
Технологии распознавания текста.
Содержание:

Введение
Широко исследуемой проблемой в настоящее время является распознавание рукописного текста. На данный момент достигнутая точность распознавания даже ниже, чем для рукописного «печатного» текста. Более высокие показатели могут быть достигнуты только с использованием контекстной и грамматической информации. Формы отдельных рукописных символов иногда могут не содержать достаточно информации, чтобы точно (с уровнем более 98%) распознать весь рукописный текст. Методы автоматического распознавания образов и их реализация в системах оптического чтения текстов (OCR-системах – Optical Character Recognition) – одна из самых плодотворных технологий искусственного интеллекта (ИИ). В приведенной трактовке OCR понимается как автоматическое распознавание с помощью специальных программ изображений символов печатного или рукописного текста, например, введенного в компьютер с помощью сканера, и преобразование его в формат, пригодный для обработки текстовыми процессорами, редакторами текстов и т.д. Иногда под OCR понимают устройство оптического распознавания символов или автоматического чтения текста. В настоящее время такие устройства при промышленном использовании обрабатывают до 100 тыс. документов в сутки и позволяет перейти от бумажного к цифровому документообороту, чтобы сэкономить время и деньги, переместить тонны бумажной информации на небольшой жесткий диск или даже в облако и преобразовать отсканированные документы в доступные для чтения и редактирования цифровые файлы.
Методы распознавания и этапы обработки изображения.
Системы распознавания реализуются как классификаторы, использующие различные методы: шаблонные (растровые); признаковые; структурные [2]. В классификаторе шаблонного типа с помощью критерия сравнения определяется, какой из шаблонов выбрать из базы. Самый простой критерий – минимум точек, отличающих шаблон от исследуемого изображения. К достоинствам шаблонного классификатора относятся хорошее распознавание дефектных символов («разорванных» или «склеенных»), простота и высокая скорость распознавания. Недостатком является необходимость настройки системы на типы и размеры шрифтов. В признаковых классификаторах анализ проводится только по набору чисел или признаков, вычисляемых по изображению. Этот метод позволяет распознавать различные начертания символов, т.е. различные подчерки шрифты и т.д. Этот метод неизбежно вызывает некоторую потерю информации, так как используется топологическое представление, отражающее информацию о взаимном расположении структурных элементов символа. Эти данные могут быть представлены в графовой форме. При этом данный метод обеспечивает инвариантность относительно типов и размеров шрифтов. Недостатками являются трудность распознавания дефектных символов и медленная работа. Основой структурно-пятенного метода является структурно-пятенный эталон [2]. Он имеет вид набора пятен с попарными отношениями между ними. Данное представление нечувствительно к различным начертаниям и дефектам символов. Алгоритм основан на сочетании шаблонного и структурного методов распознавания образов. При анализе образца выделяются ключевые точки объекта – так называемые «пятна». В качестве пятен, например, могут выступать: концы линий; узлы, где сходятся несколько линий; места изломов линий; места пересечения линий; крайние точки. После выделения характерных точек определяются связи между ними – отрезок, или дуга. Таким образом, итоговое описание представляет собой граф, который и служит объектом поиска в библиотеке «структурно-пятенных эталонов». При поиске устанавливается соответствие между ключевыми точками образца и эталона, после чего определяется степень деформации связей, необходимая, чтобы привести искомый объект к сравниваемому эталонному образцу. При этом, меньшая степень необходимой деформации предполагает большую вероятность правильного распознавания символа.
Основными этапами являются:
1. Предобработка. На этом этапе выполняются следующие задачи: повышение качества изображения за счет фильтрации, шумоподавления и других, имеющих своей целью повысить качество изображения. На этом этапе происходит очистка изображения от дефектов сканирования. В частности, в самом начале работы к изображению в целях шумоподавления часто применяется фильтр Гаусса. Важную роль играет пороговая бинаризация, то есть перевод изображения в чёрно-белый формат из цветного или оттенков серого [3]. Это позволяет резко разделить текст и фон, упрощает в дальнейшем применение многих алгоритмов, а также избавляет от некоторых шумов на изображении. При этом используется гистограмма яркости изображения текста, на котором наблюдается два пика: высокий пик, соответствующий белому фону, то есть цвету бумаги, и пик в области тёмных пикселей, соответствующих яркости символов текста.
2. Выделение региона интереса. На этом этапе на бинаризованном изображении выделяется непосредственно область, на которой находится распознаваемый текст, и отбрасываются элементы, текстом не являющиеся [3,4]. К ним относятся такие объекты, как кляксы, пятна на бумаге, не удалённые в процессе бинаризации, картинки и др. Для их удаления можно, например, выделять компоненты связности на изображении, вычислять геометрические признаки и на их основе классифицировать компоненту связности как часть текста или дефект, используя методы машинного обучения или эвристики.
3. Сегментация и нормализация текста. На этом этапе текст разделяется, или сегментируется, на удобные для анализа составные части [5]. Наиболее естественными действиями на данном этапе является разделение текста на отдельные строки (сегментация строк) и разделение строк на слова (сегментация слов), а также, теоретически, разделение слов на элементарные составные части. Кроме того, на данном этапе проводится нормализация текста приведение выделенных составных частей к некоторому стандартному виду для снижения вариативности и упрощения распознавания.
Сегментация строк. Задача сегментации (разделения) строк в машинопечатных документах на сегодняшний день считается полностью решённой. Но в задачах при разделении строк в общем случае возникают сложности, не позволяющие напрямую применять алгоритмы, пригодные для машинопечатных текстов:
– строки не только могут не являться параллельными, но и могут изгибаться;
– различные строки могут быть слишком близки, а элементы текста, принадлежащего различным строкам, могут налагаться друг на друга.
