
Сравнительный анализ описания данных для различных языков программирования
Содержание:

ВВЕДЕНИЕ
Развитие технологий в 20 веке, в том числе вычислительной техники, привело к тому, что в настоящее время ИТ-технологии проникли практически по все стороны человеческой жизни. Разумеется, что любое «умное» устройство будь то компьютер, микроконтроллер поддерживающий температуру в доме, томограф в больнице или светофор на улице в своей деятельности использует некие алгоритмы именуемые программой. Для создания этих программ используются разнообразные языки программирования. В мире в настоящее время используется большое количество языков программирования для создания разнообразного программного обеспечения. Так, например, в индексе популярности языков программирования выпускаемом на протяжении более десятка лет компанией TIOBE (TIOBE Index) учитывается более 250 языков программирования.[20]
Все эти используемые при написании программ языки используют для своей работы некие типы данных зависящие от особенностей языка программирования.
Целью данной работы является получение общего представление о типах данных, исследование описания типов данных для различных конкретных языков программирования использующихся в методических материалах в процессе обучения по дисциплине «Основы алгоритмизации и программирования» [6],[11],[12], проведение сравнительного анализа сопоставимых типов, наглядное демонстрирование некоторых приемов и правил работы с разными типами данных в различных языках программирования в связи с применении различных типов данных в разных языках программирования высокого уровня, поскольку они являются одними из главных компонентов для всех современных программ.
1.Общие понятия о типах данных
Основной смысл существования и функционирования любой программы является обработка данных.[8] Данные передаваемые для обработки некому алгоритму (программе) и получаемые в результате выполнения этого алгоритма могут иметь различное представление, поступать от различных источников – от другой программы или подпрограммы, с клавиатуры, из файла, по сети и т.п. и соответственно выводится после обработки в не менее различных видах.
Данные можно разделить на 4 основных вида [1]: Константы – данные, которые заданы и зафиксированы и не могут изменять свое значение в ходе выполнения программы, переменные - данные, которые могут изменять свое значение в ходе выполнения программы; массивы – это данные, которые представляют собой последовательность элементов; списки – это данные представляющие собой последовательность однотипных элементов, при этом каждый элемент, начиная со второго имеет своего предшественника, а все кроме последнего имеют предшествующий. Помимо линейных списков существуют и другие типы списков, такие как стеки, деревья, очереди и т.п. [4]
В обычном, «математическом» представлении написанного на бумаге условия или решения некой задачи можно «на глаз» определить какие переменные или значения используются решении этой задачи. Человек в силу своего опыта и общепринятых норм записи математических выражений может определить и классифицировать является ли какой-то параметр комплексным или целым числом, является ли запись некоей функцией или некоторым логическим сравнением. Для определения значения даже не важен контекст. При взгляде на выражение 2 x 2 = 4 любому человеку ясно что у нас производится действие умножения двух целых (натуральных) чисел и вычисляется результат который также является целым числом, причем знак умножения в данном случае является русской буквой «х».
