
ТЕХНОЛОГИИ ПРОГРАММИРОВАНИЯ. Методы кодирования данных.
Содержание:

ВВЕДЕНИЕ
В настоящее время весь мир переживает эпоху информатизации. Научные и технические достижения очень плотно обосновались в жизни каждого современного человека. Компьютеры и смартфоны используют цифровой вид преставления информации. Однако большой объем данных требует и большой пропускной способности линий. Современные каналы передачи данных не могут справляться с такими потоками. Следовательно, очень важной является задача кодирования данных.
Под кодированием принято понимать такое описание блока данных, при котором создаваемый блок содержит меньше битов, чем исходный, однако, по нему возможно однозначно восстановить каждый бит исходного блока. Обратный процесс называют декодированием.
Кроме того, кодирование находит применение и в процессах шифрования. Алгоритмы шифрования на сегодняшний день являются очень перспективным направлением информатики и вычислительной техники. Большинство повседневных процессов, так или иначе, связано с зашифрованной информацией. Например, мы регулярно сталкиваемся с кодовыми замками, pin-кодами блокировок мобильных телефонов и банковских карт и т.п.
Все вышесказанное объясняет актуальность рассматриваемой темы. Фактически, теория кодирования представляет собой отдельный раздел теории информации, который изучает способы отображения дискретных сообщений сигналами в виде определенных сочетаний символов [11].
Фрэнсис Бэкон сформулировал основные требования, которые должны применяться к используемому шифру:
- простота использования;
- трудность расшифровки;
- шифр должен быть скрытен, но не должен вызывать подозрений.
Сам Бэкон предложил сочетание шифрованного текста с дезинформацией в виде нулей. Таким образом, двузначные коды и шифры использовались еще до появления вычислительной техники [4].
Объектом исследования данной работы является теория кодирования данных. Предмет исследования – основные методы кодирования.
Цель работы – раскрыть базовые тематические понятия, а также привести описание наиболее распространенных методов кодирования данных. Для достижения данной цели необходимо выполнить ряд задач:
- проанализировать литературу по заданной теме;
- описать основные понятия;
- изучить методы кодирования данных;
- привести примеры.
При написании работы в качестве опорных источников были использованы труды таких авторов, как А.С. Гуменюк, В.Н. Думачев, А.А. Понятов, Е.Г. Чепкунова и некоторых других, а также материал из сети Интернет, указанный в списке литературы в конце данной работы.
1. Основные понятия теории кодирования
Для рассмотрения методов кодирования важно определить основные понятия, которыми будем оперировать в дальнейшем.
Цели теории кодирования:
- разработка принципов экономного представления информации;
- разработка приемов повышения надежности в процессе передачи информации;
- согласование особенностей канала связи с параметрами передаваемой информации.
Задачей кодирования является перевод дискретного сообщения из одного алфавита в другой без потерь информации. Алфавит, при помощи которого представляется информация до преобразования назван первичным. Алфавит конечного представления – вторичным.
Однозначного определения понятию «код» нет. С одной стороны, код – это определенное правило, которое описывает соответствие знаков или их сочетаний первичного алфавита знакам или их сочетаниям вторичного алфавита. С другой, под кодом понимается набор знаков вторичного алфавита, который используется для представления знаков или их сочетаний первичного алфавита [9].
Процесс кодирования представляет собой перевод информации из символов первичного алфавита в последовательность кодов. Обратный этому процесс – декодирование. Устройство, реализующее операцию кодирования – кодер. Устройство, реализующее операцию декодирования – декодер.
Операции кодирования и декодирования называются обратимыми в том случае, когда их последовательное применение не приводит к утере информации. Примерами такого кодирования являются телеграф, помехоустойчивое кодирование, а также сжатие информации без потерь.
Необратимое кодирование происходит в случае перевода с одного естественного языка на другой, например, при аналого-цифровом преобразовании или при сжатии с потерями.
