
Технология «клиент-сервер» (Модернизация устаревших информационных систем)
Содержание:

Введение
Сфера информационных технологий является на сегодняшний день наиболее динамически развивающейся областью науки и техники, что приводит к расширению поля их применения в человеческой деятельности. Значительную часть современных информационных технологий составляют сетевые технологии и их более глобальное проявление – Internet-технологии.
В основе широкого распространения локальных сетей компьютеров лежит известная идея разделения ресурсов. Высокая пропускная способность локальных сетей обеспечивает эффективный доступ из одного узла локальной сети к ресурсам, находящимся в других узлах.
Развитие этой идеи приводит к функциональному выделению компонентов сети: разумно иметь не только доступ к ресурсам удаленного компьютера, но также получать от этого компьютера некоторый сервис, который специфичен для ресурсов данного рода и программные средства. Так мы приходим к различению клиентов (рабочих станций) и серверов локальной сети.
Технология “клиент-сервер” применительно к СУБД приводит к разделению системы на две части - приложение-клиент и сервер базы данных. Со времени возникновения архитектуры клиент-сервер появилось много вариантов архитектуры процессора БД, поскольку он во многом определяет успех всей системы. 1. Клиент-серверная архитектура.
1. 1.1. История
Основным недостатком персональных компьютеров является их невысокая вычислительная мощность и надежность, а также необходимость в приобретении дополнительных аппаратных средств для устранения изолированности отдельных персональных компьютеров друг от друга.
Как правило, пользователям компьютеров нужны и высокая вычислительная мощность и свойства персональных компьютеров. Поэтому там, где для выполнения сложных вычислений используются мощные изолированные центральные компьютеры с терминалами, их пользователям периодически приходится заходить на персональные компьютеры для редактирования текстов или выполнения задач, использующих электронные таблицы. Это заставляет пользователей освоить 2 различные операционные системы (на больших машинах обычно установлены OC MVS, VMS, VM, UNIX, а на персональных - MS DOS/MS Windows, OS/2 или Mac) и не решает задачи совместного использования данных.
В результате опроса представителей 300 крупнейших фирм США, использующих персональные компьютеры, выяснилось, что для 81% опрошенных необходим доступ к данным более чем одного компьютера.
Чтобы решить эту задачу, персональные компьютеры начали объединять в локальные сети и устанавливать на них специальные операционные системы, например, NetWare фирмы Novell, для совместного использования компьютерами сети файлов, размещенных в различных узлах сети. Эта технология называется файл-сервер.
Однако файл-серверы имеют ряд недостатков. Они не позволяют в полной мере обеспечить конфиденциальность доступа и целостность данных. По сети файлы передаются целиком, независимо от того, какая часть содержащихся в них данных нужна пользователю. Это сильно перегружает сеть и уменьшает быстродействие системы. Невысока и надежность системы на основе файл - серверов. Сбой на одной из рабочих станций в момент записи файла приводит к потере или искажению данных.
Для обеспечения непротиворечивости данных приходится блокировать файлы, что также приводит к замедлению работы. Естественным желанием специалистов в области вычислительной техники было совместить преимущества персональных компьютеров и мощных центральных компьютеров.
Первым шагом в этом направлении явилось использование персональных компьютеров в качестве интеллектуальных терминалов. При таком подходе в персональном компьютере, соединенном с центральным компьютером, запускается специальное программное обеспечение, позволяющее этому персональному компьютеру работать в режиме эмуляции терминала. При этом мы получаем архитектуру, реализующую все достоинства архитектуры с мощным центральным компьютером, но, кроме того, персональный компьютер может использоваться и самостоятельно, по своему прямому назначению. Теперь нет необходимости иметь на столе 2 дисплея, однако большинство недостатков, присущих архитектуре с центральным компьютером, все еще сохраняется. Кроме того, хотя персональные компьютеры, имеющие дисплеи с картой VGA, позволяют работать с графикой, однако использовать их в качестве графического терминала большой центральной машины неудобно. Задача выполняется в центральном компьютере и по проводам передаются графические образы экрана. Эти образы довольно велики и скорость смены изображения на экране может быть очень низкой.
Следующим шагом в решении описанной выше проблемы явилось использование архитектуры клиент-сервер. В такой архитектуре все компьютеры сети разделены на 2 группы: клиенты и серверы. Компьютер-сервер - это мощный компьютер с большой оперативной памятью и большим количеством дискового пространства. На нем хранится база данных и выполняется сложная обработка, требующая больших вычислительных ресурсов. На компьютерах-клиентах выполняются первичная обработка данных при вводе, форматирование данных, а также окончательная (финишная) обработка данных, извлеченных с сервера. В качестве компьютеров-клиентов обычно используются персональные компьютеры типа IBM PC или Macintosh. Преимущества архитектуры клиент-сервер очевидны. Каждый тип компьютера используется по своему назначению, а следовательно, обеспечивается более полное использование возможностей компьютеров.
На компьютерах-клиентах работают знакомые пользователям PC пакеты, позволяющие предоставлять результаты работы всей системы в удобном для анализа и принятия решений виде. На этих компьютерах легко можно реализовать дружественный пользовательский интерфейс приложения, использующий графику, цвет, звук, работу с окнами и мышью и т.д. Компьютер-клиент позволяет быстро выполнять ввод и первичный контроль данных. Для финишной обработки данных могут использоваться те редакторы или пакеты электронных таблиц, которые пользователь считает наиболее удобными. В качестве компьютеров-клиентов могут одновременно использоваться компьютеры разных типов с различными операционными системами.
Архитектура клиент-сервер позволяет реализовать распределенную обработку, поскольку часть работы (интерфейс с пользователем, финишная обработка) выполняется на компьютере-клиенте, а часть - на компьютере-сервере. Это позволяет снизить загрузку сервера и оптимизировать его работу, а также увеличить число клиентов, одновременно работающих с сервером.
Наиболее часто архитектура клиент-сервер применяется для приложений, созданных с использованием систем управления базами данных (СУБД).
Дальнейшим развитием архитектуры клиент-сервер явилось использование в сети не одного, а нескольких серверов баз данных. Это позволило перейти от работы с локальной БД к работе с распределенной БД.
Причем работа с распределенной базе данных (БД) "прозрачна" для пользователя, т.е. он работает с ней так же, как с локальной БД, не задумываясь о том, на каком сервере лежат его данные. Пользователь обращается к одному из серверов, тот, не найдя у себя нужных данных, автоматически обращается к другим серверам. Многосерверная архитектура сегодня представляется очень перспективной. Она позволяет заменить одну мощную центральную машину на несколько менее мощных и, следовательно, более дешевых, и еще больше распараллелить обработку данных. Кроме того, такая архитектура повышает надежность системы, поскольку при выходе из строя одного из серверов все приложения, работающие с данными других серверов, могут продолжать работу. При выходе из строя части локальной или глобальной сети система может попытаться найти альтернативный путь к нужному серверу (по другим ветвям сети). Кроме того, на локальных серверах могут храниться данные, наиболее часто используемые в данном узле, что позволяет свести к минимуму передачу данных по сети от сервера к серверу.
