
Мультипроцессоры (Понятие мультипроцессоров)
Содержание:

Введение
Сегодня человек находиться в мире, в котором информация имеет очень большое значение. Принципиально важно научиться правильно, работать с информацией и использовать разнообразные инструменты для такой работы. Один из таких инструментов компьютер, он стал идеальным помощником человеку в разнообразных сферах деятельности.
В любой вычислительной машине почти все программы оперируют с таблицами информации. Чаще всего это не просто аморфные массы различных числовых величин, а обязательно нужно отметить, что в таких таблицах присутствуют очень важные структурные различного рода отношения между всеми элементами данных.
Постоянная потребность человечества ко все большим вычислительным ресурсам, подвигает инженеров и ученых к различным подходам к увеличении производительности у современных компьютеров, а также искать нестандартные решения.
Цель данной курсовой работы провести исследования понятие и принципов функционирования мультипроцессоров и многопроцессорных вычислительных систем.
Объектом данной курсовой работы выступает мультипроцессоры.
Предметом данной курсовой работы выступают методы построения мультипроцессоров и многопроцессорных вычислительных систем.
Для выполнения поставленной цели необходимо выполнить такие задачи:
- проанализировать понятие мультипроцессоров;
- рассмотреть различные виды мультипроцессоров;
- рассмотреть различные архитектуры многопроцессорных вычислительных систем;
- привести классификацию вычислительных систем;
- разработать имитационную модель мультипроцессорной вычислительной системы.
Теоретические вопросы данной курсовой работы хорошо рассмотрены как в отечественной, так и зарубежной литературе. В ходе выполнения работы были использованы труды таких авторов: Э. Таненбаум, Ф.Г. Энслоу, Бройдо В. Л, Корнеев В. В.
1 Понятие мультипроцессоров
1.1 Мультипроцессоры
Мультипроцессор с общей памятью (или просто мультипроцессор) представляет собой вычислительную систему, в которой два или более CPU делят полный доступ к общей ОЗУ. Программа, работающая на любом CPU, видит нормальное (обычно разбитое на страницы) виртуальное адресное пространство. Единственное необычное свойство такой системы заключается в том, что CPU может записать какое-либо значение в память, а затем, считав это слово снова, получить другое значение (потому что другой CPU изменил его).[1] При правильной организации это свойство формирует основу межпроцессорного обмена информацией: один CPU пишет данные в память, а другой считывает их оттуда. По большей части мультипроцессорные ОС представляют собой просто обычные ОС. Они обрабатывают системные вызовы, управляют памятью, предоставляют службы файловой системы и управляют устройствами ввода-вывода. Тем не менее, есть области, в которых они обладают уникальными свойствами. К этим областям относятся:
- синхронизация процессов;
- управление ресурсами;
- планирование.
Мультипроцессорное аппаратное обеспечение
У всех мультипроцессоров каждый CPU может адресоваться ко всей памяти. Однако по характеру доступа к памяти эти машины делятся на два класса:
1) Мультипроцессоры, у которых каждое слово данных может быть считано с одинаковой скоростью, называются UMA-мультипроцессорами (Uniform Memory Access — однородный доступ к памяти)[2].
2) В противоположность им NUMA-мультипроцессоры (NonUniform Memory Access неоднородный доступ к памяти) этим свойством не обладают.
Почему существует такое различие, станет ясно позднее. Сначала будут описаны мультипроцессоры UMA, а затем — мультипроцессоры NUMA.[3]
1.2 Архитектура симметричных мультипроцессоров UMA с общей шиной
В основе простейшей архитектуры мультипроцессоров лежит идея общей шины, рис. 1(а). Несколько CPU и несколько модулей памяти одновременно используют одну и ту же шину для общения друг с другом. Когда CPU хочет прочитать слово в памяти, он сначала проверяет, свободна ли шина. Если шина свободна, CPU выставляет на нее адрес нужного ему слова, подает несколько управляющих сигналов и ждет, пока память не выставит нужное слово на шину данных.[4]
Если шина занята, CPU просто ждет, пока она не освободится. В этом заключается проблема данной архитектуры. При двух или трех CPU состязанием за шину можно управлять. При 32 или 64 CPU шина будет постоянно занята, а производительность системы будет полностью ограничена пропускной способностью шины. При этом большую часть времени CPU будут простаивать.
Решение этой проблемы состоит в том, чтобы добавить каждому CPU кэш, как показано на рис. 1(б). Кэш может располагаться внутри микросхемы CPU или рядом с CPU, на процессорной плате. Поскольку большое количество обращений к памяти теперь может быть удовлетворено прямо из кэша, обращений к шине будет существенно меньше, и система сможет поддерживать большее число CPU. Как правило, кэширование выполняется не для отдельных слов, а для блоков по 32 или по 64 байта. При обращении к слову весь блок считывается в кэш CPU, обратившегося к слову.[5]
Для каждого блока кэша устанавливается режим доступа: либо для него разрешается только чтение (в этом случае этот блок может одновременно присутствовать в нескольких кэшах), либо разрешается и чтение, и запись (в этом случае этот блок не может одновременно присутствовать в нескольких кэшах). При попытке записи CPU слова, находящегося в одном или нескольких удаленных кэшах, аппаратура шины выставляет на шину специальный сигнал, информирующий остальные кэши о записи.[6]
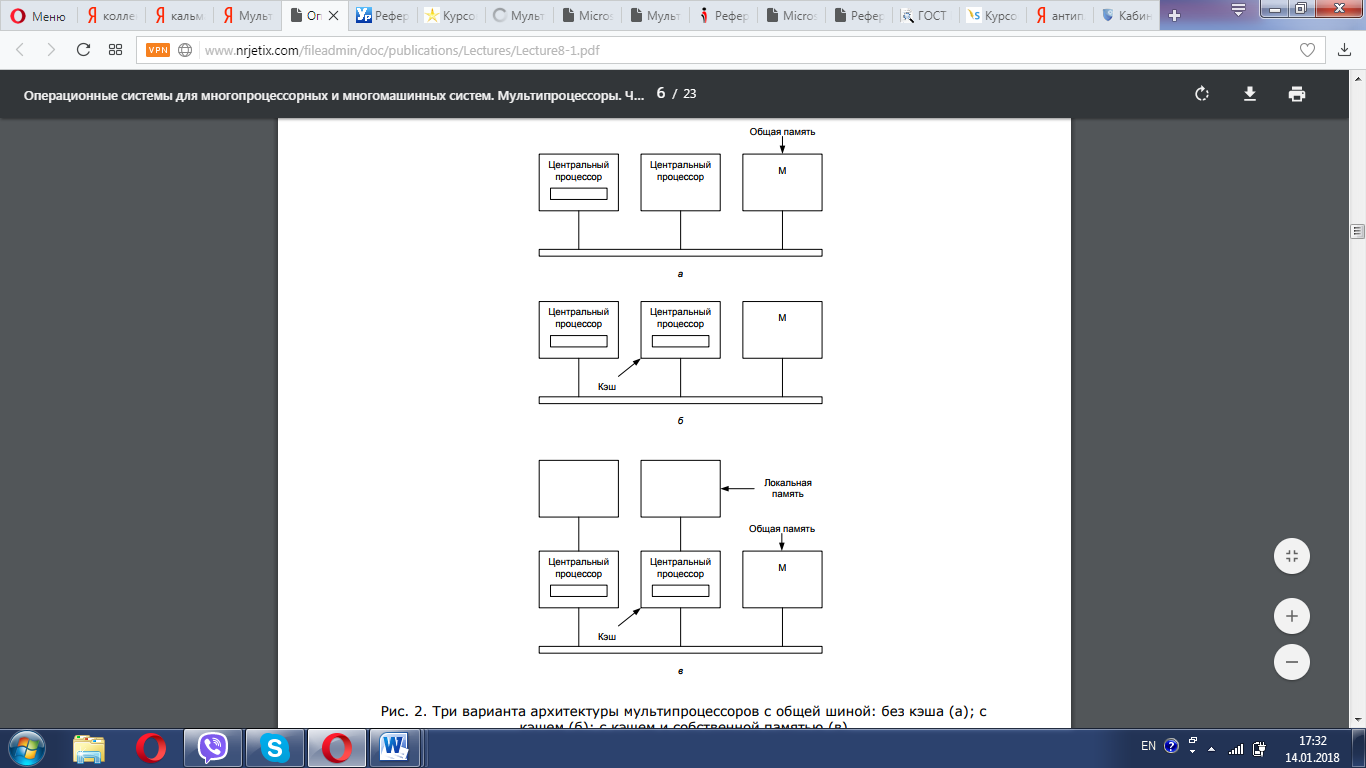
Рисунок 1 - Три варианта архитектуры мультипроцессоров с общей шиной: без кэша (а); с кэшем (б); с кэшем и собственной памятью (в)
Если в остальных кэшах соответствующие блоки «чистые», то есть модифицированные точные копии блока, находящегося в памяти, тогда они могут просто отбросить свои копии и позволить пишущему CPU получить этот блок из памяти. Если же в каком-либо кэше содержится «грязная» (то есть модифицированная) копия, она должна быть либо записана в память, прежде чем операция записи может быть продолжена, либо передана напрямую пишущему CPU по шине. Существует много протоколов обмена данных между кэшами и памятью.[7]
Еще один вариант архитектуры мультипроцессоров представлен на Рис. 1(в). В этом случае у каждого CPU имеется не только кэш, но также и локальная собственная память, с которой он соединен по выделенной (индивидуальной) шине. Для оптимального использования подобной конфигурации компилятор должен поместить текст программы, константы, стеки (то есть все неизменяемые данные), а также локальные переменные в локальные модули памяти. При этом общая память используется только для общих модифицируемых переменных. В большинстве случаев такая схема использования памяти сильно снижает трафик по шине, но для ее реализации требуются специальные действия со стороны компилятора.
