
Облачные сервисы (МОДЕЛИРОВАНИЕ ОБЛАЧНОЙ СРЕДЫ ДАННЫХ И АНАЛИЗ МЕТОДОВ ИХ ПЕРЕДАЧИ)
Содержание:

ВВЕДЕНИЕ
Актуальность темы. На сегодня, в условиях высокой конвергенции бизнес процессов в глобальном информационном пространстве, высокой актуальность приобретают вопросы информационного взаимодействия корпоративных клиентов, например, транснациональных корпораций, размещаемых на территориях, которые имеют осложнения в свободном доступе к глобальной информационной инфраструктуры (КНР, страны Персидского залива, Африки, некоторые страны Азии и т.д.). Облачные хранилища данных позволяют кардинально повысить доступность клиентских данных и необходимых сетевых элементов для их надежной передачи, и хранения. На сегодня методы локальной обработки и хранения имеют чрезвычайно низкий уровень консолидации вычислительных ресурсов и памяти (менее 18%). Географическая распределенность клиентских приложений, их мобильность с одновременной потребностью в сохранении целостности данных порождают противоречие, которое заключается в необходимости повышения пропускной способности, существующей телекоммуникационной составляющей распределенных хранилищ данных в условиях повышения требований к их доступности, а также относительно несанкционированного доступа и защиты от повреждений.
Итак, научная задача разработки моделей и методов повышения пропускной способности распределенных телекоммуникационных систем высокодоступных облачных хранилищ данных на основе новых протоколов доступа является актуальным и своевременным.
Наряду с этим, существует ряд недостаточно проработанных научных задач, препятствуют эффективной организации облачных хранилищ данных и, соответственно, распределенных вычислительных систем на их основе, а именно:
• недостаточно развита теоретическая база, которая пришла бы на смену классической теории массового обслуживания при проектировании современных телекоммуникационных систем распределения информации по самоподобным трафиком;
• недостаточно проработаны вопросы определения показателей качества функционирования систем передачи и распределения информации в распределенной гетерогенной сетевой среде;
• недостаточно развитые методы и алгоритмы, которые обеспечивают качество обслуживания, в частности пропускную способность в условиях гетерогенности сетевых платформ.
Итак, научная задача разработки моделей и методов повышения пропускной способности распределенных телекоммуникационных систем высокодоступных облачных хранилищ данных на основе новых протоколов доступа является актуальным и своевременным.
Цель и задачи исследования. Целью курсовой работы является разработка элементов телекоммуникационной сетевой архитектуры для передачи данных через облако хранилища.
Цель курсовой работы определяет необходимость решения следующих задач:
1. Анализ проблемы внедрения и функционирования облачных хранилищ данных;
2. Разработка метода мультипротокольного доступа к потоковым данным при их сквозной передаче в распределенной телекоммуникационной системе;
3. Разработка метода агрегации нагрузки нескольких источников данных для их одновременной передачи через распределены телекоммуникационные системы облачных хранилищ;
4. Разработка метода выбора сетевого шлюза по сложности запросов;
Объект исследования - процесс передачи данных через облако хранилища.
Предмет исследования - методы и средства организации облачных хранилищ данных на основе распределенных телекоммуникационных систем.
Методы исследования. Исследования, выполненные во время работы над курсовой работой, основанные на методах системного анализа - для решения задачи анализа процессов функционирования облачных хранилищ данных и совершенствование действующих подходов к организации таких хранилищ; компьютерного (имитационного численного) моделирования - для проведения стендовых экспериментов с разработанными телекоммуникационными протоколами, наблюдения, синтеза; статистических - для обработки и анализа результатов экспериментов; объектно-ориентированного анализа и проектирования - для разработки элементов телекоммуникационной сетевой архитектуры системы.
Научная новизна полученных результатов. Получены следующие новые научные результаты:
1. Впервые разработан метод мультипротокольной сквозной передачи данных в распределенной телекоммуникационной системе облачных хранилищ, который, в отличие от метода выбора протокола в сегментированной сети, характеризуется высокой производительностью, адаптируясь под каждый отдельный сетевой сегмент.
2. Усовершенствована модель облачного хранилища данных, представленную как алгебраическую систему, отличающуюся от существующих введением в архитектуру связанной телекоммуникационной сети системы методов обработки данных на основе протокольных средств сеансового уровня, что позволило более точно и полно определить и использовать ее пропускную способность соответственно.
3. Вступил дальнейшего развития метод агрегации нагрузки нескольких источников данных, который, в отличие от метода балансировки нагрузки, в режиме реального времени определяет загруженность сервисов облачного хранилища данных и каналов телекоммуникационной системы, что позволяет оптимизировать их производительность.
Практическое значение полученных результатов заключается в достижении следующих результатов:
-
-
- разработаны унифицированный протокол передачи данных сеансового уровня. Это позволило увеличить пропускную способность телекоммуникационных каналов распределенной системы хранилищ данных от 1,5 до 2 раз;
- разработан метод мультипротокольной передачи данных, что позволило адаптироваться к сквозному каналу передачи данных и ограничений, которые на него наложены;
- разработан метод агрегации нагрузки нескольких источников данных, что позволило их параллельную передачу;
- усовершенствованы элементы сетевой архитектуры облачных хранилищ данных, что позволило увеличить их производительность и отказоустойчивость путем оптимального выбора шлюза для передачи данных;
- на основе разработанной архитектуры построено и введено облачное хранилище данных для промышленного использования.
-
Полученные в курсовой работе результаты использованы при разработке облачного хранилища данных и организации вычислений на его основе компаниями ООО «Глобальная платежная сеть» (WIDEUP), Ypsilon.Net AG (ФРН).
ГЛАВА 1.
МОДЕЛИРОВАНИЕ ОБЛАЧНОЙ СРЕДЫ ДАННЫХ И АНАЛИЗ МЕТОДОВ ИХ ПЕРЕДАЧИ
В главе разработана модель облачного хранилища данных и методы передачи данных. Введено модель гибридных протоколов передачи данных через облачное хранилище, обоснована модель сетевого трафика, проведено моделирование загруженности хранилища данных.
Модели передачи данных в облачных технологиях.
Первой моделью передачи данных между абонентами была модель типа "точка - точка". Эта модель предусматривала выделенный канал передачи от абонента, который перешел к абоненту, который его получил. Эта модель была использована в телефонии до 1990-ых лет. Именно эта модель была использована для создания первых компьютерных сетей.
Сеть типа «точка–точка» – является простейшим видом компьютерной сети, в котором два компьютера взаимосвязаны непосредственно через коммуникационное оборудование (рис. 1.1). Преимуществом этого типа соединения является простота и дешевизна, недостатком – подключение таким образом можно только 2 компьютера и не более того.
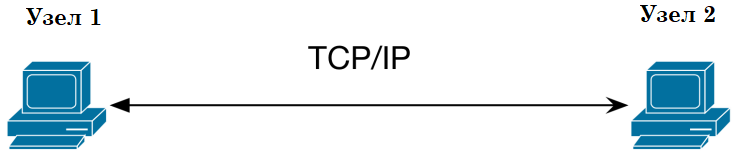
Рис. 1.1. Модель сети «точка-точка», построенная по данным [11].
Эта модель соединения часто используется в тех случаях, когда вам нужно быстро передавать информацию с одного компьютера на другой.
Следует отметить, что эта модель может быть использована в качестве наиболее обобщенные модели передачи данных между двумя объектами.
При моделировании передачи данных от одного абонента к другому можно использовать модель в виде графа G = (V, E) , вершинами V, которые будут абонентами сети, а ребрами E – связей между ними. Ребра будут иметь соответствующие весы, которые определяются необходимостью моделирования. В одном случае это может быть скорость передачи информационной единицы, в противном случае - качество обслуживания абонента. Но, в любом случае, весы будут определять обобщенные характеристики тракта передачи данных.
Для преодоления недостатков подключения типа «точка-точка» была предложена виртуальная частная сеть (VPN) [3] с сопоставимым качеством обслуживания, но при гораздо меньших затратах. Переключение трафика для оптимального использования каналов они смогли лучше использовать сеть. В этой модели символ облака был впервые использован для обозначения различия между пользователем и поставщиком.
Модель VPN представляет собой логическую сеть, созданную поверх других сетей, на основе общедоступных или виртуальных каналов других сетей (Интернет). Безопасность передачи пакетов через публичные сети может быть реализована с помощью шифрования, что приведет к закрытию стороннего канала связи. VPN позволяет объединить, например, несколько географически удаленных сетей организации в единую сеть, используя их для связи между ними неконтролируемыми каналами.
VPN состоит из двух частей: «внутренняя» (контролируемая) сеть, которых может быть несколько, и «внешняя» сеть, через которую проходят инкапсулированые соединения (обычно используется Интернет) (рис. 1.2).
