
Операции, производимые с данными (Описание работы с данными)
Содержание:

ВВЕДЕНИЕ
Сегодня объемы данных растут, а темпы роста данных постоянно ускоряются. Данные датчиков, логи файловых систем, социальные сети и другие источники, приносящие объём, скорость и разнообразные данные, которые намного превосходят по качеству и количеству обычный хранимые данные в базах.
Организации, ориентированные на яркую перспективу развития, творчески используют все новые источники для достижения беспрецедентных преимуществ и конкурентного превосходства на рынке. Это не так просто, как поместить все эти данные в одном месте. Реальная стоимость использования этих данных для бизнеса расшифровывается с помощью подробного рассмотрения конкретных случаев использования и кейсов в рамках дальнейшего анализа. Применение конкретных кейсов может сильно различаться между отделами и отраслями. Хотя встречаются и интересные технические проблемы, связанные с интеграцией и управлением всеми имеющимися источниками данных, с которыми сталкивается каждый крупный игрок.
Организации должны сначала найти достаточное количество времени, чтобы определить и отточить оптимальное использование или варианты использования для своих собственных бизнес потребностей каждого имеющегося решения на рынке. Это и есть важнейший первый шаг, который поможет понять основные веяния. Такие бизнес веяния могут быть использованы бизнесом в целях улучшения результатов, которые можно достичь с помощью используемых кейсов в рамках анализа данных.
Таким образом, целью моей работы является:
- разработка концепции нового инструмента помощи принятия управленческих решений в рамках крупных маркетинговых компаний (вся карта вычисляемых показателей также разрабатывается самостоятельно автором работы).
Для достижения поставленной цели автором были поставлены следующие задачи:
- определить основные составляющие тенденций систем обработки потоковой информации;
- определить основные недостатки имеющихся систем обработки потоковой информации в выбранной области;
- составить карту вычисляемых показателей маркетинговых компаний для определения ценности принимаемого решения бизнес подразделением;
- разработать концепцию нового инструмента на основе выбранных решений, решающее проблему принятия управленческих решений в рамках крупных маркетинговых компаний бизнеса с использованием полученных знаний по тенденциям в сфере потоковых данных.
Объектом исследования в моей работе является деятельность компании, являющейся одним из лидеров продаж строительных материалов на рынке России.
Предметом исследования в работе является процесс принятия управленческих решений в рамках маркетинговых компаний, связанных с действиями digital департамента компании - интернет канал продаж и привлечения новой аудитории.
Глава 1. Основные понятия области решений операций, производимые с данными
Термин «потоковая передача» сегодня имеет историю развития, аналогичную термину «большие данные», а конкретнее обозначает слишком разнородное и разнообразное множество вещей. Суть проблемы данных терминов в том, что их описание было сформировано исторически в просторечии нежели в формате подачи конкретной информации о том, что это и как это работает. Неизбежно это приводит к отсутствию окончательного сложившегося корректного понимания в отношении того, что же на самом деле такое потоковая передача или что могут делать потоковые систем в действительности. Зачастую существующая терминология не только ограничивает характеристики описываемого далее механизма прикрывая все классическим термином обывателей «потоковые данные», а более того – приписывает дополнительные ложные характеристики, например, приблизительность результатов обработки данных.
Стоит понимать, что корректно разработанные системы анализа потоковых данных способны производить такие же (и даже более) корректные результаты, как и любое уже существующее решение на основе пакетного метода.
С целью снизить вероятность разобщения терминологического единства исследования и отсутствия некорректного понимания ограничений используемого механизма стоит определить единое понимание термина «потоковая передача», которого будет придерживаться автор в работе. При составлении такого понятия я буду опираться на такую сторону изначального обывательского термина как «подход», разработанный на основе идеологии работы с бесконечными наборами данных в памяти, и оперировать не единым определением, а характеристиками, свойственными данному «подходу»:
- Безграничные данные в качестве источника информации для анализа в модели. В данном свойстве мы поговорим о типах постоянно растущих сетов данных. Такие данные априори зачастую называются пользователями как «потоковые данные». Однако, данная формулировка достаточно однобока, ввиду того, что при такой формулировке и «потоковый» процесс обработки данных и «пакетный» процесс обработки данных являются одинаковыми (так как могут работать с любым объемом данных при корректном использовании подхода), но целью составления определения является попытка отметки яркого отличия. Таким образом, отметим ключевое отличие между двумя типами наборов данных для разных подходов в разрезе их «конечности/непрерывности»: в своем исследовании я буду ссылаться именно на бесконечный «потоковый» набор данных как на бесконечный и непрерывный поток информации, в то время как «пакетный» набор данных при такой стороне рассмотрения становится ограниченным.
- Неограниченная обработка данных. Данное свойство подразумевает непрерывный режим обработки данных, который применяется к вышеописанному безграничному объему данных в качестве источника информации для анализа в моделях. Именно такая формулировка также поможет нам избежать ошибок при первичном сравнении «потоковых» и «пакетных» подходов к обработке данных. Ведь стоит отметить, что уже давно были разработаны повторные запуски пакетных триггеров обработки для обработки данных. И наоборот, хорошо спроектированные потоковые подходы способны на использование при обработке «пакетных» нагрузок более ограниченных данных.
- Результаты с приближенной информацией. Данная характеристика результатов чаще всего связана именно с потоковыми системами обработки информации. Факт того, что пакетные системы традиционно разрабатывались для получения именно верных результатов, а не приблизительных, а потоковый подход изначально был инициирован под манифестом приблизительных данных – исторический артефакт и не более того. На данный момент практика показывает, что те же пакетные системы могут спокойно демонстрировать приблизительные результаты при определенном применении метода. Таким образом, такой тип данных в данной характеристике результатов гораздо корректнее будет описать именно так, как они и названы (приблизительные без относительности к конкретному термину) чем так, как они исторически появлялись – через ассоциации с потоковыми данными.