Необратимое кодирование бывает нескольких видов:
- принципиально необратимое – представляет собой хэширование. Примером применения является хранение паролей в операционных системах. При первом вводе пароль преобразуется при помощи односторонних функций, подобранных таким образом, чтобы из полученной на их выходе строки принципиально нельзя было получить первоначальное значение пароля. При дальнейшем вводе пароль каждый раз преобразуется такой же функцией и сравнивается с первоначальным хэшем. В итоге получается информация, объем которой равен одному биту – пароли либо совпали, либо нет. Однако такой метод проверки не всегда является достаточным [3];
- обратимое с помощью дополнительной информации – использует ключ шифрования. При помощи пароля входная информация подвергается преобразованиям таким образом, чтобы обратное преобразование также требовало знания пароля. Примером использования данного способа являются архивированные файлы;
- безусловно обратимое кодирование – кодирование, при котором обратное преобразование не требует знания какой-либо дополнительной информации.
Сформулируем условие обратимости кодирования в математическом виде. Введем обозначения:
- I1 – количество информации в исходном сообщении;
- I2 – количество информации в кодированном сообщении.
Характерной чертой кодирования является сжатие информации без ее потери. Следовательно, условие обратимости кодирования записывается в виде (1):
I1 ≤ I2 (1)
2. Способы кодирования: классификация
2.1. В соответствии с условием построения кодовых комбинаций
По данному признаку коды бывают равномерные и неравномерные. Равномерные коды характеризуются тем, что сообщения в них передаются кодовыми группами с одинаковым числом элементов. Пример такого кода – код Бодо, представляющий собой пятибитную кодировку, а также использование цифрового и буквенного регистров.
В случае использования неравномерных кодов разные сообщения могут быть переданы кодовыми группами, содержащими различное число элементов. Пример такого кода – код Морзе. Сегодня кодом Морзе называют способ знакового кодирования, в котором в качестве символов используются последовательности троичных сигналов – длинных и коротких «точек» и «тире».
С точки зрения обеспечения помехозащищенности равномерный код обладает большими возможностями. Это объясняется тем, что в нем легко обнаруживается потеря элементов или их возникновение. Однако неравномерные коды обеспечивают большую экономичность построения кодов и большее быстродействие передачи сообщений. Неравномерные коды требуют наличия особых разделительных символов, которые указывают на конец одной последовательности и начало новой [10].
2.2. В соответствии с количеством уникальных символов
По числу уникальных символов методы кодирования бывают единичные, двоичные и позиционные. Единичный код предполагает использование одинаковых символов. При этом отличие кодовых комбинаций заключается в числе этих символов. Другое название таких кодов – числоимпульсные. Единичные коды нашли свое применение в машине Поста при кодировании целых положительных чисел, в машине Тьюринга, а также в цифровых электронных счетчиках, где измеряемая величина преобразуется в пропорциональное ей число импульсов. Характерная черта единичного кода – простота. Однако его отрицательной стороной является малая помехозащищенность. Кроме того, в процессе передачи большого числа сообщений происходит изменение в широких пределах длины кода, что становится причиной неудобств. Это объясняет тот факт, что единичный код крайне редко применяется для передачи информации по каналу связи. Свое применение данный код нашел в промежуточных преобразованиях сигналов на принимающей и передающей сторонах.
Более широко распространены двоичные коды. Формирование кодовых сигналов и их декодирование производятся при помощи релейных устройств, которые способны находиться в одном из нескольких устойчивых состояний. Число состояний определяется основанием кода. Простейшее устройство характеризуется двумя состояниями, например электронное бесконтактное реле. Кроме того, данный подход обеспечивает простоту хранения информации, а также выполнения логических и арифметических операций.
Многопозиционные коды, алфавит которых состоит из большого числа символов, пока еще не нашли широкого применения в информационных системах [7].
2.3. В соответствии с формой представления
По форме представления в канале передачи данных коды бывают последовательные и параллельные. В последовательных кодах элементарные сигналы, которые составляют кодовую комбинацию, посылаются в канале передачи последовательно во времени. В большинстве случаев они разделены определенным временным интервалом.
