
Методы кодирования данных (Биполярный код AMI и Потенциальный код NRZI)
Содержание:

ВВЕДЕНИЕ
Существует множество методов кодирования данных. Выбор кодировки должен соответствовать целям проекта реализуемых программистом. Поэтому каждый специалист занимающийся программированием должен иметь представление о способах кодирования информации. Данные навыки например необходимы для передачи данных между передатчиком и приемником.
Для того чтобы передатчик и приемник, соединенные некоторой средой, могли обмениваться информацией, им необходимо договориться о том, какие сигналы будут соответствовать двоичным единицам и нулям дискретной информации. Для представления дискретной информации в среде передачи данных применяются сигналы двух типов: прямоугольные импульсы и синусоидальные волны. В первом случае используют термин «кодирование», во втором — «модуляция».
Методы кодирования отличаются шириной спектра сигнала при одной и той же скорости передачи данных. Для передачи данных с минимальным числом ошибок полоса пропускания канала должна быть шире, чем спектр сигнала — иначе выбранные для представления единиц и нулей сигналы значительно исказятся, и приемник не сможет правильно распознать переданную информацию. Поэтому спектр сигнала является одним из главных критериев оценки эффективности способа кодирования.
Кроме того, способ кодирования должен способствовать синхронизации приемника с передатчиком, а также обеспечивать приемлемое соотношение мощности сигнала к шуму. Эти требования являются взаимно противоречивыми, поэтому каждый применяемый на практике способ кодирования представляет собой компромисс между основными требованиями. Битовые ошибки в каналах связи нельзя исключить полностью, даже если выбранный код обеспечивает хорошую степень синхронизации и высокий уровень отношения сигнала к шуму. Поэтому при передаче дискретной информации применяются специальные коды, которые позволяют обнаруживать (а иногда даже исправлять) битовые ошибки.
1. Выбор способа кодирования
При выборе способа кодирования нужно одновременно стремиться к достижению нескольких целей:
- минимизировать ширину спектра сигнала, полученного в результате кодирования;
- обеспечивать синхронизацию между передатчиком и приемником;
- обеспечивать устойчивость к шумам;
- обнаруживать и по возможности исправлять битовые ошибки;
- минимизировать мощность передатчика.
Более узкий спектр сигнала позволяет на одной и той же линии (с одной и той же полосой пропускания) добиваться более высокой скорости передачи данных. Спектр сигнала в общем случае зависит как от способа кодирования, так и от тактовой частоты передатчика.
Синхронизация передатчика и приемника нужна для того, чтобы приемник точно знал, в какой момент времени считывать новую порцию информации с линии связи. При передаче дискретной информации время всегда разбивается на такты одинаковой длительности, и приемник старается считать новый сигнал в середине каждого такта, то есть синхронизировать свои действия с передатчиком
Распознавание и коррекцию искаженных данных сложно осуществить средствами физического уровня, поэтому чаще всего эту работу берут на себя протоколы, лежащие выше: канальный, сетевой, транспортный или прикладной. В то же время распознавание ошибок на физическом уровне экономит время, так как приемник не ждет полного помещения кадра в буфер, а отбраковывает его сразу при распознавании ошибочных битов внутри кадра.
Требования, предъявляемые к методам кодирования, являются взаимно противоречивыми, поэтому каждый из рассматриваемых далее популярных методов кодирования обладает своими достоинствами и недостатками в сравнении с другими.
2. Способы физического/сигнального кодирования данных
Физическое кодирование
|
|
|
Примеры физического кодирования |
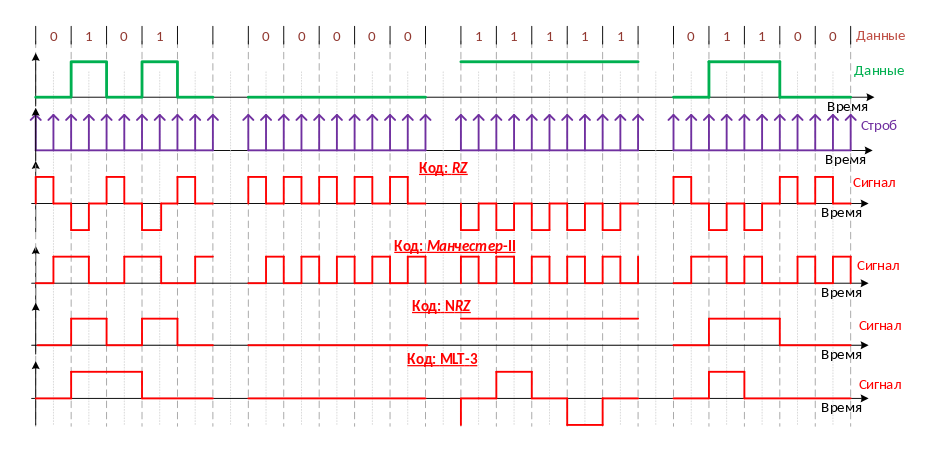
Нижним уровнем в иерархии кодирования является физическое кодирование, которое определяет число дискретных уровней сигнала (амплитуды напряжения, амплитуды тока, амплитуды яркости).
Физическое кодирование рассматривает кодирование только на самом низшем уровне иерархии кодирования— на физическом уровне и не рассматривает более высокие уровни в иерархии кодирования, к которым относятся логические кодирования различных уровней.
