
Задача на определение затрат на свадьбу
Содержание:

Введение.
Задачей данной курсовой работы является изучения истории развития нейронных сетей. Изучить понятие искусственного нейрона и виды искусственных нейронных сетей. Также рассмотрено обучение нейронных сетей.
В результате выполнения практической части курсовой работы необходимо создать модель нечёткой логики для заданного объекта: затраты на проведение свадьбы на основе трёх входных параметров. Предложить и реализовать в пакете MATLAB нечеткая модель управления затратами на свадьбу.
1. Теоретическая часть
1.1. История развития нейронных сетей
С появлением современной электроники, начались попытки аппаратного воспроизведения процесса мышления. Первый шаг был сделан в 1943 г. с выходом статьи нейрофизиолога Уоррена Маккалоха (Warren McCulloch) и математика Уолтера Питтса (Walter Pitts) про работу искусственных нейронов и представления модели нейронной сети на электрических схемах.
1949 г. – опубликована книга Дональда Хебба (Donald Hebb) «Организация поведения», где исследована проблематика настройки синаптических связей между нейронами.
1950-е гг. – появляются программные модели искусственных нейросетей. Первые работы проведены Натаниелом Рочестером (Nathanial Rochester)
из исследовательской лаборатории IBM. И хотя дальнейшие реализации были успешными, эта модель потерпела неудачу, поскольку бурний рост традиционных вычислений оставил в тени нейронные исследования.
1956 г. – Дартмутский исследовательский институт искусственного интеллекта обеспечил подъем искусственного интеллекта, в частности, нейронных мереж. Стимулирование исследований искусственного интеллекта разделилось
на два направления: промышленные применения систем искусственного интеллекта (экспертные системы) и моделирование мозга.
1958 г. – Джон фон Нейман (John fon Neumann) предложил имитацию простых функций нейронов с использованием вакуумных трубок.
1959 г. – Бернард Видроу (Bernard Widrow) и Марсиан Хофф (Marcian Hoff) разработали модели ADALINE и MADALINE (Множественные Адаптивные Линейные Элементы (Multiple ADAptive LINear Elements)). MADALINE действовала, как адаптивный фильтр, устраняющих эхо на телефонных линиях. Эта нейросеть до сих пор в коммерческом использовании.
Нейробиолог Френк Розенблатт (Frank Rosenblatt) начал работу над перцептроном. Однослойный перцептрон был построен аппаратно и считается классической нейросетью. Тогда перцептрон использовался для классификации входных сигналов в один из двух классов. К сожалению, однослойный перцептрон был ограниченым и подвергся критике в 1969 г., в книге Марвина Мински
(Marvin Minsky) и Сеймура Пейперта (Seymour Papert) «Перцептроны».
Ранние успехи, способствовали преувеличению потенциала нейронных мереж, в частности в свете ограниченной на те времена электроники. Чрезмерное ожидание, процветающее в академическом и техническом мире, заразило общую литературу этого времени. Опасение, что эффект «мыслящей машины» отразится на человеке все время подогревалось писателями, в частности, серия книг Азимова про роботов показала последствия на моральных ценностях человека, в случае возможности интеллектуальных роботов выполнять функции человека.
Эти опасения, объединенные с невыполненными обещаниями, вызвали множество разочарований специалистов, подвергших критике исследования нейронных мереж. Результатом было прекращение финансирования. Период спада продолжался до 80-х годов.
1982 г. – к возрождению интереса привело несколько событий. Джон Хопфилд (John Hopfield) представил статью в национальную Академию Наук США. Подход Хопфилда показал возможности моделирования нейронных сетей на принципе новой архитектуры.
В то же время в Киото (Япония) состоялась Объединенная американо-японская конференция по нейронным сетям, которые объявили достижением пятой генерации. Американские периодические издания подняли эту историю, акцентируя, что США могут остаться позади, что привело к росту финансирования в области нейросетей.
С 1985 г. Американский Институт Физики начал ежегодные встречи – «Нейронные сети для вычислений».
1989 г. – на встрече «Нейронные сети для обороны» Бернард Видров сообщил аудитории о начале четвертой мировой войны, где полем боя являются мировые рынки и производства.
1990 г. – Департамент программ инновационных исследований защиты малого бизнеса назвал 16 основных и 13 дополнительных тем, где возможно использование нейронных мереж.
Сегодня, обсуждение нейронных сетей происходят везде. Перспектива
их использования кажется довольно яркой, в свете решения нетрадиционных проблем и является ключом к целой технологии. На данное время большинство разработок нейронных мереж принципиально работающие, но могут существовать процессорные ограничения. Исследования направлены на программные
и аппаратные реализации нейросетей. Компании работают над созданием трех типов нейрочипов: цифровых, аналоговых и оптических, которые обещают быть волной близкого будущего.
