
Курсовая работаПроцессор персонального компьютера. Назначение, функции, классификация процессора.
Содержание:

Введение
Центральным процессором (ЦП), часто называемым просто процессором, является компонент на электронном компьютере, который выполняет всю активную обработку всех направлений программирования и манипулирует данными; это включает в себя выполнение вычислений по номерам и определение того, какие конкретные шаги нужны для выполнения.
Конкретная функция, которая должна выполняться в каждый момент времени, основана на машинной инструкции, также называемой машинным кодом или кодом операции, который обычно автоматически извлекается из памяти. Алгоритм кодов операций, выполняемых последовательно, называется компьютерной программой.
В зависимости от конструкции конкретного процессора, арифметические операции могут выполняться по двум номерам, которые ранее были сохранены внутри процессора в специальных элементах хранения, называемых регистрами; или один или оба могут быть извлечены из памяти. После выполнения вычисления итоговое (вновь вычисленное) число может быть сохранено в регистре или записано обратно в память компьютера (опять же, в зависимости от конкретного процессора).
Сегодняшние процессоры также выполняют гораздо больше, чем просто выполняют операции, выбранные программными кодами операций; они также выполняют анализ потока данных в потоке команд и применяют ряд расширенных эвристик для повышения скорости передачи инструкций. В этой статье обсуждаются некоторые способы ускорения работы процессоров.
Процессор, который производится как единая интегральная схема, обычно известен как микропроцессор. Большинство процессоров на современных компьютерах являются микропроцессорами, а микропроцессоры также используются во многих повседневных вещах: от автомобилей и бытовой техники до сотовых телефонов и детских игрушек.
1. История изобретения современного процессора
Фраза «центральный процессор» и ее аббревиатура, CPU, использовались в компьютерной индустрии, начиная с 1960-х годов. Термин представляет собой описание определенного класса логических машин, которые могут выполнять инструкции.
Это широкое определение может быть легко применено ко многим ранним компьютерам, которые существовали задолго до того, как термин «ЦП» когда-либо широко использовался. Форма, дизайн и реализация процессоров сильно изменились с самых ранних экземпляров. [1]

Рис. 1 EDVAC, один из первых программных компьютеров
2. Работа ЦП
Основная операция большинства процессоров, независимо от физической формы, которую они принимают, заключается в выполнении последовательности хранимых инструкций, называемых программой. Программа представлена серией чисел, которые хранятся в памяти.
Для взаимодействия с этими данными используются четыре шага: выборка, декодирование, выполнение и обратная запись. Процессоры, которые следуют этой схеме хранения и вызова данных, следуют архитектуре фон Ноймана, обычно используемой сегодня в процессорах.
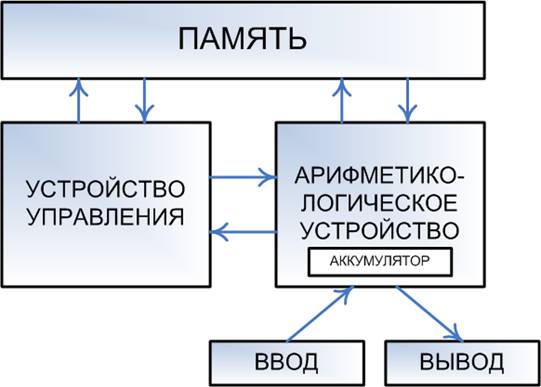
Рис. 2 Архитектура фон Ноймана
2.1 Выборка
Первый шаг, выборка, включает в себя извлечение инструкции из памяти. Место в памяти программы определяется программным счетчиком, который является регистром, который сначала определяет последовательность команд, которые должны быть выполнены, а затем сохраняет эти команды этой последовательностью в памяти.
Другими словами, счетчик программ отслеживает место CPU в текущей программе. После получения команды, счетчик программ увеличивается на длину слова команды в единицах памяти. Часто, требуемая команда должна извлекаться из относительно медленной памяти, в результате чего CPU останавливается, ожидая возвращения команды. Это называется узким местом.
2.2 Декодирование
Команда, которую CPU извлекает из памяти, используется для определения того, что должен делать процессор. На этапе декодирования команда разбивается на части, которые могут интерпретировать различные части ЦП. Способ интерпретации значения числовой команды определяется архитектурой набора команд процессора (ISA).
