
Алгоритмы сортировки данных (Алгоритмы устойчивой сортировки)
Содержание:

Введение
Данная курсовая работа будет посвящена одной из самой важных тем, на мой взгляд. Ведь в XXI веке данные – это крайне важный ресурс, сортировка которого позволяет систематизировать их, для упрощения работы с ними. Но для начала пройдемся по терминам, которые необходимо знать, изучая этот вопрос. Начнём с того, что такое данные. Данные - это информация, которая передаётся при помощи определённых способов кодирования: словами, цифрами, кодами, алгоритмами и т.д. Вообще, алгоритмы поиска делятся на поиск в неупорядоченном множестве данных и поиск в упорядоченном множестве данных. Упорядоченность – это наличие сортировки в ключевом поле. Сортировка - перестановка элементов в подмножестве данных по определенному критерию. Например: в качестве критерия используется некоторое числовое поле, называемое ключевым. Упорядочение элементов по ключевому полю предполагает, что ключевое поле каждого следующего элемента не больше предыдущего (сортировка по убыванию). Если ключевое поле каждого последующего элемента не меньше предыдущего, то говорят о сортировке по возрастанию. А теперь перейдём к самому интересному – видам сортировки данных. Они подразделяются на алгоритмы устойчивой сортировки и алгоритмы неустойчивой сортировки
Глава I. Алгоритмы устойчивой сортировки
1.1 Сортировка пузырьком
Есть достаточно много различных методов, большинство из них не имеет широкой известности. Сортировка методом пузырька , которую также называют сортировкой простого обмена.
Для начала , что такое сортировка в паскале и зачем она нужна? Сортировка - это метод упорядочить массив (обычно по возрастанию или убыванию) . В задачах встречаются такие строки "расположить элементы массива , начиная от минимального (максимального)" . Имейте ввиду , что это то же самое.
Вернемся к сортировке пузырьком. Почему ее назвали именно так? Дело в том , что это аналогия. Представьте себе обычный массив , расположенный вертикально. В результате сортировки более меньшие элементы поднимаются вверх . То есть здесь массив можно представить в виде воды , а меньшие элементы в виде пузырька , которые всплывают наверх.
Сортировка методом пузырька
Теперь подробнее о самом алгоритме. Все достаточно просто :
1. Для сортировки используется 2 цикла , один вложен в другой . Один используется на шаги , другой на подшаги.
2. Суть алгоритма - это сравнение двух элементов . Именно двух . Поясняю , например имеем массив с 10-ю элементами. Элементы будут сравниваться парами : 1 и 2, 2и 3,3 и 4,4 и 5,6 и 7 и т.д. При сравнении пар , если предыдущий элемент оказался больше чем последующий - то их меняют местами . Например если второй элемент равен 5 , а третий 2 , то они их поменяют местами.
3. Сортировка методом пузырька делится на шаги. В каждом шаге выполняется попарное сравнение. В результате каждого шага наибольшие элементы начинают выстраиваться с конца массива. То есть после первого шага самый большой по значению элемент массива будут стоять на последнем месте. Во втором шаге работа производится со всеми элементами кроме последнего. Опять находится самый большой элемент и ставится в конец массива, с которым производится работа. Третий шаг повторяет второй и так до тех пор, пока массив не будет отсортирован. Для более удобного восприятия приведу наглядный пример. Возьмем массив, состоящий из 7 элементов : 2,5,11,1,7,8,3. Смотрим.(Кликните на картинку для увеличения изображения)
Идея алгоритма очень простая. Идём по массиву чисел и проверяем порядок (следующее число должно быть больше и равно предыдущему), как только наткнулись на нарушение порядка, тут же обмениваем местами элементы, доходим до конца массива, после чего начинаем сначала. Например:
Отсортируем массив {1, 5, 2, 7, 6, 3}
Идём по массиву, проверяем первое число и второе, они идут в порядке возрастания. Далее идёт нарушение порядка, меняем местами эти элементы
1, 2, 5, 7, 6, 3
Продолжаем идти по массиву, 7 больше 5, а вот 6 меньше, так что обмениваем из местами
1, 2, 5, 6, 7, 3
3 нарушает порядок, меняем местами с 7
1, 2, 5, 6, 3, 7
Возвращаемся к началу массива и проделываем то же самое
1, 2, 5, 3, 6, 7
1, 2, 3, 5, 6, 7
Это больше похоже на "всплытие" более "лёгких" элементов, как пузырьков, отчего алгоритм и получил такое название.
(см. приложение, Рисунок 1 Пример написания такой сортировки в JavaScript:)
1.2 Шейкер сортировка
Рассмотрев «пузырьковую» сортировку массива можно перейти к разбору её разновидности — «шейкер»-сортировке. Внимательно присмотревшись к тому, как проходит сортировка «пузырьком» — можно сказать следующее: часть массива, в котором перестановки элементов уже не происходят (отсортированная часть массива), то эту часть можно исключить из рассмотрения и не обрабатывать на следующих итерациях. Поэтому была придумана более эффективная форма сортировки «пузырьком» -«шейкер»-сортировка. В ней пределы той части массива в которой есть перестановки, сужаются. Плюс — внутренние циклы проходят по массиву то в одну, то в другую сторону, поднимая самый легкий элемент вверх и опуская самый тяжелый элемент в самый низ за одну итерацию внешнего цикла.
Шейкер-сортировка является усовершенствованным методом пузырьковой сортировки.
Анализируя метод пузырьковой сортировки, можно отметить два обстоятельства:
если при движении по части массива перестановки не происходят, то эта часть массива уже отсортирована и, следовательно, ее можно исключить из рассмотрения.
при движении от конца массива к началу минимальный элемент "всплывает" на первую позицию, а максимальный элемент сдвигается только на одну позицию вправо.
Эти две идеи приводят к модификациям в методе пузырьковой сортировки.
От последней перестановки до конца (начала) массива находятся отсортированные элементы. Учитывая данный факт, просмотр осуществляется не до конца (начала) массива, а до конкретной позиции. Границы сортируемой части массива сдвигаются на 1 позицию на каждой итерации.
Массив просматривается поочередно справа налево и слева направо.
Просмотр массива осуществляется до тех пор, пока все элементы не встанут в порядке возрастания (убывания).
Количество просмотров элементов массива определяется моментом упорядочивания его элементов.
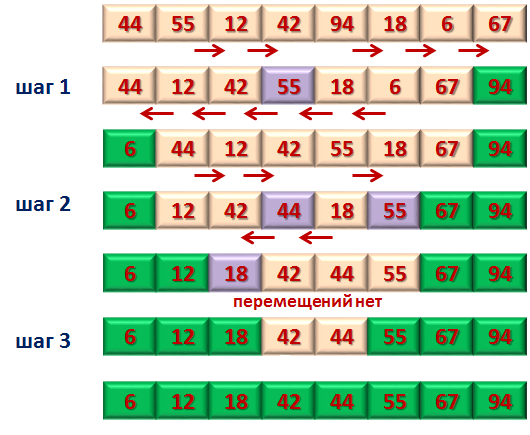
Рассмотрим алгоритм Шейкер-сортировки на примере. Дана последовательность
(см. приложение, рисунок 2 Пример)
(См. приложение, Рисунок 3 Пример написания такой сортировки в Pascal)
1.3 Гномья сортировка
Гномья сортировка (англ. Gnome sort) — алгоритм сортировки, который перед вставкой на нужное место происходит серия обменов, как в сортировке пузырьком. Алгоритм находит первое место, где два соседних элемента стоят в неправильном порядке и меняет их местами. Он пользуется тем фактом, что обмен может породить новую пару, стоящую в неправильном порядке, только до или после переставленных элементов. Он не допускает, что элементы после текущей позиции отсортированы, таким образом, нужно только проверить позицию до переставленных элементов. В пример можно отнести причину названия этого способа гномьим. Гномья сортировка основана на технике, используемой обычным голландским садовым гномом (нидерл. tuinkabouter). Это метод, которым садовый гном сортирует линию цветочных горшков. По существу он смотрит на следующий и предыдущий садовые горшки: если они в правильном порядке, он шагает на один горшок вперёд, иначе он меняет их местами и шагает на один горшок назад. Граничные условия: если нет предыдущего горшка, он шагает вперёд; если нет следующего горшка, он закончил.
