
Исследование алгоритмов поиска и сортировки данных.
Содержание:

ВВЕДЕНИЕ
Программирование содержит целый ряд важных внутренних задач. Одной из наиболее важных задач для программирования является задача сортировки. Под сортировкой обычно понимают перестановки элементов любой последовательности в определенном порядке. Эта задача является одной из важнейших потому, что ее целью является облегчение последующей обработки определенных данных и, в первую очередь, задачи поиска.
Цель данной курсовой работы - исследование алгоритмов поиска и сортировки данных.
Объектом исследования в данной курсовой работе являются алгоритмы сортировки данных и алгоритмы поиска данных.
Предметом исследования в данной курсовой работе являются способы и методы реализации алгоритмов сортировки на языках программирования высокого уровня, в частности на языке Delphi. Pascal, C++.
В рамках выполнения курсовой работе необходимо решить следующие основные задачи:
- Изучить научно методическую литературу по теме исследования,
- ознакомление с алгоритмами сортировки,
- проанализировать с алгоритмами сортировки и осветить каждый из них.
ГЛАВА I. АЛГОРИТМЫ СОРТИРОВКИ
Часто данные приходится упорядочивать, прежде чем обрабатывать их. Если набор данных не упорядочен, то чтобы выяснить, есть ли среди них определённый элемент, нужно перебрать все данные. Если данные упорядочены, то можно воспользоваться методом дихотомического поиска, или метода деления пополам, который работает гораздо быстрее, чем полный перебор. Для того, чтобы данные были упорядочены, можно заполнять специальные структуры данных, которые автоматически упорядочивают по- падающую в них информацию, а можно и воспользоваться алгоритмами сортировки, чтобы перегруппировать уже записанные в массив неупорядоченные данные. Алгоритмы сортировки отличаются друг от друга по многим показателям. Одни алгоритмы пользуются дополнительной памятью, а другие — нет. Когда носителями больших объёмов данных были магнитные ленты, было принципиально важно обойтись без дополнительной памяти. В случае жёсткого диска безразлично, далеко или близко находятся обрабатываемые данные, но в случае магнитной ленты это не так. Чтобы сравнить данные, далеко отстоящие друг от друга на ленте, придётся перематывать ленту, а это занимает намного больше времени, чем операции записи и чтения. Поэтому на то, требует определённый алгоритм, чтобы данные лежали близко, или нет, тоже нужно обращать внимание. Применительно к алгоритмам сортировки введём два понятия: 𝐶 — количество сравнений, 𝑀 — количество перестановок. Эти понятия разделяются, так как иногда операция чтения производится значительно быстрее, чем операция записи. Выбор алгоритма сортировки иногда зависит от специфических требований по объёмам данных или по носителям. В каждом языке программирования есть реализованная стандартная функция сортировки, которая обычно работает быстро. В языке C это функция qsort. С прикладной точки зрения студенту достаточно только знать, как ей пользоваться, а отличать сортировку пузырьком от сортировки Шелла он уметь не обязан. Однако разные алгоритмы стоит пройти, так как некоторым студентам это может быть как полезно, так и интересно. Методы сортировки без привлечения дополнительной памяти — это сортировка включением, или сортировка вставками, сортировка прямым выбором и сортировка пузырьком. Эти алгоритмы имеют самую плохую временную сложность; их обычно проходят в школе, и они обычно запоминаются лучше всего. Сортировка включением происходит следующим образом. В начале массив данных пуст, затем начинается его заполнение. Каждый новый элемент входных данных ставится в массив так, чтобы получившийся массив оказался отсортирован. Когда все входные данные окажутся вставлены в массив, тот будет упорядочен. Можно привести аналогию с колодой карт. Карты по очереди берутся в руку, причём каждая карта ставится на своё место по величине. Когда вся колода окажется в руке, она будет упорядочена, это гарантирует сам метод расположения карт. Наилучший случай по перестановкам, когда мало количество сдвигов правой части массива (считая от вставляемого элемента), — это уже отсортированный массив входных данных. Тогда каждый новый элемент становится в конец массива, существующего на момент его добавления, и никаких сдвигов не происходит. Этот же случай является наилучшим по сравнениям, так как достаточно одного сравнения, чтобы понять, что новый элемент нужно добавить в конец массива. Худший случай и по сравнениям, и по перестановкам — когда входные данные отсортированы в обратном порядке. Тогда каждый новый элемент нужно сравнивать с каждым уже имеющимся элементом, ставить его в начало массива и сдвигать весь массив вправо
В среднем, если частично заполненный массив имеет 𝑘 элементов, на вставку очередного элемента потребуется 𝑘 + 1 2 сравнений. Среднее количество присвоений на каждом шаге равно 𝑘 + 1 2 + 2. Пусть размер конечного массива — 𝑛. Тогда минимальные, максимальные и средние временны́е сложности сортировки включением можно представить в
таблице 1:
min 𝐶 = 𝑂(𝑛) min 𝑀 = 𝑂(1)
max 𝐶 = 𝑂(𝑛2 ) max 𝑀 = 𝑂(𝑛2 )
avr 𝐶 = 𝑂(𝑛2 ) avr 𝑀 = 𝑂(𝑛2 )
Таблица 1: Сортировка вставками
Таким образом, временная сложность алгоритма почти всегда равна 𝑂(𝑛2 ). Может повезти, и входные данные будут уже отсортированы, но в общем случае сортировка включением имеет квадратичную от размера входных данных сложность. Это нехорошо, так как количество операций быстро растёт при увеличении 𝑛. Произведём модификацию этого алгоритма. Сразу заметим, что модификацию нужно производить, когда сложность удовлетворительна, нужно только улучшить скорость алгоритма не более, чем в разы. Но если требуется провести сортировку за час, а данному алгоритму нужны для работы трое суток, то модификация бесполезна — нужно менять сам алгоритм.