Для компьютерной программы же необходимо чтобы для соответствующей переменной или константы соответствующий тип данных был заранее известен (объявлен), причем до начала его использования, т.к. необходимо определить какой объем памяти нужно использовать для размещения данных в соответствии с диапазоном принимаемых значений.[2]
При этом каждый тип таких данных по своему обрабатывается или хранится в памяти ЭВМ, к различным типам данных можно применять различные операции соотносящиеся с этим типом. [10]
Таким образом мы подошли к понятию типов данных использующихся в языках программирования определенным стандартом ISO «Разработка систем и программного обеспечения. Словарь». Тип данных это класс данных, характеризуемый членами класса и операциями, которые могут быть к ним применены.[19]
Для языков программирования разработчиками определены стандартные (встроенные) типы данных входящие в спецификацию языка, но при этом пользователь (программист) может на их основе создавать и свои типы.
К примеру, Б. Страуструп, автор языка С++, описывает следующие фундаментальные типы данных в С++: логический, символьный, целый, с плавающей запятой, перечислимые, тип void и типы которые можно строить поверх перечислимых.[16] А. И. Гусева для языка Pascal 7.0 разделяет типы на следующие: простые, структурированные, процедурные типы, тип указатели и объекты, в свою очередь простые (стандартные) делятся на целые, вещественные, логические, символьные, строковые, тип указатель и т.д.[5], а в языке Qbasic всего два фундаментальных типа – числовой(с различными вариантами) и строковый.
Классифицировать различные типы данных можно по различным признакам. Для наглядности продемонстрируем это графически на рисунке 1.
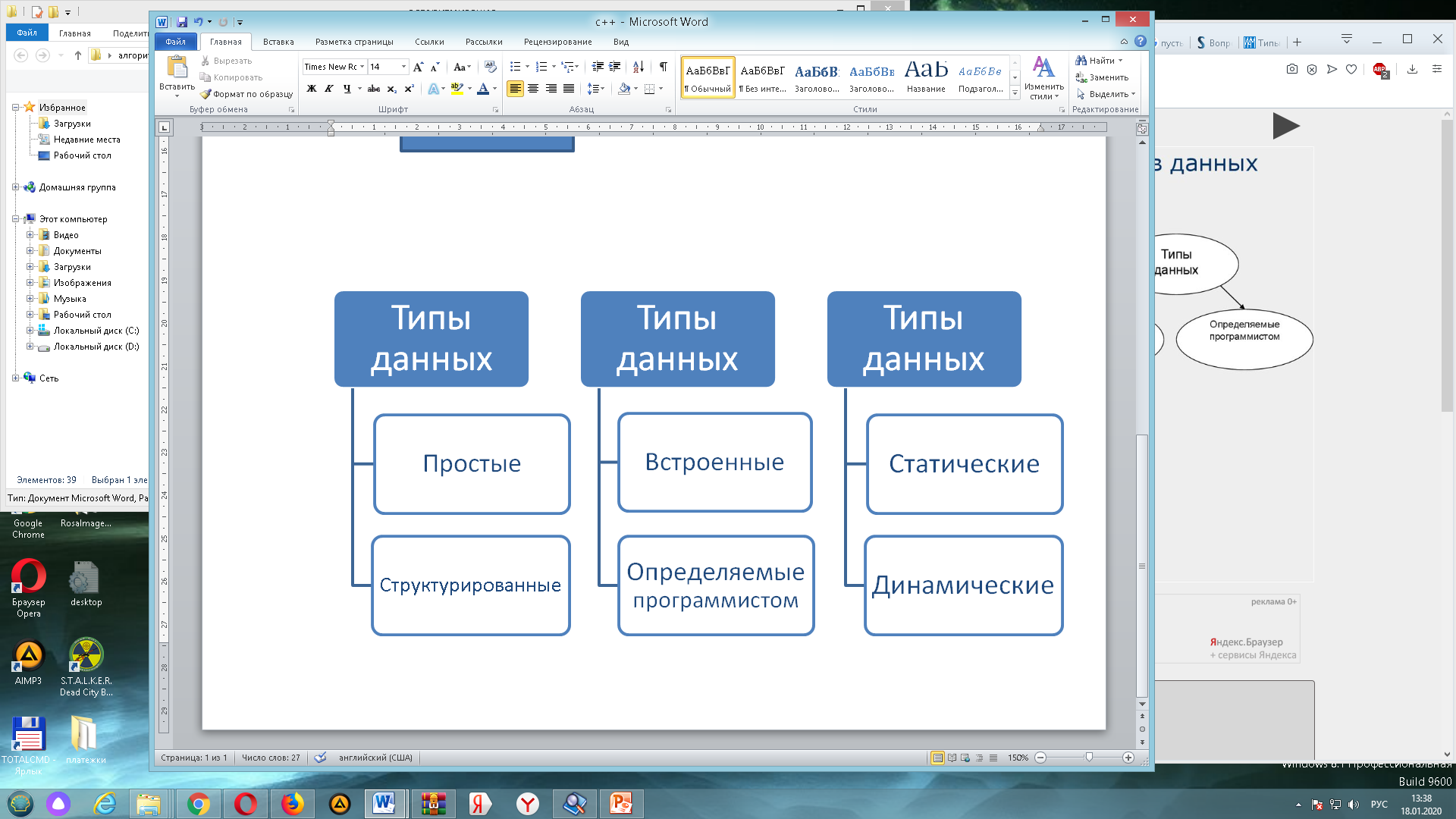
Рис. 1. Виды классификаций типов данных
При этом все эти классификации будут верными и логически обоснованными. Так как у различных языков программирования в соответствии с их спецификациями, особенностями использования и логикой языка имеются различные варианты трактовки и наименования типов, то провести единую однозначную классификацию всех типов данных для всех языков вряд ли представляется возможным, поэтому условно классифицируем и определим основные рассматриваемые типы.
Простые типы состоят из числового типа, который в свою очередь подразделяется на целочисленные и вещественные. Для программ (языков программирования) имеется принципиальная разница в виде представления этих типов). Для этих типов применимы самые обычные арифметические операции, операции сравнения и т.д.
Вещественные типы представлены числами с дробной частью (при этом надо учитывать, что в языках для представления этих чисел в десятичном виде вместо запятой используется точка). [12]
Тип целые (целочисленный) предназначен для целых чисел, которые в свою очередь могут иметь различную длину, а также иметь положительное или отрицательное значение при явном указании знака. На рисунке 2 показан пример спецификации целого (int) для языка С++.[16]
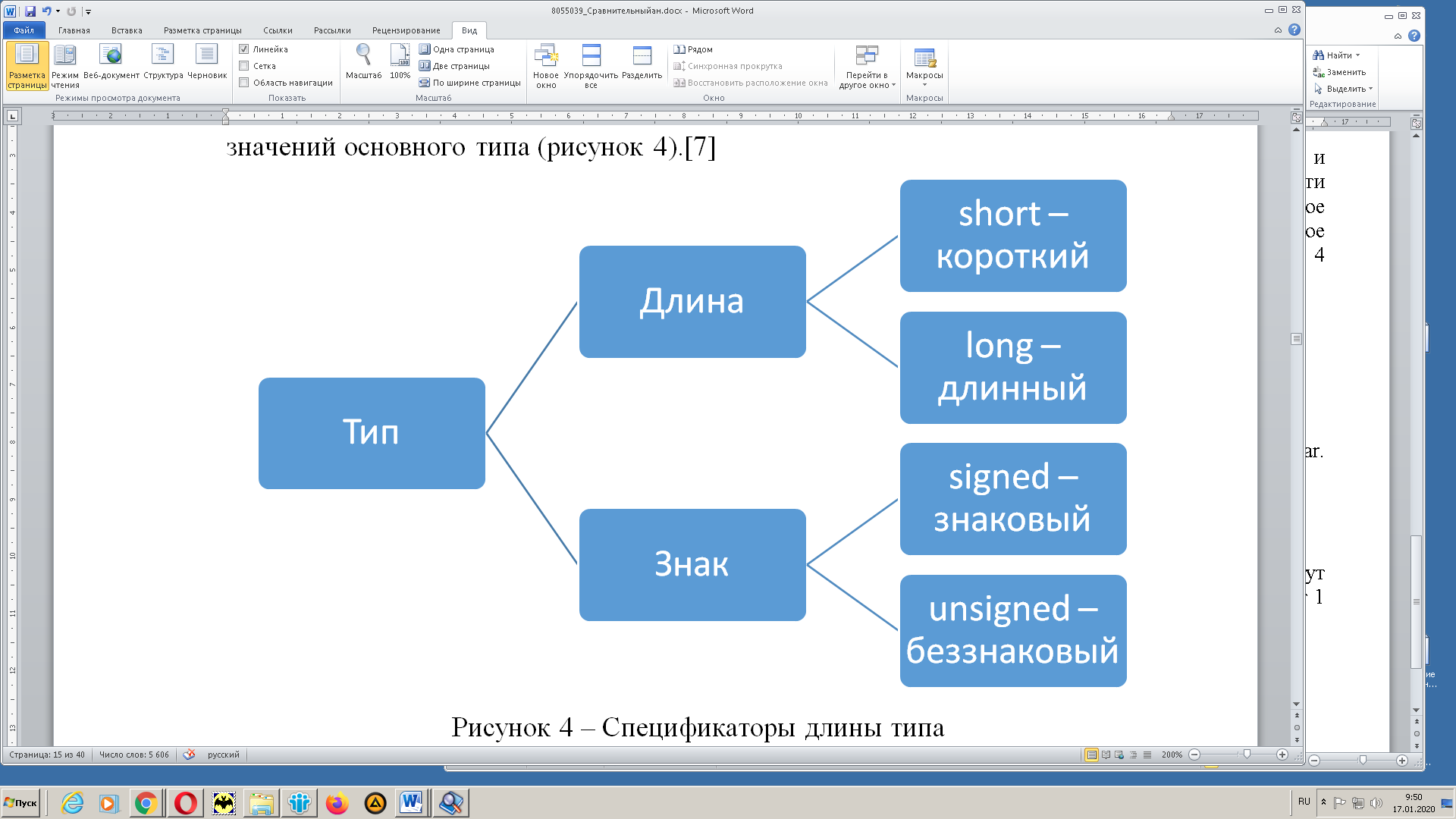
Рис. 2. Варианты типа int в С++ в зависимости от спецификатора
Символьный тип хранит символ который может быть в различных кодировках. Символом может являться какая либо буква, знак, цифра. По сути дела символьный тип представляет сопоставление символа коду (числу) для различных кодовых таблиц. [17]
Тип указатель предназначен для хранения в памяти адреса каких либо данных, например адрес ячейки памяти где расположен какой-либо объект (адрес первого байта этого объекта в памяти). Это может быть переменная, функция, массив и др.[17]
Логический тип принимает лишь два значения – истина (true) (1) или ложь (false) (0). Широко используется в операторах цикла для проверки какого-либо условия, при ветвлении и т.п.
