
Нейронные сети и их экономические задачи
Содержание:

ВВЕДЕНИЕ
Данная работа посвящена изучению основных понятий нечеткой логики и нейронных сетей, а так же применение данных познаний в решении экономических задач современного мира. Актуальность темы заключается в том, что современное общество невозможно представить без экономики, которая участвует во всех аспектах жизни современного человека. Для решения задач связанных с экономикой задач, число которых ежедневно растет, применяются различного рода инструменты, в число которых на сегодняшний день начала входить нечеткая логика и вычислительная технология нейронных сетей.
Цель курсовой работы заключается в глубоком изучении инструментов нечеткой логики и нейронных сетей, способствующих развитию методик и инструментов для решения поставленных задач экономического уклона, и применения их на практике. Для осуществления обозначенной цели служат следующие задачи:
- изучение литературы по теме исследования;
- формулировка основных понятий, касающихся темы изыскания;
- разработка мероприятий, направленных на решение экономических задач.
Методологической основой послужили научные труды известных отечественных и зарубежных ученых. В качестве теоретической базы исследования были использованы публикации, посвящённые нечеткой логике и нейронным сетям.
ГЛАВА 1. ИСТОРИЯ РАЗВИТИЯ НЕЙРОННЫХ СЕТЕЙ
Термин «нейронная сеть» появился в середине XX века. Первые работы, в которых были получены основные результаты в данном направлении, были проделаны Мак-Каллоком и Питтсом. В 1943 году ими была разработана компьютерная модель нейронной сети на основе математических алгоритмов и теории деятельности головного мозга. Они выдвинули предположение, что нейроны можно упрощённо рассматривать как устройства, оперирующие двоичными числами, и назвали эту модель «пороговой логикой». Подобно своему биологическому прототипу нейроны Мак-Каллока–Питтса были способны обучаться путём подстройки параметров, описывающих синаптическую проводимость. Исследователи предложили конструкцию сети из электронных нейронов и показали, что подобная сеть может выполнять практически любые вообразимые числовые или логические операции. Мак-Каллок и Питтс предположили, что такая сеть в состоянии также обучаться, распознавать образы, обобщать, т. е. обладает всеми чертами интеллекта.
Данная модель заложила основы двух различных подходов исследований нейронных сетей. Один подход был ориентирован собственно на изучение биологических процессов в головном мозге, другой – на применение нейронных сетей как метода искусственного интеллекта для решения различных прикладных задач.
В 1949 году канадский физиолог и психолог Хебб высказал идеи о характере соединения нейронов мозга и их взаимодействии. Он первым предположил, что обучение заключается в первую очередь в изменениях силы синаптических связей. Теория Хебба считается типичным случаем самообучения, при котором испытуемая система спонтанно обучается выполнять поставленную задачу без вмешательства со стороны экспериментатора. В более поздних вариантах теория Хебба легла в основу описания явления долговременной потенциации.
В 1954 году в Массачусетском технологическом институте с использованием компьютеров Фарли и Кларк разработали имитацию сети Хебба. Также исследования нейронных сетей с помощью компьютерного моделирования были проведены Рочестером, Холландом, Хебитом и Дудой в 1956 году.
В 1957 году Розенблаттом были разработаны математическая и компьютерная модели восприятия информации мозгом на основе двухслойной обучающейся нейронной сети. При обучении данная сеть использовала арифметические действия сложения и вычитания. Розенблатт описал также схему не только основного перцептрона, но и схему логического сложения. В 1958 году им была предложена модель электронного устройства, которое должно было имитировать процессы человеческого мышления, а два года спустя была продемонстрирована первая действующая машина, которая могла научиться распознавать некоторые из букв, написанных на карточках, которые подносили к его «глазам», напоминающим кинокамеры.
Интерес к исследованию нейронных сетей угас после публикации работы по машинному обучению Минского и Пейперта в 1969 году. Ими были обнаружены основные вычислительные проблемы, возникающие при компьютерной реализации искусственных нейронных сетей. Первая проблема состояла в том, что однослойные нейронные сети не могли совершать «сложение по модулю 2», то есть реализовать функцию «Исключающее ИЛИ». Второй важной проблемой было то, что компьютеры не обладали достаточной вычислительной мощностью, чтобы эффективно обрабатывать огромный объём вычислений, необходимый для больших нейронных сетей.
Исследования нейронных сетей замедлились до того времени, когда компьютеры достигли больших вычислительных мощностей. Одним из важных шагов, стимулировавших дальнейшие исследования, стала разработка в 1975 году Вербосом метода обратного распространения ошибки, который позволил эффективно решать задачу обучения многослойных сетей и решить проблему со «сложением по модулю 2».
В 1975 году Фукусимой был разработан когнитрон, который стал одной из первых многослойных нейронных сетей. Фактическая структура сети и методы, используемые в когнитроне для настройки относительных весов связей, варьировались от одной стратегии к другой. Каждая из стратегий имела свои преимущества и недостатки. Сети могли распространять информацию только в одном направлении или перебрасывать информацию из одного конца в другой, пока не активировались все узлы и сеть не приходила в конечное состояние. Достичь двусторонней передачи информации между нейронами удалось лишь в сети Хопфилда (1982), и специализация этих узлов для конкретных целей была введена в первых гибридных сетях.
Алгоритм параллельной распределённой обработки данных в середине 1980 годов стал популярен под названием коннективизма. В 1986 году в работе Руммельхарта и Мак-Клелланда коннективизм был использован для компьютерного моделирования нейронных процессов.
Несмотря на большой энтузиазм, вызванный в научном сообществе разработкой метода обратного распространения ошибки, это также породило многочисленные споры о том, может ли такое обучение быть на самом деле реализовано в головном мозге. Отчасти это связывали с тем, что механизм обратного прохождения сигнала не был очевидным в то время, так как не было явного источника обучающего и целевого сигналов. Тем не менее, в 2006 году было предложено несколько неконтролируемых процедур обучения нейронных сетей с одним или несколькими слоями с использованием так называемых алгоритмов глубокого обучения. Эти алгоритмы могут быть использованы для изучения промежуточных представлений, как с выходным сигналом, так и без него, чтобы понять основные особенности распределения сенсорных сигналов, поступающих на каждый слой нейронной сети.
Как и во многих других случаях, задачи высокой сложности требуют применения не одного, а нескольких методов решения или их синтеза. Не исключение и искусственные нейронные сети. С самого начала нынешнего столетия в работах различных исследователей активно описываются нейро-нечёткие сети, ячеечно-нейросетевые модели. Также нейронные сети используются, например, для настройки параметров нечётких систем управления. В общем, нет никаких сомнений и в дальнейшей интеграции методов искусственного интеллекта между собой и с другими методами решения задач.
ГЛАВА 2. АНАЛОГИЯ НЕЙРОННЫХ СЕТЕЙ С МОЗГОМ И БИОЛОГИЧЕСКИМ НЕЙРОНОМ
2.1. АНАЛОГИЯ С МОЗГОМ
Точная работа мозга человека - все еще тайна. Тем не менее некоторые аспекты этого удивительного процессора известны. Базовым элементом мозга человека являются специфические клетки, известные как нейроны, способные запоминать, думать и применять предыдущий опыт к каждому действию, что отличает их от остальных клеток тела.
Кора головного мозга человека является плоской, образованной из нейронов поверхностью, толщиной от 2 до 3 мм площадью около 2200 см2, что вдвое превышает площадь поверхности стандартной клавиатуры. Кора главного мозга содержит около 1011 нейронов, что приблизительно равно числу звезд Млечного пути. Каждый нейрон связан с 103 - 104 другими нейронами. В целом мозг человека имеет приблизительно от 1014 до 1015 взаимосвязей.
Сила человеческого ума зависит от числа базовых компонент, многообразия соединений между ними, а также от генетического программирования и обучения.
Индивидуальный нейрон является сложным, имеет свои составляющие, подсистемы и механизмы управления и передает информацию через большое количество электрохимических связей. Насчитывают около сотни разных классов нейронов. Вместе нейроны и соединения между ними формируют недвоичный, нестойкий и несинхронный процесс, отличающийся от процесса вычислений традиционных компьютеров. Искусственные нейросети моделируют лишь главнейшие элементы сложного мозга, вдохновляющий ученых и разработчиков к новым путям решения проблемы.
2.2. БИОЛОГИЧЕСКИЙ НЕЙРОН
Нейрон (нервная клетка) состоит из тела клетки - сомы (soma), и двух типов внешних древовидных ответвлений: аксона (axon) и дендритов (dendrites). Тело клетки содержит ядро (nucleus), где находится информация про свойства нейрона, и плазму, которая производит необходимые для нейрона материалы. Нейрон получает сигналы (импульсы) от других нейронов через дендриты (приемника) и передает сигналы, сгенерированные телом клетки, вдоль аксона (передатчик), который в конце разветвляется на волокна (strands). На окончаниях волокон находятся синапсы (synapses).
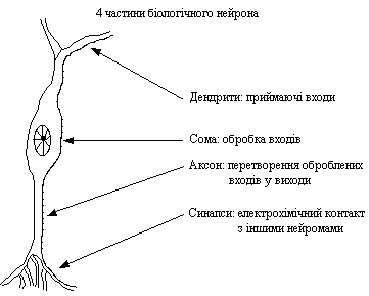
Рис. 1. Схема биологического нейрона.
Синапс является функциональным узлом между двумя нейронами (волокно аксона одного нейрона и дендрит другого). Когда импульс достигает синаптического окончания, вырабатываются химические вещества, называемые нейротрансмиттерами. Нейротрансмиттери проходят через синаптичную щель, и в зависимости от типа синапса, возбуждая или тормозя способность нейрона-приемника генерировать электрические импульсы. Результативность синапса настраивается проходящими через него сигналами, поэтому синапсы обучаются в зависимости от активности процессов, в которых они принимают участие. Нейроны взаимодействуют с помощью короткой серии импульсов. Сообщение передается с помощью частотно-импульсной модуляции.
Последние экспериментальные исследования доказывают, что биологические нейроны структурно сложнее, чем упрощенное объяснение существующих искусственных нейронов, которые являются элементами современных искусственных нейронных сетей. Поскольку нейрофизиология предоставляет ученым расширенное понимание действия нейронов, а технология вычислений постоянно совершенствуется, разработчики сетей имеют неограниченное пространство для улучшения моделей биологического мозга.
ГЛАВА 3. ИСКУССТВЕННЫЙ НЕЙРОН
Искусственный нейрон является структурной единицей искусственной нейронной сети и представляет собой аналог биологического нейрона.
С математической точки зрения искусственный нейрон — это сумматор всех входящих сигналов, применяющий к полученной взвешенной сумме некоторую простую, в общем случае, нелинейную функцию, непрерывную на всей области определения. Обычно, данная функция монотонно возрастает. Полученный результат посылается на единственный выход.
3.1. РАСШИРЕННАЯ МОДЕЛЬ ИСКУССТВЕННОГО НЕЙРОНА
Углубленные представления относительно строения биологического позволяют представить модель технического нейрона в расширенном виде, детализированная структура которого приведена на рис. 1, где
1.сумматор, моделирующий функции тела биологического нейрона
2.функциональный преобразователь, который выполняет роль аксонного бугорка
3.возбуждающий синапс
4.тормозящий синапс
5.входной сигнал
6.дихотомическое разветвление входного сигнала
7.выходной сигнал
8.дихотомическое разветвление выходного сигнала
9.прямая связь, соответствующая аксодендритной связи между биологическими нейронами
10.обратная (аксосоматичная) связь.
