
Операции, производимые с данными (Классификация структур данных)
Содержание:

ВВЕДЕНИЕ
Традиционно в программировании понятия сложности алгоритм связано с использованием ресурсов компьютера: насколько много процессорного времени требует программа для своего выполнения, сколько при этом тратится памяти, насколько сложной есть реализация с точки зрения дальнейшего развития и поддержки программного средства[1]. Практически любая программа оперирует данными, то есть выполняет определённые преобразования и операции с данными. Сегодня термин «данные» можно трактовать очень широко, сюда можно отнести, практически, любую информацию, хранящуюся в компьютере начиная от двоичного числа заканчивая сложными структурными представлениями данных. Как следствие – данные занимают на порядки больше памяти нежели сам исполнительный код, который обрабатывает эти данные. Как правило, память, которая тратится для записи команд программы не берется к вниманию, а учет ведется по объему данных.
Тема, сформулированная для курсовой работы, очень широка и может подразумевать различные аспекты, в разрезе темы могут рассматриваться:
реализация операций на аппаратном уровне, арифметико-логическое устройство как неотъемлемая структурная единица архитектуры ЭВМ;
операции с данными в рамках конкретной ОС;
операции с данными их типы и особенности в рамках конкретного языка программирования;
анализ данных определенных структур и операции с ними.
И этот перечень далеко не полон, в широком понимании темы даже преобразование графических файлов и реализация каких-либо графических эффектов в графических файлах также, формально, отвечают тематике.
Исходя из этого, уже во введении стоит очертить рамки исследования и выбрать конкретизированное направление для исследования.
В ходе данной курсовой работы будут исследованы последние два пункта из выше приведенного списка, а именно динамические структуры данных и операции с ними, реализация этих операций и механизмов обработки динамических структур данных в языке С/С++.
Язык С/С++ выбран по ряду причин: это классический широко используемый язык программирования для написания системных (и других) программ, по этому языку существует множество материалов и учебников (упрощается подбор материала и исследование), язык до сих очень востребован и входит в топ-10 популярных языков программирования [26, 27].
Что касается данных, то их разделяют: на внешние (файлы, БД, потоки от внешних устройств) и внутренние. Внутренние данные (переменные) программ разделяют на статические и динамические.
Объектом исследования курсовой работы есть принципы работы с памятью ЭВМ, теория структур данных и алгоритмов (операций) связанных с этими структурами.
Предметом исследования является роль и использования указателей при реализации операций и обработке динамических структур данных.
В данной работе будут рассмотрены:
‑ понятие указателя, особенности работы с указателем;
‑ роль и назначения динамических данных;
‑ основные типы динамических структур;
‑ особенности реализации базовых операций над динамическими структурами;
‑ практическое применение структур на примере выбранных задач.
РАЗДЕЛ 1 ПОНЯТИЕ УКАЗАТЕЛЯ, РАБОТА С УКАЗАТЕЛЯМИ
1.1 Указатели в языке С
Если рассматривать тему в разрезе языка С, то можно сказать крылатыми словами ‑ «указатели это наше ВСЕ». Дело в том, что язык С построен на основе косвенного обращения к памяти, в некоторых источниках язык С называют «язык указателей». Такое название язык получил так как на принципе использования указателей полностью построены передача данных между функциями, вызов функций и методов из библиотек и классов[13]. Язык С оперирует целым рядом механизмов связанных с указателями: простые адреса, «дальние» far - указатели, указатели на указатели и другие конструкции.
Основная идея появления именно динамических структур данных заключается в разности механизмов работы с памятью в случае статических и динамических данных. Для статической переменной резервируется место в памяти в момент ее описания и сохраняется на протяжении всего времени работы программы. Более детально механизмы выделения памяти будут рассмотрены ниже. Но однозначно такой механизм имеет ряд недостатков:
- Не эффективное использование памяти ‑ например: переменная отработала свою функцию и больше не будет использоваться, но память все равно занята.
- Особенно недостатки проявляются в случае использования не одиночных переменных простых стандартных типов, а в случае использования последовательностей данных (в широком понимании массивов) ‑ вызывает осложнение в случае когда длину (количество элементов массива) заведомо не задано, то есть наперед не известно сколько памяти необходимо резервировать под хранение данных.
Рассмотренные проблемные ситуации могут быть решены при помощи динамических данных: память выделяется в момент использования, может быть освобождена в нужное время, длина структуры не фиксируется и динамично изменяется в зависимости от нужд программы. Данный короткий анализ показывает актуальность и необходимость владения такими инструментами как динамические структуры и динамическое управление памятью (выделение памяти под программные данные). С другой стороны следует заметить, что язык С определенной мерой злоупотребляет упомянутыми механизмами, чем существенно усложняется программный код и его понимание. Например в языке С#, который во многом подражает языку С/С++, на данный фактор обратили внимание и во многих моментах упростили работу. В первую очередь через использование стандартных структур типа List, Set, dynamic Array и других, где работа с указателями скрыта от разработчика инкапсулирующим пластом и набором методов. За счет, в том числе, и этого факта, язык С#, Java потеснили язык С, который длительное время удерживал первые позиции по популярности и массовости использования в коммерческом программировании [26].
1.2 Механизмы работы и операции с указателями
При объявлении переменных, структур, объединений и т.п. операционная система выделяет необходимый объем памяти для хранения данных программы. Например, задавая цело-численную переменную
int a = 10;
в памяти ЭВМ выделяется или 2, или 4 байта (в зависимости от стандарта языка С), которые расположены один за другим (последовательно), начиная с определенного адреса. Здесь под адресом следует понимать номер байта в памяти, который показывает, где начинается область хранения той или другой переменной или любых произвольных данных. Условно память ЭВМ можно представить в виде последовательности байт

Рисунок 1.1 ‑ схематическое представление данных в памяти
Переменная а расположенная в 100 и 101 ячейках и занимает соответственно два байта. Адрес этой переменной равняется 100. Учитывая то, что значение переменной а равняется 10, то в ячейке под номером 100 будет записано число 10, а в ячейке под номером 101 ‑ нуль. Аналогичная картина остается справедливой и при объявлении произвольных переменных и структур, только в этом случае тратится разный объем памяти в зависимости от типа переменной[12].
