
Методы кодирования данных (История кодирования данных)
Содержание:

ВВЕДЕНИЕ
Получение и эффективная обработка данных есть неотделимое от жизни явление, ведь от этого зависит любое живое существо. От простейших до высших млекопитающих – любое животное воспринимает данные из окружающей среды, обрабатывает их и благодаря этому благостно существует в природе. Кроме того, любое живое существо представляет собой носитель определенного набора генетической информации, которая потом передастся потомкам. Генетические данные определяют строение, здоровье, внутренний и внешний вид и развитие живого существа, которому принадлежат.
Если говорить в частности о человеке, то людьми окружающая действительность воспринимается посредством органов чувств, после чего она обрабатывается мозгом и предоставляет субъективную информацию об объективной реальности. Иначе говоря – человек формирует, а после и живет в мире информации.
И сегодня, чем дальше развивается человечество, тем более изощренные способы и методы ее обработки появляются. Это, в некоторой степени связано и с тем, что потоки информации огромны и всеобъемлющи, и одной из наиболее зависимых сфер является экономическая сфера. Так, в зависимости от скорости обработки информации, та или иная организация может быть более или менее конкурентоспособной на своем рынке. И правда, сегодня сложно представить современную организацию без автоматизированной системы обработки информации. А информацию необходимо обрабатывать корректно и сделать это таким образом, чтобы был сохранен баланс компьютер-человек.
Для того чтобы подробнее разобраться в вопросе, необходимо достичь цели исследования – изучить методы кодирования данных.
Для достижения данной цели необходимо выполнить следующие задачи:
- проанализировать историю кодирования данных;
- рассмотреть понятие и виды кодирования данных;
- охарактеризовать методы кодирования данных:
- NRZ;
- NRZI;
- RZ;
- AMI;
- HDB3;
- PE;
- подвести итоги выполнения работы.
Объектом исследования является кодирование данных, а предметом – методы кодирования данных.
Глава 1. Кодирование информации. История, понятие и виды
1.1 История кодирования данных
Кодирование в самой своей примитивной форме появилось еще в давней древности, и ранее называлась тайнопись. Тайнопись использовали дабы засекретить важные послания от лиц, которым они не предназначались. Так, еще Геродот, живший и действующий в пятом веке до нашей эры, изучал письма, которые были понятны исключительно тому, кто был адресатом послания. Также исторически известно, что специализированный механический прибор был у спартанцев. Посредством данного прибора писались важнейшие письма и послания, которые, даже попав в не те руки, не могли быть прочитаны злоумышленниками. Также известно, что особенная тайная азбука была и у Юлия Цезаря. В эпоху Ренессанса и в средние века разработки секретных кодов продолжались, так свои тайные шифры были у Френсиса Бэкона, Леонардо да Винчи, Франсуа Виета, Джона Валлиса и др.[1].
Тем не менее, данные языки отличались относительной примитивностью, и со временем начали изобретаться все более сложные и модифицированные шифры. Например, одним сложным шифром, используемым и сегодня, является криптографическая система Вюрцбурга Тритемиуса. Его хитроумная система кодирования применялась при папском дворе и при дворах европейских монархов.
Секретные шифры также есть неотъемлемая часть многих детективных произведений, в которых с различными целями действуют шпионы и детективы[2].
Кодированием называют процесс преобразование сообщения в определенную последовательность сигналов, а декодированием – обратную кодированию операцию[3].
Необходимо также отметить, что разные символы следует кодировать разными кодовыми словами, иначе дешифровка была бы невозможна.
Научно первый код, который был предназначен именно для передачи засекреченных сообщений, связывают с известным изобретателем телеграфного аппарата – Сэмьюэлем Морзе. Очевидно, речь идет о всемирно известном и до сих пор применяющемся коде под названием Азбука Морзе.
В этом коде каждой букве или цифре сопоставляется своя последовательность из кратковременных (называемых точками) и длительных (тире) импульсов тока, разделяемых паузами. Другой код, столь же широко распространенный в телеграфии (код Бодо), использует для кодирования два элементарных сигнала – импульс и паузу, при этом сопоставляемые буквам кодовые слова состоят из пяти таких сигналов.
Коды, использующие два различных элементарных сигнала, называются двоичными. Удобно бывает, отвлекаясь от их физической природы, обозначать эти два сигнала символами 0 и 1. Тогда кодовые слова можно представлять как последовательности из нулей и единиц[4].