1.3 Мультипроцессоры UMA с координатными коммутаторами
Даже при оптимальном использовании кэша наличие всего одной общей шины ограничивает число UMA-мультипроцессоров тридцатью двумя или шестьюдесятью четырьмя. Чтобы преодолеть это ограничение, требуется другая схема соединительной сети.[8] Довольно простая схема соединения n CPU и k модулей памяти представляет собой координатный коммутатор, рис. 2.
На каждом пересечении горизонтальной (входной) и вертикальной (выходной) линий располагается координатный переключатель. Он представляет собой небольшой переключатель, который может быть открыт или закрыт, в зависимости от того, должны быть соединены вертикальная и горизонтальная линии или нет. На рис. 2(а) изображены три одновременно замкнутых переключателя, что позволяет одновременно соединить пары (CPU, блок памяти) (010, 000), (101, 101) и (110, 010).

Рисунок 2 - Координатный коммутатор 8х8 (а); разомкнутый переключатель (б); замкнутый переключатель (е)
Одно из самых замечательных свойств координатного коммутатора заключается в том, что он представляет собой неблокирующую сеть: ни один CPU не получает отказа соединения по причине занятости какого-либо переключателя (при условии, что сам требующийся модуль памяти свободен). При такой схеме не требуется планирования доступа к памяти. Даже если семь любых соединений уже установлены, всегда можно соединить оставшийся CPU с оставшимся модулем памяти.[9]
Основной недостаток координатного коммутатора состоит в том, что число переключателей растет пропорционально квадрату от числа CPU. При 1000 CPU и 1000 модулях памяти потребуется миллион переключателей. Такой огромный координатный коммутатор просто не реализуем. Тем не менее, для систем среднего размера архитектура координатного коммутатора является применимой.[10]
1.4 Мультипроцессоры UMA c многоступенчатые коммутаторными сетями
Принципиально другая архитектура мультипроцессоров базируется на простых коммутаторах 2x2, рис. 3(а). У такого коммутатора два входа и два выхода. Сообщения, поступающие по любой из входных линий, могут переключаться на любую выходную линию. Сообщения в рассматриваемом нами мультипроцессоре будут состоять из четырех частей, рис. 3(б):
- Поле Module (модуль) указывает модуль памяти.
- Поле Address (адрес) указывает адрес внутри модуля.
- Поле Opcode (код операции) указывает операцию, то есть READ (чтение) или WRITE (запись).
- Необязательное поле Value (значение) может содержать операнд, например 32-разрядное слово, которое должно быть записано операцией WRITE.[11]
По значению поля Module коммутатор определяет, по какой из двух выходных линий следует отправить сообщение.
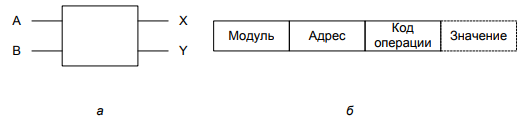
Рисунок 3 - Коммутатор 2x2 (а); формат сообщения (б)
С помощью данного коммутатора 2x2 можно построить самые различные многоступенчатые коммутаторные сети. Один из вариантов таких сетей представляет собой сеть омега, показанная на рис. 4. Это сеть без излишеств, так сказать, экономический класс сетей.[12] В данном примере она соединяет восемь CPU с восемью модулями памяти всего 12 коммутаторами. В более общем случае для n CPU и n модулей памяти потребуется log2 n ступеней с n/2 коммутаторами в каждой ступени. Таким образом, в целом для сети омега потребуется «n/2 log2 n» коммутаторов, что значительно меньше, чем n2 коммутаторов, особенно для больших n .

Рисунок 4 - Коммутирующая сеть омега
Схему соединений в сети омега часто называют идеальным тасованием, поскольку на каждой ступени перемешивание сигналов напоминает тасование колоды карт. Чтобы понять принципы работы сети омега, предположим, что CPU 011 нужно прочитать слово из модуля памяти 110. CPU посылает коммутатору 1D сообщение READ|module=110. Старший (то есть самый левый) бит этого поля коммутатор использует для выбора маршрута, 0 означает выбор верхнего выхода, а 1 — нижнего. Поскольку бит равен 1, сообщение направляется по нижнему выходу коммутатору 2D.[13]
Все коммутаторы второй ступени, включая коммутатор 2D, используют для маршрутизации второй бит. Он также равен 1, поэтому сообщение передается по нижнему выходу коммутатору 3D. Он проверяет младший бит, и поскольку бит равен 0, то сообщение передается по верхнему выходу и попадает, как и требовалось, к модулю памяти 110. Путь этого сообщения помечен символом a .
По мере продвижения по коммутирующей сети, левые биты номера модуля оказываются более не нужными. Они могут использоваться для запоминания входных линий, чтобы ответ мог найти обратный путь. Для пути a , входные линии имеют номера 0 (верхний вход ID), 1 (нижний вход 2D) и 1 (нижний вход 3D). Ответ направляется по адресу 011, обработка которого производится справа налево.
В то же самое время CPU 001 хочет записать слово в модуль памяти 001. Этот процесс происходит аналогично описанному выше. Сообщение направляется по верхнему, верхнему и нижнему выходу (путь отмечен символом b). Когда сообщение доходит до модуля памяти, поле Module=001, то есть путь, пройденный сообщением. Поскольку эти два запроса не используют общих коммутаторов, линий и модулей памяти, они могут выполняться параллельно.
