
Разработка и проектирование базы данных в Microsoft SQL Server
Содержание:

ВВЕДЕНИЕ
Современный мир информационных технологий невозможно представить в отсутствии баз данных. Они используются как в персональных компьютерах, так и в огромных вычислительных кластерах. При этом особый интерес представляют системы управления базами данных, поскольку с их помощью последние создаются, наполняются информацией и осуществляют выборку нужных данных.
В качестве объекта исследования данной работы выступают базы данных.
Предмет исследования: «Система управления базами данных MS SQL Server».
Целью данной работы является обзор современных баз данных на основе СУБД MS SQL Server 2012.
На основании поставленной цели сформулированы следующие задачи:
Проанализировать информации из литературных источников по теме исследования.
Классифицировать базы данных.
Провести обзор современных языка запросов SQL.
Рассмотреть архитектуру и особенности работы системы управления базами данных MS SQL Server.
Рассмотреть возможности среды Microsoft SQL Server Management Studio.
Создать базу данных в MS SQL Server.
Во время проведения исследования были задействована литература и научные статьи следующих авторов: Веймаер, Дэвидсон, Каратыгин
Объем фактического материала работы составляет 31 лист.
Структура курсовой работы состоит из введения, трех глав, заключения и списка литературы.
В главе «Основные понятия современных баз данных» проведен обзор и анализ различных баз данных, проведена их классификация. Также тут рассмотрены реляционные базы данный и язык запросов SQL.
В главе «Обзор системы управления базами данных MS SQL Server» рассмотрены основные характеристики, история развития и архитектура системы управления базами данных Microsoft SQL Server . Отдельно описана среда Microsoft SQL Server Management Studio, которая поставляется вместе с MS SQL Server и служит для разработки и управления базами данных.
В главе «Разработка базы данных в Microsoft SQL Server » описана разработка практической части работы. На этом этапе созданы база данных «Сотрудники», которая позволяет хранить информацию о сотрудниках организации.
В заключении обобщается информация, описанная в курсовой работе и даются краткие выводы как по каждой из глав, так и по результатам выполненной работы в целом.
1 ОСНОВНЫЕ ПОНЯТИЯ СОВРЕМЕННЫХ БАЗ ДАННЫХ
1.1 Определение и основные понятия баз данных
База данных представляет собой структурированный набор информации, которая организована таким образом, что ее можно легко получить, управлять ею и обновлять.
Данные упорядочены по строкам, столбцам и таблицам и индексируются для облегчения поиска релевантной информации. Данные обновляются, расширяются и удаляются по мере добавления новой информации. Базы данных задействуют вычислительные ресурсы компьютера для создания и обновления самих себя, запроса данных, которые они содержат, и запуска приложений.
Компьютерные базы данных обычно содержат совокупность записей или файлов данных, таких как транзакции продаж, каталоги продуктов и запасы, а также профили клиентов.
Как правило, диспетчер баз данных предоставляет пользователям возможность контролировать доступ для чтения/записи, определять создание отчетов и анализировать использование. Некоторые базы данных обеспечивают соответствие ACID (атомарность, согласованность, изоляцию и долговечность), чтобы гарантировать совместимость данных и завершение транзакций [1].
Базы данных распространены в крупных вычислительных системах, но также присутствуют в небольших распределенных рабочих станциях и системах среднего уровня, таких как AS/400 IBM и персональных компьютерах.
Базы данных развиваются с момента их создания в 1960-х годах, начиная с иерархических и сетевых баз данных, в 1980-х годах с объектно-ориентированных баз данных и сегодня с базами данных SQL и NoSQL и облачными базами данных.
Базы данных можно классифицировать в соответствии с типом контента: библиографическим, полнотекстовым, цифровым и изображениями. При вычислении базы данных иногда классифицируются в соответствии с их организационным подходом. Существует множество различных типов баз данных, начиная от наиболее распространенного подхода, реляционной базы данных до распределенной базы данных, облачной базы данных или базы данных NoSQL [2].
Реляционная база данных представляет собой набор элементов данных, организованных в виде формально описанных таблиц, из которых данные могут быть получены разными способами без необходимости реорганизации таблиц базы данных. Реляционная база данных была изобретена Е. Ф. Коддом в IBM в 1970 году.
Стандартный интерфейс пользователя и прикладной программы для реляционной базы данных - это язык структурированных запросов (SQL). Операторы SQL используются как для интерактивных запросов для информации из реляционной базы данных, так и для сбора данных для отчетов.
В дополнение к относительно легкому созданию и доступу, реляционная база данных имеет важное преимущество в том, что ее легко расширить. После создания исходной базы данных можно добавить новую категорию данных, не требуя изменения всех существующих приложений.
Реляционная база данных представляет собой набор таблиц, содержащих данные, помещенные в предопределенные категории. Каждая таблица (которая иногда называется отношением) содержит одну или несколько категорий данных в столбцах. Каждая строка содержит уникальный экземпляр данных для категорий, определенных столбцами. Например, типичная база данных ввода бизнес-заявки будет включать таблицу, описывающую клиента с столбцами для имени, адреса, номера телефона и т.д. В другой таблице описывается заказ: продукт, клиент, дата, цена продажи и т.д. Пользователь базы данных может получить представление о базе данных, которая соответствует его потребностям. Например, диспетчеру филиала может понравиться представление или отчет обо всех клиентах, которые купили продукты после определенной даты. Менеджер финансовых услуг в той же компании мог бы из тех же таблиц получить отчет о счетах, которые необходимо оплатить.
При создании реляционной базы данных вы можете определить диапазон возможных значений в столбце данных и дополнительные ограничения, которые могут применяться к этому значению данных. Например, диапазон потенциальных клиентов может содержать до десяти возможных имен клиентов, но ограничивается одной таблицей, что позволяет указывать только три из этих имен клиентов [3-5].
Определение реляционной базы данных приводит к таблице метаданных или формальным описаниям таблиц, столбцов, доменов и ограничений.
Другой тип - это распределенная база данных - это база данных, в которой ее части хранятся в нескольких физических местоположениях и в которых обработка распределяется между различными точками в сети.
Распределенные базы данных могут быть однородными или гетерогенными. Все физические местоположения в однородной распределенной системе баз данных имеют одно и то же базовое оборудование и запускают те же операционные системы и приложения баз данных. Аппаратные средства, операционные системы или приложения в гетерогенной распределенной базе данных могут быть разными в каждом из местоположений.
Облачная база данных - это база данных, оптимизированная или построенная для виртуальной среды, либо в гибридном облаке. Облачные базы данных обеспечивают такие преимущества, как способность оплачивать емкость и пропускную способность для каждого использования, а также обеспечивают масштабируемость по требованию и высокую доступность [6].
Облачная база данных также дает предприятиям возможность поддерживать бизнес-приложения в развертывании программного обеспечения как услуги.
Еще один тип базы данных - NoSQL полезны для больших объемов, распределенных данных.
Базы данных NoSQL эффективны для решения проблем с производительностью больших объемов данных, поскольку реляционные базы данных не созданы для этого. Они наиболее эффективны, когда организация должна анализировать большие куски неструктурированных данных или данных, которые хранятся на нескольких виртуальных серверах в облаке.
Элементы, созданные с использованием объектно-ориентированных языков программирования, часто хранятся в реляционных базах данных, но объектно-ориентированные базы данных хорошо подходят для этих элементов.
Объектно-ориентированная база данных организована вокруг объектов, а не действий, и скорее для данных, чем логики. Например, мультимедийная запись в реляционной базе данных может быть определяемым объектом данных, а не буквенно-цифровым значением.
Графовая база данных или база данных графов - это тип базы данных NoSQL, которая использует теорию графов для хранения, сопоставления и запросов. Графовые базы данных представляют собой в основном коллекции узлов и ребер, где каждый узел представляет собой сущность, и каждый ребро представляет собой соединение между узлами.
Этот вид базы данных становятся все более популярными для анализа взаимосвязей. Например, компании могут использовать базу данных графов для сбора данных о клиентах из социальных сетей [7,8].
SQL (язык структурированных запросов) - это стандартизованный язык программирования, используемый для управления реляционными базами данных и выполнения различных операций над ними них. SQL-сервер, первоначально созданный в 1970-х годах, регулярно используется администраторами баз данных, а также разработчиками, пишущими сценарии интеграции и аналитики данных, которые хотят настроить и запустить аналитические запросы.
Использование SQL включает в себя изменение таблицы базы данных и структур индексов; добавление, обновление и удаление строк данных; получение подмножеств информации из базы данных для приложений обработки транзакций и аналитики. Запросы и другие операции SQL принимают форму команд, написанных в качестве операторов. Обычно используемые операторы SQL включают в себя выбор, добавление, вставку, обновление, удаление, создание, изменение и усечение.
