
Разветвляющийся алгоритм С++
Содержание:

ВВЕДЕНИЕ
Данная работа посвящена области алгоритмов и касается изучения реализации алгоритмических механизмов в современных языках программирования.
Цель курсовой работы заключается в изучении реализации разветвляющихся алгоритмов в языке высокого уровня С++, для дальнейшего применения полученных знаний на практике.
Для осуществления обозначенной цели служат следующие задачи:
- Изучение понятий алгоритмизации;
- Получение знаний об основах реализации алгоритмов в программирование.
- Получение знаний об основных типах данных языка С++
- Получение знаний об основных арифметических и логических операторах языка С++
- Изучение способов реализации разветвляющихся алгоритмов в языке C++.
- Получение навыков по применению разветвляющихся алгоритмов на практике.
Объект исследования – разветвляющиеся алгоритмы.
Предмет исследования – способы реализации разветвляющихся алгоритмов, применяемые при написание программного обеспечения на языке С++.
1. АЛГОРИТМЫ
Определение понятия алгоритм. Свойства алгоритмов. Формы записи алгоритмов.
Понятие алгоритма такое же основополагающее для информатики, как и понятие информации. Именно поэтому важно в нем разобраться.
Название "алгоритм" произошло от латинской формы имени величайшего среднеазиатского математика Мухаммеда ибн Муса ал-Хорезми (Alhorithmi), жившего в 783—850 гг. В своей книге "Об индийском счете" он изложил правила записи натуральных чисел с помощью арабских цифр и правила действий над ними "столбиком", знакомые теперь каждому школьнику. В XII веке эта книга была переведена на латынь и получила широкое распространение в Европе.
Человек ежедневно встречается с необходимостью следовать тем или иным правилам, выполнять различные инструкции и указания. Например, переходя через дорогу на перекрестке без светофора надо сначала посмотреть направо. Если машин нет, то перейти полдороги, а если машины есть, ждать, пока они пройдут, затем перейти полдороги. После этого посмотреть налево и, если машин нет, то перейти дорогу до конца, а если машины есть, ждать, пока они пройдут, а затем перейти дорогу до конца.
В математике для решения типовых задач используются определенные правила, описывающие последовательности действий. Например, правила сложения дробных чисел, решения квадратных уравнений и т. д. Обычно любые инструкции и правила представляют собой последовательность действий, которые необходимо выполнить в определенном порядке. Для решения задачи надо знать, что дано, что следует получить и какие действия и в каком порядке следует для этого выполнить.
Исходя из этого можно определить алгоритм как конечную совокупность точно сформулированных инструкций, описывающих последовательность действий для достижения результата решения задачи.
2. ОСНОВНЫЕ СВОЙСТВА АЛГОРИТМОВ
Основными свойствами алгоритмов являются:
- Дискретность:
Алгоритм должен представлять процесс решения задачи как последовательное выполнение элементарных шагов; для выполнения каждого шага требуется конечный отрезок времени;
- Определенность (детерминированность):
каждый шаг алгоритма должен однозначно определять действие;
- Конечность (результативность):
- конечное число шагов должно приводить к решению задачи;
- если невозможно получить решение после конечного числа шагов, то алгоритм прерывается с выдачей соответствующего сообщения;
- алгоритм может продолжаться в течение времени, отведенного для его исполнения, с выдачей промежуточных
результатов;
- Массовость:
Необязательное свойство, означающее, что алгоритм может быть применим не только для одной конкретной задачи, а для целого класса подобных задач, различающихся лишь исходными данными, которые могут выбираться из некоторой области, называемой областью пpименимости алгоpитма.
- Корректность (правильность):
Выполнение правильного алгоритма приводит к получению правильных результатов решения задачи.
3. ОБЩИЕ ПРИНЦИПЫ РАЗРАБОТКИ АЛГОРИТМОВ
Существуют три основные алгоритмические структуры (базовые структуры алгоритма), с помощью которых создается алгоритм для решения поставленной задачи:
1) линейный (последовательный) алгоритм, который
обеспечивает получение результата путем однократного выполнения последовательности действий, независимо от входных данных и промежуточных результатов (действия выполняются последовательно, одно за другим, т.е. линейно);
2) альтернативный (разветвленный) алгоритм, в котором предусматривается возможность выбора решения в зависимости от
заданного условия;
3) циклический алгоритм (структура повторения), в котором предусматривается многократное повторение определенных
действий; совокупность действий, образующих тело цикла, может
содержать другой цикл, называемый вложенным циклом.
Существуют два типа циклов:
1) цикл с параметром (со счетчиком, арифметический цикл) – это цикл, как правило, с заранее известным количеством повторений тела цикла; условие выполнения цикла проверяется до исполнения его тела (если условие истинно, цикл работает, иначе – завершается), поэтому цикл с параметром относится к циклам с предусловием;
2) итерационный цикл – цикл с заранее не известным количеством повторений тела цикла; число повторений определяется условием выполнения или завершения цикла; если условие проверяется до тела цикла, то такой цикл будет с предусловием, если условие проверяется после тела цикла, то с постусловием.
4. СПОСОБЫ ОПИСАНИЯ АЛГОРИТМОВ
Алгоритм должен быть формализован по некоторым правилам посредством конкретных средств. Существуют четыре основных способа описания алгоритмов: словесный, графический, на языке псевдокода, на языке программирования.
- Словесный способ – описание на естественном языке – доступная форма представления алгоритма, ориентированного на выполнение независимо от его подготовки. В данном пособии словесный способ используется в качестве описательного алгоритма.
- Графический способ в виде структурных схем (блок-схем) требует знаний правил построения графических символов, поэтому необходимо ознакомиться со стандартами графических изображений блоков алгоритмов.
