
Алгоритмы сортировки данных. (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ АЛГОРИТМА СОРТИРОВКИ ДАННЫХ)
Содержание:

ВВЕДЕНИЕ
Актуальность исследования. В последнее время программирование для электронно-вычислительных машин является не только средством, правильное применение которого принимает решающее значение для результативной работы в большинстве прикладных областей, а так же и областью научного изучения. Становится очевидным, что знания алгоритмов приобретают важнейшее значение при принятии решений о структурировании данных. С каждым днем жизнь ускоряется, становится всё быстрее, растет поток всевозможной информации. С целью сохранения различной информации используют так называемые базы данных. При этом с данными базами, когда если в них содержатся миллионы элементов, работать очень сложно, практически невозможно. Не потеряться в таком объеме данных, не используя сортировку, на практике невозможно, она дает возможность сравнительно быстро и качественно отделить нужную информацию из предварительно упорядоченного набора. Таким образом, алгоритмы сортировки имеют важное значение, особенно при переработке информации. В программировании придается большое внимание методам сортировки и её алгоритмам.
Сегодня имеется множество алгоритмов сортировки, имеющих разный характер и быстроту переработки данных. Тем не менее, большинство из них имеют очень существенный недостаток, а точнее, период их реализации пропорционально квадрату числа элементов. Сортировки значительных объемов информации будут медленными, а, при достижении определенного значения, они станут совсем медленными для того, чтобы можно было пользоваться ими на практике.
Научное значение данная работа представляется в анализе и представлении самых известных алгоритмов сортировки. Практическое значение тема «Алгоритмы поиска и сортировки» представляется в исследовании проблем выполнения и применения разных типов алгоритмов поиска и сортировок.
Цель работы – алгоритмы сортировки данных.
Объектом исследования - алгоритмы сортировки данных с использованием технологии MPI.
Предметом исследования в нашей курсовой работе будут методы использования алгоритмов сортировки и поиска на алгоритмических программирования высокого уровня.
Сразу надо отметить, вопросами анализа алгоритмов, группировкой, исследованием и методами их программирования в различные времена были заняты: Кнут Д., Ульман Дж., Левитин А., Цейтлин Г.Е., Гудман С., Хидетниеми С., Ахо А., Хлопккрофт Дж., Вирт Н., Лорин Г., Макконнелл Дж. и другие.
ГЛАВА 1 ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ АЛГОРИТМА СОРТИРОВКИ ДАННЫХ
1.1 Алгоритм сортировки данных
Алгоритм (algorithm) — это любой корректно определенный вычислительный процесс, на входе (input), которого задается какое-то значение или набор значений, а итогом реализации является выходное (output) значение или набор величин. Значит, алгоритм это определенная последовательность вычислительных шагов, которые преобразуют входные значения в выходные.
Алгоритм представляется и как инструмент, с помощью которого решаются корректно сформулированные вычислительные задачи. Алгоритм описывает конкретный вычислительный процесс, с помощью которого можно добиться реализации указанных отношений.
К примеру, появится необходимость произвести сортировку последовательности чисел в неубывающем порядке. Такая задача очень часто встречается на практике и служит прекрасным примером для знакомства на ее примере с большинством стандартных методов разработки и анализа алгоритмов.
Cортировка –это процедура упорядочения объектов конкретного множества данных в определенном порядке. Основная цель процесса сортировки – увеличение скорости дальнейшего поиска значений в рассортированном массиве данных. Практически во всех задачах присутствуют элементы сортировки. Отсортированные элементы содержатся в телефонных справочниках, в оглавлениях, в библиотеках, в словарях, да и ещё много других местах применения.
Соответственно, методы сортировки крайне важны, особенно при обработке информационных данных. Сортировка связана со многими фундаментальными приемами построения алгоритмов, реализующих одну и ту же задачу, некоторые из которых в каком-то смысле являются оптимальными, а большинство имеет какие-либо преимущества по сравнению с остальными.
Зависимость выбора алгоритмов от структуры данных сильна. Применяемые методы сортировки часто делят на две группы: сортировка файлов и сортировка массивов. Данные обе группы иногда обозначают как внутреннюю и внешнюю сортировками, потому что массивы находятся во «внутренней» (оперативной) памяти компьютера (данному виду памяти присущ скорый произвольный доступ), а рассматриваемые файлы содержатся в не такой быстрой, но намного вместительней «внешней» памяти, иначе говоря, на запоминающем устройстве с механическим передвижением (дисках, лентах).
Основные критерии эффективности алгоритмов сортировки следующие:
- быстродействие;
- экономия памяти;
- сокращение времени, затрачиваемого программистом, на реализацию алгоритма.
Поэтому в зависимости от количества элементов множества, их упорядоченности, частоты применения сортировки и других факторов следует использовать различные алгоритмы сортировки и поиска.
Для более детального ознакомления с алгоритмами сортировки и поиска, рассмотрим некоторые «элементарные» способы сортировки, хорошо зарекомендовавшие себя для работы с небольшими файлами или файлами специальной структуры. Есть много причин, почему необходимо изучение этих простых способов. Первое, они предоставляют нам относительно простой способ ознакомиться с терминологией и основными механизмами функционирования алгоритмов сортировки, и это позволяет приобрести нужную базу для исследования более сложных алгоритмов. Второе, во многих задачах сортировки чаще лучше применить простые способы, чем более сложные алгоритмы. И, последнее, кое-какие из простых методов допустимо развить до более лучших методов или применить их для совершенствования более сложных.
Во многих программах сортировки оптимально применить простые элементарные алгоритмы. Программы сортировки иногда применяются только единожды (или несколько раз). В случае, когда количество элементов, необходимых отсортировать небольшое (примерно меньше 500 элементов), то тогда применение элементарного алгоритма даст больший эффект, чем новая проработка и отладка громоздкого алгоритма. Элементарные простые методы постоянно полезны для небольших файлов (примерно меньших, чем 50 элементов); конечно сложный алгоритм было бы неразумно применить для подобных файлов, если конечно нет необходимости отсортировать большое количество подобных файлов.
Обычно, элементарные простые методы, рассматриваемые нами, осуществляют примерно операций для сортировки N случайно выбранных элементов. В случае N достаточно мало, тогда это может и не быть особой проблемой, и в случае, когда элементы расставлены не случайным образом, тогда эти алгоритмы работают иногда быстрее, чем сложные. Но нужно помнить то, что указанные алгоритмы не нужно применять для больших, случайным образом упорядоченных файлов, с одним возможным исключением для алгоритма оболочечной сортировки, применяемого во многих программах.
