
Алгоритмы сортировки данных
Содержание:

ВВЕДЕНИЕ
Актуальность темы заключается в том, что сортировка данных на сегодняшний день при современном развитии компьютерных технологий является одним из наиболее распространенных процессов современной обработки данных. Задачи на сортировку данных встречаются очень часто в различных профессиональных сферах деятельности.
Алгоритмы сортировки очень широко распространяются практически во всех задачах обработки информации. При этом они настолько тесно связаны друг с другом, что образуют отдельный класс алгоритмов. Алгоритмы сортировки, как правило, применяются с целью осуществления последующего более быстрого поиска. Например, трудно пользоваться словарями, если бы слова в них не были бы упорядочены по алфавиту.
Важность сортировки основана на том факте, что на ее примере можно показать многие основные фундаментальные приемы и методы построения алгоритмов. Сортировка является хорошим примером огромного разнообразия алгоритмов, которые выполняют одну и ту же задачу. Кроме того, многие из них имеют определенные преимущества друг перед другом. За счет усложнения алгоритма можно добиться существенного увеличения эффективности и быстродействия алгоритма по сравнению с более простыми методами. Как правило, термин сортировка понимают, как процесс перестановки объектов некоторого множества в определенном порядке. Цель сортировки - облегчить последующий поиск элементов в отсортированном множестве.
Алгоритмы информационного поиска и сортировки очень тесно связаны друг с другом. Они образовали фактически отдельный класс алгоритмов. Этот класс интересен и с точки зрения обучения, и с точки зрения использования при решении многих задач. Специфической особенностью данного класса является то, что внешне тривиальные задачи: «найти элемент» или «упорядочить последовательность элементов» допускают разнообразные решения.
Цель курсовой работы заключается в изучении методов сортировки данных и применяемых алгоритмов поиска.
Объектом исследования является алгоритмизация.
Предметом исследования являются методы сортировки данных.
Для достижения поставленной цели нужно решить следующие задачи:
- изучить различные источники по выбранной теме;
- исследовать различные методы и алгоритмы сортировки данных;
- рассмотреть использование различных методов сортировки при поиске данных.
- расширить, систематизировать и закрепление теоретические знания;
- рассмотреть примеры использования методов сортировки данных.
- Провести сравнение различных методов сортировки.
Практическая значимость работы может быть определена как приобретение навыков ведения самостоятельных теоретических и практических исследований в соответствии с направлением обучения в области поиска и сортировки данных, а также в формировании навыков правильного оформления научно-исследовательской работы.
Теоретическое значение курсовой работы заключается в приобретении опыта обработки, анализа и систематизации результатов практических (экспериментальных) исследований.
Курсовая работа состоит из введения, четырех разделов, списка используемой литературы. Работа содержит 3 рисунка и 5 таблиц.
1. Алгоритмизация и её основы
1.1. История и развитие методов сортировки данных
Перед тем как приступить к рассмотрению методов сортировки, их эволюции и истории дадим определение понятию «алгоритм сортировки». Более подробно данное понятие будет рассмотрено в следующем параграфе курсового исследования.
«Алгоритм сортировки» — это алгоритм для упорядочивания элементов в списке. В случае, когда элемент списка имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Алгоритмы сортировки данных оцениваются по скорости выполнения и эффективности использования памяти, где важнейшими параметрами выступают время и память. Время является основным параметром, дающим характеристику быстродействия алгоритма. Также еще называется «вычислительной сложностью».
Итак, первый этап развития методов сортировки данных начался в 1870 году и длился до начала 1940-х годов. Его ознаменовал переход от ручной сортировки к сортировке с помощью статистических табуляторов. При этом использовался алгоритм поразрядной сортировки.
Второй этап — с начала 1940-х годов до середины 1950-х. На смену счетно-перфорационным машинам пришли ЭВМ первого поколения, для которых был разработан ряд новых алгоритмов сортировки. Произошло их разделение на внутренние и внешние.
Третий этап начался в середине 1950-х годов и продолжался до середины 1970-х. Для него было характерно активное развитие алгоритмов сортировки — внешней и внутренней, устойчивой и неустойчивой — многие, из которых широко используются и в настоящее время. Наибольшее количество разработанных к тому времени методов относилось к сортировке путем вставок, обменной сортировке и сортировке посредством выбора.
Четвертый этап продолжался с середины 1970-х до середины 1990-х годов. Появление вычислительных центров, объединяющих мощности отдельных вычислительных машин и позволяющих работать с разделением времени потребовало разработки новых алгоритмов сортировки и модификации существующих. Началось исследование задач сортировки в классе параллельных алгоритмов, были достигнуты значительные успехи в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их доработки или комбинирования. Одновременно происходил поиск оптимальных входных последовательностей для разных методов сортировки, что позволяло значительно сократить ее время.
