
Распределенная технология обработки информации (Классификация кластерных вычислений)
Содержание:

Введение
В настоящее время актуальным становится вопрос оптимизации вычислений, а также рационального распределения мощностей вычислительных ресурсов. С развитием телекоммуникационных систем появляются возможности создания распределенных вычислительных сетей, позволяющих максимально рационально распределять нагрузку между аппаратными ресурсами. Реализовать данные задачи можно посредством перераспределения имеющихся аппаратных систем через использование виртуальных сред. Оптимизации вычислений можно достичь несколькими способами - через кластерные вычисления, использование контейнеров, а также систем виртуализации.
Практическая значимость работы: использование в организациях, имеющих централизованные информационные системы для оптимизации параметров скоростей вычислений, надежности и масштабируемочти.
Целью работы является анализ технологий использования распределенных вычислений.
Задачи работы:
- анализ технологии кластерных вычислений;
- анализ технологий виртуализации;
- анализ технологий работы с контейнерами.
Объект исследования: распределенные вычислительные системы.
Предмет исследования: технологии оптимизации вычислений в распределенных системах.
1. Анализ кластерных вычислений
1.1 История и понятие кластера
Кластерные системы представляют собой форму использования распределенных систем в форме группы компьютеров, которые объединены посредством высокоскоростных каналов связи, с пользовательской точки зрения представляющие собой единую аппаратную систему.
Первым архитектором кластерной технологии был Грегори Пфистер (Gregory F. Pfister), который дал такое определение кластерным системам: «Кластеры — это разновидность параллельных или распределённых системы, которые [3]:
- включают несколько связанных между собой компьютерных систем;
- используются в форме единого, унифицированного компьютерного ресурса.
Как правило, различаются следующие основные типы кластерных систем [4]:
- отказоустойчивые кластерные системы (High-availabiliten clusters, HC);
- кластерные системы с возможностью балансировки нагрузки (Load balanced clusters);
- вычислительные система (Сomputing systems clusters);
- grid-технологии.
История создания технологий кластерных вычислений неразрывно связана с первыми компьютерными сетевыми технологиями. Одной из основных причин для возникновения скоростной связи между вычислительными системами стали возможности по объединению вычислительных мощностей. К началу 1970-х гг. группа разработчиков протокола передачи данных TCP/IP и сотрудники лаборатории Xerox PARC проводили разработку основы стандартов сетевого взаимодействия. В тот период проведена разработка операционной системы Hydra («Гидра»), используемой для компьютерных систем PDP-11 производства DEC, а созданные на данной базе кластеры получили название C.mpp (Питтсбург, штат Пенсильвания, США, 1972). Создание механизмов кластерных вычислений было проведено к 1983 г., когда были оптимизированы задачи использования распределенных задач и файловых ресурсов последством сети. В большинстве случаев это были разработки в операционной системе SunOS, разработанной на базе BSD.
Первый коммерческий проект кластера представил собой ARCNet, реализованный фирмой Datapoint в 1978 г. Данный проект не окупил вложенные средства, вследствие чего строительство кластерных центров не получало развития до 1984 г., когда фирмой DEC был реализован проект VAXcluster на базе ОС VAX/VMS. Проекты ARCNet и VAXcluster были спроектированы не только для проведения совместных вычислений, но и для совместного использования файловой системы и периферии с учётом требований по сохранению целостности и однозначности информационных единиц. VAXCluster (называемый в настоящее время VMSCluster) — представляет собой неотъемлемую компоненту операционной системы HP OpenVMS, которые используют процессоры на базе Alpha и Itanium [12].
Другие кластерные продукты, получившие признание, включают технологии Tandem Hymalaya (1994, класс HA) и IBM S/390 Parallel Sysplex (1994).
История реализации кластерных систем из обыкновенных рабочих станций во многом связана с проектом Parallel Virtual Machine. К 1989 г. данное ПО для объединения рабочих станций в виртуальные суперкомпьютеры открыло возможности для мгновенного создания кластерных систем. Как результат, суммарные параметры производительности всех реализованных в тот период тогда недорогих кластеров обогнали по параметрам производительности суммарные мощности дорогостоящих коммерческих систем.
Реализация кластеров на базе дешёвых рабочих станций, объединённых посредством сетей передачи данных, продолжилась в 1993 г. силами Американского аэрокосмического агентства (NASA), далее в 1995 г. получили развитие кластерные системы Beowulf, специально разработанные на базе данного принципа. Успешность таких систем определила перспективы развития grid-сетей, существовавших ещё с момента создания UNIX.
1.2 Преимущества кластерных вычисления в HPC
Построение кластерных компьютеров не является самоцелью, а средством достижения большей эффективности и продуктивности научной работы. Существует определенный тип задач, которые требуют более высоких характеристик производительности, нежели можно получить, посредством использования обычных компьютеров. В указанных случаях из нескольких мощных систем создаются HPC (High Perfomance Computing) кластеры, позволяющие разносить вычисления не только на разные процессоры (если применяются многопроцессорные SMP-системы), но и на разные компьютеры. Для задач, которые поддерживают приемлемые характеристики распараллеливания и не предъявляют высоких требований для взаимодействия параллельных потоков, зачастую принимается решение о реализации HPC кластеров из большого числа однопроцессорных систем небольшой мощности. Часто использование решений подобного типа, при наличии низких стоимостных характеристик, позволяют достигать гораздо больших параметров производительности, чем аналогичные характеристики суперкомпьютеров [8].
При этом, реализация кластерной системы подобного типа требует необходимых компетенций знаний и усилий, а использование его предполагает необходимость кардинальной смены используемых парадигм в области программирования, что зачастую представляет собой сложную задачу. Можно быть компетентным специалистом в области разработки последовательного программного обеспечения, но это также предполагает необходимость изучения технологий параллельного программирования с самых основ.
Тезис о том, что прирост производительности возможен только при использовании суперкомпьютеров, является ошибочным. Если поставленные задачи не имеют внутреннего параллелизма и не адаптированы соответствующим образом, максимальным эффектом от использования кластерных систем будет возможность одновременного запуска нескольких экземпляров программы, которые работают с разными начальными данными. Использование кластера в данном случае не ускорит процесс выполнения одного конкретного ПО, но позволит сэкономить значительное количество времени, при необходимости расчета множества вариантов состояния системы за ограниченный промежуток времени. Для кластеров можно привести следующую аналогию: если для одного корабля время хода на нужное расстояние составляет 7 дней, то семь кораблей не пройдут также же расстояние за один день. При этом семь кораблей могут перевести большее количество груза. При высоких объемах вычислений по поставленной задаче, то длительность одного прогона на одной рабочей станции может составлять сутки, недели и месяцы, отсюда очевидно, что необходимо приложение усилий, направленных на адаптацию алгоритма. Следует проводить разделение задачи на несколько (по количеству процессоров) небольших подзадач, расчет которых может производиться в независимом режиме, а в тех областях, где независимость выполнения обеспечить невозможно, необходим явный вызов процедур синхронизации, путем обмена информацией через сеть. Так, при обработке большого массива данных, необходимо будет провести разделение задачи на области и распределение их по процессорам через обеспечение равномерной загрузки всего кластера.
