
Технология построения распределенных информационных систем
Содержание:

ВВЕДЕНИЕ
Актуальность исследования. Обширное использование в современном мире средств доступа к информационным ресурсам дало возможность открывать кардинально новые способы применения вычислительной техники и информационных технологий. На современном этапе данные технологии, дающие возможность создавать, перерабатывать и сохранять информацию, а также позволяющие передавать ее потребителю в эффективной форме, явлются одним из основополагающих факторов жизнедеятельности человеческого общества и управления различными его сферами. Так как сложно переоценить важность информационных ресурсов в современном мире, очевидно, что успешными на социальной, экономической и политической аренах на сегодняшний день выступают страны, которые шагают в ногу со временем и являются активными пользователями сетей, коммуникаций, тезнологий и систем управления данными.
На сегодняшний день в мировом информационном поле есть большое количество готовых к использованию информационно-вычислительных ресурсов. Практически в любом случае, разрабатывая новый продукт, специалист может найти к этому продукту подходящие и уже реализованные компоненты. Однако, зачастую они бывают несовместимы, компоненты не понимают один другого, поэтому совместная работа невозможна. Соответственно, на первый план выходит вопрос наличия механизма, который нейтрализует несовместимость подобных независимо разработанных ресурсов.
Учитывая скачок в развитии глобальных информационных и вычислительных сетей, вполне очевидным выступает тот факт, что изменилась основная парадигма обработки данных. На первый план теперь выходит использование распределенных информационно–вычислительных ресурсов, а также организация свободного доступа к ним. И в итоге возникает противостояние двух направлений информационно-вычислительной мысли: переход к исключительно распределенной схеме хранения ресурсов против стремления к виртуальному единству через предоставление свободного доступа к любым ресурсам сети. Данный подход ускоряет и оптимизирует работу с этими данными и оставляет возможность работать с остальными данными БД.
Таким образом, в современном информационном мире технологии использования распределенных информационно-вычислительных ресурсов выходят на первое место, так как безусловно являются перспективным катализатором прогресса в информационном поле.
Объектом исследования являются распределенные информационные системы.
Предметом исследования являются технологии построения распределенных информационных систем.
Целью работы является исследование технологий и методов построения распределенных информационных систем. Для достижения данной цели в работе были поставлены следующие научные задачи:
- изучение теоретических основ понятия распределенных информационных систем;
- выявление основных принципов и свойств распределенных информационных систем;
- изучение основных технологий построения современных распределенных систем;
- разработка проекта распределенной информационной системы для организации, сдающей помещения в аренду;
- реализация проекта распределенной информационной системы для организации, сдающей помещения в аренду.
В качестве методов исследования будут использованы: анализ научной и учебной литературы, изучение и анализ мнений экспертов.
Структура работы. Данная работа стоит из введения, трех глав, заключения, списка использованной литературы из 23 наименований. Общий объем работы составляет 49 страниц.
1. Теоретические основы понятия распределенных информационных систем
C самого начала развития вычислительной техники образовались два основных направления ее использования.
Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность информации[1].
Но поскольку информационные системы требуют сложных структур данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной создания различных систем управления[2].
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных, например, хранение информации в нескольких файлах. Таким образом, все это способствовало созданию распределенных информационных систем.
Фактически, если информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна иметь некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных.
В мире существует громадное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты[3].
Обычно, распределенной считают такую систему, в которой функционирует более одного сервера БД. Это применяется для уменьшения нагрузки на сервер и обеспечения работы территориально удаленных подразделений. Различная сложность создания, модификации, сопровождения, интеграции с другими системами позволяют разделить ИС на классы: малых, средних и крупных распределенных систем[4].
Малые ИС имеют небольшой жизненный цикл (ЖЦ), ориентацию на массовое использование, невысокую цену, невозможность модификации без участия разработчиков, использующие в основном настольные системы управления базами данных (СУБД), однородное аппаратно-программное обеспечение, не имеющие средств обеспечения безопасности.
Крупные корпоративные ИС, системы федерального уровня и другие имеют длительный жизненный цикл, миграцию унаследованных систем, разнообразие аппаратно-программного обеспечения, масштабность и сложность решаемых задач, пересечение множества предметных областей, аналитическую обработку данных, территориальную распределенность компонент[5].
К функциям таких ИС следует отнести, прежде всего, работу с распределенными данными, расположенными на разных физических серверах, различных аппаратно-программных платформах и хранящихся в различных внутренних форматах. В этом случае система должна предоставлять полную информацию о себе и всех своих ресурсах, легко расширяться, быть основана на открытых стандартах и протоколах, обеспечивать возможность интегрировать свои ресурсы с ресурсами других ИС. Для пользователей система должна обеспечивать различные уровни привилегий для пользователей и предоставлять простые интерфейсы доступа к информации.
Данные из разнородных систем обычно объединяются в логические группы, к которой и адресуются запросы. Абстрактная система запросов предполагает, что система оперирует не конкретным синтаксисом запросов, а его логической сутью на основе абстрактных атрибутов.
При построении распределенных ИС, как правило, используются две базовые архитектуры: Клиент/сервер и Internet Intranet[6].
Корпоративные ИС, построенные по архитектуре Клиент/сервер, предоставляют клиентам широкий спектр приложений и инструментов разработки, которые ориентированы на максимальное использование вычислительных возможностей клиентских рабочих мест. Ресурсы сервера используются в основном для хранения и обмена документами, а также для выхода во внешнюю среду. Данная архитектура позволяет лучше защитить серверную часть приложений, при этом, предоставляя возможность приложениям либо непосредственно адресоваться к другим серверным приложениям, либо маршрутизировать запросы к ним. Однако, частые обращения клиента к серверу снижают производительность работы сети. Приходится решать вопросы безопасной работы в сети, так как приложения и данные распределены между различными клиентами. Распределенный характер построения системы обусловливает сложность ее настройки и сопровождения[7].
В основе ИС на базе Internet Intranet лежит принцип «открытой архитектуры». ПО ИС реализуется в виде апплетов или сервлетов (программ на языке JAVA) или в виде cgi модулей (программ на Perl или С). ИС данной архитектуры включает Web-порталы, реализованные при помощи технологий CORBA Enterprise JavaBeans, ActiveX 1X'ОМ, многоуровневые приложения на основе Java и XML, .Net-концепция с XML, в которой обмен между различными серверами (хранилищами данных, бизнес-приложениями, серверами для мобильных клиентов и другое) производится при помощи нейтрального к любой архитектуре XML.
Под распределенной информационной базой понимается неограниченное количество баз данных, дистанционно отдаленных друг от друга и имеющих ряд общих характеристик:
- функционирующих по единым правилам, определенным централизованно для всех баз данных, входящих в распределенную информационную базу;
- обмен данными осуществляется по правилам, также определенным централизованно[8].
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
- необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
- необходимость введения централизованного изменения структуры и правил работы баз данных для работы всех дистанционно отдаленных подразделений (филиалов) и юридических лиц (с невозможностью изменения определенных правил непосредственно в отдаленном подразделении);
- необходимость ограничения и осуществления контроля изменения данных в дистанционно отдаленных подразделениях компании (филиалах)[9].
Чтобы достигнуть цели своего существования – улучшения выполнения запросов пользователя – распределенная информационная система должна удовлетворять некоторым необходимым требованиям.
Можно сформулировать следующий набор требований, которым в наилучшем случае должна удовлетворять РИС.
Открытость. Все протоколы взаимодействия компонент внутри распределенной системы в идеальном случае должны быть основаны на общедоступных стандартах. Это позволяет использовать для создания компонент различные средства разработки и операционные системы. Каждая компонента должна иметь точную и полную спецификацию своих сервисов. В этом случае компоненты распределенной системы могут быть созданы независимыми разработчиками. При нарушении этого требования может исчезнуть возможность создания распределенной системы, охватывающей несколько независимых организаций.
Масштабируемость. Масштабируемость вычислительных систем имеет несколько аспектов. Наиболее важный из них – возможность добавления в распределенную систему новых компьютеров для увеличения производительности системы, что связано с понятием балансировки нагрузки (load balancing) на серверы системы. К масштабированию относятся так же вопросы эффективного распределения ресурсов сервера, обслуживающего запросы клиентов.
Поддержание логической целостности данных. Запрос пользователя в распределенной системе должен либо корректно выполняться целиком, либо не выполняться вообще. Ситуация, когда часть компонент системы корректно обработали поступивший запрос, а часть – нет, является наихудшей.
Устойчивость. Под устойчивостью понимается возможность дублирования несколькими компьютерами одних и тех же функций или же возможность автоматического распределения функций внутри системы в случае выхода из строя одного из компьютеров. В идеальном случае это означает полное отсутствие уникальной точки сбоя, то есть выход из строя одного любого компьютера не приводит к невозможности обслужить запрос пользователя[10].
Безопасность. Каждый компонент, образующий распределенную систему, должен быть уверен, что его функции используются авторизированными на это компонентами или пользователями. Данные, передаваемые между компонентами, должны быть защищены как от искажения, так и от просмотра третьими сторонами.
Эффективность. В узком смысле применительно к распределенным системам под эффективностью будет пониматься минимизация накладных расходов, связанных с распределенным характером системы. Поскольку эффективность в данном узком смысле может противоречить безопасности, открытости и надежности системы, следует отметить, что требование эффективности в данном контексте является наименее приоритетным. Например, на поддержку логической целостности данных в распределенной системе могут тратиться значительные ресурсы времени и памяти, однако система с недостоверными данными вряд ли нужна пользователям[11].