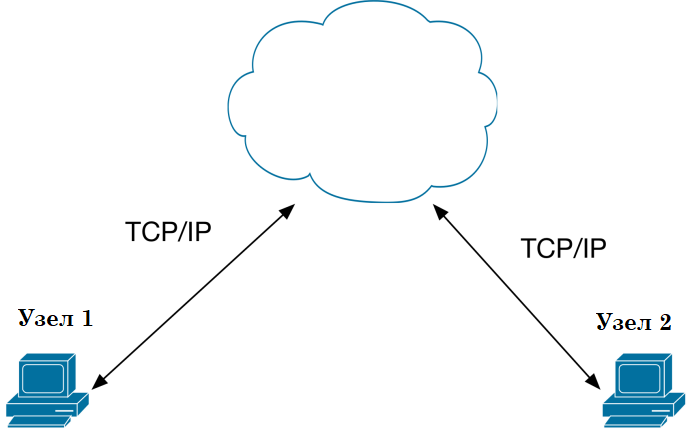
Рис. 1.2. Модель передачи данных через VPN, построено за данными [11].
Подключение к VPN удаленного пользователя осуществляется с помощью сервера доступа, который подключен как к внутренней, так и к внешней (публично доступной) сети. При подключении удаленного пользователя (или при установке соединения с другой защищенной сетью) доступ к серверу требует, чтобы вы прошли процесс идентификации, а затем процесс аутентификации. После успешного прохождения обоих процессов удаленный пользователь получает право работать в сети, то есть происходит процесс авторизации.
При объединении локальных сетей в общую VPN-сеть можно получить полностью трудоспособное пространство с минимальными затратами и высокой защитой. Для создания такой сети необходимо будет установить на один компьютер с каждым сегментом специальный VPN шлюз, который отвечает за передачу данных между аффилированными лицами. Обмен информацией в каждом отделе осуществляется обычным способом, но в случае необходимости передачи данных в другую область VPN-сети, они отправляются на шлюз. В свою очередь, шлюз осуществляет обработку данных, шифрует их надежным алгоритмом и передает сеть в интернет-шлюз в другую ветку. В пункте назначения данные расшифровываются и передаются на компьютер назначения обычным способом.
Все это остается совершенно незамеченным пользователем и ничем не отличается от работы в локальной сети. Кроме того, VPN является лучшим способом организации индивидуального доступа компьютера к локальной сети компании.
Одним из немногих недостатков, которые есть у модели VPN, является необходимость приобретения небольшого количества оборудования и программного обеспечения, а также увеличение объемов внешнего трафика. Однако эти затраты довольно малы и с учетом огромного количества преимуществ VPN, с ними вполне можно переносить.
Однако такие две модели передачи данных между абонентами имеют одну существенную - они требуют прямого участия абонентов в процессе передачи данных. Необходимость постоянной коммуникации несколько ограничивает сферу их использования.
Лишенная этого отсутствия модель на основе центра обработки данных, центра хранения и обработки данных, дата-центра) - специализированная техническая платформа для размещения информации в интернете, подключенной к ней в автономной системе (или Сеть через набор каналов связи.
Дата-цент представляет собой набор запланированных определенным путем территорий, внешних платформ, зданий, помещений, с установленными инженерными системами и обслуживающим персоналом, которые формируют общее физическое пространство и технологическая среда для размещения компьютеров, электронных и других средств приема, передачи, обработки, хранения информации и обеспечения определенной степени доступности, установленного оборудования в данном режиме функционирования [12].
Создание и эксплуатация дата-центров осуществляется в соответствии с рядом строгими стандартами. Центр обработки данных может быть подразделением телекоммуникационной компании или отдельной организацией. Основной деятельностью дата-центра является установка и последующее техническое обслуживание серверного и коммуникационного оборудования клиентов в соответствии с условиями колокации или выделением серверов. Оборудование крепится к серверным стойкам и/или шкафам. Качество и пропускная способность каналов связи дата-центра напрямую влияют на качество предоставляемых им услуг, так как основным критерием его оценки является время доступности, размещенное в дата-центре сервера.
Согласно TIA/EIA-942 структура центра обработки данных состоит из трех основных подсистем [13]:
- MDA – Main Distribution Area – главная распределительная подсистема, обеспечивающая интерфейс доступа к центру и распределяет трафик главной магистрали на внутренние магистрали. Она включает конечное оборудование операторов связи, маршрутизаторы, магистральные коммутаторы;
- HDA – Horizontal Distribution Area – горизонтальная распределительная подсистема, направляет трафики внутренних магистралей через локальные линии, входящие в аппаратные зоны (стойкие);
- EDA – Equipment Distribution Area – подсистема разводки на оборудование, которое доставляет трафик в рабочие области к серверам, дисковых массивов.
Центр обработки данных представляет собой комплексную централизованную систему, обеспечивающую непрерывность бизнес-процессов с высоким уровнем производительности и готовности услуг, в ключая:
-
- высоконадежное серверное оборудование,
- систему хранения данных,
- активное сетевое оборудование,
- архитектурно-технические решения по резервированию и дублированию критически важных сервисов информационных систем,
- «обеспечительную» инженерную инфраструктуру,
- физическая защита помещений,
- системы управления и мониторинга,
- комплекс организационных мероприятий.
При цьому дає вигоди у:
-
- Минимизация времени доступа к информации при любом количестве запросов;
- Увеличение доступного для каждого пользователя дискового пространства;
- Увеличение доступности данных;
- Отсутствие временных затрат на резервное копирование и восстановление данных;
- Повышение защищенности системы от сбоев и потери информации.
Формально модель обмена данными через дата-центр можно изобразить графически (рис. 1.3).
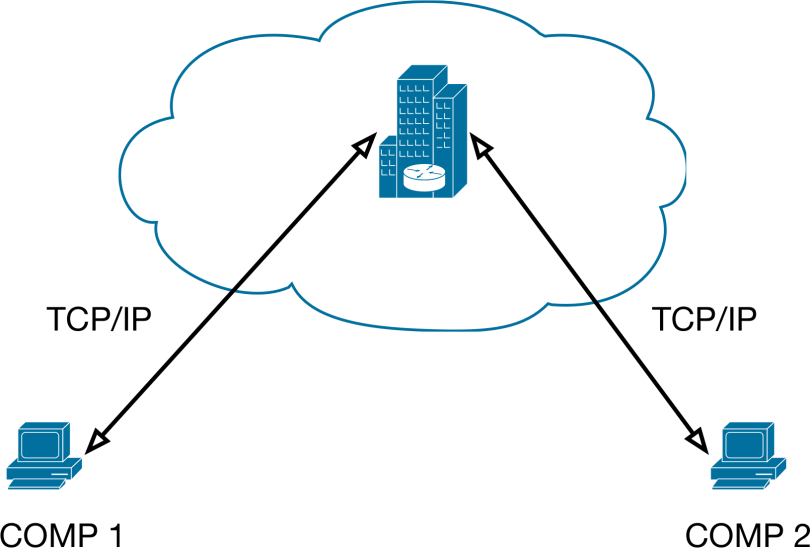
Рис. 1.3. Модель передачи данных через дата-центр, построено за данными [11].
Представление в модели всего центра обработки данных одним элементом ничего не говорит о его внутренней структуре, но позволяет моделировать внешние связи центра и отслеживать возможность обмена данными между абонентами с помощью центра обработки данных.
Реально, центр обработки данных содержит несколько серверов, которые могут быть даже разделены по регионам. Но, в любом случае, есть центральные серверы и сателлиты.
Файлы, обмениваемые подписчиками, физически хранятся на основных серверах. Весь доступ к хранимой информации осуществляется через так называемые сателлиты.
Основной сервер – сервер на котором физически находятся файлы клиентов.
Основных серверов может быть несколько. Клиент оплачивает хранение информации на одном из них, или по дополнительному соглашению, на нескольких. Основная характеристика основного сервера – хранение больших объемов информации, но медленный доступ к ней.
Обобщенная модель основного сервера содержит (рис. 1.4):
- Firewall – защитный барьер сервера.
- Nginx – Web-сервер для обработки запросов и перенаправления их на программную аппликацию сервера (интерфейсный модуль основного сервера).
- Программная реализация сервера – программа которая обеспечивает авторизацию, аутентификацию, разграничение прав доступа к файлам и сам доступ к файлам.
- База данных – в которой находится информация о пользователях, счетах, файлах и др.
- Файлы – документы пользователей к которым они имеют права доступа.
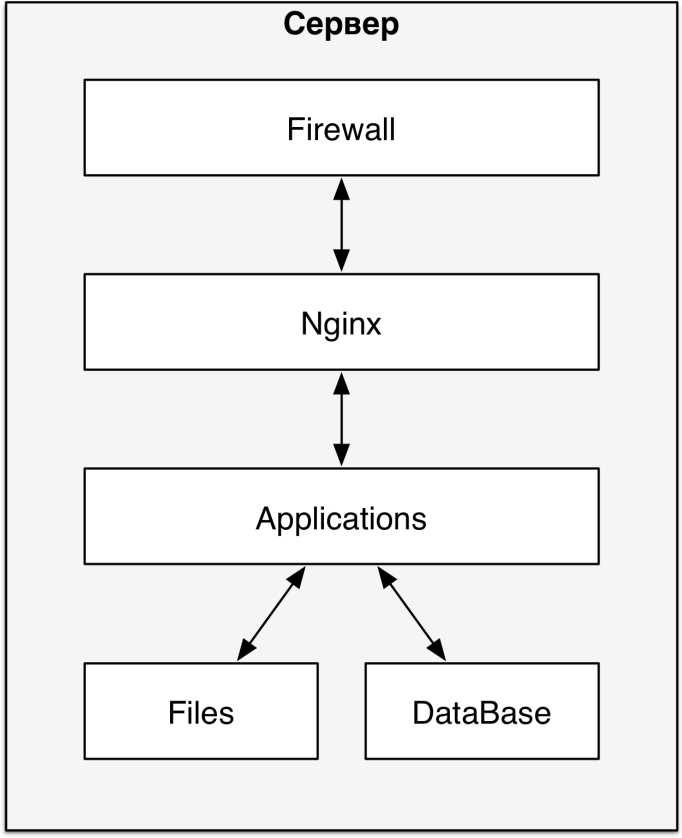
Рис. 1.4. Модель основного сервера.
