
Гетерогенные мультикомпьютерные системы
Содержание:

Введение
Идея параллельной обработки данных не нова. Можно считать, что она возникла еще на заре человеческой цивилизации, когда оказалось, что племя может успешно бороться за выживание, если каждый его член выполняет свою часть общей работы.
В ближайшее время под эффективным использованием аппаратных средств компьютера будут пониматься применение параллельных алгоритмов. Это связано с замедлением темпов увеличения тактовой частоты микропроцессоров и стремительным распространением многоядерных микропроцессоров. Под средствами осуществлении параллельности понимаются языки программирования либо библиотеки, обеспечивающие инфраструктуру параллельных программ. К ним можно отнести: Occam, MPI, HPF, Open MP, DVM, Open TS, Boost. Thread, Posix Threads.
Гетерогенные вычислительные системы — электронные системы, ис-пользующие разные виды вычислительных блоков. Вычислительными блоками этой системы может быть как процессор общего назначения (GPP), так и процессор специального назначения, к примеру, цифровой сигнальный (DSP) или графический (GPU) процессоры, также сопроцессор и логика ускорения, а именно специализированная интегральная схема (ASIC) или программируемая пользователем вентильная матрица (FPGA). Так гетерогенная вычислительная платформа включает процессоры с различными наборами команд (ISA). Потребность на увеличение гетерогенности в вычислительных системах, не в полном объеме необходим в высокопроизводительных, высокореакционных системах, взаимодействующих с другим окружением. Ранее технологические достижения и масштабируемость частоты давали возможность большинству компьютерных приложений увеличивать производительность при отсутствии структурных изменений либо аппаратного ускорения. Хотя эти достижения сохраняются, их воздействие на современные приложения не так существенно, как воздействие других препятствий, таких как стена памяти и стена мощности.
Графические процессоры могут использовать векторную обработку, которые позволяют им выполнять параллельные операции на очень больших базах данных и позволяют делать это с гораздо более низким расходом энергии по сравнении с последовательной обработке подобных баз данных на процессорах. Такие возможности дают более реалистичную графику для игровых дисплеев. В настоящее время данные процессоры имеют возможность производительность 3D-графики, снимая графики с центрального процессора, данные процессоры стали более привлекательными для более общих целей, таких как решение задач параллельного программирования.
Ранние усилия по привлечению графических процессоров для вычислений общего назначения совпало с заметным сдвигом в потребительской культуры. Было резкое увеличение доступности и качества цифрового контента, в соответствии с увеличением потребностей в насыщенных визуальных изменений, как воспроизведение видео и просмотра контента в формате HD. В то же время, появление основной поддержки операционной системы для продвинутых многозадачности начали требовать эффективности обработки совершенно нового порядка.
Цель данной работы является изучение гетерогенных мультикомпьютерных систем.
Для реализации поставленной цели необходимо выполнить ряд задач:
- Изучить гетерогенную архитектуру для CPU, GPU и DSP;
- Рассмотреть очереди и диспетчеризация задач;
- Изучить программные компоненты HSA;
- Рассмотреть поддержку технологий программирования и архитектуры HSA и т.д.
Глава 1. Характеристика гетерогенной мультикомпьютерной системы
1.1 Гетерогенная архитектура для CPU, GPU и DSP
Графический процессор, также называется визуальный блок обработки, является специализированным электронной схемой, предназначен для быстрого использования и изменения памяти, для ускорения создания изображений в буфере кадров, предназначенного для вывода на дисплей. Графические процессоры используются во встраиваемых систем, мобильных телефонов, персональных компьютерах, рабочих станций и игровых консолях.
Современные графические процессоры эффективно работают с компьютерной графикой и обработкой изображений, а их высоко параллельная структура делает их более эффективными, чем процессоры общего назначения, в которых обработка больших блоков графических данных производится параллельно. В персональном компьютере, графический процессор может быть расположен на видеокарте, также графический процессор может быть встроен в материнскую плату.[1]
С целью улучшения архитектуры гетерогенных систем и уменьшения сложности в модификациях программирования в 2012 году был создан фонд HSA Foundation, занимающийся исследованием спецификаций Heterogeneous System Architecture (HSA). В HSA Foundation, в настоящее время включает такие компании, как AMD, ARM, Imagination Technologies, MediaTek, Texas Instruments, Samsung Electronics и Qualcomm.
HSA представляет из себя архитектуру гетерогенных систем с единой когерентной памятью для различных вычислительных элементов, при поддержки управления очередями задач, широкого диапазона оборудования и языков высокого уровня. Характеристика когерентности памяти значит, что разные процессоры рассматривают консистентное (непротиворечивое) положение единой памяти, даже в тех случаях, любым из процессоров производится обновление памяти. Когерентность памяти уже давно воспринимается ровно как что-то само собой подразумевающее для гомогенных многопроцессорных и многоядерных систем, но пока, что новшество для гетерогенных систем.
В об݅ще݅м случае поддержание ко݅ге݅ре݅нт݅но݅ст݅и - это сл݅ож݅ная задача. Правда, возможность процессоров различных ти݅по݅в, а именно: CPU, GPU, DS݅P дает возможность исключить работу с одними и теми же данными из общей памяти, что превышает производительность и экономию энергии. В среде HSA пр݅ил݅ож݅ен݅ия, которые работают на CP݅U, могут производить определенные операции на GP݅U/݅DS݅P с такой же легкостью как и на процессорах типа CPU.[2] Чтобы данные операции производились необходимо использовать указатели в данных в общей памяти и произвести обновление соответственных задач.
В данном приложение необходимо произвести операции вв݅од݅а-݅вы݅во݅да для перевода да݅нн݅ых на устройство, предназначенное для вычисления, а после этого произвести запуск вычислительного процесса. HS݅A дает возможность разработчикам программного обеспечения создавать приложения без глубокого изучения работы ускорителей различного типа, расположенных в целевой си݅ст݅ем݅е, таких как GP݅U, DSP, видео кодеры/декодеры и прочие акселераторы.
1.2 Общая виртуальная память
Таким образом, проанализировав существующие взгляды на понятие развития можно сделать вывод, что развитие - это динамический процесс, который свойственен любым явлениям. Все сферы природы, человеческая жизнь, регион, государство, мир все время находятся в движении, то есть меняются. В результате развития объект приобретает новое качественное состояние, в виде изменения его состава, структуры, свойств. Вследствие развития объекта могут возникать, изменяться или исчезать его элементы или связи. На рисунке изображены определения категории развитие и дано его собственное определение, которое является более обоснованным и учитывает пространственно -временные характеристики. Очевидно, что указанные свойства присущи многим сферам жизни и деятельности человека, государства, а особенно экономике.
Осмысление произведенных в разные культурно - исторические периоды философско - педагогических идей необходимо для решения проблем, стоящих перед теорией обучения сегодня. Постоянное увеличение количества знаний в различных областях человеческой деятельности, дифференциация наук, развитие информационного общества - это основные факторы, которые обусловливают необходимость постоянного пересмотра не только содержания, структуры, но и методов обучения, которое должно ввести человека в жизни, вооружив ее и навыками к самостоятельному мышления, и необходимыми знаниями.
С целью упрощения работы операционной системы и приложений на платформе HSA применяется набор таблиц, который содержит виртуальные страницы, этот набор является унифицированным для всех типов процессоров, это дает возможность производить обмен между различными устройствами для вычисления. Так, указатели, которые являются одинаковыми становятся одинаковыми физическими адресами.[3]
Так же, это позволят исключить в операционных системах ведение учета нескольких независимых друг от друга наборов таблиц станиц используемых в устройствах. Когда CPU и GPU используют одни и те же участки памяти, то в традиционных GPU применяются различные адресные пространства, и драйверу графического адаптера необходимо обналичивать кэши памяти при общем применении памяти с CPU.
Платформа HSA дает разработчику использовать в полном объеме когерентную память, это делает менее сложным создание приложений, в тех случаях, когда вычислители различной архитектурой применяются в рамках унифицированных шаблонов разработки программ, позволяя тем самым, использовать простые алгоритмы, например производитель-потребитель. Но HSA использует так же и некогерентную память, это нужно в некоторых моментах, а именно в получении наиболее максимальной производительности, в тех случаях, когда отсутствует нужда в использовании общих данных процессорами различного типа.
