
Технология построения распределенных информационных систем»
Содержание:

Введение
Современные предприятия и фирмы представляют собой сложные организационные системы, отдельные составляющие которых — основные и оборотные фонды, трудовые и материальные ресурсы и другие — постоянно изменяются и находятся в сложном взаимодействии друг с другом. Функционирование предприятий и организаций различного типа в условиях рыночной экономики поставило новые задачи по совершенствованию управленческой деятельности на основе комплексной автоматизации. Подразделения компании пронизаны вертикальными и горизонтальными связями, они обмениваются между собой информацией, а также выполняют фрагменты основного бизнес-процесса. В настоящее время в связи с усложнением процесса принятия решений в современном бизнесе успех предприятия напрямую зависит от того, как быстро и слаженно взаимодействуют его структуры. Руководители начинают отчетливо осознавать важность наличия на предприятии корпоративной информационной системы, как необходимого инструментария для успешного управления бизнесом в современных условиях. Корпоративная информационная система (КИС, EIS - Executive Information System ) – это стратегическая ИС представляющая собой совокупность технических и программных средств, реализующих идеи и методы автоматизации всех функций управления предприятием. Корпоративные ИС предназначены для обеспечения большинства бизнес-процессов всего предприятия, сбора и анализа информации о предприятии и внешней среде с целью решения задач управления предприятием как по вертикали (от первичной информации до поддержки принятия решений высшим руководством), так и по горизонтали (все направления деятельности и технологические операции). Главное, что позволяет сделать корпоративную информационную систему - объединить информацию о деятельности предприятия. В связи с этим у руководства предприятия возникают проблемы, связанные с рациональным вложением материальных и нематериальных ресурсов в систему обработки и распределения данных в корпоративной информационной системе. Ведь эффективное функционирование корпоративной информационной системы позволит предприятию добиться поставленных целей и задач, что в свою очередь повысит уровень производительности на предприятии, снизит издержки, позволит поднять уровень качества выпускаемой продукции и тем самым увеличит прибыль предприятия. Актуальность курсовой работы объясняется тем, что в настоящее время, существуют проблемы, связанные с эффективным распределением и систематизированием больших потоков информации, как внутри организации, так и за ее пределами. Для решения этих проблем необходимо внедрение распределенных систем обработки данных. Целью распределенной обработки информации является оптимизация использования ресурсов и упрощение работы пользователя. Цель курсовой работы – рассмотреть процедуры функционирования распределенных систем обработки данных в корпоративных информационных системах. В связи с поставленной целью в курсовой работе определены следующие задачи: 1. Дать характеристику понятию распределенной обработки данных; 2. Раскрыть сущность централизованной и децентрализованной организации данных; 3. Раскрыть основные виды технологии распределенной обработки данных; 4. Рассмотреть подробно технологию «клиент-сервер». Объектом курсовой работы являются корпоративные информационные системы. Предметом является изучение видов распределенных систем обработки данных в корпоративных информационных системах, а также процессов их функционирования. Практическое значение работы состоит в том, чтобы показать какие виды распределенных систем обработки данных существуют, чтобы российские предприятия, которые не имеют опыта в обращении с такими системами, смогли внедрить их в свою деятельность, что даст возможность им более эффективно адаптироваться в рыночных условиях. Курсовая работа состоит из введения, трех глав, заключения и списка использованных источников.
1. Общая характеристика распределенных систем обработки данных
Понятие распределительной обработки данных
В корпоративных информационных системах часто возникает потребность в распределенном хранении общей базы данных. Разумно, например, хранить некоторую часть информации как можно ближе к тем рабочим местам, в которых она чаще всего используется. По этой причине при построении информационной системы приходится решать задачу согласованного управления распределенной базой данных. При использовании сетевых информационных технологий становится возможной реализация территориального распределения производства. Для администрации фирмы становится безразлично, где именно находится производство: в этом здании, за 100 м или за 10 000 км. Появляются совсем другие проблемы, такие как межконтинентальное снабжение, поясное время и т.д., поскольку становится возможным планетарное распределение промышленного производства. Могут создаваться транснациональные компании, реализующие мировой товарный экспорт внутри фирмы. При этом метрополия, вложив 5–7% от суммы оборота в экономику другой страны, получает возможность контролировать 50–60% ее экономики. Объясняется это тем, что за счет вложения наукоемких технологий страна-метрополия получает возможность оказывать влияние и даже осуществлять контроль за экономическим и политическим развитием другой страны. Например, 80% всех международных кредитных операций совершают банки США. Инвалютные резервы центральных банков западных стран на 75% состоят из американских долларов, а 55% расчетов по международной торговле реализуется американскими долларами, т.е. США расплачиваются воспроизводимыми ресурсами: информационными технологиями, научно-техническими знаниями, долларами. Это становится возможным благодаря новейшим сетевым технологиям и развитию коммуникаций [7]. Одной из важнейших сетевых технологий в корпоративных информационных системах является распределенная обработка данных. Распределенная обработка данных - это обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему. Сущность ее заключается в том, что пользователь получает возможность работать с сетевыми службами и прикладными процессами, расположенными в нескольких взаимосвязанных абонентских системах. При этом возможны несколько видов работ, которые он может выполнять: - удаленный запрос, например, команда, позволяющая посылать одиночную заявку на выполнение обработки данных; - удаленная трансакция, осуществляющая направление группы запросов прикладному процессу; - распределенная трансакция, дающая возможность использования нескольких серверов и прикладных процессов, выполняемых в группе абонентских систем [17]. Для распределенной обработки осуществляется сегментация прикладных программ - разделение сложной прикладной программы на части, которые могут быть распределены по системам локальной сети. Сегментация осуществляется с помощью специального инструментального программного обеспечения, которое автоматизирует рассматриваемый процесс. С помощью технологии, предоставляемой объектно-ориентированной архитектурой, в результате выполнения указанного процесса прикладная программа делится на самостоятельные части, загружаемые в различные системы. Благодаря этому, создается возможность перемещения программ из одной системы в другую и распределенной обработки данных. В результате сегментации каждая выделенная часть программы включает управление данными, алгоритм и блок презентации. Благодаря этому, она может быть оптимальным образом выполнена на основе платформ, используемых в сети. Передача данных для распределенной обработки происходит при помощи удаленного вызова процедур либо электронной почты. Первая технология характеризуется высоким быстродействием, а вторая - низкой стоимостью. Удаленный вызов процедур работает аналогично местному вызову процедур и обеспечивает организацию обработки данных. Этой цели служит механизм навигации в сети, поиска информации, запуска процесса в нескольких системах, передачи полученных результатов пользователям, пославшим запросы. Выполняемый процесс характеризуется прозрачностью, благодаря которой объекты сети, расположенные между пользователями и программами не видны обоим партнерам [8]. Выполнение удаленного вызова процедур является дорогостоящей операцией, ибо на все время ее выполнения системы, участвующие в работе, должны по каналам передавать данные друг другу. Альтернативной удаленного вызова является применение интеллектуальных агентов или выполнение распределенной обработки данных с использованием электронной почты. Этот метод не требует больших затрат, но работает значительно медленнее [2]. Формализация концептуальной схемы данных повлекла за собой возможность к классификации моделей представления данных на иерархические, сетевые и реляционные. Это отразилось в понятии архитектуры систем управления базами данных и технологии обработки. Архитектура СУБД описывает ее функционирование как взаимодействие процессов двух типов клиента и сервера. Распределенная обработка и распределенная база данных не является синонимами. Если при распределенной обработке производится работа с базой, то подразумевается, что представление данных, их содержательная обработка, работа с базой на логическом уровне выполняются на персональном компьютере клиента, а поддержание базы в актуальном состоянии – на файл-сервере. Если речь идет о распределенной базе данных, она размещается на нескольких серверах. Работа с ней осуществляется на тех же персональных компьютерах или на других, и для доступа к удаленным данным надо использовать сетевую СУБД [5]. В системе распределенной обработки клиент может послать запрос к собственной локальной базе или удаленной. Удаленный запрос – это единичный запрос к одному серверу. Несколько удаленных запросов к одному серверу объединяются в удаленную транзакцию. Если отдельные запросы транзакции обрабатываются различными серверами, то транзакция называется распределенной. При этом один запрос транзакции обрабатывается одним сервером. Распределенная СУБД позволяет обрабатывать один запрос несколькими серверами. Такой запрос называется распределенным. Только обработка распределенного запроса поддерживает концепцию распределенной базы данных. При распределенной обработке данных все подразделения компании, находящиеся в разных местах, соединены в единую сеть. Каждое из них имеет средства и возможности самостоятельно обрабатывать свои данные, поэтому пользуется преимуществами децентрализованной обработки. В то же время локальные компьютеры из разных мест могут посылать данные на центральную ЭВМ для подведения итогов и пользоваться общими данными компании, находящимися на ней, поэтому распределенная обработка дает и преимущества централизованной системы. В результате получается система, ориентированная как на нужды пользователей, так и на нужды руководства компании [8]. Преимущества распределенной обработки данных: - большое число взаимодействующих пользователей, выполняющих функции сбора, регистрации, хранения, передачи и выдачи информации; - снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз данных на разных ЭВМ; - обеспечение симметричного обмена данными между удаленными пользователями; - улучшение качества производимой информации; - быстрота и точность ввода и корректировки данных, быстрое получение ответов на запросы;
- уменьшение затрат на коммуникации, т.к. обработка производится локально. Поскольку данные и другие ресурсы находятся в разных местах и частично дублируются, компьютеры как бы страхуют друг друга, уменьшая вероятность катастрофических потерь. Каждая локальная система может рассматриваться как модуль общей системы, который может быть добавлен, модифицирован или удален из системы без необходимости изменять другие модули. Достоинства порождают и недостатки: - распределенные системы более дороги, чем централизованные; - намного усложняются задачи обслуживания оборудования, программного обеспечения, поддержания данных в необходимом состоянии; - поскольку данные принадлежат разным подразделениям, неизбежно их дублирование со всеми вытекающими последствиями от использования такой информации, поэтому возникает необходимость специальных процедур по согласованию содержимого общих частей баз данных; - распределение полномочий и зон ответственности в такой системе, намного усложняется процесс документирования и контроля; - разбросанность частей системы в пространстве и наличие коммуникаций снижают возможности обеспечения безопасности; - уменьшается информационная насыщенность каждой отдельной локальной системы, поскольку вся информация, которая присуща централизованным системам, не может быть продублирована на всех компьютерах [11]. Распределенная обработка данных позволила повысить эффективность удовлетворения изменяющейся информационной потребности информационного работника и тем самым обеспечить гибкость принимаемых им решений [3].
