
Операции, производимые с данными (История развития баз данных)
Содержание:

ВВЕДЕНИЕ
Одной из важнейших областей применения компьютеров является переработка и хранение больших объемов информации в различных сферах деятельности человека: в экономике, банковском деле, торговле, транспорте, медицине, науке и т.д.
Существующие современные информационные системы характеризуются огромными объемами хранимых и обрабатываемых данных, сложной организацией, необходимостью удовлетворять разнообразные требования многочисленных пользователей.
Цель любой информационной системы - обработка и представление данных об объектах реального мира. Основой информационной системы является база данных. В широком смысле слова база данных - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления его объектами и, в конечном счете, автоматизации, например, предприятие, вуз и т. д.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро производить выборку с произвольным сочетанием признаков.
Актуальность работы вызвана непрерывным совершенствованием рассматриваемой области, а также постоянным появлением новых технологий. В широком смысле слова база данных (БД) – это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Для удобной работы с данными их необходимо структурировать, т.е. ввести определенные соглашения о способах их представления. База данных (в узком смысле слова) – поименованная совокупность структурированных данных относящихся к некоторой предметной области. В реальной деятельности в основном используют системы БД.
Объект исследования - данные как диалектическая составная часть информации, а база данных как информационная система; предмет – операции, производимые с данными.
Таким образом, цель написания данной курсовой работы – изучить основные теоретические аспекты по теме курсовой работы, применив полученную информацию на практике.
Соответственно, для достижения поставленной цели необходимо решить задачи следующего порядка:
- ознакомиться с историей развития баз данных;
- рассмотреть общее сведения о базах данных, основные понятия и элементы;
- определить основные особенности работы с базой данных;
- рассмотреть практические аспекты применения операций, производимых с данными на примере проектирования базы данных;
- получить навыки по использованию дополнительных инструментов проектирования БД.
Структурно работа состоит из двух глав, введения и заключения. Наибольший вклад в изучения данного направления внести такие авторы как Кренке, Д., Моррисон, Дж., Ухтомский, М. Пере, Ульман, Д., Г. Гарсиа-Молина, Дж. Уидом, Боуман, Д., С. Эмерсон, М. Дарновски., Грабер, М., Баженова И.Ю.
1. Теоретические аспекты по теме исследования
1.1 История развития баз данных
Между физической базой данных (т.е. данными, которые реально хранятся) и пользователями системы располагается уровень программного обеспечения - система управления базами данных. Все запросы пользователей на доступ к базе данных обрабатываются СУБД; все имеющиеся средства добавления файлов данных, выборки и обновления данных в этих файлах также обеспечивает СУБД[5,с.133].
Основная задача СУБД - предоставить пользователю базы данных возможность работать с ней, не вникая в детали на уровне аппаратного обеспечения (пользователь более отстранен от этих деталей, чем прикладной программист, использующий среду программирования) [11,с.109].
Иными словами, СУБД позволяет конечному пользователю рассматривать базу данных как объект более высокого уровня по сравнению с аппаратным обеспечением, а также предоставляет в его распоряжение набор операций, выражаемых в терминах языка высокого уровня (например, набор операций, которые можно выполнять с помощью языка SQL).СУБД являются посредниками между логической структурой данных, необходимых разным приложениям, и физическими хранилищами данных (обычно это файловая система персонального компьютера или сервера, хотя последнее время хранилища могут распределяться между многими серверами).
Физическая структура данных (в частности, файловая) должна быть скрыта от программистов. СУБД должны хранить логическую структуру (метаданные), предотвращая несогласованные изменения данных, нарушающие эту структуру
Таким образом, любая СУБД должна обеспечивать следующее[10,с.93]:
-компактное хранение данных (без дублирования);
-оптимизацию доступа к данным;
-логическую целостность (согласованность) данных;
-универсальный интерфейс (язык или протокол), позволяющий задавать структуру данных, изменять и извлекать их неизвестному заранее алгоритму.
Обеспечение этих требований к информационным системам на уровне СУБД позволяет избегать повторения одной и той же работы при разработке программ[5,с.121].
Системы управления базами данных обладают следующими функциями[7,с.88]:
1) Управление данными во внешней памяти
Управление данными включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей. В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но, в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то, как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
2) Управление буферами оперативной памяти[16,с.115]
СУБД обычно работают с БД значительного размера; по крайней мере, этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
3) Управление транзакциями[2,с.166].
Транзакция - это последовательность операций над базой данных, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения в базе данных, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии базы данных[17,с.109].
Понятие транзакции необходимо для поддержания логической целостности базы данных. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег) [12,с.175].
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализацией параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
1.2 Общее сведения о базах данных, основные понятия и элементы
База данных – это информационная система, которая представляет собой программный комплекс, главными функциями этой системы являются поддержка надежного хранения информации в памяти компьютера, выполнение специфических, для данного приложения, преобразований информации и/или вычислений, предоставление пользователям легко осваиваемого интерфейса[15,с.322].
Виды БД[11,с.63].:
- Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
- Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
- Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
- Централизованная – база данных, хранящихся на одном компьютере;
- Реляционная – база данных с табличной организацией данных.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные[12,с.78].
Базой данных является представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины.
Существует множество других определений понятия «база данных», так или иначе сводящихся к понятию «совокупность хранимых данных». Однако большинство из этих определений не позволяет отличить базу данных от объектов, которые базой данных заведомо не являются, например, от архивов документов, картотек, библиотек и т.п.
Таким образом, база данных есть не просто совокупность хранимых данных (записей, документов, фактов и т.п.), но такая совокупность, которая обладает, по меньшей мере, тремя важными свойствами (признаками) [11,с.77]:
- База данных хранится и обрабатывается в вычислительной системе. Любые внекомпьютерные хранилища информации (архивы, библиотеки и т. п.) базами данных не являются.
- Данные в базе данных хорошо структурированы (систематизированы). Под структурированностью в данном случае понимается явное выделение составных частей (элементов), связей между ними, а также типизация элементов и связей, при которой с каждым типом элемента или связи соотносится определенная семантика и допустимые операции.
- Структура базы данных обеспечивает эффективный поиск и обработку данных. Эффективность здесь главным образом определяется тем, как соотносятся гибкость и мощность возможностей (поиска и обработки) с затратами усилий и ресурсов[2,с.217].
Из трех перечисленных признаков только первый является строгим, а два других допускают различные трактовки и различные степени оценки. Не существует возможности строго формально определить, является ли некоторая совокупность данных на компьютере базой данных или нет. Можно лишь установить некоторую степень соответствия требованиям к БД[11,с.84].
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы или электронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
Основные понятия и элементы баз данных.
Основное требование к базам данных – прежде всего удобство доступа к данным, возможность быстро получить исчерпывающую информацию по любому интересующему вопросу (важно не только то, что информация содержится в базе, важно то, насколько она хорошо структуирована и целостна) [10,с.87].
Лишь только начали появляться и распространяться компьютеры, почти сразу на них возложили тяжёлый и кропотливый труд по обработке и структурированию данных, появились базы данных (БД) в их нынешнем понимании.
Согласно современным требованиям к базам данных, информация, содержащаяся в них, должна быть[14,с.66]:
• непротиворечивой (не должно быть каких-либо данных, противоречащих друг другу);
• не избыточной (следует предотвращать ненужное дублирования информации в базе, избыточность может привести к противоречивости – например, если какие – то данные изменяют, а их копию в другой части базы забыли изменить);
• целостной (все данные должны быть связаны, не должно быть ссылок на несуществующие в базе данные) [12,с.72].
