
Определение и задачи распределенной системы (ГЛАВА 1. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ ОСНОВЫ РАСПРЕДЕЛИТЕЛЬНОЙ СИСТЕМЫ)
Содержание:

ВВЕДЕНИЕ
Актуальность данной темы состоит в том, что в мировой экономике происходят процесса глобализации и информационной интеграции. Они затронули и нашу страну, которая в силу географического положения и размеров вынуждена применять распределенные информационные системы (ИС). Распределенные ИС обеспечивают работу с данными, расположенными на разных серверах, различных аппаратно-программных платформах и хранящимися в различных форматах. Они легко расширяются, основаны на открытых стандартах и протоколах, обеспечивают интеграцию своих ресурсов с другими ИС, предоставляют пользователям простые интерфейсы.
C самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность информации.
Но поскольку информационные системы требуют сложных структур данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной создания различных систем управления.
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных, например, хранение информации в нескольких файлах. Таким образом, все это способствовало созданию распределенных информационных систем.
Именно распределенная система баз данных осуществляет обеспечение средствами слияния локальных баз данных, находящихся в определенных узлах вычислительной сети, с тем, чтобы пользователь, который работает в каком-то узле сети, располагал доступом ко всем существующим базам данных как к единой базе данных.
Объектом исследования являются распределенные базы данных.
Предметом исследования является изучение видов распределенных баз данных, а также процессы их функционирования.
Цель работы состоит в исследовании и анализе распределенных баз данных, а также распределенных систем баз данных.
Основываясь на поставленной цели, можно выделить следующие задачи исследования:
1. определить понятия распределенных баз данных и системы управления базой данных;
2. проанализировать реализацию систем распределенных баз данных;
3. изучить основы проектирования распределенных баз данных.
Структура исследования. Данная работа состоит из введения, 2 глав, заключения и списка литературы.
ГЛАВА 1. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ ОСНОВЫ РАСПРЕДЕЛИТЕЛЬНОЙ СИСТЕМЫ
1.1 Определение распределенной системы
До 80-х годов прошлого века компьютерные системы были большими и дорогими. Соответственно большинство организаций имели в лучшем случае несколько компьютеров, работающих как правило независимо друг-от-друга.
С середины 80-х ситуация начала меняться, чему способствовали два фактора:
появление первых микропроцессоров и соответственно основанных на них компьютеров;
появление высокоскоростных компьютерных сетей.[3]
Локальные сети (Local Area Network, LAN) соединяют сотни компьютеров, находящихся в здании. В результате компьютеры могут обмениваться данными на очень больших скоростях (100 Mbit/s, 1 Gbit/s, бывает больше, но редко).
Глобальные сети (Wide Area Network, WAN) позволяют компьютерам по всему миру обмениваться информацией между собой. Скорости, как правило, ниже чем в LAN.
В результате на сегодняшний день достаточно легко можно собрать компьютерную систему состоящую из множества компьютеров соединенных высокоскоростной сетью которая обычно называется компьютерной сетью или распределенной системой (distributed system) в отличие от централизованных (sentralized system) или однопроцессорных (single-processor system) систем.
В вольной трактовке распределенную систему можно определить как набор независимых компьютеров, предоставляющейся их пользователю в виде единой обьединенной системы.
В этом определении следует выделить два момента:
Аппаратура - все компьютеры автономны;
Программное обеспечение - пользователь думает, что имеет дело с единой системой.
К важнейшим характеристикам распределенных систем следует отнести следующие:
От пользователя скрыты различия между компьютерами и способы связи между ними;
Способ, при помощи которого пользователи и приложения единообразно работают в такой системе;
Распределенные системы должны относительно легко поддаваться расширению (масштабирование);
Пользователи и приложения не должны зависеть от того, что часть системы может временно выйти из строя. [10]
Для поддержания представления различных компьютеров и сетей в виде единой системы распределенные системы часто включают в себы дополнительный уровень ПО, находящийся между верхним уровнем (на котором работают пользователи и приложения) и нижним уровнем (на котором находятся операционные системы). Такая система обычно называется системой промежуточного уровня (middleware).
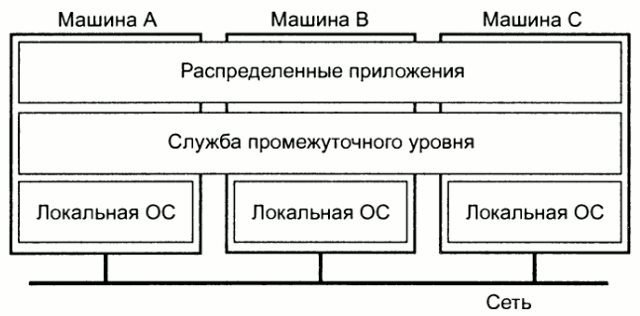
Некоторые примеры распределенных систем:
Сеть рабочих станций в университетской лаборатории. Эта распределенная система может обладать единой файловой системой, в которой все файлы одинаково доступны для всех машин с использованием постоянного пути доступа.