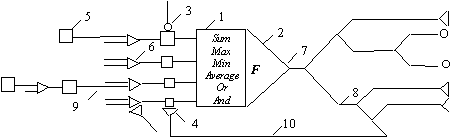
Рис. 1. Расширенная модель нейронного элемента
Основанием для детализации модели нейронного элемента можно считать установление новых фактов в области нейрофизиологии, в частности:
1.Наличие нескольких мест синаптического контакта.
2.Дихотомическое разветвление дендритов разных порядков, отвечающих в технических аналогах логическим операциям "И", "ИЛИ", "Исключающее ИЛИ", выделение максимального или минимального сигнала .
3.Разные диаметры стволовых дендритов, ветвей, непосредственно прилегающих к телу нейрона, причем величина диаметра определяет степень важности информации, проходящей через дендрит.
4.Наличие "дорожек" на поверхности сомы, проходящих от главных ствольных дендритов к аксону, обуславливает наличие параллельных путей обработки информации и предоставляет возможность применения логических операций над сигналами, поступающих от разных стволових дендритов.
5.Особенности функционирования аксонного бугорка; именно аксонный бугорок устанавливает передаточную функцию нейрона, которая имеет более сложную форму, чем принятые в нейросетевых технологиях сигмоидальные или линейные передаточные функций.
6.Наличие дихотомического разветвления аксона; в узлах разветвления происходит управление прохождением сигнала, зависящего от соотношения диаметров разных ветвей аксона; при математическом моделировании эти особенности можно реализовать с помощью логических операций.
7.Наличие обратной аксосоматичной связи, что уже нашло свою реализацию при построении рекурентных нейросетей.
Углубленные знания относительно строения биологического нейрона, как эффективного преобразующего инструмента, можно рассматривать как источник базовых идей и концепций по созданию новых парадигм нейросетей не только в настоящем времени, но и на отдаленную перспективу.
Компоненты искусственного нейрона
Независимо от расположения и функционального назначения, все искусственные нейронные элементы имеют общие компоненты. Рассмотрим семь основных компонентов искусственного нейрона.
Компонент 1. Весовые коэффициенты
При функционировании нейрон получает множество входных сигналов одновременно. Каждый вход имеет свой собственный синаптический вес, который влияет на него и необходим для функции сумматора. Вес является мерой важности входных связей и моделирует поведение синапсов биологических нейронов. Весы влиятельного входа усиливаются и, наоборот, вес несущественного входа принудительно уменьшается, что определяет интенсивность входного сигнала. Весы могут изменяться в соответствии с обучающими примерами, архитектурой сети и правилами обучения.
Компонента 2. Функция сумматора
Первым действием нейрона является вычисление взвешенной суммы всех входов. Математически, входные сигналы и соответствующие им весы представлены векторами (х10, х20 ... хn0) и (w10, w20 . . . wn0). Произведение этих векторов будет общим входным сигналом. Упрощенной функцией суматора является умножение каждого компонента вектора х на соответствующий компонент вектора w: вход1 = х10 * w10, вход2 = х20 * w20, и нахождение суммы всех произведений: вход1 + вход2 + . . . + вхoдn. Результатом будет одно число, а не многоэлементный вектор.
Функция сумматора может быть сложнее, например, выбор минимума, максимума, среднего арифметического, произведение или другой алгоритм. Входные сигналы и весовые коэффициенты перед поступлением в передаточную функцию могут комбинироваться многими способами. Алгоритмы для комбинирования входов нейронов определяются в зависимости от архитектуры и правил обучения.
В некоторых нейросетях к функции сумматора добавляют функцию активации, которая смещает выход функции сумматора относительно времени. К сожалению, функции активации в настоящее время используются ограничено и большинство современных нейронных реализаций используют функцию активации "тождественности", которая эквивалентна ее отсутствию. Ее лучше использовать как компонент сети в целом, чем как компонент отдельного нейрона.
Компонента 3. Передаточная функция
Результат функции сумматора проходит через передаточную функцию и превращается в выходной сигнал. В передаточной функции для определения выхода нейрона общая сумма сравнивается с некоторым порогом. Если сумма больше значения порога, нейрон генерирует сигнал, в противном случае сигнал будет нулевым или тормозящим.
Преимущественно применяют нелинейную передаточную функцию, поскольку линейные (прямолинейные) функции ограничены и их выход пропорционален входу. Применение линейных передаточных функций было проблемой в ранних моделях сетей, и их ограниченность и нецелесообразность была доказана в книге Мински и Пейперта "Перцептроны".
На рис. 2 изображены типичные передаточные функции
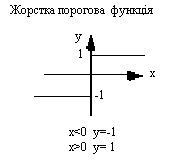
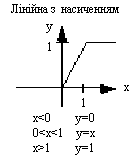
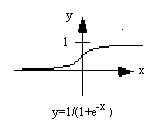
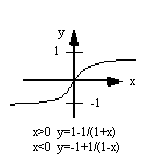
Для простой передаточной функции нейросеть может выдавать 0 и 1, 1 и -1 или другие числовые комбинации. Передаточная функция в таких случаях является "жестким ограничителем" или пороговой функцией (рис. 2а).
Другой тип передаточной функции - линейная с насыщением отзеркаливает вход внутри заданного диапазона и действует как жесткий ограничитель за пределами этого диапазона. Это линейная функция, которая отсекается минимальным и максимальным значениями, делая ее нелинейной (рис. 2б).
Следующей является S-подобная кривая, которая приближает минимальное и максимальное значения в асимптотах и называется сигмоидой (рис. 2в), когда ее диапазон [0, 1], или гиперболическим тангенсом (рис. 2г), при диапазоне [-1, 1]. Важной чертой этих кривых является непрерывность функций и их производных. Применение S-функций дает хорошие результаты и имеет широкое применение.
Для разных нейросетей могут выбираться разные передаточные функции.
Перед поступлением в передаточную функцию к входному сигналу порой прибавляют равномерно распределенный случайный шум, источник и количество которого определяется режимом обучения. В литературе этот шум, упоминается как "температура" искусственных нейронов, придающая математической модели элемент реальности.
Компонент 4. Масштабирование
После передаточной функции выходной сигнал проходит дополнительную обработку масштабирования, то есть результат передаточной функции множится на масштабирующий коэффициент и добавляется смещение.
Компонент 5. Выходная функция (соревнование)
По аналогии с биологическим нейроном, каждый искусственный нейрон имеет один выходной сигнал, который передается сотням других нейронов. Преимущественно, выход прямо пропорциональный результата передаточной функции. В некоторых сетевых архитектурах результаты передаточной функции изменяются для создания соревнования между соседними нейронами. Нейронам разрешается соревноваться между собой, блокируя действия нейронов, имеющих слабый сигнал. Соревнование (конкуренция) может происходить между нейронами, находящихся на одном или разных слоях. Во-первых, конкуренция определяет, какой искусственный нейрон будет активным и обеспечит выходной сигнал. Во-вторых, конкурирующие выходы помогают определить, какой нейрон примет участие в процессе обучения.
Компонент 6. Функция погрешности и распространяемое назад значение
В большинстве сетей, применяющих контролируемое обучение вычисляется разность между пполученным и желаемым выходом. Погрешность отклонения (поточная погрешность) преобразовывается функцией погрешности в соответствии с заданной архитектурой. В базовых архитектурах погрешность отклонения используется непосредственно, в некоторых парадигмах используется квадрат или куб погрешности с сохранением знака.
После прохождения всех слоев поточная погрешность распространяется назад к предыдущему слою и может быть непосредственно погрешностью или погрешностью, масштабированной определенным образом в зависимости от типа сети (например, производной от передаточной функции). Это распространенное назад значение учитывается в следующем цикле обучения.
Компонент 7. Функция обучения
Целью обучения является настраивание весов соединений на входах каждого нейрона в соответствии с определенным алгоритмом обучения для достижения желаемого результата. Существует два типа обучения: контролируемое и неконтролируемое. Контролируемое обучение требует обучающего множества данных или наблюдателя, который отслеживает эффективность результатов сети. В случае неконтролируемого обучения система самоорганизовывается по внутреннему критерию, заложенному в алгоритм обучения.
3.2. ТИПЫ ИСКУССТВЕННЫХ НЕЙРОНОВ
На данный момент можно описать шесть типов искусственных нейронов:
1.Персептрон
2. Сигмоидальный нейрон
3. Инстар Гроссберга
4. Нейроны типа WTA
5. Нейрон Хебба
6. Радиальный нейрон
3.2.1. ПЕРСЕПТРОН
Персептрон предложен в 1943 г. и называется также моделью МакКаллока-Пится. В этой модели искусственный нейрон считается бинарным элементом, его структурная схема представлена на рис. 1.
|
|
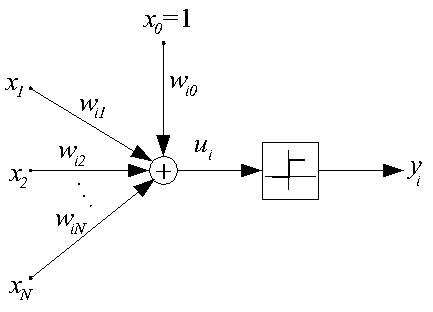
Рис. 1. Структурная схема персептрона
Выходной сигнал нейрона может принимать только два значения 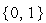 по следующему правилу:
по следующему правилу:
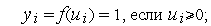
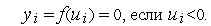
Обучение персептрона требует учителя,т.е.множества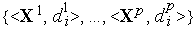 пар векторов входных сигналов
пар векторов входных сигналов  , и соответствующих им ожидаемым значениям выходного сигнала
, и соответствующих им ожидаемым значениям выходного сигнала 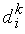 . Обучение (отыскание весовых коэффициентов ) сводится к задаче минимизации целевой функции
. Обучение (отыскание весовых коэффициентов ) сводится к задаче минимизации целевой функции 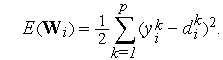
К сожалению, для персептрона в силу разрывности функции 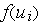 при отыскании минимума
при отыскании минимума 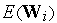 применимы методы оптимизации только нулевого порядка.
применимы методы оптимизации только нулевого порядка.
На практике для обучения персептрона чаще всего используется правило персептрона, представляющее собой следующий простой алгоритм.
- Выбираются (как правило, случайно) начальные значения весов
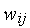 (
(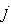 = 0, 1, 2, ...,
= 0, 1, 2, ..., 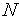 ) нейрона.
) нейрона. - Для каждой обучающей пары
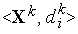 выполняется ряд циклов (их номера обозначим через
выполняется ряд циклов (их номера обозначим через 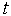 ) уточнения значений входных весов по формуле :
) уточнения значений входных весов по формуле :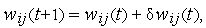
где
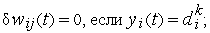
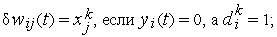
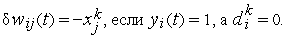
Процесс обработки текущей обучающей пары завершается:
- либо на цикле, в котором все
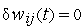 ,
, - либо после достижения предельного количества циклов.
Следует отметить, что правило персептрона представляет собой частный случай предложенного много позже универсального правил обучения Видроу-Хоффа: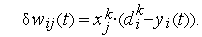
Функционирование обученного персептрона в режиме классификации легко проиллюстрировать графически на примере двухвходового нейрона с поляризацией, структурная схема которого дана на рис. 2.
|
|
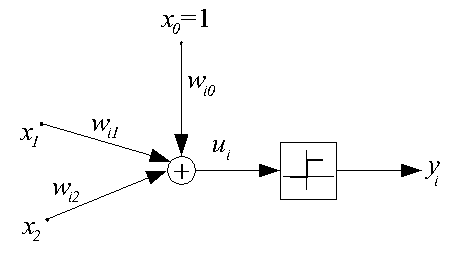
Рис. 2. Структурная схема двухвходового персептрона
Для такого нейрона 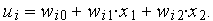 Это выражение определяет плоскость в трехмерном пространстве
Это выражение определяет плоскость в трехмерном пространстве 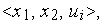 эта плоскость пересекается с плоскостью
эта плоскость пересекается с плоскостью 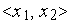 по линии, определяемой уравнением
по линии, определяемой уравнением 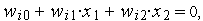 как это показано на рис. 3.