Основная проблема заключается в том, что серверы физически удалены от всех возможных клиентов. Из-за какого времени клиентский запрос довольно низок.
Существуют решения для зеркальных серверов, чтобы увеличить скорость доступа к файлам. То есть, серверы, выполняющие данные репликации друг на друга.
Большой проблемой данной архитектурной модели является актуальность данных. Еще одной проблемой является то, что клоны сервера должны быть такой же конфигурации, как и основные, что достаточно дорого.
Существует другой подход к решению проблем доступа к центрам обработки данных. Эта, так называемая сеть доставки и распространения контента (Content Delivery Network, или Content Distribution Network, CDN) представляет собой географически распределенную сетевую инфраструктуру, которая позволяет оптимизировать доставку и распространение контента конечным пользователям в сети Интернет [2]. Использование провайдеров CDN помогает увеличить скорость загрузки Интернета – пользователей аудио, видео, программного обеспечения, игр и других видов цифрового контента в точках сети CDN.
Скорость загрузки значительно влияет на то, как далеко пользователь от сервера. Это объясняется тем, что использование технологии TCP/IP, используемой для распространения информации в Интернете, задержки с передачей информации зависят от количества маршрутизаторов, которые находятся на пути между источником и потребительским контентом. Размещение контента между несколькими серверами CDN означает сокращение маршрута передачи сетевых данных и делает загрузку сайта быстрее с точки зрения пользователя.
При такой модели организации время хранения данных облачного сервиса между двумя абонентами будет определяться суммой в два часа передачи - от первого до центра и от центра до второго. В случае, если абоненты и дата-центр находятся близко друг к другу, это время невелико и существенно на качество обслуживания это не влияет. Но учитывая, что подключение к дата-центру происходит по протоколу TCP/IP, который является надежным протоколом передачи, но со ссылками на большие расстояния, скорость гарантированной передачи существенно снижается. То есть использование такой модели для организации передачи данных в континентальном масштабе приводит к потере качества обслуживания.
Независимо от того где буде находиться сервер дата-центра – возле первого абонента, возле второго, или где-то посередине. В первом случае данные будут быстро доставлены на сервер, но долго будут передаваться с сервера абоненту (рис. 1.5).
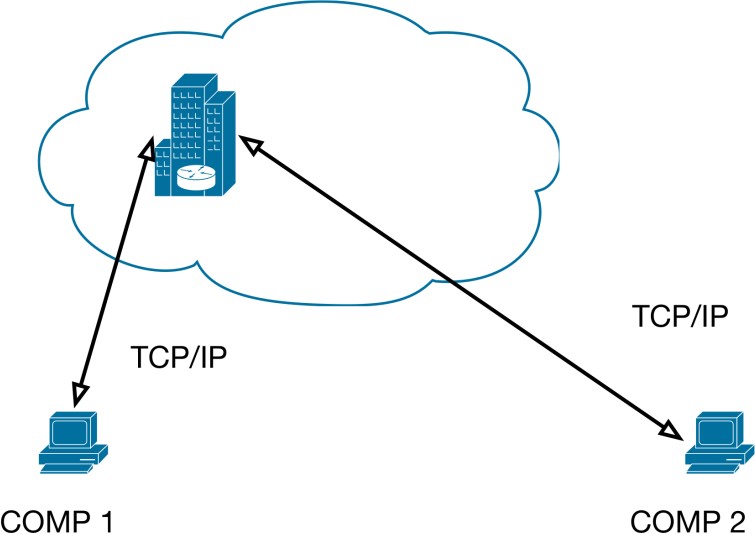
Рис. 1.5. Модель несимметричной передачи данных через дата-центр.
Во втором случае, наоборот, данные будут долго передаваться от вызываемого на сервер, но быстро будут передаваться с сервера вызывающему абоненту. Основной проблемой этого является низкоскоростная TCP/IP стандартная передача данных на большие расстояния.
Поэтому можно рассмотреть такой подход, как модель одноточечной дистрибуции.
В отличие от этого, можно использовать модель многоточечной дистрибуции, которая предусматривает наличие сателлитов основных серверов в местах наибольшей сетевой активности абонентов (рис. 1.6).
Использование такой модели доставки данных сокращает количество хостов, что значительно увеличивает скорость загрузки контента из Интернета. Хоп (hop, прыжок) – название процесса передачи сетевого пакета (или datagrams) между хостами (узлами) сети. Обычно он используется для определения «расстояния» между узлами (чем больше узлов – тем сложнее путь маршрутизации и «следующий» — это узлы друг от друга) [6].
То есть при снижении количества хопов, конечные пользователи испытывают меньшую задержку при загрузке контента, отсутствие резких изменений скорости загрузки и высокое качество потока данных. Такая стабильность позволяет операторам дата-центра доставлять видеоконтент в формате HD,
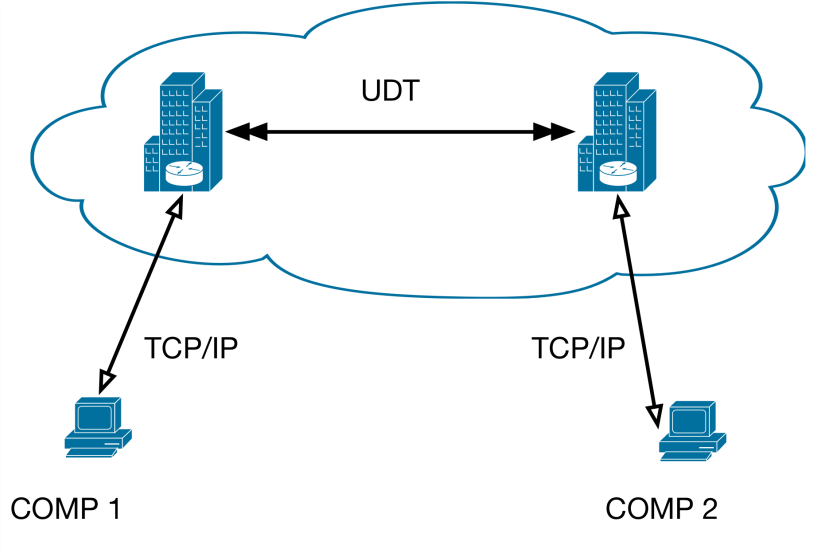 обеспечивать быструю загрузку файлов больших размеров или организовывать видеотрансляцию с высоким качеством сервиса (QoS) и низкими затратами на сеть.
обеспечивать быструю загрузку файлов больших размеров или организовывать видеотрансляцию с высоким качеством сервиса (QoS) и низкими затратами на сеть.
Рис. 1.6. Модель многоточечной дистрибуции данных через дата-центр.
Модель многоточечного распределения способна предотвращать задержки в передаче данных, возможные перебои в связи и потери перегруженных каналов и связи между ними. Управление нагрузкой при передачи сетевого трафика позволяет разгрузить магистральные и сетевые узлы, распределить нагрузку между удаленными серверами.
Размещение серверов в непосредственной близости от конечных пользователей может увеличить выходную мощность всей системы. Например, наличие единого порта 100 Мбит/с не означает такой скорости на всех участках сети, так как свободная пропускная способность магистрального канала на момент передачи может сойти всего 10 Мбит/с. В случае использования 10 распределенных серверов общая пропускная способность может составят 10-100 Мбит/с.
При таком подходе дата-центр будет состоять из географически распределенных многофункциональных платформ, взаимодействие которых позволяет максимально эффективно обрабатывать и удовлетворять запросы пользователей для получения контента.
Однако возможны две модели реализации. При первом подходе данные центрального сервера реплицируются на периферийных платформах. Каждая платформа поддерживает полную или частичную копию распределенных данных в актуальном состоянии. В противном случае данные кэшируется на сателлитах и хранятся там в течение нескольких дней.
Узел сети, который является частью платформы, взаимодействует с локальными сетями провайдеров и распространяет содержимое конечным пользователям по кратчайшем сетевому маршруту от оптимальной рабочей нагрузки сервера. Протяженность сетевого маршрута зависит от географического или топологического расстояния компьютера пользователя от сервера или стоимости переноса трафика в регионе присутствия.
Большие центры обработки данных могут состоять из огромного количества распределенных узлов и размещать свои серверы непосредственно в сети каждого локального интернет-провайдера. Многие операторы подчеркивают пропускную способность соединительных каналов и минимальное количество точек присоединения в регионе присутствия. Независимо от используемой архитектуры, основной целью таких сетей является ускорение передачи как статического содержимого, так и непрерывного потока данных.