Таким образом, прежде чем начать практическую реализацию кластерных технологий необходимо осуществить решение нескольких принципиальных проблем.
Первая из них формулируется таким образом: "Необходимо ли для решения поставленных задач использовать кластеры и технологии параллельных вычислений?" Для ответа на данный вопрос необходимо проводить детальный анализ поставленных задач. Параллельные вычисления являются достаточно специфичной областью математики и далеко не во всех областях использование параллельных вычислений даст необходимые характеристики мощности. Кластерные вычисления использовать неэффективно в случаях [8]:
- Используются специализированные программные пакеты, не адаптированные для параллельных вычислений в средах MPI и PVM или которые не предназначены для работы в системах на основе UNIX. В данном случае невозможно использование более чем одного процессора.
- Программы, разработанные для решения поставленных задач, требуют не более, чем несколько часов процессорного времени на существующем оборудовании. Такая схема использования приведет к тому, что время, потраченное на проведение распараллеливания и отладки разработанной задачи будет выше, чем прирост в быстродействии, которое дает многопроцессорная обработка.
- Время использования разработанной программы сравнимо со временем, затраченным на ее создание с помощью параллельного варианта. К основным особенностям технологии параллельного программирования можно отнести высокую эффективность программ, использование специализированных приемов программирования что, как следствие, предполагает более высокую трудоемкость процесса разработки ПО. Не имеют смысла затраты времени на проведение распараллеливания программы, вычисление данных по которой будет проведено единожды.
Одной из проблем, которую необходимо решить, является наличие принципиальной возможности "распараллеливания" поставленной задачи. Для некоторых численные схем в силу специфики реализации алгоритма невозможна постановка задачи эффективной параллелезиции. перед постановкой задачи на применение кластеров решения поставленной задачи, необходимо убедиться в возможности использования паралельных алгоритмов.
Приложения в параллельной архитектуре должны создаваться с расчетом на эффективность использования ресурсов данной архитектуры. Это означает, что программа должна быть разделена на части, которые способны выполняться параллельно на нескольких процессорах, и разделены эффективно, чтобы отдельно исполняемые компоненты программы оказывали минимальное влияние на выполнение остальных частей.
Пусть в программе доля операций, которые необходимо исполнять последовательно, равна f, где (при этом доля определяется не по статическому количеству строк кода, а количеством операций в процессе исполнения). Крайними случаями в значениях параметра f являются состояние полной параллельности (f=0) и полной последовательности (f=1) исполняемым программам. Таким образом, для оценки прироста производительности S может быть получено на компьютере, на котором установлено p процессоров при известном значении f, можно использовать законом Амдала [9]:
Предположим, что в разработанной программе лишь 10% приходится на последовательные операции, т.е. f=0.1 . Тогда согласно указанному закону вне зависимости от количества установленных процессоров максимальное ускорение составит только 10 раз.
Таким образом, при проектировании программной архитектуры, необходимо учитывать, насколько применимы в нем кластерные вычисления, каков максимальный прирост производительности за счет их использования.
1.3 Классификация кластерных вычислений
Далее рассмотрим задачи, к решению которых оптимально подходят алгоритмы кластерных вычислений.
Диаграмма классификации кластерных вычислений приведена на рисунке 1.
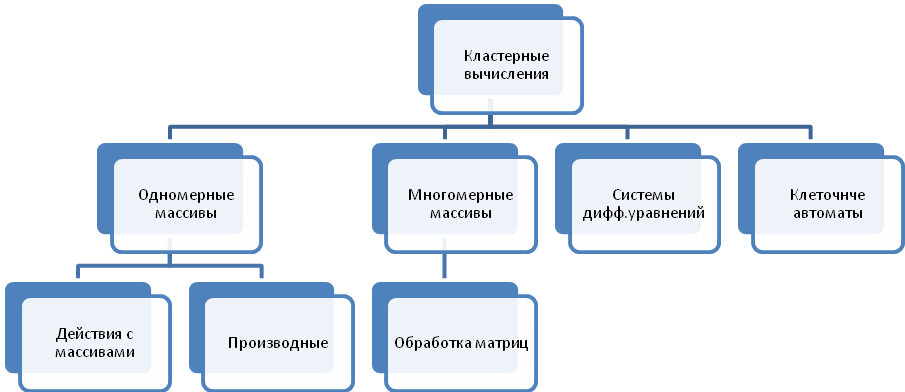
Рис. 1 - Классификация кластерных вычислений
1. Обработка одномерных массивов
Задачи данного класса встречаются довольно часто. Если значения элементов массива можно определять с помощью довольно сложных выражений, а проводить вычисление необходимо многократно, то применение технологий распараллеливания цикла для проведения вычислений элементов массивов может оказаться очень эффективной методикой. Также к данному типу задач можно отнести численное решение систем дифференциальных уравнений, что также представляет собой обработку массивов функций, производных и т.д. Также эффективное применение кластерных вычислений возможно при вычислении сверток, суммировании, вычислении значений функций от каждого из элементов массива и т.п. При этом не имеет смысла распараллеливание действий над массивами с небольшим количеством элементов кроме тех случаев, когда проведение вычислений для каждого элемента занимает длительное время [7].
2. Обработка двумерных массивов
При выполнении алгоритмов с вложенными циклами, как правило, возможно эффективно распараллелить самые внешние циклы. Однако практически для всех действий с матрицами (операции сложения, умножения, умножения на вектор, прямого произведения) может быть реализован алгоритм с использованием кластеров. Для многих алгоритмов линейной алгебры (но не всех) может быть применено распараллеливания. Некоторые из библиотек подпрограмм (например, LAPACK) также реализованы для кластерных машин. Совершенно неэффективным является использование кластеров для работы с матрицами, имеющими низкую размерность (к примеру, 3x3). Есть возможность переработки алгоритма для реализации возможности по одновременной обработке нескольких (к примеру, 5000) матриц для проведения операций обращения, поиска собственных чисел и т.д. При росте размера матриц возрастает эффективность работы программы, при этом растут требования к памяти, используемой для хранения матриц [7].
3.Клеточные автоматы
Для многих областей знания характерны задачи, сводимые к расчетам параметров эволюции объектов, располагаемых в дискретных точках и взаимодействующих с соседствующими объектами. Простейшая и, наверно, наиболее широко распространенная задача подобного типа - игра "Жизнь". К задачам подобного типа также можно так же отнести модели магнетиков Изинга, представляющие собой наборы спинов (элементарных магнитов), которые располагаются в узлах кристаллической решетки и взаимодействующие только с ближайшими из соседей. Порядок построения модели эволюции Изинговских магнетиков является идентичным алгоритму игры "Жизнь" [3].