1.2. Аналогия нейронных сетей с мозгом и биологическим нейроном
Точная работа мозга человека - все еще тайна. Тем не менее, некоторые аспекты этого удивительного процессора известны. Базовым элементом мозга человека являются специфические клетки, известные как нейроны, способные запоминать, думать и применять предыдущий опыт к каждому действию,
что отличает их от остальных клеток тела.
Кора головного мозга человека является плоской, образованной из нейронов поверхностью, толщиной от 2 до 3 мм площадью около 2200 см2, что вдвое превышает площадь поверхности стандартной клавиатуры. Кора главного мозга содержит около 1011 нейронов, что приблизительно равно числу звезд Млечного пути. Каждый нейрон связан с 103 – 104 другими нейронами. В целом мозг человека имеет приблизительно от 1014 до 1015 взаимосвязей.
Сила человеческого ума зависит от числа базовых компонент, многообразия соединений между ними, а также от генетического программирования и обучения.
Индивидуальный нейрон является сложным, имеет свои составляющие, подсистемы и механизмы управления и передает информацию через большое количество электрохимических связей. Насчитывают около сотни разных классов нейронов. Вместе нейроны и соединения между ними формируют недвоичный, нестойкий и несинхронный процесс, отличающийся от процесса вычислений традиционных компьютеров. Искусственные нейросети моделируют лишь главнейшие элементы сложного мозга, вдохновляющие ученых и разработчиков
к новым путям решения проблемы.
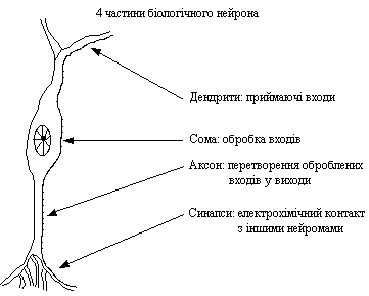
Рис.1.1 – Биологический нейрон
Нейрон (нервная клетка) является особой биологической клеткой, которая обрабатывает информацию. Она состоит из тела клетки – сомы (soma), и двух типов внешних древовидных ответвлений: аксона (axon) и дендритов (dendrites). Тело клетки содержит ядро (nucleus), которое содержит информацию о наследственных свойствах нейрона, и плазму, обладающую молекулярными средствами
для производства необходимых нейрону материалов. Нейрон получает сигналы (импульсы) от других нейронов через дендриты (приемники) и передает сигналы, сгенерированные телом клетки, вдоль аксона (передатчика), который в конце разветвляется на волокна (strands). На окончаниях волокон находятся синапсы (synapses).
Синапс является элементарной структурой и функциональным узлом между двумя нейронами (волокно аксона одного нейрона и дендрит другого). Когда импульс достигает синаптического окончания, высвобождаются определенные химические вещества, называемые нейротрансмиттерами. Нейротрансмиттеры проходят через синаптичную щель и, в зависимости от типа синапса, возбуждают или тормозят способность нейрона-приемника генерировать электрические импульсы. Результативность синапса настраивается проходящими через него сигналами, поэтому синапсы обучаются в зависимости от активности процессов,
в которых они участвуют. Эта зависимость от предыстории действует как память, которая, возможно, отвечает за память человека. Нейроны способны запоминать, думать и применять предыдущий опыт к каждому действию, что отличает их
от других клеток тела. Нейроны взаимодействуют с помощью короткой серии импульсов. Сообщение передается с помощью частотно-импульсной модуляции.
Последние экспериментальные исследования доказывают, что биологические нейроны структурно сложнее, чем упрощенное объяснение существующих искусственных нейронов, которые являются элементами современных искусственных нейронных сетей. Поскольку нейрофизиология предоставляет ученым расширенное понимание действия нейронов, а технология вычислений постоянно совершенствуется, разработчики сетей имеют неограниченное пространство для улучшения моделей биологического мозга.
1.3. Понятие искусственного нейрона
Искусственный нейрон имитирует в первом приближении свойства биологического нейрона. На вход искусственного нейрона поступает некоторое множество сигналов, каждый из которых является выходом другого нейрона. Каждый вход умножается на соответствующий вес, аналогичный синаптической силе, и все произведения суммируются, определяя уровень активации нейрона.
На рис. 1.2 представлена модель, реализующая эту идею.
