
Методы кодирования данных (Многобуквенные шифры)
Содержание:

ВВЕДЕНИЕ
Тема данной курсовой работы – методы кодирования данных. Выбранная тема является актуальной, т.к. научный и технический прогресс не стоят на месте. Информации стало настолько много, что людям потребовалось создать различные способы ее представления и кодирования.
Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки текстовой, звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Одним из ключевых методов кодирования информации является кодирование с помощью криптографии. В данной работе будет подробно рассмотрены виды шифров и их использование при кодировании информации.
Объектом изучения являются наука криптография.
Целью работы является рассмотрение видов кодирования информации шифрами разных видов и сложности.
Для достижения поставленной цели необходимо решить следующие задачи:
- Изучить шифры моноалфавитной подстановки ;
- Рассмотреть многобуквенные шифры и шифры полиалфавитной подстановки;
- Изучить симметричные системы защиты информации;
- Понять применение перестановок.
1.1 Основные понятия
Рассмотрим ряд терминов:
Криптография – наука о методах обеспечения конфиденциальности (невозможности прочтения информации посторонним), целостности данных (невозможности незаметного изменения информации) и аутентификации (проверки подлинности авторства или иных свойств объекта), а также невозможности отказа от авторства.[2]
Изначально криптография изучала методы шифрования информации – обратимого преобразования открытого (исходного) текста на основе секретного алгоритма и/или ключа в шифрованный текст (шифротекст). Традиционная криптография образует раздел симметричных криптосистем, в которых шифрование и расшифровывание проводится с использованием одного и того же секретного ключа. Помимо этого раздела современная криптография включает в себя асимметричные криптосистемы, использующие два ключа, системы электронной подписи (ЭП), хеш-функции, управление ключами, получение скрытой информации, квантовую криптографию.[4]
Шифр – это совокупность условных знаков (условная азбука из цифр или букв) для секретной переписки, для передачи текста секретных документов, в том числе по техническим средствам связи. В общем случае понятие шифр идентично понятию криптосистема и означает семейство обратимых преобразований открытого текста в шифрованный. Шифр состоит, по меньшей мере, из четырех элементов[2]:
- открытый текст X;
- функция шифрования f(X);
- ключ К;
- закрытый текст Y.
Открытый (исходный) текст – данные (текстовые или иного вида), представляемые и/или передаваемые без использования криптографии.
Шифротекст, шифрованный (закрытый) текст – данные, полученные после применения криптосистемы (обычно с некоторым указанным ключом).
Код – это алгоритм криптографических преобразований (шифрования) множества возможных открытых данных во множество возможных зашифрованных данных, и обратных им преобразований.[2]
Ключ – это параметр криптографического алгоритма, обеспечивающий выбор одного преобразования из совокупности преобразований, возможных для этого алгоритма. В современной криптографии предполагается, что вся секретность криптографического алгоритма сосредоточена в ключе, но не деталях самого алгоритма (принцип Керкгоффса).[2]
Шифры могут использовать один ключ для шифрования и дешифрования или два различных ключа. По этому признаку различают симметричный и асимметричный шифры.
Симметричный шифр – это шифр, который использует один ключ для шифрования и расшифровывания.[2]
Асимметричный (несимметричный) шифр – это шифр, который для шифрования и расшифровывания использует два различных ключа, определенным образом связанных между собой.[2]
Шифрование – процесс нормального применения криптографического преобразования открытого текста на основе алгоритма и ключа, в результате которого возникает шифрованный текст.[2]
Расшифровывание (расшифровка) – процесс нормального применения криптографического преобразования шифрованного текста в открытый (то есть, на основе известного алгоритма и ключа).[2]
Криптоанализ – наука, изучающая математические методы нарушения конфиденциальности и целостности информации. В то же время криптоанализ занимается не только разработкой методов, позволяющих взламывать криптосистемы, но и оценкой сильных и слабых сторон методов шифрования.[4]
Криптоаналитик – человек, создающий и применяющий методы криптоанализа.
Криптография и криптоанализ составляют криптологию как единую науку о создании и взломе шифров (такое деление привнесено с Запада, ранее в СССР и России не применялось специального деления).
Дешифрование (дешифровка) – процесс извлечения открытого текста без знания криптографического ключа на основе известного шифрованного текста. Термин «дешифрование» обычно применяют по отношению к процессу криптоанализа шифротекста. В некоторых источниках понятия дешифрования и расшифровывания объединяют вместе под термином дешифрование.[4]
Криптографическая стойкость – способность криптографического алгоритма противостоять криптоанализу, то есть к дешифрованию без знания ключа.
Алфавит – конечное множество используемых для кодирования информации знаков. В качестве примеров алфавитов можно привести следующие[3]:
- алфавит Z33 - 32 буквы русского алфавита и пробел;
- алфавит Z27 - 26 букв латинского алфавита и пробел;
- алфавит Z256 - символы, входящие в стандартные коды ASCII и КОИ-8;
- бинарный алфавит – Z2 = {0,1};
- восьмеричный или шестнадцатеричный алфавит.
Если указанные алфавиты используют расположение символов в соответствии с установленными правилами или стандартами для естественных языков, то их можно рассматривать как естественные алфавиты открытых текстов. Изменение порядка расположения символов может преобразовать их в специальные алфавиты шифротекстов, которые используются в некоторых алгоритмах криптографических преобразований (например, в шифрах замены).
В данном пункте были рассмотрены основные понятия криптографии, которые необходимо изучить перед написанием последующих пунктов курсовой работы.
1.2. Классификация криптографических алгоритмов шифрования
Криптографические алгоритмы шифрования информации можно разделить на[2]:
- симметричные;
- несимметричные;
- гибридные.
Также, алгоритмы делят по типу преобразования и по способу обработки информации (рис. 1).
В симметричных криптографических алгоритмах шифрование и расшифровывание производятся с помощью одного и того же ключа. И соответственно этот ключ необходимо хранить в секрете (отсюда другое название симметричных криптоалгоритмов – криптоалгоритмы с секретным ключом).
В несимметричных криптографических алгоритмах существуют два разных ключа – один используется для шифрования, который еще называют открытым, другой – для расшифровывания, который называют закрытым. Главное отличие асимметричных криптоалгоритмов заключается в том, что даже тот, кто с помощью открытого ключа зашифровал сообщение, не сможет его самостоятельно расшифровать без знания закрытого ключа. Поэтому эти криптоалгоритмы называются несимметричными (асимметричными), или алгоритмами с открытым ключом.[3]
Если криптоалгоритм использует индивидуальное сообщение и индивидуальный открытый ключ, то он называется криптоалгоритмом с одним открытым ключом.
Если криптоалгоритм использует одно сообщение и п ключей (в схеме с п агентами), то он называется криптоалгоритмом с несколькими открытыми ключами.
Гибридными принято называть криптоалгоритмы, сочетающие оба типа, в них, как правило, текст сообщения шифруется с использованием симметричного криптоалгоритма, а секретный ключ использованного симметричного криптоалгоритма шифруется с использованием асимметричного криптоалгоритма.[4]
По типу обработки входящей информационной последовательности криптоалгоритмы делятся на поточные, в которых преобразуется всё сообщение сразу, и блочные, в которых сообщение обрабатывается в виде блоков определенной длины. Комбинированные криптоалгоритмы сочетают в себе элементы поточного и блочного шифрования.
По типу шифрующего преобразования криптосистемы делятся на:
- шифры замены (подстановки);
- шифры перестановок;
- шифры гаммирования;
- шифры, основанные на аналитических преобразованиях шифруемых данных;
- композиционные шифры.
Шифрование заменой (подстановкой) заключается в том, что символы шифруемого текста заменяются символами того же или другого естественного алфавита в соответствии с заранее обусловленной схемой замены. Этот тезис можно сформулировать по-другому: символы шифруемого текста на естественном языке заменяются символами специального алфавита для записи шифротекста, сконструированного на базе естественного языка по заранее обусловленному правилу. [3]
Шифрование перестановкой заключается в том, что символы шифруемого текста переставляются по определенному правилу в пределах некоторого блока этого текста. При достаточной длине блока, в пределах которого осуществляется перестановка, и сложном неповторяющемся порядке перестановки можно достигнуть приемлемой для простых практических приложений стойкости шифра.[4]
По сути дела, шифры перестановки и замены являются кирпичиками, из которых строятся различные более стойкие шифры.
Шифрование гаммированием заключается в том, что символы шифруемого текста складываются с символами некоторой случайной последовательности, именуемой гаммой шифра. Стойкость шифрования определяется в основном длиной (периодом) неповторяющейся части гаммы шифра. Поскольку с помощью ЭВМ можно генерировать практически бесконечную гамму шифра, то данный способ является одним из основных для шифрования информации в автоматизированных системах.[4]
Шифрование аналитическим преобразованием заключается в том, что шифруемый текст преобразуется по некоторому аналитическому правилу (формуле). Например, можно использовать правило умножения вектора на матрицу, причем умножаемая матрица является ключом шифрования (поэтому ее размер и содержание должны храниться в секрете), а символами умножаемого вектора последовательно служат символы шифруемого текста.
Идея, лежащая в основе составных, или композиционных, шифров, состоит в построении криптостойкой системы путем многократного применения относительно простых криптографических преобразований, в качестве которых К. Шеннон предложил использовать преобразования подстановки (substitution) и транспозиции (permutation) . Многократное использование этих преобразований позволяет обеспечить два свойства, которые должны быть присущи стойким шифрам: рассеивание (diffusion) и перемешивание (confusion).[2]
Рассеивание предполагает распространение влияния одного знака открытого текста, а также одного знака ключа на значительное количество знаков шифротекста.
Наличие у шифра этого свойства, с одной стороны, позволяет скрывать статистическую зависимость между знаками открытого текста, иначе говоря, перераспределить избыточность исходного языка посредством распространения ее на весь текст; а с другой – не позволяет восстановить неизвестный ключ по частям. Например, обычная перестановка символов позволяет скрыть частоты появления биграмм (комбинации из 2-х букв), триграмм и т.д.[4]