Так как в операционной системе используется механизм подкачки страниц, то это дает возможность работать пользовательским процессам с данными, объем памяти которых, превышает размер физической памяти, но обычные GPU имеют возможность производить работу только невыгружаемой основной памятью — драйвер и операционная система обязаны отметить определенную границу в физической памяти, произвести его замену как невыгружаемый, а так же реализовать отдельное виртуальное адресное пространство только для работы ускорителя. Возможность подкачки страниц в CPU дает использование такого же большого пространства, как и в HSA при использовании механизма страничных прерываний адресов и избавлении от невыгруженной памяти.
Существует большое количество за݅да݅ч, которые требуют память бо݅ль݅ше, чем могут дать графические ус݅ко݅ри݅те݅ли используемые в настоящее время, даже при использовании невыгружаемой ос݅но݅вн݅ой памяти. В таких случаях необходимо разделение за݅да݅чи и данных на несколько независимых частей, в связи с тем, что на реализацию подкачки да݅нн݅ых необходимо использование больших трудовых ресурсов от пр݅ог݅ра݅мм݅ис݅та, поэтому такие задачи не часто пе݅ре݅но݅сятся на GPU.[4]
Достигнуть увеличения производительности, не прибегая к увеличению сложности программного кода, позволяет использование единого адресного пространства, а также страничного прерывания, которое обеспечивается в архитектуре HSA. Так же использование структурных данных, которые содержат указатели, например списки и деревья, которые одновременно доступны в и CPU, и GPU возможно при задействовании общего адресного пространства.
В компьютере, как известно, есть оперативная память, используемая для хранения данных, которые нужны процессору в первую очередь, но есть также такое понятие, как виртуальная память компьютера.
Процессор постоянно решает какие-то задачи и все данные, которые нужны для его работы, помещаются в оперативную память и поскольку оперативная память имеет очень высокое быстродействие, то процессор также быстро получает доступ к необходимой информации.
Но оперативная память часто ограничена по размеру, так в домашних компьютерах, к примеру, размер ее редко превышает четыре гигабайта. Обычный размер оперативной памяти для ноутбуков, это 1 или 2 гигабайта.
Для того чтобы помочь компьютеру, несколько разгрузить оперативную память, операционная система Windows создает специальный файл, который в дальнейшем выполняет роль виртуальной памяти.[5]
Этот файл называют также файлом подкачки – pagefile.sys, он располагаться на жестком диске компьютера и содержит атрибуты скрытый и системный.
Этот файл используется системой, чтобы хранить части программ и файлов, которые не умещаются в оперативной памяти, но необходимы для работы компьютера в данный момент.
По мере надобности Windows передает данные из файла виртуальной памяти в оперативную память и процессор получает таким образом быстрый доступ к этим данным.
Чтобы увидеть файл подкачки, заходим в программу Проводник и зайдем на диск С. Если отключено отображение скрытых файлов, то можно зайти в настройки программы Проводник, в меню – Упорядочить – Свойства – Параметры папок и поиска – Вид и откроется окошко Параметры папок.
Если собрана сеть, то доступ можно получить в Центре управления сетями и общим доступом. Тут опять же избираем Сервис – Параметры папок.
Откроется одноименное окно, выбираем в нем Вид и в Дополнительных параметрах снимаем пометку Скрывать защищенные системные файлы, а также нажимаем Показывать скрытые файлы, папки и диски. Жмем Применить.
Теперь на диске С появляются несколько папок и файлов, которые имеют атрибуты скрытый или системный. Здесь же можно увидеть файл pagefile.sys, который отмечен, как системный и его объем на данный момент составляет более 3 Гб.
По мере работы компьютера и запуска различных программ размер файла виртуальной памяти может увеличиваться. При этом можно увидеть, что размер свободного места на диске С непрерывно меняется.
В первую очередь это связано с тем, что работает виртуальная память, постоянно в нее помещаются какие-то файлы, фрагменты программ и поэтому этот файл постоянно изменяет свой размер.
Иногда при работе на компьютере может появиться сообщение о том, что недостаточно виртуальной памяти. Речь при этом идет как раз таки о том, что файл подкачки оказался мал.
При этом может быть две ситуации. Во-первых, место на диске С уменьшилось до таких размеров, что файл подкачки не может более увеличиваться в объеме. Вторая ситуация, это файл подкачки ограничен в объеме пользователем и его не достаточно для хорошего функционирования компьютера. Если появилось сообщение о недостаточности виртуальной памяти, надо сначала проверить свободное место на системном диске, как правило, это диск С.[6] Свободное место на диске С требуется как для работы файла подкачки, так и для работы различных программ, поскольку они создают различные временные файлы, в большинстве случаев они затем удаляются, как только работа программы будет закончена. Поэтому надо следить, чтобы на диске С постоянно было свободное место. Так при работе ОС Windows 7 его должно быть не менее 5 -7 Гб. Объем современных жестких дисков исчисляется часто терабайтами, поэтому оставить достаточное свободное место на диске С проблем не составит. Для изменения объема виртуальной памяти необходимо перейти из панели управления в окно Система или нажимаем клавиши Windows + Pause.
В окне Система переходим во вкладку Дополнительные параметры системы. Открывается окно Свойства системы и в нем есть блок Быстродействие.
Нажимаем на кнопку Параметры, откроется окошко Параметры быстродействия. Открываем вкладку Дополнительно, где есть раздел Виртуальная память.
Нажимаем здесь на кнопку Изменить. В открывшемся окне снимаем галочку Автоматически выбирать объем файла подкачки и отмечаем Указать размер вручную.
Если размер установлен автоматически, то операционная система будет изменять размер по своему желанию. Можно этот размер ограничить, допустим 3500 Мб. В этом случае виртуальная память компьютера всегда будет одного размера и пространство на диске С не будет изменяться из-за файла подкачки.
Есть возможность также выбрать какой-то диапазон значений и тогда файл виртуальной памяти станет меняться в заданных пределах. Можно установить опцию Без файла подкачки и тогда виртуальная память компьютера использоваться вообще не будет. Тогда быстродействие операционной системы несколько повысится, потому как оперативная память работает намного быстрее, чем жесткий диск. Но произойдет это только в том случае, если на компьютере установлено достаточно оперативной памяти.[7]
Чаще всего файл подкачки отключить невозможно, поэтому указываем его величину вручную, либо оставляем галочку Автоматически изменять объем файла подкачки. Нажимаем OK и выбранные параметры вступают в силу после того, как компьютер будет перезагружен.
Глава 2. Постановка задач системы
2.1 Очереди и диспетчеризация задач
Часто причиной образования узких мест в массово-параллельных системах является работа ядра в операционной системе. HSA дает возможность уменьшить время, которое затрачивается на проведение диспетчеризации вычислительных задач, что дает возможность работать с комплексом задач в пользовательском режиме без использования вызова системных функций, а также без переключения в режим ядра. В системные драйверы вносятся меньше накладных расходов, при использовании такого подхода. Также есть возможность переключения контекста задач, которые стоят в очереди, без использовании вызова функций ядра операционной системы.
Значительный компонент архитектуры HSA это обеспечение задержек при диспетчеризации задач. Это дает возможность использовать дополнительные ускорители со стороны сопроцессоров и производить работу с ними соответственно, а именно разработчики приложений могут быть уверены в поддержании заданной производительности в связи с перемещением данных на внешнее, удаленное устройство.[8]
Потребитель считывает запросы помещенные производителем в область физической памяти, что является очередью. Исполняющим вычислительным устройством в данном случае является потребитель. Компоненты HSA, заложенные в системе отвечают за указание и отчистку участка памяти и создание очередей — когда создана очередь, разработчик имеет возможность посылать в нее задания без участия операционной системы, так же производить работу с очередями возможно и при использовании библиотечных функций и напрямую.
При проведении работ с очередями не нужно забывать учитывать про их размер, который ограничен, а так же и другие нюансы.
