
Алгоритмы сортировки данных (Выбор языка программирования)
Содержание:

ВВЕДЕНИЕ
Программирование современных приложений, для различного рода вычислительных пользовательских устройств, будь то персональный компьютер или мобильный телефон, содержит довольно разнообразные стандартные алгоритмы обработки данных. К примеру, такими алгоритмами являются алгоритмы поиска и сортировки. Именно эти алгоритмы, присутствуют практически в каждом программном приложении, выполняя ту или иную задачу. Данным алгоритмам посвящено множество научных исследований и научных работ, потому как от скорости выполнения алгоритмов, зависит скорость обработки данных программами, в которых эти алгоритмы реализованы. Поэтому, знания алгоритмов и правильность их применения, приобретают ключевое значение при принятии решений о структурировании данных. С каждым днем объемы обрабатываемой информации увеличиваются, ее структура становится сложнее. С целью хранения разнообразной по назначению и своему составу информации используют базы и банки данных. Современные базы данных содержат миллионы, в некоторых случаях и миллиарды записей. И с такими объемами работать очень сложно, практически невозможно, без использования специальных алгоритмов поиска и сортировки, они позволяют сравнительно быстро и качественно отделить нужную информацию из неупорядоченного массива данных. Таким образом, алгоритмы сортировки имеют очень важное значение. При изучении языков программирования, на начальном этапе проходится курс по изучению алгоритмов, потому как, без знания таковых, большинство задач будет выполнить не под силу, или на обработку данных будет уходить огромное количество времени.
На сегодняшний день, существует множество алгоритмов сортировки, имеющих разные характеристики и скорость обработки данных. Но тем не менее, в преобладающей части из них, есть существенный недостаток, он заключается в том, что период их реализации пропорционален квадрату количества элементов, поэтому сортировка больших объемов данных будет медленной.
Исследовательское значение данной работы, представляется в анализе и реализации большинства самых распространенных алгоритмов сортировки. Практическое значение темы «Алгоритмы сортировки данных» представляется в исследовании проблем реализации и применения разных видов алгоритмов сортировки.
Основная цель данной курсовой работы – это анализ алгоритмов сортировки данных, получение навыков их программирования и получение статистических данных результатов работы этих алгоритмов.
Объектом исследования являются алгоритмы сортировки данных.
Предмет исследования - методы использования алгоритмов сортировки и их применение при реализации на языках программирования высокого уровня.
В процессе выполнения курсовой работы будут решены следующие задачи:
1. Провести анализ предметной области.
2. Рассмотреть и провести анализ основных алгоритмов сортировки данных.
3. Выбрать средства реализации программного обеспечения для получения практических результатов работы запрограммированных алгоритмов сортировки.
4. Запрограммировать выделенные алгоритмы сортировки.
5. Провести тестовые запуски алгоритмов и снятие показателей (количество операций перестановки и времени работы алгоритмов).
6. Разработать руководство пользователя для работы с программой.
1.Теоретический раздел.
1.1 Общие понятия и описание.
Следует отметить, что вопросами анализа алгоритмов, группировкой, а так же исследованием методов их программирования, в различные времена занимались следующие ученые: Левитин А., Кнут Д., Гудман С., Ахо А., Хлопккрофт Дж., Хидетниеми С., Лорин Г., Макконнелл Дж. и другие.
Алгоритм (algorithm) — это любой точно и однозначно определенный вычислительный процесс, на вход (input), которого подается определнное значение или их набор, а итогом(финалом) реализации является выходное (output) значение или их набор. Другими словами, алгоритм - это определенная последовательность действии(вычислительных шагов), которые преобразуют входные данные в выходные.
Алгоритм является инструментом, с помощью которого решаются конкретно сформулированные вычислительные задачи. Алгоритм описывает конкретный вычислительный процесс, с помощью которого добиваются реализации поставленной задачи.
Например, есть необходимость провести сортировку чисел в неубывающем порядке. Данная задача часто встречается на практике и является прекрасным примером для ознакомления на ее примере с большинством стандартных методов разработки и анализа алгоритмов.
Cортировка - это некая процедура упорядочения значений определенного множества данных в конкретном порядке. Главная задача процесса сортировки - увеличение скорости дальнейшего поиска значений в конкретном массиве данных. В большинстве задачах присутствуют элементы сортировки. Отсортированные данные содержатся в телефонных справочниках, в оглавлениях, в библиотеках, картах, в словарях, и во многих других подручных справочных материалах.
Соответственно, методы сортировки очень важны, особенно при обработке информационных данных. Сортировка связана со многими фундаментальными законами построения алгоритмов, реализующих одну и ту же задачу, некоторые из которых в каком-то смысле являются оптимальными, а большинство имеет какие-либо преимущества по сравнению с остальными.
Зависимость выбора алгоритмов от структуры самих данных очень сильна. Применяемые методы сортировки часто делят на две группы: сортировка файлов и сортировка массивов. Эти две группы порой определяют как внутреннюю и внешнюю сортировки, потому что массивы находятся во «внутренней» (оперативной) памяти компьютера (данному виду памяти присущ скорый произвольный доступ), а рассматриваемые файлы содержатся в не такой быстрой, но намного вместительней «внешней» памяти, другими словами, на запоминающем устройстве с механическим принципом действия.
Основные критерии эффективности алгоритмов сортировки следующие:
- быстродействие;
- экономия памяти;
- сокращение времени, на конкретную реализацию алгоритма программистом.
Поэтому в зависимости от количества элементов множества, их упорядоченности, частоты применения сортировки и других факторов следует использовать различные алгоритмы сортировки и поиска.
Для более детального ознакомления с алгоритмами сортировки и поиска, будут рассмотрены некоторые «элементарные» способы сортировки, хорошо зарекомендовавшие себя для работы с небольшими файлами или файлами со специальной структурой. Есть множество причин, почему необходимо изучение этих простых способов. Первое, они предоставляют нам относительно простой способ ознакомиться с терминологией и основными механизмами функционирования алгоритмов сортировки, и это позволяет приобрести нужную базу для исследования более сложных алгоритмов. Второе, во многих задачах сортировки чаще лучше применить простые способы, чем более сложные алгоритмы. И, последнее, кое-какие из простых методов допустимо развить до более лучших методов или применить их для совершенствования более сложных.
Во многих программах сортировки оптимально применить простые элементарные алгоритмы. Программы сортировки иногда применяются только единожды (или несколько раз). В случае, когда количество элементов, необходимых отсортировать небольшое (примерно меньше 500 элементов), то тогда применение элементарного алгоритма даст больший эффект, чем новая проработка и отладка громоздкого алгоритма. Элементарные простые методы постоянно полезны для небольших файлов (примерно меньших, чем 50 элементов); конечно сложный алгоритм было бы неразумно применить для подобных файлов, если конечно нет необходимости отсортировать большое количество подобных файлов.