Цель перемешивания – сделать как можно более сложной зависимость между ключом и шифротекстом. Криптоаналитик на основе статистического анализа перемешанного текста не должен получить сколь-нибудь значительного количества информации об использованном ключе. Обычно перемешивание осуществляется при помощи подстановок. Применение рассеивания и перемешивания порознь не обеспечивает необходимую стойкость, стойкая криптосистема получается только в результате их совместного использования.[3]
В этом пункте достаточно емко рассмотрена классификация криптографических алгоритмов шифрования. Они делятся на симметричные, несимметричные, гибридные. А также, их делят по типу преобразования и по способу обработки информации.
Далее, некоторые из упомянутых алгоритмов шифрования рассматриваются более подробно.
1.3. Шифры моноалфавитной подстановки
Шифры моноалфавитной (одноалфавитной) подстановки относятся к категории шифров замены (подстановки). Другое их название – шифры простой замены. В шифре простой замены каждый символ исходного текста заменяется по определенному правилу символами одного и того же специального алфавита шифротекста на всем протяжении текста.
Историческим примером шифра замены является шифр Цезаря (I век до н.э.), описанный историком Древнего Рима Светонием. Гай Юлий Цезарь использовал в своей переписке шифр собственного изобретения. Применительно к современному русскому языку он состоял в следующем. Выписывался алфавит: А, Б, В, Г, Д, Е, ...; затем под ним выписывался тот же алфавит, но со сдвигом на 3 буквы влево (табл. 1). Можно сказать, что осуществился переход к специальному алфавиту, на котором будет записываться шифротекст.[5]
Алфавит считается “циклическим”, поэтому после Я идет А. При шифровке буква А заменялась буквой Г, Б заменялась на Д, В – на Е и т.д. Так, например, слово “РИМ” превращалось в слово “УЛП”. Получатель сообщения “УЛП” искал эти буквы в нижней строке и по буквам над ними восстанавливал исходное слово “РИМ”. Ключом в шифре Цезаря является величина сдвига 3 алфавита открытого текста. Преемник Юлия Цезаря – цезарь Август – использовал тот же шифр, но с ключом-сдвигом 4. Слово “РИМ” он в этом случае зашифровал бы в буквосочетание “ФМР”.[5]
Итак, смещение K=3 или K=4 можно рассматривать как ключ шифра.
В таблице 2. показаны подстановки, соответствующие шифру Цезаря для латинского алфавита. Английская фраза (открытый текст) meet me after the toga party после шифрования примет следующий вид (шифрованный текст): PHHW PH DIWHU WKH WRJD SDUMB.
Послание Цезаря «VENI VIDI VICI» в переводе на русский язык означающее «Пришел. Увидел. Победил», направленное его другу Аминтию после победы над понтийским царем Фернаком, сыном Митридата, выглядело бы в зашифрованном виде так: YHQL YLGL YLFL.
Если каждой букве назначить числовой эквивалент (а = 1, b = 2 и т.д.), то алгоритм шифрования по Цезарю применительно к латинскому алфавиту можно выразить следующей формулой, которая показывает, каким образом каждая буква открытого текста p заменяется буквой шифрованного текста C:
С = Е(p) = (p + 3) mod(26).
Введем понятие обобщенного алгоритма (шифра) Цезаря, сдвиг K исходного алфавита в котором возможен на любую величину, но не больше, чем количество букв в применяемом алфавите минус 1. Для латинского алфавита обобщенный алгоритм Цезаря записывается формулой[5]:
С = Е(р) = (р + K) mod(26),
где K принимает значения в диапазоне от 1 до 25. Алгоритм расшифровывания также прост:
p = D(С) = (С – K)mod(26)
Достоинством системы шифрования Цезаря является простота шифрования и расшифровывания. К недостаткам системы Цезаря следует отнести:
— подстановки, выполняемые в соответствии с системой Цезаря, не маскируют частот появления различных букв исходного открытого текста;
- сохраняется алфавитный порядок в последовательности заменяющих букв; при изменении значения К изменяются только начальные позиции такой последовательности;
- число возможных ключей К мало;
- шифр Цезаря легко вскрывается на основе анализа частот появления букв в шифротексте и даже на основе простого перебора вариантов.
Две практические задачи криптоанализа: доказательство слабой криптографической стойкости алгоритма Цезаря и шифров моноалфавитной подстановки.[5]
Если известно, что определенный текст был шифрован с помощью шифра Цезаря, то с помощью простого перебора всех вариантов раскрыть шифр очень просто – для этого достаточно проверить 25 возможных вариантов ключей. На рис. 2. показаны результаты применения этой стратегии к указанному выше первому сообщению. В данном случае открытый текст распознается в третьей строке.
Применение метода последовательного перебора всех возможных вариантов оправдано следующими тремя важными характеристиками данного шифра.
1. Известны алгоритмы шифрования и дешифрования.
2. Необходимо перебрать всего 25 вариантов.
3. Язык открытого текста известен и легко узнаваем.
В большинстве случаев, когда речь идет о защите сетей, можно предполагать, что алгоритм известен. Единственное, что делает криптоанализ на основе метода последовательного перебора практически бесполезным – это применение алгоритма, для которого требуется перебрать слишком много ключей. Например, алгоритм DES, использующий 56-битовые ключи, требует при последовательном переборе рассмотреть пространство из 256, или более чем 7х1016 ключей.[5]
Третья характеристика также важна. Если язык, на котором написан открытый текст, неизвестен, то расшифровыванный текст можно не распознать. Более того, исходный текст может состоять из сокращений или быть каким-либо образом сжат – это также затрудняет распознавание.
Рассмотрим теперь более простую возможность повысить криптостойкость шифров моноалфавитной подстановки. Если в латинском алфавите шифротекста допустить использование любой из перестановок 26 символов алфавита, то мы получим 26!, или более чем 4х1026 возможных ключей (ключ в данном случае – применяемый для записи шифротекста алфавит, полученный на основе перестановок символов обычного алфавита, а данный подход можно охарактеризовать как наивысший уровень развития идеи «шифра Цезаря»). Это на 10 порядков больше, чем размер пространства ключей DES, и это кажется достаточным для того, чтобы сделать невозможным успешное применение криптоанализа на основе метода последовательного перебора.[5]
1.3.2 Система шифрования Цезаря с ключевым словом
Особенностью этой системы является использование ключевого слова для смещения и изменения порядка символов в алфавите подстановки.
Выберем некоторое число 0 < К< 25 и слово или короткую фразу в качестве ключевого слова. Желательно, чтобы все буквы ключевого слова были различными. Пусть выбрано слово DIPLOMAT в качестве ключевого слова и число К = 5 (в отличие от ключевого слова это число можно назвать ключевым параметром).[5]
Ключевое слово записывается под буквами алфавита, начиная с буквы, числовой код которой совпадает с выбранным числом К, так как это представлено в табл.3
Оставшиеся буквы алфавита подстановки записываются после ключевого слова в алфавитном порядке, так как это представлено в табл.4. Естественно, что при этом исключаются буквы, входящие в ключевое слово.
Теперь имеем подстановку для каждой буквы произвольного сообщения. Возьмем исходным следующее сообщение: SEND MORE MONEY. Тогда в соответствии с табл. 4 исходное сообщение зашифруется и будет выглядеть как HZBY TCGZ TCBZS.
Следует отметить, что требование о различии всех букв ключевого слова необязательно: буквы, повторяющиеся в ключевом слове, могут быть из него исключены. Несомненным достоинством системы Цезаря с ключевым словом является то, что количество возможных ключевых слов практически неисчерпаемо. Недостатком этой системы является возможность взлома шифротекста на основе анализа частот появления букв.[5]
Выше был сделан вывод о том, что моноалфавитные шифры легко раскрываются, так как они наследуют частотность употребления букв оригинального алфавита. Контрмерой в данном случае может стать применение для одной буквы не одного, а нескольких заменителей (называемых омофонами). Число замен берется пропорциональным вероятности (относительной частоте) появления буквы в открытом тексте. Шифруя букву исходного сообщения, выбирают случайным образом одну из ее замен. Замены (омофоны) могут быть представлены трехразрядными числами от 000 до 999. Например, в английском алфавите букве Е присваиваются 123 случайных номера, буквам В и G – по 16 номеров, а буквам J и Z – по 1 номеру. [3]
Шифротекст представляет собой комбинацию указанных номеров. Выделяемые для каждой буквы номера можно рассматривать в качестве ключей.
Если омофоны (замены) присваиваются случайным образом различным появлениям одной и той же буквы, тогда каждый омофон появляется в шифротексте равновероятно. В этом случае подсчет частотности употребления букв в шифрованном тексте становится бессмысленным. Однако даже при употреблении омофонов по-прежнему будут наблюдаться характерные показатели частоты повторения комбинаций нескольких букв (например, биграмм), и в результате криптоанализ, хотя и усложнился, но, тем не менее, позволяет дешифровать исходный текст при применении шифра омофонной замены.[2]
В разделе 1.3.были рассмотрены и были приведены примеры шифров моноалфавитной (одноалфавитной) подстановки. Такие как, шифр Цезаря, система шифрования Цезаря с ключевым словом и шифр омофонной замены. Такие шифры являются самыми простыми, т.к. они наследуют частотность употребления букв оригинального алфавита.
1.4 Многобуквенные шифры
Данные методы шифрования заключается в замещении не отдельных символов открытого текста, а комбинаций нескольких символов.
Одним из наиболее известных шифров, базирующихся на методе многобуквенного шифрования, является шифр Плейфейера, в котором биграммы открытого текста рассматриваются как самостоятельные единицы, преобразуемые в биграммы шифрованного текста.
Алгоритм Плейфейера применительно к английскому языку основан на использовании матрицы букв размерности 5x5, созданной на основе некоторого ключевого слова. В приведенной в табл. 5 матрице ключевым словом является monarchy (монархия). [3]
Матрица создается путем размещения букв, использованных в ключевом слове, слева направо с продолжением сверху вниз (повторяющиеся буквы отбрасываются). Затем оставшиеся буквы алфавита размещаются в естественном порядке в оставшихся строках и столбцах матрицы. Буквы I и J считаются одной и той же буквой.[1]
Открытый текст шифруется порциями по две буквы в соответствии со следующими правилами.
1. Если оказывается, что повторяющиеся буквы открытого текста образуют одну пару для шифрования, то между этими буквами вставляется специальная буква-заполнитель, например x. В частности, такое слово как balloon будет преобразовано к виду ba lx lo on. Буквы-заполнители можно использовать и в других случаях, например, в конце текста, в конце слова.[1]
2. Если буквы открытого текста, входящие в одну порцию для шифрования, попадают в одну и ту же строку матрицы, каждая из них заменяется буквой, следующей за ней в той же строке справа – с тем условием, что для замены последнего элемента строки матрицы служит первый элемент той же строки. Например, аг шифруется как RM.[1]