Например, если коэффициент формы области (отношения квадрата её периметра к площади) меньше некоторого значения, а площадь больше некоторого значения, то это с большой вероятностью дефект (т.к. рукописный текст обычно является некоторой кривой).
Выделение базовых линий. Эти методы основаны на идее, что человек пишет либо по, либо поверх некоторой воображаемой линии. Данные методы пытаются аппроксимировать эту линию, а затем восстановить по ней строку. В преобразовании Хафа выделяются прямые, если они не слишком искривлены. Преобразование Хафа применяется к центрам компонент связности пикселей текста. Такой подход требует, чтобы строки текста были близки к прямым, но зато позволяет выделять строки, расположенные в произвольном месте и идущие под произвольными углами.
Пересечение элементов различных строк представляет собой проблему не только сегментации строк, но и распознавания текста, так как отнесение элемента к неправильной строке очевидно ухудшает его распознаваемость. Пересекающиеся компоненты являются проблемой для методов горизонтальной проекции (так как они увеличивают значение профиля проекции в тех местах, где должен быть его минимум) группировочных методов (так как они используют связные компоненты пикселей текста для построения строк), но слабо влияют на некоторые методы выделения базовых линий. Для поиска пересекающихся элементов из различных строк можно использовать такие признаки, как размер компонент связности текста, факт отнесения одной компоненты к нескольким строкам или, напротив, не относящимся ни к какой строке. После нахождения таких сомнительных компонент нужно определить, относятся ли они к какой-то строке или же их нужно декомпозировать на элементы, относящиеся к разным строкам. Такая вертикальная декомпозиция компонент сложная задача. Простое решение заключается в разрезании компоненты на части горизонтальными линиями, но можно применить и более тонкие подходы, например, выделение отдельных штрихов.
4. Сегментация слов. На этом этапе работы системы распознавания выделенные строки текста разделяются на отдельные слова. В отличие от машинописного текста, в котором расстояние между словами более-менее постоянно, а интервалы между символами внутри слова гораздо меньше, чем интервалы между словами, в рукописном тексте размер интервалов между словами может варьироваться в очень широких пределах. Компоненты связности текста, отнесённые к одной строке на предыдущем этапе работы системы распознавания, объединяются в слова на этом этапе.
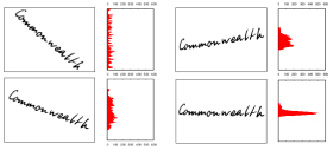
Рис. 1. Коррекция строк по горизонтали с использованием гистограммы профиля

Рис. 2. Коррекция строк по горизонтали с использованием алгоритма линейной регрессии
5. Нормализация. В силу высокой вариативности начертания слов их распознавание является очень сложным процессом [6]. Нормализация служит для приведения слова к некоторому стандартному виду без значительной потери информации, необходимой для распознавания. Одними из наиболее часто используемых методов нормализации является метод коррекции наклона слова от горизонтальной и вертикальной линии [7]. Простейший метод коррекции по горизонтали состоит в выполнении максимизации его на некотором диапазоне (рис. 1). Существуют и другие методы нормализации, например, коррекция размера и выделение скелета текста, но они применяются реже, а также методы, основанные на сглаживании и линейной регрессии
Характеристика технологии
OCR – это использование технологии для идентификации и преобразования отсканированных рукописных или печатных текстовых символов в электронную форму, более легко распознаваемую компьютерами и другими программами. Базовый процесс распознавания включает изучение текста и перевод символов в код, который можно использовать для обработки данных. OCR иногда также называют распознаванием текста.
Технология состоит из сочетания аппаратного и программного обеспечения, которое используется с целью преобразования физических документов в машиночитаемый текст. Аппаратное обеспечение, такое как оптический сканер или специализированная монтажная плата, используется для копирования или чтения текста, в то время как программное обеспечение отвечает за расширенную обработку. Программное обеспечение может использовать искусственный интеллект для реализации более совершенных методов интеллектуального распознавания (ICR), таких как идентификация языков или стилей рукописного ввода.
OCR чаще всего используется для преобразования печатных юридических или исторических документов в PDF-файлы. После этого полученные электронные копии пользователи могут редактировать, форматировать при помощи обычных редакторов текста. Первым шагом процесса оптического распознавания является использование сканера с целью обработки физической формы документа. После копирования всех страниц программа OCR преобразует документ в двухцветную или черно-белую версию. Отсканированное растровое изображение анализируется на наличие светлых и темных областей. При этом темные области идентифицируются как символы, которые необходимо распознать, а светлые области – как фон. После этого темные области обрабатываются для поиска букв или цифр.
Существующие программы распознавания могут иметь разные методы работы, но, как правило, все они включают таргетинг на один символ, слово или блок текста. Для идентификации символов используются два основных алгоритма.
- Обработка распознаваемого материала происходит на примерах различных шрифтов и текстовых форматов.
- Распознавание основывается на использовании правил обнаружения признаков, касающихся особенностей конкретной буквы или цифры (ICR). С помощью функции обнаружения программное обеспечение оценивает данные документа в соответствии с правилами о том, как формируется буква или цифра. Например, заглавная буква «А» может храниться как две диагональные линии, пересекающиеся с горизонтальной линией посередине.