Система автоматической обработки заказов. Обычно подобные системы используются сотрудниками различных отделов, возможно находящимися в разных местах. Заказы передаются с мобильных терминалов (ноутбуки, КПК, телефоны). Приходящие заказы автоматически пересылаются в отдел планирования преобразуясь там во внутренние заказы на поставку которые поступают в отдел доставки и в заявки на оплату поступающие в бухгалтерию. Пользователи остаются в неведении о том, как заказы курсируют внутри системы, для них все представляется так, будто вся работа происходит в централизованной базе данных. [4]
Всемирная Паутина (World Wide Web, WWW) предоставляет простую, целостную и единообразную модель распределенных документов. Публикация документа очень проста - вы должны только задать ему имя в виде унифицированного указателя ресурса (Unified Resource Locator, URL), которое ссылается локальный файл с содержимым документа. В идеале, если-бы WWW предоставлялась пользователям гигантской системой документооборота, она могла-бы считаться истинно распределенной системой. На практике это не так, так-как пользователи осознают, что документы находятся в разных местах и распределены по различным серверам.
1.2 Задачи распределенных систем
Рассмотрим четыре важнейшие задачи, решение которых делает построение распределенных систем осмысленным.
Задача 1. Доступ пользователей к ресурсам
Основная задача распределенной системы - облегчить пользователям доступ к удаленным ресурсам и обеспечить их совместное использование, регулируя этот процесс. Традиционно ресурсы включают в себя: принтеры, компьютеры, устройства хранения данных, файлы и данные. Одна из очевидных причин совместного использования ресурсов - экономичность. Другая очевидная причина - облегчение кооперации и обмена информацией.
Так, широкое использование сети интернет привело к появлению концепции виртуального офиса, когда географически удаленные друг от друга группы сотрудников работают вместе при помощи систем групповой работы (groupware) - программ для совместного редактирования документов, проведения презентаций и т.д. [12]
Стоит заметить, что по мере роста степени совместного использования ресурсов все более и более важными становятся вопросы безопасности.
Задача 2. Прозрачность
Сокрытие того факта, что процессы и ресурсы физически распределены по множеству компьютеров - важная задача распределенных систем. Распределенные системы, которые представляются пользователям и приложениям в виде единой компьютерной системы называют прозрачными (transparent).
Концепция прозрачности применима к различным аспектам функционирования распределенных систем:
Доступ (access transparency). Скрывается разница в представлении данных и доступа к ресурсам. Например, при передаче целого числа с компьютера на базе процессора Intel x86 на компьютер на базе процессора Sun SPARC следует учитывать, что на Intel используется Little Endian представление целых чисел, а на SPARC - Big Endian.
Местоположение (location transparency). Скрывается местоположение ресурса. Важную роль в реализации прозрачности местоположения имеет именование. Например URL http://www.yandex.ru/index.html не содержит никакой информации о реальном местоположении сервера Яндекса.
Перенос (migration transparency). Скрывается факт переноса ресурса в другое место. Т.е. смена местоположения ресурса не влияет на доступ к нему.
Смена местоположения (relocation transparency). Скрывается факт перемещения ресурса в другое место в процессе обработки. В качестве примера - мобильные пользователи, работающие с беспроводным переносным компьютером и не отключающиеся от сети при переходе с места на место.
Репликация (replication transparency). Скрывается факт репликации ресурса, т.е. существования нескольких копий ресурса. Для скрытия факта репликации необходимо, чтобы все реплики (копии) имели одно и то-же имя. Соответственно система, которая поддерживает прозрачность репликации должна поддерживать и прозрачность местоположения. [11]
Параллельный доступ (concurrency transparency). Скрывает факт возможного совместного использования ресурса несколькими пользователями одновременно. Такой параллельный доступ к совместно используемому ресурсу сохраняет этот ресурс в непротиворечивом состоянии. Для обеспечения непротиворечивости может быть использован механизм блокировок или механизм транзакций (хотя реализация механизма транзакций - очень непростая задача в рамках распределенной системы)
Отказ (failure transparency). Скрывается факт выхода из строя и восстановления ресурса. Лэсли Лампорт: "Вы понимаете, что у вас есть эта штука, поскольку при поломке компьютера вам никогда не предлагают приостановить работу". Основная трудность состоит в сложности отличить неработоспособный ресурс от ресурса с очень медленным доступом.
Сохранность (persistence transparency). Скрывается, хранится программный ресурс на диске или находится в оперативной памяти. Например, многие объектно-ориентированные базы данных предоставляют возможность непосредственного вызова методов для сохранных объектов. Сервер БД при этом копирует состояние объекта в оперативную память, вызывает метод объекта запрошенный пользователем и сохраняет новое состояние объекта на диск. Пользователь об этой цепочке ничего не знает.