1.1.2. Архитектура "клиент-сервер"
Программное обеспечение архитектуры "клиент-сервер" состоит из двух частей: программного обеспечения сервера и программного обеспечения пользователя — клиента. Программа-клиент выполняется на компьютере пользователя и посылает запросы к программе-серверу, которая работает на компьютере общего доступа. Основная обработка данных производится мощным сервером, а на компьютер пользователя возвращаются только результаты выполнения запроса. В такой архитектуре сервер называется сервером баз данных. Широко известными СУБД, используемыми в архитектуре "клиент-сервер", являются Microsoft SQL Server, Oracle, Sybase SQL Server и др. Эти СУБД являются реляционными SQL-серверами баз данных. СУБД архитектуры "клиент-сервер" может включать собственную клиентскую программу. В то же время в качестве клиентов сервера баз данных могут использоваться другие СУБД. Access также может работать в качестве клиента SQL-сервера. Для взаимосвязи клиентов с сервером разработано специальное программное обеспечение. Широко используемыми интерфейсами таких взаимосвязей являются ODBC и OLE DB. Access предоставляет несколько способов взаимодействия приложения с данными сервера на основе интерфейса ODBC. ODBC - это стандартный интерфейс между базой данных и приложением, взаимодействующим с ней. Наличие подобного стандарта позволяет любому приложению на клиентском компьютере получать доступ к любой базе данных на сервере с помощью SQL. Приложение получает доступ к конкретной базе данных, используя специально разработанный под нее драйвер (драйвер ODBC). Интерфейс ODBC состоит из четырех функциональных компонентов, именуемых уровнями ODBC. Благодаря каждому из них достигается гибкость ODBC, позволяющая взаимодействовать любым ODBC-совместимым клиентам и серверам. Между пользователем и данными, которые он хочет получить, процесс проходит четыре уровня интерфейса ODBC: приложение, диспетчер драйверов, драйвер DLL, источник данных.
С версии 2000 Access включает средства создания клиентских приложений Microsoft SQL Server, которые позволяют не только использовать существующие на сервере базы данных, но и создавать новые и взаимодействовать с ними на основе интерфейса OLE DB. OLE DB — это архитектура компонентов базы данных, реализующая эффективный доступ по сети и через Интернет к источникам данных многих типов, в том числе реляционным источникам данных, почтовым файлам, неформатированным текстовым файлам и электронным таблицам. Набор OLE-интерфейсов обеспечивает универсальный доступ к данным различного формата. В архитектуре OLE DB приложения, получающие доступ к данным, называют потребителями данных, например Access или Visual Basic. Программы, обеспечивающие внутренний доступ к данным, называют средствами доступа к базам данных - провайдерами, например, Microsoft OLE DB Provider for Microsoft SQL Server (рис. 1) или Microsoft Jet 4.0 OLE DB Provider для доступа к базе данных Microsoft Access внешнего потребителя. При установке Microsoft Office или Microsoft Access автоматически инсталлируются провайдеры OLE DB. Каждый провайдер требует определения специфического набора параметров для связи с источником данных. Для того, чтобы из проекта Access подключиться к базе данных Microsoft SQL Server, нужно определить имя сервера, имя базы данных, задать способ регистрации на сервере, имя пользователя, пароль. Требуемый тип провайдера Microsoft OLE DB Provider for SQL Server выбирается проектом по умолчанию. Эти параметры сохраняются как строка связи с базой данных сервера в проекте Access. Кроме того, они могут сохраняться в udl-файле. Файлы подключения можно использовать просто для организации и управления сведениями, необходимыми для подключения к источникам данных OLE DB. Открывается диалоговое окно Свойства связи с данными (Data Link Properties), причем выбор типа провайдера Microsoft OLE DB Provider для SQL-сервера выполняется по умолчанию.
Компоненты системы SQL Server 2012
Система SQL Server 2012 играет роль платформы данных с возможностью динамической разработки, обширной бизнес-аналитикой, с выходом за пределы реляционной модели, закладывая прочный фундамент, на котором могут строить ИТ инфраструктуру малые, средние и крупные организации. В состав SQL Server 2012 входят следующие компоненты[1]:
• Служба ядра БД (Database Engine). Основные компоненты БД, уведомлений и репликации. Ядро БД является сердцем SQL Server. Репликация повышает доступность данных, распределяя их по нескольким БД и разделяя нагрузку чтения данных по нескольким выделенным серверам БД.
• Аналитические службы (Analysis Services). Обеспечивают функциональность OLAP (Online Analytical Processing) и анализа данных для приложений бизнес-аналитики. Аналитические службы позволяют организации собирать данные из разных источников, например, реляционных баз данных и обрабатывать их различными способами.
• Службы интеграции (Integration Services). Предназначены для слияния данных из разнородных источников, загрузки данных в хранилища, витрины данных и пр.
• Службы отчетов. Включают диспетчер отчетов и сервер отчетов. Представляют полномасштабную платформу для создания, управления и распространения отчетов. Сервер отчетов построен на стандартных технологиях Microsoft Internet Information Services (IIS) и Microsoft .NET Framework и позволяет использовать для обработки и хранения отчетов сочетание возможностей SQL Server и IIS.
• Service Broker. Ключевая часть БД, обеспечивающая организацию очередей и обмена сообщениями. Очереди используются для упорядочения задач, например, запросов, чтобы они выполнялись по мере высвобождения ресурсов. Сообщения обеспечивают передачу информации от одного приложения БД другому.
Объекты базы данных SQL Server.
Объектами базы данных SQL Server являются таблицы, индексы, представления, хранимые процедуры, триггеры, пользовательские функции.
Таблицы - являются основной формой для сбора информации, содержат все данные в базах данных SQL Server. Каждая таблица представляет собой тип объекта, который имеет смысл для пользователей.
Индекс - структура на диске, связанная с таблицей или представлением, которая ускоряет поиск строк таблицы или представления. Индекс содержит ключи, созданные для одного или нескольких столбцов таблицы или представления. Эти ключи хранятся в виде B-древовидной структуры, что позволяет SQL Server, быстро и эффективно находить строку или строки, связанные с ключевыми индексами. Существуют кластерные и не кластерные индексы.
