
Алгоритмы сортировки данных (Алгоритмы сортировки)
Содержание:

Введение
Целью данной курсовой работы является изучения основных алгоритмов внутренней сортировки массивов данных, сравнение сложности их реализации и производительности. Более подробно рассмотрен метод обменной сортировки.
Если обратиться к литературе, то можно обнаружить два крайних подхода к представлению материала. Некоторые авторы любят излагать материал на высоком теоретическом уровне. Например, для того, чтобы ввести понятие типа данных и предложить классификацию возможных типов, используются развитые механизмы абстрактной алгебры; при описании алгоритмов в обязательном порядке приводятся асимптотические оценки их сложности. Другой подход состоит в максимальном приближении к практике. Обычно выбирается некоторый конкретный язык программирования, и все описываемые структуры данных и алгоритмы представляются на этом языке.
Глава 1. Понятие и виды алгоритмов сортировки данных
1.1.Алгоритмы сортировки
Алгоритм сортировки — это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле по которому производится сортировка, называется ключом сортировки. На практике, в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Пожалуй, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Существует ли некий «универсальный», наилучший алгоритм? Вообще говоря, нет. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом.
Оценка алгоритма сортировки
Для того, чтобы обоснованно сделать такой выбор, рассмотрим параметры, по которым будет производиться оценка алгоритмов.
Время сортировки— основной параметр, характеризующий быстродействие алгоритма. Называется также вычислительной сложностью. Для сортировки важны худшее, среднее и лучшее поведения алгоритма в терминах размера списка (n). Для типичного алгоритма хорошее поведение— это O(n log n) и плохое поведение— это Ω(n²). Идеальное поведение для сортировки— O(n). Алгоритмы сортировки, которые используют только абстрактную операцию сравнения ключей, всегда нуждаются, по меньшей мере, в Ω(n log n) сравнениях в среднем;
Память— ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость (stability)— устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, а сортировка происходит по одному из них.
Естественность поведения— эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов сортировки две:
Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
Внешняя сортировка оперирует с запоминающими устройствами большого объёма, но с доступом не произвольным, а последовательным (сортировка файлов), т.е в данный момент мы 'видим' только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью.
доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим
объём данных не позволяет им разместиться в ОЗУ
Список алгоритмов сортировки
В этой таблице n— это количество записей, которые необходимо отсортировать, а k— это количество уникальных ключей.
Алгоритмы устойчивой сортировки
Сортировка пузырьком (англ. Bubble sort) — сложность алгоритма: Q(n2); для каждой пары индексов производится обмен, если элементы расположены не по порядку
Сортировка перемешиванием (Сортировка коктейлем, Cocktail sort, bidirectional bubble sort) — Сложность алгоритма: O(n2)
Сортировка методом вставок (Insertion sort) — Сложность алгоритма: O(n2); определяем где текущий элемент должен находится в отсортированном списке и вставляем его туда
Блочная сортировка (Корзинная сортировка, Bucket sort) — Сложность алгоритма: O(n); требуется O(k) дополнительной памяти
Сортировка подсчетом (Counting sort) — Сложность алгоритма: O(n+k); требуется O(n+k) дополнительной памяти
Сортировка слиянием (Merge sort) — Сложность алгоритма: O(n log n); требуется O(n) дополнительной памяти; сортируем первую и вторую половину списка отдельно, а затем — сливаем отсортированные списки
In-place merge sort — Сложностьалгоритма: O(n2)
Двоичное древо сортировки (Binary tree sort) — Сложность алгоритма: O(n log n); требуется O(n) дополнительной памяти
Цифровая сортировка (Сортировка по отделениям, Pigeonhole sort) — Сложность алгоритма: O(n+k); требуется O(k) дополнительной памяти
Поразрядная сортировка (Radix sort) — Сложность алгоритма: O(n·k); требуется O(n) дополнительной памяти сортирует строки буква за буквой
Гномья сортировка(Gnome sort) — Сложность алгоритма: O(n2)
Алгоритмы неустойчивой сортировки
Сортировка методом выбора (Selection sort)— Сложность алгоритма: O(n2); поиск наименьшего или наибольшего элемента и помещения его в начало или конец отсортированного списка
Сортировка методом Шелла (Shell sort)— Сложность алгоритма: O(n log n); попытка улучшить сортировку вставками
Сортировка расчёской (Comb sort)— Сложность алгоритма: O(n log n)
Пирамидальная сортировка (Сортировка кучи, Heapsort)— Сложность алгоритма: O(n log n); превращаем список в кучу, берём наибольший элемент и добавляем его в конец списка
Плавная сортировка (Smoothsort)— Сложность алгоритма: O(n log n)
Быстрая сортировка (Quicksort)— Сложность алгоритма: O(n log n)— среднее время, O(n2)— худший случай; широко известен как быстрейший из известных для сортировки больших случайных списков; с разбиением исходного набора данных на две половины так, что любой элемент первой половины упорядочен относительно любого элемента второй половины; затем алгоритм применяется рекурсивно к каждой половине
Introsort— Сложность алгоритма: O(n log n)
Patience sorting— Сложность алгоритма: O(n log n + k)— наихудший случай, требует дополнительно O(n + k) памяти, также находит самую длинную увеличивающуюся подпоследовательность
Непрактичные алгоритмы сортировки
Сортировка Акульшина (Akulshin sort)— O(n × n!)— худшее время. Генерируем всевозможные перестановки исходного массива и для каждой осуществдяем проверку верной отсортированности.