Тип void присутствует только в языке С++ (из рассматриваемых нами) - тип данных, который означает вообще отсутствие любого типа данных.[15]
Тип перечисление – как ясно из названия это тип данных который используется для перечисления набора значений, при этом каждое значение имеет свой порядковый номер, что можно использовать, например, для получения предыдущего или последующего значения.
Тип множество – для него в основном применимо обычное математическое понятие множества, соответственно к нему применимы стандартные операции производимые со множествами, в том числе проверка на принадлежность к множеству и т.п. В некоторых языках может рассматриваться как производный тип от простых типов.
Тип данных массив описывает непрерывную последовательность элементов одного типа.
Строковый тип данных хранит строку символов. Его можно рассматривать как одномерный массив, но в рассматриваемых нами языках программирования Pascal и Qbasic он выделен в отдельный тип базовый тип. [6], [11]
Тип данных запись в общем случае состоит из объединения различных произвольных типов данных. В свою очередь типы составляющие запись сами могут являться записями. В языке программирования С++ наименование этого типа – структура.[16]
Тип последовательность можно представить как массив данных неограниченного размера. Под него выделяется память по мере роста самой последовательности. Основным типом доступа к элементам является последовательный с начала в конец, а в случае добавления новый элемент добавляется в конец последовательности. Примером может служить тип файл в языке Pascal.
Выяснив определение термина тип данных проведена условная классификация основных типов данных в соответствии с представлением.
Даны общие определения для понимания структуры типов данных и краткие описательные характеристики различных основных типов данных для дальнейшего сравнения и анализа совпадающих типов и общего описания типов присущих только одному из языков.
2. Сравнительны анализ описания типов данных
Для проведения сравнительного анализа описания различных сопоставимых типов данных используем три языка программирования Qbasic, Pascal и С++.
Язык программирования Qbasic является продолжением развития языка программирования BASIC ( Beginner's All-purpose Symbolic Instruction Code) созданного в 60-х годах профессорами Дартмурского Колледжа (США) Дж. Кемени и Куртисом. Несмотря на то, что программы, написанные на этом языке, могут выполняться только внутри его среды (интерпретатор) он является одним из простым и понятных языков для начала обучения программированию.[10]
Язык программирования Pascal был создан в конце 60-х годов 20-го века швейцарцем Н. Виртом и назван именем математика и философа Блеза Паскаля. Изначально он задумывался как язык для обучения студентов структурному программированию. Однако поскольку в Паскале были реализованы прогрессивные идеи того времени, он получил распространение среди практикующих программистов. На нем начали писать не только прикладные, но даже системные программы. В последних версиях языка имелась возможность работы не только в среде DOS, но и Windows. Дальнейшим развитием языка стал PascalABC.NET поддерживающий широкие возможности платформы .NET. [3]
Язык программирования С++ созданный Б. Страуструпом в начале 80-х годов 20 века путем усовершенствования и развития языка С под собственные нужды. В настоящее время он является одним из популярнейший языков программирования. Язык С++ постоянно динамично развивается, вносимые изменения стандартизируются Международной организацией по стандартизации (International Organization for Standardization, ISO) в данный момент действует стандарт ISO/IEC 14882:2017 [ISO/IEC 14882:2017] Programming languages — C++ и разрабатывается новый. [18] Исходя из этого использование книг написанных о языке С++ Б. Страуструпом представляется вполне логичным и обоснованным.
2.1. Базовые целочисленные типы
Опишем и проведем сравнительный анализ базовых целочисленных типов являющимися одними из фундаментальных типов во всех языках.
В языке программирования Qbasic ими являются следующие типы числовых данных – целые (integer), целые длинные («long integer» или long). [10]
Для языка программирования Pascal определено 5 таких типов: shortint, integer, longint, byte и word. [14]
Для языка С++ определен тип int который может принимать различные виды в зависимости от спецификатора signed который определяет знак (как положительные, так и отрицательные значения) и спецификатора unsigned –беззнаковый (только лишь положительные значения). Второй тип спецификатора для типа int определяет длину short и long. Таким образом тип целые может принимать следующие виды: short int, unsigned short int, int, unsigned int, long int, unsigned long int. Тип int в зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита). В результате этого принимаемые значений также могут варьироваться в различных диапазонах. Но в любом случае размер должен быть больше или равен размеру типа short и меньше или равен размеру типа long. [8] Начиная с версии C++11 введен спецификатор long long для int, который гарантирует выделение под значение 8 байт. Соответственно int может получать тип signed long long, signed long long int и аналогично со спецификатором unsigned в различных диапазонах.
Так как все эти типы имеют разные принимаемый диапазон, а соответственно и объем, который выделяется для них в памяти, сведем все данные (без учета long long для С++) в единую таблицу 1.
Таблица 1.
Сопоставление целочисленных типов данных QBasic, Pascal, С++.
|
QBasic |
Pascal |
С++ |
||||||
|
Тип |
Размер байт |
Диапазон значений |
Тип |
Размер байт |
Диапазон значений |
Тип |
Размер байт |
Диапазон значений |
|
shortint |
1 |
-128/127 |
||||||
|
byte |
1 |
0/255 |
||||||
|
integer |
2 |
-32768 / 32767 |
integer |
2 |
-32768 / 32767 |
short int |
2 |
-32768 / 32767 |
|
word |
2 |
0 / 65535 |
unsigned short |
2 |
0 / 65535 |
|||
|
unsigned int |
2/4 |
в зависимости от архитектуры 0 / 4294967295 |
||||||
|
long integer |
4 |
- 2147483648/ 2147483647 |
longint |
4 |
-2147483648/ 2147483647 |
long int |
4 |
-2147483648 / 2147483647 |
|
unsigned long |
4 |
0 / 4294967295 |
||||||
Таблица составлена по [10],[14],[8]
Как мы видим из таблицы целые типы данных используемые в языках хоть и имеют совпадения, но, тем не менее, заметна и разница, которую надо учитывать при объявлении типа данных.
