
мЕТОДЫ КОДИРОВАНИЯ ДАННЫХ (Системы счисления)
Содержание:

ВВЕДЕНИЕ
Актуальность темы состоит в том, что вычислительная техника первоначально возникла как средство автоматизации вычислений. Следующим видом обрабатываемой информации стала текстовая. Сначала тексты просто поясняли труднообозримые столбики цифр, но затем машины все более существенным образом стали преобразовывать текстовую информацию. Оформление текстов достаточно быстро вызвали у людей стремление дополнить их графиками и рисунками. Делались попытки частично решить эти проблемы в рамках символьного подхода: вводились специальные символы для рисования таблиц и диаграммам. Но практические потребности людей в графике делали ее появление среди видов компьютерной информации неизбежной. Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи. Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Объектом изучения, представленным в теоретической части, являются данные в компьютере.
Цель работы – рассмотреть форматы данных их представление и кодирование в компьютере.
ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ИЗУЧЕНИЯ МЕТОДОВ КОДИРОВАНИЯ ДАННЫХ
Кодирование информации - это процесс формирования определенного представления информации.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (например, звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью программ для компьютера можно выполнить преобразования полученной информации, например: "наложить" друг на друга звуки от разных источников.
Аналогичным образом на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
1.1 Системы счисления
Разнообразные системы счисления, которые существовали раньше и которые используются в наше время, можно разделить на непозиционные и позиционные. Знаки, используемые при записи чисел, называются цифрами.
В непозиционных системах счисления от положения цифры в записи числа не зависит величина, которую она обозначает. Примером непозиционной системы счисления является римская система, в которой в качестве цифр используются латинские буквы:
|
I |
V |
X |
L |
C |
D |
M |
|
1 |
5 |
10 |
50 |
100 |
500 |
1000 |
Например, VI = 5 + 1 = 6, а IX = 10 -- 1 = 9.
В позиционных системах счисления величина, обозначаемая цифрой в записи числа, зависит от ее позиции. Количество используемых цифр называется основанием системы счисления. Место каждой цифры в числе называется позицией. Первая известная нам система, основанная на позиционном принципе -- шестидесятeричная вавилонская. Цифры в ней были двух видов, одним из которых обозначались единицы, другим -- десятки. Следы вавилонской системы сохранились до наших дней в способах измерения и записи величин углов и промежутков времени.
Однако наибольшую ценность для нас имеет индо-арабская десятичная система. В этой системе впервые использовался ноль для указания позиционной значимости величины в строке цифр. Эта система получила название десятичной, так как в ней десять цифр.
Основание системы счисления, в которой записано число, обычно обозначается нижним индексом. Например, 5557 -- число, записанное в семеричной системе счисления. Если число записано в десятичной системе, то основание, как правило, не указывается. Основание системы -- это тоже число, и его мы будем указывать в обычной десятичной системе. Вообще, число x может быть представлено в системе с основанием p, как x=an*pn+an-1*pn-1+ a1*p1+a0*p0, где an...a0 -- цифры в представлении данного числа. Так, например,
103510=1*103+0*102+3*101+5*100;
10102 = 1*23+0*22+1*21+0*20 = 10.
Наибольший интерес при работе на ЭВМ представляют системы счисления с основаниями 2, 8 и 16. Вообще говоря, этих систем счисления обычно хватает для полноценной работы как человека, так и вычислительной машины. Однако иногда в силу различных обстоятельств все-таки приходится обращаться к другим системам счисления, например: к троичной, семеричной или системе счисления по основанию 32.
Для того чтобы нормально оперировать с числами, записанными в таких нетрадиционных системах, важно понимать, что принципиально они ничем не отличаются от привычной нам десятичной. Сложение, вычитание, умножение в них осуществляется по одной и той же схеме.
Почему же мы не пользуемся другими системами счисления? В основном потому, что в повседневной жизни мы привыкли пользоваться десятичной системой счисления, и нам не требуется никакая другая. В вычислительных же машинах используется двоичная система счисления, так как оперировать над числами, записанными в двоичном виде, довольно просто.
