
Цифровая экономика. Машинное обучение
Содержание:

ВВЕДЕНИЕ
Машинное обучение – это обширный раздел связанный с искусственным интеллектом. Машинное обучение изучает методы построения алгоритмов, которые способны самостоятельно изучаться или воспринимать опыт и знания у экспертов в виде базы знаний.
Сама идея создания искусственного интеллекта или правильнее сказать подобия человека, который будет моделировать человеческий разум для решения сложных задач зародилась ещё в древние времена. Но первым экспериментатором и по совместительству родоначальником искусственного интеллекта необходимо считать ученого и философа родившийся в Майорке (нынешней Испании) Раймонд Луллий, который в 14 веке попытался создать механическую машину для решения различных задач, на основе разработанной им классификации понятий, связанные с комбинаторикой. И после него было много попыток продолжения этой идеи создания нечто похожего на разум.
Окончательное рождение искусственного интеллекта как научного направления произошло только после создания ЭВМ в 40-х годах ХХ века, людям уже тогда было любопытно, могут ли компьютеры обучаться. Если мы осознаем, как запрограммировать их для самообучения, чтобы они улучшались автоматически от каждого байта информации в нем, то исходом может быть... Представьте человека который выучился в мед. Вузе, данный врач способен определить болезнь и какие виды лечения более эффективны, а теперь представьте, что те же знания и опыт множества врачей передать компьютеру, но накапливая опыт он способен это делать быстрее и точнее, а также при обнаружение новых болезней сможет определить угрозу новой болезни и выявить максимально эффективные способы лечения. Но в отличие от человека это можно будет делать без посещения врача или просто анализировать результаты исследований и выдавать высокоточные «врачебные рекомендации». Или дома, обучающиеся на опыте, оптимизировать энергетические издержки, основываясь на обычных данных употребления энергии его жителями; или персональная компьютерная программа, которая изучает изменения интересов своих пользователей, чтобы поместить на передний план, главным образом, ту новость из сегодняшних утренних газет, которая была бы уместна конкретному пользователю.
Умение научить компьютер самообучению могло бы открыть новые уровни знания, компетентности, производительности. И подробное понимание информационной обработки алгоритмов для машинного обучения могло бы привести также к лучшему пониманию человеческой обучающей способности.
Целью данной курсовой работы является разбор понятий и определений, которые связанны с машинным обучением, как работает машинное обучение, где уже работает машинное обучение, как может помочь в экономике машинное обучение и какие проблемы для экономики ещё не решены.
Глава 1: Анализ проблемной области и постановка задач
Интеллектуальный анализ данных представляет собой процесс обнаружения пригодных к использованию сведений в крупных наборах данных. В интеллектуальном анализе данных применяется математический анализ для выявления закономерностей и тенденций, существующих в данных. Обычно такие закономерности нельзя обнаружить при традиционном просмотре данных, поскольку связи слишком сложны, или из-за чрезмерного объема данных. Таким образом получаем что у нас есть некая информация, которую будем анализировать математическими, статистическими и другими методами для понимая, что из себя представляет данная информация и на сколько она полезна.
Давайте чуть подробнее разберемся как формируется весь процесс интеллектуального анализ в машинном обучении:
- Подготовка данных к анализу.
Термин "OLAP" напрямую связан с таким термином как "хранилище данных".
Данные в хранилище данных попадают из оперативных систем (транзакционных систем или OLTP-систем,), которые работают с маленькими по размерам данными, но подгружаемые огромным потоком, и они предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, как например статистические отчеты.
Задача хранилища - предоставить данные для анализа в одном месте в простой и удобной для системы структуре, для последующей работы с данными внутри неё.
Так же причиной появления отдельного хранилища служит сложные аналитические запросы к оперативной информации, которые тормозят текущую работу компании, надолго блокируя таблицы данных и захватывая ресурсы сервера, а могу при слабых мощностях серверов и вовсе оставить (повиснуть) рабочий процесс.
Централизованная и удобная структура - это далеко не все, что нужно для аналитики данных, так же необходимы инструмент для просмотра и визуализации информации. Традиционные отчеты, лишены гибкости из-за чего невозможно получить желаемого представления данных. Таким инструментом и выступает OLAP, который позволяет разворачивать и сворачивать данные в простые и удобные кучки информации для восприятия.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Оперативные данные собираются из разных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные подготавливаются для OLAP-анализа. Они могут быть загружены в специальную базу данных OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Как итог, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище.
Оперативный анализ данных.
В основе концепции OLAP лежит принцип многомерного представления данных. Недостатком реляционной модели, в первую очередь можно назвать невозможность объединять, просматривать и анализировать данные с точки зрения множественности измерений. В 1993 году британский ученый Эдгар Кодд и определил общие требования к системам OLAP, расширяющие функциональность реляционных систем управления базы данных(СУБД) и включающим многомерный анализ как одну из своих характеристик.
По мнению Эдгара Кодда, многомерное концептуальное представление данных представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных.