Обычно, элементарные простые методы, рассматриваемые нами, осуществляют примерно  операций для сортировки N случайно выбранных элементов. В случае N достаточно мало, тогда это может и не быть особой проблемой, и в случае, когда элементы расставлены не случайным образом, тогда эти алгоритмы работают иногда быстрее, чем сложные. Но нужно помнить то, что указанные алгоритмы не нужно применять для больших, случайным образом упорядоченных файлов, с одним возможным исключением для алгоритма оболочечной сортировки, применяемого во многих программах.
операций для сортировки N случайно выбранных элементов. В случае N достаточно мало, тогда это может и не быть особой проблемой, и в случае, когда элементы расставлены не случайным образом, тогда эти алгоритмы работают иногда быстрее, чем сложные. Но нужно помнить то, что указанные алгоритмы не нужно применять для больших, случайным образом упорядоченных файлов, с одним возможным исключением для алгоритма оболочечной сортировки, применяемого во многих программах.
Прежде чем рассматривать произвольный алгоритм, необходимо исследовать терминологию и некоторые понятия об алгоритмах сортировки. Рассмтрим алгоритмы для сортировки файлов записей, включающих ключи. Ключи, являющиеся только частью записи (в основном, очень небольшой их частью), применяются для управления процедурой сортировки. Цель алгоритма сортировки – новая организация записей в файле таким образом, чтобы их размещение в нем, было в каком то строго определенном порядке (чаще всего в алфавитном либо числовом).
В случае, когда сортируемый файл полностью помещается в память (либо полностью помещается в массив), то для него используются внутренние методы сортировки. Сортировку данных с ленты или диска называют внешней сортировкой. Основное отличие их состоит в том, что внутренняя сортировка делает любую запись легко доступной, тогда как при внешней сортировке можно применять записи только последовательно, либо большими блоками. В основном, алгоритмы сортировки, рассматриваемые ниже – внутренние.
В основном, главное, что обычно интересует в алгоритме – это продолжительность его работы. Начальные четыре алгоритма, рассматриваемые ниже, для сортировки N элементов тратят период работы пропорциональное  , когда как посложнее алгоритмы тратят время пропорциональное
, когда как посложнее алгоритмы тратят время пропорциональное  . (Возможно показать, что любой алгоритм сортировки не в состоянии использовать меньше, чем
. (Возможно показать, что любой алгоритм сортировки не в состоянии использовать меньше, чем  сравнений между ключами.) Изучив простые методы, рассмотрим посложнее методы, время работы которых пропорционально
сравнений между ключами.) Изучив простые методы, рассмотрим посложнее методы, время работы которых пропорционально  и алгоритмы, применяемые бинарные свойства ключей для сокращения всего периода работы до N.
и алгоритмы, применяемые бинарные свойства ключей для сокращения всего периода работы до N.
Объем применяемой дополнительной памяти алгоритма сортировки – также дополнительный фактор, принимаемый во внимание. Обычно методы сортировки делят на три группы:
- методы сортировки, сортирующие без применения дополнительной памяти, исключая, возможно, маленького стека и / или массива;
- и методы, нуждающиеся в дополняемой памяти для сохранения дубликата отсортированного файла.
- методы, применяемые в случаях сортировки связанных списков и поэтому использующих N дополнительных указателей, находящихся в памяти;
Стабильность – также важная свойство методов сортировки. Метод сортировки является стабильным в случае, когда он сохраняет относительный порядок расположения записей с одинаковыми ключами. К примеру, когда алфавитный список учащихся ранжируется по оценкам, тогда стабильный метод организует список, где фамилии учащихся с одинаковыми баллами будут отсортированы по алфавиту, а нестабильный метод организует список, где, возможно, начальный порядок будет нарушен. Большая часть простых методов стабильны, тогда как большая часть всем известных сложных методов – нет. В случае, когда стабильность необходима, тогда можно её добиться путем добавления к ключу маленького индекса перед процессом сортировки или посредством удлинения, каким-то путем, ключа. Стабильность легко принимают за норму; к нестабильности у людей отношение с недоверием. Фактически, только некоторые методы добиваются стабильности без применения дополнительного времени или места.
Для выявления эффективности алгоритма необходимо оценить числа С – нужных сравнений ключей и М – присваиваний элементов. Указанные числа рассчитываются определенными формулами от числа n сортируемых элементов. Удовлетворительные алгоритмы сортировки используют примерно  сравнений.
сравнений.
Условимся по терминологии: мы имеем элементы – a1, a2, …, an. Процедура сортировки предполагает такую перестановку данных элементов в следующем порядке: ak1, ak2, …, akn, что при данной функции упорядочения f верно отношение f(ak1)<=f(ak2)<=…<=f(akn).
Чаще всего функция упорядочения не определяется по определенному правилу, а входит в каждый элемент в виде явной компоненты (поля).
Прочие элементы – совокупность всех существенных данных об элементе, поле key предназначено только для идентификации элементов. Тем не менее, рассматривая алгоритмы сортировки, имеем ключ – единственная важная компонента, и все остальные не требуют выделения.
Сортировка устойчивая, в случае, когда записи с одинаковыми ключами сохраняются в исходном порядке.
1.2 Алгоритм сортировки простым включением.
Данный метод, в основном, применяют играющие в карты. Элементы (карты) условно делятся на готовую конкретную последовательность  и входную последовательность
и входную последовательность  . Постоянно на следующем шаге, считая с I = 2 и увеличивая i на один, берется i-й элемент входной последовательности и перекладывается в готовую последовательность, ставя его на нужное место(Табл.1).
. Постоянно на следующем шаге, считая с I = 2 и увеличивая i на один, берется i-й элемент входной последовательности и перекладывается в готовую последовательность, ставя его на нужное место(Табл.1).
Табл.1. Карта с пояснениями работы алгоритма включением
|
Исходные ключи |
45 |
59 |
12 |
42 |
94 |
18 |
06 |
67 |
|
I=2 |
45 |
59 |
12 |
42 |
94 |
18 |
06 |
67 |
|
I=3 |
12 |
45 |
59 |
42 |
94 |
18 |
06 |
67 |
|
I=4 |
12 |
42 |
45 |
59 |
94 |
18 |
06 |
67 |
|
I=5 |
12 |
42 |
45 |
59 |
94 |
18 |
06 |
67 |
|
I=6 |
18 |
12 |
42 |
45 |
59 |
94 |
06 |
67 |
|
I=7 |
06 |
18 |
12 |
42 |
45 |
59 |
94 |
67 |
|
I=8 |
06 |
18 |
12 |
42 |
45 |
59 |
67 |
94 |
При поиске нужного места можно чередовать сравнения и пересылки, таким образом, как бы «просеивать» x, сравнивая его со следующим элементом  и или вставляя x, или перенаправляя
и или вставляя x, или перенаправляя  направо и двигаясь налево. «Просеивание» можно закончить при двух разных условиях:
направо и двигаясь налево. «Просеивание» можно закончить при двух разных условиях:
1. Найден элемент  ключ, которого меньше, чем ключ x.