В языке С существует механизм работы с переменными через их адрес. Для этого необходимо объявить указатель соответствующего типа. Указатель объявляется также как и переменная, но перед его именем указывается символ '*':
int * ptr_a;
char * ptr_ch, * ptr_var;
Для того чтобы с помощью указателя ptr_a работать с переменной a он должен указывать на адрес этой переменной. Это означает, что значение указателя ptr_a должно равняться адресу переменной a. Здесь возникает два задачи: во-первых, необходимо определить адресу переменной, во-вторых, присвоить этот адрес указателю. Для определения адреса в языке С ++ используется символ '&' как показано ниже:
ptr_a = & a; // Инициализация указателя
По сути значит, что указатель это переменная, которая сохраняет адрес на задан область памяти. Но в отличие от обычной переменной разрешает еще, и работать с данной областью памяти, т.е. записывать у нее значение и считывать их. Предположим, что переменная a содержит число 10, а указатель ptr_a указывает на эту переменную. Тогда для того чтобы считывать и записывать значение переменной a с помощью указателя ptr_a используется следующая конструкция:
int b = * ptr_a; // Считывание значения переменной а
* рtr_a = 20; // Запись числа 20 в переменную а
Здесь переменной b присваивается значение переменной a через указатель ptr_a, а, потом, переменной a присваивается значение 20. Таким образом, для записи и считывания значений с помощью указателя необходимо перед его именем ставить символ '*' и использовать оператор присваивания.
Каждый раз при работе с указателями необходимо выполнять их инициализацию, т.е. указывать адресу на выделенную область памяти. Сложность работы с указателями заключается в том, что при их объявлении они указывают на произвольную область памяти, с которой можно работать как с обычной переменной, например:
іnt * ptr;
* рtr = 10;
В результате в произвольную область памяти будет записано два байта со значениями 10 и 0. Это может привести к необратимым последствиям в работе программы и к ее ошибочному завершению. Поэтому перед использованием указателей всегда нужно быть уверенным, что они предварительно были инициализированы.
Рассмотрим возможность использования указателей при работе с массивами. Предположим, что объявленный массив целого типа int размерностью в 20 элементов:
int array [20];
Элементы массивов всегда располагаются один за другим в памяти ЭВМ, начиная с первого, индекс которого равняется 0 (в языке С/С++)
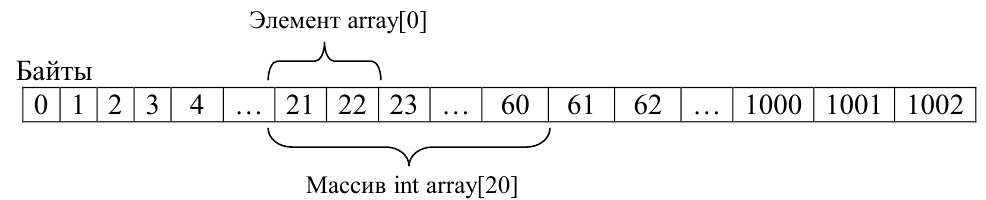
Рисунок 1.2 ‑ схематическое представление массива в памяти
Из рис. 1.2 видно, что для получения адреса массива array достаточно знать адрес его первого элемента array [0], который можно определить как адрес переменной и присвоить его указателю:
int * ptr_ar = & array [0];
Однако в языке С предусмотренная более простая конструкция для определения адреса массивов, которая записывается в такой способ:
int * ptr_ar = array;
т.е. имя массива задает его адрес. Следует отметить, что величины
&array [0] и array являются константами, т.е. не могут изменять своего значения. Это означает, что массив (как и переменная) не изменяют своего адреса, пока существуют в зоне своей видимости.
Формально, имея указатель на массив, можно считывать и записывать в него значение элементов. Сначала, когда указатель указывает на первый элемент, его значение можно изменять в такой способ:
int a = * ptr_ar;
* рtr_ar = 20;
Для того чтобы перейти к следующему элементу массива, довольно выполнить операцию ptr_ar + = 1; или ptr_ar ++;
Особенностью применения данной операции есть то, что адрес, т.е. значение указателя ptr_ar изменится не на единицу (как бы это было в случае обычной численной переменной), а на четыре, ровно на столько, сколько занимает один элемент с которым связан указатель в памяти, в данном случае четыре байта. В результате указатель ptr_ar будет указывать на следующий элемент массива, с которым можно работать, равно как и с предыдущим.
В языке С при работе с массивами через указатель допускается более простая форма чем рассмотренная раньше. Предположим, что ptr_ar указывает на первый элемент массива array. Тогда для работы с элементами массива можно воспользоваться следующей записью:
int * ptr_ar = array;
ptr_ar [0] = 10;
ptr_ar [1] = 20;
т.е. доступ к элементам массива осуществляется по его индексу. Массивы удобно передавать функциям через указатели. Пусть есть функция вычисления суммы элементов массива:
int sum (int * ar, int n);
и массив элементов
int array [5] = {1,2,3,4,5};
Тогда для передачи массива функции sum нужно использовать такую запись:
int s = sum (array, 5);
т.е. указатель ar инициализируется по имени массива array и будет указывать на его первый элемент. Следует отметить, что все возможные изменения, выполненные с массивом внутри функции sum (), сохраняются в массиве array. Это свойство можно использовать для модификации элементов массива внутри функций. Данный механизм может быть применен не только к массивам, а и к любым другим данным, он называется ‑ «механизм передачи данных в функцию по адресу»
Например, функция strcpy (char * dest, char * src), выполняет изменение массива, на который указывает указатель dest. Для того чтобы «защитить» массив от изменений нужно использовать ключевое слово const или при объявлении массива, или в объявлении аргумента функции как показано ниже.
char * strcpy (char * dest, const char * src)
{
while (* src! = '\ 0') * dest ++ = * src ++;
* Dest = * src;
return dest;
}
В общем случае можно выполнять следующие операции над указателями:
pt1 = pt2; // Присвоение значения одного указателя другому
pt1 + = * pt2; // Увеличение значения первого указателя на величину * pt2
pt1 - = * pt2; // Уменьшение адреса указателя на величину * pt2
pt 1-pt2; // Отнимание значений адресов первого и второго указателей
pt1 ++; и ++ pt1; // Увеличение адреса на единицу информации
pt1--; и --pt1; // Уменьшение адреса на единицу информации
Если указатели pt1 и pt2 имеют разные типы, то операция присваивания должна осуществляться с приведением типов, например:
int * pt1;
double * pt2;
pt1 = (int *) pt2;
Язык С допускает инициализацию указателя строкой, т.е. будет верной следующая команда:
char * str = "Лекция";
Здесь задается массив символов, которые содержат строку «Лекция» и адрес этого массива связанная с str. Таким образом, это означает, что есть массив, но нет его имени[16]. Есть только указатель в его адрес. Подобный подход есть удобным, когда необходимо обрабатывать массив строк. В этом случае возможная такая конструкция:
char * text [] = { «Язык С ++ имеет»,
«отличные механизме»,
«для работы с памятью.»};
Здесь задается массив указателей, каждый из которых указывает на начало соответствующей строки. Допустимо форматировать и указатели на структуры. Пусть заданная структура
struct tag_person {
char name [100];
int old;
} Person;
и инициируется следующий указатель:
struct tag_person * pt_man = & person;
В этом случае, для доступа к элементам структуры можно использовать следующий синтаксис:
(* Pt_man) .name;
pt_man-> name;
Последний вариант показывает особенность использования указателя на структуры, в котором для доступа к элементу используется операция ->.