С точки зрения физического кодирования цифровой сигнал может иметь два, три, четыре, пять ит.д. уровней амплитуды напряжения, амплитуды тока, амплитуды света.
Ни в одной из версий технологии Ethernet не применяется прямое двоичное кодирование бита 0 напряжением 0 вольт и бита 1 — напряжением +5 вольт, так как такой способ приводит к неоднозначности. Если одна станция посылает битовую строку 00010000, то другая станция может интерпретировать её либо как 10000, либо как 01000, так как она не может отличить «отсутствие сигнала» от бита 0. Поэтому принимающей машине необходим способ однозначного определения начала, конца и середины каждого бита без помощи внешнего таймера. Кодирование сигнала на физическом уровне позволяет приемнику синхронизироваться с передатчиком по смене напряжения в середине периода битов.
В некоторых случаях физическое кодирование решает проблемы:
- Ёмкостного сопротивления — нарастание в проводном канале связи постоянной составляющей (паразитной ёмкости), которое препятствует функциональности электрооборудования;
- Нарушение плотности следования единичных импульсов — при передачи последовательности логических нулей или единиц происходит рассинхронизация передатчика и приемника.
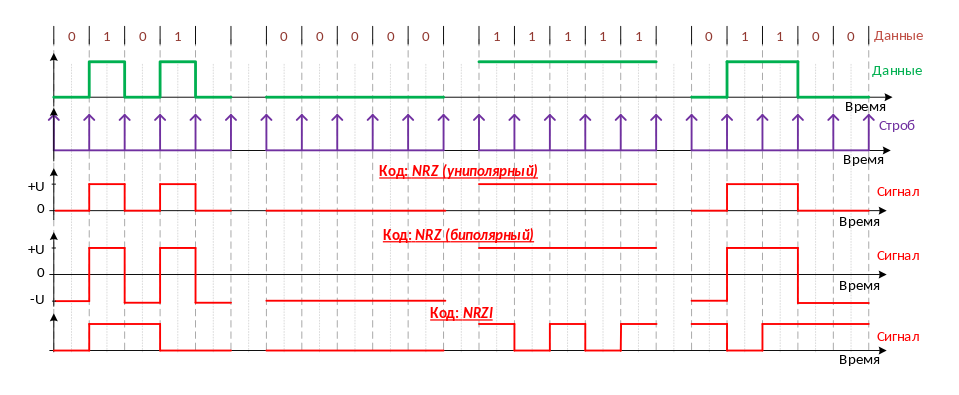
Потенциальный код NRZ
Метод потенциального кодирования, называемый также кодированием без возвращения к нулю (Non Return to Zero, NRZ). Последнее название отражает то обстоятельство, что в отличие от других методов кодирования при передаче последовательности единиц сигнал не возвращается к нулю в течение такта. Это биполярная нетранзиктивная схема (состояния меняются на границе), которая имеет два варианта. Первый вариант это недифференциальное NRZ (используется в RS-232) состояние напрямую отражает значение бита . В другом варианте — дифференциальном, NRZ состояние меняется в начале битового интервала для 1 и не меняется для 0. . Привязки 1 и 0 к определенному состоянию нету.
Достоинства метода NRZ.
- Простота реализации.
- Метод обладает хорошей распознаваемостью ошибок (благодаря наличию двух резко отличающихся потенциалов).
- Основная гармоника fо имеет достаточно низкую частоту (равную N/2 Гц, как было показано в предыдущем разделе), что приводит к узкому спектру.
Недостатки метода NRZ.
- Метод не обладает свойством самосинхронизации. Даже при наличии высокоточного тактового генератора приемник может ошибиться с выбором момента съема данных, так как частоты двух генераторов никогда не бывают полностью идентичными. Поэтому при высоких скоростях обмена данными и длинных последовательностях единиц или нулей небольшое рассогласование тактовых частот может привести к ошибке в целый такт и, соответственно, считыванию некорректного значения бита.
- Вторым серьезным недостатком метода NRZ является наличие низкочастотной составляющей, которая приближается к постоянному сигналу при передаче длинных последовательностей единиц или нулей. Из-за этого многие линии связи, не обеспечивающие прямого гальванического соединения между приемником и источником, этот вид кодирования не поддерживают. Поэтому в сетях код NRZ в основном используется в виде различных его модификаций, в которых устранены проблемы плохой самосинхронизации и постоянной составляющей.
Биполярный код AMI и Потенциальный код NRZI
Одной из модификаций метода NRZ является метод биполярного кодирования с альтер нативной инверсией (Alternate Mark Inversion, AMI). В этом методе применяются три уровня потенциала — отрицательный, нулевой и положительный. Для кодирования логического нуля используется нулевой потенциал, а логическая единица кодируется либо положительным потенциалом, либо отрицательным, при этом потенциал каждой новой единицы противоположен потенциалу предыдущей.
При передаче длинных последовательностей единиц код AMI частично решает проблемы наличия постоянной составляющей и отсутствия самосинхронизации, присущие коду NRZ. В этих случаях сигнал на линии представляет собой последовательность разно полярных импульсов с тем же спектром, что и у кода NRZ, передающего чередующиеся нули и единицы, то есть без постоянной составляющей и с основной гармоникой N/2 Гц (где N — битовая скорость передачи данных). Длинные же последовательности нулей для кода AMI столь же опасны, как и для кода NRZ — сигнал вырождается в постоянный потенциал нулевой амплитуды.