1.2 Понятие и виды кодирования данных
Код – система условных обозначений или сигналов.
Длина кода – количество знаков, используемых для представления кодируемой информации
Кодирование данных – это процесс формирования определенного представления информации.
Декодирование – расшифровка кодированных знаков, преобразование кода символа в его изображение
Двоичное кодирование – кодирование информации в виде 0 и 1[5].
В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Любой способ кодирования характеризуется наличием основы (алфавит, система координат, основание системы счисления и т.д.) и правил конструирования информационных образов на этой основе. Кодирование числовых данных осуществляется с помощью системы счисления.
Двоичное кодирование
Представление информации в двоичной системе использовалось человеком с давних времен. Так, жители островов Полинезии передавали необходимую информацию при помощи барабанов: чередование звонких и глухих ударов. Звук над поверхностью воды распространялся на достаточно большое расстояние, таким образом «работал» полинезийский телеграф. В телеграфе в XIX–XX веках информация передавалась с помощью азбуки Морзе – в виде последовательности из точек и тире.
Самюэл Морзе в 1838 г. изобрел код – телеграфную азбуку – систему кодировки символов короткими и длинными посылками для передачи их по линиям связи, известную как «код Морзе» или «морзянка». Современный вариант международного «кода Морзе» (International Morse) появился совсем недавно – в 1939 году, когда была проведена последняя корректировка[6].
Своя система существует и в вычислительной технике – она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами. Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.п.).
Кодирование чисел
Вопрос о кодировании чисел возникает по той причине, что в машину нельзя либо нерационально вводить числа в том виде, в котором они изображаются человеком на бумаге. Во–первых, нужно кодировать знак числа. Во–вторых, по различным причинам, которые будут рассмотрены ниже, приходится иногда кодировать и остальную часть числа.
Кодирование целых чисел производиться через их представление в двоичной системе счисления: именно в этом виде они и помещаются в ячейке. Один бит отводиться при этом для представления знака числа (нулем кодируется знак «плюс», единицей – «минус»).
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде: N = M * qp, где M – мантисса, p – порядок числа N, q – основание системы счисления. Если при этом мантисса M удовлетворяет условию 0,1 <= | M | <= 1 то число N называют нормализованным[7].
Кодирование текста
Для кодирования букв и других символов, используемых в печатных документах, необходимо закрепить за каждым символом числовой номер – код. В англоязычных странах используются 26 прописных и 26 строчных букв (A … Z, a … z), 9 знаков препинания (. , : ! « ; ? ( ) ), пробел, 10 цифр, 5 знаков арифметических действий (+,–,*, /, ^) и специальные символы (№, %, _, #, $, &, >, <, |, \) – всего чуть больше 100 символов. Таким образом, для кодирования этих символов можно ограничиться максимальным 7–разрядным двоичным числом (от 0 до 1111111, в десятичной системе счисления – от 0 до 127).
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия. Каждый элемент векторного изображения является объектом, который описывается с помощью математических уравнений. Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов[8].
Кодирование звука
На компьютере работать со звуковыми файлами начали в 90–х годах. В основе цифрового кодирования звука лежит – процесс преобразования колебаний воздуха в колебания электрического тока и последующая дискретизация аналогового электрического сигнала. Кодирование и воспроизведение звуковой информации осуществляется с помощью специальных программ (редактор звукозаписи).
Временная дискретизация – способ преобразования звука в цифровую форму путем разбивания звуковой волны на отдельные маленькие временные участки где амплитуды этих участков квантуются (им присваивается определенное значение).
Это производится с помощью аналого–цифрового преобразователя, размещенного на звуковой плате. Таким образом, непрерывная зависимость амплитуды сигнала от времени заменяется дискретной последовательностью уровней громкости. Современные 16–битные звуковые карты кодируют 65536 различных уровней громкости или 16–битную глубину звука (каждому значению амплитуды звука сигнала присваивается 16–битный код)
Качество кодирования звука зависит от:
- глубины кодирования звука – количество уровней звука
- частоты дискретизации – количество изменений уровня сигнала в единицу[9].