Таблица БД представляет собой двумерный массив, в котором хранятся данные. Столбцы таблицы (в рамках принятых обозначений БД) называются полями, строки – записями. Количество полей таблицы фиксировано, количество записей – нет. Фактически таблица – нефиксированный массив записей с одинаковой структурой полей в каждой записи. Добавить в таблицу новую запись не составляет труда, а то время как добавление нового поля влечёт за собой реструктуризацию всей таблицы и может вызвать некоторые трудности.
В качестве значений полей в записях могут храниться некоторые числа, строки, картинки и т.д. Таблицы баз данных хранятся на жёстком диске (на локальном компьютере или на сервере баз данных – в зависимости от типа БД) [4,с.186].
Одной таблице соответствуют обычно несколько файлов – один основной и несколько вспомогательных.
Ключ – поле или комбинация полей таблицы, значения в которых однозначно определяют запись. Ключ потому так и называется, что, имея необходимые значения ключевых полей, можно однозначно получить доступ к нужной записи[1,с.173].
Таким образом, ключи чрезвычайно полезны для связи таблиц. Записывая значения ключа в отведённые поля подчинённой таблицы и тем самым, задавая ссылку, обеспечиваем связь двух записей – записи в главной таблице и записи в подчинённой таблице. В одной записи подчинённой таблицы может находиться порядка нескольких ссылок на записи главной таблицы.
1.3 Работа с базой данных
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя[17,с.49].
Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти.
Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать - как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией[6,с.177].
Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД[8,с.53].
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализируются на разных уровнях[12,с.144]: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции, путем выполнения обратных операций, следуя от конца локального журнала[2,с.76]. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу) [17,с.183]. При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает) [11,с.177].
При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является: состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций.
Для того чтобы этого добиться, сначала производят откат незавершенных транзакций, а потом повторно воспроизводят те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала[7,с.193].
Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что исходя из архивной копии, по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным[16,с.209].
Таким образом, в ходе написания первой главы курсовой работы было определено следующее. Ключи чрезвычайно полезны для связи таблиц. Записывая значения ключа в отведённые поля подчинённой таблицы и тем самым, задавая ссылку, обеспечиваем связь двух записей – записи в главной таблице и записи в подчинённой таблице. В одной записи подчинённой таблицы может находиться порядка нескольких ссылок на записи главной таблицы. Так, для работы с базами данных используются специальные языки, в целом называемые языками баз данных[15,с.43].
В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка: язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям [9,с.96].
2. Практические аспекты применения операций, производимых с данными
Тип данных определяет, какое значение может содержать столбец: целочисленные данные, символьные данные, денежные данные, данные даты и времени, двоичные строки и т. д.
Каждый столбец в таблице базы данных должен иметь имя и тип данных[16,с.283].
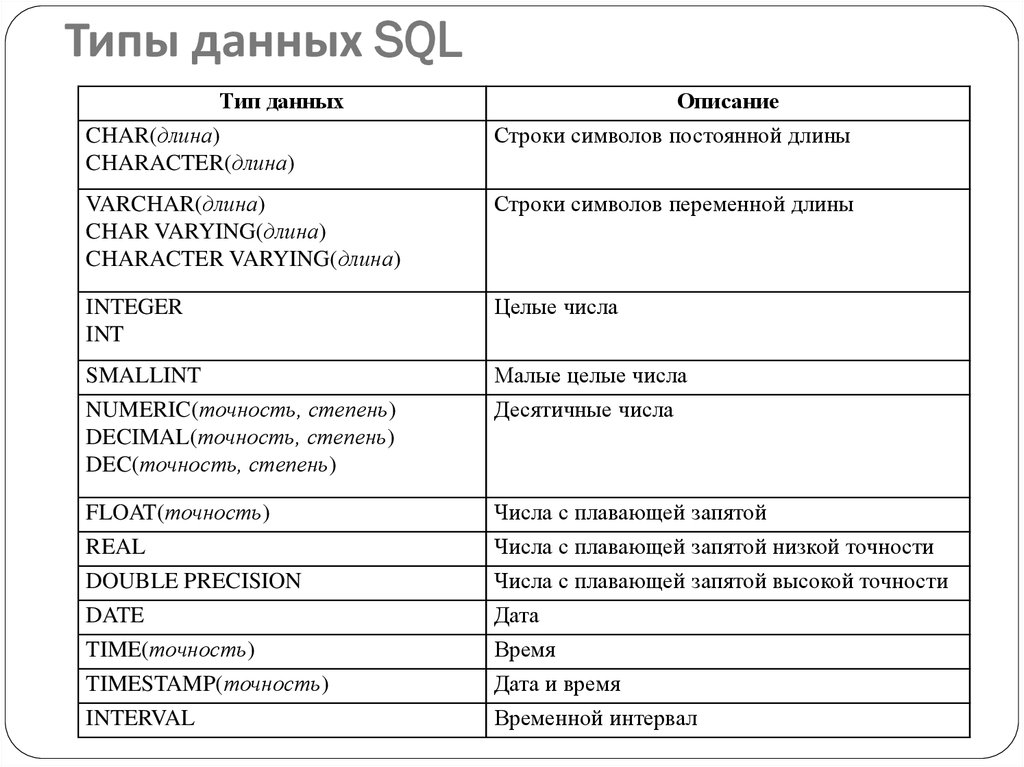
Рисунок 1 – Структура иерархической модели баз данных [12,с.83].
2.1 Проектирование базы данных
2.1.1 Создание таблиц с помощью SQL Server Management Studio
Введём имена столбцов, выберем типы данных и определим для каждого столбца, могут ли в нем присутствовать значения NULL. Определим также первичный ключ для каждой таблицы (Рис. 2 – Рис. 8).