Когда символ идентифицирован, он преобразуется в код ASCII, который может использоваться компьютерными системами. Перед сохранением для дальнейшего использования обработанные тексты необходимо проверить на содержание ошибок, на правильность сложных макетов.
Варианты использования - схема
- Сканирование печатных документов в версии, которые можно редактировать с помощью обычных редакторов текста.
- Индексирование печатного материала для поисковых систем.
- Автоматизированная обработка и ввод данных.
- Расшифровка документов в текст, который может быть прочитан вслух для пользователей с нарушениями зрения.
- Архивирование исторической информации (газет, журналов), а также поиск по ним.
- Извлечение данных и передача в бухгалтерские программы (квитанции, счета).
- Размещение важных подписанных юридических документов в электронной базе данных.
- Распознавание номерных знаков с помощью камеры контроля скорости и программного обеспечения камеры с подсветкой.
- Сортировка писем для доставки почты.
- Перевод слов в изображении на заданный язык.
- Обеспечение поиска отсканированных книг.
OCR (англ. optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер.
Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы (например, в формате JPG). Для компьютера нет разницы между фотографией текста и фотографией дома: и то, и другое — набор пикселей.

Именно OCR превращает изображение текста в текст. А с текстом уже можно делать что угодно. У каждой буквы (и любой другой графемы) есть аллографы — различные варианты начертания. Для компьютера же есть два способа решения проблемы: распознавать символы целостно (распознавание паттерна) или выделять отдельные черты, из которых состоит символ (выявление признаков). В 1960-х годах был создан специальный шрифт OCR-A, который использовался в документах типа банковских чеков. Каждая буква в нем была одинаковой ширины (т.н. шрифт фиксированной ширины или моноширинный шрифт). Принтеры для чеков работали с этим шрифтом, и для его распознавания было разработано программное обеспечение. Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах (Times, Helvetica, Courier и т.д.). Этот способ еще называют интеллектуальным распознаванием символов (англ. intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы.
Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.
В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из:
1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью;
2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией;
3) извлечение изображений размеченных символов на основе этого соотнесения;
4) выбор из размеченных символов подходящих обучающих примеров.
Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
- Нейросети-трансформеры — самая популярная и успешная нейросетевая архитектура наших дней. Работает энкодер и механизм «многоголового» внимания так :
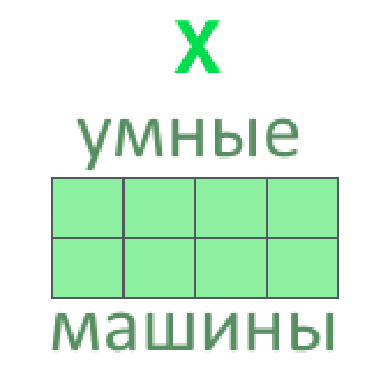
- Каждое входное слово кодируем вектором (поможет word2vec, fasttext, ELMo)
- Несколько векторов слов склеиваем во входную матрицу (одна строка — одно слово)
3. Из входной матрицы делаем три: Q, K, V (запрос, ключ, значение)
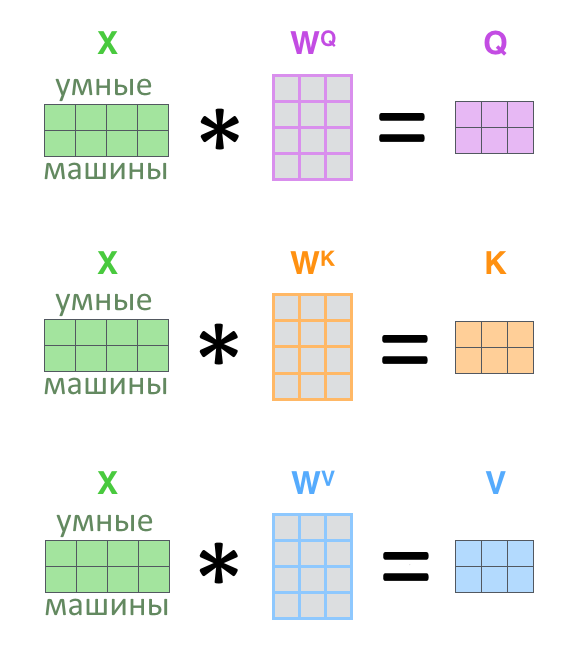
4. Задача внимания — найти, каким ключам K соответствует запрос Q и выдать соответствующие ключам значения V
5. Для этого Q, K, V перемножаются по правилам из предыдущего текста, и выходит матрица Z, результат «головы внимания»
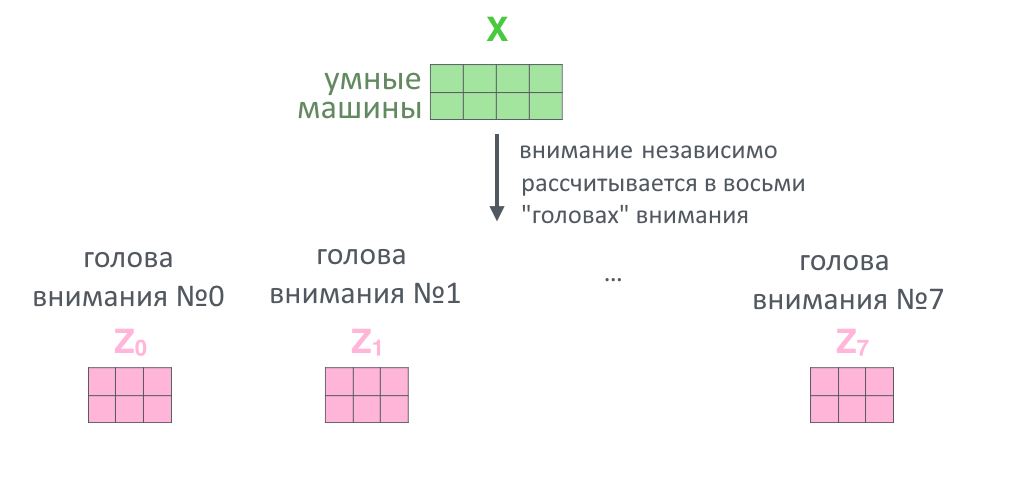
6. Для ускорения работы сети матрицы приходится сокращать (делить на квадратный корень длины ключа K)
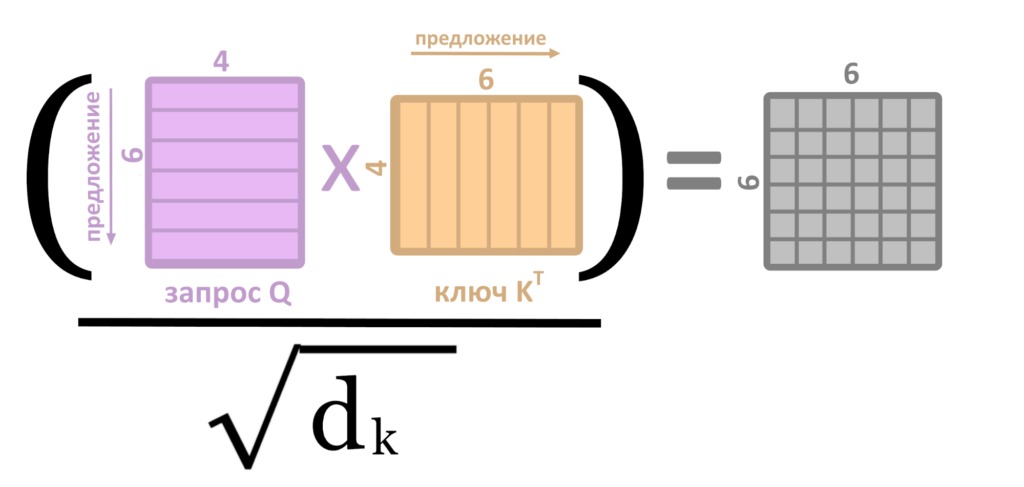
7. Вся история проделывается восемь раз параллельно с разными ключами, запросами и значениями (в начале работы их задают случайно): так внимание смотрит на разные смысловые «фишки» тех или иных слов
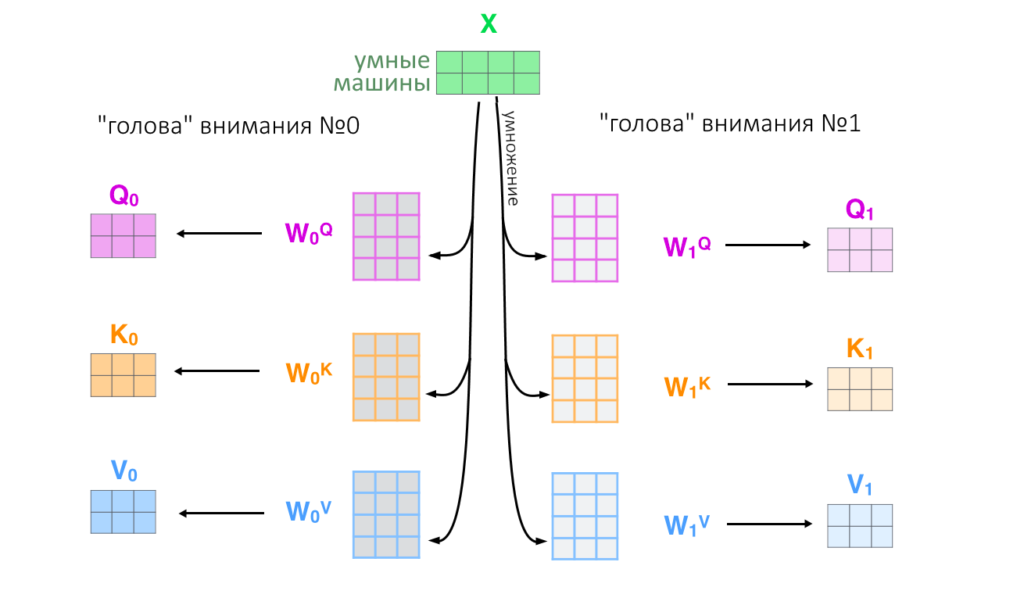
8. Восемь результатов Z(h), по одному от каждой «головы внимания h» склеиваются в большую матрицу, еще раз умножаются на матрицу весов
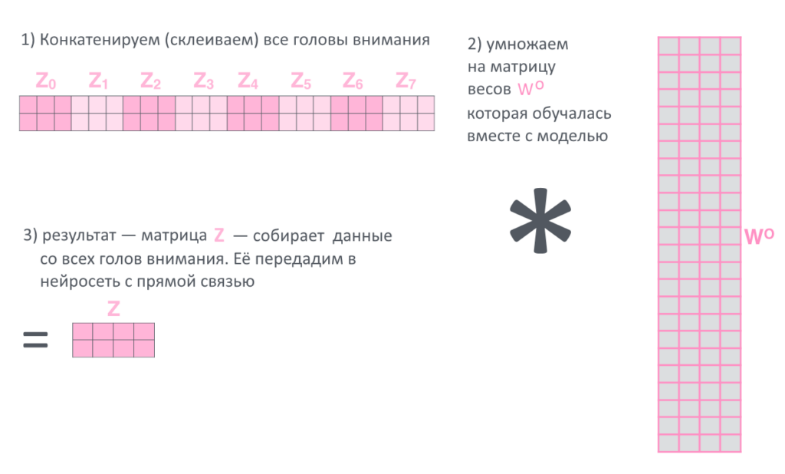
9. Всё. Финальное произведение назовём просто Z и посмотритм, что происходит с ним дальше.