Глава 2. Методы кодирования данных
2.1 NRZ – Non Return to Zero (без возврата к нулю) и NRZ I – Non Return to Zero Invertive (инверсное кодирование без возврата к нулю)
Код NRZ (Non Return to Zero – без возврата к нулю) – это простейший код, представляющий собой обычный цифровой сигнал. Логическому нулю соответствует высокий уровень напряжения в кабеле, логической единице – низкий уровень напряжения (или наоборот, что не принципиально). Уровни могут быть разной полярности или же одной полярности. В течение битового интервала, то есть времени передачи одного бита никаких изменений уровня сигнала в кабеле не происходит[10].
К несомненным достоинствам кода NRZ относятся его довольно простая реализация (исходный сигнал не надо ни специально кодировать на передающем конце, ни декодировать на приемном конце), а также минимальная среди других кодов пропускная способность линии связи, требуемая при данной скорости передачи. Ведь наиболее частое изменение сигнала в сети будет при непрерывном чередовании единиц и нулей, то есть при последовательности 1010101010..., поэтому при скорости передачи, равной 10 Мбит/с (длительность одного бита равна 100 нс) частота изменения сигнала и соответственно требуемая пропускная способность линии составит 1 / 200нс = 5 МГц (рис. 1).
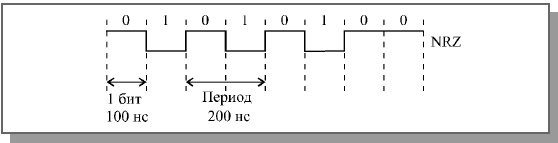
Рисунок 1 Скорость передачи и требуемая пропускная способность при коде NRZ
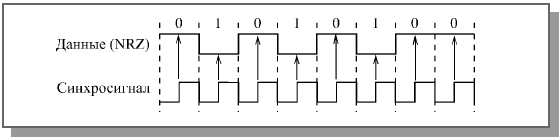
Рисунок 2 Передача в коде NRZ с синхросигналом
Самый большой недостаток кода NRZ – это возможность потери синхронизации приемником во время приема слишком длинных блоков (пакетов) информации. Приемник может привязывать момент начала приема только к первому (стартовому) биту пакета, а в течение приема пакета он вынужден пользоваться только внутренним тактовым генератором (внутренними часами). Например, если передается последовательность нулей или последовательность единиц, то приемник может определить, где проходят границы битовых интервалов, только по внутренним часам. И если часы приемника расходятся с часами передатчика, то временной сдвиг к концу приема пакета может превысить длительность одного или даже нескольких бит. В результате произойдет потеря переданных данных. Так, при длине пакета в 10000 бит допустимое расхождение часов составит не более 0,01% даже при идеальной передаче формы сигнала по кабелю.
Во избежание потери синхронизации, можно было бы ввести вторую линию связи для синхросигнала (Рисунок 2). Но при этом требуемое количество кабеля, число приемников и передатчиков увеличивается в два раза. При большой длине сети и значительном количестве абонентов это невыгодно.
В связи с этим код NRZ используется только для передачи короткими пакетами (обычно до 1 Кбита)[11].
Значительный недостаток кода NRZ состоит еще и в том, что он может обеспечить обмен сообщениями (последовательностями, пакетами) только фиксированной, заранее обговоренной длины. Дело в том, что по принимаемой информации приемник не может определить, идет ли еще передача или уже закончилась. Для синхронизации начала приема пакета используется стартовый служебный бит, чей уровень отличается от пассивного состояния линии связи (например, пассивное состояние линии при отсутствии передачи – 0, стартовый бит – 1). Заканчивается прием после отсчета приемником заданного количества бит последовательности (Рисунок 3).
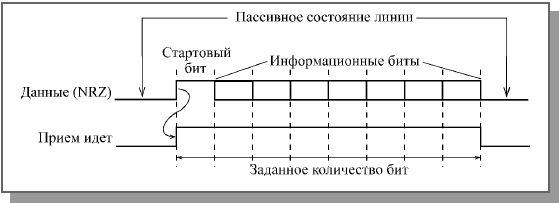
Рисунок 3 Определение окончания последовательности при коде NRZ
Код NRZI (без возврата к нулю с инверсией единиц – Non–Return to Zero, Invert to one) предполагает, что уровень сигнала меняется на противоположный в начале единичного битового интервала и не меняется при передаче нулевого битового интервала. При последовательности единиц на границах битовых интервалов имеются переходы, при последовательности нулей – переходов нет. В этом смысле код NRZI лучше синхронизируется, чем NRZ (там нет переходов ни при последовательности нулей, ни при последовательности единиц)[12].