Поскольку на каждом шаге частичный массив отсортирован, то вовсе не обязательно сравнивать новый элемент со всеми элементами подряд. Методом деления пополам можно значительно уменьшить количество сравнений. Сложность по сравнениям теперь будет не 𝑂(𝑛2 ), а 𝑂(𝑛 log 𝑛). Количество перестановок при этом не затрагивается, так что результирующая сложность алгоритма по-прежнему равна 𝑂(𝑛2 ).
1.1 Сортировка прямым выбором
Может быть как устойчивый, так и неустойчивый. На массиве из n элементов имеет время выполнения в худшем, среднем и лучшем случае Θ(n2), предполагая что сравнения делаются за постоянное время.
Сортировка прямым выбором, или сортировка выборкой, работает следующим образом (Рисунок 1). В неупорядоченном массиве входных данных размера 𝑛 производится цикл по всем элементам. На итерации 𝑖 выбираем самый маленький элемент из части массива [𝑖, 𝑛] и меняем его местами с элементом с номером 𝑖. По мере функционирования алгоритма в левой части массива будут накапливаться уже отсортированные элементы. Для того чтобы найти наименьший элемент из 𝑛, требуется 𝑂(𝑛) операций сравнения. Количество перестановок всего алгоритма будет равняться 𝑂(𝑛). Так как во внешнем цикле алгоритма 𝑛 итераций, то суммарная сложность алгоритма — 𝑂(𝑛2 ), как и у алгоритма сортировки включением. Однако времена работы алгоритма будут немного лучше за счёт коэффициента у 𝑛 2 . В настоящее время алгоритм сортировки выбором используется исключительно в учебных целях. Лучший случай — когда массив входных данных полностью отсортирован. Тогда количество перестановок равно нулю. Однако количество сравнений при этом не изменится — 𝑂(𝑛2 ). Худший случай — когда приходится делать перестановку на каждой итерации алгоритма, например, когда весь массив отсортирован, кроме того, что наибольший элемент стоит на первой позиции. Тогда 𝑀 = 𝑂(𝑛), а количество сравнений — то же самое.

Рисунок 1 Сортировка прямым выбором.
1.2. Сортировка пузырьком
Простой алгоритм сортировки. Для понимания и реализации этот алгоритм — простейший, но эффективен он лишь для небольших массивов. Алгоритм считается учебным и практически не применяется вне учебной литературы, вместо него на практике применяются более эффективные алгоритмы сортировки. В то же время метод сортировки обменами лежит в основе некоторых более совершенных алгоритмов, таких как шейкерная сортировка, пирамидальная сортировка и быстрая сортировка.
Алгоритм состоит из повторяющихся проходов по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются N-1 раз или до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При каждом проходе алгоритма по внутреннему циклу, очередной наибольший элемент массива ставится на своё место в конце массива рядом с предыдущим «наибольшим элементом», а наименьший элемент перемещается на одну позицию к началу массива («всплывает» до нужной позиции, как пузырёк в воде, отсюда и название алгоритма).