Создадим SQL таблицу «Auto»
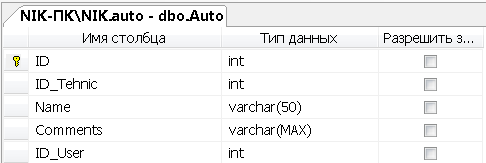
Рисунок 2 - Создание атрибутов таблицы «Auto»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[Auto](
[ID] [int] IDENTITY(1,1) NOT NULL,
[ID_Tehnic] [int] NOT NULL,
[Name] [varchar](50) NOT NULL,
[Comments] [varchar](max) NOT NULL,
[ID_User] [int] NOT NULL,
CONSTRAINT [PK_Auto] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Создадим таблицу SQL «Comments»
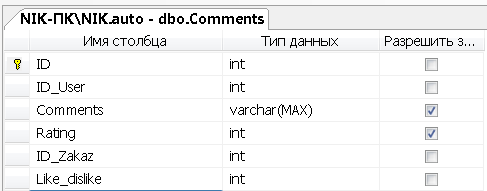
Рисунок 3 - Создание атрибутов таблицы «Comments»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[Comments](
[ID] [int] IDENTITY(1,1) NOT NULL,
[ID_User] [int] NOT NULL,
[Comments] [varchar](max) NULL,
[Rating] [int] NULL,
[ID_Zakaz] [int] NOT NULL,
[Like_dislike] [int] NOT NULL,
CONSTRAINT [PK_Comments] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Создадим SQL таблицу «Report»
Рисунок 4 - Создание атрибутов таблицы «Report»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[Report](
[ID] [int] IDENTITY(1,1) NOT NULL,
[ID_User] [int] NOT NULL,
[ID_Auto] [int] NOT NULL,
[Time] [datetime] NOT NULL,
[Activ] [int] NOT NULL,
[Cost] [int] NOT NULL,
CONSTRAINT [PK_Report] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Создадим SQL таблицу «Tehnic»

Рисунок 5 - Создание атрибутов таблицы «Tehnic»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[Tehnic](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](50) NOT NULL,
CONSTRAINT [PK_Tehnic] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Создадим SQL таблицу «userr»
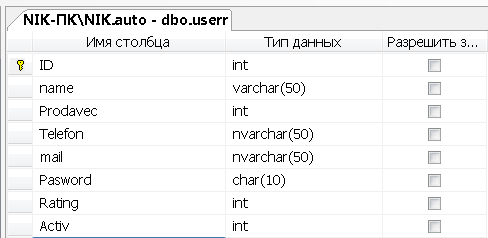
Рисунок 6 - Создание атрибутов таблицы «userr»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[userr](
[ID] [int] IDENTITY(1,1) NOT NULL,
[name] [varchar](50) NOT NULL,
[Prodavec] [int] NOT NULL,
[Telefon] [nvarchar](50) NOT NULL,
[mail] [nvarchar](50) NOT NULL,
[Pasword] [char](10) NOT NULL,
[Rating] [int] NOT NULL,
[Activ] [int] NOT NULL,
CONSTRAINT [PK_user] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Создадим SQL таблицу «Zakaz»
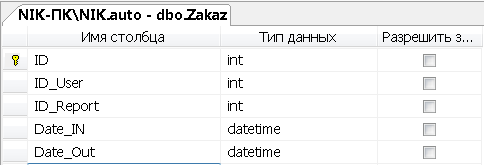
Рисунок 7 - Создание атрибутов таблицы «Zakaz»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[Zakaz](
[ID] [int] IDENTITY(1,1) NOT NULL,
[ID_User] [int] NOT NULL,
[ID_Report] [int] NOT NULL,
[Date_IN] [datetime] NOT NULL,
[Date_Out] [datetime] NOT NULL,
CONSTRAINT [PK_Zakaz] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Создадим SQL таблицу «Chat»
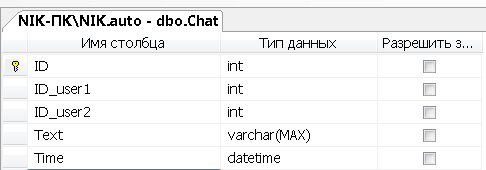
Рисунок 8 - Создание атрибутов таблицы «Chat»
Программное создание атрибутов и ключей данной таблицы
CREATE TABLE [dbo].[Chat](
[ID] [int] IDENTITY(1,1) NOT NULL,
[ID_user1] [int] NOT NULL,
[ID_user2] [int] NOT NULL,
[Text] [varchar](max) NOT NULL,
[Time] [datetime] NOT NULL,
CONSTRAINT [PK_Chat] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
2.1.2 Создание логической диаграммы
Построим диаграмму базы данных и создадим связи между таблицами.
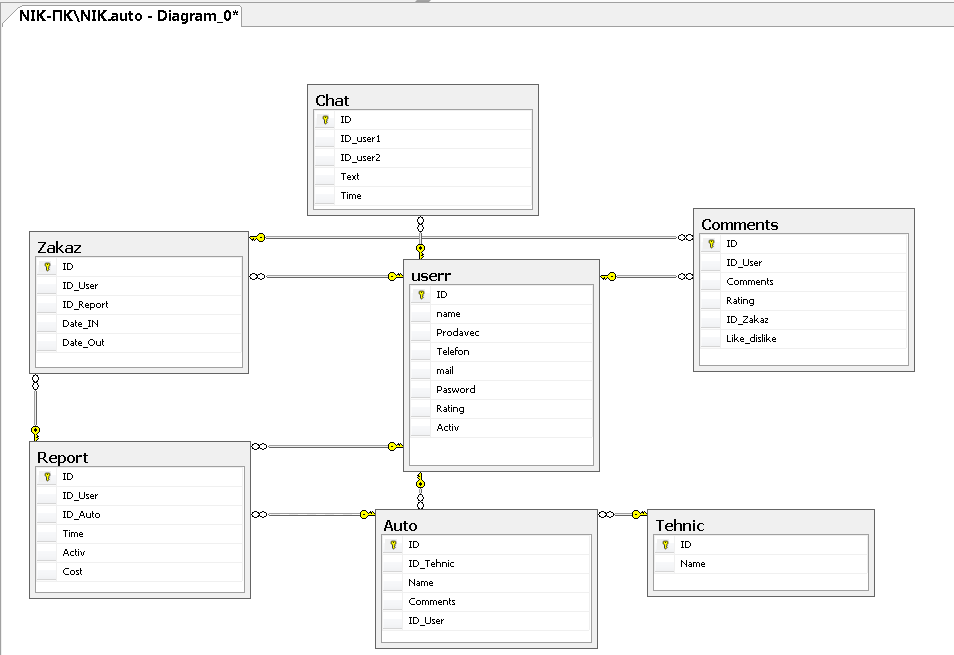
Рисунок 9 - Развёрнутая логическая диаграмма БД со связями
Описание создаваемых таблиц, с комментариями о назначении полей представлено ниже.