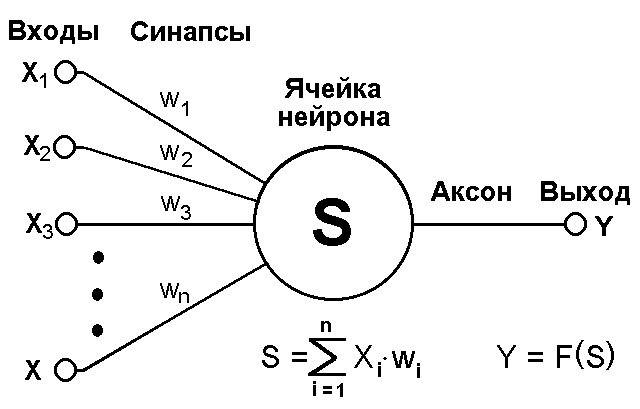
Рис. 1.2 – Искусственный нейрон
Хотя сетевые парадигмы весьма разнообразны, в основе почти всех их лежит эта конфигурация. Здесь множество входных сигналов, обозначенных x1, x2,…, xn, поступает на искусственный нейрон. Эти входные сигналы, в совокупности обозначаемые вектором X, соответствуют сигналам, приходящим в синапсы биологического нейрона. Каждый сигнал умножается на соответствующий вес w1, w2,…, wn, и поступает на суммирующий блок. Каждый вес соответствует «силе» одной биологической синаптической связи.
Текущее состояние нейрона определяется, как взвешенная сумма его входов:
Выход нейрона есть функция его состояния: .
Нелинейная функция называется активационной и может иметь различный вид, как показано на рисунке 1.3.
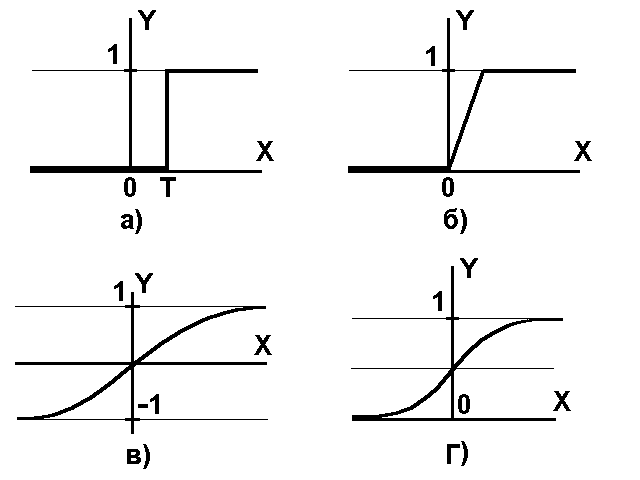
Рис. 1.3 – Функции состояния: а) – функция единичного скачка; б) – линейный порог (гистерезис); в) – гиперболический тангенс; г) – сигмоид
Одной из наиболее распространенных является нелинейная функция
с насыщением, так называемая логистическая функция или сигмоид
(т.е. функция S-образного вида):
1.4. Виды искусственных нейронных сетей
Для создания искусственных нейронных сетей используют несколько стандартных архитектур, из которых путем вырезания лишнего или (реже) добавления строят большинство используемых сетей.
Можно выделить две базовых архитектуры – слоистые и полносвязные сети.
Слоистые сети: нейроны расположены в несколько слоев. Нейроны первого слоя получают входные сигналы, преобразуют их и через точки ветвления передают нейронам второго слоя. Далее срабатывает второй слой и т.д. до k-го слоя, который выдает выходные сигналы для интерпретатора и пользователя. Если не оговорено противное, то каждый выходной сигнал i-го слоя подается на вход всех нейронов i+1-го. Число нейронов в каждом слое может быть любым и никак заранее
не связано с количеством нейронов в других слоях. Стандартный способ подачи входных сигналов: все нейроны первого слоя получают каждый входной сигнал. Особое распространение получили трехслойные сети, в которых каждый слой имеет свое наименование: первый – входной, второй – скрытый, третий – выходной.
На рис. 1.4 приведен пример архитектуры нейросетевой модели – 4-х слойный персептрон.
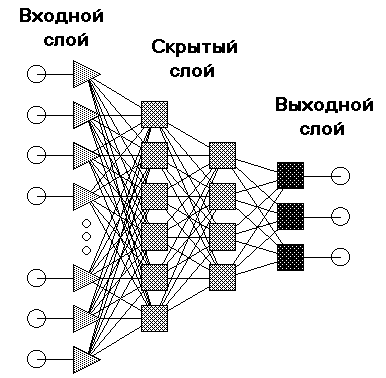
Рис. 1.4 – Архитектура нейросетевой модели – многослойный персептрон
Полносвязные сети: каждый нейрон передает свой выходной сигнал остальным нейронам, включая самого себя. Выходными сигналами сети могут быть все или некоторые выходные сигналы нейронов после нескольких тактов функционирования сети. Все входные сигналы подаются всем нейронам.