При сортировке пузырьком сравниваются пары рядом стоящих элементов. Если они стоят в правильном порядке, то ничего не происходит, а если левый больше, чем правый, то они меняются местами. Затем сравнивается пара элементов, смещённая на единицу относительно предыдущей. Когда один проход по массиву заканчивается, начинается следующий, в котором происходит то же самое. Такие проходы производятся до тех пор, пока весь массив не будет отсортирован. Критерием этого является условие, что на очередном проходе не было произведено ни одной перестановки. Название алгоритма связано с тем, что большой элемент в начале массива в процессе одного прохода как бы «всплывает» вверх (то есть вправо), как пузырь. Маленькое число, наоборот, может сдвинуться влево только на одну позицию за проход. По мере работы алгоритма проходы занимают всё меньше времени, потому что правая часть массива оказывается отсортирована. Этот алгоритм прекрасно подходит для сортировки на магнитных лентах, так как каждый раз сравнивается пара рядом стоящих элементов. Правда, за каждым проходом следует холостая перемотка на начало массива. Так как большие числа «всплывают» быстро, а маленькие «тонут» медленно, то напрашивается модификация алгоритма сортировки пузырьком. Нужно чередовать проходы вправо и влево, тогда эти два процесса происходят одинаково быстро. Такая модификация называется шейкерной сортировкой. Лучший случай — когда массив входных данных изначально отсортирован, тогда производится только один проход, за который программа убеждается, что в массиве ничего менять не нужно. Худший случай — когда массив отсортирован в обратном порядке, тогда за один проход большое число с первой позиции поднимается до своего места в конечном массиве, а количество перестановок максимально. Временна́я сложность алгоритма сортировки пузырьком даже в среднем случае равна 𝑂(𝑛2 ). Её модификация, шейкерная сортировка, имеет такую же сложность.
1.3. Сортировка Шелла
Алгоритм сортировки, являющийся усовершенствованным вариантом сортировки вставками. Идея метода Дональда Шелла состоит в сравнении элементов, стоящих не только рядом, но и на определённом расстоянии друг от друга; иными словами — это сортировка вставками, но с предварительными «грубыми» проходами (Рисунок 2).
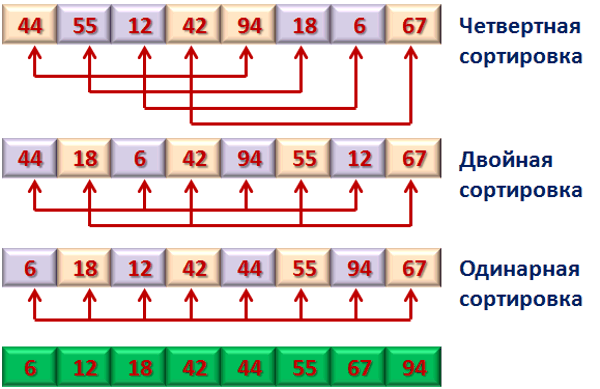
Рисунок 2 Сортировка Шелла.
Аналогичный метод усовершенствования «пузырьковой» сортировки называется «сортировка расчёской».
Выбираем из массива подпоследовательность чисел, расположенных друг от друга на расстоянии 𝑘. Эта подпоследовательность сортируется тем или иным методом. Затем сортируется подпоследовательность, получающаяся из предыдущей сдвигом вправо на одну позицию. После того, как все возможные подпоследовательности с шагом 𝑘 отсортированы, выбирается другое значение шага, и процедура повторяется. Каким образом выбирать шаг 𝑘 — сложный вопрос, на эту тему пишутся научные статьи. В отличие от предыдущих алгоритмов, где всё очень наглядно, для обоснования сложности этого алгоритма нужна математика. Количество перестановок 𝑀 у алгоритма Шелла оценивается как 𝑂 (𝑛4 3). На больших наборах данных это намного лучше, чем 𝑂(𝑛2 ).
1.4. Сортировка слиянием
Если имеются две отсортированные подпоследовательности, то чтобы составить из них отсортированную последовательность, нужно попарно сравнивать очередные элементы из них, и перемещать в результирующую последовательность меньший из них (Рисунок 3).

Рисунок 3 Сортировка слиянием.
На этом принципе основана сортировка слиянием mergesort. Из той подпоследовательности, из которой только что был перемещён элемент, на следующей итерации берётся следующий по величине элемент, а из другой подпоследовательности — тот же самый, что и на прошлой итерации. Если в одной из подпоследовательностей закончились элементы, то остаток другой просто пристыковывается справа к результирующей последовательности. Если в обеих подпоследовательностях содержится по 𝑛 элементов, то сложность такого слияния этих подпоследовательностей — 𝑂(𝑛). На глобальном уровне принцип данного алгоритма таков. Разбиваем весь массив на две части. После того, как обе части отсортированы, применим вышеописанную процедуру для их слияния в отсортированный массив. Чтобы отсортировать одну такую часть, разобьём и её пополам. После того, как обе четверти отсортированы, применим вышеописанную процедуру слияния, чтобы получить отсортированную половину. Продолжаем дробить части массива до тех пор, пока одна подпоследовательность не достигнет размера в 1 или 2 элемента — такую группу элементов легко отсортировать. Рекурсивно применяя процедуру разбиения пополам и слияния подпоследовательности, можно отсортировать и весь массив. Сложность алгоритма сортировки слиянием — 𝑂(𝑛 log 𝑛).