Глупая сортировка (Stupid sort)— O(n3); рекурсивная версия требует дополнительно O(n2) памяти
Bead Sort— O(n) or O(√n), требуется специализированное железо
Блинная сортировка (Pancake sorting)— O(n), требуется специализированное железо
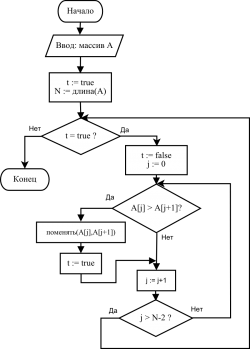
1.2.Сортировка пузырьком
Сортиро́вка пузырько́м (англ. bubble sort) — простой алгоритм сортировки. Алгоритм состоит в повторяющихся проходах по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При проходе алгоритма, элемент, стоящий не на своём месте, «всплывает» до нужной позиции как пузырёк в воде, отсюда и название алгоритма.
Сортировка методом пузырька имеет сложность O(n2). Для понимания и реализации это — простейший алгоритм сортировки, но эффективен он лишь для небольших массивов.
Пример реализации алгоритма (C#):
void BubbleSort(int[] A)
{
for (int i = 0; i < A.Length; i++)
{
for (int j = i+1; j < A.Length; j++)
{
if (A[j] < A[i])
{
var temp = A[i];
A[i] = A[j];
A[j] = temp;
}
}
}
}
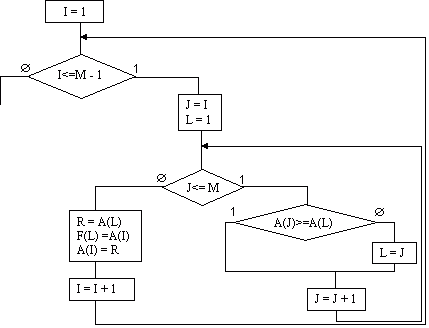
1.3.Сортировка методом вставок
Сортировка методом вставок (англ. insertion sort) — простой алгоритм сортировки. Хотя этот метод сортировки намного менее эффективен чем более сложные алгоритмы (такие как быстрая сортировка), у него есть ряд преимуществ:
прост в реализации
эффективен на небольших наборах данных
эффективен на наборах данных, которые уже частично отсортированы
это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы)
может сортировать список по мере его получения
На каждом шаге алгоритма, мы выбираем один из элементов входных данных и вставляем его на нужную позицию в уже отсортированном списке, до тех пор пока набор входных данных не будет исчерпан. Выбор очередного элемента, выбираемого из исходного массива — произволен, может использоваться практически любой алгоритм выбора.
C# (Бездополнительнойпамяти)
public void InsertionSort(int[] array)
{
for (int i = 1; i < array.Length; i++)
{
int j;
int buf = array[i];
for (j = i - 1; j >= 0; j--)
{
if (array[j] < buf)
break;
array[j + 1] = array[j];
}
array[j + 1] = buf;
}
}
1.4.Сортировка методом выбора
Сортировка методом выбора (англ. selection sort) — алгоритм сортировки, относящийся к неустойчивым алгоритмам сортировки. На массиве из n элементов имеет время выполнения в худшем, среднем и лучшем случае Θ(n2), предполагая, что сравнения делаются за постоянное время.
Алгоритм
Шаги алгоритма:
находим минимальное значение в текущем списке
производим обмен этого значения со значением на первой позиции
теперь сортируем хвост списка, исключив из рассмотрения уже отсортированный первый элемент
Пирамидальная сортировка сильно улучшает базовый алгоритм, используя структуру данных ключа для ускорения нахождения и удаления минимального элемента.
Существует также двунаправленный вариант сортировки методом вставок, в котором на каждом проходе отыскивается и устанавливается на своё место и минимальное, и максимальное значения.