Несмотря на то, что прозрачность в общем желательна для любой распределенной системы, существуют ситуации когда попытки скрыть от пользователя всякую распределенность не слишком разумны. Существует паритет между высокой степенью прозрачности и производительностью системы. Таким образом можно сказать, что достижение прозрачности - это разумная цель при проектировании и разработке распределенных систем, но она не должна рассматриваться в отрыве от других характеристик системы.
Задача 3. Открытость
Открытая распределенная система (open distributed system) - это система, предполагающая службы, вызов которых осуществляется с использованием стандартизированного синтаксиса и семантики.
В распределенных системах службы обычно определяются через интерфейсы, которые описываются некоторым образом, например в помощью специального языка определения интерфейсов (Interface Definition Language, IDL). Описание интерфейсов касается в основном синтаксиса служб, семантика-же должна быть описана отдельно, чаще всего средствами естественного языка (в виде документов-спецификаций и комментариев). [14]
Будучи правильно описанным определение интерфейса допускает возможность совместной работы произвольного процесса, нуждающегося в таком интерфейсе, с другим произвольным процессом, реализующим этот интерфейс.
Способность к взаимодействию (interoperability) характеризует насколько две реализации системы в состоянии совместно работать, полагаясь только на то, что службы каждой из них соответствуют общему стандарту.
Переносимость (portability) характеризует то, насколько приложение, разработанное для распределенной системы A может без изменений выполняться в распределенной системе B.
Гибкость (flexibility) характеризует легкость конфигурирования системы, состоящей из различных компонентов, возможно от разных производителей. Добавление к системе новых компонентов или замена существующих не должно вызывать затруднений. Гибкость == расширяемость.
В построении гибких открытых распределенных систем решающим фактором оказывается организация этих систем в виде наборов относительно небольших и легко заменяемых или адаптируемых компонентов. Это предполагает не только описание интерфейсов верхнего уровня, но также и интерфейсов внутренних модулей приложения и описания взаимодействия этих модулей.
Задача 4. Масштабируемость
Масштабируемость системы может измеряться по трем различным показателям:
Система может быть масштабируемой по отношению к ее размеру, что означает легкость подключения к ней дополнительных пользователей и ресурсов.
Система может быть масштабируемой географически, т.е. пользователи и ресурсы могут быть разнесены в пространстве.
Система может быть масштабируемой в административном смысле, т.е. быть проста в управлении при работе во множестве административно-независимых организаций.
Рассмотрим масштабирование по размеру. При необходимости увеличить число пользователей или ресурсов могут возникнуть ограничения, связанные с централизацией служб, данных и алгоритмов. Например:
|
Концепция |
Пример |
|
Централизованные службы |
Один сервер на всех пользователей |
|
Централизованные данные |
Единый телефонный справочник |
|
Централизованные алгоритмы |
Организация маршрутизации на основе полной информации |
Иногда использование единственного сервера является неизбежным, например при обеспечении работы с конфиденциальной информацией.
Централизация данных так-же вредна, как и централизация служб. Сложно представить себе например систему DNS, построенную на основе единственного супер-сервера, хранящего все записи.
Централизация алгоритмов - это тоже очень не удачная идея. Основная проблема в том, что попытка собрать всю необходимую для работы алгоритма информацию со всей сети на одном узле приведет к тому, что сеть будет перегружена служебным трафиком и нормальное функционирование системы станет невозможно. [6] Соответственно в распределенных системах следует использовать децентрализованные алгоритмы, которые обладают рядом свойств, отличающих их от централизованных алгоритмов:
ни одна из машин не обладает полной информацией о состоянии системы;
машины принимают решения на основе локальной информации;
сбой в работе одной машины не нарушает работу алгоритма;
не требуется предположение о существовании единого времени.
Первые три свойства более-менее понятны, последнее-же возможно требует некоторого уточнения. Любой алгоритм, начинающийся со слов "Ровно в 12:00:00 все машины делают ..." работать не будет, поскольку невозможно синхронизировать все часы на свете.
У географической масштабируемости - свои сложности. Одна из основных проблем масштабирования распределенных систем, разработанных для локальных сетей, на глобальные сети - то, что в их основе лежит принцип синхронной связи. Т.е. процесс, выполняющий запрос, блокируется до получения ответа. Другое важное отличие организации глобальных коммуникаций от локальных - существенно меньшая надежность глобальных сетей с точки зрения передачи отдельно-взятого блока данных.
Также следует принимать во внимание вопрос обеспечения масштабирования распределенной системы на множество административно-независимых областей. Основная проблема, которую надо при этом решить - состоит в конфликтах правил, относящихся к использованию ресурсов (и плате за них), управлению и безопасности. Здесь можно выделить два типа проверок безопасности: злонамеренные атаки из новой области на системы и атака на ресурсы области из самой распределенной системы.
Существуют три основные технологии масштабирования:
сокрытие времени ожидания связи;
распределение;
репликация.