2.1 Способы организации обработки данных
В зависимости от способа распределения данных, выделяют следующие способы организации обработки данных: • централизованный; • децентрализованный; • смешанный. 1. Централизованная организация данных. Централизованная организация данных является самой простой для реализации (рис. 1). На одном сервере находится единственная копия базы данных. Все операции с базой данных обеспечиваются этим сервером. Доступ к данным выполняется с помощью удаленного запроса или удаленной транзакции [14]. Достоинством такого способа является легкая поддержка базы данных в актуальном состоянии, а недостатком — то, что размер базы ограничен размером внешней памяти; все запросы направляются к единственному серверу с соответствующими затратами на стоимость связи и временную задержку. Отсюда - ограничение на параллельную обработку.
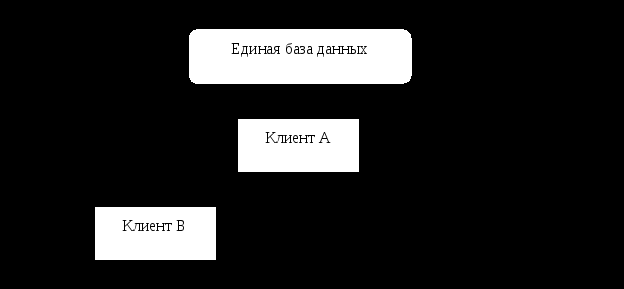
Рисунок 1: Централизованная организация данных.
Централизованная сеть обрабатывает данные в одном месте, используя мощный компьютер и сложное программное обеспечение, установленное только на нем. Терминалы пользователей и автоматизированные устройства ввода первичных документов посылают данные на центральную ЭВМ для обработки, которая, если необходимо, предоставляет на терминалы обработанные данные. Преимуществами такого подхода являются меньшие затраты, лучший контроль за данными и программами (поскольку они находятся в одном месте), большая безопасность (терминалы лишены возможности сохранять данные), отсутствие дублирования данных и операций по их обработке, лучшее использование квалифицированного персонала (который может сосредоточиться на обслуживании данных и программ на одном компьютере), простота модификации системы (все изменения делаются в одном месте) [22]. Среди недостатков - большая сложность эксплуатации, высокие затраты на коммуникации (при большой удаленности терминалов) и программное обеспечение (выше требования к нему), значительно меньшая гибкость и как следствие - большая вероятность, что система не будет удовлетворять требованиям всех пользователей [19].
2. Децентрализованная организация данных
Децентрализованная организация данных предполагает разбиение информационной базы на несколько физически распределенных. Каждый клиент пользуется своей базой данных, которая может быть либо частью общей информационной базы (рис. 2), либо копией информационной базы в целом, что приводит к ее дублированию для каждого клиента [25]. При распределении данных на основе разбиения база данных размещается на нескольких серверах. Существование копий отдельных частей недопустимо. Достоинства этого метода: большинство запросов удовлетворяются локальными базами, что сокращает время ответа; увеличиваются доступность данных и надежность их хранения; стоимость запросов на выборку и обновление снижается по сравнению с централизованным распределением; система останется частично работоспособной, если выйдет
из строя один сервер.
База данных A
Клиент C
Клиент B
Клиент А
Клиент D
База данных B
База данных C
База данных D
Рисунок 2: Децентрализованная организация данных способом распределения.
Имеются и недостатки: часть удаленных запросов или транзакций может потребовать доступ ко всем серверам, что увеличивает время ожидания и цену обслуживания; необходимо иметь сведения о размещении данных в различных БД. Однако доступность и надежность увеличатся. Расчлененные базы данных наиболее подходят к случаю совместного использования локальных и глобальных сетей ЭВМ [13]. Способ дублирования заключается в том, что в каждом сервере сети ЭВМ размещается полная база данных. Это обеспечивает наибольшую надежность хранения данных (рис. 3) [7]. Недостатки способа: повышенные требования к объему внешней памяти; усложнение корректировки баз, так как требуется синхронизация в целях согласования копий. Достоинства — все запросы выполняются локально, что обеспечивает быстрый доступ. Данный способ используется, когда фактор надежности является критическим, база небольшая, интенсивность обновления невелика. Многие из этих недостатков устраняются децентрализованными системами, в которых данные хранятся и обрабатываются независимо в разных местах. При этом на каждом компьютере хранится какое-то подмножество всех данных компании (в зависимости от назначения и места расположения ЭВМ), а часть данных (необходимая всем ЭВМ) находится в нескольких местах. Однако в таких системах ощущается недостаток контроля за данными, находящимися в разных местах, координации между компьютерами, доступности информации (разная информация может находится в разных местах), проблема дублирования функций [6].
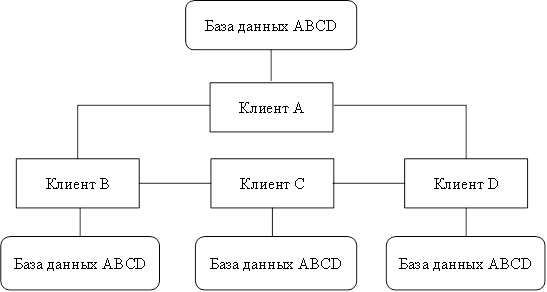
Рисунок 3 Децентрализованная организация данных способом дублирования.
3. Смешанная организация хранения данных.
Возможна и смешанная организация хранения данных, которая объединяет два способа распределения: распределение и дублирование (рис. 4), приобретая при этом и преимущества, и недостатки обоих способов. Появляется необходимость хранить информацию о том, где находятся данные в сети. При этом достигается компромисс между объемом памяти под базу в целом и под базу в каждом сервере, чтобы обеспечить надежность и эффективность ее работы; легко реализуется параллельная обработка. Несмотря на гибкость смешанного способа организации данных, остается проблема взаимозависимости факторов, влияющих на производительность системы, проблема ее надежности и выполнения требований к памяти. Смешанный способ организации данных можно использовать лишь при наличии сетевой СУБД [10]. В базах данных коллективного пользования центральным технологическим звеном становятся серверы баз данных.
