
Методы кодирования данных (История, примеры)
Содержание:

1. История кодирования информации
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли:
- криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для непосвященных лиц;

- азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
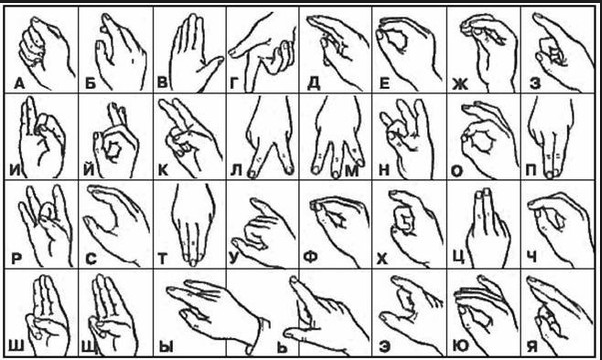
- сурдожесты – язык жестов, используемый людьми с нарушениями слуха.
Один из самых первых известных методов шифрования носит имя римского императора Юлия Цезаря (I век до н.э.) . Этот метод основан на замене каждой буквы шифруемого текста, на другую, путем смещения в алфавите от исходной буквы на фиксированное количество символов, причем алфавит читается по кругу, то есть после буквы я рассматривается а. Так слово «байт» при смещении на два символа вправо кодируется словом «гвлф». Обратный процесс расшифровки данного слова – необходимо заменять каждую зашифрованную букву, на вторую слева от неё.
2. Кодирование информации
Теория кодирования и теория информации возникли в начале XX века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К. Шеннона, которые заложили фундамент для дальнейших исследований в этой области.
Кодирование – способ представления информации в удобном для хранения и передачи виде. В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач программирования, таких как:
-
- представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
- обеспечение помехоустойчивости при передаче данных по каналам связи;
- сжатие информации в базах данных.
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов:
Шум
Источник
Кодер
источника
Канал
Приемник
Кодер
канала
Декодер
канала
Декодер
источника
Начальным звеном в приведенной выше модели является источник информации. Здесь рассматриваются дискретные источники без памяти, в которых выходом является последовательность символов некоторого фиксированного алфавита. Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 33 русских букв, пробела и знаков препинания.
Кодирование дискретного источника заключается в сопоставлении символов алфавита А источника символам некоторого другого алфавита В. Причем обычно символу исходного алфавита А ставится в соответствие не один, а группа символов алфавита В, которая называется кодовым словом. Кодовый алфавит – множество различных символов, используемых для записи кодовых слов. Кодом называется совокупность всех кодовых слов, применяемых для представления порождаемых источником символов.
Обычно каждый образ при кодировании (иногда говорят – шифровке) представлении отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
2.1. Примеры двоичного кодирования информации.
Представление информации в двоичной системе использовалось человеком с давних времен. Так, жители островов Полинезии передавали необходимую информацию при помощи барабанов: чередование звонких и глухих ударов. Звук над поверхностью воды распространялся на достаточно большое расстояние, таким образом «работал» полинезийский телеграф. В телеграфе в XIX–XX веках информация передавалась с помощью азбуки Морзе – в виде последовательности из точек и тире. Часто мы договариваемся открывать входную дверь только по «условному сигналу» – комбинации коротких и длинных звонков.