С#:
public static List<int> Selection(List<int> list)
{
for (int i = 0; i < list.Count-1; i++)
{
int min = i;
for (int j = i + 1; j < list.Count; j++)
{
if (list[j] < list[min])
{
min = j;
}
}
int dummy = list[i];
list[i] = list[min];
list[min] = dummy;
}
return list;
}
1.5.Сортировка методом Шелла
Идея алгоритма состоит в обмене элементов, расположенных не только рядом, как в сортировке методом вставок, но и далеко друг от друга, что значительно сокращает общее число операций перемещения элементов.
Для примера возьмем файл из 16 элементов. Сначала просматриваются пары с шагом 8. Это пары элементов 1-9, 2-10, 3-11, 4-12, 5-13, 6-14, 7-15, 8-16. Если значения элементов в паре не упорядочены по возрастанию, то элементы меняются местами. Назовем этот этап 8-сортировкой. Следующий этап — 4-сортировка, на котором элементы в файле делятся на четверки: 1-5-9-13, 2-6-10-14, 3-7-11-15, 4-8-12-16. Выполняется сортировка в каждой четверке.
Следующий этап — 2-сортировка, когда элементы в файле делятся на 2 группы по 8: 1-3-5-7-9-11-13-15 и 2-4-6-8-10-12-14-16. Выполняется сортировка в каждой восьмерке. Наконец весь файл упорядочивается методом вставок. Поскольку дальние элементы уже переместились на свое место или находятся вблизи от него, этот этап будет значительно менее трудоемким, чем при сортировке вставками без предварительных «дальних» обменов.
Анализ алгоритма сортировки Шелла
Время выполнения сортировки пропорционально n1.2. Эта зависимость значительно лучше квадратичной зависимости n2, которой подчиняется большинство простых алгоритмов сортировки.
Примерреализации
void shellSort(int[] arr)
{
int j;
int step = arr.Length / 2;
while (step > 0)
{
for (int i = 0; i < (arr.Length - step); i++)
{
j = i;
while ((j >= 0) && (arr[j] > arr[j + step]))
{
int tmp = arr[j];
arr[j] = arr[j + step];
arr[j + step] = tmp;
j-=step;
}
}
step = step / 2;
}
}
1.6.Быстрая сортировка
Быстрая сортировка (англ. quicksort) — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром. Даёт в среднем O(nlogn) сравнений при сортировке n элементов. В худшем случае, однако, получается O(n2) сравнений. Обычно на практике быстрая сортировка значительно быстрее, чем другие алгоритмы с оценкой O(nlogn), по причине того, что внутренний цикл алгоритма может быть эффективно реализован почти на любой архитектуре, и на большинстве реальных данных можно найти решения, которые минимизируют вероятность того, что понадобится квадратичное время.
Интересно, что Хоар разработал этот метод применительно к машинному переводу: дело в том, что в то время словарь хранился на магнитной ленте, и если отсортировать все слова в тексте, их переводы можно получить за один прогон ленты.
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
Выбираем в массиве некоторый элемент, который будем называть опорным элементом.
Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него.
Рекурсивно сортируем подсписки, лежащие слева и справа от опорного элемента.
Базой рекурсии являются списки, состоящие из одного или двух элементов, которые уже отсортированы. Алгоритм всегда завершается, поскольку за каждую итерацию он ставит по крайней мере один элемент на его окончательное место.
сортировка данные алгоритм внутренний
C#:
int partition (int[] array, int start, int end)
{
int marker = start;
for (int i = start; i <= end; i++)
{
if (array[i] <= array[end])
{
int temp = array[marker]; // swap
array[marker] = array[i];
array[i] = temp;
marker += 1;
}
}
return marker - 1;
}
void quicksort (int[] array, int start, int end)
{
if (start >= end)
{
return;
}
int pivot = partition (array, start, end);
quicksort (array, start, pivot-1);
quicksort (array, pivot+1, end);
}
Улучшения
При выборе опорного элемента из данного диапазона случайным образом, худший случай становится очень маловероятным и ожидаемое время выполнения алгоритма сортировки - O(nlogn).
ГЛАВА 2. СИСТЕМА СОРТИРОВКИ НА БАЗЕ АРХИТЕКТУРЫ СУПЕРКОМПЬЮТЕРА
При разработке программного обеспечения для HPC-системы, нельзя не учитывать особенности её реализации, в частности архитектуру вычислительной машины. Разработчику следует понимать способы коммутации вычислительных узлов для эффективной работы с памятью. Организация вычислительной машины может существенно влиять на работу конкретного приложения. Это обуславливает проблемы, связанные с переносимостью программного обеспечения для сложных HPC-систем. Поэтому на начальном этапе разработки следует классифицировать вычислительную машину.
2.1. Классификация параллельных компьютерных систем
За последние годы было построено и предложено множество видов параллельных компьютерных систем. Исследователи пытались произвести классификацию таких систем [13, 14], но наиболее полной классификации до сих пор нет [12]. Чаще всего используется классификация Флинна или классификации на её основе (табл. 2.1).