Начиная с этого момента, в данном исследовании при упоминании термина «потоковая передача и обработка данных» будет подразумеваться именно механизм, предназначенный для обработки и осуществления манипуляций с неограниченным набором данных, и ничего более персонализированного. Аналогично, в случае упоминания такого термина как «неограниченные данные» будет иметься именно свойство данных поступать без разреза «конечности» в представлении.
Одной из основных целей данного параграфа является показать на сколько много способна хорошо спроектированная потоковая система, которая на данный момент низведена до некоторой степени «неоцененности» на рынке ввиду присвоенным ассоциациям с такими терминами как приближенность результатов и задержка, в особенности в рамках искусственного сравнения с пакетными системами обработками данных, которые в конечном итоге предоставляют корректный результат.
Хорошо спроектированные потоковые системы фактически обеспечивают четкое надмножество пакетной функциональности решений. Можно точно утверждать, что пакетные системы в таком виде, как они существуют сейчас, не нужны в применении ни одной организации: они массивны и тяжелы в обслуживании того самого «точного» результата. Следствием эволюции таких систем, начиная с Lambda Architecture, является широкое созревание потоковых систем в сочетании с надежными инфраструктурами для неограниченной обработки данных. Для воплощения этого в жестких реалиях необходимо только две вещи:
- Правильность. Данный пункт позволит новому подходу конкурировать с пресловутым пакетным подходом к обработке данных. По сути, корректность результата сводится к постоянному хранению промежуточных данных. Потоковым системам нужен некий определенный метод для контроля точки устойчивого состояния в течение долгого времени, и она должна быть достаточно хорошо определена. Строгая согласованность необходима для точной однократной обработки, которая необходима для последующей корректности, что является требованием для любой системы, которая собирается претендовать на удовлетворение или превышение возможностей существующих решений пакетных систем.
- Временные инструменты, которые переносят потоковые системы дальше пакетных. Хорошие инструменты для рассуждения о времени имеют важное значение для работы с неограниченными неупорядоченными данными с переменным временем события. Все большее число современных наборов данных демонстрируют эти характеристики, а в существующих системах пакетной обработки отсутствуют необходимые инструменты для преодоления трудностей, которые данные характеристики налагают. Сосредоточимся на данном вопросе, начав с общего представления о концепции временного перекоса неограниченных данных с разным временем события.
Итак, чтобы говорить о неограниченной обработке данных необходимо четко определиться с пониманием временных областей. В данном исследовании мы будем предполагать наличие двух периодов времени, а именно:
- Время события, которое является реальным временем происхождения того или иного события.
- Время обработки, которое является реальным временем, когда произошедшее событие отображено и наблюдается в системе.
В идеальном мире время события и время обработки всегда будут равны, при этом события обрабатываются сразу по мере их возникновения. Реальность, однако, не такая уж приятная, и перекос между временем события и временем обработки не только не равен нулю, но часто является сильно изменяемой функцией характеристик исходных входных источников, механизма выполнения и аппаратных средств. Таким образом, вещи, которые могут повлиять на уровень перекоса, включают:
- Общие ограничения ресурсов, такие как перегрузка сети, сетевые разделы или общий процессор в неспецифической среде.
- Программные причины, такие как распределенная системная логика, конкуренция и т. д.
- Особенности самих данных, в том числе распределение ключей, отклонение в пропускной способности или дисперсия в беспорядке (например, самолет, полный людей, выводящих свои телефоны из режима полета после их использования в автономном режиме на весь рейс).
В результате, если построить ход времени события и времени обработки в любой реальной системе, как правило, получится что-то похожее на диаграмму на Рис 1.
Рис 1 Зависимость времени обработки от времени события в
система обработки данных
Кривая «Идеальный мир без временных сдвигов» представляет собой идеал, где время обработки и время события в точности равны; кривая «реальный мир с временным сдвигом»- реальность. В этом примере система немного отстает в начале времени обработки, поворачивается ближе к идеалу в середине, затем немного отстает к концу. Горизонтальное расстояние между идеальной и реальной кривыми - это перекос между временем обработки и временем события. Этот перекос по своей сути - латентность, создаваемая конвейером обработки.
Поскольку сопоставление между временем события и временем обработки не является статическим, это означает, что невозможно проанализировать данные исключительно в контексте того, когда они наблюдаются, если конечно в системе подразумевается забота о времени события (то есть, когда события действительно произошли). К сожалению, таким способом работают большинство существующих систем, разработанных для неограниченных данных.
Нас же интересует правильность, а значит мы заинтересованы в анализе данных в контексте их времени событий и не можем определить эти временные границы, используя время обработки, как это делают большинство существующих систем. При отсутствии постоянной корреляции между временем обработки и временем события некоторые данные события будут попадать в неправильные окна времени обработки (из-за присущего отставания в распределенных системах, онлайнового / автономного режима многих типов источников ввода, и т. д.).
К сожалению, картинка не слишком радужная, когда работа осуществляется с окном по времени события. В контексте неограниченных данных беспорядок и переменный перекос вызывают проблему полноты для окон времени события, так как вы не можете четко определить, когда вы наблюдали все данные за заданное время события x? Подавляющее большинство систем обработки данных, используемый сегодня полагается на некоторое представление о полноте, что ставит их в невыгодное положение при применении неограниченных наборов данных.