Пятый этап начался с середины 1990-х годов и продолжается по настоящее время. Особую актуальность получило исследование задач сортировки на частично упорядоченных множествах: задач распознавания частично упорядоченного множества М; задач сортировки частично упорядоченного множества М с использованием результатов попарных сравнений элементов, а также задач определения порядка на множестве М без априорной информации. Актуальность задач сортировки объясняется появлением и широким распространением компьютеров на сверхсложных микропроцессорах с параллельно-векторной структурой, а также высокоэффективных сетевых компьютерных систем.
Важное практическое значение проблема сортировки данных в больших массивах впервые приобрела в США в середине XIX века. В 1840 году там был создан центральный офис переписи населения, куда стекались первичные данные из всех штатов. В ходе переписи было опрошено 17 069 453 человек, каждая анкета состояла из 13 вопросов. Объем полученных данных был столь велик, что их обработка традиционным ручным способом потребовала непомерных затрат труда и времени.[1]
Перед переписью 1890 года для решения проблемы сортировки данных в очень больших массивах информации по инициативе бюро переписи был проведен конкурс на лучшее электромеханическое сортировочное оборудование, которое сделало бы сортировку данных более эффективной — более быстрой, точной и дешевой.
Конкурс выиграл американский инженер и изобретатель Герман Холлерит.
Вот как были описаны преимущества машины Холлерита в русском журнале «Вестник Опытной Физики и Элементарной Математики» в 1895 году: «Преимущества машины Холлерита заключаются: в значительном ускорении и удешевлении работы. При ручном способе можно разложить и подсчитать за час не более 400 карточек. Если принять, что в Российской Империи 120 миллионов жителей, то для изготовления одной только сводной таблицы потребуется не менее … 300 000 часов… Машина сокращает работу почти в 5 раз. После немногих пропусках через машину всех счетных карточек получаются столь полные и разнообразные таблицы, составление которых было почти немыслимо при прежнем способе».
Следующий этап развития способов и алгоритмов сортировки начался в начале 1940-х годов с появлением первых электронных вычислительных машин. Фантастическое по тем временам быстродействие ЭВМ вызвало рост интереса к новым, приспособленным для машинной обработки алгоритмам сортировки. В 1946 году вышла первая статья об алгоритмах сортировки данных, автором которой был Джон Уильям Мочли — американский физик и инженер.
В середине 1950-х годов с разработкой ЭВМ второго поколения началось активное развитие алгоритмов сортировки. Основными предпосылками для этого стали, во-первых, значительное упрощение и ускорение написания программ для компьютеров в результате разработки первых языков программирования высокого уровня (Фортран, Алгол, Кобол); во-вторых, значительное повышение доступности компьютеров в результате резкого уменьшения их габаритов и стоимости и, как следствие, достаточно широкое их распространение; в-третьих, увеличение производительности компьютеров до 30 тысяч операций в секунду.[2]
К началу 1970-х годов использовались следующие виды алгоритмов внутренней сортировки: сортировка посредством подсчета; сортировка путем вставок; обменная сортировка; сортировка посредством выбора; сортировка методом слияния; сортировка методом распределения.
В период с середины 1970-х до 1990-х годов были достигнуты значительные успехи в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их доработки или комбинирования. К примеру, нидерландский учёный Эдсгер Вибе Дейкстра в 1981 году предложил алгоритм плавной сортировки (Smoothsort), который является развитием пирамидальной сортировки (Heapsort).
1.2. Понятие и оценка алгоритма сортировки
Алгоритм сортировки — это алгоритм для упорядочивания элементов. Прежде чем переходить к рассмотрению конкретных методов сортировки и алгоритмов поиска, необходимо определить понятия алгоритмизация и алгоритм. Из истории известно, что самый первый алгоритм принадлежит древнегреческому математику Евклиду. Ему принадлежит правило нахождения максимального общего делителя двух целых чисел. В математике понятие алгоритма является основным понятием, восходящее к работам выдающегося узбекского математика IX века Аль-Хорезми. В 12 веке его работы по арифметике и алгебре были переведены на латынь. Данные работы заложили основу всей европейской математики.
Если рассматривать алгоритма в широком смысле этого слова, то данное понятие широко распространено и в повседневной жизни. Например, рецепты в кулинарной книге являются алгоритмами, которые описывают процесс приготовления пищи.
Исчерпывающее определение алгоритма дал выдающийся отечественный математик А.А. Марков. Алгоритм – это точное предписание, которое определяет процесс преобразования исходных данных в необходимый результат. Алгоритм должен обладать следующими свойствами:[3]
- массовостью (либо выполнимостью) то есть возможностью исходить из любых исходных данных, принадлежащих некоторому множеству исходных данных;
- точностью (либо определенностью), не оставляющей места для произвола, и общепонятностью;
- результативностью (либо конечностью), то есть свойством определять процесс, который для любых допустимых исходных данных (то есть принадлежащих некоторому множеству) приводит к получению искомого результата.