Часто одна группа бит в инструкции, называемая кодом операции, указывает, какую операцию выполнить. Остальные части номера обычно предоставляют информацию, необходимую для этой команды, такую как операнды для операции добавления. Такие операнды могут быть заданы как постоянное значение или как ссылка на местоположение значения: регистр или адрес памяти.
В старых проектах, части ЦП, отвечающие за декодирование команд, были фиксированными аппаратными устройствами. Однако в более абстрактных и сложных процессорах, микропрограмма ISA часто используется для перевода инструкций в различные сигналы конфигурации для ЦП.
Эта микропрограмма иногда перезаписывается, поэтому её можно изменить, чтобы изменить способ, которым CPU декодирует инструкции даже после того, как он был изготовлен.
2.3 Выполнение
После шагов выборки и декодирования выполняется шаг выполнения. Во время этого шага подключаются различные части процессора, чтобы они могли выполнять требуемую операцию. Если, например, была запрошена операция сложения, арифметический логический блок (ALU) будет подключен к набору входов и набору выходов.
Входы содержат номера, которые будут добавлены, а выходы будут содержать окончательную сумму. ALU содержит схему для выполнения простых арифметических и логических операций на входах (например, сложения и побитовые операции).
Если операция добавления приводит к слишком большому результату для процессора для обработки, также может быть установлен флаг арифметического переполнения в регистре.
2.4 Обратная запись
Заключительный шаг, обратная запись, просто «записывает» результаты этапа выполнения в форму памяти. Очень часто результаты записываются в некоторый внутренний регистр CPU для быстрого доступа с помощью последующих инструкций.
В других случаях, результаты могут быть записаны в более медленную, но более дешевую и большую, основную память. Некоторые типы инструкций управляют счетчиком программ, а не напрямую производят данные результата. Они обычно называются «прыжками» и облегчают выполнение условной программы (с помощью условного перехода) и функции в программах. [2]
Многие инструкции также изменяют состояние цифр в регистре «flags». Эти флаги могут использоваться, чтобы влиять на поведение программы, поскольку они часто указывают на результат различных операций.
Например, один тип команды «сравнения» рассматривает два значения и устанавливает число в регистре флагов, в соответствии с которым он больше. Этот флаг затем может использоваться более поздней командой перехода для определения потока программы.
2.5 Цикл
После выполнения инструкции и обратной записи результирующих данных весь процесс повторяется, причем следующий цикл команды обычно извлекает команду next-in-sequence из-за увеличенного значения в счетчике программы.
Если инструкция была «прыжком», счетчик программ будет изменен, чтобы содержать адрес команды, на которую был перескок, и выполнение программы продолжится нормально. В более сложных процессорах, чем описанные здесь, несколько команд могут быть извлечены, декодированы и выполнены одновременно.
В этом разделе описывается упрощенная форма того, что обычно называют «классическим конвейером RISC», что на самом деле довольно распространено среди простых процессоров, используемых во многих электронных устройствах (часто называемых микроконтроллерами).
3. Конструкция и реализация
3.1 Целочисленный диапазон
Способ, которым CPU представляет числа, обусловлен выбором конструкции, который влияет на самые основные способы работы устройства. На некоторых ранних цифровых компьютерах использовалась электрическая модель общей десятичной (базовой десятичной) системы цифр для внутреннего представления чисел.
Несколько других компьютеров использовали более экзотические системы с числами, такие как тройной (базовый три). Почти все современные процессоры представляют числа в двоичной форме, причем каждая цифра представлена некоторой двузначной физической величиной, такой как «высокое» или «низкое» напряжение. [3]
Что связано с представлением чисел – так это размер и точность чисел, которые может представлять ЦП. В случае двоичного процессора бит относится к одному существенному месту в числах, с которыми имеет дело CPU.
Количество бит (или мест), которое ЦП использует для представления чисел, часто называют «размер слова», «ширина бита», «ширина пути данных» или «целочисленная точность» при работе со строго целыми числами (в отличие от чисел с плавающей запятой).
