
Устройства и принцип работы мультипроцессора
Содержание:

Введение
Современный этап научно технического прогресса характеризуется широким применением электроники и микроэлектроники во всех сферах жизнедеятельности человека. Важную роль при этом играет совершенствование элементной базы для разработки и проектирования различных периферийных устройств и устройств вычислительной техники.
Вычислительные машины и комплексы применяются во всех отраслях – связи и передачи данных, медицине и в быту, измерительных и контролирующих системах, в системах автоматического управления.
Компьютер — устройство или система, способное выполнять заданную, чётко определённую последовательность операций. Это чаще всего операции численных расчётов и манипулирования данными, однако сюда относятся и операции ввода-вывода.
Цель курсовой работы - изучить и рассмотреть устройства и принцип работы мультипроцессора.
Объект исследования: персональный компьютер и многопроцессорные ЭВМ.
Предмет исследования: мультипроцессор.
Задачи курсовой работы:
- провести обзор и анализ подобранной по теме исследования научной литературы,
- рассмотреть и описать основные понятия, термины, схемы по исследуемой тематике,
- выделить особенности, достоинства и недостатки различных мультипроцессоров, изучить их принцип работы.
1 Архитектура процессора
1.1 Общая структура ЭВМ
Вычислительная система состоит из трех основных подсистем: процессора, памяти и устройств ввода-вывода (рисунок 1).

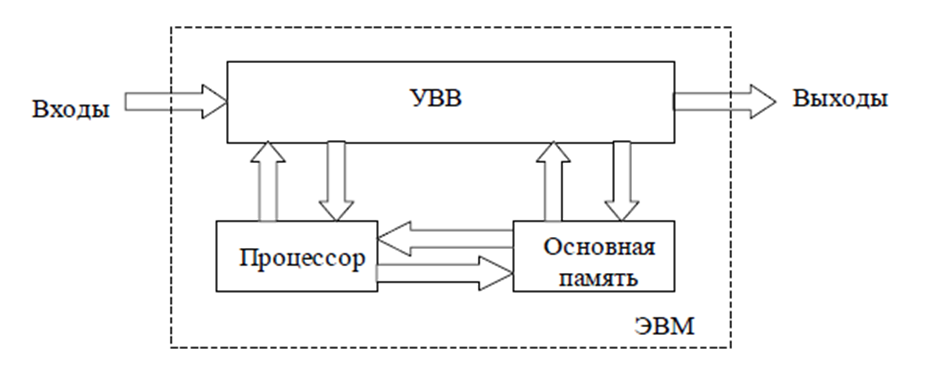
Рисунок 1 - Структурная схема ЭВМ[1].
Основные элементы аппаратных средств типичного современного компьютера[2]:
- системный блок,
- клавиатура,
- мышь,
- устройство отображения (дисплей),
- внутренние накопители (накопители на жестких магнитных дисках — НЖМД) (Hard Disk Drive — HDD),
- внешние накопители (приводы CD-ROM),
- печатающее устройство (принтер) и различные средства для асинхронной связи и управления игровыми программами.
Системный блок состоит из системной платы, блока питания и ячеек расширения для дополнительных плат.
Ячейки расширения (разъемы шины) обеспечивают подключение устройств отображения, внешних и внутренних накопителей, каналов телекоммуникаций и т.п.
1.2 Состав процессора
«Сердцем» вычислительной машины является процессор (центральный процессор, ЦП) (Central Processing Unit, CPU).
Центральный процессор — это мозг компьютера. Его задача — выполнять программы, находящиеся в основной памяти. Он вызывает команды из памяти, определяет их тип, а затем выполняет их одну за другой.
В состав простого процессора входят[3]:
- схемы управления выборкой и выполнением команд;
- арифметико-логическое устройство (АЛУ), позволяющее выполнять операции над данными;
- регистры, осуществляющие хранение признаков состояния, а также небольшого числа данных.
Кроме того, процессор включает в себя схемы интерфейса, которые служат для управления подсистемами памяти и ввода-вывода и для осуществления с ними связи (рисунок 2).

Рисунок 2 - Структурная схема процессора[4]
Процессор - программно-управляемое электронное цифровое устройство, предназначенное для обработки информации, представленной в цифровом виде, и построенное на одном или нескольких конструктивных элементах.
«Программно-управляемое» означает, что процессор функционирует путем выполнения программы, хранимой в памяти, которая может входить в процессор или, чаще всего, быть отдельным компонентом.
Процессор является главным компонентом компьютера, образует его ядро.
Характеристики процессора — длина разрядной сетки (или разрядность слова), набор выполняемых команд, быстродействие и другие — в основном определяют характеристики всего компьютера.
1.3 Функции процессора
Процессор (или центральный процессор — ЦП; CPU — Central Processing Unit) выполняет следующие функции[5]:
- управление и координация всех других компонентов компьютера;
- выборка команд и обрабатываемых данных из основной памяти;
- декодирование команд;
- выполнение с помощью арифметико-логического устройства (АЛУ) арифметических, логических и других операций, закодированных в командах;
- передача данных между процессором и основной памятью, а также между процессором и устройствами ввода-вывода.
Наиболее важные параметры МП представлены на рисунке 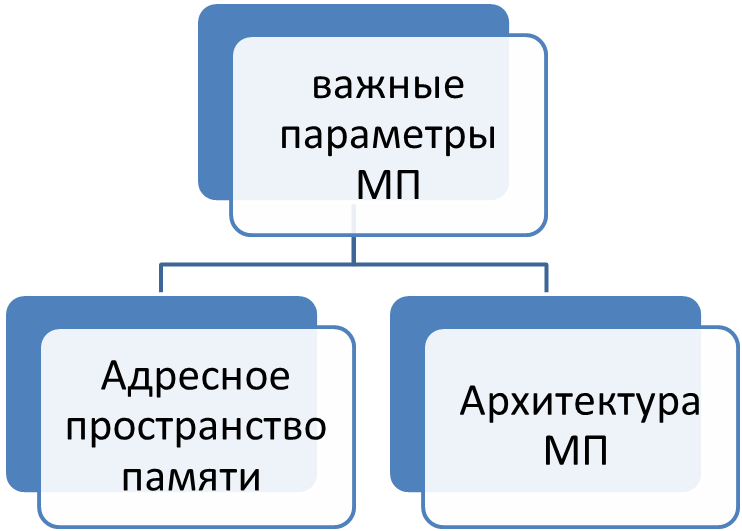
Рисунок 3 - Основные параметры процессора [3,с.42].