- Способ описания алгоритмов на псевдокоде (алгоритмическом языке) использует служебные слова и специальные правила записи отдельных действий; в псевдокоде приняты жесткие синтаксические правила записи команд, что стандартизирует и облегчает запись алгоритма на стадии его проектирования, а также дает возможность расширения системы команд,
рассчитанных на абстрактного исполнителя.
- Способ описания алгоритмов на языке программирования, как правило, используется после предварительного описания алгоритма одним из вышеперечисленных способов, так как они являются более общими, не зависящими от программных конструкций конкретного языка. Для описания алгоритма на каком-либо языке программирования необходим определенный профессиональный уровень.
Проверка работы алгоритма является существенным шагом на пути к его пониманию и доказательству правильности. Каждый разработанный алгоритм должен пройти тестирование – простой и эффективный способ понимания и проверки правильности алгоритма.
Наибольшее распространение благодаря наглядности получил графический способ описания алгоритмов.
Структурная схема или блок-схема алгоритма – это его графическое представление, изображаемое последовательностью связанных между собой с помощью линий перехода функциональных блоков (графических символов), каждый из которых соответствует выполнению одного шага алгоритма и содержит описание соответствующего действия. Таким образом, графические символы обозначают выполняемые действия, а линии перехода – последовательность их выполнения.
Виды графических символов для построения блок-схемы алгоритма:
- начальный символ (терминатор – пуск): не имеет входа и имеет только один выход;
- конечный символ (терминатор – останов): не имеет выхода и имеет только один вход;
- вычислительный символ (процесс): имеет один вход и один выход;
- условный символ (решение): имеет один вход и два выхода, которые можно обозначать «+» («1», «да», «true») и «–» («0»,«нет», «false»);
- выходы и входы символов: соединяются друг с другом с помощью линий перехода, направленных от выхода одного символа к входу другого; каждый выход соединяется только с одним входом; любой вход соединяется по крайней мере с одним выходом.
ГОСТ 19.701-90(ИСО 5807-85) ЕСПД (Единая система программной документации) предусматривает основные символы схем алгоритмов.
- Терминатор (пуск-останов): начальный символ отображает начало алгоритма, конечный – его конец (рис. 1).

Рис. 1
- Процесс: вычислительный символ отображает функцию обработки данных любого вида, т.е. выполнение одной инструкции (оператора – наименьшей автономной части языка программирования) или группы инструкций (рис. 2).
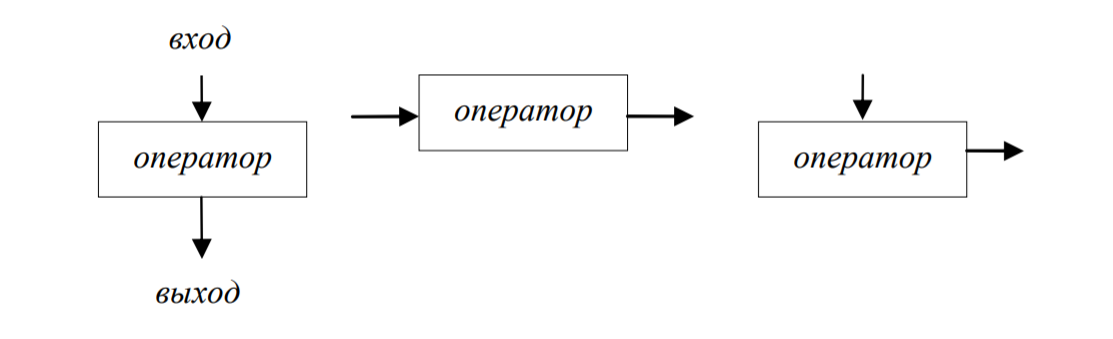
Рис.2
- Решение: условный символ или символ выбора (переключатель), имеющий один вход и, в случае условного символа, два альтернативных выхода («+», если условие истинно, и «–», если ложно) или, в случае символа выбора, несколько альтернативных выходов («+», если есть равное значение из перечисленных заданному, и «–», если нет), один из которых может быть активизирован (рис. 3).
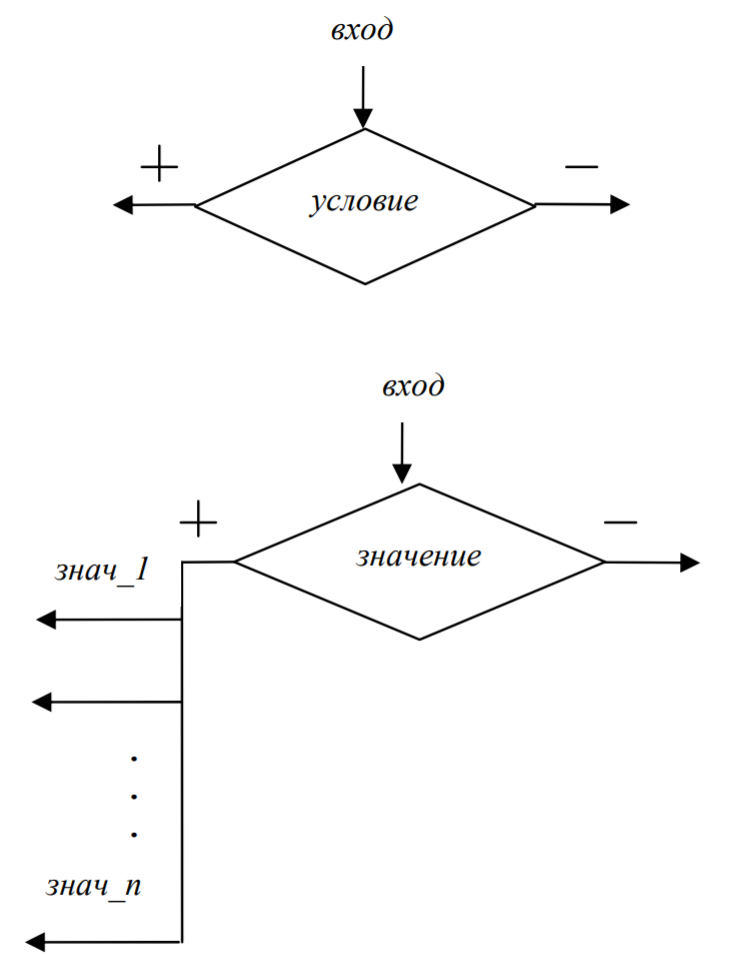
Рис.3
- Граница цикла: единый блок для обозначения различных циклов – символ, отображающий начало и конец цикла; условия для инициализации, приращения, завершения или продолжения цикла помещается внутри символа в начале или в конце в зависимости от расположения операции, проверяющей условие(рис. 4).