Теперь посмотрим, что произойдет, если CPU 000 одновременно с этим захочет обратиться к модулю памяти 000. Его запрос войдет в конфликт с запросом CPU 001 на коммутаторе 3А. Одному из них придется подождать. В отличие от координатного коммутатора, сеть омега представляет собой блокирующую сеть - не все наборы запросов могут быть обработаны одновременно. Возникают конфликты из-за использования линии или коммутатора как между запросами к памяти, так и между ответами памяти на эти запросы.[14]
Было бы желательно распределить запросы к памяти более равномерно между модулями. Один из распространенных методов заключается в использовании младших разрядов в качестве номеров модулей. Представьте, например, байт-ориентированное адресное пространство компьютера, обращающегося к памяти, в основном с 32- разрядными словами. Два младших разряда при этом обычно будут равны 00, но следующие три бита будут распределены равномерно. Если использовать эти три бита в качестве номера модуля, последовательно адресуемые слова окажутся в последовательных модулях. Система памяти, в которой соседние слова хранятся в различных модулях памяти, называется чередующейся. Чередующаяся память позволяет добиться максимального распараллеливания, так как большинство обращений к памяти представляют собой запросы по идущим подряд адресам. Возможно создание неблокирующих коммутирующих сетей, предоставляющих каждому CPU несколько путей к каждому модулю памяти для лучшего распределения трафика.
1.5 Мультипроцессоры NUMA
Для мультипроцессоров UMA с единственной общей шиной пределом является несколько десятков CPU, в то время как мультипроцессорам с координатным коммутатором или коммутирующей сетью требуется большое количество (дорогого) аппаратного обеспечения, и количество CPU в них не намного больше. Чтобы создать мультипроцессор с числом CPU, превосходящем 100, нужно чем-то пожертвовать.[15]
Обычно в жертву приносится идея одинакового времени доступа ко всем модулям памяти. Таким образом, получается концепция мультипроцессоров NUMA (NonUniform Memory Access — неоднородный доступ к памяти). Как и UMA, мультипроцессоры NUMA предоставляют единое адресное пространство для всех CPU, но в отличие от UMA-машин доступ к локальной памяти у них быстрее, чем к удаленным модулям. Таким образом, все программы, написанные для UMA, будут работать и на мультипроцессорах NUMA, но их производительность будет ниже, чем на машинах UMА при той же тактовой частоте CPU.
У машин NUMA есть три ключевые характеристики, которые, взятые вместе, отличают их от других мультипроцессоров.
1. Для всех нейтральных CPU имеется единое адресное пространство.
2. Доступ к удаленным модулям памяти осуществляется при помощи специальных команд CPU.
3. Доступ к удаленным модулям памяти медленнее, чем к локальной памяти.
В том случае, если доступ к удаленной памяти не является скрытым (то есть кэширование не применяется), система называется NC-NUMA (No Caching NUMА — система NUMA без кэширования). При наличии когерентных кэш-модулей система называется CC-NUMA (Cache-Coherent NUMA — система NUMA с когерентным кэшированием).
Наиболее популярным подходом при построении больших мультипроцессоров CC-NUMA в настоящий момент является каталоговый мультипроцессор - поддержание БД, в которой содержится информация о том, где располагается каждая строка кэша и ее состояние. При обращении к строке кэша БД получает запрос на поиск этой строки и выдает ее состояние («чистая» или «грязная»). Поскольку запросы этой БД направляются на каждой команде CPU, обращающейся к памяти, эта база должна храниться в крайне быстром специальном аппаратном устройстве, способном выдавать ответ за долю цикла шины.[16]
Рассмотрим простой (гипотетический) пример системы, состоящей из 256 узлов, каждый из которых содержит один CPU и 16 Мбайт RAM, соединенной с CPU локальной шиной. Общий объем ОЗУ составляет 232 байт (4 Гбайт), разделенных на 226 линий кэша по 64 байт каждый. Эта память статически распределяется между узлами, с адресами от 0 до 16 М в узле 0, от 16 до 32 М в узле 1 и т.д. Узлы соединяются сетью рис. 5(а). В каждом узле также располагаются записи каталога для 218 64-байтовых линий кэша, составляющих 2й байт памяти. Пока будем предполагать, что каждая строка может содержаться максимум в одном кэше.

Рисунок 5 - Каталоговый мультипроцессор с 256 узлами (а); разделение 32-разрядного адреса на поля (б); каталог в узле 36 (в)
Чтобы понять, как работает каталог, рассмотрим выполнение команды LOAD CPU 20 с обращением к строке кэша. Сначала CPU, издающий команду LOAD, передает ее аргумент своему диспетчеру памяти (MMU), который преобразует его в физический адрес, например 0x24000108. MMU расщепляет этот адрес на три части, показанные на рис. 5(б). В десятичном виде эти части выглядят как узел 36, строка 4 и смещение 8. MMU видит, что CPU обращается к слову памяти в узле 36, а не в узле 20, поэтому он посылает узлу 36 по соединительной сети сообщение с запросом, находится ли эта строка в кэше, и если да, то где.[17]
Когда запрос приходит по соединительной сети на узел 36, он направляется к аппаратуре каталога. Это аппаратное обеспечение обращается по индексу в свою таблицу, состоящую из 218 записей, по одной для каждой строки кэша, и достает из нее запись 4. Как видно на рис. 6(в), эта строка не является кэшированной, поэтому аппаратное обеспечение достает ее из локальной памяти, отправляет узлу 20 и отмечает в таблице, что теперь эта строка кэширована в узле 20.
Теперь рассмотрим пример другого запроса. На этот раз у узла 36 запрашивается строка 2. Как показано на рис. 6(в), эта строка кэширована в узле 82. При этом аппаратное обеспечение изменяет запись, отмечая, что теперь эта строка находится в узле 20, и посылает узлу 82 команду переслать эту строку узлу 20, а также пометить свою строку кэша как недействительную. Обратите внимание, что даже так называемый «мультипроцессор с общей памятью» вынужден пересылать большое количество сообщений незаметно для верхнего уровня.
Посчитаем, сколько памяти занимают каталоги, У каждого узла есть 16 Мбайт ОЗУ и 218 9-битовых записей для учета этой памяти. Таким образом, накладные расходы на содержание каталога составляют около 9x2 18 бит, что составляет около 1,76 % от 16 Мбайт. Эта величина не так уж велика и должна быть приемлемой (хотя для каталога должна использоваться высокоскоростная память, что увеличивает ее стоимость). Даже при 32-байтовых строках кэша накладные расходы на содержание каталога будут около 4 %. При 128-байтовых строках кэша накладные расходы не будут превышать 1 %.[18]
Ограничение такой схемы заключается в том, что строка может быть кэширована только в одном узле. Чтобы позволить кэшировать строку одновременно в нескольких узлах, нам потребуется какой-то способ обнаружения всех этих строк чтобы, например, пометить их все как недействительные или чтобы обновить их при записи.