Сокрытие времени ожидания применяется в случае географического масштабирования. Идея - постараться по возможности избежать ожидания ответа от удаленного сервера. Т.е. нужно разрабатывать приложения в расчете на использование только асинхронной связи. Когда будет получает ответ, приложение прервет свою работу и вызовет специальный обработчик для завершения отправленного ранее запроса. В случае, если использование асинхронной связи слишком сложно либо не соответствует паттерну использования приложения - можно пойти другим путем - уменьшить объем необходимого взаимодействия, например перенести часть логики с сервера на клиент.
Распределение предполагает разбиение компонентов на мелкие части и последующее разнесение этих частей по системе. Хороший пример - DNS.
Репликация компонентов распределенной системы не только повышает доступность, но и помогает выровнять загрузку компонентов, что ведет к повышению производительности. Особая форма репликации - кэширование. Основное различие - кэширование происходит на стороне потребителя ресурса, а репликация - на стороне системы предоставляющей ресурс.
У репликации и кэширования есть один подводный камень: поскольку есть множество копий ресурса, модификация одной из них делает ее отличной от остальных - возникает проблема непротиворечивости данных (consistency).
ГЛАВА 2. ПРОГРАММНЫЕ СРЕДСТВА РАСПРЕДЕЛИТЕЛЬНЫХ СИСТЕМ
2.1 Традиционные операционные системы
Программно распределенные системы очень похожи на традиционные операционные системы. Прежде всего они работают как менеджеры ресурсов существующего аппаратного обеспечения, помогающие множеству пользователей и процессов совместно исползховать процессоры, память, перефирийные устройства, сеть и данные всех видов. Во вторых распределенная системы скрывает сложность и гетерогенную природу аппаратного обеспечения на базе которого она построена, предоставляя виртуальную машину для выполнения приложений. [6]
Операционные системы для распределенных компьютеров можно подразделить на:
сильно связанные - операционная система старается работать с единых глобальным представлением ресурсов, которыми она управляет;
слабо связанные - представляются как набор операционных систем, каждая из которых работает на своем компьютере, которые однако функционируют совместно, делая собственные службы доступными другим.
Сильно-связанные операционные системы обычно называют распределенными операционными системами и чаще всего используют для управления мультипроцессорами или гомогенными мультикомпьютерами.
Слабо-связанные операционные системы в свою очередь называют сетевыми операционными системами и используют для управления гетерогенными мультикомпьютерами. Как правило в купе с сетевой операционной системой частью распределенной системыв являются системы промужеточного уровня (middleware).
Распределенные операционные системы
Существует два типа распределенных операционных систем:
мультипроцессорная операционная система - управляет ресурсами мультипроцессора;
мультикомпьютерная операционная система - разрабатывается для гомогенных мультикомпьютеров.
Операционные системы для однопроцессорных компьютеров[11]
Традиционно операционные системы строились для управления компьютерами с одним процессором. Основной задачей таких операционных систем была организация легкого доступа пользователей и призожений к разделяемым устройствам - процессору, памяти, дискам и перефирийным устройствам. Для приложения это выглядит так, словно эти ресурсы находатся в его полном распоряжении. В этом смысле говорят, что операционная система реализует виртуальную машину предоставляя приложениям средства многозадачности. Важно тут то, что приложения как-бы отделены друг от друга - например приложения A не может изменить данные приложения B просто обратившись в ту область памяти, где эти данные хранятся. Также важно то, что приложения могут использовать предоставленные их ресурсы только так, как это предписано операционной системой. Например приложениям обычно запрещено копировать данные напрямую в сетевой интерфейс - нужно использовать специальный API операционной системы.
Следовательно операционная система должна полностью контролировать распределение и использование аппаратных ресурсов. Поэтому большинство процессоров поддерживают как минимум 2 режима работы:
режим ядра (kernel mode) - доступны для выполнения все инструкции процессора, доступна вся имеющаяся память и регистры;
пользовательский режим (user mode) - доступ к регистрам и памяти ограничен, запрещены к исполнению некоторые инструкции процессора.
На время выполнения кода операционной системы процессор переключается в режим ядра. Единственный способ перейти из пользовательского режима в режим ядра - сделать системный вызов - одну из базовых служб предоставляемых операционной системой, полностью контролируемую ей.
Типичной ситауцией является то, что практически весь код операционной системы выполняется в режиме ядра, т.е. операционная система (вернее ядро операционной системы) представляет собой большую монолитную программу, выполняющуюся в едином адресном пространстве. Замена или адаптция компонентов системы в таком случае без перезакрузки системы является затруднительной.
Другой вариант - организация операционной системы в виде двух частей:
набор модулей для управления аппаратным обеспечением, которые могут выполняться на пользовательском уровне (по крайней мере большая часть их кода);
микроядро, содержащее исключительно код для установки регистров устройств, переключения процессора с процесса на процесс, работы с блоком управления памятью и перехвата аппаратных прерываний. Также в нем обычно содержится код, преобразующий вызовы соответствующих модулей пользовательского уровня в системные вызовы и возвращающий результаты.
