
Технологии распознавания текстов (Задачи распознания текста)
Содержание:

Введение
Представьте, вам надо оцифровать журнальную статью или распечатанный договор. Конечно, вы можете провести несколько часов, перепечатывая документ и исправляя опечатки. Либо вы можете перевести все требуемые материалы в редактируемый формат за несколько минут, используя сканер (или цифровую камеру) и программу для оптического распознавания символов (OCR).
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные документы, PDF-файлы или фото с цифровой камеры, в редактируемые форматы с возможностью поиска.
Предположим, у вас есть бумажный документ, например, статья в журнале, брошюра или договор в формате PDF, присланный вам партнером по электронной почте. Очевидно, для того чтобы получить возможность редактировать документ, его недостаточно просто отсканировать. Единственное, что может сделать сканер, – это создать изображение документа, представляющее собой всего лишь совокупность черно-белых или цветных точек, то есть растровое изображение.
Для того чтобы копировать, извлекать и редактировать данные, вам понадобится программа для распознавания символов, которая сможет выделить в изображении буквы, составить их в слова, а затем объединить слова в предложения, что в дальнейшем позволит работать с содержимым исходного документа.
Современные системы оптического распознавания символов ( optical character recognition , OCR ) могут быть условно разделены на две категории. Собственно OCR-системы решают ставшую классической задачу распознавания печатных символов, нанесенных на бумагу при помощи принтера, плоттера или пишущей машинки (при этом подразумевается, что любая система распознавания работает с электронным изображением документа, обычно получаемым при помощи сканера). Кроме того, выделяют класс ICR -систем (intelligent character recognition), в задачи которых входит обработка документов, заполненных печатными буквами и цифрами от руки, или, иначе говоря, распознавание рукопечатных символов.
В обоих случаях качество функционирования системы распознавания может быть оценено по ряду параметров. Однако наиболее важным параметром системы любого типа является точность распознавания.
Глава 1. Задачи распознания текста
Технология оптического распознавания символов
На протяжении последних шести лет на мировом рынке присутствуют OCR\ICR-системы, построенные на базе технологий компании ABBYY. На сегодняшний день они хорошо известны и пользуются стабильным спросом. В частности, программное ядро (engine) OCR -системы ABBYY FineReader лицензировано и успешно эксплуатируется такими известными компаниями, как Cardiff Software, Inc., Cobra Technologies, Kofax Image Products, Kurzweil Educational Systems, Inc., Legato Systems, Inc., Notable Solutions Inc., ReadSoft AB, Saperion AG, SER Systems AG, Siemens Nixdorf, Toshiba Corporations.
В рамках данного документа будут описаны базовые принципы технологий ABBYY, и, кроме того, будут подробно рассмотрены процедуры распознавания печатных (OCR) и рукопечатных (ICR) символов, реализованные в продуктах ABBYY .
Базовые принципы технологий распознавания текста ABBYY
Компания ABBYY, опираясь на результаты многолетних исследований, реализовала принципы IPA в компьютерной программе. Система оптического распознавания символов ABBYY FineReader – единственная в мире система OCR, действующая в соответствии с вышеописанными принципами на всех этапах обработки документа. Эти принципы делают программу максимально гибкой и интеллектуальной, предельно приближая ее работу к тому, как распознает символы человек. На первом этапе распознавания система постранично анализирует изображения, из которых состоит документ, определяет структуру страниц, выделяет текстовые блоки, таблицы. Кроме того, современные документы часто содержат всевозможные элементы дизайна: иллюстрации, колонтитулы, цветной фон или фоновые изображения. Поэтому недостаточно просто найти и распознать обнаруженный текст, важно с самого начала определить, как устроен рассматриваемый документ: есть ли в нем разделы и подразделы, ссылки и сноски, таблицы и графики, оглавление, проставлены ли номера страниц и т. д. Затем в текстовых блоках выделяются строки, отдельные строки делятся на слова, слова на символы.
Важно отметить, что выделение символов и их распознавание также реализовано в виде составных частей единой процедуры. Это позволяет в полной мере использовать преимущества принципов IPA. Выделенные изображения символов поступают на рассмотрение механизмов распознавания букв, называемых классификаторами.