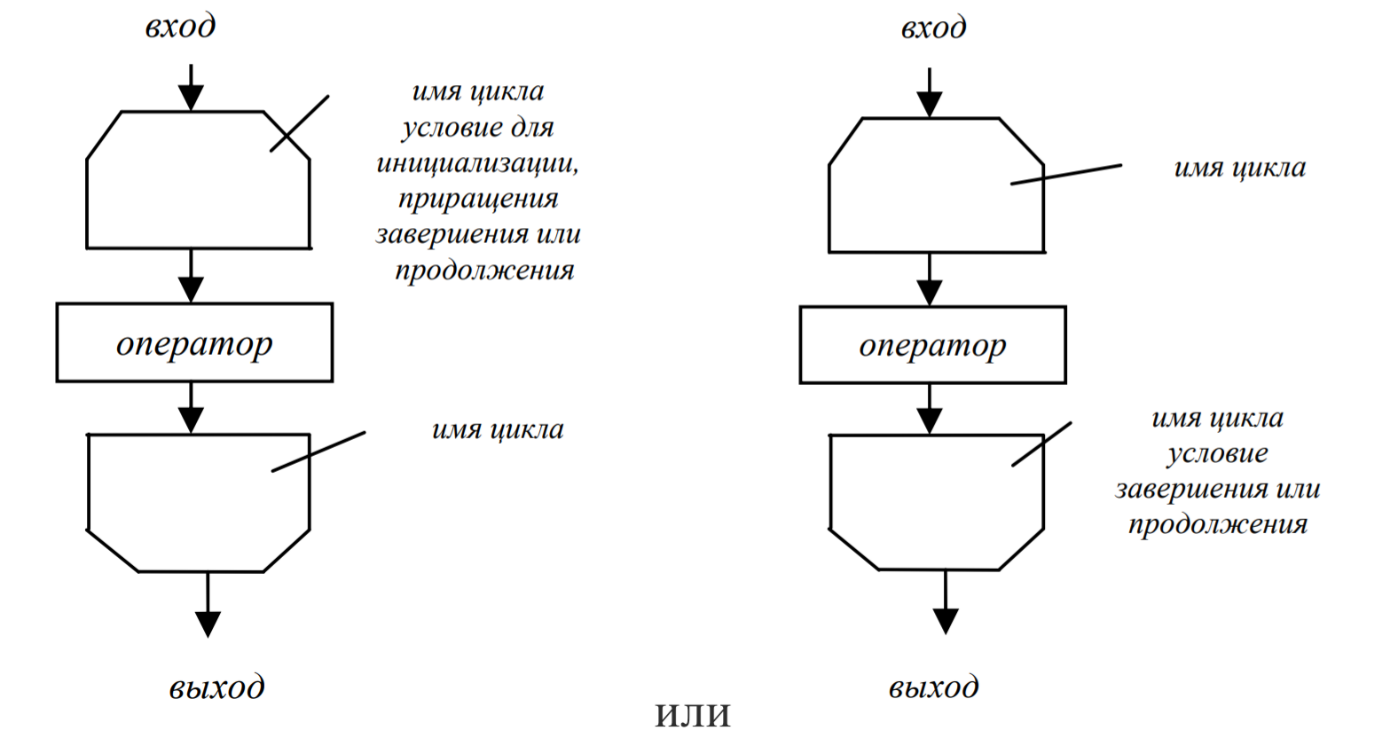
Рис.4
- Подготовка: символ отображает модификацию (изменение) команды или группы команд; в данном пособии используется как символ отображения структуры цикл с параметром (рис. 5).
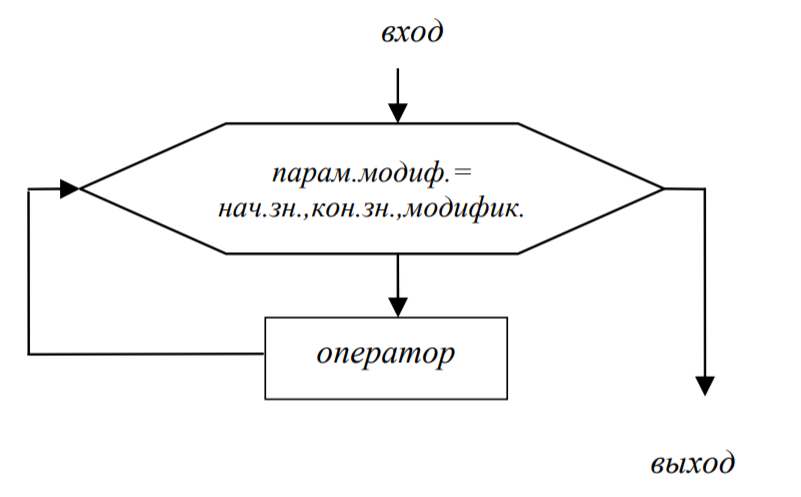
Рис.5
- Решение (условный символ): в данном пособии используется для более наглядного отображения структур итерационных циклов: для цикла с предусловием (рис. 6, а), с постусловием(рис. 6, б).
