
Технология «клиент-сервер» (Определение сервера и клиента )
Содержание:

Введение
Выполнение какой-либо совокупности действий ("запрашивает услугу"), а другая ее выполняет, называется технологией "клиент-сервер". Участники такого взаимодействия называются соответственно клиентом (client) и сервером (server). Достаточно часто клиентом (или сервером) называют компьютеры, на которых функционирует то или иное клиентское (или серверное) программное обеспечение[9]. Следует особо отметить, что набор действий, понимаемых как запрашиваемая услуга, - это не обязательно чтение (получение) объекта. В том числе это может быть сохранение (запись), пересылка объекта и т.д. Целью работы является изучение структуры и алгоритмов взаимодействия программных блоков интеллектуальной системы для оценки сложных объектов, построенной по принципу «клиент\сервер». В связи с поставленной целью были определенны следующие задачи:
- Рассмотреть понятие сервера и клиента ;
- Выявить роль сервера и клиента в архитектуре клиент-сервер;
- Изучить понятие прикладных протоколов;
- Рассмотреть основные принципы построения распределённых информационных систем;
- Охарактеризовать сетевые операционные системы.
Объектом исследования курсовой работы является изучение модели«клиент\сервер». Предметом исследования является взаимодействия программных блоков интеллектуальной системы для оценки сложных объектов, построенной по принципу «клиент\сервер».
Определение сервера и клиента
При большом числе компьютеров (десятки, сотни и даже тысячи) предприятия чаще всего полагаются на сети модели «клиент-сервер». Упрощенно можно считать, что в такой сети отдельный компьютер подключается к одному или нескольким мощным компьютерам, которые называются серверами.
Сервер - это компьютер, или выполняющаяся на нём программа, которая предоставляет клиентам доступ к общим ресурсам и управляет этими ресурсами.
Клиент - пользователь (получатель) услуг и/или ресурсов, которые предоставляет сервер.
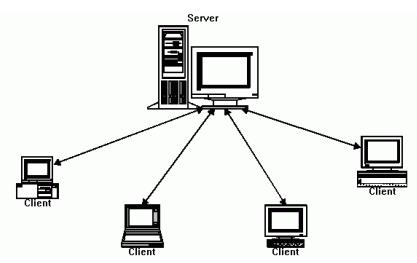
Рис. 1. Модель клиент-сервер
В серверных сетях серверы оснащены процессорами типа Intel Pentium 4 и сетевой операционной системой.
Роль сервера и клиента в архитектуре клиент-сервер
Роль серверов состоит в обеспечение централизованной защиты и управлении трафиком, а так же в предоставление клиентам ресурсов: информации, приложений и доступа к устройствам совместного пользования (например, к принтерам). В клиент - серверной среде в роли клиентов выступают настольные ПК (именно ПК, а не неинтеллектуальные терминалы!) под управлением операционной системы типа Windows 95 или Windows NT Workstation. Как правило, клиент использует собственные вычислительные мощности для обработки информации, полученной от сервера, но полагается на сервер в части предоставления необходимых данных и приложений[2]. Такое распределение ролей в обработке информации носит название клиентской (front - end) и серверной (back - end) обработки.
Наряду с успешным функционированием в собственной «родной» среде, сети модели клиент - сервер могут работать с микрокомпьютерами и мэйнфреймами. Именно эта гибкость в сочетании достаточно низкой (по сравнению с традиционными решениями) стоимостью и составляет привлекательность клиент - серверных сетей. Работая в такой среде на компьютере - клиенте, можно «вкушать плоды» трех разных методов обработки информации: автономной работы, взаимодействия с другими ПК сети и подключения к серверу или мэйнфрейму для доступа к хранящейся там информации.