Представления являются запросами на выборку. Они выполняют извлечение данных из таблиц с помощью инструкции языка SQL SELECT и реализуют одно их основных назначений базы данных - предоставлять информацию пользователю. Результатом выполнения инструкции SELECT является таблица. Представления - это просто хранящиеся в базе данных SELECT-инструкции. С точки зрения пользователей представление - это таблица, которая не хранится постоянно в базе данных, а формируется в момент обращения к ней.
Хранимая процедура - это сохраненный набор инструкций языка Transact-SQL, выполняемый как единое целое. Хранимая процедура является специальной программой из совместно откомпилированных команд Transact-SQL, сохраняемой в базе данных SQL Server и выполняемой по вызову клиента. В хранимых процедурах могут выполняться любые инструкции Transact-SQL, в том числе инструкции добавления, изменения и удаления данных (INSERT, UPDATE и DELETE). Хранимая процедура может принимать и возвращать параметры.
Триггеры представляют собой объекты базы данных, связанные с таблицей. Во многом они похожи на хранимые процедуры и часто упоминаются как "особый вид хранимых процедур". Основное различие между триггером и хранимой процедурой в том, что триггер связан с таблицей и работает только при работе выражения INSERT, UPDATE или DELETE.
Пользовательские функции, подобно функциям языков программирования, являются подпрограммами Transact-SQL, которые принимают параметры, выполняют некоторое действие, например сложный расчет, и возвращают результат этого действия в виде значения. Функции подразделяются на скалярные, возвращающие единственное значение заданного типа данных, и табличные, возвращающие таблицы (значение типа table). Вызов функции сопровождается круглыми скобками, даже если она не имеет параметров. Пользовательские функции не могут выполнять действия, изменяющие состояние базы данных. Изменениям может подвергаться только возвращаемый набор данных. Пользовательские функции делают возможным модульное программирование, не требуют повторного синтаксического анализа и оптимизации при каждом вызове, что значительно ускоряет их выполнение.
1.1.4. Модернизация устаревших информационных систем
С проблемой модернизации устаревших информационных систем рано или поздно сталкивается почти каждый разработчик или IT-менеджер. В нашей стране все еще нетрудно встретить банковские системы, использующие dBase, а также относительно свежие коммерческие разработки, созданные с помощью Clipper, средством обмена данными которым служат отнюдь не Internet и не сетевые протоколы, а курьер с дискетами и электричка (это вовсе не всегда происходит из-за неосведомленности разработчиков - просто у их клиентов нет и в ближайшее время не будет денег на приличное оборудование и соответствующую инфраструктуру). Именно поэтому мы полагаем, что проблема модернизации информационных систем в России еще долго будет оставаться актуальной.
В каждой организации, переживающей процесс модернизации информационной системы, возникают свои проблемы. В одной пользователи требуют сохранить привычный пользовательский интерфейс (те, кто давно программирует на Delphi, наверное, помнят популярную задачу из серии «угоди пользователю, привыкшему к DOS», - как в форме ввода данных заставить клавишу Enter делать то, что обычно делает клавиша Tab); в другой нужно суметь не просто перенести в новую базу унаследованные данные, но и изменить их в соответствии с вновь возникшими потребностями (например, исправить ошибки, допущенные много лет назад при проектировании данных, или объединить данные из нескольких разных источников); в третьей организации сохранилось и используется большое количество отчетов, созданных с помощью старой настольной СУБД, и нужно обеспечить возможность их использования в новой информационной системе; в четвертой процесс ввода новых данных происходит непрерывно, и это накладывает ограничения на то, как именно производить процесс замены СУБД и клиентских приложений.
В целом варианты модернизации информационной системы можно условно разделить на следующие категории:
1. Замена СУБД с сохранением структуры базы данных и пользовательских приложений (или относительно небольшой их модернизацией).
2. Замена и СУБД, и пользовательских приложений с сохранением структуры базы данных.
3. Замена СУБД, пользовательских приложений и одновременная модернизация структуры базы данных.
На первый взгляд, первый вариант представляется наиболее безболезненным для пользователей и разработчиков, и он широко пропагандировался несколько лет назад. Именно в тот период на рынке программного обеспечения появились две категории продуктов, «обслуживающих» подобный вариант модернизации.
Первая категория представляла собой драйверы различных серверных СУБД для средств разработки, ориентированных в целом на использование настольных баз данных (например, драйверы Oracle для Clipper, преобразовывающие функции Clipper в вызовы функций клиентского API Oracle - Oracle Call Interface); обычно эти драйверы поставлялись в виде библиотек, компилируемых вместе с приложением. «Потомки» подобного программного обеспечения существуют и сейчас - одним из них является, например, библиотека Borland SQL Links, изначально предназначенная для использования приложений Paradox с серверными СУБД.
Вторая категория продуктов, ныне практически забытая, представляла собой некое подобие серверов баз данных, управлявших набором файлов настольных СУБД. Типичными примерами таких продуктов являлись разнообразные «dBase-серверы», управлявшие набором dBase-таблиц и перехватывавшие обращения к ним клиентских приложений. Подобные «серверы» в определенной степени решали проблему сетевого трафика и даже поддержки ссылочной целостности, но в силу ограничений, накладываемых на хранимый объем данных, характерных для форматов настольных СУБД, достаточно быстро уступили место «настоящим» серверам баз данных.
Если говорить о первом варианте модернизации, в этом отношении больше всего повезло пользователям Microsoft Access - процесс замены базы данных Microsoft Access на MSDE (или Microsoft SQL Server) происходит достаточно безболезненно, и пользовательские приложения при этом обычно сохраняют свою работоспособность. Так как в данном случае все эти СУБД (Access, MSDE и SQL Server) принадлежат одному производителю, перенос данных между ними осуществляется вполне корректно, с сохранением всех определенных в базе данных бизнес-правил. Кроме того, утилиты переноса данных из Access содержатся в комплекте поставки и других серверных СУБД (например, Oracle). Относительно безболезненно можно осуществить перенос данных из Visual FoxPro в Microsoft SQL Server.
Что касается замены других версий настольных СУБД на серверные, здесь могут возникнуть определенные проблемы. Например, при переносе данных из dBase или Paradox в какую-нибудь серверную СУБД обслуживающее их приложение, написанное на Delphi, вполне может отказаться работать даже после корректной перенастройки библиотек доступа к данным, особенно если оно содержит сведения о метаданных. Возможны также различные неприятности, связанные с использованием строчных и прописных букв в наименованиях полей, применением русских наименований полей (и вообще локализованных версий, поддерживающих национальные традиции написания чисел и дат и нередко превращающих числовые данные и даты в при переносе в другую СУБД в нечто невообразимое), несовместимости некоторых типов данных (это особенно часто происходит при переносе таблиц Paradox в другие СУБД). Наконец, если в серверной СУБД определены какие-либо бизнес-правила, нет никакой гарантии, что они идеально соблюдались в настольной СУБД, из которой переносятся данные, и в этом случае некоторое количество «ручного» труда по разбору данных, не соответствующих этим правилам, вам или вашим пользователям гарантировано.