ключ, которого меньше, чем ключ x.
2. Достигли левого конца готовой последовательности.
Данный стандартный образец цикла с количеством двух условий окончания предоставляет возможность исследовать всем знакомый способ фиктивного элемента («барьера»). Он легко используется в этом случае, если установить барьер  .
.
for (int i = 1; i < arr.Length; i++)
{
int tmp = arr[i];
int j;
for (j = i - 1; j >= 0 && arr[j] > tmp; j--)
arr[j + 1] = arr[j];
arr[j + 1] = tmp;
}
Анализ сортировки простыми включениями. Значение  сравнений ключей на i-м просеивании будет наибольшим i-1, и наименьшим 1 если допустить, что у всех переводов n ключей равная вероятность, в среднем равная i/2. Число
сравнений ключей на i-м просеивании будет наибольшим i-1, и наименьшим 1 если допустить, что у всех переводов n ключей равная вероятность, в среднем равная i/2. Число  пересылок (присваиваний) рассчитывается, как
пересылок (присваиваний) рассчитывается, как  (с учетом барьера). Таким образом, итоговое значений сравнений и пересылок рассчитывается следующим образом:
(с учетом барьера). Таким образом, итоговое значений сравнений и пересылок рассчитывается следующим образом:



Наименьшие возникают числа тогда, когда элементы с самого начала упорядочены, а самый худший случай появляется тогда, когда элементы стоят в обратном порядке. С этой точки зрения сортировка включениями ведет вполне нормально. Кроме того ясно, что этот алгоритм выражает устойчивую сортировку: последовательность элементов с одинаковыми ключами остается прежней.
Алгоритм сортировки простыми включениями легко улучшить, применяя то, что готовая последовательность, куда надо внести очередной элемент, к тому моменту также упорядочена. Поэтому место включения определяется более быстро. Понятно, что тут можно применить бинарный поиск, который исследует средний элемент готовой последовательности и ведёт деление пополам до момента, когда будет найдено место включения. Усовершенствованный алгоритм сортировки по другому определяют сортировкой бинарными включениями.
Анализ сортировки бинарными включениями. В целом число сравнений не очень зависит от исходного порядка элементов. Тем не менее из-за округления в момент деления диапазона поиска надвое настоящее число сравнений для i элементов получается иногда на 1 больше, чем ждали. Причина этого «перекоса» заключается в следующем: места включения в нижней части рассчитываются в среднем немного быстрее, чем в верхней части. Поэтому из этого получается преимущество тогда, когда элементы с самого начала находятся далеко от правильного порядка. На самом деле же наименьшее значение сравнений надо будет, когда элементы с самого начала расположены в обратном порядке, а наибольшее число сравнений – в случае, когда они уже упорядочены. Соответственно, это случай необычного выражения алгоритма сортировки
С = n (Log(n) – Log(e) ± 0,5).
Усовершенствование, получаемое нами при применении метода бинарного поиска, касается только числа сравнений, а не числа необходимых пересылок. На самом деле перестановка элементов, т.е. ключей и соответствующей информации, в основном требует поболее времени, чем сравнение двух ключей. Это улучшение никоим образом не есть решающее: важнейший показатель М по-прежнему остается  . И в самом деле, для пересортировки уже отсортированного массива нужно больше времени, чем для сортировки простыми включениями со следующим поиском! Получше результаты могут быть от метода, если пересылки элементов применяются лишь для единичных элементов и на большие расстояния. Этот момент обращает внимание к сортировке выбором.
. И в самом деле, для пересортировки уже отсортированного массива нужно больше времени, чем для сортировки простыми включениями со следующим поиском! Получше результаты могут быть от метода, если пересылки элементов применяются лишь для единичных элементов и на большие расстояния. Этот момент обращает внимание к сортировке выбором.
1.3 Алгоритм сортировки простым выбором.
алгоритм сортировка программирование поиск
Этот метод включает следующие условия:
1. Определяется элемент с самым маленьким ключом.
2. Выбранный элемент меняется расположением с первым элементом а[1].
Эти операции затем повторяются с прочими n - 1 элементами, затем c n - 2 элементами, до тех пор, пока в остатке не будет только один элемент – наибольший(табл.2).
Табл.2. Карта с пояснениями работы алгоритма выбором
|
44 |
55 |
12 |
42 |
94 |
18 |
06 |
67 |
|
|
06 |
55 |
12 |
42 |
94 |
18 |
44 |
67 |
|
|
06 |
12 |
55 |
42 |
94 |
18 |
44 |
67 |
|
|
06 |
12 |
18 |
42 |
94 |
55 |
44 |
67 |
|
|
06 |
12 |
18 |
42 |
94 |
55 |
44 |
67 |
|
|
06 |
12 |
18 |
42 |
44 |
55 |
94 |
67 |
|
|
06 |
12 |
18 |
42 |
44 |
55 |
94 |
67 |
|
|
06 |
12 |
18 |
42 |
44 |
55 |
67 |
94 |
Этот метод, называемый часто сортировкой простым выбором, в каком-то смысле противоположен сортировке простыми вставками; сортировка простыми вставками при следующем каждом шаге засчитывает лишь один следующий в текущий момент элемент входной последовательности и все элементы готового массива для расчета места включения; сортировка простым выбором ведет учёт всех элементов входного массива, чтобы определить элемент с самым маленьким ключом, и данный один очередной элемент направляется в готовую последовательность. В целом алгоритм сортировки простым выбором отражается в следующем виде:
int tmp;
for (int i = 0; i < arr.Length; ++i)
{
int pos = i;
tmp = arr[i];
for (int j = i + 1; j < arr.Length; ++j)
{
if (arr[j] < tmp)
{
pos = j;
tmp = arr[j];
}
}
arr[pos] = arr[i];
arr[i] = tmp;
}
Анализ сортировки простым выбором. Ясно, что значение С сравнений ключей отличается от исходного порядка ключей. В этом отношении можно сформулировать: сортировка простым выбором выражает себя менее просто, чем сортировка простыми включениями. В результате получается

Наименьшее значение присваиваний равно  когда с самого начала упорядочены ключи и равно наибольшему значению
когда с самого начала упорядочены ключи и равно наибольшему значению  когда изначально ключи выстроены в обратном порядке. Усредненное
когда изначально ключи выстроены в обратном порядке. Усредненное  у Д. Кнута определено в виде
у Д. Кнута определено в виде  , при этом
, при этом  =0,577216… (константа Эйлера).
=0,577216… (константа Эйлера).
Таким образом, возможно сделать заключение о том, что в основном алгоритм сортировки простым выбором более предпочтителен, чем алгоритм сортировки простыми вставками, несмотря на то, что иногда, когда ключи изначально рассортированы либо в какой-то степени отсортированы, сортировка простыми вставками все же выдает итоги чуть быстрее.
1.4 Алгоритм сортировки простым обменом.