Классическим примером системы, в значительной мере отвечающей всем представленным выше требованиям, является система преобразования символьных имен в сетевые IP-адреса (DNS). Система имен – организованная иерархически распределенная система, с дублированием всех функций между двумя и более серверами.
Повышение отношения производительности к затратам. Любая задача может быть разделена между различными компьютерами в распределенной системе. Такая конфигурация обеспечивает лучшее соотношение производительности к стоимости системы. Это особенно актуально для конфигурации «сеть рабочих станций».
Масштабируемость. Компьютеры, как правило, подключены к глобальной компьютерной сети, поэтому установка новых компьютеров непосредственно не создает узких мест в компьютерной сети.
Модульность и дополнительная расширяемость. Гетерогенные единицы могут быть добавлены в систему без снижения производительности, так как используется промежуточный уровень взаимодействия. Аналогично, существующие единицы могут быть легко заменены новыми.
Итак, можно считать, что предметная область обозначена и выделены проблемные вопросы, которые решаются специалистами информационных технологий[12].
Итак, подведем итоги первой главы.
Информационно-технический прогресс, произошедший в XX-XXI вв. потребовал от человечества изменений в части концепции использования средств хранения и обработки информации. Одним из новых терминов в информационно-вычислительной среде стало понятие «распределенная информационная система». Определение данного понятия достаточно сложное, однако, уже сегодня очевидно, что без использования данных систем дальнейшее движение человечества весьма затруднительно.
Итак, распределенная информационная система – это совокупность независимых компьютеров, которые осуществляют взаимодействие посредством компьютерной сети и определенной среды, в которой компьютеры координируют свою деятельность, а также дают доступ к ресурсам системы таким образом, что для пользователей система выглядит единой и целостной.
Очевидными свойствами распределенной системы являются отсутствие общей физической шины и общей памяти, географическое распределение, а также автономность и гетерогенность[13].
Объектом изучения обозначим корпоративную распределенную информационную систему организации, предприятия (рисунок 1.1).
Типовой пример РИС такой сети можно представить схемой компьютерного интегрированного полиграфического производства (рисунок 1.2).
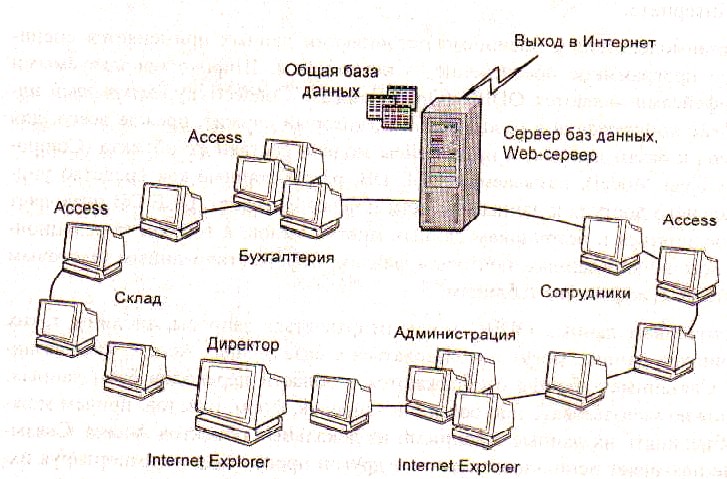
Рис.1.1. Корпоративная сеть с SQL -и WEB-серверами[14]
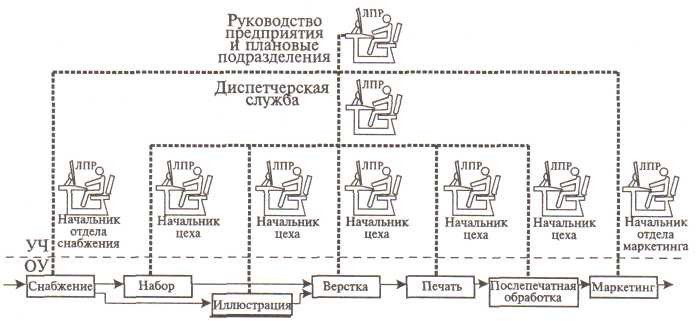
Рис.1.2. УЧ – управляющая часть; ОУ – объект управления
2. Основные технологии построения современных распределенных систем
Сокращение COM означает Component Object Model, что можно перевести с английского языка как компонентная объектная модель. Технология была разработана фирмой Microsoft в начале 90-ых годов прошлого века для обеспечения взаимодействия между различными приложениями, запущенными на одном или даже на разных компьютерах. Сущность технологии COM заключается в программировании с использованием компонентов – подход, который знаком всем программистам, использующим в своей работе среду разработки Delphi или C++ Builder. Под компонентом в данном случае понимается законченный (и откомпилированный) объект со своими свойствами и методами, который может легко встраиваться в различные приложения и распространяться как отдельный продукт.
Компоненты, созданные в соответствии со спецификацией COM, могут функционировать в различной языковой и операционной средах. Это значит, что если разработчик оформил некоторый набор функций как объект COM, то функциями этого объекта могут воспользоваться программисты самых разных языков программирования: C++, Delphi, Visual Basic и т. д. – достаточно, чтобы соответствующая среда разработки поддерживала технологию COM. По этой причине модель COM может являться базовой для создания распределенных информационных систем – составляющие ее объекты могут быть реализованы с использованием различных технологий и инструментов программирования, однако их взаимодействие может осуществляться в соответствии со спецификацией COM (посредством определенных интерфейсов и протоколов). Принципы обращения к свойствам и методам COM-объекта из других приложений полностью соответствуют модели клиент-сервер[15].
Компонент, в котором реализованы некоторые полезные свойства и методы, выступает в качестве COM-сервера, а обращающиеся к нему приложения – в качестве клиентов. Одно и то же приложение, очевидно, может выступать и в качестве клиента, и в качестве COM-сервера, в зависимости от характера взаимодействия с другими приложениями в каждый конкретный момент времени.
Для именования объектов COM используются так называемые глобальные уникальные идентификаторы (Globally unique identifier, GUID3). Глобальный уникальный идентификатор представляет собой 128-разрядное число, которое генерируется с использованием алгоритмов получения случайных чисел и специальной хеш-функции. Глобальный уникальный идентификатор принято записывать в следующем формате: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX, например: B502D1BE-9A57-11d0-8FDE-00C04FD9189D Операционная система должна хранить список доступных COM-объектов и информацию о месте их хранения (то есть путь к соответствующим исполняемым модулям, в которых реализованы сервисы этих объектов). В ОС Windows для этих целей используется специальный подраздел системного реестра: HKEY_CLASSES_ROOT\CLSID\, у которого в качестве вложенных подразделов выступают имена (глобальные уникальные идентификаторы) зарегистрированных в системе объектов, например: {00000000-0E4D-0463-87B5-D411BEBE0010} {00000001-4FEF-40D3-B3FA-E0531B897F98} {00000010-0000-0010-8000-00AA006D2EA4} {00000100-0000-0010-8000-00AA006D2EA4}[16].
Каждый из указанных разделов содержит описание свойств соответствующего COM-объекта. Например, свойство ProgID содержит программный идентификатор объекта – кодовое наименование, которое присваивается разработчиком и которое, в отличие от глобального уникального идентификатора, несет некоторую смысловую нагрузку. Чтобы задать местонахождение исполняемого модуля для объекта COM используются свойства InprocServer32 (если реализация объекта располагается в DLL-файле), LocalServer32 (если объект реализован как EXE-файл) или RemoteServer32 (для объектов, расположенных на удаленных ЭВМ в компьютерной сети). Операционная система, под управлением которой работает COM-сервер, должна иметь возможность единообразного получения адреса зарегистрированного COM-объекта, чтобы передавать соответствующую ссылку запросившим ее клиентам. Кроме того, для взаимодействия клиента с удаленными COM-серверами необходим специальный протокол сетевого взаимодействия, реализующий, в том числе, правила аутентификации и авторизации. На основании указанного выше можно сделать вывод, что создание полноценных COM-объектов – это весьма сложная задача, требующая от разработчика глубоких знаний в области системного и объектно-ориентированного программирования[17]. Среда разработки Borland C++ Builder предоставляют программисту возможность не только создавать собственные, но и эффективно использовать уже существующие COM-объекты в своих приложениях. В некоторых случаях взаимодействие создаваемого приложения с объектами COM реализуется незаметно («прозрачно») для разработчика, в других – требует от него осознанных действий. Полезным примером практического и осознанного использования технологии COM является использование механизма автоматизации для взаимодействия с внешними приложениями. Механизм автоматизации (Automation5) позволяет разработчикам приложения привлекать для обработки данных функциональные возможности других приложений. Например, для формирования отчетов часто используются возможности Microsoft Excel или Microsoft Word[18].
Все началось в 1989 году, когда группа компаний, в которую входили HP, Sun, American Airlines, Canon и некоторые другие производители, а также – что очень важно – и потребители программных продуктов, организовала некоммерческое сообщество, которое назвали Object Management Group (OMG). Стратегическая задача, которую поставило перед собой это сообщество, состояла в создании технологии, позволяющей объединить программные приложения, выполняющиеся на различных программных и аппаратных платформах, взаимодействующие по различным протоколам, написанные на разных языках программирования, созданные в различных уголках мира совершенно разными группами разработчиков. При этом были сформулированы два важнейших концептуальных момента.
- Результаты деятельности OMG должны представлять собой набор спецификаций, а не готовый продукт.
- В качестве идеологии построения такой технологии решили использовать объектно-ориентированный подход.