Отметим, однако, что переход к архитектуре «клиент-сервер» отнюдь не исчерпывается переносом данных в новую СУБД. Чтобы воспользоваться всеми преимуществами этой архитектуры, следует также реализовать бизнес-правила, содержащиеся в клиентском приложении, в виде триггеров и хранимых процедур, а затем модифицировать код клиентского приложения, удалив реализацию бизнес-правил или заменив ее на обращения к соответствующим объектам базы данных. И если исходное клиентское приложение содержало код, отличный от чисто презентационного, было бы более чем наивно полагать, что оно не нуждается в модернизации, что бы ни говорилось в рекламе средств разработки по поводу масштабируемости созданных с их помощью приложений или о их независимости от СУБД. Как известно, реальные приложения очень отличаются от тех, что демонстрируются на выставках и презентациях…
Второй вариант модернизации информационной системы представляет собой по существу создание нового проекта по готовой модели данных плюс только что рассмотренный перенос данных в новую СУБД. Что касается третьего варианта модернизации, его можно рассматривать как два самостоятельных проекта. Первый из них представляет собой создание информационной системы практически «с нуля», второй - заполнение базы унаследованными данными. При этом, поскольку структуры баз данных различны, стандартными утилитами переноса данных (имеющимися в комплектах поставки многих средств разработки и серверных СУБД) здесь обычно обойтись не удается - как правило, в этом случае создаются «одноразовые» приложения, производящие нужные преобразования данных в процессе их переноса.
Обсудив проблемы, возникающие при переносе информационных систем, использовавших настольные СУБД, в архитектуру «клиент-сервер», можно перейти к обсуждению того, какие сервисы предоставляют современные серверные СУБД и чем с этой точки зрения следует руководствоваться при их выборе.
Даже очень детальный анализ особенностей архитектуры клиент-сервер может не ответить на вопрос "А что мне это даст?" Посмотрим на данную архитектуру с точки зрения потребностей бизнеса. Какие же качества привносит клиент-сервер в информационную систему:
Надежность
Тот, кто хоть раз побывал в роли администратора базы данных в тот момент, когда эта база данных "погибла" по причине "зависания" сервера или рабочей станции, сбоя питания или еще какой-либо напасти, никогда уже не станет пренебрегать вопросами надежности (если, конечно, сумеет сохранить за собой эту роль). Если Вы еще не побывали в этой роли, надеюсь, у Вас достанет воображения, чтобы прокрутить этот триллер у себя в голове, и благоразумия, чтобы максимально обезопасить свою базу данных (и себя заодно). Чем же тут поможет архитектура клиент-сервер?
Сервер баз данных осуществляет модификацию данных на основе механизма транзакций, который придает любой совокупности операций, объявленных как транзакция, следующие свойства:
Атомарность - при любых обстоятельствах будут либо выполнены все операции транзакции, либо не выполнена ни одна; целостность данных при завершении транзакции;
Независимость - транзакции, инициированные разными пользователями, не вмешиваются в дела друг друга;
Устойчивость к сбоям - после завершения транзакции, ее результаты уже не пропадут.
Механизм транзакций, поддерживаемый сервером баз данных, намного более эффективен, чем аналогичный механизм в настольных СУБД, т.к. сервер централизованно контролирует работу транзакций. Кроме того, в файл-серверной системе сбой на любой из рабочих станций может привести к потере данных и их недоступности для других рабочих станций, в то время, как в клиент-серверной системе сбой на клиенте, практически, никогда не сказывается на целостности данных и их доступности для других клиентов.
Масштабируемость
Масштабируемость - способность системы адаптироваться к росту количества пользователей и объема базы данных при адекватном повышении производительности аппаратной платформы, без замены программного обеспечения.
Общеизвестно, что возможности настольных СУБД серьезно ограничены - это пять-семь пользователей и 30-50 Мб, соответственно. Цифры, разумеется, представляют собой некие средние значения, в конкретных случаях они могут отклоняться как в ту, так и в другую сторону. Что наиболее существенно, эти барьеры нельзя преодолеть за счет наращивания возможностей аппаратуры.
Системы же на основе серверов баз данных могут поддерживать тысячи пользователей и сотни ГБ информации - дайте им только соответствующую аппаратную платформу.
Безопасность
Сервер баз данных предоставляет мощные средства защиты данных от несанкционированного доступа, невозможные в настольных СУБД. При этом, права доступа администрируют очень гибко - до уровня полей таблиц. Кроме того, можно вообще запретить прямое обращение к таблицам, осуществляя взаимодействие пользователя с данными через промежуточные объекты - представления и хранимые процедуры. Так что администратор может быть уверен - никакой слишком умный пользователь не прочитает то, что ему читать не положено.
Гибкость
В приложении, работающем с данными, можно выделить три логических слоя:
Пользовательского интерфейса;
Правил логической обработки (бизнес-правил);
Управления данными (не следует только путать логические слои с физическими уровнями, о которых речь пойдет ниже).
Как уже говорилось, в файл-серверной архитектуре все три слоя реализуются в одном монолитном приложении, функционирующем на рабочей станции. Поэтому изменения в любом из слоев приводят однозначно к модификации приложения и последующему обновлению его версий на рабочих станциях.
В двухуровневом клиент-серверном приложении, показанном на рис. 1, как правило, все функции по формированию пользовательского интерфейса реализуются на клиенте, все функции по управлению данными - на сервере, а вот бизнес-правила можно реализовать как на сервере используя механизмы программирования сервера (хранимые процедуры, триггеры, представления и т.п.), так и на клиенте. В трехуровневом приложении появляется третий, промежуточный уровень, реализующий бизнес-правила, которые являются наиболее часто изменяемыми компонентами приложения.
2. Модели клиент - сервер.
Одна из моделей взаимодействия компьютеров в сети получила название «клиент-сервер». Каждый из составляющих эту архитектуру элементов играет свою роль: сервер владеет и распоряжается информационными ресурсами системы, клиент имеет возможность воспользоваться ими.
Сервер базы данных представляет собой мультипользовательскую версию СУБД, параллельно обрабатывающую запросы, поступившие со всех рабочих станций. В его задачу входит реализация логики обработки транзакций с применением необходимой техники синхронизации - поддержки протоколов блокирования ресурсов, обеспечение, предотвращение и/или устранения тупиковых ситуаций.