Группировка способов сортировки не имеет ясного и однозначного определения. Два представленных выше способа при желании можно определить в качестве сортировки обменом. Тем не менее, есть метод, при применении которого взаимообмен двух элементов есть основная характеристика процесса. Рассмотренный далее алгоритм сортировки простым обменом базируется на основе сравнивания и обмена двух рядом стоящих элементов до момента, когда не будут отсортированы все элементы.
Так же, как и в рассмотренных способах простого выбора, совершаются повторяющиеся переходы по массиву, всякий раз определяя самый маленький элемент оставшегося множества, продвигаясь к левому краю массива. В случае, когда для разнообразия рассматривать массив, находящийся вертикально, а не горизонтально, и с помощью доли воображения представить себе элементы пузырьками в чане с водой, имеющими «веса», соответствующие их ключам, то тогда очередной переход по массиву приведет к «всплыванию» пузырька на уровень, который соответствует его весу. Такой метод всем знаком в качестве сортировки методом пузырька(табл.3).
int i, j;
int x;
for (i = 0; i < arr.Length; i++)
{
for (j = arr.Length - 1; j > i; j--)
{
if(arr[j-1]>arr[j]){
x=arr[j-1];
arr[j-1]=arr[j];
arr[j]=x;
}
}
}
return arr;
Табл.3. Карта с пояснениями работы алгоритма обменом
|
Исходные ключи |
i = 02 |
i = 03 |
i = 04 |
i = 05 |
i = 06 |
i = 07 |
i =08 |
|
045 |
06 |
06 |
06 |
06 |
06 |
06 |
06 |
|
059 |
045 |
012 |
012 |
012 |
012 |
012 |
012 |
|
012 |
059 |
045 |
018 |
018 |
018 |
018 |
018 |
|
042 |
012 |
059 |
045 |
042 |
042 |
042 |
042 |
|
094 |
042 |
018 |
059 |
045 |
045 |
045 |
045 |
|
018 |
094 |
042 |
042 |
059 |
059 |
059 |
059 |
|
006 |
018 |
094 |
067 |
067 |
067 |
067 |
067 |
|
067 |
067 |
067 |
094 |
094 |
094 |
094 |
094 |
Данный алгоритм нетрудно оптимизировать. Данный пример демонстрирует, что три последних прохода никоим образом не оказывают влияния на распорядок элементов, так как они уже отсортированы. Простой способ усовершенствовать этот алгоритм в том, что надо запоминать, был ли на этом проходе какой-нибудь обмен. В случае отрицательного ответа, это значит, что алгоритм может закрыть процесс. Эту процедуру улучшения возможно продолжить, в случае запоминания не только самого факта обмена, но и места (индекса) последнего обмена. Очевидно, что все пары соседcтвующих элементов имеют индексы, которые меньше данного индекса k, уже находятся в необходимом порядке. Соответственно последующие переходы можно окончить на данном индексе, чем двигаться до определенного ранее нижнего уровня i. Тем не менее, если внимательней посмотреть, то тогда возможно отметить необычную асимметрию: один не там, где нужно находящийся «пузырек» в «тяжелом» краю отсортированного массива всплывет на нужное место за один переход, а не там, где нужно, находящийся «пузырек» в «легком» краю опускается на нужное место всего лишь на один шаг на каждом переходе.
К примеру, массив
1218424455679406
будет отсортирован с помощью метода пузырька за один переход, а рассортировать массив
9406121842445567
придется за семь переходов. Эта необычная асимметрия наводит на третье усовершенствование: поменять направление чередующих один за другим переходов. Представленный таким образом алгоритм часто называют шейкер-сортировкой(табл.4).
Табл.4. Карта с пояснениями работы шейкерной сортировки
|
I=2 |
3 |
3 |
4 |
4 |
|
R=8 |
8 |
7 |
7 |
4 |
|
44 |
06 |
06 |
06 |
06 |
|
55 |
44 |
44 |
12 |
12 |
|
12 |
55 |
12 |
44 |
18 |
|
42 |
12 |
42 |
18 |
42 |
|
94 |
42 |
55 |
42 |
44 |
|
18 |
94 |
18 |
55 |
55 |
|
06 |
18 |
67 |
67 |
67 |
|
67 |
67 |
94 |
94 |
94 |
int b = 0, prm = 0;
int left = 0;
int right = arr.Length - 1;
while (left < right)
{
for (int i = left; i < right; i++)
{
if (arr[i] > arr[i + 1])
{
b = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = b;
b = i;
prm++;
}
}
right = b;
if (left >= right) break;
for (int i = right; i > left; i--)
{
if (arr[i - 1] > arr[i])
{
b = arr[i];
arr[i] = arr[i - 1];
arr[i - 1] = b;
b = i;
prm++;
}
}
left = b;
}
Анализ сортировки методом пузырька и шейкер-сортировки. Число сравнений в алгоритме простого обмена равняется  , наименьшее, усредненное и наибольшее значения переброски ( присваивание элементов) равняется
, наименьшее, усредненное и наибольшее значения переброски ( присваивание элементов) равняется



Анализ усовершенствованных методов, таких как метод шейкер-сортировка, довольно сложен. Наименьшее количество сравнений равно  . Для улучшенного метода пузырька Д. Кнут выявил, что усредненное число переходов пропорционально
. Для улучшенного метода пузырька Д. Кнут выявил, что усредненное число переходов пропорционально  и среднее значение сравнений прямо пропорционально
и среднее значение сравнений прямо пропорционально  . Однако видно, что все предлагаемые до того улучшения никак не оказывают влияния на количество обменов; они только сокращают число лишних повторных проверок. Жаль, но операция взаимообмена двух элементов – часто намного дороже стоит, чем сравнение ключей, соответственно все наши улучшения приводят к значительно меньшему эффекту, чем ожидалось.
. Однако видно, что все предлагаемые до того улучшения никак не оказывают влияния на количество обменов; они только сокращают число лишних повторных проверок. Жаль, но операция взаимообмена двух элементов – часто намного дороже стоит, чем сравнение ключей, соответственно все наши улучшения приводят к значительно меньшему эффекту, чем ожидалось.
Анализ отражает, что сортировка обменом и некоторые её усовершенствования уступает сортировке включениями и выбором, и в самом деле, сомнительно, чтобы сортировка методом пузырька имела какие-либо преимущества, за исключением соответствующего просто запоминающегося названия. Алгоритм шейкер-сортировки удобно применять тогда, когда ясно, что элементы уже, в основном, упорядочены – довольно редкий практический случай.
Легко показывается, что усредненное расстояние, на которое переместится всякий из n элементов в момент сортировки, – это n/3 мест. Данное число предоставляет ключ к поиску улучшенных, намного эффективнее методов сортировки. Каждый простой метод в принципе переносит каждый элемент на одну позицию на каждом элементарном этапе. Соответственно им нужно порядка n2 таких этапов. Каждое усовершенствование обязано основываться на принципе пересылки элементов за каждый цикл на более большее расстояние.