CORBA создавалась как технология, призванная объединить разрозненные сообщества компьютерных приложений. Архитектуру OMA, которая является основой CORBA, OMG назвала «архитектурой для объединения мира». С одной стороны, CORBA старается научить приложения общаться, причем не делает различия между «правоверными» объектно-ориентированными или «еретиками», написанными на Коболе. CORBA – демократическая технология и, несмотря на заведомую сложность (если не сказать – невыполнимость) подобной задачи, OMG всегда твердо стояла на своем:
- Объединяются приложения как новые, так и наследуемые (legacy).
- Эти приложения могут выполняться на различных операционных платформах (вплоть до самых экзотических, типа Open VMS, Digital UNIX или OS390).
- Стандарты не стоят ничего – их может получить и использовать любой желающий[19].
Когда мы первый раз увидели этот невероятный список принципов, нам показалось, что реализовать все это невозможно. Мы решили, что, как и во многих других случаях, прекрасные замыслы потихоньку растеряются по мере продвижения к результату. Велико было наше удивление, когда обнаружилось, что стандарты не просто позволяют использовать в распределенной среде «старые» приложения, но есть немалое число успешно реализованных проектов, которые построены именно таким образом. Огромное количество «тяжелых» корпоративных приложений, написанных на Коболе и выполняющихся на мэйнфреймах, благодаря технологии CORBA получили единственный шанс прижиться в современном мире Интернета и всеобщей открытости.
Возможно, именно поэтому, не поступаясь принципами, CORBA к концу XX века заняла подобающее место, а не стала еще одним печальным опытом построения «компьютерного коммунизма».
В OMG входят сотни компаний. Но компании состоят из людей, и развитие OMG определяется добровольной и самоотверженной работой сотен и тысяч специалистов – как лидеров компьютерной науки, так и их добросовестных помощников. Мы надеемся, что по мере чтения этой книги вы увидите, какие полезные и передовые идеи открыла для нас OMG. Мы не будем перечислять имен из боязни кого-то пропустить, а всех перечислить просто невозможно. В следующих главах вам встретятся некоторые известные фамилии, другие вы можете увидеть на сайтах OMG http://www.omg.org, http://www.corba.org и на других сайтах по технологии CORBA[20].
Конек CORBA – это, несомненно, интеграция legacy-приложений. Как мы уже говорили, для многих из них это единственная возможность приспособиться к изменившимся условиям функционирования и научиться взаимодействовать с более современными приложениями.
В области EAI (Enterprise Application Integration) существуют два направления, которые по очереди одерживают верх друг над другом. В соответствии с первым из них интеграцией занимается отдельно выделенный функциональный элемент. Второе направление возлагает эту обязанность на программных агентов, расположенных на каждом узле системы. Первое – область интеграционных серверов, второе – CORBA. В реальной жизни обычно используют некоторую комбинацию обеих возможностей. В любом случае при выборе технологии надо исходить из конкретной задачи и имеющихся в наличии возможностей. К последним относится знание и опыт использования той или иной технологии.
Стандарт для анализа и проектирования программных систем – язык моделирования Unified Modelling Language (UML) – используется повсеместно в различных областях компьютерных технологий. Постепенно приобретает популярность средство описания метамоделей и репозитариев – Meta Object Facility (MOF)[21].
Технология J2EE (Java 2 Enterprise Edition), формально объявленная в декабре 1999 года, представляет собой первый стандарт для создания корпоративных распределенных многозвенных приложений. Впитав, как губка, другие стандарты, среди которых важнейшими являются CORBA и XML, J2EE позволяет существенно упростить труд системных архитекторов, проектировщиков и разработчиков, предлагая ясную и гибкую архитектуру и набор взаимосвязанных стандартов для использования важнейших системных сервисов. J2EE объединяет такие стандарты, как компонентная модель Enterprise JavaBeans, стандарты Web-приложений для формирования динамических откликов на действия пользователей – Java Servlets и JavaServer Pages, стандарт для доступа к базам данных JDBC. Мы посвятим каждому из этих стандартов по отдельной главе, здесь же хотим показать их взаимосвязь и место в общей картине J2EE и в области распределенных компьютерных приложений.
Прикладная модель J2EE состоит из четырех слоев, каждый из которых может функционировать на одном или нескольких узлах распределенной системы. В отличие от традиционной трехзвенной архитектуры, появился слой Web-серверов, который занимается подготовкой презентационной части для клиентов. Модель состоит из четырех уровней:
- уровень client-tier, объединяющий клиентские компоненты, выполняющиеся на клиентских компьютерах;
- уровень web-tier, объединяющий Web-компоненты, выполняющиеся на Web-серверах;
- уровень business-tier, объединяющий бизнес-компоненты, выполняющиеся на J2EE-серверах, которые называются серверами приложений;
- уровень EIS-tier1, объединяющий элементы информационных систем, выполняющиеся на EIS-серверах, обычно на серверах баз данных.
Приложения, удовлетворяющие стандарту J2EE, состоят из компонентов, которые в процессе выполнения приложений взаимодействуют друг с другом. Спецификация определяет компоненты следующих типов:
- клиентские приложения и апплеты, которые выполняются на клиентских компьютерах;
- сервлеты и Java Server Pages, которые представляют собой Web-компоненты и выполняются на Web-серверах;
- Enterprise JavaBeans, которые являются бизнес-компонентами и выполняются на прикладных серверах[22].
Эти компоненты общаются с помощью различных средств: HTML, XML, RMI – и взаимодействуют через различные протоколы: HTTP, HTTPS, IIOP. Они устанавливаются и выполняются в специальной прикладной среде – контейнерах, которые берут на себя груз системной поддержки и переговоры с клиентами. Для взаимодействия с существующими приложениями в рамках J2EE стандартизована модель коннекторов.
Все компоненты J2EE имеют одно общее свойство: они должны быть написаны на языке Java. Исключением являются только клиентские приложения.
Основным элементом J2EE, несомненно, является компонентная модель Enterprise JavaBeans. Можно сказать, что J2EE предоставляет стандартное API, инфраструктуру и набор типовых клиентов для EJB.
Одна из отличительных особенностей современных стандартов в области разработки – это пристальное внимание не только к самому процессу создания приложений, но и к специалистам, которые управляют этим процессом и осуществляют его. Наиболее подробна и внимательна в этом смысле технология J2EE, которая определяет отдельные роли, сопровождающие компонентные приложения на всех этапах жизненного цикла. Для корпоративных приложений, которые могут объединять сотни и тысячи компонентов, разделение обязанностей становится непременным условием успешности проекта[23].
J2EE представляет собой популярный стандарт, который используется в сотнях реализаций, называемых серверами приложений. Этот тип программного обеспечения без сомнения можно назвать одной из наиболее бурно развивающихся областей компьютерных технологий и, как следствие, областью, в которой царит острая конкуренция.
Серверы приложений наиболее активно используются для создания Web-приложений. Пережив всплеск повышенного спроса, Web-приложения постепенно занимают свое достойное место в компьютерном мире. Именно серверы приложений позволяют относительно быстро создавать гибкие, масштабируемые и производительные Web-порталы. На самом деле пока нет технологии, которая бы лучше подходила для этих целей. Но не будем ограничивать область применения серверов приложений только порталами. Нам известны успешные примеры создания J2EE-приложений корпоративного уровня, реализующих функциональность ERP- и CRM-систем[24].
В соответствии с определением, Microsoft .NET – это среда выполнения Web-приложений в ОС Windows 2000. Цель создания .NET все та же – сократить и упростить разработку, внедрение и поддержку распределенных программных систем, в данном случае – функционирующих на платформах Windows. Среда .NET добавляет к операционной системе Windows такие важные функции, как автоматическая сборка мусора и простой доступ к базам данных и Интернету, и расширяет компонентную модель COM+. Она развивает среду ASP (Active Server Page), созданную Microsoft в 1997 году как элемент Internet Information Server, который входил в Windows NT 4 Option Pack.
Основная идея .NET заключается в понятии управляемого кода, который выполняется не просто на операционной системе Windows, а под управлением ее дополнительного элемента – среды CLR (Common Language Runtime) – общей среды выполнения для программных приложений, написанных на различных языках. CLR очень похожа на Java Runtime Environment (JRE). При этом программы (с помощью, например, Visual Sudio .NET) компилируются в код на специальном языке Microsoft Intermediate Language (MSIL, или IL). Среда CLR, в частности, освобождает программистов от сборки мусора не хуже, чем Java, проводя автоматическую чистку неиспользуемой памяти (garbage collection). На нее также возложено управление доступом к программному коду.
В настоящее время существует множество компиляторов программных языков в IL, в дополнение к предоставляемым Microsoft для Visual Basic, C#, JScript и C++. Такая унификация вынудила Microsoft сблизить языки, которые поддерживаются в Visual Studio .Net. Особенно это касается новой версии Visual Basic.
Таким образом в .NET реализована идея формирования машинного кода «на лету», которая с успехом используется в Java. JITter с помощью специальных настроек может формировать машинный код только один раз – во время первого вызова программы, а может повторять эту процедуру каждый раз при вызове программы.
Технология .NET также обещает избавить от одной из основных головных болей, связанную с ведением версий программных компонентов. Теперь описательный файл приложений содержит полную информацию об используемых версиях библиотек и других компонентов, а само объединение элементов приложения, получающееся в результате сборки компонентов, может содержать несколько различных версий одного и того же компонента.