SQL стал стандартным языком программирования для реляционных баз данных после того, как они появились в конце 1970-х и начале 1980-х годов. Также, как базы данных SQL, реляционные системы содержат набор таблиц, содержащих данные в строках и столбцах. Каждый столбец в таблице соответствует категории данных - например, имя клиента или адрес - в то время как каждая строка содержит значение данных для пересекающегося столбца [10-13].
В данной главе проведен обзор и анализ различных баз данных, проведена их классификация. Также тут рассмотрены реляционные базы данный и язык запросов SQL.
2 ОБЗОР СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ MS SQL SERVER
2.1 История создания MS SQL Server
Microsoft SQL Server - это система управления реляционными базами данных или RDBMS, которая поддерживает широкий спектр приложений для обработки транзакций, бизнес-аналитики и аналитики в корпоративных ИТ-средах. Это одна из трех ведущих в отрасли технологий баз данных, совместно с Oracle Database и IBM DB2 [14].
Как и другое программное обеспечение RDBMS, Microsoft SQL Server построен поверх SQL, стандартизованного языка программирования, который администраторы баз данных (DBAs) и другие ИТ-специалисты используют для управления базами данных и запроса данных. SQL Server привязан к Transact-SQL (T-SQL), реализация SQL от Microsoft, которая добавляет набор проприетарных расширений программирования в стандартный язык.
Исходный код SQL Server был разработан в 1980-х годах бывшей Sybase Inc., которая теперь принадлежит SAP. Sybase первоначально проектировала программное обеспечение для работы на Unix-системах и платформах миникомпьютера. Microsoft и Ashton-Tate Corp., затем ведущий поставщик баз данных для ПК, объединились для создания первой версии Microsoft SQL Server, предназначенной для операционной системы OS/2 и выпущенной в 1989 году.
После этого Ashton-Tate оставил этот проект, но Microsoft и Sybase продолжили свое сотрудничество до 1994 года, когда Microsoft взяла на себя все разработки и маркетинг SQL Server для своих собственных операционных систем. Microsoft также сделала программное обеспечение доступным для недавно выпущенной Windows NT. В 1996 году Sybase переименовала свою версию Adaptive Server Enterprise, оставив имя SQL Server в Microsoft [15-17].
2.2 Обзор архитектуры SQL Server
Как и другие технологии RDBMS, SQL Server в первую очередь строится вокруг структуры таблицы, которая соединяет связанные элементы данных в разных таблицах друг с другом, избегая необходимости избыточно хранить данные в нескольких местах в базе данных. Реляционная модель также обеспечивает ссылочную целостность и другие ограничения целостности для поддержания точности данных; эти проверки являются частью принципов атомарности, согласованности, изоляции и долговечности, которые в совокупности известны как свойства ACID и предназначены для обеспечения надежной обработки транзакций базы данных.
Основным компонентом Microsoft SQL Server является SQL Server Database Engine, который контролирует хранение, обработку и безопасность данных. Он включает реляционный движок, который обрабатывает команды и запросы, а также механизм хранения, который управляет файлами базы данных, таблицами, страницами, индексами, буферами данных и транзакциями. Хранимые процедуры, триггеры, представления и другие объекты базы данных также создаются и выполняются механизмом Database Engine [18].
Управляет базой данных операционная система SQL Server или SQLOS; он обрабатывает функции нижнего уровня, такие как управление памятью и вводом-выводом, планирование работы и блокирование данных во избежание возникновения конфликтов. Уровень сетевого интерфейса находится над механизмом Database Engine, который использует протокол табличного потока данных Microsoft для облегчения взаимодействия запросов и ответов с серверами баз данных. На уровне пользователя администраторы баз данных SQL Server и разработчики пишут инструкции T-SQL для создания и изменения структур баз данных, управления данными, обеспечения безопасности и резервного копирования баз данных, среди других задач.
Архитектуру MS SQL Server можно разделить на следующие составляющие:
- Общая архитектура
- Архитектура памяти
- Архитектура файловой системы данных
- Архитектура файла журнала
- К общей архитектуре относят следующие компоненты:
- Клиент - если запрос инициирован.
- SQL-запрос, который является языком высокого уровня.
- Логические единицы - ключевые слова, выражения и операторы и т. д.
- Протоколы.
- Общая память
- Именованные каналы (для соединений, подключенных к локальной сети).
- TCP/IP (для соединений, подключенных к WAN).
- VIA-Virtual Interface Adapter
- Сервер - где установлены службы SQL и базы данных.
- Реляционный движок - здесь выполняются запросы БД. Он содержит парсер запросов, оптимизатор запросов и исполнитель запросов.
- Парсер команд (Command Parser) и компилятор (Translator). Проверяют синтаксис запроса и преобразуют запрос в машинный язык.
- Storage Engine - отвечает за хранение и извлечение данных в системе хранения
- Операционная система SQL – это промежуточное звено между главной машиной (ОС Windows) и SQL Server. Все действия, выполняемые с помощью ядра базы данных, выполняются ОС SQL. SQL OS предоставляет различные службы операционной системы, такие как управление памятью с пулом буферов, буфером журнала и обнаружением блокировки с использованием блокировки и блокировки.
- Checkpoint Process - контрольная точка - это внутренний процесс, который записывает все измененные страницы из буфера на физический диск. Контрольная точка помогает сократить время восстановления для SQL Server в случае неожиданного отключения или сбоя системы [19,20].
Ниже приведены некоторые из основных особенностей архитектуры памяти.
Одной из основных целей проектирования всего программного обеспечения базы данных является минимизация дискового ввода-вывода, поскольку чтение и запись дисков относятся к числу наиболее ресурсоемких операций.
Память в Windows может быть ассоциирована с виртуальным адресным пространством, разделяемым режимом ядра (режим ОС) и пользовательским режимом (приложение, подобное SQL Server).
Управление буфером является ключевым компонентом в достижении высокой эффективности ввода-вывода. Компонент управления буфером состоит из двух механизмов: диспетчера буфера для доступа и обновления страниц базы данных и пула буферов для сокращения ввода-вывода файлов базы данных.
Пул буферов разделен на несколько разделов. Наиболее важными из них являются буферный кэш (также называемый кэшем данных) и кэш процедур. Буферный кэш хранит страницы данных в памяти, так что часто используемые данные могут быть извлечены из кэша. Альтернативой будет чтение данных с диска. Чтение страниц данных из кэша оптимизирует производительность, сводя к минимуму количество необходимых операций ввода-вывода, которые по своей природе медленнее, чем извлечение данных из памяти [21].
Хранилище процедур содержит процедуры и планы выполнения запросов, чтобы свести к минимуму количество раз, когда планы запросов должны быть сгенерированы. Более подробную информацию о размере и активности в кэше процедур, можно узнать, используя инструкцию DBCC PROCCACHE.
Другие части буферного пула включают в себя:
- Структуры данных уровня системы - содержат данные уровня экземпляра SQL Server о базах данных и блокировках.
- Кэш журнала - зарезервирован для чтения и записи страниц журнала транзакций.
- Контекст соединения. Каждое подключение к экземпляру занимает небольшую область памяти для записи текущего состояния соединения. Эта информация включает хранимую процедуру и пользовательские параметры функции, позиции курсора и многое другое.
- Стековое пространство - Windows выделяет пространство стека для каждого потока, запущенного SQL Server [22].
- Архитектура файла данных имеет следующие компоненты:
- Группы файлов. Файлы базы данных можно сгруппировать в группы файлов для целей распределения и администрирования. Ни один файл не может быть членом более чем одной группы файлов. Файлы журналов никогда не входят в группу файлов. Лог-пространство управляется отдельно от пространства данных. Существует два типа групп файлов в SQL Server: Primary и User-defined.
- Файлы. Базы данных имеют три типа файлов: первичный файл данных, файл вторичных данных и файл журнала. Первичный файл данных является отправной точкой базы данных и указывает на другие файлы в базе данных. Каждая база данных имеет один первичный файл данных. Мы можем предоставить любое расширение для основного файла данных, но рекомендуемое расширение - .mdf. Вторичный файл данных - это файл, отличный от основного файла данных в этой базе данных. Некоторые базы данных могут иметь несколько вторичных файлов данных. В некоторых базах данных может отсутствовать один дополнительный файл данных. Рекомендуемым расширением для файла вторичных данных является .ndf. Файлы журнала содержат всю информацию журнала, используемую для восстановления базы данных. База данных должна иметь как минимум один файл журнала. Рекомендуемым расширением для файла журнала является ldf. Расположение всех файлов в базе данных записывается как в основной базе данных, так и в основной файл базы данных. В большинстве случаев механизм базы данных использует расположение файла из основной базы данных. Файлы имеют два имени - логическое и физическое. Логическое имя используется для ссылки на файл во всех операторах T-SQL. Физическое имя является именем OS_file_name, оно должно соответствовать правилам ОС. Файлы данных и журнала могут быть расположены в файловых системах FAT или NTFS, но не могут работать со сжатыми файловыми системами [23]. В одной базе данных может быть до 32 767 файлов.