В целом, для различных комбинаций битов на линии использование кода AMI приводит к более узкому спектру сигнала, чем для кода NRZ, а значит, и к более высокой пропускной способности линии. Например, при передаче чередующихся единиц и нулей основная гармоника /о имеет частоту N/A Гц.
Код AMI предоставляет также некоторые возможности по распознаванию ошибочных сигналов. Так, нарушение строгой очередности в полярности сигналов говорит о ложном импульсе или исчезновении с линии корректного импульса.
В коде AMI используются не два, а три уровня сигнала на линии. Дополнительный уровень требует увеличение мощности передатчика примерно на 3 дБ для обеспечения той же достоверности приема битов на линии, что является общим недостатком кодов с несколькими состояниями сигнала по сравнению с кодами, в которых различают только два состояния.
Существует код, похожий на AMI, но только с двумя уровнями сигнала. При передаче нуля он передает потенциал, который был установлен на предыдущем такте (то есть не меняет его), а при передаче единицы потенциал инвертируется на противоположный. Этот код называется потенциальным кодом с инверсией при единице (Non Return to Zero with ones Inverted, NRZI). Он удобен в тех случаях, когда наличие третьего уровня сигнала весьма нежелательно, например в оптических кабелях, где устойчиво распознаются только два состояния сигнала — свет и темнота.
Код NRZI хорош тем, что в среднем требует меньше изменений сигнала при передаче произвольной двоичной информации, чем манчестерский код, за счет чего спектр его сигналов уже. Однако код NRZI обладает плохой самосинхронизацией, так как при передаче длинных последовательностей нулей сигнал вообще не меняется (например, при передаче последних 3-х нулей на рис. 1 a), и, значит, у приемника исчезает возможностьсинхронизации с передатчиком на значительное время, что может приводить к ошибкам распознавания данных. Для улучшения потенциальных кодов, подобных AMI и NRZI, используются два метода. Первый метод основан на добавлении в исходный код избыточных битов, содержащих логические единицы. Очевидно, что в этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных.
Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Однако этот метод снижает полезную пропускную способность линии, так как избыточные единицы пользовательской информации не несут.
Другой метод основан на предварительном «перемешивании» исходной информации таким образом, чтобы вероятность появления единиц и нулей на линии становилась близкой к нулю. Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами. При скремблировании используется известный алгоритм, поэтому приемник, получив двоичные данные, передает их на дескрэмблер, который восстанавливает исходную последовательность битов.
Биполярный импульсны код
Помимо потенциальных кодов в сетях используются и импульсные коды, в которых данные представлены полным импульсом или же его частью — фронтом. Наиболее простым кодом такого рода является биполярный импульсный код, в котором единица представляется импульсом одной полярности, а ноль — другой (см. рис.1, в). Каждый импульс длится половину такта. Подобный код обладает отличными самосинхронизирующими свойствами, но постоянная составляющая может присутствовать, например, при передаче длинной последовательности единиц или нулей. Кроме того, спектр у него шире, чем у потенциальных кодов. Так, при передаче всех нулей или единиц частота основной гармоники кода равнаМГц, что в два раза выше основной гармоники кода NRZ и в четыре раза выше основной гармоники кода AMI при передаче чередующихся единиц и нулей. Из-за слишком широкого спектра биполярный импульсный код используется редко.
Манчестерский код
В локальных сетях до недавнего времени самым распространенным был так называемый манчестерский код. Он применяется в технологиях Ethernet и Token Ring.
В манчестерском коде для кодирования единиц и нулей используется перепад потенциала, то есть фронт импульса. При манчестерском кодировании каждый такт делится на две части. Информация кодируется перепадами потенциала, происходящими в середине каждого такта. Единица кодируется перепадом от низкого уровня сигнала к высокому, а ноль — обратным перепадом. В начале каждого такта может происходить служебный перепад сигнала, если нужно представить несколько единиц или нулей подряд.
Так как сигнал изменяется, по крайней мере, один раз за такт передачи одного бита данных, то манчестерский код обладает хорошими самосинхронизирующими свойствами. Полоса пропускания манчестерского кода уже, чем у биполярного импульсного. У него также нет постоянной составляющей, к тому же основная гармоника в худшем случае (при передаче последовательности единиц или нулей) имеет частоту N Гц, а в лучшем (при передаче чередующихся единиц и нулей) — N/2 Гц, как и у кодов AMI и NRZ. В среднем ширина полосы манчестерского кода в полтора раза уже, чем у биполярного импульсного кода, а основная гармоника колеблется вблизи значения 3N/A. Манчестерский код имеет еще одно преимущество перед биполярным импульсным кодом. В последнем для передачи данных используются три уровня сигнала, а в манчестерском — два.
Потенциальный код 2B1Q
Потенциальный код с четырьмя уровнями сигнала для кодирования данных. Это код 2B1Q, название которого отражает его суть — каждые два бита (2В) передаются за один такт (1) сигналом, имеющим четыре состояния (Q — Quadra). Паре битов 00 соответствует потенциал -2,5 В, паре 01 — потенциал -0,833 В, паре 11 — потенциал +0,833 В, а паре 10 — потенциал +2,5 В.
При этом способе кодирования требуются дополнительные меры по борьбе с длинными последовательностями одинаковых пар битов, так как при этом сигнал превращается в постоянную составляющую. При случайном чередовании битов спектр сигнала в два раза уже, чем у кода NRZ, так как при той же битовой скорости длительность такта увеличивается в два раза. ТакиМ образом, с помощью кода 2B1Q можно по одной и той же линии передавать данные в два раза быстрее, чем с помощью кода AMI или NRZI.