Незамысловатый обменный алгоритм с неплохой сложностью O(n2), который, как ни парадоксально, совсем недавно был впервые описан в научной литературе.
«Новую сортировку» презентовал на страницах научного издания Newsletter Университета Глазго, некий Хамид Сарбази-Асад (Hamid Sarbazi-Azad) в 2000 году. Он предложил название «Глупая сортировка».
Голландский учёный Дик Грун (Dick Grune) исследовал метод подробнее и переименовал в «Гномью сортировку», под этим именем алгоритм сейчас и известен.
Алгоритм
«Гномья сортировка основана на технике, используемой обычным голландским садовым гномом (нидерл. tuinkabouter). Это метод, которым садовый гном сортирует линию цветочных горшков. По существу он смотрит на следующий и предыдущий садовые горшки: если они в правильном порядке, он шагает на один горшок вперёд, иначе он меняет их местами и шагает на один горшок назад. Граничные условия: если нет предыдущего горшка, он шагает вперёд; если нет следующего горшка, он закончил.»
Гномья сортировка это оптимизированная глупая сортировка. В глупой сортировке при нахождении неотсортированной пары соседей происходит обмен и возврат в начало массива. В гномьей сортировке просто делается один шаг назад.
Также алгоритм интересен тем, что используется всего лишь один цикл, что для алгоритмов сортировок большая редкость.
Оптимизация
Метод можно ускорить, если запоминать индекс крайнего неотсортированного элемента. После того как сделан ряд шагов назад, дальнейшую обработку массива можно продолжить с того места, где прервались.
Гномья сортировка
Если в оптимизированной гномьей сортировке вместо обменов использовать сдвиг элементов с помощью буферной области памяти, то мы получаем сортировку вставками.
(см. приложение, Рисунок 4 Пример применения такой сортировки в Java)
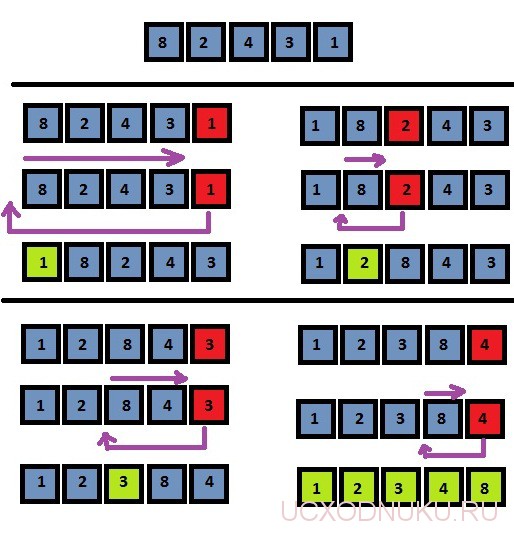
1.4 Сортировка вставками
Сортировка вставками — третий и последний из простых алгоритмов сортировки. Сначала он сортирует два первых элемента массива. Затем алгоритм вставляет третий элемент в соответствующую порядку позицию по отношению к первым двум элементам. После этого он вставляет четвертый элемент в список из трех элементов. Этот процесс повторяется до тех пор, пока не будут вставлены все элементы. Например, при сортировке массива dcab каждый проход алгоритма будет выглядеть следующим образом:
Начало d c a b
Проход 1 c d a b
Проход 2 a c d b
Проход 3 a b c d
В отличие от пузырьковой сортировки и сортировки посредством выбора, количество сравнений в сортировке вставками зависит от изначальной упорядоченности списка. Если список уже отсортирован, количество сравнений равно n - 1; в противном случае его производительность является величиной порядка n2.
Вообще говоря, в худших случаях сортировка вставками настолько же плоха, как и пузырьковая сортировка и сортировка посредством выбора, а в среднем она лишь немного лучше. Тем не менее, у сортировки вставками есть два преимущества. Во-первых, ее поведение естественно. Другими словами, она работает меньше всего, когда массив уже упорядочен, и больше всего, когда массив отсортирован в обратном порядке. Поэтому сортировка вставками — идеальный алгоритм для почти упорядоченных списков. Второе преимущество заключается в том, что данный алгоритм не меняет порядок одинаковых ключей. Это значит, что если список отсортирован по двум ключам, то после сортировки вставками он останется упорядоченным по обоим.
Несмотря на то, что количество сравнений при определенных наборах данных может быть довольно низким, при каждой вставке элемента на свое место массив необходимо сдвигать. Вследствие этого количество перемещений может быть значительным.
Данный алгоритм представляет собой сортировку, в котором элементы входной последовательности просматриваются по одному, и каждый новый поступивший элемент размещается в подходящее место среди ранее упорядоченных элементов.
(см. приложение, рисунок 5 Пример)
(см. приложение, рисунок 6 Пример реализации в Java)
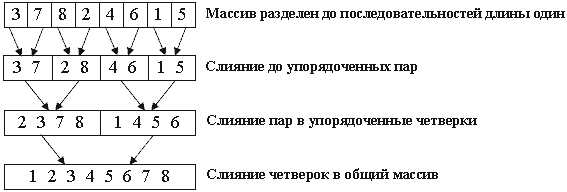
1.5 Сортировка слиянием
Сортировка слиянием (marge sort) — алгоритм сортировки, который упорядочивает списки (или другие структуры данных, доступ к элементам которых можно получать только последовательно, например — потоки) в определённом порядке. Эта сортировка — хороший пример использования принципа «разделяй и властвуй». Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются с помощью рекурсивного вызова или непосредственно, если их размер достаточно мал. Наконец, их решения комбинируются, и получается решение исходной задачи. (так говорит Википедия).
То есть, на входе мы получаем некий массив данных (для простоты и удобства, будем рассматривать целочисленный массив) на n элементов. Затем, делим этот массив на два подмассива размером n/2. И так до тех пор, пока массив не уменьшится до двух элементов, которые достаточно просто отсортировать. Как вы уже могли понять, процедура дробления осуществляется путем рекурсии.
После сравнения двух элементов наш процесс начинает возвращаться и собирать себя по отсортированным кусочкам массива. В процессе обратного слияния элементы подмассивов сравниваются между собой и в окончательный массив вставляется меньший элемент.
Данный способ означает объединение двух (или более) последовательностей в одну упорядоченную последовательность при помощи циклического выбора элементов, доступных в данный момент.
Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются с помощью рекурсивного вызова или непосредственно, если их размер достаточно мал. Затем их решения комбинируются, и получается решение исходной задачи.