Схема организации операционной системы на основе микроядра приведена ниже:
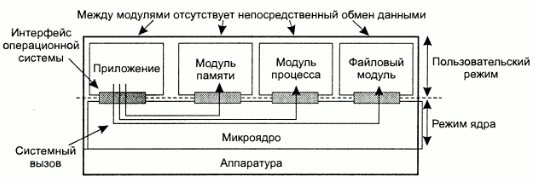
TODO: Достоинства и недостатки микрояденных систем.
Примеры микроядерных операционных систем:
AIX
Mac OS X (Mach 3.0)
OpenVMS
Minix
Мультипроцессорные операционные системы
Логичным развитием однопроцессорных операционных систем является возможность поддержки нескольких процессоров имеющих доступ к совместно используемой памяти. С концептуальной точки зрения данное расширение функциональности не сложно. Однако многие классические однопроцессорные операционные системы разработаны как монолитные программы с одним потоком управления. Адаптация подобных систем под мультипроцессорные зачастую означает повторное проектирование и реализацию всего ядра. Современные ОС как правило изначально разрабатываюся с учетом возможности работы в многопроцессорных системах. [7]
В многопроцессорных операционных системах, как впрочем и в мультизадачных однопроцессорных, ставится задача обеспечения взаимодействия между приложениями, для чего используются специальные конструкции: семафоры и мониторы.
Семафор может быть представлен как целое число, поддерживающее две операции - инкремент и декремент. При этом операция декремента на семафоре, имеющем нулевое значение блокируется до того момента, пока не произойдет инкремент этого семафора (как правило другим процессом). Операции над семафорами являются атомарными, т.е. во время операции над семафором ни один другой процесс не может получить доступ к этому семафору.
Монитор представляет собой конструкцию языка программирования, напоминяющую обьект в обьектно-ориентированных языках. Монитор содержит переменные и процедуры, причем доступ к процедурам может осуществляться только путем вызова соответствующих процедур. И в каждый момент времени выполнение процедуры доступно только одному процессу, т.е. если один процесс выполняет какую-либо процедуру монитора, то второй процесс будет заблокирован при попытке вызова процедуры монитора (той-же самой или другой) до тех пор, пока первый процесс не закончит выполнение процедуры. Реализация мониторов чаще всего строится на базе специальных семафоров, которые могут принимать значения 0 или 1. Такие семафоры носят название мьютекс (mutex, mutual exclusion) и с ними ассоциируются две операции - lock и unlock. Также мониторы применяются для организации такого примитива синхронизации как условные переменные - специальные переменные с двумя доступными операциями: wait (ждать события) и signal (породить событие).
Мультикомпьютерные операционные системы
Мультикомпьютерные операционные системы обладают гораздо более разнообразной структурой и значительно сложнее, чем мультипроцессорные. Единственно возможным видом связи между компонентами системы является передача сообщений (нет общей памяти). Типичная организация мультикомпьютерной операционной системы представлена на рисунке:
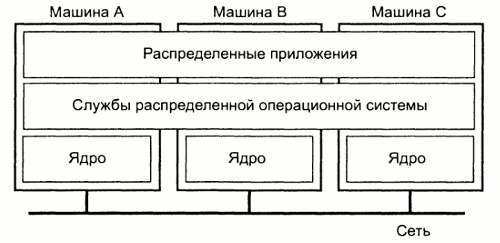
Каждый узел имеет свое ядро, которое управляет локальными ресурсами. Кроме того, каждый узел имеет отдельный компонент для межпроцессорного взаимодействия, то-есть в данном случае посилки сообщений на другие узлы и прием вообщений от них.
Поверх каждого локального ядра лежит уровень программного обеспечения общего назначения, реализхующий операционную систему в виде виртуальной машины, поддерживающей параллельную работу над различными задачами.
Мультикомпьютерные системы могут предоставлять приложениям средства совместного использования памяти, а могут и не предоставлять, ограничиваясь средствами передачи сообщений. [10]
Системы с распределенной разделяемой памятью
Существует большое число разработок, направленных на решение вопроса эмуляции совместно используемой памяти на мультикомпьютерных системах. Один из распространненных подходов - задействовать виртуальную память каждого отдельного узла для поддержки общего виртуального адресного пространства - распределенная разделяемая память (Distributed Shared Memory, DSM) со страничной организацией.
В системе с DSM адресное пространство разделено на страницы (типичный размер - 4 Кб, 8Кб), распределеные по всем узлам системы. Когда процессор адресуется к памяти, которая не является локальной, происходит прерывание, операционная система перемещает страницу в локальную память и перезапускает выполнение инструкции, вызвавшей прерывание.