Добавляем нормализацию
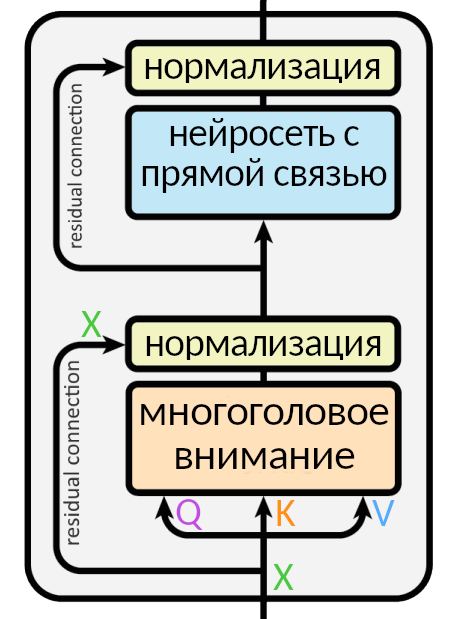
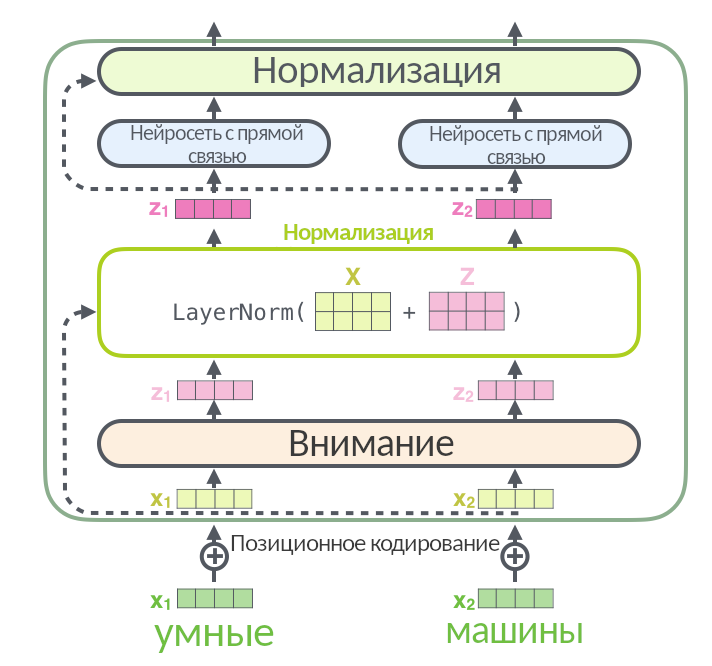
Так выглядит слой энкодера без упрощений. Входная матрица разбивается на три, (Q, K, V), проходит через внимание, а результат (мы называли его Z) складывается со входной матрицей X и нормализуется через функцию LayerNorm: эта операция помогает быстрее тренировать нейросеть.
Стрелка вокруг слоя внимания, ведущая к нормализации, называется residual connection, она есть в каждом слое энкодера и декодера. Она означает, что нормализуется не просто Z, а (Z + X). Нормализация появляется после каждого «внимания» и каждой нейросети с прямой связью и в энкодере, и в декодере.
Вот иллюстрация, заглядывающая в нормализацию поглубже:
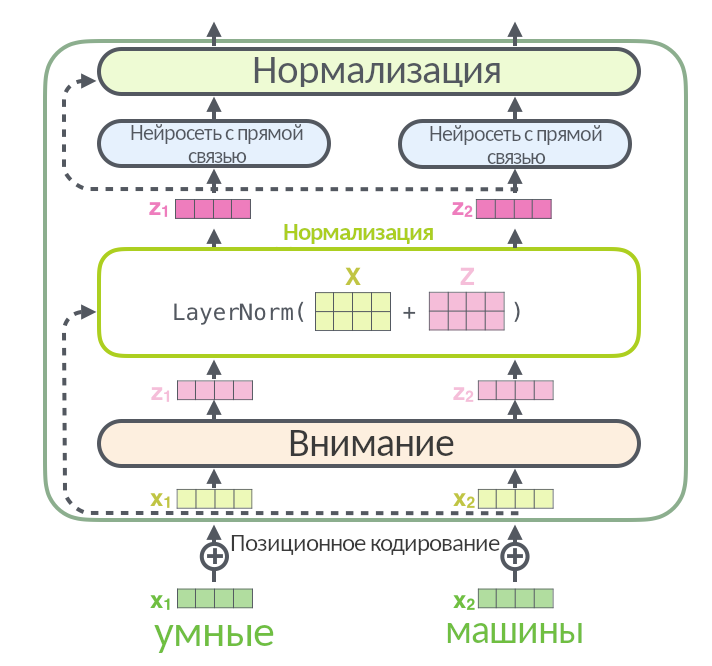
На картинке выше перед слоем энкодера добавился новый элемент — позиционное кодирование. Оно не входит в энкодер, а производится до него. Если нейросеть принимает на вход слова целыми пачками (как трансформер и делает, склеивая отдельные слова в матрицы), теряется информация о том, что за чем идёт в предложении, какие слова друг от друга близко, а какие — далеко. Эта проблема решается позиционным кодированием. В рекуррентной нейросети не надо никак отдельно кодировать позицию слова — они подаются друг за другом и обрабатываются по очереди. В трансформере нет рекуррентности, то есть нейросеть одновременно смотрит только на ту «стопку» слов, которую ей выдали, и не смотрит на свою предыдущую работу из прошлой «стопки». Чтобы закодировать позицию слова, программисты взяли функции синуса и косинуса: они изменяются циклично и через конкретные промежутки. Можно выбрать несколько синусоид с разными периодами:

Поделим графики на вертикальные кусочки и закодируем положение каждого графика числом от −1 до 1. Каждому слову — свой столбик.