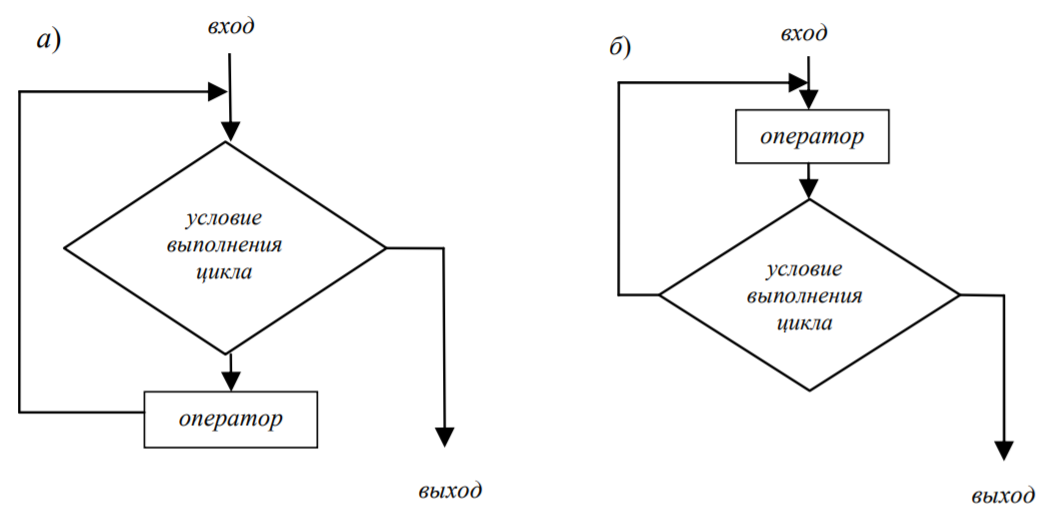
Рис. 6
- Предопределенный процесс: символ отображает предопределенный процесс, состоящий из инструкций программы, которые определены в подпрограмме, реализующей вспомогательный алгоритм, являющийся таковым по отношению к основному алгоритму(рис. 7).
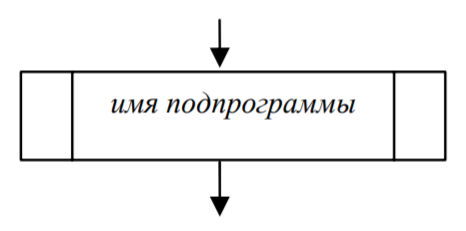
Рис. 7
- Данные: символ отображает данные, носитель которых не определен; (рис. 8).
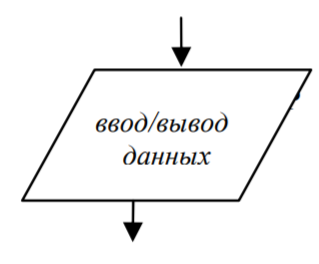
Рис.8
- Соединитель: символ прерывания блок-схемы отображает указание связи между прерванными линиями потока, связывающими символы; соответствующие символы-соединители должны содержать одно и то же уникальное обозначение (рис. 9).
Рис.9
- Комментарии: символ используют для добавления описательных комментариев; пунктирные линии связываются с символом, к которому относится комментарий; текст помещается около ограничивающей фигуры (рис. 10).
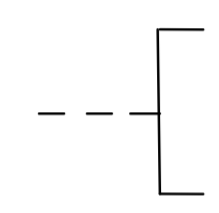
Рис.10
5. РАЗВЕТВЛЯЮЩИЙСЯ АЛГОРИТМ С++
Для полного понимания процесса реализации разветвляющегося алгоритма на С++ необходимо получить понимание общего механизма реализации алгоритмов на любом языке программирования, понимание алгоритмического языка, а так - же понимания основ программирования на языке С++.
5.1. РЕАЛИЗАЦИЯ АЛГОРИТМОВ НА ЯЗЫКАХ ПРОГРАММИРОВАНИЯ
В процессе программирования сначала разрабатывается алгоритм решения поставленной задачи, затем он записывается на одном из языков программирования, т.е. создается текст программы, который является полным, законченным и детальным описанием алгоритма на данном языке. После этого специальной программой, называемой транслятором, текст программы переводится в машинный код или сразу исполняется. Проверка программистом правильности работы алгоритма и программы при определенных наборах исходных данных называется тестированием. Процесс устранения программистом ошибок в программе после ее тестирования называется отладкой.
Языки программирования характеризуются ограниченным числом слов, смысл которых понятен транслятору, и строгими правилами записи команд, называемых операторами. Совокупность таких требований образует синтаксис языка, а смысл каждой команды и других конструкций языка – его семантику.
Для получения работающей программы ее текст, созданный с помощью языка программирования, переводится в машинный код при помощи программы-транслятора для дальнейшего использования либо отдельно от исходного текста, либо для выполнения указанных в тексте команд языка. К трансляторам относятся программы-компиляторы и программы-интерпретаторы.
Компилятор переводит текст программы в машинный код: полностью обрабатывает текст, называемый исходным кодом, т.е. производит поиск синтаксических ошибок, выполняет определенный смысловой анализ, переводит (транслирует) на машинный язык (генерирует машинный код).
Интерпретатор выполняет команды языка, указанные в тексте программы. Сначала структура очередного оператора текста анализируется, транслируется в некоторое промежуточное представление или даже в машинный код, после чего оператор исполняется; если текущий оператор успешно выполнен, анализируется следующий оператор. Без соответствующего интерпретатора текст программы является просто набором символов. Таким образом, интерпретатор моделирует некую виртуальную вычислительную машину, для которой базовыми инструкциями являются не элементарные команды процессора, а операторы программирования. Недостатком интерпретаторов является то, что интерпретированные программы работают медленнее, чем откомпилированные программы.