Этот метод кодирования использует следующие представления битов цифрового потока: * биты 0 представляются нулевым напряжением (0 В); * биты 1 представляются напряжением 0 или +V в зависимости от предшествовавшего этому биту напряжения. Если предыдущее напряжение было равно 0, единица будет представлена значением +V, а в случаях, когда предыдущий уровень составлял +V для представления единицы, будет использовано напряжение 0 В. Этот алгоритм обеспечивает малую полосу (как при методе NRZ) в сочетании с частыми изменениями напряжения (как в RZ), а кроме того, обеспечивает неполярный сигнал (т. е. проводники в линии можно поменять местами)[13].
2.2 RZ – Return to Zero (возврат к нулю)
Код RZ (Return to Zero – с возвратом к нулю) – этот трехуровневый код получил такое название потому, что после значащего уровня сигнала в первой половине битового интервала следует возврат к некоему «нулевому», среднему уровню (например, к нулевому потенциалу). Переход к нему происходит в середине каждого битового интервала. Логическому нулю, таким образом, соответствует положительный импульс, логической единице – отрицательный (или наоборот) в первой половине битового интервала.
В центре битового интервала всегда есть переход сигнала (положительный или отрицательный), следовательно, из этого кода приемник легко может выделить синхроимпульс (строб). Возможна временная привязка не только к началу пакета, как в случае кода NRZ, но и к каждому отдельному биту, поэтому потери синхронизации не произойдет при любой длине пакета[14].
Еще одно важное достоинство кода RZ – простая временная привязка приема, как к началу последовательности, так и к ее концу. Приемник просто должен анализировать, есть изменение уровня сигнала в течение битового интервала или нет. Первый битовый интервал без изменения уровня сигнала соответствует окончанию принимаемой последовательности бит (рисунок 4). Поэтому в коде RZ можно использовать передачу последовательностями переменной длины.
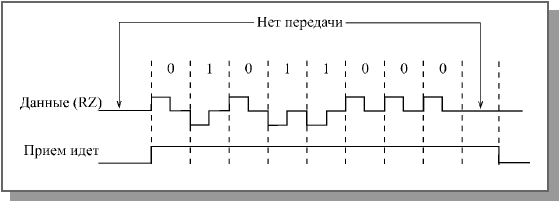
Рисунок 4 Определение начала и конца приема при коде RZ
Недостаток кода RZ состоит в том, что для него требуется вдвое большая полоса пропускания канала при той же скорости передачи по сравнению с NRZ (так как здесь на один битовый интервал приходится два изменения уровня сигнала). Например, для скорости передачи информации 10 Мбит/с требуется пропускная способность линии связи 10 МГц, а не 5 МГц, как при коде NRZ (рисунок 5).
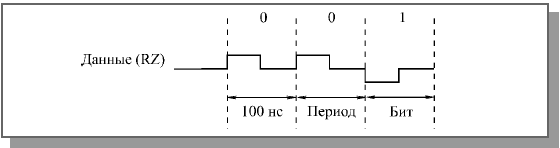
Рисунок 5 Скорость передачи и пропускная способность при коде RZ
Другой важный недостаток – наличие трех уровней, что всегда усложняет аппаратуру как передатчика, так и приемника[15].
Код RZ применяется не только в сетях на основе электрического кабеля, но и в оптоволоконных сетях. Правда, в них не существует положительных и отрицательных уровней сигнала, поэтому используется три следующие уровня: отсутствие света, «средний» свет, «сильный» свет. Это очень удобно: даже когда нет передачи информации, свет все равно присутствует, что позволяет легко определить целостность оптоволоконной линии связи без дополнительных мер (рисунок 6).
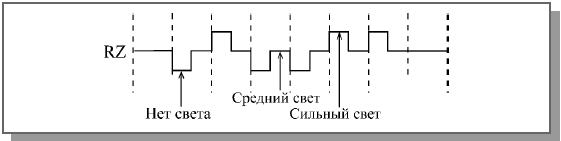
Рисунок 6. Использование кода RZ в оптоволоконных сетях
2.3 AMI – Alternate Mark Inversion (поочередная инверсия единиц)
AMI код (от англ. Alternate Mark Inversion, иногда в литературе встречается название «биполярный AMI код») – один из способов линейного кодирования (физического кодирования, канального кодирования, цифровое кодирование, манипуляция сигнала, импульсно–кодовая модуляция). Является трехуровневым кодом, при поступлении на вход кодера логической единицы осуществляется смена потенциала либо на верхний, либо на нижний уровень, в зависимости от предыдущего уровня, на котором передавалась логическая единица. В процессе синхронизации, физическая привязка к синхронной последовательности на приемной стороне осуществляется при передаче смены логической единицы и логического нуля, либо за счет скремблирования.