Глава 2. Описание работы с данными
2.1 Предпосылки актуальности проведения исследования
С целью просмотра рынка кейсов и решений для большой аналитики данных были отобраны основные случаи применения такой аналитики в компаниях в качестве предпосылок проведения дальнейших исследований в работе (Таблица 1):
Таблица 1 Анализ предпосылок исследования
2.2 Постановка проблемы и задач исследования
Сегодняшней проблемой всей области e-commerce является полная несовместимость мощных инструментов с анализом большого потока данных в режиме реального времени. Таким инструментам постоянно требуется участие человека и постоянные выгрузки данных. Поэтому требуются некоторые другие инструменты, в ожидании того, что в будущем и мощные передовики индустрии анализа дотянут свою функциональность для ведения подхода в режиме реального времени. Более того большинство организаций сегодня видят основные инструменты лишь в качестве «поверхностного анализа» данных, а именно – отображение основных метрик в удобных срезах для менеджеров, на основе которых все так же будут приниматься ошибочные решения ввиду отсутствия по-настоящему ценной информации, в виде формата основного потребителя или потенциала кросс-продаж.
Таким образом, главной целью исследования является создание нового инструмента по покрытию разработанной карты новых показателей аналитики данных e-commerce для дальнейшей помощи в принятии управленческих решений. Для достижения поставленной цели автором были поставлены следующие задачи:
- определить недостатки имеющихся систем обработки потоковой информации в выбранной области и выбрать системную базу для дальнейшей реализации нового инструментария для принятия решений;
- составить карту вычисляемых показателей маркетинговых компаний для определения ценности принимаемого решения бизнес подразделением на основе статистических инструментов;
- построить новый двухзвенный инструмент на основе выбранных решений решающий проблему принятия управленческих решений в рамках крупных маркетинговых компаний бизнеса.
2.3 Инструментальные методы и средства поставленной проблемы
На данный момент уже проанализировано достаточно информации, чтобы можно было начать смотреть на основные типы шаблонов использования, общие для всей ограниченной и неограниченной обработки данных сегодня. В работе будут рассмотрены основные типы обработки и там, где это уместно, они будут разбиты для более корректного анализа в контексте двух основных типов подходов, о которых говорилось ранее в исследовании и анализе теоретических предпосылок (пакетная обработка и потоковая передача).
- Ограниченные данные.
Обработка ограниченных данных достаточно проста. Работа всегда начинается с обработки определенного набора данных (потока пользовательской информации), который наполнен определенного рода энтропией данных. Далее процесс обработки двигается через процесс переработки определенным заранее методом или алгоритмом (как правило, пакетами данных, хотя стоит обязательно отметить, что и корректно и деятельно продуманное потоковое решение будет работать так же хорошо). На выходе всего процесса пользователь уже имеет новые окончательно структурированные данные, представленные уже с большей существенной ценностью для конечного использования.
Однако, гораздо интереснее задача обработки неограниченного набора данных. Поэтому далее в исследовании будут рассматриваться различные способы обработки неограниченных данных, начиная с подходов, используемых традиционными подходами, основанными на пакетном решении, а далее заканчивая подходами, которые можно использовать с системой, предназначенной для неограниченных данных, таких как большинство потоковых или микро-пакетных движков.
- Неограниченные данные – пакетное решение.
Пакетные механизмы хоть и не разрабатывались изначально явно для работы с неограниченными данными, но в конечном счете все-таки были использованы для обработки неограниченных наборов данных вынужденно в виду поступившей и нарастающей со стороны пользователей необходимости в таковой обработке (так как в них был задуман подход пакетных систем). Как и следовало ожидать, такие подходы сводятся к разрезанию неограниченных данных на набор определенных ограниченных наборов данных, подходящих для классических способов пакетной обработки поступающих данных.
-
- Фиксированные окна.
Наиболее распространенный способ обработки неограниченного набора данных с использованием повторных запусков пакетного ядра - это обрезание входных данных в окна фиксированного размера, а затем обработка каждого из этих окон в качестве отдельного ограниченного источника данных. В частности, для источников входных данных, таких как журналы, где события могут записываться в каталоги и иерархии файлов, имена которых кодируют окно, которому они соответствуют, такая вещь кажется довольно простой при первом же рассмотрении, поскольку по существу было выполнено перемещение по времени для получения данных в соответствующие окна времени события загодя.
Однако на самом деле в большинстве систем по-прежнему существует проблема полноты: если некоторые из событий задерживаются в пути к журналам из-за сетевого раздела? Что делать, если события собираются по всему миру и должны быть перенесены в общую папку перед обработкой? Что делать, если мероприятия происходят с мобильных устройств? Это означает, что может потребоваться смягчение (например, откладывание обработки до тех пор, пока вы не убедитесь, что все события собраны или повторная обработка всего пакета для данного окна всякий раз, когда данные задерживаются).
-
- Сессии
Этот подход еще более разрушается, когда система пытается использовать пакетный движок для обработки неограниченных данных в более сложных стратегиях использования окон, таких как сеансы.
Сеансы обычно определяются как периоды активности (например, для конкретного пользователя), которые заканчиваются разрывом после определенного периода бездействия. При расчете сеансов с использованием типичного пакетного механизма часто система получает сеансы, которые разбиваются на группы. Количество расколов можно уменьшить, увеличив размер пакета, но за счет соответствующего увеличения задержки. Другим вариантом является добавление дополнительной логики для сшивания сессий из предыдущих прогонов, но за счет соответствующего уровня дополнительной сложности. В любом случае, использование классического пакетного подхода для расчета сессий не является идеальным. Лучше было бы создать сеансы потоковым способом.