В параллельных кодах, напротив, элементарные сигналы отправляются одновременно по нескольким электрическим цепям. Число таких цепей соответствует числу элементов кода. Передача данных при таком кодировании требует меньше времени, однако редко применяется в каналах связи по причине значительных материальных затрат на многопроводные линии связи. Свое применение параллельный код нашел в преобразовании аналоговых величин в код и обратных преобразованиях, в устройствах регистрации, ячейках памяти, при математической и логической обработке информации и т.п. Важным признаком данного кода является его быстродействие.
2.4. В соответствии с возможностями обнаружения/исправления ошибок
В зависимости от возможности обнаружения и исправления ошибок в полученных сообщениях различают простые и корректирующие коды. В простых кодах все доступные кодовые комбинации применяются непосредственно для передачи информации. В таком случае ошибка в приеме хотя бы одного элемента становится причиной неправильной регистрации всего сообщения.
Корректирующие коды позволяют обнаружить и исправляться некоторые ошибки по имеющейся избыточности в кодовой комбинации. Такие коды нашли свое применение в обработке информации, технике связи, телемеханике, везде, где возможны искажения сигнала под воздействием различного рода помех. Кодовые слова в таких кодах содержат особые проверочные разряды. В процессе кодирования при передаче информации из информационных разрядов в соответствии с определенными для каждого корректирующего кода правилами формируются дополнительные символы, которые и являются проверочными разрядами. При декодировании вновь формируются проверочные разряды, которые сравниваются с установленными. В случае их несовпадения устанавливается ошибка. В настоящее время существуют и коды, которые обнаруживают факт искажения сообщения, и коды, способные исправлять ошибки [4].
2.5. В соответствии с количеством одновременно кодируемых символов
По данному признаку коды делятся на алфавитные и блочные. Алфавитное кодирование представляет сообщение в виде последовательности кодов отдельных знаков первичного алфавита. Однако возможны варианты кодирования, когда кодовый знак относится сразу к нескольким буквам первичного алфавита или сразу к слову. Кодирование блоков понижает избыточность. Применение блочного метода имеет свои недостатки. Во‑ первых, требуется хранить огромную кодовую таблицу и постоянно к ней обращаться в процессах кодирования и декодирования, что существенно замедляет работу и требует значительных ресурсов памяти. Во-вторых, кроме основных слов любой разговорный язык содержит много производных, например, падежи существительных в русском языке или глагольные формы в английском; в данном способе кодирования им всем необходимо присвоить свои коды, что ведет к увеличению кодовой таблицы еще в несколько раз. В‑ третьих, возникает проблема согласования (стандартизации) этих громадных таблиц, что весьма непросто. Наконец, в-четвертых, алфавитное кодирование имеет то преимущество, что буквами можно закодировать любое слово, а при кодировании слов – можно использовать только имеющийся словарный запас [6].
3. Методы кодирования: классификация
3.1. Коды префиксные
Под префиксом традиционно принято понимать приставку. В теории кодирования префиксным кодом является код переменной длины, который удовлетворяет условию Роберта Фано: неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с префиксом какого-либо другого, более длинного кода.
Так, например, если один из символов алфавита имеет код «101», то в качестве других кодов не могут быть использованы последовательности «1» и «10», но можно использовать «0» и «11».
Декодирование таких слов выполняется однозначно слева направо. Сопоставление с таблицей при этом всегда дает точное указание конца одного кода и начало другого, что позволяет избавиться от использования разделителей.
Одним из примеров префиксных кодов является код Шеннона-Фано. Алгоритм данного метода использует избыточность сообщения, которая заключается в неоднородном распределении частот символов первичного алфавита. Другими словами, коды более частых символов заменяются короткими двоичными последовательностями, а коды редко встречающихся символов – более длинными.
Другой пример – код Хаффмана, являющийся оптимальным префиксным кодом для дискретных источников без памяти. Алгоритм данного метода состоит из двух этапов:
- первый этап – первичный алфавит на каждом шаге сокращается на один символ. На следующем шаге рассматривается уже новый первичный алфавит. Соответственно, количество шагов на две единицы меньше количества символов исходного алфавита;
- второй этап – пошаговое формирование кода символов. Заполнение кода при этом осуществляется с символов последнего сокращенного первичного алфавита.