Часто в информатике используют шестнадцатеричную систему, так как запись чисел в ней значительно короче записи чисел в двоичной системе. Может возникнуть вопрос: почему бы не использовать для записи очень больших чисел систему счисления, например по основанию 50? Для такой системы счисления необходимы 10 обычных цифр плюс 40 знаков, которые соответствовали бы числам от 10 до 49 и вряд ли кому-нибудь понравится работать с этими сорока знаками. Поэтому в реальной жизни системы счисления по основанию, большему 16, практически не используются.
Двоичная система счисления
Люди предпочитают десятичную систему, вероятно, потому, что с древних времен считали по пальцам. Но, не всегда и не везде люди пользовались десятичной системой счисления. В Китае, например, долгое время применялась пятеричная система счисления. В ЭВМ используют двоичную систему потому, что она имеет ряд преимуществ перед другими:
- для ее реализации используются технические элементы с двумя возможными состояниями (есть ток -- нет тока, намагничен – не намагничен);
- представление информации посредством только двух состояний надежно и помехоустойчиво;
- возможно применение аппарата булевой алгебры для выполнения логических преобразований информации;
- двоичная арифметика проще десятичной (двоичные таблицы сложения и умножения предельно просты).
В двоичной системе счисления всего две цифры, называемые двоичными (binary digits). Сокращение этого наименования привело к появлению термина бит, ставшего названием разряда двоичного числа. Веса разрядов в двоичной системе изменяются по степеням двойки. Поскольку вес каждого разряда умножается либо на 0, либо на 1, то в результате значение числа определяется как сумма соответствующих значений степеней двойки. Если какой-либо разряд двоичного числа равен 1, то он называется значащим разрядом. Запись числа в двоичном виде намного длиннее записи в десятичной системе счисления.
Арифметические действия, выполняемые в двоичной системе, подчиняются тем же правилам, что и в десятичной системе. Только в двоичной системе перенос единиц в старший разряд возникает чаще, чем в десятичной. Вот как выглядит таблица сложения в двоичной системе:
|
0 + 0 = 0 |
0 + 1 = 1 |
|
1 + 0 = 1 |
1 + 1 = 0 (перенос в старший разряд) |
Таблица умножения для двоичных чисел еще проще:
|
0 * 0 = 0 |
0 * 1 = 0 |
1 * 0 = 0 |
1 * 1 = 1 |
Рассмотрим подробнее, как происходит процесс умножения двоичных чисел. Пусть надо умножить число 1101 на 101 (оба числа в двоичной системе счисления). Машина делает это следующим образом: она берет число 1101 и, если первый элемент второго множителя равен 1, то она заносит его в сумму. Затем сдвигает число 1101 влево на одну позицию, получая тем самым 11010, и если, второй элемент второго множителя равен единице, то тоже заносит его в сумму. Если элемент второго множителя равен нулю, то сумма не изменяется.
Двоичное деление основано на методе, знакомом вам по десятичному делению, т. е. сводится к выполнению операций умножения и вычитания. Выполнение основной процедуры -- выбор числа, кратного делителю и предназначенного для уменьшения делимого, здесь проще, так как таким числом могут быть только либо 0, либо сам делитель.
Следует отметить, что большинство калькуляторов, реализованных на ЭВМ (в том числе и KCalc) позволяют осуществлять работу в системах счисления с основаниями 2, 8, 16 и, конечно, 10.
Перевод чисел из одной системы счисления в другую
Наиболее часто встречающиеся системы счисления -- это двоичная, шестнадцатеричная и десятичная. Как же связаны между собой представления числа в различных системах счисления? Рассмотрим различные способы перевода чисел из одной системы счисления в другую на конкретных примерах.