(см. приложение Рисунок 7 Пример)
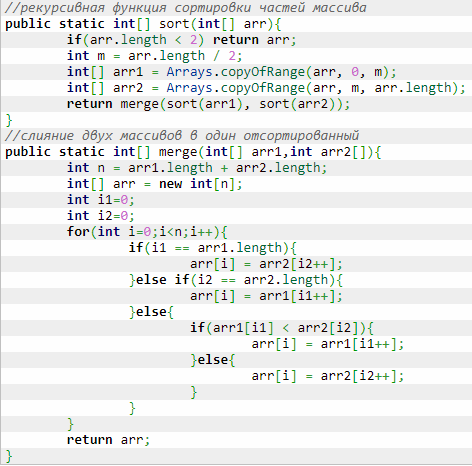
(см. приложение Рисунок 8 Пример реализации в Java)
1.6 Сортировка с помощью двоичного дерева
Сортировка с помощью двоичного дерева (сортировка двоичным деревом, сортировка деревом, древесная сортировка, сортировка с помощью бинарного дерева, англ. tree sort) — универсальный алгоритм сортировки, заключающийся в построении двоичного дерева поиска по ключам массива (списка), с последующей сборкой результирующего массива путём обхода узлов построенного дерева в необходимом порядке следования ключей. Данная сортировка является оптимальной при получении данных путём непосредственного чтения с потока (например с файла, сокета или консоли).
Алгоритм
1. Построение двоичного дерева.
2. Сборка результирующего массива путём обхода узлов в необходимом порядке следования ключей.
Эффективность
Процедура добавления объекта в бинарное дерево имеет среднюю алгоритмическую сложность порядка O(log(n)). Соответственно, для n объектов сложность будет составлять O(n log(n)), что относит сортировку с помощью двоичного дерева к группе «быстрых сортировок». Однако, сложность добавления объекта в разбалансированное дерево может достигать O(n), что может привести к общей сложности порядка O(n²).
При физическом развёртывании древовидной структуры в памяти требуется не менее чем 4n ячеек дополнительной памяти (каждый узел должен содержать ссылки на элемент исходного массива, на родительский элемент, на левый и правый лист), однако, существуют способы уменьшить требуемую дополнительную память.
Двоичным(бинарным) деревом назовем упорядоченную структуру данных,
в которой каждому элементу - предшественнику или корню (под)дерева -
поставлены в соответствие по крайней мере два других элемента (преемника).
Причем для каждого предшественника выполнено следующее правило:
левый преемник всегда меньше, а правый преемник всегда больше или равен
предшественнику.
Вместо 'предшественник' и 'преемник' также употребляют термины
'родитель' и 'сын'. Все элементы дерева также называют 'узлами'.
При добавлении в дерево нового элемента его последовательно сравнивают
с нижестоящими узлами, таким образом вставляя на место.
Если элемент >= корня - он идет в правое поддерево, сравниваем его уже
с правым сыном, иначе - он идет в левое поддерево, сравниваем с левым,
и так далее, пока есть сыновья, с которыми можно сравнить
Представляет собой универсальный алгоритм сортировки, заключающийся в построении двоичного дерева поиска по ключам массива (списка), с последующей сборкой результирующего массива путём обхода узлов построенного дерева в необходимом порядке следования ключей. Данная сортировка является оптимальной при получении данных путём непосредственного чтения с потока (например из файла, сокета или консоли).
(см. приложение Рисунок 9 Пример)
(см. приложение Рисунок 10 Реализация в Java)
1.7 Сортировка подсчетом
Это сортировка может использоваться только для дискретных данных. Допустим, у нас
есть числа от 0 до 99, которые нам следует отсортировать. Заведем массив размером в 100
элементов, в котором будем запоминать, сколько раз встречалось каждое число (т.е. при
появлении числа будем увеличивать элемент вспомогательного массива с индексом, равным
этому числу, на 1). Затем просто пройдем по всем числам от 0 до 99 и выведем каждое
столько раз, сколько оно встречалось. Сортировка реализуется следующим образом:
for (i=0; i<MAXV; i++)
c[i] = 0;
for (i=0; i<n; i++)
c[a[i]]++;
k=0;
for (i=0; i<MAXV; i++)
for (j=0; j<c[i]; j++)
a[k++]=i;
Здесь MAXV – максимальное значение, которое может встречаться (т.е. все числа
массива должны лежать в пределах от 0 до MAXV-1).
Алгоритм использует O(MAXV) дополнительной памяти и имеет сложность
O(N+MAXV). Его применение дает отличный результат, если MAXV намного меньше, чем
количество элементов в массиве
Сортировка подсчётом - алгоритм сортировки, в котором используется диапазон чисел сортируемого списка для подсчёта совпадающих элементов. Применение сортировки подсчётом целесообразно лишь тогда, когда сортируемые числа имеют (или их можно отобразить в) диапазон возможных значений, который достаточно мал по сравнению с сортируемым множеством, например, миллион натуральных чисел меньших 1000. Простыми словами звучит так: подсчитываем сколько раз в массиве встречается каждое значение и заполняем массив подсчитанными элементами в соответствующих количествах.
(см. приложение Рисунок 11 Реализация в Java)
1.8 Блочная сортировка
Блочная сортировка (Карманная сортировка, корзинная сортировка, англ. Bucket sort) — алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков (карманов, корзин) так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше (или меньше), чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо иным другим. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем исполнения.
Данный алгоритм требует знаний о природе сортируемых данных, выходящих за рамки функций "сравнить" и "поменять местами", достаточных для сортировки слиянием, сортировки пирамидой, быстрой сортировки, сортировки Шелла, сортировки вставкой.
Преимущества: относится к классу быстрых алгоритмов с линейным временем исполнения O(N) (на удачных входных данных).
Недостатки: сильно деградирует при большом количестве мало отличных элементов, или же на неудачной функции получения номера корзины по содержимому элемента. В некоторых таких случаях для строк, возникающих в реализациях основанного на сортировке строк алгоритма сжатия BWT, оказывается, что быстрая сортировка строк в версии Седжвика значительно превосходит блочную сортировку скоростью.
АЛГОРИТМ
Если входные элементы подчиняются равномерному закону распределения, то математическое ожидание времени работы алгоритма карманной сортировки является линейным. Это возможно благодаря определенным предположениям о входных данных. При карманной сортировке предполагается, что входные данные равномерно распределены на отрезке [0, 1).
Идея алгоритма заключается в том, чтобы разбить интервал [0, 1) на n одинаковых отрезков (карманов), и разделить по этим карманам n входных величин. Поскольку входные числа равномерно распределены, предполагается, что в каждый карман попадет небольшое количество чисел. Затем последовательно сортируются числа в карманах. Отсортированный массив получается путем последовательного перечисления элементов каждого кармана.
Блочная— алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков (карманов, корзин) так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше (или меньше), чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо другим. Затем элементы помещаются обратно в массив. Пример:
(см. приложение Рисунок 12 Элементы распределяются по корзинам)
(см. приложение Рисунок 13 Затем элементы в каждой корзине сортируются)
(см. приложение Рисунок 14 Реализация в C)
1.9 Поразрядная сортировка
Массив несколько раз перебирается и элементы перегруппировываются в зависимости от того, какая цифра находится в определённом разряде. После обработки разрядов (всех или почти всех) массив оказывается упорядоченным.
При этом разряды могут обрабатываться в противоположных направлениях — от младших к старшим или наоборот.
Поразрядная сортировка по младшим разрядам
Элементы перебираются по порядку и группируются по самому младшему разряду (сначала все, заканчивающиеся на 0, затем заканчивающиеся на 1, …, заканчивающиеся на 9). Возникает новая последовательность. Затем группируются по следующему разряду с конца, затем по следующему и т.д. пока не будут перебраны все разряды, от младших к старшим.