1.5. Стабильность алгоритма сортировки
Пусть дана таблица студентов, в которой содержатся такие поля, как «фамилия» и «средний балл». Изначально строки отсортированы по фамилии. Требуется отсортировать их по среднему баллу, при этом строки с одинаковыми средними баллами должны оставаться отсортированными по фамилии. Сортировка, которая не меняет местами элементы с одинаковыми значениями, называется стабильной. Чтобы решить вышеописанную задачу, нужна стабильная сортировка. Сортировка выборкой, например, стабильна, потому что если имеются несколько эле- ментов с одинаковыми значениями, то этот алгоритм сначала выберет первый из них, затем второй, и т. д., так что их порядок в массиве сохранится. Однако если изменить алгоритм так, чтобы он выбирал последний из равных элементов, а не первый, то свойство стабильности пропадает. Это можно сделать, изменив в условии выбора текущего элемента строгое неравенство на нестрогое: i f ( x <= min ) min=x ;
1.6. Быстрая сортировка
В неотсортированном массиве выбирается какой-то элемент. Проводится цикл по массиву, в котором тот разделяется на две части: в одной из них лежат элементы, меньшие, чем выбранный, а в другом — большие. Группы элементов ставятся одна за другой, между ними вставляется выбранный элемент. Для каждой части эта процедура рекурсивно повторяется, пока весь массив не окажется отсортированным. Выбор разделяющего элемента является важным этапом алгоритма. Очевидно, что наименьший или наибольший элемент — это плохой выбор, так как все элементы массива окажутся в одной части. Хорошим выбором был бы выбор среднего по значению, но на каждой итерации для его вычисления нужно потратить 𝑂(𝑛) операций. Часто делают проще: берут три произвольных элемента в группе и выбирают средний из них. Сложность этого алгоритма составляет 𝑂(𝑛 log 𝑛). В общем случае быстрая сортировка является нестабильной: может сложиться ситуация, когда порядок одинаковых по значению элементов нарушится. Например, пусть имеется три одинаковых элемента, а на очередной итерации быстрой сортировки выбран второй из них. Тогда первый и третий элементы окажутся по одну сторону от второго элемента.
1.7. Сортировка деревом
Универсальный алгоритм сортировки, заключающийся в построении двоичного дерева поиска по ключам массива (списка), с последующей сборкой результирующего массива путём обхода узлов построенного дерева в необходимом порядке следования ключей. Данная сортировка является оптимальной при получении данных путём непосредственного чтения с потока (например из файла, сокета или консоли).
Например, исходная последовательность имеет вид:
4, 3, 5, 1, 7, 8, 6, 2
Корнем дерева будет начальный элемент последовательности. Далее все элементы, меньшие корневого, располагаются в левом поддереве, все элементы, большие корневого, располагаются в правом поддереве. Причем это правило должно соблюдаться на каждом уровне (Рисунок 4).
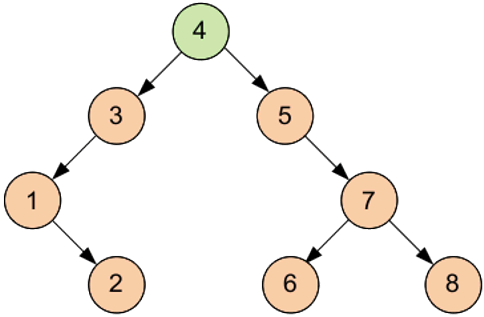
Рисунок 4 Сортировка деревом.
Для этой сортировки даже не обязательно выучить структуры данных типа «дерево»: дерево можно организовать на массиве. Это дерево — просто удобное представление массива, а не реальная структура данных в памяти компьютера. Такое дерево будет плоским и ветвистым, что, несомненно, эффективно для хранения данных. Будем заполнять дерево следующим образом. Берём элементы входных данных тройками, и максимальный из них ставим над двумя другими. Вставляем эту тройку в массив. Если в воображаемом дереве при этом нарушается порядок следования чисел, то нужно менять местами соответствующие элементы, пока порядок не будет восстановлен. Легче всего это показать на анимированном примере.
1.8. Сортировка подсчётом
Алгоритм сортировки, в котором используется диапазон чисел сортируемого массива (списка) для подсчёта совпадающих элементов. Применение сортировки подсчётом целесообразно лишь тогда, когда сортируемые числа имеют (или их можно отобразить в) диапазон возможных значений, который достаточно мал по сравнению с сортируемым множеством, например, миллион натуральных чисел меньших 1000. Эффективность алгоритма падает, если при попадании нескольких различных элементов в одну ячейку, их надо дополнительно сортировать. Необходимость сортировки внутри ячеек лишает алгоритм смысла[уточнить], так как каждый элемент придётся просматривать более одного раза.