Для динамического Web .NET предлагает модернизированную среду ASP .NET. В ней реализована идея отделения динамического кода от статического текста HTML-страниц, причем первый можно создавать и отлаживать в Visual Studio с помощью специальной модели Web Forms. Кроме того, ASP .NET выгодно отличается от просто ASP в возможностях сохранения состояния сессий. Конфигурационная информация Web-приложения хранится в специальном файле в формате XML, так же, как и в J2EE[25].
Сегодня практически все крупнейшие производители систем управления базами данных предлагают решения в области управления распределенными ресурсами. Однако все эти решения поддерживают ограниченные функции построения неоднородных распределенных систем.
Что касается коммерческих продуктов, то в настоящее время в большинстве реляционных систем предусмотрены разные виды поддержки использования распределенных баз данных с разной степенью функциональности. Среди таких систем наиболее известны система INGRES/STAR отделения Ingres Division фирмы The ASK Group Inc., система ORACLE фирмы Oracle Corporation, а также модуль распределенной работы системы DB2 фирмы IBM.
Сегодня многие фирмы - разработчики СУБД заявляют о том, что они поддерживают работу с распределенными БД, однако при ближайшем рассмотрении в большинстве случаев эти заявления оказываются несколько преувеличенными. Специалисты в области СУБД считают, что только несколько пакетов СУБД позволяют в некоторой степени реализовать распределенную базу данных.
Подчеркнем следующее определение распределенной БД: «Распределенная БД - это множество физических баз данных, которые выглядят для пользователя как одна логическая БД». К сожалению, на сегодняшний день ни одна СУБД полностью не реализует это определение. Наиболее близко к его реализации подошли следующие СУБД:
-
- Informix On-Line фирмы Informix Software;
- Ingres Intelligent Database фирмы Ingres Corp;
- Oracle (version 7) фирмы Oracle Corp;
- Sybase System 10 фирмы Sybase Inc.
Хотя ни одна из этих 4 СУБД полностью не реализует все функции распределенной СУБД, однако каждая из них реализует или в скором времени будет реализовывать поддержку работы с распределенной БД.
Наиболее полно функции распределенной СУБД реализованы в СУБД Ingres и Oracle. Коротко рассмотрим возможности этих пакетов.
СУБД Ingres работает на множестве UNIX-платформ, на платформах DEC VMS, Hewlett-Packard MPE, DOS, Microsoft Windows 3.1, OS/2, Macintosh. Она также работает со многими сетевыми протоколами, включая Open System Interconnection Transport Class 4[26]. Ingres имеет средства для доступа к данным СУБД DB2, Rdb, Allbase. Основные функции распределенной СУБД обеспечиваются дополнительной компонентой Ingres/Star. Она поддерживает оптимизацию распределенных запросов, позволяет читать и обновлять в рамках одной транзакции данные разных узлов, обеспечивает возможность удалять записи одновременно в нескольких узлах[27].
СУБД Informix-Online разработана для среды UNIX, но может также работать под Novell. Informix-Online имеет оптимизатор запросов и реализует те же функции работы с распределенной БД, что и Ingres, однако у Informix более жесткие требования к ресурсам компьютера, в частности ему требуется больше оперативной памяти.
СУБД System 10 фирмы Sybase в настоящее время находится в состоянии разработки. Она должна работать на UNIX-платформах, на платформах OS/2, Window NT, NetWare. System 10 будет работать с несколькими сетевыми протоколами и поддерживать связь с СУБД DB2, Oracle 7, Informix-Online, Rdb. System 10 будет иметь оптимизатор распределенных запросов, она позволит читать и обновлять данные нескольких узлов. Функции работы с распределенной БД будут реализованы с помощью дополнительной компоненты Replication Server[28].
В 7 версии СУБД Oracle реализовано множество функций для работы с распределенной БД. Среди них следует выделить оптимизатор распределенных запросов и средство чтения и обновления данных нескольких узлов в рамках одной транзакции. Oracle v 7 работает на более чем 80 вычислительных платформах, поддерживает большинство существующих коммерческих сетевых протоколов и может обмениваться данными с СУБД DB2, SQL/DS, Tandem Computers, NonStop SQL, Rdb, HP TurboImage. Разрабатываются шлюзы еще к 18 СУБД.
В СУБД Oracle словарь данных хранится также, как остальные данные, поэтому его таблицы могут быть распределены по узлам сети. Все операции с распределенной БД «прозрачны» для пользователей и разработчиков. В области обновления распределенной БД Oracle обогнал всех своих конкурентов. Пользователи Oracle могут с помощью компоненты SQL*Net «прозрачно» работать с данными (не обязательно данными Oracle), размещающимися на различных типах компьютеров и в различных узлах сети. Высокопроизводительное средство «прозрачного» обновления распределенной БД реализовано на основе оригинально выполненного двухфазного протокола фиксации изменений.
Все фирмы-разработчики распределенных СУБД намерены в будущем поддерживать архитектуру распределенной базы данных фирмы IBM (Distributed Relational Database Architecture). Правда хотя IBM уже давно объявила о начале работ по реализации этой архитектуры, она до сих пор не закончена. Это очевидно связано с очень высокой сложностью реализации объявленной архитектуры[29].
Подводя итоги второй главы отметим, что на практике использование распределенной информационной системы имеет смысл в компаниях, ведущих несколько различных видов деятельности и, соответственно, решающих в своей операционной деятельности ряд задач, касающихся следующих направлений:
- получение оперативной информации от удаленных филиалов;
- консолидация в единой базе данных по компаниям, входящим в группу, с целью дальнейшего анализа и обработки данных и получения управленческой отчетности как по Группе компаний так и по каждому юридическому лицу в частности;
- централизация изменений структуры и прав доступа (введение ограничений и контроль) баз данных для всех отдаленно расположенных подразделений.
Применение распределенной информационной системы весьма широко и перспективно, в связи с набирающей обороты общей информатизацией общества. Соответственно, главной задачей систем управления распределенными базами данных выступает обеспечение средств интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе данных.
Подводя итог, можно сделать вывод о том, что распределенные информационные системы являются неотъемлемой и очень важной частью современной информационной системы.
3. Пример разработки проекта РИС предметной области
Поставим целью данной главы: демонстрация приемов и правил создания и разработки распределенной базы данных в SQL Server и программной системы приложения на базе инструментальной среды Microsoft Visual Studioи языка программирования С#.
Для достижения цели сформулируем конкретные задачи:
- создать таблицы, определить связи между таблицами и обеспечить ссылочную целостность, создать представления;
- разработать функции, триггеры и роли;
- разработать клиентское приложение пользователя базы данных;
- разработать руководство по эксплуатации системы баз данных.
Организация (Код, Название, Краткое название, Адрес, Контактные телефоны, Электронный адрес) сдает в аренду помещения. Каждое помещение характеризуется следующими показателями:
Адрес, площадь (кв.м.), площадь подвала (кв.м.) при наличии, коэффициент подвала (значение от 0 до 1), коэффициент технического обустройства помещения (КТ) – значение от 1 до 2.
Арендная плата зависит от базовой ставки за 1 кв.м. (в рублях), которая утверждается документом (Номер, Дата) агентства Госкомимущества России.
Формула расчета месячной арендной платы (МАП): МАП = (базовая ставка/12 * площадь помещения + базовая ставка/12 * площадь подвала * коэффициент подвала) * КТ[30].
При изменении базовой ставки МАП изменяется со следующего месяца после даты изменения ставки. Оплата производится ежемесячно.
Договор об аренде может заключаться как с организациями (юридическими лицами), так и с физическими лицами. В договоре об аренде помещения, имеющего номер, дату, фиксируется дата начала аренды, дата завершения аренды. Для юридического лица в БД заносится название, адрес, ИНН, номер и дата лицензии о деятельности. Для физического лица – ФИО, паспортные данные (Серия, Номер, Дата выдачи, Кем выдан), ИНН и адрес.
Необходимо осуществить следующую обработку данных:
-
- итоговая сумма оплат за текущий месяц (на заданную дату);
- список арендаторов (тип, название, адрес и другие характеристики арендуемого помещения) на текущую дату;
- список помещений, не сданных в аренду на текущую дату.
- Проектирование базы данных
На рисунке 3.1 представлена даталогичекая модель реляционной базы данных.
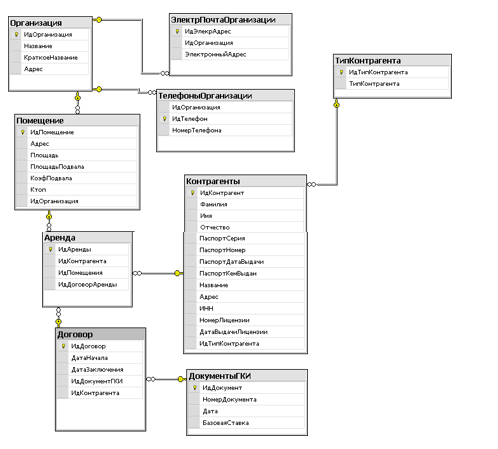
Рис. 3.1. Даталогическая модель[31]
- Работа с сервером баз данных Обоснование выбора СУБД
Для разработки приложения была использована СУБД Microsoft SQL Server. Современный сервер баз данных, сочетающий в себе простоту установки, актуальный набор объектов БД, средств регламентации доступа и защиты данных, возможность генерации отчетов и наиболее полное взаимодействие с продуктами компании-разработчика, как офисными (Office System), так и инструментальными (Visual Studio).