Точное название способа LSD radix sort (Least significant digit radix sorts) — поразрядная сортировка по наименьшей значащей цифре.
Поразрядная сортировка по старшим разрядам
Элементы перегруппировываются по определённому разряду (сначала по самому старшему). Затем разбиваются на подгруппы в зависимости от значения этого разряда: равного 0, равного 1, равного 2, …, равного 9. Каждая подгруппа обрабатывается отдельно, в ней к следующему разряду рекурсивно применяется radix sort.
Точное название способа MSD radix sort (Most significant digit radix sorts) — поразрядная сортировка по наибольшей значащей цифре.
MSD реализовывается несколько сложнее, чем LSD, но при этом она эффективнее. При ориентации на наименьшие значащие цифры для всех элементов обрабатываются все разряды. А вот в случае наибольших значащих цифр рекурсия продолжается только до той глубины, до которой это необходимо, то есть пока у элементов подгруппы есть различия в определённом разряде.
Кроме того, MSD, в отличие от LSD, является устойчивым алгоритмом.
Применение поразрядной сортировки имеет одно ограничение: перед началом сортировки необходимо знать
length - максимальное количество разрядов в сортируемых величинах (например, при сортировке слов необходимо знать максимальное количество букв в слове),
range - количество возможных значений одного разряда (при сортировке слов - количество букв в алфавите).
Количество проходов равно числу length.
Пошаговое описание алгоритма
Допустим у нас есть числа: 39, 47, 54, 59, 34, 41, 32 (length = 2, range = 10)
1. Создаем пустые списки, количество которых равно числу range.
2. Распределяем исходные числа по этим спискам в зависимости от величины младшего разряда (по возрастанию).
Для нашего примера получим:
41
32
54, 34
47
59, 39
(Вообще надо создать 10 списков, но некоторые из них оказались пустыми)
3. Собираем числа в той последовательности, в которой они находятся после распределения по спискам.
Получим: 41, 32, 54, 34, 47, 59, 39
4. Повторяем пункты 2 и 3 для всех более старших разрядов поочередно.
Для двузначных чисел мы должны сделать еще один проход. Распределение по спискам будет выглядеть так:
32, 34, 39
41, 47
54, 59
Объединив числа в последовательность, получим отсортированный массив.
(см. приложение Рисунок 15 Реализация в С#)
Глава 2. Алгоритмы неустойчивой сортировки
2.1 Сортировка расческой
Основная идея «расчёски» в том, чтобы первоначально брать достаточно большое расстояние между сравниваемыми элементами и по мере упорядочивания массива сужать это расстояние вплоть до минимального. Таким образом мы как бы причёсываем массив, постепенно разглаживая на всё более аккуратные пряди.
Сортировка расчёской
Первоначальный разрыв между сравниваемыми элементами лучше брать не абы какой, а с учётом специальной величины называемой фактором уменьшения, оптимальное значение которой равно примерно 1,247. Сначала расстояние между элементами равно размеру массива разделённого на фактор уменьшения (результат, естественно, округляется до ближайшего целого). Затем, пройдя массив с этим шагом, мы снова делим шаг на фактор уменьшения и проходим по списку вновь. Так продолжается до тех пор, пока разность индексов не достигнет единицы. В этом случае массив досортировывается обычным пузырьком.
Опытным и теоретическим путём установлено оптимальное значение фактора уменьшения: 1,247330950103979
Когда был изобретён этот метод, на него на стыке 70-х и 80-х мало кто обратил внимание. Десятилетие спустя, когда программирование перестало быть уделом учёных и инженеров IBM, а уже лавинообразно набирало массовый характер, способ переоткрыли, исследовали и популяризировали в 1991 году Стивен Лейси и Ричард Бокс..
(см. приложение Рисунок 16 Пример сортировки расческой)
(см. приложение Рисунок 17 Реализация в C#)
2.2 Сортировка Шелла
В 1959 году американский ученый Дональд Шелл опубликовал алгоритм сортировки, который впоследствии получил его имя – «Сортировка Шелла». Этот алгоритм может рассматриваться и как обобщение пузырьковой сортировки, так и сортировки вставками.
Идея метода заключается в сравнение разделенных на группы элементов последовательности, находящихся друг от друга на некотором расстоянии. Изначально это расстояние равно d или N/2, где N — общее число элементов. На первом шаге каждая группа включает в себя два элемента расположенных друг от друга на расстоянии N/2; они сравниваются между собой, и, в случае необходимости, меняются местами. На последующих шагах также происходят проверка и обмен, но расстояние d сокращается на d/2, и количество групп, соответственно, уменьшается. Постепенно расстояние между элементами уменьшается, и на d=1 проход по массиву происходит в последний раз.
Сортировка Шелла - алгоритм сортировки, являющийся усовершенствованным вариантом сортировки вставками. Идея метода Шелла состоит в сравнении элементов, стоящих не только рядом, но и на определённом расстоянии друг от друга. Пример исполнения данного вида сортировки:
(см. приложение Рисунок 18 Реализация в C)
2.3 Пирамидальная сортировка
Пирамидальная сортировка (она же сортировка кучей) – классический алгоритм который, пожалуй, должен знать любой программист. Старая добрая «пирамидка» примечательна тем, что в независимости от набора данных у неё одна и та же сложность по времени (причём, очень пристойная) – O(n log n). Лучших и вырожденных случаев для неё нет.
С момента изобретения метода (а в этом году алгоритм празднует свой полувековой юбилей) было немало желающих кардинально оптимизировать процесс накладывания сортирующих куч. Тернарная пирамидальная сортировка, плавная сортировка, сортировка декартовым деревом – вот неполный список инноваций. Перечисленные алгоритмы хотя при тестировании и опережают оригинал по абсолютной скорости кто на 12, а кто и на 25%, в оценке временной сложности всё равно крутятся вокруг O(n log n). При этом данные методы весьма изощрённо реализованы.
Своё видение пирамидальной сортировки предложил и скромный труженик Университета Манитобы Джейсон Моррисон. При этом способ в некоторых случаях по скорости приближается к O(n).
HeapSort
Как работает пирамидальная сортировка?
Массив можно отсортировать, если на его основе строить и перестраивать сортирующее дерево, известное как двоичная куча или просто пирамида.
Что есть сортирующее дерево? Это дерево, у которого любой родитель больше (или меньше, смотря в какую сторону оно сортирующее) чем его потомки.
Как из обычного дерева сделать сортирующее дерево? Очень просто – нужно двигаться от потомков вверх к родителям и если потомок больше родителя, то менять местами. Если такой обмен произошёл, опустившегося на один уровень родителя нужно сравнить с потомками ниже – может и там тоже будет повод для обмена.
Преобразовывая неотсортированную часть массива в сортирующее дерево, в итоге в корень «всплывёт» наибольший элемент. Обмениваем максимум с последним ключом неотсортированного подмассива. Структура перестанет быть сортирующим деревом, но в качестве моральной компенсации его неотсортированная часть станет меньше на один узел. К этой неотсортированной части заново применим всю процедуру, то есть преобразуем её в сортирующее дерево с последующей перестановкой найденного максимума в конец. И так действуем до тех пор, пока неотсортированная часть не скукожится до одного-единственного элемента.