Понятие прикладных протоколов
Необходимо различать понятия сетевых приложений и протоколов прикладного уровня. Протоколы прикладного уровня являются частью (хотя и весьма большой) сетевых приложений. Рассмотрим два примера. Web является сетевым приложением, позволяющим пользователям получать web-документы по запросу и состоящим из множества компонентов, включая стандарт формата документов (HTML), браузеры (Netscape Navigator, Microsoft Internet Explorer и др.), web-серверы (например, Apache, Microsoft или Netscape), протоколы прикладного уровня. Протокол прикладного уровня для web носит название протокола передачи гипертекста (HyperText Transfer Protocol, HTTP) и описывает формат и порядок обмена сообщениями между клиентом и сервером (RFC 2646). Таким образом, HTTP является лишь частью web-приложения.
В качестве второго примера рассмотрим приложение электронной почты. Электронная почта Интернета также состоит из множества компонентов: почтовых серверов, содержащих почтовые ящики пользователей, программ для просмотра и создания электронных писем, стандартов, описывающих структуру электронных писем, протоколов прикладного уровня, регламентирующих порядок обмена сообщениями серверов между собой и с оконечными системами пользователей, а также интерпретацию полей, из которых состоят электронные письма[8]. Основным протоколом прикладного уровня для электронной почты является протокол простой передачи сообщений (Simple Mail Transfer Protocol, SMTP). Как мы видим, SMTP (RFC 2821) -- лишь часть (хотя и достаточно большая) структуры приложений электронной почты.
Как сказано выше, протоколы прикладного уровня определяют способ обмена сообщениями между двумя процессами, выполняющимися на разных оконечных системах. Обычно протокол определяет следующие элементы:
- типы используемых сообщений, например запросы и ответы;
- синтаксис каждого из типов сообщений, описывающий поля сообщения и их разделители;
- семантику полей, то есть смысл информации, содержащейся в каждом из полей сообщения;
- правила, описывающие события, которые вызывают генерацию сообщений.
Некоторые из протоколов прикладного доступа (HTTP, SMTP и др.) являются официально документированными в RFC. Это означает, что если разработчик нового браузера будет следовать стандарту, то браузер сможет получать документы с любого web-сервера, построенного по этому же стандарту. Тем не менее существует множество протоколов прикладного уровня, которые не стандартизированы и при этом используются для поддержки коммерческих продуктов. В частности, это характерно для Интернет-телефонии.
Протокол ICMP (Internet Control Message Protocol) - протокол межсетевых управляющих сообщений. С помощью этого протокола компьютеры и устройства сети обмениваются друг с другом управляющей информацией. К примеру, этот протокол используется для передачи сообщений об ошибках, проверки доступности узла и т.д.
Протокол FTP (File Transfer Protocol) - протокол передачи файлов. Служит для обмена файлами между компьютерами. Например, вам нужно передать файл на сервер или, наоборот, скачать файл с сервера. Для этого вам нужно подключиться к файловому серверу (он же FTP-сервер) и выполнить необходимую вам операцию скачивания или закачки. Подключение осуществляется с помощью FTP-клиента. Простейший FTP-клиент входит в состав практически любой операционной системы. Кстати, просматривать FTP-серверы могут и обычные браузеры.
Протокол HTTP (Hyper Text Transfer Protocol) - протокол обмена гипертекстовой информацией, то есть документами HTML. Вы, наверное, слышали, что HTML является базовым языком для создания веб-страниц. Так вот, протокол HTTP предназначен для передачи веб-страниц по сети. Таким образом, протокол HTTP используется веб-серверами, а браузеры - программы, служащие для просмотра веб-страниц, - являются HTTP-клиентами.
Протоколы POP и SMTP. Протокол POP (Post Office Protocol) - протокол почтового отделения. Этот протокол используется для получения электронной почты с почтовых серверов. А для передачи электронной почты служит протокол SMTP (Simple Mail Transfer Protocol).