При таком подходе в ключевых областях (зонах) (где много клиентов) размещаются серверы сателлиты. Это не хранить данные и файлы, а только обеспечить быстрый доступ через себя к основным серверам. Промежуточные серверы создаются для ускорения обслуживания клиентов и дополнительной защиты, в то время как доступ к какой стороне клиента меньше и, следовательно, более высокую производительность. Эти серверы называются сателлитами.
Сателлит – является промежуточным сервером, который не имеет клиентских файлов. Он предназначен для оптимизации передачи данных с основного сервера клиенту и наоборот. Количество серверов-сателлитов намного превышает количество основных серверов.
Все серверы размещены в определенных IP-зонах, чтобы обеспечить минимальное время предоставления услуг клиентам. Клиенты могут находиться в любой IP-зоне. Кроме того, клиенты могут быть мобильными – менять свои IP адреса, перемещаться с зоны в зону. Последнее обстоятельство требует динамичности в определении времени доступа к их информации.
Структурно сателлит состоит из трех частей (Рис. 1.7):
- Firewall – защитный барьер.
- Nginx – веб сервер для обработки запросов и перенаправления их на программную аппликацию сателлита.
- Application – Программная реализация сателлита – программа которая обеспечивает определение на каком из серверов физически находятся файлы пользователя и предоставляет доступ к ним.
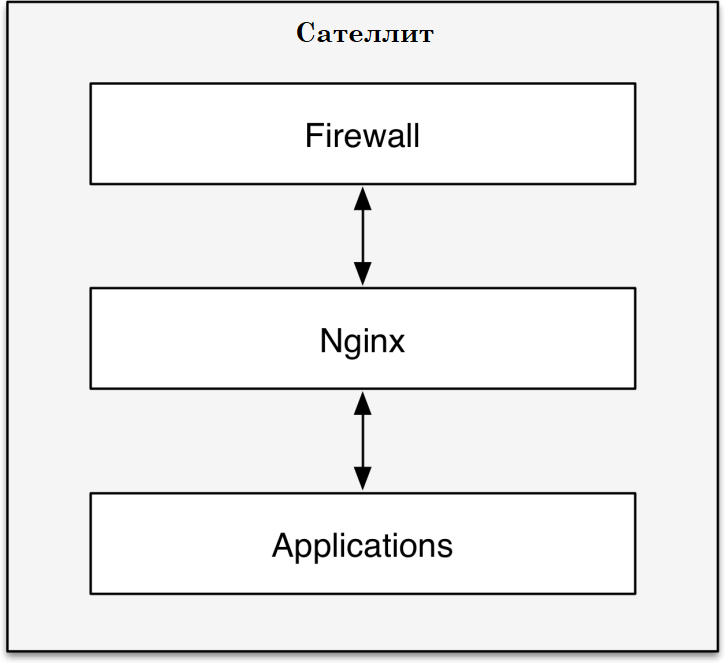
Рис. 1.7. Модель сателлита.
Таким образом, клиент все взаимодействие по размещению и получению своей информации проводит непосредственно через сателлит, независимо от того на каком основном сервере в него определенно место для информации. Конечно, если клиент статический, то для него определяется сателлит, который ближе расположен к нему (минимальное количество хопов). Но ситуация изменится при перемещении клиента в другую зону, или при технических неполадках в сети, или при очень большой нагрузке на сателлит от различных клиентов. При этом теряется преимущество данной модели.
В основе модели хранилища данных целесообразно использовать модель хранилища данных, предложенную Робинсоном:
|
S F, D,G,C, L , |
(1.1) |
де F f , f ,..., f - множество элементов данных,
1 2 n
f p , p
1
2
,..., pm
– множество пакетов данных,
D d , d ,...,d – множество устройств хранения,
1 2 k
G : F D C : D Z L : D Z
- размещение устройств хранения,
- емкость устройств хранения,
- загруженность устройств хранения.
Для нужд моделирования облачных хранилищ данных лучше использовать ее масштабируемый вариант, введенный Петровым:
|
Sm F, D(t),G,C, L . |
(1.2) |
Тогда модель облачного хранилища данных подана как:
|
Scloud D, Dfree , Sms , |
(1.3) |
де Dfree D
- подмножество свободных устройств хранения,
S S , S ,..., S – множество масштабируемых хранилищ.
ms m1 m 2 ml
Масштабируемые устройства в данном случае - это устройства из множества общих устройств, которые не включают в себя подмножество свободных устройств Di (t) D \ Dfree . Масштабируемые устройства не имеют общих устройств
хранения: t,i, j,i
j Di (t) Dj (t) .
Усовершенствована модель облачного хранилища как алгебраическую систему:
|
Cdw Scloud _ m ;Y ; L , |
|
Scloud _ m D, Dfree , Sms , PR , |
|
Y I I , I , cc, mpp mpd |
де Icc
- метод выбора шлюза по сложности запроса,
Impp
- метод мультипротокольной передачи потоковых данных,
Impd
передачи,
- метод мультиплексирования разных источников данных, для одновременной
PR – протокол передачи данных,
L – предикат загруженности
Scloud .
Элемент даних
f i St SemSt UnSt
может быть представленный
структурированными, слабоструктурированными и неструктурированными данными [15].
Предикат загруженности облачного хранилища представлен как отношение
загруженности облачного хранилища данных в моменты вр.
t1 та
t2 . Для ее
определения исследуются трафики данных в облачных хранилищах, анализируются объединённые потоки данных, устанавливается зависимость уровня фрактальности суммарного потока:
|
LS , S Z . cloud _ mt 1 cloud _ mt 2 |
(1.4) |
Параметры облачного хранилища данных
Scloud _ m : входной/выходной
трафик, количество запущенных процессов, загруженность и простой процессоров, средняя нагрузка на процессор та объем кэш-памяти.
Организация доступа к облачному хранилищу.
Сложность систем связи для передачи данных через облачное хранилище данных до наших дней во многом определяется сложностью протоколов и их комбинацией [14], которую они реализуют. Протоколы представляют собой набор правил, взаимодействующих с системой. При разработке систем передачи данных протокол внедряется аппаратным или программным обеспечением. В связи с тем, что внедрение облачных технологий происходит поверх существующего аппаратного оборудования и создавать и заменять его довольно проблематично, для облачных технологий в основном используют программную реализацию протоколов. Спецификации протоколов представлены в стандартах, которые являются наиболее важной информацией при разработке систем и должны быть правильными и обеспечивать эффективное взаимодействие. Процесс разработки протоколов и их комбинаций становится все более динамичным (количество известных протоколов удваивается каждые пять лет). Кроме того, возрастает сложность самих протоколов, что косвенно подтверждается увеличением объема их стандартных спецификаций. Таким образом, формальное доказательство правильности протоколов и их сочетания представляет собой важную научную проблему.
Формально процесс передачи с использованием гибридного протокола или мультипротокольной передачи может быть представлен в виде переходов:
|
d1 fi { d1 p1 , d1 p2 ,, d1 pm } { c1 , p1 , pr1 , c2 , p2 , pr1 ,, cn , pm , pr1 } { d2 p1 , d2 p2 ,, d2 pm } { d2 p1 , d2 p2 ,, d2 pm } , { c1 , p1 , pr2 , c2 , p2 , pr2 ,, cn , pm , pr2 } { d3 p1 , d3 p2 ,, d3 pm } d3 fi |
(1.5) |
где C {c1 ,c2 ,...,cm } — множество каналов передачи данных.
Для целей образования эффективных облачных хранилищ данных необходимо обеспечить:
-
- организацию асинхронной передачи файлов многими каналами связи;
- организацию потокового чтения файла и его передачи;
- организацию приема файла через несколько каналов связи и его кэширования для последующей записи;
- организацию потоковой записи файла из кэша;
- организацию синхронного подтверждения для завершения передачи файла.
Как известно, для организации предоставления любого сервиса в облачных технологиях и доступа к облачному хранению, в частности, необходимо наличие соответствующего хранилища. То есть это сервер или сеть серверов, через которые клиентам предоставляется услуга доступа в хранилище.
Самым простым способом предоставления сервиса клиенту – это обслуживание его запросов. Обслужить запрос – означает получить запрос и направить стороне, которая создала, в ответ на него.
Сервер облачного хранилища имеет ограниченные вычислительные ресурсы, то есть может выполнять лишь ограниченное количество операций за единицу времени. Но для создания ответа на запрос нужно провести некоторое количество операций. Соответственно, сервер хранилища может обслужить за единицу времени лишь ограниченное число запросов, которая определяется вычислительной мощностью сервера.
Если за единицу времени количество запросов, поступающих от клиентов, превышает вычислительные возможности сервера, то определенное количество запросов останется не обслуженных. Чтобы уменьшить количество необслуженных запросов, необходимо увеличить вычислительную мощность сервера хранилища.
Наиболее прямолинейный подход к увеличению мощности сервера хранилища – использовать более мощные компьютеры в качестве серверов. Это решение имеет недостатки: во-первых, в любом случае мощность компьютеров ограничена, а во-вторых - стоимость такого хранилища за счет используемых компьютеров растет быстрее его производительности, то есть стоимость в два раза более мощного компьютера для хранилища вырастет более чем в два раза.