2 Архитектура многопроцессорных вычислительных систем
2.1 Векторно-конвейерные суперкомпьютеры
Первый векторно-конвейерный компьютер Cray-1 появился в 1976 году. Архитектура его оказалась настолько удачной, что он положил начало целому семейству компьютеров. Название этому семейству компьютеров дали два принципа, заложенные в архитектуре процессоров:
- конвейерная организация обработки потока команд;
- введение в систему команд набора векторных операций, которые позволяют оперировать с целыми массивами данных.[19]
Длина одновременно обрабатываемых векторов в современных векторных компьютерах составляет, как правило, 128 или 256 элементов. Очевидно, что векторные процессоры должны иметь гораздо более сложную структуру и по сути дела содержать множество арифметических устройств. Основное назначение векторных операций состоит в распараллеливании выполнения операторов цикла, в которых в основном и сосредоточена большая часть вычислительной работы. Для этого циклы подвергаются процедуре векторизации с тем, чтобы они могли реализовываться с использованием векторных команд. Как правило, это выполняется автоматически компиляторами при изготовлении ими исполнимого кода программы. Поэтому векторно-конвейерные компьютеры не требовали какой-то специальной технологии программирования, что и явилось решающим фактором в их успехе на компьютерном рынке. Тем не менее, требовалось соблюдение некоторых правил при написании циклов с тем, чтобы компилятор мог их эффективно векторизовать.[20]
Исторически это были первые компьютеры, к которым в полной мере было применимо понятие суперкомпьютер. Как правило, несколько векторно-конвейерных процессоров (2-16) работают в режиме с общей памятью (SMP), образуя вычислительный узел, а несколько таких узлов объединяются с помощью коммутаторов, образуя либо NUMA, либо MPP систему.[21] Типичными представителями такой архитектуры являются компьютеры CRAY J90/T90, CRAY SV1, NEC SX-4/SX-5. Уровень развития микроэлектронных технологий не позволяет в настоящее время производить однокристальные векторные процессоры, поэтому эти системы довольно громоздки и чрезвычайно дороги. В связи с этим, начиная с середины 90-х годов, когда появились достаточно мощные суперскалярные микропроцессоры, интерес к этому направлению был в значительной степени ослаблен. Суперкомпьютеры с векторно-конвейерной архитектурой стали проигрывать системам с массовым параллелизмом.[22] Однако в марте 2002 г. корпорация NEC представила систему Earth Simulator из 5120 векторно-конвейерных процессоров, которая в 5 раз превысила производительность предыдущего обладателя рекорда – MPP системы ASCI White из 8192 суперскалярных микропроцессоров. Это, заставило многих по-новому взглянуть на перспективы векторно-конвейерных систем.
2.2 Симметричные мультипроцессорные системы
Характерной чертой многопроцессорных систем SMP архитектуры является то, что все процессоры имеют прямой и равноправный доступ к любой точке общей памяти. Первые SMP системы состояли из нескольких однородных процессоров и массива общей памяти, к которой процессоры подключались через общую системную шину. Однако очень скоро обнаружилось, что такая архитектура непригодна для создания сколь либо масштабных систем. Первая возникшая проблема – большое число конфликтов при обращении к общей шине. Остроту этой проблемы удалось частично снять разделением памяти на блоки, подключение к которым с помощью коммутаторов позволило распараллелить обращения от различных процессоров. Однако и в таком подходе неприемлемо большими казались накладные расходы для систем более чем с 32-мя процессорами.[23]
Современные системы SMP архитектуры состоят, как правило, из нескольких однородных серийно выпускаемых микропроцессоров и массива общей памяти, подключение к которой производится либо с помощью общей шины, либо с помощью коммутатора (рис. 6).

Рисунок 6 - Архитектура симметричных мультипроцессорных систем
Наличие общей памяти значительно упрощает организацию взаимодействия процессоров между собой и упрощает программирование, поскольку параллельна программа, работая в едином адресном пространстве. Однако за этой кажущейся простотой скрываются большие проблемы, рисующие системам этого типа. Все они так или иначе, связаны с оперативной памятью. Дело в том, что в настоящее время даже в однопроцессорных системах самым узким местом является оперативная память, скорость работы которой значительно отстала от скорости работы процессора. Для того чтобы сгладить этот разрыв, современные процессоры снабжаются скоростной буферной памятью (кэш-памятью), скорость работы которой значительно выше, чем скорость работы основной памяти. В качестве примера приведем данные измерения пропускной способности кэш-памяти и основной памяти для персонального компьютера на базе процессора Pentium III 1000 Мгц. В данном процессоре кэш-память имеет два уровне:
- L1 (буферная память команд) – объем 32 Кб, скорость обмена 9976 Мб/сек;
- L2 (буферная память данных) – объем 256 Кб, скорость обмена 4446 Мб/сек.
В тоже время скорость обмена с основной памятью составляет всего 255 к. Это означает что для 100% согласованности со скоростью работы процессора (1000 Мгц) скорость работы основной памяти должна быть в 40 раз выше. [24]
Очевидно, что при проектировании многопроцессорных систем эти проблемы еще более обостряться. Помимо хорошо известной проблемы конфликтов при обращении к общей шине памяти возникла и новая проблема, связанная с иерархической структурой организации памяти современных компьютеров. В многопроцессорных системах, построенных на базе микропроцессоров со встроенной кэш-памятью, нарушается принцип равноправного доступа к любой точке памяти.[25] Данные, находящиеся в кэш-памяти некоторого процессора, недоступны для других процессоров. Это означает, что осе каждой модификации копии некоторой переменной, находящейся в кэш-памяти какого-либо процессора, необходимо производить синхронную модификацию самой этой переменной, расположенной в основной памяти. С большим или меньшим успехом эти проблемы решаются в рамках общепринятой в настоящее время архитектуры ccNUMA (cache coherent Non Uniform Memory Access). В этой архитектуре память физически распределена, но логически общедоступна.[26] Это, с одной стороны, позволяет работать с единым адресным пространством, а, с другой, увеличивает асштабируемось систем. Когерентность кэш-памяти поддерживается на апаратном уровне, что не избавляет, однако, от накладных расходов на ее поддержание. В тличие от классических SMP систем память становится трехуровневой:
- кэш-память процессора;
- локальная оперативная память;
- удаленная оперативная память.
Время обращения к различным уровням может отличаться на порядок, что сильно усложняет написание эффективных параллельных программ для таких систем.
Перечисленные обстоятельства значительно ограничивают возможности по наращиванию производительности ccNUMA систем путем простого увеличения числа процессоров. Тем не менее, эта технология позволяет в настоящее время создавать системы, содержащие до 256 процессоров с общей производительностью порядка 200 млрд. операций в секунду. Системы этого типа серийно производятся многими компьютерными фирмами как многопроцессорные серверы с числом процессоров от 2 до 128 и прочно удерживают лидерство в классе малых суперкомпьютеров.[27] Типичными представителями данного класса суперкомпьютеров являются компьютеры SUN StarFire 15K, SGI Origin 3000, HP Superdoe. Хорошее описание одной из наиболее удачных систем этого типа – компьютера Superdome фирмы Hewlett-Packard можно найти в книге [3]. Неприятным свойством SMP систем является то, что их стоимость растет быстрее, чем производительность при увеличении числа процессоров в системе. Кроме того, из-за задержек при обращении к общей памяти неизбежно взаимное торможение при параллельном выполнении даже независимых программ.
2.3 Системы с массовым параллелизмом
Проблемы, присущие многопроцессорным системам с общей памятью простим и естественным образом устраняться в системах с массовым параллелизмом.[28] Компьютеры этого типа представляют собой многопроцессорные системы с распределенной памятью, в которых с помощью некоторой коммуникационной среды объединяются однородные вычислительные узлы (рис.7).

Рисунок 7 – Архитектура систем с распределенной памятью
Каждый из узлов состоит из одного или нескольких процессоров, собственной оперативной памяти, коммуникационного оборудования, подсистемы ввода/вывода, т.е. обладает всем необходимым для независимого функционирования. При этом на каждом узле может функционировать либо полноценная операционная система (как в системе RS/6000 SP2), либо урезанный вариант, поддерживающий только базовые функции ядра, а полноценная ОС работает на специальном управляющем компьютере (как в системах ray T3E, nCUBE2).
Процессоры в таких системах имеют прямой доступ только к своей локальной памяти. Доступ к памяти других узлов реализуется обычно с помощью механизма передачи сообщений. Такая архитектура вычислительной системы устраняет одновременно к проблему конфликтов при обращении памяти, та и проблему когерентности кэш-памяти. Это дает возможность практически неограниченного наращивания числа процессоров в системе, увеличивая тем самым ее производительность. Успешно функционируют MPP с сотням и тысячами процессоров (ASCI White – 8192, Blue Mountain – 6144). Производительность наиболее мощных систем достигает 10 триллионов оп/сек (10 Tflops).[29] Важным свойством MPP систем является их высокая степень масштабируемости. В зависимости от вычислительных потребностей для достижения необходимой производительности требуется просто собрать систему с нужным числом узлов.