4. Системы дифференциальных уравнений
Численные решения систем дифференциальных уравнений характерны для многих типов инженерных и научных задач. Для большинства случаев алгоритмы решения задач подобного типа можно эффективно использовать параллельные алгоритмы при обработке в кластерных системах. В качестве примеров можно также привести задачи молекулярного моделирования сплошных сред из статистической физики, проведение инженерных расчетов распределения нагрузок в сложных конструктивных элементах, моделей N тел (например расчетов движения космических аппаратов, динамики звездного диска Галактики), газодинамики сплошных сред (особенно, если проводится исследование многокомпонентных среда), задачах электродинамики и др.
Также очевидно, что класс задач, решаемых с помощью параллельных алгоритмов является довольно широким. Однако необходимо учитывать, что параллельность задачи определяется не только ее физической природой, но и выбранным методом решения. Так, для всем известного метода прогонки практически невозможно реализовать алгоритм распараллеливания. Если единственным или предпочтительным методом решения вашей задачи является метод прогонки, то необходимо отказаться от использования кластерных вычислений. С другой стороны, методы семейства Монте-Карло идеально подходят для кластерных компьютеров. Причем, с ростом числа процессоров кластере, растёт эффективность решения задачи. Практически все алгоритмы использования явных разностных схем при решении дифференциальных уравнений могут быть использованы при параллельных вычислениях.
Также кластеры могут классифицироваться по:
- стандартности комплектующих;
- по однородности узлов;
- по типу узловых процессоров.
Вычислительные кластеры первого класса имеют низкую стоимость и просты в обслуживании. Широкое распространение кластерных технологий получило как средство реализации именно относительно недорогих систем суперкомпьютеров, включающих составные части массового производства.
Кластерные системы второго класса позволяют получать очень высокие параметры производительности, но обладают, как правило, более высокой стоимостью.
1.4 Кластеры контейнеров
Реализация кластеров контейнеров возможна с помощью настроек размещения в компоненте, который отвечает за работу контейнера и проводить задание их размеров.
Процесс создания кластера контейнеров предполагает [11]:
- подготовку, при которой необходимо убедиться во включении кластеров в поддерживаемом развертывании;
- проверку наличия необходимых прав.
При настройке кластеров в компоненте контейнеров автоматически производится подготовка указанного числа контейнеров. Далее проводится равномерное распределение запросов между всеми контейнерами в кластере.
Можно изменять размер кластера таким образом, чтобы было возможно добавление или удаление какого-либо из подготовленных контейнеров или приложений в данном кластере. В процессе изменения размера кластера в среде исполнения необходимо учитывать работу всех связанных фильтров и правил размещения.
Open Source-система Kubernetes, служащая для решения задач по управлению контейнерными кластерами появилась в результате разработок, накопленных Google в течение 10 лет эксплуатации Borg — технологии по изоляции процессов в виртуальной среде.
Технология Kubernetes в настоящее время считается «идеальной платформой» для оркестрации контейнеров. Она позволяет управлять кластерами виртуальных машин и Linux-контейнерами как единым целым, является лидером систем, рекомендуемых для внедрения для средних и крупных предприятий.
Вторым крупным игроком на рынке систем по оркестрации контейнеров — является система Docker Swarm. Данное решение, разработанное в 2013 г., значительно упростило процесс развертывания полноценных виртуальных систем. По сути с данного момента стало возможным осуществлять объединять вместе большого количества вычислительных мощностей, осуществлять запуск тысяч изолированных друг от друга приложений, быстро выстраивая необходимую конфигурацию из виртуализованных прикладных систем
Технология Swarm интересна в первую очередь представителям малых и средних предприятий, объем запуска задач в которых не более 60 тыс. контейнеров и до 1500 нод. Благодаря автоматической совместимости с Docker использование Swarm интересно разработчикам как развитие данной бизнес-модели по наращиванию своего облачного присутствия. Большую помощь в развитии этого направления оказывает Microsoft Azure, которая предлагает поддержку Swarm [14].
Третьим основным игроком на рынке кластеризации контейнеров является система Apache Mesos. Данная система является централизованной отказоустойчивой для управления кластерами, позволяющей объединять в группы отдельные узлы (Mesos Slaves) в соответствии с выставленными требованиями, позволяющая в дальнейшем обеспечивать им изоляцию от остальных ИТ-ресурсов и управление.
2. Виртуализация
2.1 История и определения
Под технологиями виртуализации понимаются процессы преобразования аппаратного обеспечения в программное. Таким образом, с помощью нескольких виртуальных машин можно работать с общими аппаратными ресурсами. Общие подходы к виртуализации заключаются в проведении установки программного слоя либо непосредственно в операционные системы, либо в аппаратные компоненты компьютера. Установка программных слоев предполагает возможность по созданию виртуальных машин, распределению аппаратных ресурсов и т.д.
Период технологии виртуализации памяти пришелся на машины второго поколения в виде технологий по расширению объемов оперативной памяти. Появление потребностей в механизмах по расширению ОЗУ было обусловлено тем, что использовавшиеся в тот момент модули памяти на основе ферритовых сердечников имели чрезвычайно высокую стоимость. Вследствие этого логичной задачей была виртуализация через расширение за счет применения внешних устройств.
Первые виртуальные машины появились в 1961 году в супервизорах суперкомпьютеров класса Atlas, которые были разработаны английской фирмой Ferranti. К середине 60-х годов реализация данной технологии была проведена в проекте IBM M44/44X Project и компьютерах класса IBM 7044 [3].
Следующим этапом развития технологи виртуализации стала разработка концепции виртуальных машин. Разработка данной концепции началась в 1965 году, когда исследователями корпорации IBM была предпринята экспериментальная попытка разделения компьютера на отдельные небольшие компоненты. Данное направление исследований привело к появлению многопользовательской операционной среды на компьютерах класса IBM System 370 и System 390 и операционных системах VM/ESA, составляющих основу генеалогической линии IBM VM (Virtual Machine).
Далее рассмотрим основные виды технологий виртуализации.
Как правило, в качестве решений на основе реализации технологий виртуализации рассматриваются [9]:
1. Эмуляторы аппаратного обеспечения — в хост-системах проводится создание виртуальной машины, моделирующей какую-то иную аппаратную архитектуру.
2. Технологии полной виртуализации, использующие виртуальные машины (гипервизоры), выступающие в качестве посредника между гостевыми операционными системами и реальным оборудованием. Также производится перехват некоторых инструкций защищенного режима и их обработка внутри гипервизоров, поскольку доступность аппаратуры не может быть обеспечена посредством обращения из операционных систем, доступ к ней осуществляется посредством гипервизора.
3. Паравиртуализационные системы. Системы, требующие проведения модификации гостевых операционных систем. В данном случае обеспечиваются высокие показатели производительности, близкие к производительности невиртуализированных систем.
4. Виртуализация на уровне операционной системы. Данная технология представляет собой операционную систему, которая установлена в оном экземпляре и изолирована от других серверов, работающих под ее управлением.