Другой подход, который исключает указанные недостатки, заключается в том, чтобы использовать для обслуживания клиентских запросов несколько серверов хранилища. При этом стоимость решения будет прямо пропорциональна его мощности, и верхний предел на вычислительную мощность определяется не уровнем аппаратных технологий, а количеством серверов хранилища. Однако, при большом распределенности хранилища растут затраты на передачу данных между серверами хранилища, данные которых должны копироваться одновременно на все серверы хранилища.
Согласно принципам организации глобальной сети Интернет, запрос, который направляется на определенный адрес, может получить только один компьютер в сети. Таким образом, для того, чтобы запросы на доступ к данным хранилища, которые
направляются в адрес сервера хранилища, могли бы быть разработаны несколькими реальными серверами на компьютере, который принимает запросы на данные, должен быть запущен специальный сервис сателлита. Основная цель этого сервиса – выполнение следующих основных задач:
-
- получение запросов от клиента;
- выбор реального сервера хранилища, который будет обрабатывать данный запрос от клиента;
- перенаправление запроса от клиента к реальному серверу хранилища;
- получение ответа от реального сервера хранилища на запрос клиента;
- перенаправление ответа реального сервера на запрос к клиенту.
Таким образом, все запросы, которые попадают в хранилище, проходят сначала через сервис сателлита. Соответственно, на обработку одного запроса сервиса сателлита нужно процессорное время. Поэтому мощность сервера хранилища в целом ограничена не только мощностью компьютеров хранилища, но и мощностью компьютера, на котором запущен сервис сателлита. Отсюда следует, насколько важно реализовать сервис сателлита максимально эффективно.
Можно представить такую модель облачного хранилища в виде графовой модели. Пусть облачное хранилище данных включает N серверов данных D ={d1 ,...,d N }, которые объединены между собой каналами связи. Специфика организации надежных хранилищ данных предполагает, что все серверы хранилища имеют непосредственную связь с любым другим. Таким образом такая сеть
серверов хранилища представляет собой полносвязный граф
GD = (D, LD ) , в
Котором LD представляют дуги графа, которые символизируют каналы связи между серверами данных.
Кроме серверов данных к облачному хранилищу принадлежат также K
Сателлитов St ={St1 ,..., StK }, которые также объединены между собою каналами связи. И, как в случае с серверами, все сателлиты имеют непосредственные связи с каждым сателлитом ( LSt ). Кроме того, все сателлиты связаны отдельными связями ( LZ ) из серверами данных, образуя полную модель сети хранилища данных, которая также представляет собой полносвязный граф
L = LD LSt LZ .
G = (P, L), в котором
P = St D ,
Для пользователя облачное хранилище данных представлено, как сеть
сателлитов данных.GSt
G GD , через которые он может получать доступ к хранилищу
Данная модель представления облачного хранилища данных не ограничивается его типом – частная, публичная или гибридная. Она позволяет абстрагироваться от типа хранилища, а сконцентрироваться на организации доступа к нему.
Проблема заключается в том, чтобы обеспечить пользователю качественный сервис. С технической точки зрения – при получении запроса от пользователя переадресовать его на тот сателлит (точку подключения к облачному хранилищу), который обеспечит для клиента качественное предоставление услуги доступа к данным.
Решением данной проблемы может быть два варианта.
При первом варианте сервис сателлита не должен определять в каких данных хочет получить доступ клиент, сателлит будет оптимальным в данной ситуации, так как все сателлиты имеют доступ к необходимым серверам данных. Поэтому сервис сателлита должен принять соединение и, не дожидаясь поступления запроса, выбрать произвольный сателлит и произвольный сервер данных для его обслуживания.
Хотя данный подход достаточно прост, его сложно обслуживать. Администратор должен постоянно заботиться о том, чтобы все серверы данных имели одинаковое содержание – проводить репликацию на N серверов данных. Это достаточно сложно с технической точки зрения. Кроме того, это приводит к дополнительным затратам долгосрочной памяти, так как копия каждого ресурса должна присутствовать на каждом сервере данных. Еще одним недостатком такого подхода является то, что он не позволяет его масштабировать на регионально-распределенные хранилища данных, учитывать удаленность клиентов от сателлитов и серверов данных.
Второй подход должен исправить приведенные недостатки первого подхода, то есть учесть региональное распределения серверов данных, вызывает дополнительные передачи данных между серверами. Взаимное расположение клиентов и сателлитов, вызывает выбора оптимальной точки подключения к облачного хранилища.
Используя данную модель можно оценить эффективное время обмена между пользователями и хранилищем данных.
Так для получения данных с облачного хранилища, независимо на каком сервере эти данные находятся в виде файла f нужно затратить время:
|
T ( f ) F , down V ( f ) down _ k |
(1.6) |
где k – пользователь данных,
Tdown
- время загрузки,
F – размер файла данных f .
Скорость получения файла f пользователем Vdown _ k ( f )
Vdown _ k ( f ) min(Vdown _ k ,Vdown _ St ( f )) ,
j
определяется:
де Vdown _ k
- скорость получения данных клиентом,
Vdown _ St ( f )
j
- скорость передачи файла f из хранилища к сателлиту
St j .
А скорость передачи файла f из хранилища к сателиту
St j
определяется
по формуле, учитывая, что файл может быть размещен на нескольких серверах и считываться параллельно с ним:
|
K Vdown _ St ( f ) min{Vupl _ St ,Vdown _ St ,Vdown _ d (St j , f )}, j j j i i1 |
(1.7) |
где S
t
j
- сателлит j ,
d j – хранилище i ,
Vupl _ St
i
- скорость предоставления данных сателлитом,
Vdown _ St
- скорость получения данных сателлитом из хранилища.
Итак, суммарная формула времени получения файла из хранилища будет определяться:
i
|
T ( f ) F . down K min{Vdown _ k ,Vupl _ St ,Vdown _ St , Vdown _ d (St j , f )} j j i i1 |
(1.8) |
Оценка времени загрузки данных от клиента в облачное хранилище может быть проведена аналогично, учитывая тот факт, что загружать нужно не на несколько серверов хранилища, а только на один:
|
T ( f ) F . upl V ( f ) upl _ k |
(1.9) |
Скорость загрузки данных от k-го клиента:
|
Vupl _ k ( f ) min{Vupl _ k ,Vupl _ St ( f )}, j |
(1.10) |
|
Vupl _ St ( f ) min{Vdown _ St ,Vupl _ St , max(Vdown _ d (Sti , f ))}. j j j i |
Итак, время загрузки в хранилище будет определяться:
|
T ( f ) F . upl min{V ,V ,V , max{V (St , f )}} upl _ k down _ St j upl _ St j down _ di j |
(1.11) |
Таким образом, предлагаемая модель представления организации облачного хранилища данных позволила оценить время загрузки и считывания файлов в хранилище данных.
Заключение к 1-ой главе.
В результате работы в данном разделе:
- На основе существующих подходов и их недостатков, разработана модель облачного хранилища данных и методы передачи данных.
- Введена модель гибридных протоколов передачи данных через облачное хранилище, обоснована модель сетевого трафика.
- Усовершенствована модель облачного хранилища как системы алгебраических уравнений.
- Построена модель облачного хранилища хранения данных. Предложены методы повышения эффективности облачных хранилищ данных:
- метод мультипротокольной передачи потоковых данных, который в отличие от метода выбора протокола на всем участке сети характеризуется высокой производительностью, адаптируясь под каждый участок сети отдельно;
- метод мультиплексирования различных источников данных для облачного хранилища данных, который в отличие от метода балансировки нагрузки в режиме реального времени определяет загруженность каналов передачи, что позволяет задействовать свободные каналы передачи данных;
- метод выбора шлюза по сложности запроса, основанный на нечетких данных о скорости обмена с клиентом и позволяет выбрать оптимальный по скорости маршрут и шлюз передачи данных на текущий момент.
Основные результаты раздела опубликованы в трудах [4, 5, 6, 10, 15, 16].
ГЛАВА 2.
РАЗРАБОТКА МЕТОДОВ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ РАСПРЕДЕЛЕННЫХ ТЕЛЕКОММУНИКАЦИОННЫХ СИСТЕМ ОБЛАЧНЫХ ХРАНИЛИЩ ДАННЫХ
В главе – разработаны методы повышения эффективности вычислений в облачных хранилищах данных. Основное внимание сосредоточено на разработке метода мультипротокольный передачи потоковых данных и метода мультиплексирования различных источников для одновременной передачи.
2.1. Разработка метода мультипротокольного доступа к потоковым данным.
Современные приложения производят данные с очень большой скоростью, и эта скорость возрастает с каждым годом, особенно при переходе к облачным технологиям. Несмотря на постоянное повышение пропускной способности сетей связи, в частности Internet, пользователям нужна возможность доступа к данным с все меньшими задержками. Этому, в частности способствуют достижения в области аппаратуры компьютеров (удешевление основной и дисковой памяти, увеличение количества ядер процессоров), а где этого недостаточно для удовлетворения потребностей повышения пропускной способности при одновременном снижении времени задержки.