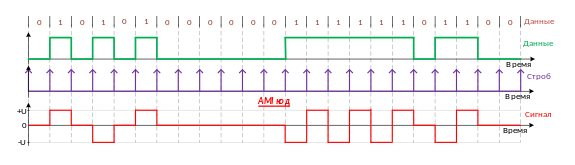
Рисунок 7 Линейное кодирование
Преимущества:
- Самосинхронизирующийся код (слабая синхронизация в сравнении с манчестерским кодированием, поскольку синхронизация не производится при передаче логических нулей)
- Спектр сигнала уже, чем у NRZ
- Сравнительно простая в реализации
Недостатки:
- Мощность передатчика должна быть выше в сравнение с двухуровневым кодированием
- Сложность построения аппаратуры в сравнение с двухуровневым кодированием[16]
Этот метод кодирования использует следующие представления битов: * биты 0 представляются нулевым напряжением (0 В); * биты 1' представляются поочередно значениями +V и –V. Этот метод подобен алгоритму RZ, но обеспечивает в линии нулевой уровень постоянного напряжения. Недостатком метода AMI является ограничение на плотность нулей в потоке данных, поскольку длинные последовательности 0 ведут к потере синхронизации
2.4 HDB3 – High Density Bipolar 3 (биполярное кодирование с высокой плотностью) и PE – Phase Encode (фазовое кодирование)
Для высоких скоростей передачи используются биполярное кодирование с высокой плотностью (High density bipolar code of order 3 – HDB3). Представление битов в методе HDB3 лишь незначительно отличается от представления, используемого алгоритмом AMI. При наличии в потоке данных 4 последовательных битов 0 последовательность изменяется на 000V, где полярность бита V такая же, как для предшествующего ненулевого.
High Density Bipolar code – Биполярный код высокой плотности второго (третьего) порядка. Эквивалентен коду с возвратом к нулю (RZ) и с инверсией для логических 1. Последовательность 000 (соответственно 0000) заменяется на 00V или B0V (соответственно 000V или B00V). Число B сигналов между V–сигналами всегда нечетно. В результате возникает трехуровневый код
Представление битов в методе HDB3 лишь незначительно отличается от представления, используемого алгоритмом AMI: При наличии в потоке данных 4 последовательных битов 0 последовательность изменяется на 000V, где полярность бита V такая же, как для предшествующего ненулевого импульса (в отличие от кодирования битов 1, для которых знак сигнала V изменяется поочередно для каждой единицы в потоке данных). Этот алгоритм снимает ограничения на плотность 0, присущие кодированию AMI, но порождает взамен новую проблему – в линии появляется отличный от нуля уровень постоянного напряжения за счет того, что полярность отличных от нуля импульсов совпадает[17].
Для решения этой проблемы полярность бита V изменяется по сравнению с полярностью предшествующего бита V. Когда это происходит, битовый поток изменяется на B00V, где полярность бита B совпадает с полярностью бита V. Когда приемник получает бит B, он думает, что этот сигнал соответствует значению 1, но после получения бита V (с такой же полярностью) приемник может корректно трактовать биты B и V как 0. Метод HDB3 удовлетворяет всем требованиям, предъявляемым к алгоритмам цифрового кодирования, но при использовании этого метода могут возникать некоторые проблемы.
Ни в одной из версий Ethernet не применяется прямое двоичное кодирование бита 0 напряжением О В и бита 1 – напряжением 5В, так как такой способ приводит к неоднозначности. Если одна станция посылает битовую строку 00010000, то другая может интерпретировать ее как 10000000 или 01000000, так как они не смогут отличить отсутствие сигнала (О В) от бита О (О В). Можно, конечно, кодировать единицу положительным напряжением +1 В, а ноль – отрицательным напряжением –1В. Но при этом все равно возникает проблема, связанная с синхронизацией передатчика и приемника. Разные частоты работы их системных часов могу привести к рассинхронизации и неверной интерпретации данных. В результате приемник может потерять границу битового интервала. Особенно велика вероятность этого в случае длинной последовательности нулей или единиц.