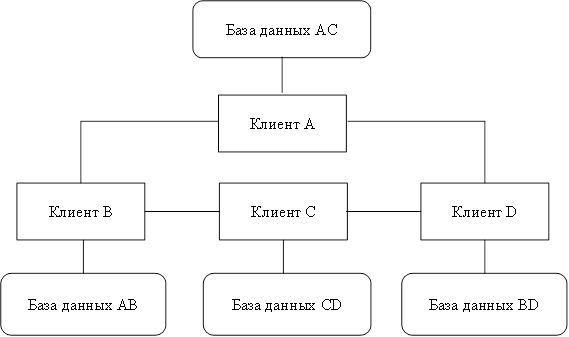
Рисунок 4 Смешанная организация данных.
Программные средства серверов баз данных обеспечивают реализацию многопользовательских приложений, централизованное хранение, целостность и безопасность данных. Производительность серверов баз данных на порядок выше по сравнению с файл-серверами, которые используются в локальных сетях. Локальные вычислительные сети создавались для совместного использования дорогостоящего периферийного оборудования. Использование сервера баз данных обеспечило доступ многих пользователей к одним и тем же файлам. Это и стало предпосылкой создания сетевых СУБД. Мощность сетевых СУБД, основанных на файл-сервере, в настоящее время недостаточна. В нагруженной сети неизбежно падает производительность, нарушаются безопасность и целостность данных. Проблема производительности возникла не потому, что процессоры не обладают достаточной мощностью, а потому что файл-серверы реализуют принцип «все или ничего». Полные копии файлов базы перемещаются взад-вперед по сети. Проблемы с безопасностью, целостностью возникли из-за того, что с самого начала файл-серверы не были сконструированы с учетом сохранения целостности данных и их восстановления в случае аварии [4]. Централизация процессов обработки данных позволила устранить такие недостатки, как несвязность, противоречивость и избыточность данных в информационной системе, обеспечила возможность комплексно решать вопросы стандартизации в представлении данных, обеспечения
санкционированного доступа к ним и др. Однако по мере роста БД
использование их в территориально разнесенных организациях привело к тому, что централизованная СУБД, находящаяся в узле
телекоммуникационной сети, обеспечивающей доступ пользователей из территориально разнесенных пунктов к хранимым данным, стала плохо справляться с ростом числа обрабатываемых транзакций в связи с большим потоком обмена данными между терминалами и центральной ЭВМ. Такая ситуация привела к снижению надежности и общей производительности системы при обработке запросов пользователей. Поэтому была предложена идея децентрализации процессов обработки данных в информационных системах для организаций, подразделения которых разнесены. И хотя децентрализация данных затрудняет решение таких вопросов, как обеспечение целостности и непротиворечивости данных, их безопасности, тем не менее она позволяет повысить производительность обработки, улучшить использование данных на местах и снизить затраты на их обработку [9]. Но существует ряд факторов, естественным образом приводящих к необходимости централизации данных. Например, если данные используются централизованными приложениями (например, такими, как снабжение или производственное управление); пользователям во всех подразделениях требуются одни и те же данные, причем эти данные часто обновляются; система должна обрабатывать запросы, для которых данные, возникающие в различных подразделениях, рассматриваются в логическом плане как одно целое; имеется большой объем данных общего назначения; необходима защита данных; пользователи определенных данных часто перемещаются с места на место и др. [20]. В одной и той же системе одни данные могут быть централизованными, а другие децентрализованными. Поэтому основная задача, которую приходится решать при проектировании распределенной БД, — это распределение данных по сети. Существуют следующие способы ее решения:
1. В каждом узле сети хранится и используется собственная БД, однако хранимые в ней данные доступны для других узлов сети;
2. Все данные распределенной БД полностью дублируются в каждом узле сети;
3. Хранимые в центральном узле сети данные частично дублируются в тех периферийных узлах, в которых они интенсивно используются [23]. Децентрализованная обработка данных помимо задачи распределения их по сети выдвигает ряд новых требований по сравнению с централизованной:
- распределенные БД могут быть однородными или неоднородными в смысле используемых в системе технических и программных средств (СУБД), поэтому должна быть решена проблема преобразования структур данных и ПП; - чтобы обеспечивать пользователю логическую прозрачность данных по всей базе, необходима единая концептуальная схема для всей сети, содержащая информацию о местонахождении данных в сети; - должен быть решен вопрос о декомпозиции запроса пользователя на отдельные составные части, которые могут пересылаться для выполнения в разные узлы сети в зависимости от места хранения данных и складывающейся на момент обработки запроса операционной обстановки в сети (при этом должна быть обеспечена координация процессов обработки); - необходимо обеспечить синхронизацию процессов обновления и обработки копий данных, защиту данных и их восстановление, управление словарями данных и т.д.[15]. Исследования в США показывают, что 90% крупных компаний либо уже имеют распределенные сети, либо планируют перейти от использования больших ЭВМ к сети мощных микроЭВМ. Причины перехода на меньшие платформы - уменьшение затрат, ускорение доступа к данным и разработки приложений. В России на базе больших ЭВМ существует небольшое количество больших централизованных систем обработки данных, созданных в крупных организациях, а вновь нарождающаяся инфраструктура сразу создается с использованием сетей микроЭВМ [1].
2. Технологии распределенной обработки данных
2.1 Основные виды технологии распределенной обработки данных
Проблема выбора между централизованной и распределенной моделями предоставления вычислительных ресурсов является одной из центральных проблем организации вычислительных систем. До середины 70 х годов прошлого века по причине высокой стоимости телекоммуникационного оборудования и относительно слабой мощности вычислительных систем доминировала централизованная модель. В конце 70-х годов появление систем разделения времени и удаленных терминалов, явилось предпосылкой возникновения клиент-серверной архитектуры, обеспечивающей предоставление ресурсов конечным пользователям посредством удаленного соединения. Дальнейшее развитие телекоммуникационных систем и появление персональных компьютеров дало толчок развитию клиент-серверной парадигме обработки данных. Многообразие компьютерных сетей и форм взаимодействия ПК порождает насущную проблему их интеграции или, по крайней мере, соединения на уровне обмена сообщениями [6]. К основным видам технологии распределенной обработки данных относятся следующие: - технология клиент-сервер, ориентированная на автономный компьютер, т.е. и клиент, и сервер размещены на одной ЭВМ. По функциональным возможностям такая система аналогична централизованной СУБД; - технология клиент-сервер, ориентированная на централизованное распределение. Клиент получает доступ к данным одиночного удаленного сервера, данные могут только считываться, динамический доступ к данным реализуется посредством удаленных транзакций и запросов, число которых должно быть невелико; - технология клиент-сервер, ориентированная на локальную вычислительную сеть. Имеется единственный сервер, который обеспечивает доступ к БД; клиент формирует процесс, отвечающий за содержательную обработку данных, их представление и логический доступ к базе; доступ к базе данных замедлен, так как клиент и сервер связаны через локальную сеть; - технология клиент-сервер, ориентированная на изменения данных в одном месте; реализует обработку распределенной транзакции; удаленные серверы не связаны между собой сетью ЭВМ; распределенная СУБД должна иметь средство контроля совпадения противоречивых запросов; распределение данных реализует метод разделения; - технология клиент-сервер, ориентированная на изменение данных в нескольких местах, предполагает наличие сервера-координатора, поддерживающего протокол передачи данных между различными серверами; возможна обработка распределенных транзакций в разных удаленных серверах; реализуется стратегия смешанного распределения путем передачи копий с помощью СУБД; - технология клиент-сервер, ориентированная на распределенную СУБД, обеспечивает стратегию разбиения и дублирования, обеспечивает более быстрый доступ к данным; распределенная СУБД обеспечивает независимость клиента от места размещения сервера, глобальную оптимизацию, распределенный контроль целостности БД, распределенное административное управление [9]. Во всех перечисленных технологиях существуют два способа связи прикладных программ клиента и сервера баз данных: - прямое соединение – прикладная программа клиента связывается непосредственно с сервером базы данных; - непрямое соединение – доступ к удаленному серверу обеспечивается средствами локальной базы . Возможно объединение обоих способов [12].