Методы наращивания мощности приложений для работы с облачными технологиями должны быть достаточно простыми, во-первых, поскольку должна обеспечиваться возможность их быстрой смены и масштабного внедрения с минимальными усилиями, а во-вторых, потому что люди, которые создают облако приложения, являются специалистами широкого профиля и они не готовы изучать сложные технологии, которые используют системные программисты, и тяжелые в настройке.
Выполнение различных действий над потоками данных - это новая технология, которая обеспечивает обработку данных, очень быстро поступают и производит результаты с небольшими задержками. В основном, такой подход стал использоваться в сообществе исследователей баз данных, и поэтому он имеет некоторые характеристики, характерные для реляционных систем баз данных. В традиционных системах баз данных сначала данные поступают в базу данных и хранятся на дисках, а затем уже пользователи применяют к этим сохраненным данных запросы. Аналогично происходит и при работе с облачными хранилищами данных – сначала данные поступают на один из сателлитов, а уже потом проводится их перемещения на хранилища данных и репликация.
Последовательная передача блоков файлов, даже при параллельной их физической передачи высокоскоростными каналами связи, становится узким местом использования облачных хранилищ. Приемник не может использовать файл до того момента, пока он полностью не будет передан. Ничего страшного в этом нет, в
случаях, когда, или файл небольшой, или файл передается непосредственно от одного абонента другому. При существовании в системе передачи достаточного количества промежуточных элементов приема-передачи, на каждом из них будет происходить задержка на передачу до того момента, пока весь файл не будет принят промежуточным элементом. Можно сказать, что при традиционном подходе данные обрабатываются в состоянии покоя, а в системах обработки запросов над потоковыми данными – на лету.
Преимущества таких методов обработки, проявили себя с положительной стороны в системах баз данных, целесообразно расширить на облаках хранилища, учитывая особенности функционирования последних.
Так для целей облачных хранилищ данных необходимо:
-
-
- Организация асинхронной передачи файлов многими каналами связи;
- Организация потокового чтения файла и его передача;
- Организация приема файла через несколько каналов связи и кэширования его для последующей записи;
- Организация потоковой записи файла из кэша;
- Организация синхронного подтверждения для завершения передачи файла.
-
Так как методика сопоставления данных на лету переносим из существующих методов обработки запросов к базам данных, то стоит провести аналогию сроков и операций.
В реляционных базах данных основным примитивом являются таблицы. Таблица заполняется записями, каждая из которых имеет один и тот же тип записи, задается несколькими именуемыми строго типизированными столбцами. В середине записей отсутствует какой-либо внутренний порядок столбцов. При выполнении запросов, которые обычно представляются на языке SQL, выбираются записи из одной или нескольких таблиц, и они превращаются с использованием небольшого набора мощных реляционных операций.При использовании метода обработки запросов над потоковыми данными соответствующими примитивами уже выступают потоки. Как и в таблице, в потоке есть некоторый тип записи, но записи не сохраняются, а поступают в потоке. В поточной системе записи упорядочены естественным образом, и в каждой записи есть временная метка, указывающая, когда эта запись была создана. Для реляционных операций, поддерживаемых в реляционных базах данных, аналоги и в потоковых системах, и эти аналоги достаточно похожи на реляционные операции, чтобы для формулировки потоковых запросов можно было использовать SQL. Аналогичный подход, но уже не с использованием языка структурированных запросов, а «языка передачи и обработки файлов в хмаркових хранилищах» позволяет использовать все преимущества потокового подхода, который, как показала практика использования, намного эффективнее.
То есть, процесс передачи файла F от одного абонента другому заключается в
разделении его на K блоков
F F1 ,, FK и последовательной передачи этих блоков через
сеть. В свою очередь, приемная сторона обеспечивает прием четко определенной последовательности блоков, собрание из них файла и предоставления доступа к нему пользователю (рис. 2.1). Последовательность передачи определяется тем, что следующий блок не может быть передан, пока не поступило подтверждение о приеме предыдущего. То есть, если система передачи и имеет несколько каналов передачи, такая дисциплина передачи ограничивает скорость передачи файла.

Рис. 2.1. Последовательная передача файла.
То есть, время через которое конечный пользователь получит доступ к файлу определяется суммарным временем передачи всех блоков файла. При больших файлах он достаточно существенный.
Особенно возрастает время доступа к файлу, когда в звене передачи размещены промежуточные серверы, буферизованных передачу (данный подход используется в облачных хранилищах). Тогда время доступа к информации заметно растет.
Все системы для работы в сети используют аналогичный принцип передачи. И изменить этот принцип – означает изменение всего программного обеспечения, выглядит абсурдным.
Другое дело, когда файлы передаются через облачные хранилища данных, для которых создается новое программное обеспечение. Для совместимости с существующими методами нужно только, чтобы системы приема-передачи на сателлитах:
-
-
- разрешали получать последовательный поток блоков файлов для
-
приема от передающего абонента;
-
-
- генерировали соответствующий последовательный поток блоков файлов для приемного абонента.
-
Все, что будет происходить в середине облака для внешних абонентов не должно быть доступным. То есть задача модификации заключается в изменении передачи файлов между облачными серверами (сателлитами и хранилищами) для повышения скорости обмена.
Для доступа к данным в таком мультипротокольной среде при разделении файла на блоки, каждый из них содержит offset, что определяется место с которого начинается блок данных в файле.
Передача между облачными абонентами проводится параллельно по нескольким каналам связи. Причем разные каналы могут иметь разную скорость передачи. Соответственно на приемной стороне облачного элемента блоки файла могут поступать не в упорядоченном порядке, а случайным образом. Для восстановления из этих блоков конечного файла принятые блоки помещаются в кэш блоков, который организуем по структуре приоритетной очереди (приоритет определяется offset). Таким образом в процессе приема блоков в кэше формируется конечный файл.
То есть, между двумя точками сети передача данных осуществляется через N TCP-соединений.
Поскольку, как было отмечено, нужно использовать асинхронную передачу, то следует использовать IOLOOP (цикл активных входящих / исходящих / ложных соединений). Алгоритм работы IOLOOP есть:
- Создание цикла IOLOOP.
- Создание необходимых соединений (sockets).
- Назначить события каждого socket с указанием, какие именно события интересуют (чтение / запись / ошибка сокета).
- Обращение к IOLOOP (с указанием таймаута), чтобы получить доступный сокет, который соответствует предназначенным условиям.
- Если в течение определенного времени (таймаута) ни один socket не соответствует условиям, управление возвращается к программе. Если какой-то готов, то IOLOOP вместе с управления возвращает список готовых соединений и с указанием условия (чтение и / или запись и / или ошибка сокета).
Такой принцип достаточно легко реализовать по структуре (рис. 2.2).

Рис. 2.2. Метод получения доступа к асинхронной передачи.
Используя этот подход, позволяет реализовать метод мультипротокольного доступа к потоковым данным.
- Обращение к циклу IOLOOP, которое возвращает готовность к чтению с управляющего сокета (сокет управления программой).
- Считывание сокета управления и получение команды отправки файла.
- Считывание из файла M байт.
- Упаковка данных в пакет.
- Добавление пакета в очередь.
- Если очередь не заполнена – вернуться к пункту 2.
- Проверка на существование N соединений. Если они закрыты, не созданы – то создать и выполнить необходимые действия для соединения. После соединения сокеты добавляются в цикл IOLOOP с указанием ожидания: «готовности записи», «готовности чтения», «ошибки сокета».
- Обращение к IOLOOP по списку «готовых» сокетов.
- Если ошибка сокета: закрывают сокет, удаляют его из IOLOOP, замечают пакеты, переданные этим сокетом и не подтверждены, как отправленные, создают новый сокет, образуют новый сокет и добавляют его в IOLOOP.
- Если готовность сокета к записи, для каждого из сокетов: получить пакет из очереди, шифрование его и запись в буфер обмена сокета, а сам пакет замечает, как отправлен через данный сокет.
- Если готовность сокета к чтению, тогда для каждого сокета: прочитать пакет, расшифровать, получить подтверждение пакета; удалить данный пакет из очереди.
- Если файл еще не весь прочитан, и есть место в очереди, тогда перейти
к 3.
- Если файл прочитан и очередь пуска, закрыть соединения и удалить их з IOLOOP та перейти до 1.
- Перейти к 8.
Кроме того, что приоритетная очередь позволяет производить сбор файла из блоков в процессе их приема, несмотря на последовательность поступления блоков, такой метод позволяет параллельно проводить последовательную дальнейшую передачу файла в момент поступления соответствующего последовательного блока.
Обобщенная схема работы этого метода может быть представлена графически (рис. 2.3).
К основному преимуществу предложенного метода следует отнести то, что транспортировка данных используется более быстрый протокол UDP, а для обеспечения доставки – TCP.