Небольшое улучшение сортировки простыми вставками сделано Д.Л. Шеллом ещё в 1959году. Данный метод рассмотрим с помощью примера с восьмью элементами (рис. 1).
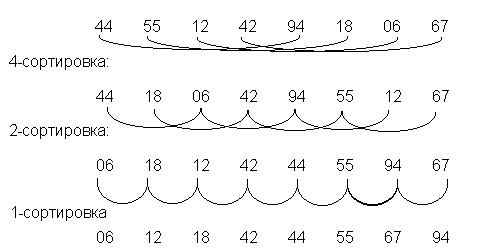
Рис.1. Сортировка по методу Шелла
В процессе первого прохода самостоятельно собираются и рассортировываются все элементы, которые отстоят друг относительно друга на четыре позиции. Данный шаг является 4-сортировкой. В рассматриваемом примере с восьмью элементами все группы содержат ровно по два элемента. Затем элементы снова объединяются в группы с элементами, которые отстоят друг относительно друга на две позиции, и рассортировываются вновь. Данный шаг является 2-сортировкой. В заключение на третьем проходе каждый элемент сортируется простой сортировкой или 1-сортировкой.
В начале кажется, что потребность нескольких проходов сортировки, в которых в каждом проходе принимают участие все элементы, займет больше работы, чем даст экономию. Тем не менее, на каждом этапе сортировки или участвует относительно немного элементов, или они к тому моменту достаточно неплохо упорядочены и им нужно относительно немного перестановок.
Ясно, что данный метод в итоге формирует упорядоченный массив, и тоже совершенно понятно, что всякий проход будет применять итоги предшествующего прохода, так как всякая i-сортировка соединяет две группы, отсортированные предшествующей 2i-сортировкой. Тоже понятно, что подойдет всякая последовательность приращений, только бы последнее равнялось 1, потому, что в наихудшем случае работа целиком будет исполняться на последнем проходе. Тем не менее, не так очевидно, что метод убывающего приращения выдает более лучшие результаты, в случае, если приращения не есть степени двойки.
Поэтому, программа формируется независимо от конкретной последовательности приращений. Все t приращений условно обозначиваются как  с условиями
с условиями 
 .
.
Всякая h-сортировка программируется в качестве сортировки простыми включениями. И для того, чтобы условие заканчивания поиска места включения являлось простым, применяется барьер.
Понятно, что всякая h-сортировке нужен собственный барьер, и что программе нужно определить его место, как можно проще. Соответственно в массив a нужно включить не одну компоненту, а [0], a  компонент, так что теперь его можно описать как: а: array [-
компонент, так что теперь его можно описать как: а: array [- .. n] of item;
.. n] of item;
Вот как выглядит алгоритм сортировки Шелла:
int j, prm = 0;
int step = arr.Length / 2;
while (step > 0)
{
for (int i = 0; i < (arr.Length - step); i++)
{
j = i;
while ((j >= 0) && (arr[j] > arr[j + step]))
{
int tmp = arr[j];
arr[j] = arr[j + step];
arr[j + step] = tmp;
j -= step;
prm++;
}
}
step = step / 2;
}
Анализ сортировки Шелла. Анализируя этот алгоритм, приходится сталкиваться с определенными очень сложными математическими задачами, часть из которых пока не решены. Например, неясно, какая последовательность приращений выдает лучшие итоги. Тем не менее, обнаружен странный принцип, в том, что они должны быть некратны друг относительно друга. Так можно избежать ситуации, видной в приведенном ранее примере, когда всякий проход сортировки соединяет две цепочки, которые до того никоим образом не взаимодействовавшие. В то же время желательно, чтобы взаимодействие разных цепочек проходило как можно чаще. Таким образом формулируется следующая теория:
В случае, когда k-рассортированная последовательность i-сортируется, тогда она по прежнему будет k-рассортированной.
Д.Кнут показал, что правильным выбором может быть следующая последовательность приращений (отраженная в обратном порядке):
1, 4, 13, 40, 121, ...,
где 
 и
и  .
.
Им тоже была рекомендована следующая последовательность
1, 3, 7, 15, 31, ...,
где 
 и
и  .
.
В дальнейшем анализ указывает, что в последнем случае издержки, требуемые для сортировки n элементов при помощи алгоритма сортировки Шелла, прямо пропорциональны n6/5. Это намного лучше по сравнению с n2.
2. Практический раздел.
2.1 Выбор средств реализации.
2.1.1 Выбор языка программирования.
Ниже будет рассмотрено несколько языков программирования, которые были в роли кандидатов для написания практической части работы.
На данный момент существует большой выбор языков программирования. Под каждую задачу можно выбрать оптимальный язык, на котором будет проще и удобней реализовывать ту или иную задачу. В качестве кандидатов для выполнения данной задачи были выбраны следующие нижеперечисленные языки программирования.
Microsoft Visual C++. Язык ООП Visual C++ компании Microsoft – довольно мощный инструмент разработки системных приложение. Однако, есть очень серьезный недостаток - разработка приложений на этом языке программирования это трудоемкий, затратный по времени, сложный процесс.
Microsoft Visual Basic. Visual Basic (от корпоряции Microsoft) явдяется системой быстрой разработки программ RAD (Rapid Application Development), чем то похожую на среду разработки Delphi. Ероятнее всего, это можно объяснить вечной конкуренцией между Microsoft и Borland. Но все же, не смотря на похожесть интерфейсов, языки очень отличаются друг от друга.
Visual Basic - объектно-ориентированный язык программирования, зачастую встроенный во многие приложения Microsoft Office. Достоиствами этого языка: простота создания не сложных приложений и возможность создания и редактирования компонентов Microsoft Office.
Delphi - среда быстрой разработки, продукт компании Borland, основана на объектно-ориентированном языке программирования Pascal, среда имеет удобные и функциональные средства для разработки оконных приложений. Также, Delphi имеет стандартные компоненты для разработки приложений для работы с базами данных и веб-сервисами.
С#.NET. C# содержит C стиль синтаксиса (для управляющих конструкций, блоков кода, описания сигнатуры методов и др.), очень много общего с языком Java (отсутствие множественного наследования и шаблонов, наличие сборщика мусора) и Делфи (ориентированность на создание компонент), в то же время имеет и свой особенный колорит.
При создании языка за основу дизайна легла легкость и простота использования, а так же мощностью языка, которые доминируют над и скоростью выполнения приложений. Отсюда и сборщик мусора с управляемыми объектными ссылками, который автоматически освобождает память. Следят за безопасностью работы с типами, а это, по мнению многих программистов, является вторым важным фактором недопущения ошибок.
C# объектно-ориентированный язык, как и вся платформа .NET. Более того, это язык, ориентированный на написание компонент. C# создан для программирования в управляемой среде с присутствующим сборщиком мусора, но позволяет писать и неуправляемый (unmanaged) код.
С# дает возможность реализации графически приложений. Windows. Forms - это набор различных управляемых библиотек, с помощью которых можно выполнить все необходимые для оконного приложения действия, начиная от обмена сообщениями с операционной системой для отслеживания любых событий клиентского окна, заканчивая диалоговыми системами, связью с другими компьютерами по сети и многими другими возможностями.