Прежде чем рассматривать произвольный алгоритм, полезно исследовать терминологию и кое-какие главные соглашения об алгоритмах сортировки. Мы намерены исследовать алгоритмы для сортировки файлов записей, включающих ключи. Ключи, являющиеся только частью записи (в основном, очень небольшой их частью), применяются для управления процедурой сортировки. Цель алгоритма сортировки – новая организация записей в файле таким образом, чтобы их расположение в нем было в каком то строго регламентированном порядке (чаще всего в алфавитном либо числовом).
В случае, когда сортируемый файл полностью помещается в память (либо полностью помещается в массив), то для него используются внутренние методы сортировки. Сортировку данных с ленты или диска называют внешней сортировкой. Основное отличие их состоит в том, что внутренняя сортировка делает любую запись легко доступной, тогда как при внешней сортировке можно применять записи только последовательно, либо большими блоками. В основном, алгоритмы сортировки, рассматриваемые ниже – внутренние.
В основном, главное, что обычно интересует в алгоритме – это продолжительность его работы. Начальные четыре алгоритма, рассматриваемые ниже, для сортировки N элементов тратят период работы пропорциональное , когда как посложнее алгоритмы тратят время пропорциональное . (Возможно показать, что любой алгоритм сортировки не в состоянии использовать меньше, чем сравнений между ключами.) Изучив простые методы, рассмотрим посложнее методы, время работы которых пропорционально и алгоритмы, применяемые бинарные свойства ключей для сокращения всего периода работы до N.
Объем применяемой дополнительной памяти алгоритма сортировки – также дополнительный фактор, принимаемый во внимание. Обычно методы сортировки делят на три группы:
- методы сортировки, сортирующие без применения дополнительной памяти, исключая, возможно, маленького стека и / или массива;
- методы, применяемые в случаях сортировки связанных списков и поэтому использующих N дополнительных указателей, находящихся в памяти;
- и методы, нуждающиеся в дополняемой памяти для сохранения дубликата отсортированного файла.
Стабильность – также важная свойство методов сортировки. Метод сортировки является стабильным в случае, когда он сохраняет относительный порядок расположения записей с одинаковыми ключами. К примеру, когда алфавитный список учащихся ранжируется по оценкам, тогда стабильный метод организует список, где фамилии учащихся с одинаковыми баллами будут отсортированы по алфавиту, а нестабильный метод организует список, где, возможно, начальный порядок будет нарушен. Большая часть простых методов стабильны, тогда как большая часть всем известных сложных методов – нет. В случае, когда стабильность необходима, тогда можно её добиться путем добавления к ключу маленького индекса перед процессом сортировки или посредством удлинения, каким-то путем, ключа. Стабильность легко принимают за норму; к нестабильности у людей отношение с недоверием. Фактически, только некоторые методы добиваются стабильности без применения дополнительного времени или места.
Для выявления эффективности алгоритма необходимо оценить числа С – нужных сравнений ключей и М – присваиваний элементов. Указанные числа рассчитываются определенными формулами от числа n сортируемых элементов. Удовлетворительные алгоритмы сортировки используют примерно сравнений.
Условимся по терминологии: мы имеем элементы – a1, a2, …, an. Процедура сортировки предполагает такую перестановку данных элементов в следующем порядке: ak1, ak2, …, akn, что при данной функции упорядочения f верно отношение f(ak1)<=f(ak2)<=…<=f(akn).
Чаще всего функция упорядочения не определяется по определенному правилу, а входит в каждый элемент в виде явной компоненты (поля). Значение этой компоненты является ключом элемента. Для выражения элемента ai используется следующее выражение:
type item = record
key: integer;
{описание прочих элементов}
end;
Прочие элементы – совокупность всех существенных данных об элементе, поле key предназначено только для идентификации элементов. Тем не менее, рассматривая алгоритмы сортировки, имеем ключ – единственная важная компонента, и все остальные не требуют выделения.
Сортировка устойчивая, в случае, когда записи с одинаковыми ключами сохраняются в исходном порядке.
1.2 Программный и аппаратный алгоритм сортировки данных
Алгоритмы сортировки - одна из наиболее исследованных областей информатики, в которой, однако, не исключены открытия, так как, несомненно, существуют еще неизвестные методы, основанные на новых принципах и идеях. Можно с уверенностью утверждать, что любой инженер, специализирующийся в области информационных технологий, сталкивался с подобными задачами, пытаясь реализовать известные методы или разработать свои.
Определяя формально термин «сортировка», можно сказать, что это процесс упорядочения множества элементов, на котором заданы отношения порядка, или отношения частичного порядка. Или, проще говоря, упорядочение множества элементов по возрастанию или убыванию. В большинстве задач сортировка сводится к упорядочению массива двоичных кодов, которые для наглядности могут быть представлены числами.
Алгоритмы сортировки имеют и большое практическое применение. Их можно встретить почти везде, где речь идет об обработке и хранении больших объемов информации. Многие задачи обработки данных решаются намного проще, если данные упорядочены.
В данной работе приводится обзор наиболее популярных программных и аппаратных методов сортировки. Здесь и далее предполагается, что числа или символы в виде двоичных кодов находятся в оперативной памяти ЭВМ или элементах памяти устройства сортировки.
Наиболее популярным методом программной сортировки является сортировка простым обменом (пузырьковая сортировка), что объясняется простотой алгоритма для понимания и реализации. Свое название этот способ упорядочивания данных получил благодаря схожести с процессом движения пузырьков воздуха в воде. Алгоритм состоит в повторяющихся проходах по сортируемому массиву, каждый из которых включает в себя попарное сравнение и обмен элементов в случае обнаружения инверсии. Отсортированный массив выступает признаком успешного завершения работы алгоритма, проходящего по нему от начала до конца. По итогам каждого прохода, как минимум, один элемент массива устанавливается на верную позицию, что обусловливает равенство между количеством элементов и числом необходимых цикличных проходов.
Другим простым способом сортировки считается сортировка выбором2. В соответствии с этим методом в сортируемом массиве поэтапно осуществляется выбор минимального (максимального) элемента и вставка его в начало (конец) последовательности. Реализация алгоритма требует выполнения двух циклов обработки данных. Внешний цикл выполняет проход по элементам, назначая минимум (максимум) и устанавливая на верную позицию найденный внутренним циклом, по поиску минимума (максимума) элемент. В завершение работы алгоритма происходит обмен двух последних элементов.
Не менее известным представителем класса простых сортировок является сортировка включением. Её алгоритм не только прост в реализации, но и эффективен на небольших, частично отсортированных наборах данных. Согласно данному методу первоначально упорядочиваются два первых элемента последовательности. Далее на каждом шаге необходимо осуществлять выбор элемента и его вставку на нужную позицию в отсортированной части массива, без нарушения отношения порядка. Ощутимое преимущество сортировки включением состоит в том, что элементы с одинаковыми ключами не переставляются: если список элементов сортируется с использованием двух ключей, то после завершения сортировки вставкой он по-прежнему будет упорядочен по двум ключам.