как это показано на рис. 3.
|
|
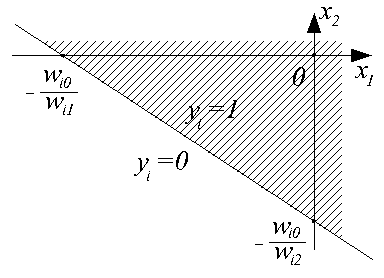
Рис. 3. Разделение пространства входных данных двухвходовым персептроном
Эта линия разбивает пространство входных сигналов 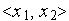 на две области: в одной из них (заштрихованной) значения
на две области: в одной из них (заштрихованной) значения 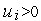 , и, следовательно, функция активации принимает значение 1; в другой —
, и, следовательно, функция активации принимает значение 1; в другой — 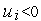 , и
, и  .
.
Таким образом, наглядно видно, что персептрон является простейшим линейным классификатором
3.2.2. СИГМОИДАЛЬНЫЙ НЕЙРОН
Сигмоидальный нейрон устраняет основной недостаток персептрона — разрывность функции активации 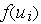 . Структурная схема нейрона данного типа представлена на рис. 1.
. Структурная схема нейрона данного типа представлена на рис. 1.
|
|
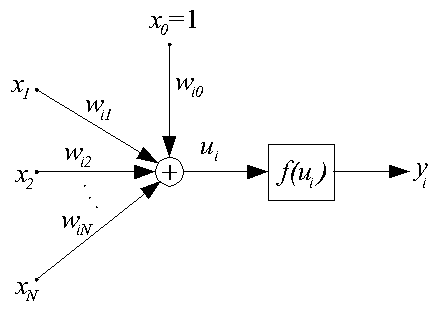
Рис. 1. Структурная схема сигмоидального нейрона
В качестве функции активации 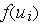 выступает сигмоидальная функция (т.е. функция, график которой похож на букву "S"). На практике используются как униполярные, так и биполярные функции активации.
выступает сигмоидальная функция (т.е. функция, график которой похож на букву "S"). На практике используются как униполярные, так и биполярные функции активации.
Униполярная функция, как правило, представляется формулой :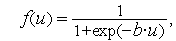
тогда как биполярная функция задается в виде :
Графики униполярных и биполярных сигмоидальных функций представлены на рис. 2 и рис. 3 соответственно.
|
|
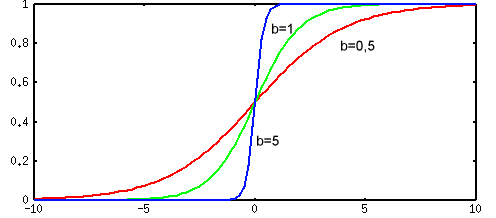
Рис. 2. График униполярной сигмоидальной функции
|
|
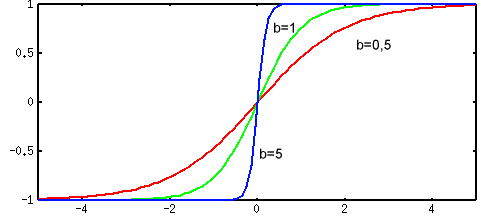
Рис. 3. График биполярной сигмоидальной функции
Коэффициент 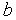 определяет "крутизну" функций и выбирается разработчиком сети (на практике
определяет "крутизну" функций и выбирается разработчиком сети (на практике 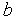 для упрощения назначают обычно равным 1).
для упрощения назначают обычно равным 1).
Производная униполярной функции активации имеет вид :
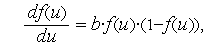
а производная биполярной функции —
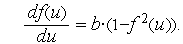
Графики производных имеют колоколобразный вид и представлены на рис. 4 и рис. 5.
|
|
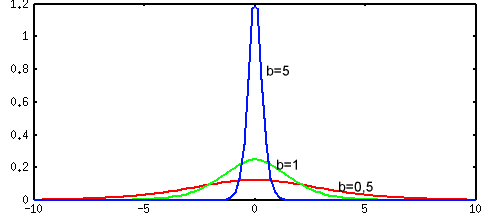
Рис. 4. График производной униполярной сигмоидальной функции
|
|
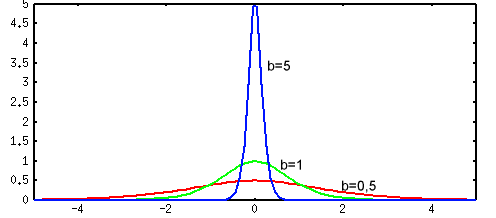
Рис. 5. График производной биполярной сигмоидальной функции
Для обучения сигмоидального нейрона используется стратегия "с учителем", однако, в отличие от персептрона, для поиска минимума целевой функции 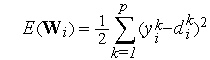
здесь используются методы поисковой оптимизации первого порядка, в которых целенаправленное изменение весовых коэффициентов 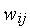 осуществляется в направлении отрицательного градиента
осуществляется в направлении отрицательного градиента 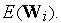
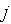 -ая компонента вектора градиента имеет вид :
-ая компонента вектора градиента имеет вид :
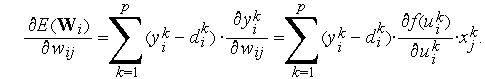
Обозначив 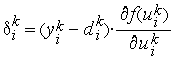 ,имеем
,имеем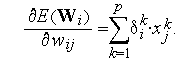
Также возможно обучение сигмоидального нейрона и дискретным способом — сериями циклов уточнения входных весов для каждой эталонной пары 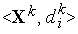 (см. правило персептрона). При этом коррекция весов после каждого цикла выполняется по следующей формуле:
(см. правило персептрона). При этом коррекция весов после каждого цикла выполняется по следующей формуле:
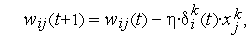
где 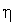 — коэффициент обучения, значение которого выбирается из диапазона (0, 1).
— коэффициент обучения, значение которого выбирается из диапазона (0, 1).
Необходимо напомнить, что все методы поисковой оптимизации первого порядка — это методы локального поиска, не гарантирующие достижения глобального экстремума. В качестве попытки преодолеть этот недостаток было предложено обучение с моментом, в котором коррекция весов выполняется следующим образом:
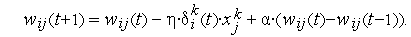
Последнее слагаемое в формуле называется моментом и характеризует фактическое изменение веса в предыдущем цикле (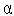 выбирается в диапазоне (0, 1)). Существует надежда, что при приближении к точке локального минимума (где градиентная составляющая
выбирается в диапазоне (0, 1)). Существует надежда, что при приближении к точке локального минимума (где градиентная составляющая  стремится к нулю) составляющая момента выведет поиск из области локального минимума в более перспективную область.
стремится к нулю) составляющая момента выведет поиск из области локального минимума в более перспективную область.
3.2.3.ИНСТАРА ГРОССБЕРГА
Структурная схема инстара Гроссберга представлена на рис. 1.
|
|
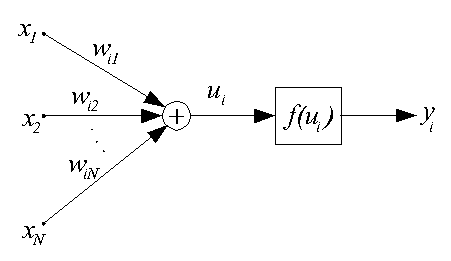
Рис. 1. Структурная схема инстара Гроссберга
Особенностями инстара, отличающими его от нейронов других типов, являются следующие:
- функция активации
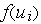 часто линейна, т.е.
часто линейна, т.е. 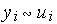 ;
; - входной вектор
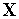 нормализован так, что его эвклидова норма равна 1;
нормализован так, что его эвклидова норма равна 1; - обучение инстара возможно как с учителем, так и без него.
Нормализация элементов вектора 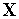 производится по следующей формуле:
производится по следующей формуле:
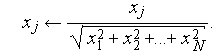
Обучение инстара с учителем производится дискретно по правилу Гроссберга
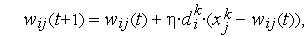
где 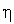 — коэффициент обучения, значение которого выбирается в диапазоне (0, 1). В качестве начальных обычно выбираются нулевые значения весовых коэффициентов. Необходимо обратить внимание, что на изменение значений весовых коэффициентов оказывают влияние только положительные примеры эталонных пар, для которых
— коэффициент обучения, значение которого выбирается в диапазоне (0, 1). В качестве начальных обычно выбираются нулевые значения весовых коэффициентов. Необходимо обратить внимание, что на изменение значений весовых коэффициентов оказывают влияние только положительные примеры эталонных пар, для которых 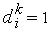 .
.
На процесс обучения инстара решающее влияние оказывает величина коэффициента обучения 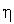 . При
. При 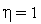 веса
веса 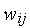 принимают значения соответствующих входов
принимают значения соответствующих входов 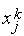 текущей эталонной пары за один цикл обучения (при этом происходит абсолютное "забывание" предыдущих значений
текущей эталонной пары за один цикл обучения (при этом происходит абсолютное "забывание" предыдущих значений 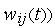 . При
. При 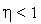 в результате обучения коэффициенты
в результате обучения коэффициенты 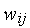 принимают некоторые "усредненные" значения обучающих векторов
принимают некоторые "усредненные" значения обучающих векторов 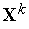 ,
, 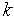 = 1, 2, ...,
= 1, 2, ..., 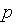 .
.
Предположим, что 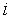 -ый инстар был обучен на единственной положительной эталонной паре
-ый инстар был обучен на единственной положительной эталонной паре 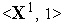 . При этом вектор входных весов инстара
. При этом вектор входных весов инстара 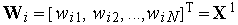 . В режиме классификации на вход инстара подается вектор
. В режиме классификации на вход инстара подается вектор 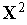 , тогда на выходе вырабатывается сигнал
, тогда на выходе вырабатывается сигнал
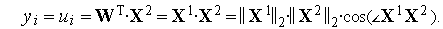
Поскольку входные векторы 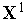 и
и 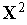 нормализованы (т.е.
нормализованы (т.е. 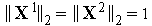 ), то выходной сигнал инстара равен просто косинусу угла между векторами
), то выходной сигнал инстара равен просто косинусу угла между векторами 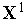 и
и 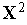 .
.
Функционирование инстара наглядно иллюстрируется графически. В режиме обучения при предъявлении, например, трех положительных примеров, содержащих двухкомпонентные векторы 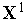 ,
, 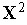 и
и 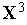 , подбирается вектор входных весов
, подбирается вектор входных весов 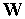 , представляющий собой "усреднение" этих входных векторов, как это показано на рис. 2.
, представляющий собой "усреднение" этих входных векторов, как это показано на рис. 2.
|
|
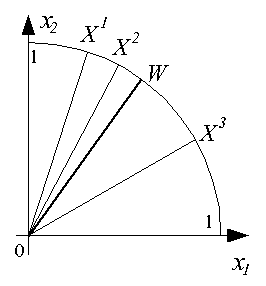
Рис. 2. Результат обучения инстара Гроссберга
В режиме классификации при подаче на вход инстара очередного вектора 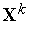 определяется степень его близости к "типичному" вектору
определяется степень его близости к "типичному" вектору 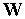 в виде косинуса угла между этими векторами, как это показано на рис. 3.