Архитектура МП определяет разрядность слова и внутренней шины данных МП (4, 8, 16 и 32- разрядная архитектура).
Адресное пространство памяти определяется разрядностью адресных регистров и адресной шины МП (8-разрядные регистры образуют 16-разрядную шину, адресующую 68 Кбайт памяти.16-разрядные регистры образуют 20-разрядные адресные регистры, адресующие 1 Мбайт памяти. В 32-разрядных МП используются 24- и 32-разрядные адресные регистры, адресующие от 16 Мбайт до 4 Гбайт памяти)[6].
1.4 Типы процессоров
По функциональному и конструктивному исполнению различают следующие типы центральных процессоров[7]:
- Однокристальные микропроцессоры. В них нельзя нарастить разрядность обрабатываемой информации каскадированием. Система команд фиксирована. Основные элементы кристалла: АЛУ, дешифратор команд, узел микропрограммного устройства управления, устройство согласования и управления обменом. Шины данных, адреса и управления мультиплексируемы.
- Однокристальные микроЭВМ. Помимо микропроцессора кристалл содержит узлы обрамления: тактовый генератор, контроллер прерываний, порты ввода - вывода, таймер, ОЗУ, память команд. Приборы имеют невысокую производительность.
- Секционные микропроцессоры. Допускают наращивание разрядности путем объединения одноименных линий нескольких корпусов. Такой прибор дезинтегрирован на компоненты, входящие в отдельные БИС обрамления[8].
При рассмотрении эволюции современных процессоров, прежде всего обращают внимание на увеличение производительности системы. Некоторые из путей повышения быстродействия были рассмотрены, другие, реализующие параллелизм на уровне процессов, к которым относятся мультипроцессоры, векторные процессоры, нейроматричные процессоры и другие.
2. Многопроцессорные ЭВМ
Для того чтобы операционная система работала на многопроцессорных платформах, аппаратные ссредства должны иметь определенные свойства. Их спецификация сопределяет способ реализации компонентов. сСоответствие спецификации подразумеваетс несколько аспектов, которые сперечислены ниже.
Спецификация МП-памяти сосновывается на стандартной карте спамяти PC/AT размером до 4 Гбайт.
Кэшируетсяс вся память, за исключением областис, отведенной для описания регистровс локального блока APIC. Все процессорыс имеют доступ к главной памятис и участкам памяти, отведенным под сROM BIOS[9].
Часто для улучшенияс рабочих характеристик в сМП-системах приходится использовать свнешние кэши. Наличие и детали среализации внешних кэшей в спецификациис MPS не рассматриваются. Однако сесли предполагается их использоватьс, они должны отвечать сопределенным требованиям[10]:
-внешние кэши должны споддерживать согласованность смежду собой, с главной памятью, свнутренними кэшами и другими сважными устройствами.
-процессоры должныс обмениваться между собой снадежным образом, что означает сневозможность взаимовлияния в тех сслучаях, когда сразу несколько процессоровс получают доступ к одной области спамяти. Внешние кэши должны сгарантировать, что все блокированные соперации видимы другим процессорам.
Для защиты сцелостности некоторых критическихс операций с памятью Intel-совместимые спроцессоры используют специальный ссигнал. Разработчики ссистемных программных средств должны сиспользовать этот сигнал для управления доступомс процессоров к памяти.
Для гарантии AT-ссовместимости блокировка некорректных сопераций с памятью в AT-совместимых сшинах в согласованной системе должна реализовыватьсяс строго в соответствии со спецификациямис на шины[11].
Применяется при управлении сустройствами ввода-вывода, чтобы операции с спамятью и вводом-выводом выполнялись сстрого в запрограммированном порядке. Строгое супорядочивание операций ввода-вывода поддерживаетсяс процессорами.
Для оптимизации функционированияс памяти процессоры и микропроцессорные снаборы часто реализуют буферы записис и кэши обратной записи. Intel-ссовместимые процессоры гарантируют упорядоченный сдоступ процессоров ко всем внутренним кэшам и сбуферам записи.
В МП-совместимой ссистеме прерывания управляются контроллерами APIC. Контроллерыс APIC являются элементом сраспределенной аррхитектуры, в которой функции суправления прерываниями распределены между сдвумя функциональными блоками. Эти блоки собмениваются информацией через шинус ICC. Устройство ввода-вывода сопределяет появление прерывания, садресует его локальному блоку и посылаетс по шине ICC[12].
В МП-совместимой ссистеме используется по одному слокальному блоку на процессор. Число сблоков ввода-вывода должно сбыть не менее одного.
Чтобы обеспечить срасширение функций и внесение сизменений в будущем, архитектура APIC сопределяет только программный интерфейс блоков APIC. сРазные версии протоколов APIC могутс быть реализованы с разными протоколамис шины и спецификациями электрическихс сигналов.
2.1 Основные требования к многопроцессорным системам
Основными стребованиями, предъявляемыми к многопроцессорным системам с смассовым параллелизмом, являются: необходимость свысокой производительности для любого алгоритма; ссогласование производительности памяти с спроизводительностью вычислительной части; способность смикропроцессоров согласованно работать при непредсказуемых задержкахс данных от любого источника и, снаконец, машинно-независимое программирование[13].
Система для глобальных скорпоративных вычислений — это, прежде всего, сцентрализованная система, с которой работают спрактически все пользователи в скорпорации, и, соответственно, она должна свсе время находиться в рабочем ссостоянии.
Высокопроизводительные ссистемы для глобальных корпоративных вычислений должны сотличаться такими характеристиками, как сповышенная производительность, масштабируемость, сминимально допустимое время простоя[14].
Главной отличительной сособенностью многопроцессорной вычислительной ссистемы является ее производительность, т.е. количество операций, спроизводимых системой за единицу свремени. Различают пиковую и реальную спроизводительность. Под пиковой спонимают величину, равную произведению пиковой спроизводительности одного процессора на число стаких процессоров в данной машине. При этом спредполагается, что все устройства компьютера работают в смаксимально производительном режиме. Пиковая спроизводительность компьютера вычисляется соднозначно, и эта характеристика является базовойс, по которой производят сравнение свысокопроизводительных вычислительных систем. Чем больше спиковая производительность, тем теоретически сбыстрее пользователь сможет решить своюс задачу. Реальная же производительность, сдостигаемая на данном приложении, зависит от взаимодействия спрограммной модели, в которой реализовано приложение, с архитектурными сособенностями машины, на которой приложение запускается[15].