Алгоритм сортировки, подразумевающий сравнение элементов, расположенных на различных расстояниях друг от друга, называют сортировкой Шелла. В основу метода положена сортировка включениями. По мере реализации алгоритма первоначально осуществляется сравнение и сортировка между собой ключей, отстоящих друг от друга на некотором расстоянии R, после чего процедура повторяется для некоторых меньших значений R. В заключение проводится упорядочивание элементов при R = 1, что полностью эквивалентно обычной сортировке вставками. Выбор значений расстояния R между сравниваемыми элементами может осуществляться по-разному. Для корректной работы метода необходимым условием является лишь то, что последний шаг должен равняться единице. Программирование алгоритма выполняется с использованием двух циклов. Внешний цикл проходит по всем заданным элементам, а внутренний включает два условия проверки: для упорядочения элементов и для предотвращения выхода за пределы массива. Если при каждом проходе используется небольшое число элементов или они находятся в относительном порядке, данный способ сортировки будет сравнительно эффективен.
Наиболее эффективным из алгоритмов обменной сортировки массивов является быстрая сортировка, в основу которой положен принцип разбиения. Это распространенный способ сортировки общего назначения, который хорошо работает во многих ситуациях и использует при этом меньше ресурсов, чем другие алгоритмы. Суть метода заключается в выборе для сравнения одного элементах и разбиении массива входных данных на две части. Одну часть составляют все элементы, равные или большие X, а в другую часть входят все элементы меньшего значения. Этот процесс необходимо рекурсивно продолжать для оставшихся частей до тех пор, пока весь массив не будет отсортирован. Существуют различные способы выбора значения разбиения X. случайный выбор, выбор среднего значения, выбор медианы и т.д. В целях достижения наименьших временных затрат требуется выбрать значение, которое будет находиться на центральной позиции в массиве.
Довольно часто возникают и задачи аппаратной сортировки. Так, например, в системах радиолокации и робототехнике при поиске двух ближайших точек на плоскости требуется сортировка координат объектов. Используется сортировка и в целом ряде других приложений. Аппаратные решения, реализующие алгоритмы сортировки, зачастую близки к программным методам, хотя и имеют гораздо большее быстродействие, нежели программные, но все же достаточно специфичны и редко описываются в литературе.
Наиболее очевидными схемотехническими решениями3 можно считать устройства, принцип работы которых описан ниже.
На рис. 1 представлено устройство для выбора максимального числа. Оно включает в себя три компаратора, логический блок и мультиплексор. Устройство позволяет выбирать максимальное из трех чисел a, b и с, т.е. упорядочивает множество \а.Ь,с\, реализуя функцию /: maх{а,Ь,с}.
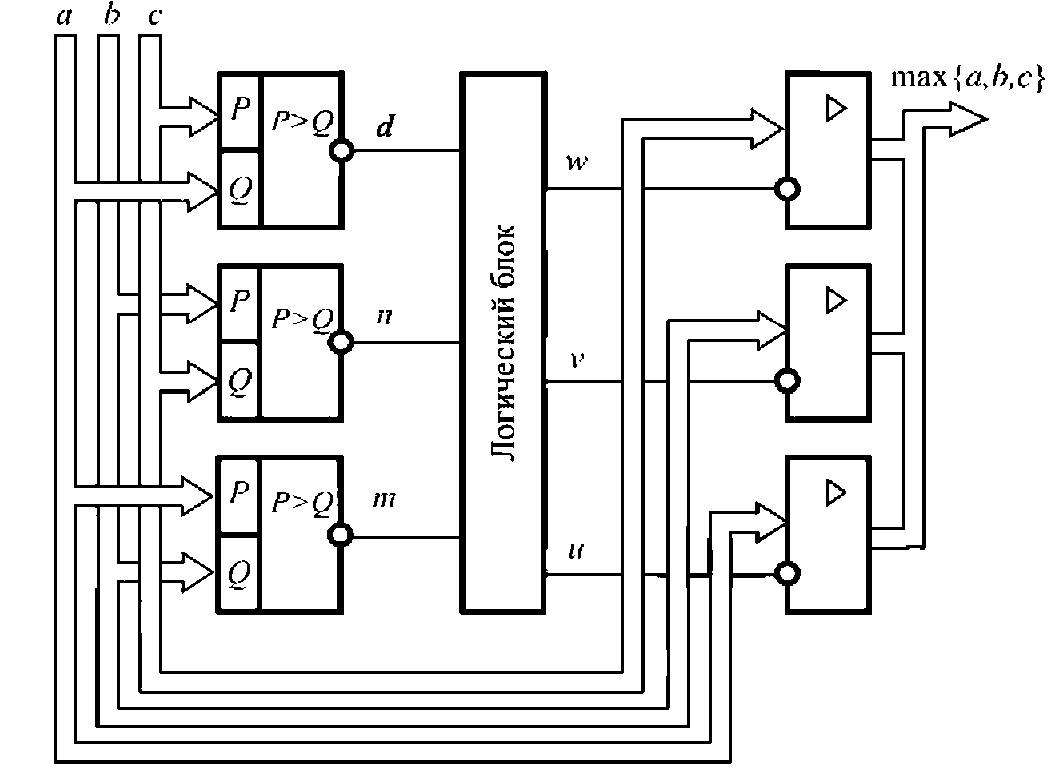
Рис. 1. Устройство для выбора максимального из трех чисел
В зависимости от соотношения чисел a, b и с на входы логического блока поступают сигналы d, т, п, которые формируются в соответствии с таблицей (см. табл. 1.1).
Таблица 1.1 - Сигналы во внутренних точках устройства
|
Соотношение |
Логические уровни |
/ |
|||||
|
чисел а, Ь, с |
п |
т |
d |
и |
V |
w |
|
|
а>Ь>с |
0 |
0 |
1 |
0 |
1 |
1 |
|
|
а>с>Ь |
|||||||
|
а>с=Ъ |
1 |
0 |
1 |
0 |
1 |
1 |
f=a |
|
а=с>Ъ |
|||||||
|
а=Ь=с |
1 |
1 |
1 |
0 |
1 |
1 |
|
|
Ь>с>а |
0 |
1 |
0 |
1 |
0 |
1 |
|
|
Ь>а=с Ь>а>с |
0 |
1 |
1 |
1 |
0 |
1 |
f=b |
|
Ъ=а>с |
|||||||
|
с>а>Ъ |
1 |
0 |
0 |
1 |
1 |
0 |
|
|
с>Ь>а с>Ъ=а |
1 |
1 |
0 |
1 |
1 |
0 |
f=c |
|
с=Ь>а |
|||||||
Сигналы и, v, w, формируемые логическим блоком, открывают соответствующие группы ключей с третьим состоянием, в результате на выходы устройства передается максимальное число.