Протокол IMAP. Для чтения почты может использоваться еще один протокол - IMAP. Его отличие от протокола POP состоит в том, что пользователь читает сообщения электронной почты, не загружая их на свой компьютер. Все сообщения хранятся на сервере. При удалении сообщения оно удаляется с сервера.
Протокол SLIP (Serial Line Internet Protocol) - протокол подключения к сети Интернет по последовательной линии. Используется для установления связи с удаленными узлами через низкоскоростные последовательные интерфейсы. В настоящее время вытеснен протоколом РРР и практически не используется.
Протокол РРР (Point-to-Point Protocol) - обеспечивает управление конфигурацией, обнаружение ошибок и повышенную безопасность при передаче данных на более высоком уровне, чем протокол SLIP. Поэтому при настройке сервера рекомендуется использовать именно этот протокол. Протокол РРР рассмотрен в RFC 1547 и RFC 1661.
Протокол RIP (Routing Information Protocol) - используется для маршрутизации пакетов в компьютерных сетях. Для маршрутизации также используется протокол OSPF (Open Shortest Path First), который является более эффективным, чем RIP.
Представление данных в системах обработки данных
Уровни представления данных. СОД хранят и обрабатывают информацию об объектах реального мира. Некоторую совокупность информации, описывающую конкретный объект, называют логической записью или просто записью. Совокупность записей, охватывающих множество объектов определенного класса, называют информационным массивом. В реальном мире между объектами существуют определенные отношения и взаимосвязи, имеющие различную степень сложности. В процессе разработки в СОД эти отношения выявляются и отображаются путем структуризации записей и информационных массивов. Организация информационного массива, обеспечивающая определенные связи и отношения между данными, называется структурой данных. Любые манипуляции над данными в процессе их обработки на ЭВМ не должны разрушать структуру данных, поэтому ее необходимо все время поддерживать.
Существует 3 уровня представления данных: логический уровень,уровень хранения и физический уровень.
На логическом уровне работают с логическими структурами данных, отражающими реальные отношения между объектами и их характеристиками.
При разработке логических структур данных учитывается также информационная потребность пользователей системы и характер задач, для решения которых редназначена СОД. Единицей информации на этом уровне является логическая запись. Каждый объект, описываемый соответствующей логической записью, характеризуется определенными признаками, являющимися атрибутами записи.
На логическом уровне устанавливается перечень признаков, полностью характеризующий описываемый класс объектов. Совокупность признаков и их взаимосвязь определяют внутреннюю структуру логической записи.
Логическая структура данных должна исчерпывающе характеризовать объекты, сведения о которых обрабатываются СОД, адекватно отражать реальные отношения между объектами и их характеристиками, обеспечивать удовлетворение информационных потребностей пользователей системы и решение задач приложений.
На логическом уровне представления данных не учитывается техническое и математическое обеспечение системы (тип ЭВМ, типы памяти, язык программирования, операционная система).
На уровне хранения оперируют со структурами хранения ? представлениями логической структуры данных в памяти ЭВМ. Структура хранения должна полностью отображать логическую структуру данных и поддерживать ее в процессе функционирования СОД. Единицей информации на этом уровне также является логическая запись.
При разработке или выборе структуры хранения должны учитываться особенности организации памяти ЭВМ. При этом устанавливается тип и формат данных, определяется способ поддержания логической структуры[7].
Известны различные способы представления данных в оперативной памяти и на внешних носителях, причем одна и та же логическая структура данных может быть реализована в памяти ЭВМ различными структурами хранения. Каждая структура хранения предоставляет определенный способ доступа к данным и определенные возможности манипулирования данными. Структура хранения характеризуется объемом памяти, необходимым для размещения данных.
От выбора структуры хранения непосредственно зависит эффективность обработки данных. Правильно выбранная структура хранения обеспечивает минимальный расход машинной памяти, быстрый поиск нужных данных, возможность добавления новых и удаления устаревших записей без разрушения логической структуры, а также возможность корректировки записей.