в виде косинуса угла между этими векторами, как это показано на рис. 3.
|
|
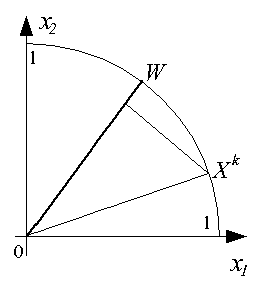
Рис. 3. Классификация входного вектора обученным инстаром Гроссберга
Обучение инстара Гроссберга без учителя предполагает случайный выбор начальных значений входных весов 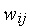 и их нормализацию, подобную нормализации вектора входных сигналов
и их нормализацию, подобную нормализации вектора входных сигналов 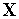 . Дальнейшее уточнение весов реализуется следующей формулой:
. Дальнейшее уточнение весов реализуется следующей формулой:
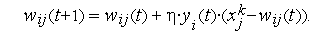
3.2.4. НЕЙРОНЫ ТИПА WTA (WINNER TAKES ALL — ПОБЕДИТЕЛЬ ПОЛУЧАЕТ ВСЕ)
Данный тип нейронов всегда используется группами, в которых конкурируют между собой. Структурная схема группы (слоя) нейронов типа WTA представлена на рис. 1.
|
|
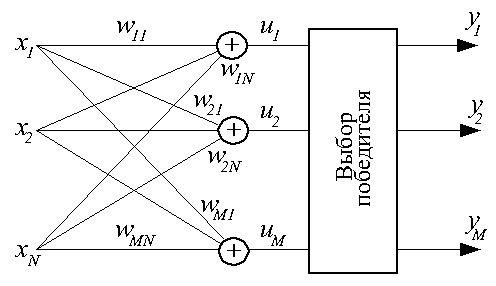
Рис. 1. Структурная схема слоя нейронов типа WTA
Каждый конкурирующий нейрон в группе получает одни и те же входные сигналы. Каждый нейрон рассчитывает выходной сигнал своего сумматора обычным образом 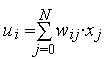 . По результатам сравнения всех
. По результатам сравнения всех 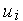 ,
, 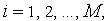 выбирается нейрон-победитель, обладающий наибольшим значением
выбирается нейрон-победитель, обладающий наибольшим значением 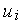 . Выходной сигнал
. Выходной сигнал 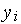 нейрона-победителя получает значение 1, выходные сигналы всех остальных нейронов — 0.
нейрона-победителя получает значение 1, выходные сигналы всех остальных нейронов — 0.
Для обучения нейронов типа WTA не требуется учитель, оно практически полностью аналогично обучению инстара Гроссберга. Начальные значения весовых коэффициентов всех нейронов выбираются случайным образом с последующей нормализацией относительно 1.
При предъявлении каждого обучающего вектора 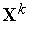 определяется нейрон-победитель, что дает ему право уточнить свои весовые коэффициенты по упрощенному (в силу бинарности
определяется нейрон-победитель, что дает ему право уточнить свои весовые коэффициенты по упрощенному (в силу бинарности 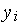 ) правилу Гроссберга
) правилу Гроссберга
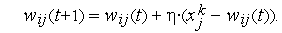
Все проигравшие нейроны оставляют свои весовые коэффициенты неизменными.
Понятно, что в каждом цикле обучения побеждает тот нейрон, чей текущий вектор входных весов 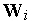 наиболее близок входному вектору
наиболее близок входному вектору 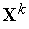 . При этом вектор
. При этом вектор 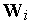 корректируется в сторону вектора
корректируется в сторону вектора 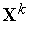 . Поэтому в ходе обучения каждая группа близких друг другу входных векторов (кластер) обслуживается отдельным нейроном.
. Поэтому в ходе обучения каждая группа близких друг другу входных векторов (кластер) обслуживается отдельным нейроном.
Результат обучения слоя нейронов типа WTA на последовательности девяти двухкомпонентных входных векторов 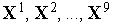 иллюстрирует рис. 2. Здесь были выделены три кластера входных векторов
иллюстрирует рис. 2. Здесь были выделены три кластера входных векторов 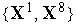 ,
, 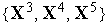 и
и 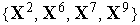 . За их распознавание отвечают три нейрона с векторами входных весов
. За их распознавание отвечают три нейрона с векторами входных весов 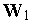 ,
, 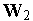 и
и 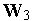 соответственно.
соответственно.
|
|
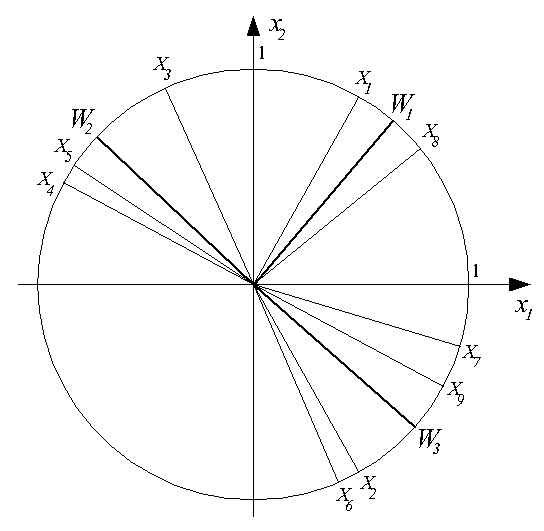
Рис. 2. Результат обучения слоя нейронов типа WTA
Серьезная проблема в использовании нейронов типа WTA — возможность возникновения "мертвых" нейронов, т.е. нейронов, ни разу не победивших в конкурентной борьбе в ходе обучения и поэтому оставшихся в начальном состоянии. Для исключения "ложных" срабатываний в режиме классификации мертвые нейроны после окончания обучения должны быть удалены.
Для уменьшения количества мертвых нейронов (и, следовательно, повышения точности распознавания) используется модифицированное обучение, основанное на учете числа побед нейронов и шрафовании наиболее "зарвавшихся" среди них. Дисквалификация может быть реализована либо назначением порога числа побед, после которого слишком активный нейрон "засыпает" на заданное число циклов обучения, либо искусственным уменьшением величины 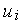 пропорционально числу побед.
пропорционально числу побед.
3.2.5. НЕЙРОН ХЕББА
Д.Хебб, исследуя поведение природных нервных клеток, зафиксировал (1949 г.) усиление связи двух взаимодействующих клеток при их одновременном возбуждении. Это позволило ему предложить правило уточнения входных весов нейрона в следующем виде:
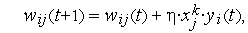
где 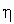 — коэффициент обучения, значение которого выбирается из интервала (0, 1). Правило Хебба применимо для нейронов с различными функциями активации. Обучение нейрона может производиться как с учителем, так и без него. В первом случае в правиле Хебба вместо фактического значения выходного сигнала
— коэффициент обучения, значение которого выбирается из интервала (0, 1). Правило Хебба применимо для нейронов с различными функциями активации. Обучение нейрона может производиться как с учителем, так и без него. В первом случае в правиле Хебба вместо фактического значения выходного сигнала 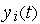 используется ожидаемая реакция
используется ожидаемая реакция 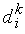 .
.
Особенностью правила Хебба является возможность достижения весом 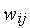 произвольно большого значения за счет многократного суммирования приращения в циклах обучения. Одним из способов стабилизации процесса обучения по Хеббу служит уменьшение уточняемого веса
произвольно большого значения за счет многократного суммирования приращения в циклах обучения. Одним из способов стабилизации процесса обучения по Хеббу служит уменьшение уточняемого веса 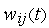 на величину, пропорциональную коэффициенту забывания
на величину, пропорциональную коэффициенту забывания 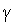 . При этом правило Хебба принимает вид :
. При этом правило Хебба принимает вид :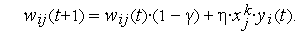
Значение коэффициента забывания 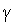 выбирается из интервала
выбирается из интервала 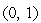 , рекомендуется соблюдать условие
, рекомендуется соблюдать условие 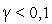 .
.
К сожалению, при обучении по правилу Хебба нейрона с линейной функцией активации стабилизация не достигается даже при использовании забывания. В 1991 г. Е.Ойя предложил модификацию правила Хебба, имеющую следующий вид:
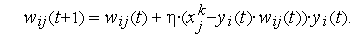
3.2.6. РАДИАЛЬНЫЕ НЕЙРОНЫ.
Радиальные нейроны существенно отличаются от нейронов других типов. Они используются только группами, составляя первый слой в многослойных радиальных нейронных сетях. Структурная схема такого нейрона дана на рис. 1.
|
|
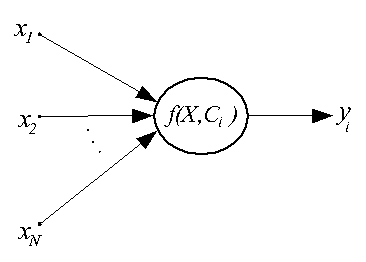
Рис. 1. Структурная схема радиального нейрона
Здесь 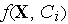 — радиальная функция с центром в точке с координатами
— радиальная функция с центром в точке с координатами 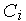 . Такие функции разнообразны, но на практике чаще всего используется функция Гаусса, имеющая следующий вид:
. Такие функции разнообразны, но на практике чаще всего используется функция Гаусса, имеющая следующий вид: 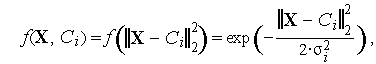 где
где 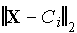 — эвклидова норма расстояния между входным вектором
— эвклидова норма расстояния между входным вектором 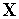 и центром
и центром 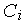 нейрона,
нейрона, 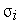 — параметр, определяющий "ширину" функции. На рис. 2 даны графики этой функции в скалярном варианте для различных значений
— параметр, определяющий "ширину" функции. На рис. 2 даны графики этой функции в скалярном варианте для различных значений 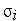 .
.
|
|
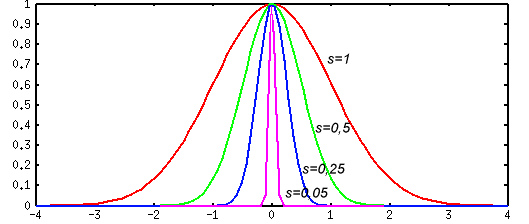
Рис. 2. График одномерной радиальной функции
На рис. 3 дан график для двух входных сигналов.
|
|
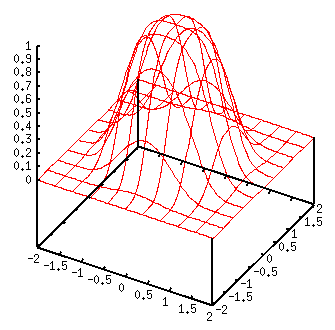
Рис. 3. График двумерной радиальной функции
Принципиальное отличие радиального нейрона от сигмоидального нейрона и персептрона в том, что они разбивают многомерное пространство входных сигналов гиперплоскостью, а радиальный — гиперсферой.
Обучение радиального нейрона заключается в подборе параметров радиальной функции 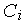 и
и 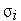 . В качестве примера приведем выражение, часто используемое для корректировки положения центра нейрона после предъявления
. В качестве примера приведем выражение, часто используемое для корректировки положения центра нейрона после предъявления 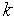 -ого обучающего вектора
-ого обучающего вектора
где 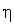 — коэффициент обучения
— коэффициент обучения 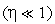 . Причем такому уточнению подвергается только центр, ближайший к входному вектору
. Причем такому уточнению подвергается только центр, ближайший к входному вектору 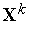 (подобный подход используется и при обучении нейронов типа WTA).
(подобный подход используется и при обучении нейронов типа WTA).