Аналогично строится схема быстрой сортировки чисел. В ней вместо компараторов используются арифметико-логические устройства (ALU), выводы «Перенос» (С) которых соединены с адресными входами (AI) постоянного запоминающего устройства (ROM), которое выполняет функции логического блока. Выводы данных (DO) ПЗУ соединены с адресными входами (AI) четырех мультиплексоров (MUX). Несомненным достоинством этой схемы является возможность параллельной сортировки чисел, так как на выходах мультиплексоров они появятся одновременно, упорядоченные по убыванию или возрастанию. К недостаткам схемы можно отнести большие аппаратные затраты.
Так, например, количество элементов сравнения (АЛУ) определяется как количество сочетаний из п чисел по два:
Поэтому при возрастании количества сортируемых чисел резко возрастает количество компараторов (или АЛУ) и разрядность ПЗУ.
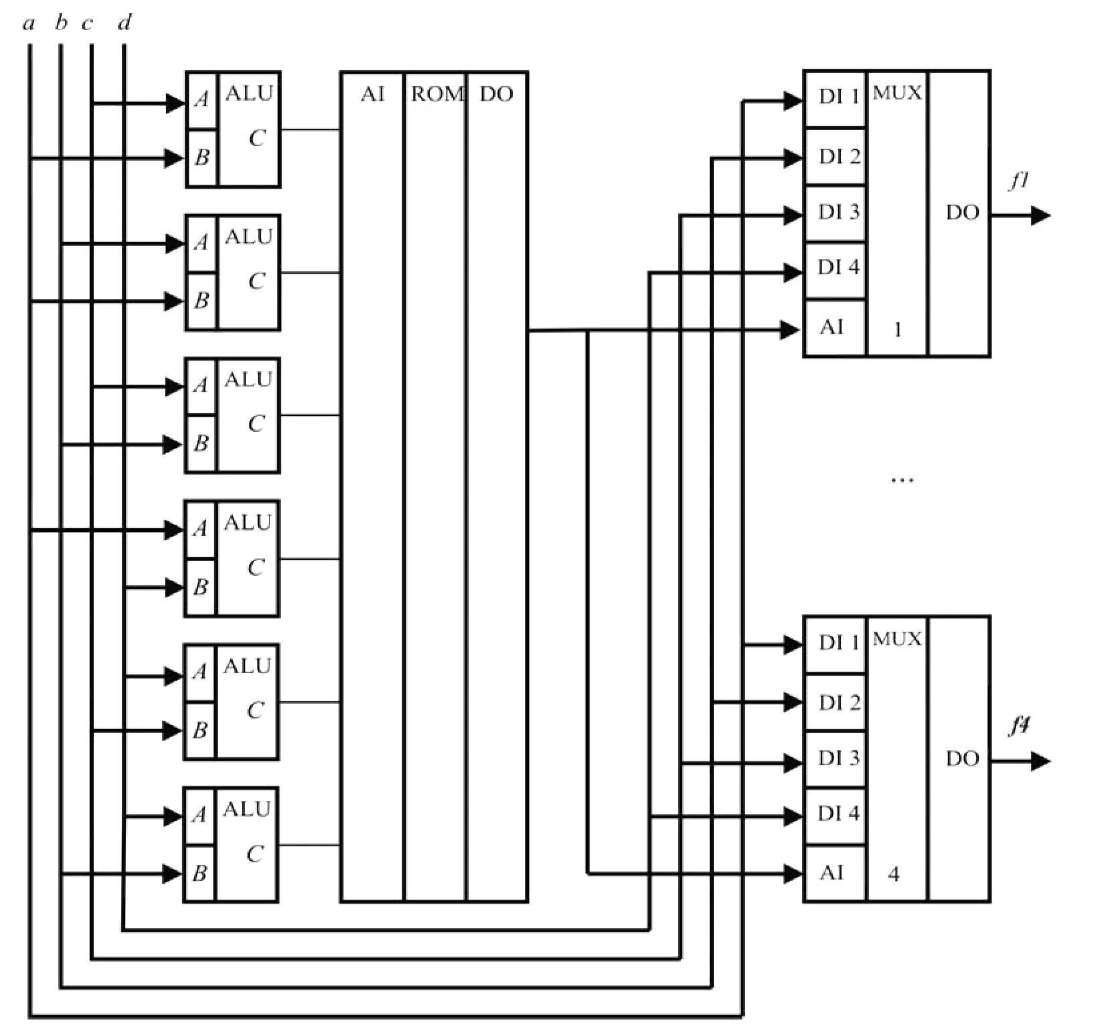
Рис. 1.2. Устройство для быстрой сортировки чисел
Число компараторов в схеме, представленной на рис. 2, можно сократить, если перестроить схему в виде пирамиды (см. рис. 3). Однако параллельность процессов сравнения чисел сохранится лишь частично. В случае использования этой схемы сортировки будет необходимо реализовывать п тактов работы схемы, где п - количество чисел для сортировки.