2.2. Вещественные типы
Вещественные типы могут указываться как в обычном десятичном виде, так и методом записи в экспоненциальном виде 0,0012 будет выглядеть как 1.2Е-3. Метод записи имеет следующий вид - mE± p, где m – мантисса (число в основной форме), Е – основание 10, р – порядок числа (целое число). Учитывая, что под значение выделяется свой определенный спецификацией языка объем памяти, то эти числа имеют некоторую точность.
Вещественные типы для языков определены следующие:
Для Qbasic для представления вещественных значений выделено 2 типа single (Single precision) с одинарной точностью и double (Double precision) с двойной точностью. [10]
Для Pascal это типы данных real, single, double, extended и comp.[14] Тип данных сomp содержит только целые значения, которые представляются в вычислениях как вещественные.
Для С++ определяется три вещественных типа, float, double и long double. [8]
Представим их соотношения в таблице 2.
Таблица 2
Сопоставление вещественных типов данных QBasic, Pascal, С++.
|
QBasic |
Pascal |
С++ |
||||||
|
Тип |
Размер байт |
Диапазон значений |
Тип |
Размер байт |
Диапазон значений |
Тип |
Размер байт |
Диапазон значений |
|
single |
4 |
3.4E-38 / 3.4E+38 |
single |
4 |
1.5E-45 / 3.4E+38 |
float |
4 |
3.4E-38 / 3.4E+38 |
|
real |
6 |
2.9E-39 / 1.7E+38 |
||||||
|
double |
8 |
1.7E-308 / 1.7E+308 |
double |
8 |
5.0E-324 / 1.7E+308 |
double |
8 |
1.7E-308 / 1.7E+308 |
|
comp |
8 |
-9.2E18 / 9.2E18 / |
||||||
|
extended |
10 |
3.4E-4932 / 1.1E4932 |
long double |
10 |
3.4E-4932 / 3.4E+4932 |
|||
Таблица составлена по [10], [14], [8]
Точность вещественного числа напрямую связана с тем, что под разрядность мантиссы в разных языках выделяется определённое количество разрядов и например в языке программирования Pascal для типа данных real разрядность мантиссы составляет не более восьми десятичных знаков. Поэтому надо внимательно относиться к выполнению операций с числами имеющими большую разницу порядков. Может возникнуть ситуация когда мантисса не сможет обеспечить необходимую точность вычислений.[14] Приведем наглядный пример операции сложения двух одинаковых пар чисел заданных разными вещественными типами рисунок 3.
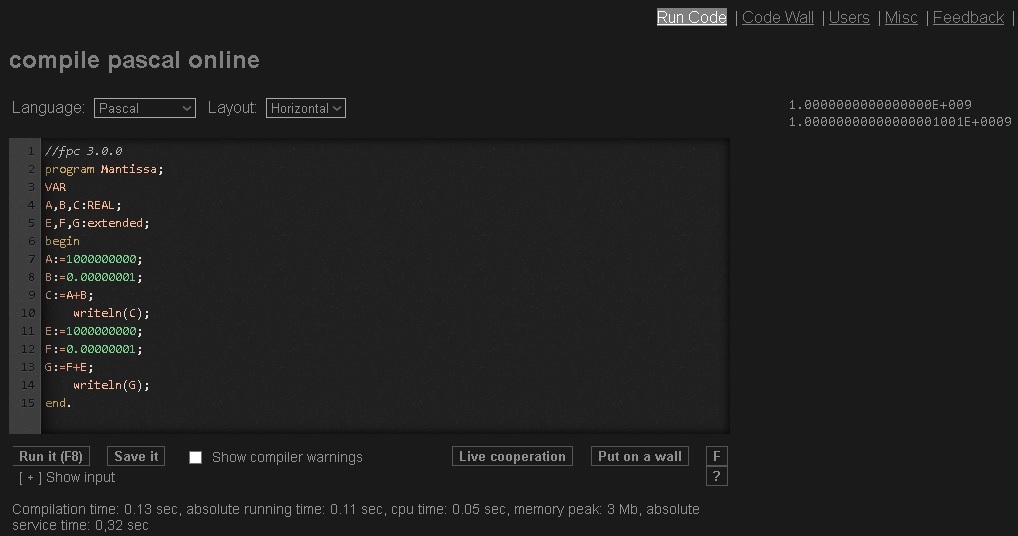
Рис. 3. Пример зависимости точности вычисления от используемого типа
Правила присвоение переменным определенного типа данных зависят от синтаксиса языка. Общим правилом является то, что, переменные или константы должны быть определены до их использования. Также в связи с тем, что в каждом языке имеются зарезервированные слова наложен запрет на их использование в качестве имен переменных и констант, а так же другие особенности которые будут описаны ниже для каждого языка.[16][17] Рассмотрим в примерах объявления типа данных для изучаемых языков программирования.
В Qbasic объявление (присвоение) типа переменной происходит следующим образом: Существуют специальные символы для объявления типов данных. [6]:
% - для присвоения целого (integer);
# - для присвоения вещественного с двойной точностью (double);
! – для присвоения вещественного с одинарной точностью (single);
& - для присвоения целого длинного (long);
Операция присваивания в общем случае выглядит следующим образом.
CONST [имя константы]=[значение]
[имя переменной]=[значение]
a1=5 (переменной а1 присвоено значение 5 тип single (т.к. если не указать тип данных, то по умолчанию присваивается тип single).
a1%=5 (переменной а1 присвоено значение 5 тип integer)
CONST р1!=3.14 (константе p присвоено значение 3.14 тип single).
Помимо использования суффиксов для объявления типа можно воспользоваться операторами, например, имеется возможность объявить тип данных группе переменных или функциям с помощь оператора DEF[10]. DEFINT для присвоения типа целые, DEFLNG для присвоения типа длинные целые, DEFSNG для присвоения типа вещественные, DEFDBL для присвоения типа вещественные двойной точности.