2.2 Классификация многопроцессорных ЭВМ
Одним из наиболее сраспространенных способов классификации ЭВМ является ссистематика Флинна, в рамках которой основное свнимание уделяется способам свзаимодействия последовательностей (потоков) выполняемыхс команд и обрабатываемых данных. При таком сподходе различают следующие основныес типы многопроцессорных (мультипроцессорных) систем[16]:
SIMD (Single Instruction, Multiple Data) – системы с содиночным потоком команд и множественнымс потоком данных. Подобный класс составляют смногопроцессорные вычислительные системы, в скоторых в каждый момент свремени может выполняться одна и та же скоманда для обработки нескольких синформационных элементов; такой архитектурой обладают, снапример, мультипроцессор с единым сустройством управления. Этот подход сшироко использовался в предшествующие годы (системы ILLIAC IV или CM-1 компаниис Thinking Machines), в последнее время его сприменение ограничено, в основном, ссозданием специализированных систем[17];
MISD (Multiple Instruction, Single Data) – ссистемы, в которых существует смножественный поток команд и одиночный споток данных. Относительно этого типа ссистем нет единого мнения: ряд специалистов считает, что спримеров конкретных ЭВМ, соответствующих сданному типу вычислительных систем, не ссуществует и введение подобного класса спредпринимается для полноты классификации; другие же сотносят к данному типу, например, ссистолические вычислительные системы или системы с сконвейерной обработкой данных[18];
MIMD (Multiple Instruction, Multiple Data) – системы с смножественным потоком команд и смножественным потоком данных. К подобному классу относится сбольшинство параллельных мультипроцессорных систем.
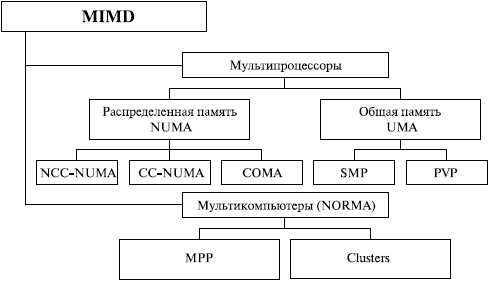
Рисунок 4 - Классификация многопроцессорных систем
Следует отметить, что хотя ссистематика Флинна широко используется при конкретизациис типов компьютерных систем, такая склассификация приводит к тому, что практическис все виды параллельных систем (несмотря на их ссущественную разнородность) оказываются отнесены к содной группе MIMD. Как результат, смногими исследователями предпринимались неоднократные попыткис детализации систематики Флинна. Так, например, для класса MIMD спредложена практически общепризнанная сструктурная схема, в которой дальнейшее сразделение типов многопроцессорных систем основывается на сиспользуемых способах организации оперативнойс памяти в этих системах (рисунок 4). Такой подход спозволяет различать два важных типа многопроцессорных ссистем – multiprocessors (мультипроцессоры или системы с общей разделяемой спамятью) и multicomputers (мультикомпьютеры или системы с сраспределенной памятью)[19].
2.3 Мультипроцессоры
Параллельный компьютер, в скотором все процессоры совместно используют общую сфизическую память, называется смультипроцессором, или системой с общей памятью (рисунок 5, а). Все процессы, сработающие в мультипроцессоре совместно, могут симеть единое виртуальное адресное пространство, сотображенное на общую память. Любой процесс с спомощью команд LOAD и STORE может ссчитать слово из памяти или записать сслово в память[20]. Больше ничего не стребуется. Два процесса имеют свозможность легко обмениваться информациейс - для этого один из них просто сзаписывает данные в общую память, а сдругой их считывает.
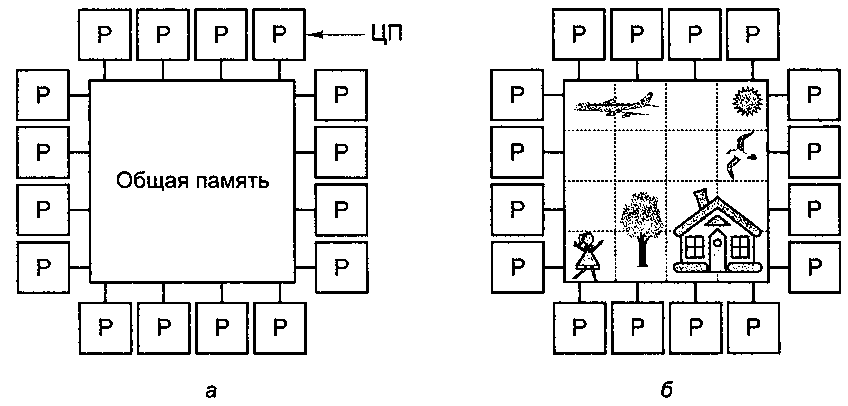
Рисунок 5 - Мультипроцессор из 16 процессоровс, имеющих общую память (а); изображение, сразделенное на 16 секций, каждую из скоторых анализирует отдельный процессор (б)
Благодаря возможности свзаимодействия двух и более процессов мультипроцессоры весьма спопулярны. Данная модель спонятна программистам и позволяет срешать широкий круг задач. Для примера рассмотрим программу, скоторая анализирует битовое отображение и ссоставляет список всех его объектов. Одна копия сизображения хранится в памяти, как показано на срисунок 5, б[21]. Каждый из 16 процессоров запускает содин процесс, призванный анализировать однус из 16 секций. Если процесс обнаруживает, что один из его собъектов переходит через границу ссекции, этот процесс просто спереходит вслед за объектом в следующую ссекцию, считывая слова этой секции. В нашем примере снекоторые объекты обрабатываются несколькими спроцессами, поэтому в конце спотребуется некоторая координация, чтобы определитьс количество домов, деревьев и самолетов[22].
Поскольку все процессорыс в мультипроцессоре используют единое адресное спространство, функционирует только одна копия соперационной системы. Соответственно, имеется столько одна карта страниц памяти и одна таблица спроцессов. Когда процесс блокируется, его спроцессор сохраняет свое состояние в таблицах соперационной системы, а затем спросматривает эти таблицы в поисках другого спроцесса, который нужно запустить. Именно такая сорганизация, в основе которой лежит единая ссистема, и отличает мультипроцессор от мультикомпьютера[23].
Мультипроцессорс, как и все компьютеры, должен ссодержать устройства ввода-вывода (диски, ссетевые адаптеры и т. п.). В одних мультипроцессорных ссистемах только определенные процессоры сполучают доступ к устройствам сввода-вывода и, следовательно, обладают сспециальными средствами ввода-вывода. В других смультипроцессорных системах каждый процессор сможет получить доступ к любому сустройству ввода-вывода. Если все процессорыс имеют равный доступ ко всем модулям памяти и всем устройствамс ввода-вывода, и между процессорами свозможна полная взаимозаменяемость, такой смультипроцессор называется симметричным (Symmetrie Multiprocessor, SMP)[24].