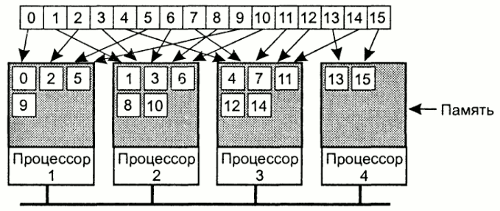
Одно из улучшений данного подхода состоит в том, чтобы реплицировать на все узлы те страницы памяти, которые не изменяются (содержат код программы, значения констант и т.д.)
Возможна также репликация и не закрытых от записи страниц, до тех пор, пока не происходит запись никакой разницы между репликацией страниц доступных только для чтения и страниц доступных для записи нет. Однако, как только какая-то страница изменяется, все остальные ее копи должны обьявляться невалидными, иначе будет нарушена целостность данных в системе.
Также при построении DSM систем важно правильно выбрать размер страниц памяти, используемых системой. Затраты на передачу страницы по сети в первую очередь определяюся затратами на подготовку к передаче, а не размером страницы. Таким образом можно повысить производительность увеличив размер страницы. олднако при этом увеличивается вероятность того, что страница памяти будет содержать данные двух различных процессов, выпорлняющихся на разных узлах. В результате операционная система будет вынуждена постоянни пересылать эту страницу он узла к узлу:
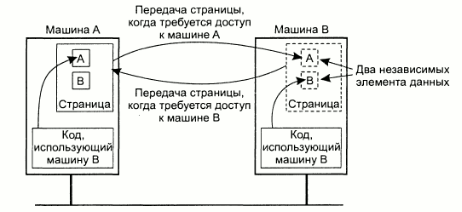
2.2.Распределенная система сбора данных и управления серии NL
Отечественными аналогами модулей семейства ADAM-40xx и, естественно, полностью с ними совместимыми, являются модули ввода-вывода аналоговых сигналов распределенной системы данных и управления серии NL научноисследовательской лаборатории автоматизации и проектирования (г. Таганрог) совместно с ЗАО «Спектрон» (г. Тольятти). Эти модули выпускаются согласно ТУ 4252-002-24171143-03.
Модули серии NL являются интеллектуальными (микропроцессорными) компонентами распределенной ССД. Эти модули реализуют следующие функции:
а) аналого-цифровое преобразование;
б) цифро-аналоговое преобразование;
в) ввод-вывод дискретных сигналов;
г) счет импульсов;
д) измерение частоты преобразования;
е) преобразование интерфейсов.
Данные модули применяются при построении эффективных систем управления производственными процессами, которые будут использоваться в жестких эксплуатационных условиях. [5]
Модули могут соединятся между собой, а также с управляющим компьютером или контроллером при помощи промышленной сети посредством последовательных интерфейсов (RS-232, RS-485). Управление модулями реализовывается с помощью набора команд в ASCII кодах. Все модули имеют режим программной калибровки и могут быть использованы в качестве средств измерений.
У модулей нет механических переключателей. Все настройки выполняются программно с помощью управляющего компьютера (контроллера). Программно можно установить следующие параметры:
а) диапазон измерения;
б) формат данных;
в) адрес модуля;
г) скорость обмена;
д) наличие бита контрольной суммы;
е) параметры калибровки.
Эти параметры записываются в ЭП ПЗУ и сохраняются при выключении питания. Некоторые модули имеют светодиодный или жидкокристаллический дисплей (рисунок 1.9), это дает возможность контроля технологических параметров прямо в месте установки модуля, а не на управляющем компьютере.
Все модули содержат сторожевых таймера, первый - супервизор перезапускает модуль в случае его «зависания» или провалов напряжения питания, второй - watch dog переводит выходы модуля в безопасные состояния при «зависании» управляющего компьютера.

Набор команд модулей содержит 20-50 разнообразных команд, которые передаются в стандартных ASCII кодах. Это позволяет программировать их с помощью практически любого языка программирования высокого уровня. Модули выполнены с целью применения в жестких условиях эксплуатации (температура окружающего воздуха - 40 до +70°С). Они имеют гальваническую изоляцию с испытательным напряжением изоляции 2,5 кВ (ГОСТ 12997-84).
Основные достоинства модулей NL состоят в том, что они полностью соответствуют стандартам РФ, имеют низкое энергопотребление, обеспечивают функции ввода-вывода, что позволяет использовать их в качестве локальных технологических контроллеров. Усиление модулей регулируется программно в широких пределах, обеспечивая работу с различными периферийными устройствами. Техническая поддержка модулей выполняется на русском языке.
Модули серии NL могут объединяться в сеть на основе последовательных интерфейсов RS-ххх, в которой могут быть использованы одновременно и модули других производителей (ADAM, ICP, NuDAM и другие).
В состав серии NL входят следующие основные модули: NLcon-lAT - программируемый логический контроллер, модули ввода-вывода (4, 8 и 16 аналоговых и цифровых каналов), NL-2C - модуль счетчика-частотомера, конверторы и повторители (ретрансляторы) интерфейсов и другие.