Разные типы процессоров имеют различные наборы команд. Если язык программирования ориентирован на конкретный тип процессора и учитывает его особенности, то он называется языком программирования низкого уровня (операторы языка близки к машинному коду).
Одним из языков низкого уровня является ассемблер, который представляет каждую команду машинного кода символьным условным обозначением, называемым мнемоникой. Каждой конкретной компьютерной архитектуре соответствует свой язык ассемблера. Обычно ассемблеры применяются для написания небольших системных приложений, драйверов устройств.
Языки программирования высокого уровня больше понятны человеку, чем компьютеру, и в них особенности конкретных компьютерных архитектур не учитываются. К языкам программирования высокого уровня относятся такие языки, как Фортран, Алгол, Паскаль, Си, C++ и др.
5.2. СОСТАВ И ОПИСАНИЕ АЛГОРИТМИЧЕСКОГО ЯЗЫКА
Алгоритмический язык – формальный язык, который используется для записи и реализации алгоритмов. Любой императивный (процедурный) язык программирования является алгоритмическим языком, хотя не всякий алгоритмический язык пригоден для использования в качестве языка программирования. Алгоритмический язык содержит следующие элементы: символы, элементарные конструкции, выражения, операторы. Они составляют иерархическую структуру, так как элементарные конструкции образуются из последовательности символов, выражения – из последовательности элементарных конструкций и символов, оператор – из последовательности выражений, элементарных конструкций и символов.
Описание языка – это описание четырех элементов: символов, элементарных конструкций, выражений и операторов.
Описание символов заключается в перечислении допустимых символов языка, являющихся основными неделимыми знаками, в терминах которых пишутся все тексты на языке. Основные символы языка – буквы, цифры и специальные символы – составляют алфавит языка.
Под описанием элементарных конструкций понимают правила их образования. Элементарные конструкции (лексемы) – минимальные единицы языка, имеющие самостоятельный смысл и образующиеся из основных символов языка.
Описание выражений – это правила образования любых выражений, имеющих смысл в данном языке. Выражение состоит из элементарных конструкций и символов и задает правило вычисления некоторого значения.
Описание операторов включает рассмотрение всех типов операторов, допустимых в языке. Оператор задает полное описание некоторого действия, которое необходимо выполнить. Для описания сложного действия используется группа операторов, тогда операторы объединяются в составной оператор (блок). Как правило, действия, заданные операторами, выполняются над данными.
Предложения алгоритмического языка, в которых даются сведения о типах данных, называются описаниями (объявлениями), являющимися неисполняемыми операторами. Описание каждого элемента языка задается его синтаксисом и семантикой. Синтаксические определения устанавливают правила построения элементов языка. Семантика определяет смысл и правила использования тех элементов языка, для которых были даны синтаксические определения.
Объединенная единым алгоритмом совокупность описаний (объявлений – неисполняемых операторов) и исполняемых операторов составляет программу на алгоритмическом языке.
5.3. ОСНОВЫ ЯЗЫКА С++
C++ представляет собой результат развития языка C, является универсальным языком программирования, позволяющим разрабатывать как объектно-ориентированные, так и алгоритмические программы.За исключением второстепенных деталей он содержит язык С как подмножество. Язык С расширяется введением гибких и эффективных средств, предназначенных для построения новых типов. Программист структурирует свою задачу, определив новые типы, которые точно соответствуют понятиям предметной области задачи.
Ключевым понятием С++ является класс. Класс - это определяемый пользователем тип. Классы обеспечивают упрятывание данных, их инициализацию, неявное преобразование пользовательских типов, динамическое задание типов, контролируемое пользователем управление памятью и средства для перегрузки операций. В языке С++ концепции контроля типов и модульного построения программ реализованы более полно, чем в С. Кроме того, С++ содержит усовершенствования, прямо с классами не связанные: символические константы, функции-подстановки, стандартные значения параметров функций, перегрузка имен функций, операции управления свободной памятью и ссылочный тип. В С++ сохранены все возможности С эффективной работы с основными объектами, отражающими аппаратную "реальность" (разряды, байты, слова, адреса и т.д.).
Как язык, так и стандартные библиотеки С++ проектировались в расчете на переносимость. Имеющиеся реализации языка будут работать в большинстве систем, поддерживающих С. В программах на С++ можно использовать библиотеки С. Большинство служебных программ, рассчитанных на С, можно использовать и в С++.
5.3.1. ТИПЫ ДАННЫХ В ЯЗЫКЕ С++
Каждое имя и каждое выражение обязаны иметь тип. Именно тип определяет операции, которые могут выполняться над ними.
Описание - это оператор, который вводит имя в программу. В описании указывается тип имени. Тип, в свою очередь, определяет, как правильно использовать имя или выражение.
Основные типы данных языка С++ приведены в таблице 1.
|
Тип |
байт |
Диапазон принимаемых значений |
|
Целочисленный (логический) тип данных |
||
|
bool |
1 |
0 / 255 |
|
целочисленный (символьный) тип данных |
||
|
char |
1 |
0 / 255 |
|
целочисленные типы данных |
||
|
short int |
2 |
-32 768 / 32 767 |
|
unsigned short int |
2 |
0 / 65 535 |
|
int |
4 |
-2 147 483 648 / 2 147 483 647 |
|
unsigned int |
4 |
0 / 4 294 967 295 |
|
long int |
4 |
-2 147 483 648 / 2 147 483 647 |
|
unsigned long int |
4 |
0 / 4 294 967 295 |
|
типы данных с плавающей точкой |
||
|
float |
4 |
-2 147 483 648.0 / 2 147 483 647.0 |
|
long float |
8 |
-9 223 372 036 854 775 808 .0 / 9 223 372 036 854 775 807.0 |
|
double |
8 |
-9 223 372 036 854 775 808 .0 / 9 223 372 036 854 775 807.0 |
Таблица 1
Вся таблица делится на три столбца. В первом столбце указывается зарезервированное слово, которое будет определять, каждое свой, тип данных. Во втором столбце указывается количество байт, которое отводится под переменную с соответствующим типом данных. В третьем столбце показан диапазон допустимых значений.