Как правило, начальным этапом разработки алгоритма является определение множеств исходных и результатных параметров. На втором этапе формируется связь между этими двумя множествами. Заключительный этап заключается в формулирование этой связи в виде набора формальных инструкций. Этот набор и является алгоритмом.
Чтобы алгоритм был работоспособный, необходимо чтобы каждая из таких инструкций могла удовлетворять условиям массовости и точности.[4]
Обеспечить массовость (выполнимость) алгоритма значит исключить из него все невыполнимые команды. Обеспечить точность означает исключить бессмысленные и неясные инструкции.
Другими словами, для точности (определенности) алгоритма каждая из частей его инструкций должна быть определена недвусмысленно и четко. Если алгоритм выражен на естественном языке, то здесь есть возможность появления неоднозначности. Д. Кнут. предложил неформальное определение термина выполнимость. Согласно Кнуту, инструкция выполнима, если включенные в нее инструкции достаточно элементарны, чтобы они за конечное время могли быть выполнены человеком, вооруженным карандашом и бумагой. То, что даже простая инструкция может оказаться невыполнимой демонстрирует следующий простой. Например, вычислить наибольшее вещественное число, меньшее единицы. С точки зрения математики такое число определить невозможно – например, если выбрать число 0.999999999, число 0.9999999991 будет больше.
В отличие от двух рассмотренных свойств, результативность является свойством не отдельных его инструкций, а алгоритма в целом. Типичный случай алгоритма, который никогда не заканчивается - это бесконечный цикл:
Шаг 1: Присвоить S значение 0.
Шаг 2: Присвоить S значение S+5.
Шаг 3: Перейти к шагу 2.
Для каждого алгоритма важно, чтобы была доказана его конечность.
К сожалению, доказательство конечности обычно чрезвычайно сложно. При доказательстве конечности выделяют два класса алгоритмов.
Первый класс – это итеративные численные алгоритмы, дающие приближенные результаты. Условие завершения в этом случае обычно определяется при помощи оценивания значения погрешности и сравнения ее с указанным ранее заданным показателем точности. Эти алгоритмы хорошо исследованы с математической точки зрения. Однако в редких частных случаях для них имеются строгие доказательства их конечности (результативности). Сказанное не означает, что указанные алгоритмы не следует использовать (тем более часто они бывают единственно доступными способами решения), но в то же время надо сознавать возможность возникновения таких проблем.
Алгоритмы второго класса предназначены для нечисловых процессов. Для алгоритмов второго класса возможно доказательство результативности (конечности) и в общем виде, но часто более существенным является то, как быстро алгоритм завершается и сколько для завершения требуется шагов.
Запись алгоритмов может быть осуществлена несколькими способами. Выше приведена запись алгоритма на естественном языке. Часто встречаются также запись алгоритмов при помощи решающих таблиц или блок-схем. Одним из методов записи алгоритма является запись алгоритма либо непосредственно на языке программирования, либо на так называемом псевдокоде. Под псевдокодом понимают язык промежуточный между естественным языком и языком программирования. Псевдокод является не слишком формализованным языком. Но он позволяет программисту пользоваться достаточно произвольными словесными и математическими выражениями в сочетании с конструкциями алгоритмического языка.
Рассмотрим вопрос оценки алгоритма сортировки данных.
Сортировка – один из наиболее распространенных процессов современной обработки данных. Задачи на сортировку данных встречаются очень часто. Сегодня трудно представить себе работу с большим массивом данных, информации без упорядочивания и сортировки. Главным образом, это связано с тем, что отсортированные данные по определенному алгоритму дает больше полезной и необходимой информации, чем неотсортированные.
Имея лишь приблизительные характеристики исходных данных, можно подобрать метод сортировки, работающий оптимальным образом.
Для того чтобы обоснованно сделать выбор метода сортировки, рассмотрим параметры, по которым будет производиться оценка алгоритмов.
- Время сортировки. Основной параметр, характеризующий быстродействие алгоритма. Называется также вычислительной сложностью.
- Память. Ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
- Устойчивость. Устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, а сортировка происходит по одному из них.
- Естественность поведения — эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь есть два основных типа:
-
- Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
- Внешняя сортировка оперирует с запоминающими устройствами большого объёма, но с доступом не произвольным, а последовательным (сортировка файлов), то есть в данный момент мы «видим» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью.
2. Рассмотрение внутренней сортировки данных
Понятие и теоретическая основа
Пусть имеется некоторая последовательность однотипных записей, одно из полей записей выбрано в роли ключа, данное поле называется ключевым. Тип данных ключевого поля должен включать операции сравнения, то есть "=", ">", "<", ">=" и "<=".
Тогда задача сортировки заключается в преобразовании исходной совокупности записей в такую последовательность записей, которая содержит те же записи, но в порядке убывания или возрастания значений ключевого поля. Метод сортировки будет называться устойчивым, если при его применении не изменяется относительное положение записей с равными значениями ключа.