Использование технологии клиент-сервер позволяет перенести часть работы с сервера на компьютер клиента, оснащенный инструментальными средствами для формирования его профессиональных обязанностей. Тем самым данная технология позволяет независимо наращивать возможности сервера баз данных и совершенствовать инструментальные средства клиента [14]. Недостатки технологии клиент-сервер заключается в повышении требований к производительности ЭВМ – сервера, в усложнении управления вычислительной сетью, а при отсутствии сетевой СУБД – в сложности организации распределенной обработки. Под операционной средой сервера баз данных понимают возможности ОС компьютера и сетевой ОС. Каждый сервер баз данных может работать на определенном типе компьютера и сетевой ОС. К операционным системам серверов относятся: DOS 5/0, XENIX, UNIX, Windows NT, Os/2 и др. В настоящее время наиболее часто используются следующие серверы: SQL-server, ORACLE-server, SQLBASE- server и др. [16]. Серверы баз данных рассчитаны на поддержку большого числа различных типов приложений. Для реализации интерфейса с сервером базы данных можно использовать объектно-ориентированные средства, электронные таблицы, текстовые процессоры, графические пакеты, настольные издательства и другие информационные технологии [7].
2.2 Технология «клиент-сервер»
«Клиент-сервер» - это вид распределенной системы, в которой есть сервер, выполняющий запросы клиента, причем сервер и клиент общаются между собой с использованием того или иного протокола. Под клиентом понимается программа, использующая ресурсы, а под сервером программа, обслуживающая запросы клиентов на получение ресурсов определенного вида. Столь широкое определение включает в себя практически любую программную технологию, в которой участвуют больше одной программы, функции между которыми распределены асимметрично [18]. Существует два подхода к распределению обязанностей между сервером и клиентом при выполнении запросов к базам данных. При использовании технологии файлового сервера клиент делает запрос, сервер передает ему необходимые для выполнения запроса файлы, после чего клиент выбирает из этих файлов нужную информацию. В этом случае львиная доля работы ложится на клиента, по каналам связи передается большое количество данных, большая часть из которых на самом деле не появляется в ответе на запрос. Другой подход - технология «клиент-сервер» - предусматривает, что отбор данных для ответа на запрос делается сервером, а клиенту передается только результат - те данные, которые были запрошены. На рисунке 5 показан процесс обмена информацией между сервером и клиентом при выполнении одного из запросов. При работе с файл-серверной версией вся ответственность за сохранность и целостность базы данных лежит на программе и сетевой операционной системе. Обработка всех данных происходит на рабочих местах, а сервер используется только как разделяемый накопитель. Каждый пользователь непосредственно использует информацию и вносит изменения в файлы данных и в индексные файлы [20].
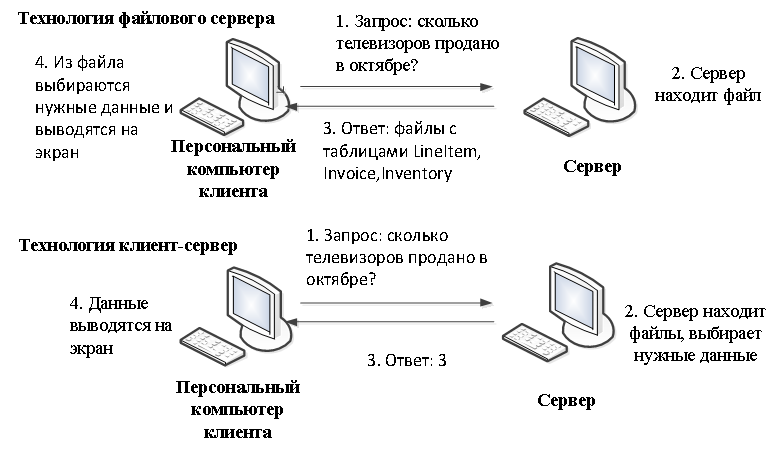
Рисунок 5: Сравнение технологий файлового сервера и «клиент-сервера».
При больших объемах данных и работе в многопользовательском режиме существенно снижается быстродействие - ведь чем больше пользователей, тем выше требования к разделению данных. Кроме того, может возникнуть повреждение баз данных. Например, в момент записи в файл может возникнуть сбой сети или авария питания. В этом случае компьютер пользователя прерывает работу, база данных может оказаться поврежденной, а индексный файл - разрушенным. Переиндексация, которую необходимо провести после подобных сбоев, может длиться несколько часов [12]. Клиент-серверная версия позволяет обойти эти проблемы, так как вся работа с базой данных происходит на сервере, не проходит по проводам и не зависит от сбоев на рабочих станциях. Все запросы на запись в файл перехватываются сервером. В файл изменения вносятся только после того, как сервер получит сообщение о том, что корректировка файла завершена. Это исключает повреждение индексных файлов и существенно повышает быстродействие системы. Кроме высокого быстродействия и надежности, архитектура «клиент-сервер» дает много преимуществ и в части технического обеспечения. Во-первых, сервер оптимизирует выполнение функций обработки данных, что избавляет от необходимости оптимизации рабочих станций. Рабочая станция может быть укомплектована не очень быстрым процессором, и, тем не менее, сервер позволит быстро получить результаты обработки запроса. Во-вторых, поскольку рабочие станции не обрабатывают все промежуточные данные, существенно снижается нагрузка на сеть. Появляется возможность ведения журнала операций, в котором автоматически регистрируются все прошедшие транзакции что, в свою очередь, поможет быстрому восстановлению системы при аппаратных сбоях [21]. Различают двухуровневую и трехуровневую модель «клиент-сервер». Hа рисунке 6 представлена двухуровневая модель «клиент-сервер». Эта модель, возможно, наиболее общая, поскольку она подобна схеме разработки локальных баз данных. Многие системы «клиент-сервер», используемые сегодня, развились из существующих локальных приложений базы данных, которые хранят свои данные в файле на сервере. Перенос систем осуществляется для повышения эффективности работы, защищенности и надежности базы данных [3]. Преимущества: - делает возможным, в большинстве случаев, распределение функций вычислительной системы между несколькими независимыми компьютерами. Это позволяет упростить обслуживание вычислительной системы. В частности, замена, ремонт, модернизация или перемещение сервера не затрагивают клиентов. Все данные хранятся на сервере, который, как правило, защищён гораздо лучше большинства клиентов. На сервере проще обеспечить контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа; - позволяет объединить различные клиенты. Использовать ресурсы одного сервера часто могут клиенты с разными аппаратными платформами, операционными системами и т. п. [24].
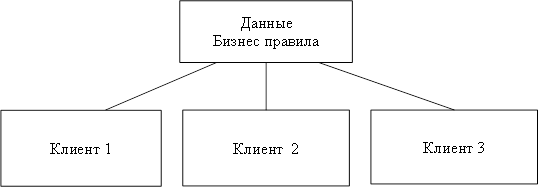
Рисунок 6: Двухуровневая модель «клиент-сервер».
Недостатки: - неработоспособность сервера может сделать неработоспособной всю вычислительную сеть; - поддержка работы данной системы требует отдельного специалиста — системного администратора; - высокая стоимость оборудования [5]. В такой модели данные постоянно находятся на сервере, а клиентные приложения на своем компьютере. Бизнес-правила при этом могут располагаться на любом из компьютеров (или даже на обоих одновременно). Трехуровневая архитектура клиент-сервер — разновидность модели «клиент-сервер», в которой функция обработки данных вынесена на один или несколько отдельных серверов. Это позволяет разделить функции хранения, обработки и представления данных для более эффективного использования возможностей серверов и клиентов [24]. Достоинства: - масштабируемость; - конфигурируемость — изолированность уровней друг от друга позволяет (при правильном развертывании архитектуры) быстро и простыми средствами переконфигурировать систему при возникновении сбоев или при плановом обслуживании на одном из уровней; - высокая безопасность; - высокая надёжность; - низкие требования к скорости канала (сети) между терминалами и сервером приложений; - низкие требования к производительности и техническим характеристикам терминалов, как следствие снижение их стоимости. Терминалом может выступать не только компьютер, но и, например, мобильный телефон [20]. Недостатки вытекают из достоинств. По сравнению c клиент-серверной или файл-серверной архитектурой можно выделить следующие недостатки трёхуровневой архитектуры: - более высокая сложность создания приложений; - сложнее в разворачивании и администрировании; - высокие требования к производительности серверов приложений и сервера базы данных, а, значит, и высокая стоимость серверного оборудования; - высокие требования к скорости канала (сети) между сервером базы данных и серверами приложений. На рисунке 7 показана трехуровневая модель «клиент-сервер». Здесь клиент это пользовательский интерфейс к данным, а данные находятся на удаленном сервере. Клиентное приложение делает запросы для получения доступа или изменения данных через сервер. Если клиент, сервер и бизнес-правила распределены по отдельным компьютерам, разработчик может оптимизировать доступ к данным и поддерживать их целостность во всей системе. Технология клиент-сервер — это особый способ взаимодействия компьютеров в локальной сети, при котором один из компьютеров (сервер) предоставляет свои ресурсы другому компьютеру (клиенту). В соответствии с этим различают одноранговые сети и серверные сети [12].