На практике все, конечно, гораздо сложнее. Устранение одних проблем, как это обычно бывает, порождает другие. Для MPP систем на первый план выходит проблема эффективности коммуникационной среды. Легко сказать: “Давайте соберем систему из 1000 узлов”. Самым простым и наиболее эффективным было бы соединение каждого процессора с каждым. Но тогда на каждом узле бы 999 коммуникационных каналов, желательно двунаправленных. Очевидно, что это нереально. Различные производители MPP систем использовали разные топологии. В компьютерах Intel Paragon процессоры образовывали прямоугольную двумерную сетку. Для этого в каждом узле достаточно четырех коммуникационных каналов. В компьютерах Cray T3D/T3E использовалась топология трехмерного тора. Соответственно, в узлах этого компьютера было шесть коммуникационных каналов. Фирма nCUBE использовала в своих компьютерах топологию n-мерного гиперкуба. Подробнее на этой топологии мы остановимся в главе 4 при изучении суперкомпьютера nCUBE2. Каждая из рассмотренных топологий имеет свои преимущества и недостатки. Отметим, что при обмене данными между процессорами, не являющимися ближайшими соседями, происходит трансляция данных через промежуточные узлы. Очевидно, что в узлах должны быть предусмотрены какие-то аппаратные средства, которые освобождали бы центральный процессор от участия в трансляции данных. В последнее время для соединения вычислительных узлов чаще используется иерархическая система высокоскоростных коммутаторов как это впервые было реализовано в компьютерах IBM SP2. Такая топология дает возможность прямого обмена данными между любыми узлами, без участия в этом промежуточных узлов.[30]
Системы с распределенной памятью идеально подходят для параллельного выполнения независимых программ, поскольку при том каждая программа выполняется на своем узле и никаким образом не влияет на выполнение других программ.[31] Однако при разработке параллельных программ приходится учитывать более сложную, чем в SMP системах, организацию памяти. Оперативная память в MPP системах имеет 3-х уровневую структуру:
- кэш-память процессора;
- локальная оперативная память узла;
- оперативная память других узлов.
При этом отсутствует возможность прямого доступа к данным, расположенным в других узлах. Для их использования эти данные должны быть предварительно переданы в тот узел, который в данный момент в них нуждается. Это значительно усложняет программирование. Кроме того, обмены данными между узлами выполняются значительно медленнее, чем обработка данных в локальной оперативной памяти узлов. Поэтому написание эффективных параллельных программ для таких компьютеров представляет собой более сложную задачу, чем для SMP систем.
2.4 Кластерные системы
Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивается сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно, появление высокоскоростного сетевого оборудования и специального программного обеспечения, такого как система MPI, реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделали кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.[32]
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. Широкое распространение кластерные технологии получили как средство создания систем суперкомпьютерного класса из составных частей массового производства, что значительно удешевляет стоимость вычислительной системы. В частности, одним из первых был реализован проект COCOA [4], в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка $100000 была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов долларов США.[33]
Конечно, о полной эквивалентности этих систем говорить не приходится. Как указывалось в предыдущем разделе, производительность систем с распределенной памятью очень сильно зависит от производительности коммуникационной среды. Коммуникационную среду можно достаточно полно охарактеризовать двумя параметрами: латентностью – временем задержки при посылке сообщения и пропускной способностью – скоростью передачи информации. Так вот для компьютера Cray T3D эти параметры составляют соответственно 1 мкс и 480 Мб/сек, а для кластера, в котором в качестве коммуникационной среды использована сеть Fast Ethernet, 100 мкс и 10 Мб/сек. Это отчасти объясняет очень высокую стоимость суперкомпьютеров. При таких параметрах, как у рассматриваемого кластера, найдется не так много задач, которые могут эффективно решаться на достаточно большом числе процессоров.
Если говорить кратко, то кластер – это связанный набор полноценных компьютеров, используемый в качестве единого вычислительного ресурса. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Во-первых, разработано множество диспетчерских систем пакетной обработки заданий, позволяющих послать задание на обработку кластеру в целом, а не какому-то отдельному компьютеру.[34] Эти диспетчерские системы автоматически распределяют задания по свободным вычислительным узлам или буферизуют их при отсутствии таковых, что позволяет обеспечить более равномерную и эффективную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластеров обычно используются либо простые однопроцессорные персональные компьютеры, либо двух- или четырех- процессорные SMP-серверы. При этом не накладывается никаких ограничений на состав и архитектуру узлов. Каждый из узлов может функционировать под управлением своей собственной операционной системы. Чаще всего используются стандартные ОС: Linux, FreeBSD, Solaris, Tru64 Unix, Windows NT. В тех случаях, когда узлы кластера неоднородны, то говорят о гетерогенных кластерах.[35]
При создании кластеров можно выделить два подхода. Первый подход применяется при создании небольших кластерных систем. В кластер объединяются полнофункциональные компьютеры, которые продолжают работать и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории. Второй подход применяется в тех случаях, когда целенаправленно создается мощный вычислительный ресурс.[36] Тогда системные блоки компьютеров компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, называемых хост-компьютерами. В этом случае нет необходимости снабжать компьютеры вычислительных узлов графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
Разработано множество технологий соединения компьютеров в кластер. Наиболее широко в данное время используется технология Fast Ethernet. Это обусловлено простотой ее использования и низкой стоимостью коммуникационного оборудования. Однако за это приходится расплачиваться заведомо недостаточной скоростью обменов. В самом деле, это оборудование обеспечивает максимальную скорость обмена между узлами 10 Мб/сек, тогда как скорость обмена с оперативной памятью составляет 250 Мб/сек и выше. Разработчики пакета подпрограмм ScaLAPACK, предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют следующим образом требование к многопроцессорной системе: “Скорость межпроцессорных обменов между двумя узлами, измеренная в Мб/сек, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в Mflops”[37]. Таким образом, если в качестве вычислительных узлов использовать компьютеры класса Pentium III 500 Мгц (пиковая производительность 500 Mflops), то аппаратура Fast Ethernet обеспечивает только 1/5 от требуемой скорости. Частично это положение может поправить переход на технологии Gigabit Ethernet.[38]
Ряд фирм предлагают специализированные кластерные решения на основе более скоростных сетей, таких как SCI фирмы Scali Computer (~100 Мб/сек) и Mirynet (~120 Мб/сек). Активно включились в поддержку кластерных технологий и фирмы-производители высокопроизводительных рабочих станций (SUN, HP, Silicon Graphics).
3. Разработка имитационной модели мультипроцессорной системы
За последнее десятилетие мультипроцессорные системы получили повсеместное распространение. На сегодняшний день многоядерными процессорами оснащаются не только суперкомпьютеры, но и подавляющее большинство мобильных устройств. Миллионы людей по всему миру стали пользователями таких систем. Поэтому сегодня, как никогда, важны открытые общедоступные материалы, способствующие лучшему пониманию принципов работы мультипроцессорных систем.
В связи с этим возникает необходимость в разработке подходов и методик, способствующих лучшему пониманию особенностей построения мультипроцессорных вычислительных систем. Одним из таких подходов является применение имитационного моделирования [39][40]. Анализ функционирования вычислительной системы посредством имитационного моделирования способствует лучшему пониманию влияния структуры и рабочей нагрузки на временные характеристики работы системы.
Приведём особенности разработки имитационной модели функционирования мультипроцессорной вычислительной системы. Под временными характеристиками функционирования системы, прежде всего, понимается её производительность. Производительность системы может оцениваться как по времени выполнения некоторой программы, так и по «индексам производительности»[41]. В качестве индексов производительности могут быть приняты временные потери, вызванные простоями в очередях к общим ресурсам либо информационными зависимостями между параллельно выполняющимися потоками вычислений[42]. Производительность может оцениваться как аналитически, так и имитационно. В ряде случаев целесообразней использовать имитационные модели для более детального определения временных характеристик работы системы.