В системе ABBYY FineReader применяются классификаторы следующих типов: растровый, признаковый, контурный, структурный, признаково-дифференциальный и структурно-дифференциальный. Растровый и признаковый классификаторы анализируют изображение и выдвигают несколько гипотез о том, какой символ на нем представлен. В ходе анализа каждой гипотезе присваивается определенная оценка (так называемый вес). По итогам проверки мы получаем список гипотез, проранжированный по весу (то есть по степени уверенности в том, что перед нами именно такой символ). Можно сказать, что в данный момент система уже «догадывается», на что похож рассматриваемый символ.
После этого в соответствии с принципами IPA ABBYY FineReader проводит проверку выдвинутых гипотез. Это делается с помощью дифференциального признакового классификатора.
Кроме того, следует отметить, что ABBYY FineReader поддерживает 192 языка распознавания. Интеграция системы распознавания со словарями помогает программе при анализе документов: распознавание происходит более точно и упрощает дальнейшую проверку результата с учетом данных об основном языке документа и словарной проверки отдельных предположений. После подробной обработки огромного числа гипотез программа принимает решение и предоставляет пользователю распознанный текст.
Принципы IPA
Преобразование документа в электронный вид выполняется OCR-системами поэтапно: сканирование и предварительная обработка изображения, анализ структуры документа, распознавание, проверка результатов, затем производится реконструкция (воссоздание исходного вида) документа, и экспорт. Методы, применяемые при распознавании, весьма разнообразны.
Но, как известно, лучшие в мире системы оптического распознавания конструирует природа. Устройство участков нервной системы, доставляющих и обрабатывающих сигналы органов зрения, настолько сложно, что задача моделирования живых «распознавателей» в общем виде до сих пор не решена наукой. Однако базовые принципы их функционирования изучены хорошо и могут быть использованы на практике. Их насчитывают три:
Принцип целостности (integrity) , согласно которому объект рассматривается как целое, состоящее из связанных частей. Связь частей выражается в пространственных отношениях между ними, и сами части получают толкование только в составе предполагаемого целого, то есть в рамках гипотезы об объекте. Преимущество системы, следующей вышеописанным правилам, выражается в способности точнее классифицировать распознаваемый объект, исключая из рассмотрения сразу множество гипотез, противоречащих хотя бы одному из положений принципа.
Принцип целенаправленности (purposefulness) : любая интерпретация данных преследует определённую цель. Следовательно, распознавание должно представлять собой процесс выдвижения гипотез о целом объекте и целенаправленной их проверки. Понятно, что система, действующая в соответствии с принципом целенаправленности, не только экономнее расходует вычислительные мощности, но и существенно реже ошибается.
Принцип адаптивности (adaptability) подразумевает способность системы к самообучению. Полученная при распознавании информация упорядочивается, сохраняется и используется впоследствии при решении аналогичных задач. Преимущество самообучающихся систем заключается в способности «спрямлять» путь логических рассуждений, опираясь на ранее накопленные знания.
Технологии распознавания, разработанные компанией ABBYY, построены именно на этих принципах. Вместо полных названий принципов часто употребляют аббревиатуру IPA , составленную из первых букв соответствующих английских слов. Очевидно, что система распознавания, работающая в соответствии с принципами IPA , будет функционировать максимально гибко и точно, на грани осмысленного действия.
Компания ABBYY , опираясь на результаты многолетних исследований, реализовала принципы IPA в рамках своих технологий оптического распознавания символов. ABBYY FineReader – единственная в мире OCR -система, которая действует в соответствии с вышеописанными принципами на всех этапах обработки документа.
В частности, на этапе распознавания фрагмент изображения, согласно принципу целостности , будет интерпретирован как некий объект (символ), только если на нём присутствуют все структурные части этого объекта, и эти части находятся в соответствующих отношениях. Поэтому ABBYY FineReader не пытается принимать решение, перебирая тысячи эталонов в поисках наиболее подходящего. Вместо этого выдвигается ряд гипотез относительно того, на что похоже обнаруженное изображение, затем каждая гипотеза целенаправленно проверяется. Причём проверять, верна ли выдвинутая гипотеза, система будет, используя принцип адаптивности , опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Глава 2. Способы распознавания
2.1 Распознавание объектов высших уровней. Бинаризация
Прежде, чем приступить к структурированию страницы, выделению и идентификации блоков, OCR -система производит бинаризацию , то есть преобразование цветного или полутонового образа в монохромный (глубина цвета 1 бит). Однако современные документы часто содержат такие элементы дизайна, как фоновые текстуры или изображения. После типовой процедуры бинаризации любая текстура оставит большое количество «лишних» точек, расположенных вокруг символов и резко снижающих качество распознавания. Бинаризация фоновых изображений приводит к аналогичным последствиям. Поэтому способность системы правильно отделять текст от «подложенных» текстур и картинок очень важна.