Разработку клиент-серверного приложения необходимо начать с подготовки к выполнению своих функций серверной части, в качестве которой выступает СУБД. База данных должна быть окончательно физически реализована и наполнена тестовым набором данных, прежде чем будет осуществлен этап реализации клиентской части – программы языке высокого уровня.
Таким образом, на данном этапе необходимо создать базу данных, добавить таблицы, с помощью диаграммы связей установить связи между первичными и внешними ключами таблиц, а также реализовать представления и триггеры[32].
- Создание базы данных
Для создания базы данных необходимо авторизоваться в качестве пользователя СУБД посредством среды Management Studio. В панели Обозреватель объектов появится дерево объектов соответствующего сервера. Для создания базы данных необходимо вызвать контекстное меню узла Базы данных и выбрать пункт «Создать базу данных» как показано на рисунке 3.2.
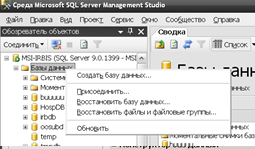
Рис. 3.2. Создание базы данных
В появившемся окне следует указать имя новой базы данных, а также можно указать собственный путь к файлам БД в таблице «Файлы базы данных», оперируя значением параметров столбца «Путь». Для остальных настроек рекомендуется сохранить значения по умолчанию. Вид диалогового окна добавления базы данных показан на рисунке 3.3.
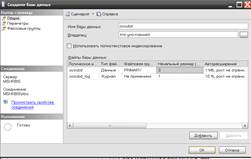
Рис. 3.3 Окно параметров создаваемой БД
После создания база данных появится в качестве потомка узла базы данных, которая содержит в качестве дочерних узлов объекты СУБД различных классов.
- Добавление таблиц
Добавление таблиц происходит аналогично добавлению базы данных на сервер: в контекстном меню категории объектов «Таблицы» выбирается пункт «Создать таблицу». Интерфейс добавления новой таблицы состоит из 3 колонок «Имя столбца», «Тип данных», «Разрешить значения Null». Выбранная версия СУБД поддерживает русскоязычные наименования полей таблиц, однако, сложные названия с использованием пробелов и других допустимых символов могут быть автоматически заключены в квадратные скобки. Таким образом, в качестве имени столбцов следует использовать короткие, но емкие названия, адекватно отражающие семантику предметной области. Вид интерфейса создания новой таблицы показан на рисунке 3.4.
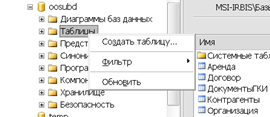
Рис.3.4. Создание новой таблицы[33]
Сохранение таблицы можно произвести как из строки меню с помощью ко- манды Файл–Сохранить (имя таблицы), так и через контекстное меню заголовка вкладки соответствующего интерфейса добавления.
- Добавление диаграммы баз данных
Структура связей, полученная на этапе физического проектирования базы данных, переносится на таблицы СУБД SQL Server 2005 посредством объекта «Диаграмма баз данных».
После добавления в иерархию объектов БД новой диаграммы необходимо разместить на ней созданные на предыдущем этапе таблицы и организовать между ними требуемые связи[34].
Добавление новых таблиц на рабочее поле редактирования элементов диаграммы происходит с помощью диалога Добавление таблицы, как показано на рисунке 3.5.
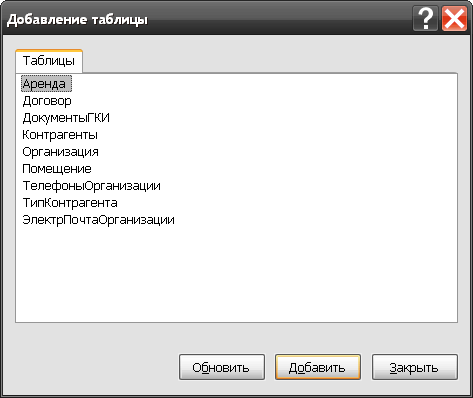
Рисунок 3.5. Добавление таблиц в область диаграммы данных
Организация связей между таблицами осуществляется посредством протягивания мышью строки ключевого поля до поля внешнего ключа другой таблицы. Дальнейшие настройки связи происходят в окне «Отношение внешнего ключа», вид которого представлен на рисунке 3.6.
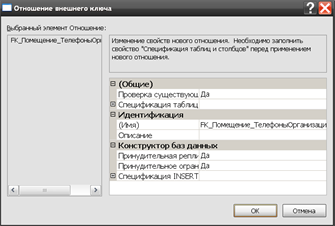
Рис. 3.6. Редактирование параметров связи
При грамотно спроектированной логической модели БД физическая реализация связей между таблицами в используемой СУБД обеспечит целостность и непротиворечивость данных в процессе использования[35].
- Создание представлений
При выполнении работы был использован метод выборки информации из базы данных посредством такого объекта СУБД SQL Server как представления. Данный подход доступа к данным имеет явные преимущества, например, код SQL-сценариев хранится в базе данных, что не требует перекомпиляции приложения при незначительных изменениях в структуре запроса. Также использование представлений наравне с таблицами в качестве источника данных очень удобно для клиентов, построенных на технологии ADO.NET. Представления позволяют сосредоточить в себе запросы с привилегиями, отличными от уровня доступа пользователя, которому разрешен только просмотр результатов запроса, что делает процесс разграничения прав пользователей более гибким.
Для добавления нового представления в иерархию объектов БД следует в контекстном меню категории Представления выбрать пункт «Создать представление», как показано на рисунке 3.7.
Рис. 3.7. Создание представления[36]
Код представления, возвращающего информацию о количестве помещений, не арендованных на текущую дату представлен в следующем листинге:
SELECT ИдПомещение, Адрес FROM dbo.Помещение WHERE (ИдПомещение <> (SELECT Помещение_1.ИдПомещение FROM dbo.Договор INNER JOIN
dbo.Аренда ON dbo.Договор.ИдДоговор = dbo.Аренда.ИдДоговорАренды INNER JOIN
dbo.Помещение AS Помещение_1 ON dbo.Аренда.ИдПомещения = Помещение_1.ИдПомещение
WHERE (dbo.Договор.ДатаНачала < GETDATE()) AND (dbo.Договор.ДатаЗаключения > GETDATE())
GROUP BY Помещение_1.ИдПомещение))
SQL-код представления, возвращающего информацию о списке арендато- ров, представлен в следующем листинге:
SELECT dbo.Помещение.ИдПомещение, dbo.Помещение.Адрес, dbo.Контрагенты.Фамилия, dbo.Контрагенты.Имя, dbo.Контрагенты.Отчество,
dbo.ТипКонтрагента.ТипКонтрагента, dbo.Контрагенты.Название, dbo.Контрагенты.Адрес AS АдресАрендатора,
dbo.Контрагенты.НомерЛицензии, dbo.Контрагенты.ПаспортСерия, dbo.Контрагенты.ПаспортНомер
FROM dbo.Аренда INNER JOIN
dbo.Договор ON dbo.Аренда.ИдДоговорАренды = dbo.Договор.ИдДоговор INNER JOIN
dbo.Контрагенты ON dbo.Аренда.ИдКонтрагента = dbo.Контрагенты.ИдКонтрагент INNER JOIN
dbo.Помещение ON dbo.Аренда.ИдПомещения = dbo.Помещение.ИдПомещение INNER JOIN
dbo.ТипКонтрагента ON dbo.Контрагенты.ИдТипКонтрагента = dbo.ТипКонтрагента.ИдТипКонтрагента
WHERE (dbo.Помещение.ИдПомещение = 1) AND (dbo.Договор.ДатаЗаключения > GETDATE()) AND (dbo.Договор.ДатаНачала < GETDATE())[37]
Код представления отчета о сумме оплат за текущий месяц SELECT SUM(МАП) AS СуммаМАП
FROM (SELECT dbo.Помещение.ИдПомещение, dbo.ДокументыГКИ.ИдДокумент, dbo.Договор.ИдДоговор, dbo.ДокументыГКИ.БазоваяСтавка, dbo.Помещение.Площадь, dbo.Помещение.ПлощадьПодвала, dbo.Помещение.КоэфПодвала, dbo.Помещение.Ктоп, (dbo.ДокументыГКИ.БазоваяСтавка / 12 * dbo.Помещение.Площадь + dbo.ДокументыГКИ.БазоваяСтавка / 12 * dbo.Помещение.ПлощадьПодвала * dbo.Помещение.КоэфПодвала) * dbo.Помещение.Ктоп AS МАП
FROM dbo.Помещение INNER JOIN
dbo.Аренда ON dbo.Помещение.ИдПомещение = dbo.Аренда.ИдПомещения INNER JOIN dbo.Договор ON dbo.Аренда.ИдДоговорАренды = dbo.Договор.ИдДоговор INNER JOIN dbo.ДокументыГКИ ON dbo.Договор.ИдДокументГКИ = dbo.ДокументыГКИ.ИдДокумент WHERE (MONTH(dbo.ДокументыГКИ.Дата)
= 10)) AS derivedtbl_1[38]
- Создание триггеров
C помощью ограничений целостности, правил и значений по умолчанию не всегда можно добиться нужного уровня функциональности. Часто требуется реализовать сложные алгоритмы проверки данных, чтобы гарантировать их достоверность и реальность. Кроме того, бывает необходимо отслеживать изменения значений таблицы, чтобы нужным образом изменить связанные данные. Для решения этих и многих других проблем используются триггеры.
Триггер – это специальный тип хранимых процедур, запускаемых сервером автоматически при выполнении тех или иных действий с данными таблицы или при глобальном событии[39].