Таблица 2.1 Классификация параллельных компьютерных систем по Флинну [12]
|
Потоки команд |
Потоки данных |
Категория |
Примеры |
|
1 |
1 |
SISD |
Классическая машина фон Неймана |
|
1 |
Много |
SIMD |
Векторный суперкомпьютер |
|
Много |
1 |
MISD |
Отказоустойчивые системы |
|
Много |
Много |
MIMD |
Кластеры |
Основу классификации Флинна [13] составляют понятия потоков команд и потоков данных. В SISD-архитектуре один поток выполнения работает с одним потоком данных. Компьютеры с SIMD-архитектурой, как правило, имеют один управляющий модуль, который назначает инструкцию выполнения для всех потоков выполнения, каждый из которых имеет собственный поток данных. Архитектура MISDподразумевает выполнение различных операцийнад одними и теми же данными.
К вычислительным машинам с MIMD-архитектурой относят мультипроцессорные машины, многоядерные и многопоточные процессоры и компьютерные кластеры (рис. 2.1). Безусловно, СКЦ «Политехнический» следует классифицировать как вычислительную систему с MIMD- архитектурой.
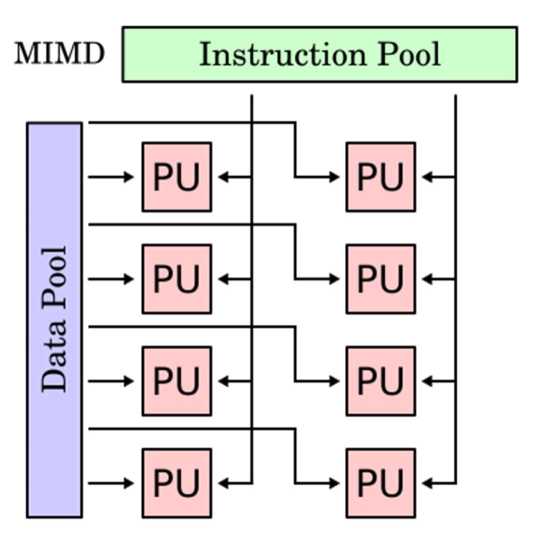
Рис. 2.1 Схема MIMD-архитектуры
На практике такой классификации недостаточно: классификация Флинна не даёт разработчику понимание системы с точки зрения организации памяти. Существует более подробная классификация, учитывающая такие особенности [12] (рис. 2.2). MIMD-машины разделяют на две категории: мультипроцессоры и мультикомпьютеры. К мультипроцессорам относят системы с общей памятью, к мультикомпьютерам – машины с обменом сообщениями.
с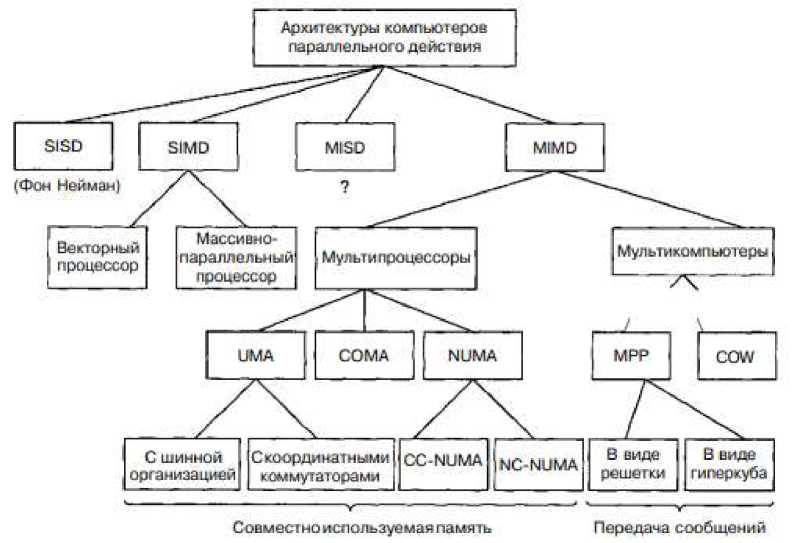
Рис. 2.2 Классификация параллельных систем с учётом организации памяти [12]
Мультикомпьютеры не имеют общей памяти на архитектурном уровне. Можно сказать, что операционная система процессора, входящего в мультикомпьютер, может получить доступ к памяти другого процессора только посредством обмена сообщениями. Существует две категории мультикомпьютеров: MPP (MassiveParallelProcessor- процессор с массовым параллелизмом) и COW (ClusterofWorkstation - кластер рабочих станций). MPPхарактерна для дорогостоящих компьютеров, состоящих из большого числа процессоров, соединённых высокоскоростной коммутационной сетью. К COWотносят набор вычислительных устройств, использующих некоторую коммутационную технологию. Принципиальной разницы между такими машинами нет: последние менее производительные и намного дешевле [12].