- Неограниченные данные – потоковый подход
В противоположность специальному характеру большинства методов неограниченной обработки данных на основе пакетной обработки, потоковые системы строятся для неограниченных данных. Как уже было отмечено ранее, для многих реальных источников распределенных входных данных не только приходится иметь дело с неограниченными данными, но также и с данными, которые:
- Неупорядоченные по времени события. То есть необходим какой-то поток, образованный на основе временного промежутка, внутри общего потока данных, чтобы анализировать данные в контексте, в котором они имели место.
- Варьирование временного перекоса. То есть можно просто предположить, что большинство данных для временного события X будет всегда попадать в некоторую постоянную эпсилон времени Y.
Есть несколько подходов, которые можно использовать при работе с данными, которые имеют эти характеристики. Данные походы можно квалифицировать в четыре группы.
-
- Время-агностик.
Данный тип обработки используется в тех случаях, когда время по существу не имеет значения - т.е. вся соответствующая логика является управляемой данными. Поскольку все, что касается таких случаев, продиктовано появлением большего количества данных, нет ничего сверх необычного в том, что потоковый механизм должен поддерживать, кроме базового получения данных. В результате практически все существующие потоковые системы поддерживают не зависящие от времени варианты использования. Пакетные системы также хорошо подходят для агрегированной по времени обработки неограниченных источников данных, просто разбивая неограниченный источник на произвольную последовательность ограниченных наборов данных и независимо обрабатывая эти наборы данных.
-
-
- Фильтрация.
-
Фильтрация является очень простой формой агностической обработки во времени. Необходимо представить, что система обрабатывает журналы веб-трафика, и пользователю необходимо отфильтровать весь трафик, который не происходит из определенного домена. Тогда бы стоило заставить систему посмотреть на каждую запись по мере ее поступления, принадлежит ли она интересующей области, и отбросите ее, если нет.
Поскольку такого рода вещи зависят только от одного элемента в любой момент времени, тот факт, что источник данных неограничен, не упорядочен и различного времени перекос, не имеет значения.
-
-
- Внутренние соединения.
-
Другой пример, не зависящий от времени, - это внутреннее соединение (или хэш-соединение). При объединении двух неограниченных источников данных, когда элемент из обоих источников прибывает, для этой логики нет временного элемента. Когда система видит значение из одного источника, алгоритм может просто сохранить его в постоянном состоянии. Системе нужно только отпустить захваченную запись однажды, как только второе сопутствующее необходимое по информации значение поступит из другого источника.
Но что если, когда система увидели одну сторону соединения, алгоритм заранее не может определить, придет ли когда-нибудь другая сторона или нет (реальные события не в идеальной системе моделирования)? Поэтому в систему необходимо ввести некоторое понятие тайм-аута, которое вводит элемент времени, необходимый для решения данной проблемы в рамках системы.
-
- Приближение.
Еще одна основная категория подходов — это алгоритмы аппроксимации. Они принимают неограниченный источник входных данных и предоставляют выходные данные. Если посмотреть на предоставленные данные сквозь розовые очки, то пользователю будет более или менее нравиться результат (то что пользователь и хотели получить).
Достоинством аппроксимирующих алгоритмов является то, что они, как правило, предназначены для неограниченных данных. Недостатком является то, что их существует ограниченный набор. В то же самое время данные алгоритмы часто являются слишком сложными (что затрудняет создание новых алгоритмов аппроксимации), а их приблизительная природа ограничивает их полезность для пользователя при обработке данных и получении корректного точного конечного результата.
-
- Окно по времени обработки и окно по времени события.
Остальные подходы к неограниченной обработке данных - это вариации оконной обработки. Прежде чем погрузиться в различия между ними, нужно четко дать понять, что имеется в виду под окном. Округление - это просто понятие взятия источника данных (неограниченного или ограниченного) и измельчения его по временным границам в конечные фрагменты для финальной обработки системой. Существует три разных шаблона окна:
- Фиксированные окна. Фиксированные окна нарезаются на отрезки времени с фиксированным размером временной длины. Сегменты для фиксированных окон применяются равномерно по всему набору данных, который является примером выровненных окон. В некоторых случаях желательно постепенно сдвигать окна для различных подмножеств данных (например, за ключ) для распространения нагрузки завершающего окна более равномерно в течение долгого времени, что вместо того, является примером не выровненных окон, так как они изменяются по данным
- Раздвижные окна. Обобщение фиксированных окон, раздвижные окна определяются фиксированной длины и фиксированного периода. Если период меньше длины, то окна перекрываются. Если период равен длине, система попала в покрываемое окно. И если срок больше, чем длина, у системы есть странный вид окна выборки, который выглядит только на подмножестве данных с течением времени. Как с фиксированными окнами, раздвижные окна, как правило, выравниваются, хотя могут быть выровненными путем оптимизации производительности в некоторых случаях использования.
- Сессии. Пример динамических окон, сеансы которых состоят из последовательности событий, заканчивающихся щелью неактивности больше, чем какой - то тайм - аут. Сессии обычно используются для анализа поведения пользователей с течением времени, путем объединения ряда событий, связанных для пользователя во времени (например, последовательность видео, просматриваемых пользователем в рамках одномоментного присутствия за компьютером в одном заседании). Сессии интересны тем, что их длина не может быть определена априори заранее автоматически независимым алгоритмом; они зависят от фактических данных, которые поступают от участвующих в данных итерациях пользователей. Данный вариант также является каноническим примером выровненных окон, так как сеансы практически никогда не бывают идентичными друг другу в разных подмножествах данных (например, в любой момент это могут быть различные пользователи).
Среди выделенных для анализа типов в исследовании будут интересовать два основных из них: окна по времени обработки и окна по времени события.