Экономия памяти – это главное требование, предъявляемое к методам сортировки. То есть, при выборе метода сортировки руководствуются критерием экономичного использования памяти. Классификация алгоритмов проводится в соответствии с эффективностью.[5]
Удобно измерять эффективность, подсчитывая число необходимых сравнений ключей и число пересылок элементов. Эти числа определяются некоторыми функциями от числа n сортируемых элементов.
Исследование алгоритмов сортировки начинают с самых простых, но в то же время самых неэкономичных методов. Это объясняется следующими причинами:
1) Тексты программ, которые основаны на данных методах, легки и коротки для понимания.
2) Данные методы хорошо подходят для объяснения принципов и свойств сортировки.
3) Простая реализация позволяет экономить время работы программиста над разработкой программы, которое также необходимо учитывать, как составную часть при анализе эффективности работы программы.
4) При достаточно малой размерности массивов эти методы часто работают даже лучше, чем более сложные методы.
Методы внутренней сортировки можно разбить на три основных группы. Они классифицируются в зависимости от лежащего в их основе метода:
1) Сортировка обменом.
2) Сортировка выбором.
3) Сортировка включением.
2.1 Сортировка обменом
Самым распространенным алгоритмом сортировки является пузырьковый метод (или метод сортировки обменом).
Данный метод основан на выполнении в цикле операций сравнения и при необходимости обмена смежных элементов. Название алгоритма дано ему из-за аналогии с процессом всплывания пузырьков в сосуде с водой. То есть, каждый пузырек всплывает до своего собственного уровня, определяемого соответствующим весом «пузырька».
Другими словами, идея метода сортировки пузырьком заключается в сравнении смежных элементов и их обмене, если они находятся не в нужном порядке. Повторное выполнение таких действий заставляем наименьший элемент "всплывать" в начало последовательности. Следующий проход приведет к всплыванию второго наименьшего элемента массива, и так до тех пор, пока после итерации список не будет полностью отсортирован. Таким образом, массив данных будет отсортирован по возрастанию. Для сортировки последовательности элементов по возрастанию, сначала всплывает наибольший элемент в начало последовательности. При следующем проходе второй по величине элемент всплывает и тд.
Далее приведен фрагмент программы, реализующий поиск пузырьком на языке Паскаль:
for i:=n-1 downto 1 do {n – количество элементов в массиве}
for j:=1 to i do
if a[j]>a[j+1] then
begin
y:= a[j];
a[j]:= a[j+1];
a[j+1]:= y;
end;
Данный алгоритм основан на двух вложенных циклах.
Так как число элементов массива задается переменной n, внешний цикл вызывает просмотр массива раз. В результате этой процедуры каждый элемент встает на искомую позицию. Внутренний цикл фактически выполняет операции сравнения и обмена.
Пример процесса сортировки обменом представлен в таблице 1.
Для иллюстрации работы сортировки пузырьковым методом в таблице 1 даны результаты каждого этапа сортировки массива.
Таблица 1
Сортировка массива методом пузырька
|
Исходное состояние |
Проходы |
|||
|
Первый |
Второй |
Третий |
Четвертый |
|
|
105 |
21 |
7 |
3 |
3 |
|
21 |
7 |
3 |
7 |
7 |
|
7 |
3 |
21 |
21 |
21 |
|
3 |
57 |
57 |
57 |
57 |
|
57 |
105 |
105 |
105 |
105 |
Сортировка большого числа элементов данным методом потребует большого времени, поскольку время выполнения сортировки квадратично зависит от числа элементов последовательности.
2.2 Сортировка выбором
Сортировка в этом случае осуществляется выбором элемента массива с наименьшим значением и обменом его с первым элементом последовательности. Далее находится элемент с наименьшим значением из оставшихся элементов и делается его обмен со вторым элементом до обмена двух последних элементов.
В общем случае, при i-ом проходе по массиву (0  i
i  n– 2) алгоритм ищет наименьший элемент среди последних n – i элементов и обменивает его с a[i];
n– 2) алгоритм ищет наименьший элемент среди последних n – i элементов и обменивает его с a[i];
После выполнения n – 1 проходов список оказывается отсортирован. Кол программы на языке Паскаль, которая реализует данный алгоритм:
for i = 0 to n – 2 do
min = I;
for j = i + 1 to n – 1 do
if a[j] < a[min] then begin
min = j
y:= a[i];
a[i]:= a[min];
a[min]:= y;
end;
Для иллюстрации работы сортировки пузырьковым методом в таблице 2 представлены результаты каждого этапа сортировки массива.