3.2. Коды арифметические
Алгоритмы арифметического кодирования обеспечивают практически оптимальную степень сжатия сообщения с точки зрения энтропийной оценки Шеннона. Данные методы позволяют упаковывать символы первичного алфавита без потерь при условии, что известно распределение частот этих символов.
Наиболее простым методом является унарный код, сопоставляющий некоторому числу i двоичную комбинацию вида 1i0. Запись вида 0 или 1 означает соответственно серию из m нулей или единиц. Например, унарными кодами чисел 1, 2, и 3 являются последовательности unar(1)=10, unar(2)=110 и unar(3)=1110 соответственно.
Еще одним примером арифметических кодов являются коды Фибоначчи. Числа Фибоначчи – элементы числовой последовательности:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, …,
в которой каждое последующее число равно сумме двух предыдущих чисел. Название по имени средневекового математика Леонардо Пизанского (или Фибоначчи) [12].
Данное кодирование предполагает разложение исходного числа n в сумму чисел Фибоначчи fi (f1 = 1; f2 = 2; fi = fi-1 + fi-2). Любое натуральное число может быть однозначно представлено в виде суммы чисел Фибоначчи. Следовательно, можно построить код числа как последовательность битов, каждый из которых указывает факт наличия в n определенного числа Фибоначчи. Кроме того, если в разложении числа n присутствует fi, то в этом разложении не может быть числа fi+1. Следовательно, логично для конца кода использовать дополнительную единицу. Это значит, что две идущие подряд единицы будут означать окончание кодирования текущего числа. Примеры кода Фибоначчи приведены в таблице 1 [8].
Таблица 1 – Примеры кода Фибоначчи
|
n \ fi |
1 |
2 |
3 |
5 |
8 |
13 |
21 |
31 |
|
1 |
1 |
(1) |
||||||
|
2 |
0 |
1 |
(1) |
|||||
|
3 |
0 |
0 |
1 |
(1) |
||||
|
4 |
1 |
0 |
1 |
(1) |
||||
|
5 |
0 |
0 |
0 |
1 |
(1) |
|||
|
6 |
1 |
0 |
0 |
1 |
(1) |
|||
|
7 |
0 |
1 |
0 |
1 |
(1) |
|||
|
8 |
0 |
0 |
0 |
0 |
1 |
(1) |
||
|
… |
… |
… |
… |
… |
… |
… |
||
|
12 |
1 |
0 |
1 |
0 |
1 |
(1) |
||
|
13 |
0 |
0 |
0 |
0 |
0 |
0 |
(1) |
|
|
… |
… |
… |
… |
… |
… |
… |
… |
|
|
20 |
0 |
1 |
0 |
1 |
0 |
1 |
(1) |
|
|
21 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
(1) |
Последовательность символов, при сжатии методом арифметического кодирования рассматривается как некоторая двоичная дробь из интервала [0, 1). Результат сжатия представляется как последовательность двоичных цифр из записи этой дроби.
Опишем алгоритм построения этого кода. Пусть у нас есть некий первичный алфавит, состоящий из трех символов: A = {a, b, !}, а также данные о вероятности использования символов P = {0,3; 0,6; 0,1}. Последний символ рассматриваемого алфавита («!») не несет информационной нагрузки, а лишь является признаком окончания сообщения. Он требуется декодировщику для однозначного декодирования полученного сообщения. На практике вероятность его использования берут заведомо малой. Данный символ можно не использовать только в том случае, когда декодировщику точно известна длина кодируемого сообщения.
Существует особый адаптивный алгоритм, позволяющий реализовать метод арифметического кодирования. Данный алгоритм при каждом сопоставлении символу кода, меняет внутренний ход вычислений таким образом, что в следующий раз этому же символу может быть сопоставлен другой код. Другими словами, происходит адаптация алгоритма к символам, поступающим для кодирования.