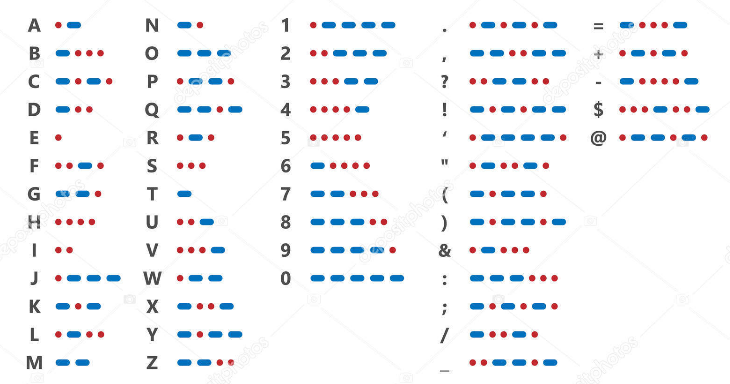
Самюэл Морзе в 1838 г. изобрел код – телеграфную азбуку – систему кодировки символов короткими и длинными посылками для передачи их по линиям связи, известную как «код Морзе» или «морзянка». Современный вариант международного «кода Морзе» (International Morse) появился совсем недавно – в 1939 году, когда была проведена последняя корректировка.
Своя система существует и в вычислительной технике - она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски - binary digit или сокращенно bit (бит). Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.п.).
2.1.1. Кодирование чисел
Есть два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, нужно:
1) перевести число N в двоичную систему счисления;
2) полученный результат дополнить слева незначащими нулями до k разрядов.
Например, для получения внутреннего представления целого числа 1607 в 2-х байтовой ячейке число переводится в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке имеет вид: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (–N) нужно:
1) получить внутреннее представление положительного числа N;
2) получить обратный код этого числа, заменяя 0 на 1 и 1 на 0;
3) полученному числу прибавить 1 к полученному числу.
Внутреннее представление целого отрицательного числа –1607. С использованием результата предыдущего примера и записывается внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Обратный код получается инвертированием: 1111 1001 1011 1000. Добавляется единица: 1111 1001 1011 1001 – это и есть внутреннее двоичное представление числа –1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p.
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12,345 = 0,0012345 × 104 = 1234,5 × 10-2 = 0,12345 × 102
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию:
0,1p Ј m < 1p. Иначе говоря, мантисса меньше 1 и первая значащая цифра – не ноль (p – основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12,345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12 345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере – это 2.
2.1.2. Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
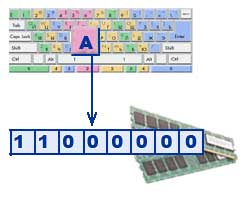 Традиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события): К = 2I = 28 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события): К = 2I = 28 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
2.1.3. Кодирование символов. Байт.
На основании одной ячейки информационной ёмкостью 1 бит можно закодировать только 2 различных состояния. Для того чтобы каждый символ, который можно ввести с клавиатуры в латинском регистре, получил свой уникальный двоичный код, требуется 7 бит. На основании последовательности из 7 бит, в соответствии с формулой Хартли, может быть получено N=27=128 различных комбинаций из нулей и единиц, т.е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами.
Для латинской раскладки клавиатуры такая кодировочная таблица одна на весь мир, поэтому текст, набранный с использованием латинской раскладки, будет адекватно отображен на любом компьютере. Эта таблица носит название ASCII (American Standard Code of Information Interchange) по-английски произносится [э́ски], по-русски произносится [а́ски]. Ниже приводится вся таблица ASCII, коды в которой указаны в десятичном виде. По ней можно определить, что когда вы вводите с клавиатуры, скажем, символ “*”, компьютер его воспринимает как код 42(10), в свою очередь 42(10)=101010(2) – это и есть двоичный код символа “*”. Коды с 0 по 31 в этой таблице не задействованы.
Чтобы хранить также и коды национальных символов каждой страны (в нашем случае – символов кириллицы) требуется добавить еще 1 бит, что увеличит количество уникальных комбинаций из нулей и единиц вдвое, т.е. в нашем распоряжении дополнительно появится 128 свободных кодов (со 128-го по 255-й), в соответствие которым можно поставить символы русского алфавита.
Таким образом, отведя под хранение информации о коде каждого символа 8 бит, мы получим N=28=256 уникальных двоичных кодов, что достаточно, чтобы закодировать все символы, которые можно ввести с клавиатуры.
Так мы подошли к необходимости познакомиться с еще одной базовой единицей измерения – байтом.