Поддержание структуры хранения осуществляется программными средствами. Для реализации структуры хранения требуются определенные языки программирования, возможности которых следует учитывать при разработке или выборе структуры хранения.
На физическом уровне представления данных оперируют с физическими структурами данных. На этом уровне решается задача реализации структуры хранения непосредственно в конкретной памяти конкретной ЭВМ. Единицей информации на этом уровне является физическая запись, представляющая собой участок носителя, на котором размещается одна или несколько логических записей. При разработке структур памяти анализируются параметры конкретных технических средств: тип и объем памяти, способ адресации, методы и время доступа. На этом же уровне решаются задачи по организации обмена данными между оперативной и внешней памятью ЭВМ.
При разработке структур данных всех уровней должен обеспечиваться принцип независимости данных. Физическая независимость данных означает, что изменения в физическом расположении данных и в техническом обеспечении системы не должны отражаться на логических структурах и прикладных программах, т.е. не должны вызывать их изменений. Логическая независимость данных означает, что изменения в структурах хранения не должны вызывать изменений в логических структурах данных и в прикладных программах. Кроме того, изменения, вносимые в логические структуры данных в связи с появлением новых пользователей и новых запросов, не должны отражаться на прикладных программах других пользователей системы.
Основные принципы построения распределённых информационных систем
В основу функционально-модульного подхода положен принцип алгоритмической декомпозиции, в соответствии с которым производится разделение функций ИС на модули по функциональной принадлежности, когда каждый модуль системы реализует один из этапов общего процесса. Традиционный функционально-модульный подход к разработке ИС предусматривает строго последовательный порядок действий (так называемая "модель водопада"). По мнению Страуструпа[1], главный недостаток модели "водопада" заключается в склонности информации течь только в одну сторону. Если проблема оказывается "внизу по течению", то часто возникает сильный организационный и методический нажим с целью проводить лишь ограниченные исправления и разрешить проблему без воздействия на предыдущие стадии проекта. Такая недостаточная обратная связь приводит к проектированию, ущербному во многих отношениях, а ограниченные исправления ведут к деформированным реализациям[9]. Изменение требований к системе может привести к ее полному перепроектированию, поэтому ошибки, заложенные на ранних этапах, сильно сказываются на времени и конечной цене разработки. Ориентация на такую последовательную модель увеличивает вероятность того, что будет утрачен контроль над решением возникающих проблем.
Следующей проблемой, на которую необходимо обратить внимание, является разнородность информационных ресурсов, используемых в корпоративных системах.
Проблема разнородности требует решения в виде методики интеграции ресурсов ИС. Такая методика должна определять системную архитектуру, позволяющую обеспечить взаимодействие компонентов ИС. В силу организационных и технических причин подобная интеграционная архитектура должна базироваться на распределенной модели вычислений, так как ни одна другая модель не соответствует реалиям информационных систем масштаба корпорации. В свою очередь, наиболее естественным применительно к проектированию и реализации разнородных распределенных систем представляется объектно-ориентированный подход, являющийся предметом настоящей статьи.
Основные понятия объектно-ориентированного подхода - объект, класс и экземпляр.
Объект - это абстракция множества предметов реального мира, обладающих одинаковыми характеристиками и законами поведения. Объект представляет собой типичный неопределенный элемент такого множества. Экземпляр объекта - это конкретный определенный элемент множества. Например, в банковском деле объектом является некоторый лицевой счет, а экземпляром этого объекта - лицевой счет #123.
Класс - это множество предметов реального мира, связанных общностью структуры и поведением. Элемент класса - это конкретный элемент данного множества. Например, в сфере банковской деятельности существует класс расчетно-денежных документов.
Таким образом, объект - это типичный представитель класса, а термины "экземпляр объекта" и "элемент класса" равнозначны.
С точки зрения объектного моделирования понятия "описание класса" и "описание объекта" эквивалентны, так как для определения множества схожих элементов, образующих класс, достаточно описать его типичного представителя, то есть объект.