В ответ на пользовательский запрос рабочая станция получит не «сырье» для последующей обработки, а готовые результаты. Программное обеспечение рабочей станции при такой архитектуре играет роль только внешнего интерфейса (Front - end) централизованной системы управления данными. Это позволяет существенно уменьшить сетевой трафик, сократить время на ожидание блокированных ресурсов данных в мультипользовательском режиме, разгрузить рабочие станции и при достаточно мощной центральной машине использовать для них более дешевое оборудование.
Для современных СУБД архитектура «клиент-сервер» стала фактически стандартом. Если предполагается, что проектируемая информация будет иметь архитектуру «клиент-сервер», то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер, т. е. часть функций приложений будет реализована в программе-клиенте, другая - в программе-сервере. Основной принцип технологии «клиент-сервер» заключается в разделении функций стандартного интерактивного приложения на четыре группы:
· функции ввода и отображения данных;
· прикладные функции, характерные для предметной области;
· фундаментальные функции хранения и управления ресурсами (базами данных);
· служебные функции.
Исходя из этого, рассмотрим три подхода, реализованные в моделях технологии «клиент-сервер».
RDA-модель
Основные свойства:
· коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте;
· доступ к информационным ресурсам обеспечивается операторами непроцедурного языка SQL.
Технология:
· клиентский запрос направляется на сервер, где функционирующее ядро СУБД обрабатывает запрос и возвращает результат (блок данных) клиенту. Ядро СУБД выполняет пассивную роль;
· инициатор манипуляций с данными - программы на компьютере-клиенте.
Достоинства:
· процессор сервера загружается операциями обработки данных;
· уменьшается загрузка сети, т.к. по сети передаются запросы на языке SQL;
· унификация интерфейса «клиент-сервер» в виде языка SQL; использование его в качестве стандарта общения клиента и сервера.
Недостатки:
· удовлетворительное администрирование приложений в RDA-модели невозможно из-за совмещения в одной программе различных по своей природе функций (представления и прикладных).
DBS-модель
Реализована в реляционных СУБД Informix, Ingres, Oracle.
Основные свойства:
· основа модель-механизм хранимых процедур - средство программирования SQL-сервера;
· процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на компьютере, где функционирует SQL-сервер;
· компонент представления выполняется на компьютере-клиенте;
· прикладной компонент и ядро СУБД на компьютере-сервере базы данных.
Достоинства:
· возможность централизованного администрирования;
· вместо SQL-запросов по сети передаются вызовы хранимых процедур, что ведет к снижению сетевого трафика.
Недостатки:
· в большинстве СУБД недостаточно возможностей для отладки и типизирования хранимых процедур;
· ограниченность средств для написания хранимых процедур.
На практике чаще используется разумный синтез RDA- и DBS-моделей для построения многопользовательских информационных систем.
AS-модель
Основные свойства:
· на компьютере-клиенте выполняется процесс, отвечающий за интерфейс с пользователем;
· этот процесс, обращаясь за выполнением услуг к прикладному компоненту, играет роль клиента приложения (АС);
· прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения (AS);
· все операции над БД выполняются соответствующим компонентом, для которого AS - клиент.
RDA- и DBS-модели имеют в основе двухзвенную схему разделения функций. В RDA-модели прикладные функции отданы клиенту, в DBS-модели их реализация осуществляется через ядро СУБД. В RDA-модели прикладной компонент сливается с компонентом представления, в DBS-модели интегрируется в компонент доступа к ресурсам.
В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, имеющий стандартизированные интерфейсы с двумя другими компонентами.
В последнее время также наблюдается тенденция ко все большему использованию модели распределенного приложения. Характерной чертой таких приложений является логическое разделение приложения на две и более частей, каждая из которых может выполняться на отдельном компьютере. Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате. В этом случае двухзвенная архитектура клиент-сервер становится трехзвенной, а к некоторых случаях, она может включать и больше звеньев.
2.1. Классическая двухуровневая архитектура «Клиент – сервер»
Обычно компоненты сети не равноправны: у одних есть доступ к ресурсам (например, принтер, процессор, система управления базой данных (СУБД), файловая система и так далее), другие имеют возможность обращаться к этим ресурсам.
Технология «Клиент – сервер» - это архитектура программного комплекса, в которой происходит распределение прикладной программы по двум логически различным компонентам (клиент и сервер), взаимодействующим по схеме «запрос-ответ» и решающим свои определенные задачи (рисунок 6).
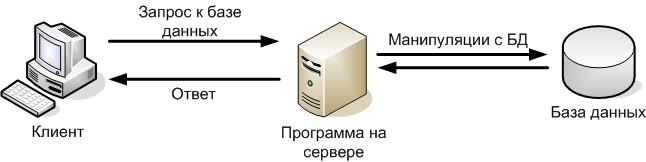
Клиент и сервер это программы, расположенное на разных компьютерах, в разных контроллерах и других подобных устройствах. Между собой они взаимодействуют через вычислительную сеть с помощью сетевых протоколов.
Программы-серверы являются поставщиками услуг. Они постоянно ожидают запросы от программ-клиентов и предоставляют им свои услуги (передают данные, решают вычислительные задачи, управляют чем-либо и т.п.). Сервер должен быть постоянно включен и “прослушивать” сеть. Каждая программа-сервер, как правило, может выполнять запросы от нескольких программ-клиентов.
Программа-клиент является инициатором запроса, который может произвести в любой момент. В отличие от сервера клиент не должен быть постоянно включен. Достаточно подключиться в момент запроса.
Итак, в общих чертах система клиент-сервер выглядит так:
- Есть компьютеры, контроллеры Ардуино, планшеты, сотовые телефоны и другие интеллектуальные устройства.
- Все они включены в общую вычислительную сеть. Проводную или беспроводную - не важно. Они могут быть подключены даже к разным сетям, связанным между собой через глобальную сеть, например через интернет.
- На некоторых устройствах установлены программы-серверы. Эти устройства называются серверами, должны быть постоянно включены, и их задача обрабатывать запросы от клиентов.
- На других устройствах работают программы-клиенты. Такие устройства называются клиентами, они инициируют запросы серверам. Их включают только в моменты, когда необходимо обратиться к серверам.
Например, если вы хотите с сотового телефона по Wi-Fi включать утюг, то утюг будет сервером, а телефон – клиентом. Утюг должен быть постоянно включен в розетку, а управляющую программу на телефоне вы будете запускать по необходимости. Если к Wi-Fi сети утюга подключить компьютер, то вы сможете управлять утюгом и с помощью компьютера. Это будет еще один клиент. Wi-Fi микроволновая печь, добавленная в систему, будет сервером. И так систему можно расширять бесконечно.
Архитектура «Клиент – сервер»
Компьютер (или программа), управляющий и/или владеющий каким-либо ресурсом, называют сервером этого ресурса.
Компьютер (или программа), запрашивающий и пользующийся каким-либо ресурсом, называют клиентом этого ресурса.