- Extents. Это базовая единица, в которой пространство выделяется для таблиц и индексов. Объем - 8 непрерывных страниц или 64 КБ. SQL Server имеет два типа экстентов - Uniform и Mixed. Равномерные экстенты состоят из одного объекта. Смешанные экстенты разделяются на количество до восьми объектов.
- Страницы. Это фундаментальная единица хранения данных в MS SQL Server. Размер страницы - 8 КБ. Начало каждой страницы - это 96-байтовый заголовок, используемый для хранения системной информации, такой как тип страницы, количество свободного места на странице и идентификатор объекта, владеющего страницей. В SQL Server имеется 9 типов страниц данных.
- Данные. Строки данных со всеми данными, кроме текстовых, текстовых и графических данных.
- Индекс - записи индекса
Журнал транзакций SQL Server работает логически, как если бы журнал транзакций представлял собой строку записей журнала. Каждая запись журнала идентифицируется по порядковому номеру журнала. Она содержит идентификатор транзакции, к которой принадлежит.
SQL Server Database Engine делит каждый физический файл журнала на внутренние файлы виртуальных журналов. Файлы виртуального журнала не имеют фиксированного размера, и нет фиксированного количества файлов виртуальных журналов для физического файла журнала.
Механизм Database Engine динамически выбирает размер виртуальных файлов журнала, когда он создает или расширяет файлы журналов. Движок базы данных пытается поддерживать небольшое количество виртуальных файлов. Размер или количество виртуальных файлов журнала не может быть настроено или установлено администраторами. Если файлы журналов увеличиваются до большого размера из-за большого количества небольших приращений, у них будет много виртуальных файлов журнала. Это может замедлить запуск базы данных, а также резервное копирование и восстановление.
Microsoft также объединяет множество инструментов управления данными, бизнес-аналитики (BI) и аналитики с SQL Server. В дополнение к технологиям R Services и технологии Machine Learning Services, впервые появившимся в SQL Server 2016, предложения по анализу данных включают SQL Server Analysis Services, аналитический механизм, который обрабатывает данные для использования в приложениях BI и визуализации данных, а также службы отчетов SQL Server , который поддерживает создание и доставку отчетов BI.
На стороне управления данными Microsoft SQL Server включает службы интеграции SQL Server, службы качества данных SQL Server и основные службы данных SQL Server. Также в комплекте с СУБД находятся два набора инструментов для администраторов баз данных и разработчиков: инструменты данных SQL Server для использования в разработке баз данных и SQL Server Management Studio для использования при развертывании, мониторинге и управлении базами данных.
Microsoft предлагает SQL Server в четырех основных версиях, которые предоставляют разные уровни услуг. Две из них доступны бесплатно: полнофункциональная версия для разработчиков для использования в разработке и тестировании базы данных, а также версия Express, которая может использоваться для запуска небольших баз данных объемом до 10 ГБ. Для больших приложений Microsoft продает корпоративную версию, которая включает в себя все функции SQL Server, а также стандартную версию с частичным набором функций и ограничениями на количество ядер процессора и размеров памяти, которые пользователи могут настраивать на своих серверах баз данных.
Однако, когда SQL Server 2016 с пакетом обновления 1 (SP1) был выпущен в конце 2016 года, Microsoft сделала некоторые функции, ранее ограниченные версией Enterprise, доступной как часть стандартных и экспресс-версий. Это включало OLTP, PolyBase, индексы столбцов и разделение, сжатие данных и возможность изменения данных для хранилищ данных, а также несколько функций безопасности. Кроме того, компания реализовала согласованную модель программирования в разных выпусках с пакетом обновления 1 (SP1) для SQL Server 2016, что упростило масштабирование приложений от одного издания к другому [24].
Расширенные функции безопасности, поддерживаемые во всех выпусках Microsoft SQL Server, начиная с пакета обновления 1 (SP1) для SQL Server 2016, включают в себя три технологии, добавленные к версии 2016:
- Always Encrypted, которая позволяет пользователю обновлять зашифрованные данные без необходимости их расшифровки;
- безопасность на уровне строк, которая позволяет контролировать доступ к данным на уровне строк в таблицах базы данных;
- динамическое маскирование данных, которое автоматически скрывает элементы конфиденциальных данных от пользователей без прав на полный доступ.
Другие важные функции безопасности SQL Server включают прозрачное шифрование данных, которое шифрует файлы данных в базах данных и мелкомасштабный аудит, который собирает подробную информацию об использовании базы данных для представления отчетности о соответствии нормативным требованиям. Microsoft также поддерживает протокол безопасности транспортного уровня для обеспечения связи между клиентами SQL Server и серверами баз данных.
Большинство этих инструментов и других функций в Microsoft SQL Server также поддерживаются в Azure SQL Database, службе облачной базы данных, созданной на базе SQL Server Database Engine. Кроме того, пользователи могут запускать SQL Server непосредственно на Azure с помощью технологии SQL Server на Azure Virtual Machines; он настраивает СУБД в виртуальных машинах Windows Server, работающих на Azure [25]. Предложение VM оптимизировано для переноса или расширения локальных приложений SQL Server в облаке, а база данных Azure SQL предназначена для использования в новых облачных приложениях.
В облаке Microsoft также предлагает Azure SQL Data Warehouse, службу хранилища данных, основанную на реализации SQL Server с использованием массивной параллельной обработки (MPP). Версия MPP, первоначально автономный продукт под названием SQL Server Parallel Data Warehouse, также доступна для использования на местах как часть платформы Microsoft Analytics Platform System, которая сочетает ее с PolyBase и другими крупными технологиями данных.
В период с 1995 по 2016 год Microsoft выпустила 10 версий SQL Server. Ранние версии были нацелены в первую очередь на ведомственные и рабочие группы, но Microsoft расширила возможности SQL Server в последующих, превратив их в реляционную СУБД корпоративного класса, которая может конкурировать с Oracle Database, DB2 и другими платформами для использования в высокопроизводительных СУБД. За прошедшие годы Microsoft также включила в SQL Server различные инструменты управления данными и аналитики данных, а также функциональность для поддержки новых технологий, в том числе веб-технологий, облачных вычислений и мобильных устройств.
Microsoft SQL Server 2016, который стал общедоступным в июне 2016 года, был разработан в рамках «первой технологии мобильных технологий», принятой Microsoft двумя годами ранее. Среди прочего, SQL Server 2016 добавил новые функции для настройки производительности, аналитики в реальном времени, визуализации данных и отчетности на мобильных устройствах, а также поддержку гибридных облаков, которая позволяет администраторам баз данных запускать базы данных на основе комбинации локальных и общедоступных облачных сервисов для снижения затрат на. Например, технология SQL Server Stretch Database перемещает редко получаемые данные с локальных устройств хранения в облако Microsoft Azure, сохраняя при этом данные для запросов, если это необходимо.
SQL Server 2016 также увеличил поддержку аналитики больших объемов данных и других приложений расширенной аналитики через службы SQL Server R, что позволяет СУБД запускать аналитические приложения, написанные на языке программирования с открытым исходным кодом R, и PolyBase - технологию, которая позволяет пользователям SQL Server получать доступ к данным хранятся в кластерах Hadoop или хранилище Azure blob для анализа. Кроме того, SQL Server 2016 был первой версией СУБД для работы исключительно на 64-битных серверах на базе микропроцессоров x64.
Предыдущие версии включали SQL Server 2005, SQL Server 2008 и SQL Server 2008 R2, который считался основным выпуском. Далее появились SQL Server 2012 и SQL Server 2014. В SQL Server 2012 появились новые функции, такие как индексы столбцов. В SQL Server 2014 добавлен встроенный OLTP-модуль, который позволяет пользователям запускать приложения обработки транзакций онлайн (OLTP) с данными, хранящимися в таблицах с оптимизацией памяти, а не на стандартных дисковых. Еще одной новой особенностью SQL Server 2014 было расширение пула буферов, которое объединяет кеш-память буферного пула SQL Server с твердотельным диском - еще одна функция, предназначенная для увеличения пропускной способности ввода-вывода за счет выгрузки данных с обычных жестких дисков.
Microsoft SQL Server работает в Windows более 20 лет. Но в 2016 году Microsoft заявила, что планирует также сделать СУБД доступной в Linux, начиная с новой версии, которая первоначально была назвала SQL Server vNext; позже он был официально назван SQL Server 2017 и запланирован на общую доступность летом 2017 года.
Поддержка запуска SQL Server в Linux переместила его на операционную систему с открытым исходным кодом, которая обычно обнаруживается на предприятиях, что дает Microsoft потенциальные возможности для клиентов, которые не используют Windows или имеют смешанные серверные среды. Кроме того, он добавил возможность запуска SQL Server в контейнерах Docker, технологию виртуализации, которая изолирует приложения друг от друга в общей операционной системе.