Однако для его реализации мощность передатчика должна быть выше, чтобы четыре уровня четко различались приемником на фоне помех. Для улучшения потенциальных кодов типа AMI, NRZI или 2Q1B используются избыточные коды и скрэмблирование.
3. Логическое кодирование.
Логическое кодирование данных изменяет поток бит созданного кадра МАС-уровня в последовательность символов, которые подлежат физическому кодированию для транспортировки по каналу связи. Для логического кодирования используют разные схемы:
- 4B/5B — каждые 4 бита входного потока кодируются 5-битным символом. Получается двукратная избыточность, так как 24=16 входных комбинаций показываются символами из 25= 32. Расходы по количеству битовых интервалов составляют: (5-4)/4 = 1/4 (25%). Такая избыточность разрешает определить ряд служебных символов, которые служат для синхронизации. Применяется в 100BaseFX/TX, FDDI
- 8B/10B — аналогичная схема (8 бит кодируются 10-битным символом) но уже избыточность равна 4 раза (256 входных в 1024 выходных).
- 5B/6B — 5 бит входного потока кодируются 6-битными символами. Применяется в 100VG-AnyLAN
- 8B/6T — 8 бит входного потока кодируются шестью троичными (T = ternary) цифрами (-,0,+). К примеру: 00h: +-00+-; 01h: 0+-+=0; Код имеет избыточность 36/28= 729/256 = 2,85. Скорость транспортировки символов в линию является ниже битовой скорости и их поступления на кодирования. Применяется в 100BaseT4.
- Вставка бит — такая схема работает на исключение недопустимых последовательностей бит. Ее работу объясним на реализации в протоколе HDLC. Тут входной поток смотрится как непрерывная последовательность бит, для которой цепочка из более чем пяти смежных 1 анализируется как служебный сигнал (пример: 01111110 является флагом-разделителем кадра). Если в транслируемом потоке встречается непрерывная последовательность из 1, то после каждой пятой в выходной поток передатчик вставляет 0. Приемник анализирует входящую цепочку, и если после цепочки 011111 он видит 0, то он его отбрасывает и последовательность 011111 присоединяет к остальному выходному потоку данных. Если принят бит 1, то последовательность 011111 смотрится как служебный символ. Такая техника решает две задачи — исключать длинные монотонные последовательности, которые неудобные для самосинхронизации физического кодирования и разрешает опознание границ кадра и особых состояний в непрерывном битовом потоке.
Избыточные коды
4B/5B
Избыточные коды основаны на разбиении исходной последовательности битов на порции, которые часто называют символами. Затем каждый исходный символ заменяется новым с большим количество битов, чем исходный.
Например, в логическом коде 4В/5В, используемом в технологиях FDDI и Fast Ethernet, исходные символы длиной 4 бит заменяются символами длиной 5 бит. Так как результирующие символы содержат избыточные биты, то общее количество битовых комбинаций в них больше, чем в исходных. Так, в коде 4В/5В результирующие символы могут содержать 32 битовые комбинации, в то время как исходные символы — только 16
Поэтому в результирующем коде можно отобрать 16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами (code violations). Помимо устранения постоянной составляющей и придания коду свойства самосинхронизации, избыточные коды позволяют приемнику распознавать искаженные биты. Если приемник принимает запрещенный код, значит, на линии произошло искажение сигнала.
После разбиения получившийся код 4В/5В передается по линии путем преобразования с помощью какого-либо из методов потенциального кодирования, чувствительного только к длинным последовательностям нулей. Таким кодом является, например, код NRZI.
Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не встретятся более трех нулей подряд.
Таблица Соответствие исходных и результирующих кодов 4В/5В
|
Исходный код |
Результирующий код |
Исходный код |
Результирующий код |
|
0000 |
11110 |
1000 |
10010 |
|
0001 |
01001 |
1001 |
10011 |
|
0010 |
10100 |
1010 |
10110 |
|
0011 |
10101 |
1011 |
10111 |
|
0100 |
01010 |
1100 |
11010 |
|
0101 |
01011 |
1101 |
11011 |
|
0110 |
01110 |
1110 |
11100 |
|
0111 |
01111 |
1111 |
11101 |
ПРИМЕЧАНИЕ
Буква В в названии кода 4В/5В означает, что элементарный сигнал имеет два состояния (от английского binary — двоичный). Имеются также коды и с тремя состояниями сигнала, например в коде 8В/6Т для кодирования 8 бит исходной информации используется код из 6 сигналов, каждый из которых имеет три состояния. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 256 исходных кодов приходится З6 - 729 результирующих символов.
Использование таблицы перекодировки является очень простой операцией, поэтому этот подход не усложняет сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов.
Для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код, должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5В со скоростью 100 Мбит/с требуется тактовая частота 125 МГц. При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по линии передается не избыточный код. Тем не менее спектр избыточного потенциального кода оказывается уже спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника и передатчика на повышенной тактовой частоте.