Следующую группу важнейших понятий объектного подхода составляют инкапсуляция, наследование и полиморфизм.
Объектный подход предполагает, что собственные ресурсы, которыми могут манипулировать только методы самого объекта, скрыты от внешних компонентов. Сокрытие данных и методов в качестве собственных ресурсов объекта получило название инкапсуляции.
Понятие полиморфизма может быть интерпретировано как способность объекта принадлежать более чем одному типу. Существуют и другие виды полиморфизма, такие как перегрузка и параметрический полиморфизм. С помощью перегрузки имена, обозначающие названия методов, могут быть использованы для указания различающихся реализаций. Для разрешения конфликтов применяется контекстная информация. Наиболее распространенная форма параметрического полиморфизма в большинстве языков программирования состоит в возможности использования типов в качестве параметров программных единиц.
Наследование означает построение новых классов на основе существующих с возможностью добавления или переопределения данных и методов.
Объекты - сущности, инкапсулирующие данные, - это основные элементы, моделирующие реальный мир. В отличие от структурного подхода, где основное внимание уделяется функциональной декомпозиции, в объектном подходе предметная область разбивается на некоторое множество относительно независимых сущностей - объектов. Объектная декомпозиция, отраженная в спецификациях и кодах приложений, есть главное отличие объектного подхода. Например, объект "Покупатель" может представлять собой структуру данных, хранящую детализированную информацию о покупателе: его имя, адрес и состояние банковского счета.
Класс объектов, кроме структур данных, определяет функции (методы), применимые к этим структурам.
В примере с объектом "Покупатель" класс может содержать такие функции (методы), как проверить кредитоспособность, выставить счет и т. д. Класс - это ключевой элемент, обеспечивающий модульность в проектных спецификациях ИС и программных решениях.
Объектно-ориентированная система изначально строится с учетом ее эволюции. Ключевые элементы объектного подхода - наследование и полиморфизм - обеспечивают возможность определения новой функциональности классов объектов с помощью создания производных классов - потомков базовых классов. Потомки наследуют характеристики родительских классов без изменения их первоначального описания и добавляют при необходимости собственные структуры данных и методы. Определение производных классов, при котором задаются только различия или уточнения, в огромной степени экономит время и усилия при производстве и использовании спецификаций и программного кода.
Третьим важным качеством объектного подхода является согласованность моделей системы от стадии анализа до программных модулей. Требование согласованности моделей выполняется благодаря возможности применения абстрагирования, модульности, полиморфизма на всех стадиях разработки. Модели анализа могут быть непосредственно подвергнуты сравнению с моделями реализации. По объектным моделям может быть прослежено отображение реальных сущностей моделируемой предметной области в объекты и классы информационной системы.
Операционные системы с сетевыми функциями также представлены двумя не всегда легко различными разновидностями: серверным и клиентским. Это вызвано различием возможностей и функций серверов и клиентов сети на базе ПК. Серверная ОС концентрируется на управлении ресурсами, а клиентская - на удовлетворении потребностей владельца, то есть на выполнении задания с максимальной скоростью и эффективностью. Это не значит что быстрота и эффективность не важны для сервера, но его основная задача все же в поддержке большого числа компьютеров - клиентов, тогда как клиент чаще всего работает с конкретным приложением типа текстового процессора, электронной таблицы или почтовой программы. И если проверка орфографии, подготовка сообщения или пересечет, таблицы занимают непомерное много времени, владелец компьютера едва ли будет вообще им пользоваться.
Выбор серверных ОС для корпоративных сетей на базе ПК весьма широк: Windows NT, OS/2, Novell NetWare, UNIX и Mac OS с сетевыми службами AppleShare и AppleTalk. Как правило, эти ОС способны функционировать и в качестве ПО клиента, и в качестве ПО сервера. Более того, часто существует «младшая» версия для настольных ПК. Такие программные продукты как Windows NT Workstation, OS/2 Workstation, и ПО рабочей станции от NetWare, по существу, представляют собой несколько упрощенные версии своих «старших братьев», работающих на серверах.