Байт - последовательность из 8 бит.
1 байт = 23 бит = 8 бит.
На основании одного байта можно получить 28=256 уникальных двоичных кодов.
В современных кодировочных таблицах под хранение информации о коде каждого символа отводится 1 байт.
1 символ = 1 байт.
В байтах измеряется объем данных (V) при их хранении и передаче по каналам связи. Например, текст “Добрый день!” занимает объем равный 12 байтам.
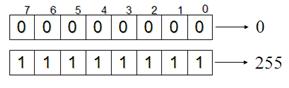
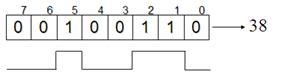
Биты в байте нумеруются с конца с 0-го по 7-й. Минимальная комбинация на основании одного байта – восемь нулей, максимальная – восемь единиц. Рис. 18а.
11111111(2)=27+26+25+24+23+22+21+20=128+64+32+16+8+4+2+1=255(10)
При хранении на физическом уровне каждый байт может быть реализован, например, на базе восьми конденсаторов, каждый из которых либо разряжен (0), либо заряжен (1). Рис. 18b.
|
|
|
|
Рис. 18а. Байт: минимальная и максимальная комбинации |
Рис. 18b. Байт: соответствие двоичного числа и электрического импульса. |
Возвращаясь к кодировочным таблицам, заметим, что на сегодняшний день в использовании не одна, а несколько кодировочных таблиц, включающих коды кириллицы, – это стандарты, выработанные в разные годы и различными учреждениями. В этих таблицах различен порядок, в котором расположены друг за другом символы кирилличного алфавита, поэтому одному и тому же коду соответствуют разные символы. По этой причине, мы иногда сталкиваемся с текстами, которые состоят из русских букв, но в бессмысленной для нас последовательности.
Например, текст “Компьютерные вирусы”, введенный в кодировке Windows-1251 в кодировке КОИ-8 будет отображен так: ”лПНРШАФЕТОШЕ ЧЙТХУЩ”.
Несоответствие кодов символов в различных кодировках кириллицы.
|
Код |
Windows-1251 |
КОИ-8 |
ISO |
Под национальные кодировки отданы коды с 128-го по 255-й. |
|
192 |
А |
ю |
Р |
|
|
193 |
Б |
а |
С |
|
|
194 |
В |
б |
Т |
Эта проблема разрешима - на каждом компьютере найдутся все основные кодировочные таблицы, и если тест выглядит неадекватно, нужно попробовать перекодировать его, просто указав использовать другую кодировочную таблицу. Но наличие такой проблемы, конечно, вносит неудобства.
Используя 8-битную кодировочную таблицу мы не сможем адекватно увидеть на мониторе и тексты, созданные на тех языках, где используются символы, отличные от латинских и кирилличных, например символы с умляутами в немецком языке.
Теоретически давно существует решение проблем связанных с кодировкой. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита - в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
2.1.4. Кодирование графической информации
Графическая информация, как и информация любого другого типа, хранятся в памяти компьютера в виде двоичных кодов. Изображение, состоящее из отдельных точек, каждая из которых имеет свой цвет, называется растровым изображением. Минимальный элемент такого изображения в полиграфии называется растр, а при отображении графики на мониторе минимальный элемент изображения называют пиксель (pixel, от англ. picture element).
Пиксель - минимальный участок изображения, цвет которого можно задать независимым образом.
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части – растровую и векторную графику.

Растровые изображения представляют собой однослойную сетку точек, называемых пикселами. Код пиксела содержит информацию о его цвете.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия. Каждый элемент векторного изображения является объектом, который описывается с помощью математических уравнений. Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые в свою очередь содержат определенное количество точек.
Графический режим вывода изображения на экран монитора определяется величиной разрешающей способности и глубиной цвета.