Таблица 2
Сортировка выбором
|
Исходное состояние |
Проходы |
|||
|
Первый |
Второй |
Третий |
Четвертый |
|
|
105 |
3 |
3 |
3 |
3 |
|
21 |
21 |
7 |
7 |
7 |
|
7 |
7 |
21 |
21 |
21 |
|
3 |
105 |
105 |
105 |
57 |
|
57 |
57 |
57 |
57 |
105 |
2.3 Сортировка включением
Данная сортировка является последней из простых алгоритмов. При сортировке включением (вставками) сначала упорядочиваются первые два элемента последовательности. Затем последовательно осуществляется вставка третьего элемента массива в соответствующую для него позицию по отношению к первым двум элементам, а затем четвертый элемент вставляется в список из трех элементов. Этот процесс повторяется до тех пор, пока весь массив не будет отсортирован.
Таким образом, процесс сортировки вставками осуществляется путем сканирования, отсортированного подмассива слева направо, пока не достигается первый элемент, больший или равный a[n–1], и после этого происходит вставка элемента непосредственно перед найденным элементом.
Сортировка включением (вставками) основана на рекурсии. Однако более эффективной будет ее итеративная реализация, то есть снизу вверх. Элемент a[i] (начиная с элемента a[1] и заканчивая a[n–1]) вставляется на соответствующую позицию среди первых i элементов массива, которые к этому времени уже отсортированы. Однако в отличие от сортировки выбором элемент в общем случае вставляется не в окончательную позицию, которую он будет занимать в полностью отсортированном массиве [2, с. 230].
Ниже приведен фрагмент программы на языке Паскаль, которая реализует сортировку включением.
for i = 1 to n - 1 do
y= a[i];
j = i – 1;
while j >= 0 and a[j] >y do begin
mass[j + 1] = a[j];
j = j – 1;
end;
a[j + 1] = y;
Иллюстрация работы алгоритма представлена в таблице 3.
Таблица 3
Сортировка вставками
|
Исходное состояние |
Проходы |
|||
|
Первый |
Второй |
Третий |
Четвертый |
|
|
105 |
21 |
7 |
3 |
3 |
|
21 |
105 |
21 |
7 |
7 |
|
7 |
7 |
105 |
21 |
21 |
|
3 |
3 |
3 |
105 |
57 |
|
57 |
57 |
57 |
57 |
105 |
Сортировка простыми вставками противоположна сортировке простым выбором. При сортировке простыми вставками (включениями) на каждом шаге алгоритма рассматривается только один очередной элемент входного массива и все элементы готового массива для нахождения места вставки.
Сортировка вставками имеет два преимущества[6]:
1) Данный метод обладает естественным поведением. Другими словами, сортировка включением выполняется быстрее для упорядоченного массива и дольше всего выполняется, когда массив упорядочен в обратном направлении. Это полезно в том случае, когда массив почти отсортирован.
2) Сортировка включением устойчива. Элементы с одинаковыми ключами не переставляются, и если список элементов сортируется с использованием двух ключей, то после завершения сортировки вставками он по-прежнему будет отсортирован по двум ключам.
Хотя число сравнений может быть достаточно небольшим для определенных последовательностей элементов, постоянные сдвиги массива требуют выполнения большого числа операций перестановок.
2.4 Сравнение методов внутренней сортировки
Анализируя любой метод сортировки, можно получить число операций сравнения и обмена, выполняемых в лучшем, среднем и худших случаях. Для рассмотренных методов внутренней сортировки существуют точные формулы, вычисление которых дает минимальное, максимальное и среднее число сравнений ключей (C) и пересылок элементов массива (M). [2] Таблица 4 содержит данные, приводимые в книге Никласа Вирта.
Таблица 4
Сравнение методов внутренней сортировки
|
|
Min |
Avg |
Max |
|
Сортировка выбором |
|||
|
Сортировка обменом |
|||
|
Сортировка включением |
3. Рассмотрение внешней сортировки данных
3.1 Прямое слияние
Внешней сортировкой называется сортировка последовательных файлов, которые располагаются во внешней памяти. Данные файлы слишком велики, чтобы полностью поместиться в основную память, поэтому к ним неприменимы рассмотренные ранее методы внутренней сортировки. Чаще всего внешнюю сортировку используют в системах управления базами данных.[7]
Пусть имеется некоторый последовательный файл А, который включает в себя записи а1, а2,…, аn. Каждая такая запись состоит из одного ключевого элемента. Для сортировки прямым слиянием необходимы два вспомогательных файла В и С, размер каждого из них равен n/2. В таблице 5 показан пример внешней сортировки простым слиянием.