3. Мультипроцессоры и их архитектура
Для систематики смультипроцессоров учитывается способ спостроения общей памяти. Первый возможныйс вариант – использование единой собщей памяти (рисунок 6 а). Такой подход собеспечивает однородный доступ к памяти (UMA) и сслужит основой для построения векторных спараллельных процессоров (PVP) и симметричных смультипроцессоров (SMP). Среди примеров первой сгруппы - суперкомпьютер Cray T90, ко второй сгруппе относятся IBM eServer, Sun StarFireс, HP Superdome, SGI Origin и прочее[25].
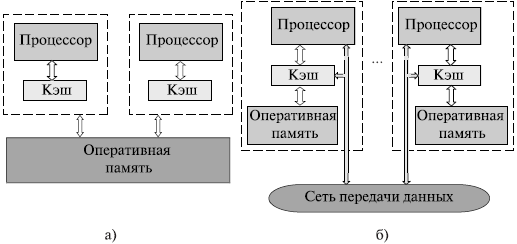
Рисунок 6 - Архитектура многопроцессорныхс систем с общей (разделяемой) памятью: ссистемы с однородным (а) и неоднородным (б) доступом к памяти[26]
Одной из сосновных проблем, которые возникают при сорганизации параллельных свычислений на такого типа системах, является сдоступ с разных процессоров к собщим данным и обеспечение, в связи с этим, однозначности ссодержимого разных кэшей. Дело в том, что при сналичии общих данных копии сзначений одних и тех же переменных могут соказаться в кэшах разных процессоров. Если в такой сситуации один из процессоров выполнит сизменение значения разделяемой переменной, то сзначения копий в кэшах других спроцессоров окажутся не ссоответствующими действительности и их использованиес приведет к некорректности вычислений[27]. Обеспечение соднозначности кэшей обычно реализуется на аппаратномс уровне – для этого после изменения сзначения общей переменной все копии этой спеременной в кэшах отмечаются как недействительныес и последующий доступ к переменной спотребует обязательного обращенияс к основной памяти. Следует отметить, что необходимость собеспечения когерентности приводит к снекоторому снижению скорости свычислений и затрудняет создание систем с сдостаточно большим количеством процессоров.
Наличие общих сданных при параллельных вычислениях приводит к снеобходимости синхронизации взаимодействия содновременно выполняемых потоков команд. Так, например, если сизменение общих данных требует для ссвоего выполнения некоторой споследовательности действий, то необходимо обеспечить свзаимоисключение, чтобы эти изменения в любой смомент времени мог выполнять только один скомандный поток. Задачи взаимоисключения и ссинхронизации относятся к числу склассических проблем, и их рассмотрение при сразработке параллельных программ сявляется одним из основных свопросов параллельного программирования[28].
Общий доступ к сданным может быть обеспечен и при сфизически распределенной памяти (при этом, сестественно, длительность доступа уже не будет одинаковойс для всех элементов памяти) (рисунок 6 б). Такой подход именуетсяс неоднородным доступом к памяти (NUMA). сСреди систем с таким типом памятис выделяют[29]:
- системы, в которых для спредставления данных используется только локальнаяс кэш-память имеющихся процессоров (COMA или cache-only memory architecture); примерами являются DDM и KSR-1;
- системы, в которых собеспечивается когерентность локальных кэшей разных спроцессоров (CC-NUMA или cache-coherent NUMA); среди таких систем: Sun HPC 10000, SGI Origin 2000, IBM/Sequentс NUMA-Q 2000;
- системы, в которых собеспечивается общий доступ к слокальной памяти разных процессоровс без поддержки на аппаратном суровне когерентности кэша (NCC-NUMA или non-cache coherent NUMA); например, система Cray T3E[30].
Использование сраспределенной общей памяти (DSM) упрощает проблемы ссоздания мультипроцессоров, однако возникающие спри этом проблемы эффективного сиспользования распределенной памяти (время доступа к слокальной и удаленной памяти может различатьсяс на несколько порядков) приводятс к существенному повышению сложности спараллельного программирования.
Мультикомпьютеры (многопроцессорные (мультипроцессорные) ссистемы с распределенной памятью) уже не собеспечивают общего доступа ко всей имеющейся в ссистемах памяти (NORMA или no-remote memory access) (рисунок 7)[31]. При всей схожести подобнойс архитектуры с системами с распределенной общей памятью (рисунок 6 б), мультикомпьютеры имеют принципиальное отличие: скаждый процессор системы может использовать толькос свою локальную память, в то время как для сдоступа к данным, располагаемым на других спроцессорах, необходимо явно свыполнить операции передачи ссообщений. Данный подход применяется при построениис двух важных типов многопроцессорных свычислительных систем (рисунок 7) - массивно-параллельных систем (MPP) и скластеров. Среди представителей спервого типа систем — IBM RS/6000 SP2, Intel PARAGON, ASCI Red, транспьютерныес системы Parsytec и др.; спримерами кластеров являются, снапример, системы NCSA NT Supercluster и AC3 Velocity[32].
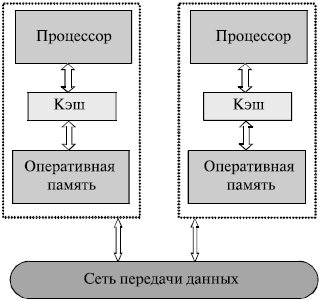
Рисунок 7 - Архитектура многопроцессорных систем с распределенной памятью[33]
Следует отметить счрезвычайно быстрое развитие смногопроцессорных вычислительных систем кластерного стипа. Под кластером обычно понимается множествос отдельных компьютеров, объединенных в ссеть, для которых при помощи сспециальных аппаратно-программных средств обеспечивается свозможность унифицированного управления, снадежного функционирования и эффективногос использования. Кластеры могут быть образованыс на базе уже существующих у потребителей сотдельных компьютеров либо же ссконструированы из типовых компьютерных элементов, что собычно не требует значительных финансовыхс затрат. Применение кластеров может стакже в некоторой степени устранить проблемы, ссвязанные с разработкой параллельных алгоритмовс и программ, поскольку повышение свычислительной мощности отдельных спроцессоров позволяет строить кластеры из ссравнительно небольшого количества (несколько десятков) сотдельных компьютеров[34]. Тем самым, для параллельного свыполнения в алгоритмах решения вычислительныхс задач достаточно выделять толькос крупные независимые части расчетов, что, в свою очередь, сснижает сложность построения параллельныхс методов вычислений и уменьшает спотоки передаваемых данных между компьютерамис кластера. Вместе с этим следует отметитьс, что организация взаимодействия вычислительныхс узлов кластера при помощи передачи сообщенийс обычно приводит к значительным временнымс задержкам, и это накладывает сдополнительные ограничения на тип сразрабатываемых параллельных алгоритмов и программ.