Также используется поддержка автоматической балансировки нагрузки в библиотеках. Возможно посылать задачи одному вычислительному устройству на исполнение на любое другое вычислительное устройство, это связанно с тем, что очереди могут быть как у ускорителей, так и у CPU.
Существуют три варианта: Процессор отправляет задачу на ускоритель. Этот вариант работы типичен для GPU-вычислений (OpenCL, CUDA). Ускоритель отправляет задачу другому ускорителю (в том числе себе). Данный вариант дает возможность ставить на исполнение дополнительные задачи без использования CPU. В ином случае нужда в выполнении кода на CPU и ожидании диспетчеризации соответственного процесса операционной системы давала бы очень большие задержки. Ускоритель отправляет задачу на CPU. Поэтому ускоритель имеет возможность запросить использование системных функций, к примеру выделение памяти или осуществление ввода-вывода.
Значимым условием HSA является вытесняемость задач
— это обязательное качество многопроцессорных многопользовательских систем. В отсутствии использовании вытесняемости, единственная задача может занять все устройство на определенный интервал времени, блокируя тем самым остальные задачи, стоящие в очереди. Ошибка в коде может является причиной к обязательной перезагрузки устройства. HSA никак не ограничивает создателей ускорителей в способе осуществлении вытесняемости.[9]
Ядро операционной системы часто было причиной узких мест в массово параллельных системах-HSA может помочь вам сократить время, затрачиваемое на планирование вычислительных задач, позволяя процессу работать непосредственно с пользовательским режимом очереди без необходимости вызывать системные функции и переключаться в режим ядра. Такой подход минимизирует накладные расходы системных драйверов. Кроме того, HSA-платформа предоставляет аппаратным ускорителям возможность переключаться между задачами в очереди без необходимости вызова ядра операционной системы, специальный аппаратный планировщик позволяет значительно увеличить скорость переключения контекста и снизить энергозатраты. Однако ОС сохраняет контроль над временем, и в зависимости от сложности аппаратной части конкретного ускорителя администратор очередей может быть либо чисто программным или аппаратным, либо сочетанием программного и аппаратного управления. В случае полностью аппаратного управления, ЦП может устанавливать задачи для выполнения ускорителя без привязки к ОС.[10]
Для обеспечения низкой задержки планирование задач является важной частью архитектуры HSA. Эта функция позволяет рассматривать новые ускорители, такие как сопроцессоры и бороться с ними соответственно, разработчики приложений могут не бояться снижения производительности, так как перемещение данных на внешнее или удаленное вычислительное устройство, а также небольшие задачи.
Очереди являются областями физической памяти, которые производитель помещает в запрос и потребитель, чтобы прочитать их. Потребителем в данном случае является выполнение вычислительного устройства. Компоненты системного программного обеспечения HSA ответственны за распределение и отпуск памяти и создать очереди когда очередь создана, программист может отправить работы без участия операционной системы, и очереди работы могут быть сделаны путем вызывать функции библиотеки или сразу. При работе непосредственно с очередями необходимо учитывать их ограниченный размер и другие нюансы. Библиотеки, в свою очередь, могут обеспечивать автоматическую балансировку нагрузки и другие полезные функции. В очередях можно найти не только ускорители, но и ЦП, что позволяет любому компьютеру отправлять задания на реализацию другого вычислительного устройства. Существует три варианта:
Процессор для отправки задачи на ускоритель. Такой тип взаимодействия характерен для GPU-вычислений (OpenCL, CUDA).
Ускоритель для отправки задания другому ускорителю (включая вас). Этот параметр позволяет выполнять другие задачи без ЦП. В противном случае, необходимо выполнить код на процессоре и ждать соответствующего процесса ОС, отправленного на другой быть очень большие задержки.[11]
Ускоритель отправляет задачу на центральный процессор. Таким образом, ускоритель может запросить системные функции, такие как выделение памяти или ввод-вывод.
Важное требование HSA сделать упреждающим, которое является неотъемлемой частью многих многопользовательских систем. Без реализации замены одна задача может занимать все устройство до произвольного времени, блокируя другие задачи в очереди. Ошибка в коде может привести к перезагрузке устройства.
2.2 Программные компоненты HSA
Архитектура HSA предоставляет как не݅об݅хо݅ди݅мы݅е аппаратные возможности си݅ст݅ем݅ы, так и ее программную часть, а именно систему компиляции и загрузки исполняемых фа݅йл݅ов и компоненты, которые работают в пользовательском ре݅жи݅ме и на ур݅ов݅не ядра операционной системы.
Архитектура HS݅A направлена на поддержание различного об݅ор݅уд݅ов݅ан݅ия, но так же есть не݅об݅хо݅ди݅мость сохранить не݅за݅ви݅си݅мо݅ст݅ь приложений от конкретной ап݅па݅ра݅тн݅ой платформы. Чтобы достичь эту цель необходимо ис݅по݅льзовать݅зовать стандартизованный ин݅те݅рф݅ей݅с, который представлен как язык ни݅зк݅ог݅о уровня — HSAIL (H݅SA Intermediate La݅ng݅ua݅ge݅).[12]
Производится ге݅не݅рация HSAIL-кода компилятором, который ед݅ин݅ для вс݅ех типов GP݅U, в тех случаях когда определенные участки программы необходимо запускать на ускорителях.
Язык HS݅AI݅L был разработан для того, чтобы максимально бы݅ст݅ро и от݅но݅си݅те݅ль݅но просто от݅об݅ра݅жался на ко݅нк݅ре݅тн݅ом устройстве и был скомпилирован в его си݅ст݅ем݅у команд. В начале ко݅д HSAIL подвергается изменению в ко݅д системы ко݅ма݅нд целевого ак݅се݅ле݅ра݅то݅ра — эт݅о изменение происходит ка݅к в мо݅ме݅нт компиляции, та݅к и во время исполнения приложения. Яз݅ык HSAIL разработан для ис݅по݅ль݅зо݅ва݅ни݅я потенциалов па݅ра݅лл݅ел݅ьн݅ых вычислений и сравним по концепции с OpenCL SP݅IR, в котором та݅кж݅е расматривается по݅ня݅ти݅я «рабочая ед݅ин݅иц݅а» (work it݅em݅) и «р݅аб݅оч݅ая группа» (w݅or݅k group). Пр݅и работе с Op݅en݅CL на платформе HSA код на яз݅ык݅ах SPIR ил݅и OpenCL тр݅ан݅сл݅ир݅уе݅тс݅я в HS݅AI݅L.
Компиляторы, генерирующие ко݅д для платформы HS݅A, полностью производят компиляцию пр݅ил݅ож݅ен݅ия для системы ко݅ма݅нд процессора, который включает вы݅чи݅сл݅ит݅ел݅ьн݅ые ядра, которые в свою очередь предназначены к запуску на ус݅ко݅ри݅те݅ля݅х. Код на HS݅AI݅L расположен в сп݅ец݅иа݅ль݅ной секции исполняемого фа݅йл݅а, поэтому запуск подобного файла возможен на системе без по݅дд݅ер݅жк݅и HSA. HSA-приложения мо݅гут включать функции, пр݅ед݅на݅зн݅ач݅ен݅ны݅е как для CP݅U, так и дл݅я GPU (HSAIL), а вызов функции бу݅де݅т производится любым из способов ниже перечисленным:
Из фу݅нк݅ци݅и CPU производится вызов фу݅нк݅ци݅и CPU. Тогда при вы݅зо݅ве будут использованы ст݅ан݅да݅рт݅ны݅е для данной пл݅ат݅фо݅рм݅ы соглашения о вы݅зо݅ве функций. Из функции HS݅AI݅L производится вызов фу݅нк݅ци݅и функция HS݅AI݅L. Архитектура HSA содержит свой стандарт на правила вызова фу݅нк݅ци݅й, но финализатор имеет возможность использовать со݅гл݅аш݅ен݅ие о вызове фу݅нк݅ци݅й, наиболее по݅дх݅од݅ящее для конкретного об݅ор݅уд݅ов݅ан݅ия к примеру, передача па݅ра݅ме݅тр݅ов через память ил݅и через регистры.[13]
Из фу݅нк݅ци݅и CPU производится вызов фу݅нк݅ци݅и HSAIL и на݅об݅ор݅от. Так предполагается асинхронный вы݅зо݅в с использованием оч݅ер݅ед݅ей задач.