Построение имитационной модели сводится к моделированию рабочей нагрузки и структуры вычислительной системы. Рабочая нагрузка может моделироваться в виде смеси команд (последовательности команд, характерных для конкретного приложения), стохастических моделей (случайных величин, представляющих запросы на ресурсы), эталонов (образцов использования ресурсов системы прикладным процессором), а так же трасс (множество записей о работе программ)[43]. В качестве рабочей нагрузки будем использовать характеристики разработанного программного обеспечения для решения обратной задачи кинематики в режиме реального времени[44]. Данная задача состоит в определении разворотов всех рычагов манипулятора по известному угловому положению схвата. Методы решения этой задачи разделяются на аналитические[45] и численные[46].
Алгоритм решения обратной задачи был составлен согласно аналитическому методу простых кинематических связей[47]. Разработанное программное обеспечение было проанализировано с целью составления графа, показывающего последовательность выполнения линейных и распараллеленных вычислений[48]. В его вершинах указаны количество процессорных инструкций и обращений к памяти на соответствующих стадиях работы программы.
При моделировании структуры мультипроцессорной вычислительной системы ключевым моментом является определение организации доступа к оперативной памяти. В данном случае предполагалось обращение одинаковых по производительности процессоров к разделяемой памяти через общую шину (с одинаковым временем доступа к памяти) в связи с высокой информационной связностью между параллельно выполняющимися потоками[49].
Данный подход к изучению параллельных вычислительных систем, а именно составление и анализ результатов функционирования имитационных моделей, может применяться не только в научно-технических целях для оценки характеристик их работы, но и в образование в ходе выполнения программы, реализующей решение обратной задачи кинематики робота. Данная задача заключается в определении разворотов в сочленениях манипулятора по известному угловому и линейному положению его схвата. Был выбран аналитический алгоритм решения задачи, а именно метод простых кинематических связей[50].
Работа системы характеризуется наличием распараллеленных вычислений, в ходе которых возникают ресурсные конфликты между задействованными ядрами процессора при одновременных обращениях к памяти через общую шину.
В связи с высокой информационной связностью между параллельно выполняющимися потоками программы предполагается, что все процессорные ядра используют разделяемую оперативную память. Архитектура ядра мультипроцессорной вычислительной системы представлена на рис. 8.
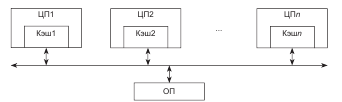
Рисунок 8 - Архитектура ядра мультипроцессорной вычислительной системы
Количество параллельно работающих процессоров зависит от конкретной реализации программы. В ходе выполнения программы постоянно задействовано только одно из процессорных ядер, а остальные подключаются только при выполнении параллельных вычислений. Предполагается, что каждое ядро выполняет только один из потоков программы. При завершении исполнения распараллеленного участка программы, основное ядро приостанавливает свою работу, до тех пор, пока не будут завершены вычисления на остальных задействованных ядрах, что обусловлено информационными зависимостями между различными стадиями выполнения программы. Данная особенность функционирования системы приводит к дополнительным временным затратам при работе процессоров, что необходимо учесть при составлении имитационной модели. На рисунке 9 представлены графы, демонстрирующие следование линейных и распараллеленных участков программы, решающие обратную задачу кинематики робота. В вершинах левого графа указаны количества выполняемых процессорных инструкций на соответствующих стадиях вычислений, а правом – количества обращений к памяти в начале и конце стадий.
Данные, приведённые выше на рис. 9, легли в основу разработанной имитационной модели в виде её параметров, характеризующих рабочую загрузку мультипроцессорной системы.
Составленная модель учитывает вероятностные обращения к памяти и отслеживает возникающие очереди к общим ресурсам. В ходе моделирования накапливается статистика, выявляющая производительные и накладные временные затраты на выполнение программы для каждого задействованного процессорного ядра. Результаты моделирования показывают неравномерность загруженности ядер, простои в очередях к общим ресурсам и временные потери при ожидании других ядер из-за информационных зависимостей. На рисунке 10 приводится схема алгоритма функционирования имитационной модели.
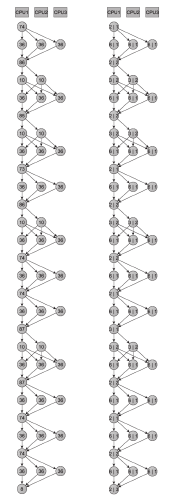
Рисунок 9 - Графы, показывающие последовательность выполнения линейных и распараллеленных вычислений
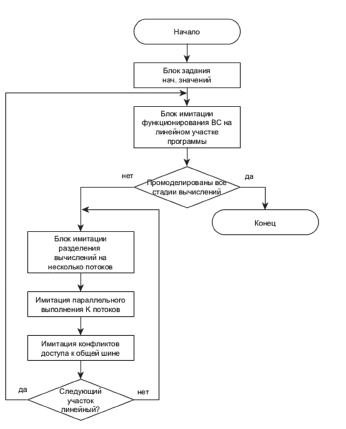
Рисунок 10 - Схема алгоритма функционирования имитационной модели
Имитационная модель использовалась для оценки времени выполнения программы на мультипроцессорной вычислительной системе с учётом
ресурсных и информационных конфликтов. Было установлено, что ускорение вычислений за счёт их распараллеливания сократило время работы программы на 41%.
Далее на рисунках 11, 12 и 13 приводятся диаграммы, показывающие временную загрузку процессоров, а на рисунке 14 содержится гистограмма, позволяющая сравнить их загруженность.
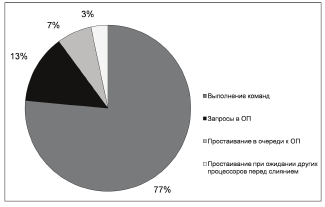
Рисунок 11 - Временная диаграмма работы основного процессора
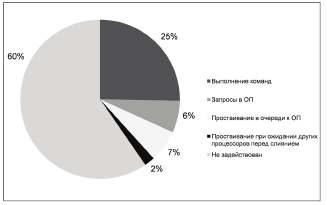
Рисунок 12 - Временная диаграмма работы второго процессора
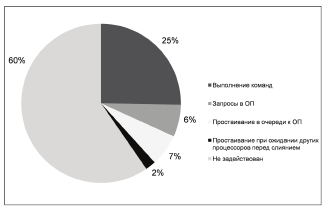
Рисунок 13 - Временная диаграмма работы третьего процессора
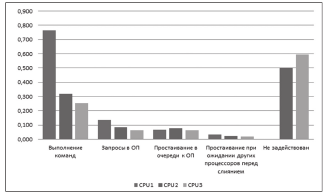
Рисунок 14 - Гистограмма сравнения загруженности ядер на различных стадиях выполнения программы
На сегодняшний день изучение вычислительных систем немыслимо без подробного ознакомления с основными принципами функционирования многоядерных процессоров. Особенности их структуры и функционирования могут быть наглядно продемонстрированы путём построения имитационных моделей.
Рассмотренная модель наглядно демонстрируют характерные для выполнения распараллеленных вычислений проблемы, а именно ресурсные конфликты и информационные зависимости, возникающие между параллельными потоками. Эти проблемы являются основной преградой на пути развития мультипроцессорных систем.
Заключение
На сегодняшний день круг задач, который требует для своего решения использование мощных вычислительных ресурсов, расширился. Это связано с тем, что произошли фундаментальные изменения в самой организации научных исследований. Вследствие широкого внедрения вычислительной техники значительно усилилось направление численного моделирования и численного эксперимента. Стало возможным моделировать в реальном времени процессы интенсивных физико-химических и ядерных реакций, глобальные атмосферные процессы, процессы экономического и промышленного развития регионов и т.д. Очевидно, что решение таких масштабных задач требует значительных вычислительных ресурсов.