ГЛАВА 4. ВИДЫ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ
Объединенные (путем передачи сигналов с выходов одних искусственныхм нейронов на входы других) между собой нейроны образуют искусственную нейронную сеть (ИНС).
4.1. ОДНОСЛОЙНЫЕ НЕЙРОННЫЕ СЕТИ
В однослойных нейронных сетях сигналы с входного слоя сразу подаются на выходной слой. Он производит необходимые вычисления, результаты которых сразу подаются на выходы.
Выглядит однослойная нейронная сеть следующим образом:
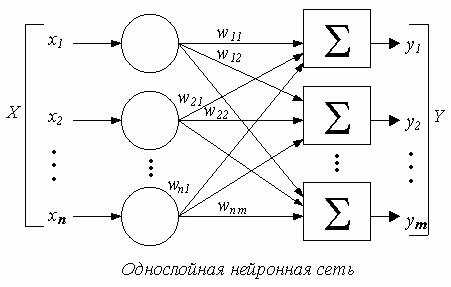
На этой картинке входной слой обозначен кружками (он не считается за слой нейронной сети), а справа расположен слой обычных нейронов.
Нейроны соединены друг с другом стрелками. Над стрелками расположены веса соответствующих связей (весовые коэффициенты).
Однослойная нейронная сеть (Single-layer neural network) – сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
4.2. МНОГОСЛОЙНЫЕ НЕЙРОННЫЕ СЕТИ
Такие сети, помимо входного и выходного слоев нейронов, характеризуются еще и скрытым слоем (слоями). Понять их расположение просто – эти слои находятся между входным и выходным слоями.
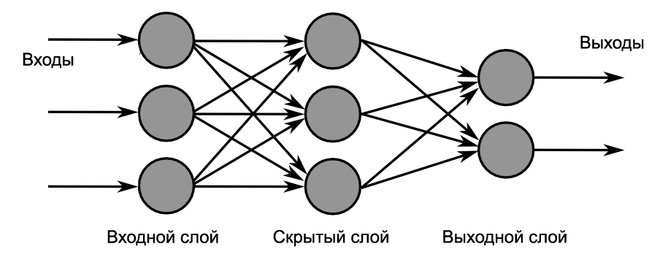
Такая структура нейронных сетей копирует многослойную структуру определенных отделов мозга.
Название скрытый слой получил неслучайно. Дело в том, что только относительно недавно были разработаны методы обучения нейронов скрытого слоя. До этого обходились только однослойными нейросетями.
Многослойные нейронные сети обладают гораздо большими возможностями, чем однослойные.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Многослойная нейронная сеть (Multilayer neural network) – нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
4.3. СЕТИ ПРЯМОГО РАСПРОСТРАНЕНИЯ (FEEDFORWARD)
Можно заметить одну очень интересную деталь на картинках нейросетей в примерах выше.
Во всех примерах стрелки строго идут слева направо, то есть сигнал в таких сетях идет строго от входного слоя к выходному.
Сети прямого распространения (Feedforward neural network) (feedforward сети) – искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
4.4. СЕТИ С ОБРАТНЫМИ СВЯЗЯМИ
В сетях такого типа сигнал может идти и в обратную сторону. В чем преимущество?Дело в том, что в сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах.
А в сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).
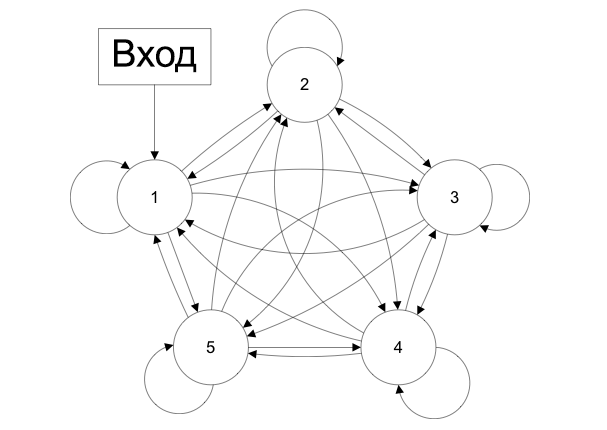
Возможность сигналов циркулировать в сети открывает новые, удивительные возможности нейронных сетей. С помощью таких сетей можно создавать нейросети, восстанавливающие или дополняющие сигналы. Другими словами такие нейросети имеют свойства кратковременной памяти (как у человека).
Сети с обратными связями (Recurrent neural network) – искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
ГЛАВА 5. ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ
Обучение нейронной сети- это процесс, в котором параметры нейронной сети настраиваются посредством моделирования среды, в которую эта сеть встроена. Тип обучения определяется способом подстройки параметров. Различают алгоритмы обучения с учителем и без учителя.
Процесс обучения с учителем представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети.
Для того, чтобы нейронная сети была способна выполнить поставленную задачу, ее необходимо обучить (см. рис. 1). Различают алгоритмы обучения с учителем и без учителя.
Процесс обучения с учителем представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети. Затем по определенному правилу вычисляется ошибка, и происходит изменение весовых коэффициентов связей внутри сети в зависимости от выбранного алгоритма. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
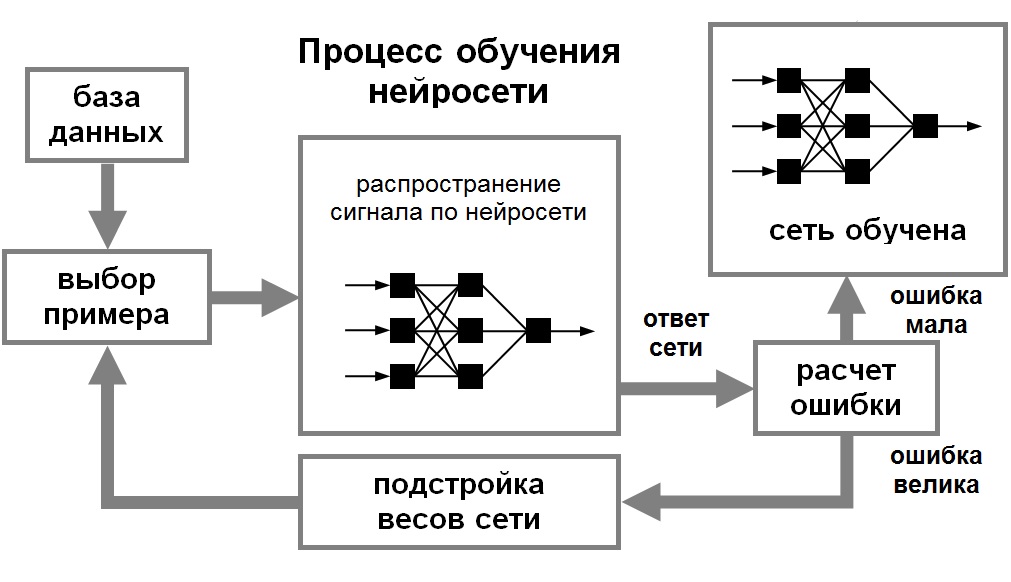
Рис. 1. Иллюстрация процесса обучения НС
При обучении без учителя обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети так, чтобы получались согласованные выходные векторы, т.е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход вектора из данного класса даст определенный выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Это не является серьезной проблемой. Обычно не сложно идентифицировать связь между входом и выходом, установленную сетью.
Для обучения нейронных сетей без учителя применяются сигнальные метод обучения Хебба и Ойа.
Математически процесс обучения можно описать следующим образом. В процессе функционирования нейронная сеть формирует выходной сигнал Y, реализуя некоторую функцию Y = G(X). Если архитектура сети задана, то вид функции G определяется значениями синаптических весов и смещенной сети.
Пусть решением некоторой задачи является функция Y = F(X), заданная параметрами входных-выходных данных (X1, Y1), (X2, Y2), …, (XN, YN), для которых Yk = F(Xk) (k = 1, 2, …, N).
Обучение состоит в поиске (синтезе) функции G, близкой к F в смысле некторой функции ошибки E. (см. рис. 1.8).
Если выбрано множество обучающих примеров – пар (XN, YN) (где k = 1, 2, …, N) и способ вычисления функции ошибки E, то обучение нейронной сети превращается в задачу многомерной оптимизации, имеющую очень большую размерность, при этом, поскольку функция E может иметь произвольный вид обучение в общем случае – многоэкстремальная невыпуклая задача оптимизации.
Для решения этой задачи могут использоваться следующие (итерационные) алгоритмы:
- алгоритмы локальной оптимизации с вычислением частных производных первого порядка:
- градиентный алгоритм (метод наискорейшего спуска),
- методы с одномерной и двумерной оптимизацией целевой функции в направлении антиградиента,
- метод сопряженных градиентов,
- методы, учитывающие направление антиградиента на нескольких шагах алгоритма;
- алгоритмы локальной оптимизации с вычислением частных производных первого и второго порядка:
- метод Ньютона,
- методы оптимизации с разреженными матрицами Гессе,
- квазиньютоновские методы,
- метод Гаусса-Ньютона,
- метод Левенберга-Марквардта и др.;
- стохастические алгоритмы оптимизации:
- поиск в случайном направлении,
- имитация отжига,
- метод Монте-Карло (численный метод статистических испытаний);
- алгоритмы глобальной оптимизации (задачи глобальной оптимизации решаются с помощью перебора значений переменных, от которых зависит целевая функция).
ГЛАВА 6. ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ.
Для отражения практического применения полученных знаний была поставлена следующая задача:
Требуется определить под какой % банку можно предоставить кредит клиенту.
Входные сигналы:
а) кредитная история (хорошая, плохая);
б) платежеспособность клиента (хорошая, средняя, плохая).
Значения выходного сигнала это % кредита для клиента:
а)низкий %;
б)средний %;
в)высокий %.
Правила применимые к данному решению:
1. Если кредитная история хорошая, платежеспособность хорошая, то % по кредиту низкий.
2. Если кредитная история хорошая, платежеспособность средняя, то % ставка средняя.
3. Если кредитная история плохая, платежеспособность плохая, то % ставка
высокая.
Для решения данной задачи будет использовано программное обеспечение MatlabFuzzyLogicToolbox.
Для реализации был выбран алгоритм логического вывода mamdani.
На его основе создана система KreditExpert из двух входящих сигналов: «Кредитная история» и «Платежеспособность». Выходным сигналом данной задачи является «процент кредита».
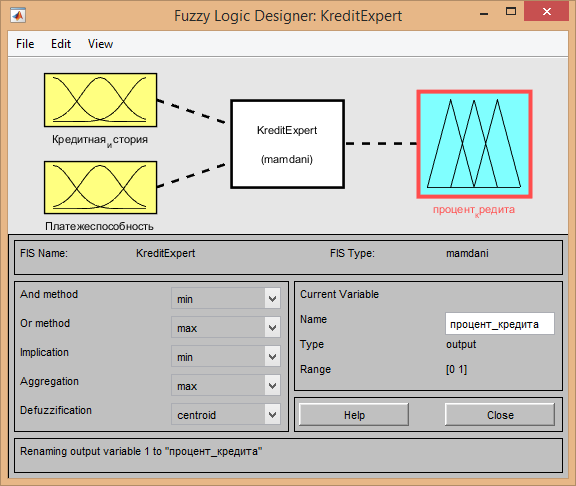
После создания всех необходимых входных и выходных сигналов необходимо для каждого сигнала описать: функцию принадлежности, диапазон изменений и наименование функций.