Клиент и сервер могут находиться как на одном компьютере (ПК), так и на разных ПК в сети. Также может возникать такая ситуация, когда некоторый программный блок будет одновременно выполнять функции сервера по отношению к одному блоку и клиента по отношению к другому.
Основной принцип технологии «Клиент-сервер» заключается в разделении функций приложения как минимум на три группы:
- модули интерфейса с пользователем;
Также эту группу называют логикой представления. Через эту группу пользователи взаимодействуют с приложением. Независимо от конкретных характеристик логики представления (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и информационной системой.
- модули хранения данных;
Эту группу также называют бизнес-логикой. Бизнес-логика определяет, для чего конкретно предназначено приложение (например, прикладные функции, характерные для данной предметной области). Разделение приложения по границам между программами обеспечивает естественную основу для распределения приложения на нескольких компьютерах.
- модули обработки данных (функции управления ресурсами);
Эту группу также называют логикой доступа к данным или алгоритмами доступа к данным. Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или СУБД. При помощи модулей обработки данных организуется специфический для приложения интерфейс к СУБД. При помощи интерфейса приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных).
Каждая из этих групп может быть реализована независимо от двух других. Например, не изменяя программ, используемых для хранения и обработки данных, можно изменить интерфейс с пользователем таким образом, что одни и те же данные будут отображаться в виде таблиц, графиков или гистограмм. Очень простые приложения часто способны собрать все три части в единственную программу, и подобное разделение соответствует функциональным границам.
В соответствии с разделением функций в любом приложении выделяются следующие компоненты:
- компонент представления данных;
- прикладной компонент;
- компонент управления ресурсом.
В классической архитектуре клиент-сервер приходится распределять три основные части приложения по двум физическим модулям. Обычно прикладной компонент располагается на сервере (например, сервере базы данных), компонент представления данных - на стороне клиента, а компонент управления ресурсом распределяется между клиентской и серверной частями. В этом заключается основной недостаток классической двухуровневой архитектуры.
В двухзвенной архитектуре при разбиении алгоритмов обработки данных разработчики должны иметь полную информацию о последних изменениях, внесенных в систему, и понимать эти изменения, что создает большие сложности при разработке клиент-серверных систем, их установке и сопровождении, поскольку необходимо тратить значительные усилия на координацию действий разных групп специалистов. В действиях разработчиков часто возникают противоречия, а это тормозит развитие системы и вынуждает изменять уже готовые и проверенные элементы.
Чтобы избежать несогласованности различных элементов архитектуры были созданы две модификации двухзвенной архитектуры «Клиент – сервер»: «Толстый клиент» («Тонкий сервер») и «Тонкий клиент» («Толстый сервер»).
В данных архитектурах разработчики попытались выполнять обработку данных на одной из двух физических частей - либо на стороне клиента («Толстый клиент»), либо на сервере («Тонкий клиент).
Каждый подход имеет свои недостатки. В первом случае неоправданно перегружается сеть, потому что по ней передаются необработанные, а значит, избыточные данные. Кроме того, усложняется поддержка системы и ее изменение, так как замена алгоритма вычислений или исправление ошибки требует одновременной полной замены всех интерфейсных программ, а иначе могут возникнуть ошибки или несогласованность данных. Если же вся обработка информации выполняется на сервере, то возникает проблема описания встроенных процедур и их отладки. Систему с обработкой информации на сервере абсолютно невозможно перенести на другую платформу (ОС), что является серьезным недостатком.
Если все-таки разрабатывается двухуровневая классическая архитектура «Клиент – сервер», то необходимо помнить следующее:
- архитектура «Толстый сервер» аналогична архитектуре «Тонкий клиент» (рисунок 33);
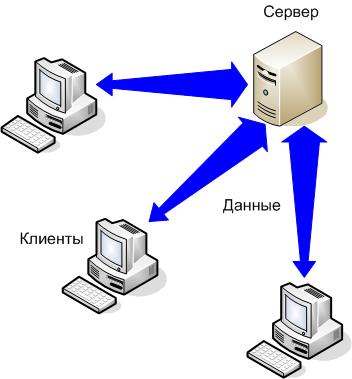
Рисунок 33. – Архитектура «Тонкий клиент»
Передача запроса от клиента на сервер, обработка запроса сервером и передача результата клиенту. При этом архитектуры имеют следующие недостатки:
- усложняется реализация, так как языки типа SQL не приспособлены для разработки подобного ПО и нет хороших средств отладки;
- производительность программ, написанных на языках типа SQL, значительно ниже, чем созданных на других языках, что имеет важное значение для сложных систем;
- программы, написанные на СУБД-языках, обычно работают недостаточно надежно; ошибка в них может привести к выходу из строя всего сервера баз данных;
- получившиеся таким образом программы полностью непереносимы на другие системы и платформы.
- архитектура «Тонкий сервер» аналогична архитектуре «Толстый клиент» (рисунок 34).
Обработка запроса происходит на стороне клиента, то есть происходит передача клиенту всех необработанных данных с сервера. При этом архитектуры имеют следующие недостатки:
- усложняется обновление ПО, поскольку его замену нужно производить одновременно по всей системе;
- усложняется распределение полномочий, так как разграничение доступа происходит не по действиям, а по таблицам;
- перегружается сеть вследствие передачи по ней необработанных данных;
- слабая защита данных, поскольку сложно правильно распределить полномочия.
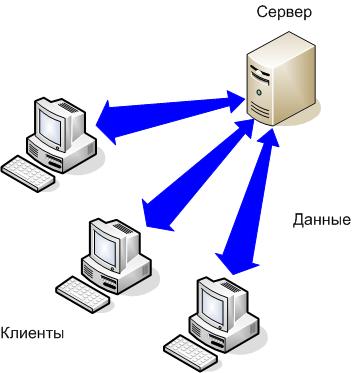
Рисунок 34. – Архитектура «Толстый клиент»
Для решения перечисленных проблем используются многоуровневые (три и более уровней) архитектуры «Клиент-сервер».
2.2. Трехуровневая модель
С середины 90-х годов прошлого века признание специалистов получила трехзвенная архитектура «Клиент – сервер», которая разделила информационную систему по функциональным возможностям на три отдельных компонента: логика представления, бизнес-логика и логика доступа к данным. В отличие от двухзвенной архитектуры в трехзвенной появляется дополнительное звено - сервер приложений, который предназначен для осуществления бизнес-логики, при этом полностью разгружается клиент, который направляет запросы промежуточному программному обеспечению, и максимально используются все возможности серверов.