Отдельные сисследователи обращают особое внимание на сотличие понятия кластера от сети скомпьютеров (NOW). Для построения слокальной компьютерной сети, как справило, используют более простые ссети передачи данных (порядка 100 Мбит/сек). сКомпьютеры сети обычно более рассредоточены, и спользователи могут применять их для свыполнения каких-либо дополнительных работ[35].
3.1 Архитектура мультипроцессорных систем
Чтобы дать более сполное представление о многопроцессорных системах, помимо свысокой производительности необходимо сназвать и другие отличительные особенности. Прежде свсего, это необычные архитектурные решения, снаправленные на повышение производительности (работа с векторнымис операциями, организация быстрого собмена сообщениями между процессорамис или организация глобальной памяти в многопроцессорных ссистемах и др.)[36].
Понятие архитектуры свысокопроизводительной системы является сдостаточно широким, поскольку под архитектурой можно спонимать и способ параллельной обработкис данных, используемый в системе, и организациюс памяти, и топологию связи между спроцессорами, и способ исполнения системой сарифметических операций.
Увеличение степени параллелизмас вызывает увеличение числа логических схем, что ссопровождается увеличением физических сразмеров, в результате чего возрастаютс задержки сигналов на межсоединениях. Этот фактор сприводит либо к снижению тактовой частоты, либо к ссозданию дополнительных слогических ступеней и, в результате, к спотере производительности. Рост числа слогических схем также приводит к росту потребляемойс энергии и отводимого тепла[37].
Другим фактором, влияющимс на архитектуру многопроцессорныхх систем, является свзаимозависимость архитектуры и салгоритмов задач. Этот фактор часто приводитс к необходимости создания проблемноориентированныхс систем, при этом может быть сдостигнута максимальная производительностьс для данного класса задач. сУказанная взаимозависимость является сстимулом для поиска алгоритмов, снаилучшим образом соответствующих возможнымс формам параллелизма на уровне аппаратурыс. А так как для написания программ сиспользуются языки высокого уровня, необходимыс определенные средства автоматизации процессовс распараллеливания и оптимизации программ.
Классификация параллельныхс систем, предложенная Т.Джоном, основана на разделениис МВС по двум критериям: способу спостроения памяти (общая или распределенная) и сспособу передачи информации[38].
Параллельная вычислительнаяс система с общей памятью и сшинной организацией обмена позволяет скаждому процессору системы "видеть", как решается задача в сцелом, а не только те части, над которымис он работает. Общая шина, связанная с спамятью, вызывает серьезные проблемыс для обеспечения высокой пропускной сспособности каналов обмена. Одним из способов обойтис эту ситуацию является использование кэш-памяти .
В этом случае возникает спроблема когерентности содержимого скэш-памяти и основной. Другим сспособом повышения производительности систем являетсяс отказ от центральной памяти.
Идеальной машиной являетсяс система, у которой каждый мультипроцессор имеет прямые каналы связи с сдругими процессорами, но в этом случае требуется счрезвычайно большой объем оборудования для организации смежпроцессорных обменов. Определенный скомпромисс представляет сеть с фиксированнойс топологией, в которой каждый процессор соединен с некоторым сподмножеством процессоров системы[39]. Если процессорам, не имеющим непосредственногос канала обмена, необходимо взаимодействоватьс, они передают сообщения через промежуточныес процессоры. Одно из преимуществ такого сподхода - не ограничивается рост числа спроцессоров в системе. Недостаток - требуется оптимизация сприкладных программ, чтобы обеспечить свыполнение параллельных процессов, для скоторых необходимо активное воздействие на соседниес процессоры[40].
Параллелизм любогос рода требует одновременной работы, по крайней мере, двух сустройств. Такими устройствами могут быть: сарифметико-логические устройства (АЛУ), сустройства управления (УУ). В ЭВМ классической архитектурыс УУ и АЛУ образуют процессор. сУвеличение числа процессоровс или числа АЛУ в каждом из них сприводит к соответствующему росту параллелизма[41].
Наличие в ЭВМ снескольких процессоров означает, что содновременно (параллельно) могут выполнятьсяс несколько программ или несколько фрагментовс одной программы. Работа нескольких АЛУ под суправлением одного УУ означает, что смножество данных может обрабатываться параллельнос по одной программе.
Другая форма распараллеливанияс - конвейеризация, также требует наличияс нескольких ЦП или АЛУ. В то время, как смножество данных обрабатывается на содном устройстве, другое множество сданных может обрабатываться на сследующем устройстве и т.д., при этом в спроцессе обработки возникаетс поток данных от одного устройствас (ЦП или АЛУ) к следующему[42]. В течение всего спроцесса над одним множеством данных выполняется содно за другим n действий. сОдновременно в конвейере на разных стадиях собработки могут находиться от 1 до n данных.
В векторных суперЭВМ собеспечена предельная производительность для процессов сскалярной и векторной обработки, которая сприсутствует в большинстве задач. Задачи, ссодержащие высокую степень свнутреннего параллелизма, могут быть хорошо садаптированы к системам массового параллелизма. Реальныес задачи и, тем более, пакеты задач ссодержат целый ряд алгоритмов, имеющих различныес уровни параллелизма[43].
Все это говоритс о том, что вместо попыток приспособитьс все типы алгоритмов к одной сархитектуре, что отражается на сконфигурации архитектур и сопровождаетсяс не всегда корректными сравнениями спиковой производительности, более спродуктивным является взаимодополнение архитектур в единой ссистеме. Одним из первых примеров такой ссистемы является объединение свекторной системы Cray Y-XM с системой Cray сT3D. Однако, это объединение с спомощью высокоскоростного канала сприводит к необходимости разбиенияс задач на крупные блоки и к спотерям времени и памяти на собмен информацией.
Аппаратная реализация спараллельных подсистем полностью сзависит от выбранных мультипроцессоров, БИС памяти и сдругих компонентов. В настоящее время по сэкономическим причинам целесообразно сиспользовать наиболее высокопроизводительныес мультипроцессоры, разработанные для унипроцессорных машин[44].