Каждый раз при инициализации указателя использовался адрес той или другой переменной. Это было связано с тем, что компилятор языка С автоматически выделяет память для сохранности переменных и с помощью указателя можно без следствий работать с этой выделенной областью. Вместе с тем существуют функции malloc () и free(), которые позволяют выделять и освобождать память по мере необходимости. Данные функции находятся в библиотеке <stdlib.h> и имеют следующий синтаксис:
void * malloc (size_t); // Функция выделения памяти
void free (void * memblock); // Функция освобождения памяти
Здесь size_t ‑ размер выделенной области памяти в байтах;
void * ‑ обобщенный тип указателя, т.е. указатель не привязан к какому-то конкретному типу.
Рассмотрим работу данных функций на примере выделения памяти для 10 элементов типа double. К этому моменту мы использовали указатели для работы со статическими переменными, следующий пример уже демонстрирует динамический массив.
Программирование динамического массива.
#include <stdio.h>
#include <stdlib.h>
int main ()
{
double * ptd;
ptd = (double *) malloc (10 * sizeof (double));
if (ptd! = NULL)
{
for (int i = 0; i <10; i ++)
ptd [i] = i;
} еlse printf ( "Не удалось выделить память.");
free (ptd);
return 0;
}
При выполнении функции malloc() выполняется расчет области памяти для хранения 10 элементов типа double. Для этого используется функция sizeof (), которая возвращает число байт, необходимых для одного элемента типа double. Потом ее значение множится на 10 и в результате выходит объем для 10 элементов типа double. В случаях, когда по каким-нибудь причинам не удается выделить указанный объем памяти, функция malloc () возвращает значение NULL. Данная константа определена в нескольких библиотеках, в том числе в <stdio.h> и <stdlib.h>. Если функция malloc () возвратила указатель на выделенную область памяти, т.е. не равняется NULL, то выполняется цикл, где записываются значение для каждого элемента.
При выходе из программы вызывается функция free(), которая освобождает раньше выделенную память. Формально, программа написанная на языке С при завершении сама автоматически освобождает всю ранее выделенную память и функция free (), в данном случае, может быть опущенная. Однако при составлении более сложных программ часто приходится много раз выделять и освобождать память. В этом случае функция free () играет большую роль, так как не освобожденная память не может быть повторно использована, что, в результате, введет в неоправданные расходы ресурсов ЭВМ[16].
РАЗДЕЛ 2 ОБЗОР ДИНАМИЧЕСКИХ СТРУКТУР, ХАРАКТЕРИСТИКА
Как отмечалось прежде, особые преимущества использования механизма указателей приобретает в случае использования сложных структур данных. Некоторые из структур, которые будут рассматриваться ниже, очень широко используются в программировании, в теории алгоритмов, на низком программно-аппаратном уровне. В частности наиболее применяемыми являются структуры: линейный список и его подвиды: очередь и стек. Рассмотрим классические структуры данных более детально.
2.1 Классификация структур данных
Структура данных ‑ это форма хранения и представление информации. Структуры данных бывают простыми и сложными: представляют атомарную единицу информации или набор однотипных данных. Сложные структуры данных делятся на динамические и статические наборы. Динамические в процессе своего жизненного цикла разрешают изменять свой размер (добавлять и удалять элементы), а статические ‑ нет. По организации взаимосвязей между элементами сложных структур данных существует следующая классификация:
Линейные:
- Массив
- Перечень
- Связанный список
- Стек
- Очередь
- Хеш-таблица
Иерархические:
- Двоичные деревья
- N-арные дерева
- Иерархический список
Сетевые (табличные):
- Простой граф
- Ориентированный граф
- Табличные
- Таблица реляционной базы данных
- Двумерный массив[7]
Приведенная классификация далеко не полная. Элементами сложных структур данных могут выступать как экземпляры простых, так и экземпляры сложных структур данных, например структура данных «лес» ‑ это список непересекающихся деревьев. Первый уровень классификации построен на основе отличий в способе адресации и поиска отдельных элементов в наборе сложной структуры данных.
2.2 Линейные структуры данных
Элемент линейной структуры данных характеризуется порядковым номером или индексом в линейной последовательности элементов.
Массив ‑ это статическая линейная структура однотипных данных, оптимизированная для операций поиска элемента по его индексу. Однозначное расположение элемента в памяти обеспечивается именно однотипностью элементов в массиве и определяется произведением его индекса на размер памяти, занимаемой одним элементом.

Рисунок 2.1 ‑ Линейный массив
Список ‑ это динамическая линейная структура данных, в которой каждый элемент ссылается или только на следующий(предыдущий) ‑ однонаправленный линейный список, или на предыдущий и следующий за ним ‑ двунаправленный линейный список. Особенность и преимущество этой структуры данных, кроме возможности изменять размер, ‑ это простота реализации. Также, благодаря наличию ссылок, каждый элемент в списке, в отличие от массива, может занимать разный объем памяти. Адрес первого элемента в линейном списке однозначно определяется адресом самого списка.
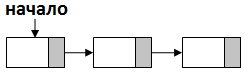
Рисунок 2.2 ‑ Однонаправленный список
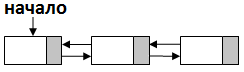
Рисунок 2.3 ‑ Двунаправленный список
Связанный список ‑ это вариант обычного линейного списка, оптимизированный для операций добавления и удаление элементов. Оптимизация заключается в том, что элементы связанного списка не обязаны в памяти располагаться «один за одним». Порядок элементов определяется ссылкам на первый элемент (не обязан быть в самом начале выделенной для списка памяти) и последовательностью ссылок на другие элементы списка.
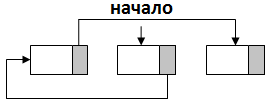
Рисунок 2.4 ‑ Связанный список
Стек ‑ это динамическая линейная структура данных, для которой определено лишь две операции изменения набора элементов: добавление элемента в конец и удаление последнего элемента. Еще говорят, что стек реализует принцип LIFO (Last Іn, First Out) ‑ последним пришел и первым пошел. Например, в ходе выполнения программного кода, вычислительная машина при необходимости вызвать процедуру или функцию сначала заносит указатель на место ее вызова в стек, чтобы при завершении выполнения ее кода корректно возвратиться к следующей после точки вызова инструкции. Такая структура данных называется стеком вызовов подпрограмм[17].