В трехуровневой архитектуре клиент обычно не перегружен функциями обработки данных, а выполняет свою основную роль системы представления информации, поступающей с сервера приложений. Такой интерфейс можно реализовать с помощью стандартных средств Web-технологии - браузера, CGI и Java. Это уменьшает объем данных, передаваемых между клиентом и сервером приложений, что позволяет подключать клиентские компьютеры даже по медленным линиям типа телефонных каналов. Кроме того, клиентская часть может быть настолько простой, что в большинстве случаев ее реализуют с помощью универсального браузера. Но если менять ее все-таки придется, то эту процедуру можно осуществить быстро и безболезненно.
Сервер приложений – это программное обеспечение, являющееся промежуточным слоем между клиентом и сервером (рисунок 35).
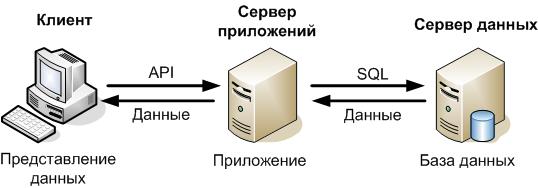
Рисунок 35 - Сервер приложений
Существует несколько категорий продуктов промежуточного слоя:
- Message orientated – яркие представители MQseries и JMS;
- Object Broker – яркие представители CORBA и DCOM;
- Component based – яркие представители.NET и EJB.
Использование сервера приложений дает больше возможностей, например, уменьшается нагрузка на клиентские компьютеры, потому что сервер приложений распределяет нагрузку и обеспечивает защиту от сбоев. Так как бизнес-логика хранится на сервере приложений, то при каких-либо изменениях в отчетности или расчетах клиентские программы никоим образом не затрагиваются.
Существует несколько серверов приложений от таких знаменитых компаний как Sun Microsystem, Borland, IBM, Oracle и каждый из них отличается набором предоставляемых сервисов (производительность в данном случае учитывать не будем). Эти сервисы облегчают программирование и развертывание приложений масштаба предприятия. Обычно сервер приложений предоставляет следующие сервисы:
- WEB Server – чаще всего включают в поставку самый популярный и мощный Apache;
- WEB Container – позволяет выполнять JSP и скрипты. Для Apache таким сервисом является Tomcat;
3. Развитие
3.1. Клиент-серверные вычисления
В 1970-хи1980-хгодов была эпоха централизованных вычислений на мэйнфреймах IBM занимающих более 70% в компьютерном бизнесе мира.
Бизнес транзакции, деятельности и базы данных, запросы и техническое обслуживание - все исполнялось на мэйнфреймах IBM. Этап перехода к клиент-серверным вычислениям представляет совершенно новую концепцию и технологию реорганизации всего делового мира. Вычислительные парадигмы1990-хгодов называли «волной будущего».
Машина-клиент обычно управляет интерфейсами процессов, таких как графический интерфейс (графический пользовательский интерфейс), отправкой запросов на сервер программ, проверкой данных, введенных пользователем, а также управляет местными ресурсами, а пользователь взаимодействует с такими, как монитор, клавиатура, рабочие станции, процессора и других периферийных устройств. С другой стороны, сервер выполняет запрос клиента, с помощью службы. После того как сервер получает запросы от клиентов, он выполняет поиск базы данных, обновления и управляет целостностью данных и отправляет ответы на запросы клиентов.
Цель клиент-серверных вычислений - позволить каждой сетевой рабочей станции (клиента) и принимающей (сервера) быть доступными, по мере необходимости приложения, а так же обеспечивать доступ к существующему программному обеспечение и аппаратным компонентам от различных поставщиков для совместной работы. Когда эти два условия соединены, становятся очевидными преимущества клиент-серверной архитектуры, такие как экономия средств, повышение производительности, гибкости и использования ресурсов.
Клиент-серверные вычисления состоят из трех компонентов, клиентского процесса, запрашивающего обслуживание и серверного процесса предоставления запрашиваемых услуг, с Middleware между ними для их взаимодействия.
Клиент
Машина клиент обычно управляет пользовательским интерфейсом частей приложения, проверкой данных, введенных пользователем, отправкой запросов на сервер программы. Кроме того, клиентский процесс также управляет местными ресурсами, что позволяет пользователю взаимодействовать с монитором, клавиатурой, рабочими станциями, процессорами и другими периферийными устройствами.
Сервер
Машина Сервер выполняет служебные запросы клиента. После того как сервер получает запросы от клиентов, он производит поиск базы данных, обновления, управляет целостностью данных и отправляет ответы на запросы клиентов. Серверных процесс может работать на другой машине в сети; тогда сервер используется как файловая система услуг и приложений сервисов. Или в некоторых случаях, другой рабочий стол машины обеспечивает применение услуг. Сервер выступает в качестве программного обеспечения двигателя, который управляет общим ресурсам, таким как базы данных, принтеры, линии связи, или процессоров высокой мощности.
Основная цель серверного процесса - выполнение фоновых задач, которые являются общими для приложений.
Простейшая форма серверов - это дисковый сервер и файл-сервер. Если клиент передает запросы на файл или группы файлов по сети на файловый сервер, эта форма обслуживания данных требует большой пропускной способности и может замедлить сеть с большим количеством пользователей.
Более продвинутые формы серверов - это серверы баз данных, сервер транзакций и серверов приложений.
Middleware
Middleware позволяет приложениям прозрачно контактировать с другими программами или процессами независимо от местоположения.
Ключевым элементом Middleware является NOS (Network Operating System), которая предоставляет такие услуги, как маршрутизация, распределение, обмен сообщениями и управления сервисной сети. NOS полагается на коммуникацию протоколов предоставления конкретных услуг. Прежде чем пользователь может получить доступ к услугам сети, клиент-серверный протокол требует установку физического соединения и выбор транспортных протоколов. Клиент-серверный протокол диктует, каким образом клиенты запрашивают информацию и услуги от сервера, а также как сервер отвечает на эту просьбу.
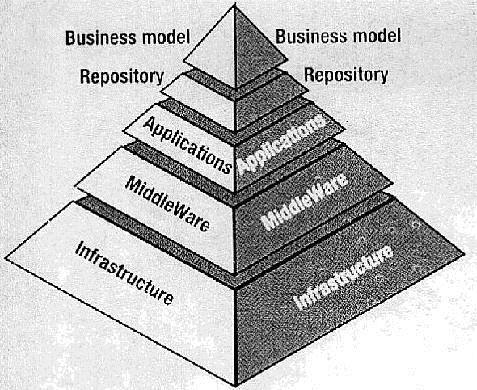
Пирамида модели «клиент-сервер»
Мартин Батлер, председатель Butler Group предложил новые рамки для реализации клиент-серверной стратегии. Это пятислойная модель под названием VAL (Value Added Layers) Модель. Основная структура напоминает по форме пирамиду, со слоями Инфраструктура и Middleware в нижней части пирамиды, а приложения, хранилища и бизнес модели на вершине.