Мультипроцессоры подразделяются на три категории по доступу к общей памяти: UMA (UniformMemoryAccess- однородный доступ к памяти), NonUniformMemoryAccess(неоднородный доступ к памяти) и COMA (CacheOnlyMemoryAccess - доступ только к кэш-памяти). Такая классификация имеет смысл, потому что память в мультипроцессорах, как правило, имеет несколько модулей [12].
В UMA-машинах процессоры имеют одинаковое время доступа к общей памяти. Другими словами: слово из общей памяти читается с той же скоростью, что и любое другое слово. При этом самые быстрые обращения намеренно замедляются, поэтому для программиста доступ к памяти является однородным.
Для NUMA-машины характерен, напротив, неоднородный доступ к памяти. Обычно процессоры имеют один модуль памяти, обращение к которому быстрее, чем к модулям, принадлежащим другим процессорам. Поэтому важно, где находится программа и данные, с которыми она работает. Если в системе отсутствует кэш, то есть доступ к удалённой памяти не замаскирован кэшем, то такую систему называют NC-NUMA (NoCachingNUMA- NUMAбез кэширования). Если присутствуют кэши и система поддержки их согласованности, то такую систему называют CC-NUMA (CoherentCacheNUMA- NUMAс кэш-когерентной памятью).
Доступ к памяти в COMA-машинах также не является однородным, но по другим причинам. COMA-машины представляют память процессора как его кэш-память:запрашиваемые строки данных перемещаются междупроцессорами по требованию и фактически не имеют «домашнего» расположения.
СКЦ «Политехнический» состоит из нескольких СК [15]. Системы СКЦ работают с общей системой хранения данных и имеют единую систему управления и мониторинга. В вычислительном центре представлены три суперкомпьютера:
- «Политехник - РСК Торнадо» - кластер с пиковой производительностью 943 тфлопс, содержащий 668 двухпроцессорных узлов Intel Xeon E5 2687 v3
- «Политехник - РСК ПетаСтрим» - массивно-параллельный суперкомпьютер с пиковой производительностью 291 тфлопс на базе сопроцессоров Intel Xeon Phi.
• «Политехник - NUMA» - массивно-параллельная система Numascaleс кэш-когерентной глобально адресуемой памятью с пиковой производительностью 30 тфлопс.
Суперкомпьютеры «Политехник - РСК Торнадо» и «Политехник - РСК ПетаСтрим» попадают под классификацию мультикомпьютеров с высокоскоростной коммутационной сетью, то есть относятся к категории MPP(табл. 2.2). Соответственно кластер Numascaleпопадает под категорию мультипроцессора с категорией CC-NUMA.
Таблица 2.2 Классификация СК СКЦ «Политехнический»
|
СК |
Классификация |
|
«Политехник - РСК Торнадо» |
MPP |
|
«Политехник - РСК ПетаСтрим» |
MPP |
|
«Политехник - NUMA» |
CC-NUMA |
Для решения поставленной задачи наибольший интерес представляет система из категории MPP, для которых характерны огромные объёмы ввода- вывода [12]. Предложенный подход (п. 1.5) всё же имеет ограничения по масштабированию, так как в его основе лежат сортировочные сети. Таким образом, для реализации поставленной задачи следует использовать СК «Политехник - РСК Торнадо» (далее РСК Торнадо).
2.2. Особенности архитектуры суперкомпьютера, используемые в системахсортировки
Распространённой топологией коммутационной сети является топология дерева. Её основная проблема - пропускная способность сечения сети соответствует пропускной способности линии связи [12]. Наиболее узким местом в такой сети является верхушка дерева, у которой, как правило, наблюдается основной трафик. Для решения этой проблемы увеличивают пропускную способность сечения путём увеличения пропускной способности верхних линий связи. Такая топология называется толстым деревом (рис. 2.3).
По такой топологии объединены узлы кластера РСК Торнадо линиями связи InfiniBandFDR[15].