Одновременный анализ по нескольким измерениям и есть как раз многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению.
К примеру, измерение «Исполнитель» может определяться направлением консолидации, состоящим из следующих уровней: предприятие, управление, подразделение, отдел (рис.1). Измерение «Время» может даже включать два направления консолидации: 1 уровень: год, квартал, месяц и день; 2 уровень: номер недели и день; всё из-за того, что счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений.
Операция спуска соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема означает движение от низших уровней к высшим:
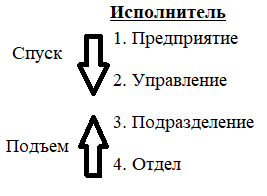
Рис.1 Уровни детализации информации.
- Интеллектуальный анализ данных (Data Mining)
Основу методов data mining составляют всевозможные методы классификации, моделирования и прогнозирования.
Основная цель технологии – поиск и выявление в данных скрытые связи и взаимозависимости с целью наглядного представления результатов вычислений (визуализация), что позволяет использовать инструментарий data mining людьми, не имеющими специальной математической подготовки. Технология включает в себя методы поиска новой информации в данных, подразумевающие использование математических алгоритмов (статистика, оптимизация, корреляция и др.), позволяющих находить эти зависимости и синтезировать дедуктивную информацию.
- Извлечение знаний из баз данных
Технология представляет новое направление в области data mining, где процесс поиска закономерностей в данных рассматривается как процесс машинного обучения. Технология объединяет в себе вопросы моделирования закономерностей и зависимостей в базах данных, а также определяет математические методы построения систем добычи новых данных на основе методов классификации, кластеризации, построения деревьев решений и др.
Термин «Обнаружение знаний в базах данных», или сокращенно KDD (Knowledge Discovery in Databases), относится к широкому процессу поиска знаний в данных и подчеркивает «высокоуровневое» применение определенных методов интеллектуального анализа данных. Он представляет интерес для исследователей в области машинного обучения, распознавания образов, баз данных, статистики, искусственного интеллекта, приобретения знаний для экспертных систем и визуализации данных.
Объединяющей целью процесса обнаружения знаний в базах данных является извлечение знаний из данных в контексте больших баз данных.
Это достигается путем использования методов (алгоритмов) интеллектуального анализа данных для извлечения (идентификации) того, что считается знаниями, в соответствии со спецификациями мер и пороговых значений, с использованием базы данных вместе с любой необходимой предварительной обработкой, подвыборкой и преобразованиями этой базы данных
Краткое описание шагов процесса KDD:
1. отбор данных, где данные, относящиеся к задаче анализа, взяты из базы данных;
2. очистка данных, то есть управление шумными, ошибочными, отсутствующими (перебойными) или несоответствующими данными;
3. интегрирование данных (обогащение), где множественные разнородные данные могут быть объединены в один;
- преобразование данных (кодирование), где данные преобразованы или объединены в формы, соответствующие различным алгоритмам анализа данных;
- добыча знаний из данных, который является существенным процессом, где интеллектуальные методы применяются, чтобы извлечь скрытое и ценное знание из данных;
- представление знания - это представление добытого знания пользователю с помощью визуализации и методов представления знания.
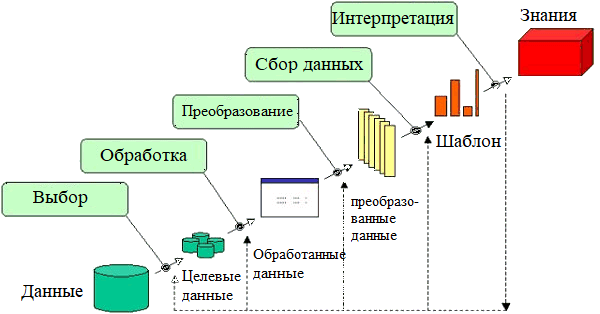
Рис.2 процесс KDD
Двумя первостепенными целями интеллектуального анализа данных на практике являются предсказание и описание.
- Прогнозирование предполагает использование некоторых переменных или полей в базе данных для прогнозирования неизвестных или будущих значений других переменных, представляющих интерес.
- Описание фокусируется на поиске интерпретируемых человеком паттернов, описывающих данные.
Относительная важность прогнозирования и описания для конкретных приложений интеллектуального анализа данных может значительно различаться. Однако в контексте KDD описание имеет тенденцию быть более важным, чем предсказание. Это в отличие от приложений распознавания образов и машинного обучения (таких как распознавание речи), где прогнозирование часто является основной целью процесса KDD.
Цели прогнозирования и описания достигаются с помощью следующих основных задач интеллектуального анализа данных:
- Классификация - это изучение функции, которая отображает (классифицирует) элемент данных в один из нескольких предопределенных классов.
- Регрессия - это изучение функции, которая отображает элемент данных в вещественные переменные прогнозирования.
- Кластеризация - это общая описательная задача, при которой каждый стремится определить конечный набор категорий или кластеров для описания данных.