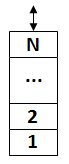
Рисунок 2.5 ‑ Стек
Очередь ‑ очень похожа не стек, динамическая структура данных, с той лишь разностью, что она реализует принцип FIFO (First Іn, First Оut) ‑ первым пришел и первым пошел. В программировании с помощью очередей, например, обрабатывают события предназначенного для пользователя интерфейса, обращение клиентов к веб - сервисов и другие информационные запросы.
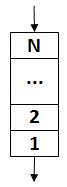
Рисунок 2.6 ‑ Очередь
2.3 Иерархические структуры данных
Элемент в иерархической структуре данных характеризуется ссылкам на вышестоящий в иерархии элемент (или ссылками на нижестоящие элементы) и (необязательно) порядковым номером в линейной последовательности своего уровня (иерархические списки).
Деревья ‑ динамическая иерархическая структура данных, представленная единым корневым узлом и его потомками. Максимальное количество потомков каждого узла и определяет размерность дерева. Отдельно выделяют двоичные или бинарные деревья, поскольку они используются в алгоритмах сортировки и поиска: каждый узел двоичного дерева поиска отвечает элементу из некоторого отсортированного набора, все его "левые" потомки – являются меньшими элементами, а все его "правые" потомки ‑ большими элементам. Каждый узел в дереве однозначно идентифицируется последовательностью неповторяемых узлов от корня и к нему, такую последовательность называют ‑ путем. Длина пути и является уровнем узла в иерархии дерева. Для двоичных или бинарных деревьев выделяют следующие виды рекурсивного обхода всех его элементов (в фигурных дужках указан порядок просмотра элементов каждого узла, начиная из корня):
• Прямой или префиксный (узел, левое поддерево, правое поддерево)
• Обратный или постфиксный (левое поддерево, правое поддерево, узел)
• Симметричный или инфиксный (левое поддерево, узел, правое поддерево)
Чтобы вывести элементы в порядке их роста (сортировка на основе структуры дерева), дерево поиска нужно обойти в симметричном порядке. Чтобы элементы оказались в обратном порядке, в процессе обхода необходимо поменять порядок просмотра поддеревьев.
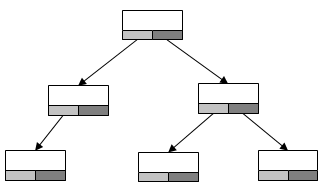
Рисунок 2.7 ‑ Двоичное (бинарное) дерево
Иерархический список ‑ симбиоз линейного списка и дерева. Каждый элемент списка может быть также началом списка следующего подуровня иерархии. Пример иерархического списка ‑ структура интернет форумов: последовательность сообщений образовывает линейный список, в то время как сообщение, которые являются ответами на другие сообщения, порождают новые потоки обсуждения[17].
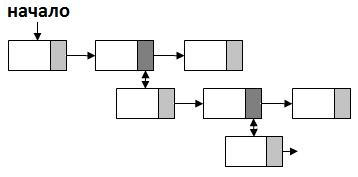
Рисунок 2.8 ‑ Иерархический список
2.4 Операции с линейными структурами и их реализация
Виды связанных списков делятся на:
• односвязный список
• двухсвязный список (двунаправленный)
• кольцевой связный список
Код описания связанного списка:
public class Node {
private int data;
private Node next;
public int getData () {
return this.data;
}
public void setData (int data) {
this.data = data;
}
public void setNext (Node next) {
this.next = next;
}
public Node getNext () {
return this.next;
}
}
// Класс представляет список
public class List {
private Node first;
public List () {
this.first = null;
}
}
К связанным спискам применимые три основных операции над элементами:
1) Добавление
2) Удаление
3) Поиск[21]
Эти операции являются различными по реализации для разных структур данных, и они есть одними из основных факторов, которые определяют, какая структура будет использована в определенной ситуации. С другой стороны на особенности реализации операций влияет сама структура данных и правила присущие ей.
В данном случае мы рассматриваем простой линейный список без наложения дополнительных правил.
Добавление
Добавление в связанный список довольно стандартная простая операция. Она заключается в простом добавлении нового элемента в начало списка и модификации указателя так, чтобы первый указатель был направлен к новому элементу.
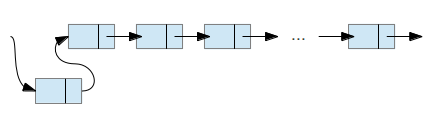
Рисунок 2.9 ‑ Добавление элемента к списку (в начало)
Код Добавления элементов к списку
public void insert (int data) {
Node node = new Node ();
node.setData (data);
node.setNext (first);
first = node;
}
Добавление элемента в конец списка существенно не имеет отличий. Немного сложнее реализуется добавление (вставка) элемента внутрь списка. Обычно такая задача ставится как: вставить новый элемент списка «D» после заданного (искомого) элемента «Х». Механизм реализации этой операции представлен на рис. 2.10
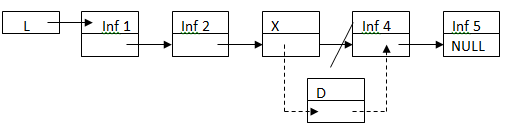
Рисунок 2.10 ‑ Добавление элемента в середину списка
Удаление
Удаления сложнее реализуется в связанных списках. Оно включает в себя несколько этапов:
1) Выявление элемента, который находится перед тем, который необходимо удалить
2) Изменение указателя этого элемента на элемент, следующий за тем, что удаляем
3) Удаление элемента
В тоже время, в случае списков, удаление алгоритмически проще и намного эффективнее реализуется, нежели в статическом массиве. В статическом массиве, в «чистом» виде, этого вообще невозможно сделать и при необходимости реализуется, например, так:
- Находим элемент, который нужно удалить
- Заменяем его значение, каким то выбранным «маркерным» значением (удалить элемент не возможно, так если в массиве все значения положительны, то можно использовать «0» как маркер удаленного элемента)
- Смещаем все элементы, которые находятся справа от удаляемого
- Перемещаем маркированный элемент в конец массива (зона удаляемых элементов)
Как видно из этой последовательности действий, удаление в статическом массиве – это только имитация удаления, программу можно научить понимать такой элемент как «удаленный», но, по сути, элемент не удаляется.
С точки зрения оценки сложности операции, удаления в связанном списке имеем линейную сложность, это обосновано необходимостью поиска удаляемого элемента по заданному критерию, а поиск в таких структурах можно реализовать только полным перебором. Об этом стоит помнить, когда выбирается та или иная структура для хранения данных. Этот пример ярко иллюстрирует – выбор структур данных напрямую зависит от типа и процентного соотношения требуемых для выполнения операций.