Рисунок 1. Обработка процедурой IBF документа с фоновой текстурой
Иллюстрацией последнего тезиса может послужить пример, показанный на рис.2. Как показывают многочисленные эксперименты, OCR-система, начинающая обработку этой или похожей страницы с типовой процедуры бинаризации, показывает крайне низкий результат. В среднем точность на страницах подобного вида составляет для разных систем от 31,1% до 62,7%, что фактически равносильно отказу от распознавания .
Однако ABBYY FineReader вполне корректно обрабатывает подобные документы; как показывают эксперименты, средняя точность распознавания страниц такого вида равна 98,7% . Успешно разрешить вышеописанную проблему позволяет процедура интеллектуальной фильтрации фоновых текстур, ( intelligent background filtering , IBF ). Запускаемая при необходимости, в зависимости от результатов предварительного анализа страницы, эта процедура позволяет уверенно отделять текст от сколь угодно сложного фона. Более того, и выделение объектов высших уровней – текстовых блоков, таблиц, и т.п. – на страницах сложной структуры после обработки процедурой IBF выполняется значительно точнее.
|
Кол – во пакетов |
Общее кол – во страниц |
Общее кол – во символов |
FineReader без AB |
FineReader с AB |
Разница в кол – ве ошибок |
Улучшение точности, % |
|
4 |
293 |
1.417.126 |
Кол – во ошибок: 22.006 AREC %: 98,45 |
Кол – во ошибок: 18.817 AREC %: 98,67 |
- 3.189 |
14,5 |
Таблица 1. Повышение качества распознавания с помощью адаптивной бинаризации
Как видно из таблицы, применение адаптивной бинаризации позволяет существенно повысить точность распознавания. С точки зрения технического исполнения, идея AB , являющейся частью усовершенствованного алгоритма MDA , заключается в использовании обратной связи для оценки качества преобразования того или иного участка.
2.2 Распознавание символов. Классификаторы
Деление строки на слова и слов на буквы в программном ядре ABBYY FineReader выполняется так называемой процедурой линейного деления. Процедура завершается по достижении конца строки и передаёт для дальнейшей обработки список гипотез, выдвинутых относительно возможных вариантов деления. При этом каждой гипотезе приписывается определённый вес; по смыслу эта величина соответствует численному выражению уверенности. Соответствующий каждой из гипотез набор графических объектов уровня «символ» поступает на вход механизма распознавания символов. Последний представляет собой комбинацию ряда элементарных распознавателей, называемых классификаторами.
Рисунок 2. Примерная схема работы классификатора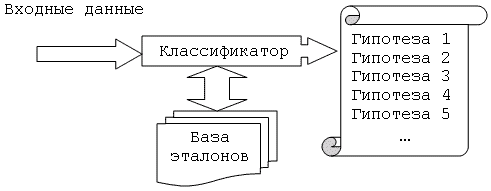
Как показано, по окончании обработки классификатор порождает список гипотез относительно принадлежности очередного изображения к тому или иному классу, либо – в том случае, когда входные данные уже представляют собой список – соответствующим образом изменяет веса имеющихся гипотез, подтверждает или опровергает их. Выходной список всегда ранжирован по весу (уверенности).
Одной из важнейших характеристик классификатора является среднее положение правильной гипотезы. Это обусловлено особенностями процедур контекстной и словарной проверки, обычно задействуемых на этапах дальнейшей обработки списков гипотез. Упомянутые процедуры существенно увеличивают общую точность распознавания, однако лишь в том случае, если правильный вариант в списке расположен не слишком глубоко. Для оценки среднего положения правильного варианта могут быть использованы различные критерии, например, точность по первым трем вариантам распознавания , т.е. процент символов, для которых правильная гипотеза оказалась не ниже третьего места в выходном списке.