- С кластеризацией тесно связана задача оценки плотности вероятности, которая состоит из методов оценки, основанной на данных, совместной многовариантной функции плотности вероятности всех переменных / полей в базе данных.
- Суммирование включает в себя методы поиска компактного описания для подмножества данных.
- Моделирование зависимостей состоит в нахождении модели, которая описывает существенные зависимости между переменными.
Модели зависимости существуют на двух уровнях:
- Структурный уровень модели специфицирует (часто графически) какие переменные локально зависят друг от друга;
- Количественный уровень модели определяет сильные стороны зависимостей, используя некоторую числовую шкалу.
- Обнаружение изменений и отклонений направлено на выявление наиболее значительных изменений данных по ранее измеренным или нормативным значениям.
Алгоритмы машинного обучения используют статистику для поиска шаблонов в огромных объемах данных. И данные здесь включают в себя множество вещей - цифры, слова, изображения, щелчки… Если информация может храниться в цифровом виде, она может быть введена в алгоритм машинного обучения.
Обозначим входной набор данных как X и набор выходных данных как Y. Будет принято, что i-ый элемент X (обозначенный как xi) имеет соответствующий выходной элемент yi. Пара {xi, yi} названа тогда примером. Элементы X также могут быть названы входными примерами (отдельными случаями).
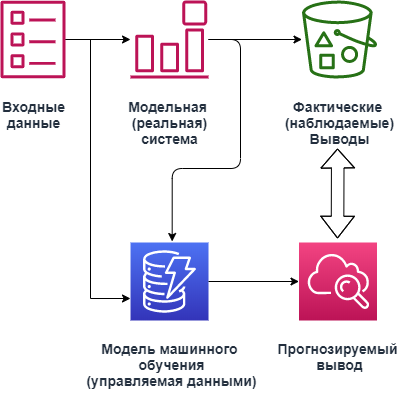
Рис. 3 Машинное обучение.
Рисунок 4 показывает процесс машинного обучения. ML модель, на основе примеров данных, пробует "учить" целевую функцию Y=f(X), которая характеризует поведение реальной системы.
Обучение - это процесс уменьшения отличий между наблюдаемыми данными и модели выхода (погрешность модели). После изучения, модель ML, пополняемая новыми входами, может прогнозировать, какой для новой входного xi генерируется набор выходных данных yi, величина которого близка к той, что произвела бы реальная система.
Вообще говоря, задача машинного обучения содержит три больших компонента: образцовая архитектура (или функциональный класс) М., который имеет набор регулируемых параметров P и измеренных данных D. Пример М. может быть многочлен данного порядка, где P - коэффициенты. Цель состоит в том, чтобы определить образцовую архитектуру М. и величины параметров P, которые могут привести к лучшему соглашению, в некотором роде, между прогнозами модели и данными D.
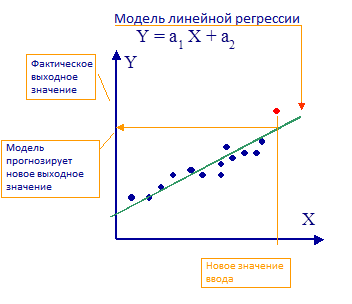
Рис. 4 Линейная регрессия, как модель машинного обучения.
Один из самых простых примеров модели машинного обучения - модель линейной регрессии (М. - линейная функция); в этом на основе наблюдений алгоритм обучен, приблизительно воспроизводить действительное значение. Методы машинного обучения позволяют построить модели, которые являются намного более точными, чем линейные.
Провести сравнительный анализ основных направлений искусственного интеллекта, найти соотношение и взаимосвязь таких дисциплин: машинное обучение, интеллектуальный анализ данных, добыча знаний из данных, нахождение закономерностей в базах данных.
- Дерево принятия решений
Это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчётом вероятности наступления того или иного события), эффективность, ресурсозатратность.
Для бизнес-процессов это дерево складывается из минимального числа вопросов, предполагающих однозначный ответ — «да» или «нет». Последовательно дав ответы на все эти вопросы, мы приходим к правильному выбору. Методологические преимущества дерева принятия решений – в том, что оно структурирует и систематизирует проблему, а итоговое решение принимается на основе логических выводов.
- Наивная байесовская классификация
Наивные байесовские классификаторы относятся к семейству простых вероятностных классификаторов и берут начало из теоремы Байеса, которая применительно к данному случаю рассматривает функции как независимые (это называется строгим, или наивным, предположением). На практике используется в следующих областях машинного обучения:
- определение спама, приходящего на электронную почту;
- автоматическая привязка новостных статей к тематическим рубрикам;
- выявление эмоциональной окраски текста;
- распознавание лиц и других паттернов на изображениях.