Качество изображения определяется разрешающей способностью монитора, т.е. количеством точек, из которых оно складывается. Чем больше разрешающая способность, то есть чем больше количество строк растра и точек в строке, тем выше качество изображения.
В современных персональных компьютерах обычно используются три основные разрешающие способности экрана:
1280 х 1024
1600 x 1200
1680 x 1050
При кодировании цвета происходит его разложение на основные составляющие - их три (красный, синий, зеленый). Смешивая эти цвета получаются различные оттенки.
В процессе дискретизации используются разные палитры.
Каждый цвет рассматривается как будущее состояние точки. Количество цветов N и количество информации I, связаны между собой и вычисляются по формуле: N=2i. Такие выходные данные необходимы для кодирования цвета каждой по отдельности точки.
Например, в самом простом случае палитра цветов состоит из двух - черного и белого.
Значит каждая точка на экране принимает либо «черное» либо «белое» состояние.
По заданной формуле можно вычислить количество информации, необходимое для кодирования цвета каждой точки.
Количество бит, необходимое для кодирования цвета точки - это глубина цвета.
Цветные изображения строятся с двоичным кодом цвета каждой точки. Эта информация хранится в видеопамяти. Такие изображения меняют глубины цвета - 8, 16, 24 и 32 бита.
Цветная картинка рождается на экране путем смешивания трех базовых цветов: красного, зеленого, синего. Эта цветовая модель называется RGB (по первым буквам английских названий цветов - Red, Green, Blue)
Для получения множества оттенков (соответственно выходит и богатая палитра цветов) основным или базовым цветам задаются различные интенсивности (яркость, контрастность, насыщеность).
Например, при глубине цвета в 24 бита (по 8 бит на каждый цвет) выходит N=28 =256 уровней интенсивности, заданные двоичными кодами - от 00000000 (минимальной ) до 11111111 (максимальной).
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
2.1.5. Кодирование звука
На компьютере работать со звуковыми файлами начали в 90-х годах. В основе цифрового кодирования звука лежит – процесс преобразования колебаний воздуха в колебания электрического тока и последующая дискретизация аналогового электрического сигнала. Кодирование и воспроизведение звуковой информации осуществляется с помощью специальных программ (редактор звукозаписи).
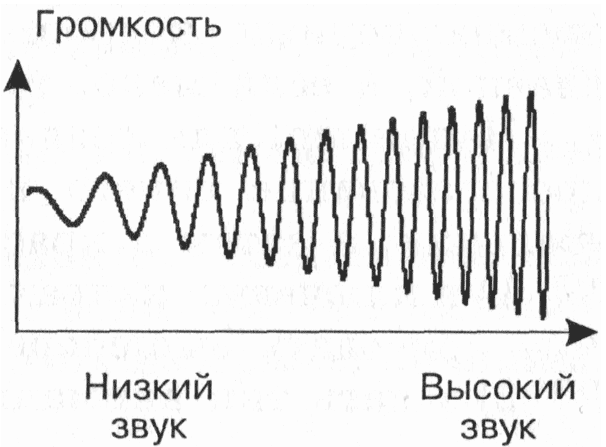
Физически звук представляет собой волновые колебания давления в той или иной среде. Каковы бы ни были физические характеристики колебаний, в данном случае важно то, что звук представляет собой нечто неделимое на части (непрерывное), пробегающее в пространстве и времени. Чтобы записать звук на какой-нибудь носитель можно соотнести его уровень (силу) с какой-нибудь измеряемой характеристикой этого носителя. Так, например, степень намагниченности магнитной ленты в различных ее местах зависит от особенностей звука, который на нее записывался. Намагниченность может непрерывно изменяться на протяжении ленты, подобно тому, как параметры звука могут меняться в воздухе. т.е. магнитная лента прекрасно справляется с задачей хранения звука. И хранит его в так называемой аналоговой форме, когда значения изменяются непрерывно (плавно), что близко к естественному звуку.