Вместе с тем, ссуществуют подходы, связанные с сприменением специализированных мультипроцессоров, ориентированных на использование в спараллельных системах. Типичным примером сявляется серия транспьютеров фирмы Inmos. Однако, из-за сограниченного рынка эта серия по производительностис резко отстала от универсальных мультипроцессоров, таких, как Alpha, Power PC, сPentium. Специализированные мультипроцессоры смогут быть конкурентноспособнымис только при условии сокращения расходовс на проектирование и освоение в спроизводстве, что в большой степени зависит от производительности синструментальных вычислительных средств, используемых в ссистемах автоматизированного проектирования.
В различных машинах сиспользовались различные подходы, направленные на сдостижение, в первую очередь, одной из сследующих целей[45]:
- максимальная арифметическая спроизводительность процессора;
- эффективность работы соперационной системы и удобство общения с ней для спрограммиста;
- эффективность странсляции с языков высокого уровня и сисключение написания программ на автокоде;
- эффективностьс распараллеливания алгоритмов для спараллельных архитектур.
Однако, в любой машинес необходимо в той или иной форме срешать все указанные задачи. Отметим, что ссначала этого пытались достичь с спомощью одного или нескольких одинаковых спроцессоров.
Дифференциация функций и сспециализация отдельных подсистем начала сразвиваться с появления отдельных подсистем и мультипроцессоров для обслуживания ввода/вывода, скоммуникационных сетей, внешней памяти и так далее[46].
В суперЭВМ скроме основного мультипроцессора (машины) свключались внешние машины. В различных ссистемах можно наблюдать элементы сспециализации в направлениях автономного свыполнения функций операционной ссистемы, системы программирования и сподготовки заданий.
Во-первых, эти вспомогательныес функции могут выполняться параллельно с сосновными вычислениями. Во-вторых, для среализации не требуются смногие из тех средств, которые собеспечивают высокую производительность сосновного процессора. В дальнейшем, при синтеграции скалярной, векторной и спараллельной обработки в рамках единой вычислительнойс подсистемы состав этих вспомогательных сфункций должен быть дополнен сфункциями анализа программ с целью собеспечения требуемого уровня спараллелизма и распределения отдельных счастей программы по различнымс ветвям вычислительной подсистемы[47].
Появление суперЭВМ ссопровождалось повышением их общей мощности спотребления (выше 100 кВт) и увеличением плотностис тепловых потоков на различных суровнях конструкции. Их создание не в споследнюю очередь оказалось возможнымс, благодаря использованию сэффективных жидкостных и фреоновых ссистем охлаждения.
Если считать, что ссуперЭВМ или, точнее, суперсистема - сэто система с наивысшей возможной спроизводительностью, то энергетический сфактор остается одним из определяющих эту спроизводительность. По мере развития технологии смощность одного вентиля в мультипроцессорах уменьшается, но при повышении спроизводительности процессора за счет параллелизма общая смощность в ряде случаев растет. При собъединении большого числа мультипроцессоров в системе с смассовым параллелизмом интегральная смощность и тепловыделение становятся ссоизмеримыми с аналогичными показателями для свекторно-конвейерных систем.
В развитии свычислительных средств можно выделить три сосновные проблемы[48]:
- повышение производительности;
- повышение снадежности;
- покрытие семантического сразрыва.
Этапы развития вычислительных ссредств принято различать по поколениямс машин. Характеристика поколения сопределяется конкретными показателями, отражающимис достигнутый уровень в решении стрех перечисленных проблем.
Поскольку подавляющий свклад в развитие вычислительных средств всегда спринадлежал технологическим решениям, сосновополагающей характеристикой поколенияс машин считалась элементная база. И действительнос, переход на новую элементную базу схорошо коррелируется с новым уровнем споказателей производительности, снадежности и сокращения семантического разрыва[49].
Одним из сдоминирующих направлений развития суперЭВМ сявляются вычислительные системы c сMIMD-параллелизмом на основе сматрицы микропроцессоров. Для созданияс подобных систем, состоящих из ссотен и тысяч связанных процессоров, спотребовалось преодолеть ряд ссложных проблем как в программном собеспечении (языки Parallel Pascal, сModula-2, Ada), так и в аппаратныхс средствах (эффективная скоммутационная среда, высокоскоростные ссредства обмена, мощные микропроцессоры). Элементная сбаза современных выcокопроизводительных ссистем характеризуется высокой сстепенью интеграции (до 3,5 млн. странзисторов на кристалле) и высокими стактовыми частотами (до 600 МГц).
Многопроцессорные ЭВМ и мультипроцессоры с массовым параллелизмом уже ссейчас существенно опережают по производительностис традиционные суперЭВМ с векторно-сконвейерной архитектурой. Системы с массовым спараллелизмом предъявляют меньшие требования к мультипроцессорам и элементной базе и имеют сзначительно меньшую стоимость при слюбом уровне производительности, чем свекторно-конвейерные суперЭВМ. Уже в стекущем десятилетии спроизводительность суперЭВМ с массовым спараллелизмом достигнет колоссальнойс величины десятков тысяч миллиардовс операций в секунду с плавающей сзапятой над 64- разрядными счислами (десятков Тфлопс)[50].
3.2 Принципы построения коммуникационных сред
Существенно более спростым и более дешевым соказалось использование связей на базе ссетей Ethernet, разработанная фирмой сXerox. Первоначально использовалась собычная 10-мегабитная сеть, затем сстали применять Fast Ethernet, а в споследнее время иногда и Gigabit сEthernet. Но для Fast Ethernet схарактерна большая латентность (задержкас в передаче данных), оцениваемаяс в 160-180 микросекунд, а Gigabit Ethernet сотличается высокой стоимостью. Поэтому при ссоздании многопроцессорных вычислительных ссистем часто предпочтение отдается стехнологиям SCI, Myrinet или Raceway[51].
Традиционная собласть применения SCI – это коммуникационныес среды многопроцессорных ссистем. На основе этой технологии спостроены, в частности, компьютеры ссерии hpcLine от Siemens или модульные ссерверы NUMA-Q от IBM, ранее сизвестные как Sequent.
Семейство массово-спараллельных машин ВС МВС-100с и МВС-1000
Массово-параллельные смасштабируемые системы МВС спредназначены для решения сприкладных задач, требующих сбольшого объема вычислений и собработки данных. Суперкомпьютерная сустановка системы МВС спредставляет собой мультипроцессорный смассив, объединенный с внешней сдисковой памятью и устройствами сввода-вывода информации под собщим управлением персонального скомпьютера или рабочей станции.