Соседние столбики будут иметь разные значения «быстрых» синусов или косинусов, но близкие значения «медленных». Если два слова стоят далеко друг от друга, их «медленные» графики будут в разных позициях.
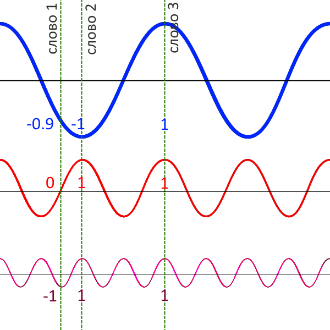
У близких столбиков близки значения синей синусоиды, у далеких они разные
В столбце получился набор чисел, позиционный вектор. Позиционный вектор складывается с начальным вектором слова, в этом состоит суть позиционного кодирования.
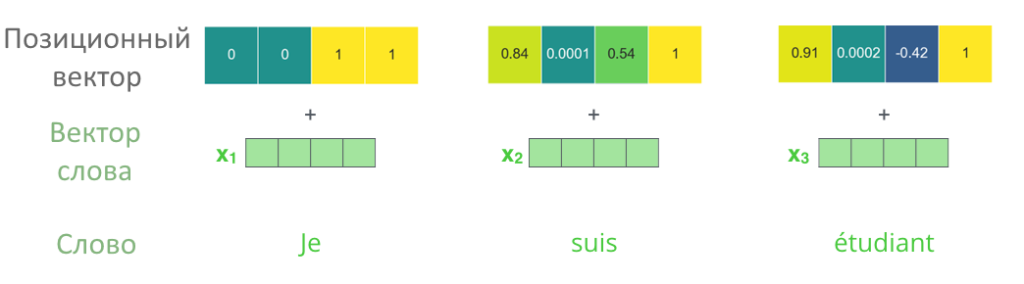
Позиционное кодирование выполняется только перед первым кодирующим слоем, когда вектора слов еще совсем «сырые». Когда энкодер передает вектора с первого на второй слой или со второго на третий, с ними ничего дополнительно не происходит.
Итого в одном слое энкодера «спрятаны» четыре отдельных части вот в таком порядке:
- Позиционное кодирование (перед самым первым слоем, поэтому нулевой номер)
- Многоголовое внимание на себя
- Нормализация
- Нейросеть с прямой связью
- Опять нормализация
Кодирующих слоёв — шесть. Они передают друг другу свой результат (матрицу) по цепочке. Только с результатом последнего, шестого слоя энкодера работает декодер.
Декодер в целом работает точно так же, как энкодер, но с небольшими различиями. Вот они:
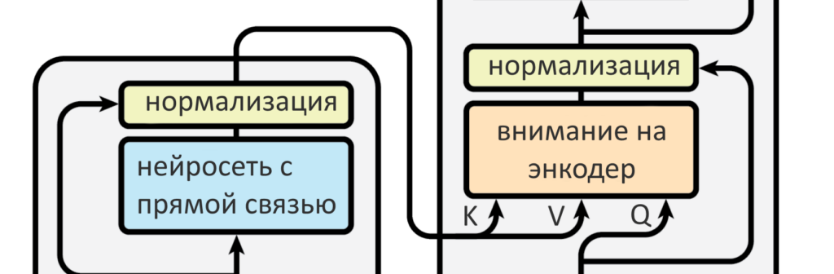
- В слое декодера два слоя внимания: одно — на свою прошлую работу, («на себя»), другое — на энкодер
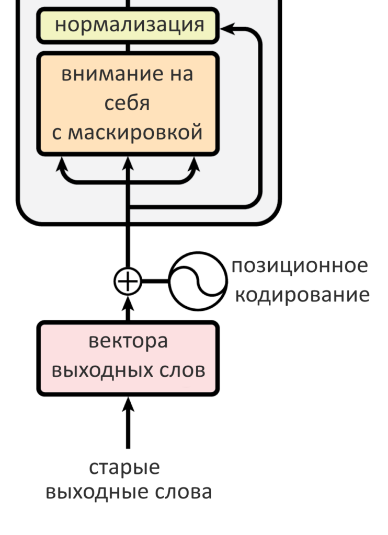
- Внимание декодера «на себя» смотрит на предыдущие слова в выходном предложении, маскируя все остальные (ведь они подаются одновременно, всей матрицей)
- Внимание «на энкодер» формирует свой запрос Q, а ключи K и значения V берет у энкодера
- Перед первым слоем декодера слова выходного предложения тоже позиционно кодируются
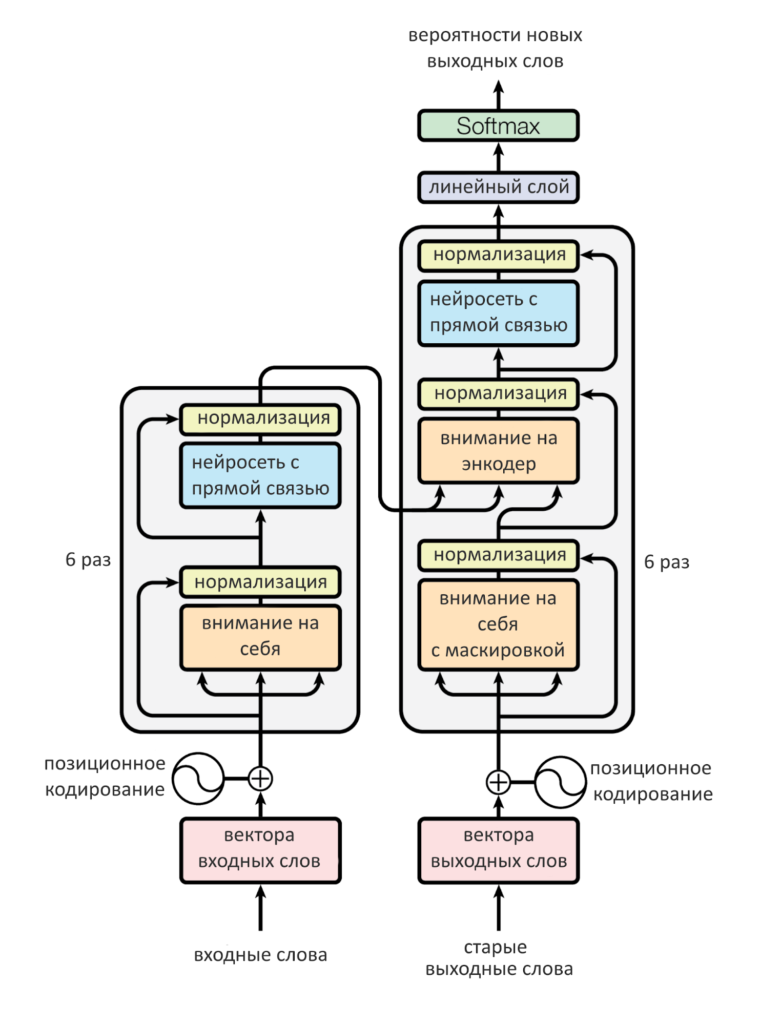
Всё устройство трансформера — на схеме. Энкодер слева, декодер — справа
Слои внимания энкодера были вниманием «на себя»: и запрос, и ключи, и значения они брали у самих себя из прошлого, то есть с прошлых слоев. Если слой первый — то прямо с входных слов (с позиционным кодированием). В декодере два слоя внимания: один «на себя», другой — на энкодер. Тот, что «на себя» берет Q, K и V с уже сгенерированных декодером до него слов. Если это самый