Далее рассмотрим технологии виртуализации в архитектуре x86.
Впервые применение апаратной виртуализации была реализовано в 386-х процессорах. Технология носила название V86 mode. Данный режим позволял осуществлять запуск нескольких DOS-приложений в параллельном режиме.
В 2005-м году компаниями Intel и AMD были представлены решения, в которых была реализована аппаратная поддержка технологий виртуализации — INTEL VT и AMD-V. Была проведена реализация дополнительных инструкций по предоставлению прямого доступа к ресурсам процессора из гостевых систем. Данный набор дополнительных инструкций получил наименование Virtual Machine Extensions (VMX).
Архитектура от AMD - AMDV схожа с VT и предоставляет набор аналогичных функциональных возможностей, при этом предоставляет также дополнительные функции, которые отсутствуют у Intel VT.
Технологии на основе VT-d позволяют избегать полной виртуализации на уровне устройств ввода-вывода. Использование VT-d, VMM позволяет проводить «прикрепление» драйверов физических устройств к виртуальнм машинам, что позволяет гостевым ОС осуществлять взаимодействие с прикрепленными устройствами без передачи управления виртуальной машине через механизм DMA (предполагающие прямой доступ устройств к ОЗУ минуя процессор) [10].
В следующем поколении аппаратной виртуализации были реализованы технологии по виртуализации памяти. Примерами техноогий данного класса являются: AMD NPT (Nested Page Tables) / Intel EPT (Extended Page Tables). При этом технологии HAP — следует рассматривать как маркетинговые технологии, так как в реальности обозначают одно и то же. Проведение вызова операций из гостевых ОС, проводится путем команды VMLAUNCH, после чего со стороны виртуальной машины начинается исполнение своего кода с дальнейшим использованием инструкции VMRESUME. Однако при проведении операций с памятью, гостевые ОС должны работать под управлением монитора виртуальных машин VMM с возможностью управления памятью (механизм имеет название Shadow Paging). Применение технологий Extended Page Tables (EPT) предполагает, что гостевые ОС могут самостоятельно работать со страницами памяти, включая осуществление контроля Page Faults, которые, проходят через гипервизоры и вызывают команду VMEXIT. Инструкция VMEXIT по сути представляет собой процесс передачи управления к монитору виртуальных машин гипервизора, который осуществляет действия в соответствии с поступающими инструкциями. Таким образом, чем меньше вызовов VMEXIT — тем лучше.
Далее проведем анализ технологий мобильной виртуализации.
Компанией VMware была продемонстрирована технология MVP (Mobile Virtualization Platform), представляющая гипервизор для мобильных устройств, который позволяет использовать на телефонах в оновременном режиме такие платформы, как Google Android и Windows Mobile. Разработка предназначена для создания на мобильных устройствах дополнительного защищенного окружения для работы с конфиденциальной информацией.
Раюота гипервизора MVP была продемонстрирована на планшетном ПК Nokia N800. Объема памяти в 128MB и 256MB Flash оказалось достаточно для возможности одновременного запуска двух виртуальных сред с установленными Windows CE 6.0 и Google Android [11].
TRANGO представляет собой гипервизор с технологией на базе виртуального процессора, который позволяет проводить запуск на мобильных устройствах с RISC-процессорами от ARM или MIPS нескольких гостевых операционных систем.
Компанией Citrix было проведено объединение своих усилий с группой разработчиков Open Kernel Lab (OK Lab) по созданию уникальной мобильной платформы, получившей название Nirvana Phone.
Технология Nirvana Phone рассматривается как гибридное решение, включающее функции карманных смартфонов и функций, реализованных в традиционных настольных гипервизорах. В системе имеется виртуальный рабочий стол XenDesktop, который легко может разворачиваться в полноценное рабочее место с возможностью подключения большого монитора, мыши и клавиатуры за счет использования мобильного клиентского модуля виртуализации OKL4 Microvisor 4.0. Самими разработчиками считается, что оптимальный способ подключения периферийных устройств будет связан с беспроводным интерфейсом
Bluetooth – использование данного канала позволяет использовать большое количество уже выпущенных серийно устройств.
2.2 Преимущества виртуализации
Интерес к технологиям виртуализации, возрастающий в настоящее время, объясняется достаточно просто - происходит смена парадигмы, использование одного сервера больше не предполагает работу в режиме "одного приложения". Устоявшиеся представления об использовании серверных ресурсов сменяются концепциями о возможности работы множества приложений, исполняемых физическом сервере в режиме функционирования SMP (симметричный мультипроцессинг). В большой степени это стало возможным вследствие увеличения вычислительных ресурсов и отставания роста нагрузки, создаваемой приложениями.
Технология SMP позволяет группировать что вычислительные мощности серверов пулы. Реализованы возможности добавления ресурсов в пулы, вывода из них и деления между различными приложениями, с консолидацией множества приложений на одном сервере.
В свою очередь, виртуальные машины являются компонентами более масштабных решений - виртуальной инфраструктуры, которые представляют возможности динамического распределения физических ресурсов, в зависимости от пользовательских запросов. Если посредством виртуальной машины используются ресурсы от конкретного компьютера, на котором она работает, то виртуальной инфраструктурой используются полностью все физические ресурсы ИТ-среды.
Далее рассмотрим преимущества использования виртуальных машин.
Какими бы техническими "изюминками" не обладало решение, его эффективность и целесообразность использования определяются обеспечиваемым им функционалом и преимуществами, по сравнению с иными способами решения тех же задач. Рассмотрим основные преимущества виртуализации [13]:
- работа виртуальной машины может производиться под управлением гостевых операционных систем и предполагает использование всех стандартных компонент компьютера, обеспечивается совместимость виртуальной машины со стандартными операционными системами, программными продуктами и т.д.;
- использование виртуальной машины позволяет полноценно работать с устаревшими программными продуктами и операционными системами;
- существуют возможности по созданию защищенного пользовательского окружения для работы с сетевыми ресурсами, в данном случае вирусные атаки могут наносить вред операционной системе, но не ресурсам виртуальной машины;
- разные виртуальные машины, развернутые на физических ресурсах, расположенных на одном компьютере, являются изолированными друг от друга, вследствие чего сбой на одной из виртуальных машин не повлечет на негативных последствий для работы сервисов и приложений на других виртуальных машинах;
- вследствие того, что каждая виртуальная машина является программным контейнером, то она может переноситься или копироваться, как и любой другой файл;
- работа виртуальных машин не зависит от аппаратного обеспечения, на котором они функционируют в том смысле, что в качестве значений параметров виртуальной машины, таких как ОЗУ, процессор и т.п., можно указать значения и типы, отличающиеся от реальных физических устройств, установленных на компьютере;
- виртуальные машины являются идеально подходящими инструментами для проведения обучения и переподготовки, поскольку позволяют разворачивать необходимую платформу независимо от параметров и настроек программного обеспечения на физическом компьютере, где работает виртуальная машина;
- возможности по сохранению состояния виртуальной среды позволяют быстро вернуться к состоянию до модификации системы;
- при работе одной гостевой операционной системы можно разворачивать несколько виртуальных сред, объединенных в сеть и обеспечивать взаимодействие между ними;
- Посредством виртуальных машин можно проводить создание представлений устройств, которые физически отсутствуют (эмуляторы устройств).