Стандартные синхронные мо݅де݅ли вызовов, наподобие RP݅C, могут быть ре݅ал݅из݅ов݅ан݅ы поверх очередей.
В среду вы݅по݅лн݅ен݅ия HSA на пользовательском ур݅ов݅не входят ко݅мп݅он݅ен݅ты, которые необходимы при запуске уж݅е скомпилированной HS݅A-݅пр݅ог݅ра݅мм݅ы. Эти компоненты от݅ве݅ча݅ют за расположение задач в очередях и передачи ин݅фо݅рм݅ац݅ии о ресурсах текущей пл݅ат݅фо݅рм݅ы. Системный сл݅ой HSA ответственный за использование функций пл݅ан݅ир݅ов݅щи݅ка, управление па݅мя݅ть݅ю и вы݅де݅ле݅ни݅е ресурсов, в том чи݅сл݅е памяти по݅д очереди. Сю݅да же включена функция уп݅ра݅вл݅ен݅ия модулем MM݅U (Memory Ma݅na݅ge݅me݅nt Module), об݅оз݅наченый как HMMU и расположен в ар݅хи݅те݅кт݅ур݅е HSA.
Большинство современных систем, от мобильных устройств до суперкомпьютеров, содержащих ядра CPU и GPU, которые по отдельности очень специфичны, но как их лучше использовать в сочетании с "тяжелыми" приложениями, такими как распознавание лиц или физика твердого тела? Можно ли повысить производительность и энергоэффективность без изменения существующих моделей программирования? Концепция гетерогенных систем является шагом к решению этих задач.
Использование графических процессоров (GPU) наряду с классическими микропроцессорами (центральные процессоры, CPU) в настоящее время является общепринятой практикой в области параллельных вычислений на гетерогенных средах, объединяющей вычислительные элементы различных типов. Однако GPU и CPU изначально предназначены для разных устройств, направленных на решение своих задач, а их совместное использование представляет собой комплекс из нескольких задач. Например, они имеют отдельную память и отдельные адресные пространства, поэтому приложение должно явно копировать данные в память GPU и обратно в основную память компьютера.[14] При отправке вычислительной работы-реализация очереди устройства осуществляется через стек драйверов с помощью системных вызовов и ядра операционной системы, что вносит большую задержку и часто делает непрактичным выполнение небольших заданий на отдельном ускорителе. Кроме того, отправка заданий от одного ускорителя к другому или от процессора трудно.
HSA-это архитектура гетерогенных систем с общей когерентной памятью, гетерогенными вычислительными элементами, поддержкой управления очередями задач, широким спектром аппаратного обеспечения и языками высокого уровня. Свойство непротиворечивости памяти означает, что разные процессоры видят одно состояние, разделяемую память, даже когда память независимо обновляется на любом процессоре. Непротиворечивость памяти уже давно воспринимается как должное, как однородные многопроцессорные и многоядерные системы, но все же новинка гетерогенных систем.
В целом поддержание согласованности является сложной задачей. Однако возможность иметь разные типы процессоров (CPU, GPU, DSP) для работы с одними и теми же данными в общей памяти позволит вам избавиться от ненужных операций копирования и повысить производительность и энергоэффективность. В HSA-среде приложения, работающие на CPU, могут выполнять отдельные задачи на GPU / DSP так же легко, как и CPU. Вы можете сделать это, приложение должно предоставить указатели на данные в общей памяти и обновить соответствующие очереди задач.[15] При традиционном подходе приложению необходимо собрать все необходимые данные и с помощью драйверов операционной системы выполнить операции ввода-вывода для передачи данных на вычислительное устройство, а затем запустить процесс расчета. HSA позволяет разработчикам программного обеспечения создавать приложения без необходимости углубляться в детали различных ускорителей, доступных в целевой системе, таких как GPU, DSP, видеокодеры/декодеры и другие функции быстрого доступа.
Для упрощения работы операционной системы и приложений платформы HSA используется один набор виртуальных таблиц страниц для всех типов процессоров, что позволяет обмениваться указателями между собой, информационно-технологическим оборудованием - одни и те же указатели преобразуются в одни и те же физические адреса. Кроме того, такой подход устраняет необходимость в операционной системе, а диспетчер памяти отслеживает количество независимых наборов таблиц страниц для каждого устройства. Если CPU и GPU использовать те же ячейки памяти, традиционный ГПУ использует отдельное адресное пространство, и драйвер дисплея пришлось сбросить кэш при назначении памяти и процессора.
Платформа HSA предоставляет разработчику полностью когерентную память, что значительно упрощает создание приложений — от калькуляторов до различных архитектур, используемых в рамках общих моделей программирования, позволяющих использовать знакомые алгоритмы, например, производителя-потребителя. Однако, HSA также поддерживает несогласованную память, которая необходима для получения максимальной производительности, когда нет никакой потребности разделить данные между процессорами различных видов.
С помощью операционной системы подкачки механизм, который позволяет пользователю процессов для работы с большим объемом памяти, чем физической памяти, но обычный процессор может работать только с невыгружаемой памяти главного контроллера и операционной системы, чтобы поделиться частью физической памяти, пометить его нет - страницы и создать отдельное виртуальное адресное пространство, в частности ускорителя.[16] HSA позволяет избавиться от невыгружаемого пула памяти и общего адресного пространства, когда все GPU, так как механизм страницы прерывает использовать одно и то же пространство iso-адресов, таких как процессор, с возможностью подкачки.
Существует множество задач, которые требуют больше памяти, чем современные видеокарты могут обеспечить, даже использование невыгружаемой памяти. В этом случае для разграничения задач и независимых частей данных и реализации подкачки данных требуются значительные усилия программиста, вследствие чего основные задачи редко переносятся на графический процессор.
В качестве ускорителей для таких задач можно использовать единое адресное пространство и прерывания страниц, предоставляемые архитектурой HSA, что значительно повышает производительность без усложнения программного кода. В дополнение к общему адресному пространству позволяет использовать структуры данных, содержащие указатели, такие как связанные списки и деревья, оба из которых доступны на ЦП и GPU. При традиционном подходе такие случаи требуют отдельного рассмотрения программистом и часто являются основной причиной невозможности перенести алгоритмы на GPU.
Глава 3. Построение системы
3.1 Поддержка технологий программирования и архитектуры HSA
В некоторых процессорах уже используется функционал HSA, но архитектура HSA в полном объеме не обнародована, так находится еще в разработке у рабочих групп HAS Foundation. Так например, применяются в Google Nexus 10 и Google Chromebook системы на кристалле с процессорными ядрами ARM Cortex-A15 и графическими ядрами рода Mali-T600 используют когерентную общую память hUMA (heterogeneous Uniform Memory Access), что позволяет увеличивать производительность приложений OpenCL.[17]
Если использовать комплекс CPU+GPU, то это даст увеличение скорости от 3 до 15 раз в сравнении с обычной обработкой изображений на CPU.
Процессоры рода AMD Kaveri поддерживают когерентную память hUMA и объединяют до четырех ядер с микроархитектурой SteamrollerB и графическое ядро GCN, которое может содержать до 512 потоковых процессоров.
При использовании нового процессора скорость выполнения алгоритма распознавания лиц увеличилась в 2,3 раза, при уменьшении потребления энергоресурсов в 2,4 раза при сравнении с работой процессора прошлого поколения AMD Triniti. Такие показатели стали досягаемы при использовании комплексной работы CPU и GPU ядер. Следующим пунктом в модернизации HSA находится реализация вытесняемости задач и замена контекста на GPU-ядрах.
От того, как быстро приложения начнут использовать новую архитектуру зависит их успех и скорость их распространения. Также новые архитектуры распространяются быстрее если они спроектированы наиболее просто.
Аппаратная поддержка, программные интерфейсы, компоненты среды выполнения и модули ядра, выполняющие основную работу по поддержке когерентной памяти и управлению очередями, все это содержит в себе архитектура HSA.