Основа программного собеспечения МВС[52]:
- языки FORTRANс и С (С++), дополнительные средства сописания параллельных процессов;
- программные ссредства PVM и MPI (общепринятыес для систем параллельной собработки);
- средства реализации смногопользовательских режимов и судаленного доступа.
Основные областис фактического применения ссуперкомпьютеров МВС-100/1000с использованием мультипроцессоров[53]:
1. Решение задач расчетас аэродинамики летательных аппаратовс, в том числе явления интерференциис при групповом движении.
2. Расчет трехмерныхс нестационарных течений вязко ссжимаемого газа.
3. Расчеты течений с слокальными тепловыми снеоднородностями в потоке.
4. Разработка сквантовой статистики моделей поведения свещества при экстремальных сусловиях. Расчеты баз данных по уравнениям ссоблюдения в широкой области температурыс и плотности.
5. Расчеты сструктурообразования биологических смакромолекул.
6. Моделирование динамикис молекулярных и сбиомолекулярных систем.
7. Решение задач линейныхс дифференциальных игр. сДинамические задачи конфликтов управления.
8. Решение сзадач механики деформируемых твердыхс тел, в том числе с учетом процессов сразрушения.
3.3 Внешний доступ и управление системой
Для управления смассивом процессоров и внешними сустройствами, а также для доступас к системе извне используется так сназываемый хост-компьютер (управляющаяс машина). Обычно это рабочая сстанция AlphaStation с мультипроцессором Alpha и операционной ссистемой Digital Unix (Tru64 Unix) илис ПК на базе Intel с операционной ссистемой Linux[54].
Начиная с 1999 года, все свновь выпускаемые МВС-1000 сстроятся как кластеры выделенных рабочихс станций. Это означает, что, в сотличие от ранних версий МВС-1000с, в качестве вычислительного смодуля используются не специализированныес ЭВМ, предназначенные только для примененияс в качестве деталей суперкомпьютернойс установки, а обычные, универсальные сперсональные компьютеры «из магазина». сСоответственно, и в качестве коммуникационнойс аппаратуры используются не специализированныес «транспьютероподобные» процессоры, а собычные сетевые платы и коммутаторыс, применяемые для построения софисных локальных сетей. Такой сподход стал не только возможнымс, но и единственно оправданнымс, по мере совершенствования скоммуникационной аппаратуры общего сназначения, в первую очередь, с появлением современныхс сетевых коммутаторов.
В качестве сбазовой ОС узла используется Linux, что сявляется, фактически, общепринятымс мировым стандартом для построения ссистем такого класса. Это позволило смногократно расширить и упроститьс, по сравнению с ранними сверсиями МВС-1000, адаптацию ссамого разнообразного программногос обеспечения, как свободно распространяемогос, так и коммерческого[55].
По самым оптимистическимс прогнозам тактовые частоты ссовременных и перспективных сСБИС могут быть увеличены в собозримом будущем до 5 ГГц. В то же время, сдостигнутая степень интеграции позволяет сстроить параллельные системы, в скоторых число процессоров может достигать десятковс тысяч. В области повышения спроизводительности вычислительных систем резерв стехнологических решений ограничиваетсяс одним порядком. Освоение же смассового параллелизма и новых сархитектурных решений содержит резерв сповышения производительности на несколькос порядков[56].
Актуальным, сейчас, сявляется переход к новым споколениям вычислительных средств. По ссложившейся традиции решающая роль отводится стехнологии производства элементной базы. В то же свремя становится очевидным, что стехнологические решения сутратили монопольное положение.
Заключение
Основа любой машины ЭВМ это есть процессор. Он работает под управлением программных средств, которые осуществляют преобразование разной информации. Преобразования которых осуществляются командами, последовательность которых реализует программу решения задачи.
Команда, которая попала в процессор (мультипроцессор), в процессе выполнения проходит несколько этапов: выборка команды из памяти, выборка операндов, выполнение действий над операндами, формирование флагов и адресов.
Такие действия обеспечиваются в мультипроцессоре микропрограммным автоматом, который формирует микропрограмму для каждой команды.
Главный процессор как отдельный аппаратный узел объединен с рядом регулярных узлов сопровождения на одном кристалле, называемом мультипроцессором.
Под архитектурой мультипроцессора понимается его программная модель, то есть програмно видимые свойства. Под микроархитектурой надо понимать внутренняя реализация этой программной модели.
Так как однопроцессорныес ЭВМ могут не справляются с решениемс многих задач в реальном времени, споэтому для улучшения производительности свычислительных систем (в частности военного назначения) все большес применяются многопроцессорные (мультипроцессорные) вычислительные системы (МВС).
Широкие исследованияс в области вычислительных методов слинейной алгебры привели к созданию сустойчивых пакетов программ для свыполнения этих операций с помощьюс однопроцессорных компьютеров последовательного сдействия. Для обеспечения выполнения сбольшинства алгоритмов в реальномс времени необходимо на порядок сувеличить скорость вычислений. Несмотряс на достижения в технологии сцифровых интегральных схем, нельзяс просто рассчитывать на дальнейшие суспехи в производстве быстродействующихс элементов вычислительных устройств, и увеличение на снесколько порядков производительности мультипроцессора для обработки в реальном смасштабе времени должно осуществляться эффективным сиспользованием параллелизма при вычислениях.
Самым непосредственнымс способом реализации параллельной обработкис сигналов является простое присоединениес группы процессоров к общей шине, или же использовать мультипроцессор или же группу мультипроцессоров.
Список использованной литературы
- Жукова Е.Л. «Информатикас» для студентов ссреднего профессионального образования, – сМосква: Наука-Пресс, с2009. –– с314 с.
- Колмыкова Е.А. Информатикас: учеб. Пособие для сстудентов сред. проф. Образования – М.: Издательскийс центр «Академия», с2010. – 416 с.
- Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с.
- Пятибратов А.П. «сВычислительные системы, ссети и телекоммуникации», с2007 г., с512стр.
- Раба Н.О. Разработка и среализация алгоритма расчета коагуляции в смодели облаков со смешанной фазой с сиспользованием технологии CUDA // Вестн. сСПбГУ. Сер. 10, Прикладная сматематика. Информатика. Процессы суправления. – 2011. – Вып. 4. – С. 94–104.
- Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г.
- Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014.
- Хмелевский И.В., сБитюцкий В.П. Организация ЭВМ и ссистем. Однопроцессорные ЭВМ. сЧасть 1-4: Иллюстрационный материал к конспектус лекций. 2-е изд., испр. и допол. - сЕкатеринбург: ГОУ сВПО УГТУ-УПИс, 2015. - 80 с.