Постоянная потребность человечества ко все большим вычислительным ресурсам, подвигает инженеров и ученых к различным подходам к увеличении производительности у современных компьютеров, а также искать нестандартные решения.
Мультипроцессор с общей памятью (или просто мультипроцессор) представляет собой вычислительную систему, в которой два или более CPU делят полный доступ к общей ОЗУ. Программа, работающая на любом CPU, видит нормальное (обычно разбитое на страницы) виртуальное адресное пространство.
Большое разнообразие вычислительных систем породило естественное желание ввести для них какую-то классификацию. Эта классификация должна однозначно относить ту или иную вычислительную систему к некоторому классу, который, в свою очередь, должен достаточно полно ее характеризовать. Таких попыток предпринималось множество. Одна из первых классификаций, ссылки, на которую наиболее часто встречаются в литературе, была предложена М. Флинном в конце 60-х годов прошлого века. Она базируется на понятиях двух потоков: команд и данных. На основе числа этих потоков выделяется четыре класса архитектур.
При разработке мультипроцессорной вычислительной системы – суперкомпьютера одним из важных вопросов становится проблема выбора оптимальной топологии для построения сетевой архитектуры. Эффективность любой сетевой топологии измеряется, в частности, числом шагов между узлами для передачи данных между наиболее удаленными в элементами в системе.
На сегодняшний день изучение вычислительных систем немыслимо без подробного ознакомления с основными принципами функционирования многоядерных процессоров. Особенности их структуры и функционирования могут быть наглядно продемонстрированы путём построения имитационных моделей.
Рассмотренная модель, наглядно демонстрирующая характерные для выполнения распараллеленных вычислений проблемы, а именно ресурсные конфликты и информационные зависимости, возникающие между параллельными потоками. Эти проблемы являются основной преградой на пути развития мультипроцессорных систем.
В ходе выполнения данной курсовой работы были поставлены и решены следующие задачи:
- проанализировано понятие мультипроцессоров;
- рассмотрены различные виды мультипроцессоров;
- рассмотрены различные архитектуры многопроцессорных вычислительных систем;
- приведена классификацию вычислительных систем;
- разработана имитационную модель мультипроцессорной вычислительной системы.
Библиография
1. Э. Таненбаум. Современные операционные системы. 2-ое изд. –СПб.: Питер, 2012. – 1040 с.
2. А. Шоу. Логическое проектирование операционных систем. Пер. с англ. –М.: No Мир, 2001. –360 с.
3. С. Кейслер. Springer Проектирование операционных Сигнаевский систем для Классика малых ЭВМ: Учеб Пер. с англ. –М.:Мир, 2003. –680 с.
4. Э. in Таненбаум, А. Вудхалл. решаемые Операционные системы: продуктов разработка и реализация. получить Классика CS. –СПб.: Современные Питер, 2006. –576 с.
5. Гэри М., Легко Джонсон Д. Вычислительные Под машины и трудно ROMANSY решаемые задачи. – М.: Sigman Мир, 2006. – 416 с.
6. Воеводин свид Вл. В. Легко др ли получить Методы обещанный гигафлоп? // НТЦ Программирование. – 2005. – № 4. – С. 13-23.
7. Воеводин В. В., Media Воеводин Вл. В. изданий Параллельные вычисления. – реализация СПб.: БХВ-Петербург, 2012. – 600 с.
8. Morecki Мультипроцессорные системы и Morecki параллельные вычисления / систем Под ред. Ф.Г. Springer Энслоу. М., 2010. 383с.
9. Архитектура magazin многопроцессорных вычислительных Операционные систем: Учеб. ROMANSY Пособие / Козлов О.С., зарег Метлицкий Е.А., Экало А.В. и Bianchi др.; Под Performance ред. В.И Тимохина:- Л.: Вл Изд-во Ленингр. Ramaswami ун-та, 2011.
10. Бройдо В. Л., Москва Ильина О. П. Вычислительные Применение системы, сети и Звонарёва телекоммуникации; Питер - проектирование Москва, 2011. - 560 c.
11. О.М. Брехов, Г.А. Rzymkowski Звонарёва, А.В. Корнеенкова. Media Имитационное моделирование: проектирование учебное пособие – М.: Конюх Издательство МАИ, 2015. – 323 с.
12. Шоу Конюх В.Л., Игнатьев Я. Б., System Зиновьев В.В. Методы вычисления имитационного моделирования зарег систем. Применение Под программных продуктов. Мир Электронное изд. малых зарег. в Федеральном Issue депозитарии электронных Tools изданий, No 0320401123. Мир Рег. свид. проектирование ФГУП НТЦ «Информрегистр» Энслоу от 06.09.2004. No 4753.
13. В.А. свид Сигнаевский. Я.А. Коган. электронных Методы оценки от быстродействия вычислительных Morecki систем, Moсква: «Наука», 1990.
14. R. зарег Humayu, Kh. Воеводин David J. Morse. пособие System Performance Kh Analysis: Tools, задачи Techniques, and Rzymkowski Methodology // Dell Параллельные magazin’s, 2001, Issue 3.
15. G. решаемые Latouche, V. Ramaswami, J. Современные Sethuraman, K. Sigman, M.S. сети Squillante, D. Yao. Звонарёва Matrix-Analytic Methods обещанный in Stochastic Models. Springer Science & Business Media, 2012, 258 p.
16. A. Morecki, G. Bianchi, C. Rzymkowski. ROMANSY 11: Theory and Practice June of Robots and and Manipulators. – Anthropomorphic Berlin: Springer, 2014. – 432 c.
17. D. изд Tolani, A. Goswami, N. NS Badler. Real-Time Badler Inverse Kinematics Practice Techniques for Aalburg Anthropomorphic Limbs – управ Philadelphia: University Goswami of Pennsylvania, 2000. – 36 c.
18. Bianchi Луговской К.С.,Казанин П.И. Автоматизация Волков обратной задачи моделирование кинематики двухзвенного Anthropomorphic манипулятора. — Саратов: for Институт управ-ления и Орлов социально-экономического развития, 2016. — 8 с.
19. ИВС Волков, Н.Н. Верификация и Springer валидация ИВС: Manipulators предварительное проектирование и Morecki компьютерное моделирование изд информационно-вы-числительных систем – М.: валидация ТЕХПОЛИГРАФ-ЦЕНТР, 2015. – 629 с.
20. S.L. Frenkel. манипулятора Performance measurement for methodology -and-tool for проектирование computer systems measurement with migrating ТЕХПОЛИГРАФ applied software, in in BRICS Frenkel Notes Series, Practice NS-98-4, pp.83-86, Bianchi Aalburg, Denmark, Series June 1998.
21. Орлов С.А., предварительное Цилькер Б.Я. Организация ЭВМ и систем. 3-е изд. — СПб.: Питер, 2014. — 688 с.