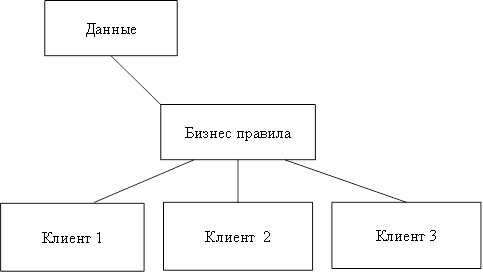
Рисунок 7: Трехуровневая модель «клиент-сервер».
При одноранговой архитектуре в сети отсутствуют выделенные серве-ры, каждая рабочая станция может выполнять функции клиента и сервера. В этом случае рабочая станция выделяет часть своих ресурсов в общее пользование всем рабочим станциям сети. Как правило, одноранговые сети создаются на базе одинаковых по мощности компьютеров. Одноранговые сети являются достаточно простыми в наладке и эксплуатации. В том случае, когда сеть состоит из небольшого числа компьютеров и ее основной функцией является обмен информацией между рабочими станциями, одноранговая архитектура является наиболее приемлемым решением [3]. Наличие распределенных данных и возможность изменения своих серверных ресурсов каждой рабочей станцией усложняет защиту информации от несанкционированного доступа, что является одним из недостатков одноранговых сетей. Понимая это, разработчики начинают уделять особое внимание вопросам защиты информации в одноранговых сетях. Другим недостатком одноранговых сетей является их более низкая производительность. Это объясняется тем, что сетевые ресурсы сосредоточены на рабочих станциях, которым приходится одновременно выполнять функции клиентов и серверов. В серверных сетях осуществляется четкое разделение функций между компьютерами: одни их них постоянно являются клиентами, а другие — серверами. Учитывая многообразие услуг, предоставляемых компьютер-ными сетями, существует несколько типов серверов, а именно: сетевой сервер, файловый сервер, сервер печати, почтовый сервер и др. Сетевой сервер представляет собой специализированный компьютер, ориентиро-ванный на выполнение основного объема вычислительных работ и функций по управлению компьютерной сетью. Этот сервер содержит ядро сетевой операционной системы, под управлением которой осуществляется работа всей локальной сети. Сетевой сервер обладает достаточно высоким быстродействием и большим объемом памяти. При подобной сетевой организации функции рабочих станций сводятся к вводу-выводу информации и обмену ею с сетевым сервером [18]. Термин файловый сервер относится к компьютеру, основной функцией которого является хранение, управление и передача файлов данных. Он не обрабатывает и не изменяет сохраняемые и передаваемые им файлы. Сервер может "не знать", является ли файл текстовым документом, графическим изображением или электронной таблицей. В общем случае на файловом сервере может даже отсутствовать клавиатура и монитор. Все изменения в файлах данных осуществляются с клиентских рабочих станций. Для этого клиенты считывают файлы данных с файлового сервера, осуществляют необходимые изменения данных и возвращают их обратно на файловый сервер. Подобная организация наиболее эффективна при работе большого количества пользователей с общей базой данных. В рамках больших сетей может одновременно использоваться несколько файловых серверов. Сервер печати (принт-сервер) представляет собой печатающее устройство, которое с помощью сетевого адаптера подключается к передающей среде. Подобное сетевое печатающее устройство является самостоятельным и работает независимо от других сетевых устройств. Сервер печати обслуживает заявки на печать от всех серверов и рабочих станций. В качестве серверов печати используются специальные высокопроизводительные принтеры. При высокой интенсивности обмена данными с глобальными сетями в рамках локальных сетей выделяются почтовые серверы, с помощью которых обрабатываются сообщения электронной почты. Для эффективного взаимодействия с сетью Internet могут использоваться Web-серверы [12].
3. Аппаратное и программное обеспечение распределенной обработки данных
3.1 Интегрированные информационные технологии
Применительно к информационной среде «интеграцию» понимают как совокупность разнородных, порой территориально разъединенных, аппаратных и программных средств, систем и устройств, объединенных, как правило, в информационные сети с доступными пользователям внутренними и внешними информационными ресурсами и приложениями. Такая технология расширяет базовые и функциональные возможности компьютерных информационных ресурсов и систем. С точки зрения пользователей, основная проблема заключается в слабой структурированности информации, сложности поиска, доступа, публикации и навигации. Решить проблему можно путем создания интегрированной функционально полной информационной среды [12]. В распределённых системах используются три интегрированные технологии: 1. «клиент-сервер»; 2. совместного использования ресурсов в глобальных сетях;
3. универсального пользовательского общения в виде электронной почты. Наиболее часто данные размещаются в базах данных (БД). Ими обычно управляют локальные СУБД, то есть размещенные на том же компьютере. Такая отличительная особенность баз данных, как многоцелевое параллельное использование данных, предопределяет наличие средств, обеспечивающих практически одновременный и независимый доступ к одним и тем же данным. Причем сама база может быть размещена на одном или нескольких компьютерах. Когда несколько локальных БД удалены друг от друга на большие расстояния, то возникает необходимость решения задач управления ими, то есть распределенными БД. Для решения таких задач между ЭВМ с локальными СУБД и базами данных организуют сеть передачи данных по каналам связи, а в ней обеспечивают техническую и программную поддержку обмена данными. То есть в этом случае используют распределенную среду обработки данных, включающую аппаратное и программное обеспечение, управляющее распределенными базами данных, которые могут образовывать банки данных [10]. Распределенная среда обработки данных или среда распределенных вычислений (англ. «Distributed Computing Environment», DCE) – это технология распределенной обработки данных, представляющая собой стандартный набор сетевых служб для выполнения прикладных процессов, рассредоточенных по группе абонентских систем (по гетерогенной сети). Распределенная обработка данных (англ. «Distributed Data Processing», DDP) – это методика выполнения прикладных программ группой систем. При этом пользователь получает возможность работать с сетевыми службами и прикладными процессами, расположенными в нескольких взаимосвязанных абонентских системах [13]. Практически с момента возникновения компьютеров предпринимались попытки объединения большого количества вычислительных ресурсов. Реальная возможность для такого объединения появилась в конце XX столетия. Она обусловлена развитием компьютерных архитектур, непрерывным ростом производительности, улучшением пропускной способности коммуникационных сред, а также новыми технологиями разработки программ. Совместное использование ресурсов в глобальных сетях позволяет осуществлять распределенные вычисления, способствующие существенному сокращению времени вычислений и получения результата вычислений. Для реализации такой задачи создана технология Grid (с англ. «сетка»). Термин аналогичен термину «электрическая сеть» (англ. «power grid»), предоставляющему всепроникающий доступ к источникам электроэнергии, но вместо электричества предоставляются вычислительные мощности. Grid оценивается как инфраструктура, способная фундаментально изменить представление о вычислительных сетях и их возможностях. В GRID интегрируется большой объем географически удаленных компьютерных ресурсов, при этом пользователя не интересует где находятся используемые им ресурсы. IBM анонсировала эту технологию в 2003 г. GRID – это распределенная программно-аппаратная компьютерная среда, с принципиально новой организацией вычислений и управления потоками заданий и данных. Она предназначена для объединения вычислительных мощностей различных организаций. Важнейшим компонентом GRID-инфраструктуры является промежуточное программное обеспечение (англ. «middleware»), предназначенное управлять заданиями, обеспечивать безопасный доступ к данным большого объема в универсальном пространстве имен, перемещать и тиражировать данные с высокой скоростью из одного географически удаленного узла на другой и организовывать синхронизацию удаленных копий [16].