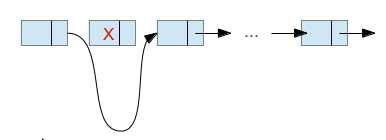
Рисунок 2.11 – Удаление элемента списка
Код Удаления элемента со списка
public Node findPredecessor (int i) {
return findPredecessor (first, i);
}
private Node findPredecessor (Node node, int i) {
if (node == null || node.getNext () == null) return null;
if (node.getNext (). getData () == i) return node;
return findPredecessor (node.getNext (), i);
}
public void delete (int i) {
Node element = find (i);
if (element! = null) {
Node predecessor = findPredecessor (i);
if (predecessor! = null) {
predecessor.setNext (element.getNext ());
} Else {
first = element.getNext ();
}
element = null;
}
}
Операцию поиска иллюстрировать не станем, так как ее механизм достаточно прост. Поиск реализуется циклическим линейным просмотром элементов списка с проверкой двух условий:
- Не достигнут конец списка.
- Искомый элемент не найден.
Как видим из приведенных примеров, операция поиска достаточно не эффективно реализуется в линейных динамических списках и ее линейная оценка намного уступает желаемой (логарифмической) оценке быстродействия. Исходя из этого – линейные списки не применимы в случае частой необходимости организации поиска и удаления произвольно заданных элементов. Линейные списки эффективны, когда порядок попадания (добавления) и удаления элементов четко определен, в зависимости от типа порядка выполнения этих операций применяется очередь или стек. Возможно применение и более сложных комбинированных структур (типа «дек»), но их применяют достаточно редко.
В случае необходимости реализации частого поиска более эффективно применять иерархические структуры данных, где алгоритм поиска полагается на саму структуру, то есть элементы в структуре изначально располагаются с учетом критерия по которому в дальнейшем предполагается поиск (например величина числового значения для числовых данных). Такой способ формирования структур позволяет реализовывать операции поиска гораздо эффективнее линейной оценки.
РАЗДЕЛ 3 ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ ДИНАМИЧЕСКИХ СТРУКТУР ДАННЫХ И ОПЕРАЦИЙ С НИМИ
В качестве практических примеров рассмотрим несколько прикладных задач связанных с использованием динамических структур данных.
Эти примеры призваны продемонстрировать использование операций над указателями и динамическими структурами данных в конкретных целевых задачах.
Для примера рассмотрим такую задачу:
Задание:
Необходимо построить линейный список с динамических переменных, которые содержат целые числа (вводятся из клавиатуры). В середину списка (в указанную позицию) вставить новый элемент с дополнительно введенным значением. Вывести полученный список.
Полный листинг реализации приведено в приложении 1. Тут приведем только скрин тестирования программы и фрагмент, отвечающий за операцию вставки.
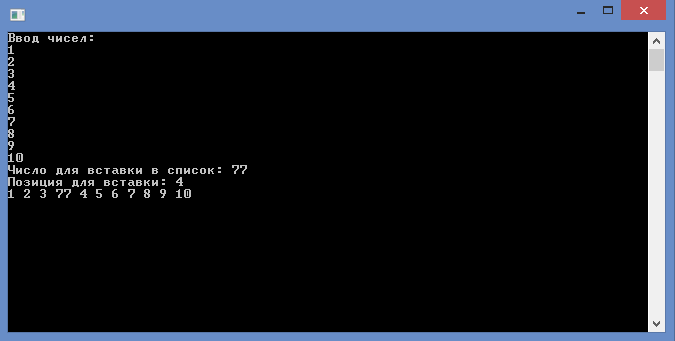
Рисунок 3.1 ‑ Результат выполнения задачи
Ниже приведем листинг метода основного класса List, который реализует вставку в указанную позицию (пояснения по реализации внесем в виде комментариев):
public void Insert(int index, T data)
{
//Проверка на корректность параметра индекс и генерация исключения в случае
//некорректного параметра
if(index < 0 || index >= count)
throw new ArgumentOutOfRangeException();
//Если индекс равен 0 – вставка в начало списка
if(index == 0)
{
AddFront(data);
}
//в противном случае ищем позицию
else
{
Node r = head;
//пропускаем все предыдущие элементы – проход по списку
for(int i = 1; i < index; ++i)
r = r.next;
//вставляем новый элемент
Node new_node = new Node(data, r.next);
r.next = new_node;
++count;
}
}
Пример 3.2 Обработка структуры «стек»
Задание:
Создать стек, заполнить его числами в диапазоне (-50,50). Определить сколько элементов стека находятся между минимальным и максимальным элементами.
Для заполнения стека использовалась функция генерации случайного числа
srand (GetTickCount ());
numb = 50-rand ()% 101;
Описание элемента стека:
class Node
{
public:
int number;
Node* last;
};
Цикл заполнения стека:
for (int i=0;i<count;i++)
{
numb= 50-rand()%101;
Node* ptr = new Node;
ptr->number = numb;
if (top == NULL)
{
ptr->last = NULL;
top = ptr;
ptrLast = ptr;
system("CLS");
continue;
}
top = ptr;
ptr->last = ptrLast;
ptrLast = ptr;
}
Цикл поиска интервала:
Node* ptr = NULL;
ptr = top;i_max =0 ;i_min=0;
int flag = -1;
while (1)
{ count_in++;
if (ptr->number>max) {max = ptr->number;
i_max =count_in; }
if (ptr->number<min) {min = ptr->number;
i_min = count_in;
}
ptr = ptr->last;
if (ptr == NULL){break;}
}
Полный листинг представлен в приложении 2
Результаты тестирования программы:
Стек после заполнения (12 элементов)
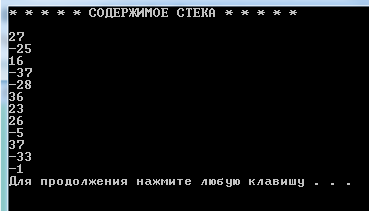
Рисунок 3.2 – Заполненный стек
Результаты поиска длины интервала между (мин : макс)
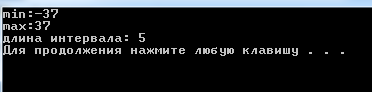
Рисунок 3.3 – Вывод результата (длина интервала)
Пример 3.3 Обработка двусвязных структур
Для примера рассмотрим работу с двухсвязным списком
Задание:
Создать «двухсвязный список», заполнить ее числами в диапазоне (-50,50). Реализовать поиск, вывод списка. Удалить по одному элементу справа и слева от минимального. Если минимальный элемент крайний – удалить его.