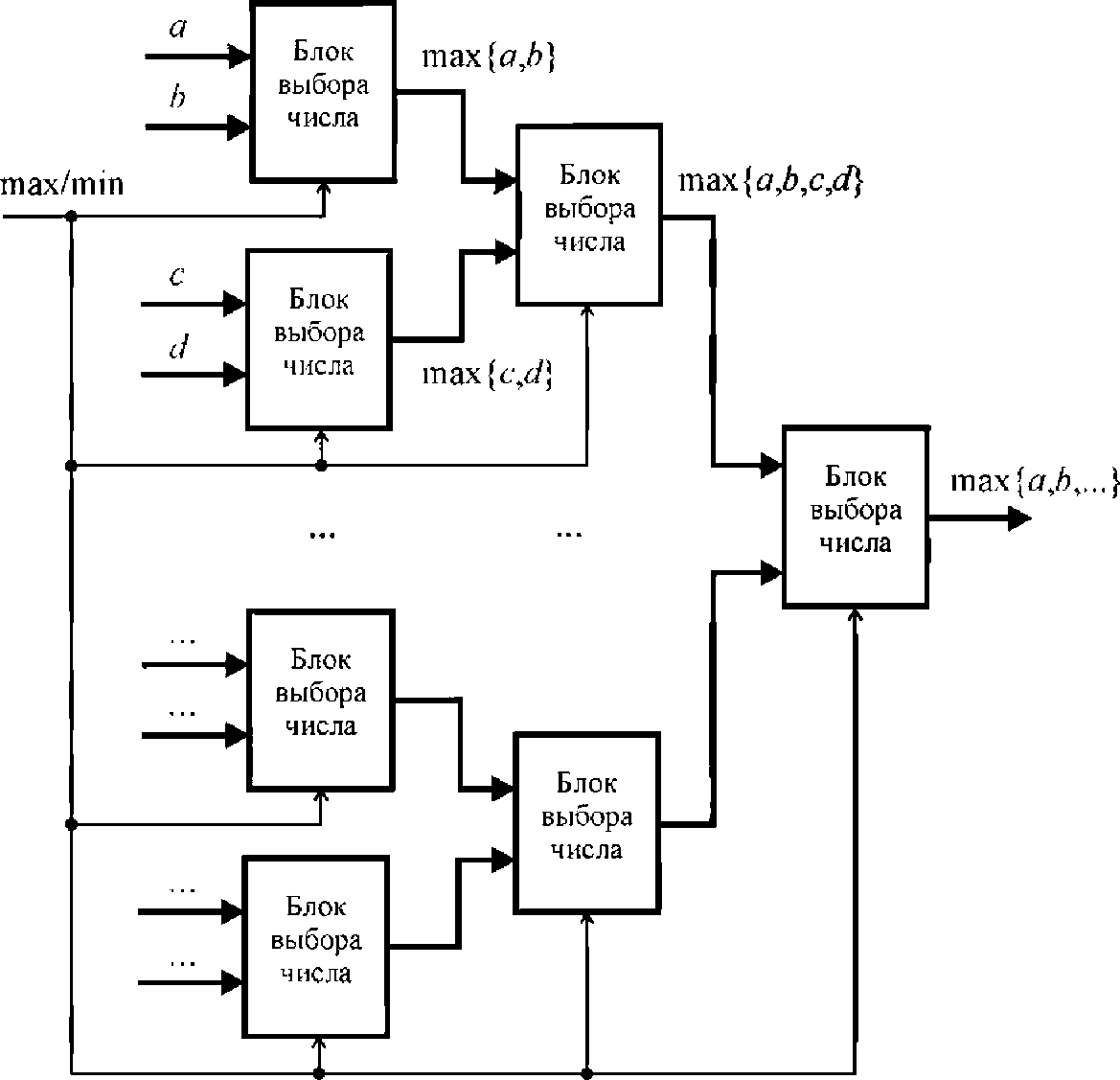
Рис. 1.3. Схема пирамидальной сортировки чисел
Схема пирамидальной сортировки (рис. 1.3) состоит из блоков выбора наибольшего/наименьшего числа (рис. 1.4).
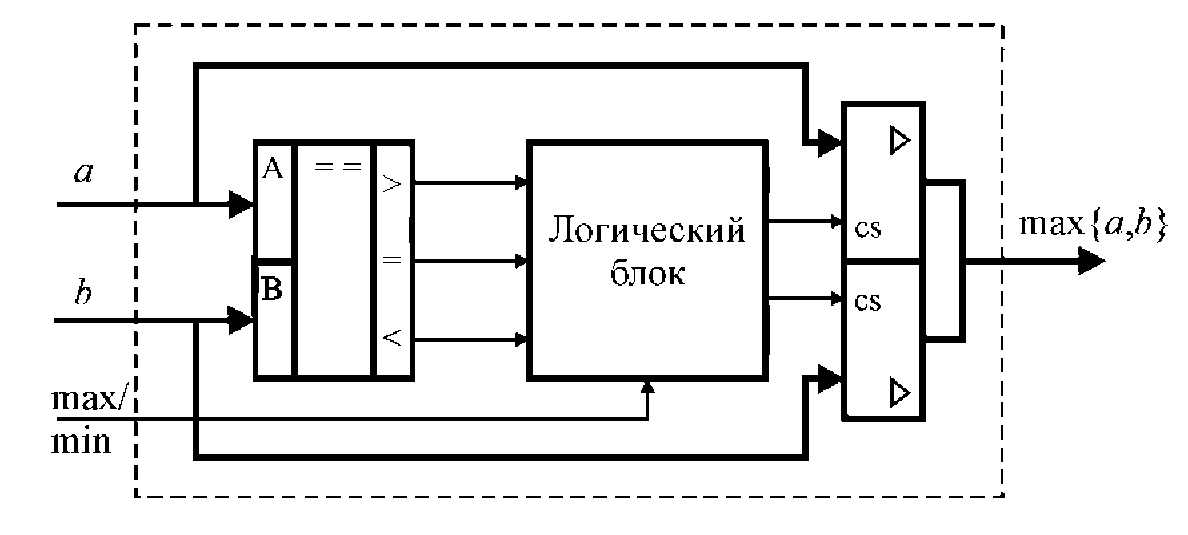
Рис. 1.4. Блок выбора наибольшего/наименьшего числа из двух
Каждый блок выбора (рис. 1.4) в зависимости от режима сортировки выбирает одно из двух чисел - наибольшее или наименьшее. Он состоит из схемы сравнения, логического блока и буферов с третьим состоянием, включение/отключение которых производится сигналом (CS). Режим сортировки определяется сигналом (max/min).
Другими, возможно, неочевидными способами сортировки чисел, являются схемы, представленные на рис. 1.5. Рассмотрим устройство4, изображенное на рис. 1.5а.
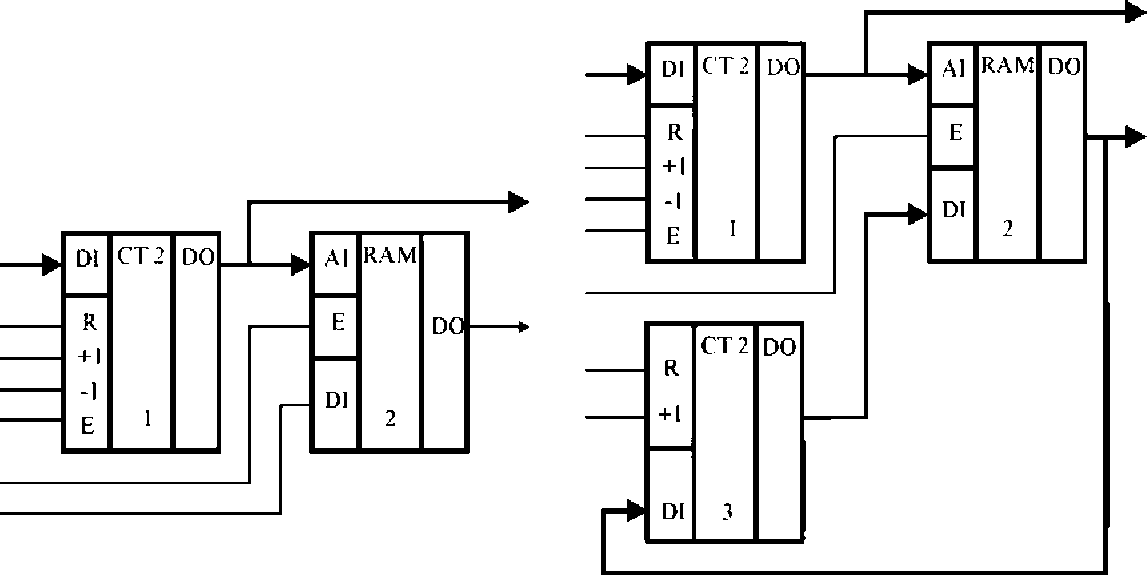
а б
Рис. 1.5. Устройства для сортировки чисел
Оно состоит из оперативного запоминающего устройства (RAM) и двоичного счетчика с возможностью параллельной загрузки (СТ2). Основная идея состоит в том, что каждое число для сортировки представляется единицей, записанной по адресу, равному этому числу. Очевидно, что емкость ОЗУ в этом случае должна быть равна 2" бит, где п - разрядность чисел.