Сортировка подсчётом также называется countsort. Для каждого элемента вводится число, которое хранит количество раз, когда этот элемент встретился в массиве. Пройдёмся в цикле по массиву и заполним все такие числа. После этого наберём новый массив, заполненный соответствующими количествами элементов. Такая процедура эквивалент- на сортировке исходного массива. Пусть исходный массив состоит из чисел от 0 до 19. Для того, чтобы его отсортировать, заведём ещё один массив из 20 целых чисел. Заполним его так, как только что было описано. После этого запишем в новый массив столько чисел от 0 до 19, сколь- ко их было подсчитано при заполнении массива из 20 элементов. Например, если нулей встретилось 4, то в позиции 0, 1, 2 и 3 нового массива нужно поставить нули. Если число единиц равно 3, то следующие три позиции будут заняты единицами, и т. д. Сортировка подсчётом эффективна тогда, когда элементы массива входных данных имеют ограниченный диапазон и повторяются. Если же элементы могут принимать широкий диапазон значений, или количество повторов чисел мало, то эта сортировка невыгодна. Стабильность алгоритма может быть достигнута, если использовать допол- нительную память, в противном случае алгоритм нестабилен. Времен- на́я сложность алгоритма — 𝑂(𝑛).
1.9. Поразрядная сортировка
Алгоритм сортировки за линейное время. Поразрядная сортировка (radixsort) имеет два варианта: 1. если сначала сортировка производится по младшим разрядам, затем по старшим, то это LSD (least significant digit); 2. если сначала сортировка производится по старшим разрядам, а затем по младшим, то это MSD (most significant digit). Эта сортировка применима в случае, когда, например, нужно отсортировать миллион трёхзначных чисел. В случае LSD применим сортировку подсчётом сначала по единицам, потом — по десяткам, потом — по сотням. При этом нужен вспомогательный массив размером в 10 элементов. После того, как произведена сортировка по единицам, взаимное расположение чисел по единицам в дальнейшем сохраняется, то же самое и для десятков. Можно взять не десятичную разрядность, а, например, шестнадцатеричную. Тогда вспомогательный массив вводится не на 10, а на 16 элементов. Алгоритм поразрядной сортировки, как и сортировка подсчётом, работает за линейное время.
1.10. Сортировка корзинками
Алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков (карманов, корзин) так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше (или меньше), чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо другим. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем исполнения.
Данный алгоритм требует знаний о природе сортируемых данных, выходящих за рамки функций "сравнить" и "поменять местами", достаточных для сортировки слиянием, сортировки пирамидой, быстрой сортировки, сортировки Шелла, сортировки вставкой.
Преимущества: относится к классу быстрых алгоритмов с линейным временем исполнения O(N) (на удачных входных данных).
Недостатки: сильно деградирует при большом количестве мало отличных элементов, или же на неудачной функции получения номера корзины по содержимому элемента. В некоторых таких случаях для строк, возникающих в реализациях основанного на сортировке строк алгоритма сжатия BWT, оказывается, что быстрая сортировка строк в версии Седжвика значительно превосходит блочную сортировку скоростью.
Сортировка корзинками также называется basketsort. Этот алгоритм удобно проиллюстрировать на примере стирки в семье с 12 детьми. Если постирать чьи-то джинсы с чьим-то белым платьем, то после этого начнутся внутрисемейные конфликты. Нужно распределить всю одежду для стирки на несколько корзинок. В одну корзину пойдут грязные немаркие вещи, в другую — белую одежду. Пусть все элементы (для определённости, числа) могут принимать малый диапазон значений. Разобьём числа на «корзинки»: от 0 до 2, от 3 до 5, от 6 до 8. Для каждой корзинки заводим свой упорядоченный список чисел. Каждый элемент из входного массива попадает в одну корзинку и занимает своё место в соответствующем списке. После этого списки всех корзинок склеиваются вместе, и получается отсортированный массив. Этот алгоритм лучше всего работает, когда в каждую корзинку попадает примерно одинаковое количество элементов. Если же входные данные разбросаны неравномерно, например, большое количество данных в одной-двух корзинках, то сортировка работает медленно.
Сложности алгоритмов удобно изобразить в виде таблицы (Рисунок 5). Заметим, что в худшем случае быстрая сортировка quicksort даёт сложность 𝑂(𝑛2 ).