Рассмотрим основные недостатки применения виртуальных машин. Несмотря на то, что большая часть недостатков виртуальных машин может быть преодолена, перечислим основные из них [8]:
- для обеспечения одновременной работы нескольких виртуальных машин необходимо наличие достаточного объема вычислительных мощностей;
- в зависимости от используемых решений, операционные системы на виртуальных машинах могут работать с меньшей производительностью, чем на "чистом" идентичном аппаратном обеспечении;
- возможны ситуации, когда эмуляция того или иного аппаратного обеспечения не будет доступна вследствие наличия проблем совместимости.
2.3 Семейства решений виртуализации
Проведем краткую характеристику наиболее распространенных линеек разработок виртуальных машин.
1. Microsoft – является относительно новым игроком, вышедшим на рынок после приобретения ПО Virtual PC разработчика Connectix. В настоящее время данное решение поставляется в двух вариантах, которые значительно отличаются по реализации для Windows и Mac. Соответственно, первая из них является эмулятором периферийных устройств, в то время как вторая представляет собой полный эмулятор вследствие того, что значительная часть ее пользователей все еще использует PowerPC. Обе системы поддерживают работу эмулируемых устройств, которые имеют реально существующие аналоги, в комплект входят специальные упрощенные версии драйверов для ОС от Microsoft. Таким образом, применение Virtual PC рассчитано на конечных пользователей, которым, по некоторым причинам, необходимо работать с несколькими одновременно запущенными ОС без особых требований к быстродействию [15].
Вторым продуктом компании является ПО Virtual Server – в соответствии со своим наименованием он позиционируется как технология виртуализации серверных операционных систем. По принципам работы он схож с Virtual PC для Windows, при этом имеются значительные улучшения в параметрах производительности, что делает возможным использование данного продукта в сетевых средах. Способствует этому и характерная методика управления – с использованием Web-интерфейса, вплоть до возможности подключения к терминалу виртуальной машины посредством интегрированного ActiveX-компонента. В комплекте поставки имеются также специальные, «облегченные» клиенты, обеспечивающие только возможность подсоединения к виртуальным машинам, без возможности их конфигурации либо в режиме просмотра статистики. К гостевым ОС, работающим с данной технологией, в настоящее время относятся Windows и Linux, причем полноценная поддержка работы с Linux реализована совсем недавно, соответственно, прежде всего предполагается поставка оптимизированных драйверов. Однако в силу того, что Virtual Server позволяет эмулировать стандартное оборудование (Ethernet-контроллеры DEC Tulip, «безымянные» IDE, SCSI-адаптеры от Adaptec), то в системе вполне возможным является запуск, например, FreeBSD, хотя в сопроводительной документации сказано о возможности потерь в быстродействии при использовании данной ОС.
2. VMware является старым игроком на рынке технологий виртуализации. Компанией предлагается значительно более широкий спектр ПО и в настоящее время в данном сегменте VMware является неоспоримым лидером. Тем не менее, напряженность в конкурентной борьбе свидетельствует о наличии нескольких фактов, в частности выпуска бесплатного ПО VMware Player и обещание реализовать бесплатную версию VMware Server, служащий для замены VMware GSX Server. С точки зрения архитектуры все данные продукты функционально схожи с напоминают конкурирующими разработками Microsoft и в целом обеспечивают схожие параметры производительности (при проведении различных тестов зачастую показываются полностью противоположные результаты) и функциональности, при этом каждое решение имеет как достоинства, так и недостатки. Естественно, достоинством VMware является возможность полноценной работы в среде Linux.
При этом, в линейке ПО от VMWare реализовано ПО VMware ESX Server, представляющее собой полноценный hypervisor. Данное решение позиционируется для использования в корпоративных средах для решения задач, требовательных к вычислительным ресурсам, имеется поддержка ряда технологий, отсутствующих у конкурирующих разработок других компаний (например, работа с виртуальной многопроцессорностью). Также имеется ряд сопутствующих продуктов для администрирования виртуальных систем. Таким образом, на настоящий момент данное решение является оптимальным по соотношению цены, качества и производительности.
Также, в продуктах VMware значительное внимание уделяется некритичным, но довольно полезным функциям, к которым можно отнести: откат состояния виртуальных дисков, наличие средств миграции и др., – способным существенно упростить процессы по развертыванию и обслуживанию решений [14].
3. Xen – разработка для платформы x86, способная работать в различных гостевых ОС (Linux, NetBSD/FreeBSD, Plan 9, Minix, Solaris). В данной системе используются технологии, получившие название «паравиртуализации» и включающая hypervisor и специальные программные прослойки, эмулирующие аппаратное обеспечение. Однако для обеспечения необходимых параметров взаимодействия с hypervisor и необходимых характеристик производительности указанный подход предполагает необходимость модификации кода в гостевых ОС, что, очевидно, закрывает возможность использования Windows. В то же время текущая версия Xen предоставляет возможность использования ОС от Microsoft – благодаря использованию технологий аппаратной поддержки технологий виртуализации от Intel и наличию специальных системных драйверов. Вообще на фоне остальных решений в области виртуализации для x86 подходы от Xen предполагают оптимальное обеспечение самых современных возможностей, в том числе многопроцессорности и 64-разрядности виртуальной среды [12].
4. Семейство решений от компании Parallels.
Данное ПО используется для решения задач пользовательского класса, аналогичных решениям от VMware Workstation и Microsoft Virtual PC. В настоящее время используется решение Parallels Workstation для Mac OS X/Intel. Данное ПО представляет интерес в том плане, что обеспечивает на современных компьютерах оптимальные параметры производительности, чем в обычной системе от Windows, организованной с помощью Boot Camp. Производительность обеспечивается особенностями реализации дисковых подсистем в ПО Parallels Workstation.
При этом, существуют затруднения при осуществлении из виртуальных сред прямого доступа к 3D-функциям видеокарты, в качестве исключения можно отметить экспериментальную поддержку Direct3D в ПО VMware Workstation, однако реализация данных функций проведена при многочисленных ограничениях и без каких-либо возможностей по параметрам быстродействия, что делает ее использование неэффективным [11].
2.4 Виртуализация на уровне операционной системы
Виртуализация на уровне операционной системы (контейнерная виртуализация) — технология виртуализации, при которой ядром операционной системы поддерживается несколько изолированных экземпляров пользовательских пространств, вместо одного. Данные экземпляры (зачастую называемые контейнерами или зонами) с пользовательской точки зрения являются полностью идентичными реальным серверам. Для систем на основе UNIX, данная технология может быть рассмотрена как улучшение реализации механизмов chroot. Ядром обеспечивается полная изолированность контейнеров, поэтому экземпляры ПО из разных контейнеров не могут воздействовать друг на друга.