При декодировании происходит аналогичный процесс. Необходимость применения адаптивного алгоритма возникает в том случае, когда до начала работы алгоритма вероятностные оценки для символов сообщения неизвестны.
3.3. Коды цифровые
Одним из наиболее ярких примеров цифровых кодов является двоично-десятичный код. Основная система счисления здесь десятичная, но каждая значащая цифра представляется в виде четырех двоичных знаков и содержит десять значений сигнала от 0 до 9. В таблице 2 представлено изображение двоично-десятичных кодов с различными весами разрядов.
Как видно из таблицы, практически все двоично-десятичные коды не имеют однозначности в отображении. Исключением является код с весами 8‑4‑2-1.
Двоично-десятичные коды нашли широкое применение в аналого-цифровых преобразователях. Каждая значимая десятичная цифра в таком коде представляется четырьмя двоичными знаками и содержит десять значений сигнала от нуля до девяти.
Код 8-4-2-1 позволяет осуществлять арифметические операции с использованием двоично-десятичных сумматоров, которые проектируются как обычные двоичные сумматоры с добавлением устройств формирования дополнительных переносов, которые требуются в тех случаях, когда сумма двух двоично-десятичных чисел становится больше или равна десяти [5].
Таблица 2 – Двоично-десятичное представление
|
Десятичный код |
Двоично-десятичный код |
||
|
8-4-2-1 |
2-4-2-1 |
5-1-2-1 |
|
|
0 |
0000_0000 |
0000_0000 |
0000_0000 |
|
1 |
0000_0001 |
0000_0001 |
0000_0001 или 0000_0100 |
|
2 |
0000_0010 |
0000_0010 или 0000_1000 |
0000_0010 или 0000_0101 |
|
3 |
0000_0011 |
0000_0011 или 0000_1001 |
0000_0011 или 0000_0110 |
|
4 |
0000_0100 |
0000_0100 или 0000_1010 |
0000_0111 |
|
5 |
0000_0101 |
0000_0101 или 0000_1011 |
0000_1000 |
|
6 |
0000_0110 |
0000_0110 или 0000_1100 |
0000_1001 или 0000_1100 |
|
7 |
0000_0111 |
0000_0111 или 0000_1101 |
0000_1101 или 0000_1010 |
|
8 |
0000_1000 |
0000_1110 |
0000_1110 или 0000_1011 |
|
9 |
0000_1001 |
0000_1111 |
0000_1111 |
Еще одним примером цифровых кодов является циклический код Грея. Характерная особенность данного кода – изменение только одной позиции при переходе от одной кодовой комбинации к другой. Данное свойство широко применяется как для построения некоторых типов аналого-цифровых преобразователей, так и для повышения надежности преобразователей при помощи самоконтроля и резервирования.
Для того чтобы перейти от натурального двоичного кода к коду Грея, необходимо соблюдать следующие правила:
- если в предыдущем разряде двоичного кода стоит 0, то в данном разряде цифра сохраняется;
- если в предыдущем разряде двоичного кода стоит 1, то данном разряде цифра меняется на противоположную.
Такое представление приведено в таблице 3.
Таблица 3 – Цифровой код Грея
|
А10 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
А2 |
0000 |
0001 |
0010 |
0011 |
0100 |
0101 |
0110 |
0111 |
|
АГр |
0000 |
0001 |
0011 |
0010 |
0110 |
0111 |
0101 |
0100 |
|
А10 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
А2 |
1000 |
1001 |
1010 |
1011 |
1100 |
1101 |
1110 |
1111 |
|
АГр |
1100 |
1101 |
1111 |
1110 |
1010 |
1011 |
1001 |
1000 |
Главной трудностью применения кода Грея является непостоянство весов разрядов, а также изменение их знаков.
Чтобы перейти от кода Грея к натуральному числу, необходимо воспользоваться следующим правилом: если слева от данной цифры находится четное число единиц, то цифра сохраняется, в противном случае меняется на противоположную.