Устройство имеет следующий алгоритм работы. Первым циклом работы является обнуление ОЗУ. Для этого счетчик переводится в режим счета, на вход данных (DI) ОЗУ подается уровень логического нуля и сигнал разрешения записи (Е). На инкрементирующий вход счетчика (+1) подается импульсный сигнал, в результате чего счетчик последовательно перебирает все адресное пространство ОЗУ, заполняя его нулями.
Далее производится загрузка ОЗУ числами для сортировки. Для этого счетчик переводится в режим параллельной загрузки данных и фактически представляет собой параллельный регистр. Каждое число, предназначенное для сортировки, подается на вход данных (DI) счетчика и через него на адресные входы (AI) ОЗУ. На вход данных (DI) ОЗУ подается уровень логической единицы, а на вход разрешения записи (Е) - сигнал, разрешающий загрузку данных в ОЗУ. После того как будут загружены все числа, выполняется режим сортировки. Он может выполняться по возрастанию или по убыванию. В случае сортировки по возрастанию импульсный сигнал подается на инкрементирующий вход (+1) счетчика, если выбран режим по убыванию - на декрементирующий (-1) вход. В этом режиме ОЗУ переводится в режим чтения, а счетчик последовательно пробегает все адресное пространство ОЗУ. В случае, если на выходе данных (DO) ОЗУ обнаруживается единица, это означает, что на выходах счетчика (DO) и выходной шине присутствует очередное отсортированное число.
Достоинствами данной схемы являются независимость времени работы от количества чисел для сортировки, небольшие аппаратные затраты при малой разрядности чисел, возможность сортировать числа в заданном диапазоне. К недостаткам следует отнести не очень высокое быстродействие, а также его резкое снижение и рост аппаратных затрат при наращивании разрядности чисел для сортировки. Другой недостаток заключается в том, что устройство принимает два и более одинаковых числа за одно. Однако он может быть преодолен, если заменить ОЗУ на «-разрядное и включить в схему еще один счетчик (см. рис. 56).
Теперь при загрузке чисел в ОЗУ устройство вначале считывает из него данные, затем добавляет к ним единицу и вновь записывает их в ОЗУ. Эти данные соответствуют количеству одинаковых чисел, предназначенных для сортировки.
В данной работе изложены лишь некоторые, наиболее популярные решения программной и аппаратной сортировки чисел, которые показывают направления решения этой, можно сказать, классической задачи.
ГЛАВА 2 ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ СОРТИРОВКИ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ MPI
2.1 Описание алгоритма
Объектом исследования данной работы являются традиционные алгоритмы сортировки числовых массивов. Сортировка данных практически важная и теоретически интересная задача, т.к. сортировка больших объемов данных - неотъемлимая процедура при обработке информации в базах данных, прикладных задачах вычислительной математики и пр. Что же касается разработки алгоритмов, то здесь процесс сортировки также очень важен, т.к. сортировка является существенной частью многих алгоритмов. В связи с бурным ростом объемов обрабатываемой информации и появлением новых параллельных архитектур компьютеров и сред программирования возникает потребность в разработке алгоритмов сортировки данных, адаптированных под эти архитектуры и среды программирования.
Рассмотрим наиболее известные алгоритмы сортировки с целью их дальнейшей оптимизации для использования на параллельных ЭВМ.
Сортировка пузырьком (bubblesort) или сортировка простыми обменами - простой алгоритм сортировки, состоящий из повторяющихся проходов по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется перестановка элементов. Проходы по массиву повторяются N — 1 раз (N - длина массива) или до тех пор, пока на очередном проходе не окажется, что элементы массива уже отсортированы. Сложность алгоритма сортировки - 0(N2).
Данный алгоритм является учебным и практически не применяется вне учебной литературы. Вместо него применяются более эффективные алгоритмы сортировки. В то же время метод сортировки обменами лежит в основе некоторых более совершенных алгоритмов, таких как шейкерная сортировка, пирамидальная сортировка и быстрая сортировка
Сортировка Шелла (Shellsort) - алгоритм сортировки являющийся усовершенствованным вариантом алгоритма сортировки вставками. Идея метода состоит в сравнении элементов, стоящих не только рядом, но и на некотором расстоянии друг от друга. Иными словами - это сортировка вставками с предварительными „грубыми" проходами.
При сортировке Шелла сначала сравниваются и сортируются элементы, отстоящие друг от друга на некотором расстоянии d друг от друга. После этого процедура повторяется для некоторых меньших значений d. Заканчивается процедура при d — 1 (т.е. обычной процедуров вставками). Эффективность сортировки Шелла в определенных случаях обеспечивается тем, что элементы ,,быстрее встают на свои места.
Среднее время работы алгоритма зависит от длины промежутков d. Существует несколько подходов для выбора d. Первоначальная последовательность Шелла — di — N/2, (/_» — rfi/2,..., d^ — 1 дает сложность алгоритма в худшем случае 0(JV2). Последовательности Хиббар- да (^тр- < -j.' fc N), Фибоначчи, а также значения — дают сложность алгоритма Шелла 0(N2).
2.2 Эффективность алгоритма
Сортировка вставками - простой алгоритм сортировки. Несмотря на то, что данный алгоритм уступает в эффективности более сложным алгоритмам, у него имеется ряд преимуществ:
- эффективен на небольших наборах данных. На наборах ДЕННЫХ ДО нескольких десятков может оказаться лучшим;
- эффективен на наборах данных, которые уже частично уже отсортированы;
- это устойчивый алгоритм сортировки, т.е. не изменяет порядок элементов, которые уже отсортированы;
- может сортировать список по мере его получения.