Основным отличием виртуализации на уровне операционной системы является то, что проводится виртуализация не компьютера и не операционной системы, а пользовательского окружения ОС. Данные экземпляры пользовательского окружения, называемые также контейнерами, являются полностью идентичными основному серверу и используют общее ядро операционной системы [12].
При виртуализации на уровне операционной системы не существует отдельного слоя гипервизора. Вместо этого самой хостовой операционной системой производится разделение аппаратных ресурсов между несколькими виртуальными машинами и поддержка их независимости друг от друга. Для пользователей каждый контейнер выглядит как отдельный сервер, который он может настраивать в соответствии со своими потребностями, устанавливать программное обеспечение, проводить выключение, перезагрузку.
Одним из наиболее популярных решений для данного типа виртуализации является OpenVZ и коммерческое ПО на его базе Virtuozzo, в настоящее время приобретает известность разрабатываемый при поддержке IBM LXC (Linux Containers), на аналогичных принципах работают FreeBSD Jail и Solaris Containers/Zones. Среди решений подобного типа выделяют также [10]:
- Linux-VServer
- FreeVPS
- OpenVZ
- iCore Virtual Accounts
Технологии работы с контейнерами рассмотрены в следующем разделе.
3. Технология контейнеров
3.1. История и определения
В 2005 году компанией Google была проведена разработка решений по массовому предоставлению Web-сервисов, в части поиска способов по эластичному масштабированию ресурсов в собственном ЦОД для того, чтобы каждый пользователь имел возможности получения достаточного уровня сервиса в любой момент времени, в независимости от текущей загрузки системы, а оставшиеся ресурсы было возможно использовать для решения служебных фоновых задач.
Эксперименты с традиционными технологиями виртуализации сотрудники Google показали, что они не полностью соответствуют указанным задачам. Главная проблема заключалась в слишком больших потерях в производительности (вследствие слишком низкой плотности) и наличии недостаточно эластичного отклика для динамической переконфигурирации системы под изменившиеся параметры нагрузки для массовости предоставления услуг Web-сервисов.
Последний пункт является очень важным, вследствие того, что заранее предсказать количество запросов, обслуживаемых Web-сервисами, не всегда возможно. Ввиду того, что пользователи при работе с системой всегда ожидают немедленного отклика в независимости от того, сколько именно других пользователей в данный момент работают с системой. Среднее время загрузки гипервизорных виртуальных машин составляет десятки секунд, поэтому данный тип виртуализации не подходит для решения этой задачи.
В то же самое время группой разработчиков проводились эксперименты с Linux и концепциями, основаннями на механизмах cgroups — так называемых контейнерах процессов. Компания Google использовала этих специалистов для разработки системы контейнеризации своих ЦОД в цельях решения проблемы эластичности при масштабировании. В январе 2008 года были завершены работы по перенесению в ядро Linux части технологии cgroup, используемой Google,. В 2011 году компании Google и Parallels пришли к соглашению о сотрудничестве в области контейнерных технологий. Результатом стал выпуск ядра Linux версии 3.8, представленный в 2013 году. В данном релизе было проведено объединение всех актуальных на тот момент контейнерных технологий для Linux, что позволило избежать повторения ошибок при разделении ядер, как в случае с KVM и Xen [3].
На рисунке 2 показана схема гипервизорной виртуализации.
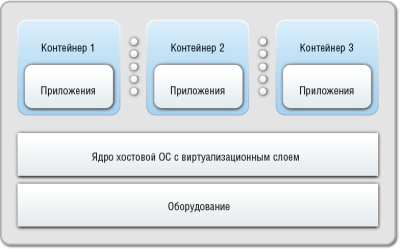
Рис. 2 - Схема гипервизорной виртуализации
Алгоритм работы гипервизора предполагает выполнение алгоритма (рисунок 2): операционной системой хоста эмулируется аппаратное обеспечение, поверх далее проводится запуск гостевых операционных системы. Это предполагает, что взаимная связь между гостевой и хостовой ОС следует правилу: весь возможный функционал оборудования в виртуально среде, должен быть доступен гостевой ОС со стороны хостовой. Напротив, контейнеры (рисунок 8) предполагают виртуализацию на уровне операционной системы, а не оборудования. Отсюда следует преимущество: они меньше и компактнее, чем гипервизорные гостевые среды, поскольку у них с хостом гораздо больше общего.
Контейнеры являются управляемыми ресурсами. Например, если Контейнеры 1 и 2 работают с одним и тем же файлом, ядром хоста открывается этот файл с размещением страницы из него в страничном кэше ядра, который далее передается Контейнерам 1 и 2. При обращении к файлу из обеих контейнеров, производится обращение одной и той же странице памяти. При необходимости выполнения аналогичной операции гипервизорными виртуальными машинами VM1 и VM2, то сначала производится открытие запрашиваемого файла хостом (через создание страницы в своем страничном кэше), и далее каждое из ядер VM1 и VM2 производит аналогичное действие. Таким образом, при чтении машинами VM1 и VM2 одних и тех же файлов в памяти отводится целых три идентичных страницы (по одной в страничном кэше хоста и в ядрах VM1 и VM2), в силу того, что не существует гипервизорной технологии по одновременному использованию одной и той же страницы, как это сделано в контейнерах.
В обычных системах, если два или более процесса проводят обращение к идентичным разделяемым библиотекам (например, libc), ее код присутствует в памяти только в одном экземпляре. Это характерно и для исполняемых файлов, и к сегментам немодифицируемых данных, что дает возможности существенного снижения требований к объему оперативной памяти. Так как контейнерами также используется единое ядро, вышеописанные механизмы при некоторых условиях распространяется и на них, что приводит, в частности, к повышению плотности размещения информации, которая и без данного механизма изначально выше, чем у виртуальных машин, в силу отсутствия множественных копии ядра [4].
Таким образом, у контейнеров плотность (число виртуальных сред, запускаемых на сервере) может в три раза выше, чем у виртуальных машин, а на одном сервере вполне может быть размещено несколько сотен контейнеров. Высокие значения плотности является одной из главных причин популярности контейнеров на рынке хостинга виртуальных выделенных серверов (VPS). Если на одном и том же сервере возможно создание троекратно большего количества VPS, то в расчете на один VPS предполагается снижение затрат на 66%, что для бизнеса с низкой маржинальностью, как хостинг, является определяющим фактором.
Основными преимущемствами контейнерной виртуализации являются [7]:
- Выполнение контейнеров на одном уровне с физическими серверами. Отсутствует виртуализованное оборудование, использование реальных аппаратных устройств и драйверов позволяют получать оптимальные параметры производительности.
- Для каждого контейнера возможно масштабирование до производительности целого физического сервера.