Этот момент архитектуры ЦП может отличаться даже в разных частях одного и того же CPU. Например, 8-разрядный ЦП имеет ряд чисел, которые могут быть представлены восемью двоичными цифрами (каждая цифра имеет два возможных значения), то есть 28 или 256 дискретных чисел. Фактически, целочисленный размер устанавливает аппаратное ограничение в диапазоне целых чисел, которое может использовать программное обеспечение, выполняемое ЦП. [4]
Целочисленный диапазон также может влиять на количество мест в памяти, которые CPU может адресовать (найти). Например, если двоичный процессор использует 32 бита для представления адреса памяти, и каждый адрес памяти представляет собой один октет (8 бит), максимальное количество памяти, на которое может обращаться центральный процессор, составляет 232 октета или 4 гигабайта.
Это очень простой взгляд на адресное пространство процессора, и во многих проектах используются более сложные методы адресации, такие как пейджинг, чтобы найти больше памяти, чем их целочисленный диапазон позволил бы с плоским адресным пространством.
Более высокие уровни целочисленного диапазона требуют больше структур для обработки дополнительных цифр и, следовательно, большей сложности, размера, энергопотребления и, как правило, расходов.
Таким образом, нет ничего необычного в том, чтобы встретить 4- или 8-битные микроконтроллеры, используемые в современных устройствах, хотя доступны процессоры с гораздо более высоким диапазоном (например, 16, 32, 64, даже 128 бит).
Более простые микроконтроллеры, как правило, дешевле, потребляют меньше энергии и, следовательно, рассеивают меньше тепла, и все это может быть решающим в контексте выбора конструкции для электронных устройств.
Однако в приложениях более высокого уровня преимущества, предоставляемые дополнительным диапазоном (чаще всего дополнительным адресным пространством), более значительны и часто влияют на выбор дизайна. Чтобы получить некоторые преимущества, обеспечиваемые как более низкой, так и более высокой длиной бит, многие процессоры разработаны с разной шириной битов для разных частей устройства.
Например, в IBM System / 370 использовался центральный процессор, который был в основном 32-разрядным, но использовал 128-битную точность внутри своих блоков с плавающей запятой, чтобы повысить точность и диапазон чисел с плавающей запятой (Amdahl et al., 1964).
Многие более поздние версии процессоров используют аналогичную смешанную ширину битов, особенно когда процессор предназначен для общего использования, когда требуется разумный баланс целых чисел и возможностей с плавающей запятой.
3.2 Тактовая частота
Большинство процессоров и даже большинство последовательных логических устройств работают синхронно. [5] Процессоры «делают ход» каждый раз, когда происходит сигнал синхронизации.
Этот сигнал, известный как тактовый сигнал, обычно принимает форму периодической прямоугольной волны. Вычисляя максимальное время, в течение которого электрические сигналы могут распространяться по различным ветвям многих схем процессора, разработчики могут выбрать подходящий период для тактового сигнала.
Этот период должен быть больше, чем время, необходимое для того, чтобы сигнал двигался или распространялся в наихудшем случае. При настройке периода тактовых импульсов на значение, значительно превышающее задержку распространения наихудшего случая, можно сконструировать весь процессор и способ перемещения данных по «краям» восходящего и падающего тактового сигнала.
Это имеет преимущественное значение для упрощения ЦП, как с точки зрения дизайна, так и с точки зрения компонентов. Тем не менее, это также обуславливает тот недостаток, что весь процессор должен ждать своих самых медленных элементов, хотя некоторые его части намного быстрее. Это ограничение в значительной степени компенсировалось различными способами увеличения параллелизма ЦП.
Однако, только архитектурные улучшения не устраняют все недостатки глобальных синхронных процессоров. Например, тактовый сигнал подвергается задержкам любого другого электрического сигнала. Более высокие тактовые частоты во все более сложных ЦП затрудняют сохранение синхронизирующего сигнала в фазе (синхронно) по всему блоку.
Это привело к тому, что многие современные процессоры потребовали множественных идентичных тактовых сигналов, чтобы избежать задержки одного сигнала, достаточного для того, чтобы вызвать неисправность ЦП. Еще одна важная проблема, поскольку тактовые частоты резко возрастают, - это количество тепла, которое рассеивается процессором.