2.4 Подход к решению поставленных задач
Задачей данного параграфа является определение основных недостатков имеющихся систем обработки потоковой информации в выбранной области. Определение недостатков будет осуществляться в рамках сравнения имеющихся решений визуализации и анализа данных в режиме реального времени в формате Таблицы 2.
Таблица 2 Сравнение систем визуализации данных
На основе такого важного критерия как совместимость инструмента с источниками данных реального времени для постоянного отслеживания изменения в показателях был выбран такой инструмент как PowerBI. При этом стоит отметить, что PowerBI имеет интересное представление данных которые анализируется посредством встроенных мощных скрипnов обработки данных на языке R.
Был разработан сам R-скрипт для реализации поставленных в рамках проектирования карты вычисляемых показателей маркетинговых компаний статистическими методами анализа данных.
ggplot(data1, aes(paste(substr(date,1,4),"-",substr(date,5,6),"-", substr(date,7,8),sep=""),total_pageviews_per_user)) + geom_boxplot()
p1 + labs(title="Avg Pageviews for Users with Purchase", x = "Date", y = "Pageviews")
p1 + ylim(c(0,y_max))
p1 + theme(axis.text.x = element_text(angle = 35, hjust = 1))
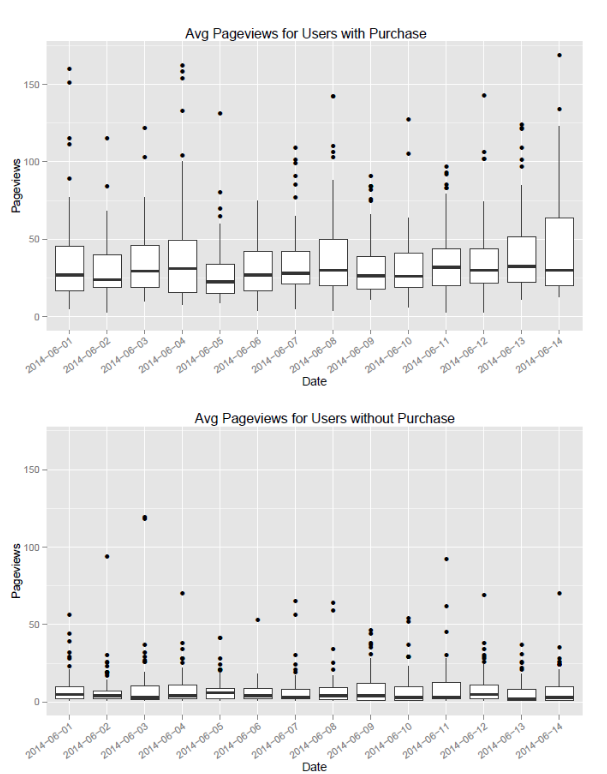
Рисунок 1 Средние просмотры страниц с транзакциями
ggplot(data2, aes(paste(substr(date,1,4),"-",substr(date,5,6),"-",
substr(date,7,8),sep=""),total_pageviews_per_user)) + geom_boxplot()
p2 + labs(title="Avg Pageviews for Users without Purchase",
x = "Date", y = "Pageviews")
p2 + ylim(c(0,y_max))
p2 + theme(axis.text.x = element_text(angle = 35, hjust = 1))
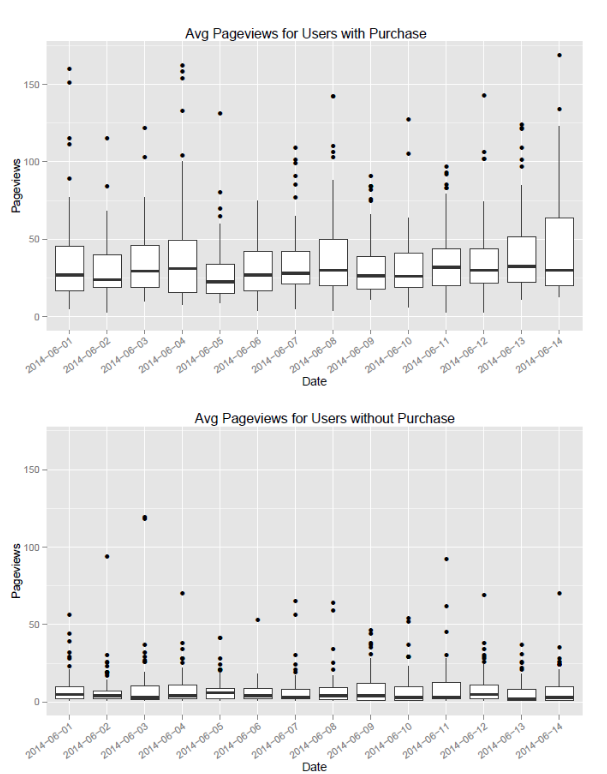
Рисунок 2 Средние просмотры страниц без транзакций