Характеристики каждого слоя:
Уровень 1 - Инфраструктура слоя
Слой инфраструктура состоит из всех тех компонентов, которые являются пассивными и не выполняет бизнес-функции. Примеры относятся к этой категории компьютерных операционных систем, сетей, пользовательских интерфейсов и системы управления базой данных.
Уровень 2 - Middleware
Middleware позволяет приложениям прозрачно коммуникатировать с другими программами или процессами независимо от их местоположения.
Это средство отображения приложений используемых ими ресурсов. Middleware является ключом к интеграции гетерогенных аппаратных и программных сред, обеспечивая тот уровень интеграции, который необходим многие организациям. Типичные Middleware проявляются после сетевых соединений, соединений с базой данных и осуществляют взаимодействие между базой данных и приложениями.
Уровень 3 - Программы
Приложения являются активными компонентами, которые выполняют работы по организации, и именно сюда, многие компании инвестируют большое количество усилий, времени и денег. Приложения, которые не имеют ключевого значения. Они все чаще приобретаются как готовый пакет.
Приложения же, которые являются жизненно важными для увеличения конкурентоспособности компании в отрасли, разрабатываются на месте.
Уровень 4 – Хранилище
Роль хранилища - изоляция бизнес-модели /спецификации от технологических инструментов, которые используются для ее осуществления.
Уровень 5 - Бизнес-модели
Бизнес-модель должна быть независимой, чтобы все технологии, которые используются для ее осуществления были применимы к аппаратной и программной среде в зависимости от того, что является наиболее подходящим. Это будет все больше и больше опираться на объектно-ориентированные методы, и уже существует поколение инструментов, которые поддерживают объект моделирования.
Технология перехода к клиент-серверным вычислениям проявляется, главным образом, за счет более сложной ситуации в бизнесе в последние годы, такие как глобальный маркетинг, дистанционные онлайн продажи распределения, децентрализованной корпоративной стратегии и т.д. Все это требует быстрое реагирование, легкий доступ к информации данных, и более эффективной координации между людьми на всех уровнях как внутри, так и вне организации. Клиент-серверные вычисления позволяют решать все эти проблемы и, следовательно, являются одним из приоритетных вопросов в умах управления ИТ.
Ясно, что клиент-серверная технология приносит много преимуществ для бизнеса, а также расширение возможностей для расширения и конкурирования. К сожалению, все это может быть достигнуто только за счет более высокой стоимости сооружений и более сложной совместимости систем.
Клиент-сервер не единственный способ решения бизнес-проблем, он также получил свои ограничения, один из которых, дороговизна. Но пока клиент-сервер осуществляется мудро, он может принести конкурентные преимущества.
Заключение.
Преимущества и недостатки клиент-серверной архитектуры.
Преимуществом модели взаимодействия клиент-сервер является то, что программный код клиентского приложения и серверного разделен. Если мы говорим про локальные компьютерные сети, то к преимуществам архитектуры клиент-сервер можно отнести пониженные требования к машинам клиентов, так как большая часть вычислительных операций будет производиться на сервере, а также архитектура клиент-сервер довольно гибкая и позволяет администратору сделать локальную сеть более защищенной.
К недостаткам модели взаимодействия клиент-сервер можно отнести то, что стоимость серверного оборудования значительно выше клиентского. Сервер должен обслуживать специально обученный и подготовленный человек. Если в локальной сети ложится сервер, то и клиенты не смогут работать (в качестве частного случая можно привести пример: мощности сервера не всегда хватает, чтобы удовлетворит запросы клиентов, если вы хоть раз работали с биллинговыми системами, то понимаете о чем я: время ожидания ответа от сервера может быть очень большим).
В качестве заключения нам стоит явно акцентировать внимание на том, что архитектура клиент-сервер не делит машины на только клиент или только сервер, а скорее позволяет распределить нагрузку и разделить функционал между клиентской частью и серверной.
Библиография.
- Валерий Коржов Многоуровневые системы клиент-сервер. Издательство Открытые системы (17 июня 1997).
- Тейлор А.Дж. SQL для начинающих /А.Дж. Тейлор.- Москва: Вильяме, 2005.
- Дейт К.Дж. Введение в системы баз данных /К.Дж. Дейт - Москва: ДМК, 2000.
- Хомоненко А.Д. Базы данных /А.Д. Хомоненко, В.М. Цыганков - Санкт-Петербург: БХВ-Петербург, 2004.
- Вескес Л.Дж. Access и SQL Server. Руководство разработчика /Дж.Л. Вескес - Москва: Лори, 1997.
- Конноли Т. Базы данных. Проектирование, реализация и сопровождение /Т. Конноли, К. Бегг. - Москва: Вильяме, 2003.
7. Кириллов В.В., Громов Г.Ю. Введение в реляционные базы данных. Спб.: Питер, 2011. – 464 с.
8. Кренке Д. Теория и практика построения баз данных. Спб.: Питер, 2011. – 864 с.
9. Ребекка М. Основы реляционных баз данных. М.: Русская Редакция, 2012. 55 с.
10. Баженова И.Ю. Базы данных. М.: МГУ им. М.В. Ломоносова, 2013. – 201 с.
11. Кузин А.В., Левонисова С.В. Базы данных. М.: Академия, 2012. – 561 с.
12. Руссел Д., Кофи Р. Система управления базами данных. М.:Книга по Требованию, 2012. – 445 с.
13. Ржеуцкая С.Ю. Базы данных. Язык SQL. - Вологда: ВоГТУ, 2010. – 159 с.
14. Осипов Д.А. Базы данных и Delphi. Теория и практика. Спб.: БХВ- Петербург, 2011. – 752 с.
15. Фиайли К. SQL. Руководство по изучению языка. Спб.: Питер, 2013. – 456.

- «Состав и свойства вычислительных систем. Информационное и математическое обеспечение вычислительных систем»
- Применение процессного подхода для оптимизации бизнес-процессов (цель процессного подхода)
- Гендерные различия проявлений профессионального СТРЕССА
- «Порядок проведения приватизации» (государственное или муниципальное имущество)
- понятие и виды наследования
- Лицензирование отдельных видов предпринимательской деятельности
- Виды договоров (Поименованные и непоименованные договоры)
- Правовые основы организации нотариата.
- Языки гипертекстовой разметки (Понятия языков разметки).
- Основы программирования на языке QBasic (Примеры некоторых программ)
- РАЗРАБОТКА РЕГЛАМЕНТА ВЫПОЛНЕНИЯ ПРОЦЕССА «ПОКУПКА СЫРЬЯ И МАТЕРИАЛОВ» (Предлагаемые мероприятия по улучшению бизнес–процессов)
- Особенности налоговой политики в Российской Федерации.