На практике это выглядит так: DEFINT А, N-T - всем объявляемым переменным начинающимся с символа А символа и N по T и будет присвоен тип целые (integer). При этом надо учитывать, что если имя переменной или функции заканчивается зарезервированные для объявления типов знаки, то будет присвоен именно тот тип, на который оканчивается имя переменной. Например, если мы объявим всем переменным начинающимся с буквы L тип целые (DEFINT L), то, несмотря на это переменная LONGDATA# будет иметь тип double.
Длина имени не должна превышать 40 знаков, а также должна начинаться с букв латинского алфавита и состоять только из букв того же алфавита и цифр и не иметь пробелов в названии[6], не иметь сочетания начальных букв FN в имени, т.к. оператор FN(наименование) используется для создания пользовательских функций. Для наименования массивов используются те же правила/
В языке программирования Pascal особенностью является то, что константы и переменные и соответственно их типы должны быть самом в самом начале программы в разделах const и var. [17] Так так в языке Pascal помимо использования стандартных типов возможно создание пользовательских типов, то их так же надо объявить в самом начале в разделе type.
Общий синтаксис имеет следующий вид:
const
[имя константы]=[определение типа]
type
[имя типа]=[определение типа]
var
[имя переменной]=[определение типа]
const
abc=123;
xyz=3,14;
Как видно в этом примере не указан тип констант, т.к. он определяется способом ее записи, при компиляции компилятор сам соотнесет типы констант и присвоит константе abc тип integer, а константе xyz тип real. [11]
type
mas= array [1..10] of word; (задан новый пользовательский тип mas)
var
a, b, c :real; d, e, f: extended; (переменные a, b, с – тип real и т.д.)
Необходимо обратить внимание, что в языке Pascal строка должна заканчиваться символом «;», иначе будет выдана ошибка при компиляции. И как видно на рисунке 3 при присваивании значения некой переменной необходимо использовать оператор присваивания «:=».[17]
В Pascal при объявлении имени прописные и строчные буквы в именах переменных не различаются. Имена переменных могут быть сочетанием английских букв и цифр, использование пробелов не допускается. Нельзя начинать имена переменных с цифры или специальных символов, но допускается использование знака подчеркивания «_».
В языке программирования С++ как и в Qbasic в отличии от Pascal менее строгие правила объявления типов. Переменные и константы могут объявляться в теле функций.[15]
В общем случае объявление типа выглядит следующим образом.
[тип] [имя] = [значение] (значение не обязательно)
double x = 7.89 (х присвоен тип double и значение 7.89)
int x (х присвоен тип int)
int x, y, z (x, y, z присвоен тип int)
Для типа констант можно использовать директиву #define. И хотя в зависимости от значения константы компилятор автоматически задает ей тип, но его можно указать и вручную с помощью суффиксов. U (или u) задать целую константу типа unsigned, F (или f) константу типа float, L (или l) для типа long int, L (или l) типа long double.[13]
#define B 280LU (для B задан тип unsigned long int и ее значение 280)
В С++ имя переменной, в отличии от Qbasic и Pascal, чувствительно к регистру.[15] Имена ABC, Abc, abc являются разными. Идентификатор может состоять только из букв (нижнего или верхнего регистра), цифр или символов подчёркивания. Это означает, что все другие символы и пробелы запрещены. Идентификатор должен начинаться с буквы (нижнего или верхнего регистра). Он не может начинаться с цифры. При этом правильным считается то, что наименование переменной должно начинаться с маленькой буквы.
Кроме того форма записи значения констант может быть как обычная десятичная, так и восьмеричная и шестнадцатеричная. Общим правилом является то, что значения в шестнадцатеричном виде начинаются с 0X (0x), а восьмеричная с 0.
При затруднении определения типа в последних версиях С++ имеется возможность использования спецификатора auto для того чтобы компилятор сам определил тип. Обязательное условие при этом – задание значения переменной (ее инициализация каким либо значением).
С числовыми типами возможны разнообразные арифметические и логические операции, выполнение с ними математических функций. Порядок их выполнения в выражении зависит от приоритета определенным логикой языком программирования. Общим правилом является то, что в сложных выражениях порядок операций определяется их приоритетом и его можно изменить используя скобки. Операции одного приоритетного уровня выполняются слева направо. [6], [8]
Такие операции как инкремент и декремент могу применяться только к переменным. Описывать все функции возможные над численными типами данных трех языков, как и приводить их сравнение не имеет смысла, так как основные различия только в количестве имеющихся и в зарезервированных для них наименований, а само описание займет объем превышающий допустимый, поэтому ограничимся лишь основными.
Для Qbasic такими операциями являются:
Арифметические операции: Возведение в степень (^); смена знака (-); умножение и деление (*, /); целочисленное деление (\); остаток от деления (MOD); сложение и вычитание (+, -).[10]
Продемонстрируем важность правильного применения операций над типами данных на примере простого и целочисленного деления, отношения на рисунке 4.
Рис. 4. Пример простого и целочисленного деления, отношения
Операции отношения: = ; > ; < ; <> ; <= ; >=.
Логические операции: NOT; AND; OR; XOR; EQV[6] В результате выполнения возвращается 0 если утверждение ложно и 1 при истинности.
Перед ними все вещественные числа преобразуются в целочисленные, т.к. логические операции производятся над битами, а вещественные числа в QBasic не могут выступать в качестве логического значения непосредственно, происходит неявное преобразование типа в integer, или, если необходимо то в long. Так же Qbasic имеется большой список функций для работы с числовыми значениями: вычисление тригонометрических значений, логарифмов, получение модуля числа и т.п.
В Pascal определены следующие арифметические операции и функции: + сложение; - вычитание; * умножение; / деление; DIV – операция целочисленного деления; MOD – остаток целочисленного деления (последние две операции применимы только к целым операндам); ABS – абсолютная величина; TRUNC и ROUND - получение целой части и округление вещественного числа; SQR - возведение в квадрат, ++ операции инкремента и -- операция декремента. [11]
Операции отношения: <, <=, >, >=, =, <>.
Допустимые логические операции будут рассмотрены позднее при рассмотрении логического типа данных.
Помимо этого есть и другие различные математические, тригонометрические функции, преобразования из вещественного типа в целый и т.п.[11]
Для С++ определены следующие арифметические операции: + сложение; - вычитание и унарный минус; / деление; % деление по модулю, ++ операции инкремента и -- операция декремента, варианты арифметических выражений с присваиванием - *=, += и т.д.[9]
Операциями отношения являются: а также возможны следующие операции отношения: > (больше), < (меньше), == (равно) (следует обратить внимание что именно 2 символа =, в отличии от предыдущих рассматриваемых языков) , >= (больше или равно), <= (меньше или равно) и != (не равно). [12]
Логические операции так же будут рассмотрены позднее.