Постоянно изменяющиеся часы заставляют переключать многие компоненты независимо от того, используются ли они в это время. В общем, компонент, который переключается, использует больше энергии, чем элемент в статическом состоянии. Таким образом, по мере увеличения тактовой частоты происходит также рассеяние тепла, в результате чего ЦП требует более эффективных решений для охлаждения.
Один из способов обращения с ненужными компонентами называется синхронизацией часов, которая включает в себя выключение тактового сигнала для ненужных компонентов (что фактически отключает их). Однако это часто считается сложным для реализации и поэтому не видит общего использования вне конструкций с очень малой мощностью [6].
Другим методом решения некоторых проблем с глобальным тактовым сигналом является удаление тактового сигнала в целом. При удалении глобального тактового сигнала процесс проектирования значительно усложняется по многим параметрам, асинхронные (или не требующие времени) конструкции имеют заметные преимущества в потреблении энергии и рассеивании тепла по сравнению с аналогичными синхронными конструкциями.
В то время как некоторые необычные, целые процессоры были построены без использования глобального тактового сигнала. Двумя примечательными примерами этого являются ARM-совместимый AMULET и совместимый с MIPS R3000 MiniMIPS.
Вместо полного удаления тактового сигнала некоторые конструкции процессора позволяют некоторым частям устройства быть асинхронными, например, используя асинхронные ALU в сочетании с суперскалярной конвейерной обработкой для достижения некоторой арифметической производительности.
Хотя совершенно неясно, могут ли полностью асинхронные проекты работать на сравнимом или более высоком уровне, чем их синхронные аналоги, очевидно, что они, по крайней мере, превосходят более простые математические операции. Это в сочетании с их превосходным энергопотреблением и свойствами рассеивания тепла делает их очень подходящими для встроенных компьютеров.
4. Параллелизм
Описание базовой операции CPU, предлагаемой в предыдущем разделе, описывает простейшую форму, которую может принять процессор. Этот тип ЦП, обычно называемый субскалярным, работает и выполняет одну инструкцию по одному или двум частям данных за раз.
Этот процесс приводит к присущей неэффективности в субскалярных ЦП. Поскольку за один раз выполняется только одна команда, весь процессор должен дождаться завершения этой команды, прежде чем перейти к следующей инструкции. В результате подкалиберный процессор получает «зависание» по инструкциям, для выполнения которых требуется более одного тактового цикла.
Даже добавление второго исполнительного блока не улучшает производительность; вместо того, чтобы подвешивать один путь, в настоящее используются время два канала, а количество неиспользуемых транзисторов увеличивается.
Эта конструкция, в которой ресурсы выполнения ЦП могут работать только по одной команде за раз, может достигать скалярной производительности (одна инструкция за такт). Тем не менее, производительность почти всегда субскалярная (менее одной инструкции за цикл).
Попытки добиться скалярной и лучшей производительности привели к появлению различных методологий проектирования, которые приводят к тому, что ЦП будет вести себя менее линейно и более параллельно. Когда речь идет о параллельности в процессорах, для классификации этих методов проектирования обычно используются два термина.
Параллельность уровня инструкций (ILP) направлена на увеличение скорости, с которой инструкции выполняются в ЦП (то есть для увеличения использования ресурсов выполнения на диске) и целей параллелизма уровня потока (TLP) для увеличения количества потоков, которые CPU может выполнять одновременно.
Каждая методология отличается как тем, как они реализованы, так и относительной эффективностью, которую они позволяют увеличить производительность процессора для приложения. [7]
4.1 Параллельность уровня инструкций
Одним из простейших методов, используемых для достижения увеличенного параллелизма, является начало первых шагов извлечения и декодирования команд до того, как предыдущая инструкция завершит выполнение.
Это простейшая форма метода, известная как конвейерная обработка инструкций, и используется практически во всех современных ЦП общего назначения. Конвейеризация позволяет выполнять несколько команд в любой момент времени, разбивая путь выполнения на отдельные этапы.
Это разделение можно сравнить с конвейерной линией, в которой инструкция становится более полной на каждом этапе до тех пор, пока она не выйдет из конвейера выполнения и не будет удалена.
Однако, конвейеризация дает возможность для ситуации, когда результат предыдущей операции необходим для завершения следующей операции; условие, часто называемое конфликтом зависимости от данных. Чтобы справиться с этим, необходимо соблюдать дополнительную осторожность, чтобы проверить эти условия и задержать часть конвейера команд, если это произойдет.