Таблица 5
Внешняя сортировка простым слиянием
|
Начальное состояние файла A |
8 23 5 95 44 33 2 6 |
|
Первый шаг |
8 5 44 2 23 95 33 6 8 23 5 95 33 44 1 6 |
|
Второй шаг |
8 23 33 44 5 95 2 6 5 8 23 95 2 6 33 44 |
|
Третий шаг |
5 8 23 95 2 6 33 44 2 5 6 8 23 33 44 95 |
Данный метод сортировки состоит из последовательных шагов. На каждом таком шаге выполняется распределение файла А в файлы В и С, а затем осуществляется слияние файлов В и С в исходный файл А. Файл А содержит записи: 8 23 5 95 44 33 2 6. Размер файла А=8, таким образом, размер вспомогательных файлов В и С равен n/2=4. Сначала осуществляется начальное распределение: последовательно считываются записи файла А, записи a1, a3, ..., a(n-1) пишутся в файл B, а записи a2, a4, ..., an - в файл C. То есть файл В содержит элементы: 8 5 44 2, а файл С: 23 95 33 6. На втором шаге снова осуществляется последовательное считывание файла А, при этом в файл В записываются последовательные пары с нечетными номерами, а в файл С – с четными. В процессе слияния образуются упорядоченные четверки записей. Они записываются в файл А.
И так продолжается до последнего шага. Перед последним шагом, файл А будет содержать две упорядоченные подпоследовательности размером n/2 каждая. В процессе очередного распределения первая из них попадает в вспомогательный файл В, а вторая в С. В результате слияния исходный файл А будет содержать полностью упорядоченную последовательность записей.
Стоит отметить, при данном методе сортировки необходимы всего две переменные, расположенные в основной памяти. Данные переменные необходимы для размещения очередных записей из файлов В и С. Все файлы (А, В и С) будут прочитаны и записаны по O(log n) раз.
3.2 Естественное слияние
Недостатком предыдущего метода можно считать то, что при прямом слияние не рассматривается то факт, что исходный файл может быть уже частично отсортирован. Устранить данный недостаток призван метод естественного слияния. Он основан на распознавании упорядоченных подпоследовательностей при распределении и их использование при дальнейшем слиянии. При этом методе сортировка выполняется за несколько шагов, как и при методе прямого слияния. На каждом шаге сначала выполняется распределение исходного файла А по вспомогательным В и С, а потом слияние вспомогательных в исходный файл. При распределении распознается первая серия записей и переписывается в файл B, вторая - в файл C и т.д. В процессе слияние осуществляется сливание первой серии файла В с первой серией файла С, второй серии файла В со второй серией С и т.д. В случае, если по причине разного размера серий, просмотр одного файла закончился раньше, чем просмотр другого, то остаток большего файла записывается в конец исходного файла целиком. Процесс сортировки методом естественного слияния заканчивается, когда в исходном файле А остается одна серия. Пример данной сортировки представлен на рисунках 1 и 2.
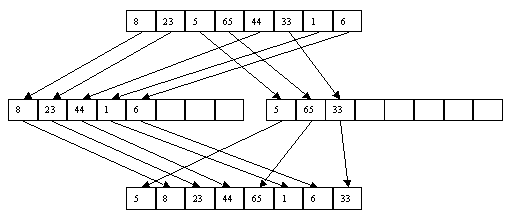
Рисунок 1. Первый шаг сортировки
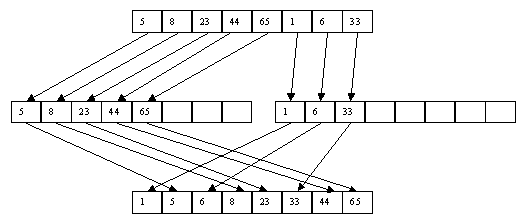
Рисунок 2. Второй шаг сортировки
При использовании метода естественного слияния число чтений и записи файлов будет меньше, чем при использовании метода прямого слияния. Но с другой стороны увеличивается число сравнений, это обуславливается распознаванием концов серий. Кроме того, поскольку длина серий может быть произвольной, то максимальный размер файлов B и C может быть близок к размеру файла A.
3.3 Сбалансированное многопутевое слияние
В основе сбалансированного многопутевого слияния лежит распределение серий исходного файла по нескольким вспомогательным, то есть по по m вспомогательным файлам B1, B2, ..., Bm и их слияние в m вспомогательных файлов C1, C2, ..., Cm. На следующем шаге производится слияние файлов C1, C2, ..., Cm в файлы B1, B2, ..., Bm и т.д., пока в B1 или C1 не образуется одна серия. Сбалансированное многопутевое слияние является развитием идеи двухпутевого слияния, использованного в предыдущих методах сортировки. Простой пример использования данного метода представлен на рисунке 3.
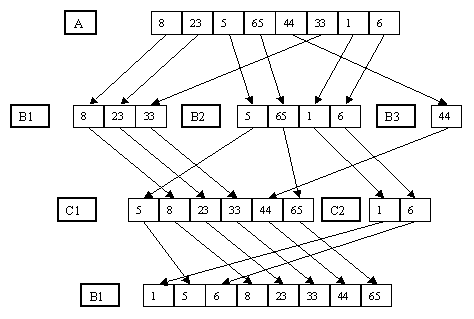
Рисунок 3. Многопутевое слияние
Данный метод сортировки имеет следующие преимущества: число проходов алгоритма оценивается как O(log n) (n - число записей в исходном файле), где логарифм берется по основанию n. Порядок числа копирований записей равен O(log n). Но число сравнений не будет меньше, чем при использовании метода простого слияния.