Подход, что и говорить, остроумный, но при этом специалисты по алгоритмам отмечают у сортировки кучей целую кучу недостатков, как-то: неустойчивость, хаотичность выборки, нечувствительность к почти упорядоченным массивам и пр. Смущает всех также неулучшаемая скорость O(n log n), демонстрируемая сортировкой абсолютно при любых наборах входящих данных.
JSort
Канадский учёный пришёл к выводу, что заново перестраивать кучу для каждого элемента – дорогое удовольствие. Так уж ли необходимо массив из n элементов радикально перелопачивать n раз?
Если для массива построить всего пару куч (нисходящую и восходящую), то это значительно его упорядочит в обоих направлениях.
Сначала нужно осуществить построение невозрастающей кучи. В результате меньшие элементы повсплывают в верхние узлы пирамиды (что будет соответствовать левой половине массива), наименьший элемент вообще окажется в корне. Чем выше элементы находятся в сортирующем дереве – тем более упорядоченной будет соответствующая часть массива. Элементы находящиеся ближе к листьям дерева (им будет соответствовать вторая половина массива) будут иметь менее упорядоченный вид, поскольку они не сравнивались друг с другом, а просто были оттеснены на задворки в результате перемещения их родителей.
Для наведения относительного порядка в правой части массива следует построить кучу ещё раз, во всём противоположную первой. Во-первых, эта куча должна быть неубывающей (мы ведь теперь хотим разобраться с крупными по значению ключами). Во-вторых, она должна быть «зеркальной» к массиву, то есть её корень должен соответствовать не первому, а последнему элементу и выстраивать дерево следует, перебирая массив от конца к началу.
Пирамидальная сортировка - алгоритм сортировки, работающий в худшем, в среднем и в лучшем случае (то есть гарантированно). Может рассматриваться как усовершенствованная сортировка пузырьком, в которой элемент всплывает / тонет по многим путям.
(см. приложение Рисунок 19 Пример, часть 1)
(см. приложение Рисунок 20 Пример, часть 2)
2.4 Быстрая сортировка
Один из самых быстрых известных универсальных алгоритмов сортировки массивов. Общая идея алгоритма состоит в следующем:
Выбрать из массива элемент, называемый опорным. Это может быть любой из элементов массива. От выбора опорного элемента не зависит корректность алгоритма, но в отдельных случаях может сильно зависеть его эффективность.
Сравнить все остальные элементы с опорным и переставить их в массиве так, чтобы разбить массив на три непрерывных отрезка, следующие друг за другом: «меньшие опорного», «равные» и «большие».
Для отрезков «меньших» и «больших» значений выполнить рекурсивно ту же последовательность операций, если длина отрезка больше единицы.
(см. приложение Рисунок 21 Реализация в C)
2.5 Интроспективная сортировка
Introsort
В основе алгоритма лежит быстрая сортировка. На случай, если имеем дело с «массивом-убийцей» (т.е. являющийся для быстрой сортировки вырожденным случаем), происходит переключение на пирамидальную сортировку.
Массивы-убийцы
Быстрая сортировка, по всей видимости, в самом общем случае является наиболее эффективным методом для упорядочивания данных. Однако не всё так просто. Самое слабое звено алгоритма — подбор базовых элементов для подмассивов при рекурсивных вызовах. При неудачном раскладе сортировка сама себя вызывает максимальное количество раз, а рекурсия — процесс дорогостоящий для памяти.
Легендарный учёный Никлаус Вирт предложил для преодоления проблемы выбор опоры осуществлять по принципу «медиана из трёх», т.е. в качестве базового ключа подмассива брать средний по величине элемент из 3-х претендентов: первого элемента подмассиса, последнего элемента подмассива и элемента посередине.
Хотя в абсолютном большинстве случаев это позволяло избежать неприятностей, оно не гарантировало 100%-го решения проблемы. Оставалась возможность специально подобрать такой массив, на котором быстрая сортировка, даже реализованная с помощью принципа «медиана из 3-х», всё равно быстро деградировала.
Если использовать вместо правила «медиана из 3-х» какое-нибудь другое, то это принципиально ничего не меняет — вырожденный случай подбирается в соответствии с конкретной реализацией.
С помощью «массива-убийцы» теоретически можно было атаковать веб-сервер, написанный на языке, использующего быструю сортировку по умолчанию (то есть, в 90-х годах практически на любом ЯП). Предложив серверу для обработки «массив-убийцу» из миллиона элементов, можно было вызвать перегрузку и вывести из строя объект атаки.
Решение проблемы
В качестве отражения потенциальных угроз Девид Мюссер предложил контролировать максимальную глубину рекурсии, допустимую для алгоритма быстрой сортировки (например, можно ориентироваться на величину log n). Если глубина рекурсии достигала этой величины, то дальнейшее упорядочивание подмассива, от которого поступил тревожный сигнал, производится с помощью пирамидальной сортировки. Пирамидальная сортировка характерна тем, что у неё нет ни вырожденных, ни лучших наборов данных, любые массивы она сортирует всегда с одинаковой временной сложностью — O(n log n).
Мюссер подобрал «киллер» из 100 тысяч элементов и протестировал его. Introsort обработал массив в 200 раз быстрее чем QuickSort.
2.6 Придурковатая сортировка
Неэффективная сортировка, представляющая чисто академический интерес.
Метод назван в честь американской комик-группы «Three stooges» («Три придурка»), развлекавшая публику в 30-х-60-х годах прошлого века. Коллектив трио периодически менялся, всего в труппе было 6 актёров за 40 лет существования. В алгоритм заложен элемент абсурда — обычно массив давно отсортирован, но сортировка продолжает безумно метаться по третям списка.
Придурковатая сортировка
Алгоритм
Сравниваем элементы на концах отрезка (первоначально это весь массив). Если на левом конце больше чем на правом, то меняем местами.
Рекурсивно применяем сортировку для первых 2/3 элементов списка.
Рекурсивно применяем сортировку для последних 2/3 элементов списка.
Снова рекурсивно применяем сортировку для первых 2/3 элементов списка.
Глава 3. Прочие алгоритмы сортировки
3.1 Топологическая сортировка
Топологическая сортировка (Topological sort) — один из основных алгоритмов на графах, который применяется для решения множества более сложных задач.
Задача топологической сортировки графа состоит в следующем: указать такой линейный порядок на его вершинах, чтобы любое ребро вело от вершины с меньшим номером к вершине с большим номером. Очевидно, что если в графе есть циклы, то такого порядка не существует.
Существует несколько способов топологической сортировки — из наиболее известных:
Алгоритм Демукрона
Метод сортировки для представления графа в виде нескольких уровней
Метод топологической сортировки с помощью обхода в глубину
Суть алгоритма
Поиск в глубину или обход в глубину (англ. Depth-first search, сокращенно DFS) — один из методов обхода графа. Алгоритм поиска описывается следующим образом: для каждой не пройденной вершины необходимо найти все не пройденные смежные вершины и повторить поиск для них.
Запускаем обход в глубину, и когда вершина обработана, заносим ее в стек. По окончании обхода в глубину вершины достаются из стека. Новые номера присваиваются в порядке вытаскивания из стека.
Цвет: во время обхода в глубину используется 3 цвета. Изначально все вершины белые. Когда вершина обнаружена, красим ее в серый цвет. Когда просмотрен список всех смежных с ней вершин, красим ее в черный цвет.