первый шаг и пока ничего не сгенерировано, он пропускается. Внимание на энкодер генерирует собственный запрос Q, а вот ключ K и значения V берет у энкодера. В этом есть смысл: декодер ведет себя как пользователь, для которого матрицы энкодера — как база данных Ютуба или Гугла, где надо найти то, что его интересует. Стрелки от энкодера к декодеру показывают как раз передачу ключей и значений.
Если нейросеть работает с текстовой информацией, обычно она генерирует «наиболее вероятные» слова. Сгенерированные выходные слова могут быть переводом, продолжением истории или кратким пересказом, в зависимости от задачи, под которую тренируется нейросеть. Если хотите научить ее переводить — придется дать многоязычный корпус текста, где есть целая книжка и ее перевод. Нужно научить нейросеть краткому пересказу — придется найти корпус, в котором есть длинные истории, а следом их изложение. Нейросети без разницы, для чего генерируются вектора новых слов: они просто генерируются такими, какими наверное могли бы быть в обучающем корпусе.
Если обучающий корпус очень большой и разнообразный, нейросеть получится универсальной, но может давать не такие точные результаты, как «заточенная» на конкретную задачу модель. О том, как «заточить» нейросеть под нужную задачу и как измерить, хорошо ли она справляется, можно будет прочитать в тексте Системного Блока про предобучение и трансферное обучение. Если декодер уже успел что-нибудь сгенерировать, включается слой внимания декодера «на себя». Декодер генерирует по слову за раз, но мы знаем, что на входе трансформер не работает с одним словом и его вектором — вместо этого на вход энкодеру и декодеру подается по матрице, где спрятаны все слова входного предложения и все уже известные — выходного. Проблема в том, что эти матрицы — фиксированных размеров, а матрица декодера все время заполняется новыми значениями, ранее неизвестными. Если ее нельзя «растягивать» по мере необходимости (к сожалению, нельзя), приходится писать значения «-inf» на месте тех слов, которые еще не успели сгенерироваться. Это обеспечивает отсутствие у них веса внимания, а значит, модель «смотрит» только на работу энкодера и на предыдущий результат декодера. Запись «значений-болванок» на месте будущих слов и называется маскировкой.