Первый в таблице — это тип данных bool — целочисленный тип данных, так как диапазон допустимых значений — целые числа от 0 до 255. Но как Вы уже заметили, в круглых скобочках написано — логический тип данных, и это тоже верно. Так как bool используется исключительно для хранения результатов логических выражений. У логического выражения может быть один из двух результатов true или false. true — если логическое выражение истинно, false — если логическое выражение ложно.
Но так как диапазон допустимых значений типа данных bool от 0 до 255, то необходимо было как-то сопоставить данный диапазон с определёнными в языке программирования логическими константами true и false. Таким образом, константе true эквивалентны все числа от 1 до 255 включительно, тогда как константе false эквивалентно только одно целое число — 0.
Тип данных char — это целочисленный тип данных, который используется для представления символов. То есть, каждому символу соответствует определённое число из диапазона [0;255]. Тип данных char также ещё называют символьным типом данных, так как графическое представление символов в С++ возможно благодаря char. Для представления символов в C++ типу данных char отводится один байт, в одном байте — 8 бит, тогда возведем двойку в степень 8 и получим значение 256 — количество символов, которое можно закодировать. Таким образом, используя тип данных char можно отобразить любой из 256 символов. Все закодированные символы представлены в таблице ASCII.
ASCII ( от англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией.
Целочисленные типы данных используются для представления чисел. В таблице 1 их аж шесть штук: short int, unsigned short int, int, unsigned int, long int, unsigned long int. Все они имеют свой собственный размер занимаемой памяти и диапазоном принимаемых значений. В зависимости от компилятора, размер занимаемой памяти и диапазон принимаемых значений могут изменяться. В таблице 1 все диапазоны принимаемых значений и размеры занимаемой памяти взяты для компилятора MVS2010. Причём все типы данных в таблице 1 расположены в порядке возрастания размера занимаемой памяти и диапазона принимаемых значений. Диапазон принимаемых значений, так или иначе, зависит от размера занимаемой памяти. Соответственно, чем больше размер занимаемой памяти, тем больше диапазон принимаемых значений. Также диапазон принимаемых значений меняется в случае, если тип данных объявляется с приставкой unsigned — без знака. Приставка unsigned говорит о том, что тип данных не может хранить знаковые значения, тогда и диапазон положительных значений увеличивается в два раза, например, типы данных short int и unsigned short int.
Приставки целочисленных типов данных:
short — приставка укорачивает тип данных, к которому применяется, путём уменьшения размера занимаемой памяти;
long — приставка удлиняет тип данных, к которому применяется, путём увеличения размера занимаемой памяти;
unsigned (без знака) — приставка увеличивает диапазон положительных значений в два раза, при этом диапазон отрицательных значений в таком типе данных храниться не может.
Так, что, по сути, мы имеем один целочисленный тип для представления целых чисел — это тип данных int.
Благодаря приставкам short, long, unsigned появляется некоторое разнообразие типов данных int, различающихся размером занимаемой памяти и (или) диапазоном принимаемых значений.
Типы данных с плавающей точкой
В С++ существуют два типа данных с плавающей точкой: float и double. Типы данных с плавающей точкой предназначены для хранения чисел с плавающей точкой. Типы данных float и double могут хранить как положительные, так и отрицательные числа с плавающей точкой. У типа данных float размер занимаемой памяти в два раза меньше, чем у типа данных double, а значит и диапазон принимаемых значений тоже меньше. Если тип данных float объявить с приставкой long, то диапазон принимаемых значений станет равен диапазону принимаемых значений типа данных double. В основном, типы данных с плавающей точкой нужны для решения задач с высокой точностью вычислений, например, операции с деньгами.
Итак, мы рассмотрели главные моменты, касающиеся основных типов данных в С++. Осталось только показать, откуда взялись все эти диапазоны принимаемых значений и размеры занимаемой памяти. А для этого разработаем программу, которая будет вычислять основные характеристики всех, выше рассмотренных, типов данных.
Если, например, переменной типа short int присвоить значение 33000, то произойдет переполнение разрядной сетки, так как максимальное значение в переменной типа short int это 32767. То есть в переменной типа short int сохранится какое-то другое значение, скорее всего будет отрицательным. Раз уж мы затронули тип данных int, стоит отметить, что можно опускать ключевое слово int и писать, например, просто short. Компилятор будет интерпретировать такую запись как short int. Тоже самое относится и к приставкам long и unsigned.
5.3.2. АРИФМЕТИЧЕСКИЕ ОПЕРАТОРЫ И ОПЕРАТОРЫ ОТНОШЕНИЯ ЯЗЫКА С++
Существуют унарные операторы (unary operator) и парные операторы (binary operator). Унарные операторы, такие как обращение к адресу (&) и обращение к значению (*), воздействуют на один операнд. Парные операторы, такие как равенство (==) и умножение (*), воздействуют на два операнда. Существует также (всего один) тройственный оператор (ternary operator), который использует три операнда, а также оператор вызова функции (function call), который получает неограниченное количество операндов.
Некоторые символы (symbol), например *, используются для обозначения как унарных (обращение к значению), так и парных (умножение) операторов. Представляет ли символ унарный оператор или парный, определяет контекст, в котором он используется. В использовании таких символов нет никакой взаимосвязи, поэтому их можно считать двумя разными символами. Группировка операторов и операндов Чтобы лучше понять порядок выполнения выражений с несколькими операторами, следует рассмотреть концепцию приоритета (precedence), порядка (associativity) и порядка вычисления (order of evaluation) операторов.
В ходе вычисления выражения операнды нередко преобразуются из одного типа в другой. Например, парные операторы обычно ожидают операндов одинакового типа. Но операторы применимы и к операндам с разными типами, если они допускают преобразование в общий тип.