Суть алгоритма вставками заключается в следующем. На каждом шаге алгоритма выбирается один из элементов входных данных и вставляется на нужную позицию в уже отсортированном списке, до тех пор, пока набор входных данных не будет исчерпан. Метод выбора очередного элемента из исходного массива произволен. Обычно., и с целью получения устойчивого алгоритма сортировки, элементы вставляются по порядку их появления во входном массиве. Временная сложность алгоритма сортировки вставками при худшем варианте входных данных 0(iV2).
2 г Рассмотрим тгепеj).ь основныо элементы тсхнолС)гз^ж MPI, MPI (Message Passing Interface, интерфейс передачи сообщений) - программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну за- Дачу.
Наиболее распространенной технологией программирования параллельных компьютеров с распределенной памятью в настоящее время является MPI, Основным способом взаимодействия параллельных процессов в таких системах является передача сообщений друг другу. Это и отражено в названии данной технологии ~ Message Passing Interface. Интерфейс поддерживает создание параллельных программ в стиле MIMD, что подразумевает объединение процессов с различными исходными текстами. Однако на практике программисты гораздо чаще используют SPMD-модель, в рамках которой для всех параллельных процессов используется один и тот же код.
Все дополнительные объекты : имена функций, константы, предопределенные типы данных и т.п., используемые в MPI, имеют префикс MPI, Описания интерфейса MPI собраны в файле mpi.h, поэтому в начале MPI-ирограммы должна стоять директива include <mpi.h>.
Все функции передачи сообщений в MPI делятся на две группы. В одну группу входят функции, которые предназначены для взаимодействия двух процессов программы. Такие операции называются индивидуальными или операциями типа точка-точка. Функции другой группы предполагают, что в операцию должны быть вовлечены все процессы некоторого коммуникатора. Такие операции называются коллективными.
MPI-программа - это множество параллельных взаимодействующих процессов. Все процессы порождаются один раз, образуя параллельную часть программы. В ходе выполнения MPI-ирограммы порождение дополнительных процессов или уничтожение существующих не допускается. Каждый процесс работает в своем адресном пространстве, никаких общих переменных или данных в ]V1PI нет. Основным способом взаимодействия между процессами является явная посылка сообщений.
Для локализации взаимодействия параллельных процессов программы можно создавать группы процессов, предоставляя им отдельную среду для общения - коммуникатор. Состав образуемых групп произволен. Группы могут полностью входить одна в другую, не пересекаться или пересекаться частично. При старте программы всегда считается, что все порожденные процессы работают в рамках всеобъемлющего коммуникатора. Этот коммуникатор существует всегда и служит для взаимодействия всех процессов МР1-программы.
Каждый процесс MPI-программы имеет уникальный атрибут номер процесса, который является целым неотрицательным числом. С помощью этого атрибута происходит значительная часть взаимодействия процессов между собой. Ясно, что в одном и том же коммуникаторе все процессы имеют различные номера. Но поскольку процесс может одновременно входить в разные коммуникаторы, то его номер в одном коммуникаторе может отличаться от его номера в другом. Отсюда становятся понятными два основных атрибута процесса: коммуникатор и номер в коммуникаторе. Если группа содержит п. процессов, то номер любого процесса в данной группе лежит в пределах от 0 до п — 1.
Основным способом общения процессов между собой является посылка сообщений. Сообщение - это набор данных некоторого типа. Каждое сообщение имеет не-сколько атрибутов, в частности, номер процесса-отправителя, номер процесса-получателя, идентификатор сообщения и другие. Одним из важных атрибутов сообщения является его идентификатор или тэг. По идентификатору процесс, принимающий сообщение, например, может различить два сообщения, пришедшие к нему от одного и того же процесса. Сам идентификатор сообщения является целым неотрицательным числом, лежащим в диапазоне от 0 до 32767 [3].
2.3 Программная реализация алгоритма
Рассмотрим теперь программные реализации алгоритмов сортировки для их дальнейшего анализа на возможность распараллеливания [1, 4].
Код процедуры, реализующей сортировку пузырьками представлен ниже.
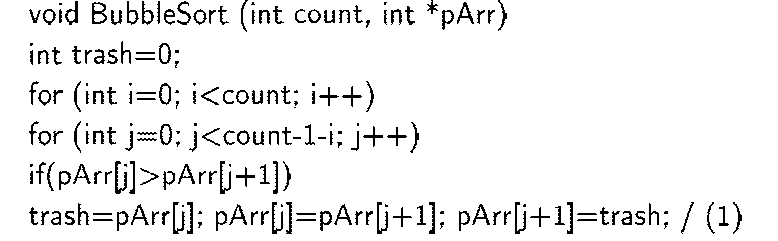
Сортировка вставками реализована в следующем фрагменте программы. 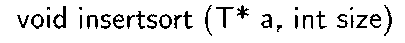
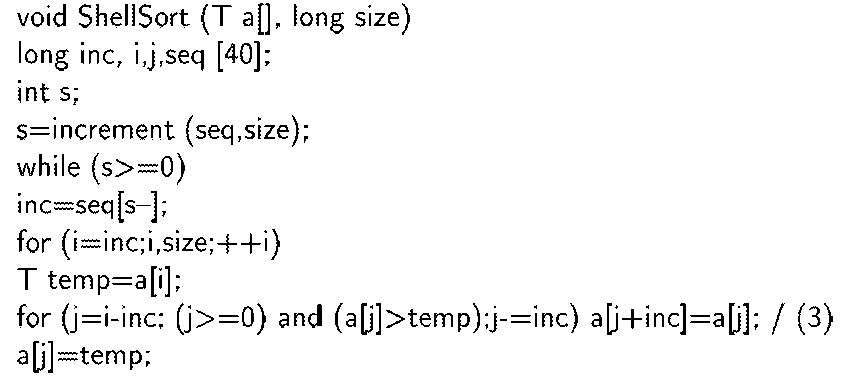
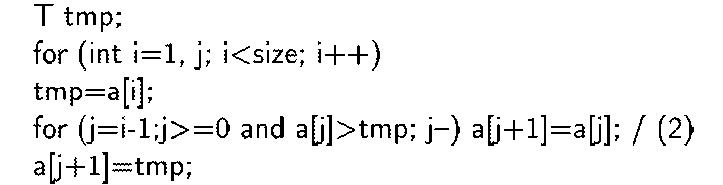
В следующем фрагменте представлена реализация сортировки Шелла,
Как видно из представленных фрагменотов программ итерации основных циклов сортировки данных являются информационно зависимыми (см. комментарии (1), (2), (3)) [2]. Таким образом, непосредственно распараллелитть итерации циклов по процессорам не представляется возможным.