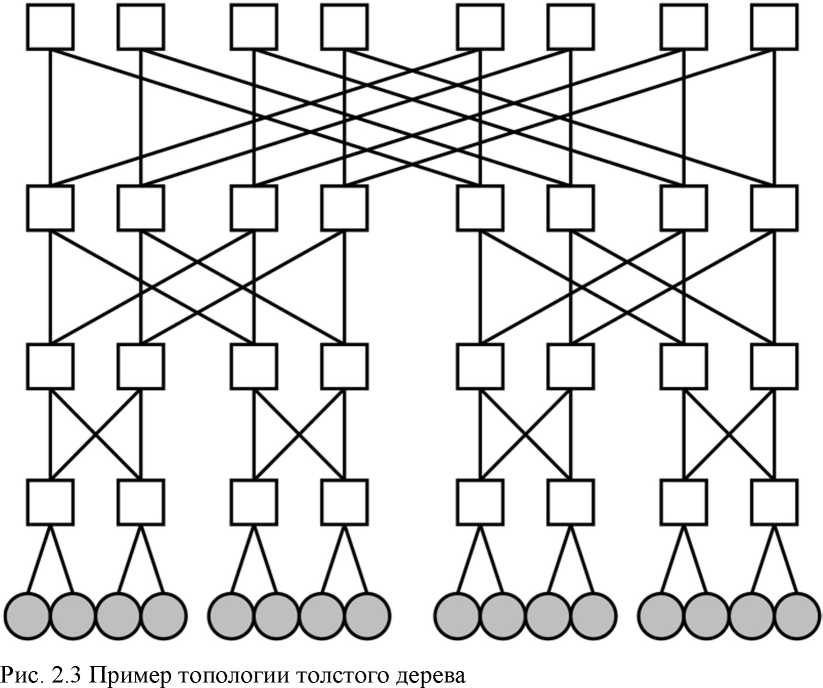
При построении сортирующей системы необходимо учесть топологию кластера для повышения скорости выполнения задачи. Рассмотрим прототип сортирующей системы для кластера с топологией толстого дерева.
Пусть имеется большой массив данных. Распределим фрагменты массива по первому уровню топологии. Пусть фрагменты массива в узлах сортируются, некоторым образом. Построим на базе узлов этого уровня сортировочную сеть с компаратором, операнды которого - фрагменты массива. Построение такой сети возможно.
Пусть первоначальная сортировка фрагментовосуществляется путём разбиения фрагмента массива на фрагменты меньшего размера, которые передаются на следующий уровень топологии для создания сортировочной подсети фрагментов. Аналогично вычисление компаратора осуществляется на нижестоящих уровнях топологии.
На таких принципахможно построить систему сортировки, адаптированную под древовидную топологию (рис. 2.4).
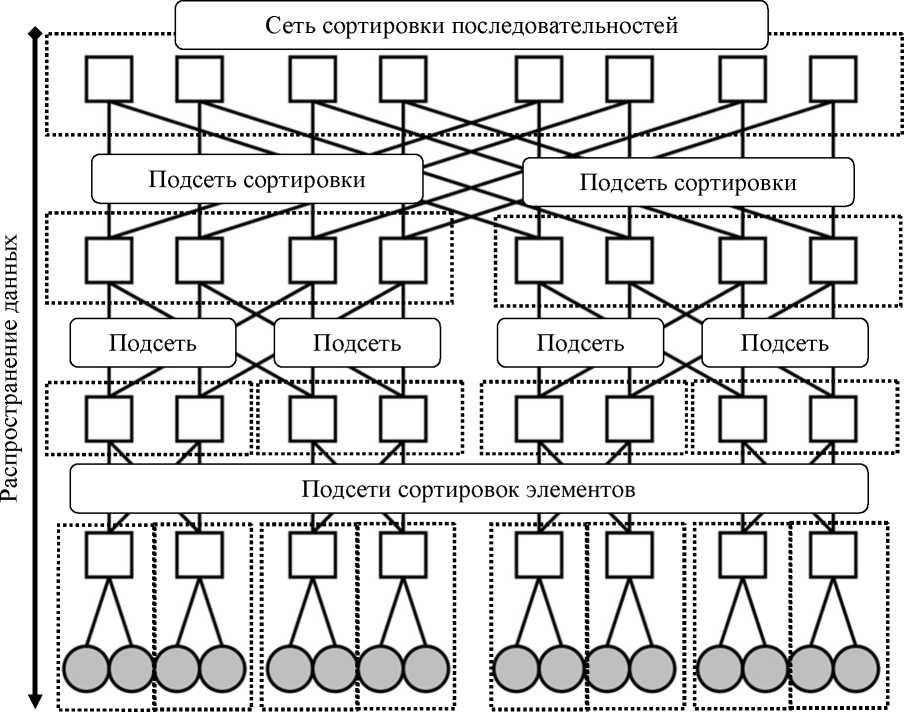
Рис. 2.4 Архитектура сети сортировки на базе топологии толстого дерева
В работе реализован частный случай базового компонента системы сортировки. (рис. 2.5), на основе которого будет возможно построение всей системы: сортировка массива с использованием пары узлов - процессоров IntelXeonE5-2697 v3 (14 ядер, 2.6 ГГц).
2.3. Требования к базовому компоненту системы сортировки
Компонент должен работать в соответствии с принципами со следующими принципами :
• Компонент осуществляет сортировку, разделяя исходный массив на фрагменты, с помощью сортировочной сети на базе компаратора, операндами которого являются подпоследовательности,
- Предварительная сортировка фрагментов инварианта относительно алгоритма сортировки: будь то последовательный или параллельный алгоритм,
- Сортировка эффективно распараллелена, то есть загрузка потоков выполнения должна быть равномерной.