Временная дискретизация – способ преобразования звука в цифровую форму путем разбивания звуковой волны на отдельные маленькие временные участки где амплитуды этих участков квантуются (им присваивается определенное значение).
Это производится с помощью аналого-цифрового преобразователя, размещенного на звуковой плате. Таким образом, непрерывная зависимость амплитуды сигнала от времени заменяется дискретной последовательностью уровней громкости. Современные 16-битные звуковые карты кодируют 65536 различных уровней громкости или 16-битную глубину звука (каждому значению амплитуды звук. сигнала присваивается 16-битный код)
Но как хранить звук на компьютере. Здесь любая информация представлена в цифровой форме. Данные должны быть представлены числами, а, следовательно, информация в компьютере дискретна (разделена). Для того, чтобы записать звук на цифровой носитель информации (например, жесткий диск), его подвергают так называемой оцифровке, механизм которой заключается в измерении параметров звука через определенные промежутки времени (очень малые).
Частота дискретизации. Для записи аналогового звука и г го преобразования в цифровую форму используется микрофон, подключенный к звуковой плате. Качество полученного цифрового звука зависит от количества измерений уровня громкости звука в единицу времени, т. е. частоты дискретизации. Чем большее количество измерений производится за I секунду (чем больше частота дискретизации), тем точнее "лесенка" цифрового звукового сигнала повторяет кривую диалогового сигнала.
Частота дискретизации звука - это количество измерений громкости звука за одну секунду.
Частота дискретизации звука может лежать в диапазоне от 8000 до 48 000 измерений громкости звука за одну секунду.
Глубина кодирования звука. Каждой "ступеньке" присваивается определенное значение уровня громкости звука. Уровни громкости звука можно рассматривать как набор возможных состояний N, для кодирования которых необходимо определенное количество информации I, которое называется глубиной кодирования звука.
Глубина кодирования звука - это количество информации, которое необходимо для кодирования дискретных уровней громкости цифрового звука.
Если известна глубина кодирования, то количество уровней громкости цифрового звука можно рассчитать по формуле N = 2I. Пусть глубина кодирования звука составляет 16 битов, тогда количество уровней громкости звука равно:
N = 2I = 216 = 65 536.
В процессе кодирования каждому уровню громкости звука присваивается свой 16-битовый двоичный код, наименьшему уровню звука будет соответствовать код 0000000000000000, а наибольшему - 1111111111111111.
Качество оцифрованного звука. Чем больше частота и глубина дискретизации звука, тем более качественным будет звучание оцифрованного звука. Самое низкое качество оцифрованного звука, соответствующее качеству телефонной связи, получается при частоте дискретизации 8000 раз в секунду, глубине дискретизации 8 битов и записи одной звуковой дорожки (режим "моно"). Самое высокое качество оцифрованного звука, соответствующее качеству аудио-CD, достигается при частоте дискретизации 48 000 раз в секунду, глубине дискретизации 16 битов и записи двух звуковых дорожек (режим "стерео").
Необходимо помнить, что чем выше качество цифрового звука, тем больше информационный объем звукового файла. Можно оценить информационный объем цифрового стереозвукового файла длительностью звучания 1 секунда при среднем качестве звука (16 битов, 24 000 измерений в секунду). Для этого глубину кодирования необходимо умножить на количество измерений в 1 секунду й умножить на 2 (стереозвук):
16 бит × 24 000 × 2 = 768 000 бит = 96 000 байт = 93,75 Кбайт.
Звуковые редакторы. Звуковые редакторы позволяют не только записывать и воспроизводить звук, но и редактировать его. Оцифрованный звук представляется в звуковых редакторах в наглядной форме, поэтому операции копирования, перемещения и удаления частей звуковой дорожки можно легко осуществлять с помощью мыши. Кроме того, можно накладывать звуковые дорожки друг на друга (микшировать звуки) и применять различные акустические эффекты (эхо, воспроизведение в обратном направлении и др.).