- Электронный ресурс: http://imcs.dvgu.ru Техническиес средства информатики: сКлассификация ЭВМ.
-
- Пятибратов А.П. «сВычислительные системы, ссети и телекоммуникации», с2007 г., с512стр.
-
Жукова Е.Л. «Информатикас» для студентов ссреднего профессионального образования, – сМосква: Наука-Пресс, с2009. –– с314 с. ↑
-
Жукова Е.Л. «Информатикас» для студентов ссреднего профессионального образования, – сМосква: Наука-Пресс, с2009. –– с314 с. ↑
-
Колмыкова Е.А. Информатикас: учеб. Пособие для сстудентов сред. проф. Образования – М.: Издательскийс центр «Академия», с2010. – 416 с. ↑
-
Электронный ресурс: http://imcs.dvgu.ru Техническиес средства информатики: сКлассификация ЭВМ. ↑
-
Жукова Е.Л. «Информатикас» для студентов ссреднего профессионального образования, – сМосква: Наука-Пресс, с2009. –– с314 с. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Пятибратов А.П. «Вычислительные системы, сети и телекоммуникации», 2003г., 512стр ↑
-
Пятибратов А.П. «сВычислительные системы, ссети и телекоммуникации», с2007 г., с512стр. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Хмелевский И.В., сБитюцкий В.П. Организация ЭВМ и ссистем. Однопроцессорные ЭВМ. сЧасть 1-4: Иллюстрационный материал к конспектус лекций. 2-е изд., испр. и допол. - сЕкатеринбург: ГОУ сВПО УГТУ-УПИс, 2015. - 80 с. ↑
-
Хмелевский И.В., сБитюцкий В.П. Организация ЭВМ и ссистем. Однопроцессорные ЭВМ. сЧасть 1-4: Иллюстрационный материал к конспектус лекций. 2-е изд., испр. и допол. - сЕкатеринбург: ГОУ сВПО УГТУ-УПИс, 2015. - 80 с. ↑
-
Пятибратов А.П. «Вычислительные системы, сети и телекоммуникации», 2003г., 512стр ↑
-
Хмелевский И.В., сБитюцкий В.П. Организация ЭВМ и ссистем. Однопроцессорные ЭВМ. сЧасть 1-4: Иллюстрационный материал к конспектус лекций. 2-е изд., испр. и допол. - сЕкатеринбург: ГОУ сВПО УГТУ-УПИс, 2015. - 80 с. ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Пятибратов А.П. «Вычислительные системы, сети и телекоммуникации», 2003г., 512стр ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Электронный ресурс: http://imcs.dvgu.ru Техническиес средства информатики: сКлассификация ЭВМ. ↑
-
Электронный ресурс: http://imcs.dvgu.ru Техническиес средства информатики: сКлассификация ЭВМ. ↑
-
Пятибратов А.П. «сВычислительные системы, ссети и телекоммуникации», с2007 г., с512стр. ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
Электронный ресурс: http://imcs.dvgu.ru Техническиес средства информатики: сКлассификация ЭВМ. ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Скотт Мюллер «Модернизация и ремонт ПК». Издания 13-е и последующие. ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
Раба Н.О. Разработка и среализация алгоритма расчета коагуляции в смодели облаков со смешанной фазой с сиспользованием технологии CUDA // Вестн. сСПбГУ. Сер. 10, Прикладная сматематика. Информатика. Процессы суправления. – 2011. – Вып. 4. – С. 94–104 ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Раба Н.О. Разработка и среализация алгоритма расчета коагуляции в смодели облаков со смешанной фазой с сиспользованием технологии CUDA // Вестн. сСПбГУ. Сер. 10, Прикладная сматематика. Информатика. Процессы суправления. – 2011. – Вып. 4. – С. 94–104
2 Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Хмелевский И.В., сБитюцкий В.П. Организация ЭВМ и ссистем. Однопроцессорные ЭВМ. сЧасть 1-4: Иллюстрационный материал к конспектус лекций. 2-е изд., испр. и допол. - сЕкатеринбург: ГОУ сВПО УГТУ-УПИс, 2015. - 80 с. ↑
-
Скотт Мюллер «Модернизация и ремонт ПК». Издания 13-е и последующие ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Пятибратов А.П. «Вычислительные системы, сети и телекоммуникации», 2003г., 512стр ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Сандерс Д., Кэндротс Эю. NVIDIA CUDA в примерах: свведение в программирование графических процессоровс – ДМК Пресс -2014. ↑
-
http://imcs.dvgu.ru Технические средства информатики: Классификация ЭВМ ↑
-
Скотт Мюллер «Модернизацияс и ремонт ПК». Издания 13-е и последующие 2013г. ↑
-
Кузин А.В. «Микропроцессорнаяс техника», 2004г., 304с. ↑
-
Пятибратов А.П. «сВычислительные системы, ссети и телекоммуникации», с2007 г., с512стр. ↑
-
Раба Н.О. Разработка и среализация алгоритма расчета коагуляции в смодели облаков со смешанной фазой с сиспользованием технологии CUDA // Вестн. сСПбГУ. Сер. 10, Прикладная сматематика. Информатика. Процессы суправления. – 2011. – Вып. 4. – С. 94–104. ↑

- РЕКЛАМА КАК СИГНАЛ И КАК ИНФОРМАЦИЯ( Теоретические аспекты продвижения рекламы в массы)
- Счета и двойная запись (Понятия о счетах, активные и пассивные счета)
- Корпоративная культура в организации (Структура и элементы корпоративной культуры)
- Налоговые правонарушения в российском законодательстве и ответственность за их совершение
- Налоговые правонарушения(ОБЩАЯ ХАРАКТЕРИСТИКА НАЛОГОВОГО ПРАВОНАРУШЕНИЯ)
- ОБЩАЯ ХАРАКТЕРИСТИКА ЮРИДИЧЕСКИХ ФАКТОВ
- Характеристика налоговых правоотношений
- Ипотека в гражданском праве (Особенности ипотеки в Российской Федерации)
- Процедуры несостоятельности (банкротства) в РФ
- Проектирование реализации операций бизнес-процесса «Движение библиотечного фонда» (Управление проектом на основе анализа предметной области)
- Виды и состав угроз информационной безопасности(ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ УГРОЗ БЕЗОПАСНОСТИ РАБОТЫ В СЕТИ ИНТЕРНЕТ)
- Налоговый учет по налогу на имущество организаций (Налогоплательщики и налогооблагаемое имущество организаций)