8B/10B
Кодирование по способу 8B/10B, схема блочного кодирования 8B/10B
8-битовые данные передаются как 10-битовые символы, или знаки, причём младшие 5 битов данныхкодируются (преобразуются) в 6-бит группу, а старшие 3 бита - в 4-бит группу. Кроме 10-бит символовданных стандарты, предусматривающие схему кодирования 8B/10B, определяют также специальные, илиуправляющие, символы - для обозначения конца кадра, незанятости линии передачи и других условий, связанных с работой линии. Поскольку 8-бит слова преобразуются в 10-бит символы, каждое из возможных256 слов можно представить в одном из двух видов - прямом и инвертированном. Благодаря этому схемаобеспечивает для последовательного потока данных в линии баланс по постоянному току и достаточноечисло изменений состояния, переходов от 0 к 1 и обратно - а переходы дают информацию длявосстановления тактового сигнала (для восстановления синхронизации); это позволяет уменьшить"межсимвольные помехи" и повысить скорость передачи. Кодирование обычно делается полностьюаппаратным способом, при помощи просмотровых (кодировочных) таблиц (lookup table), так чтопрограммы верхних уровней могут ничего не знать об этом.
8B/6T
Символьное кодирование 8B/6T. Если использовалось бы манчестерское кодирование, то битовая скорость в расчете на одну витую пару была бы 33.33 Мбит/с, что превышало установленный предел 30 МГц для таких кабелей. Эффективное уменьшить частоты модуляции достигается, если вместо прямого (2-х уровневого) бинарного кода использовать 3-х уровневый (ternary) код. Этот код известен как 8B6T бестраншейная прокладка трубопроводов Воронеж.
это означает, что прежде, чем происходит передача, каждый набор из 8 бинарных битов (символ) сначала преобразуется в соответствии с определенными правилами в 6 тройных (3-х уровневых) символов. На примере, показанном на рис.3б, можно определить скорость 3-х уровневого символьного сигнала:
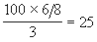 МГц
МГц
значение которое не превышает установленный предел.
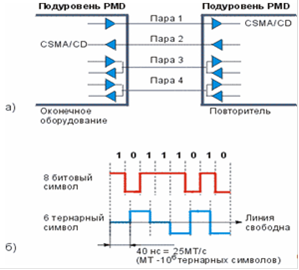
Рис 3. Физические интерфейсы 100Base-T4: а) Использование витых пар; б) Кодирование 6B/8T


Интерфейс 100Base-T4 имеет один существенный недостаток - принципиальную невозможность поддержки дуплексного режима передачи. И если при строительстве небольших сетей Fast Ethernet с использованием повторителей, 100Base-TX не имеет преимуществ перед 100Base-T4 (существует коллизионный домен, полоса пропускания которого не больше 100 Мбит/с), то при строительстве сетей с использованием коммутаторов недостаток интерфейса 100Base-T4 становится очевидным и очень серьезным. Поэтому данный интерфейс не получи столь большого распространения, как 100Base-TX и 100Base-FX.
3. Высокоскоростные коды- код MLT-3и PAM5.
Код трехуровневой передачи MLT-3 (Multi Level Transmission - 3) имеет много общего с кодом NRZ. Важнейшее отличие - три уровня сигнала. Единице соответствует переход с одного уровня сигнала на другой. Изменение уровня сигнала происходит последовательно с учетом предыдущего перехода. Максимальной частоте сигнала соответствует передача последовательности единиц. При передаче нулей сигнал не меняется. Информационные переходы фиксируются на границе битов. Один цикл сигнала вмещает четыре бита.
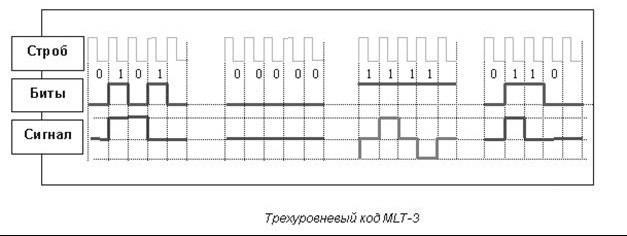 Трехуровневый код MLT-3 Недостаток кода MLT-3, как и кода NRZ - отсутствие синхронизации. Эту проблему решают с помощью преобразования данных, которое исключает в коде длинные последовательности нулей и исключает возможность рассинхронизации. Дополнительное преобразование данных производится при помощи метода предварительного перекодирования данных 4B5B Протоколы, использующие код NRZ, чаще всего дополняют кодированием данных 4B5B. В отличие от кодирования сигналов, которое использует тактовую частоту и обеспечивает переход от импульсов к битам и наоборот, кодирование данных преобразует одну последовательность битов в другую. В коде 4B5B используется пяти-битовая основа для передачи четырех-битовых информационных сигналов. Пяти-битовая схема дает 32 (два в пятой степени) двухразрядных буквенно-цифровых символа, имеющих значение в десятичном коде от 00 до 31. Для данных отводится четыре бита или 16 (два в четвертой степени) символов. Четырех-битовый информационный сигнал перекодируется в пяти-битовый сигнал в кодере передатчика. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере приемника пять битов расшифровываются как информационные и служебные сигналы. Для служебных сигналов отведены девять символов, семь символов - исключены. Исключены комбинации, имеющие более трех нулей (01 - 00001, 02 - 00010, 03 - 00011, 08 - 01000, 16 - 10000). Такие сигналы интерпретируются символом V и командой приемника VIOLATION - сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная комбинация из пяти нулей (00 - 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET - отсутствие сигнала в линии. Кодирование данных решает две задачи - синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения последовательности более трех нулей. Высокая помехоустойчивость достигается контролем принимаемых данных на пяти-битовом интервале. Цена кодирования данных - снижение скорости передачи полезной информации. В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы частот в протоколах с кодом MLT-3 и кодированием данных 4B5B уменьшается соответственно на 25%. При совместном использовании кодирования сигналов MLT-3 и данных 4В5В скорость передачи- 3 бита информации на 1 герц несущей частоты сигнала. Такая схема используется в протоколе TP-PMD.