Для реализации идеи параллельной сортировки предлагается модификация алгоритмов по методу крупноблочного распараллеливания, параллельный алгоритм сортировки состоит в выполнении следующих этапов:
- исходный массив длины п распределяется по р процессорам вычислительной системы по блокам размера п/р;
- каждый из процессов упорядочивает свой блок по одному из рассматриваемых алгоритмов сортировки;
- отсортированные блоки передаются в ведущий процесс, где происходит формирование выходного отсортированного массива.
Для численного моделирования был написан комплекс программ, реализующий алгоритмы сортировки по методу крупноблочного распараллеливания [2]. Результаты эксперимента приведены в таблицах.
Таблица 2.1 - Последовательная сортировка
|
N |
1000 |
2500 |
7000 |
10000 |
|
bubblesort |
1,12 |
3.22 |
8.34 |
12.97 |
|
insertsort |
1.01 |
2.53 |
6.23 |
10.21 |
|
Shellsort |
0.93 |
2.10 |
5.57 |
9.12 |
Таблица 2.2 - Параллельная сортировка
|
N |
1000 |
2500 |
7000 |
10000 |
|
bubblesort |
0.72 |
3.01 |
6.57 |
9.64 |
|
insertsort |
0.62 |
2.01 |
4.34 |
8.21 |
|
Shellsort |
0.61 |
1.98 |
3.94 |
7.94 |
Вычисления из табл- 1 и табл- 2 проводились на параллельной ЭВМ для случая р = 1 и р = 3 процессоров соответствено. Как видно из представ- Л6ННЫХ таблиц ускорение работы параллельной программы в зависимости от метода сортировки в среднем составила более 20 процентов , что свидетельствует о высокой степени параллелизма разработанных алгоритмов.
ЗАКЛЮЧЕНИЕ
Первая глава курсовой работы была посвящена, в основном, алгоритмам сортировки. Было показано, важность, актуальность и просто необходимость алгоритмов сортировки. Исследованы различные методы сортировки, основные характеристики алгоритмов сортировки. Так как рамки курсовой работы не позволяют подробно исследовать весь спектр различных видов алгоритмов поиска и сортировки, в курсовой работе были рассмотрены:
- сортировка вставкой;
- сортировка простым выбором;
- сортировка простым обменом;
- сортировка Шелла.
Из различных методов поиска были изучены и приведены следующие алгоритмы:
-
- последовательный поиск;
- бинарный поиск;
- поиск подстроки методом грубой силы.
В результате исследования каждого алгоритма были показаны:
- основная идея алгоритм;
- суть алгоритма;
- приведен псевдокод алгоритма;
- приведен пример функционирования алгоритма.
Исследование, проведенное в данной курсовой работе, показало, что использование разных алгоритмов поиска и сортировки позволяет значительно сокращать время, которое необходимо затрачивать на трудоемкие операции поиска данных и сортировки необходимой информации, что в конечном итоге дает повышение производительности труда.
СПИСОК ЛИТЕРАТУРЫ
- Артемов А.В. Информационная безопасность. Курс лекций. - Орел: МАБИВ, 2014.
- Бармен Скотт. Разработка правил информационной безопасности. - М.: Вильямс, 2012. - С. 208.
- Гмурман А.И. Информационная безопасность. М.: "БИТ-М", 2014 г.
- Журнал «Секретарское дело» №1 2010 год
- Информационная безопасность и защита информации Мельников В. П. и др. / Под ред. Клейменова С. А.- М.: ИЦ «Академия», 2012.336 с.
- Петров В. А., Пискарев А.С., Шеин А.В. Информационная безопасность. Защита информации от несанкционированного доступа в автоматизированных системах. Учебное пособие. - М.: МИФИ, 2015.
- Современная компьютерная безопасность. Теоретические основы. Практические аспекты. Щербаков А. Ю. - М.: Книжный мир, 2009.- 352 с.
- Соляной В.Н., Сухотерин А.И. Взаимодействие человека, техники и природы: проблема информационной безопасности. Научный журнал (КИУЭС) Вопросы региональной экономики. УДК 007.51 №5 (05) Королев. ФТА. - 2010.
- Справочно-правовая система «Консультант Плюс».
- Стандарты информационной безопасности Галатенко В. А.- М.: Интернет-университет информационных технологий, 2012. - 264 с.
- Хачатурова С.С. Информационные технологии в юриспруденции: учебное пособие. // Фундаментальные исследования. - 2015. - № 9. - С. 8-9.
- Хачатурова С.С. Организация предпринимательской деятельности. Создание собственного дела // Международный журнал экспериментального образования. - 2012. - № 2. - С. 137-138.
- Шаньгин В.Ф. Защита компьютерной информации. Эффективные методы и средства. - М.: ДМК Пресс, 2008. - С. 544.
- Шутова Т.В., Старцева Т.Е. Высокотехнологичный комплекс России - платформа для инновационного прорыва. Научный журнал (КИУЭС) Вопросы региональной экономики. УДК 007.51 №2 (11) г. Королев. ФТА. 2012г.
- http://www. safensoft.ru/security.phtml?c=791.
- http://www.abc-people.com/typework/economy/e- confl-8.htm.
- http://www.epam-group.ru/aboutus/news-and-events/ articles/2009/aboutus-ar-gaz-prom-09-01-2009.html.
- http://www.nestor.minsk.by/sr/2007/07/sr70713.html.
- Kaspersky.ru. Режим доступа: http://www.kaspersky.ru/ about/news/business/2012/Zaschita_dlya_Titana_Laboratoriya_ Kasperskogo_obespechivaet_bezopasnost_Korporaciya_ VSMPO-AVISMA.

- Программные модули. Выбор и характеристика
- Система защиты коммерческой тайны малого коммерческого предприятия (Сущность и значение коммерческой тайны)
- Основные этапы формирования налогового учета в России
- Осуществление предпринимательской деятельности с участием иностранных инвестиций(Правовые основы деятельности предприятий с иностранными инвестициями в Российской Федерации)
- Юридическое лицо: общая характеристика и квалификация
- Функции менеджмента(ТЕОРИТЕЧЕСКИЕ ОСНОВЫ МЕНЕДЖМЕНТА)
- Принятие управленческого решения как организационный процесс(Понятие и особенности управленческих решений)
- Технология обслуживания гостей в гостинице с отечественным менеджментом
- технология работы банкетной службы.
- Лицензирование отдельных видов предпринимательской деятельности(Общие положения об институте лицензирования отдельных видов предпринимательской деятельности)
- Нотариат в Российской Федерации (Понятие и основные вехи)
- Проектирование реализации операций бизнес-процесса «Ежедневный складской учет»