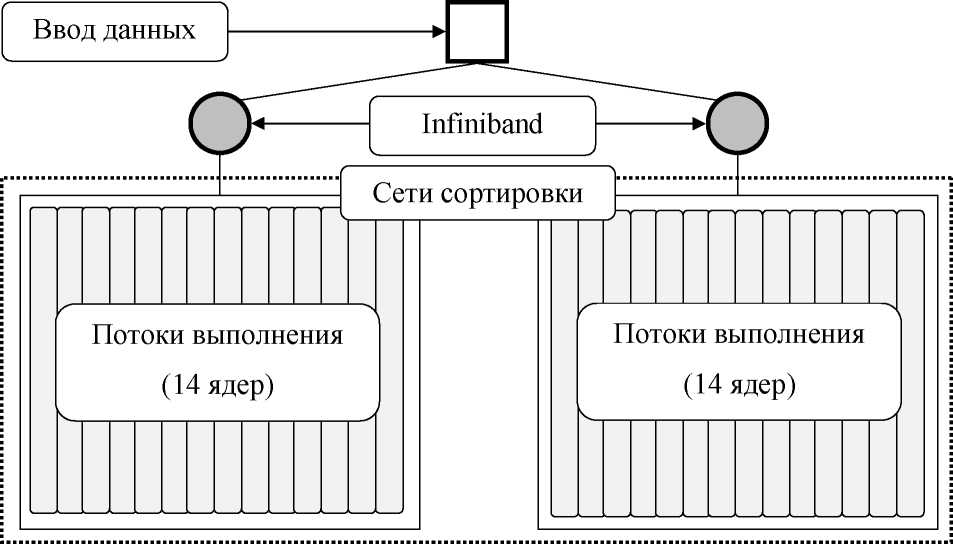
Рис. 2.5 Архитектура базового компонента системы с процессорами IntelXeonE5-2697 v3 (14 ядер)
2.4. Способы построения параллельной программы
Наиболее распространённым языком программирования в области HPC- систем являются языки Си и С++ [7]. В рамках реализации компонента будет использована модель с общей памятью. Модель передачи сообщений должна быть использована для более высокоуровневых компонент системы, разработка которых является предметом дальнейшей работы.
Существует несколько способов создания многопоточных программ, реализуемые компиляторами [18, 19]. В рамках модели с общей памятью среди них следует выделить следующие:
- ФреймворкIntel Threading Building Blocks [0]
- Расширение OpenMP [1]
- Расширение Intel Cilk Plus [2]
- Расширение OpenACC [2]
- Средства языка С++ (std: :thread) [4]
- Использование потоков операционной системы PThreads[5]
Выбор фреймворка обуславливается требованиями к реализации поставленной задачи [2].
Стандарт OpenACCиспользуется для гетерогенного программирования, то есть программирования с использованием центрального и графического процессоров. В настоящей работе не рассматривается возможность использования графических процессоров в решении задачи, поэтому предпочтение отдаётся другим расширениям и фреймворкам.
Использование встроенных средств распараллеливания, предоставляемых языком С++ или операционной системой, позволяет реализовывать специфичные низкоуровневые задачи. Реализация компараторов и процедур сортировки не относится к таким задачам.
IntelCilkPlusи OpenMPимеют существенное преимущество перед другими расширениями и фреймворками. Основная идея этих расширений - преобразование последовательной программы в параллельную путём использования директив компилятора или особых версий операторов (например, оператора цикла). Как известно, разработка параллельных программ сопряжена с рядом трудностей, в основе которых лежит смена парадигмы. OpenMPсчитается переносимым решением [2], что более предпочтительно в исследовании возможностей системы сортировки.
IntelTBB- мощная библиотека шаблонов разработки программного обеспечения для многопроцессорных систем. Фреймворк содержит различные структуры данных и ряд алгоритмов, использование которых позволяет избежать работы с низкоуровневыми интерфейсами и синхронизацией потоков. Однако использование IntelTBBзатрудняет разработку последовательной программы, которую легче отлаживать и изменять - в отличие от расширений OpenMPи IntelCilkPlus, которые позволяют преобразовать последовательную программу в параллельную без существенных изменений в логике работы программы.
Таким образом, среди описанных способов создания параллельных программ, с учётом особенностей решаемой задачи, выбрано расширение OpenMP, поддерживаемое компиляторами GCC (GNUCompilerCollection) и ICC (IntelC++ Compiler).
Заключение
По результатам замеров производительности методов можно сделать следующие выводы:
Наиболее универсальным методом, является метод быстрой сортировки («QuickSort»), он показывает стабильно высокие результаты на любых размерах массивов. На втором месте находится метод Шелла. Его использование может быть обосновано большее простым алгоритмом с точки зрения программиста.