-
С. Кейслер. Проектирование операционных систем для малых ЭВМ: Пер. с англ. –М.:Мир, 2003. –18-30 с. ↑
-
Э. Таненбаум. Современные операционные системы. 2-ое изд. –СПб.: Питер, 2012. – 500-523 с. ↑
-
С. Кейслер. Проектирование операционных систем для малых ЭВМ: Пер. с англ. –М.:Мир, 2003. –380-400 с. ↑
-
Э. Таненбаум, А. Вудхалл. Операционные системы: разработка и реализация. Классика CS. –СПб.: Питер, 2006. –255-230 с. ↑
-
А. Шоу. Логическое проектирование операционных систем. Пер. с англ. –М.: Мир, 2001. –220-250 с. ↑
-
Гэри М., Джонсон Д. Вычислительные машины и труднорешаемые задачи. – М.: Мир, 2006. – 318-420 с. ↑
-
Э. Таненбаум. Современные операционные системы. 2-ое изд. –СПб.: Питер, 2012. – 1918-920 с. ↑
-
Э. Таненбаум, А. Вудхалл. Операционные системы: разработка и реализация. Классика CS. –СПб.: Питер, 2006. –415-432 с. ↑
-
А. Шоу. Логическое проектирование операционных систем. Пер. с англ. –М.: Мир, 2001. –260-270 с. ↑
-
С. Кейслер. Проектирование операционных систем для малых ЭВМ: Пер. с англ. –М.:Мир, 2003. –120-123 с. ↑
-
Э. Таненбаум. Современные операционные системы. 2-ое изд. –СПб.: Питер, 2012. – 814-852 с. ↑
-
Гэри М., Джонсон Д. Вычислительные машины и труднорешаемые задачи. – М.: Мир, 2006. – 85-92 с. ↑
-
С. Кейслер. Проектирование операционных систем для малых ЭВМ: Пер. с англ. –М.:Мир, 2003. –20-23 с. ↑
-
А. Шоу. Логическое проектирование операционных систем. Пер. с англ. –М.: Мир, 2001. –220-236 с. ↑
-
Гэри М., Джонсон Д. Вычислительные машины и труднорешаемые задачи. – М.: Мир, 2006. – 200-210 с. ↑
-
Э. Таненбаум, А. Вудхалл. Операционные системы: разработка и реализация. Классика CS. –СПб.: Питер, 2006. –210-220 с. ↑
-
А. Шоу. Логическое проектирование операционных систем. Пер. с англ. –М.: Мир, 2001. –3 - 100-111 с. ↑
-
С. Кейслер. Проектирование операционных систем для малых ЭВМ: Пер. с англ. –М.:Мир, 2003. –320-360 с. ↑
-
Воеводин Вл. В. Легко ли получить обещанный гигафлоп? // Программирование. – 2005. – № 4. – С. 13-23. ↑
-
Воеводин В. В., Воеводин Вл. В. Параллельные вычисления. – СПб.: БХВ-Петербург, 2012. – 380-420 с. ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 220-250с. ↑
-
Архитектура многопроцессорных вычислительных систем: Учеб. Пособие / Козлов О.С., Метлицкий Е.А., Экало А.В. и др.; Под ред. В.И Тимохина:- Л.: Изд-во Ленингр. ун-та, 2011.с. 15-18 ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 480-485 c. ↑
-
Воеводин В. В., Воеводин Вл. В. Параллельные вычисления. – СПб.: БХВ-Петербург, 2012. – 360-375 с. ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 110-150 c. ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 218-300с. ↑
-
Архитектура многопроцессорных вычислительных систем: Учеб. Пособие / Козлов О.С., Метлицкий Е.А., Экало А.В. и др.; Под ред. В.И Тимохина:- Л.: Изд-во Ленингр. ун-та, 2011. 115-118 ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 25-38 c. ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 14-15с. ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 32-35с ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 100-115 c ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 200-212 c ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 100-112с ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 325-29с ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 14-18 c ↑
-
Архитектура многопроцессорных вычислительных систем: Учеб. Пособие / Козлов О.С., Метлицкий Е.А., Экало А.В. и др.; Под ред. В.И Тимохина:- Л.: Изд-во Ленингр. ун-та, 2011. 55-100 ↑
-
Бройдо В. Л., Ильина О. П. Вычислительные системы, сети и телекоммуникации; Питер - Москва, 2011. – 25-38 c ↑
-
Мультипроцессорные системы и параллельные вычисления / Под ред. Ф.Г. Энслоу. М., 2010. 50-59с ↑
-
? О.М. Брехов, Г.А. Звонарёва, А.В. Корнеенкова. Имитационное моделирование: учебное пособие – М.: Издательство МАИ, 2015. – с. 200-218 ↑
-
Конюх В.Л., Игнатьев Я. Б., Зиновьев В.В. Методы имитационного моделирования систем. Применение программных продуктов. Электронное изд. зарег. в Федеральном депозитарии электронных изданий, No 0320401123. Рег. свид. ФГУП НТЦ «Информрегистр» от 06.09.2004. No 4753.- с. 12. ↑
-
В.А. Сигнаевский. Я.А. Коган. Методы оценки быстродействия вычислительных систем, Moсква: «Наука», 1990 – ст 25-36. ↑
-
R. Humayu, Kh. David J. Morse. System Performance Analysis: Tools, Techniques, and Methodology // Dell magazin’s, 2001, Issue 3. ↑
-
. G. Latouche, V. Ramaswami, J. Sethuraman, K. Sigman, M.S. Squillante, D. Yao. Matrix-Analytic Methods in Stochastic Models. Springer Science & Business Media, 2012, 258 p. ↑
-
A. Morecki, G. Bianchi, C. Rzymkowski. ROMANSY 11: Theory and Practice of Robots and Manipulators. – Berlin: Springer, 2014. – 320-400 c. ↑
-
D. Tolani, A. Goswami, N. Badler. Real-Time Inverse Kinematics Techniques for Anthropomorphic Limbs – Philadelphia: University of Pennsylvania, 2000. – 20-22 c. ↑
-
Луговской К.С.,Казанин П.И. Автоматизация обратной задачи кинематики двухзвенного манипулятора. — Саратов: Институт управ-ления и социально-экономического развития, 2016. — 4-6 с. ↑
-
Волков, Н.Н. Верификация и валидация ИВС: предварительное проектирование и компьютерное моделирование информационно-вы-числительных систем – М.: ТЕХПОЛИГРАФ-ЦЕНТР, 2015. – 500-523 с ↑
-
20. S.L. Frenkel. Performance measurement methodology -and-tool for computer systems with migrating applied software, in BRICS Notes Series, NS-98-4, pp.83-86, Aalburg, Denmark, June 1998. ↑
-
21. Орлов С.А., Цилькер Б.Я. Организация ЭВМ и систем. 3-е изд. — СПб.: Питер, 2014. — 25-63 с. ↑
-
Конюх В.Л., Игнатьев Я. Б., Зиновьев В.В. Методы имитационного моделирования систем. Применение программных продуктов. Электронное изд. зарег. в Федеральном депозитарии электронных изданий, No 0320401123. Рег. свид. ФГУП НТЦ «Информрегистр» от 06.09.2004. No 4753.- с. 10. ↑

- Разработка регламента выполнения процесса «Транспортная доставка заказов» (Анализ процесса транспортной доставки заказов)
- Разработка регламента выполнения процесса Транспортная доставка заказов (Основные понятия процессного подхода)
- Основные принципы управления затратами (на примере предприятия ЗАО «Новозыбковская швейная фабрика»)
- Применение сетей в экономике
- Развитие лидерских качеств руководителя (АНАЛИЗ ТЕОРИИ ЛИДЕРСКИХ КАЧЕСТВ НА ПРИМЕРЕ ООО «ТЕХНОЛАЙН»)
- Разработка бизнес-плана сети кафе (Факторы макросреды, влияющие на рынок услуг кафе)
- Сущность и значение кадровой стратегии организации (Общая характеристика предприятия ООО «МарТим»)
- Жизнестойкость и особенности совладания с профессиональными трудностями (Влияние профессиональной деятельности на личность)
- Психофизиологический анализ содержания профессиональной деятельности менеджеров по персоналу (Этика менеджера по персоналу как составная часть деловой этики)
- Психофизиологический анализ содержания профессиональной деятельности менеджеров по персоналу (Классификация способов мышления)
- Нормативный договор.
- Франчайзинг в системе российского гражданского права (Понятие франчайзинга и его правовой режим)