Трехуровневый код MLT-3 Недостаток кода MLT-3, как и кода NRZ - отсутствие синхронизации. Эту проблему решают с помощью преобразования данных, которое исключает в коде длинные последовательности нулей и исключает возможность рассинхронизации. Дополнительное преобразование данных производится при помощи метода предварительного перекодирования данных 4B5B Протоколы, использующие код NRZ, чаще всего дополняют кодированием данных 4B5B. В отличие от кодирования сигналов, которое использует тактовую частоту и обеспечивает переход от импульсов к битам и наоборот, кодирование данных преобразует одну последовательность битов в другую. В коде 4B5B используется пяти-битовая основа для передачи четырех-битовых информационных сигналов. Пяти-битовая схема дает 32 (два в пятой степени) двухразрядных буквенно-цифровых символа, имеющих значение в десятичном коде от 00 до 31. Для данных отводится четыре бита или 16 (два в четвертой степени) символов. Четырех-битовый информационный сигнал перекодируется в пяти-битовый сигнал в кодере передатчика. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере приемника пять битов расшифровываются как информационные и служебные сигналы. Для служебных сигналов отведены девять символов, семь символов - исключены. Исключены комбинации, имеющие более трех нулей (01 - 00001, 02 - 00010, 03 - 00011, 08 - 01000, 16 - 10000). Такие сигналы интерпретируются символом V и командой приемника VIOLATION - сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная комбинация из пяти нулей (00 - 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET - отсутствие сигнала в линии. Кодирование данных решает две задачи - синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения последовательности более трех нулей. Высокая помехоустойчивость достигается контролем принимаемых данных на пяти-битовом интервале. Цена кодирования данных - снижение скорости передачи полезной информации. В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы частот в протоколах с кодом MLT-3 и кодированием данных 4B5B уменьшается соответственно на 25%. При совместном использовании кодирования сигналов MLT-3 и данных 4В5В скорость передачи- 3 бита информации на 1 герц несущей частоты сигнала. Такая схема используется в протоколе TP-PMD.
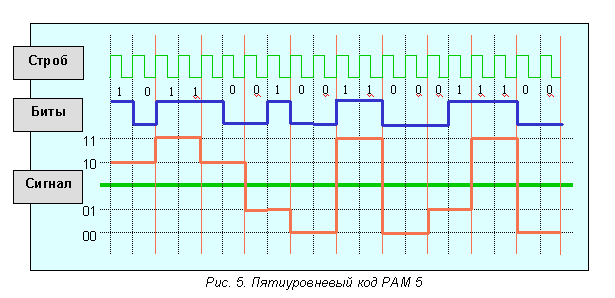
Еще более высокоскоростной код- код PAM 5 Рассмотренные выше схемы кодирования сигналов были битовыми. При битовом кодировании каждому биту соответствует значение сигнала, определяемое логикой протокола.
Пятиуровневый код RAM 5 Прикодировании уровень сигнала задают блоки из двух бит. В пятиуровневом коде PAM 5используется 5 уровней амплитуды и двухбитовое кодирование. Для каждой комбинации задается уровень напряжения. При двухбитовом кодировании для передачи информации необходимо четыре уровня (два во второй степени - 00, 01, 10, 11). Передача двух битов одновременно обеспечивает уменьшение в два раза частоты изменения сигнала. Пятый уровень добавлен для создания избыточности кода, используемого для исправления ошибок. Это дает дополнительный резерв соотношения сигнал / шум 6 дБ. Код PAM 5 используется в протоколе1000 Base T Gigabit Ethernet. Данный протокол обеспечивает передачу данных со скоростью 1000 Мбит/с при ширине спектра сигнала всего 125 МГц.
4. Скремблирование
Скремблирование заключается в побитном вычислении результирующего кода на основании битов исходного кода и полученных в предыдущих тактах битов результирующего кода. Например, скрэмблер может реализовывать следующее соотношение:
В1=Ai Bi-3Bi-5.
Здесь Bi — двоичная цифра результирующего кода, полученная на г-м такте работы скрэмблера, Ai— двоичная цифра исходного кода, поступающая на г-м такте на вход скрэмблера, Bi-3и Bi-5 — двоичные цифры результирующего кода, полученные на предыдущих тактах работы скрэмблера (соответственно на 3 и на 5 тактов ранее текущего такта) и объединенные операцией исключающего ИЛИ (сложение по модулю 2).
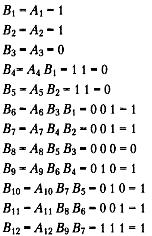
Таким образом, на выходе скрэмблера появится код 110001101111, в котором нет посл довательности из шести нулей, присутствовавшей в исходном коде. После получения результирующей последовательности приемник передает ее дескрэблеру, который восстанавливает исходную последовательность на основании обратносоотношения:
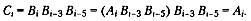
Различные алгоритмы скрэмблирования отличаются количеством слагаемых, дающих цифру результирующего кода, и сдвигом между слагаемыми. Так, в сетях ISDN при передаче данных от сети к абоненту используется преобразование со сдвигами на 5 и 23 позиции, а при передаче данных от абонента в сеть — со сдвигами на 18 и 23 позиции.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования. Для улучшения биполярного кода AMI-используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
Рисунок 1 иллюстрирует использование методов B8ZS (Bipolar with 8-Zeros Substitution) и HDB3 (High-Density Bipolar 3-Zeros) для корректировки кода AMI. Исходный код состоит из двух длинных последовательностей нулей: в первом случае — из 8, а во втором из 5.