Думаю будет проще рассмотреть данный алгоритм на примере:
Применение
Топологическая сортировка применяется в самых разных ситуациях, например при распараллеливании алгоритмов, когда по некоторому описанию алгоритма нужно составить граф зависимостей его операций и, отсортировав его топологически, определить, какие из операций являются независимыми и могут выполняться параллельно (одновременно). Примером использования топологической сортировки может служить создание карты сайта, где имеет место древовидная система разделов.
3.2 Внешняя сортировка
Внешняя сортировка — сортировка данных, расположенных на периферийных устройствах и не вмещающихся в оперативную память, то есть когда применить одну из внутренних сортировок невозможно. Стоит отметить, что внутренняя сортировка значительно эффективней внешней, так как на обращение к оперативной памяти затрачивается намного меньше времени, чем к магнитным дискам, лентам и т. п.
Наиболее часто внешняя сортировка используется в СУБД. Основным понятием при использовании внешней сортировки является понятие отрезка. Например, в некотором файле А есть одномерный массив:
12 35 65 0 24 36 3 5 84 90 6 2 30
Поделим массив на отрезки:
12 35 65 | 0 24 36 | 3 5 84 90 | 6 | 2 30
Можно сказать, что массив в файле А состоит из 5 отрезков.
Например, в некотором файле B есть одномерный массив:
1 2 3 4 5 6 7 8 9 10
Поделим массив на отрезки:
| 1 2 3 4 5 6 7 8 9 10 |
Можно сказать, что массив в файле B состоит из 1 отрезка.
Например, в некотором файле А есть одномерный массив:
20 17 16 14 13 10 9 8 6 4 3 2 0
Поделим массив на отрезки:
| 20 | 17 | 16 | 14 | 13 | 10 | 9 | 8 | 6 | 4 | 3 | 2 | 0 |
Можно сказать, что массив в файле А состоит из 13 отрезков.
Идея большинства методов заключается в расчленении данных на ряд последовательностей помещающихся в оперативную память. Далее применяется один из методов внутренней сортировки, после чего последовательности сливаются. Чем больше объём оперативной памяти, тем длиннее будут последовательности и, следовательно, тем меньшим окажется их количество, что увеличит скорость сортировки.
Если же объём оперативной памяти мал, то можно разделить исходные данные на несколько последовательностей, после чего непосредственно использовать процедуру слияния.
Основные методы сортировок:
Естественная сортировка (метод естественного слияния)
Сортировка методом двухпутевого сбалансированного слияния
Сортировка методом n-путевого слияния.
Многофазная сортировка (Фибоначчиевая)
Внешняя сортировка – это сортировка данных, которые расположены на внешних устройствах и не вмещающихся в оперативную память.
Данные, хранящиеся на внешних устройствах, имеют большой объем, что не позволяет их целиком переместить в оперативную память, отсортировать с использованием одного из алгоритмов внутренней сортировки, а затем вернуть их на внешнее устройство. В этом случае осуществлялось бы минимальное количество проходов через файл, то есть было бы однократное чтение и однократная запись данных. Однако на практике приходится осуществлять чтение, обработку и запись данных в файл по блокам, размер которых зависит от операционной системы и имеющегося объема оперативной памяти, что приводит к увеличению числа проходов через файл и заметному снижению скорости сортировки.
К наиболее известным алгоритмам внешних сортировок относятся:
сортировки слиянием (простое слияние и естественное слияние);
улучшенные сортировки (многофазная сортировка и каскадная сортировка).
Из представленных внешних сортировок наиболее важным является метод сортировки с помощью слияния. Прежде чем описывать алгоритм сортировки слиянием введем несколько определений.
Основным понятием при использовании внешней сортировки является понятие серии. Серия (упорядоченный отрезок) – это последовательность элементов, которая упорядочена по ключу.
Количество элементов в серии называется длиной серии. Серия, состоящая из одного элемента, упорядочена всегда. Последняя серия может иметь длину меньшую, чем остальные серии файлов. Максимальное количество серий в файле N (все элементы не упорядочены). Минимальное количество серий одна (все элементы упорядочены).
В основе большинства методов внешних сортировок лежит процедура слияния и процедура распределения. Слияние – это процесс объединения двух (или более) упорядоченных серий в одну упорядоченную последовательность при помощи циклического выбора элементов, доступных в данный момент.
Распределение – это процесс разделения упорядоченных серий на два и несколько вспомогательных файла.
Фаза – это действия по однократной обработке всей последовательности элементов. Двухфазная сортировка – это сортировка, в которой отдельно реализуется две фазы: распределение и слияние. Однофазная сортировка – это сортировка, в которой объединены фазы распределения и слияния в одну.
Двухпутевым слиянием называется сортировка, в которой данные распределяются на два вспомогательных файла. Многопутевым слиянием называется сортировка, в которой данные распределяются на N (N > 2) вспомогательных файлов.
Общий алгоритм сортировки слиянием
Сначала серии распределяются на два или более вспомогательных файлов. Данное распределение идет поочередно: первая серия записывается в первый вспомогательный файл, вторая – во второй и так далее до последнего вспомогательного файла. Затем опять запись серии начинается в первый вспомогательный файл. После распределения всех серий, они объединяются в более длинные упорядоченные отрезки, то есть из каждого вспомогательного файла берется по одной серии, которые сливаются. Если в каком-то файле серия заканчивается, то переход к следующей серии не осуществляется. В зависимости от вида сортировки сформированная более длинная упорядоченная серия записывается либо в исходный файл, либо в один из вспомогательных файлов. После того как все серии из всех вспомогательных файлов объединены в новые серии, потом опять начинается их распределение. И так до тех пор, пока все данные не будут отсортированы.
Выделим основные характеристики сортировки слиянием:
количество фаз в реализации сортировки;
количество вспомогательных файлов, на которые распределяются серии.
3.3. Блинная сортировка
Непрактичность ее состоит в том, что в данном алгоритме вообще не учитывается количество сравнений элементов (считается, что эти операции очень дешевы и быстры), а единственной операцией, имеющей цену, является переворот верхушки стопки сортируемых «блинов». Разумеется, изначально они расположены в произвольном порядке, а желаемым результатом является некое подобие ханойской башни, когда блины большего диаметра лежат снизу, а меньшего располагаются сверху.
По поводу этой задачи хочется отметить два интересных факта. Во-первых, способ нахождения достаточно эффективного (хотя и неоптимального) решения был в свое время предложен небезызвестным Биллом Гейтсом, пока тот был еще студентом. Этот алгоритм, предложенный в 1979 году, оставался наиболее эффективным вплоть до 2008, когда результат был превзойден. Во-вторых, как было доказано впоследствии, задача нахождения оптимального решения относится к классу NP-полных. Также Гейтсом и его руководителем Христосом Пападимитриу был предложен усложненный вариант задачи, известный как задача о подгоревших блинах.
Задача о подгоревших блинах
В этой форме задачи каждый элемент, помимо размера, имеет еще и бинарный атрибут «направление», то есть у каждого «блина» одна сторона подгоревшая, а другая румяная; результатом решения задачи является стопка, упорядоченная по размеру, но, помимо этого, все «блины» лежат подгоревшей стороной вниз. Не вдаваясь в подробности, скажем, что и эта задача NP-полна, и что в общем случае известны ее достаточно эффективные, но неоптимальные решения. Тем не менее, существуют ограничения на данные, при выполнении которых задача становится полиномиальной. Для рассматриваемой задачи такими данными являются простые перестановки. Чтобы понять, что это такое, рассмотрим перестановку чисел от 1 до 7: 2647513. Заметим, что выделенная жирным шрифтом последовательность сама является перестановкой чисел от 4 до 7 (называется блоком). Простые перестановки — это те, где нет нетривиальных блоков (блоков длины 1 и n).