Параграф 3.3.2 Средний доход по отношению к сеансу пользователя
par(mfrow=c(1,1))
ggplot(data3, aes(x = medium,y=avg_rev_per_visit,
fill=sessions,label=sessions))+
geom_bar(stat="identity")+scale_fill_gradient(low = colors()[600],
high = colors()[639])
p3 + geom_text(data=data3,aes(x=medium,
label=paste("$",round(avg_rev_per_visit,2)),
vjust=-0.5))
p3+ labs(title="Avg Revenue/Session by Medium", x = "medium",
y = "Avg Reveune per Session")
p3 + theme(plot.title = element_text(size = rel(2)))
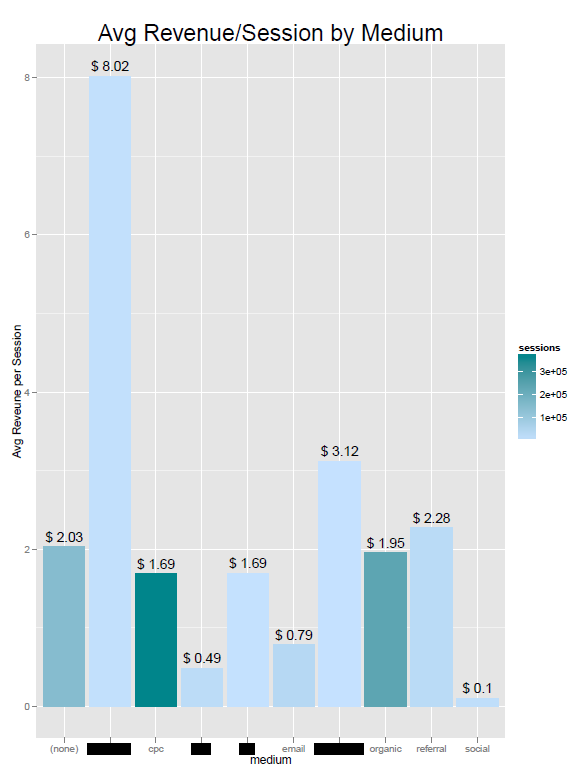
Рисунок 3 Средний доход по отношению к сеансу пользователя
Параграф 3.3.3 Лучшие компании по доходам по отношению к сессиям
par(mfrow=c(1,1))
ggplot(data4, aes(x = campaign,y=avg_rev_per_visit,fill=sessions,
label=sessions))+geom_bar(stat="identity")+
scale_fill_gradient(low = colors()[600], high = colors()[639])
p4 + geom_text(data=data4,aes(x=campaign,label=paste("$",
round(avg_rev_per_visit,2)),vjust=-0.5))
p4 + labs(title="Top Campaigns by Rev/Session (min 10 sess)",
x = "campaign", y = "Avg Reveune per Session")
p4 + theme(plot.title = element_text(size = rel(2)))
p4 + theme(axis.text.x = element_text(angle = 25, hjust = 1))
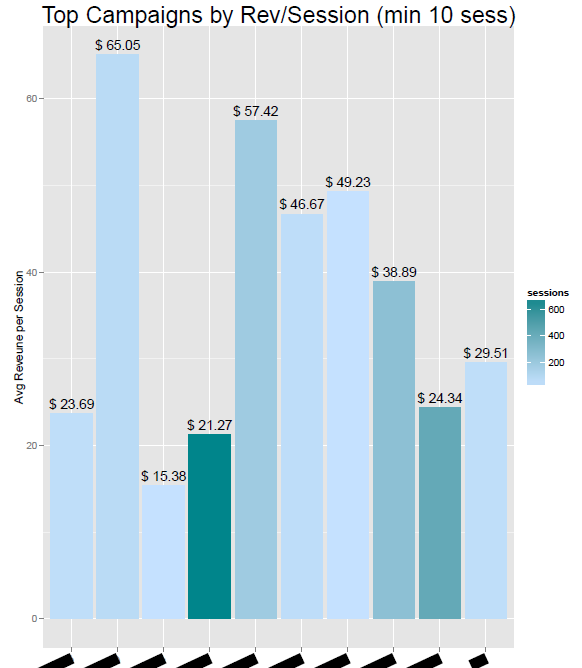
Рисунок 4 Лучшие компании по доходам по отношению к сессиям
Параграф 3.3.4 Категория закупок продукта по средним показателям
par(mfrow=c(1,1))
qplot(category,data=data5, weight=value, geom="histogram",
fill = medium, horizontal=TRUE)+coord_flip()
p5 + labs(title="Category of Product Purchase by Medium (a)",
x = "Product Category", y = "Transactions")
p5+ theme(plot.title = element_text(size = rel(2)))
p5 + theme(axis.text.x = element_text(angle = 25, hjust = 1))
.