Раз у сетевой операционной системы так много обязанностей, то она должна работать с максимально возможной скоростью. Добиться этого удаётся с помощью «трёх М»: многопоточности, многозадачности и многопроцессорности.
Одна из главных отличительных особенностей сетевой операционной системы. Этот метод оптимизации производительности посредством наиболее полного использования процессорного времени представляет собой подлинное чудо сложности. Многопоточная обработка основана на том, что процессор работает с невероятной скоростью, измеряемой тактами. Эти такты выполняются независимо от того, занят процессор или нет.
При многопоточной обработке процесс подразделяется на потоки, каждый из которых выполняется микропроцессором по отдельности. Планирование потоков осуществляется операционной системой.
На самом деле многозадачность - это нечто ловкости рук фокусника, ибо на одном процессоре два процесса не выполняются. Время процессора предоставляется каждому процессу отдельно, а человеку кажется, что эти процессы идут параллельно. Такое впечатление создаётся благодаря высокой скорости работы процессора и способностью перемешивать выделенные интервалы времени. Весь фокус в том, что для компьютера и операционной системы время течет намного быстрее, чем для людей.
Многозадачность в любом виде выгодна, как средство повышения производительности. На сильно загруженном сервере, например, преимущества очевидны. Ясно, что выигрыш будет ещё более, если многозадачность реализована на компьютере-клиенте - это позволяет ещё лучше координировать взаимодействие сервера с клиентом и управлять им с ещё большей эффективностью, нежели в случае, когда клиент и сервер в определённый момент времени решают вместе или порознь одну единственную задачу.
Для сред с высокой нагрузкой многопроцессорная обработка просто необходима. В этом случае система может ещё успешнее справляться с задачами за счет того, что нагрузка перекладывается на много параллельных процессоров.
Многопроцессорная обработка может быть симметричной и асимметричной[3]. При симметричной обработке любой процесс может быть поручен любому, в данный момент свободному процессору.
При асимметричной обработке нагрузка распределяется так, что один или несколько процессоров обслуживают только операционную систему, а остальные работают только с приложениями.
В силу больше гибкости симметричной обработки, система с ее поддержкой обеспечивает два важных преимущества.
Во-первых, повышается отказоустойчивость, потому что один процессор способен справиться с любой задачей и отказ одного процессора не ведёт к отказу всей системы.
Во-вторых, улучшается балансировка нагрузки, так как операционная система способна распределять её среди процессоров равномерно и тем самым предотвращать появление узких мест из-за слишком частых обращений к одним процессорам и пренебрежения остальными.
Преимущества технологии клиент-сервер:
- Отсутствие дублирования кода программы-сервера программами-клиентами.
- Так как все вычисления выполняются на сервере, то требования к компьютерам на которых установлен клиент снижаются.
- Все данные хранятся на сервере, который, как правило, защищён гораздо лучше большинства клиентов. На сервере проще обеспечить контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа.
- Позволяет объединить различные клиенты. Использовать ресурсы одного сервера часто могут клиенты с разными аппаратными платформами, операционными системами и т. п.
- Позволяет разгрузить сети за счёт того, что между сервером и клиентом передаются небольшие порции данных.
Недостатки технологии клиент-сервер:
- Неработоспособность сервера может сделать неработоспособной всю вычислительную сеть. Неработоспособным сервером следует считать сервер, производительности которого не хватает на обслуживание всех клиентов, а также сервер, находящийся на ремонте, профилактике и т. п.
- Поддержка работы данной системы требует отдельного специалиста — системного администратора.
- Высокая стоимость оборудования.