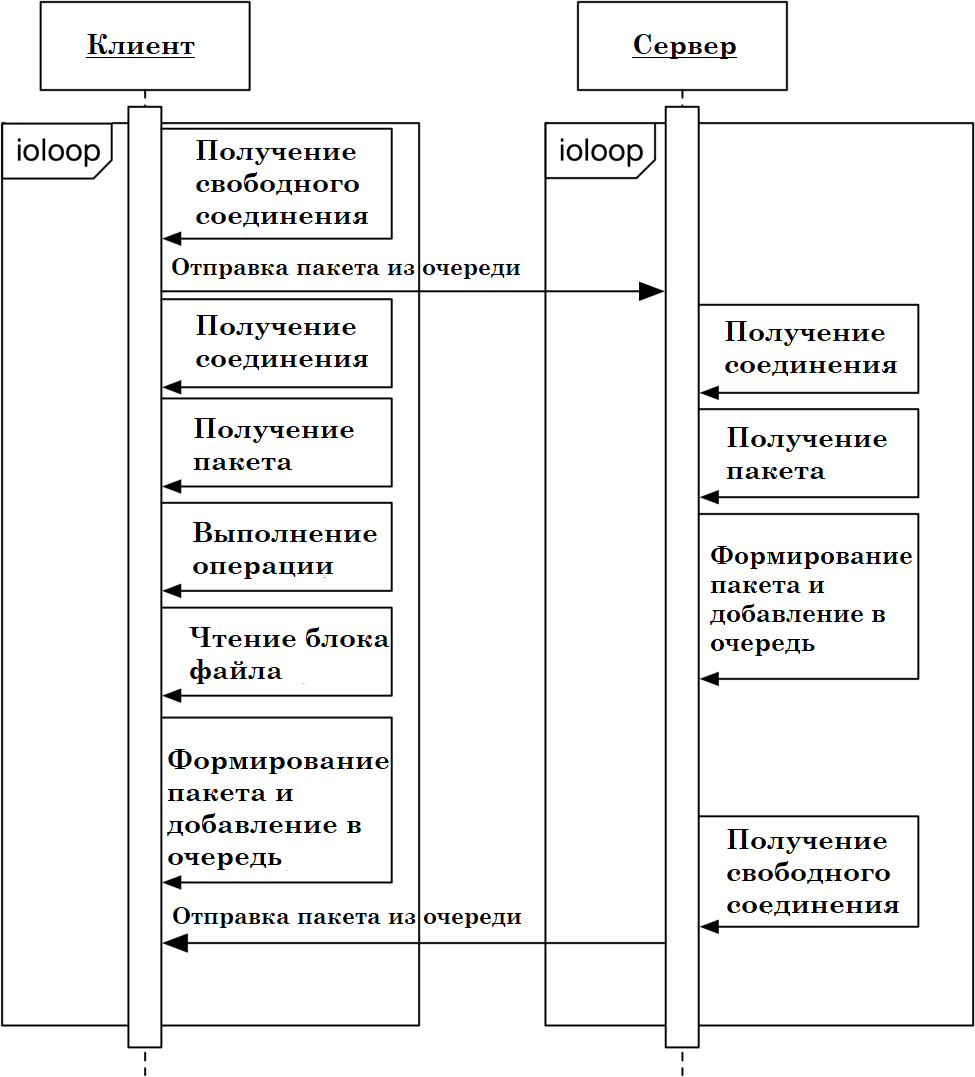
Рис. 2.3. Диаграмма последовательности мультипротокольного доступа к потоковым данным.
Фактически, для транспортировки данных используется средство, которое при создании было предназначено для контроля передачи, а для контроля – тот, который предназначен для самой передачи. Таким образом, используя существующие протоколы транспортного уровня, были повышены скорость передачи на большие расстояния потоковых данных.
Учитывая все вышеизложенное, можно сказать, что преимуществами такого модифицированного метода является:
-
-
- Возможность потоковой передачи данных через N-узлов (серверов) облачных хранилищ, не дожидаясь завершения передачи одиночного файла.
- Однако предложенный подход имеет определенные недостатки:
- Динамичное увеличение кэша, при ожидании правильной последовательности блоков файла для дальнейшей потоковой записи;
- Синхронное подтверждения завершения записи файла.
-
Разработка метода мультиплексирования различных источников данных для одновременной передачи.
Объемы информации и базы данных, с которыми работают сегодняшние предприятия и компании с каждым годом растут в геометрической прогрессии. Растут запросы руководителей предприятий не только к скорости работы машин с огромными объемами информации, но и к качеству, надежности хранения данных, накопителей информации. Именно поэтому правильно выбранная система хранения данных – очень важная составляющая успеха в бизнесе. Использование облачного хранилища данных, позволяет не только обеспечить резервирование данных, но и размещение их вблизи потребителя данных.
При выборе высокоскоростных протоколов передачи данных, следует обратить внимание на возможность мультиплексирования документов и получение одного документа из различных источников.
Мультиплексирование документов необходимо для одновременного получения нескольких документов из одного источника. При использовании последовательного получения документов, пользователь может столкнуться с проблемой, когда получение достаточно малых рабочих документов, может отложиться на большой промежуток времени из-за попадания в очередь больших документов [1].
Существуют несколько видов обеспечения мультиплексирования:
-
-
- Канальное мультиплексирование – документы делятся на пакеты, каждый пакет получает идентификатор документа (канала передачи данных), который однозначно связывает несколько пакетов, касающиеся одного документа.
- Мультиплексирование с разделением во времени – мультиплексор в каждый момент времени выдает в общий канал данные одного документа, отдавая ему всю полосу пропускания, но по дежурно для документов через равные промежутки времени.
- Мультиплексирование с разделением по соединениям – между двумя
-
точками передачи данных создается столько соединений, сколько нужно одновременно передавать документы.
Поскольку использование облачных хранилищ данных должно обеспечивать быстрый доступ к клиентским документам из разных уголков мира, а узлы облачного хранилища могут находиться достаточно «далеко» (плохой / медленный канал связи) целесообразно использование методов получения документа из различных источников и сопоставления его на клиентской части.
Существует два подхода к обеспечению данного режима работы:
- Получение одного файла с одного узла – клиентское программное обеспечение делает запросы к узлу для получения целого документа (рис. 2.4). Таким образом документы приходят целостно. Данный метод эффективен когда на хранилище расположено много файлов небольшого размера.
- Получение одного документа с разных узлов – в данном случае клиентское программное обеспечение же решает какую часть документа с какого узла получить (рис. 2.5). Таким образом с «близких» (с которыми лучший / быстрая связь) узлов можно получить большие части документа. Данный метод эффективен в случае, когда необходимо получить один достаточно большой файл, а пропускная способность входящего канала передачи данных значительно превышает передачу данных с одним узлом.
Для обеспечения одновременного доступа к данным через один и тот же сателлит различных пользователей, возникла необходимость в создании метода мультиплексирования данных в пределах протокола передачи данных. Данный метод обеспечивает одновременную независимую передачу различных данных.
|
d1 fi { d1 , c1 , fi , d1 , c2 , fi ,, d1 , cn , fi } . { c1 , p1 , c2 , p2 ,, cn , pm } { p1 , p2 ,, pm } d2 fi |
(2.1) |
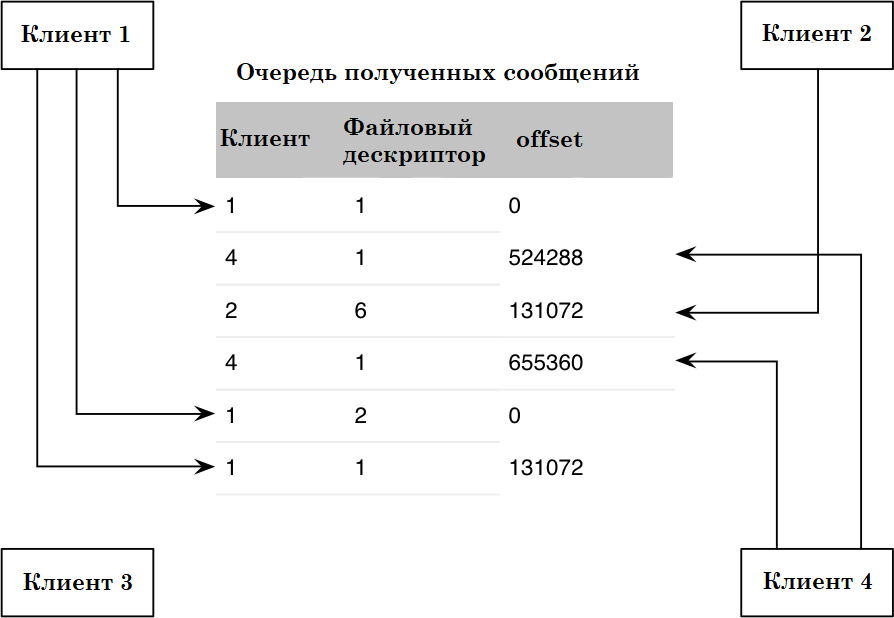
Рис. 2.4. Мультиплексирование с одним узлом.
Для решения данной проблемы без мультиплексирования данных существуют следующие варианты реализации:
-
-
- Создание многих каналов связи, создает накладные ресурсы и
-
потери быстродействия системы.
-
-
- Реализация последовательной передачи данных, что может создать сложности, когда один клиент для получения достаточно малого количества данных ожидает пока канал связи освободится от передачи данных клиентом с более крупным объемом трафика.