Таблица 1 – Объект «Comments»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор |
ID |
1 |
INT, NOT NULL, PRIMARY KEY |
|
Ссылка на идентификатор пользователя |
ID_User |
1 |
INT, NOT NULL |
|
Содержимое комментария |
Comments |
Исполнением заказа удовлетворен |
TEXT, NULL |
|
Оценка за заказ (0 - 10) |
Rating |
10 |
INT, NULL |
|
Ссылка на идентификатор заказа |
ID_Zakaz |
1 |
INT, NOT NULL |
|
Лайк или дизлайк(1 – лайк, 0 – дизлайк) |
Like_dislike |
1 |
INT, NOT NULL |
Таблица 2 – Объект «userr»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор пользователя |
ID |
1 |
INT, NOT NULL, PRIMARY KEY |
|
Имя пользователя |
name |
Николай |
VARCHAR(50) , NOT NULL |
|
Роль (1 – арендодатель, 0 - покупатель) |
Prodavec |
0 |
INT,NOT NULL |
|
Общий рейтинг пользователя |
Rating |
10 |
INT, NOT NULL |
|
Статус учетной записи (1 – активна, 0 - заблокирована) |
Activ |
1 |
INT, NOT NULL |
|
Контактный телефон |
Telefon |
8-910-725-34-42 |
NVARCHAR(50) ,NOT NULL |
|
Контактный @mail (он же логин для входа в систему) |
|
test@bk.ru |
NVARCHAR(50) ,NOT NULL |
|
Пароль пользователя для входа в систему |
Pasword |
qwerty |
CHAR(10) ,NOT NULL |
Таблица 3 – Объект «Report»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор |
ID |
4 |
INT,NOT NULL, PRIMARY KEY |
|
Ссылка на идентификатор пользователя - арендодателя |
ID_User |
2 |
INT,NOT NULL |
|
Ссылка на идентификатор спецтехники |
ID_Auto |
3 |
INT,NOT NULL |
|
Дата и время публикации |
Time |
2018-09-26 00:00:00.000 |
DATETIME,NOT NULL |
|
Показать объявление (1 – показать, 0 – не показать) |
Activ |
1 |
INT,NOT NULL |
|
Цена аренды |
Cost |
3000 |
INT,NOT NULL |
Таблица 4 – Объект «Zakaz»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор |
ID |
1 |
INT,NOT NULL, PRIMARY KEY |
|
Ссылка на идентификатор пользователя - заказчика |
ID_User |
1 |
INT,NOT NULL |
|
Ссылка на идентификатор объявления арендодателя |
ID_Report |
1 |
INT,NOT NULL |
|
Дата и время начала аренды |
Date_IN |
2018-09-28 00:00:00.000 |
DATETIME,NOT NULL |
|
Дата и время завершения аренды |
Date_Out |
2018-09-29 00:00:00.000 |
DATETIME,NOT NULL |
Таблица 5 – Объект «Auto»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор спецтехники |
ID |
1 |
INT,NOT NULL, PRIMARY KEY |
|
Уникальный идентификатор вида спецтехники |
ID_Tehnic |
3 |
INT,NOT NULL |
|
Наименование спецтехники |
Name |
«ЧТЗ - 2100» |
VARCHAR(50), NOT NULL |
|
Описание спецтехники |
Comments |
Гусеничный бульдозер мощностью 2100 л/с |
TEXT,NOT NULL |
|
Ссылка на идентификатор пользователя |
ID_User |
2 |
INT,NOT NULL |
Таблица 6 – Объект «Tehnic»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор вида спецтехники |
ID |
3 |
INT,NOT NULL, PRIMARY KEY |
|
Наименование вида спецтехники |
Name |
Бульдозер |
VARCHAR(50),NOT NULL |
Таблица 7 – Объект «Chat»
|
Meaning |
Designation |
Example |
Type |
|
Уникальный идентификатор |
ID |
4 |
INT,NOT NULL, PRIMARY KEY |
|
Ссылка на идентификатор пользователя 1 |
ID_user1 |
2 |
INT,NOT NULL |
|
Ссылка на идентификатор пользователя 2 |
ID_user2 |
3 |
INT,NOT NULL |
|
Текст сообщения |
Text |
Мне нужен бульдозер на 2 ближайших дня |
TEXT,NOT NULL |
|
Дата и время сообщения |
Time |
2018-09-26 00:00:00.000 |
DATETIME,NOT NULL |
Системы функциональных зависимостей:
(1) Объяснить, почему был выбран первичный ключ.
(2) F1- Описание таблицы, первым выделяются первичные ключевые
атрибуты таблицы, после знака -> идёт описание остальных атрибутов.
(3) K1- Только первичные ключи.
1) «Comments» Не может быть нескольких комментариев с одним идентификационным номером.
F1: ID -> ID_User, Comments, Rating, ID_Zakaz, Like_dislike
K1 = ID
2) «userr» Не может быть двух пользователей с одинаковыми идентификаторами.
F2: ID -> name, Prodavec, Rating, Activ, Telefon, mail
K2 = ID
«Report»
3) Не может быть двух объявлений с одинаковым идентификационным номером.
F3: ID -> ID_User, ID_Auto, Time, Activ, Cost
K3 = ID
«Zakaz»
4) Не может быть нескольких заказов с одним идентификационным номером.
F4: ID -> ID_User, ID_Report, Date_IN, Date_Out
K4 = ID
5) «Auto» Не может быть двух одинаковых спецмашин с одним идентификационным номером.
F5: ID -> ID_Tehnic, Name, Comments, ID_User
K5 = ID
6) «Tehnic» Не может быть двух одинаковых типов классификации техники.
F6: ID -> Name
K6 = ID
7) «Chat» Не может быть двух одинаковых сообщений с одним идентификационным номером.
F7: ID -> ID_user1, ID_user2, Text, Time
K7 = ID
2.1.3 Заполнение данными таблиц базы данных auto
Заполним данными таблицу Auto
Вносим технику, которую владельцы предлагают в аренду, снабжаем записи комментариями с характеристиками машин
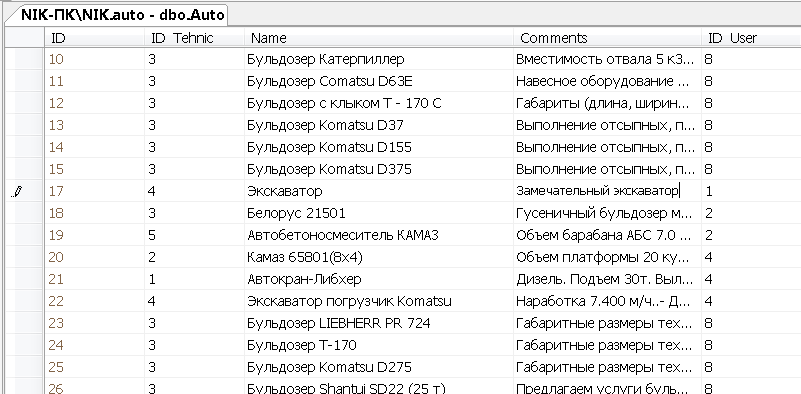
Рисунок 10 – Данные таблицы Auto
Заполним данными таблицу Comments
В этой таблице у нас будет содержаться информация о комментариях к заказам.
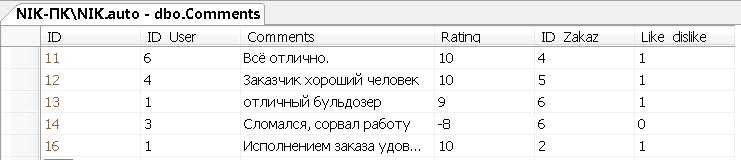
Рисунок 11 – Данные таблицы Comments
Заполним данными таблицу Report
В этой таблице у нас будет содержаться информация об объявлениях.
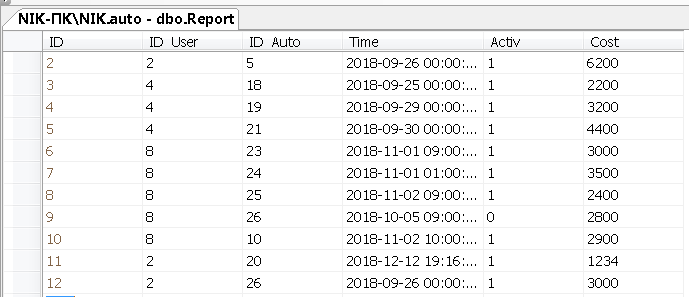
Рисунок 12 – Данные таблицы Report
Заполним данными таблицу Tehnic
Внесем группы машин по их назначению.
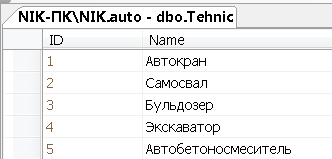
Рисунок 13 – Данные таблицы Tehnic
Заполним данными таблицу user
Здесь будет содержаться вся информация о пользователях.