За образной постановкой задачи, когда элементы представлены подгоревшими блинами, сложно разглядеть тот факт, что она имеет биологическое значение. Тем не менее, распространенной мутацией является переворот в молекуле ДНК, и если посчитать минимальное количество переворотов, необходимое для преобразования одной молекулы в другую (без рассмотрения более мелких точечных мутаций), то можно примерно оценить родство организмов. Например, геном человека и мыши разделен всего лишь порядка 120 глобальными мутациями; признаюсь, я раньше полагал, что между этими видами разницы гораздо больше…
Генетический алгоритм решения задачи о подгоревших блинах
В сравнительной геномике алгоритм используется для аналитического нахождения количества мутаций, разделяющих организмы, но посмотрим на задачу в другой проекции. Теперь уже решение аналитической задачи объявим целью, а живые организмы и процессы, в них протекающие, сделаем инструментом для ее решения.
Как известно, бактерии в состоянии делиться обеспечивая экспоненциальный рост популяции, если им предоставлены необходимые условия; разумеется, через некоторое время колонии бактерий уже не будет хватать питательной среды, также появятся другие факторы, влияющие на рост колонии, но на это необходимо время. Экспериментальным путем мы можем выяснить среднее время, которое требуется бактериям данного вида на появление глобальной мутации, связанной с переворотом части ДНК.
Теперь поставим бактериям задачу. Генетически модифицируем одну из них (биологи любят в подобных экспериментах использовать кишечную палочку), где ген устойчивости к антибиотику разобьем на несколько частей и перемешаем между собой, меняя при этом не только порядок, но и направление некоторых кусков. Таким образом, каждый перевернутый и переставленный кусок гена в нашем случае будет представлять собой «подгоревший блин».
Задача бактерии поставлена, можно начинать эксперимент. Помещаем ее в питательную среду и ждем отведенное время, за которое ожидается появление одной мутации-переворота ДНК. Обращаю внимание на то, что мы считаем одной мутацией: она единственна не на всю колонию (как раз в колонии этих мутаций будет много); это всего лишь ожидаемое количество переворотов у каждой из ныне живущих бактерий по сравнению с их прародителем.
Достаточно ли одного переворота блина для решения задачи? Мы легко это можем проверить, поместив часть колонии в опасную для нее среду. Помещенные в антибиотик бактерии не выжили, и мы продолжаем наблюдать за оставшимися. Пройдет еще два-три периода, и, наконец, в группе бактерий, помещенных в антибиотик, останутся живые. «Коллективный разум» справился с задачей!
Итоги
Конечно, полезность решенной задачи нас вряд ли впечатлит: в реальных проведенных экспериментах количество сортируемых «блинов» не превышает четырех, а количество мутаций, происходящее за отведенное время, может быть оценено лишь вероятностно. И все же лично меня поразила фантазия тех биологов, которые смогли поставить эксперимент; не меньшей фантазией обладали и те, кто смог биологическим методом решить задачу коммивояжера (подробности этого эксперимента я оставлю за рамками данной статьи). Во многом сложность задач, решаемых генетическими алгоритмами, сравнима с квантовыми вычислениями, и хочется верить, что оба направления неклассических вычислений смогут дать результаты пока не достижимые в современных условиях.
Заключение
Сортировка применяется во всех без исключения областях программирования, будь то базы данных или математические программы. Алгоритмы сортировки представляют собой пошаговое упорядочение элементов в определенном массиве данных, независимо от его размеров.
Практически каждый алгоритм сортировки можно разбить на три части:
- сравнение, определяющее упорядоченность пары элементов;
- перестановку, меняющую местами пару элементов;
- собственно сортирующий алгоритм, который осуществляет сравнение и перестановку элементов до тех пор, пока все элементы множества не будут упорядочены.