3. Если буквы открытого текста, входящие в одну порцию для шифрования, попадают в один и тот же столбец матрицы, каждая из них заменяется буквой, стоящей в том же столбце сразу под ней, с тем условием, что для замены самого нижнего элемента столбца матрицы берется самый верхний элемент того же столбца. Например, mu шифруется как СМ. [1]
4. Если не выполняется ни одно из приведенных выше условий, каждая буква из пары букв открытого текста заменяется буквой, находящейся на пересечении содержащей эту букву строки матрицы и столбца, в котором находится другая буква из пары букв открытого текста. Например, hs шифруется как BP, а ea – как IM (или JM, по желанию шифровальщика). [1]
Таким образом, слово balloon = ba lx lo on в зашифрованном с помощью алгоритма Плейфейера виде будет выглядеть следующим образом:
IBSUPMNA
При расшифровке:
1. Если буквы шифротекста, входящие в одну порцию для расшифровывания, попадают в одну и ту же строку матрицы, каждая из них заменяется буквой, стоящей перед ней слева – с тем условием, что для замены первого элемента строки матрицы служит последний элемент той же строки. [1]
2. Если буквы шифротекста, входящие в одну порцию для шифрования, попадают в один и тот же столбец матрицы, каждая из них заменяется буквой, стоящей в том же столбце непосредственно перед ней, с тем условием, что для замены самого верхнего элемента столбца матрицы берется самый нижний элемент того же столбца. [1]
3. Если не выполняется ни одно из приведенных выше условий расшифровывания, порядок расшифровывания полностью совпадает с порядком шифрования. [1]
В данном примере при расшифровке вначале «проявится» слово ba lx lo on, которое затем редактируется.
Шифр Плейфейера может быть использован и для текста на русском языке. Целесообразный размер матрицы в этом случае 5×6. Из алфавита удаляются буквы Ё (заменяется буквой Е) и буква Й (заменяется буквой И). Буквы Ъ и Ь считаются одной и той же буквой.
Шифр Плейфейера значительно надежнее простых моноалфавитных шифров. С одной стороны, латинских букв всего 26, а биграмм – 26 х 26 = 676, и уже поэтому идентифицировать биграммы сложнее, чем отдельные буквы. С другой стороны, относительная частота появления отдельных букв колеблется гораздо в более широком диапазоне, чем частота появления биграмм, поэтому анализ частотности употребления биграмм тоже оказывается сложнее анализа частотности употребления букв. По этим причинам очень долго считалось, что шифр Плейфейера взломать невозможно. Он служил стандартом шифрования в Британской армии во время Первой мировой войны и нередко применялся в армии США и союзных войсках даже в период Второй мировой войны. [1]
Несмотря на столь высокую репутацию в прошлом, шифр Плейфейера на самом деле вскрыть относительно легко, так как шифрованный с его помощью текст все равно сохраняет многие статистические характеристики открытого текста. Для взлома этого шифра криптоаналитику, как правило, достаточно иметь шифрованный текст, состоящий из нескольких сотен букв.
Еще одним интересным многобуквенным шифром является шифр, разработанный математиком Лестером Хиллом (Lester Hill) в 1929 г. Являясь многобуквенным моноалфавитным шифром, он относится также к категории шифров, реализуемых с помощью аналитических преобразований. Лежащий в его основе алгоритм заменяет каждые m последовательных букв открытого текста m буквами шифрованного текста. Подстановка определяется m линейными уравнениями, для решения которых каждому символу исходного алфавита присваивается числовое значение (для латинского алфавита: а = 0, b = 1,..., z = 25). Например, при m = 3, получаем следующую систему уравнений[1]:
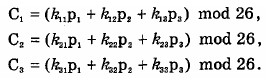
Эту систему уравнений можно записать в виде произведения вектора и матрицы в следующем виде:
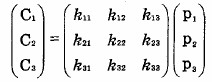
или С=К*Р;
где С и Р – векторы длины 3, представляющие соответственно шифрованный и открытый текст, а К – это матрица размерности 3x3, представляющая ключ шифрования. Операции выполняются по модулю 26 (бинарная операция взятия остатка от деления на 26). [1]
Рассмотрим, например, как будет шифрован текст “рауmоrеmоnеу” при использовании ключа
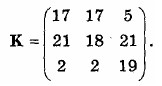
Первые три буквы открытого текста представлены вектором (15 0 24). Таким образом, К(15 0 24) = (375 819 486) mоd 26 = (11 13 18) = LNS. Правила умножения вектора на матрицу раскрыты в представленной выше системе уравнений. Продолжая вычисления и используя тот же ключ, получим для данного примера шифрованный текст вида LNSHDLEWMTRW.
Для расшифровки нужно воспользоваться матрицей, обратной К. Обратной по отношению к матрице К называется такая матрица К-1, для которой выполняется равенство КК-1 = К-1К = I, где I – это единичная матрица (матрица, состоящая из нулей всюду, за исключением главной диагонали, проходящей с левого верхнего угла в правый нижний, на которой предполагаются единицы – см. ниже) [3].Обратная матрица существует не для всякой матрицы, однако, когда обратная матрица имеется, для нее обязательно выполняется приведенное выше равенство. В нашем примере обратной матрицей является матрица
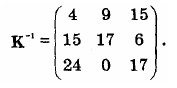
Это проверяется следующими вычислениями:
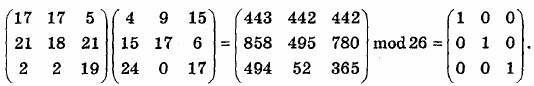
Легко увидеть, что в результате применения матрицы К-1 к шифрованному тексту получается открытый текст.
Для получения обратной матрицы необходимо вычислить определитель заданной матрицы. Определителем квадратной матрицы (т×т) называют сумму таких всевозможных произведений элементов матрицы, что в произведении каждый столбец и каждая строка представлены ровно одним элементом, причем некоторые из этих произведений умножаются на -1. В частности, для матрицы 2×2 вида 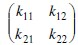 определитель вычисляется по формуле k11k22 – k12k21. Для матрицы 3×3 значение определителя подсчитывается по формуле k11k22k33 + k21k32k13 + k31k12k23 - k31k22k13 - k21k12k33 - k11k32k23. Если квадратная матрица А имеет отличный от нуля определитель, то обратная матрица вычисляется как [А-1]ij= (-1)i+j(Dij)/det(A), где (Dij) – определитель матрицы, получаемой путем удаления i-й строки и j-го столбца из матрицы А, а det(А) – определитель самой матрицы А. В нашем случае все эти вычисления проводятся по модулю 26. Нетрудно видеть, что по указанной формуле определяется каждый элемент обратной матрицы. [1]
определитель вычисляется по формуле k11k22 – k12k21. Для матрицы 3×3 значение определителя подсчитывается по формуле k11k22k33 + k21k32k13 + k31k12k23 - k31k22k13 - k21k12k33 - k11k32k23. Если квадратная матрица А имеет отличный от нуля определитель, то обратная матрица вычисляется как [А-1]ij= (-1)i+j(Dij)/det(A), где (Dij) – определитель матрицы, получаемой путем удаления i-й строки и j-го столбца из матрицы А, а det(А) – определитель самой матрицы А. В нашем случае все эти вычисления проводятся по модулю 26. Нетрудно видеть, что по указанной формуле определяется каждый элемент обратной матрицы. [1]
В общем виде систему Хилла можно записать в следующей форме:
Как и в случае шифра Плейфейера, преимущество шифра Хилла состоит в том, что он полностью маскирует частоту вхождения отдельных букв. Кроме того, для шифра Хилла чем больше размер матрицы в шифре, тем больше в шифрованном тексте скрывается информации о различиях в значениях частоты появления других комбинаций символов. Так, шифр Хилла с матрицей 3×3 скрывает частоту появления не только отдельных букв, но и двухбуквенных комбинаций. [1]
Хотя шифр Хилла устойчив к попыткам криптоанализа в тех случаях, когда известен только шифрованный текст, этот шифр легко раскрыть при наличии известного открытого текста (или хотя бы его части), который может быть получен криптоаналитиком на основе агентурных действий. В этом случае достаточно просто определить матрицу-ключ и использовать ее для расшифровки сообщений до тех пор, пока ключ не будет изменен. Следовательно, для каждого нового сообщения необходимо использовать новый ключ и, желательно, другой размер шифруемой последовательности букв, обозначенный выше как число m. Сложность заключается в синхронизации этого процесса отправителем и получателем сообщения. [1]
В разделе 1.4 рассмотрены более сложные шифры, по сравнению с моноалфавитными шифрами – многобуквенные. Их отличие заключается в том, что заменяются не отдельные символы, а целые комбинации отдельных символов. На примерах были разобраны шифр Плейфейера и шифр Хилла. Эти шифры могут полностью замаскировать частоту вхождения отдельных букв и они достаточно устойчивы к попыткам криптоанализа.
1.5. Шифры полиалфавитной подстановки
Слабая криптостойкость моноалфавитных подстановок преодолевается с применением подстановок многоалфавитных (полиалфавитных). Многоалфавитное шифрование (многоалфавитная замена) заключается в том, что для шифрования последовательных символов исходного текста используются одноалфавитные методы с различными ключами или, иными словами, – свои специальные алфавиты.
Например, первый символ заменяется по методу Цезаря со смещением 18, второй – со смещением 12 и т.д. до конца ключа, задающего переход к новому смещению. Затем процедура продолжается периодически. Более общей является ситуация, когда используется не шифр Цезаря, а последовательность произвольных подстановок, соответствующих одноалфавитным методам.
Самым широко известным и одновременно самым простым алгоритмом такого рода является шифр Виженера (Vigenere). Этот шифр базируется на наборе правил моноалфавитной подстановки, представленных для латинского алфавита из 26 букв шифрами Цезаря со сдвигом от 0 до 25. Каждый из таких шифров можно обозначить ключевой буквой, являющейся буквой шифрованного текста, соответствующей букве a открытого текста. Например, шифр Цезаря, для которого смещение равно 3, обозначается ключевой буквой d. Для полного алфавита русского языка могут использоваться 32 шифра Цезаря со сдвигом от 0 до 32.[5]
Для облегчения понимания и применения этой схемы была предложена матрица, названная “табло Виженера” (рис. 3 и 4). Все 26 (для русского алфавита – 33, а в данном случае – 32) шифров располагаются по горизонтали, и каждому из шифров соответствует своя ключевая буква, представленная в крайнем столбце слева. Алфавит, соответствующий буквам открытого текста, находится в первой сверху строке таблицы. Процесс шифрования прост – необходимо по букве Х, задаваемой ключом, и букве открытого текста У найти букву шифрованного текста, которая находится на пересечении строки Х и столбца У. В данном случае такой буквой является буква V.[2]
Чтобы зашифровать сообщение, нужен ключ, имеющий ту же длину, что и само сообщение. Обычно ключ представляет собой повторяющееся нужное число раз ключевое слово, чтобы получить строку подходящей длины. Например, если ключевым словом является deceptive /обманчивый/, сообщение «we are discovered save yourself» /мы раскрыты, спасайте себя/ шифруется следующим образом.