Пусть требуется перевести число 567 из десятичной в двоичную систему. Сначала определим максимальную степень двойки, такую, чтобы два в этой степени было меньше или равно исходному числу. В нашем случае это 9, т. к. 29=512, а 210=1024, что больше начального числа. Таким образом, мы получим число разрядов результата. Оно равно 9+1=10. Поэтому результат будет иметь вид 1ххххххххх, где вместо х могут стоять любые двоичные цифры. Найдем вторую цифру результата. Возведем двойку в степень 9 и вычтем из исходного числа: 567-29=55. Остаток сравним с числом 28=256. Так как 55 меньше 256, то девятый разряд будет нулем, т. е. результат примет вид 10хххххххх. Рассмотрим восьмой разряд. Так как 27=128>55, то и он будет нулевым.
Седьмой разряд также оказывается нулевым. Искомая двоичная запись числа принимает вид 1000хххххх. 25=32<55, поэтому шестой разряд равен 1 (результат 10001ххххх). Для остатка 55-32=23 справедливо неравенство 24=16<23, что означает равенство единице пятого разряда. Действуя аналогично, получаем в результате число. Мы разложили данное число по степеням двойки:
567=1*29+0*28+0*27+0*26+1*25+1*24+0*23+1*22 +1*21+1*20
При другом способом перевода чисел используется операция деления в столбик. Рассмотрим то же самое число 567. Разделив его на 2, получим частное 283 и остаток 1. Проведем ту же самую операцию с числом 283. Получим частное 141, остаток 1. Опять делим полученное частное на 2, и так до тех пор, пока частное не станет меньше делителя. Теперь для того, чтобы получить число в двоичной системе счисления, достаточно записать последнее частное, то есть 1, и приписать к нему в обратном порядке все полученные в процессе деления остатки.
|
|
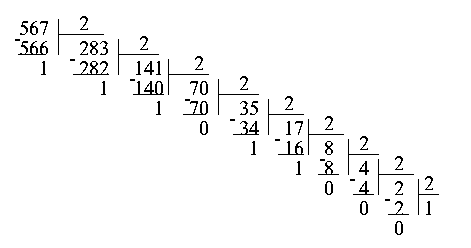
Результат, естественно, не изменился: 567 в двоичной системе счисления записывается как.
Эти два способа применимы при переводе числа из десятичной системы в систему с любым основанием. Для закрепления навыков рассмотрим перевод числа 567 в систему счисления с основанием 16.
Сначала осуществим разложение данного числа по степеням основания. Искомое число будет состоять из трех цифр, т. к. 162=256 < 567 < 163=4096. Определим цифру старшего разряда. 2*162=512<567<3*162=768, следовательно, искомое число имеет вид 2хх, где вместо х могут стоять любые шестнадцатеричные цифры. Остается распределить по следующим разрядам число*16=48<55<4*16=64, значит во втором разряде находится цифра 3. Последняя цифра равна 7 (55-48). Искомое шестнадцатеричное число равно 237.
Второй способ состоит в осуществлении последовательного деления в столбик, с единственным отличием в том, что делить надо не на 2, а на 16, и процесс деления заканчивается, когда частное становится строго меньше 16.
|
Конечно, не надо забывать и о том, что для записи числа в шестнадцатеричной системе счисления, необходимо заменить 10 на A, 11 на B и так далее. |
|
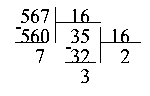
Операция перевода в десятичную систему выглядит гораздо проще, так как любое десятичное число можно представить в виде x = a0*pn + a1*pn-1 + ... + an-1*p1 + an*p0, где a0 ... an -- это цифры данного числа в системе счисления с основанием p.
Естественные человеческие языки — это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов). История знает интересные, хотя и безуспешные попытки создания «универсальных» языков и азбук. По-видимому, безуспешность попыток их внедрения связана с тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования общественных данных непременно приводит к изменению общественных методов (то есть норм права и морали), а это может быть связано с социальными потрясениями.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Код Морзе
Код Брайля
Код морской сигнальный


Рисунок 1. Примеры различных систем кодирования
1.2 Кодирование и его виды
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
1) перевести число N в двоичную систему счисления;
2) полученный результат дополнить слева незначащими нулями до k разрядов.
Пример
Получить внутреннее представление целого числа 1607 в 2-х байтовой ячейке.