Кроме того, среди важных характеристик классификатора называют точность по первому варианту распознавания, быстродействие, простоту реализации, а также устойчивость к различным искажениям, встречающимся в реальных документах (разорванные, залитые, сильно изменившие свою форму символы).
|
типы классификаторов |
|||||
|
растровый |
признаковый |
признаковый дифференциаль -ный |
контурный |
структурный |
структурный дифференциальный |
Таблица 2. Типы классификаторов
Растровый классификатор. Принцип действия основан на прямом сравнении изображения символа с эталоном. Степень несходства при этом вычисляется как количество несовпадающих пикселей. Для обеспечения приемлемой точности растрового классификатора требуется предварительная обработка изображения: нормализация размера, наклона и толщины штриха. Эталон для каждого класса обычно получают, усредняя изображения символов обучающей выборки.
Этот классификатор прост в реализации, работает быстро, устойчив к случайным дефектам изображения, однако имеет относительно невысокую точность. Широко используется в современных системах распознавания символов. В системе ABBYY FineReader на начальном этапе распознавания для быстрого порождения предварительного списка гипотез задействована одна из разновидностей растрового классификатора. Точность этого распознавателя2, оцененная по первым трём позициям списка, составляет 99,29% , точность по первому варианту 97,57%.
Признаковый классификатор. Принцип действия: изображению ставится в соответствие N-мерный вектор признаков. Собственно классификация заключается в сравнении его с набором эталонных векторов той же размерности. Тип и количество признаков в немалой степени определяют качество распознавания. Формирование вектора (вычисление его координат в N -мерном пространстве) производится во время анализа предварительно подготовленного изображения. Данный процесс называют извлечением признаков. Эталон для каждого класса получают путём аналогичной обработки символов обучающей выборки.
Основные достоинства признакового классификатора – простота реализации, хорошая обобщающая способность, хорошая устойчивость к изменениям формы символов, низкое число отказов от распознавания, высокое быстродействие. Наиболее серьёзный его недостаток – неустойчивость к различным дефектам изображения. Кроме того, признаковые классификаторы обладают другим серьёзным недостатком – на этапе извлечения признаков происходит необратимая потеря части информации о символе. Извлечение признаков ведётся независимо, поэтому информация о взаимном расположении элементов символа утрачивается.
Точность работы признакового классификатора сильно зависит от качества выбранных признаков. Под качеством в данном случае понимается их способность максимально точно, но не избыточно, охарактеризовать начертание символа. Чётких правил отбора признаков не существует, поэтому классификаторы от разных разработчиков оперируют различными наборами признаков.
Контурный классификатор. Обособленная разновидность признакового классификатора. Отличается от последнего тем, что для извлечения признаков использует контуры, предварительно выделенные на изображении символа. Принципы функционирования, основные достоинства и недостатки совпадают с названными выше.
Этот классификатор предназначен для распознавания текста, набранного декоративными шрифтами (например, стилизованного под готический, старорусский стиль, и т.п.). Работает несколько медленнее обычного признакового классификатора. Точность контурного классификатора по первым трём вариантам 99,30% , точность по первому варианту 95,10% .
Признаковый дифференциальный классификатор. Предназначен для различения похожих друг на друга объектов, таких, например, как буква « m » и сочетание « rn ». Анализирует только те области изображения, где может находиться информация, позволяющая отдать предпочтение одному из вариантов. Так, в случае с « m » и « rn » ключом к ответу служит наличие и ширина разрыва в месте касания предполагаемых букв.
Признаковый дифференциальный классификатор (ПДК) п редставляет собой набор признаковых классификаторов. Эти последние оперируют эталонами, полученными для каждой пары схожих символов. Для всех пар используется один и тот же набор признаков, аналогичный имеющемуся у соответствующего признакового классификатора. ПДК отличается хорошим быстродействием. Используется в различных системах распознавания символов.
Структурный классификатор. Одна из революционных разработок компании ABBYY. Первоначально был создан и использовался для распознавания рукопечатного текста ( ICR ), затем был успешно применён и для обработки.
Структурно-дифференциальный классификатор. Был разработан и первоначально применялся для обработки рукописных текстов. Как и признаково-дифференциальный , этот классификатор решает задачи различения похожих объектов. Входными данными для структурно-дифференциального классификатора (СДК) также являются ранжированный список гипотез и изображение символа.