Естественно, для этого требуется дополнительная схема, поэтому конвейерные процессоры более сложны, чем субскалярные (хотя и не очень значительно). Конвейерный процессор может стать почти скалярным, запрещенным только конвейерными стойлами (инструкция, затрачивающая более одного такта на этап).
Дальнейшее совершенствование идеи конвейерной обработки инструкций привело к разработке метода, который еще больше сокращает время простоя компонентов ЦП. Конструкции, которые, как говорят, являются суперскалярными, включают в себя длинный конвейер команд и несколько идентичных исполнительных блоков.
В суперскалярном конвейере несколько команд считываются и передаются диспетчеру, который решает, могут ли команды выполняться параллельно (одновременно). Если это так, они отправляются в доступные исполняемые модули, что приводит к одновременному выполнению нескольких команд.
В общем, чем больше инструкций, которые суперскалярный процессор может отправлять одновременно ожиданиям, тем больше инструкций будет завершено в заданном цикле.
Большая часть сложности в разработке архитектуры суперскалярного процессора заключается в создании эффективного диспетчера. Диспетчер должен иметь возможность быстро и правильно определить, могут ли команды выполняться параллельно, а также отправлять их таким образом, чтобы как можно большее количество исполнительных блоков было занято.
Это требует, чтобы конвейер команд заполнялся как можно чаще и вызывал необходимость в суперскалярных архитектурах для значительных объемов кэша процессора. Он также делает методы предотвращения опасности, такие как предсказание ветвей, спекулятивное исполнение и исполнение вне порядка, что крайне важно для поддержания высоких уровней производительности.
Путем попытки предсказать, какая ветвь (или путь) примет условная инструкция, ЦП может свести к минимуму количество раз, когда весь конвейер должен ждать завершения условной инструкции. Спекулятивное выполнение часто обеспечивает умеренное повышение производительности за счет выполнения частей кода, которые могут потребоваться или не понадобиться после завершения условной операции.
Выполнение вне порядка несколько изменяет порядок выполнения инструкций, чтобы уменьшить задержки из-за зависимостей данных.
В случае, когда часть ЦП является суперскалярной, а часть - нет, то часть, которая не подвергается штрафу за производительность из-за расписания ларьков. Первоначально Intel Pentium (P5) имел два суперскалярных ALU, которые могли принимать одну инструкцию за каждый такт, но ее FPU не мог принять одну инструкцию за такт.
Таким образом, P5 был целым суперскалярным, но не суперскалярным с плавающей запятой. Преемник Intel в архитектуре Pentium, P6, добавил суперскалярные возможности к своим функциям с плавающей запятой и, следовательно, значительно увеличил производительность команд с плавающей запятой.
Как простая конвейерная обработка, так и суперскалярная конструкция увеличивают ILP процессора, позволяя одному процессору завершить выполнение инструкций со скоростью, превышающей одну команду за цикл (IPC). [8]
Большинство современных процессоров, по крайней мере, несколько сверхскалярных, и почти все процессоры общего назначения, разработанные в последнее десятилетие, являются суперскалярными. В последующие годы некоторые из акцентов при разработке компьютеров с высоким уровнем ILP были перенесены из аппаратного обеспечения процессора и в его программный интерфейс или ISA.
Стратегия очень длинного слова инструкции (VLIW) приводит к тому, что ILP напрямую подразумевается программным обеспечением, уменьшая объем работы, которую должен выполнять процессор, чтобы повысить ILP и тем самым уменьшить сложность дизайна.
4.2 Параллельность уровня нити
Другая стратегия, обычно используемая для увеличения параллелизма процессоров, заключается в том, чтобы включить возможность одновременного запуска нескольких потоков (программ). В целом, процессоры с высоким уровнем TLP используются намного дольше, чем высоко-ILP.
Многие из проектов, разработанных Cray в конце 1970-х и 1980-х годов, были сосредоточены на TLP в качестве основного метода, позволяющего использовать огромные вычислительные возможности. Фактически, TLP в виде усовершенствований выполнения нескольких потоков использовался уже в 1950-х годах (Smotherman 2005).