Описание структуры отличается наличием двух указателей:
class Node
{
public:
int number;
Node* next;
Node* last;
};
Алгоритм создания и выполнение операций добавления элементов к списку должно учитывать наличие двух указателей и имеет некоторые особенности:
russia("Введите кол. элементов: ");
cin>>count;
srand(GetTickCount());
for (int i=0;i<count;i++)
{
Node* ptr = new Node;
numb=50-rand()%101;
ptr->number = numb;
ptr->next = NULL;
tail = ptr;
if (head == NULL)
{
head = ptr;
ptrLast = ptr;
ptr->last = NULL;
system("CLS");
continue;
}
ptr->last = ptrLast;
ptrLast->next = ptr;
ptrLast = ptr;
}
Созданный список
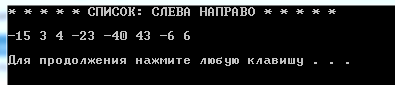
Рисунок 3.4 – Вывод созданного списка
Ключевым моменом в этой задаче является поиск минимума. Приведем листинг реализующий эту операцию:
/*********************************************************************
* Возвращает указатель на структуру в списке с минимальным значением
* элемента, если передан единственный элемент списка, то возвращает NULL*
*********************************************************************/
Node* minimum(Node* snach)
{
Node* minimum;
Node* tek;
minimum=snach;
tek=snach;
if(tek->next!=NULL)
{
while(tek->next!=NULL)
{
tek=tek->next;
if((tek->number)<(minimum->number))
{ minimum=tek; }
}
} else return NULL;
return minimum;
}
Как видно из приведенного примера – минимум ищется полным проходом по структуре с поэлементным сравнением на каждом шаге прохода.
После удаления минимума или соседей
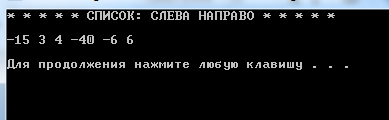
Рисунок 3.5 – Вывод результата (после удаления)
Полный листинг кода приведен в приложении 3.
ВЫВОДЫ
Тема курсовой работы локализирована в области динамических структур данных, операций с этими структурами и особенностями их реализации в я зыке С/С++.
Указатели играют ключевую роль в организации и механизмах работы с памятью. При помощи указателей становится возможным обрабатывать данные не статически, а выделять и освобождать память по необходимости, тем самым повысить качество программного обеспечения за счет эффективной организации данных.
Курсовая работа состоит из вступления, выводов и 3 разделов в составе основной части.
Первый раздел посвящен обзору динамической памяти и понятие указателя вообще. Во втором разделе рассматриваются основные типы динамических структур, описываются их особенности. Тут же рассмотрены основные операции применимые к динамическим структурам данных.
Третий раздел посвящен практическому применению динамических структур данных в ходе разработки прикладных задач.
Курсовая работа полностью отвечает тематике и раскрывает поставленные в работе вопросы и задачи.
ЛИТЕРАТУРА
- Ахо А., Хопкрофт Д., Ульман Д. Структуры данных и алгоритмы. М.: Издательский дом «Вильямс», 2000. 384 с.
- Бакнелл Д. Фундаментальные алгоритмы и структуры данных в Delphi. Спб.: Диасофтюп, 2003. 560 с.
- Беллман Р. Динамическое программирование. М.: ИЛ, 1960.
- Берзтисс А. Структуры данных. М.: Статистика, 1974. 405 с.
- Вирт Н. Алгоритмы +структуры данных = программы. М.: Мир, 1985. 406 с.
- Вирт Н. Алгоритмы и структуры данных. Спб.: Невский диалект, 2001. 360 с.
- Далекая В. Д., Деревянко А. С., Кравец О. Г., Тимановская Л. Э. Модели и структуры данных. Харьков: ХГПУ, 2000. 241 с.
- Дейкстра Э. Дисциплина программирования. М.: Мир, 2008. 275 с.
- Кнут Д. Искусство программирования. Том 1: Основные алгоритмы. М.: Издательский дом «Вильямс», 2000. 720 с.
- Кнут Д. Искусство программирования. Том 3: Сортировка и поиск. М: Издательский дом «Вильямс», 2000. 832 с.
- Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. М.: МЦНМО, 2000. 960 с.
- Райли Д.. Абстракция и структуры данных: Вводный курс. М.: Мир, 1993. 752 с.
- Седжвик Р. Фундаментальные алгоритмы на С++. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск. Спб.: Диасофтюп, 2002. 688 с.
- Седжвик Р. Фундаментальные алгоритмы на Java. Части 1-4. Анализ. Структуры данных. Сортировка. Поиск. Спб.: ТИД «ДС», 2003. 688 с.
- Топп У., Форд У. Структуры данных в Си++. М.: Издательство БИНОМ, 2000. 816 с.
- Хусаинов Б. С. Структуры и алгоритмы обработки данных. Примеры на языке Си. М.: Финансы и статистика, 2004. 464 с.
- (ЭУМКД) «Структуры и алгоритмы обработки данных» (Сиаод) Составитель: Л.В. Серебряная, доцент кафедры ПОИТ «Белорусский государственный университет информатики и радиоэлектроники».
- Й. Лэнгсам, М. Огенстайн, А. Тененбаум, Структуры данных для персональных ЭВМ.- М.: Мир, 1989.
- 3.1.4. Г. Кормен, Алгоритмы, построение и анализ. 2-изд.- М.: Мир. - 2005.