4. Обзор методов помехоустойчивого кодирования
В процессе передачи информации по цифровым каналам она подвергается кодированию. Существует особый американский стандарт ASCII, который в соответствие каждой букве алфавита ставит определенное шестнадцатеричное число. Таблица кодов ASCII приведена на рисунке 1.

Рисунок 1 – Таблица кодов ASCII
Глядя на эту таблицу, можно сделать вывод, что для передачи одной буквы, она должна быть заменена соответствующей кодой комбинацией из семи разрядов. Любая двоичная комбинация из семи разрядов определяет какой-то знак алфавита. Если в процессе передачи произойдет хотя бы одна ошибка, символ будет распознан неверно.
В основе идеи помехоустойчивого кодирования лежит добавление лишних символов к сообщению, которые помогают обнаружить ошибку. Таким образом, множество кодовых комбинаций разбивается на два:
- множество разрешенных комбинаций;
- множество запрещенных комбинаций.
Если в результате ошибки исходная комбинация перешла в множество запрещенных, то ошибку можно обнаружить. Однако, возможно, что совокупность ошибок переведет передаваемую кодовую комбинацию в другую разрешенную. Тогда вместо одной буквы мы получим другую букву, и ошибка не будет обнаружена.
Чтобы иметь возможность вовремя находить и исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от запрещенной. Количество разрядов, которыми отличаются две соседние комбинации называется расстоянием. Вес комбинации – число единиц в ее записи.
Рассмотрим исправление ошибок на примере комбинаций 000 и 111 (см. рисунок 2). Расстояние между этими комбинациями d = 3. Следовательно, любые единичные ошибки в этих комбинациях остаются в области t ≤ 1. Другими словами, области не пересекаются и ошибки могут быть исправлены.
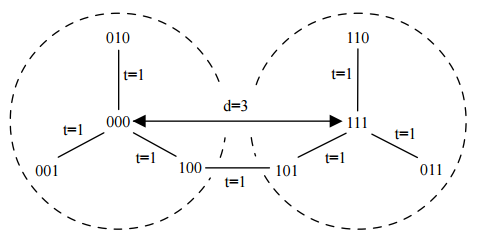
Рисунок 2 – Пример исправления ошибок
Введем следующие обозначения:
- ti – число (кратность) исправляемых ошибок;
- d0 – расстояние между разрешенными комбинациями.
Следовательно, получим условие, при котором код сможет исправить ошибки (2):
d0 ≥ 2ti + 1 (2)
Для построения помехоустойчивого кода необходимо к k информационным разрядам добавить r проверочных. Число проверочных разрядов, которое требуется для построения кода, способного исправить одну ошибку вычисляется по формуле (3):
2r ≥ k + r + 1 (3)
При этом общее число разрядов равняется n = k + r. Код, построенный с такими параметрами называется [n, k] кодом. Например, для передачи четырехразрядной комбинации дополнительно нужно три проверочных символа. Следовательно, получается код [7, 4].
Экономичность и эффективность кодов с обнаружением ошибок определяют особые параметры: коэффициент избыточности (4) и коэффициент обнаружения (5).
RU = 1 – ln(M1) / ln(M) (4)
K0 = Q / (Q + Q1) (5)
где М = 2n – общее количество кодовых слов, которое может быть получено в n‑элементном коде;
М1 – число используемых комбинаций;
Q – общее число искаженных комбинаций, в которых может быть обнаружена ошибка;
Q1 – общее количество искаженных комбинаций, в которых не может быть обнаружена ошибка [1].
4.1. Коды Хэмминга
Рассмотрим правила построения [7, 4] кода Хэмминга, исправляющего одну ошибку в передаваемой информационной комбинации (a1, a2, a3, a4). Выпишем таблицу истинности для трех проверочных разрядов:
|
x2 |
x1 |
x0 |
|
|
0 |
0 |
0 |
|
|
0 |
0 |
1 |
b0 |
|
0 |
1 |
0 |
b1 |
|
0 |
1 |
1 |
a1 |
|
1 |
0 |
0 |
b2 |
|
1 |
0 |
1 |
a2 |
|
1 |
1 |
0 |
a3 |
|
1 |
1 |
1 |
a4 |
Где аi – информационные разряды, а bi – проверочные.