В контексте проектирования с одним процессором двумя основными методологиями, используемыми для выполнения TLP, являются многопроцессорность на чипе (CMP) и одновременная многопоточность (SMT). На более высоком уровне очень часто приходится создавать компьютеры с несколькими полностью независимыми процессорами в таких устройствах, как симметричная многопроцессорность (SMP) и неравномерный доступ к памяти (NUMA). [9]
При использовании самых разных средств все эти методы достигают той же цели: увеличение количества потоков, которые CPU (ы) могут выполнять параллельно.
Методы параллелизма CMP и SMP похожи друг на друга и наиболее просты. Они подразумевают концептуальную концепцию, а не использование двух или более полных и независимых процессоров. В случае CMP несколько процессорных «ядер» входят в один и тот же пакет, иногда в одну и ту же интегральную схему. [10]
SMP, с другой стороны, включает в себя несколько независимых пакетов. NUMA несколько похожа на SMP, но использует неравномерную модель доступа к памяти. Это важно для компьютеров с большим количеством процессоров, потому что время доступа каждого процессора к памяти быстро исчерпано с использованием модели общей памяти SMP, что приводит к значительным задержкам из-за ожидающих памяти процессоров.
Таким образом, NUMA считается гораздо более масштабируемой моделью, успешно позволяя использовать еще много процессоров на одном компьютере, чем SMP может реально поддерживать. SMT несколько отличается от других улучшений TLP тем, что он пытается дублировать как можно больше частей процессора.
Несмотря на то, что стратегия TLP считается стратегией TLP, ее реализация на самом деле больше напоминает суперскалярную конструкцию, и ее часто используют в суперскалярных микропроцессорах (таких как IBM POWER5). Вместо того, чтобы дублировать весь процессор, SMT разрабатывает только дублирующие части, необходимые для извлечения, декодирования и отправки команд, а также для таких вещей, как регистры общего назначения.
Это позволяет процессору SMT поддерживать работу своих исполнительных блоков чаще, предоставляя им инструкции из двух разных потоков программного обеспечения. Опять же, это очень похоже на суперскалярный метод ILP, но одновременно выполняет команды из нескольких потоков, а не одновременно выполняет несколько инструкций из одного потока.
4.3 Параллелизм данных
Менее распространенная, но все более важная парадигма процессоров (и, вообще говоря, вычисления в целом) касается векторов. Процессы, обсуждавшиеся ранее, все называют «скалярным» устройством определенного типа [11].
Как следует из названия, векторные процессоры имеют дело с несколькими частями данных в контексте одной инструкции. Это контрастирует со скалярными процессорами, которые обрабатывают одну часть данных для каждой команды.
Эти две схемы работы с данными обычно называются SISD (одна команда, отдельные данные) и SIMD (одна команда, несколько данных), соответственно. Большая полезность при создании процессоров, которые касаются векторов данных, заключается в оптимизации задач, которые требуют выполнения одной и той же операции (например, суммы или точечного продукта) для большого набора данных.
Некоторые классические примеры этих типов задач - мультимедийные приложения (изображения, видео и звук), а также многие виды научных и инженерных задач. В то время как скалярный ЦП должен завершить весь процесс выборки, декодирования и выполнения каждой команды и значения в наборе данных, векторный ЦП может выполнять одну операцию на сравнительно большом наборе данных с одной инструкцией.
Конечно, это возможно только тогда, когда приложение имеет тенденцию требовать много шагов, которые применяют одну операцию к большому набору данных.
Большинство ранних векторных процессоров, таких как Cray-1, были связаны почти исключительно с научными исследованиями и криптографическими приложениями. Однако, поскольку мультимедиа в значительной степени переместилась на цифровые носители, необходимость в некоторой форме SIMD в ЦП общего назначения стала более значительной.
Вскоре после того, как единицы с плавающей точкой начали становиться обычным явлением для включения в процессоры общего назначения, спецификации и реализации блоков выполнения SIMD также стали появляться для процессоров общего назначения.
Некоторые из этих ранних спецификаций SIMD, таких как MMX от MMX, были целыми. Это оказалось существенным препятствием для некоторых разработчиков программного обеспечения, поскольку многие приложения, которые извлекают выгоду из SIMD, в основном касаются чисел с плавающей запятой.