- http://kufas.ru/ Динамические структуры
- http://www.intuit.ru/ Структуры и алгоритмы компьютерной обработки данных
- http://www.codenet.ru/progr/cpp/dlist.php
- http://ocw.mit.edu
- http://www.cs.mcgill.ca
- http://algolist.manual.ru
- Динамика изменения позиций популярности языков Электронный ресурс [режим доступа]: https://cosmonova.net/ru/page/top_popular_programming_language
- Сравнение популярности и востребованности языков программирования Электронный ресурс [режим доступа]: https://habrahabr.ru/hub/github/
Приложение 1 Листинг «Линейный список»
class LinkedList<T>
{
private class Node
{
public T data;
public Node next;
public Node(T data, Node next)
{
this.data = data;
this.next = next;
}
}
private int count = 0;
private Node head = null;
private Node tail = null;
public void AddBack(T data)
{
if(head == null)
{
head = new Node(data, null);
tail = head;
}
else
{
tail.next = new Node(data, null);
tail = tail.next;
}
++count;
}
public void AddFront(T data)
{
if(head == null)
{
head = new Node(data, null);
tail = head;
}
else
{
Node new_node = new Node(data, head);
head = new_node;
}
++count;
}
public void Insert(int index, T data)
{
if(index < 0 || index >= count)
throw new ArgumentOutOfRangeException();
if(index == 0)
{
AddFront(data);
}
else
{
Node r = head;
for(int i = 1; i < index; ++i)
r = r.next;
Node new_node = new Node(data, r.next);
r.next = new_node;
++count;
}
}
public int Count
{
get
{
return count;
}
}
public IEnumerator GetEnumerator()
{
for(Node r = head; r != null; r = r.next)
yield return r.data;
}
}
class Program
{
static void Main(string[] args)
{
const int n = 10;
LineList.LinkedList<int> list = new LineList.LinkedList<int>();
Console.WriteLine("Ввод чисел:");
for (int i = 1; i <= n; ++i)
list.AddBack(int.Parse(Console.ReadLine()));
Console.Write("Число для вставки в список: ");
int val = int.Parse(Console.ReadLine());
Console.Write("Позиция для вставки: ");
int pos = int.Parse(Console.ReadLine()) - 1;
list.Insert(pos, val);
foreach (int item in list)
Console.Write("{0} ", item);
Console.WriteLine();
Console.ReadKey();
}
}
Приложение 2 Листинг «Поиск диапазона в стеке»
#include "stdafx.h"
#include <iostream>
#include <windows.h>
using namespace std;
class Node
{
public:
int number;
Node* last;
};
void rus_lang (const char*);
void ReadStac(Node *top)
{
system("CLS");
Node* ptr = NULL;
if (top == NULL)
{
rus_lang ("\t!!! СТЕК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
}
rus_lang ("* * * * * СОДЕРЖИМОЕ СТЕКА * * * * *\n\n");
ptr = top;
while (1)
{
cout<<ptr->number<<endl;
if (ptr->last == NULL)
{
system("PAUSE");
system("CLS");
break;
}
ptr = ptr->last;
}
}
int LengthStack (Node *top)
{
int len=0;
Node* ptr = NULL;
if (top == NULL)
{
return 0;
}
ptr =top;
while (1)
{
len++;
if (ptr->last == NULL)
{return len;}
ptr = ptr->last;
}
}
void ClearAll(Node **pstack)
{
Node *tmp;
while(*pstack!=NULL)
{
tmp=*pstack;
*pstack=(*pstack)->last;
delete tmp;
}
}
void main()
{
Node* ptrLast = NULL;
Node* top = NULL;
short action = -1;
while (1)
{
rus_lang ("1. Создать Стек из n ел.\n");
rus_lang ("2. Вытолкнуть Из Стека\n");
rus_lang ("3. Вершина Стека\n");
rus_lang ("4. Содержимое Стека\n");
rus_lang ("5. Поиск интервала между min:max\n");
rus_lang ("0. Выход\n\n");
rus_lang ("Ваш Выбор: ");
cin>>action;
if (action == 0)
{
ClearAll(&top);
system("CLS");
break;
}
if (action == 1)
{
system("CLS");
int numb = -1;
int count=0;
rus_lang ("Введите колличество эл. размещаемых в стеке: ");
cin>> count;
srand(GetTickCount());
//цикл создания стека
for (int i=0;i<count;i++)
{
numb= 50-rand()%101;
Node* ptr = new Node;
ptr->number = numb;
if (top == NULL)
{
ptr->last = NULL;
top = ptr;
ptrLast = ptr;
system("CLS");
continue;
}
top = ptr;
ptr->last = ptrLast;
ptrLast = ptr;
}
system("CLS");
continue;
}
if (action == 2)
{
system("CLS");
Node* ptrDelete = NULL;
if (top == NULL)
{
rus_lang ("\t!!! СТЕК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
ptrDelete = top;
if (ptrDelete->last == NULL)
{
top = NULL;
delete ptrDelete;
system("CLS");
continue;
}
top = ptrDelete->last;
ptrLast = top;
delete ptrDelete;
continue;
}
if (action == 3)
{
system("CLS");
if (top == NULL)
{
rus_lang ("\t!!! СТЕК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
rus_lang ("Вершина Стека: ");
cout<<top->number<<"\n\n";
system("PAUSE");
system("CLS");
continue;
}
if (action == 4)
{
ReadStac(top);
}
if (action == 5)
{
int min=0, max=0;
int count_in=0,i_max,i_min;
system("CLS");
Node* ptr = NULL;
//cout<<LengthStack (top)<<endl;
if (LengthStack (top)<3)
{
rus_lang ("\t!!! Интервал не существует, в СТЕКЕ меньше 3 эл. !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
else
{
Node* ptr = NULL;
ptr = top;i_max =0 ;i_min=0;
int flag = -1;
while (1)
{ count_in++;
if (ptr->number>max) {max = ptr->number;
i_max =count_in; }
if (ptr->number<min) {min = ptr->number;
i_min = count_in;
}
ptr = ptr->last;
if (ptr == NULL){break;}
}
cout<<"min:"<<min<<endl;
cout<<"max:"<<max<<endl;
count_in = labs(i_ min-i_max)-1;
rus_lang ("длина интервала: ");
cout<<count_in<<endl;
system("PAUSE");
system("CLS");
}
}
if (action > 5)
{
system("CLS");
rus_lang ("\t!!! НЕВЕРНЫЙ ВЫБОР. ПОВТОРИТЕ ВВОД !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
}
}
void rus_lang (const char* rus)
{
char word[100];
CharToOem(rus, word);
cout<<word;
}
Приложение 3 Листинг «Удаление элементов по условию из двусвязного списка»
#include "stdafx.h"
#include <iostream>
#include <windows.h>
using namespace std;
class Node
{
public:
int number;
Node* next;
Node* last;
};
void russia(const char*);
void DelList (Node *sl, Node *sr );
/*************************************************************************
* Возвращает указатель на структуру в списке с минимальным значением *
* элемента, если передан единственный элемент списка, то возвращает NULL*
*************************************************************************/
Node* minimum(Node* snach)
{
Node* minimum;
Node* tek;
minimum=snach;
tek=snach;
if(tek->next!=NULL)
{
while(tek->next!=NULL)
{
tek=tek->next;