Переведем число в двоичную систему: 160710 = . Внутреннее представление этого числа в ячейке будет следующим: 011.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
1) получить внутреннее представление положительного числа N;
2) обратный код этого числа заменой 0 на 1 и 1 на 0;
3) полученному числу прибавить 1.
Пример
Получим внутреннее представление целого отрицательного числа -1607. Воспользуемся результатом предыдущего примера и запишем внутреннее представление положительного числа 1607: 011. Инвертированием получим обратный код: 100. Добавим единицу: 101 -- это и есть внутреннее двоичное представление числа -1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p.
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12.345 = 0.0012345 x 104 = 1234.5 x 10-2 = 0.12345 x 102
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию: 0.1p <= m < 1p. Иначе говоря, мантисса меньше 1 и первая значащая цифра -- не ноль (p -- основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12.345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере -- это 2.
Единицы представления данных
Существует множество систем представления данных. С одной из них, принятой в информатике и вычислительной технике, двоичным кодом, мы познакомились выше. Наименьшей единицей такого представления является бит (двоичный разряд).
Совокупность двоичных разрядов, выражающих числовые или иные данные, образует некий битовый рисунок. Практика показывает, что с битовым представлением удобнее работать, если этот рисунок имеет регулярную форму. В настоящее время в качестве таких форм используются группы из восьми битов, которые называются байтами.
Понятие о байте, как группе взаимосвязанных битов, появилось вместе с первыми образцами электронной вычислительной техники. Долгое время оно было машинно-зависимым, то есть для разных вычислительных машин длина байта была разной. Только в конце 60-х годов понятие байта стало универсальным и маишннонезависимым.
Выше мы видели, что во многих случаях целесообразно использовать не восьмиразрядное кодирование, а 16-разрядное, 24-разрядное, 32-разрядное и более. Группа из 16 взаимосвязанных бит (двух взаимосвязанных байтов) в информатике называется словом. Соответственно, группы из четырех взаимосвязанных байтов (32 разряда) называются удвоенным словом, а группы из восьми байтов (64 разряда) — учетверенным словом. Пока, на сегодняшний день, такой системы обозначения достаточно.
Кодирование текста
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 28 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Все символы такого алфавита пронумерованы от 0 до 255, а каждому номеру соответствует 8-разрядный двоичный код от до. Этот код является порядковым номером символа в двоичной системе счисления.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII. (американский стандартный код для обмена информацией)
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код ) до Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код ) и кончая , используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов.
Исторически сложилось так, что для представления печатных символов (кодирования текста) в первых ЭВМ отвели 7 бит. 27=128. Этого количества вполне хватало для кодирования всех строчных и прописных букв латинского алфавита, десяти цифр и различных знаков и скобок. Именно такой, 7-битной, является таблица символов ASCII. Когда возникла необходимость кодировать национальные алфавиты, то 128 символов стало недостаточно. Было решено перейти на кодирование с помощью 8 бит (т. е. одного байта). В результате количество символов, которые можно закодировать таким образом стало равно 28=256. При этом символы национальных алфавитов располагались во второй половине кодовой таблицы, т. е. содержали единицу в старшем разряде байта, отведенного для кодирования символа. Так появился стандарт ISO 8859, содержащий множество кодировок для наиболее распространенных языков.
Кодирование русского текста
Среди них была и одна из первых таблиц для кодировки русских букв -- ISO 8859-5.
Задачи передачи текстовой информации по сети вынудили разработать еще одну кодировку для русских букв, названную Koi8-R (код отображения информации 8-битный, русифицированный). Рассмотрим ситуацию, когда письмо, содержащее русский текст, отправлено по электронной почте. Случалось, что в процессе путешествия по сетям письмо обрабатывалось программой, которая работала с 7-битной кодировкой и обнуляла восьмой бит. В результате такого преобразования код символа уменьшался на 128, превращаясь в код символа латинского алфавита. Возникла необходимость повысить устойчивость передаваемой текстовой информации к обнулению 8 бита.