Еще одна заметная особенность в SQL Server 2017 - это поддержка языка программирования Python, языка с открытым исходным кодом, который широко используется в приложениях аналитики. С его добавлением службы SQL Server R были переименованы в службы машинного обучения (In-Database) и расширены для запуска приложений R и Python. Первоначально он и множество других функций доступны только в версии программного обеспечения для Windows с более ограниченным набором функций, поддерживаемым в Linux.
2.4 Обзор Microsoft SQL Server Management Studio
Microsoft SQL Server Management Studio (SSMS) - это интегрированная среда для управления инфраструктурой SQL Server. Она предоставляет пользовательский интерфейс и группу инструментов с редакторами сценариев, которые взаимодействуют с SQL Server.
SSMS предоставляет инструменты для настройки, управления и администрирования экземпляров Microsoft SQL Server, а также объединяет ряд инструментов графического и визуального дизайна и редакторов сценариев для упрощения работы с SQL Server. Комбинированные функции SSMS поставляются с Enterprise Manager, Query Analyzer и Analysis Manager, а также с функциями, включенными в предыдущие версии SQL Server. Она поддерживает большинство административных задач SQL Server и единую интегрированную среду для управления и создания SQL Server Database Engine.
Возможности Microsoft SQL Server Management Studio включают Object Explorer, который позволяет просматривать и управлять всеми объектами в экземпляре SQL Server, Template Explorer, который строит и управляет файлами текста, которые можно использовать повторно для ускорения разработки запросов и скриптов, Solution Explorer, который создает проекты, используемые для управления элементами администрирования, такие как запросы и скрипты. Компоненты SSMS позволяют настраивать сочетания клавиш и просматривают страницы свойств, подключаться к экземплярам Database Engine и Analysis Services использовать инструменты визуального проектирования и интерактивно создавать и отлаживать запросы и скрипты [26].
В данной главе рассмотрены основные характеристики, история развития и архитектура системы управления базами данных Microsoft SQL Server . Отдельно описана среда Microsoft SQL Server Management Studio, которая поставляется вместе с MS SQL Server и служит для разработки и управления базами данных
3 РАЗРАБОТКА БАЗЫ ДАННЫХ В MICROSOFT SQL SERVER
В данной работе разработана база данных учета заработной платы. Разработка базы данных проводилась в несколько этапов. На первом этапе были построены модели базы данных с помощью программы Power Designer, затем на основе созданных моделей была реализована база данных.
3.1 Разработка модели базы данных
Концептуальная, логическая и физическая модель (или ERD) - это три различных способа моделирования данных.
Хотя все они содержат сущности и отношения, они различаются в целях, для которых они созданы, и аудитории, на которую они нацелены. Общее понимание трех моделей состоит в том, что бизнес-аналитик использует концептуальную и логическую модель для моделирования данных, требуемых и создаваемых системой с точки зрения бизнеса, в то время как разработчик баз данных уточняет ранний дизайн для создания физической модели с целью представления физической структуры базы данных.
В ходе первого этапа создания информационной системы разработана концептуальная модель базы данных (Рисунок 1). Концептуальная схема или концептуальная модель данных представляют собой карту сущностей и их отношений, используемых для баз данных. Она описывает семантику организации и представляет собой ряд утверждений о ее природе. В частности, он описывает вещи, имеющие значение для организации (классы сущностей), о которых необходимо собирать информацию, а также характеристики (атрибуты) и ассоциации между сущностями (отношения). Модель создана в программе PowerDesigner.
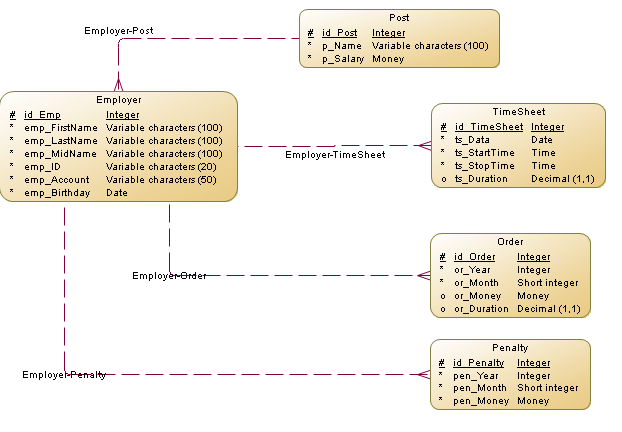
Рисунок 1. Концептуальная модель базы данных
Как видно из рисунка, база данных будет состоять из пяти сущностей:
- Employer (Сотрудники)
- Post (Должности)
- TimeSheet (Учет рабочего времени)
- Order (Начисления)
- Penalty (Штрафы)
Сущность «Сотрудники» описывает сотрудников организации (Таблица 1). Атрибуты данной сущности однозначно описывают свойства сотрудников.
Таблица 1 ‑ Атрибуты сущности «Сотрудники»
|
Название |
Тип данных |
Обязательное поле? |
Первичный ключ? |
Описание |
|
id_Emp |
Integer |
X |
X |
Идентификатор сотрудника |
|
emp_FirstName |
Variable characters (100) |
X |
Имя сотрудника |
|
|
emp_LastName |
Variable characters (100) |
X |
Фамилия сотрудника |
|
|
emp_MidName |
Variable characters (100) |
X |
Отчество сотрудника |
|
|
emp_ID |
Variable characters (20) |
X |
Номер паспорта |
|
|
emp_Account |
Variable characters (50) |
X |
Номер счета |
|
|
emp_Birthday |
Date |
X |
Дата рождения |
Сущность «Должности» описывает должности в организации и соответствующую им заработную плату (Таблица 2).
Таблица 2 ‑ Атрибуты сущности «Должности»
|
Название |
Тап данных |
Обязательное поле? |
Первичный ключ? |
Описание |
|
id_Post |
Integer |
X |
X |
Идентификатор должности |
|
p_Name |
Variable characters (100) |
X |
Название должности |
|
|
p_Salary |
Money |
X |
Почасовой оклад |
Сущность «Учет рабочего времени» предназначена для хранения информации о проработанных часах каждого сотрудника (Таблица 3).
Таблица 3 ‑ Атрибуты сущности «Учет рабочего времени»
|
Название |
Тип данных |
Обязательное поле? |
Первичный ключ? |
Описание |
|
id_TimeSheet |
Integer |
X |
X |
Идентификатор табеля рабочего времени |
|
ts_Data |
Date |
X |
Дата |
|
|
ts_StartTime |
Time |
X |
Время начала работы |
|
|
ts_StopTime |
Time |
X |
Время окончания работы |
|
|
ts_Duration |
Decimal |
Продолжительность работы |
Сущность «Начисления» описывает месячные начисления заработной платы каждого сотрудника (Таблица 4).
Таблица 4 ‑ Атрибуты сущности «Начисления»
|
Название |
Тип данных |
Обязательное поле? |
Первичный ключ? |
Описание |
|
id_Order |
Integer |
X |
X |
Идентификатор начисления |
|
or_Year |
Integer |
X |
Год начисления |
|
|
or_Month |
Short integer |
X |
Месяц начисления |
|
|
or_Money |
Money |
Сумма |
||
|
or_Duration |
Decimal |
Количество отработанных часов |
Сущность «Штрафы» описывает возможные штрафы сотрудника (Таблица 5).