Windows Forms представляет собой одну из двух технологий, используемую в Visual C# для создания интеллектуальных клиентских приложения на основе Windows, выполняемых в среде .NET Framework. Технология Windows Forms специально создана для быстрой разработки приложений, в которых обширный графический пользовательский интерфейс не является приоритетом. Для создания пользовательского интерфейса используется конструктор Windows Forms.
Java. В языке Java используется технология обьектно ориентированного программирования, которая позволяет сократить общее время разработки и писать повторно используемый код. Java-приложения являются независимыми от платформы. Это достигается путем совмещения в языке свойств компилятора и интерпретатора. Платформонезависимость байт-кода обеспечивается наличием виртуальных java-машин для всех основных платформ. В комплект поставки Java входят стандартные классы, которые обладают достаточной функциональностью для быстрой разработки приложений, Развитые средства безопасности позволяют использовать Java для разработки приложений, работающих в Интернете. Единственным недостатком Java является - медленная скорость работы, обусловленная использованием ЛТ - компиляторов - цена кроссплатформенности.
После анализа, сделан вывод, что самый подходящий язык программирования для реализации нашего программного продукта – именно С#. Он легок в освоении и в написании прикладных программ. Имеет инструментарий для работы с таймерами и потоками. На нем легко и практично реализовывать программы с графическим интерфейсом.
2.1.2 Выбор среды разработки.
В ходе поиска среды разработки, были выделены следующие:
- SharpDeveloper;
- MonoDevelop IDE;
- Microsoft Visual Studio.
Далее приведена информация по каждой из них:
SharpDeveloper - свободная среда разработки для C#, Visual Basic .NET, Boo, IronPython, IronRuby, F#, C++. SharpDevelop предоставляет интегрированный отладчик, который использует собственные библиотеки и взаимодействует с исполняющей средой .NET через COM Interop.
Хотя SharpDevelop использует файлы проекта в формате MSBuild, он по-прежнему может использовать компиляторы от .NET Framework 1.0 и 1.1, а также от Mono.
Возможности и особенности:
- Написана полностью на C#.
- Подсветка синтаксиса для C#, IronPython, HTML, ASP, ASP.NET, VBScript, VB.NET, XML, XAML.
- Визуальный редактор для WPF и форм Windows Forms (COM-компоненты не поддерживаются).
- поддержка NUnit, MbUnit и NCover.
- профайлер.
- поддержка SVN, Mercurial и Git.
- Конвертор кода между C#, VB.NET, IronPython и Boo.
- Расширяемость внешними инструментами.
- Расширяемость на основе Add-Ins.
- Интегрированная поддержка анализатора сборок FxCop.
- Интегрированный отладчик.
MonoDevelop IDE - свободная мультиплатформенная среда разработки, предназначенная для создания приложений на языках C#, C, C++, Java, Visual Basic.NET, CIL, Nemerle, Boo. На данный момент среда является частью проекта Mono и является одной из самых лучших IDE для разработки проектов на базе Mono.
MonoDevelop обладает всеми основными возможностями, необходимыми для современной интегрированной среды разработки:
- настраиваемая подсветка синтаксиса;
- автоматическое дополнение кода;
- выделение блоков кода с возможностью их сворачивания, разворачивания;
- интеллектуальная работа с отступами в коде;
- возможности рефакторинга (переименование классов и методов, автоматическая реализация интерфейсов в производных классах);
- удобная навигация по коду (навигация по классам, методам, свойствам);
- визуальный редактор форм для проектов на Gtk#;
- создание нескольких раскладок интерфейса и переключение между ними;
- работа с базами данных;
- создание приложений с GUI, поддерживающим несколько языков;
- интеграция с Subversion для управления исходным кодом;
- поддержка NUnit для создания Unit-тестов;
- множество стандартных шаблонов проектов;
- возможность автоматического создания бинарных пакетов и архивов после компиляции исходного кода;
- автоматическое создание документации;
- расширение возможностей за счет дополнений и внешних инструментов;
- возможность интеграции со средами Microsoft Visual Studio и .NET Framework (в среде Microsoft Windows).
Microsoft Visual Studio - набор продуктов от корпорпции Microsoft, которые включают интегрированную среду разработки программных продуктов и набор других инструментальных средств. Такие средства позволяют разрабатывать как обычные консольные приложения, так и сложные приложения с графическим интерфейсом, например технология Windows Forms., Также веб-приложения, веб-сайты, веб-службы как в родном, так и в управляемом кодах для всех платформ, кторые поддерживают Windows, Windows Mobile, .NET Framework Windows CE, Xbox, Windows Phone .NET Compact Framework и Silverlight.
Visual Studio содержит редактор исходного кода поддерживающий технологии IntelliSense с возможностью простейшего рефакторинга кода.
Встроенный отладчик имеет возможность работать как отладчик уровня исходного кода, а также как отладчик машинного уровня. Другие встроенные инструменты содержат в себе редактор форм для упрощенного создания визуального (графического) интерфейса приложений, веб-редактор, дизайнер классов и дизайнер схем БД. Visual Studio дает возможность создавать и подключать сторонние плагины, для расширения функциональности практически на любом уровне, включая добавление поддержки систем контроля версий исходного кода (как, например, Subversion и Visual SourceSafe), включение новых наборов инструментов (например, для редактирования и визуального проектирования кода на предметно-ориентированных языках программирования) или инструментов для других аспектов процесса разработки программных приложений (например, клиент Team Explorer для работы с Team Foundation Server).
Visual Studio включает один или несколько компонентов из следующих:
- Visual Basic .NET, а до его появления - Visual Basic.
- Visual C#.
- Visual C++.
- Visual F# (включён начиная с Visual Studio 2010).
Многие варианты поставки также включают:
Microsoft SQL Server либо Microsoft SQL Server Express;
В прошлом в состав Visual Studio также входили продукты:
- Visual InterDev.
- Visual J++.
- Visual J#.
- Visual FoxPro.
Таким образом, безусловное превосходство среды разработки Microsoft Visual Studio над другими средами разработки стало фактором выбора именно этого средства для разработки программного обеспечения.
2.2 Разработка программного обеспечения.
Первым делом, в среде разработки был создан проект WinForms - проект с графическим интерфейсом. Консольный вариант программы не совсем подходит для выполнения поставленной задачи, по причине того, что оконный вариант будет более наглядным, удобным и практичным.
Структурно, программный будет состоять из двух главных составляющих:
- интерфейсная часть;
- логическая часть;
а) Интерфейс программы будет реализован в виде графического окна, на котором размещены элементы управления программы, а также поля для ввода и вывода информации.
б) Логическая часть программы. Это программный код, который отвечает за логику работы программы. Другими словами - это все составные функции программы, которые отвечают за ее функционал и работу.