К счастью, значительное число букв кириллицы имеет фонетические аналоги в латинском алфавите. Например, Ф и F, Р и R. Есть несколько букв, совпадающих даже по начертанию. Расположив русские буквы в кодовой таблице таким образом, чтобы их код превышал код аналогичных латинских на число 128, добились того, что потеря 8-го бита превращала текст хотя и в состоящий из одной латиницы, но все равно понимаемый русскоязычным пользователем.
Так как из всех операционных систем, распространенных в то время, самыми удобными средствами работы с сетью обладали различные клоны операционной системы Unix, то эта кодировка стала фактическим стандартом в этих системах. Таковой она является и сейчас в ОС Linux. И именно эта кодировка чаще всего применяется для обмена почтой и новостями в Интернет.
Далее наступила эра персональных компьютеров и операционной системы MS DOS. Как выяснилось, кодировка Koi8-R для нее не подходила (так же, как и ISO 8859-5), в ее таблице некоторые русские буквы находились на тех местах, которые многие программы предполагали заполненными псевдографикой (горизонтальные и вертикальные черточки, уголки и т. д.). Поэтому была придумана еще одна кодировка кириллицы, в таблице которой русские буквы "обтекали" со всех сторон графические символы. Назвали эту кодировку альтернативной (alt), поскольку она была альтернативой официальному стандарту -- кодировке ISO-8859-5. Неоспоримым достоинством этой кодировки является то, что русские буквы в ней расположены в алфавитном порядке.
После появления ОС Windows от фирмы Microsoft выяснилось, что альтернативная кодировка по некоторым причинам для нее не подходит. Снова передвинув русские буквы в таблице (появилась возможность -- ведь псевдографика в Windows не требуется), получили кодировку Windows 1251 (Win-1251).
Но компьютерные технологии постоянно совершенствуются и в настоящее время все большее число программ начинает поддерживать стандарт Unicode, который позволяет кодировать практически все языки и диалекты жителей Земли.
Итак, в различных ОС предпочтение отдается разным кодировкам. Для того чтобы стало возможным чтение и редактирования текста, набранного в другой кодировке, используются программы перекодирования русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики, позволяющие читать текст в различных кодировках.
Наряду с байтами для измерения количества информации используются более крупные единицы:
|
1 Кбайт (один килобайт) = 210 байт = 1024 байта; |
|
1 Мбайт (один мегабайт) = 210 Кбайт = 1024 Кбайта; |
|
1 Гбайт (один гигабайт) = 210 Мбайт = 1024 Мбайта. |
Условно можно считать, что 1 Кбайт примерно равен 1000 байт. Условность связана с тем, что для вычислительной техники, работающей с двоичными числами, более удобно представление чисел в виде степени двойки, и потому на самом деле 1 Кбайт равен 210 байт (1024 байт). Однако всюду, где это не принципиально, с инженерной погрешностью (до 3 %) «забывают» о «лишних» байтах.
Пример
Книга содержит 100 страниц; на каждой странице -- 35 строк, в каждой строке -- 50 символов. Рассчитаем объем информации, содержащийся в книге.
Страница содержит 35 x 50 = 1750 байт информации. В килобайтах измеряют сравнительно небольшие объемы данных. Условно можно считать, что одна страница неформатированного машинописного текста составляет около 2 Кбайт.
Объем всей информации в книге (в разных единицах):
|
1750 x 100 = 175000 байт. |
|
175000 / 1024 = 170,8984 Кбайт. |
|
170,8984 / 1024 = 0,166893 Мбайт. |
Более крупные единицы измерения данных образуются добавлением префиксов мега-, гига-, тера-; в более крупных единицах пока нет практической надобности.
1 Мбайт = 1024 Кбайт = 1020 байт
1 Гбайт = 1024 Мбайт = 1030 байт
1 Тбайт = 1024 Гбайт = 1040 байт
Особо обратим внимание на то, что при переходе к более крупным единицам «инженерная» погрешность, связанная с округлением, накапливается и становится недопустимой, поэтому на старших единицах измерения округление производится реже.