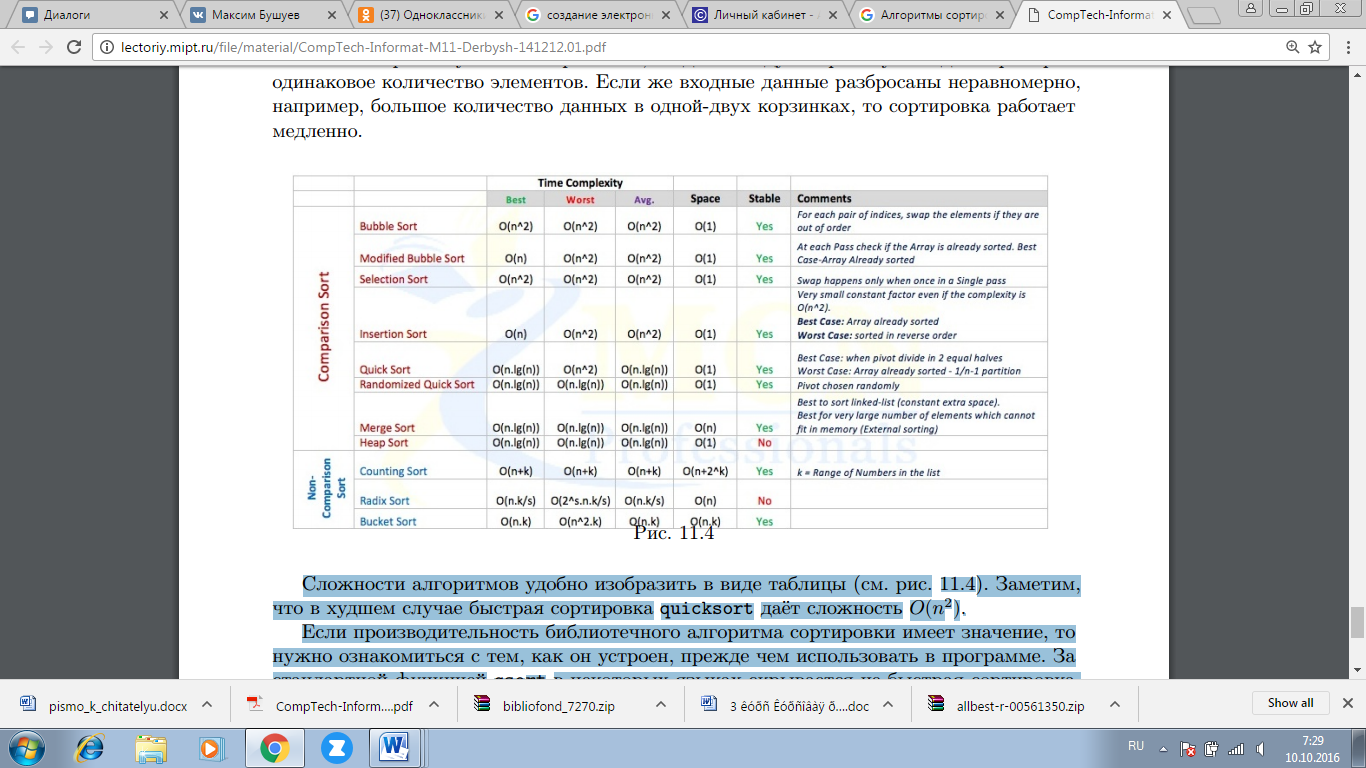
Рисунок 5 Сложности алгоритмов.
Если производительность библиотечного алгоритма сортировки имеет значение, то нужно ознакомиться с тем, как он устроен, прежде чем использовать в программе. За стандартной функцией qsort в некоторых языках скрывается не быстрая сортировка, а другие алгоритмы. При выборе алгоритма сортировки нужно учитывать специфику конкретной задачи, понимать, какие данные нужно сортировать, и насколько важны скорость алгоритма и объём дополнительной памяти, которые он требует.
ГЛАВА II. РАЗРАБОТКА КОДА ДЛЯ РЕШЕНИЯ ЗАДАЧ НА СОРТИРОВКУ
Задача 1. Составить программу, которая выводит несортированный массив целых чисел на экран, затем выполняет его сортировку методом линейной сортировки по невозрастанию и выводит отсортированный массив на экран.
program Sort_Lin;
crt;
Count=20;
M:array [1..Count] of byte=(9,11,12,3,19,1,5,17,10,18,3,19,17,9, 12,20,20,19,2,5);
I, J, N, L: Byte;
A: integer;;(Исходный массив:);I:=1 to Count do Write( , M[I]); Writeln;:=0;I:=1 to Count-1 do
for J:=I+1 to Count do
begin
A:=A+1;
if M[I] < M[J] then
begin
N:=M[I];
M[I]:=M[J];
M[J]:=N;
end;
for L:=1 to Count do Write( , M[L]); Writeln(Число итераций=, A);
end;;.