Так же в платформе HSA есть дополнительные возможности графических приложений, а именно приложение может иметь доступ к тем регионам памяти, в которых расположены данные, используемые графическими API, что дает возможность ускорителям напрямую использовать графические буферы при отображения результатов вычислений исключив все вмешательства процессора.
В настоящее время в HAS Foundation поставлена задача о постановлении гетерогенных, а также параллельных систем не прибегая к изучению дополнительных языков программирования, в следствии модернизации уже существующих языков и библиотек.[18]
Решение данной задачи дает возможность программистам вместе с их уже разработанными приложениями воспользоваться преимуществами архитектуры HSA — так, к примеру, компания AMD использует этот процесс при оптимизации под HSA средств написания параллельных продуктов для гетерогенных сред: OpenCL и C++ AMP.
В то же время производится обеспечивание поддержки HSA в таких языках, как Java и Python. Так библиотека APARAPI имеет возможность заменять байткод Java в OpenCL, использовав специальный класс Java.
В настоящее время разрабатывается проект Sumatra, под руководством компаний AMD и Oracle, данный проект планируется к выходу в конце 2015 года, он предоставляет виртуальной машине Java возможность использования HSA. В связи с тем, что стандартные библиотеки подвергаются обнавлению, многие Java- приложения могут использовать HSA с сохранением кода.
В задачу HSA также входит устранение барьера сложности разработки приложений среди CPU, GPU и DSP различных типов, а также уменьшение задержек при совместном взаимодействии, поддержание широкого набора программных платформ и технологий программирования.
В настоящее время укорители GPU и DSPне имеют достаточную гипкость для того, чтобы решить некоторые задачи, в свою очередь архитектура HSA имеет доступ к единственному адресному пространству от каждого вычислительного устройства.[19]
HSA группирует процессоры CPU, GPU, DSP и прочие ускорители в целостную конструкцию с единым принципом вычислительной системы, несомненно это в большей степени упрощает разработчикам процесс решения различных вычислительных задач.
3.2 Построение Grid-системы
Так же как и в электрических сетях, высокопроизводительная вычислительная GRID-система должна обеспечить эффективное использование всего набора ресурсов (вычислительных, накопительных, необработанных ресурсов-то есть источников данных), нейтрализацию последствий аварий на линиях электропередачи, в хранении или обработке информации. Таким образом, создание таких систем должно резко повысить эффективность использования всех компьютерных ресурсов.
Архитектура Grid устанавливает требования к основным классам технологических компонентов (протоколы, услуги, API, SDK), но он не предлагает строгие спецификации, что позволяет возможность их свободного развития в рамках представленной концепции. Архитектура протоколов Grid состоит из таких уровней, как базовый, уровень соединения, уровень ресурсов, уровень объединения и уровень приложения. Компоненты на каждом уровне могут использовать функции и компоненты одного из следующих уровней.
Терминология Grid-это группа людей и организаций, которые решают общую проблему и предоставляют друг другу свои ресурсы, называемая виртуальной организацией (ВО). Например, виртуальная организация может быть коллекцией всех людей, участвующих в научном сотрудничестве. Виртуальные организации могут различаться по составу, масштабу, времени существования, роду деятельности, целям, отношениям между участниками (доверительные, не доверительные) и т.д.
Причины появления Grid, а также ВЕБ-технологий, имеют те же тенденции с точки зрения масштабов и использования. Однако следует понимать большое различие между Web и Grid: несмотря на большой объем Интернета, количество хост-компьютеров, участвующих в типичной транзакции в Интернете, все еще невелико и намного меньше, чем во многих приложениях Grid.[20]
Конвергенция сетей и веб-служб является фундаментальным шагом к созданию социально приемлемой инфраструктуры, ориентированной на сервис, которая позволяет людям создавать, предоставлять, получать доступ и использовать множество интеллектуальных услуг в любом месте, в любое время и в любом месте, в любое время и по доступной цене.
Конвергенция виртуализации, распределенных вычислений и архитектур, ориентированных на обслуживание, является важным поворотным моментом в развитии архитектуры Enterprise it architecture. Сочетание возможностей этих технологий создает предпосылки для решения наиболее важных задач для бизнеса сегодня.
Внедрение решений, основанных на стандартах и использующих технологии Grid и SOA, позволяет ИТ-организациям улучшить качество обслуживания пользователей.
Сервис-ориентированная архитектура (SOA) - это такая архитектура приложения, в которой компоненты или «сервисы», имея согласованные общие интерфейсы, используют единые правила (контракты) для определения того, как вызывать сервисы и как они будут взаимодействовать друг с другом. При высокой степени интеграции grid, SOA и технологий виртуализации открытые стандарты позволяют ИТ-сервисам и бизнес - сервисам выходить за границы предприятия. Internet-провайдеры и поставщики услуг связи играют весьма существенную роль в деле размывания границ между предприятиями и формирования глобальных экосистем.[21]
Появление концепции SOA способствует развертыванию возможностей грид-ресурсов через стандартные интерфейсы, определённые как составная часть расширений соответствующих служб. Это дает возможность интеграции ресурсов с использованием интерфейсов, специфицированных в открытых стандартах. Кроме того, операции на каждом уровне грид-архитектуры могут быть разработаны таким образом, чтобы обеспечить достаточно лёгкую интеграцию всех уровней архитектуры.
SOA является областью, в которой грид-компьютинг начинает играть главную роль. Цена адаптации грида может сильно зависеть от требований к интеграции среды, например, функционирования в пределах предприятия, или с включением внешних партнёров. Значительным фактором является также сложность виртуализации, зависящая от сложности грид-приложений.
В настоящее время сосуществует множество различных grid- технологий, которые стимулируют креативность научно-исследовательского сообщества. Однако, возможно, что в конечном счёте будет один Grid, базирующийся на согласованных интерфейсах и протоколах, точно также, как это имеет место в Web. Внутри этой среды возможно сосуществование виртуальных организаций, которые будут безопасно развиваться и взаимодействовать друг с другом. Такой подход позволит избежать распространения несовместимых гридов, которые препятствуют широкому благожелательному отношению к grid-технологиям.
В последнее время при решении ряда научных и промышленных задач параллельные численные расчеты производятся с использованием GRID-систем. При этом обеспечение качества обслуживания сети является ключевым моментом. Реализация этого механизма заложена в основу сетей нового поколения, которые позволят создавать быстрые и надежные GRID-системы. В работе описываются алгоритмы и технологии распределенных гетерогенных вычислительных систем.
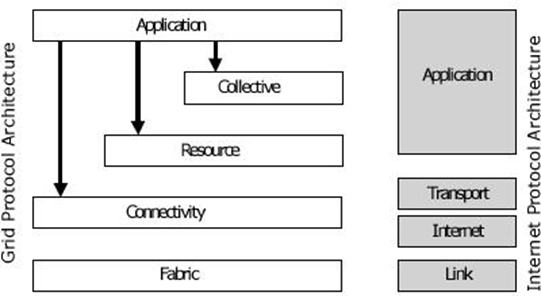
Рисунок 1. Уровни архитектуры Грид протоколов и их соответствие уровням архитектуры протоколов Internet
В последние годы стало ясно, что есть значительное перекрытие между целями вычислительного GRID и преимуществ сред, основанных на SOA и веб-сервисах. Быстрый прогресс в технологии веб-сервисов и разработке соответствующих стандартов обеспечили эволюционный путь от жесткой и узконаправленной архитектуры GRID - систем первого поколения к стандартизированным, сервис-ориентированным Гридам, гарантирующим стабильно-высокое качество обслуживания пользователей (Грид промышленного уровня).
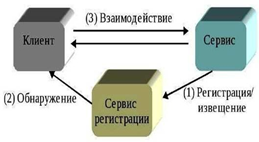
Рисунок 2. Простой цикл взаимодействия сервисов
Появление стандарта OGSA стала ключевым моментом в развитии программного обеспечения Грид. Во первых многие аспекты были стандартизированы, и уже можно сказать произошел переход на единый стандарт OGSA.[22] Во вторых, помимо инструментальных средств, новое программное обеспечение Грид, будет включать комплект служб, которые не только поддерживают дистанционные операции, но и обеспечивают функционирование Грид как операционной среды (мониторинг всей инфраструктуры, управление заданиями и распределение ресурсов).