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части -- растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится -- не светится), а для его кодирования достаточно одного бита памяти: 1 -- белый, 0 -- черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 -- черный, 10 -- зеленый, 01 -- красный, 11 -- коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов -- красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
|
|
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов -- К и количество битов для их кодировки -- N связаны между собой простой формулой: 2N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения -- линия, прямоугольник, окружность или фрагмент текста -- располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
Кодирование звука
Из курса физики вам известно, что звук -- это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой -- аналоговый -- сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его -- аналого-цифровым преобразователем (АЦП).
|
|
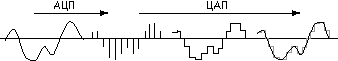
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь -- ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки -- нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Заметим, что существуют и другие, чисто компьютерные, форматы записи музыки. Среди них следует отметить формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку. При этом вместо 18--20 музыкальных композиций на стандартный компакт-диск (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Адресные данные. Если данные хранятся не как попало, а в организованной структуре (причем любой), то каждый элемент данных приобретает новое свойство (параметр), который можно назвать адресом. Конечно, работать с упорядоченными данными удобнее, но за это приходится платить их размножением, поскольку адреса элементов данных — это тоже данные, и их тоже надо хранить и обрабатывать. Типы адресных данных: списки, векторы, таблицы, матрицы. Примеры матриц в Матcad.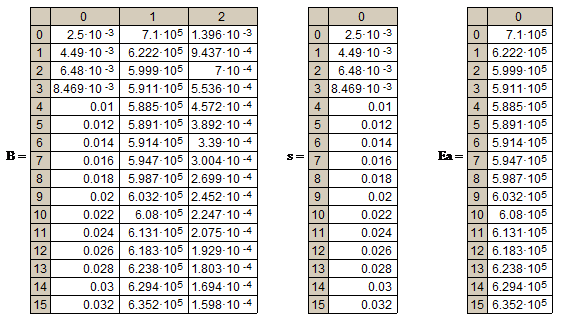
1.3 Файлы и данные
Форматы файлов
Основное назначение файлов -- хранить информацию. Они также предназначены для передачи данных от программы к программе и от системы к системе. Другими словами, файл -- это хранилище стабильных и мобильных данных. Но, файл -- это нечто большее, чем просто хранилище данных. Обычно файл имеет имя, атрибуты, время модификации и время создания.
Понятие файла менялось с течением времени. Операционные системы первых больших ЭВМ представляли файл, как хранилище для базы данных и, поэтому файл являлся набором записей. Обычно все записи в файле были одного размера, часто по 80 символов каждая. При этом много времени уходило на поиск и запись данных в большой файл.
В конце 60-х годов наметилась тенденция к упрощению операционных систем, что позволило использовать их на менее мощных компьютерах. Это нашло свое отражение и в развитии операционной системы Unix. В Unix под файлом понималась последовательность байтов. Стало легче хранить данные на диске, так как не надо было запоминать размер записи.Unix оказал очень большое влияние на другие операционные системы персональных компьютеров. Почти все они поддерживают идею Unix о том, что файл -- это просто последовательность байтов. Файлы, представляющие собой поток данных, стали использоваться при обмене информацией между компьютерными системами. Если используется более сложная структура файла (как в операционных системах OS/2 и Macintosh), она всегда может быть преобразована в поток байтов, передана и на другом конце канала связи воссоздана в исходном виде.
Итак, мы можем считать, что файл -- это поименованная последовательность байтов.
Файловая структура представляет собой систему хранения файлов на запоминающем устройстве, например, диске. Файлы организованы в каталоги (иногда называемые директориями или папками). Любой каталог может содержать произвольное число подкаталогов, в каждом из которых могут храниться файлы и другие каталоги.
Способ, которым данные организованы в байты, называется форматом файла.
Для того чтобы прочесть файл, например, электронной таблицы, необходимо знать, каким образом байты представляют числа (формулы, текст) в каждой ячейке; чтобы прочесть файл текстового редактора, надо знать, какие байты представляют символы, а какие шрифты или поля, а также другую информацию.