Выбор метода сортировки в значительной мере зависит от объема и характеристики исходных данных. Но, в целом, основными параметрами, которыми руководствуется пользователь при выборе метода сортировки, являются время действия алгоритма, память, устойчивость сортировки и эффективность поведения алгоритма.
Наиболее известными и, одновременно, базовыми алгоритмами сортировки являются обменная, блочная, пирамидальная, линейная, быстрая сортировки, а также сортировки подсчетом, слиянием, перемешиванием и методом вставок. Каждый из этих методов имеет свои достоинства и недостатки.
Термин «алгоритм» применяют весьма широко. Алгоритм – это организованная последовательность действий, допустимых в определенных случаях. Умение разбить задачу на подзадачи, распределение решений этих задач, определение выходных параметров способствуют легкому восприятию любой ситуации.
Список использованной литературы
- https://prog-cpp.ru
- https://ru.wikipedia.org/wiki/Алгоритм_сортировки
- https://learnc.info/algorithms/bubblesort.html
- http://ucxodnuku.ru/algoritm/sortirovka-vstavkami.html
- http://algolist.manual.ru/sort/merge_sort.php
- http://sadda.ru/pages/assembler-masm32/sort-comb/sort-comb.htm
- https://juja.com.ua/java/algorithms/sorting-optimizing/
- http://trubetskoy1.narod.ru/alg/radixsort.html
- http://programmado.ru/48-sortirovka-metodom-puzyrka.html
- http://sorting.valemak.com/gnome/
- http://cpp.com.ru/shildt_spr_po_c/21/2106.html
- http://orderedword.blogspot.ru/2013/11/merge-sort-c.html
- http://completepascal.blogspot.ru/2010/09/blog-post_2841.html

Приложение 1 Пример написания такой сортировки в JavaScript:
Приложение 2 Пример

Приложение 3 Пример написания такой сортировки в Pascal

Приложение 4 Пример применения такой сортировки в Java
Приложение 5 Пример

Приложение 6 Пример реализации в Java
Приложение 7 Пример
Приложение 8 Пример реализации в Java
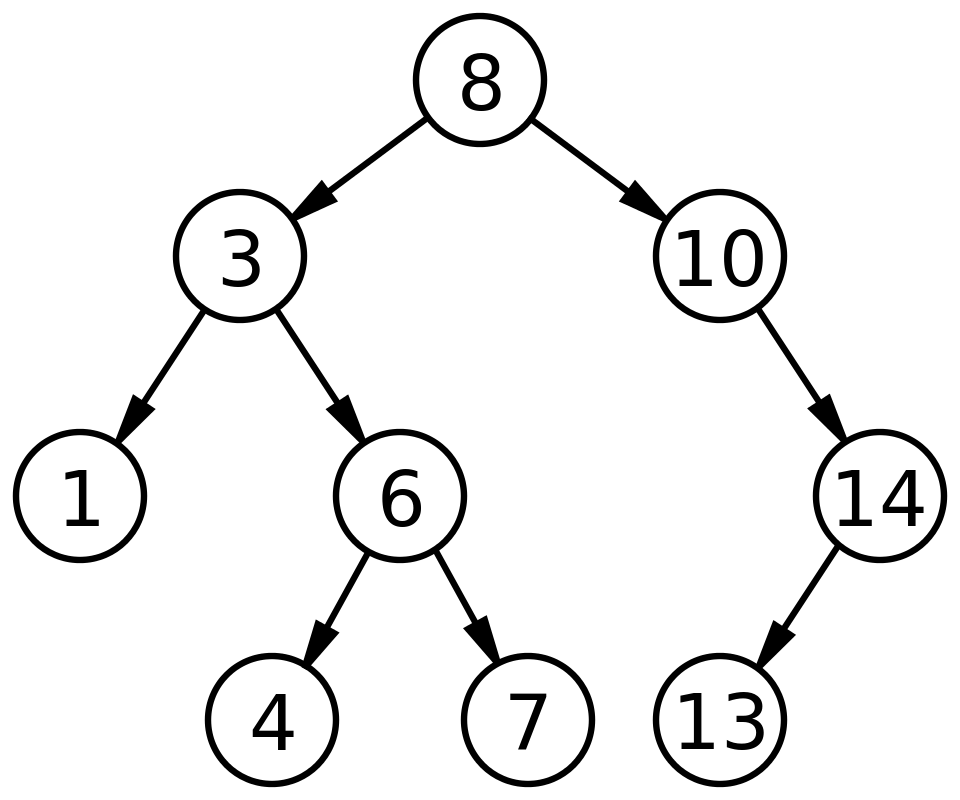
Приложение 9 Пример
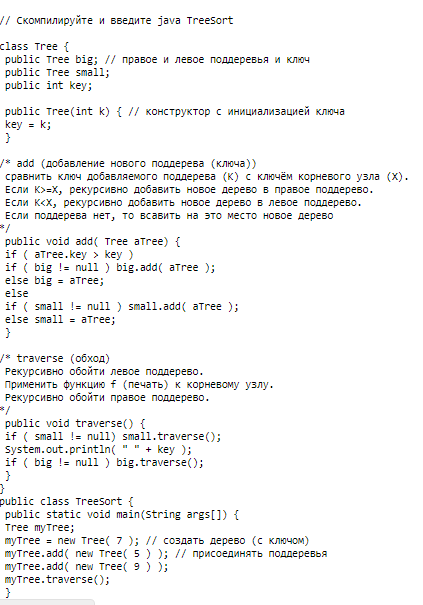
Приложение 10 Реализация в Java

Приложение 11 Реализация в Java
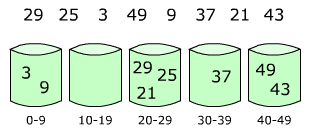
Приложение 12 Элементы распределяются по корзинам
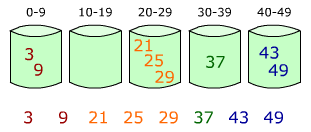
Приложение 13 Затем элементы в каждой корзине сортируются
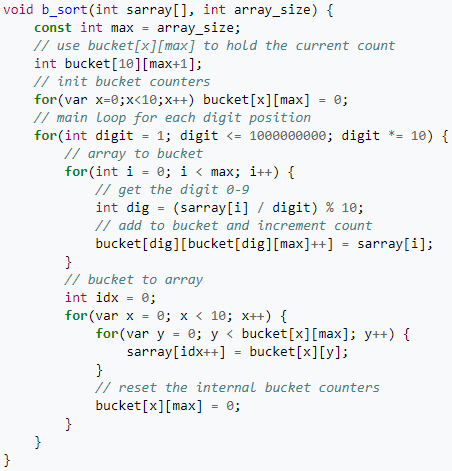
Приложение 14 Реализация в C
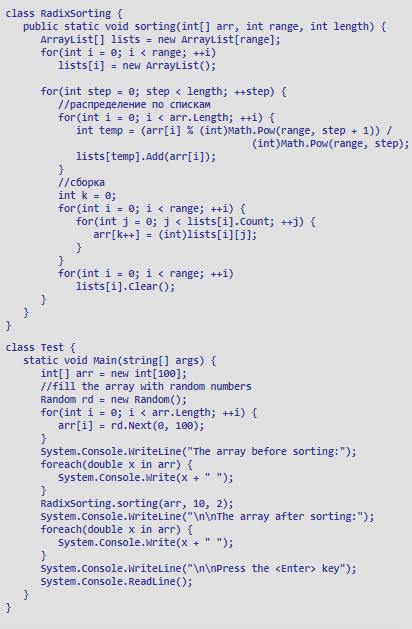
Приложение 15 Реализация в С#
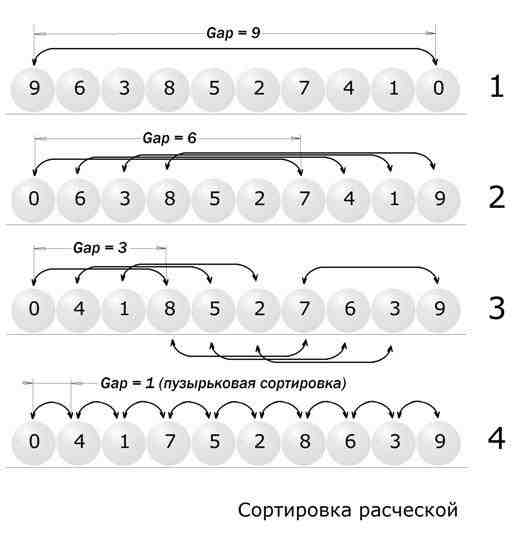
Приложение 16 Пример сортировки расческой

Приложение 17 Реализация в C#

Приложение 18 Реализация в C

Приложение 19 Пример, часть 1
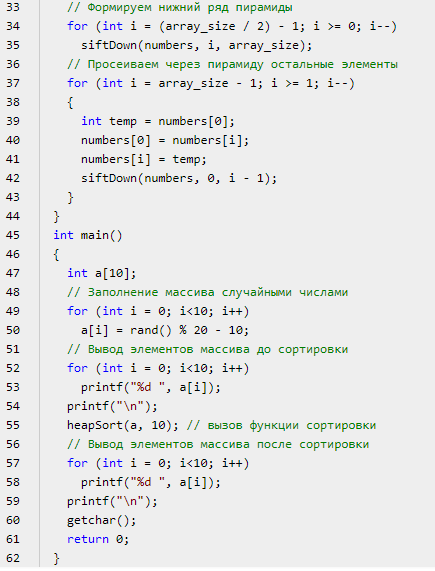
Приложение 20 Пример, часть 2

Приложение 21. Реализация в C

- Проектирование реализации операций бизнес-процесса «Расчет заработной платы» (Сущность и назначение необходимого продукта)
- Учет наличных денежных средств в кассе предприятия (Теоретические аспекты учета денежных средств в кассе организации)
- Учет труда и заработной платы (Теоретические и методологические аспекты организации затрат на оплату труда)
- Бухгалтерский баланс организации и порядок его составления (Теоретические аспекты бухгалтерского баланса предприятия)
- Исковая давность и ее гражданско-правовое значение (Отличия сроков исковой давности от других видов сроков)
- Трудовые ресурсы торговой организации, на пример реально существующей организации (Теоретические аспекты анализа эффективности использования трудовых ресурсов организации)
- Оценка эффективности стратегий и моделей копинг-поведения в профессиональной среде (Теоретические подходы к проблеме копинг-поведения)
- Информационные и мотивационные структуры в особенностях индивидуального поведения и учет их в практике работы с персоналом ( изучение особенности формирования информационных и мотивационных структур в практике работы с персоналом)
- Понятие социального обеспечения (Виды источников социального обеспечения)
- Роль мотивации в поведении организации (Теоретические основы СПОСОБОВ мотивации труда персонала в целях эффективного развития организации)
- История развития средств вычислительной техники (Фоннеймановская архитектура ЭВМ)
- Применение объектно-ориентрованного подхода при проектировании информационной системы (Объектный подход при разработке программ)