Задача 2. Составить программу, которая выводит несортированный массив целых чисел на экран, затем выполняет его сортировку методом пузырька по невозрастанию и выводит отсортированный массив на экран.
program Sort_Puz;
uses;
const
Count=10;
M:array [1..Count] of byte=(9, 11, 12, 3, 19, 1, 5, 17, 10, 18);
var
I, J, K, L: Byte;
A: integer;
ClrScr;
Writeln(Исходный массив);
for I:=1 to Count do Write(M[I], ); Writeln;
A:=0;
for I:=2 to Count do
begin
for J:=Count downto I do
begin
A:=A+1;
if M[J-1]<M[J] then
begin
K:=M[J-1];
M[J-1]:=M[J];
M[J]:=K;
for L:=1 to Count do Write( , M[L]);(Число итераций =, A);
end;
end;
end;;.
Задача 3. Составить программу, которая выводит несортированный массив целых чисел на экран, затем выполняет его сортировку методом быстрой сортировки с разделением по невозрастанию и выводит отсортированный массив на экран.
{ быстрая сортировка }
procedure QuickSort(var item: DataArray; count:integer);
procedure qs(l, r: integer; var it: DataArray);
var
i, j: integer;
x, y: DataItem;
begin
i:=l; j:=r;
x:=it[(l+r) div 2];
repeat
while it[i]<x do i := i+1;
while x<it[j] do j := j-1;
if y<=j then
begin
y := it[i];
it[i] := it[j];
it[j] := y;
i := i+1; j := j-1;
end;
until i>j;
if l<j then qs(l, j, it);
if l<r then qs(i, r, it)
end;
begin
qs(1, count, item);
end; { конец быстрой сортировки }
Задача 4. Составить программу, которая формирует двумерный массив случайных чисел и вычисляет значение среднего арифметического его элементов, больших, чем 20. Решение задачи сводится к последовательному перебору всех элементов массива с вычислением суммы тех элементов, значение которых больше, чем 20, а по окончании их суммирования - к вычислению частного полученной суммы и количества элементов массива, удовлетворяющих условию суммирования.
program Preobr_Mas_2;
Strok=10;=Strok;
array [1. .Strok, 1. .Stolb] of integer;
C: array [1. .Strok*6] of integer;
J, X,Y: integer;;;I:= 1 to Strok doJ:= 1 to Stolb do [I, J] :=Random(99);
(A[ I, J] :2, ' ');;;;;:= 0;:= 0;I:=1 to Strok doJ:= 1 to Stolb doJ >=I then:= X+1;[X] := A[I,J];:= Y+1;
C[Y] := A[I,J];
end;
Writeln('Элементы расположенные на главной диагонали и выше: ');
for I:=1 to X do Write(B[I]:2,' ');
Writeln;('Элементы, расположенные ниже главной диагонали: ') ;
for I:=1 to Y do Write(C[I]:2,' ');
Writeln;;.
Задача 5. Составить программу, которая выводит несортированный массив целых чисел на экран, затем выполняет его сортировку прямым выбором по невозрастанию и выводит отсортированный массив на экран.
#include <stdio.h>
void selectionSort(int *num, int size) {
int i, j;
int min, temp;
for (i = 0; i < size-1; i++) {
min = i;
for (j = i+1; j < size; j++) {
if (num[j] < num[min])
min = j;
}
temp = num[i];
num[i] = num[min];
num[min] = temp;
}
}
int main() {
int a[10];
int i, j, index;
for(i=0;i<10;i++) {
printf("a[%d] = ", i);
scanf("%d",&a[i]);
}
selectionSort(a,10);
for(i=0;i<10;i++)
printf("%d ", a[i]);
getchar();getchar();
return 0;
}
Задача 6. Составить программу, которая выводит несортированный массив целых чисел на экран, затем выполняет его сортировку слиянием по невозрастанию и выводит отсортированный массив на экран.
void merge(int *a, int n) {
int mid = n/2;
if(n%2==1)
mid++;
int h = 1; // шаг
int *c;
int step;
c = (int*)malloc(n*sizeof(int));
while(h < n) {
step = h;
int i = 0;
int j = mid;
int k = 0;
while(step <= mid) {
while((i<step) && (j<n) && (j<(mid+step))) {
if(a[i] < a[j]) {
c[k] = a[i];
i++; k++;
} else {
c[k] = a[j];
j++; k++;
}
}
while(i<step) {
c[k] = a[i];
i++;k++;
}
while((j < (mid+step)) && (j<n)) {
c[k] = a[j];
j++; k++;
}
step = step + h;
}
h = h * 2;
for(i=0;i<n;i++)
a[i]=c[i];
}
}
}
Задача 7. Составить программу, которая выводит несортированный массив целых чисел на экран, затем выполняет его сортировку подсчетом по невозрастанию и выводит отсортированный массив на экран.