Расшифровать текст также просто – буква ключа определяет строку, буква шифрованного текста, находящаяся в этой строке, определяет столбец, и в этом столбце в первой строке таблицы будет находиться соответствующая буква открытого текста.[6]
Рассмотрим еще один пример получения шифротекста с помощью таблицы Виженера. Пусть выбрано ключевое слово АМБРОЗИЯ. Необходимо зашифровать сообщение на русском языке ПРИЛЕТАЮ СЕДЬМОГО.
Выпишем исходное сообщение в строку и запишем под ним ключевое слово с повторением. В третью строку будем выписывать буквы шифротекста, определяемые из таблицы Виженера.

Преимущество этого шифра заключается в том, что для представления одной и той же буквы открытого текста в шифрованном тексте имеется много различных вариантов – по одному на каждую из неповторяющихся букв ключевого слова. [2] Таким образом, скрывается информация, характеризующая частотность употребления букв. Но и с помощью данного метода все же не удается полностью скрыть влияние структуры открытого текста на структуру шифрованного.
Можно отметить два предложения по усовершенствованию шифра Виженера. Инженером компании AT&T Гилбертом Вернамом (Gilbert Vernam) в 1918 г. было предложено выбирать ключевое слово, по длине равное длине открытого текста, но отличающегося от открытого текста по статистическим показателям (то есть в общем случае речь шла о фрагменте некоторого текста). Кроме того, система Вернама оперирует не буквами, а двоичными числами. Кратко ее можно выразить формулой[6]:
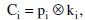
где рi – i-я двоичная цифра открытого текста; ki – i-я двоичная цифра ключа; Ci – i-я двоичная цифра шифрованного текста; ⓧ – операция XOR (исключающее “ИЛИ”).
Таким образом, шифрованный текст генерируется путем побитового выполнения операции XOR для открытого текста и ключа. Благодаря свойствам этой операции для расшифровки достаточно выполнить подобную операцию:

Сутью этой технологии является способ выбора ключа. Г.Вернам предложил использовать закольцованную ленту, что означает циклическое повторение ключевого слова, так что его система на самом деле предполагала работу хоть и с очень длинным, но все же повторяющимся ключом. Несмотря на то, что такая схема в силу очень большой длины ключа значительно усложняет задачу криптоанализа, схему, тем не менее, можно взломать, имея в распоряжении достаточно длинный фрагмент шифрованного текста, известные или вероятно известные фрагменты открытого текста либо и то, и другое сразу.[2]
Офицер армейского корпуса связи Джозеф Моборн (Joseph Mauborgne) предложил такие улучшения схемы шифрования Вернама, которые сделали эту схему исключительно надежной. Моборн предложил отказаться от повторений, а случайным образом генерировать ключ, по длине равный длине сообщения. Такая схема, получившая название ленты однократного использования (или схемы с одноразовым блокнотом), взлому не поддается. В результате ее применения на выходе получается случайная последовательность, не имеющая статистической взаимосвязи с открытом текстом. Поскольку в этом случае шифрованный текст не дает никакой информации об открытом тексте, нет способа и взломать код.[6]
Сложность практического применения этого метода заключается в том, что и отправитель, и получатель должны располагать одним и тем же случайным ключом и иметь возможность защитить его от посторонних. Поэтому, несмотря на все преимущества шифра Вернама-Моборна перед другими шифрами, на практике к нему прибегают редко.[2]
1.5.2 Шифр “двойной квадрат” Уитстона
В 1854 г. англичанин Чарльз Уитстон разработал новый метод шифрования биграммами, который называют “двойным квадратом”. Свое название этот шифр получил по аналогии с полибианским квадратом, изобретенным в древнем мире. Шифр Уитстона открыл новый этап в истории развития криптографии. В отличие от полибианского шифр «двойной квадрат» использует сразу две таблицы, размещенные по одной горизонтали, а шифрование идет биграммами, как в шифре Плейфейера. Эти не столь сложные модификации привели к появлению на свет качественно новой криптографической системы ручного шифрования. Шифр «двойной квадрат» оказался очень надежным и удобным и применялся Германией даже в годы Второй мировой войны.[2]
Поясним процедуру шифрования этим шифром на примере. Пусть имеются две таблицы со случайно расположенными в них буквами русского алфавита (рис. 5). Перед шифрованием исходное сообщение разбивают на биграммы. Каждая биграмма шифруется отдельно. Первую букву биграммы находят в левой таблице, а вторую букву – в правой таблице. Затем мысленно строят прямоугольник так, чтобы буквы биграммы лежали в его противоположных вершинах. Другие две вершины этого прямоугольника дают буквы биграммы шифротекста. Первый символ шифрованной пары должен лежать в одной строке с первым символом исходной.
Предположим, что шифруется биграмма исходного текста ИЛ. Буква И находится в столбце 1 и строке 2 левой таблицы. Буква Л находится в столбце 5 и строке 4 правой таблицы. Это означает, что прямоугольник образован строками 2 и 4, а также столбцами 1 левой таблицы и 5 правой таблицы. Следовательно, в биграмму шифротекста входят буква О, расположенная в столбце 5 и строке 2 правой таблицы, и буква В, расположенная в столбце 1 и строке 4 левой таблицы, т.е. получаем биграмму шифротекста ОВ.[2]
Если обе буквы биграммы сообщения лежат в одной строке, то и буквы шифротекста берут из этой же строки. Пусть первый символ имеет позицию (s, c) в левой таблице. Тогда он заменяется тем символом правой таблицы, какой там стоит на позиции (s, c). Пусть второй символ имеет позицию (s2, c2) в правой таблице. Тогда он заменяется тем символом левой таблицы, какой там стоит на позиции (s2, c2).[6]
Поэтому биграмма сообщения ТО превращается в биграмму шифротекста ЖБ. Аналогичным образом шифруются все биграммы сообщения:

Шифрование методом «двойного квадрата» дает весьма устойчивый к вскрытию и простой в применении шифр. Взламывание шифротекста «двойного квадрата» требует больших усилий, при этом длина сообщения должна быть не менее тридцати строк.
Расшифровывание требует тех же действий, что и шифрование, только в обратном порядке. Обратный порядок означает, между прочим, что первая буква биграммы шифротекста выбирается в правой таблице, а вторая – в левой.
Две таблицы со случайно расположенными в них буквами естественного алфавита можно рассматривать как два секретных ключа. В то же время их можно рассматривать как форму представления двух специальных алфавитов для записи шифротекстов. Это доказывает, что шифр “двойной квадрат” Уитстона является частным случаем много алфавитных шифров.[6]
В пункте 1.5 изучались полиалфавитные шифры. Они базируются на принципе моноалфавитных шифров, но их особенностью является применение специальных (новых) алфавитов. Были рассмотрены на примерах шифр Виженера и шифр “двойной квадрат” Уитстона. С помощью этих шифров скрывается информация, характеризующая частотность употребления букв, что значительно увеличивает сложность их раскрытия.
1.6 Применение перестановок
Все рассмотренные выше методы основывались на замещении по определенным правилам символов открытого текста на естественном языке различными символами специального алфавита (алфавитов), предназначенных для записи шифрованного текста. Принципиально иной класс преобразований строится на использовании перестановок букв открытого текста. Шифры, созданные с помощью перестановок, называют перестановочными шифрами.
Простейший из перестановочных шифров использует преобразование “лесенки”, заключающееся в том, что открытый текст записывается вдоль наклонных строк определенной длины («ступенек»), а затем считывается построчно по горизонтали. Например, чтобы шифровать сообщение «meet me after the toga party» /встретьте меня после вечеринки в тогах/ по методу лесенки со ступеньками длиной 2 символа, запишем это сообщение в виде[3]:

Шифрованное сообщение будет иметь следующий вид:
MEMATRHTGPRYETEFETEOAAT
Количество ступенек в «лесенке» рассматривается как ключ шифра. Такой шифр особой сложности для криптоанализа не представляет. Дешифровка может быть осуществлена на основе перебора вариантов количества ступенек в «лесенке».
При расшифровке необходимо определить количество символов в зашифрованной строке и разделить шифрованный текст на равные части в соответствии со значением ключа (количества ступенек в «лесенке»). Первая часть образует первую строку лесенки, вторая часть – вторую и т.д. Дальнейшая расшифровка не представляет труда. При делении с остатком необходимо иметь в виду, что последняя «лесенка» будет «не достроена» за счет нижних ступенек, что характерно для приведенного простого примера.[3]
1.6.2 Шифр вертикальной перестановки
Более сложная схема предполагает запись текста сообщения в горизонтальные строки одинаковой длины и последующее считывание текста столбец за столбцом, но не по порядку, а в соответствии с некоторой перестановкой столбцов. Порядок считывания столбцов при этом становится ключом алгоритма[3]. Рассмотрим пример шифрования следующей фразы: attack postponed until two am /атака отложена до двух ночи/. Первоначально фраза записывается построчно с помощью матрицы размером 4×7, затем с использованием ключа преобразуется в шифротекст[1]:

Буквы x, y, z используются в данном случае как буквы-заполнители.
Простой перестановочный шрифт очень легко распознать, так как буквы в нем встречаются с той же частотой, что и в открытом тексте.[3] Например, для только что рассмотренного способа шифрования с перестановкой столбцов анализ шифра выполнить достаточно просто – необходимо записать шифрованный текст в виде матрицы и перебрать возможные варианты перестановок для столбцов. Можно использовать также таблицы значений частоты биграмм и триграмм.
Перестановочный шифр можно сделать существенно более защищенным, выполнив шифрование с использованием перестановок несколько раз. Оказывается, что в этом случае примененную для шифрования перестановку воссоздать уже не так просто. [4]Например, если предыдущее сообщение шифровать еще раз с помощью того же самого алгоритма, то результат будет следующим:

Чтобы нагляднее представить то, что мы получим в итоге повторного применения перестановки, сопоставим каждую букву исходного открытого текста с номером соответствующей ей позиции. Наше сообщение состоит из 28 букв, и исходной последовательностью будет последовательность:

После первой перестановки получим последовательность, которая все еще сохраняет некоторую регулярность структуры.

После второй перестановки получается следующая последовательность.