Таблица 5 ‑ Атрибуты сущности «Штрафы»
|
Название |
Тип данных |
Обязательное поле? |
Первичный ключ? |
Описание |
|
id_Penalty |
Integer |
X |
X |
Идентификатор штрафа |
|
pen_Year |
Integer |
X |
Год штрафа |
|
|
pen_Month |
Short integer |
X |
Месяц штрафа |
|
|
pen_Money |
Money |
X |
Сумма штрафа |
Концептуальная модель дает общие представления о сущностях базы данных и связях между ними, но при этом абстрагируется от вопросов физического представления данных. Поэтому при проектировании базы данных необходимо также использовать физическую модель данных. Физическая модель данных может быть сгенерировано из концептуальной модели путем выбора пункта меню «Tools – Generate Physical Data Model» (Рисунок 2)
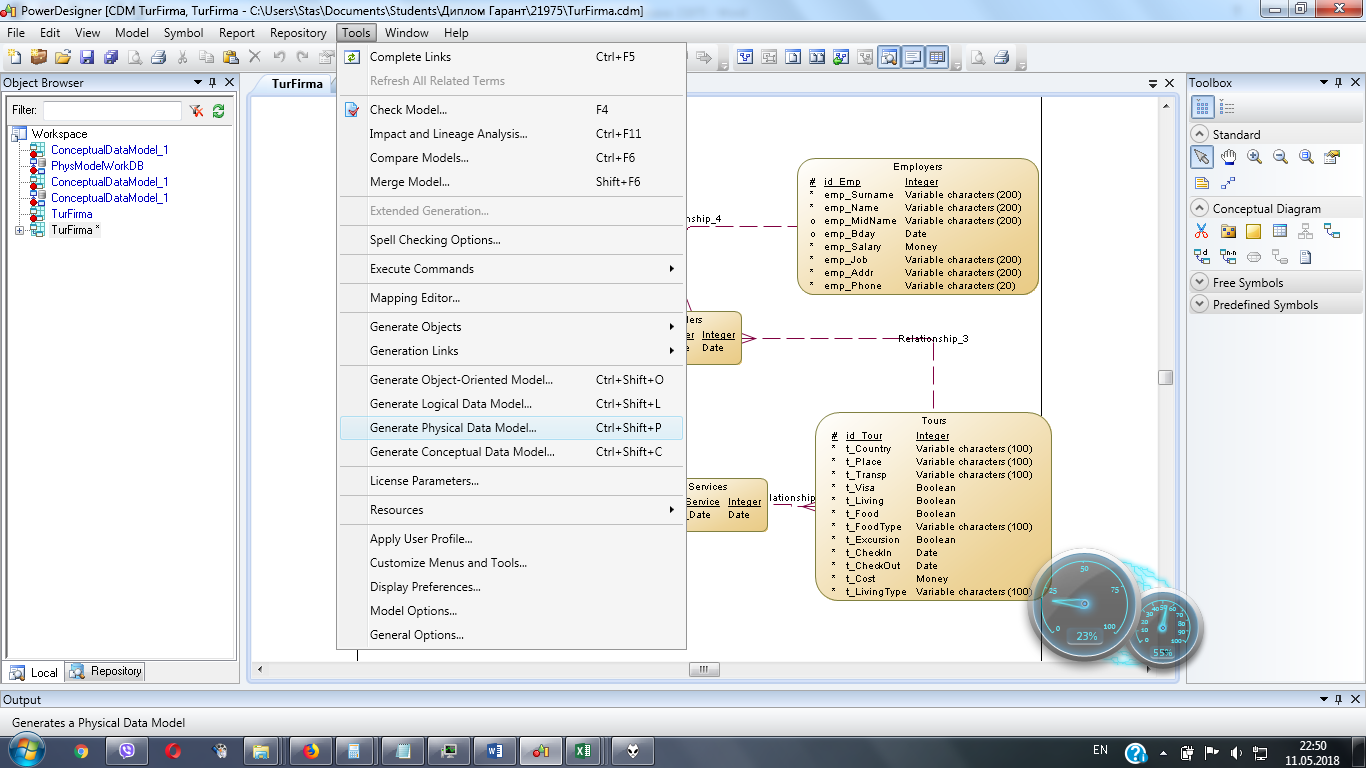
Рисунок 2. Генерация физической модели базы данных в программе PowerDesigner
Перед генерацией физической модели необходимо проверить на корректность концептуальную модели, выбрав пункт меню «Tools – Check Model». В настройках генерации физической модели необходимо выбрать из выпадающего списка тип системы управления базой данных (СУБД), которая будет использоваться при создании базы данных. В нашем случае это Microsoft SQL Server 2012 (Рисунок 3).
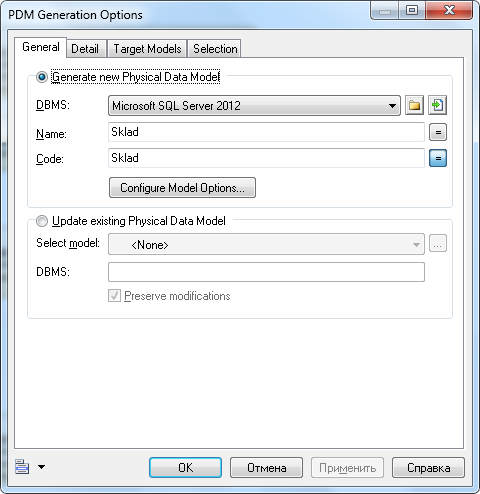
Рисунок 3. Настройки генерации физической модели данных
Сгенерированная физическая модель данных содержит в таблицах внешние ключи, которые позволяют создавать связи между сущностями (Рисунок 4).
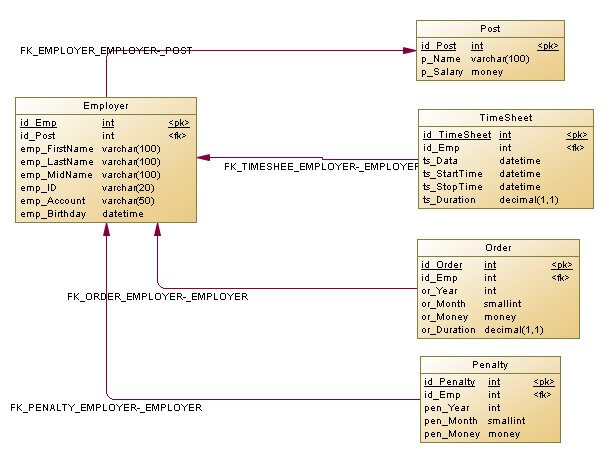
Рисунок 4. Физическая модель базы данных
Как видно из представленного выше рисунка, таблица «Employer» связана отношениями «один ко многим» с таблицей «Post» и содержит соответствующий внешний ключ. Подобная связь обусловлены тем, что одну и ту же должность может занимать несколько человек, но при этом каждый сотрудник занимает одну должность. Аналогично, связями «один ко многим» связаны таблицы «Employer» и «TimeSheet», «Employer» и «Order», а также «Employer» и «Penalty».
3.2 Проектирование базы данных
Следующим этапом после разработки E-R диаграммы является проектирование базы данных в Microsoft Server 2012. Разработка велась с помощью Microsoft SQL Management Studio. Среда SQL Server Management Studio (SSMS) - это приложение, впервые запущенное с помощью Microsoft SQL Server 2005, которое используется для настройки, управления и администрирования всех компонентов в Microsoft SQL Server. Инструмент включает в себя как редакторы скриптов, так и графические инструменты, которые работают с объектами и возможностями сервера. Центральной особенностью SSMS является обозреватель объектов, который позволяет пользователю просматривать, выбирать и воздействовать на любой из объектов на сервере.
При создании базы данных из физической модели используется скрипт, которые создается в программе PowerDesigner и выполняется в SSMS.
Для генерации скрипта, создающего базу данных по физической модели, необходимо в программе PowerDesigner выбрать пункт меню «Database – Generate Database». В появившемся окне выбирается директория для сохранения скрипта и задается его имя (Рисунок 5). В данной работе используется имя, задаваемое программой по умолчанию.
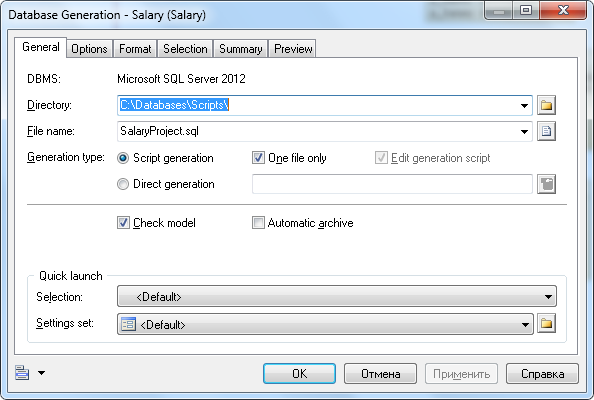
Рисунок 5. Генерация скрипта создания базы данных в PowerDesigner
Фрагмент генерируемого файла представлен на рисунке 6, полностью текст скрипта приведен в приложении А.
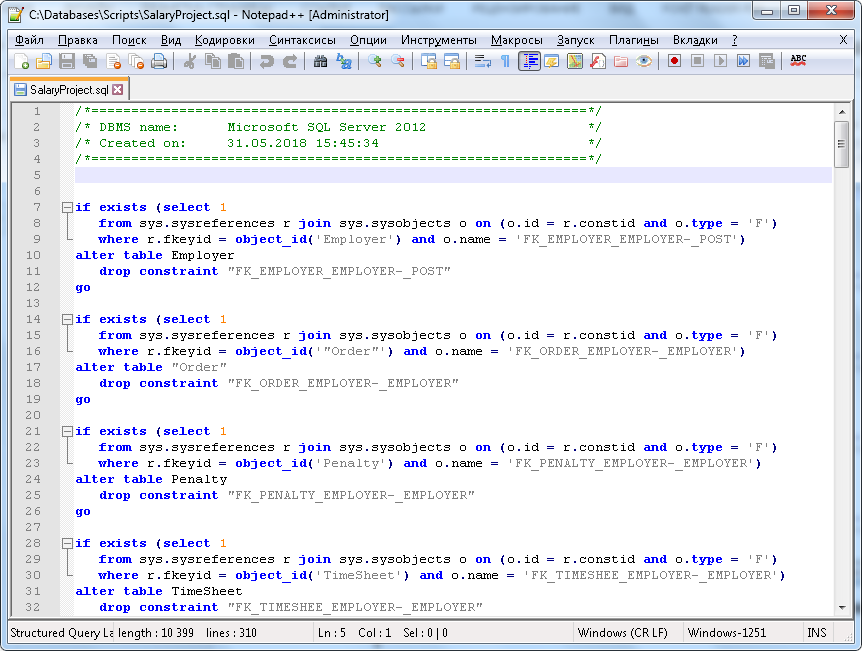
Рисунок 6. Фрагмент скрипта, генерирующего базу данных
Следующим этапом является выполнение скрипта в SSMS. Для этого создаем новую базу данных. После этого необходимо в контекстном меню созданной базы данных выбрать пункт «Создать запрос». В открывшийся редактор запросов вставляем исходный код созданного скрипта (Рисунок 7).