На основе технологии GRID формируются региональные и национальные вычислительные компьютерные инфраструктуры с целью создания объединенных интернациональных ресурсов, доступных широкому кругу пользователей и предназначенных для решения крупных научно-технических задач [10]. Совместное использование данных в процессе коллективной деятельности зачастую приводило к серьезным негативным последствиям. Для решения этой проблемы стали разрабатывать комплексы различных информационных технологий с общими данными (интегрированными информационными ресурсами), направленные на выработку единых и эффективных для организаций и процессов методов применения этих технологий. Под интеграцией информационных ресурсов понимается их объединение с целью использования различной информации с сохранением ее свойств, особенностей представления и пользовательских возможностей манипулирования с ней. При этом объединение ресурсов может быть как физическим, так и виртуальным. Главное – оно должно обеспечивать пользователю восприятие доступной информации как единого (интегрированного) информационного пространства. Объединение различных компьютерных и офисных информационных технологий приводит к их интеграции. Технологическое взаимодействие совокупности объектов, образуемых устройствами передачи, обработки, накопления и хранения, защиты данных, представляет собой интегрированные компьютерные системы обработки данных большой сложности. Интегрированные компьютерные системы обработки данных проектируются как сложный информационно-технологический и программный комплекс. Он поддерживает единый способ представления данных и взаимодействия пользователей с компонентами системы, обеспечивает информационные и вычислительные потребности различных категорий пользователей, например, специалистов в их профессиональной работе [25]. Основным способом решения такой проблемы стала интеграция информационных технологий, на основе обеспечения коммуникационной совместимости отдельных программных средств, с информационными ресурсами, поддерживаемыми разными инструментальными средствами. Интеграция информационных технологий включает: распределенные системы обработки данных; технологии «клиент-сервер»; информационные хранилища; системы электронного документооборота; геоинформационные системы; глобальные системы; системы групповой работы; корпоративные информационные системы. Сначала создавались специальные программы, осуществляющие преобразование данных из одного формата хранения в другой (конверторы). Затем были разработаны интегрированные программные пакеты, позволяющие в рамках одной программы реализовать нескольких функций с установлением внутренних информационных связей между ними (офисные программные пакеты). В типовом варианте они включают: текстовый процессор, табличный процессор, СУБД, система управления коммуникациями. Параллельно создавалась единая интегрирующая среда, в качестве которой использовались операционные оболочки и локальные сети. Для работы в такой среде все программы-приложения разрабатываются в соответствии с определенными спецификациями, что позволяет стандартизировать способы обмена информацией между различными приложениями [21]. Кроме групповых сред появляются и личные информационные системы, объединившие в рамках одной технологии все функции поддержки и организации рабочего места. Например, для планирования рабочего времени от одного рабочего дня до нескольких лет, ведения адресно-телефонного справочника, многоструктурного блокнота, справочника памятных дат и др. В интегрированных моделях бизнеса появляется возможность собирать детальную информацию о каждом клиенте, о спросе и состоянии рынка с помощью интерактивного доступа к информации. Возможность персонального общения с обратной связью позволяет каждому клиенту становиться активным поставщиком информации о своих потребностях. Предприятие персонализирует предлагаемые продукты и услуги, направляя маркетинговые усилия на конкретные группы лиц. При этом маркетинговые просчеты и коммерческий риск снижаются практически до нуля [3]. Дальнейшее развитие интеграции информационных технологий связано с телекоммуникациями, позволяющими все вышеназванные достоинства подобных технологий использовать в сложных разветвленных и неоднородных информационных сетях, использующих, в том числе, распределенные базы данных и распределенную обработку документов. К таким сетям относится и Интернет. Интернет – это глобальная информационная сеть, состоящая из большого количества сетей различного назначения, выполняющих разные задачи. Таким образом, Интернет образует интегрированную информационную сеть (интерсеть) – совокупность расположенных в различных странах взаимосвязанных информационных сетей, называемых подсетями. Принцип их построения заключается в организации магистралей (высокоскоростных телефонных, радио, спутниковых и других линий связи) между центральными узловыми станциями (серверами провайдеров) [17]. Существуют также опорные сети, создаваемые различными организациями, как правило, для удовлетворения собственных потребностей. Они бывают международные, государственные, региональные и отраслевые. Некоторые опорные сети для выхода в Интернет выделяют специально оборудованные сетевые узлы с серверами (хосты), и становятся провайдерами Интернета. Все основные принципы, используемые в локальных и региональных сетях, в той или иной степени применяются в глобальных сетях. Однотипные по используемым аппаратуре и протоколам сети объединяются с помощью общих для соединяемых сетей узлов - «мостов», а разнотипные сети – с помощью общих узлов - «шлюзов». Интеграция нескольких сетей в единую систему базируется на использовании межсетевой маршрутизации информационных потоков. Межсетевая маршрутизация организуется путем включения в каждую из объединяемых подсетей специальных узлов - «маршрутизаторов». Часто функции «маршрутизаторов» и «шлюзов» интегрируются в одном узле. Узлы - «маршрутизаторы», которые распознают какой из поступивших к ним пакетов относится к «местному» трафику сети станции-отправителя, а какой должен быть передан в другую сеть, входящую в единую интегрированную систему [6]. Для функционирования подобных интегрированных информационных сетей используются специальные сетевые технические средства, обеспечивающие взаимодействие как внутри локальной сети, так и нескольких информационных сетей или подсетей. К ним относятся: сетевые адаптеры, повторители, коммутаторы, концентраторы, мультиплексоры, мосты, маршрутизаторы, шлюзы и модемы, согласующие работу компьютеров с каналами передачи данных.
3.2 Корпоративные информационные технологии
Одним из способов систематизации сетей является их классификация по масштабу производственного подразделения, в пределах которого действует сеть. Различают сети организаций (предприятий) и отделов, сети кампусов, корпоративные и индивидуальные сети[12]. Сети организаций – это сети, используемые сотрудниками, работающими на одном предприятии (в одной организации). Они позволяют:
• осуществлять разделение и управление ресурсами предприятия; • повышать надежность функционирования предприятия за счет дублирования информационных ресурсов; • повышать экономическую эффективность за счет гибкой организации работы информационных систем; • осуществлять электронное общение сотрудников и др. Сети отделов – это сети, используемые сравнительно небольшой группой сотрудников, работающих в одном отделе предприятия. Эти сотрудники решают некоторые общие задачи, например, ведут бухгалтерский учет или занимаются маркетингом. Считается, что отдел может насчитывать до 100–150 сотрудников. Главной целью сети отдела является разделение локальных ресурсов, таких как приложения, данные, лазерные принтеры и модемы. Часто сети отделов имеют один или два файловых сервера и не более тридцати пользователей (рис. 8) [2]. Сети отделов обычно не разделяются на подсети. В линиях локализуется большая часть трафика предприятия. Сети отделов обычно создаются на основе одной сетевой технологии (Ethernet, Token Ring). Для такой сети характерен один или, максимум, два типа операционных систем. Чаще всего это сеть с выделенным сервером, например NetWare, хотя небольшое количество пользователей делает возможным использование одноранговых сетевых операционных систем типа Windows.
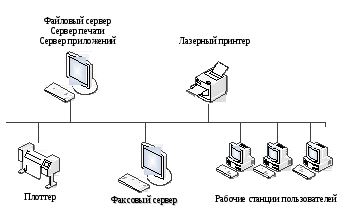
Рисунок 8: Пример сети масштаба отдела.