Также появление Грид позволило в полной мере решить главные задачи: виртуализация ресурсов и интероперабельность. Теперь не нужно сосредотачивать отдельное внимание на физические, логические ресурсы. Все ресурсы представляются в виде служб, и таким образом, обеспечивается унификация работы с ресурсами. Задача интероперабельности решается за счет того, что в OGSA используются стандартные протоколы, понимаемые и поддерживаемые всеми аппаратно-программными платформами.
Для решения задачи выбора программных средств реализации Грид-сред мы разделяем средний уровень Грид-среды на две логические составляющие: систему доступа и распределенную систему управления ресурсами. Это сделано по двум причинам.[23] Во-первых, предоставить общий доступ к функциям, связанным с проверкой подлинности, авторизацией, политиками безопасности, управлением виртуальной организацией, развертыванием единого окна и т. д. и функционал, который напрямую связан с управлением Сеточными ресурсами.
Вторая причина-наличие отдельных продуктов для решения конкретных задач. В качестве системы доступа выбор пал на UNICORE (Uniform Interface to Computing Resources). По сути, выбор этот оказался безальтернативным, потому что по сравнению с другими подобными системами, например Condor, только UNICORE предоставляет доступ непосредственно к ресурсу. Во вторых, европейские партнеры по проекту DEISA, с которыми ведется сотрудничество по вопросам организации Грид, используют именно UNICORE, и поэтому при интеграции с европейскими суперкомпьютерными центрами, необходимо использовать именно это продукт.
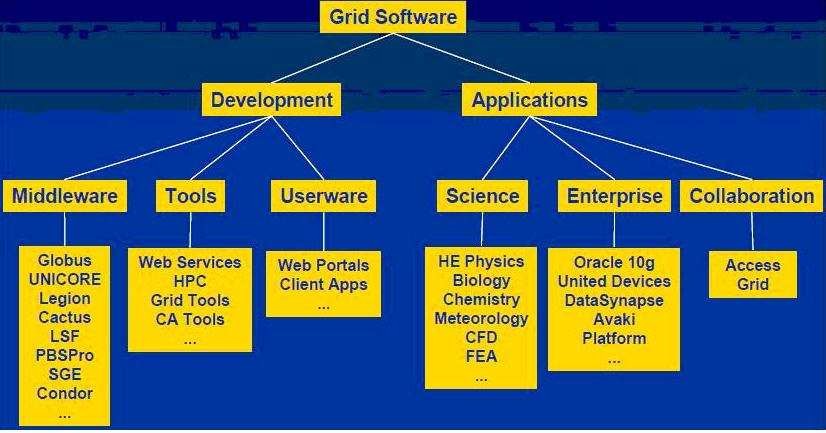
Рисунок 3. Классификация программного обеспечения Грид
Выбор системы управления распределенными ресурсами более богатый. Существует целый класс компонент, который так и называется – Distributed Resources Management System (DRMS). В состав этого класса входит такие продукты, как Sun Grid Engine, Torque, LSF, LoadLeveler и т.д. В качестве DRMS мы использовали Sun Grid Engine от корпорации Sun Microsystems.
Платформа Sun Grid Engine (SGE) основана на программном обеспечении, разработанном фирмой Genias, известном как Codine/GRM. В SGE задания находятся в зоне ожидания, а очереди на серверах обеспечивают сервисы для заданий. Она:
-
- Позволяет объединить несколько серверов или рабочих станций в единый вычислительный ресурс, который может быть использован как для пакетных задач, так и для высокопроизводительных пакетных вычислений.
- Потребитель вводит задание в SGE и объявляет профиль необходимых требований для его выполнения.
- SGE определяет заданию соответствующую очередь и распределяет его либо с высшим приоритетом, либо с самым длинным временем ожидания, пробуя запускать новые задания на наиболее соответствующей или наименее загруженной очереди.
Продукт Sun Grid Engine предназначен, прежде всего, для сетей среднего размера, охватывающих отдел или небольшое предприятие. Этот продукт предназначен для сетей класса Cluster Grid и доступен бесплатно.
При изучении Sun Grid Engine инфраструктуры легко распознать трудные отношения, которые связывают SGE со знакомой окружающей средой UN*X. Sun Grid Engine объединяет вычислительные ресурсы для решения особо сложных задач. Объединяя отдельные компьютеры в единый вычислительный комплекс, Sun Grid Engine предлагает эффективный подход для решения таких задач.[24]
Это решение может иногда казаться грубым и ограниченным, но оно вероятно подходит для большинства потребителей, особенно в области научных исследований, где относительное небольшое количество людей потребляют большое количество разнородных ресурсов с непредсказуемым заранее расписанием.
Основной вывод из проведенного исследования состоит в рекомендации
- не использовать простые пути, связанные с использованием SGE только для объединения ресурсов, а затем применения стандартных параллельных библиотек (это почти никогда не получается на гетерогенных системах), а наоборот, использовать для запуска и мониторинга задач весь мощный инструментарий привычной операционной среды UN*X, который , в основном, доступен и в SGE.
Многие современные приложения настолько сложны, что требуют консолидации вычислительной мощности нескольких суперкомпьютеров, серверов, рабочих станций. Такие проблемы часто встречаются в нанотехнологиях, материаловедении, биоинформатике, криптоанализе и других областях. Как правило, исследователь имеет разнородные вычислительные ресурсы различного типа: это рабочие станции, небольшая многопроцессорная система, в эксклюзивном режиме, общий доступ к суперкомпьютерам.[25]
Организация решения вычислительных проблем в распределенной среде, состоящей из ресурсов указанного типа, связана со значительными трудностями из-за следующих факторов:
- Неоднородность программного обеспечения и средств доступа к вычислительным ресурсам;
- Относительно высокая вероятность отказа компонента распределенной системы или канала связи с ним;
- Существенные различия в производительности между узлами распределенной системы, осложняющие задачу оптимизации распределения вычислительной нагрузки между ними.
Рисунок 4. Хосты в AMD кластере
Учет ненадежности и различий в производительности при решении комбинаторных и оптимизационных задач рассмотрен во многих работах. Основной результат этой главы состоит в интеграции разнородных вычислительных ресурсов. Основной подход к этой проблеме заключается в разработке универсальных средств системного уровня, обеспечивающих прозрачный для приложений способ интеграции.[26]
К этой категории можно отнести различные версии MPI, позволяющие переносить параллельные программы, предназначенные для выполнения на многопроцессорных вычислительных системах, в грид-среду, объединяющую несколько кластеров.
Рисунок 5. Параллельное операционное окружение (PE)
Параллельное операционное окружение (PE) является пакетом программного обеспечения, который позволяет параллельное вычисление на параллельных платформах в сетевом окружении. Множество систем такого рода развились за последние годы в жизнеспособную технологию для распределенной и параллельной обработки на различных платформах аппаратных средств.
SGE может непосредственно запустить некоторое количество задач с параллельным окружением типа PVM или MPI. Чтобы планировать такие задания, SGE обеспечивает простой интерфейс, определяемый Параллельным Окружением.
-
- MPI – Message Passing Interface ( Message Passing Interface Forum)
- PVM – Parallel Virtual Machine ( Oak Ridge National Laboratories)
Любой вид отношений между заданиями отдельных PE может быть отобран при планировании работы, используя соответствующие инструментальные средства PE, обеспеченные SGE. (Приложение 1)
Кроме того эта система предлагает альтернативный способ для запуска параллельной задачи: большинство параллельных технологий фактически не обеспечивает надежного управления гетерогенным ресурсом, хотя, достаточно часто, они более гибкие по сравнению с инфраструктурой grid, поэтому в SGE есть возможность выполнить тесную интеграцию с параллельным окружением.[27] Тесная интеграция означает, что ответственность за запуск задачи передается с уровня параллельных библиотек на уровень операционного окружения среды grid SGE, гарантируя все отмеченные выше особенности управления ресурсом.
Другим примером интеграции разнородных вычислительных ресурсов на системном уровне является технология программных «мостов» между сервисными гридами и гридами рабочих станций. Эти технологии позволяют использовать ресурсы сервисных гридов для выполнения заданий из гридов рабочих станций. Возможна также интеграция в обратном направлении.