Тогда, проверочные разряды восстанавливаются по информационным по правилам (6-8):
b0 = a1 a2 a4 (6)
b1 = a1 a3 a4 (7)
b2 = a2 a3 a4 (8)
Таким образом, видно, что значение b0 формируется из всех ak, для которых х0 = 1. Значение b1 формируется из всех аk, для которых х1 = 1 и т.д.
На передатчик канала связи подается самокорректирующийся код Хэмминга [7, 4], имеющий вид (b0, b1, a1, b2, a2, a3, a4). На приемном конце считаются проверочные символы (9-11):
В0 = a1 a2 a4 (9)
В1 = a1 a3 a4 (10)
В2 = a2 a3 a4 (11)
Разница между принимаемыми Вi и передаваемыми bi проверочными разрядами позволяет обнаружить и локализовать ошибку.
4.2. Циклические коды
Циклические коды представляют собой обобщение кодов Хэмминга. В данном коде произвольная кодовая последовательность a = (a1, a2, …, an) принимает вид полинома (12):
u(x) = a1xn-1 + a2xn-2 + … + aт-2x2 + an-1x + an (12)
Так, например, кодовой последовательности 1011 соответствует многочлен u(x) = 1х3 + 0х2 + 1х1 + 1х0 = х3 + х + 1.
При этом вводятся понятия приводимых и неприводимых многочленов. Неприводимый многочлен – это такой, который не может быть представлен в виде произведения многочленов меньшей степени. Приводимый многочлен, напротив, может быть факторизован.
4.3. Сверточные коды
Прежде чем описывать сверточные коды, введем понятие автомата. Автоматом называется система, которая изменяет свое состояние под действием обрабатываемого входного сигнала. В этом случае значения выходного сигнала зависят не только от входного значение, но и от текущего состояния самой системы.
Для описания работы автомата требуется задать:
- вектор значений входного сигнала a = (a1a2…an);
- вектор внутренних состояний автомата s = (s1s2…sn).
Во время работы на вход автомата подается очередное значение сигнала ai. В зависимости от текущего состояния sk автомат изменяет значение сигнала на zi, но и сам под воздействием входного сигнала меняет свое состояние на sm. Следующее значение сигнала ai+1 автомат принимает находясь в состоянии sm и в соответствии со своим состоянием формирует выходное значение zi+1, а сам при этом меняет свое состояние на sn и т.д.
Следовательно, описание работы автомата дополнительно требует следующих параметров:
- вектор возможных значений выходного сигнала z = (z1z2…zn);
- функцию перехода g: (aksk) → (zk), создающую значения выходного сигнала zk из входного sk с учетом текущего состояния автомата sk;
- функцию перехода f: (aksk) → (sk+1), меняющую состояние автомата sk на sm в зависимости от значения принятого сигнала ak и текущего состояния автомата sk.
Автомат, обрабатывающий двоичную последовательность и имеющий четыре возможных состояния s = (s0, s1, s2, s3) называется сверточным кодом. Его принято задавать в виде таблицы (см. таблицу 4).
Таблица 4 – Автомат сверточного кода
|
f |
g |
|||
|
0 |
1 |
0 |
1 |
|
|
s0 |
s0 |
s2 |
00 |
11 |
|
s1 |
s0 |
s2 |
11 |
00 |
|
s2 |
s1 |
s3 |
10 |
01 |
|
s3 |
s1 |
s3 |
01 |
10 |
ЗАКЛЮЧЕНИЕ
В рамках выполнения данной работы была раскрыта тема основных методов кодирования информации. Важно отличать процессы кодирования и шифрования. Код используется для передачи информации в более удобном виде. А шифр – для засекречивания.
Кодирование - изменяет форму, но оставляет прежним содержание. Для прочтения нужно знать алгоритм и таблицу кодирования.