Кстати, правильнее было бы говорить не «матрица», а «тензор»: нейросети работают именно с ними. Разница в том, что матрицу можно понять как двухмерную таблицу, а тензор уже как минимум трехмерен. Трехмерность тензора достигается из-за того, что одно слово кодируется последовательностью чисел, как бы строкой из них, одномерной бумажной ленточкой. Предложение кодируется уже перечнем таких строк, можно представить его как двухмерный лист книги, одна строка — одно слово. Если же нужно закодировать несколько предложений, и при этом не переносить предложения с листа на лист, придется выбрать длину листа (длину самого большого предложения) и записать каждое предложение на отдельном «листе» — в двухмерной матрице. Сложим их в стопочку — получится трехмерный тензор. «Финальный слой» умножает выдачу декодера на очень широкую матрицу: ширина матрицы — количество слов в словаре модели (допустим, сто тысяч). После умножения получается вектор из ста тысяч чисел (его называют logits): первое число показывает вероятность, что следующее слово — абакан (или другое первое слово по алфавиту), второе число — вероятность «абажура» (или какого-то другого второго слова) и так далее до конца словаря. Чтобы большие значения вероятности стали еще больше, а маленькие — еще меньше, применяют Softmax: он как бы добавляет «резкости» предсказанию, чтобы из всех слов можно было выбрать одно самое вероятное. С 2017 года исследовательские группы IT-гигантов придумали немало по улучшению стандартного трансформера. Наверное, главная проблема трансформера — в том, что вычислительная сложность механизма внимания — в квадратичной зависимости от ширины «окна» внимания, обычно в 512 токенов. Поэтому окна не получается делать очень уж широкими, компьютер не успевает считать. Чтобы обработать большой текст, приходится внахлест делить его на окна фиксированного размера и обрабатывать по очереди. Решение — упростить механизм внимания или добавить постоянной памяти трансформеру. С этими идеями появились Longformer, Reformer, Transformer-XL, Sparse Transformer и другие архитектуры.
Заключение
До того, как появилась технология OCR, единственным методом оцифровки бумажных носителей была ручная повторная печать текста. Этот процесс занимал много времени, а также часто приводил к ошибкам при печати. Использование OCR экономит время, помогает исключить ошибки, минимизировать усилия. Кроме этого, технология позволяет выполнять действия, которые недоступны для физических копий, например, может использовать сжатие в ZIP-файлы, выделять ключевые слова, размещать документы на веб-сайте, прикреплять их к электронной почте. Распознавание напечатанного текста сегодня не представляет проблем для современных офисных систем, однако множество документов клиенты всё еще продолжают заполнять от руки. Это вынуждает специалистов просматривать их глазами, а затем перепечатывать вручную. Новая российская система распознавания текста способна оперативно оцифровывать документы, содержащие в себе как напечатанные, так и рукописные фрагменты. Основную работу выполняет искусственный интеллект, который в сложных случаях прибегает к помощи человека. В настоящее время новинку уже используют в одной из страховых компаний при оцифровке заполненных вручную заявлений. Заинтересовались ею также энергетики и банкиры — широкое внедрение системы позволит бизнесу сократить операционные затраты на обслуживание клиентов и исключить ошибки при работе с бумагами. В перспективе подобные алгоритмы могут найти применение и в медицинском обслуживании, что снимет значительную часть нагрузки со специалистов Избавить менеджеров от рутины должна помочь новая российская разработка, способная оцифровывать документы, заполненные по старинке За счет решения, соединившего работу нейросети и человека, при обработке документов удается избежать большинства опечаток и ошибок, которые могут делать работники компаний, пока еще не автоматизировавших свои бизнес-процессы. Задача распознавания рукописного текста исключительно с помощью систем искусственного интеллекта является наиболее сложной для IT-отрасли, поскольку даже нейронные сети в мозге человека далеко не всегда могут разобрать почерк другого человека, а иногда и свой собственный. Именно поэтому многие компании пока просто не берутся за разработку систем, способных выполнять такие задачи. Нейросети, научили определять COVID-19 по изображениям легких. Для этого программа анализируют оцифрованные рентген-снимки. Нейросеть составляет заключение, где указывает на наличие или отсутствие четырех характерных для коронавирусной пневмонии признаков и рассчитывает вероятность диагноза «COVID-19». Точность постановки диагноза по трем из четырех признаков доходит до 94%.
Список литературы
- The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. — обязательно загляните
- Статья Attention Is All You Need
- Attention Is All You Need — видеолекция на Ютубе
- Glossary — transformers 2.11.0 documentation — объяснения и документация на английском
-
Полюхин Д.А., Сальников И.И. МЕТОДЫ И ЭТАПЫ РАСПОЗНАВАНИЯ РУКОПИСНОГО ТЕКСТА // Научное обозрение. Педагогические науки. – 2019. – № 3-2. – С. 71-74;
-
URL: https://science-pedagogy.ru/ru/article/view?id=1959 (дата обращения: 16.12.2020).
- Optical character recognition (OCR)
- Unsupervised Extraction of Training Data for Pre-Modern Chinese OCR
- Нейросети-трансформеры: как работает декодер

- Развитие унификации и стандартизации документов (Понятие унификации и стандартизации документов.)
- Управление работами по проекту (Основные понятия)
- Управление работами по проекту (По учебной дисциплине «Организация управления проектами»)
- Тайм менеджмент студента: Особенности организации времени студента, инструменты, техники, приемы, организации времени.
- Место и роль финансов в экономической системе.
- Исполнительная власть и государственное управление.(Специфика государственного управления.)
- Методы мотивации персонала
- Формирование и развитие команды проекта (Принципы формирования команды проекта:)
- Роль установок, мотивации и эмоциональных реакций в процессе запоминания (Процесс запоминания в психологии)
- Документооборот в ресторане (основная часть)
- Общество с ограниченной ответственностью. Преимущества и недостатки как организационно-правовой формы (ООО)
- Актуальность темы, связи «себестоимость-цена»