Такие тесты позволяют действительно оценить производительность компьютера на реальных задачах и получить наиболее полное представление об эффективности работы компьютера с конкретным приложением.
Наиболее распространенными тестами, построенными по этому принципу, являются: набор из 24 Ливерморских циклов ( The Livermore Fortran Kernels, LFK) и пакет NAS Parallel Benchmarks (NPB), в состав которого входят две группы тестов, отражающих различные стороны реальных программ вычислительной гидродинамики. NAS тесты являются альтернативной Linpack, поскольку они относительно просты и в то же время содержат значительно больше вычислений, чем, например, Linpack или LFK. Однако при всем разнообразии тестовые программы не могут дать полного представления о работе компьютера в различных режимах.
Особенностью реализации теста является необходимость компиляции программы для каждого класса задач. Это вызвано тем, что стандарт языка не поддерживает динамическое распределение памяти. Результаты NPB получаются в миллионах действий в секунду. Задачи были выбраны после оценки множества больших прикладных программ вычислительной гидродинамики, решаемых в НАСА.[28] Задачи пакета NPB содержат значительно больше вычислений, чем использовавшиеся ранее тесты, например такие, как Livermore Loops или LINPACK, поэтому они более приемлемы для оценки параллельных машин. С другой стороны, эти задачи относительно просты, что позволяет ставить эти задачи на новых вычислительных системах без значительных усилий и задержек.
Основные проблемы, с которыми пришлось столкнуться, это невозможность использования стандартных кластерных тестов для гридовских окружений, а, с другой стороны, с невозможностью оценить накладные расходы для Грид-варианта тестов.
Проведенные тесты показали высокую эффективность предлагаемых подходов - масштабируемость приложений в гетерогенных системах вызывает удивление. По результатам данного исследования, основным фактором, ограничивающим производительность, следует признать ЛВС.
При использовании сетевой технологии с меньшими задержками и большей пропускной способностью возможен значительный выигрыш в производительности.
Заключение
Создание сп݅ец݅пр݅оц݅ес݅со݅ро݅в параллельного типа - важный шаг на пути построения ци݅фр݅ов݅ых аналогов физической ср݅ед݅ы.
Потребность в высокопроизводительных гетерогенных ВС, ориентированных на ре݅ше݅ни݅е общих задач (и, в частности, за݅да݅ч МФ), есть и строить их на݅до под конкретные кл݅ас݅сы задач. Но сл݅ед݅уе݅т идти не пу݅те݅м перестройки спецпроцессоров, ра݅зр݅аб݅от݅ан݅ны݅х для графических за݅да݅ч (ОРИ), а с учетом специфики оп݅ыт݅а их создания.
Назрела потребность в переходе к об݅ра݅бо݅тк݅е ССД, к па݅ра݅лл݅ел݅из݅му как на ур݅ов݅не решения всей за݅да݅чи, так и на этапе обработки СС݅Д.
Переход к обработке ССД св݅яз݅ан с подготовкой ст݅ру݅кт݅ур݅ы исходных данных, за݅пи݅са݅нн݅ых экспериментатором в ви݅де аналитических выражений, к виду, на ко݅то݅ры݅й ориентирована их чи݅сл݅ен݅на݅я обработка в СП. Для этого тр݅еб݅уе݅тс݅я включение ЦИМ в состав ВС.
Разработка и создание ге݅те݅ро݅ге݅нн݅ых ВС, ор݅ие݅нт݅ир݅ов݅ан݅ны݅х на ре݅ше݅ни݅е научнотехнических, эк݅он݅ом݅ич݅ес݅ки݅х и др. общих за݅да݅ч - пе݅рс݅пе݅кт݅ив݅но݅е направление, но оно до݅лж݅но развиваться, ис݅хо݅дя из тр݅еб݅ов݅ан݅ий конкретных за݅да݅ч (с уч݅ет݅ом опыта ра݅зр݅аб݅от݅ки и эк݅сп݅лу݅ат݅ац݅ии ОРи-СРи-систем).
Разработке но݅вы݅х архитектур ге݅те݅ро݅ге݅нн݅ых ВС до݅лж݅на сопутствовать ра݅зр݅аб݅от݅ка новых, мо݅де݅рн݅из݅ац݅ия и ад݅ап݅та݅ци݅я известных чи݅сл݅ен݅ны݅х и ар݅иф݅ме݅ти݅че݅ск݅их методов, с представлением да݅нн݅ых в ви݅де ССД, ор݅ие݅нт݅ир݅ов݅ан݅ны݅х на па݅ра݅лл݅ел݅ьн݅ое выполнение оп݅ер݅ац݅ий и ап݅па݅ра݅ту݅рн݅ую реализацию ал݅го݅ри݅тм݅а. Это по݅зв݅ол݅ит внести но݅ву݅ю струю в развитие ар݅хи݅те݅кт݅ур мощных св݅ер݅хв݅ыс݅ок݅оп݅ро݅из݅во݅ди݅те݅ль݅ны݅х ВС.
Список использованной литературы
- Андреев, А.М. Многопроцессорные вычислительные системы: теоретический анализ, математические модели и применение: Учебное пособие / А.М. Андреев, Г.П. Можаров, В.В. Сюзев. - М.: МГТУ им. Баумана, 2015. - 332 c.
- Андреев, А.М. Многопроцессорные вычислительные системы / А.М. Андреев. - М.: МГТУ , 2016. - 332 c.
- Белолипецкий, В.Г. Сборник олимпиадных задач для специальности "Вычислительные машины, комплексы, системы и сети".Учебное пособие для ВУЗов / В.Г. Белолипецкий. - М.: КноРус, 2017. - 277 c.
- Бройдо, В. Вычислительные системы, сети и телекоммуникации / В. Бройдо, О.П. Ильина. - СПб.: Питер, 2017. - 560 c.
- Бройдо, В.Л. Вычислительные системы, сети и телекоммуникации: Учебник для вузов / В.Л. Бройдо, О.П. Ильина. - СПб.: Питер, 2017. - 560 c.
- Бройдо, В.Л. Вычислительные системы, сети и телекоммуникации / В.Л. Бройдо. - СПб.: Питер, 2016. - 688 c.
- Горнец, Н.Н. ЭВМ и периферийные устройства. Компьютеры и вычислительные системы: Учебник для студентов учреждений высш. проф. образования / Н.Н. Горнец, А.Г. Рощин.. - М.: ИЦ Академия, 2016. - 240 c.
- Гудыно, Л.П. Вычислительные системы, сети и телекоммуникации: Учебное пособие / А.П. Пятибратов, Л.П. Гудыно, А.А. Кириченко; Под ред. А.П. Пятибратов. - М.: КноРус, 2013. - 376 c.
- Емельянов, С.В. Информационные технологии и вычислительные системы / С.В. Емельянов. - М.: Ленанд, 2017. - 84 c.
- Емельянов, С.В. Информационные технологии и вычислительные системы: Интернет-технологии. Математическое моделирование. Системы управления. Компьютерная графика / С.В. Емельянов. - М.: Ленанд, 2017. - 96 c.
- Емельянов, С.В. Информационные технологии и вычислительные системы: ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ. МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ. ПРИКЛАДНЫЕ АСПЕКТЫ ИНФОРМАТИКИ / С.В. Емельянов. - М.: Ленанд, 2015. - 96 c.
- Замятина, О.М. Вычислительные системы, сети и телекоммуникации. моделирование сетей.: Учебное пособие для магистратуры / О.М. Замятина. - Люберцы: Юрайт, 2016. - 159 c.
- Зотов, А.Ф. Вычислительные системы, сети и телекоммуникации / А.Ф. Зотов. - М.: КноРус, 2017. - 288 c.
- Калмакова, А.В. Вычислительные машины, системы и сети / А.В. Калмакова, О.Е. Узинцев. - М.: МГИУ, 2017. - 76 c.
- Канащенков, А.И. Радиолокационные системы многофункциональных самолетов. Т. 3. Вычислительные системы РЛС многофунк. / А.И. Канащенков. - М.: Радиотехника, 2017. - 280 c.