-
|
{ d1 , fi , d2 , fi ,, dl , fi } { d1 , c1 , fi , d1 , c2 , fi ,, dl , cn , fi } . { d1 , c1 , p1 , d1 , c2 , p2 ,, dl , cn , pm } { p1 , p2 ,, pm } dk , fi |
(2.2) |
Метод мультиплексирования для протокола UDT разработан на основе базовых принципов мультиплексирования, и его составляющих: мультиплексор и демультиплексор.
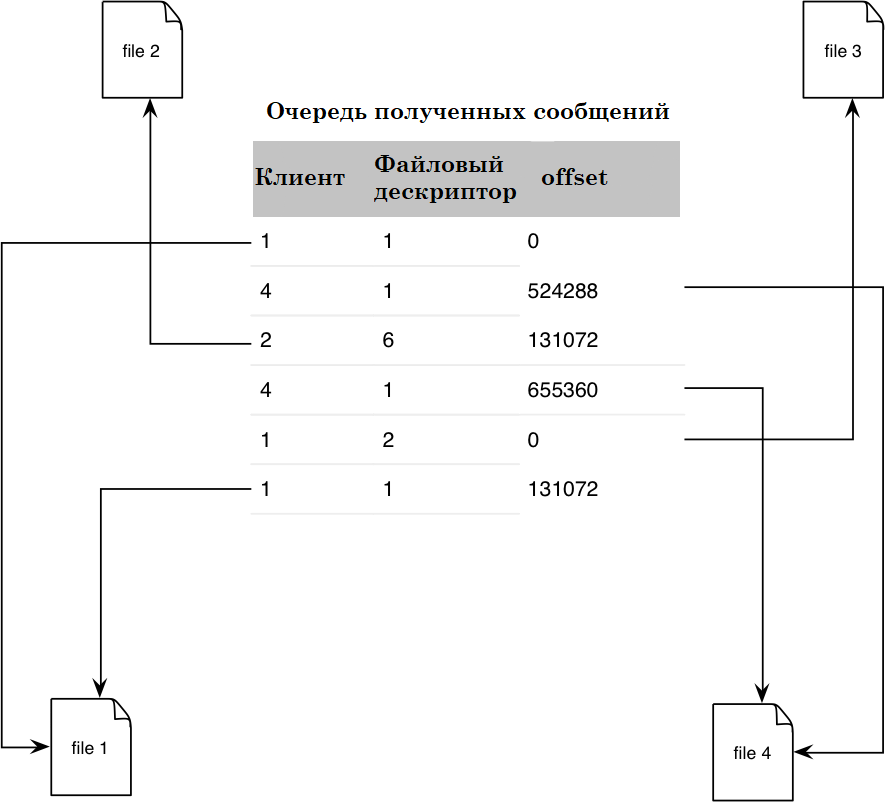
Рис. 2.5. Мультиплексирование с различными узлами.
В результате применения данного метода мы получаем гибкость системы передачи данных с конкурентным доступом к ним. И эффективно использовать ресурсы при передаче данных.
Заключение к 2-ой главе.
В результате работы в данном разделе:
- Разработан метод мультипротокольный доступ к потоковым данным.
- Разработан метод мультиплексирования данных из различных источников для одновременной передачи через облако хранилища.
Основные результаты раздела опубликованы в трудах [7, 8, 9].
ЗАКЛЮЧЕНИЕ
В курсовой работе решена актуальная научная задача разработки моделей и методов повышения пропускной способности распределенных телекоммуникационных систем высокодоступных облачных хранилищ данных на основе новых протоколов доступа. Основные результаты исследования изложены в выводах которые сводятся к следующим положениям:
- Проведен анализ проблем внедрения и функционирования облачных хранилищ данных. На основе анализа выделены технологические и функциональные проблемы внедрения облачных хранилищ данных. Сосредоточено внимание на нерешенных задачах построения распределенных систем передачи данных.
- Усовершенствована модель облачного хранилища данных путем подачи ее как алгебраической системы, которая отличается от существующих введением в архитектуру связанной телекоммуникационной сети системы методов обработки данных на основе протокольных средств сеансового уровня, что позволило более точно и полно определить, и использовать ее пропускную способность соответственно.
- Предложен метод агрегации нагрузки нескольких источников данных, который, в отличие от метода балансировки нагрузки, в режиме реального времени определяет загруженность сервисов облачного хранилища данных и каналов телекоммуникационной системы, что позволяет оптимизировать их производительность.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Кучук Г. А. Анализ и модели самоподобного трафика / Г. А. Кучук, О.О. Можаев, О. В. Воробёв. // Авиационно-космическая техника и технология. – 2006. – №9. – С. 173–180.
- Пат. US Patent 13/493,859. Content delivery network. /Gagliardi, J.D., Munger T.S., Ploesser D.W. - 2012.
- Пат. US Patent 5,768,271. Virtual private network. /Lespagnol A., Seid H.A. -
1998.
- Струбицкий Р. П. Анализ подходов к моделированию облачных хранилищ данных / Р. П. Струбицкий, Н. Б. Шаховская. // Актуальные проблемы экономики: Научный экономический журнал. – 2013 – №11. – С. 263-269.
- Струбицкий Р. П. Моделирование транспортных протоколов доступа к облачным хранилищам данных / Ростислав Павлович Струбицкий. // Материалы международной научно-практической конференции молодых ученых и студентов
«Информационные технологии, экономика и право: состояние и перспективы развития». – 2014. – №11. – С. 47–48.
- Струбицкий Р. П. Построение моделей высокоскоростных потоков для облачных хранилищ / Ростислав Павлович Струбицкий. // Материалы школы-семинара молодых учених и студентов «Современные компьютерные информационные технологии (ACИT'2015)». – 2015. – С. 161–163.
- Струбицкий Р. П. Сравнительный анализ скорости работы протоколов гарантированной передачи данных, базированных на UDP в межконтинентальной сети / Ростислав Павлович Струбицкий. // Весник Хмельницкого национального университета. – 2015. – №2. – С. 173–177.
- Струбицкий Р. П. Практический метод выбора оптимального шлюза доступа к облачному хранилищу / Р. П. Струбицкий, О.М. Найда. // «Проблемы автоматизации и управления». Сборник научных работ: выпуск 3(51). К.: НАУ. – 2015. – С. 110–115.
- Струбицкий Р. П. Разработка протокола сеансового уровня для высокоскоростных регионально-распределенных сетей / Ростислав Павлович Струбицкий. // Проблемы информатизации и управления. – 2015. – №50. – С. 109– 117.
- Струбицкий Р. П. Самоподобная модель загруженности облачных хранилищ данных / Ростислав Павлович Струбицкий. // Весник Национального университета «Львовская политехника». – 2015. – №814. – С. 147–156.
- Таненбаум Э. С. Компьютерные сети / Эндрю С. Таненбаум. – СПб: Издательский дом «Питер», 2012. – 955 с.
- Al-Fares M. A scalable, commodity data center network architecture / M. Al- Fares, A. Loukissas, A. Vahdat. // ACM SIGCOMM Computer Communication Review.
– 2008. – №38. – С. 63–74.
- Avelar V. Guidelines for Specifying Data Center Criticality / Tier Levels [Електронний ресурс] / Victor Avelar // APC. – 2007. – Режим доступу до ресурсу: http://www.lamdahellix.com/assets/contents/files/122_whitepaper.pdf.
- Russell T. Telecommunications Protocols / Travis Russell., 2000. – 427 с. 90.
- Shakhovska N. Model of Data Warehouse with Uncertain Consolidated Data / N. Shakhovska, R. Strubytskyi. // Applied computer science. – 2015. – №9. – С. 1753– 1762.
- Strubytskyi R. Modeling and forecating of cloud data warehousing load / Rostyslav Strubytskyi. // Applied Computer Science. – 2014. – №10. – С. 30–43.

- Невербальные проявления эмоциональных состояний человека (Представление о общении и эмоциях)
- Автоматизация продажи авиабилетов (Технико-экономическая характеристика предметной области и предприятия.)
- Выбор стиля руководства в организации ( Теоретические аспекты выбора стиля руководства в организации)
- Проблемы профессиональных стрессов. Профессиональное выгорание (Профессиональный стресс и общие закономерности его проявления)
- Оборотные активы предприятия ( Теоретические аспекты анализа оборотного капитала)
- Бухгалтерский баланс организации и порядок его составления ( Теоретические основы формирования бухгалтерского баланса .)
- Основы организации учета расчетов с персоналом по оплате труда на территории Российской Федерации.
- Коммерческая деятельность оптового торгового предприятия и ее совершенствование (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ КОММЕРЧЕСКОЙ ДЕЯТЕЛЬНОСТИ В СФЕРЕ ОПТОВОЙ ТОРГОВЛИ)
- История развития менеджмента ( Теоретические аспекты системы менеджмента предприятия)
- Технология организации досуга и развлечений в гостинице «four seasons лимассол 5*»
- технология работы службы консьержей и батлеров в гостинице ( ТЕОРЕТИЧЕСКОЕ ОБОСНОВАНИЕ ТЕХНОЛОГИИ РАБОТЫ КОНСЬЕРЖЕЙ И БАТЛЕРОВ В ГОСТИНИЦЕ)
- Принципы эффективного планирования деятельности предприятия