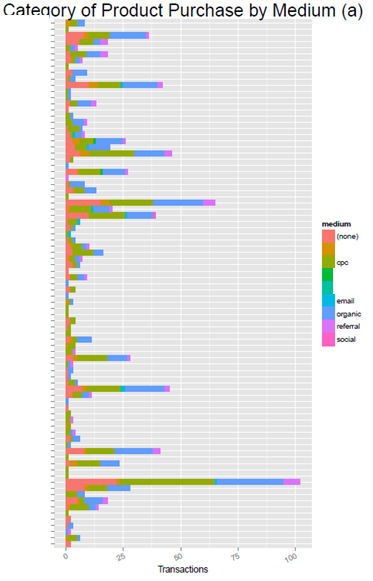
Рисунок 5 Категория закупок продукта по средним показателям
Параграф 3.3.5 Товарная категория закупки по средним показателям
par(mfrow=c(1,1))
ggplot(data5, aes(medium,category)) + geom_tile(aes(fill=value))+
scale_fill_gradient(name="transactions",low = "grey",high = "blue")
p6 + labs(title="Category of Product Purchase by Medium (b)",
x = "medium", y = "product category")
p6 + theme(plot.title = element_text(size = rel(2)))
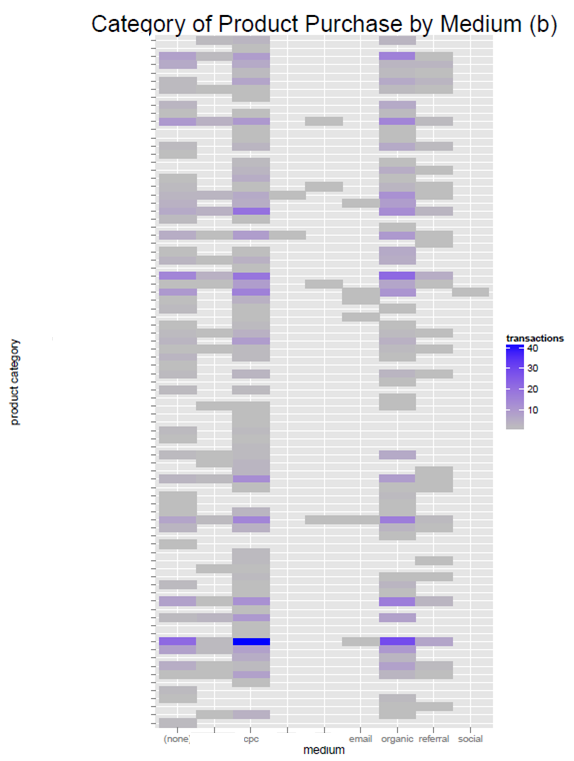
Рисунок 6 Товарная категория закупки по средним показателям
Параграф 3.3.6 Вероятность продукта для указания и/или привлечения дополнительных транзакций
par(mfrow=c(1,1))
ggplot(data9, aes(x = prod_name,y=perc,fill=transactions.y,
label=perc))+
geom_bar(stat="identity")+scale_fill_gradient(name="transactions",
low = colors()[600], high = colors()[639])
p7 + geom_text(data=data9,aes(x=prod_name,
label=paste(round(perc*100,1),"%"),vjust=-0.5))
p7 + labs(title="Percentage of Transactions resulting in Future rn
Additional Transactions by same User", x = "Product Name",
y = "Percentage of Transactions")
p7 + theme(plot.title = element_text(size = rel(2)))
p7 + theme(axis.text.x = element_text(angle = 45, hjust = 1))
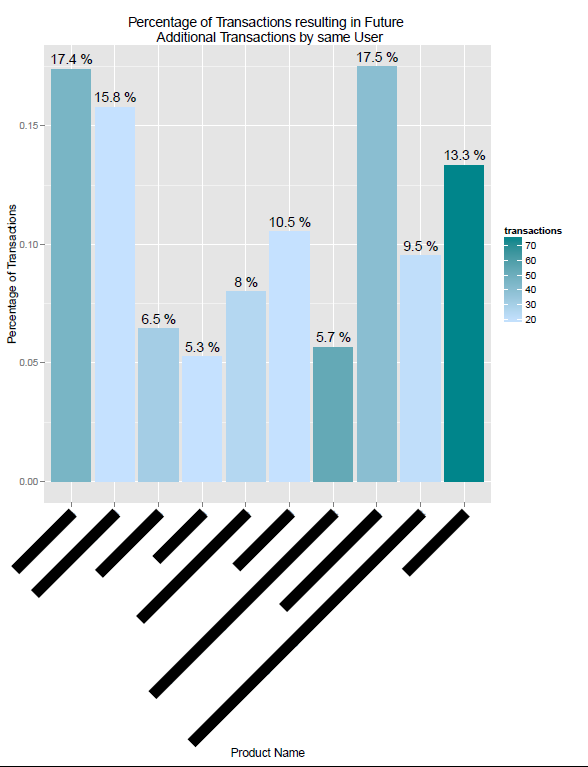
Рисунок 7 Вероятность продукта для указания и/или привлечения дополнительных транзакций
Заключение
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя - клиентом;
• преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных.
В рамках работы было найдено новое решение для предоставления достаточных данных специалистам по принятию управленческих решений в рамках маркетинговых компаний и выполнены все поставленные задачи в направлении решения стратегических задач выбранной компании.
Рассмотренное решение является инновационным и рядовым в сфере внутреннего анализа данных. Главным направлением дальнейшего развития исследования можно рассмотреть в двух задачах:
1) Настройка полной визуализации с участием отображения всех необходимых метрик в рамках выбранной компании.
2) Разработка подхода к анализу кросс-продаж и выбору продукта в качестве того, который может принести превосходную прибыль компании в паре с уже имеющимся передовиком отрасли.
3) Кластеризация имеющихся пользователей и унификация интерфейса главного потребителя.
Список использованной литературы
- x
- x
- Когаловский М.Р. Глоссарий по стандартам платформы XML. Версия 7 (17-12-2006). // Электронные библиотеки. – М.: ИРИО, 2006.
- The World Wide Web Consortium (W3C). XQuery 1.0: An XML Query Language : W3C Recommendation / Boag S. et al. (eds.). – 2007, 23 Jan.
- The World Wide Web Consortium (W3C). XQuery Update Facility 1.0 : W3C Working Draft / Chamberlin D. et al. (eds.). – 2007, 28 Aug.
- Лизоркин Д.А., Лисовский К.Ю. SXML: XML-документ как S-выражение // Электронные библиотеки. – М.: ИРИО, 2003. – Т. 6, вып. 2. – ISSN 1562-5419 = Russian digital libraries journal.
- The World Wide Web Consortium (W3C). XML Information Set : W3C recommendation / Cowan J., Tobin R. (eds.). – 2nd edition. – 2004, 4 Feb.
- Kiselyov O. SXML specification / Rev. 3.0. – ACM SIGPLAN Notices. – New York: ACM Press, 2002. – Vol. 37, N 6. – pp. 52-58. – ISSN 0362-1340.