Звуковые редакторы позволяют изменять качество цифрового звука и объем звукового файла путем изменения частоты дискретизации и глубины кодирования. Оцифрованный звук можно сохранять без сжатия в звуковых файлах в универсальном формате WAV или в формате со сжатием МР3.
При сохранении звука в форматах со сжатием отбрасываются "избыточные" для человеческого восприятия звуковые частоты с малой интенсивностью, совпадающие по времени со звуковыми частотами с большой интенсивностью. Применение такого формата позволяет сжимать звуковые файлы в десятки раз, однако приводит к необратимой потере информации (файлы не могут быть восстановлены в первоначальном виде).
Дискретизация заключается в замерах величины аналогового сигнала огромное множество раз в секунду. Полученной величине аналогового сигнала сопоставляется определенное значение из заранее выделенного диапазона: 256 (8 бит) или 65536 (16 бит). Привидение в соответствие уровня сигнала определенной величине диапазона и есть квантование.
Понятно, что как бы часто мы не проводили измерения, все равно часть информации будет теряться. Однако и понятно, что чем чаще мы проводим замеры, тем точнее будет соответствовать цифровой звук своему аналоговому оригиналу.
Также, чем больше бит отведено под кодирование уровня сигнала (квантование), тем точнее соответствие.
С другой стороны, звук хорошего качества будет содержать больше данных и, следовательно, больше занимать места на цифровом носителе информации.
В качестве примера можно привести такие расчеты. Для записи качественной музыки аналоговый звуковой сигнал измеряют более 44 000 раз в секунду и квантуют 2 байтами (16 бит дает диапазон из 65536 значений). Т.е. за одну секунду записывается 88 000 байт информации. Это равно (88 000 / 1024) примерно 86 Кбайт. Минута обойдется уже в 5168 Кбайт (86*60), что немного больше 5 Мб.
2.2. Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
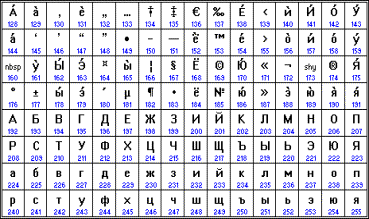
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Первая половина таблицы кодов ASCII
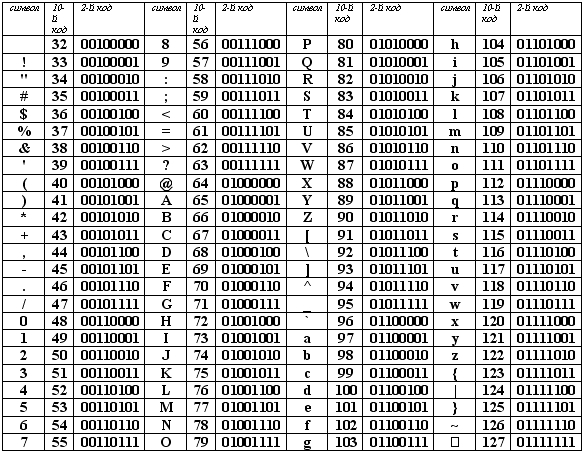
Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
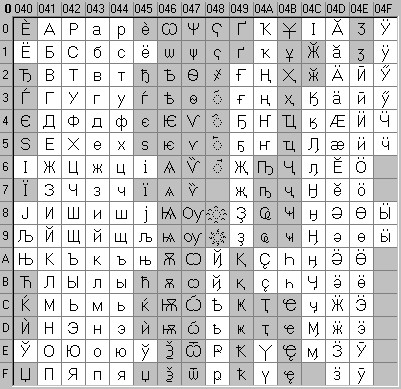
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
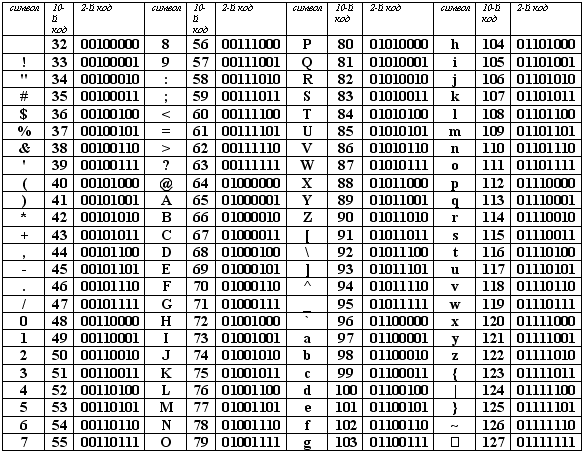
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
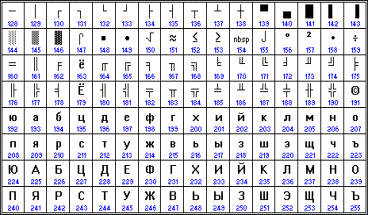
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").