- Метод наименьших квадратов
Всем, кто хоть немного изучал статистику, знакомо понятие линейной регрессии. К вариантам её реализации относятся и наименьшие квадраты. Обычно с помощью линейной регрессии решают задачи по подгонке прямой, которая проходит через множество точек. Вот как это делается с помощью метода наименьших квадратов: провести прямую, измерить расстояние от неё до каждой из точек (точки и линию соединяют вертикальными отрезками), получившуюся сумму перенести наверх. В результате та кривая, в которой сумма расстояний будет наименьшей, и есть искомая (эта линия пройдёт через точки с нормально распределённым отклонением от истинного значения).
Линейная функция обычно используется при подборе данных для машинного обучения, а метод наименьших квадратов – для сведения к минимуму погрешностей путем создания метрики ошибок.
- Логистическая регрессия
Логистическая регрессия – это способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы. Для этого применяется логистическая функция (аккумулятивное логистическое распределение). Практическое значение логистической регрессии заключается в том, что она является мощным статистическим методом предсказания событий, который включает в себя одну или несколько независимых переменных. Это востребовано в следующих ситуациях:
- кредитный скоринг;
- замеры успешности проводимых рекламных кампаний;
- прогноз прибыли с определённого товара;
- оценка вероятности землетрясения в конкретную дату.
- Метод опорных векторов (SVM)
Это целый набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ. Исходя из того, что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп. На бумаге это можно изобразить так: есть точки двух разных видов, и их можно линейно разделить. Кроме сепарации точек, данный метод генерирует гиперплоскость таким образом, чтобы она была максимально удалена от самой близкой точки каждой группы.
SVM и его модификации помогают решать такие сложные задачи машинного обучения, как сплайсинг ДНК, определение пола человека по фотографии, вывод рекламных баннеров на сайты.
- Метод ансамблей
Он базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования. Изначально метод ансамблей был частным случаем байесовского усреднения, но затем усложнился и оброс дополнительными алгоритмами:
- бустинг (boosting) – преобразует слабые модели в сильные посредством формирования ансамбля классификаторов (с математической точки зрения это является улучшающим пересечением);
- бэггинг (bagging) – собирает усложнённые классификаторы, при этом параллельно обучая базовые (улучшающее объединение);
- корректирование ошибок выходного кодирования.
Метод ансамблей – более мощный инструмент по сравнению с отдельно стоящими моделями прогнозирования, поскольку:
- он сводит к минимуму влияние случайностей, усредняя ошибки каждого базового классификатора;
- уменьшает дисперсию, поскольку несколько разных моделей, исходящих из разных гипотез, имеют больше шансов прийти к правильному результату, чем одна отдельно взятая;
- исключает выход за рамки множества: если агрегированная гипотеза оказывается вне множества базовых гипотез, то на этапе формирования комбинированной гипотезы оно расширяется при помощи того или иного способа, и гипотеза уже входит в него.
- Алгоритмы кластеризации
Кластеризация заключается в распределении множества объектов по категориям так, чтобы в каждой категории – кластере – оказались наиболее схожие между собой элементы.
- Кластеризировать объекты можно по разным алгоритмам. Чаще всего используют следующие:
- на основе центра тяжести треугольника;
- на базе подключения;
- сокращения размерности;
- плотности (основанные на пространственной кластеризации);
- вероятностные;
- машинное обучение, в том числе нейронные сети.
Алгоритмы кластеризации используются в биологии (исследование взаимодействия генов в геноме, насчитывающем до нескольких тысяч элементов), социологии (обработка результатов социологических исследований методом Уорда, на выходе дающим кластеры с минимальной дисперсией и примерно одинакового размера) и информационных технологиях.
- Метод главных компонент (PCA)
Метод главных компонент, или PCA, представляет собой статистическую операцию по ортогональному преобразованию, которая имеет своей целью перевод наблюдений за переменными, которые могут быть как-то взаимосвязаны между собой, в набор главных компонент – значений, которые линейно не коррелированы.
Практические задачи, в которых применяется PCA, – визуализация и большинство процедур сжатия, упрощения, минимизации данных для того, чтобы облегчить процесс обучения. Однако метод главных компонент не годится для ситуаций, когда исходные данные слабо упорядочены (то есть все компоненты метода характеризуются высокой дисперсией). Так что его применимость определяется тем, насколько хорошо изучена и описана предметная область.
- Сингулярное разложение
В линейной алгебре сингулярное разложение, или SVD, определяется как разложение прямоугольной матрицы, состоящей из комплексных или вещественных чисел. Так, матрицу M размерностью [m*n] можно разложить таким образом, что M = UΣV, где U и V будут унитарными матрицами, а Σ – диагональной.
Одним из частных случаев сингулярного разложения является метод главных компонент. Самые первые технологии компьютерного зрения разрабатывались на основе SVD и PCA и работали следующим образом: вначале лица (или другие паттерны, которые предстояло найти) представляли в виде суммы базисных компонент, затем уменьшали их размерность, после чего производили их сопоставление с изображениями из выборки. Современные алгоритмы сингулярного разложения в машинном обучении, конечно, значительно сложнее и изощрённее, чем их предшественники, но суть их в целом нем изменилась.