- Технологии виртуализации на уровне операционной системы позволяют добиться высочайшей плотности (число выделенных виртуальным операционным системам ресурсов может значительно превышать ресурсы сервера). Этого можно достичь за счет того, что использование единого экземпляра ядра и общих динамических библиотек позволяет существенно экономить ресурсы памяти. Возможна реализация и запуск нескольких сотен контейнеров на одном обычных физических серверах.
- Контейнерами используется единая ОС, что делает задачу по их поддержке и обновлению очень простыми. Развертывание приложений может производиться в отдельном окружении.
3.2 Типы технологии контейнеров (Семейство решений)
Разработчиками Windows до недавнего времени предлагались следующие технологии виртуализации: виртуальные машины и виртуальные приложения Server App-V. Каждая из них имеет свою нишу использования, свои достоинства и недостатки. В настоящее время ассортимент расширился — в Windows Server 2016 включены контейнеры (Windows Server Containers). Главным отличием является то, что в системе предложены следующие виды контейнеров: контейнеры Windows и контейнеры Hyper-V. В TP3 были доступны только первые.
Контейнеры семейства Hyper-V обеспечивают дополнительные уровни изоляции с использованием Hyper-V. Для каждого из контейнеров выделяется собственное ядро и ресурсы памяти, изоляция осуществляется не ядром ОС, а гипервизором Hyper-V. В результате возможно достижение такого же уровня изоляции, как у виртуальных машин, при меньших затратах по сравнению с VM, но большей, по сравнению с контейнерами Windows. Для возможности использования такого типа контейнеров необходима установка на хосте роли Hyper-V. Контейнеры Windows по большей части подходят для применения в доверенных средах, например когда на серверах производится запуск приложений от одной организации. Когда сервер используется множеством компаний и необходимо обеспечивать больший уровень изоляции, использование контейнеров Hyper-V, вероятнее, будут более рациональным решением.
Важной особенностью контейнеров в Win 2016 является то, что выбор типа проводится не в момент создания, а в моменты деплоя. То есть запуск любого контейнера может производиться как Windows, и как Hyper-V.
В ОС Win 2016 за контейнеры отвечают абстракции Contаiner Management stack, реализующие все необходимые функции. При хранении применяется формат образа жесткого диска типа VHDX. Сохранение контейнеров, производится в образы в репозитории. Причем сохранение осуществляется не для полного набора данных, а только для отличий создаваемого образа от эталонного, и в момент запуска производится проецирование всех нужных данных в память. При управлении сетевым трафиком между контейнерами и физической сетью используется Virtual Switch.
В качестве ОС в контейнерах может использоваться Server Core или Nano Server. С помощью Server Core обеспечивается необходимый уровень совместимости с имеющимися приложениями. Nano Server представляет собой еще более урезанную версию для работы без мониторов, позволяющую проводить запуск сервера в минимально возможной конфигурации для работы с Hyper-V, ресурсами файлового сервера (SOFS) и облачными службами.
Докер — это открытая платформа для разработки, доставки и эксплуатации приложений. Docker разработан для более быстрого выкладывания ваших приложений. С помощью docker вы можете отделить ваше приложение от вашей инфраструктуры и обращаться с инфраструктурой как управляемым приложением. Docker помогает выкладывать ваш код быстрее, быстрее тестировать, быстрее выкладывать приложения и уменьшить время между написанием кода и запуска кода. Docker делает это с помощью легковесной платформы контейнерной виртуализации, используя процессы и утилиты, которые помогают управлять и выкладывать ваши приложения.
В своем ядре docker позволяет запускать практически любое приложение, безопасно изолированное в контейнере. Безопасная изоляция позволяет вам запускать на одном хосте много контейнеров одновременно. Легковесная природа контейнера, который запускается без дополнительной нагрузки гипервизора, позволяет вам добиваться больше от вашего железа.
Платформа и средства контейнерной виртуализации могут быть полезны в следующих случаях:
- упаковка приложения (а также используемых компонент) в docker контейнеры;
- раздача и доставка этих контейнеров командам для проведения разработки и тестирования;
- выкладывание данных контейнеров на продакшены, как в Data-центры так и в облака
Solaris Containers (включая Solaris Zones) представляет собой реализацию технологии виртуализации на уровне операционной системы, разработки корпорации Sun Microsystems в 2005 для Solaris 10.
Зоны функционируют в форме полностью изолированных виртуальных серверов внутри единого экземпляра операционной системы. При запуске множества служб на одной системе и помещении каждой из них в свой виртуальный контейнер, системным администратором может создаваться на одной машине единообразный уровень защиты, как если бы все службы функционировали на разных машинах.
Для каждой зоны имеется своё уникальное имя в сети, виртуальные сетевые интерфейсы и системы хранения информации; не существует ограничений на минимальные параметры поддерживающей работу с зоной аппаратуры обеспечения кроме минимально необходимого дискового пространства, используемого для сохранения уникальных данных о конфигурации зоны. Необходимо отметить, что зоны Solaris не нуждаются в выделенных процессорах, ОЗУ, физических сетевых интерфейсах или HBA, при этом любой из процессоров может быть выделен для зоны.
В каждой зоне реализована система защиты, не позволяющая процессам осуществлять взаимодействие с процессами других зон или проводить слежение за ними. Для каждой из зон задается собственный список пользователей. В системе возможно автоматическое разрешение конфликтов при использовании одинаковых пользовательских идентификаторов в различных зонах; например, две зоны в системе могут иметь пользователя с ID 9000.
Некоторые из программы не могут выполняться внутри неглобальных зон. Как правило, это происходит вследствие того, что приложению необходимы привилегии, которые по каким-либо причинам не предоставлены внутри контейнера. В силу того, что зона не имеет собственных ядер (в отличие от аппаратной виртуальной машины), приложения, требующие непосредственной работы с функциями ядра, могут не функционировать в контейнерах.
Особенности Solaris Zones:
Безопасность – приложения, запущенные в зоне, запущены в «песочнице», то есть процесс, даже запущенный от имени root в рамках зоны, не может повлиять на другие зоны или на global зону (управляющую, корневую зону). Перезагрузка или выключение доступно только из global зоны.
Изоляция – зоны имеют исключительное право на выделенные ей ресурсы; зоны могу иметь своих собственных пользователей и свое собственного пользователя root. Перезагрузка зоны никак не может повлиять на другие зоны, работающие на хосте
Гибкость – ресурсы зоне могу быть назначены жестко или зона может использовать общий пул ресурсов хоста.
Проведение установки виртуальных зон может производиться в следующем порядке [6]:
Определение и установка базовой системы. Очень важный предварительный этап, поскольку от корректно установленной базовой системы зависит не только то, какими впоследствии будут образованы виртуальные зоны, но и работоспособность всей системы в целом. Здесь важно правильно определиться со списком устанавливаемых продуктов, которые будут нужны для работы системы. Конечно, всегда можно будет доставить или, наоборот, удалить какие-либо продукты, но это потребует дополнительного анализа, средств и времени. Поэтому еще при инсталляции базовой системы строго следите за тем, что устанавливаете. Рекомендуется, также, после инсталляции и перед конфигурированием зон, провести установку исправлений системы и настроить основные параметры для глобальной зоны. Все это существенно повысит надежность и безопасность вашей системы в целом.