На этапе обучения происходит вычисление синаптических коэффициентов
в процессе решения нейронной сетью задач (классификации, предсказания временных рядов и др.), в которых нужный ответ определяется не по правилам,
а с помощью примеров, сгруппированных в обучающие множества. Такое множество состоит из ряда примеров с указанным для каждого из них значением выходного параметра, которое было бы желательно получить. Действия, которые при этом происходят, можно назвать контролируемым, обучением: «учитель» подает на вход сети вектор исходных данных, а на выходной узел сообщает желаемое значение результата вычислений. Контролируемое обучение нейронной сети можно рассматривать как решение оптимизационной задачи. Ее целью является минимизация функции ошибок, или невязки, Е на данном множестве примеров путем выбора значений весов .
Целью процедуры минимизации является отыскание глобального минимума – достижение его называется сходимостью процесса обучения. Поскольку невязка зависит от весов нелинейно, получить решение в аналитической форме невозможно, и поиск глобального минимума осуществляется посредством итерационного процесса – так называемого обучающего алгоритма, который исследует поверхность невязки и стремится обнаружить на ней точку глобального минимума. Иногда такой алгоритм сравнивают с кенгуру, который хочет попасть на вершину Эвереста, прыгая случайным образом в разные стороны. Разработано уже более сотни разных обучающих алгоритмов, отличающихся друг от друга стратегией оптимизации
и критерием ошибок.
Коль скоро обучение основывается на минимизации значения некоторой функции (показывающей, насколько результат, который выдает сеть на данном обучающем множестве, далек от образцового значения), нужно, прежде всего, выбрать меру ошибки, соответствующую сути задачи. Удачный выбор меры погрешности обычно приводит к более гладкой поверхности невязки и упрощает задачу обучения. Обычно в качестве меры погрешности берется средняя квадратичная ошибка:
где – желаемая величина выхода; – реально полученное на сети значение для i-го примера; – количество примеров в обучающем множестве.
Минимизация величины осуществляется с помощью градиентных методов. В первом из них берется градиент общей ошибки, и веса пересчитываются каждый раз после обработки всей совокупности обучающих примеров («эпохи»). Изменение весов происходит в направлении, обратном к направлению наибольшей крутизны для функции ошибок:
где – определяемый пользователем параметр, который называется величиной градиентного шага или коэффициентом обучения.
В последнее время широко используется процедура обучения многослойного персептрона, получившего название алгоритма обучения с обратным распространением ошибки (error backpropagation). Этот алгоритм является обобщением на произвольное число слоев одной из процедур обучения элементарного персептрона, известный как правило Уидроу – Хоффа (дельта-правило).
В отличие от элементарного персептрона, для которого ошибки функционирования имеют единственный минимум, многослойный персептрон может иметь несколько минимумов с приблизительно равными областями притяжения. Для получения заданного качества распознавания необходимо многократного (сотни и тысячи раз) предъявления всего обучающего множества. Предложены различные модификации алгоритма обучения backpropagation, позволяющие повысить скорость обучения и улучшить точность воспроизведения требуемого отображения «вход – выход».
Перед тем, как начинать процесс обучения нейронной сети, необходимо присвоить весам начальные значения. Цель здесь, очевидно, должна состоять в том, чтобы найти как можно более хорошее начальное приближение к решению и таким образом сэкономить время обучения и улучшить сходимость. Конечно, можно положить начальные веса во всей сети равными нулю, но тогда частные производные от невязки по всем весам будут одинаковыми, и изменения весов
не будут должным образом структурированы. В результате нельзя будет надеяться на то, что сеть вообще когда-нибудь сможет решить задачу. Нужно искать способы уйти от такой симметрии.
Классический подход к проблеме выбора начальных значений весов состоит
в следующем: случайным образом выбрать малые величины весов, чтобы быть уверенным, что ни один из сигмоидных элементов не насыщен (и значения всех производных очень малы).
Поверхность невязки в пространстве весов в общем случае имеет локальные минимумы, и это является главным препятствием для процесса обучения нейронной сети, в особенности, для алгоритма спуска. Можно встретить утверждения,
что в ряде случаев локальный минимум является вполне приемлемым решением, однако в общей ситуации необходимо разработать стратегию, которая позволяла
бы избегать таких точек и гарантировала бы сходимость обучающего алгоритма
к глобальному решению.
Для того чтобы обучающий алгоритм не стал двигаться в ложном направлении, нужно, прежде всего, упорядочить случайным образом последовательность примеров, которые он обрабатывает (так называемое «перемешивание»). Более того, если какой-то из классов примеров представлен недостаточно, случайный выбор должен осуществляться таким образом, чтобы примеры из слабо представленной группы встречались чаще – этим будет устранен ложный крен при минимизации ошибки.