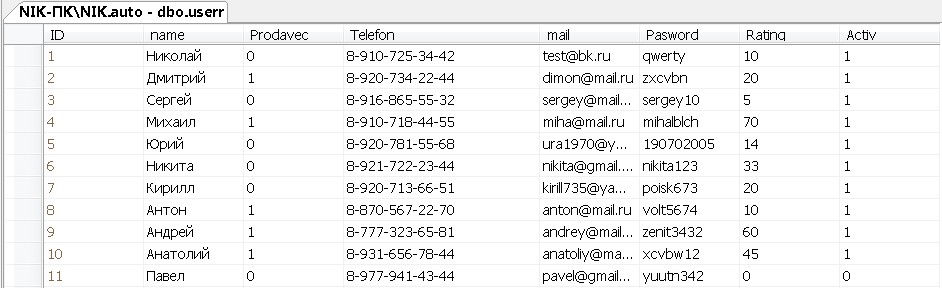
Рисунок 14 – Данные таблицы userr
Заполним данными таблицу Zakaz
В этой таблице будет содержаться информация о самих заказах (кто арендует, что арендует и с какого, по какое время)
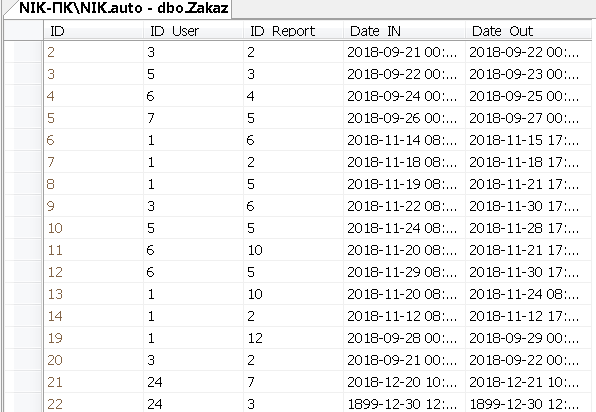
Рисунок 15 – Данные таблицы Zakaz
Заполним данными таблицу Chat
В этой таблице будет содержаться информация о переписке между пользователей программы.
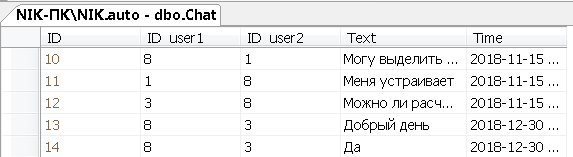
Рисунок 16 – Данные таблицы Chat
После заполнения данными таблиц перейдём к созданию запросов для работы с нашей базой данных.
2.1.4 Создание Sql запросов к базе данных auto
Запросы будем создавать в MSSQL
Рассмотрим первый запрос.
Необходимо вывести список доступных бульдозеров на конкретный день.
SELECT Name FROM [auto].[dbo].[Zakaz], [auto].[dbo].[auto], [auto].[dbo].[Report]
WHERE (([auto].[dbo].[Zakaz].Date_IN > '2018-11-21 12:00:00.000')
or ([auto].[dbo].[Zakaz].Date_Out < '2018-11-21 12:00:00.000'))
and (([auto].[dbo].[Report].ID_Auto = [auto].[dbo].[auto].ID)
and ([auto].[dbo].[Report].ID = [auto].[dbo].[Zakaz].ID_Report)
and ([auto].[dbo].[auto].ID_Tehnic = '3'))
group by Name
GO
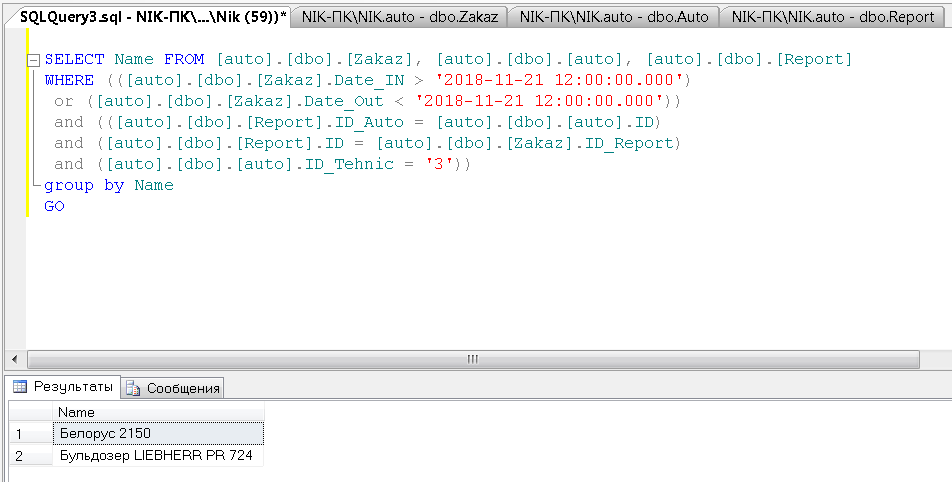
Рисунок 17 – Результат выполнения SQL запроса
Рассмотрим второй запрос.
Необходимо прочитать по указанным бульдозерам отзывы и журнал рейтинга с возможностью чтения положительных и отрицательных отзывов.
SELECT Comments,Rating,Like_dislike
FROM [auto].[dbo].[Zakaz], [auto].[dbo].[Report], [auto].[dbo].[Comments]
WHERE ([auto].[dbo].[Zakaz].ID_Report = [auto].[dbo].[Report].ID)
and ([auto].[dbo].[Comments].ID_Zakaz = [auto].[dbo].[Zakaz].ID)
and ([auto].[dbo].[Report].ID_Auto = '6')
GO
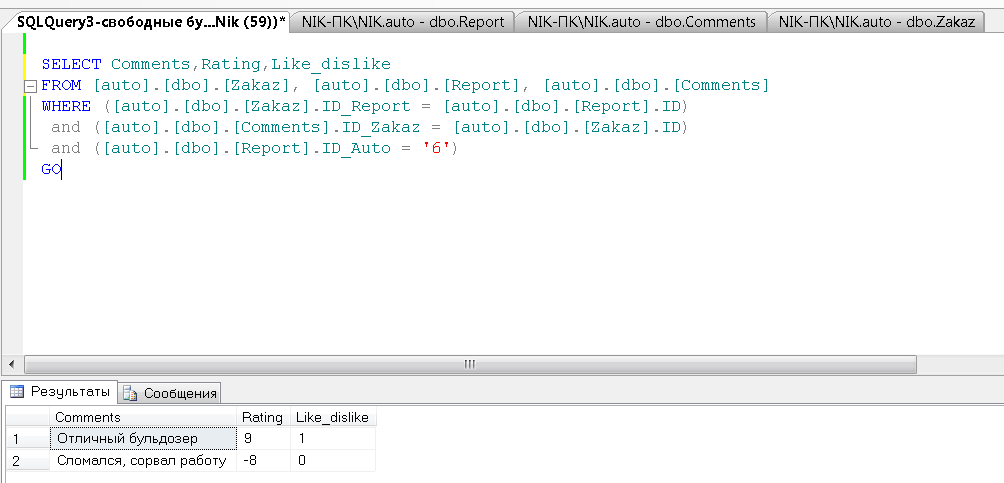
Рисунок 18 – Результат выполнения запроса
Рассмотрим третий запрос.
Необходимо вывести общий рейтинг востребовательности по типу техники по убыванию.