На форму программы были добавлены следующие компоненты:
- компоент GroupBox – для визуального выделения и группировки нескольких компонентов;
- 2 компонента panel, для визуального выделения компонентов;
- 13 текстовых полей textbox, для ввода исходных данных и вывода результатов сортировки;
- 3 кнопки button, для запуска сравнения алгоритмов сортировки, для очистки текстовых полей и для выходя из программы;
- 18 меток label, для пояснения назначения остальных компонентов в форме. После добавления всех компонентов и их настройке, форма приняла следующий вид (рис.3):
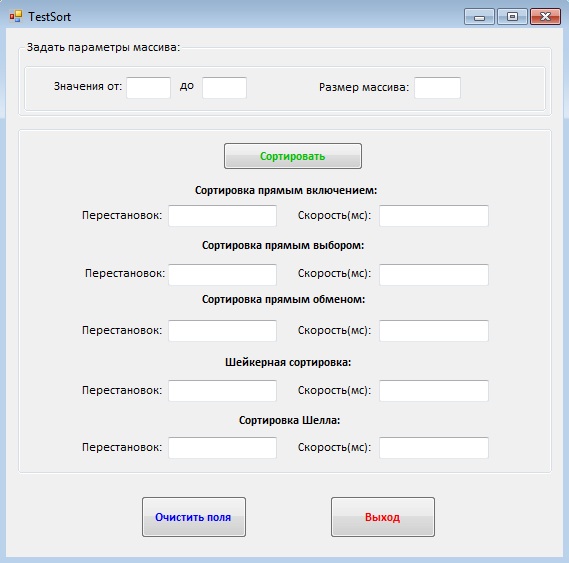
Рис.2. Пользовательский интерфейс программы.
Далее, разработаны функции программы.
При нажатии на кнопку «Выход», выполняется функция обработчик нажатия на кнопку:
private void button3_Click(object sender, EventArgs e)
{
this.Close();
}
При нажатии на кнопку «Очистить поля», выполняется функция обработчик нажатия на кнопку:
private void button2_Click(object sender, EventArgs e)
{
textBox2.Clear();
textBox3.Clear();
textBox4.Clear();
textBox5.Clear();
textBox7.Clear();
textBox8.Clear();
textBox9.Clear();
textBox10.Clear();
textBox11.Clear();
textBox12.Clear();
textBox13.Clear();
textBox14.Clear();
textBox15.Clear();
}
При нажатии на кнопку «Сортировать», выполняется главная функция, функция обработчик нажатия на кнопку:
private void button1_Click(object sender, EventArgs e)
{
if (textBox2.Text == String.Empty || textBox3.Text == String.Empty || textBox5.Text == String.Empty)
{
MessageBox.Show("Введите параметры массива!");
return;
}
int left, right;
long mlen;
left = Convert.ToInt32(textBox2.Text);
right = Convert.ToInt32(textBox3.Text);
mlen = Convert.ToInt64(textBox5.Text);
int[] mass = new int[mlen];
Random rand = new Random();
for (long i = 0; i < mlen; i++)
{
mass[i] = rand.Next(left, right);
}
Stopwatch sWatch = new Stopwatch();
long res=0;
sWatch.Start();
res = sortVk(mass);
sWatch.Stop();
textBox8.Text = res.ToString();
textBox9.Text = sWatch.ElapsedMilliseconds.ToString();
sWatch.Reset();
Thread.Sleep(500);
sWatch.Start();
res = sortVb(mass);
sWatch.Stop();
textBox4.Text = res.ToString();
textBox10.Text = sWatch.ElapsedMilliseconds.ToString();
sWatch.Reset();
Thread.Sleep(500);
sWatch.Start();
res = sortObm(mass);
sWatch.Stop();
textBox7.Text = res.ToString();
textBox11.Text = sWatch.ElapsedMilliseconds.ToString();
sWatch.Reset();
Thread.Sleep(500);
sWatch.Start();
res = shakerSort(mass);
sWatch.Stop();
textBox12.Text = res.ToString();
textBox13.Text = sWatch.ElapsedMilliseconds.ToString();
sWatch.Reset();
Thread.Sleep(500);
sWatch.Start();
res = shellSort(mass);
sWatch.Stop();
textBox15.Text = res.ToString();
textBox14.Text = sWatch.ElapsedMilliseconds.ToString();
sWatch.Reset();
}
Таким образом, после запуска функции, в первую очередь, проводится проверка на пустоту текстовых полей textBox2, textBox3, textBox5. Если хоть одно из них пустое, выводится сообщение, что нужно заполнить все поля с исходными данными. Если поля не пустые, продолжается выполнение функции.
Далее, с текстовых полей, которые содержат исходные данные, переписываются их значения. Создается целочисленный массив и заполняется случайными числами из указанного в форме диапазона.
После чего, создается обьект типа Stopwatch, для определния времени сортировки массива. Сначала запускается счетчик, затем выполняется функция сортировки, после выполнения функции, время записывается в текстовое поле, так же записывается количество перестановок, далее счетчик обнуляется и аналогично запускается следующая функция сортировки(следующий алгоритм сортировки).
После запуска поочередно всех 5-ти алгоритмов, выполнение главной функции завершается. На этом, этап разработки завершен.
Функции с алгоритмами сортировки указаны в «Приложении А».
2.3 Инструкция пользователя
Перед тем как запускать программу, необходимо убедиться, что на локальной машине есть пакет обновлений NET.FrameWork 4.5.
Для запуска программы есть определенные рекомендации, а так же обязательные условия. К рекомендациям относятся минимальные требования к конфигурации ПК(центрального ПК):
- Процессор: Intel Core 2 Duo, AMD Sempron ли выше.
- Объем ОП: не менее 16 свободной памяти.
- Объем жесткого диска: не менее 10Мб свободного места.
- Обязательными требованиями есть:
- Версия NET.FrameWork не ниже 4.5
После запуска программы, на экране появится окно (рис.3):
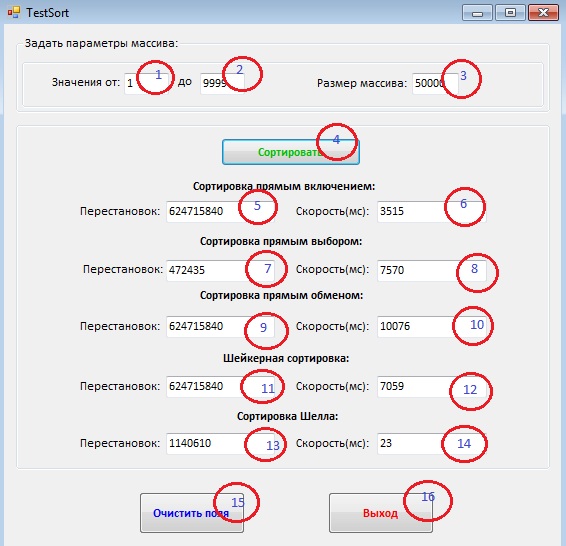
Рис.3. Окно программы после запуска
Перед запуском сортировки, в поля «1» и «2», необходимо ввести диапазон генерируемых значений будущего массива. В поле «3», вводится длина массива. Ее, желательно, указать около 50000, так как при 5000 сортировка пройдет быстро и может быть погрешность в подсчете времени, а 90000 наоборот – сортировка займет большое количество времени. В программе реализован ограничитель, в поле с длинной массива, ввести значение больше «99999» - невозможно.