- Kiselyov O. A better XML parser through functional programming : Proc. Practical Aspects of Declarative Languages: 4th int. symposium, PADL'2002, Portland, 19-20 Jan., 2002 // Lecture Notes in Computer Science / Krishnamurthi S., Ramakrishnan C.R. (eds.). – Springer-Verlag Heidelberg, 2002. – Vol. 2257. – pp. 209-224. – ISSN: 0302-9743.
- Лизоркин Д.А. Оптимизация вычисления обратных осей языка XML Path при его реализации функциональными методами // Сборник трудов Института системного программирования РАН / Под ред. чл.-корр. РАН Иванникова В.П. – М.: ИСП РАН, 2004. – Т. 8, ч. 2. – 214 c. – с. 93-119. – ISBN 5-89823-026-2.
- Abelson H., Sussman G.J., Sussman J. Structure and Interpretation of Computer Programs. – 2nd ed. – London; New York: The MIT Press; McGraw Hill, 1996. – 657 pp. – ISBN 0-262-01153-0.
- Boehm H.-J. Space efficient conservative garbage collection : Proc. conf. on Programming Language Design and Implementation (SIGPLAN'93), Albuquerque, NM, Jun. 1993 // ACM SIGPLAN Notices. – New York: ACM Press, 1993. – Vol. 28(6). – pp. 197-206; New York: ACM Press, 2004. – Vol. 39, issue 4. – pp. 490-501. – ISSN 0362-1340.
- Lehti P. Design and Implementation of a Data Manipulation Processor for a XML Query Language : Ph.D. thesis. – 2001, Aug.
- Консорциум W3C. Язык XML Path (XPath) версия 1.0 = XML Path Language (XPath) Version 1.0 : Рекомендация Консорциума W3C / Под ред. Clark J., DeRose S.; пер. с англ. Усманов Р. – 1999, 16 ноя.
- S. S. Chawathe, A. Rajaraman, H. Garcia-Molina and J. Widom. Change Detection in Hierarchically Structured Information. Technical report; detailed version of paper appearing in SIGMOD 1996.
- Igor Tatarinov, Zachary G. Ives, Alon Y. Halevy, Daniel S. Weld. Updating XML : Proc. ACM SIGMOD int. conf. on Management of Data (SIGMOD'01), Santa Barbara, California, 21-24 May, 2001 // SIGMOD Conference / Aref W.G. (ed.). – New York: ACM Press, 2001. – pp. 413-424. – ISBN 1-58113-332-4.
- Лизоркин Д.А., Лисовский К.Ю. Язык XML Path (XPath) и его функциональная реализация SXPath // Электронные библиотеки. – М.: ИРИО, 2003. – Т. 6, вып. 4. – ISSN 1562-5419 = Russian digital libraries journal.
- A. Laux, L. Martin. XUpdate update language : XML:DB Working Draft. – 14 Sep, 2000.
- Лизоркин Д.А., Лисовский К.Ю. Реализация XLink – языка ссылок XML – с помощью функциональных методов // Программирование. – М.: Наука, 2005. – N 1. – С. 52-72. – ISSN 0361-7688 = Programming and computer software.
- Лизоркин Д.А. Язык запросов к совокупности XML-документов, соединенных при помощи ссылок языка XLink // Сборник трудов Института системного программирования РАН / Под ред. чл.-корр. РАН Иванникова В.П. – М.: ИСП РАН, 2004. – Т. 8, ч. 2. – 214 c. – с. 121-153. – ISBN 5-89823-026-2; Программирование. – М.: Наука, 2005. – N 3. – ISSN 0361-7688 = Programming and computer software.
- The World Wide Web Consortium (W3C). Extensible Markup Language (XML) 1.0 (Fourth Edition) : W3C Recommendation / Bray T. et al. (eds.). – 2006, 16 Aug.
- Лизоркин Д.А., Лисовский К.Ю. Пространства имен в XML и SXML // Электронные библиотеки. – М.: ИРИО, 2003. – Т. 6, вып. 3. – ISSN 1562-5419 = Russian digital libraries journal.
- Лизоркин Д.А. Функциональные методы обработки XML-данных / Ph.D. thesis = Диссертация на соискание ученой степени кандидата физико-математических наук по специальности 05.13.11. – 2005, 11 ноя.
- Кузнецов С.Д. Современные технологии баз данных : Годовой курс для студентов 3-го курса. – Центр Информационных Технологий.
- Гарсиа-Молина Г., Ульман Дж.Д., Уидом Дж. Системы Баз Данных. Полный курс / Пер. с англ. Варакина С.А.; под ред. Слепцова А.В. – М,: Вильямс, 2003. – 1088 с.: ил. – ISBN 5-8459-0384-X (рус.)
- Гринев М., Кузнецов С.Д, Фомичев А. XML-СУБД Sedna: технические особенности и варианты использования // Открытые системы. – 2004, вып 8.

- Психосемантика рекламы ( РОЛЬ ПСИХОЛОГИИ В ПРОЦЕССЕ ФОРМИРОВАНИЯ РЕКЛАМНЫХ СООБЩЕНИЙ)
- Финансы коммерческих организаций
- Понятие права (Возникновение права и его развитие)
- Формы государственного устройства
- Формы государственного устройства ( Формы правления)
- Публичная власть (Понятие и виды социальной власти)
- Выбор стиля руководства в организации (ООО «ИНЛАЙН»)
- Бухгалтерский учет на предприятии ЗАО «Искра Ленина»
- Организационная культура и ее роль в современных организациях
- Особенности профессиональной мотивации служащих организации (Направления совершенствования работы по развитию профессиональной мотивации педагогов в ДОУ и рекомендации)
- Основы программирования на языке HTML (Пример использования языка HTML)
- Предмет и метод правового регулирования (Правовое регулирование как один из видов социального регулирования)