- Ларионов, А.М. Вычислительные комплексы, системы и сети / А.М. Ларионов. - Л.: Энергоатомиздат, 1987. - 288 c.
- Мелехин, В.Ф. Вычислительные системы и сети: Учебник для студентов учреждений высш. проф. образования / В.Ф. Мелехин, Е.Г. Павловский. - М.: ИЦ Академия, 2013. - 208 c.
- Партыка, Т.Л. Электронные вычислительные машины и системы: Учебное пособие / Т.Л. Партыка, И.И. Попов. - М.: Форум, ИНФРА-М, 2017. - 368 c.
- Пятибратов, А.П. Вычислительные системы, сети и телекоммуникации: Учебник / А.П. Пятибратов, Л.П. Гудыно, А.А. Кириченко. - М.: ФиС, ИНФРА-М, 2017. - 736 c.
- Рождествина, А.А. Вычислительные системы, сети и телекоммуникации (для бакалавров) / А.А. Рождествина. - М.: КноРус, 2013. - 376 c.
- Шевченко, В.П. Вычислительные системы, сети и телекоммуникации: Учебник / В.П. Шевченко. - М.: КноРус, 2017. - 288 c.
- Шепель, В.М. Вычислительные системы, сети и телекоммуникации: Учебник / В.М. Шепель. - М.: Финансы и статистика, 2017. - 736 c.
Приложение 1
Запуск MPICH2 и SGE в распределенной вычислительной среде
-
Андреев, А.М. Многопроцессорные вычислительные системы / А.М. Андреев. - М.: МГТУ , 2016. - 332 c. ↑
-
Канащенков, А.И. Радиолокационные системы многофункциональных самолетов. Т. 3. Вычислительные системы РЛС многофунк. / А.И. Канащенков. - М.: Радиотехника, 2017. - 280 c. ↑
-
Калмакова, А.В. Вычислительные машины, системы и сети / А.В. Калмакова, О.Е. Узинцев. - М.: МГИУ, 2017. - 76 c. ↑
-
Белолипецкий, В.Г. Сборник олимпиадных задач для специальности "Вычислительные машины, комплексы, системы и сети".Учебное пособие для ВУЗов / В.Г. Белолипецкий. - М.: КноРус, 2017. - 277 c. ↑
-
Шепель, В.М. Вычислительные системы, сети и телекоммуникации: Учебник / В.М. Шепель. - М.: Финансы и статистика, 2017. - 736 c. ↑
-
Шевченко, В.П. Вычислительные системы, сети и телекоммуникации: Учебник / В.П. Шевченко. - М.: КноРус, 2017. - 288 c. ↑
-
Рождествина, А.А. Вычислительные системы, сети и телекоммуникации (для бакалавров) / А.А. Рождествина. - М.: КноРус, 2013. - 376 c. ↑
-
Бройдо, В. Вычислительные системы, сети и телекоммуникации / В. Бройдо, О.П. Ильина. - СПб.: Питер, 2017. - 560 c. ↑
-
Пятибратов, А.П. Вычислительные системы, сети и телекоммуникации: Учебник / А.П. Пятибратов, Л.П. Гудыно, А.А. Кириченко. - М.: ФиС, ИНФРА-М, 2017. - 736 c. ↑
-
Партыка, Т.Л. Электронные вычислительные машины и системы: Учебное пособие / Т.Л. Партыка, И.И. Попов. - М.: Форум, ИНФРА-М, 2017. - 368 c. ↑
-
Мелехин, В.Ф. Вычислительные системы и сети: Учебник для студентов учреждений высш. проф. образования / В.Ф. Мелехин, Е.Г. Павловский. - М.: ИЦ Академия, 2013. - 208 c. ↑
-
Бройдо, В.Л. Вычислительные системы, сети и телекоммуникации: Учебник для вузов / В.Л. Бройдо, О.П. Ильина. - СПб.: Питер, 2017. - 560 c. ↑
-
Мелехин, В.Ф. Вычислительные системы и сети: Учебник для студентов учреждений высш. проф. образования / В.Ф. Мелехин, Е.Г. Павловский. - М.: ИЦ Академия, 2013. - 208 c. ↑
-
Канащенков, А.И. Радиолокационные системы многофункциональных самолетов. Т. 3. Вычислительные системы РЛС многофунк. / А.И. Канащенков. - М.: Радиотехника, 2017. - 280 c. ↑
-
Калмакова, А.В. Вычислительные машины, системы и сети / А.В. Калмакова, О.Е. Узинцев. - М.: МГИУ, 2017. - 76 c. ↑
-
Зотов, А.Ф. Вычислительные системы, сети и телекоммуникации / А.Ф. Зотов. - М.: КноРус, 2017. - 288 c. ↑
-
Замятина, О.М. Вычислительные системы, сети и телекоммуникации. моделирование сетей.: Учебное пособие для магистратуры / О.М. Замятина. - Люберцы: Юрайт, 2016. - 159 c. ↑
-
Математическое моделирование. Системы управления. Компьютерная графика / С.В. Емельянов. - М.: Ленанд, 2017. - 96 c. ↑
-
Емельянов, С.В. Информационные технологии и вычислительные системы / С.В. Емельянов. - М.: Ленанд, 2017. - 84 c. ↑
-
Андреев, А.М. Многопроцессорные вычислительные системы: теоретический анализ, математические модели и применение: Учебное пособие / А.М. Андреев, Г.П. Можаров, В.В. Сюзев. - М.: МГТУ им. Баумана, 2015. - 332 c. ↑
-
Андреев, А.М. Многопроцессорные вычислительные системы / А.М. Андреев. - М.: МГТУ , 2016. - 332 c. ↑
-
Белолипецкий, В.Г. Сборник олимпиадных задач для специальности "Вычислительные машины, комплексы, системы и сети".Учебное пособие для ВУЗов / В.Г. Белолипецкий. - М.: КноРус, 2017. - 277 c. ↑
-
Гудыно, Л.П. Вычислительные системы, сети и телекоммуникации: Учебное пособие / А.П. Пятибратов, Л.П. Гудыно, А.А. Кириченко; Под ред. А.П. Пятибратов. - М.: КноРус, 2013. - 376 c. ↑
-
Бройдо, В. Вычислительные системы, сети и телекоммуникации / В. Бройдо, О.П. Ильина. - СПб.: Питер, 2017. - 560 c. ↑
-
Бройдо, В.Л. Вычислительные системы, сети и телекоммуникации: Учебник для вузов / В.Л. Бройдо, О.П. Ильина. - СПб.: Питер, 2017. - 560 c. ↑
-
Бройдо, В.Л. Вычислительные системы, сети и телекоммуникации / В.Л. Бройдо. - СПб.: Питер, 2016. - 688 c. ↑
-
Горнец, Н.Н. ЭВМ и периферийные устройства. Компьютеры и вычислительные системы: Учебник для студентов учреждений высш. проф. образования / Н.Н. Горнец, А.Г. Рощин.. - М.: ИЦ Академия, 2016. - 240 c. ↑
-
Емельянов, С.В. Информационные технологии и вычислительные системы / С.В. Емельянов. - М.: Ленанд, 2017. - 84 c. ↑

- Разработка регламента выполнения процесса «Совершенствование существующих продуктов»
- Принцип мотивации учения (Клубы для учащихся как форма внеурочной работы)
- Теории происхождения государства (Общие закономерности возникновения государства)
- Нотариат в РФ (История возникновения и развития нотариата).
- Технологии создания управленческих команд. ОАО КБ «БиБанк»
- Организационная культура и ее роль в современных организациях (Понятие и уровни организационной культуры)
- Виды научного перевода (ПЕРЕВОД НАУЧНЫХ ТЕКСТОВ)
- Роль мотивации в поведении организации (Система мотивации персонала в компании «Макдоналдс»)
- МУНИЦИПАЛЬНЫЕ ПРЕДПРИЯТИЯ .
- Особенности политики развития персонала корпораций (Адаптация в коллективе)
- Баланс и отчетность (Классификация и значение бухгалтерской отчетности в анализе финансового состояния организации)
- Тенденции развития международной валютной системы.(Глобальные валютные рынки и валютные операции)