При более последовательном подходе для улучшения процесса обучения можно использовать информацию о производных второго порядка от функции невязки. Соответствующие методы оптимизации называются квадратичными: спуск по сопряженному градиенту, масштабированный метод сопряженных градиентов RBackProp, квазиньютоновский метод, метод Левенберга-де-Маркара.
В отличие от методов второго порядка, где веса изменяются пропорционально их вкладу в направление глобального поиска, в локальных методах оптимизации каждый вес меняется локально. В качестве примера таких методов можно назвать метод дельта-дельта, QuickProp.
Выбор эффективного обучающего алгоритма всегда включает в себя компромисс между сложностью решаемой задачи и техническими ограничениями (быстродействие и объем памяти компьютера, время, цена).
Как отмечалось ранее, нейронные сети могут служить универсальным средством аппроксимации в том смысле, что при достаточно разветвленной архитектуре они реализуют широкий класс функций. Как часто бывает, достоинство одновременно является и недостатком. Благодаря способности тонко улавливать структуру аппроксимируемой функции сеть достигает очень высокой степени соответствия на обучающем множестве, и в результате плохо делает обобщения при последующей работе с реальными данными. Это явление называется переобучением. Сеть моделирует не столько саму функцию, сколько присутствующий в обучающем множестве шум. Переобучение присутствует
и в таких более простых моделях, как линейная регрессия, но там оно не так выражено, поскольку через обучающие данные нужно провести всего лишь прямую линию. Чем богаче набор моделирующих функций, тем больше риск переобучения. (На рисунке показать типичные проявления переобучения, пример с распознаванием танков).
Естественное желание состоит в том, чтобы увеличивать число примеров
в обучающем множестве. Чем их больше, тем более представительны данные.
Как и в любом физическом измерении, увеличение числа наблюдений уменьшает шум. Если имеется несколько измерений одного объекта, сеть возьмет их среднее значение, и это лучше, чем точно следовать одному единственному зашумленному значению.
Однако на практике и, особенно, в приложениях к задачам биологии
и медицины невозможно получить такое количество наблюдений, которое было
бы желательно в свете положений статистики. Число необходимых примеров резко растет с увеличением сложности моделируемой функции и повышением уровня шума. Более того, доступные нам данные могут иметь все меньшее отношение
к делу. Наконец, могут существовать физические ограничения на размер базы данных, например, объем памяти или недопустимо большое время обучения.
Другой способ избавиться от переобучения заключается в том, чтобы измерить ошибку сети на некотором множестве примеров из базы данных,
не включенных в обучающее множество, – контрольном множестве. Для этого
из обучающего множества случайным образом может быть выделено некоторое множество примеров. При этом «обучение» сети производят по прежнему
на обучающем множестве, контрольное же множество используют лишь
для определения момента переобучения. В случае, когда функция ошибок
на обучающем множестве продолжает уменьшаться, а на контрольном
не изменяется либо увеличивается, обучение прекращается. Если же объем выборки не позволяет выделить контрольное множество, то может быть использован метод перекрестного подтверждения.
Еще один способ избежать переобучения состоит в том, чтобы ограничить совокупность функций отображения, реализуемых сетью. Методы такого типа называются регуляризацией. Например, в функцию ошибок может быть добавлено штрафное слагаемое, подавляющее резкие скачки отображающей функции
(на математическом языке – большие значения ее второй производной). Алгоритм обучения изменяется таким образом, чтобы учитывался этот штраф.
2. Практическая часть
Задача на определение затрат на свадьбу
В задаче требуется определить, сколько денег будет потрачено на свадьбу.
Входные сигналы:
а) количество гостей (маленькое, среднее, большое);
б) наличие приглашенных артистов (много артистов, мало артистов);
в) количество блюд на праздничном столе (много блюд, среднее количество блюд, мало блюд).
Выходной сигнал: затраты на свадьбу (богатая свадьба, средняя, бедная). Правила:
1. Если количество гостей маленькое, мало приглашенных артистов, мало блюд на столе, то свадьба бедная.
2. Если среднее количество гостей, мало артистов, среднее количество блюд, то свадьба средняя.
3. Если много приглашенных гостей, много приглашенных артистов, много блюд на столе, то свадьба богатая.
Запустим программу и откроем редактор системы нечеткого вывода FuzzyLogic. Для этого можно ввести команду fuzzy в командной строке программы, в результате чего появляется редактор системы нечёткого вывода (рис. 2.1).
Рис. 2.1 – Окно редактора системы нечёткого ввода
По умолчанию установлен алгоритм вывода mamdanni. Альтернативой к нему является алгоритм sugeno, оставим первый вариант.