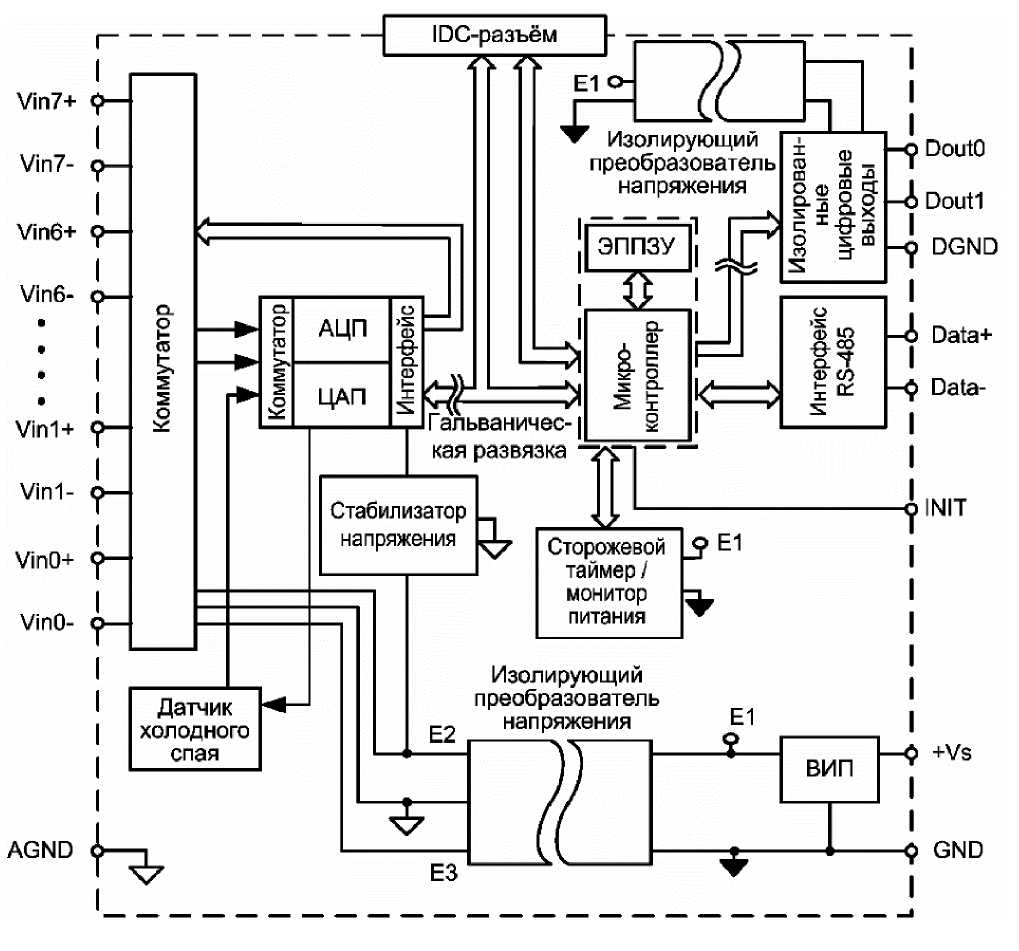
Структурная схема модуля NL-8TI.
Сигналы с входа модуля подаются на вход АЦП посредством аналогового коммутатора (мультиплексора) и преобразуются в цифровой код. У АЦП есть встроенный цифровой фильтр и усилитель с цифроуправляемым коэффициентом усиления. Это позволяет программно изменять полосу пропускания модуля и диапазон входных напряжений. Число разрядов АЦП уменьшается при увеличении усиления. Поэтому при работе с различными периферийными устройствами коэффициент усиления может быть подобран индивидуально.
Цифровой сигнал с выхода АЦП через модули гальванической развязки поступает в микроконтроллер и далее - на выход модуля NL-8TI. Тем самым обеспечивается полная гальваническая изоляция входов от блока питания и интерфейсной части.
Управляющий микроконтроллер модуля выполняет следующие функции:
а) осуществляет команды, идущие из управляющего компьютера;
б) выполняет обработку сигналов с периферийных устройств (компенсация нелинейности, калибровка и прочее);
в) реализует протокол обмена через требуемый интерфейс RS-485.
Интерфейс RS-485 реализован на стандартных микросхемах фирмы Analog
Devices. Эти микросхемы удовлетворяют стандартам EIA для интерфейсов RS- 485 и RS-422 и имеют защиту от электростатических зарядов, от выбросов на линии связи, короткого замыкания и перенапряжения. Дополнительно в модуле использована позисторная защита от перенапряжения на клеммах порта RS-485. Аналогичная защита использована для входа источника питания.
ЗАКЛЮЧЕНИЕ
В настоящее время распределенные системы сбора данных являются весьма перспективным направлением автоматизации различных систем и технологических процессов. Измерительные модули этих систем максимально приближены к объекту измерений, системы легко масштабируются и модифицируются. Поэтому разработка недорогих функциональных модулей для таких систем является весьма актуальной задачей.