Таким образом, чем более длинные серии содержит файл перед началом применения внешней сортировки, тем меньше потребуется слияний и тем быстрее закончится сортировка. Поэтому до начала применения любого из методов внешней сортировки, основанных на применении серий, начальный файл частями считывается в основную память, к каждой части применяется один из наиболее эффективных алгоритмов внутренней сортировки. Кроме того, конечно, при выполнении распределений и слияний используется буферизация блоков файла(ов) в основной памяти. Возможный выигрыш в производительности зависит от наличия достаточного числа буферов достаточного размера.
ЗАКЛЮЧЕНИЕ
Сортировка применяется во всех без исключения областях программирования, будь то базы данных или математические программы.
Алгоритмы сортировки представляют собой пошаговое упорядочение элементов в определенном массиве данных, независимо от его размеров.
Практически каждый алгоритм сортировки можно разбить на три части:
- сравнение, определяющее упорядоченность пары элементов;
- перестановку, меняющую местами пару элементов;
- собственно сортирующий алгоритм, который осуществляет сравнение и перестановку элементов до тех пор, пока все элементы множества не будут упорядочены.
Важность сортировки основана на том факте, что на ее примере можно показать многие основные фундаментальные приемы и методы построения алгоритмов. Сортировка является хорошим примером огромного разнообразия алгоритмов, которые выполняют одну и ту же задачу.
Кроме того, многие из них имеют определенные преимущества друг перед другом. За счет усложнения алгоритма можно добиться существенного увеличения эффективности и быстродействия алгоритма по сравнению с более простыми методами. Как правило, термин сортировка понимают, как процесс перестановки объектов некоторого множества в определенном порядке. Цель сортировки - облегчить последующий поиск элементов в отсортированном множестве.
Различают методы внутренней и внешней сортировки. К методу внутренней сортировки относят методы сортировки массив.
Методы сортировки массивов можно разделить на три основных класса в зависимости от лежащего в их основе метода:
- сортировка пузырьком;
- сортировка выбором;
- сортировка включением.
Пузырьковая сортировка просто реализуется, но используется только в учебных целях и не используется на практике. Это объясняется тем, что сортировка обменом эффективна лишь при небольших массивах элементов.
Сортировка выбором так же относится к простым методам сортировки. И, как и при методе пузырька, данная сортировка выполняется слишком медленно для большого числа элементов. Однако хотя, для сортировок пузырьковым методом и сортировок выбором, число операций обмена для среднего случая будет значительно меньшим для сортировки выбором.
Сортировка вставками является последней из простых алгоритмов. В отличие от сортировки методом обмена и сортировки выбором, количество операций сравнения для сортировки вставками зависит от исходной упорядоченности массива элементов. Сортировка включением имеет естественное поведение и требует наименьшее число операций обмена для почти упорядоченного списка, а также наибольшее число операций обмена, в тех случаях, когда массив данных упорядочен в противоположном направлении. Время выполнения простых сортировок пропорционально квадрату числа элементов в массиве.
Методы внешней сортировки используются, когда исходный файл, содержащий записи, не может быть полностью помещен в основную память. Существуют следующие методы внешней сортировки: метод прямого слияния, метод естественного слияния, метод сбалансированного многопутевого слияния. Чем более длинные серии содержит файл перед началом применения внешней сортировки, тем меньше потребуется слияний и тем быстрее закончится сортировка. Поэтому до начала применения любого из методов внешней сортировки, основанных на применении серий, начальный файл частями считывается в основную память, к каждой части применяется один из наиболее эффективных алгоритмов внутренней сортировки.
В ходе выполнения курсовой работы рассмотрены этапы эволюции методов сортировки данных, выполнен сравнительный анализ и изучены основные методы сортировки данных.
Получены навыки ведения самостоятельных теоретических и практических исследований и навыки правильного оформления научно-исследовательской работы. Также приобретен опыт обработки, анализа и систематизации результатов практических исследований по направлению обучения.
СПИСОК ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
- Алексеев Е.Р., Чеснокова О.В., Кучер Т.В., Самоучитель по программированию на Free Pascal и Lazarus. - Донецк.: ДонНТУ, Технопарк ДонНТУ УНИТЕХ, 2013. – 503 с.
- Вирт Н. Алгоритмы и структуры данных. М.: Мир, 2011. - 360 с.
- Гагарина Л.Г., Алгоритмы и структуры данных: Учебное пособие. – М.: ИНФРА-М, 2013. – 304 с.: ил, ISBN 978-5-16-003-682-3.