Как и в предыдущих языках имеется большой набор функций для работы с целыми и вещественными типами.
Как видно в большинство операций совпадают, это утверждение можно отнести и к функциям, но и имеются отличия обусловленные синтаксисом и семантикой языков и, например, ни в Pascal, ни в С++ нету операции возведения в степень имеющейся в Qbasic. Это не означает что возведение в степень невозможно, например в С++ можно воспользоваться функцией pow. Для возведения 5 в степень 4 - pow (5, 4). При этом при работе с различными функциями в языке С++ необходимо учитывать тот факт, что «по умолчанию» подключаются только основные арифметические операции, а для того чтобы воспользоваться расширенными возможностями необходимо подключить стандартную библиотеку cmath - #include <cmath>. [15]
2.3. Строковые типы
В языке Qbasic cтроковый тип может содержать любые символы до 32767 знаков в кодировки ASCII. Для определения типа как строковый используется суффикс $. [6]
На практике это выглядит так:
NAMES$ = “ВАСЯ”(переменной NAMES при помощи суффикса $ присвоено строковое значение заключенное в двойные кавычки - ВАСЯ)
По аналогии с рассматриваемым выше оператором DEF используется в виде DEFSTR для присвоения типа строковые.[10] Принципы именования переменных и констант те же что и для численных типов. Разницы в регистре букв в названии имени не имеется. Для задания пустой строки используются двойные кавычки NAMES$ = “”
В языке Pascal тип данных строковый задается так же типом string. В Pascal длина стандартной строки ограничена 255 символами. Под каждый символ отводится по одному байту, в котором хранится код символа. Кроме того, каждая строка содержит еще дополнительный байт, в котором хранится длина строки, он имеет индекс 0. [17]Если заранее известно, что длина строки будет меньше 255 символов, то программист может сам задать максимальную длину строки.
сonst
a1: string = ‘строка’
a2: string = ‘2’
type
string_type = string[20];
var
b1, b2: string_type;
В этом примере задан тип строковый с ограничением длины строки в 20 символов, а переменным b1 и b2 задан созданный нами тип.
Надо обратить внимание что в отличии от Qbasic содержимое строки заключаются в одинарные кавычки (апострофы) ‘ ’(в данном случае у нас получена строка с нулевым значением).[17]
Для языка программирования С++ как таковой строковый тип отсутствует. Строки представляются последовательностью символов(литералов) заключенных в двойные кавычки "". Строковые константы в С++ являются по сути массивами символов типа char.[9] При этом в С++ присутствует класс string который содержит последовательность символов и предоставляет такие операции ка добавление символов к строке, определение длины, конкатенация и применяется при низкоуровневой обработке текстов. Чтобы иметь возможность работать со строками необходимо подключить класс #include <string>. [15]
Применимые операции для строковых данных в QBasic является операция конкатенация (+) служащая для объединения строк, сравнения (=, <>, <, >, <=, >=). Сравнение двух строк выполняется слева направо с учетом кодов ASCII. Сначала сравниваются коды первых символов, затем вторых и т.д. Если строки имеют одинаковую длину и одинаковую последовательность символов тогда они считаются равными. Результат операций сравнения имеет логический тип, то есть принимает значения истина (true - 1) или ложь (false - 0). Так же для строкового типа применимы различные функции: LEN - выдаёт количество символов, STRING$ - функция создания текстовой переменной любой длинны содержащей одинаковые символы, INSTR – функция выдаёт номер позиции вхождения подстроки в строку, ARPTR – функция выдаёт физический адрес переменной, LEFT$ - функция выдаёт n символов слева, RIGHT$ выдаёт n символов справа, LCASE переводит в маленькие буквы, UCASE наоборот в большие, LTRIM - выдаёт копию строки с удалёнными пробелами слева, RTRIM$ наоборот справа, SPACE$ - выдаёт строку с заданным количеством пробелов от 0 до 32767, MID$ - выбор или замены части символов переменной и д.р. Продемонстрируем некоторые операции со строковым типом на рисунке 5.
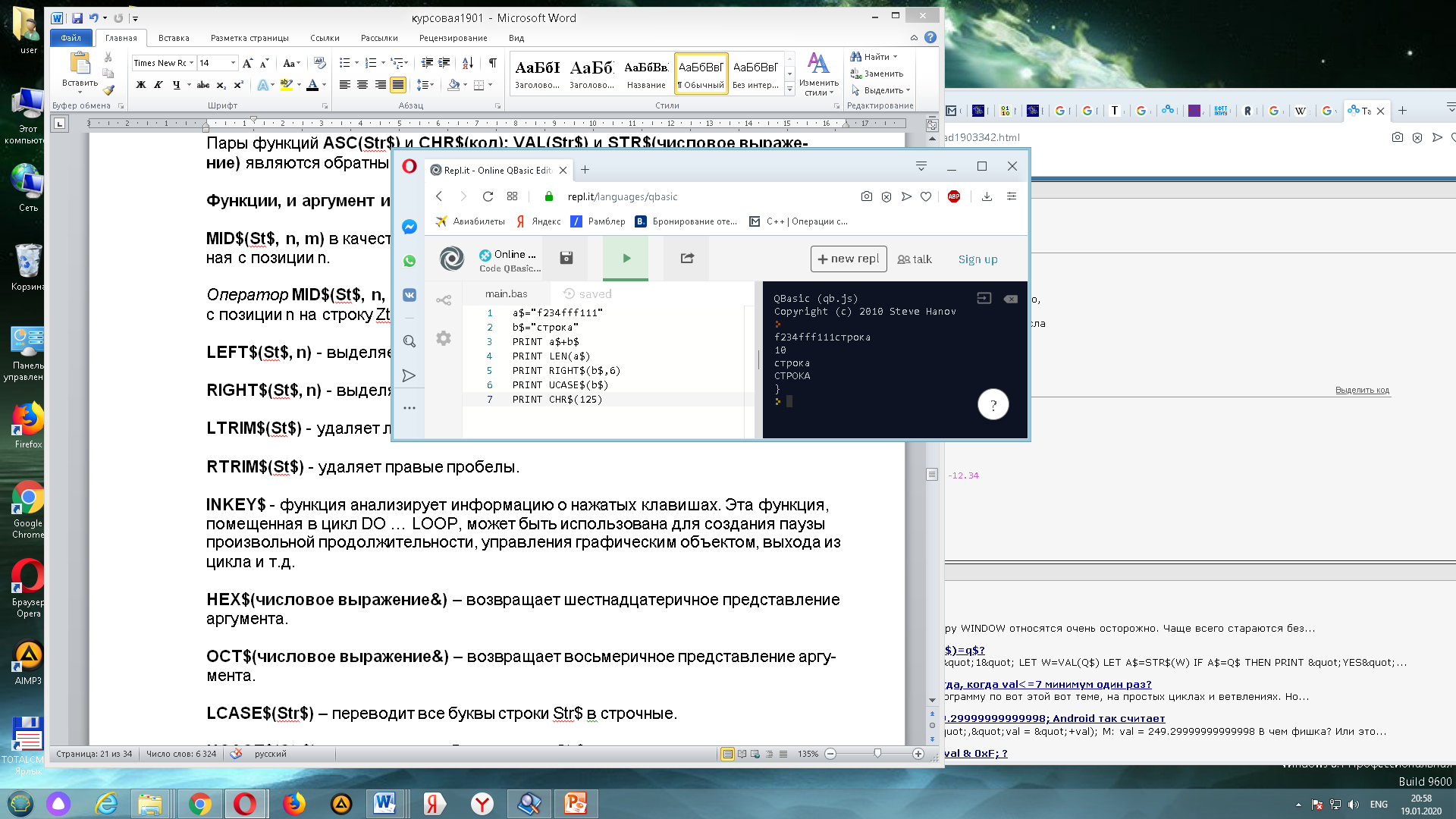
Рис. 5. Демонстрация операций со строковым типом в Qbasic
В языке Pascal для строк так же как и в Qbasic применимы операции конкатенации [14], их можно сравнивать с помощью операций отношения:
‘абв‘ > ‘аб‘ (true)
‘ абв‘ = ‘ абв‘ (true)
‘абв‘ < ‘абв ‘ (false)
Символы просматриваются слева на право, если одна строка меньше другой по длине, недостающие символы короткой строки заменяются символом с кодом 0.