Метод вставки эффективен, при условии большого времени выполнения операций перестановки, так как он является абсолютным лидером по количеству перестановок, проигрывая при этом по количеству сравнений.
При использовании небольших массивов данных нет большой разницы по скорости между методами сортировки, поэтому целесообразнее применять метод Пузырька или метод вставок.
Исследование проводилось на массивах с большой степенью неупорядоченности. Для массивов, которые уже являются почти отсортированными, наиболее применим метод сортировки вставками.
Список литературы
1. Вирт Н. Алгоритмы и структуры данных; [не указано] - М., 2010. - 449 c.
2. Вирт Н. Алгоритмы+структуры данных=программы; [не указано] - М., 2016. - 678 c.
3. Дмитриева, Марина JavaScript. Быстрый старт; СПб: БХВ - М., 2014. - 328 c.
4. Дональд Э. Кнут Искусство программирования. Том 3. Сортировка и поиск; Вильямс - М., 2012. - 824 c.
5. Кишик, А. Flash 5.0 Быстро, просто, наглядно; СПб: ДиаСофт - М., 2010. - 240 c.
6. Кнут Д.Э. Искусство программирования (Том 1. Основные алгоритмы); [не указано] - М., 2013. - 303 c.
7. Кнут Д.Э. Искусство программирования (Том 2. Получисленные алгоритмы); [не указано] - М., 2009. - 383 c.
8. Лорин Г. Сортировка и системы сортировки; Главная редакция физико-математической литературы издательства "Наука" - М., 2010. - 384 c.
9. Мюллер, К. Der schnelle, gelbe Aubus/Быстрый желтый автобус; GDR - М., 2015. - 281 c.
10. Рассел Джесси Сортировка вставками; Книга по Требованию - М., 2012. - 120 c.
11. Свами М., Тхуласираман К. Графы, сети и алгоритмы; [не указано] - М., 2013. - 948 c.
12. Симмонс, Курт Mac OS X Головная боль. Типичные и нетипичные проблемы и быстрые рецепты избавления; Вершина - М., 2013. - 416 c.
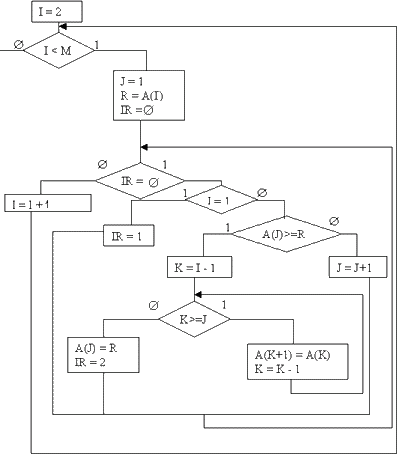
Блок схемы
Обменная сортировка
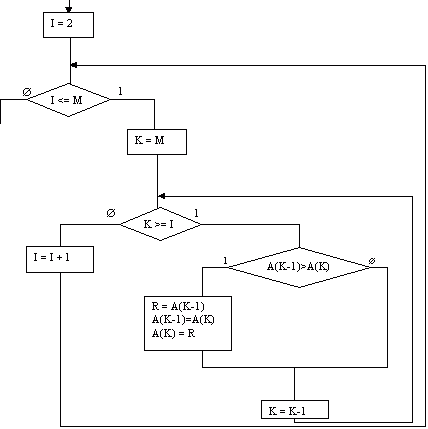
Сортировка выбором
Сортировка пузырьком
Сортировка вставкой

- Проектирование организации (Понятия и цели создания организации)
- Политика развития персонала в системе стратегического управления кадровым направлением деятельности организации (Сущность и значение развития персонала организации)
- Роль мотивации в поведении организации (Методы мотивации)
- Исключительные (имущественные) права на товарный знак ПАО «Детский мир»
- Общий порядок создания, реорганизации и ликвидации субъектов предпринимательского права (СУБЪЕКТЫ ПРЕДПРИНИМАТЕЛЬСКОГО ПРАВА)
- Изменение и расторжение договора (Изменение и расторжение договора)
- Анализ коммерческой деятельности киберспортивной команды Navi
- Конъюнктура рынка и современные задачи телевизионной промышленности
- Анализ системы отбора персонала при найме в ООО «НЗХК-Энергия»
- Коммерческая деятельность розничного торгового предприятия и ее совершенствование (Сущность коммерческой деятельности в розничной торговле)
- Страхование и его роль в развитии экономики (Сущность и значение страховой деятельности для экономики, ее функции и классификации)
- Проектирование реализации операций бизнес-процесса «Предоставление рекламных услуг» (Выбор комплекса задач автоматизации)