Для запуска процесса тестирования алгоритмов сортировки, следует нажать на кнопку «4». Через некоторое время, в полях «5»-«14» будет отображены количество перестановок и время сортировки для каждого из алгоритмов.
Для очистки полей, необходимо нажать на кнопку «15», а для выхода из программы – на кнопку «16».
После тестовых запусков программы, можно сделать вывод, что с сортировкой целочисленных массивов, лучше всех справляется алгоритм «Шелла», он не на один порядок быстрее справляется в отличии от его конкурентов. Самым медленным оказался алгоритм «простого обмена», другими словами алгоритм сортировки «пузырьком».
ЗАКЛЮЧЕНИЕ
В результате выполнения данного проекта было разработано программное обеспечение, позволяющее осуществлять сравнение самых распространенных алгоритмов сортировки данных.
В процессе выполнения работы, проведен анализ алгоритмов сортировки данных, получение навыков их программирования и получение статистических данных результатов работы этих алгоритмов.
Во втором разделе, сделан обзор языков программирования. На основании этого обзора, выбран один из них. После чего выбрана среда разработки, спроектирован интерфейс программы. Согласно интерфейсу, разработаны функции программы, алгоритмы сортировок.
В заключении можно сказать, что реализованное программное средство полностью удовлетворяет требованиям.
Проведены тестовые запуски алгоритмов сортировки по обработке целочисленных массивов. По результатам тестовых запусков, сделан вывод, сделать вывод, что с сортировкой целочисленных массивов, лучше всех справляется алгоритм «Шелла», он не на один порядок быстрее справляется в отличии от его конкурентов. Самым медленным оказался алгоритм «простого обмена», другими словами алгоритм сортировки «пузырьком». Также, разработано руководство пользователя программой.
В целом, основная цель работы достигнута, а задачи успешно выполнены.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Гудман С., Хидетними С. Введение в разработку и анализ алгоритмов- Москва: Издательство Мир, 1981 год.
- Ахо A.B., Хлокрофт Дж.., Ульмман Дд. Структура данных и алгоритмы-Москва: Издательство «Вильямс», 2000год . 384стр.
- Левитин Ананий. Алгоритмы: введение в разработку и анализ.: Перевод с английского-Москваав: Издат. дом «Вильямс», 2006год – 576стр.: илюстр.
- https://habrahabr.ru/post/181271/
- Шилдт Герберт. C# 4.0 полное руководство – 2011. 427 стр.
- Культин Н.Б. Microsoft Visual C# в задачах и примерах – 2-е издание. БВХ-Петербург,2014. – 320 стр.
ПРИЛОЖЕНИЕ А
private long sortVk(int[] ms) //Сортировка включением
{
long prm = 0;
int[] arr = new int [ms.LongLength];
Array.Copy(ms, arr, ms.LongLength);
for (long i = 1; i < arr.LongLength; i++)
{
for (long j = i; j > 0 && arr[j - 1] > arr[j]; j--)
{
prm++;
int tmp = arr[j - 1];
arr[j - 1] = arr[j];
arr[j] = tmp;
} }
return prm;
}
private long sortVb(int[] ms) //Сортировка выбором
{
int[] arr = new int[ms.LongLength];
Array.Copy(ms, arr, ms.LongLength);
int tmp;
long prm = 0;
for (long i = 0; i < arr.LongLength; ++i)
{
long pos = i;
tmp = arr[i];
for (long j = i + 1; j < arr.LongLength; ++j)
{
if (arr[j] < tmp)
{
pos = j;
tmp = arr[j];
prm++;
}}
arr[pos] = arr[i];
arr[i] = tmp;
prm++;
}
return prm;
}
private long sortObm(int[] ms) //Сортировка обменом
{
int[] arr = new int[ms.LongLength];
Array.Copy(ms, arr, ms.LongLength);
long i, j,prm=0;
int x;
for (i = 0; i < arr.LongLength-1; i++)
{
for (j = arr.LongLength - 1; j > i; j--)
{
if(arr[j-1]>arr[j]){
x=arr[j-1];
arr[j-1]=arr[j];
arr[j]=x;
prm++;
}}}
return prm;
}
private long shakerSort(int[] ms) //шейкерная сортировка
{
int[] arr = new int[ms.LongLength];
Array.Copy(ms, arr, ms.LongLength);
long b = 0;
long prm = 0;
long left = 0;
long right = arr.LongLength - 1;
while (left < right)
{
for (long i = left; i < right; i++)
{
if (arr[i] > arr[i + 1])
{
b = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = (int)b;
b = i;
prm++;
}}
right = b;
if (left >= right) break;
for (long i = right; i > left; i--)
{
if (arr[i - 1] > arr[i])
{
b = arr[i];
arr[i] = arr[i - 1];
arr[i - 1] =(int)b;
b = i;
prm++;
}}
left = b;
}
return prm;
}
private long shellSort(int[] ms) //сортировка Шелла
{
int[] arr = new int[ms.LongLength];
Array.Copy(ms, arr, ms.LongLength);
long j;
long prm = 0;
long step = arr.LongLength / 2;
while (step > 0)
{
for (long i = 0; i < (arr.LongLength - step); i++)
{
j = i;
while ((j >= 0) && (arr[j] > arr[j + step]))
{
int tmp = arr[j];
arr[j] = arr[j + step];
arr[j + step] = tmp;
j -= step;
prm++;
}}
step = step / 2;
}
return prm;
}

- Проектирование реализации операций бизнес-процесса «Контроль поставок товара» (Характеристика существующих бизнес – процессов)
- Проблемы профессиональных стрессов. Профессиональное выгорание (Теоретические аспекты профилактики стрессов)
- Невербальные проявления эмоциональных состояний человека (Проявление эмоций в интонациях)
- Технологии создания управленческих команд (Этапы формирования управленческой команды)
- Баланс и отчетность (Бухгалтерский баланс как основная форма финансовой отчетности)
- Налоговый учет по налогу на добавленную стоимость (на примере ООО «Техноресурс»)
- Корпоративная культура в организации (Анализ состояния корпоративной культуры в ООО «Омега-групп»)
- Проектирование реализации операций бизнес-процесса (Обоснование проектных решений)
- Программные и аппаратные средства ограничения доступа к ресурсам ПК и сетей (Идентификация и аутентификация)
- Виды и состав угроз информационной безопасности (Экспертные системы)
- Управление поведением в конфликтных ситуациях (Общетеоретическое исследование управления конфликтами)
- Особенности политики мотивации персонала корпораций (Основные методы управления мотивацией)