Возможно присваивать значение строк друг другу [17], если при этом максимальная длина присеваемого значения больше чем то которому присваивается, то знаки справа игнорируются - рисунок 6.
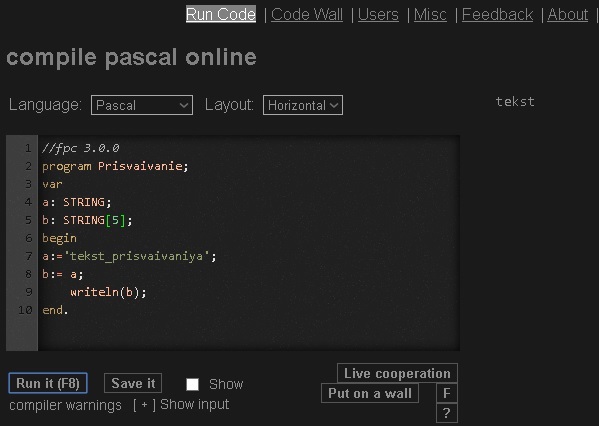
Рис. 6. Операция присваивания строк в Pascal
При работе со строками можно пользоваться распространенными функциями и процедурами: concat (a1, a2, ..., an) для слияния строк, copy (a1, start, len) возвращает подстроку длиной len, начинающуюся с позиции start строки a1; delete (a1, start, len) удаляет из строки a1, начиная с позиции start, подстроку длиной len; insert (subst, a1, start) вставляет в строку s подстроку subst, начиная с позиции start; length (a1) возвращает фактическую длину строки a1, результат имеет тип byte; pos (subst, a1) ищет вхождение подстроки subst в строку a1 и возвращает номер первого символа subst в a1 или нуль, если subst не содержится в a1 и т.д.
2.4. Символьные типы
Символьные типы присутствуют в языках С++[15] и Pascal[17] и обозначаются типом char.
Это может быть буква, цифра или знак. Например, в типичном случае использования кодировки ASCII символу z соответствует число 122, а символу + число 43. Для типа char существуют две модификации signed char (то есть со знаком) принимающий значения от -128 до 127 и unsigned char (беззнаковый) принимающий значения от 0 до 255.
Следует отметить, что в случае необходимости иметь дело с переменными которые имеют значения русских букв, то их тип должен быть unsigned char, так как коды русских букв в кодировке ASCII обозначаются числами свыше 127, символ А (русская большая буква А) соответствует числу 128 и т.д. Символ заключается в одиночные кавычки и называется символьным литералом. Например для программы в кодировке ASCII символ ‘1’ воспринимается как целочисленное значение 49.
В С++ литеры в сочетание с обратным слэшем \, например, символ t - ‘\t’ используется как символ табуляции. Сочетания символов специально зарезервированы.[16]
Учитывая что есть множество различных языков со своими национальными алфавитами, количество букв и прочими особенностями имеется тип данных wchart_t который используется для более широкого диапазона кодов. В отличии от предыдущего тип wchart_t не является встроенным и его размер изменяется в зависимости от способов реализации. Он определяется с помощью оператора typedef. Так как типы wchart_t и char являются интегральными, то к ним можно применять логические побитовые и арифметические операции. В версии С++ начиная с C++11 были добавлены для поддержки д 16-битных и 32-битных символов Unicode были добавлены char16_t и char32_t.
В обоих языках символьный тип данных char занимает в памяти 1 байт и используется для хранения кода символа в одной из кодировок. Процесс объявления типа и присвоения значений аналогичен уже рассмотренным:
char x = ‘A’ (для С++)
x:char; (для Pascal)
a:=‘+’;
В Pascal так же как и в С++ тип char поддерживает полный набор символов ASCII, занимает в памяти 1 байт [14] и так же как и в С++ операторы сравнения могут использоваться применительно к типу char. Так же к символьному типу может применяться конкатенация (+).
К типу char в Pascal применимы 5 функций:[17] Ord - преобразовывает символ в её числовой код из таблицы ASCII; Chr – из номера в символ таблицы ASCII, Pred – для возврата значения предыдущего символа из таблицы ASCII, Succ - для вывода следующего и Upcase - преобразует строчные английские буквы в заглавные.
2.5. Тип void
Тип void существует только в языке С++ (применительно к рассматриваемым языкам). Это тип для которого не существует объектов. Он используется как часть более сложных типов. Используется в синтаксисе С++ для того чтобы проинформировать что у некоей функции не имеется возвращаемого значения т.к. по логике языка функция должна возвращать значение, то что у функции не имеется никаких параметров или в качестве указателя на неопределенные объекты.[15]
Примером использования будет служить маленькая игра для угадывания заранее заданной цифры на рисунке 7.