Программы могут хранить данные в файле таким способом, какой выберет программист. Зачастую предполагается, однако, что файлы будут использоваться различными программами. По этой причине многие прикладные программы поддерживают некоторые наиболее распространенные форматы, так что другие программы могут понять данные в файле. Компании по производству программного обеспечения (которые хотят, чтобы их программы стали "стандартами"), часто публикуют информацию относительно форматов, которые они создали, чтобы их можно было бы использовать в других приложениях.
Все файлы условно можно разделить на две части -- текстовые и двоичные.
Текстовые файлы -- наиболее распространенный тип данных во всем компьютерном мире. Для хранения каждого символа чаще всего отводится один байт, а кодирование текстовых файлов выполняют с помощью специальных таблиц, в которых каждому символу соответствует определенное число, не превышающее 255. Файл, для кодировки которого используется только 127 первых чисел, называется ASCII-файлом (сокращение от American Standard Code for Information Intercange -- американский стандартный код для обмена информацией), но в таком файле не могут быть представлены буквы, отличные от латиницы (в том числе и русские). Большинство национальных алфавитов можно закодировать с помощью восьмибитной таблицы. Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов. Для экономии места зачастую применяется следующий прием: некоторые символы кодируются с помощью одного байта, в то время как для других используются два или более байтов. Одной из попыток обобщения такого подхода является стандарт Unicode, в котором для кодирования символов используется диапазон чисел от нуля до 65 536. Такой широкий диапазон позволяет представлять в численном виде символы языка людей из любого уголка планеты.
Но чисто текстовые файлы встречаются все реже. Люди хотят, чтобы документы содержали рисунки и диаграммы и использовали различные шрифты. В результате появляются форматы, представляющие собой различные комбинации текстовых, графических и других форм данных.
Двоичные файлы, в отличие от текстовых, не так просто просмотреть и в них, обычно, нет знакомых нам слов -- лишь множество непонятных символов. Эти файлы не предназначены непосредственно для чтения человеком. Примерами двоичных файлов являются исполняемые программы и файлы с графическими изображениями.
Единицы хранения данных
При хранении данных решаются две проблемы: как сохранить данные в наиболее компактном виде и как обеспечить к ним удобный и быстрый доступ (если доступ не обеспечен, то это не хранение). Для обеспечения доступа необходимо, чтобы данные имели упорядоченную структуру, а при этом, как мы уже знаем, образуется «паразитная нагрузка» в виде адресных данных. Без них нельзя получить доступ к нужным элементам данных, входящих в структуру.
Поскольку адресные данные тоже имеют размер и тоже подлежат хранению, хранить данные в виде мелких единиц, таких, как байты, неудобно. Их неудобно хранить и в более крупных единицах (килобайтах, мегабайтах и т. п.), поскольку неполное заполнение одной единицы хранения приводит к неэффективности хранения.
В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл — это последовательность произвольного числа байтов, обладающая уникальным собственным именем. Обычно в отдельном файле хранят данные, относящищиеся к одному типу. В этом случае тип данных определяет тип файла.
Проще всего представить себе файл в виде безразмерного канцелярского досье, в которое можно по желанию добавлять содержимое или извлекать его оттуда. Поскольку в определении файла нет ограничений на размер, можно представить себе файл, имеющий 0 байтов (пустой файл), и файл, имеющий любое число байтов.
В определении файла особое внимание уделяется имени. Оно фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией.
Рисунок 2. Пример иерархической структуры данных
|
|
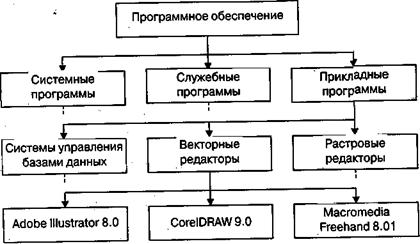
В иерархической структуре адрес каждого элемента определяется путем доступа! (маршрутом), ведущим от вершины структуры, к данному элементу. Вот, например как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Пуск > Программы > Стандартные > Калькулятор.