- Анализ независимых компонент (ICA)
Это один из статистических методов, который выявляет скрытые факторы, оказывающие влияние на случайные величины, сигналы и пр. ICA формирует порождающую модель для баз многофакторных данных. Переменные в модели содержат некоторые скрытые переменные, причем нет никакой информации о правилах их смешивания. Эти скрытые переменные являются независимыми компонентами выборки и считаются негауссовскими сигналами.
В отличие от анализа главных компонент, который связан с данным методом, анализ независимых компонент более эффективен, особенно в тех случаях, когда классические подходы оказываются бессильны. Он обнаруживает скрытые причины явлений и благодаря этому нашёл широкое применение в самых различных областях – от астрономии и медицины до распознавания речи, автоматического тестирования и анализа динамики финансовых показателей.
Глава 2: Выявление соотношение дисциплин и как машинное обучение помогает.
В анализе проблемной области были рассмотрены основные понятия данных дисциплин, которые требуется соотнести. Для наглядности существующей проблемы взаимосвязи некоторых направлений искусственного интеллекта, определения были приведены из нескольких источников. Как было показано, из-за новизны самой науки существует множество мнений, определений, классификаций. В связи с бурным развитием этого направления информатики мы сталкиваемся с проблемой однозначности.
Можно сказать, что интеллектуальный анализ данных (IDA) имеет дело с приложением методов Искусственного интеллекта для анализа данных, пересекая разнообразие дисциплин. Эти методы включают: все области визуализации данных, предварительной обработки данных (объединение, редактирование, преобразование, фильтрование, осуществление выборки), разработка данных, data mining - методы базы данных и приложения, использование знаний проблемной области в анализе данных, эволюционных алгоритмах, машинном обучении, нейронных сетях, нечеткой логике, статистическом распознавании образов, фильтровании знания, и последующей обработке.
Машинное обучение, интеллектуальный анализ данных, добыча знаний из данных, нахождение закономерностей в базах данных, можно сказать, относятся к одной и той же междисциплинарной области. Это трудно, если вообще возможно, совместить в общем определении несоизмеримые области с их собственными установленными специализациями, такие как: нечеткие наборы (fuzzy sets), нейронные сети (neural networks), эволюционное вычисление (evolutionary computation), машинное обучение (machine learning), методы Байеса и т.д. Обычно один или группа исследователей, если находят область, которая слегка отличается от уже существующей, то организовывают пресс-конференцию, публикуют в журналах, утверждаются профессорством и т.д. Это то, что и случалось с областями близкими к искусственному интеллекту в течение последних двух десятилетий. Добыча знаний из данных (DM), нахождение закономерностей в базах данных (KDD), вычислительный интеллект (CI), машинное обучение (ML), интеллектуальный анализ данных (IDA) - все эти области, очень пересекающиеся, с очень подобным направлениями и прикладными областями. Действительно трудно найти явную границу различия между ними. Но можно сформулировать некоторые отличия:
- IDA относительно новое направление и применяется больше в анализе данных в медицине и исследованиях, научной работе. Методы использованный - также из статистики и машинного обучения;
- ML - это область информатики, направление искусственного интеллекта, которое концентрируется на теоретических основах. Задачи классификации (распознавания образов) решаются методами машинного обучения чаще, чем задачи регрессии (численный прогноз). С технической точки зрения, большинство задач ML могут быть сформулированы как задачи аппроксимации функции.
- DM и KDD обычно предназначены для очень больших баз данных и связаны с приложениями в банковских, финансовых услугах и управлениях cсредствами клиента. Используемые методы, главным образом, из статистики и машинного обучения.
В результате проделанной работы была построена приблизительная диаграмма соотношений дисциплин, на которой я попыталась показать зависимость data mining (добыча знаний из данных) и knowledge discovery in databases (обнаружение знаний в базах данных), роль KDD в процессе интеллектуального анализа данных. Требовалось определить влияние машинного обучения на все эти дисциплины, выяснить какие методы какой дисциплины больше используются и какие более важные.
Из диаграммы видно, что интеллектуальный анализ данных является наиболее общей дисциплиной, которая включает в себя и KDD и DM соответственно, так как DM является одним из этапов нахождения знания в базах данных.
Влияние машинного обучения играет значительную роль, оно является теоретическим базисом для извлечения знаний. Все перечисленные дисциплины используют многие методы заимствованные из этого направления искусственного интеллекта: деревья решений, модель и деревья регрессии, искусственные нейронные сети, методы Байеса, включая вероятностные сети (belief networks), укрепление обучения (Q-обучение), Статистическая теория изучения и Машины Вектора Основания (SVM).