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого онпосле первых трех нулей вместо оставшихся пяти нулей вставляет пять цифр: V-1*-0- V-1*. Здесь Vобозначает сигнал единицы, запрещенной (Violations) для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей единицы, 1* — сигнал единицы корректной полярности (знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль). В результате на 8 тактах приемник наблюдает 2 искажения — очень маловероятно, что это случается из-за шума на линии или других сбоев передачи. Поэтому приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их исходными 8 нулями. Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
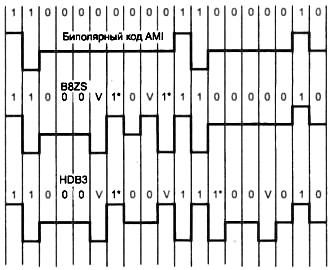
Рис. 1. Коды B8ZS и HDB3
Код HDB3 исправляет любые четыре смежных нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS. Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала V чередуется при последовательных заменах.
Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, задействуется последовательность 000V, а если число единиц было четным — последовательность 1*00V.
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей, которые встречаются в передаваемых данных. На рис. 2 приведены спектры сигналов разных кодов, полученные при передаче произвольных данных, в которых различные сочетания нулей и единиц в исходном коде равновероятны. При построении графиков спектр усреднялся по всем возможным наборам исходных последовательностей. Естественно, что результирующие коды могут иметь и другое распределение нулей и единиц. Из рисунка видно, что потенциальный код NRZ обладает хорошим спектром с одним недостатком — у него имеется постоянная составляющая. Коды, полученные из потенциального кода путем логического кодирования, обладают более узким спектром, чем манчестерский код, даже при повышенной тактовой частоте (на рисунке спектр кода 4В/5В должен был бы примерно совпадать с кодом B8ZS, но он сдвинут в область более высоких частот, так как его тактовая частота повышена на 1/4 по сравнению с другими кодами). Этим объясняется преимущественное применение в современных технологиях, подобных FDDI, Fast Ethernet, Gigabit Ethernet, ISDN и т. п., потенциальных избыточных и скрэмблированных кодов вместо манчестерского и биполярного импульсного кода.
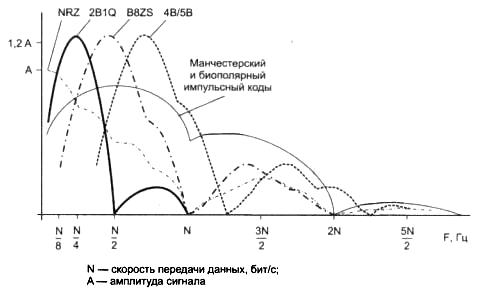
5. Компрессия данных
Компрессия, или сжатие, данных применяется для сокращения времени их передачи. Так как на компрессию данных передающая сторона тратит дополнительное время, к которому нужно еще прибавить аналогичные затраты времени на декомпрессию этих данных принимающей стороной, то выгоды от сокращения времени на передачу сжатых данных обычно бывают заметны только на низкоскоростных каналах. Соответствующий порог скорости для современной аппаратуры составляет около 64 Кбит/с. Многие программные и аппаратные средства сети способны выполнять динамическую компрессию данных в отличие от статической, когда данные сначала сжимаются (например, с помощью популярных архиваторов типа WinZip), а уже затем отсылаются в сеть.
На практике может использоваться ряд алгоритмов компрессии, каждый из которых применим к определенному типу данных. Некоторые модемы (называемые интеллектуальными) предлагают адаптивную компрессию, при которой в зависимости от передаваемых данных выбирается определенный алгоритм компрессии. Рассмотрим некоторые из общих алгоритмов компрессии данных.
Когда данные состоят только из чисел, значительную экономию можно получить путем уменьшения количества используемых на цифру битов с 7 до 4, просто заменяя десятичные цифры кода ASCII двоичными. Просмотр таблицы кодов ASCII показывает, что старшие три бита всех кодов десятичных цифр содержат комбинацию 011. Если все данные в кадре информации состоят из десятичных цифр, то, поместив в заголовок кадра соответствующий управляющий символ, можно существенно сократить длину кадра. Этот метод носит название десятичной упаковки.
Альтернативой десятичной упаковке при передаче числовых данных с небольшими отклонениями между последовательными цифрами является передача только этих отклонений вместе с известным опорным значением. Такой метод называется относительным кодированием и используется, в частности, при цифровом кодировании голоса с помощью кода ADPCM, когда в каждом такте передается только разница между соседними замерами голоса.
Часто передаваемые данные содержат большое количество повторяющихся байтов. Например, при передаче черно-белого изображения черные поверхности будут порождать большое количество нулевых значений, а максимально освещенные участки изображения — большое количество байтов, состоящих из всех единиц. Передатчик сканирует последовательность передаваемых байтов и если обнаруживает последовательность из трех или более одинаковых байтов, заменяет ее специальной трехбайтовой последовательностью, в которой указывает значение байта, количество его повторений, а также отмечает начало этой последовательности специальным управляющим символом. Этот метод носит название символьного подавления.