Постепенно эти ранние разработки были усовершенствованы и переработаны в некоторые из распространенных современных спецификаций SIMD, которые обычно связаны с одной ISA. Некоторые известные современные примеры - это SSE от Intel и связанный с PowerPC AltiVec (также известный как VMX). [12]
Заключение
С момента создания и по наши дни процессоры очень сильно изменились. Из маломощных, громоздких машин они превратились в маленькие, элегантные чипы. Производительность современных процессоров огромна – поддержка до 5 экранов одновременно, многоядерность, высочайшая тактовая частота.
Процессоры достигли огромного технологического совершенства; их возможности превышают современные запросы. Остается только гадать, для каких неведомых устройств они будут использоваться, ведь самые современные процессоры несравнимо мощнее, чем требуют самые мощные игровые ПК.

Рис. 3 Процессор AMD A12
Список литературы
1. Поначугин А.В. Создание и перспективы открытых аппаратно-программных систем сетевого управления технологическими процессами / Информационные технологии в организации единого образовательного пространства (сборник статей по материалам Международной научно-практической конференции преподавателей, студентов, аспирантов, соискателей и специалистов). Кафедра Прикладной информатики и информационных технологий в образовании. Н.Новгород: Мининский университет, 2015. – С.75–79.
2. Процессоры Intel – [Электронный ресурс] – Режим доступа: http://www.paygid.ru/articles/processori-intel/?q=726&n=749.
3. Процессоры AMD – [Электронный ресурс] – Режим доступа: http://www.amd.com/ru-ru/products/processor.
4. Процессоры Intel Core i7 6-го поколения (ранее Skylake) – [Электронный ресурс] – Режим доступа: http://www.intel.ru/content/www/ru/ru/ processors/core/core-i7-processor.html.
5. Поначугин А.В. Использование суперкомпьютеров для решения задач моделирования // Фундаментальные и прикладные исследования в современном мире. – 2015. – № 10-1. С. 22–25.
6. Рыбакова А.С., Поначугин А.В. Информационные технологии: проблемы их внедрения, достоинства, недостатки // Актуальные проблемы гуманитарных и естественных наук. – 2014. – № 11-2. – С.24–27.
7. Суханова Н.Т. Теоретические основы информатики. учеб. Пособие для студентов высш. пед. учеб. заведений: М-во образования Рос. Федерации, Мурманский гос. Пед. Университет, Мурманск, 2004, 128 с.
8. Суханова Н.Т. Методические особенности преподавания дисциплины «Информационные и коммуникационные технологии в образовании. / Научные труды SWorld, 2009, №1, С.44–45.
9. Артемова С.В., Информатика: Учебное пособие. Ч.1. Тамбов: Изд-во Тамб. гос. техн. ун-та, 2006.
10. Ершова Н.Ю., Ивашенков О.Н., Курсков С.Ю. Микропроцессоры. -
http://dfe3300.karelia.ru/koi/posob/microcpu/index.html
11. Иванько А.Ф. Структура и архитектура микропроцессоров современных персональных электронных вычислительных машин. – http://www.hi-edu.ru/x-books/glblinks/files/refs.htm
12. Калошин Р. О., Микропроцессоры. –
http://fio.ifmo.ru/archive/group19/c3wu6/lesson2.html

- Разработка регламента выполнения процесса «управление запасами»
- Выбор стиля руководства в организации (ООО «Интер М»)
- Основные этапы формирования налогового учета в России (Эволюция налоговой системы в РФ.)
- Современные проблемы финансов предприятий. (ООО «Филлари»)
- Корпоративная культура в организации»
- Эффективность менеджмента организации ( ООО «Агент»)
- Суффиксация как способ словообразования в современном английском языке. Суффиксация имен существительных
- Проблемы диагностики и управления организационной культурой (Диагностика организационной культуры ООО «Телекомпания «4 канал»)
- Невербальные проявления эмоциональных состояний человека (Коммуникационные средства)
- Невербальные проявления эмоциональных состояний человека (Виды невербальных языков)
- Первичные учетные документы
- Формирование и использование финансовых ресурсов коммерческих организаций (Меры по совершенствованию формирования финансовых ресурсов хозяйствующих субъектов)