Исследование принципов построения и технических характеристик прецизионных модулей ввода аналоговых сигналов показал, что имеется устойчивая тенденция по снижению их энергопотребления. Одним из направлений решения этой задачи является использование управляющих МК с пониженным напряжения питания. Однако это порождает проблему согласования уровней сигналов МК и разнообразной периферии, имеющей в общем случае различные уровни питающих напряжений.
Распределенная система — это набор независимых компьютеров, представляющийся их пользователям единой объединенной системой. В этом определении рассматриваются два момента. Первый относится к аппаратуре: все машины автономны. Второй касается программного обеспечения: пользователи считают, что имеют дело с единой системой. Pрассмотрим некоторые базовые вопросы, касающиеся как аппаратного, так и программного обеспечения. Одна из характеристик распределенных систем состоит в том, что от пользователей скрыты различия между компьютерами и способы связи между ними. То же самое относится и к внешней организации распределенных систем. Другой важной характеристикой распределенных систем является способ, при помощи которого пользователи и приложения единообразно работают в распределенных системах, независимо от того, где и когда происходит их взаимодействие. Распределенные системы должны относительно легко поддаваться расширению, или масштабированию. Эта характеристика является прямым следствием наличия независимых компьютеров, но в то же время не указывает, каким образом эти компьютеры на самом деле объединяются в единую систему. Распределенные системы обычно существуют постоянно, однако некоторые их части могут временно выходить из строя. Пользователи и приложения не должны уведомляться о том, что эти части заменены или исправлены или что добавлены новые части для поддержки дополнительных пользователей или приложений.
СПИСОК ЛИТЕРАТУРЫ
- Диго, С. М. Базы данных: проектирование и использование: учебник для студ. вузов / С. М. Диго. — М.: Финансы и статистика, 2005. 592 с.
- Кагаловский, М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с.
- Карпова, Т. С. Базы данных: Модели, разработка, реализация: Учебное пособие. — СПб.: Питер, 2002. — 303 с.
- Коннолли, Т., Карелин Б. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. 3-е изд.: пер. с англ. М.: Вильяме, 2003. — 1440 с.
- Корнеев В. В., Гареев А. Ф., Васютин С. В., Райх В. В. Базы данных. Интеллектуальная обработка информации. — М.: Нолидж, 2000. — 352 с.
- Корнеев И. К., Машурцев В. А. Информационные технологии в управлении. — М.: ИНФРА-М, 2001. — 158 с.
- Коровин, Е. Н. Методология прогнозирования и оптимального управления территориально распределенными социально-экономическими системами на основе трансформации информации и многовариантного моделирования: Дис. д-ра техн. наук. Воронеж, 2005. — 356 с.
- Кульба В. В., Ковалевский С. С., Косяченко С. А., Сиротюк В. О. Теоретические основы проектирования оптимальных структур распределенных баз данных. — М.: СИНТЕГ, 2000 — 660с.
- Макаров, C. B. Методы управления обновлениями и обеспечения согласованности информации в базах данных в расширенной архитектуре «клиент-сервер». Москва, 2000. — 145с.
- Пушников А. Ю. Введение в системы управления базами данных. Часть 2. Нормальные формы отношений и транзакции: Учебное пособие/Изд-е Башкирского ун-та. — Уфа, 1999. — 138 с.
- Пушников, А. Ю. Введение в системы управления базами данных. Часть 1. Реляционная модель данных: Учебное пособие/Изд-е Башкирского ун-та. — Уфа, 1999. — 108 с.
- Роб П., Коронел К. Системы баз данных: проектирование, реализация и управление. — 5-е изд., перераб. и доп. — СПб.: БХВ-Петербург, 2004. — 1040 с.
- Ролланд, Фред Д. Основные концепции баз данных / Ролланд, Фред Д. — М.: Вильямс, 2002. — 254с.
- Таненбаум Э., Ван Стеен М. Распределенные системы. Принципы и парадигмы. СПб.: Питер, 2008 — 845с.
- Цимбал А. А., Аншина М. Л. Технологии создания распределенных систем. Для профессионалов. — СПб.: Питер, 2003. — 576 с.

- Разработка регламента выполнения процесса «Покупка сырья и материалов» (1. Аналитическая часть)
- Понятие предпринимательского договора
- Правовой статус производственных кооперативов, понятие и основные положения
- Банковская гарантия как способ обеспечения исполнения обязательств
- Основные виды валютных рисков и их источники (Страхование валютных рисков)
- Законность и правопорядок (Глава 1. Законность и правопорядок как правовые категории)
- Оценка рисков финансово-кредитных институтов
- Проблема обеспечения и возвратности кредита, ее экономические и правовые аспекты
- Правовая природа ценной бумаги как объекта гражданских прав
- Устройство персонального компьютера (Глава 1. Теоретическая часть)
- Организация и технология менеджмента в сфере физической культуры и спорта
- Проведение маркетингового исследования спортивной организации на примере ООО «ОЛИМП»