Дихотомия данных
Рисунок 3. Пример, поясняющий принцип действия метода дихотомии
|
|
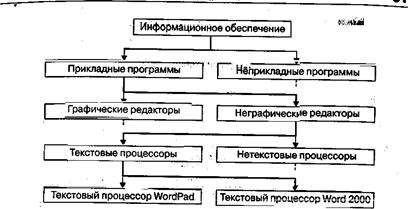
Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомш.
Его суть понятна из примера, представленного на рис. 1.6. В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи. В нашем примере путь доступа к текстовому процессору Word 2000 выразится следующим двоичным числом: 1010.
Упорядочение структур данных
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра.
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток — их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
ЗАКЛЮЧЕНИЕ
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы. Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов. Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
Л 1. Ажеронок В. А., Островерх А. В., Радченко М. Г., Хрусталева Е. Ю., Разработка управляемого интерфейса, Издательство: 1С-Паблишинг 2014.
Л 2. Бухалков, М.И. Планирование на предприятии: Учебник / М.И. Бухалков. – 3-е изд. – М.: ИНФРА-М, 2014. – 416 с. Л 2.
Л 3. Вендров, А.М. Проектирование программного обеспечения экономических информационных систем [Текст]: Учебник / А.М. Вендров. – М.: Финансы и статистика, 2014. – 352 с.
Л 4. Диденсбург В., Монкриф Р., Тейлор В. Основы оптовой торговли. Практический курс / Перевод с английского. Е. И. Подколзина. - СПБ.: Симор, 2015.- 189 с.
Л 5. Радченко М.Г. 1С:Предприятие 8.2 Практическое пособие разработчика. Примеры и типовые приему / М. Г. Радченко, Е. Ю. Хрусталева. – М.: ООО «1С-Паблишинг», 2015. – 874 с.: ил.
Л 6. Фиденко Ю. Л. Оформление курсовой работы, дипломного реферата, диплома: учебное пособие [Электронный ресурс] – Электрон. дан. – Владивосток: ДВГАИ, 2015. – 1 эл. опт. диск (CD-ROM).
Л 7. Хрусталева, Е.Ю. Язык запросов Электронная книга в формате ePub; ISBN 978-5-9677-1991-2. Версия издания от 16.09.2015.
Л 8. 1С Предприятие: 8.2. Руководство администратора – М.: ООО «1С-Паблишинг», 2014. – 216 с.
Л 9. ГОСТ 19.002-77 Единая система программной документации. Общие положения
Л 10. ГОСТ 19.102-77 Единая система программной документации. Стадии разработки.
Л 11. ГОСТ 19.103-77 Единая система программной документации. Обозначение программ и программных документов.
Л 12. ГОСТ 19.104-78 Единая система программной документации. (СТ СЭВ 2088-80) Основные надписи.
Л 13. ГОСТ 19.106-78 Единая система программной документации. СЕ СЭВ 2088-80) Требования к программным документам, выполненным печатным образом.
Л 14. ГОСТ 19.201-78 Единая система программной документации. (СЕ СЭВ 1627-79) Техническое задание. Требования к содержанию и оформлению.
Л 15. ГОСТ 19.202-78 Единая система программной документации. (СТ СЭВ 2090-80) Спецификация. Требования к содержанию и оформлению.

- Органы государственного управления (Государственное управление и ее основа)
- Исследование проблемы соотношения государства и права
- История развития программирования в России
- Анализ и оценка средств реализации объектно- ориентированного подхода к проектированию экономической информационной системы
- Разработка проекта подсистемы автоматизации складского учета (Выбор комплекса задач автоматизации и характеристика существующих бизнес процессов)
- Классификация языков программирования. Критерии выбора среды и языка программирования
- основные проблемы коммуникаций в организациях
- Управление поведением в конфликтной ситуации (Конфликты в организации: виды, причины)
- основные функции менеджмента (Функции менеджмента)
- компенсационные выплаты в системе социального обеспечения
- Курсовая работа (Роль мотивации в поведении организации)
- Правовое регулирование рекламной деятельности