SELECT COUNT(*) as count, [auto].[dbo].[auto].ID_Tehnic,[auto].[dbo].[Tehnic].Name
FROM [auto].[dbo].[Zakaz], [auto].[dbo].[auto], [auto].[dbo].[Report],[auto].[dbo].[Tehnic]
WHERE ([auto].[dbo].[Report].ID_Auto = [auto].[dbo].[auto].ID)
and ([auto].[dbo].[Report].ID = [auto].[dbo].[Zakaz].ID_Report)
and ([auto].[dbo].[auto].ID_Tehnic = [auto].[dbo].[Tehnic].ID)
group by [auto].[dbo].[auto].ID_Tehnic , [auto].[dbo].[Tehnic].Name
ORDER BY count DESC
GO
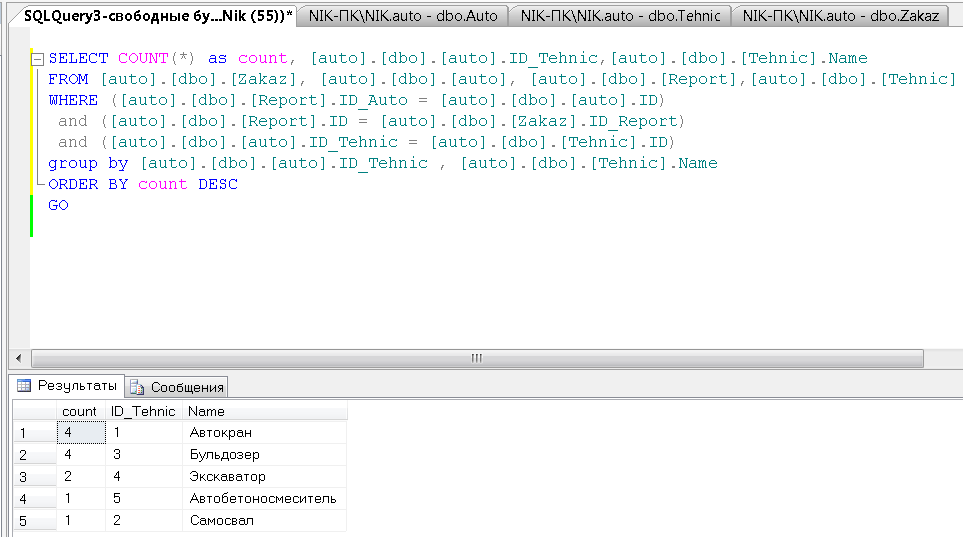
Рисунок 19 – Результат выполнения запроса
Рассмотрим четвертый запрос.
Необходимо посмотреть занятость конкретного вида спец техники на неделю вперед.
SELECT [auto].[dbo].[auto].Name ,[auto].[dbo].[Zakaz].ID as ID_Zakaz ,
[auto].[dbo].[Zakaz].Date_IN,[auto].[dbo].[Zakaz].Date_Out
FROM [auto].[dbo].[Zakaz], [auto].[dbo].[auto], [auto].[dbo].[Report],[auto].[dbo].[Tehnic]
WHERE (([auto].[dbo].[Zakaz].Date_IN < '2018-11-22 12:00:00.000')
and ([auto].[dbo].[Zakaz].Date_Out > '2018-11-22 12:00:00.000'))
and (([auto].[dbo].[Report].ID_Auto = [auto].[dbo].[auto].ID)
and ([auto].[dbo].[Report].ID = [auto].[dbo].[Zakaz].ID_Report)
and ([auto].[dbo].[auto].ID_Tehnic = [auto].[dbo].[Tehnic].ID)
and ([auto].[dbo].[auto].ID_Tehnic = '3'))
GO
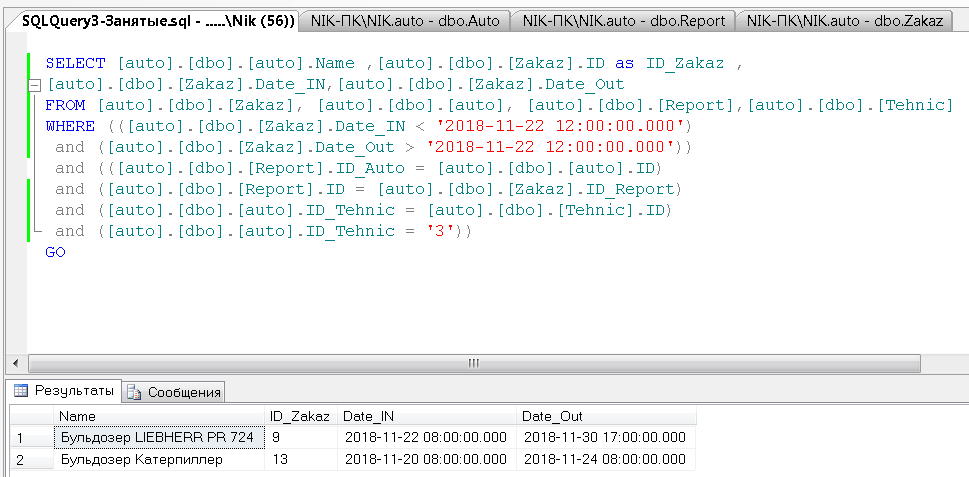
Рисунок 20 – Результат выполнения запроса
Рассмотрим пятый запрос.
Необходимо вывести рейтинг владельцев, кто, сколько заработал с учетом спецтехники, которая у него есть.
SELECT [auto].[dbo].[user].ID, [auto].[dbo].[user].name,
SUM((datediff(day, [auto].[dbo].[Zakaz].Date_IN, [auto].[dbo].[Zakaz].Date_Out))
*[auto].[dbo].[Report].Cost) as summa
FROM [auto].[dbo].[Zakaz], [auto].[dbo].[user], [auto].[dbo].[Report]
WHERE
([auto].[dbo].[Report].ID_User = [auto].[dbo].[user].ID)
and ([auto].[dbo].[Report].ID = [auto].[dbo].[Zakaz].ID_Report)
group by [auto].[dbo].[user].ID,[auto].[dbo].[user].name
ORDER BY summa DESC
GO
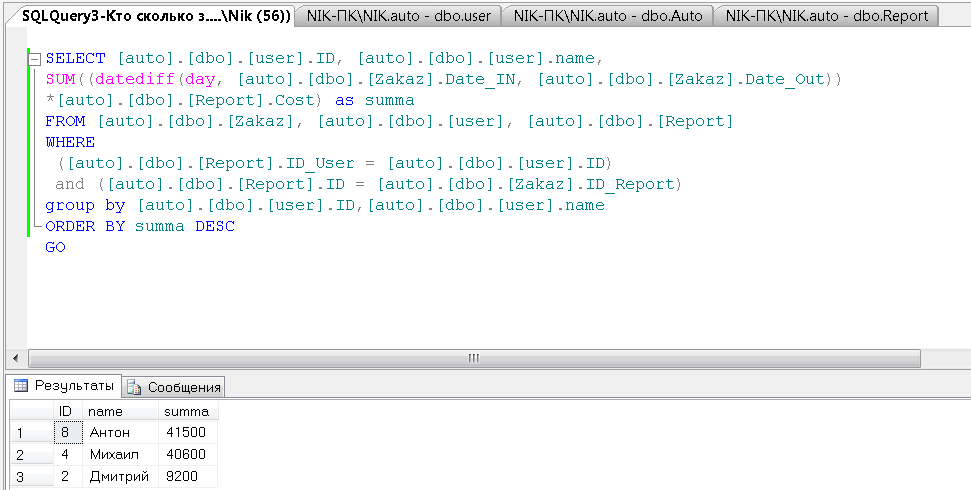
Рисунок 21 – Результат выполнения запроса
2.1.5 Создание пользователей для базы данных
Создание/Добавление пользователей.