#include <iostream>
using namespace std;
int a[100];
int c[100];
int main()
{
int n;//количество элементов в массиве
int k = 100;
cin >> n;
//считываем массив
for(int i = 0; i < n; i++)
{
cin>>a[i];
}
//строим массив с
for(int i = 0; i < n; i++)
{
c[a[i]]++;
}
//бежимся по всему отрезку
//с 0 до k-1
for(int i = 0; i < k; i++)
{
//выводим i c[i] раз
for(int j = 0; j < c[i]; j++)
cout<<i<<" ";
}
return 0;
}
ЗАКЛЮЧЕНИЕ
Для реализации различных методов сортировки необходимо применить алгоритмические языки программирования, такие как: Delphi, Pascal, С++. Применение различных языков программирования, в данной курсовой работе, необходимо для понимания самого алгоритма без привязки к лексике языка программирования.
В результате выполнения курсового проекта были написаны программы, выполняющие сортировку массивов различными методами. Программы обладают высокими параметрами быстродействия, маленькими размерами и не требовательны к системным ресурсам компьютера
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. Абрамов. С.А., Зима Е.В. Начала программирования на языке Паскаль. - М.: Наука, 1987.- 112с.
2. Абрамов С.А., Гнездилова Г.Г., Капустина Е.Н., Селюн М.И. Задачи по программированию. - М.Наука, 1988. - 224 с.
3. Алексеев Е.С., Мячев А.А. Англо-русский толковый словарь по системотехнике ЭВМ. - М.: Финансы и статистика, 1993. - 256 с.
4. Борковский А.Б. Англо-русский словарь по программированию и информатике (с толкованиями). - М.: Русский язык, 1990. - 333 с.
5. Васюкова Н.Д., Тюяева В.В. Практикум по основам программирования. Язык Паскаль: Учеб. пособ. для учащихся средн. спец. уч. завед. М.Высшая школа, 1991.- 160с.
6. Вирт Н. Язык программирования Паскаль // Алгоритмы и организация решения экономических задач.
7. Вирт Н. Алгоритмы + структуры данных = программы: Пер. с англ. - М.: Мир, 1985. - 406 с,
8. Григас Г. Начала программирования: Книга для учащихся : Пер. с лит. / Под ред. Ю.А.Первина. - М.: Просвещение, 1987.-112 с.
9. Грогоно П. Программирование на языке Паскаль : Пер. с англ. - М.: Мир, 1982. -382с.
10. Дагене В.А., Григас Г.К., Аугутис К.Ф. 100 задач по программированию: Кн. для учащихся: Пер. с лит. - М.: Просвещение, 1993. - 255 с.
11. Дал. У., Дейкстра Э., Хоор К. Структурное программирование: Пер. с англ. - М.: Мир, 1975.-247 с.
12. Довгаль С.И., Литвинов Б.Ю., Сбитнев А.И. Персональные ЭВМ: Турбо Паскаль v7.0, Объектное программирование, локальные сети (учебное пособие). - Киев: Информсис-тема сервис, 1993. - 461 с.
13. Информатика: Энциклопедический словарь для начинающих. Сост. Д.А.Поспелов. - М: Педагогика-Пресс, 1994. - 352 с.
14. К.Йенсен, Н.Вирт. Руководство для пользователя и описание языка Паскаль. - М.: Финансы и статистика, 1982. - 150 с.
15. Математический энциклопедический словарь /Гл. ред. Ю.В Прохоров. - М.: Советская энциклопедия, 1988. - 847 с.
16. Нортон П., Уилтон Р. 1ВМ РС РЗ/2. Руководство по программированию: Пер. с англ. - М.: Радио и связь, 1994. - 336 с.
17. Перминов О.Н. Язык программирования Паскаль. - М.: Радио и связь, 1988. - 220 с.
18. Першиков В.И., Савинков В.М. Толковый словарь по информатике. - М.: Финансы и статистика, 1995. - 544 с.

- Товароведная характеристика свойств обувных товаров
- «Корпоративная культура в организации» (ООО «Спортмастер»)
- Организационно-правовая форма. Структура управления предприятия.
- История развития менеджмента (Условия и предпосылки развития менеджмента)
- Создание информационной системы управления и совершенствования портфеля продукции
- Классификация, структура и основные характеристики современных микропроцессоров ПК (Определение микропроцессора)
- Активизация учебно-познавательной деятельности учащихся на современном этапе
- Психическое развитие младшего дошкольника
- Методология исследования межличностных отношений (ПРОБЛЕМА ИЗУЧЕНИЯ МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЙ В ПСИХОЛОГИИ)
- Понятие электронного учебного пособия, его отличительные характеристики.
- Анализ угроз утечки защищаемой информации
- Проектирование реализации операций бизнес-процесса «Учет предоставленных услуг салоном красоты» (Характеристика документооборота, возникающего при решении задачи)