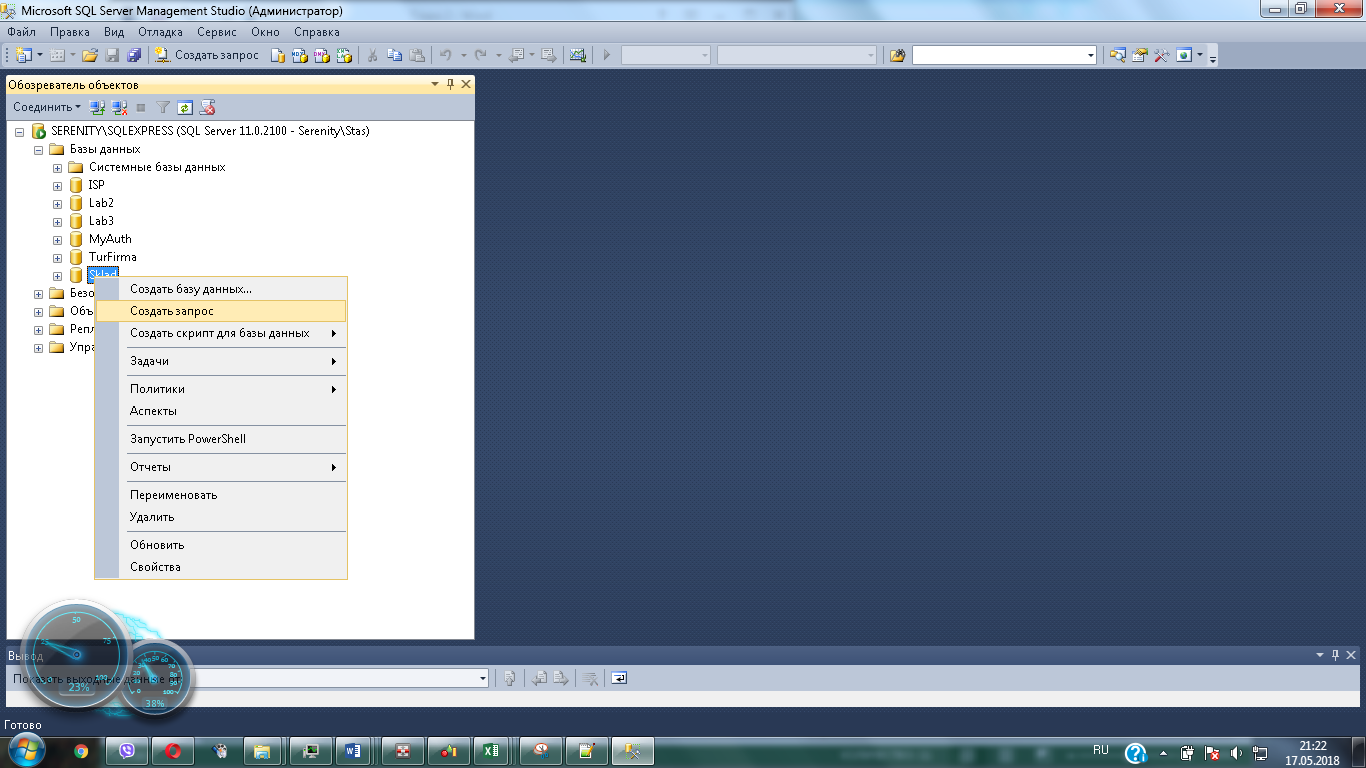
Рисунок 7. Создание базы данных в SSMS
Для выполнения скрипта нажимаем кнопку «Выполнить» на панели инструментов. После этого раскрываем список таблиц базы данных и убеждаемся, что все требуемые таблицы созданы (Рисунок 8).
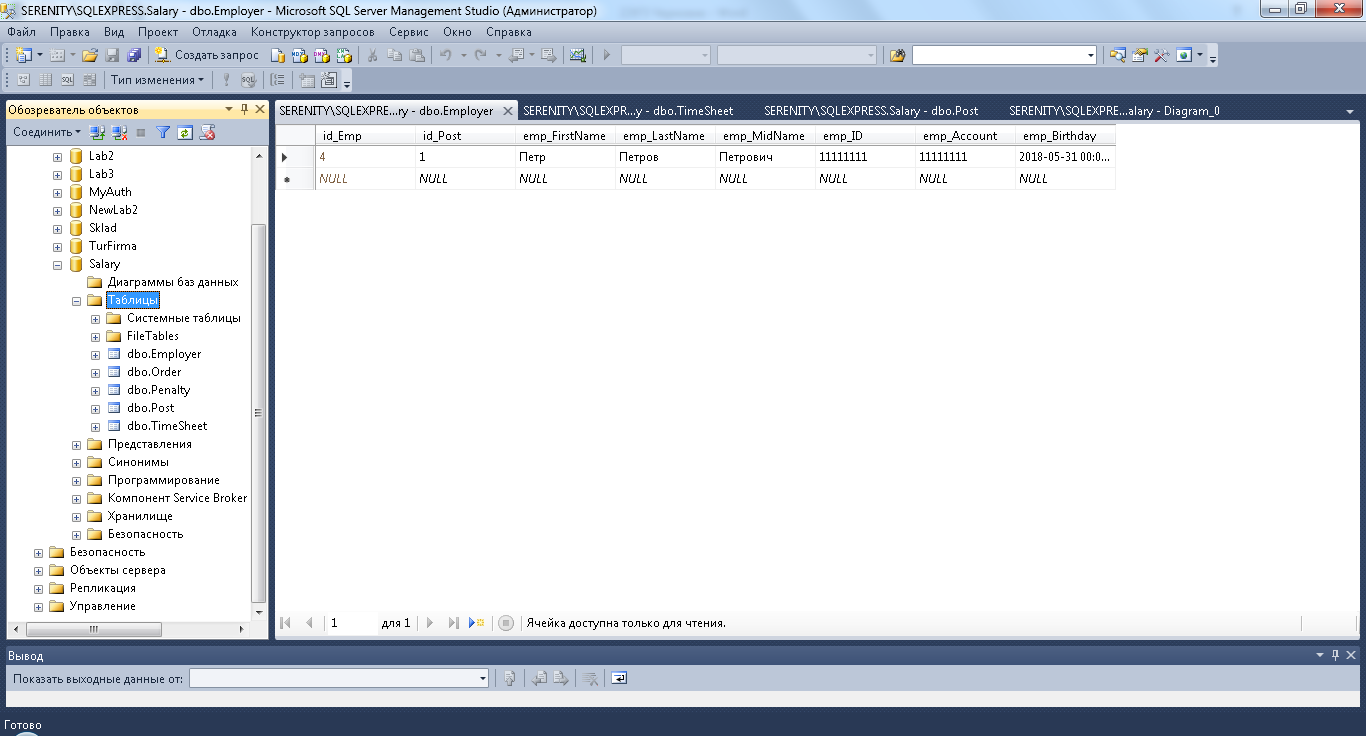
Рисунок 8. Таблицы базы данных
Для отображения связей между созданными таблицами необходимо создать новую диаграмму баз данных в SSMS. Для этого следует перейти в пункт «Диаграммы баз данных» и в контекстном меню выбрать «Создать диаграмму базы данных». В появившемся окне выбираем все таблицы базы данных и получаем диаграмму, на которой показаны таблицы и связи между ними.