Метод кодирования с помощью кодов переменной длины опирается на тот факт, что не все символы в передаваемом кадре встречаются с одинаковой частотой. Поэтому во многих схемах кодирования коды часто встречающихся символов заменяют кодами меньшей длины, а редко встречающихся — кодами большей длины. Такое кодирование называется также статистическим кодированием. Из-за того что символы имеют разную длину, для передачи кадра возможна только бит-ориентированная передача. При статистическом кодировании коды выбираются таким образом, чтобы при анализе последовательности битов можно было бы однозначно определить соответствие определенной порции битов тому или иному символу или же запрещенной комбинации битов. Если данная последовательность битов представляет собой запрещенную комбинацию, то необходимо к ней добавить еще один бит и повторить анализ. Например, если при неравномерном кодировании для наиболее часто встречающегося символа «Р» выбран код 1, состоящий из одного бита, то значение 0 однобитного кода будет запрещенным. Иначе мы сможем закодировать только дв а символа. Для другого часто встречающегося символа «О» можно использовать код 01, а код 00 оставить как запрещенный. Тогда для символа «А» можно выбрать код 001, для символа «ІІ» — код 0001 и т. п.
Неравномерное кодирование наиболее эффективно, когда неравномерность распределения частот передаваемых символов велика, как при передаче длинных текстовых строк. Напротив, при передаче двоичных данных, например кодов программ, оно малоэффективно, так как 8-битные коды при этом распределены почти равномерно.
Одним из наиболее распространенных алгоритмов, на основе которых строятся неравномерные коды, является алгоритм Хафмана, позволяющий строить коды автоматически на основании известных частот появления символов. Существуют адаптивные модификации метода Хафмана, которые позволяет строить дерево кодов «на ходу», по мере поступления данных от источника.
Многие модели коммуникационного оборудования, такие как модемы, мосты, коммутаторы и маршрутизаторы, поддерживают протоколы динамической компрессии, позволяющие сократить объем передаваемой информации в 4, а иногда и в 8 раз. В таких случаях говорят, чт о протокол обеспечивает коэффициент сжатия 1:4 или 1:8. Существуют стандартные протоколы компрессии, например V.42bis, а также большое количество нестандартных фирменных протоколов. Реальный коэффициент компрессии зависит от типа передаваемы х данных. Так, графические и текстовые данные обычно сжимаются хорошо, а коды программ — хуже.
Вывод
С помщью разных методов кодировок программист может граммотно выполнять различные технические и програмные проекты. При правильной оценки необходимости применения правильного канала кодирования скорость и качество реаилизуемого проекта программистом будет наиболее высоким.
Используемая литература
- Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. - М.: ДИАЛОГ-МИФИ, 2002. - 384 с.
- Д. Сэломон. Сжатие данных, изображения и звука. — : Техносфера, 2004.— С.368.
- М.А. Беляев, В.В. Лысенко, Л.А. Малинина Основы Информатики.
— : Высшее образование 2010г.
- Фурсов В. А. Ф 954 Теория информации: учеб. / В.А. Фурсов. - Самара: Изд-во Самар, гос. аэрокосм, ун-та, 2011. - 128 с.: ил.
- Ктн е. В. Курапова, кф-мн е. П. Мачикина. Основные методы кодирования данных: Практикум. / СибГути. – Новосибирск, 2010. – 62 с.
- Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. - М.: Издательский дом "Вильямс", 2000. - 384 с.
- Кричевский Р.Е. Сжатие и поиск информации. - М.: Радио и связь, 1989. - 168 с.
- Марченко А.И., Марченко Л.А. Программирование в среде Turbo PASCAL 7.0. Базовый курс. Киев: «ВЕК+», 2003.
- Панин В.В., Основы теории информации. Учебное пособие для ВУЗов. Бином, 2009.
- Дронов В.А. Д75 PHP, MySQL, HTML5 и CSS3. Разработка современных динамических Web-сайтов. СПб.: БХВ-Петербург, 2016. -688 с.:ил.
- М. Вернер Основы кодирования. Учебник для ВУЗов. Москва: Техносфера, 2004. - 288с
- Шувалов В. П., Захарченко Н. В., и др. Передача дискретных сообщений: учебник для вузов / под ред. Шувалов В. П..—: Радио и связь, 1990.— 464с.

- Роль мотивации в поведении организации (Первичные и современные теории мотивации труда)
- Управление поведением в конфликтных ситуациях (Способы разрешения конфликтов )
- Управление поведением в конфликтных ситуациях (Понятие, классификация и основные причины возникновения конфликтов в организации, их роль в менеджменте)
- Управление поведением в конфликтных ситуациях ( Понятия конфликта, процесс его развития и причины)
- Игра как метод воспитания (Тестирование детей )
- Основные корпоративные схемы финансовых отношений (этапы и системы финансами)
- Невербальные проявления социальных состояний человека (Психология мимики и жестов)
- Проблема личности в социальной психологии ( Социально-психологический подход к пониманию личности)
- Особенности коммуникаций в организации (Внешние коммуникации)
- Невербальные проявления эмоциональных состояний человека (Невербальные формы выражения эмоций)
- Системы программирования (Определение системы программирования)
- Применение процессного подхода для оптимизации бизнес-процессов (Разнообразные подходы к управлению)