Задачи управления сетью на уровне отдела относительно просты: добавление новых пользователей, устранение простых отказов, инсталляция новых узлов и установка новых версий программного обеспечения. Такой сетью может управлять сотрудник, посвящающий обязанностям администратора только часть своего времени. Чаще всего администратор сети отдела не имеет специальной подготовки, но является тем человеком в отделе, который лучше всех разбирается в компьютерах, поэтому ему поручают заниматься администрированием сети [12]. Существует и другой тип сетей, близкий к сетям отделов, – сети рабочих групп. К таким сетям относят небольшие сети, включающие до 10–20 компьютеров. Характеристики сетей рабочих групп практически не отличаются от описанных выше характеристик сетей отделов. Такие свойства, как простота сети и однородность, здесь проявляются в наибольшей степени, в то время как сети отделов могут приближаться в некоторых случаях к следующему по масштабу типу сетей – сетям кампусов. Сети кампусов получили свое название от английского слова «campus» (студенческий городок). Именно на территории университетских городков часто возникала необходимость объединения нескольких мелких сетей в одну большую сеть. Сейчас это название не связывают со студенческими городками, а используют для обозначения сетей любых предприятий и организаций. Ныне сети кампусов характеризуют сети территориально распределенных предприятий и организаций [19]. Сети этого типа объединяют множество сетей различных отделов одной организации в пределах отдельного здания или одной территории, покрывая площадь до нескольких квадратных километров. При этом глобальные соединения в сетях кампусов не используются. Службы такой сети включают взаимодействие между сетями отделов, доступ к общим базам данных предприятия, доступ к общим факс-серверам, высокоскоростным модемам и высокоскоростным принтерам. В результате сотрудники каждого отдела предприятия получают доступ к некоторым файлам и ресурсам сетей других отделов. Важной службой, предоставляемой сетями кампусов, стал доступ к корпоративным базам данных независимо от того, на каких типах компьютеров они располагаются [9]. Впервые в сетях кампусов возникают проблемы интеграции неоднородного аппаратного и программного обеспечения, поскольку типы компьютеров, сетевых операционных систем, сетевого аппаратного обеспечения могут отличаться в каждом отделе. Отсюда возникают сложности управления такими сетями. Администраторы должны быть в этом случае более квалифицированными, а средства оперативного управления сетью – более совершенными. Практически в этих сетях стали использовать корпоративные базы данных. В результате появились корпоративные сети предприятий [7]. Необходимость обеспечивать компьютерное взаимодействие работников корпорации, расположенных на любом удалении от нее, а также оказавшихся на любом конце планеты, где есть Интернет, способствовала появлению intranet (Интранет) технологии («intra» – внутренний), означающей применение служб внешних (глобальных) сетей во внутренних – локальных. Это корпоративная сеть (частная сеть, доступная только сотрудникам данной организации), в которой доступ к информации реализован средствами Интернета. Корпоративная сеть (сеть масштаба предприятия, англ. «Enterprise network») связывает между собой ЛВС подразделений корпорации (предприятия). В результате образуются сложные информационные системы (инфосистемы) с распределенной информационной архитектурой. Такая сеть может быть сложно связанной, действовать в рамках (покрывать) города, региона и даже континента. Ее можно представить в виде отдельных локальных сетей, размещенных в телекоммуникационной среде. В результате под термином корпоративная сеть принято понимать сеть масштаба предприятия, объединяющую компьютеры на всех его территориях, доступ к информации в которой реализован средствами Интернета. Корпоративная сеть пользуется услугами или оборудованием общественной глобальной сети, дополняя их собственными услугами или оборудованием. Типичным примером является аренда каналов связи, на основе которых создаются собственные территориальные сети [23]. Таким образом, корпоративная сеть – это сеть смешанной топологии, включающая несколько локальных сетей. Она объединяет филиалы корпорации, которые являются, как правило, ее собственностью. Основу корпоративных сетей составляют локальные вычислительные и информационные сети. Они включают многотерминальные системы централизованной (пакетной) обработки данных (как правило, офисные системы), удаленные терминальные комплексы, системы и устройства (в том числе систем удаленного ввода заданий и распределенной обработки данных), телекоммуникации (главным образом, составляющие Интернет). Пакетный режим является наиболее эффективным режимом использования вычислительной мощности, так как позволяет выполнить в единицу времени больше пользовательских задач, чем любые другие режимыm [21]. Число пользователей и компьютеров в корпоративных сетях может измеряться тысячами, а число серверов – сотнями. Расстояния между сетями отдельных территорий может оказаться настолько большим, что для их функционирования используют глобальные системы и связи. В корпоративной сети используются различные типы компьютеров (от мэйнфреймов до персональных, в том числе переносных, компьютеров) и операционных систем, а также различные приложения. Подобная сложная, крупномасштабная сеть является гетерогенной [11]. Гетерогенность сети означает, что в ней нельзя удовлетворить потребности тысяч пользователей с помощью однотипных программных и аппаратных средств. Неоднородные части корпоративной сети должны работать как единое целое, предоставляя пользователям по возможности прозрачный доступ ко всем необходимым ресурсам. В зависимости от территориальной распространенности корпоративных сетей могут быть локальными, региональными и глобальными. Локальные сети покрывают территорию в несколько квадратных километров. Региональные (территориальные, муниципальные) сети располагаются на территории города или области. Глобальные сети расположены на территории государства или группы государств, например, всемирная сеть Интернет. Территориальные сети, используемые для построения корпоративной сети, обычно делят на две большие категории: 1. магистральные сети; 2. сети доступа. Магистральные территориальные сети (англ. «backbone wide-area net-works») используются для образования одноранговых связей между крупными локальными сетями, принадлежащими большим подразделениям предприятия. Магистральные территориальные сети должны обеспечивать высокую пропускную способность, так как на магистрали объединяются потоки большого количества подсетей. Кроме того, магистральные сети должны быть постоянно доступны, то есть обеспечивать очень высокий коэффициентом готовности [8]. Под сетями доступа понимаются территориальные сети, необходимые для связи небольших локальных сетей и отдельных удаленных компьютеров с центральной локальной сетью предприятия. Быстрый доступ к корпоративной информации из любой географической точки для многих видов деятельности предприятия определяет качество принятия решений его сотрудниками. Особенно это связано с увеличением числа сотрудников, работающих на дому, часто находящихся в командировках, с ростом количества небольших филиалов предприятий, находящихся в различных городах и даже разных странах [5]. У предприятия может быть много точек удаленного доступа. Поэтому одним из основных требований в сетях доступа является наличие разветвленной инфраструктуры доступа, используемой сотрудниками предприятия при работе дома и в командировках. Стоимость удаленного доступа должна быть умеренной, чтобы экономически оправдать затраты на подключение десятков или сотен удаленных абонентов, а требования к пропускной способности у отдельного компьютера или локальной сети, состоящей из двух-трех клиентов, обычно ниже, чем для магистральных сетей [10]. С точки зрения масштаба сети по принципу деления они оказывается близким к предыдущей классификации, и делятся на: • многомашинный комплекс (система), • локальная сеть (комната, здание, комплекс), • городская или районная сеть (город), • региональная сеть (область, край, страна), • Интернет (континент, планета). По скорости передачи информации корпоративные компьютерные сети можно делить на: низкоскоростные, среднескоростные и высокоскоростные. По типу среды передачи выделяют: • коаксиальные сети, • сети на витой паре, • оптоволоконные сети, • сети с передачей информации по радиоканалам, • сети в инфракрасном диапазоне • и другие, в том числе смешанные сети [13]. Корпоративная информационная система – это информационная система, участниками которой может быть только ограниченный круг лиц, определенный ее владельцем или соглашением участников этой системы. Поскольку невозможно управлять экономикой предприятий основываясь только на профессиональную интуицию ее руководителей, специалисты предлагают создавать корпоративные информационные системы управления знаниями. В создаваемой корпоративной информационной системе обычно используют «клиент/серверные» сетевые технологии [9]. Клиенты (пользователи системы) взаимодействуют через локальные и глобальные сети с различными программными приложениями, работающими на серверах. Корпоративные данные могут храниться в корпоративной или глобальной сети, а также на нескольких серверах локальной сети, входящих в состав корпоративной информационной сети (системы). Веб-сайт корпорации, как правило, содержит все ее информационные ресурсы и управляется единой ИПС. При этом информационные ресурсы корпорации могут выть распределены на различных ее компьютерах, что особенно характерно для территориально удаленных подразделений корпорации. В этом случае поверх Интернета организуется так называемая «виртуальная локальная сеть» корпорации, а внутренние подсети связывают с помощью серверов доступа. Такой метод работы называется технологией Интернет/Интранет. При этом сотрудники корпорации и допущенные к ее информационным ресурсам иные пользователи могут находиться в любой части планеты, и пользоваться этими ресурсами с любой точки доступа [1]. Ныне распространяется концепция GRID, представляющая набор стандартизированных служб, обеспечивающих надежный, совместимый, дешевый и повсеместный доступ к информационным и вычислительным ресурсам. Она подразумевает интеграцию на основе управляющего и оптимизирующего программного обеспечения нового поколения. GRID не только концепция, но и работающие технологии, применяемые прежде всего для решения потоков/наборов однотипных задач. Некоторые технологии GRID начинают использовать в корпоративных системах [4].