Открываем "Безопасность" =>" Создать имя входа..." (Рис. 22)
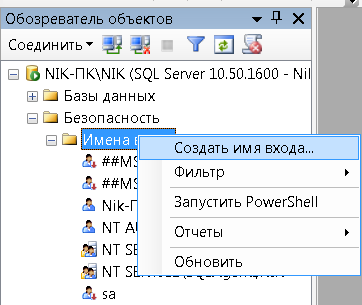
Рисунок. 22 – Порядок открытия окна «Создать имя входа»
Заполняем строку "Имя входа:". Выбираем "Проверка подлинности SQL Server". Заполняем строки "Пароль" и "Подтверждение пароля. Убираем галочку с "Требовать использование политики паролей". Выбираем нужную базу данных. Выбираем "Язык по умолчанию:" - "Russian". (Рис. 23)
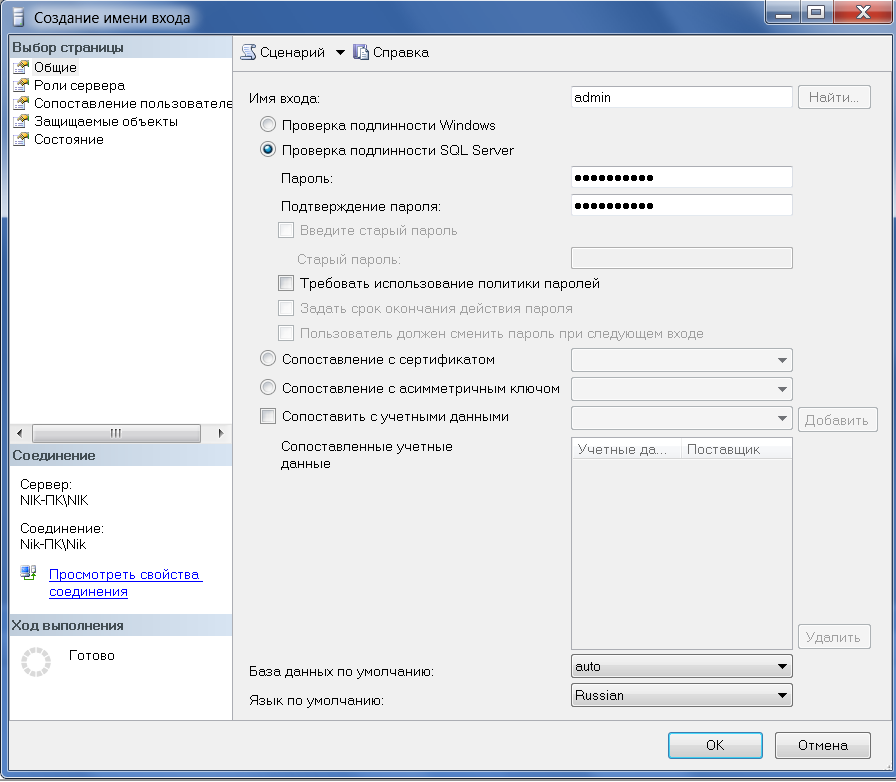
Рисунок 23 – Общие параметры «Имя входа» - admin
Переходим во вкладку "Роли сервера:". Выделяем всё галочками. (Рис.24)
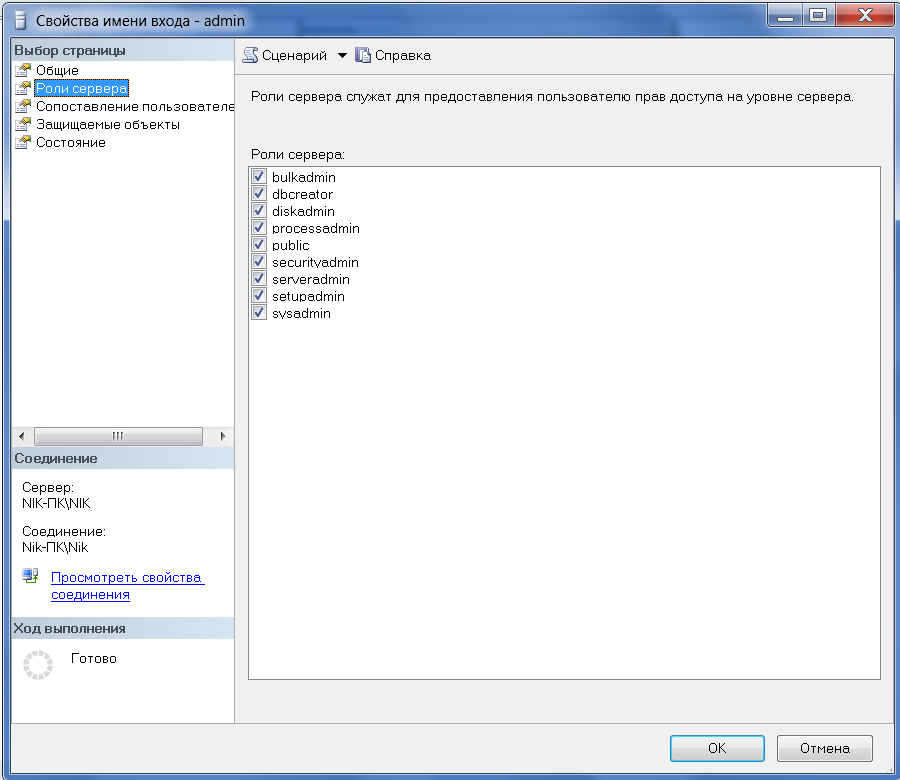
Рисунок 24 – Вкладка «Роли сервера» - admin
Переходим во вкладку "Сопоставление пользователей". Выбираем БД `auto` и назначаем роли сервера пользователю admin. (Рис. 25)
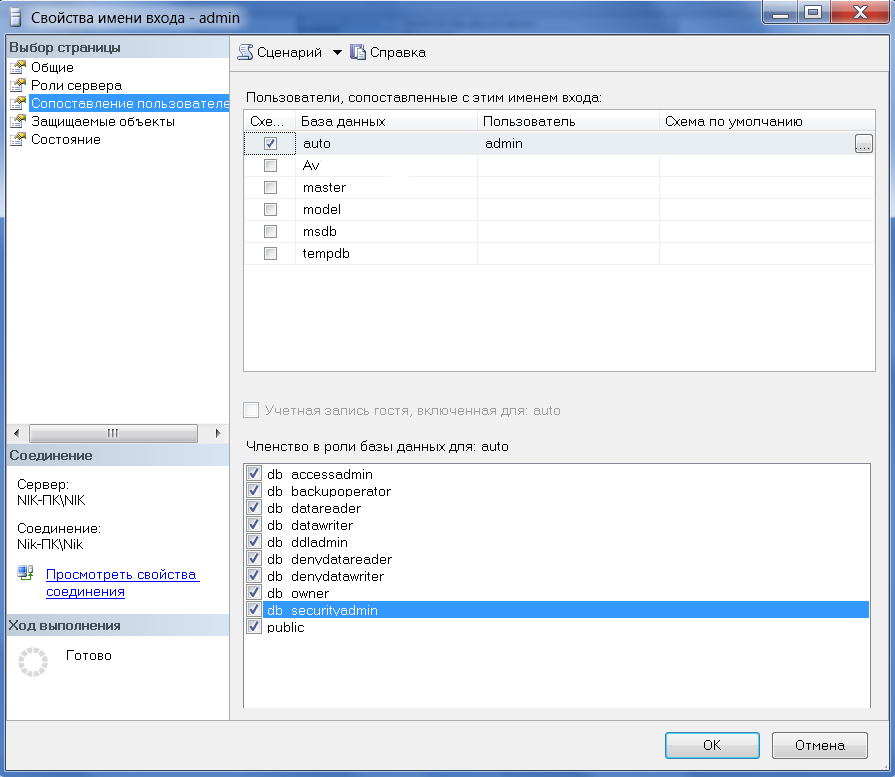
Рисунок 25 – Вкладка «Сопоставление пользователей» - admin
Сохраняем изменения, нажав на кнопку ОК. После этого аналогичным способом создадим пользователя «user».