Обычно триггер привязывается к конкретной таблице. Для его создания следует обратиться к иерархическому представления структуры БД: в дочерних узлах объекта таблица имеется контейнер «Триггеры», в контекстном меню которого имеется пункт «Создать триггер», как показано на рисунке 3.8.
Рис.3.8. Создание триггера
- Создание ролей
Чтобы продемонстрировать порядок работы с SQL-консолью в среде Management Studio были установлены уровни доступа посредством SQL-сценариев. Для добавления пользователей Оператор1, Оператор2, которые должны иметь одинаковые права доступа, были созданы SQL-сценарии, вид которых представлен ниже.
CREATE LOGIN Оператор1 WITH PASSWORD = '123';
CREATE USER Оператор1 FOR LOGIN ИнспекторОК1; GO
CREATE LOGIN Оператор2 WITH PASSWORD = '123';
CREATE USER Оператор2 FOR LOGIN ИнспекторОК2; GO
В ходе работы были созданы SQL-скрипты для реализации уровней доступа для пользователей ИнспекторОК1 и ИнспекторОК2 с использованием ролей.
Create Role R_Оператор;
Grant Select, Insert, Update (Адрес, Площадь, ПлощадьПодвала, КоэфПодва- ла, Ктоп, ИдОрганизация) On Помещение To R_Оператор;
Grant Select (ИдОрганизация, Название, КраткоеНазвание, Адрес) On Орга- низация To R_Оператор;
Grant Select, Insert (ИдАренды, ИдКонтрагента, ИдПомещения, ИдДогово- рАренды) On Аренда To R_ Оператор;
Grant Select On [неарендованныепомещения] To R_Оператор;
Предоставление роли пользователям осуществляет следующий код: Grant R_Оператор To Оператор1
Grant R_Оператор To Оператор2
Чтобы осуществить запрос к СУБД через среду Management Studio, необходимо в контекстном меню базы данных, представленной в обозревателе объектов, выбрать пункт «Создать запрос». В результате в рабочей области среды появится поле ввода сценария. По завершении написания команд следует нажать кнопку «Выполнить», это инициирует запрос к БД, результат которого будет выведен в информационном поле[40].
- Организация клиент-серверного взаимодействия
Приложения, использующие технологию ADO .NET используется модель доступа к отсоединенным данным. В основе концепция доступа к данным лежат два компонента:
-
- набор данных (представляется объектом класса DataSet) со стороны клиента, локальное временное хранилище данных;
- провайдер данных (представляется объектом класса DataProvider), посредник, обеспечивающий взаимодействие приложения и базы данных со стороны базы данных (в распределенных приложениях – со стороны сервера)[41].
Чтобы использовать возможности этих компонентов, необходимо добавить новый источник данных в проект Visual Studio, вызвав мастер, показанный на рисунке 3.9.

Рис.3.9. Вызов мастера добавления нового источника данных
В нашем случае были выбраны таблицы и представления. Новые источники данных появятся в соответствующей панели системы программирования, что продемонстрировано на рисунке 3.10.
Рис.3.10. Список активных источников данных Visual Studio
На основе полученных таблиц и представлений строится объектная структура данных, выраженная в виде классов. Редактирование данных классов происходит автоматически при работе с конструктором данных – внутренней интерпретации схемы данных БД.
Модификация конструктора данных может потребоваться при формирова- нии запросов, охватывающих несколько таблиц, а также создании параметрических запросов. Интерфейс конструктора данных показан на рисунке 3.11.
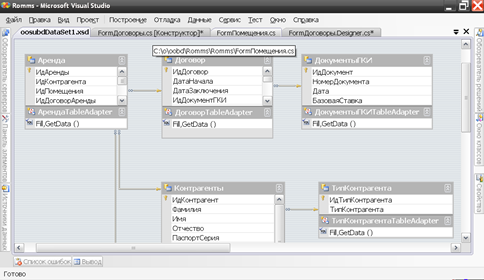
Рис.3.11. Конструктор данных Visual Studio
Программное средство предназначено для автоматизации процесса учета арендованных физическими и юридическими лицами помещений, а также позволяет рассчитать итоговую сумму оплат за текущий месяц, список арендаторов (тип, название, адрес и другие характеристики арендуемого помещения) на текущую да- ту, список помещений, не сданных в аренду на текущую дату[42].
Программное средство состоит из файлов с расширениями *.exe, *.mdf и
*.ldf. Программное средство включает в себя следующие файлы:
-
-
- Romms.exe – исполняемый файл программы;
- oosubd_log.ldf – журнал транзакций базы данных;
- oosubd.mdf – файл базы данных.
-
- Установка программного средства
Для установки программного средства необходимо скопировать все файлы и папки с носителя на свободное дисковое пространство.
Для подготовки к работе необходимо зарегистрировать в базу данных в СУБД, создать имена входа и добавить пользователей с требуемыми правами. Данная группа операций осуществляется через средство управления SQL-сервером «Management Studio», которая входит в его рекомендуемую поставку[43].
Первоначально необходимо подключить базу данных к серверу. Для этого требуется совершить следующие действия:
После запуска утилиты необходимо нажать правой кнопкой на разделе «Базы данных» и выбрать пункт «Присоединить…» согласно рисунку 3.11.
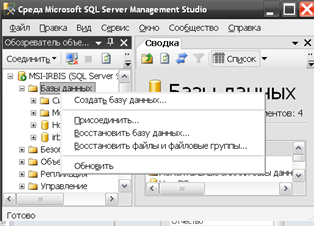
Рис. 3.11. Регистрация базы данных в MS SQL Server
После чего в появившемся окне нажать кнопку «Добавить» и в дереве каталогов найти и выбрать oosubd.mdf, как показано на рисунке 3.12. После чего, нажав кнопку «ОК» на этом и на следующем окне, база данных будет добавлена[44].
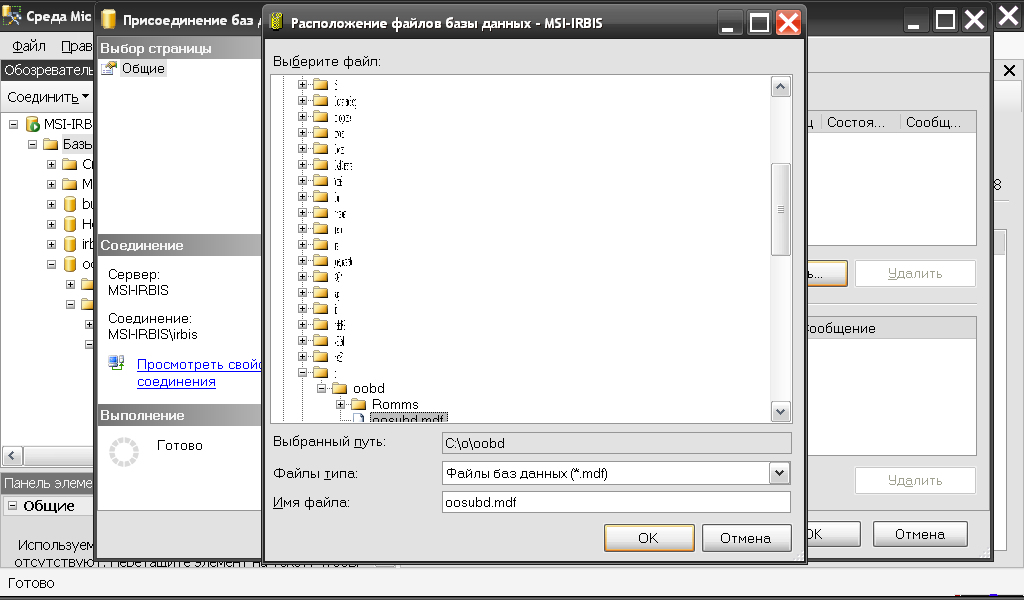
Рис.3.12. Выбор базы данных для подключения к MS SQL Server
Так как для работы с базой данных используется система авторизации Windows, необходимо проследить, чтобы роль владельца базы данных была назначена либо администратору компьютера, либо пользователю NT Authority\System. Так же можно создать имя входа, руководствуясь следующим ниже алгоритмом[45].
После запуска утилиты необходимо для каждого будущего пользователя создать логин, чтобы впоследствии выделить ему необходимые права в базе данных. Для этого необходимо нажать правой кнопкой на разделе «Имена входа» и в появившемся меню выбрать пункт «Создать имя входа» в соответствии с рисунком 3.13.
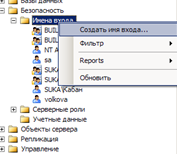
Рисунок 3.13. Добавление имени входа в MS SQL Server
Полномочия пользователя по работе с базой данных устанавливаются в окне настроек пользователя базы данных, вызываемом двойным щелчком по имени пользователя в списке, как показано на рисунке 3.14. Для администратора можно установить полномочия владельца базы данных, они же применяются при создании базы данных с нуля.
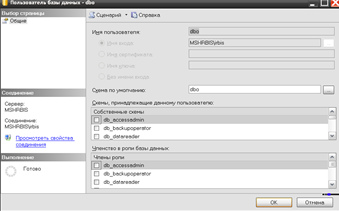
Рис.3.14. Менеджмент полномочий пользователей БД
- Эксплуатация программного средства
Запуск программы «Аренда помещений» осуществляется щелчком по пиктограмме в файловом менеджере. При запуске открывается главное окно, вид которого показан на рисунке 3.15. Главное окно является родительских для всех окон, которые будут открыты в программе, для переключения между окнами используется пункт меню «Окна». Элементы меню сгруппированы в соответствии с соображениями удобства и частоты использования функций программного средства[46].
