 1963 году[4]. В данной таблице кодировки приводятся однобайтные коды для следующих групп символов:
- арабские цифры;
- латинский алфавит (верхний и нижний регистры);
- знаки пунктуации;
- управляющие знаки;
- дополнительные буквы национальных алфавитов.
В ASCII коды цифр начинаются с 0011 в двоичной системе, а заканчиваются самим значением представляемого числа в данной системе счисления. К примеру, 0101 – двоичный код числа 5, а 01110101 – код символа «5» в таблице ASCII. Таким образом, каждое число в двоичной системе счисления можно превратить в строку ASCII путем добавления к каждому из них префикса 0011.
Кодирование видеоданных. Формат AVI
Формат AVI – RIFF-видеоформат, разработанный компанией Microsoft в 1992 году. Файлы с расширением AVI могут содержать видео- и аудиоданные, сжатые с использованием разных комбинаций кодеков, что позволяет синхронно воспроизводить видео со звуком. Файл AVI может содержать различные виды компрессированных данных (например, DivX-видео + WMA-аудио или Indeo-видео + PCM-аудио), в зависимости от того, какой кодек используется для кодирования/декодирования. Как и DVD, файлы AVI поддерживают многопоточное аудио-видео.
Файл начинается с заголовка, который приведен на рисунке 10.
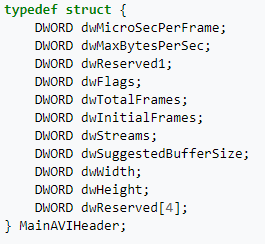
Рисунок 10 – заголовок файла AVI.
В заголовке указывается различная информация: частота кадров, потоки, флаги, общее количество кадров, ширина и высота видео, размер буфера и другие параметры.
Сам по себе файл AVI состоит из файлов формата RIFF. Они основаны на понятии «чанк», т.е. блок, содержащий три поля: заголовок, указателя размера чанка и самих графических данных. Формат чанка приведен на рисунке 11.
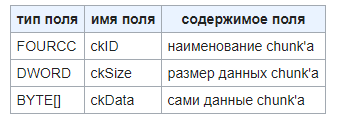
Рисунок 11 – формат чанка RIFF.
Также AVI содержит аудиоданные, которые кодируются в зависимости от своего формата.
Заключение
Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи. Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений.
Для преставления информации в компьютерной технике используются различные методы кодирования данных. Это связано с тем, что данные разбиваются на множество категорий и групп, и для каждой из них необходимо разработать способ хранения и представления.
В данной работе были рассмотрены некоторые форматы данных: текстовая информация, аудиоданные и графическая информация. Для этих данных была подробно разобрана методика их представления в компьютере.
Подводя итоги, можно сделать вывод о том, что в любом случае данные подвергаются процессу дискретизации и, в конечном счёте, представляются в виде последовательности нулей и единиц, т.е. двоичного кода. Однако на более высоком уровне кодировка данных является более интересным и сложным набором методов.
Список используемых источников
- Информация, Википедия [Электронный ресурс], режим доступа – https://ru.wikipedia.org/wiki/Информация, дата обращения - 18.06.2019.
- Цифровые аудиоформаты, Википедия [Электронный ресурс], режим доступа – https://ru.wikipedia.org/wiki/Цифровые_аудиоформаты, дата обращения - 18.06.2019.
- Алфавит, Википедия [Электронный ресурс], режим доступа – https://ru.wikipedia.org/wiki/Алфавит, дата обращения - 18.06.2019.
- Векторная графика, Википедия [Электронный ресурс], режим доступа – https://ru.wikipedia.org/wiki/Векторная_графика, дата обращения - 18.06.2019.
- Растровая графика, Википедия [Электронный ресурс], режим доступа – https://ru.wikipedia.org/wiki/Растровая_графика, дата обращения - 18.06.2019.
- Горельская Л.В. Компьютерная графика: учебное пособие по курсу «Компьютерная графика», Оренбургский государственный университет, ЭБС АСВ, 2003.— 148 c.
- Григорьева И.В. Компьютерная графика. — М.: Прометей, 2012.— 298 c.
- Дружинин А.И. Алгоритмы компьютерной графики. Часть 3 [Электронный ресурс]: учебное пособие/ Дружинин А.И., Дружинина Т.А.— Электрон. текстовые данные.— Новосибирск: Новосибирский государственный технический университет, 2009.— 48 c.— Режим доступа: http://www.iprbookshop.ru/44895.html.— ЭБС «IPRbooks»
- Гумерова Г.Х. Основы компьютерной графики [Электронный ресурс]: учебное пособие/ Гумерова Г.Х.— Электрон. текстовые данные.— Казань: Казанский национальный исследовательский технологический университет, 2013.— 87 c.— Режим доступа: http://www.iprbookshop.ru/62217.html.— ЭБС «IPRbooks»
- ASCII, Википедия [Электронный ресурс], режим доступа – https://ru.wikipedia.org/wiki/ASCII, дата обращения - 18.06.2019.
- Балюкевич Э.Л. Теория информации и кодирования. М.: Евразийский открытый институт, Московский государственный университет экономики, статистики и информатики, 2004.— 113 c.
- MP3, Википедия [Электронный ресурс], режим доступа –https://ru.wikipedia.org/wiki/MP3, дата обращения - 18.06.2019.

- Категории стандартов
- Сравнительный анализ стандартов, видов и особенностей систем контроля в российских и зарубежных компаниях (Стандартизация)
- История возникновения и развития языка программирования Си (С++) и Java.(История возникновения языка C)
- Применение объектно-ориентированного подхода при проектировании информационной систем
- Гендерные различия проявлений профессионального стресса (Типы стресса)
- Действие права в РФ
- Влияние сюжетно-ролевой игры на развитие личности детей дошкольного возраста (Сущность и характеристика понятия «развитие личности»)
- разработка проекта совершенствования организационной структуры компании с учетом требований этапов жизненного цикла.
- ОСНОВЫ ГОСУДАРСТВА.
- Управление финансами и пути его совершенствования в Российской Федерации
- Менеджмент человеческих ресурсов (Развитие эволюции управления человеческими ресурсами)
- Применение объектно-ориентированного подхода при проектировании информационной системы (Обзор языков, которые используют ООП)