После проделанного результата нашей работы мы можем увидеть:
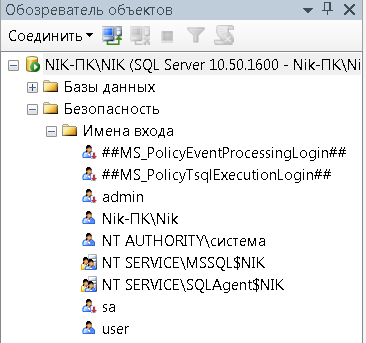
Рисунок 26 – Отображение user и admin в обозревателе объекто
ЗАКЛЮЧЕНИЕ
Таким образом, в ходе написания данной курсовой работы были рассмотрены как теоретические вопросы по теме курсовой работы, так и практика применения. Так, в ходе написания первой главы курсовой работы было определено следующее:
1) Дано определение - база данных – это информационная система, которая представляет собой программный комплекс, главными функциями этой системы являются поддержка надежного хранения информации в памяти компьютера, выполнение специфических, для данного приложения, преобразований информации и/или вычислений, предоставление пользователям легко осваиваемого интерфейса
2) Определены основные виды БД: фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате; документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные; распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть; централизованная – база данных, хранящихся на одном компьютере; реляционная – база данных с табличной организацией данных.
3) Одно из основных свойств БД – независимость данных от программы, использующих эти данные.Базой данных является представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины.
4) Существует множество других определений понятия «база данных», так или иначе сводящихся к понятию «совокупность хранимых данных». Однако большинство из этих определений не позволяет отличить базу данных от объектов, которые базой данных заведомо не являются, например, от архивов документов, картотек, библиотек и т.п.
Таким образом, база данных есть не просто совокупность хранимых данных (записей, документов, фактов и т.п.), но такая совокупность, которая обладает, по меньшей мере, тремя важными свойствами (признаками):
- База данных хранится и обрабатывается в вычислительной системе. Любые внекомпьютерные хранилища информации (архивы, библиотеки и т. п.) базами данных не являются.
- Данные в базе данных хорошо структурированы (систематизированы). Под структурированностью в данном случае понимается явное выделение составных частей (элементов), связей между ними, а также типизация элементов и связей, при которой с каждым типом элемента или связи соотносится определенная семантика и допустимые операции.
- Структура базы данных обеспечивает эффективный поиск и обработку данных. Эффективность здесь главным образом определяется тем, как соотносятся гибкость и мощность возможностей (поиска и обработки) с затратами усилий и ресурсов.
Во второй главе курсовой работы рассмотрены практические аспекты применения операций, производимых с данными – на примере проектирования базы данных: создание таблиц с помощью SQL Server Management Studio и логической диаграммы; заполнение данными таблиц базы данных; создание запросов и пользователей.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Боуман, Д. Практическое руководство по SQL / Д. Боуман, С. Эмерсон, М. Дарновски. – М.: Вильямс, 2017. – 352 с.
- Кренке, Д. Теория и практика построения баз данных. 8-е изд. – СПб.:Питер, 2016. – 800с.
- Кузин, А.В. Базы данных: учеб. пособие для студ. высш. учеб. заведений/ Кузин А.В., Левонисова С.В. - 2-е изд., стер. - М.: Издательский центр «Академия», 2018. - 320 с.
- Моррисон, Дж., Ухтомский А., Пере М. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. – СПб.: Издательский дом «Вильямс», 2016.-1120с.
- Змитрович, А.И. Базы данных: Учебное пособие для вузов.-Мн.:Университетское, 2016.-271с.
- Ульман, Д., Гарсиа-Молина Г., Уидом Дж. Системы баз данных. Полный курс. – СПб.: Издательский дом «Вильямс», 2017.-1088с.
- Боуман Д., Эмерсон С., Дарновски М. Практическое руководство по SQL. – СПб.: Издательский дом «Вильямс», 2016.-352с.
- Грабер, М. Введение в SQL. - М.: Издательство "Лори", 2016. - 382с.
- Винкоп, С. Использование Microsoft SQL Server 7.0. Специальное издание. – СПб.: Издательский дом «Вильямс», 2016. – 816с.
- Проектирование и реализация баз данных Microsoft SQL Server 2000. Уч. курс MCAD/ MCSE, MCDBA. - М.: Русская редакция, 2016.–512
- Риордан, Р. Программирование в Microsoft SQL Server 2000. Шаг за шагом. - М.: Эком, 2017.–608с.
- Вьейра, Р. SQL Server 2000. Программирование. Часть 1. - М.: Бином, 2017.–735с.
- Вьейра Р. SQL Server 2000. Программирование. Часть 2. - М.: Бином, 2017.–807с.
- Харитонова И.А., Михеева В.Д. ACCESS 2000. – СПб.:БХВ-Петербург, 2016. – 832с.
- Горев А., Ахаян Р., Макашарипов С. Эффективная работа с СУБД. - СПб.:Питер, 2017.-704с.
- Бернс П., Николсон Д. Секреты Access для Windows. – Киев, «Диалектика», 2016.- 560с.
- Хоффбауер М., Шпильманн К. ACCESS 7.0: сотни полезных рецептов. – Киев, “BHV”, 2016. – 400с.
- Кауфман Д., Матсик Б., Спенсер К. SQL. Программирование. – М.:Бином, 2017.–744с.
- Кауфман Д., Матсик Б., Спенсер К. SQL. Программирование. – М.: Бином, 2017.–744с.

- Определение и задачи распределенной системы (СУБД Oracle)
- Виды и состав угроз информационной безопасности (Информационная безопасность)
- Разработка программ с графическим интерфейсом на C#
- Психология организации труда в целях управления трудовой мотивацией (Сущность мотивации работника: принципы, модели)
- Мотивации персонала и проектирование систем стимулирования труда («АЛИДИ»)
- Корпоративная культура в организации ( АНО ДО «Детство» )
- Невербальные проявления эмоциональных состояний человека (Особенности определения эмоциональной сферы))
- Конфликты в организации: причины и функции (ООО «Каскад»)
- Влияние личности проектного менеджера на реализацию инновационного проекта (Резюме проекта «Чистые стены» )
- Понятие контроля и его виды. Отличия от ревизии
- Применение процессного подхода для оптимизации бизнес-процессов (Характеристика управления организацией с позиции процессного подхода)
- Методы кодирования данных (RZ – Return to Zero (возврат к нулю))