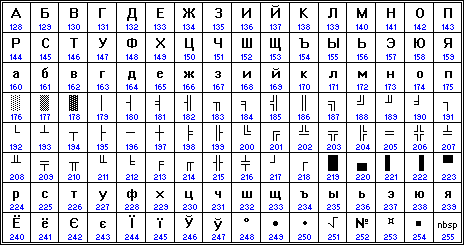
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
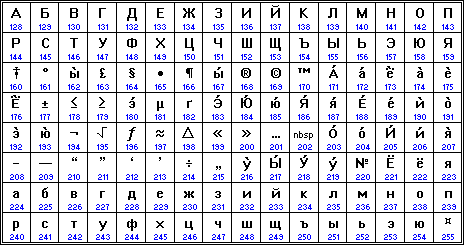
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.

Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.
Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
|
Слова |
Память |
|
file |
01100110 01101001 01101100 01100101 |
|
disk |
01100100 01101001 01110011 01101011 |
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
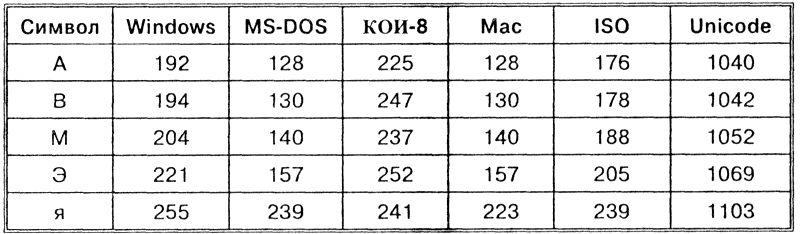 Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
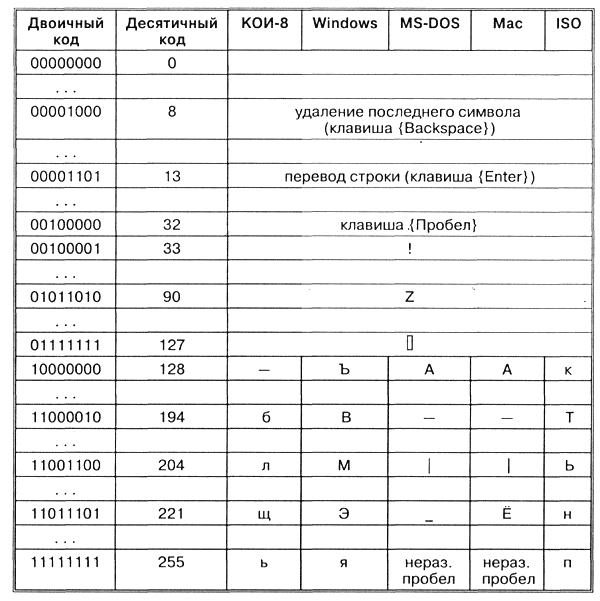 Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов.