В соответствии с условием определяем входные и выходные переменные
(рис. 2.2).
Рис. 2.2 – Добавление входных переменных
Добавляем три входные переменные в соответствии с условием задания
и осуществляем их переименование, в результате чего получается картина окна редактора нечёткого ввода, изображённая на рис. 2.3.
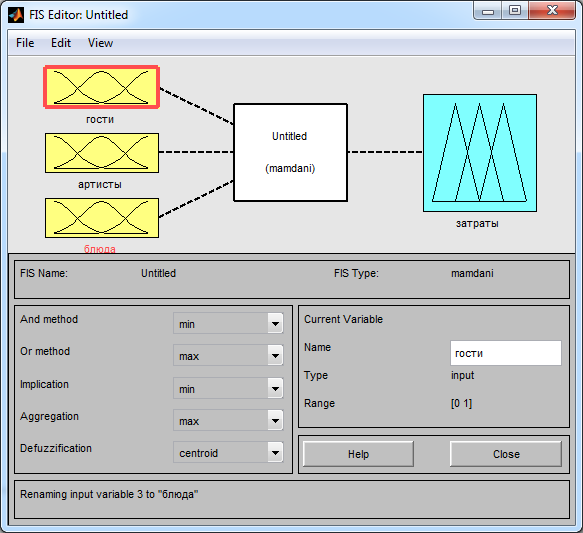
Рис. 2.3 – Окно редактора нечёткого ввода после определения количества входных переменных
Приступим к редактированию входных и выходных переменных двойным щелчком левой кнопки мыши на каждой из них (рис. 2.4 – 2.7).
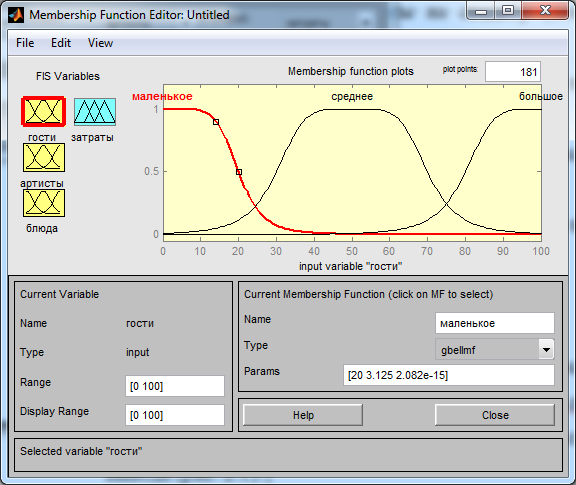
Рис. 2.4 – Редактирование входной переменной «гости»
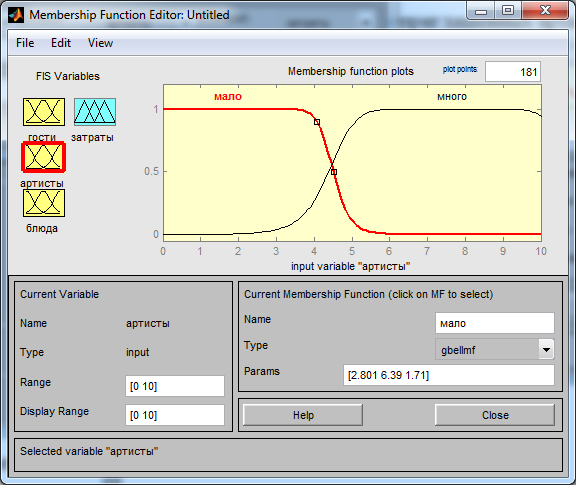
Рис. 2.5 – Редактирование входной переменной «артисты»
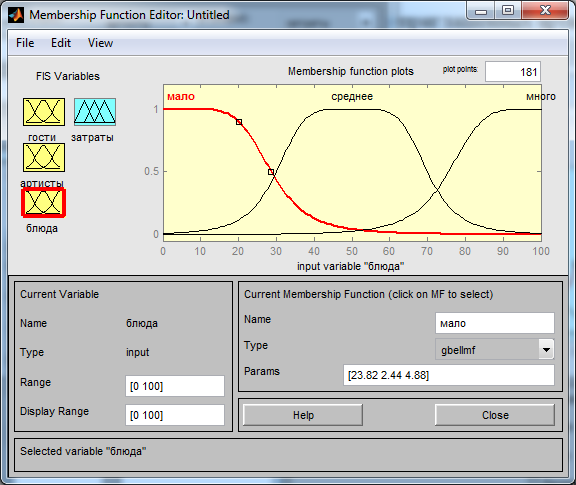
Рис. 2.6 – Редактирование входной переменной «блюда»
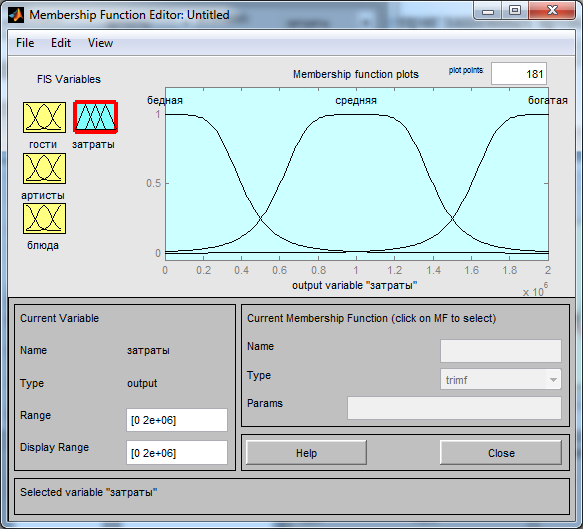
Рис. 2.7 – Редактирование выходной переменной «затраты»
Далее переходим к заданию правил. Для этого дважды щелкнем левой кнопкой мыши по центру проекта. Введем все правила, заданные в условии,
в результате чего получаем картину, изображённую на рис. 2.8.