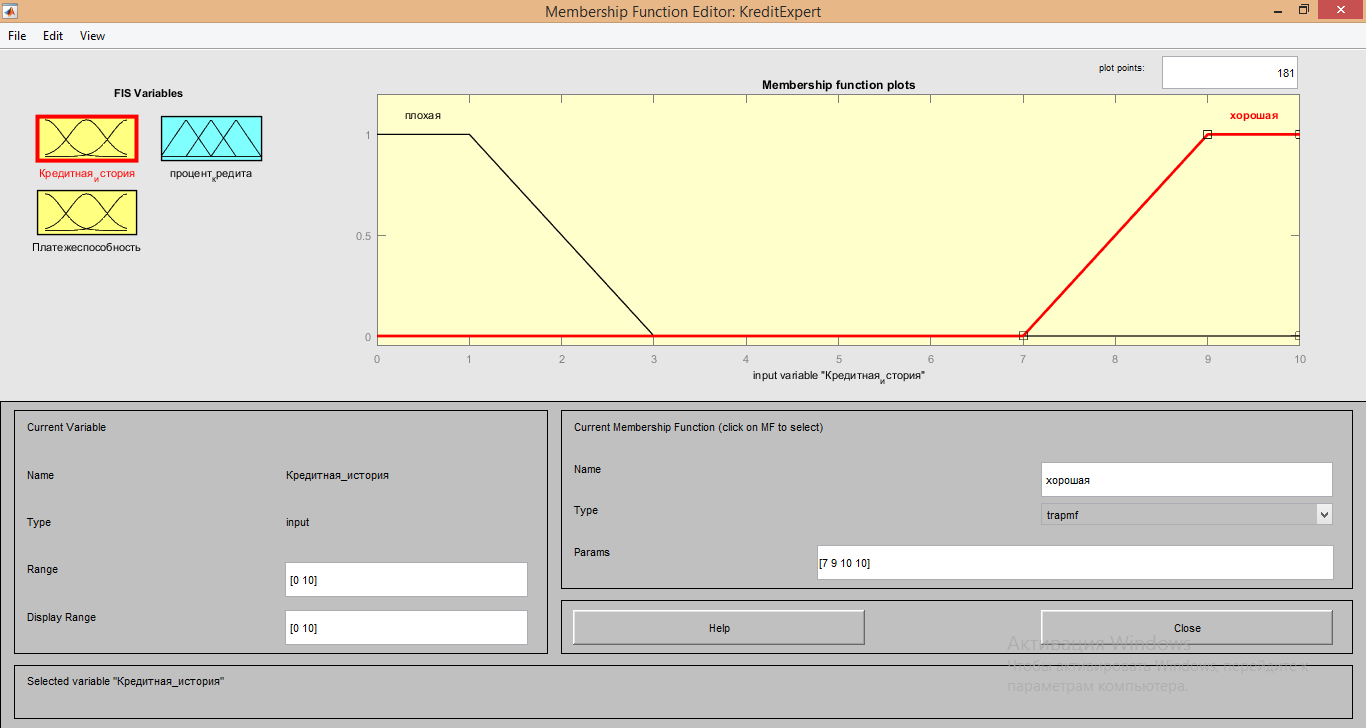
Для описания входящего сигнала «Кредитная история» использовались следующие характеристики:
1. Для обеих функций Membership function plots тип функции: «trapmf»;
2. Range и Display Range от 0 до 10;
3. Параметры для функции «Плохая» имеют значения [0 0 1 3];
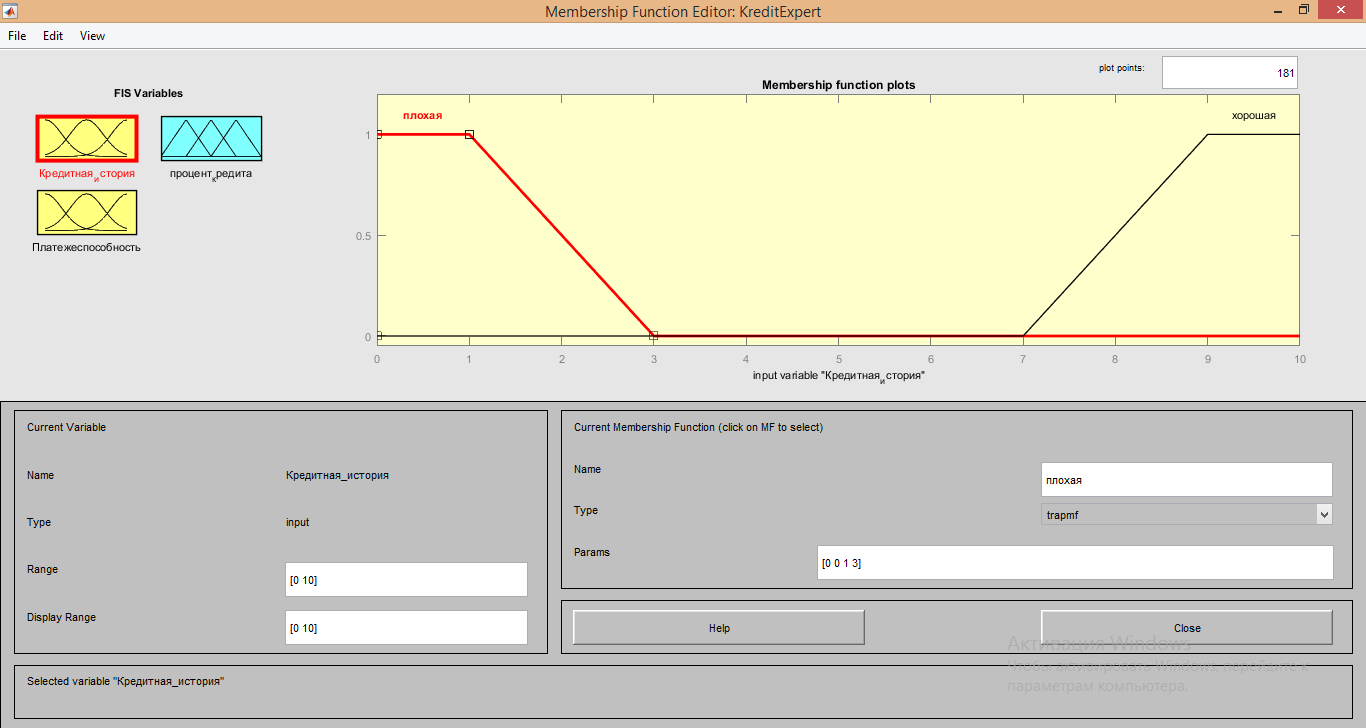 4. Параметры для функции «Хорошая» имеют значения [7 9 10 10]
4. Параметры для функции «Хорошая» имеют значения [7 9 10 10]
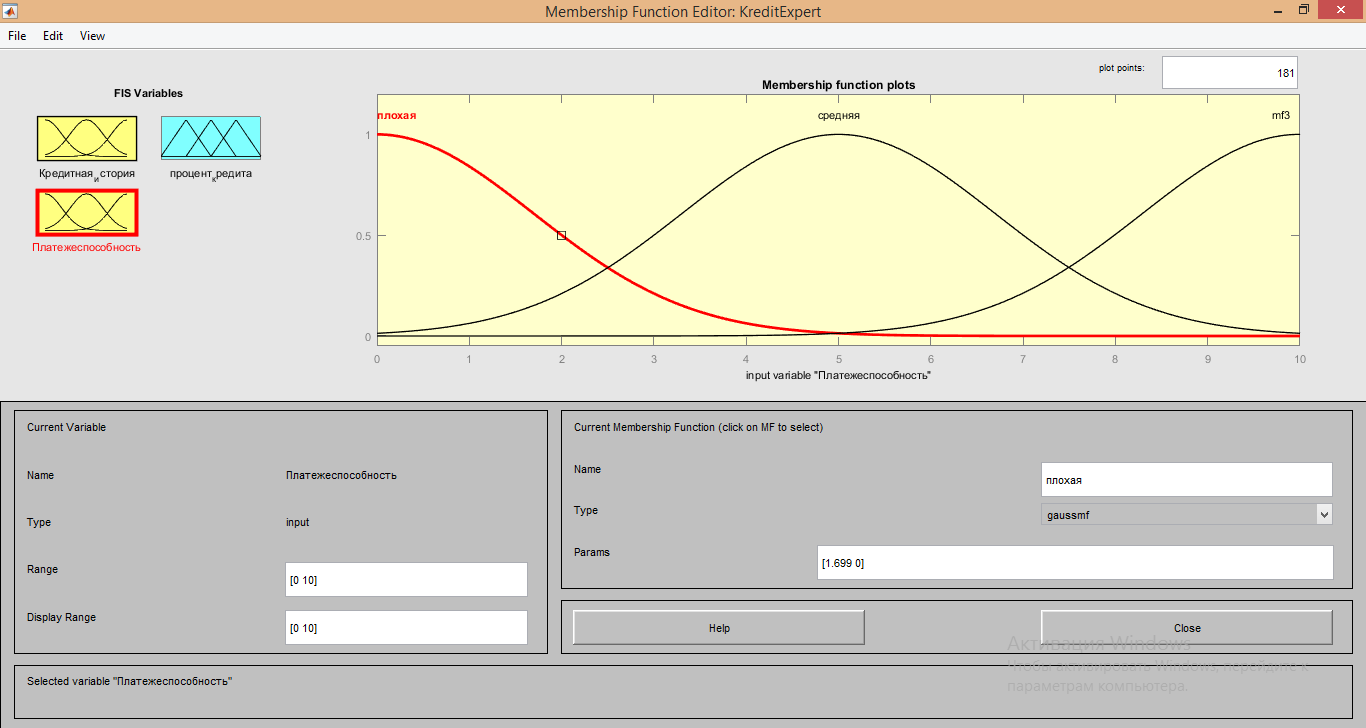
Для описания входящего сигнала «Платежеспособность» использовались следующие характеристики:
1. Для обеих функций Membership function plots тип функции: «gaussmf»;
2. Range и Display Range от 0 до 10;
3. Параметры для функции «Плохая» имеют значения [1.699 0];
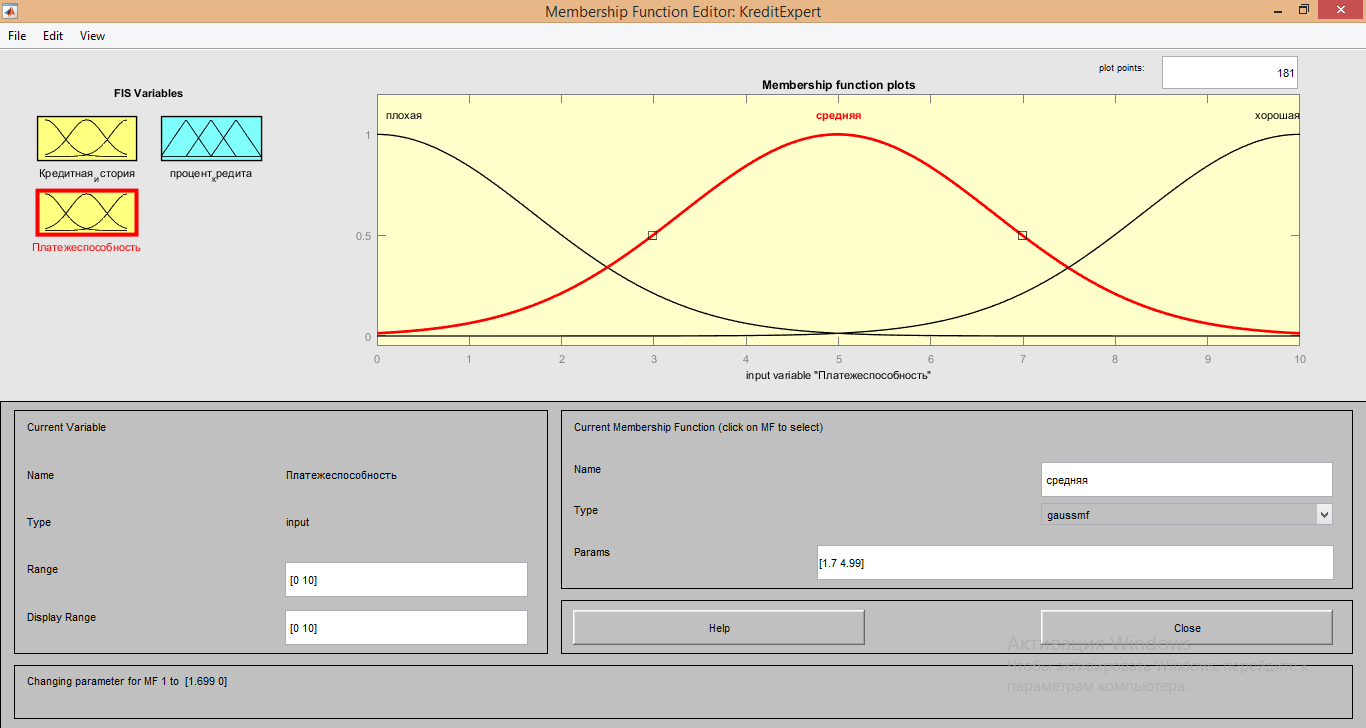
 4.Для функции «Средняя» имеют значения [1.7 4.99]