Рис. 3.15. Главное окно программы
Для организации учета необходимо задать в программе вспомогательные данные, такие как:
-
- организации,
- помещения,
- телефоны,
- адреса электронной почты,
- список арендаторов.
Когда вспомогательные данные будут введены в работу, можно приступать к созданию договоров аренды, для этого необходимо выбрать в строке меню пункт Аренда–Договоры. В результате, будет показано окно программы для работы с договорами, представленное на рисунке 3.16.
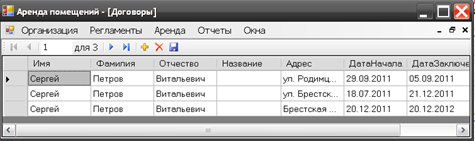
Рис.3.16. Создание договоров аренды
Чтобы добавить новый договор аренды, следует нажать на кнопку с пиктограммой «+». В результате в окне появится новая строка, куда можно будет внести данные. Пользователю необходимо выбрать фамилию клиента для физического лица, или название юридического лица, выбрать адрес арендуемого помещения, указать дату начала и номер договора, которые можно открыть двойным щелчком по целевым ячейкам[47].
Необходимо обязательно указать дату заключения договора, окно выбора даты может быть вызвано двойным щелчком по ячейке по аналогии с выбором типа документ ГКИ. Процесс выбора даты покупки представлен на рисунке 3.17.
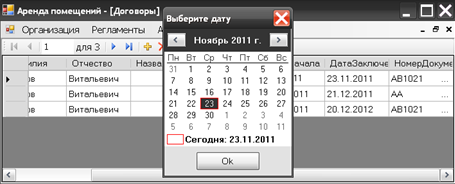
Рис. 3.17. Выбор даты заключения договора
Аналогичным образом происходит работа с данными других таблиц. Также в программе предусмотрен отчет об итоговой сумме оплат за текущий месяц (на заданную дату)[48], который может быть вызван через пункт меню Отчеты – Сумма оплат. Результат выполнения запроса по отчету показан на рисунке 3.18.
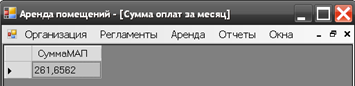
Рис. 3.18. Отчет о сумме оплат за месяц
Сведения о списке арендаторов могут быть получены при помощи отчета «Список арендаторов». Результатом выполнения отчета является таблица, в которой присутствуют имя, фамилия, отчество, паспортные данные для физических лиц и название, номер лицензии, дата ее выдачи для юридических лиц. Вид данного отчета показан на рисунке 3.19.
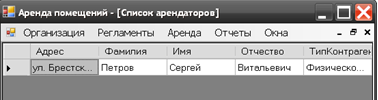
Рис. 3.19. Отчет о лицах, арендующих помещения
Информацию о количестве свободных помещениях и их адресе на заданную дату можно получить, выполнив запрос по отчету «Свободные помещения», вызов которого возможен через строку меню пункт Отчеты – Свободные помещения. Результат выполнения отчета показан на рисунке 3.20.
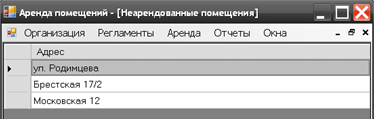
Рис.3.20. Отчет о количестве каждой модели на заданную дату[49]
В результате выполнения работы были спроектированы и реализованы реляционная база данных в СУБД MS SQL Server и клиентское приложение на языке C#, использующее технологию ADO .NET для взаимодействия с БД.
Применение этих двух компонентов в рамках клиент-серверного приложения позволило создать объектно-реляционную СУБД, в которой работа с реляционной структурой данных в БД происходит при посредничестве объектных моделей таблиц в рамках приложения.
Помимо непосредственных плюсов объектно-реляционной модели в качестве достоинства можно отметить, что использование технологии ADO .NET позволило уменьшить число обменов между клиентским приложением и сервером баз данных.
Таким образом, рассмотренная в рамках работы концепция реализации объектно-реляционной СУБД, реализованная с помощью актуальных инструментальных средств, может эффективно применяться на этапе перехода к объектно-ориентированной модели СУБД.
ЗАКЛЮЧЕНИЕ
В результате проведенной работы были решены следующие задачи:
- изучены теоретические основы понятия распределенных информационных систем;
- выявлены основные принципы и свойства распределенных информационных систем;
- изучены основные технологии построения современных распределенных систем;
- разработан проект распределенной информационной системы для организации, сдающей помещения в аренду;
- реализован проект распределенной информационной системы для организации, сдающей помещения в аренду.
По результатам исследования можно сделать следующие выводы.
Информационно-технический прогресс, произошедший в XX-XXI вв. потребовал от человечества изменений в части концепции использования средств хранения и обработки информации. Одним из новых терминов в информационно-вычислительной среде стало понятие «распределенная информационная система». Определение данного понятия достаточно сложное, однако, уже сегодня очевидно, что без использования данных систем дальнейшее движение человечества весьма затруднительно.
Итак, распределенная информационная система – это совокупность независимых компьютеров, которые осуществляют взаимодействие посредством компьютерной сети и определенной среды, в которой компьютеры координируют свою деятельность, а также дают доступ к ресурсам системы таким образом, что для пользователей система выглядит единой и целостной.
Очевидными свойствами распределенной системы являются отсутствие общей физической шины и общей памяти, географическое распределение, а также автономность и гетерогенность.
На практике использование распределенной информационной системы имеет смысл в компаниях, ведущих несколько различных видов деятельности и, соответственно, решающих в своей операционной деятельности ряд задач, касающихся следующих направлений:
- получение оперативной информации от удаленных филиалов;
- консолидация в единой базе данных по компаниям, входящим в группу, с целью дальнейшего анализа и обработки данных и получения управленческой отчетности как по Группе компаний так и по каждому юридическому лицу в частности;
- централизация изменений структуры и прав доступа (введение ограничений и контроль) баз данных для всех отдаленно расположенных подразделений.
Применение распределенной информационной системы весьма широко и перспективно, в связи с набирающей обороты общей информатизацией общества. Соответственно, главной задачей систем управления распределенными базами данных выступает обеспечение средств интеграции локальных баз данных, располагающихся в некоторых узлах вычислительной сети, с тем, чтобы пользователь, работающий в любом узле сети, имел доступ ко всем этим базам данных как к единой базе данных.
Подводя итог, можно сделать вывод о том, что распределенные информационные системы являются неотъемлемой и очень важной частью современной информационной системы.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
-
-
- Автоматизация проектирования вычислительных систем. Языки, моделирование и базы данных / ред. М. Брейер. - М.: Мир, 2015. - 463 c.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2015. - 528 c.
- Вендров А.М. Проектирование программного обеспечения экономических информационных систем: Учебник. – М.: Финансы и статистика, 2016.- 316 с.
- Вендров, А. М. Практикум по проектированию программного обеспечения экономических информационных систем / А.М. Вендров. - М.: Финансы и статистика, 2017. - 192 c.
- Зегжда, Д.П. Основы безопасности информационных систем / Д.П. Зегжда, А.М. Ивашко. - М.: Горячая линия - Телеком, 2017. - 452 c.
- Изимбал А. А., Анишина М.Л. Технология создания распределенных систем для профессионалов – СПб: М-Д, 2017.- 626 с.
- Информационные системы и технологии: Научное издание. / Под ред. Ю.Ф. Тельнова. - М.: ЮНИТИ, 2016. - 303 c.
- Ипатова, Э. Р. Методологии и технологии системного проектирования информационных систем / Э.Р. Ипатова, Ю.В. Ипатов. - М.: Флинта, 2016. - 256 c.
- Кренке. Теория и практика построения баз данных. 8-е изд./ Д. Кренке. – СПб.: Питер, 2015. – 800 с.
- Марков А.С., Лисовский К.Ю. Базы данных. Введение в теорию и методологию: Учебник. – М.: Финансы и статистика, 2016. – 512 с.
- Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2018. - 176 c.
- Мидоу, Ч. Анализ информационных систем: моногр. / Ч. Мидоу. - М.: Прогресс, 2015. - 400 c.
- Проектирование распределенных информационных систем: курс лекций по дисциплине «Проектирование распределенных информационных систем» / С.А. Щелоков, Е.Н. Чернопрудова; Оренбургский гос. ун-т. – Оренбург: ОГУ, 2017. –195 с.
- Раскин Интерфейс: новые направления в проектировании компьютерных систем / Раскин, Джеф. - М.: Символ-плюс, 2017. - 272 c.
- Распределенные системы : учебное пособие для студентов, обучающихся по направлению подготовки 38.03.05 Бизнесинформатика / [авт.-сост. А.В. Демина, О.Н. Алексенцева]. – Саратов : Саратовский социально-экономический институт (филиал) РЭУ им. Г.В. Плеханова, 2018. – 108 с.
- Советов Б.Я. Базы данных: теория и практика: Учеб. Для втузов/ Б.Я. Советов, В.В. Цехановский, В.Д. Чертовской – 2-е изд., стер. – М.: Высш. шк., 2017. - 463 с.
- Советов Б.Я. Информационная технология. Учебник для ВУЗов по спец. «Автоматизированные системы обработки информации и управления». – М.: Высш.шк.2016. – 368с.
- Таненбаум Э., Стеен М. Распределенные системы. Принципы и парадигмы. - СПб.: Питер, 2018. - 877 с.
- Таренбаум Э. Распределенные системы. Принципы и парадигмы. –СПб: Питер, 2016.– 877с.