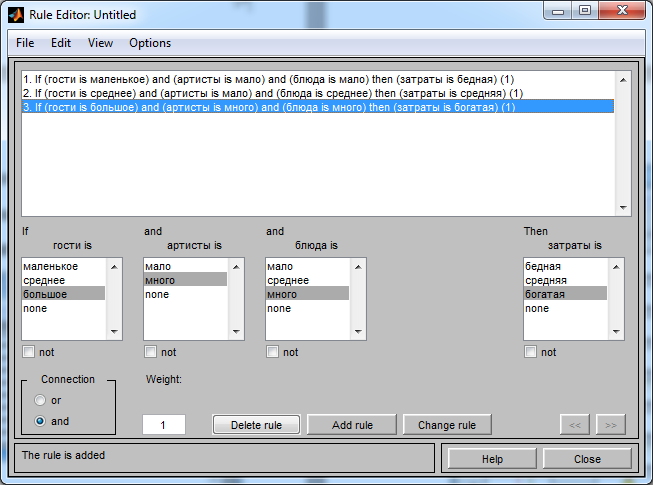
Рис. 2.8 – Правила модели
Выполнив все эти этапы, мы создали нечеткую систему определения затрат на свадьбу.
Переходим к этапу тестирования. Для этого мы откроем Rule-Viewer (рис. 2.9).
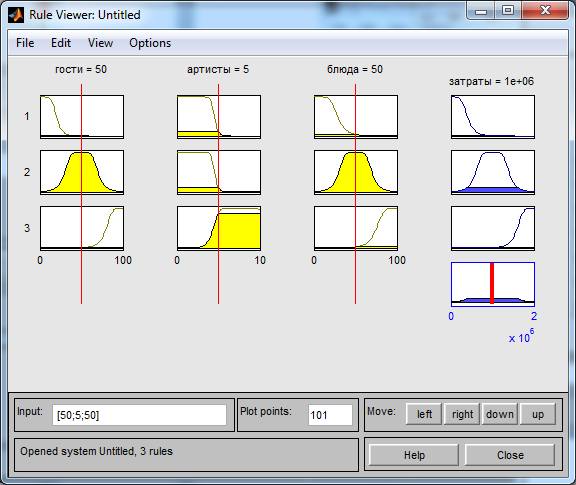
Рис. 2.9 – Окно Rule-Viewer
Проведём моделирование с параметрами входа, представленными на рис. 2.10.
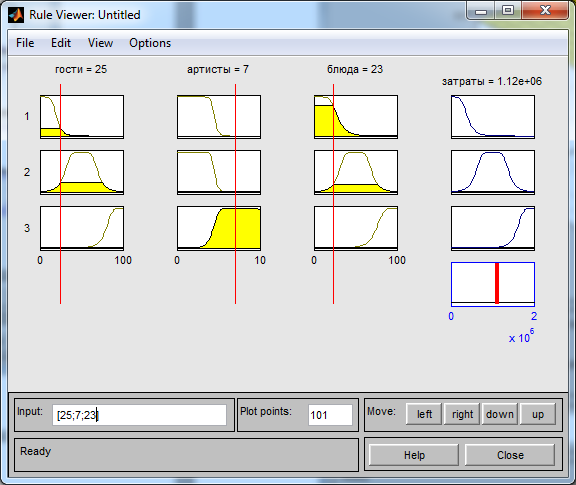
Рис. 2.10 – Окно Rule-Viewer с введёнными параметрами в строке input
Как видно из рис. 2.10 при параметрах входа:
Гости = 25
Артисты = 7
Блюда = 23
Выходные параметры:
Затраты: 1,12 млн.