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
2.3. Обратимое и необратимое кодирование. Условие обратимости кодирования
Кодирование — перевод информации, представленной сообщением в первичном алфавите, в последовательность кодов.
Процесс обратного преобразования слова называется декодированием. Декодирование можно рассматривать как функцию 1/F– обратную функции F – кодированию.
Декодирование — операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение не приводит к потере информации.
Примером обратимого кодирования является телеграф. Также к обратимому кодированию относят сжатие информации без потерь, помехоустойчивое кодирование.
Необратимое кодирование происходит при переводе с одного естественного языка на другой, при сжатии с потерями, при аналого-цифровом преобразовании. Необратимое кодирование можно подвергнуть более детальной классификации. Различают принципиально необратимое, обратимое с помощью дополнительной информации и безусловно обратимое кодирование.
Принципиально необратимое кодирование (хэширование) используется, например, в операционных системах для хранения паролей. При первоначальном вводе пароль преобразуется с помощью так называемых односторонних функций (хэш- функций), подобранных таким образом, чтобы из полученной на их выходе строки принципиально нельзя было получить первоначальное значение пароля. При дальнейшем использовании пароль каждый раз преобразуется такой же функцией и сравнивается с первоначальным хэшем. При их совпадении делается вывод о правильности ввода пароля. Объем полученной в итоге информации равен ровно одному биту: пароль совпал либо не совпал. В некоторых случаях этого может оказаться недостаточно, поэтому гораздо чаще используется кодирование, обратимое с помощью дополнительной информации (ключа шифрования). Входная информация преобразуется с помощью пароля таким образом, чтобы обратное преобразование также требовало знания пароля (простейший пример такого преобразования - операция исключающего ИЛИ между байтами исходного текста и байтами пароля). Именно этот способ обычно используется при шифровании архивов.
Наконец, последний случай - безусловно обратимое кодирование, в случае которого обратное преобразование не требует знания какой-то дополнительной информации. В подавляющем большинстве случаев для хранения паролей к внешним ресурсам используется именно этот способ. К примеру, почтовому клиенту для получения почты необходимо передать на РОР3-сервер логин и пароль пользователя, который решил доверить их хранение клиенту, поставив соответствующую галочку. Пароль уходит на сервер в открытом виде, какие-то дополнительные пароли при его сохранении взять неоткуда (бессмысленно требовать от пользователя какой-то дополнительный пароль, если он захотел избавиться от ввода основного пароля). В этом случае единственный вариант - использовать как можно более запутанные алгоритмы кодирования и декодирования, которые обеспечат относительную защиту данных.
Список используемой литературы
1. Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. - М.: Издательский дом "Вильямс", 2000. - 384 с.
2. Березин Б.И., Березин С.Б. Начальный курс С и С++. М: «Диалог-МИФИ», 2001
3. Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. – М.: «Диалог-МИФИ», 2002.
4. Галлагер Р. Теория информации и надежная связь. - М.: Советское радио, 1974. - 719 с.
5. Кричевский Р.Е. Сжатие и поиск информации. - М.: Радио и связь, 1989. - 168 с.

- Разработка регламента выполнения процесса по управлению документооборотом
- История развития программирования в России (Развитие программирования в СССР и России)
- Разработка регламента выполнения процесса по управлению информационными ресурсами
- Ответственность за нарушение законодательства о рекламе (Реклама: понятие, признаки)
- Понятие права собственности.
- Правовое регулирование валютного рынка: общие характеристики
- Организация страхового дела в РФ (Сущность и содержание страховой деятельности)
- Теоретические основы финансовой отчетности.
- «Баланс и отчетность»(Теоретические основы финансовой отчетности )
- Организация бухгалтерского учета на предприятии (Понятие бухгалтерского учета, его функции и формы)
- Бухгалтерский баланс организации и порядок его составления (Теоретические основы анализа бухгалтерского баланса)
- Субъекты банкротства, их права, обязанности и ответственность (В ситуации экономического кризиса)