Структурно-дифференциальный классификатор работает медленнее, чем все вышеназванные, а процесс его обучения ещё более трудоёмок, чем для ПДК. Поэтому СДК используется в основном для обработки тех пар символов, которые не удалось хорошо различить признаковым дифференциальным классификатором. Важным преимуществом СДК является его весьма высокая точность. Аналогично ПДК, этот классификатор использует алгоритм пузырьковой сортировки списка. Устойчив почти ко всем случайным искажениям формы символа, за исключением запечатывания.
Применяется только в системах распознавания компании ABBYY . Точность распознавателя при добавлении на выходе структурно-дифференциального классификатора увеличивается до 99,88% по первым трём вариантам и до 99,69% по первому варианту.
Заключение
Технология ABBYY FineReader OCR проста в использовании – процесс распознавания в целом состоит из трех этапов: открытие (или сканирование) документа, распознавание и сохранение в наиболее подходящем формате (DOC, RTF, XLS, PDF, HTML, TXT и т. д.) либо перенос данных напрямую в офисные программы, такие как Microsoft® Word®, Excel® или приложения для просмотра PDF.
Кроме того, последняя версия ABBYY FineReader позволяет автоматизировать задачи по распознаванию и конвертации документов с помощью приложения ABBYY Hot Folder. С помощью него можно настраивать однотипные или повторяющиеся задачи по обработке документов и увеличить производительность работы.
Высокое качество технологий распознавания текста ABBYY OCR обеспечивает точную конвертацию бумажных документов (сканов, фотографий) и PDF-документов любого типа в редактируемые форматы. Применение современных OCR-технологий позволяет сэкономить много сил и времени при работе с любыми документами. С ABBYY FineReader OCR вы можете сканировать бумажные документы и редактировать их. Вы можете извлекать цитаты из книг и журналов и использовать их без перепечатывания. С помощью цифровой фотокамеры и ABBYY FineReader OCR вы можете моментально сделать снимок увиденного постера, баннера, а также документа или книги, когда под рукой нет сканера, и распознать полученное изображение. Кроме того, ABBYY FineReader OCR можно использовать для создания архива PDF-документов с возможностью поиска.
Весь процесс преобразования из бумажного документа, снимка или PDF занимает меньше минуты, а сам распознанный документ выглядит в точности как оригинал!
Список использованных источников
- Бурлаков М. CorelDRAW 12. - С-Пб.: БХВ-Петербург,2013.-688с.
- Богданов В., Ахметов К. Системы распознавания текстов в офисе. // Компьютер-пресс - 2012 №3, 40-42 с.
- Шамис А.Л. Принципы интеллектуализации автоматического распознавания / А.Л. Шамис - K:.2000 - 312 с.
- Растригин Л. А., Эренштейн Р. Х. Метод коллективного распознавания. 79 с. ил. 20 см., М. Энергоиздат, 2006 г.
- Арлазаров В.Л., Куратов П.А., Славин О.А. Распознавание строк печатных текстов // Сб. трудов ИСА РАН «Методы и средства работы с документами». - М.: Эдиториал УРСС, 2000. - 31-51 с.
- Багрова И. А., Грицай А. А., Сорокин С. В., Пономарев С. А., Сытник Д. А. Выбор признаков для распознавания печатных кириллических символов // Вестник Тверского Государственного Университета 2010 г., 28, 59-73 с.
- https://ru.wikipedia.org/wiki
- http://remontka.pro/programmy-dlya-raspoznavaniya-teksta

- Основные черты (стилистика и семантика) монгольского центра миниатюры XVI – XVIII вв.
- Творческое мышление и способы его активизации (Понятие и специфика творчества и творческой деятельности)
- Виды трудовых договоров
- Условия привлечения работника к дисциплинарной ответственности
- Анализ методов затратного подхода в оценке бизнеса (Характеристика сравнительного подхода)
- Экспертиза в гражданском процессе (Понятие и признаки судебной экспертизы)
- Экспертиза проекта (Общее понятие экспертизы проекта)
- Интернет и Авторские права
- Содержание и основные положения школы научного управления
- Особенности художественного языка Эль-Греко.
- Основные черты (стилистика и семантика) могольского центра миниатюры XVI – XVIII вв.
- Платёжная система CISLink (О компании CISLink)