Шифрование - Может оставлять прежней форму, но изменяет, маскирует содержание. Для прочтения недостаточно знать только алгоритм шифрования, нужно знать ключ [Лаш].
Задачей кодирования является перевод дискретного сообщения из одного алфавита в другой без потерь информации с целью его более сжатого представления, либо представления в виде, удобном для вычислений или других операций.
Существует множество способов классификаций методов кодирования. В данной работе рассмотрены основные из них, а именно:
- по условию построения кодовых комбинаций (равномерные и неравномерные);
- по числу уникальных символов (единичные, двоичные и позиционные);
- по форме представления в канале передачи данных (последовательные и параллельные);
- по возможности обнаружения и исправления ошибок (простые и корректирующие);
- по числу одновременно кодируемых символов (алфавитные и блочные).
Рассмотрение методов кодирования проводилось по группам:
- префиксные коды – коды переменной длины, удовлетворяющие условию Фано;
- арифметические коды – коды упаковывания слов первичного алфавита на основании частоты использования символов;
- цифровые коды – различные методы представления чисел.
Отдельное внимание уделяется методам помехоустойчивого кодирования. В основе идеи помехоустойчивого кодирования лежит добавление лишних символов к сообщению, которые помогают обнаружить ошибку. Таким образом, множество кодовых комбинаций разбивается на два:
- множество разрешенных комбинаций;
- множество запрещенных комбинаций.
Если в результате ошибки исходная комбинация перешла в множество запрещенных, то ошибку можно обнаружить.
Примерами кодов помехоустойчивого кодирования являются коды Хэмминга, циклические коды, а также сверточные коды.
СПИСОК ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
- Гуменюк А.С. Теория информации и кодирования. – Омск: Изд-во ОмГТУ, 2015. -124 с.
- Думачев В.Н. Теория информации и кодирования – Воронеж: Воронежский институт МВД Росси, 2012. – 248 с.
- Лашина И.А. Использование заданий по кодированию информации во внеклассной работе по математике в начальной школе, – 2015. – 6 с.
- Поляков К.Ю., Еремин Е.А. Информатика - М. : БИНОМ. Лаборатория знаний, 2016. - 80 с.
- Понятов А.А.Теория информации и кодирования - М.: МИИТ, 2016. — 188 с.
- Чепкунова Е.Г. Пособие к подготовке к экзамену по дисциплине «Теоретические основы информатики». Раздел «Кодирование информации»: Учеб. пособие – Казань: Казанский университет, 2012. – 92 с.
- Шикина В.Е. Кодирование информации: методические указания – Ульяновск: УлГТУ, 2006. – 56 с.
Электронные ресурсы:
- Блочное двоичное кодирование. URL: http://studopedia.ru/3_83187_blochnoe-dvoichnoe-kodirovanie.html
- Большая энциклопедия нефти и газа. Равномерный код. URL: http://www.ngpedia.ru/id88203p1.html
- Методы арифметического кодирования информации и сравнение их коэффициентов сжатия. URL: http://bibliofond.ru/view.aspx?id=550668
- Новый принцип кодирования информации для получения субъективной реальности в искусственных нейронных сетях. URL: https://habr.com/post/399881
- Постановка задачи кодирования, Первая теорема Шеннона. URL: http://studopedia.ru/view_informatika.php?id=27

- .Защита прав собственности.
- Юридические факты в гражданском праве (История развития представлений о юридических фактах)
- Основные положения о юридическом лице в системе субъектов предпринимательского права
- Теоретические аспекты социальной политики государства
- Сравнительный анализ инструментов мотивации
- Международный валютный фонд: цели, функции, особенности (Создание МВФ и его цели)
- Аудит кассовых операции банка
- Основные программы языка.
- Правовые основы оперативно-розыскной деятельности в России.
- Внеоборотные активы предприятия (сущность, понятие, классификация)
- Косвенные налоги и их место в налоговой системе РФ ( Проблемы и перспективы развития)
- Языки гипертекстовой разметки