4.Для функции «Средняя» имеют значения [1.7 4.99]
5.Для функции «хорошая» параметры имеют значения [1.699 9.989]
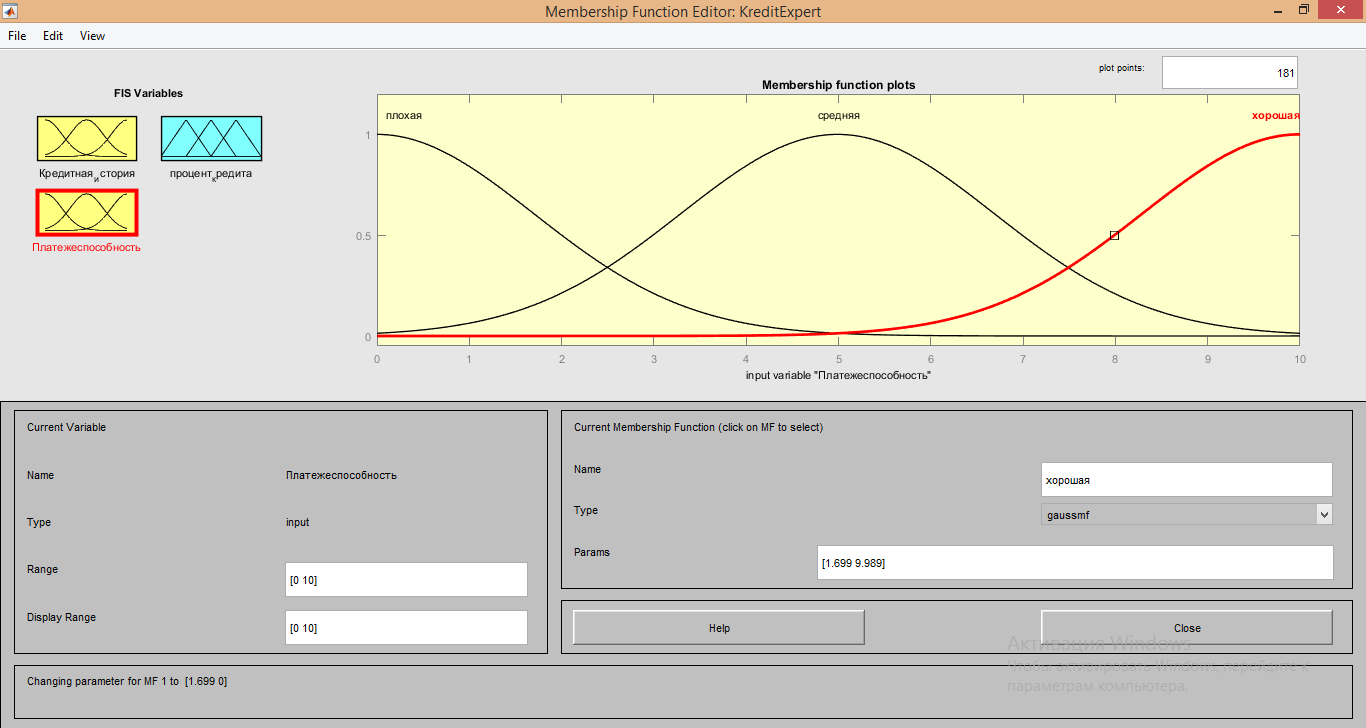
Для настройки выходного сигнала «процент кредита» использовались следующие характеристики:
Для описания входящего сигнала «Платежеспособность» использовались следующие характеристики:
1. Для обеих функций Membership function plots тип функции: «trimf»;
2. Range и Display Range от 0 до 30;
3. Параметры для функции «низкий» имеют значения [0 5 10];
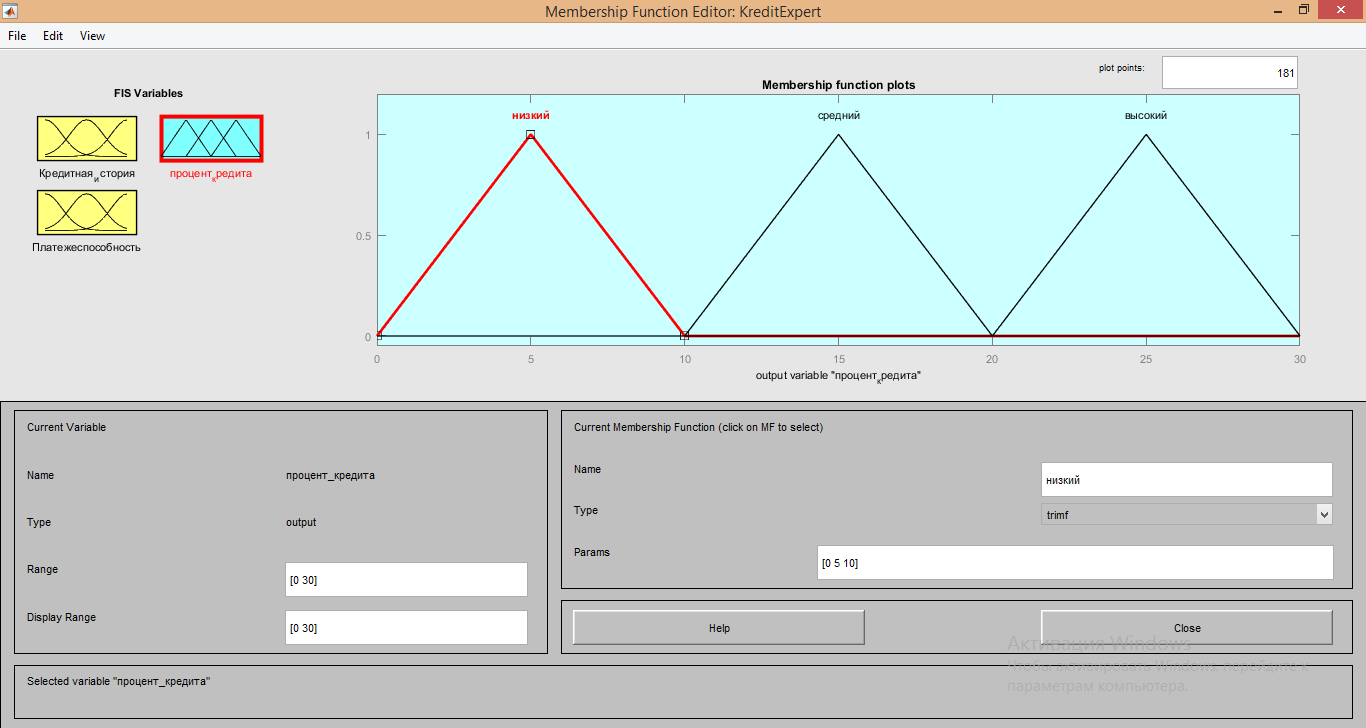
4. Параметры для функции «Средний» имеют значения [10 15 20];
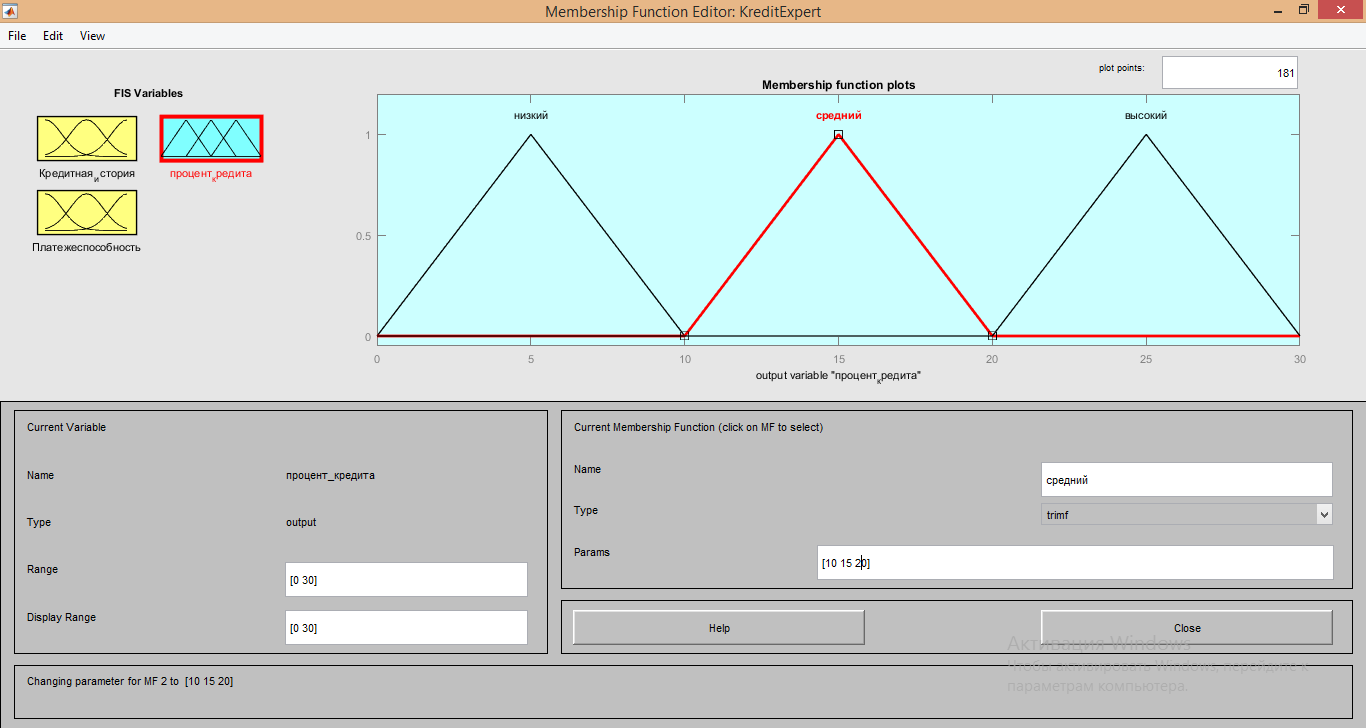
5. Параметры для функции «высокий» имеют значения [20 25 30];
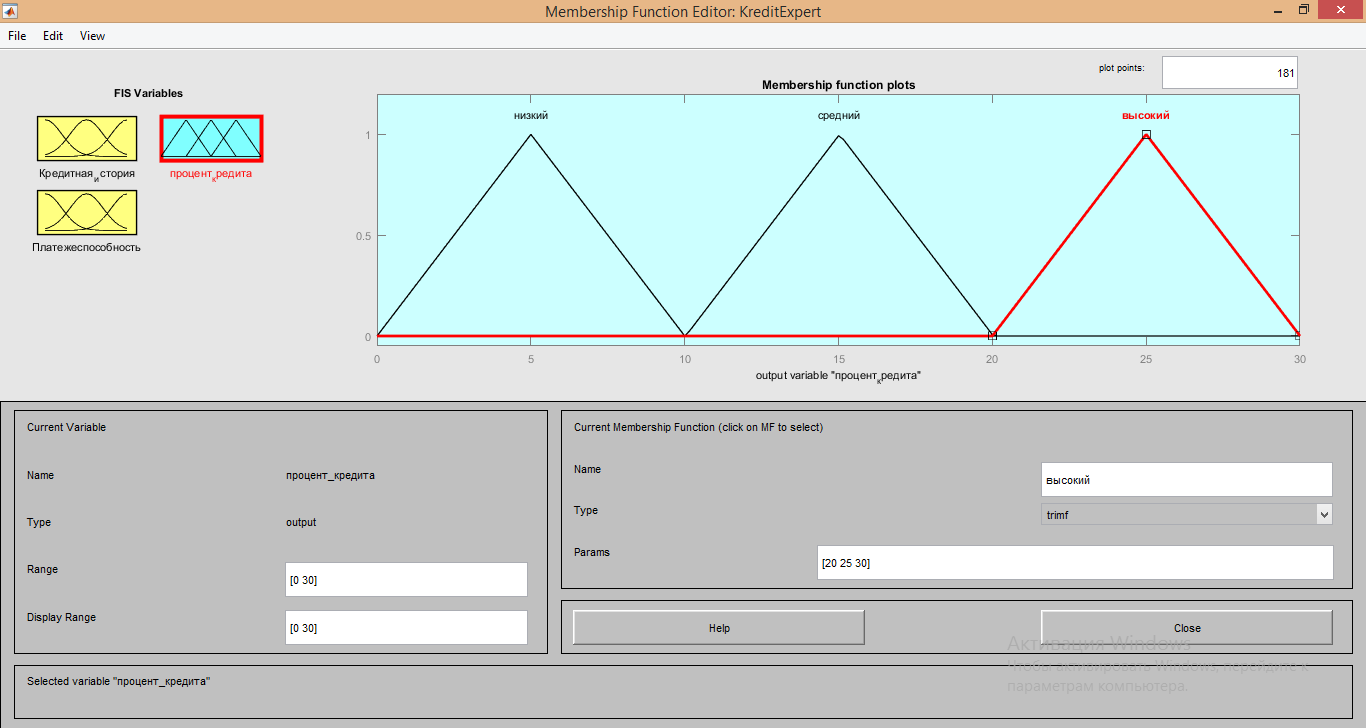
После настройки всех сигналов необходимо создать правила для вычислений.