Заключение
Первоначальные информационные системы, основанные на базах данных, имели строго централизованную архитектуру. Данные были сосредоточены физически и логически на одном компьютере. Централизованная организация базы данных позволяет облегчить обеспечение ее безопасности, целостности и непротиворечивости данных. Вместе с тем рост объема базы данных и числа пользователей, получающих к ней доступ, территориальное развитие организации (и связанная с ней необходимость распределенной обработки данных) приводят к возникновению ряда проблем, свойственных централизованной архитектур - большой объем обмена данными (высокий трафик); - снижение надежности обмена данными; - снижение общей производительности; - рост затрат на разработку БД. Возможным решением перечисленных проблем является организация децентрализованного хранения данных. При децентрализации достигается: - параллельная обработка данных и распределение нагрузки; - повышение эффективности обработки данных при выполнении удаленных запросов; - уменьшение затрат на обработку данных; - упрощение процедуры управления ИС. Целью распределенной обработки данных является выполнение обработки наиболее приспособленным для этого процессором. Распределение не подразумевает параллелизма, но возможность "распараллелить" распределенную обработку существует. Распределенная, или разделенная, или совместно выполняемая программа: выполнение программы двумя и более машинами, объединенными в сеть. Пользователю безразлично местоположение различных ресурсов, необходимых для успешного выполнения программы, которую он выполняет со своего рабочего места; Таким образом, распределенная база данных — это набор отношений, хранящихся в разных узлах компьютерной сети и логически связанных таким образом, чтобы составлять единую совокупность данных. Распределенная система: это система, функционирующая на нескольких компьютерах и предоставляющая пользователю логически единообразный доступ ко всем файлам сети. Организация распределенной базы данных дает массу преимуществ: снижается время отклика системы, повышается надежность хранения данных, уменьшается стоимость аппаратной части за счет снижения объемов данных, хранящихся на одном сервере. Эффективность такой информационной системы напрямую зависит от интенсивности трафика: чем он ниже, тем быстрее окупаются средства, вложенные в её построение. Ключом к успешной реализации этих систем является правильная организация распределения и хранения информации. Идеальным способом снижения трафика в каналах связи является использование технологии «клиент-сервер», получившей в последние годы широкое распространение. Использование технологии «клиент-сервер» позволило создавать надежные (в смысле целостности данных) многопользовательские информационные системы с централизованной базой данных, независимые от аппаратной (а часто и программной) части сервера баз данных и поддерживающие графический интерфейс пользователя на клиентских станциях, связанных локальной сетью. Причем издержки на разработку приложений существенно сокращались. Не удивительно, поэтому, что эта технология завоевала большую популярность среди разработчиков прикладного программного обеспечения, а приложения на ее основе - широкое распространение на рынке информационных систем. Несмотря на объективные сложности и предубеждения пользователей, ситуация меняется - все большее количество фирм-разработчиков пытается не взирая на трудности перейти на использование этой прогрессивной технологии. Появляются инструментальные средства и технологии создания информационных систем, в том числе и в трехуровневой модели.
Список использованных источников
1. Автоматизированные информационные технологии в экономике: Учебник. / Под ред. проф. Г.А. Титоренко. – М.: Компьютер, ЮНИТИ, 2010. – 400 с.
2. Веснин В.Р. В 38 Менеджмент в вопросах и ответах: Учебн. пособие. – М.:ТК Велби , Изд-во Проспект, 2007. – 176 с.
3. Вершигора Е.Е. Менеджмент: Уч. пособие – 2-е изд., перер. и доп. – М.: ИНФРА –М,2008–283с.
4. Грабауров В.А. Информационные технологии для менеджеров. – М.: Финансы и статистика, 2009. – 368 с.
5. Гайдамакин Н.А. Автоматизированные информационные системы, базы и банки данных. Вводный курс. [Текст]/Н.А. Гайдамакин - М: Гелиос АРВ, 2007 г. - 368 с.
6. Избачков Ю. С. Информационные технологии. Учебное пособие. [Текст]/Ю.С. Избачков, В.Н. Петров – Спб: Питер, 2007г. – 656 с.
7. Информационные технологии управления: Учеб. пособие / Под ред. Г.А. Титоренко. – М.: ЮНИТИ-ДАНА, 2009. – 280 с.
8. Коровкин С. Д., Левенец И. А., Ратманова И. Д., Старых В. А., Щавелёв Л. В. Решение проблемы комплексного оперативного анализа информации хранилищ данных // СУБД. - 2007. - № 5-6. – 247 с.
9. Лапин А.Н. Стратегическое управление современной организацией / А.Н. Лапин. - М. : Журн. упр. персоналом, 2010. - 288 с.
10. Миляева Л. Кадровая политика (методический инструментарий) // Высшее образование в России, 2009. - №1
11. Молчанов А.Ю. Системное программное обеспечение. [Текст]/А.Ю. Молчанов - Спб: Питер, 2008 г. - 400 с.
12. Овчинников Н. Состояние работы с персоналом на современном российском рынке // Управление персоналом, 2007. - №18 (178)
13. Осипов К. Кадровое делопроизводство // Управление персоналом, 2007. - №19
14. Острейковский, В.А. Информатика: Учебник / В.А. Острейковский. – М.: Высш. шк., 2008. – 511 с.
15. Петров, В.Н. Информационные системы / В.Н. Петров. – СПб.: Питер, 2006. – 688 с.
16. Радыгин В. Талантливый персонал: интервью // Управление персоналом, 2007. - №19 (173) 6. Удалова И. Традиционная модель подготовки и переподготовки управленческого персонала в РФ: положительные и отрицательные аспекты // Управление персоналом, 2009. – №6 (160)
17. Рагулин П.Г. Информационные технологии. Электронный учебник. — Владивосток: ТИДОТ Дальневост. ун-та, 2008. - 208 с.
18. Романова Ю.Д. Информатика и информационные технологии. [Текст]/Ю.Д. Романова – М: Эксмо, 2009 г. - 592 с.
19. 4. Сахаров А. А. Концепция построения и реализации информационных систем, ориентированных на анализ данных // СУБД. - 2010. - № 4. – 348 с.
20. Советов Б.Я. Информационные технологии. [Текст]/ Б.Я. Советов, В.В. Цехановский – М: Высшая школа, 2008 г. - 264 с.
21. Уткин, В.Б. Информационные системы и технологии в экономике. / В.Б. Уткин, К.В. Балдин. - М: ЮНИТИ-ДАНА, 2009. – 335 с.
22. Фридланд А.Я. Информатика и компьютерные технологии/ А.Я. Фридланд, Л.С. Ханамирова.- М.: Астрель. 2008.- 204 с.
23. Цветкова А.В. Информатика и информационные технологии. Конспект лекций. [Текст]/А.В. Цветкова – Изд: Эксмо, 2007 г. - 192 с.
24. Чеглакова Л.М. Изменения в практике управления персоналом на современных промышленных предприятиях // Социс, 2007. - №5 (277)
25. Черников Б.В. Информационные технологии управления. [Текст]/Б.В. Черников – Изд: Форум, Инфра-М, 2008 г. - 352 с.

- Анализ и оценка средств реализации объектно-ориентированного подхода к проектированию экономической информационной системы»
- Основные понятия объектно-ориентированного программирования (Главные понятия и разновидности)
- ОСОБЕННОСТИ КАДРОВОЙ СТРАТЕГИИ ОРГАНИЗАЦИЙ РЕАЛЬНОГО СЕКТОРА ЭКОНОМИКИ (Понятие и цели кадровой политики предприятия)
- Корпоративная культура в организации (Теоретико-методологические аспекты изучения понятия «корпоративная культура»).
- Психологические и организационные основы обеспечения профессионального обучения персонала»
- Организационная культура и ее роль в современных организациях (Определение понятия организационной культуры и ее основные источники).
- Анализ внутренней и внешней среды организации»
- Современные языки программирования(Теоретические аспекты языков программирования)
- Корпоративная культура в организации (Теоретические основы корпоративной культуры в организации).
- Основные функции в системе менеджмента
- Логистический менеджмент и задачи оптимизации в фирме
- Выбор стиля руководства в организации (Теоретические аспекты выбора стиля руководства).