Заключение
Наиболее бурно развивающимся направлением в области информационных технологий в последние годы стала разработка программного обеспечения на основе архитектуры клиент-сервер, связанного с сетью Internet и системами Intranet, опирающегося на Web-технологию и язык Java. Объектные, распределенные технологии консорциумов OMG и ODMG интегрируются в общие тенденции, расширяя и обобщая их. Примечательно, что все ведущие производители систем Internet/Intranet, включая Sun, IBM, Netscape, Microsoft, встраивают в свои продукты поддержку КС совместимых протоколов.
Технология клиент-сервер развивается уже давно. За это время она прошла путь от академических исследований до промышленных, стандартизованных решений, позволяющих создавать по-настоящему большие, распределенные корпоративные системы, способные эволюционировать экономически эффективным образом. Можно предположить, что консолидация современных сетевых, реляционных и объектно-ориентированных технологий позволит выйти на еще более высокий уровень интеграции и качества информационных систем.
Список использованной литературы
- Калиниченко. Л. Стандарт систем управления объектными базами данных ODMG 93: краткий обзор и оценка состояния/ Л. Калиниченко - СУБД, 1, 1996.
- Брюхов. Д. Интероперабельные информационные системы: архитектуры и технологии/ Д. Брюхов, В. Задорожный, Л. Калиниченко и др. - СУБД, 4, 1995.
- Вудворд Дж. «Технология совместной работы»/ Вудворд Дж – изд. Вильямс, Москва 2005
- Волков В.Б. Понятный самоучитель работы в Windows XP – изд. СПб, Питер, 2004
- Ладыженский Г. Ingres - современные тенденции в архитектуре сервера базы данных/ Г. Ладыженский, Г. Барон – изд. Открытые Системы, Осень 1993
- Ладыженский Г. Система обработки распределенных транзакций TUXEDO/ Г. Ладыженский – изд. Открытые Системы, Весна 1993
- Машкин М. Н.Информационные технологии Учебное пособие/ М. Н. Машкин - Москва 2008, УДК
- Учебное пособие - под общей редакцией доктора технических наук, профессора Н. А. Селезневой, Москва 2004 удк 37: 004 ббк 32. 81: 74. 04
- Дьяконов В. П. Новые информационные технологии Часть Основы и аппаратное обеспечение/ В. П. Дьяконов, А. Н. Черничин - Под общей редакцией проф. В. П. Дьяконова Смоленск 2003
- Горев А. SQL Server 6.5 для профессионалов/ А. Горев ,С. Макашарипов, Ю. Владимиров - изд. “Питер” Санкт-Петербург, 1998
- Боуман Д., Практическое руководство по SQL/ Д. Боуман, C. Эмерсон, М. Дарновски - Изд. “Диалектика”, Киев, 1997
-
Бьёрн Страуструп, Бьярне Строуструп (дат. Bjarne Stroustrup, род. 30 декабря 1950 (Орхус, Дания) — программист, автор языка программирования C++. ↑

- Обзор языков программирования высокого уровня ( Классификация языков программирования)
- «Разработка регламента выполнения процесса «Управление персоналом»
- Рынок ценных бумаг (Оборот ценных бумаг)
- Сущность нормирования труда (Сущность, содержание и значение нормирования труда)
- История возникновения и развития банковского дела, его особенности в ряде стран
- Управление кадровой безопасностью на примере компании ООО ПДК "Авангард"
- Учет наличных денежных средств в кассе предприятия (Нормативная база, значение и задачи бухгалтерского учета денежных средств)
- Фазы жизненного цикла корпоративного проекта (Концепция жизненного цикла проекта)
- Процесс построения модели управленческого решения (Динамическое моделирование управленческого решения)
- Инновации в менеджменте организаций (объектов) общественного питания
- Современные методы и приемы работы с персоналом, методики создания эффективных производственных коллективов
- Организационная культура (Анализ организационно-экономической деятельности, системы управления персоналом и организационной культуры персонала в ООО «Со»)