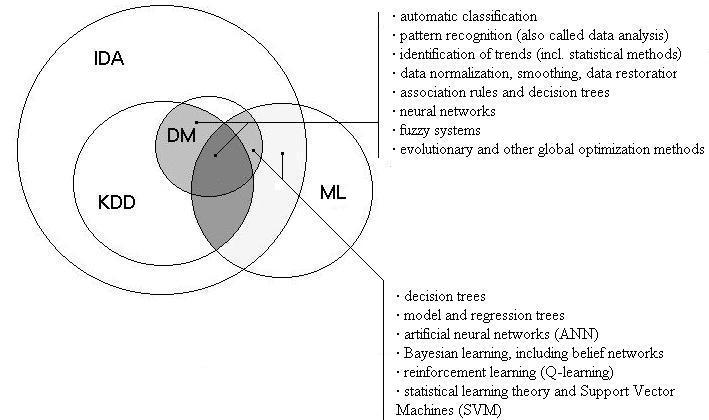
Рис5. Диаграмма соотношений
Интеллектуальный анализ данных включает в себя множество процессов, в том числе и нахождение знаний в базах данных (КДД).
Процесс нахождения знаний состоит из таких этапов: отбор данных, очистка данных, интегрирование данных, преобразование данных, добыча знаний из данных, представление знания.
Data mining (подготовка, понижение, обнаружение нового знания) использует такие методы: автоматическая классификация, распознавание изображений (также называют анализом данных), идентификация тенденций (включая Статистические методы подобно ARIMA), нормализация данных, сглаживание, восстановление данных, ассоциативные правила и деревья решений, нейронные сети, нечеткие системы, эволюционные и другие глобальные методы оптимизации, некоторое из которых взяты из машинного обучения.
В последние годы машинное обучение и искусственный интеллект приобрели известность благодаря тому, что Google, Microsoft Azure и Amazon предлагают свои платформы облачного машинного обучения. Но удивительно, что мы испытываем машинное обучение, не зная этого. Наиболее распространенными вариантами использования являются маркировка изображений с помощью Facebook и обнаружение спама почтовыми провайдерами. Теперь Facebook автоматически помечает загруженные изображения, используя технику распознавания лиц (изображений), а Gmail распознает шаблон или выбранные слова для фильтрации спам-сообщений. Давайте посмотрим на некоторые важные бизнес-проблемы, решаемые с помощью машинного обучения.
- Ручной ввод данных
Неточность и дублирование данных являются основными проблемами бизнеса для организации, которая хочет автоматизировать свои процессы. Алгоритмы машинного обучения (ML) и алгоритмы прогнозного моделирования могут значительно улучшить ситуацию. Программы ML используют обнаруженные данные для улучшения процесса по мере выполнения дополнительных расчетов. Таким образом, машины могут научиться выполнять трудоемкую документацию и задачи ввода данных. Кроме того, работники умственного труда теперь могут тратить больше времени на решение более важных задач. Компания Arria разработала технологию обработки естественного языка, которая сканирует тексты и определяет отношения между концепциями для написания отчетов.
- Обнаружение спама
Обнаружение спама - самая ранняя проблема, решаемая машинным обучением. Четыре года назад поставщики услуг электронной почты использовали существующие методы, основанные на правилах, для удаления спама. Но теперь фильтры спама сами создают новые правила, используя машинное обучение. Благодаря «нейронным сетям» в своих фильтрах спама, Google теперь может похвастаться 0,1 процентами спама. Подобные мозгу «нейронные сети» в своих фильтрах спама могут научиться распознавать нежелательную почту и фишинговые сообщения, анализируя правила на огромной коллекции компьютеров. В дополнение к обнаружению спама, сайты социальных сетей используют машинное обучение как способ выявления и фильтрации злоупотреблений.
- Рекомендация продукта
Обучение без учителя позволяет использовать систему рекомендаций по продукту. Учитывая историю покупок для покупателя и большой запас товаров, модели машинного обучения могут идентифицировать те товары, в которых этот покупатель будет заинтересован и может совершить покупку. Алгоритм идентифицирует скрытый образец среди предметов и сосредотачивается на группировании подобных продуктов в кластеры. Модель этого процесса принятия решения позволила бы программе давать рекомендации клиенту и мотивировать покупки продукта. У компаний электронной коммерции, таких как Amazon, есть такая возможность. Фейсбук обучает неконтролируемое обучение вместе с информацией о местоположении, чтобы рекомендовать пользователям подключаться к другим пользователям.
- Медицинский диагноз
Машинное обучение в медицинской сфере улучшит здоровье пациента с минимальными затратами. В случаях использования ML ставят почти идеальные диагнозы, рекомендуют лучшие лекарства, прогнозируют повторную госпитализацию и выявляют пациентов с высоким риском. Общая цель состоит в том, чтобы уменьшить количество ранних госпитализаций за счет выявления ключевых факторов риска, которые вызывают повторную госпитализацию. Эти прогнозы основаны на наборе данных анонимных записей о пациентах и симптомов, выставленных пациентом. Принятие решения машинным обучением происходит быстрыми темпами, несмотря на множество препятствий, которые могут быть преодолены практиками и консультантами, которые знают правовые, технические и медицинские препятствия.