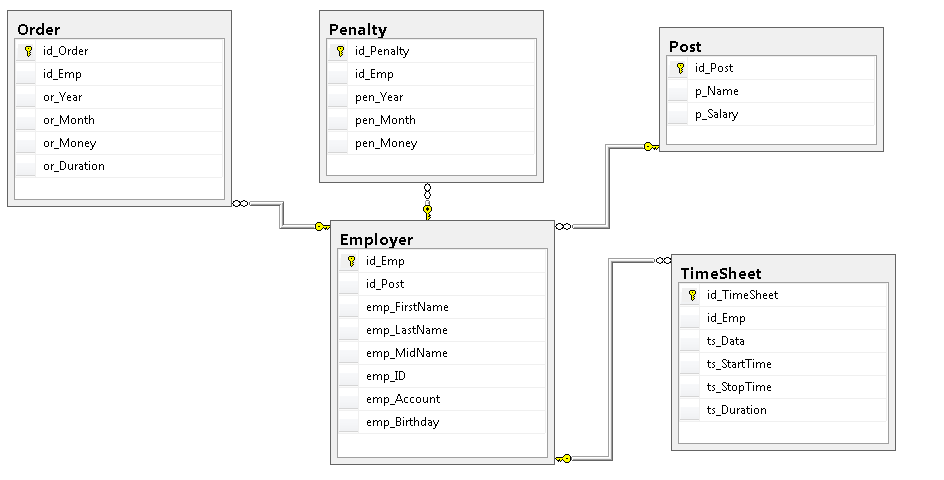
Рисунок 11. Диаграмма баз данных
Легко убедиться, что созданная база данных соответствует разработанным ранее концептуальной и физической моделям.
Таким образом, в данной главе описана разработка базы данных информационной системы. База данных создана в несколько этапов с применением программных средства, таким как PowerDesigner и Microsoft SQL Server Measurement Studio. На первом этапе создана концептуальная модель, которая описывает сущности и их отношения в будущей информационной системе. База данных состоит из шести сущностей:
- Employer (Сотрудники)
- Post (Должности)
- TimeSheet (Учет рабочего времени)
- Order (Начисления)
- Penalty (Штрафы)
Вторым этапом является генерация физической модели с последующей генерацией скрипта для создания базы данных.
Последним этапом является выполнение созданного скрипта в SSMS и проверка созданной базы данных.
ЗАКЛЮЧЕНИЕ
В данной курсовой работе было проведено исследование на тему «Базы данных»
В главе 1 был проведен обзор и анализ различных баз данных, проведена их классификация.
Отдельно в данной главе рассмотрены реляционные базы данных, которые, получили наибольшее распространение на современном этапе развития компьютерных технологий. Они представляют собой совокупность таблиц, в которых содержаться данные об, описывающие различные объекты нашего мира. Благодаря своей логичности и структурированности данные могут быть легко добавлены, удалены или изменены.
В главе также рассматривает язык запросов SQL, который по факту является стандартом при работе с реляционными базами данных.
В главе 2 рассмотрены основные характеристики, история развития и архитектура системы управления базами данных Microsoft SQL Server . Отдельно описана среда Microsoft SQL Server Management Studio, которая поставляется вместе с MS SQL Server и служит для разработки и управления базами данных.
Система управления базами данных Microsoft SQL Server является мощным средством для создания и управления современными базами данных. Наряду с продуктами от Oracle и IBM, он занимает лидирующие позиции на рынке систем управления базами данных. Он используется как в стационарных приложениях, так и в облачных и распределенных системах.
Вместе с Microsoft SQL Server поставляется среда разработки Microsoft SQL Server Management Studio, в которой создана база данных этого проекта. Она представляет собой удобное средство для создания и обслуживания баз данных. Она позволяет в интерактивном режиме создавать таблицы базы данных и определять связи между ними.
В главе 3 описана разработка базы данных информационной системы. База данных создана в несколько этапов с применением программных средства, таким как PowerDesigner и Microsoft SQL Server Measurement Studio. На первом этапе создана концептуальная модель, которая описывает сущности и их отношения в будущей информационной системе. База данных состоит из шести сущностей:
- Employer (Сотрудники)
- Post (Должности)
- TimeSheet (Учет рабочего времени)
- Order (Начисления)
- Penalty (Штрафы)
Вторым этапом является генерация физической модели с последующей генерацией скрипта для создания базы данных.
Последним этапом является выполнение созданного скрипта в SSMS и проверка созданной базы данных.
Таким образом, в ходе выполнения курсовой работы были изучены возможности MS SQL Server и создана базы данных на его основе.
СПИСОК ЛИТЕРАТУРЫ
- Александров, В.В.; Вишняков, Ю.С.; Горская, Л.М. и др. Информационное обеспечение интегрированных производственных комплексов - Л.: Машиностроение, 2012. - 511 c.
- Аткинсон, Леон MySQL. Библиотека профессионала - М.: Вильямс, 2012. - 624 c.
- Бек, Кент Шаблоны реализации корпоративных приложений - М.: Вильямс, 2012. - 369 c.
- Веймаер, Р.; Сотел, Р. Освой самостоятельно Microsoft SQL Server 2000 за 21 день (+ CD-ROM) - М.: Вильямс, 2013. - 549 c.
- Гандерлой, Майк; Харкинз, Сьюзан Сейлз Автоматизация Microsoft Access с помощью VBA - М.: Вильямс, 2013. - 416 c.
- Гетц, Кен; Джинберт, Майкл; Литвин, Пол Access 2000. Руководство разработчика. Том 1. Настольные приложения. том 1 - Киев: BHV, 2014. - 576 c.
- Голицына, О.Л. и др. Базы данных; Форум; Инфра-М, 2013. – 399 c.
- Гринченко, Н.Н. и др. Проектирование баз данных. СУБД Microsoft Access - Горячая Линия Телеком, 2012. - 613 c.
- Дейт, К.Дж. Введение в системы баз данных; К.: Диалектика - Издание 6-е, 2012. - 360 c.
- Дэвидсон, Луис проектирование баз данных на SQL Server 2000 -Бином, 2012. - 631 c.
- Дюваль, Поль М. Непрерывная интеграция. Улучшение качества программного обеспечения и снижение риска - М.: Вильямс, 2014. - 497 c.
- Каратыгин, С.; Тихонов, А. Работа в Paradox для Windows 5.0 на примерах - М.: Бином, 2012. - 512 c.
- Каратыгин, Сергей Access 2000 на примерах. Руководство пользователя с примерами - М.: Лаборатория Базовых Знаний, 2012. - 376 c.
- Кауфельд, Джон Microsoft Office Access 2003 для "чайников" - М.: Диалектика, 2013. - 439 c.
- Каучмэн, Джейсон; Швинн, Ульрике Oracle 8i CertifiedProfessionaql DBA Подготовка администраторов баз данных - ЛОРИ, 2012. - 510 c.
- Луни, Кевин; Брила, Боб Oracle 10g. Настольная книга администратора баз данных - М.: Лори, 2014. - 365 c.
- Мак-Федрис, Пол Формы, отчеты и запросы в Microsoft Access 2003 - М.: Вильямс, 2012. - 416 c.
- Наумов, А.Н.; Вендров, А.М.; Иванов, В.К. и др. Системы управления базами данных и знаний - М.: Финансы и статистика, 2012. - 352 c.
- Нимик, Ричард Дж Oracle9i. Оптимизация производительности. Советы и методы - М.: Лори, 2012. - 648 c.
- Озкарахан, Э. Машины баз данных и управление базами данных - М.: Мир, 2013. - 551 c.
- Постолит, Анатолий Visual Studio .NET: разработка приложений баз данных - СПб: БХВ, 2013. - 544 c.
- Редько, В.Н.; Бассараб, И.А. Базы данных и информационные системы - Знание, 2012. - 602 c.
- Тимошок, Т.В. Microsoft Office Access 2007: самоучитель - Вильямс, 2013. - 464 c.
- Тоу, Дэн Настройка SQL - СПб: Питер, 2012. - 539 c.
- Туманов, В.Е. Основы проектирования реляционных баз данных - Бином, 2012. - 420 c.
- Уорден, К. Новые интеллектуальные материалы и конструкции. Свойства и применение - М.: Техносфера, 2012. - 456 c.