Таким образом, принимающей машине нужен способ однозначного определения начала, конца и середины каждого бита без помощи внешнего таймера. Это реализуется с помощью двух методов: манчестерского кодирования и разностного манчестерского кодирования. В манчестерском коде каждый временной интервал передачи одного бита делится на два равных периода. Бит со значением 1 кодируется высоким уровнем напряжения в первой половине интервала и низким – во второй половине, а нулевой бит кодируется обратной последовательностью – сначала низкое напряжение, затем высокое. Такая схема гарантирует смену напряжения в середине периода битов, что позволяет приемнику синхронизироваться с передатчиком. Недостатком манчестерского кодирования является то, что оно требует двойной пропускной способности линии по отношению к прямому двоичному кодированию, так как импульсы имеют половинную ширину. Например, для того чтобы отправлять данные со скоростью 10 Мбит/с, необходимо изменять сигнал 20 миллионов раз в секунду. Манчестерское кодирование показано ниже, на схеме «б» (Рисунок 8)[18].
Разностное манчестерское кодирование, показанное на схеме «в» (Рисунок 8), является вариантом основного манчестерского кодирования. В нем бит 0 кодируется изменением состояния в начале интервала, а бит 1 – сохранением предыдущего уровня. В обоих случаях в середине интервала обязательно присутствует переход. Разностная схема требует более сложного оборудования, зато обладает хорошей защищенностью от шума. Во всех сетях Ethernet используется манчестерское кодирование благодаря его простоте. Высокий сигнал кодируется напряжением в +0,85 В, а низкий сигнал––0,85 В, в результате чего постоянная составляющая напряжения равна О В. Разностное манчестерское кодирование в Ethernet не используется, но используется в других ЛВС (например, стандарт 802.5, маркерное кольцо).
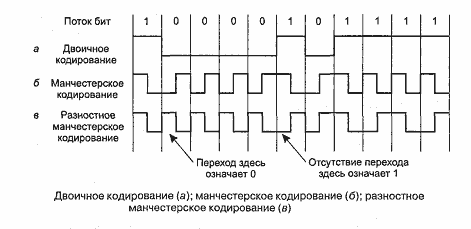
Рисунок 8 Потоковое кодирование информации
ЗАКЛЮЧЕНИЕ
В ходе выполнения работы была достигнута поставленная цель – изучены методы кодирования данных.
Для достижения цели были выполнены следующие задачи:
- проанализирована история кодирования данных;
- рассмотрены понятие и виды кодирования данных;
- охарактеризованы методы кодирования данных:
- NRZ;
- NRZI;
- RZ;
- AMI;
- HDB3;
- PE.
Информация – ключевой ресурс в развивающейся современной цивилизации, и методы, средства и способы ее обработки и кодирования будут только усложняться, множиться и совершенствоваться. В связи с этим проблему нельзя назвать до конца изученной – ведь материал для новых исследований будет только прибывать.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Баззел, Р. Д. Информация и риск в маркетинге / Р. Д. Баззел, Д. Ф. Кокс, Р. В. Браун. – М.: Финстатинформ, 2010. – 344 c.
- Белоногов, Г. Г. Автоматизация процессов накопления, поиска и обобщения информации / Г. Г. Белоногов, А. П. Новоселов. – М.: Наука, 2014. – 256 c.
- Берлекэмп, Э. Алгебраическая теория кодирования / Э. Берлекэмп. – М., 2016. – 281 c.
- Воскобойников, Я. С. Журналист и информация. Профессиональный опыт западной прессы / Я. С. Воскобойников, В. К. Юрьев. – М.: РИА–Новости, 2016. – 208 c.
- Гоппа, В. Д. Введение в алгебраическую теорию информации / В. Д. Гоппа. – М., 2017. – 370 c.
- Кадомцев, Б. Б. Динамика и информация / Б. Б. Кадомцев. – М.: [не указано], 2015. – 140 c.
- Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М. Я. Кельберт. – М.: МЦНМО, 2016. – 614 c.
- Кузнецова, Е. Ю. Информатика. Информация. Кодирование и измерение. 7–9 классы. Дидактические материалы. ФГОС / Е. Ю. Кузнецова. – М.: Бином. Лаборатория знаний, 2014. – 249 c.
- Мальцев, Ю. Н. Введение в дискретную математику. Элементы комбинаторики, теории графов и теории кодирования / Ю. Н. Мальцев, Е. П. Петров. – М., 2017. – 430 c.