Регулярность этой последовательности уже совсем не просматривается, поэтому ее криптоанализ потребует значительно больше усилий.
Если известен ключ, расшифровка весьма проста и не требует пояснений.[3]
В разделе 1.6 изучались перестановочные шифры. Их особенностью является не замещение букв, а перестановка букв открытого текста. Рассматривались шифр «Лесенка» и шифр вертикальной перестановки. Первый является наиболее простым в понимании, а шифр вертикальной перестановки – это усложненный вариант, который требует значительных усилий при расшифровке и криптоанализе.
1.7 Симметричные системы защиты информации
По мнению К.Шеннона, в практических шифрах необходимо использовать два общих принципа: рассеивание и перемешивание.
Рассеивание представляет собой распространение влияния одного знака открытого текста на много знаков шифротекста, что позволяет скрыть статистические свойства открытого текста.
Перемешивание предполагает использование таких шифрующих преобразований, которые усложняют восстановление взаимосвязи статистических свойств открытого и шифрованного текстов. Однако шифр должен не только затруднять раскрытие, но и обеспечивать легкость шифрования и расшифровывания при известном пользователю секретном ключе[4].
Распространенным способом достижения эффектов рассеивания и перемешивания является использование составного шифра, т.е. такого шифра, который может быть реализован в виде некоторой последовательности простых шифров, каждый из которых вносит свой вклад в значительное суммарное рассеивание и перемешивание.
В составных шифрах в качестве простых шифров чаще всего используются простые перестановки и подстановки. При перестановке просто перемешивают символы открытого текста, причем конкретный вид перемешивания определяется секретным ключом. При подстановке каждый символ открытого текста заменяют другим символом из того же алфавита, а конкретный вид подстановки также определяется секретным ключом. Следует заметить, что в современном блочном шифре блоки открытого текста и шифротекста представляют собой двоичные последовательности обычно длиной 64 бита. В принципе каждый блок может принимать 264 значений. Поэтому подстановки выполняются в очень большом алфавите, содержащем до 264 = 1019 «символов».
При многократном чередовании простых перестановок и подстановок, управляемых достаточно длинным секретным ключом, можно получить очень стойкий шифр с хорошим рассеиванием и перемешиванием. Рассмотренные ниже криптосистемы DES и отечественный стандарт шифрования данных ГОСТ 28147-89 построены в полном соответствии с указанной методологией.[6]
1.7.1 Американский стандарт шифрования данных DES
Стандарт шифрования данных DES (Data Encryption Standard) опубликован в 1977 г. Национальным бюро стандартов США. Стандарт DES предназначен для защиты от несанкционированного доступа к важной, но несекретной информации в государственных и коммерческих организациях США. Алгоритм, положенный в основу стандарта, распространялся достаточно быстро, и уже в 1980 г. был одобрен Национальным институтом стандартов и технологий США (НИСТ). С этого момента DES превращается в стандарт не только по названию (Data Encryption Standard), но и фактически. Появляются программное обеспечение и специализированные микро-ЭВМ, предназначенные для шифрования и расшифровывания информации в сетях передачи данных.[4] К настоящему времени DES является наиболее распространенным криптографическим алгоритмом, используемым в системах защиты коммерческой информации. Более того, реализация алгоритма DES в таких системах становится признаком хорошего тона.[4]
Основные достоинства алгоритма DES:
– используется только один ключ длиной 56 бит;
– зашифровав сообщение с помощью одного пакета программ, для расшифровки можно использовать любой другой пакет программ, соответствующий стандарту DES;
– относительная простота алгоритма обеспечивает высокую скорость обработки;
– достаточно высокая стойкость алгоритма.
Первоначально метод, лежащий в основе стандарта DES, был разработан фирмой IBM для своих целей и реализован в виде системы “Люцифер”. Система “Люцифер” основана на комбинировании методов подстановки и перестановки и состоит из чередующейся последовательности блоков перестановки и подстановки. В ней использовался ключ длиной 128 бит, управлявший состояниями блоков перестановки и подстановки. Система “Люцифер” оказалась весьма сложной для практической реализации из-за относительно малой скорости шифрования (2190 байт/с – программная реализация, 96970 байт/с – аппаратная реализация).[6]
Алгоритм DES также использует комбинацию подстановок и перестановок. DES осуществляет шифрование 64-битовых блоков данных с помощью 64-битового ключа, в котором значащими являются 56 бит (остальные 8 бит – проверочные биты для контроля на четность). Расшифровывание в DES является операцией, обратной шифрованию, и выполняется путем повторения операций шифрования в обратной последовательности. Обобщенная схема процесса шифрования в алгоритме DES показана на рис.6. Процесс шифрования заключается в начальной перестановке битов 64-битового блока, шестнадцати циклах шифрования и, наконец, в конечной перестановке битов.
Алгоритм DES вполне подходит как для шифрования, так и для аутентификации данных. Он позволяет непосредственно преобразовывать 64-битовый входной открытый текст в 64-битовый выходной шифрованный текст, однако данные редко ограничиваются 64 разрядами. Чтобы воспользоваться алгоритмом DES для решения разнообразных криптографических задач, разработаны четыре рабочих режима[6]:
• электронная кодовая книга ECB (Electronic Code Book);
• сцепление блоков шифра CBC (Cipher Block Chaining);
• обратная связь по шифротексту CFB (Cipher Feed Back);
• обратная связь по выходу OFB (Output Feed Back).
Каждому из рассмотренных режимов (ECB, СВС, CFB, OFB) свойственны свои достоинства и недостатки, что обусловливает области их применения.
Режим ЕСВ хорошо подходит для шифрования ключей; режим CFB, как правило, предназначается для шифрования отдельных символов, а режим OFB нередко применяется для шифрования в спутниковых системах связи.
Режимы СВС и CFB пригодны для аутентификации данных. Эти режимы позволяют использовать алгоритм DES[4]:
– для интерактивного шифрования при обмене данными между терминалом и главной ЭВМ;
– шифрования криптографического ключа в практике автоматизированного распространения ключей;
– шифрования файлов, почтовых отправлений, данных спутников и других практических задач.
Одним из наиболее важных применений алгоритма DES является защита сообщений электронной системы платежей (ЭСП) при операциях с широкой клиентурой и между банками.[4]
Алгоритм DES реализуется в банковских автоматах, терминалах, в торговых точках, автоматизированных рабочих местах и главных ЭВМ. Диапазон защищаемых им данных весьма широк – от оплат $50 до переводов на многие миллионы долларов. Гибкость основного алгоритма DES позволяет использовать его в самых разнообразных областях применения электронной системы платежей.
1.7.2 Отечественный стандарт шифрования данных
В нашей стране установлен единый алгоритм криптографического преобразования данных для систем обработки информации в сетях ЭВМ, отдельных вычислительных тельных комплексах и ЭВМ, который определяется ГОСТ 28147-89. Частичная модификация этого алгоритма опубликована в стандарте ГОСТ Р 34.12-2015.
Стандарт обязателен для организаций, предприятий и учреждений, применяющих криптографическую защиту данных, хранимых и передаваемых в сетях ЭВМ, в отдельных вычислительных комплексах и ЭВМ.
Этот алгоритм криптографического преобразования данных предназначен для аппаратной и программной реализации, удовлетворяет криптографическим требованиям и не накладывает ограничений на степень секретности защищаемой информации. Алгоритм шифрования данных представляет собой 64-битовый блочный алгоритм с 256-битовым ключом. Алгоритм предусматривает четыре режима работы[4]:
– шифрование данных в режиме простой замены;
– шифрование данных в режиме гаммирования;
– шифрование данных в режиме гаммирования с обратной связью;
– выработка имитовставки.
Следует иметь в виду, что режим простой замены допустимо использовать для шифрования данных только в ограниченных случаях – при выработке ключа и шифровании его с обеспечением имитозащиты для передачи по каналам связи или для хранения в памяти ЭВМ.
Режим гаммирования реализуется в данной криптосистеме как блочное шифрование, в котором сообщение обрабатывается в виде блоков определенной длины. Это основной режим рассматриваемой системы[6].
Режим гаммирования с обратной связью превращает блочный шифр в самосинхронизирующийся поточный шифр, в котором преобразуется всё сообщение сразу.
Режим выработки имитовставки обеспечивает защиту системы шифрованной связи от навязывания ложных данных. Имитовставка – это блок из Р бит, который вырабатывают по определенному правилу из открытых данных с использованием ключа и затем добавляют к зашифрованным данным для обеспечения их имитозащиты.[6]
В стандартах ГОСТ 28147-89 и ГОСТ Р 34.12-2015 определяется процесс выработки имитовставки, который единообразен для любого из режимов шифрования/расшифровывания данных. Имитовставка Ир вырабатывается из блоков открытых данных либо перед шифрованием всего сообщения, либо параллельно с шифрованием по блокам. Первые блоки открытых данных, которые участвуют в выработке имитовставки, могут содержать служебную информацию (например, адресную часть, время, синхропосылку) и не зашифровываются.
Значение параметра Р (число двоичных разрядов в имитовставке) определяется криптографическими требованиями с учетом того, что вероятность навязывания ложных помех равна 1/2p.
Алгоритм выработки имитовставок обеспечивает сравнение имитовставок, полученных при шифровании, с имитовставками, полученными при расшифровывании. В случае несовпадения имитовставок полученные в результате расшифровки блоки открытых данных считают ложными. Алгоритм формирования имитовставок может использовать функцию хеширования.[6]
В разделе 1.7 для ознакомления были рассмотрены Американский стандарт шифрования данных DES и Отечественный стандарт шифрования данных.
ЗАКЛЮЧЕНИЕ
В данной курсовой работе были подробно рассмотрены способы кодирования информации с помощью науки криптографии и методов ее шифрования. Исходя из рассмотренной информации, можно сделать вывод, что криптография – это незаменимый атрибут кодирования данных по всему миру и во все времена, т.к. информационная безопасность очень важна в работе с представлением и кодированием данных.
Таким образом, цель работы - рассмотрение форматов данных и методы кодирования их в компьютере была достигнута.
В работе были решены поставленные задачи, а именно:
- Изучены шифры моноалфавитной подстановки;
- Рассмотрены многобуквенные шифры и шифры полиалфавитной подстановки;
- Изучены симметричные системы защиты информации;
- Рассмотрено применение перестановок.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Гашков С.Б., Применко Э.А., Черепнев М.А.. Криптографические методы защиты информации: Учеб. пособие для вузов по направлению "Прикл. математика и информатика" и "Информ. технологии" /. - М.: Академия, 2010. -298 с.
- Жук А.П. Защита информации: учеб. пособ. / А.П. Жук, Е.П. Жук, О.М. Лепешкин, А.И. Тимош-кин. – 2-изд. – М.: РИОР: ИНФРА-М, 2017. – 392 с.
- Златопольский Д.М. Простейшие методы шифрования текста /. - М.: Чистые пруды, 2007. - 31 с.
- Карзаева Н.Н. Основы экономической безопасности: учебник / Н.Н. Карзаева. – М.: ИНФРА-М, 2017. – 275 с.
- Роберт Черчхаус. Коды и шифры. Юлий Цезарь, "Энигма" и Интернет: пер. с англ. / - М.: ВЕСЬ МИР, 2005. - 302 с.
- Шаханова М.В. Современные технологии информационной безопасности: учебно-методический комплекс. – М.: Проспект, 2017 – 216 с.
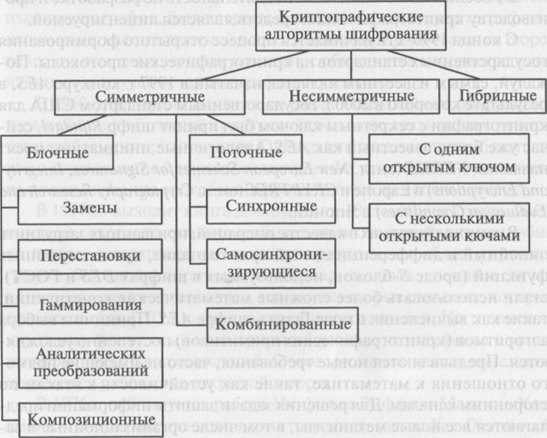
Рис. 1. Классификация криптографических алгоритмов шифрования
Таблица 1.
Подстановки по шифру Цезаря для алфавита русского языка[5]
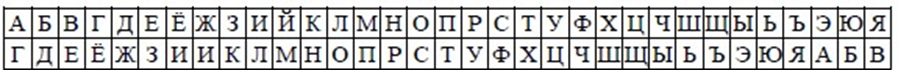
Таблица 2.
Подстановки по шифру Цезаря для латинского алфавита [5]
|
A—> D |
J—> M |
S—> V |
|
В —> Е |
К —> N |
Т —> W |
|
С —> F |
L—> O |
U—> X |
|
D —> G |
M—> P |
V—> Y |
|
E —> H |
N—> O |
W—> Z |
|
F —> I |
O—> R |
X —> А |
|
G —> J |
P—> S |
Y—> B |
|
H —> K |
Q —> Т |
Z—> C |
|
I —> L |
R—> U |