Скрипт создания базы данных
/*==============================================================*/
/* DBMS name: Microsoft SQL Server 2012 */
/* Created on: 31.05.2018 15:45:34 */
/*==============================================================*/
if exists (select 1
from sys.sysreferences r join sys.sysobjects o on (o.id = r.constid and o.type = 'F')
where r.fkeyid = object_id('Employer') and o.name = 'FK_EMPLOYER_EMPLOYER-_POST')
alter table Employer
drop constraint "FK_EMPLOYER_EMPLOYER-_POST"
go
if exists (select 1
from sys.sysreferences r join sys.sysobjects o on (o.id = r.constid and o.type = 'F')
where r.fkeyid = object_id('"Order"') and o.name = 'FK_ORDER_EMPLOYER-_EMPLOYER')
alter table "Order"
drop constraint "FK_ORDER_EMPLOYER-_EMPLOYER"
go
if exists (select 1
from sys.sysreferences r join sys.sysobjects o on (o.id = r.constid and o.type = 'F')
where r.fkeyid = object_id('Penalty') and o.name = 'FK_PENALTY_EMPLOYER-_EMPLOYER')
alter table Penalty
drop constraint "FK_PENALTY_EMPLOYER-_EMPLOYER"
go
if exists (select 1
from sys.sysreferences r join sys.sysobjects o on (o.id = r.constid and o.type = 'F')
where r.fkeyid = object_id('TimeSheet') and o.name = 'FK_TIMESHEE_EMPLOYER-_EMPLOYER')
alter table TimeSheet
drop constraint "FK_TIMESHEE_EMPLOYER-_EMPLOYER"
go
if exists (select 1
from sysindexes
where id = object_id('Employer')
and name = 'Relationship_1_FK'
and indid > 0
and indid < 255)
drop index Employer.Relationship_1_FK
go
if exists (select 1
from sysobjects
where id = object_id('Employer')
and type = 'U')
drop table Employer
go
if exists (select 1
from sysindexes
where id = object_id('"Order"')
and name = 'Employer-Order_FK'
and indid > 0
and indid < 255)
drop index "Order"."Employer-Order_FK"
go
if exists (select 1
from sysobjects
where id = object_id('"Order"')
and type = 'U')
drop table "Order"
go
if exists (select 1
from sysindexes
where id = object_id('Penalty')
and name = 'Employer-Penalty_FK'
and indid > 0
and indid < 255)
drop index Penalty."Employer-Penalty_FK"
go
if exists (select 1
from sysobjects
where id = object_id('Penalty')
and type = 'U')
drop table Penalty
go
if exists (select 1
from sysobjects
where id = object_id('Post')
and type = 'U')
drop table Post
go
if exists (select 1
from sysindexes
where id = object_id('TimeSheet')
and name = 'Employer-TimeSheet_FK'
and indid > 0
and indid < 255)
drop index TimeSheet."Employer-TimeSheet_FK"
go
if exists (select 1
from sysobjects
where id = object_id('TimeSheet')
and type = 'U')
drop table TimeSheet
go
/*==============================================================*/
/* Table: Employer */
/*==============================================================*/
create table Employer (
id_Emp int not null,
id_Post int null,
emp_FirstName varchar(100) not null,
emp_LastName varchar(100) not null,
emp_MidName varchar(100) not null,
emp_ID varchar(20) not null,
emp_Account varchar(50) not null,
emp_Birthday datetime not null,
constraint PK_EMPLOYER primary key (id_Emp)
)
go
if exists(select 1 from sys.extended_properties p where
p.major_id = object_id('Employer')
and p.minor_id = (select c.column_id from sys.columns c where c.object_id = p.major_id and c.name = 'id_Emp')
)
begin
declare @CurrentUser sysname
select @CurrentUser = user_name()
execute sp_dropextendedproperty 'MS_Description',
'user', @CurrentUser, 'table', 'Employer', 'column', 'id_Emp'
end
select @CurrentUser = user_name()
execute sp_addextendedproperty 'MS_Description',
'Идентификатор сотрудника',
'user', @CurrentUser, 'table', 'Employer', 'column', 'id_Emp'
go
/*==============================================================*/
/* Index: Relationship_1_FK */
/*==============================================================*/
create nonclustered index Relationship_1_FK on Employer (id_Post ASC)
go
/*==============================================================*/
/* Table: "Order" */
/*==============================================================*/
create table "Order" (
id_Order int not null,
id_Emp int null,
or_Year int not null,
or_Month smallint not null,
or_Money money null,
or_Duration decimal(1,1) null,
constraint PK_ORDER primary key (id_Order)
)
go
if exists(select 1 from sys.extended_properties p where
p.major_id = object_id('"Order"')
and p.minor_id = (select c.column_id from sys.columns c where c.object_id = p.major_id and c.name = 'id_Emp')
)
begin
declare @CurrentUser sysname
select @CurrentUser = user_name()
execute sp_dropextendedproperty 'MS_Description',
'user', @CurrentUser, 'table', 'Order', 'column', 'id_Emp'
end
select @CurrentUser = user_name()
execute sp_addextendedproperty 'MS_Description',
'Идентификатор сотрудника',
'user', @CurrentUser, 'table', 'Order', 'column', 'id_Emp'
go
/*==============================================================*/
/* Index: "Employer-Order_FK" */
/*==============================================================*/
create nonclustered index "Employer-Order_FK" on "Order" (id_Emp ASC)
go
/*==============================================================*/
/* Table: Penalty */
/*==============================================================*/
create table Penalty (
id_Penalty int not null,
id_Emp int null,
pen_Year int not null,
pen_Month smallint not null,
pen_Money money not null,
constraint PK_PENALTY primary key (id_Penalty)
)
go
if exists(select 1 from sys.extended_properties p where
p.major_id = object_id('Penalty')
and p.minor_id = (select c.column_id from sys.columns c where c.object_id = p.major_id and c.name = 'id_Emp')
)
begin
declare @CurrentUser sysname
select @CurrentUser = user_name()
execute sp_dropextendedproperty 'MS_Description',
'user', @CurrentUser, 'table', 'Penalty', 'column', 'id_Emp'
end
select @CurrentUser = user_name()
execute sp_addextendedproperty 'MS_Description',
'Идентификатор сотрудника',
'user', @CurrentUser, 'table', 'Penalty', 'column', 'id_Emp'
go
/*==============================================================*/
/* Index: "Employer-Penalty_FK" */
/*==============================================================*/
create nonclustered index "Employer-Penalty_FK" on Penalty (id_Emp ASC)
go
/*==============================================================*/
/* Table: Post */
/*==============================================================*/
create table Post (
id_Post int not null,
p_Name varchar(100) not null,
p_Salary money not null,
constraint PK_POST primary key (id_Post)
)
go
/*==============================================================*/
/* Table: TimeSheet */
/*==============================================================*/
create table TimeSheet (
id_TimeSheet int not null,
id_Emp int null,
ts_Data datetime not null,
ts_StartTime datetime not null,
ts_StopTime datetime not null,
ts_Duration decimal(1,1) null,
constraint PK_TIMESHEET primary key (id_TimeSheet)
)
go
if exists(select 1 from sys.extended_properties p where
p.major_id = object_id('TimeSheet')
and p.minor_id = (select c.column_id from sys.columns c where c.object_id = p.major_id and c.name = 'id_Emp')
)
begin
declare @CurrentUser sysname
select @CurrentUser = user_name()
execute sp_dropextendedproperty 'MS_Description',
'user', @CurrentUser, 'table', 'TimeSheet', 'column', 'id_Emp'
end
select @CurrentUser = user_name()
execute sp_addextendedproperty 'MS_Description',
'Идентификатор сотрудника',
'user', @CurrentUser, 'table', 'TimeSheet', 'column', 'id_Emp'
go
/*==============================================================*/
/* Index: "Employer-TimeSheet_FK" */
/*==============================================================*/
create nonclustered index "Employer-TimeSheet_FK" on TimeSheet (id_Emp ASC)
go
alter table Employer
add constraint "FK_EMPLOYER_EMPLOYER-_POST" foreign key (id_Post)
references Post (id_Post)
go
alter table "Order"
add constraint "FK_ORDER_EMPLOYER-_EMPLOYER" foreign key (id_Emp)
references Employer (id_Emp)
go
alter table Penalty
add constraint "FK_PENALTY_EMPLOYER-_EMPLOYER" foreign key (id_Emp)
references Employer (id_Emp)
go
alter table TimeSheet
add constraint "FK_TIMESHEE_EMPLOYER-_EMPLOYER" foreign key (id_Emp)
references Employer (id_Emp)
go

- Виды договоров в сфере права интеллектуальной собственности, их классификации и применение
- Кадровая стратегия в системе стратегического управления организацией ЗАО «Юг Руси»
- Ведомственный контроль за оперативно – розыскной деятельностью.
- Правовое регулирование рекламы
- Опека и попечительство. Патронаж над дееспособными и несовершеннолетними гражданами
- Понятие социального обслуживания (Сущность, цели и задачи)
- Технология разработки программы лояльности к гостям на примере Марриотт роял аврора
- Анализ функционирования и перспективы ломбардной деятельности
- Годовой бухгалтерский отчет: содержание и порядок составления (Экономическая сущность бухгалтерского баланса и его значение в системе финансовой отчетности)
- Аналитический обзор развития технологий Интернета. Проблемы и перспективы развития сети
- Разработка автоматизированной информационной системы услуги перевозок сотрудников и транспортной доставки заказов организации
- ОПИСАНИЕ ФИЗИЧЕСКИХ ОСНОВ ВОЗНИКНОВЕНИЯ ТЕХНИЧЕСКОГО КАНАЛА УТЕЧКИ РЕЧЕВОЙ ИНФОРМАЦИИ И МЕТОДА РАСЧЕТА СЛОВЕСНОЙ РАЗБОРЧИВОСТИ