- Хазен, А. М. Введение меры информации в аксиоматическую базу механики / А. М. Хазен. – М., 2013. – 986 c.
- Холево, А. С. Введение в квантовую теорию информации / А. С. Холево. – М., 2014. – 961 c.
- Цымбал, В. П. Задачник по теории информации и кодированию / В. П. Цымбал. – Москва: Машиностроение, 2014. – 512 c.
- Чечета, С. В. Введение в дискретную теорию информации и кодирования / С. В. Чечета. – М.: Московский центр непрерывного математического образования (МЦНМО), 2011. – 713 c.
- Ярыгина, И. З. Информация в банковской деятельности (на примере мирового опыта) / И. З. Ярыгина. – М.: Консалтбанкир, 2013. – 104 c.
-
Кузнецова, Е. Ю. Информатика. Информация. Кодирование и измерение. 7–9 классы. Дидактические материалы. ФГОС / Е. Ю. Кузнецова. – М.: Бином. Лаборатория знаний, 2014. –103 c ↑
-
Холево, А. С. Введение в квантовую теорию информации / А. С. Холево. – М., 2014. – 86 c ↑
-
Там же, 93 с. ↑
-
Чечета, С. В. Введение в дискретную теорию информации и кодирования / С. В. Чечета. – М.: Московский центр непрерывного математического образования (МЦНМО), 2011. – 187 c ↑
-
Белоногов, Г. Г. Автоматизация процессов накопления, поиска и обобщения информации / Г. Г. Белоногов, А. П. Новоселов. – М.: Наука, 2014. – 111 c. ↑
-
Чечета, С. В. Введение в дискретную теорию информации и кодирования / С. В. Чечета. – М.: Московский центр непрерывного математического образования (МЦНМО), 2011. – 209 c ↑
-
Берлекэмп, Э. Алгебраическая теория кодирования / Э. Берлекэмп. – М., 2016. – 221 c ↑
-
Берлекэмп, Э. Алгебраическая теория кодирования / Э. Берлекэмп. – М., 2016. – 230 c ↑
-
Гоппа, В. Д. Введение в алгебраическую теорию информации / В. Д. Гоппа. – М., 2017. – 321 c ↑
-
Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М. Я. Кельберт. – М.: МЦНМО, 2016. – 437 c. ↑
-
Мальцев, Ю. Н. Введение в дискретную математику. Элементы комбинаторики, теории графов и теории кодирования / Ю. Н. Мальцев, Е. П. Петров. – М., 2017. – 274 c ↑
-
Холево, А. С. Введение в квантовую теорию информации / А. С. Холево. – М., 2014. – 536 c. ↑
-
Холево, А. С. Введение в квантовую теорию информации / А. С. Холево. – М., 2014. – 541 c. ↑
-
Цымбал, В. П. Задачник по теории информации и кодированию / В. П. Цымбал. – Москва: Машиностроение, 2014. – 374c ↑
-
Воскобойников, Я. С. Журналист и информация. Профессиональный опыт западной прессы / Я. С. Воскобойников, В. К. Юрьев. – М.: РИА–Новости, 2016. – 121 c. ↑
-
Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М. Я. Кельберт. – М.: МЦНМО, 2016. – 215 c ↑
-
Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М. Я. Кельберт. – М.: МЦНМО, 2016. – 421c ↑
-
Хазен, А. М. Введение меры информации в аксиоматическую базу механики / А. М. Хазен. – М., 2013. – 321 c ↑

- Применение объектно–ориентированного подхода при проектировании информационной системы
- Информационное обеспечение оперативно-розыскной деятельности.
- Правовое регулирование рынка банковских услуг: общая характеристика (Понятие и сущность рынка банковских услуг)
- Порядок проведения приватизации (Понятие приватизации имущества)
- Нематериальные блага и их защита (Понятие и отличительные признаки нематериальных благ)
- История развития средств вычислительной техники (Понятие и сущность вычислительных машин)
- Понятие социального обеспечения (Социальное обеспечение: понятие и сущность)
- Сервисное обслуживание в торговле и перспективы его развития в современных условиях.
- Маркетинговые исследования и их классификация
- Индивидуальное предпринимательство (Понятие и признаки предпринимательской деятельности)
- Понятие и виды наследования (Понятие и виды наследования)
- Понятие и виды наследования (История института наследования)