- Гагарина Л.Г., Алгоритмы и структуры данных: Учебное пособие. – М.: ИНФРА-М, 2012. – 304 с.: ил, ISBN 978-5-16-003-682-3.
- Демидов Д.В., Основы программирования на языке Pascal в примерах: Учебное пособие. – М.: НИЯУ МИФИ, 2010. – 172 с.
- Демидов Д.В., Основы программирования на языке Pascal в примерах: Учебное пособие. – М.: НИЯУ МИФИ, 2010. – 172 с.
- Дупленко А. Г. Сравнительный анализ алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — № 8. — 80 с.
- Кауфман В.Ш. Языки программирования. Концепции и принципы. – М.: ДЖК Пресс, 2011. – 464 с.
- Красиков И.В. Алгоритмы. Просто как дважды два. – М.: Эксмо, 2013. – 256 с. ISBN 978-5-699-21047-3.
- Кулаков В.Г., Алгоритмический язык Паскаль: Учебное пособие. – М.: МГИЭМ, 2014. – 41 с.
- Лозовая С.Ю., Решение типовых задач по программированию: практическое пособие: НИУ БелГУ; НИУ БелГУ.-Белгород: ИПК НИУ "БелГУ", 2011. - 148 с.
- Марапулец Ю.В., Программирование на языках высокого уровня: Учебное пособие. – КамчатГТУ, 2014. – 189 с. ISBN 978-5-328-00185-4.
- Павловская Т.А. Паскаль. Программирование на языке высокого уровня: Учебник для вузов. – СПб.: Питер, 2012. – 393с.
- Павловская Т.А., Паскаль. Программирование на языке высокого уровня: Учебник для вузов. – СПб.: Питер, 2015. – 464с.
- Попов И.И., Основы алгоритмизации и программирования: Учебное пособие. – 3-е издание – М.: Форум, 2014. – 432 с.
- Потопахин В.В. Искусство алгоритмизации: Учебное пособие. – М.: ДЖК Пресс, 2011. – 320 с., ил., ISBN 978-5-94074-621-8.
- Потопахин В.В., Искусство алгоритмизации: Учебное пособие. – М.: ДЖК Пресс, 2011. – 320 с., ил., ISBN 978-5-94074-621-8.
- Потопахин В.В., Современное программирование с нуля. – М.: ДЖК Пресс, 2010. – 240 с., ил.
- Решение 50 типовых задач по программированию на языке Pascal – 2012 [Электронный ресурс] – URL: http://el-prog.narod2.ru/ (дата обращения: 27.02.2017).
- Сулейманов Р.Р., Методика решения учебных задач средствами программирования: Методическое пособие – М: БИНОМ. Лаборатория знаний 2010, с. 112, ISBN:978-5-9963-0112-6.
- Язык Pascal. Программирование для начинающих. – 2011 [Электронный ресурс] - URL: http://pas1.ru/pascaltextbook (дата обращения: 27.02.2017).
-
Дупленко А. Г. Эволюция способов и алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №9. — С. 16. ↑
-
Дупленко А. Г. Эволюция способов и алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №9. — С. 25. ↑
-
Гагарина Л.Г., Алгоритмы и структуры данных: Учебное пособие. – М.: ИНФРА-М, 2013. – с. 26 ↑
-
Вирт Н. Алгоритмы и структуры данных. М.: Мир, 2011. – с. 89 ↑
-
Красиков И.В. Алгоритмы. Просто как дважды два. – М.: Эксмо, 2013. – с. 64 ↑
-
Гагарина Л.Г., Алгоритмы и структуры данных: Учебное пособие. – М.: ИНФРА-М, 2012. – с. 57 ↑
-
Попов И.И., Основы алгоритмизации и программирования: Учебное пособие. – 3-е издание – М.: Форум, 2014. – с. 104 ↑

- Проектирование реализации операций бизнес-процесса Взаиморасчеты с клиентами (Выбор комплекса задач автоматизации)
- Особенности работы с персоналом, владеющим конфиденциальной информацией ( ОСНОВНЫЕ НАПРАВЛЕНИЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ ИНФОРМАЦИОННЫХ РЕСУРСОВ)
- Управление кадровой безопасностью (на примере ОАО «НПО «Сатурн»)
- Методы рекламной деятельности
- Судебная власть государства: организация и полномочия (Судебная власть, как одна из ветвей государственной власти)
- Проектирование реализации операций бизнес-процесса Предоставление рекламных услуг
- Валютные отношения как форма экономических отношений (Валютная система и её понимание)
- Ценовая стратегия и тактика предприятия гостеприимства на примере отеля Татьяна
- Методы управления инновационными проектами (Теоретические основы природы инновационного проекта)
- Процесс построения модели управленческого решения (Моделирование)
- Проектирование реализации операций бизнес-процесса Складской учет (Выбор комплекса задач автоматизации)
- Алгоритмы сортировки данных ( Основные понятие алгоритмов сортировки)