- Уткин В.Б. Информационные системы в экономике: Учебник для студ. высш. учеб. заведений / В.Б. Уткин, К.В. Балдин. – М.: Издательский центр «Академия», 2018. – 288 с.
- Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2018. - 208 c.
- Шоу, А. Логическое проектирование операционных систем: моногр. / А. Шоу. - М.: Мир, 2016. - 360 c.
- Ярочкин, В. Безопасность информационных систем / В. Ярочкин. - М.: Ось-89, 2015. - 320 c.
-
-
Информационные системы и технологии: Научное издание. / Под ред. Ю.Ф. Тельнова. - М.: ЮНИТИ, 2016. – С. 53. ↑
-
Проектирование распределенных информационных систем: курс лекций по дисциплине «Проектирование распределенных информационных систем» / С.А. Щелоков, Е.Н. Чернопрудова; Оренбургский гос. ун-т. – Оренбург: ОГУ, 2017. –195 с. ↑
-
Раскин Интерфейс: новые направления в проектировании компьютерных систем / Раскин, Джеф. - М.: Символ-плюс, 2017. – С. 118. ↑
-
Автоматизация проектирования вычислительных систем. Языки, моделирование и базы данных / ред. М. Брейер. - М.: Мир, 2015. – С. 112. ↑
-
Шоу, А. Логическое проектирование операционных систем: моногр. / А. Шоу. - М.: Мир, 2016. – С. 92. ↑
-
Ипатова, Э. Р. Методологии и технологии системного проектирования информационных систем / Э.Р. Ипатова, Ю.В. Ипатов. - М.: Флинта, 2016. – С. 142. ↑
-
Ярочкин, В. Безопасность информационных систем / В. Ярочкин. - М.: Ось-89, 2015. – С. 48. ↑
-
Марков А.С., Лисовский К.Ю. Базы данных. Введение в теорию и методологию: Учебник. – М.: Финансы и статистика, 2016. – С. 116. ↑
-
Изимбал А. А., Анишина М.Л. Технология создания распределенных систем для профессионалов – СПб: М-Д, 2017.- С. 316. ↑
-
Раскин Интерфейс: новые направления в проектировании компьютерных систем / Раскин, Джеф. - М.: Символ-плюс, 2017. – С. 211. ↑
-
Шоу, А. Логическое проектирование операционных систем: моногр. / А. Шоу. - М.: Мир, 2016. – С. 189. ↑
-
Таненбаум Э., Стеен М. Распределенные системы. Принципы и парадигмы. - СПб.: Питер, 2018. – С. 266. ↑
-
Шоу, А. Логическое проектирование операционных систем: моногр. / А. Шоу. - М.: Мир, 2016. – С. 212. ↑
-
Марков А.С., Лисовский К.Ю. Базы данных. Введение в теорию и методологию: Учебник. – М.: Финансы и статистика, 2016. – С. 144 ↑
-
Таненбаум Э., Стеен М. Распределенные системы. Принципы и парадигмы. - СПб.: Питер, 2018. – С. 192. ↑
-
Информационные системы и технологии: Научное издание. / Под ред. Ю.Ф. Тельнова. - М.: ЮНИТИ, 2016. – С. 170. ↑
-
Советов Б.Я. Информационная технология. Учебник для ВУЗов по спец. «Автоматизированные системы обработки информации и управления». – М.: Высш.шк.2016. – С. 85. ↑
-
Изимбал А. А., Анишина М.Л. Технология создания распределенных систем для профессионалов – СПб: М-Д, 2017.- С. 120. ↑
-
Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2015. – С. 102. ↑
-
Зегжда, Д.П. Основы безопасности информационных систем / Д.П. Зегжда, А.М. Ивашко. - М.: Горячая линия - Телеком, 2017. – С. 111. ↑
-
Зегжда, Д.П. Основы безопасности информационных систем / Д.П. Зегжда, А.М. Ивашко. - М.: Горячая линия - Телеком, 2017. – С. 311. ↑
-
Информационные системы и технологии: Научное издание. / Под ред. Ю.Ф. Тельнова. - М.: ЮНИТИ, 2016. – С. 201. ↑
-
Уткин В.Б. Информационные системы в экономике: Учебник для студ. высш. учеб. заведений / В.Б. Уткин, К.В. Балдин. – М.: Издательский центр «Академия», 2018. – С. 59. ↑
-
Марков А.С., Лисовский К.Ю. Базы данных. Введение в теорию и методологию: Учебник. – М.: Финансы и статистика, 2016. – С. 107. ↑
-
Зегжда, Д.П. Основы безопасности информационных систем / Д.П. Зегжда, А.М. Ивашко. - М.: Горячая линия - Телеком, 2017. – С. 170. ↑
-
Уткин В.Б. Информационные системы в экономике: Учебник для студ. высш. учеб. заведений / В.Б. Уткин, К.В. Балдин. – М.: Издательский центр «Академия», 2018. – С. 119. ↑
-
Изимбал А. А., Анишина М.Л. Технология создания распределенных систем для профессионалов – СПб: М-Д, 2017.- С. 109. ↑
-
Ярочкин, В. Безопасность информационных систем / В. Ярочкин. - М.: Ось-89, 2015. – С. 104. ↑
-
Вендров А.М. Проектирование программного обеспечения экономических информационных систем: Учебник. – М.: Финансы и статистика, 2016.- С. 117. ↑
-
Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2018. – С. 109. ↑
-
Кренке. Теория и практика построения баз данных. 8-е изд./ Д. Кренке. – СПб.: Питер, 2015. – С. 615. ↑
-
Вендров, А. М. Практикум по проектированию программного обеспечения экономических информационных систем / А.М. Вендров. - М.: Финансы и статистика, 2017. – С. 116. ↑
-
Ипатова, Э. Р. Методологии и технологии системного проектирования информационных систем / Э.Р. Ипатова, Ю.В. Ипатов. - М.: Флинта, 2016. – С. 188. ↑
-
Советов Б.Я. Базы данных: теория и практика: Учеб. Для втузов/ Б.Я. Советов, В.В. Цехановский, В.Д. Чертовской – 2-е изд., стер. – М.: Высш. шк., 2017. – С. 170. ↑
-
Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2018. – С. 85. ↑
-
Вендров, А. М. Практикум по проектированию программного обеспечения экономических информационных систем / А.М. Вендров. - М.: Финансы и статистика, 2017. – С. 82. ↑
-
Распределенные системы : учебное пособие для студентов, обучающихся по направлению подготовки 38.03.05 Бизнесинформатика / [авт.-сост. А.В. Демина, О.Н. Алексенцева]. – Саратов : Саратовский социально-экономический институт (филиал) РЭУ им. Г.В. Плеханова, 2018. – С. 48. ↑
-
Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2015. – С. 214. ↑
-
Мидоу, Ч. Анализ информационных систем: моногр. / Ч. Мидоу. - М.: Прогресс, 2015. – С. 86. ↑
-
Автоматизация проектирования вычислительных систем. Языки, моделирование и базы данных / ред. М. Брейер. - М.: Мир, 2015. – С. 102. ↑
-
Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2018. – С. 101. ↑
-
Проектирование распределенных информационных систем: курс лекций по дисциплине «Проектирование распределенных информационных систем» / С.А. Щелоков, Е.Н. Чернопрудова; Оренбургский гос. ун-т. – Оренбург: ОГУ, 2017. – С. 48. ↑
-
Советов Б.Я. Информационная технология. Учебник для ВУЗов по спец. «Автоматизированные системы обработки информации и управления». – М.: Высш.шк.2016. – С. 192. ↑
-
Мидоу, Ч. Анализ информационных систем: моногр. / Ч. Мидоу. - М.: Прогресс, 2015. – С. 117. ↑
-
Ипатова, Э. Р. Методологии и технологии системного проектирования информационных систем / Э.Р. Ипатова, Ю.В. Ипатов. - М.: Флинта, 2016. – С.48. ↑
-
Мидоу, Ч. Анализ информационных систем: моногр. / Ч. Мидоу. - М.: Прогресс, 2015. – С. 201. ↑
-
Вендров, А. М. Практикум по проектированию программного обеспечения экономических информационных систем / А.М. Вендров. - М.: Финансы и статистика, 2017. – С. 126. ↑
-
Вендров А.М. Проектирование программного обеспечения экономических информационных систем: Учебник. – М.: Финансы и статистика, 2016.- С. 67. ↑
-
Распределенные системы : учебное пособие для студентов, обучающихся по направлению подготовки 38.03.05 Бизнесинформатика / [авт.-сост. А.В. Демина, О.Н. Алексенцева]. – Саратов : Саратовский социально-экономический институт (филиал) РЭУ им. Г.В. Плеханова, 2018. – С. 56. ↑

- Обзор языков программирования высокого уровня
- Учет предоставленных услуг салоном красоты
- Варианты построения интерфейса программ: особенности и эволюция
- Общие особенности кадровой стратегии малых предприятий
- Бренд как конкурентное преимущество компании (Бренд: понятие и его функции )
- Управление финансовыми ресурсами на предприятии
- Проектный офис, принципы и этапы формирования
- Корпоративная культура в организации (Этапы формирования корпоративной культуры)
- Особенности политики мотивации персонала малых предприятий (Малый бизнес и мотивационный менеджмент в нем)
- Роль мотивации в поведении организации (Сущность и механизм мотивации трудовой деятельности персонала предприятия)
- Особенности политики регулирования численности персонала в организациях бюджетной сферы.
- Аппарат государственной власти (Понятие и сущность власти)