Таким образом, получили, что затраты на свадьбу с указанными выше параметрами являются достаточно большими. По результатам моделирования можно путём варьирования значения трёх входных параметров выйти на требуемый предел затрат на свадьбу.
Перейдем к просмотру общей зависимости путем рассмотрения поверхности отклика, для этого запустим View-Surface (рис. 2.11).
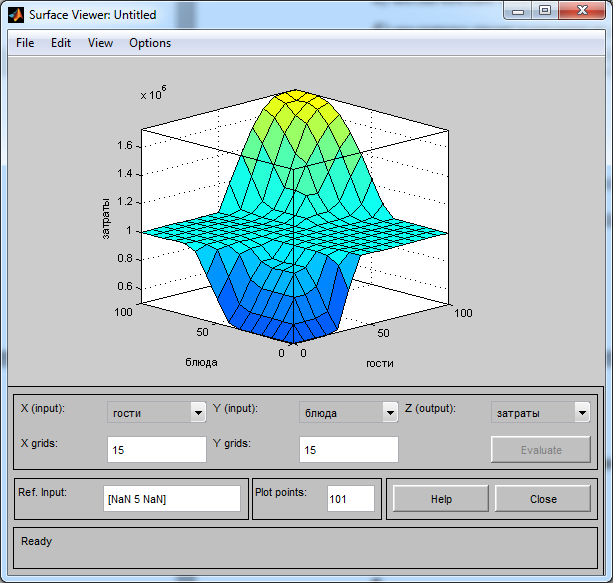
Рис. 2.11 – Окно трёхмерного графика зависимости выходной переменной
от трёх входных (одновременно можно наблюдать вид графика от двух параметров)
В процессе выполнения работы были изучены вопросы об истории развития нейронных сетей и аналогии нейронных сетей с мозгом и биологическим нейроном. Было изучено понятие искусственного нейрона и виды искусственных нейронных сетей. Также рассмотрено обучение нейронных сетей.
В результате выполнения практической части курсовой работы была создана модель нечёткой работы для заданного объекта: затрат на проведение свадьбы
на основе трёх входных параметров. Предложена и реализована в пакете MATLAB нечеткая модель управления затратами на свадьбу.
Список используемых источников
- Барский А. Б. Логические нейронные сети; Интернет-университет информационных технологий, Бином. Лаборатория знаний - Москва, 2007. - 352 c.
- Бочарников В.П. Fuzzy – Технология: математические основы практика моделирования в экономике. – СПб., 2001.
- Галушкин А. И. Нейронные сети. Основы теории. – М.: Горячая Линия – Телеком, 2012.
- Дьяконов В. П. MATLAB. Полный самоучитель; ДМК Пресс - Москва, 2010. - 768 c.
- Круглов В.В., Дли М.И., Голунов Р.Ю. Нечеткая логика и искусственные нейронные сети. – М.: Wings Comics – Москва, 2001.
- Редько В.Г. Эволюция, нейронные сети, интеллект. Модели и концепции эволюционной кибернетики. – М.: Либроком, 2013.
- Тарасян В. С. Пакет Fuzzy Logic Toolbox for Matlab : учеб, пособие /
В. С. Тарасян. – Екатеринбург: Изд-во УрГУПС, 2013. - Хайкин С. Нейронные сети: полный курс. – М.: Вильямс, 2006.
- Штовба С.Д. Проектирование нечётких систем средствами Matlab. –
М.: Горячая линия – Телеком, 2007.

- Аппаратная платформа персонального компьютера (Объектно –ориентированное программирование)
- Основные понятия объектно-ориентированного программирования)
- Анализ основных гарантий защиты и соблюдения прав и свобод человека и гражданина на территории РФ
- «Статус нотариуса» .
- «Собственность и право собственности в предпринимательских отношениях»(Правовое регулирование отношений в области собственности )
- Возмещение морального вреда)
- Особенности услуг ресторана быстрого питания (Современное состояние услуг ресторанов быстрого питания на примере ООО «Макдоналдс»)
- Менеджмент человеческих ресурсов (Работа с кадрами. Мотивация и карьера сотрудников)
- Особенности политики развития персонала корпорации (Политика развития персонала)
- Коммуникация
- ИСПОЛНЕНИЕ ОБЯЗАТЕЛЬСТВ, СВЯЗАННЫХ С ОСУЩЕСТВЛЕНИЕМ ПРЕДПРИНИМАТЕЛЬСКОЙ ДЕЯТЕЛЬНОСТИ)
- Аналитический обзор существующих систем поддержки принятия решения