Рис. 2. Криптоанализ шифра Цезаря методом перебора всех вариантов ключей [5]
Таблица 3.
Исходный алфавит и ключевое слово
|
0 |
5 |
10 |
15 |
20 |
25 |
||||||||||||||||||||
|
А |
В |
С |
D |
Е |
F |
G |
Н |
I |
J |
К |
L |
М |
N |
О |
Р |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
D |
I |
Р |
L |
О |
M |
А |
Т |
Таблица 4
Измененный алфавит для осуществления подстановки
|
0 |
5 |
10 |
15 |
20 |
25 |
||||||||||||||||||||
|
А |
В |
С |
D |
Е |
F |
G |
Н |
I |
J |
К |
L |
М |
N |
О |
Р |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
V |
W |
X |
Y |
Z |
D |
I |
Р |
L |
О |
M |
А |
Т |
В |
С |
Е |
F |
G |
H |
J |
K |
N |
0 |
R |
S |
U |
Таблица 5.
Пример матрицы для шифра Плейфейера[3]
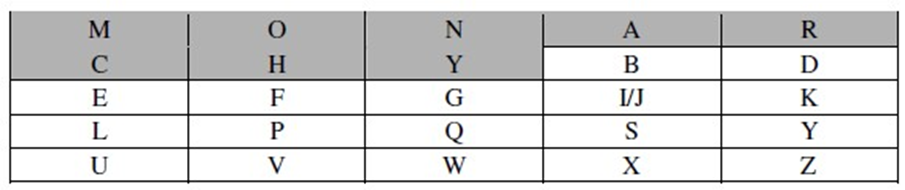

Рис. 3 Современное табло Виженера для латинского алфавита[6]

Рис. 4 Таблица Виженера для русского алфавита[6]
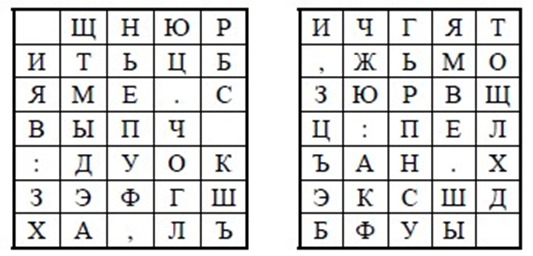
Рис. 5 Две таблицы со случайно расположенными символами русского алфавита для шифра «двойной квадрат»[2]
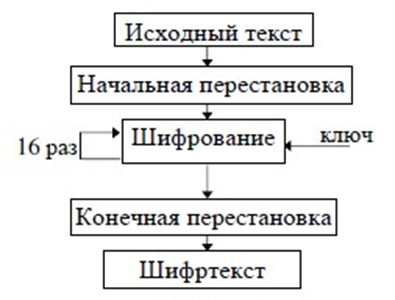
Рис. 6. Обобщенная схема шифрования в алгоритме DЕS[4]

- Применение процессного подхода для оптимизации бизнес-процессов
- Лизинг как особая форма кредитования (Сущность, виды и функции лизинга)
- Лизинг как особая форма кредитования (ЛИЗИНГ: ТЕОРЕТИЧЕСКИЙ АСПЕКТ)
- Особенности профессиональной мотивации служащих организации
- Информация в материальном мире
- Отчет о финансовых результатах: методика и техника составления
- Понятие и виды источников права
- Современные политические режимы (Политический режим современной России)
- Отчет о финансовых результатах: методика и техника составления
- Взаимодействие органов государственной власти и молодежных организаций в Российской Федерации: современное состояние и пути совершенствования
- Отличие и взаимосвязь управленческого, производственного и финансового учета ( Управленческий, производственный и финансовый учет)
- Социально-психологический климат организации ( ЗНАЧЕНИЕ СОЦИАЛЬНО-ПСИХОЛОГИЧЕСКОГО КЛИМАТА В ТРУДОВОМ КОЛЛЕКТИВЕ)