Хотя правила преобразования довольно сложны, по большей части они очевидны. Например, целое число можно преобразовать в число с плавающей запятой, и наоборот, но преобразовать тип указателя в число с плавающей точкой нельзя. Немного неочевидным может быть то, что операнды меньших целочисленных типов (например, bool, char, short и т.д.) обычно преобразуются (promotion) в больший целочисленный тип, как правило int.
Приоритет
Выражения с двумя или несколькими операторами называются составными (compound expression). Результат составного выражения определяет способ группировки операндов в отдельных операторах. Группировку операндов определяют приоритет и порядок. Таким образом, они определяют, какие части выражения будут операндами для каждого из операторов в выражении. При помощи скобок программисты могут изменять эти правила, обеспечивая необходимую группировку. Обычно значение выражения зависит от того, как группируются его части. Операнды операторов с более высоким приоритетом группируются прежде операндов операторов с более низким приоритетом. Порядок определяет то, как группируются операнды с тем же приоритетом.
Например, операторы умножения и деления имеют одинаковый приоритет относительно друг друга, но их приоритет выше, чем у операторов сложения и вычитания. Поэтому операнды операторов умножения и деления группируются прежде операндов операторов сложения и вычитания. Арифметические операторы имеют левосторонний порядок, т.е. они группируются слева направо
Таблица 2. Арифметические операторы (левосторонний порядок)
|
Оператор |
Действие |
Применение |
|
+ |
Унарный плюс |
+ выражение |
|
- |
Унарный минус |
- выражение |
|
* |
Умножение |
выражение * выражение |
|
/ |
Деление |
Выражение / выражение |
|
% |
Остаток |
Выражение % выражение |
|
+ |
Сложение |
Выражение + выражение |
|
- |
Вычитание |
Выражение - выражение |
Примененные к объектам арифметических типов, операторы +, -, * и / имеют вполне очевидные значения: сложение, вычитание, умножение и деление. Результатом деления целых чисел является целое число. Получаемая в результате деления дробная часть отбрасывается
Оператор % известен как остаток (remainder), или оператор деления по модулю (modulus). Он позволяет вычислить остаток от деления левого операнда на правый. Его операнды должны иметь целочисленный тип.
Оператор деления по модулю определен так, что если m и n целые числа и n отлично от нуля, то (m/n)*n + m%n равно m. По определению, если m%n отлично от нуля, то у него тот же знак, что и у m. Прежние версии языка разрешали результату выражения m%n иметь тот же знак, что и у m, причем на реализациях, у которых отрицательный результат выражения m/n округлялся не до нуля, но такие реализации сейчас запрещены. Кроме того, за исключением сложного случая, где -m приводит к переполнению, (-m)/n и m/(-n) всегда эквивалентны -(m/n), m%(-n) эквивалентно m%n и (-m)%n эквивалентно -(m%n)
Логические операторы и операторы отношения
|
Порядок |
Оператор |
Действие |
Применение |
|
Правосторонний |
! |
Логический Not |
! выражение |
|
Левосторонний |
< |
Меньше |
Выражение < выражение |
|
Левосторонний |
<= |
Меньше или равно |
Выражение <= выражение |
|
Левосторонний |
> |
Больше |
Выражение > выражение |
|
Левосторонний |
>= |
Больше или равно |
Выражение >= выражение |
|
Левосторонний |
== |
Равно |
Выражение == Выражение |
|
Левосторонний |
!= |
Не равно |
Выражение != Выражение |
|
Левосторонний |
&& |
Логическое AND |
Выражение && Выражение |
|
Левосторонний |
|| |
Логическое OR |
Выражение || Выражение |
Таблица 3
Теперь рассмотрим более подробно операторы рассмотренные в таблице 3.
Операторы логического AND и OR
Общим результатом оператора логического AND (&&) является true, если и только если оба его операнда рассматриваются как true. Оператор логического OR (||) возвращает значение true, если любой из его операндов рассматривается как true. Операторы логического AND и OR всегда обрабатывают свой левый операнд перед правым. Кроме того, правый операнд обрабатывается, если и только если левый операнд не определил результат. Эта стратегия известна как вычисление по сокращенной схеме (short-circuit evaluation). • Правая сторона оператора && вычисляется, если и только если левая сторона истинна. • Правая сторона оператора || вычисляется, если и только если левая сторона ложна.
Оператор логического NOT (!) возвращает инверсию исходного значения своего операнда.
Операторы отношения (<=, >, <=) имеют свой обычный смысл и возвращают значение типа bool. Эти операторы имеют левосторонний порядок.
5.3.3. ОПЕРАТОРЫ IF И SWITCH C++
Получив понимание того какие типы данных реализованы в языке С++, а так- же какие алгоритмические операторы и операторы отношения к ним могут применяться, можно перейти к изучению операторов, реализованных в языке С++ для разветвляющихся алгоритмов.
Как и в любом языке программирования, существуют два вида операторов ветвления (или, иначе, их называют условными операторами). Первый из них оператор IF. Данный оператор дает возможным два дальнейших пути для программы. Синтаксис оператора следующий:
if (условие) оператор_1; else оператор_2;
Здесь условие — это логическое выражение, переменная или константа.
Работает условный оператор следующем образом. Сначала вычисляется значения выражения, записанного в виде условия. Если оно имеет значение истина (true), выполняется оператор_1. В противном случае (значение ложное (false) ) оператор_2.
Если в задаче требуется, чтобы в зависимости от значения условия выполнялся не один оператор, а несколько, их необходимо заключить в фигурные скобки, как составной оператор.
if (условие) { оператор_1; оператор_2; … }
else { оператор_1; оператор_2; … }
Альтернативная ветвь else в условном операторе может отсутствовать, если в ней нет необходимости.