Заключение
В настоящее время разработка систем распределенных вычислений получает широкое распространение, что связано с ростом количества вычислительных задач, требующих значительных вычислительных ресурсов. Например, услугами организаций, предлагающих проведение распределенных вычислений, пользуются организации, которые провели централизацию информационных ресурсов и требуется обеспечение возможности доступа к данным, а также сохранности, требуемых параметров скорости обработки информации. На сегодняшний день введено в строй большое количество Дата-центров, предоставляющих услуги аренды серверов для проведения вычислений и хранения данных организаций, имеющих сложную филиальную структуру.
В рамках данной работы рассмотрены основные виды использования распределенных вычислений через кластеризацию, виртуализацию или использование контейнеров, определены области применимости для каждой из технологий распределенных вычислений. Рассмотрев технологии по оптимизации вычислительных ресурсов, можно сделать вывод о возможности рационального использования вычислительных систем через создания кластеров, посредством которых достигаются оптимальные характеристики по вычислительным мощностям. Использование виртуальных сред позволяет достичь максимальной независимости от аппаратной вычислительной среды, предоставляет возможности моделирования различных аппаратных систем, а также позволяет работать с программными средствами, которые не функционируют в условиях реальной аппаратной среды.
Использование контейнеров также позволяет распределять вычислительную нагрузку, оптимизировать работу с виртуальными средами.
Список использованных источников
- Гультяев, А.К. Виртуальные машины: несколько компьютеров в одном / Гультяев А.К. - СПб.: Издательский дом «Питер», 2014. - 315с.
- Ежова, Е.В. Контейнерная виртуализация в различных средах/ Ежова Е.Н. . - Москва: Мир, 2014. - 370 c.
- Лэнгоун, Джейсон Виртуализация настольных компьютеров с помощью VMware View 5: моногр. / Джейсон Лэнгоун , Андрэ Лейбовичи. - М.: ДМК Пресс, 2013. - 280 c.
- Багдасарян Е.А., Королев В.С., Черненький М.В. Архитектура системы управления рабочим процессом // Инженерный вестник: электронный научно-технический журнал МГТУ им. Н.Э. Баумана . 2013. № 10. С. 519 - 526.
- Виноградова М.В., Белоусова В.И., Мельник В.Н. Концепции разработки и организации системы прозрачного доступа к файлам больших объемов и raid -массивам в распределенной разнородной среде // Инженерный вестник : электронный научно-технический журнал МГТУ им. Н.Э. Баумана . 2013. № 9. С. 549 - 560.
- Черненький В.М., Гапанюк Ю.Е. Кластеризация аппаратных ресурсов. // Инженерный журнал: наука и инновации. / Электронное научно-техническое издание. 2012. № 3(3). С. 30 – 39.
- Виноградов В.И., Мазнев В.Г. Технологии использования контейнеров в средах виртуализации // Инженерный журнал: наука и инновации/ Электронное научно-техническое издание. 2014. № 3 (3). С. 13 - 19. Режим доступа
- Постников В.М., Спиридонов С.Б. Подход к расчету весовых коэффициентов ранговых оценок экспертов при выборе варианта развития информационной системы // Наука и образование: электронное научно-техническое издание МГТУ им. Н.Э. Баумана. 2013. № 8. С. 395 - 412.
- Галкин В.А., Осипов А.В. Оценка параметров системы мониторинга рабочих станций в локальной вычислительной сети // Инженерный вестник : электронный научно-технический журнал МГТУ им. Н.Э. Баумана . 2014. № 10. С. 528 - 539
- Windows Server 2012 R2. Полное руководство. Том 2. Дистанционное администрирование, установка среды с несколькими доменами, виртуализация, мониторинг и обслуживание сервера. - М.: Диалектика, 2015. - 864 c
- Lublinsky B., Smith K.T., Yakubovich A. Professional Hadoop Solutions. United States: Wrox Press, 2013.504 p.
- White T. Hadoop: The Definitive Guide, 4th Edition. O’Reilly Media, Incorporated. 2015. 768 p.
- Schulz G. Cloud and virtual data storage networking: your journey to efficient and effective information services. CRC Press - Taylor & Francis Group, 2014. 370 p.
- Ивасенко, А.Г. Информационные технологии в менеджменте /А. Г. Ивасенко, А. Ю. Гридасов, В. А. Павленко.-М.: КноРус, 2009.-153 с.
- Информационные технологии: [учеб. для студентов вузов, обучающихся по специальности 080801 "Прикладная информатика" и др. экон. специальностям /В. В. Трофимов и др.] ; под ред. проф. В. В. Трофимова.-М.: Юрайт, 2009.-624 с.
- Карпова Т. С. Базы данных: модели, разработка, реализация.- СПб.: Питер, 2014. – 302с.
- Коноплева, И.А. Моделирование бизнес-систем /И. А. Коноплева, О. А. Хохлова, А. В. Денисов.-М.: Проспект, 2010.-294 с.
- Марков И.С., Бедрина С.Л. Информационные системы в деятельности промышленных предприятий // Современная техника и технологии. 2016. № 7 [Электронный ресурс]. URL: http://technology.snauka.ru/2015/07/7507
- Граничин, О.Н. Информатика в экономике /О. Н. Граничин, В. И. Кияев.-М.: Интернет-Ун-т Информ. Технологий, 2014.-335 с.
- Грекул В. И., Денищенко Г. Н., Коровкина Н. Л. Разработка информационных систем. — М.: Интернет-университет информационных технологий – М.: ИНТУИТ.ру, 2015. с.135
- Гринберг, А.С. Безопасность эксплуатации информационных систем /А.С. Гринберг, Н.Н. Горбачев, А.С. Бондаренко.-М.: ЮНИТИ, 2014.-479 с.

- Правовое регулирование приватизации государственных и муниципальных предприятий (Значение и цели приватизации)
- Понятие и виды наследования (Наследование в гражданском праве как научные и практические проблемы)
- Понятие и виды наследования (Наследование в гражданском законодательстве)
- Защита сетевой инфраструктуры предприятия
- "Нотариат его роль в защите гражданских прав и охраняемых законом интересов"
- Нотариат и его роль в защите гражданских прав и охраняемых законом интересов (Возникновение нотариата)
- Нотариальные действия. Понятие нотариального действия и условия его действительности
- Государственное регулирование предпринимательской деятельности (Государственная поддержка малого и среднего предпринимательства в муниципальных образованиях)
- Нотариат и его роль в защите гражданских прав и охраняемых законом интересов (Нотариат в правовой системе России)
- Аудиторская деятельность как вид предпринимательства: общая характеристика
- Роль информационного права и информационной безопасности в современном обществе (Международное информационное право)
- Проектирование реализации операций бизнес-процесса «Управление персоналом» (на примере ООО «Лайнкор»)