- Сегментация клиентов
Сегментация клиентов, прогнозирование оттока клиентов и прогнозирование продолжительности жизни клиента (LTV) являются основными проблемами, с которыми сталкивается любой маркетолог. Предприятия располагают огромным количеством маркетинговых релевантных данных из различных источников, таких как электронная кампания, посетители сайта и данные о потенциальных клиентах. Используя интеллектуальный анализ данных и машинное обучение, можно получить точный прогноз для отдельных маркетинговых предложений и стимулов. Используя машинное обучение, опытные маркетологи могут устранить догадки, связанные с маркетингом, управляемым данными. Например, с учетом модели поведения пользователя в течение пробного периода и прошлых поведений всех пользователей можно предсказать идентификацию вероятности перехода на платную версию. Модель этой проблемы решения позволила бы программе инициировать вмешательства клиента, чтобы убедить клиента перейти на раннюю стадию или лучше участвовать в испытании.
- Финансовый анализ
Благодаря большому объему данных, количественному характеру и точным историческим данным, машинное обучение может использоваться в финансовом анализе. Существующие варианты использования машинного обучения в финансах включают алгоритмическую торговлю, управление портфелем, обнаружение мошенничества и андеррайтинг кредита. Машинное обучение может позволить проводить постоянную оценку данных для обнаружения и анализа аномалий и нюансов, чтобы повысить точность моделей и правил. Будущие приложения ML в сфере финансов включают чат-ботов и диалоговые интерфейсы для обслуживания клиентов, безопасности и анализа настроений.
- Распознавание изображений
Компьютерное зрение производит числовую или символическую информацию из изображений и многомерных данных. Он включает в себя машинное обучение, интеллектуальный анализ данных, обнаружение базы данных и распознавание образов. Потенциальное деловое использование технологии распознавания изображений можно найти в здравоохранении, автомобилях, в маркетинговых кампаниях и т.д. Компания Baidu разработала прототип DuLight для слабовидящих, который включает в себя технологию компьютерного зрения, чтобы захватить окружение и передать интерпретацию через наушник. Маркетинговые кампании, основанные на распознавании изображений, такие как Makeup Genius от L'Oreal, способствуют социальному обмену и вовлечению пользователей.
Большинство приведенных выше вариантов использования основаны на отраслевой проблеме. Эта настройка требует высококвалифицированных ученых данных или консультантов по машинному обучению. Платформы машинного обучения, без сомнения, ускорят анализ, помогая предприятиям выявлять риски и предоставлять более качественные услуги. Но качество данных является основным камнем преткновения для многих предприятий. Таким образом, помимо знания алгоритмов машинного обучения, предприятиям необходимо структурировать данные перед использованием моделей данных машинного обучения.
Стандартные эконометрические модели хорошо подходят для понимания причинно-следственных связей между различными аспектами экономики, но, когда дело доходит до прогнозирования, они имеют тенденцию «перетекать» выборки и иногда плохо обобщают новые невидимые данные.
Сосредоточив внимание на проблемах прогнозирования, модели машинного обучения могут вместо этого минимизировать ошибку прогнозирования, компенсируя смещение и дисперсию. Более того, хотя эконометрические модели лучше всего сохранять относительно простыми и легко интерпретируемыми, методы машинного обучения способны обрабатывать огромные объемы данных, часто без ущерба для интерпретации.
- Эмпирический анализ.
Вторая тема заключается в том, что ключевым преимуществом машинного обучения является то, что он рассматривает эмпирический анализ как «алгоритмы», которые оценивают и сравнивают многие альтернативные модели. Этот подход контрастирует с экономикой, где в принципе исследователь выбирает модель, основанную на принципах, и оценивает ее один раз. Третья тема касается «аутсорсинга» выбора модели по алгоритму. Хотя он достаточно хорошо справляется с «простыми» проблемами, он не очень подходит для задач, представляющих наибольший интерес для эмпирических исследователей в области экономики, таких как причинно-следственная связь, где, как правило, нет объективной оценки основной истины, доступной для сравнения. Наконец, в документе отмечается, что алгоритмы также должны быть изменены, чтобы обеспечить действительные доверительные интервалы для оценочных эффектов, когда данные используются для выбора модели.
Заключение
В данной курсовой работе я показал, как работает машинное обучение и зависимость таких дисциплин как: интеллектуальный анализ данных, добыча знаний из данных, нахождение закономерностей в базах данных. Для наглядности существующей проблемы взаимосвязи некоторых направлений искусственного интеллекта, определения были приведены из нескольких источников, и в результате сравнительного анализа построена диаграмма соотношений.
Процесс нахождения знаний состоит из таких этапов: отбор данных, очистка данных, интегрирование данных, преобразование данных, добыча знания из данных, представление знания.
Роль машинного обучения – это теоретическая поддержка, обеспечение методами и алгоритмами.