Через Rule Editor были настроены правила, указанные в условии поставленной задачи: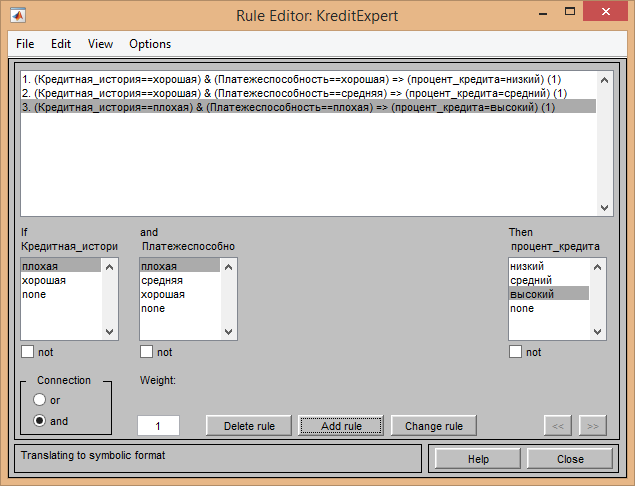
Значения весов оставлены по умолчанию и равны 1.
Далее с помощью Rule Viewer произведем проверку настроенных правил:
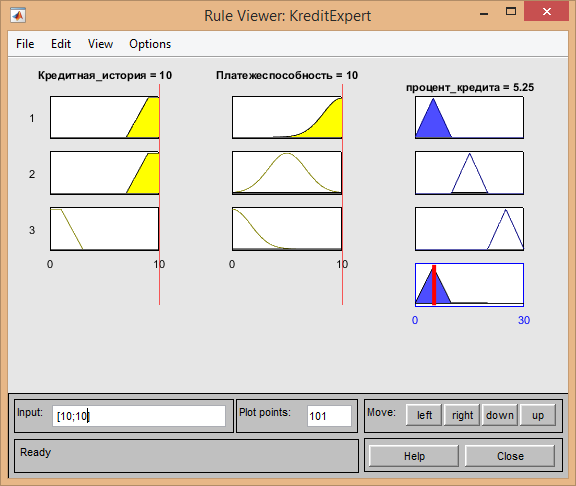
- Если кредитная история хорошая[10] и платежеспособность хорошая[10], тогда предоставляемый процент будет низким[5.25]:
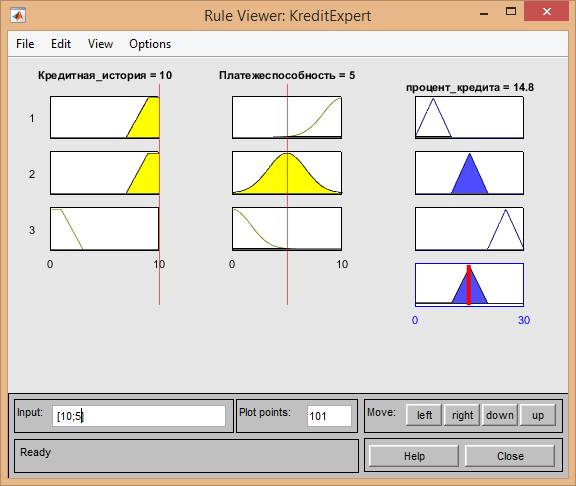
- Если кредитная история хорошая[10], платежеспособность средняя[5] то процент ставки средний[14.8]:
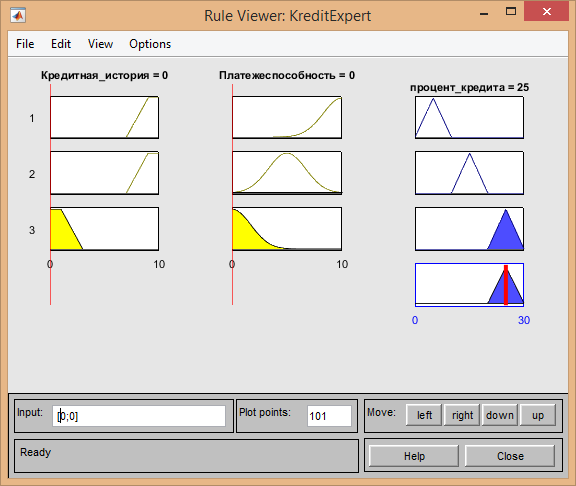
- Если кредитная история плохая[0], платежеспособность плохая[0], то % ставка высокая[25].
Для подтверждения отмеченной зависимости выходной переменной от входных послужит вид поверхности отклика:
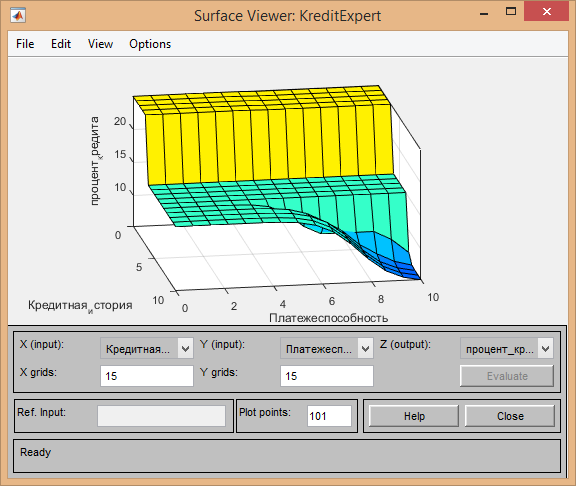
Таким образом мы получили готовое решение для расчета процентной ставки кредитов для клиентов банков. Данное решение является довольно простым. В реальной жизни перед сотрудниками ставится решение более глобальных задач, для решение которых необходимо составление более сложных систем. Но с помощью данного продукта создать необходимые решения для ускорения и автоматизации бизнес-процессов становится возможным.
ЗАКЛЮЧЕНИЕ
В данной курсовой работе мы рассмотрели лишь небольшую часть того как можно использовать нейронные сети. Их практическое применение огромно. Особенно эффективными они считаются в следующих экономических областях:
Для финансовых операций:
- Прогнозирование поведения клиента.
- Прогнозирование и оценка риска предстоящей сделки.
- Прогнозирование возможных мошеннических действий.
- Прогнозирование остатков средств на корреспондентских счетах банка.
- Прогнозирование движения наличности, объёмов оборотных средств.
- Прогнозирование экономических параметров и фондовых индексов.
Для планирования работы предприятия:
- Прогнозирование объёмов продаж.
- Прогнозирование загрузки производственных мощностей.
- Прогнозирование спроса на новую продукцию.
Для бизнес - аналитики и поддержки принятия решений:
- Выявление тенденций, корреляций, типовых образцов и исключений в больших объёмах данных.
- Анализ работы филиалов компании.
- Сравнительный анализ конкурирующих фирм.
Таким образом применение нейронных сетей и нечеткой логики в экономике напрямую влияет на развитие современных бизнес-процессов, давая необходимы инструменты для решения непрерывно возникающих бизнес-задач.
СПИСОК ЛИТЕРАТУРЫ
http://neuronus.com/history/5-istoriya-nejronnykh-setej.html
http://neuronus.com/theory/240-algoritmy-obucheniya-iskusstvennykh-nejronnykh-setej.html
http://victoria.lviv.ua/html/oio/html/theme5_rus.htm
www.victoria.lviv.ua/html/oio/html/theme6_rus.htm
http://www.victoria.lviv.ua/html/oio/html/theme7_rus.htm
http://bigor.bmstu.ru/?cnt/?doc=NN/011-neurons.mod/?cou=NN/base.cou
http://www.intuit.ru

- Проектирование диаграммы классов «Бензозаправка»
- Разветвляющийся алгоритм С++
- Влияние кадровой стратегии на работу службы персонала (Понятие и типы кадровой стратегии организации)
- Разработка рекламной компании популяризация органического бренда спорт-питания (История происхождения спортивного питания (добавок))
- Исследование процесса принятия решения о покупке (ООО «Советская бумага» )
- Проектирование реализации операций бизнес-процесса «Расчет заработной платы»» (на примере ООО «Бур-Сервис»)
- Основные понятия объектно-ориентированного программирования
- Влияние информационных технологий на развитие систем поддержки принятия решений
- Нечеткая логика и нейронные сети (Аналогия нейронных сетей с мозгом и биологическим нейроном)
- Проектирование диаграммы классов «Склад»
- «Разработка программ с графическим интерфейсом на С++»
- Оптимизация решений по Парето