if((tek->number)<(minimum->number))
{ minimum=tek; }
}
} else return NULL;
return minimum;
}
/******************************************
* Сортирует список посредством выбора и *
* возвращает указатель на начало *
* отсортированного по убыванию списка *
******************************************/
Node* sortirovka (Node* snach)
{
Node* nnach=NULL; //указатель на начало нового (сортированного) списка (для начала=NULL)
Node* tekushiy;
Node* bil;
Node* bud;
bool end=false;
while(!end)
{
tekushiy=minimum(snach);
if(tekushiy!=NULL) // если в старом списке больше 1 эл-та
{
// Вережем минимальный эл-т из старого списка
bil=tekushiy->last;
bud=tekushiy->next;
if(bil!=NULL) // если минимальным оказался не 1 эл-т
{
if(bud!=NULL) // и не последний
{
bil->next=bud;
bud->last=bil;
} else bil->next=NULL; // если последний
}
else // если первый
{
bud->last=NULL;
snach=bud;
}
// добавим мин. эл-т в нач нового списка
if(nnach!=NULL) // если в новом списке уже есть элементы
{
nnach->last=tekushiy;
tekushiy->next=nnach;
} else tekushiy->next=NULL; // если нету
tekushiy->last=NULL;
nnach=tekushiy;
}
else // если в старом списке остался 1 эл-т
{
end=true;
nnach->last=snach;
snach->next=nnach;
snach->last=NULL;
nnach=snach;
}
}
return nnach;
}
void main()
{
short action = -1;
Node* head = NULL;
Node* tail = NULL;
Node* ptrLast = NULL;
while (1)
{
russia("1. Заполнить список случайными элементами\n");
russia("2. Просмотр Списка Слева Направо\n");
russia("3. Просмотр Списка Справа Налево\n");
russia("4. Поиск минимума\n");
russia("5. Удалить эл. соседние с минимумом (мин. в случае отсутсвия соседних)\n");
russia("6. Поиск Элемента\n");
russia("7. Cортировка Списка\n");
russia("0. Выход\n\n");
russia("Ваш Выбор: ");
cin>>action;
if (action == 0)
{
DelList (head,tail);
system("CLS");
break;
}
if (action == 1)
{
system("CLS");
int numb = -1;
int count;
russia("Введите кол. элементов: ");
cin>>count;
srand(GetTickCount());
for (int i=0;i<count;i++)
{
Node* ptr = new Node;
numb=50-rand()%101;
ptr->number = numb;
ptr->next = NULL;
tail = ptr;
if (head == NULL)
{
head = ptr;
system("CLS");
continue;
}
ptr->last = ptrLast;
ptrLast->next = ptr;
ptrLast = ptr;
}
system("CLS");
continue;
}
if (action == 2)
{
system("CLS");
Node* ptr = NULL;
if (head == NULL)
{
russia("\t!!! СПИСОК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
russia("* * * * * СПИСОК: СЛЕВА НАПРАВО * * * * *\n\n");
ptr = head;
while (1)
{
cout<<ptr->number<<" ";
if (ptr->next == 0)
break;
ptr = ptr->next;
}
cout<<"\n\n";
system("PAUSE");
system("CLS");
continue;
}
if (action == 3)
{
system("CLS");
Node* ptr = NULL;
if (head == NULL)
{
russia("\t!!! СПИСОК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
russia("* * * * * СПИСОК: СПРАВА НАЛЕВО * * * * *\n\n");
ptr = tail;
while (1)
{
cout<<ptr->number<<" ";
if (ptr->last == 0)
break;
ptr = ptr->last;
}
cout<<"\n\n";
system("PAUSE");
system("CLS");
continue;
}
if (action == 5)
{
Node* ptrDelete = NULL;
system("CLS");
Node* ptr = NULL;
Node* ptr_min = NULL;
int key = -1;
if (head == NULL)
{
russia("\t!!! СПИСОК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
int min =100;
ptr = head;
while (1)
{
if ( ptr->number<min)
{
min =ptr->number;
ptr_min =ptr;
}
if (ptr->next == NULL)
{
}
ptr = ptr->next;
}
if (ptr_min->next == NULL)
{
system("CLS");
if (tail == NULL)
{
russia("\t!!! СПИСОК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
if (tail->last == NULL)
{
head = NULL;
tail = NULL;
delete tail;
continue;
}
ptrDelete = tail;
tail = ptrDelete->last;
ptrLast = tail;
delete ptrDelete;
continue;
}
ptrDelete = head;
head = ptrDelete->next;
head->last = NULL;
delete ptrDelete;
continue;
}
if ((ptr_min->last != NULL)&&(ptr_min->next != NULL))
{
Node* del1 = ptr_min->last;
Node* del2 = ptr_min->next;
del1->last->next = del1->next;
del1->next->last = del1->last;
delete del1;
del2->next->last = del2->last;
delete del2;
}
}
if (action == 7)
{
head = sortirovka (head);
russia("Список отсортирован \n\n");
Node* ptr = NULL;
if (head == NULL)
{
russia("\t!!! СПИСОК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
russia("* * * * * СПИСОК: СЛЕВА НАПРАВО * * * * *\n\n");
ptr = head;
while (1)
{
cout<<ptr->number<<" ";
if (ptr->next == 0)
break;
ptr = ptr->next;
}
tail = ptr;
cout<<"\n\n";
system("PAUSE");
system("CLS");
}
if (action == 6)
{
system("CLS");
Node* ptr = NULL;
if (head == NULL)
{
russia("\t!!! СПИСОК ПУСТ !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
russia("Введите Элемент Для Поиска: ");
cin>>key;
ptr = head;
while (1)
{
if (key == ptr->number)
{
russia("\n\t!!! ЭЛЕМЕНТ НАЙДЕН !!!\n");
break;
}
if (ptr->next == NULL)
{
russia("\n\t!!! ЭЛЕМЕНТ НЕ НАЙДЕН !!!\n");
break;
}
ptr = ptr->next;
}
system("PAUSE");
system("CLS");
continue;
}
if (action > 7)
{
system("CLS");
russia("\t!!! НЕВЕРНЫЙ ВЫБОР. ПОВТОРИТЕ ВВОД !!!\n\n");
system("PAUSE");
system("CLS");
continue;
}
}
}
void russia(const char* rus)
{
char word[100];
CharToOemA(rus, word);
cout<<word;
}
void DelList (Node *sl, Node *sr )
{
Node *spt = sl->next;
while (spt!=sr)
{
spt->last->next = spt->next;
delete spt;
spt = sl->next;
}
delete sl; sl = NULL;
delete sr; sr = NULL;
}

- Бренд как конкурентное преимущество компании
- Баланс и отчетность
- Анализ действующей в Российской Федерации системы налогообложения банков
- АНКЕТИРОВАНИЕ КАК СПОСОБ АНАЛИЗА
- Управление процессом реализации изменений и нововведений (Понятие и сущность изменений и нововведений в организации)
- Управление поведением в конфликтных ситуациях на примере ПАО «АК БАРС Банк» (Исследование конфликтной ситуации, сложившейся в ПАО "АК БАРС" Банк)
- Аудиторская деятельность как вид предпринимательства: общая характеристика
- Общее понятие о гражданском праве
- Распределенная технология обработки информации (механизм удаленного вызова процедур)
- Управление процессом реализации изменений и нововведений
- Понятие прикладных протоколов и серверы приложений (Сетевой сокет и многопоточный вариант сервера)
- Разработка регламента выполнения процесса «Совершенствование существующих продуктов» (Понятие бизнес-процесса)