Необходимость интеллектуального анализа данных стала очевидной в первую очередь из-за огромных массивов исторической и вновь собираемой информации. Трудно, даже приблизительно, оценить объем ежедневных данных, накапливаемых различными компаниями, государственными, научными и медицинскими организациями. По мнению исследовательского центра компании GTE только научные институты собирают ежедневно около терабайта новых данных. Человеческий ум, даже такой тренированный, как ум профессионального аналитика, просто не в состоянии своевременно анализировать столь огромные информационные потоки.
Ученные ещё не знают, как сделать компьютеры обучающимися так же как обучаются люди. Однако уже придуманы алгоритмы, которые эффективны для некоторых задач обучения, и появляется теоретическое обоснование этого. Много практических компьютерных программ и важных коммерческих применений развиваются для представления наиболее распространенных видов обучения. Для таких задач как распознавание речи, методы машинного обучения подходят лучше, чем другие попытки обработки данных. В такой области как data mining, алгоритмы машинного обучения используются, как правило, в нахождении полезных знаний из больших баз данных, содержащих различного рода информацию (финансовые соглашения, медицинские записи, отчеты, и т.д.).
Таким образом, наше понимание и знание компьютеров продолжает углубляться и совершенствоваться, и это значит, что неизбежно машинное обучение будет играть все более централизованную роль в компьютерных науках и современных технологиях.
Список использованных источников
- Учебники, учебные пособия, монографии, научные издания
- Вьюгин В.В. Математические основы машинного обучения и прогнозирования / В.В. Вьюгин. — Москва: «Московский центр непрерывного математического образования», 2014. — 305 с.
- Домингос П. Математические основы машинного обучения и прогнозирования / П. Домингос. — Москва: «МАНН, ИВАНОВ И ФЕРБЕР», 2013. — 305 с.
- Бринк Х. Машинное обучение Наука и искусство построения алгоритмов, которые извлекают знания из данных / Х. Бринк, Д. Ричардс, М. Феверолф. — Санкт-Петербург: «Питер», 2017. — 330 с.
- Флах П. Машинное обучение / П. Флах. — Москва: «ДМК Пресс», 2015. — 400 с.
- Рашид Т. Создаем нейронную сеть / Т. Рашид. — Москва: «Диалектика», 2017. — 274 с.
- Андреас М. Введение в машинное обучение с помощью Python / М. Андреас, С. Гвидо. — Бостон: «O’Reilly», 2016. — 338 с.
- Рашка С. Python и машинное обучение / С. Рашка. — Москва: «ДМК Пресс», 2017. — 418 с.
- Вандер Плас Дж. Python для сложных задач. Наука о данных и машинное обучение / Дж. Вандер Плас. — Санкт-Петербург: «Питер», 2018. — 576 с.
- Бурков А. Машинное обучение без лишних слов / А. Бурков. — Санкт-Петербург: «Питер», 2020. — 192 с.
- Шалев-Шварц Шай Идеи машинного обучения / Шалев-Шварц Шай, Бен-Давид Шай — Москва: «ДМК Пресс», 2019. — 436 с.
- Траск Э. Грохаем глубокое обучение / Э. Траск. — Санкт-Петербург: «Питер», 2019. — 352 с.
- Шарден Б. Крупномасштабное машинное обучение вместе с Python / Б. Шарден, Л. Массарон, А. Боскетти. — Москва: «ДМК Пресс», 2018. — 358 с.
- Райзберг Б.А Словарь современных экономических терминов: словарь / Б.А. Райзберг, Л.Ш. Лозовский. – Москва: «ИНФРА-М», 2008. - 480 с.;
- Аникина E.A. Экономическая теория / E.A. Аникина, Л.И. Гавриленко. — Томск: «Томского политехнического университета», 2014. — 413 с.
- Балдин К.В. Информационные системы в экономике / К.В. Балдин, В.Б. Уткин. — Москва: «Издательство-торговая корпорация "Дашков и К"», 2019. — 394 с.

- Организационная культура и ее роль в современных организациях (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ИЗУЧЕНИЯ МЕТОДОВ ФОРМИРОВАНИЯ И УПРАВЛЕНИЯ ОРГАНИЗАЦИОННОЙ КУЛЬТУРОЙ)
- Банки как основные участники финансового рынка (Место и роль банков на финансовом рынке)
- Основные теории происхождения права
- Организация общественной власти в первобытном обществе (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ОРГАНИЗАЦИИ ОБЩЕСТВЕННОЙ ВЛАСТИ В ПЕРВОБЫТНОМ ОБЩЕСТВЕ )
- Развитие взглядов на управление человеческими ресурсами: сущность и характеристика
- Роль мотивации в поведении на предприятиях
- Общее понятие о гражданском праве в РФ
- Менеджмент человеческих ресурсов: сущность и функции
- Анализ внешней и внутренней среды организации (Понятие и значение внутренней и внешней среды организаци и )
- Художественно-конструкторский проект малой формы с простой функцией
- Мебель в японском стиле
- Управление ростом бизнеса (Теоретические основы управления ростом бизнеса )