Рассмотрим несколько примеров использования оператора IF при написании программы.
Пример 1.
Необходимо проверить на равенство две переменные a и b. Код с блоком IF будет выглядеть следующим образом:
int a, b; //инициализация переменных
cin>>a; // ввод значения переменной a
cin>>b; // ввод значения переменной b
if (a==b)
cout<<"a equal b"; // если значения данных переменных равны вывести сообщение об этом
else
cout<<"a not equal b"; // иначе вывести сообщение о противном
Пример 2.
Необходимо произвести сравнение показателей производства относительно имеющихся стандартов.
CONST int kpdWorkers = 80;
CONST int kpdMashineTools = 75; //данные константы будут являться стандартами
Int ActualkpdWorkers, ActualkpdMashineTools; //переменные хранящие фактические значения работоспособности
Cin>> ActualkpdWorkers;
Cin>> ActualkpdMashineTools;
//теперь проводим сравнение фактических показателей со стандартами
IF (ActualkpdWorkers >= kpdWorkers) && (ActualkpdMashineTools>= kpdMashineTools)
Cout<< “Производство работает корректно”;
ELSE
{
IF (ActualkpdWorkers >= kpdWorkers)
Cout<< “Производительность станков не удовлетворяет стандартам”;
ELSE
Cout<< “Производительность рабочих не удовлетворяет стандартам”;
}
Теперь перейдем к оператору множественного выбора switch. Если IF дает возможность указать лишь два пути хода программы, то оператор switch позволяет указать множество путей.
Синтаксис оператора switch следующий:
switch (выражение)
{
case значение_1: операторы_1; break;
case значение_2: операторы_2; break;
case значение_3: операторы_3; break;
…
case значение_n: операторы_n; break;
default: операторы; break;
}
Оператор работает следующем образом. Вычисляется значение выражения.
Затем выполняются операторы, помеченные значением, совпадающим со значением выражения. То есть если, выражение принимает значение_1, то выполняются операторы_1 и т.д.. Если выражение не принимает ни одного из значений, то выполняются операторы, расположенные после слова default.
Ветвь default может отсутствовать, тогда оператор имеет вид:
switch (выражение)
{
case значение_1: операторы_1; break;
case значение_2: операторы_2; break;
case значение_3: операторы_3; break;
…
case значение_n: операторы_n; break;
}
Оператор break необходим для того, чтобы осуществить выход из операторы switch. Если он не указан, то будут выполняться следующие операторы из списка, несмотря на то, что значение, которым они помечены, не совпадает со значением выражения.
Рассмотрим пример использования данного оператора.
Необходимо вывести на название дня недели, соответствующее заданному числу D, при условии, что в месяце 31 день и 1-е число — понедельник.
unsigned int D, R; //описанны целые положительные числа
cout<<"D=";
cin>>D;
R=D%7;
switch (R)
{
case 1: cout<<"Monday \n"; break;
case 2: cout<<"Theusday \n"; break;
case 3: cout<<"Wednesday \n"; break;
case 4: cout<<"Thursday \n"; break;
case 5: cout<<"Friday \n"; break;
case 6: cout<<"Saturday \n"; break;
case 0: cout<<"Sunday \n"; break;
}
system ("pause");
return 0;
Главное преимущество этой конструкции в том, что разработчику понятно, как работает программа: единственная переменная контролирует поведение программы. В случае с if-else, придется внимательно читать каждое условие.
ЗАКЛЮЧЕНИЕ
По итогу данной работы были получены необходимые знания об алгоритмах, принципах их разработки и способах описания. Были привиты основные понятия о реализации алгоритмов языками программирования. Получены знания о типах данных и основных операторах языка С++. было проведено успешное изучение реализации разветвляющихся алгоритмов на языке С++.
В ходе работы выявлено, что язык С++ как и остальные языки программирования содержит только два оператора, реализующих разветвляющийся алгоритм. Оператор ветвления IF, реализующий ветвление с максимум двумя вариантами развития событий, и оператор SWITCH, позволяющий реализовать множественный выбор. Ключевым преимуществом оператора SWHITCH перед оператором IF, является то, что в ситуациях, когда в зависимости от значения переменной или выражения должно быть описано более двух ветвлений, предоставляет более понятную конструкцию для разработчика, так как поведение программы будет контролироваться единственной переменной.
Подытожив можно смело утверждать, что реализованные для программной реализации разветвляющегося алгоритма операторы в С++ всецело удовлетворяют потребности разработчиков на данном языке программирования.
Список литературы
1. http://book.kbsu.ru/theory/chapter7/1_7.html
2. Т.В. Панова, Н.Д. Николаева «Основы алгоритмизации и программирования на языке высокого уровня си»
3. Бьерн Страуструп. Язык программирования С++. Второе дополненное издание. Языки программирования / С++
4. http://cppstudio.com/post/259/
5. Стенли Б. Липпман,Жози Лажойе, Барбара Э. Му. Язык программирования С++ Базовый курс

- Влияние кадровой стратегии на работу службы персонала (Понятие и типы кадровой стратегии организации)
- Разработка рекламной компании популяризация органического бренда спорт-питания (История происхождения спортивного питания (добавок))
- Исследование процесса принятия решения о покупке (ООО «Советская бумага» )
- Проектирование реализации операций бизнес-процесса «Расчет заработной платы»» (на примере ООО «Бур-Сервис»)
- Алгоритмы сортировки данных (Гномья сортировка)
- Проектирование операций бизнес-процесса Расчет заработной платы
- Нечеткая логика и нейронные сети (Аналогия нейронных сетей с мозгом и биологическим нейроном)
- Проектирование диаграммы классов «Склад»
- «Разработка программ с графическим интерфейсом на С++»
- Оптимизация решений по Парето
- Нейронные сети и их экономические задачи
- Проектирование диаграммы классов «Бензозаправка»