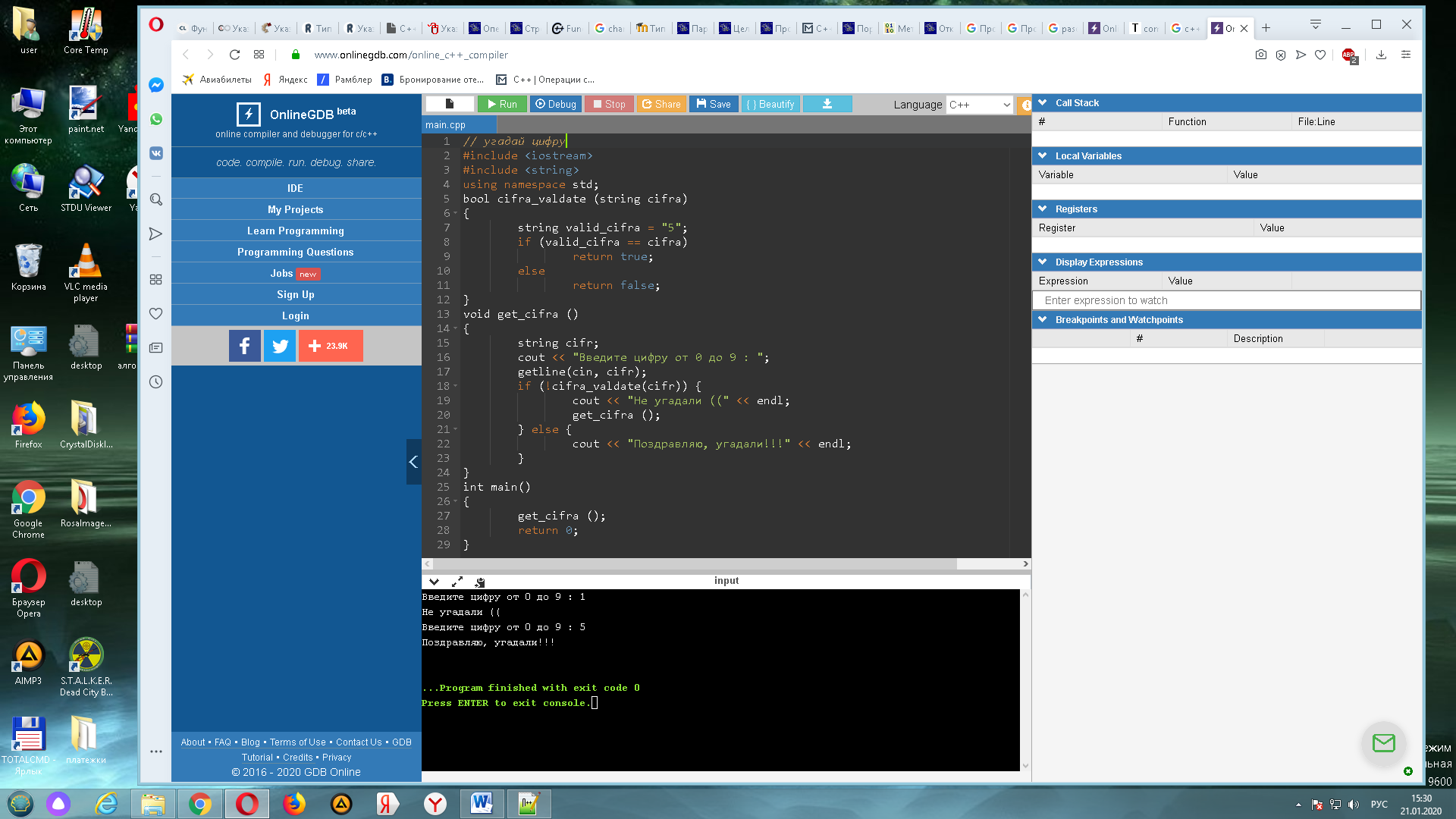
Рис. 7. Вариант использования типа void в С++
2.6. Перечисляемый тип
Перечисляемый тип используется в С++ (enum) это тип данных, который содержит определенный пользователем набор значений. [16]
Например, два перечисления enum Сolorflag {WHITE, BLUE, RED} и enum Month {JANUARY, FEBRUARY, … DECEMBER} являются различными типами данных Colorflag и Month. Каждый элемент определяется как целая константа и ему по умолчанию присваивается целое значение начиная с нуля. То есть в перечислении Colorflag первая константа WHITE имеет порядковый номер 0, а константа RED – 2, при этом все константы указанные в перечислении имеют тот же тип что и само перечисление - Colorflag. [15]
Поскольку значениями перечислителей являются целые числа, то их можно присваивать целочисленным переменным.
Этот тип широко используется в документировании кода.
Для Pascal для неявного задания перечисления можно использовать список значений:
type
Colorflag: (WHITE, BLUE, RED);
var
per: Colorflag;
К таким переменным можно применять функции ord, pred, succ и процедуры inc и dec и операции отношения.
2.7. Тип указатели
Тип указатели присутствует в языках С++[16] и Pascal[14].
Тип данных указатели – по сути дела такой тип, который содержит адрес какого то объекта (адрес первого байта этого объекта в памяти), это может быть переменная, функция, массив и др. Обязательное условие при объявлении указателя - надо задать тип соответствующий элементу на который он будет указывать [12]. Различие между именем и указателем заключается в том, что имя объекта прямо указывает на него, а указатель косвенно.
В памяти сам указатель занимает такой объем какой необходим для хранения адреса. Если у нас используется 32-битная архитектура, то указатель будет занимать 4 байта памяти, а в 64-битной 8 байт. Размер не будет зависеть от того на что он указывает.
С помощью указателей можно организовать массив, для выделения динамической памяти, указатели можно использовать чтобы передать большой объем данных без обязательного его копирования, например, от одной подпрограммы(функции) в другую подпрограмму, для передачи одной функции в качестве некого параметра в другую, используются в механизмах наследования и т.п.
В С++ указатели используются совместно с двумя операторами. Оператор & (оператор адреса) позволяет узнать адрес памяти который присвоен некоей переменной, оператор * (оператор разыменования) указать на адрес и получить значение находящееся по этому адресу. [12] Поясним на примере на рисунке 8 одновременно представив формы описания указателей.
Переменной с1 мы присвоили значение 124, следующим действием является создание указателя p который будет содержать адрес памяти где расположена с1, а результатом выполнения будет вывод значения переменной с2 с присвоенным ей значением.
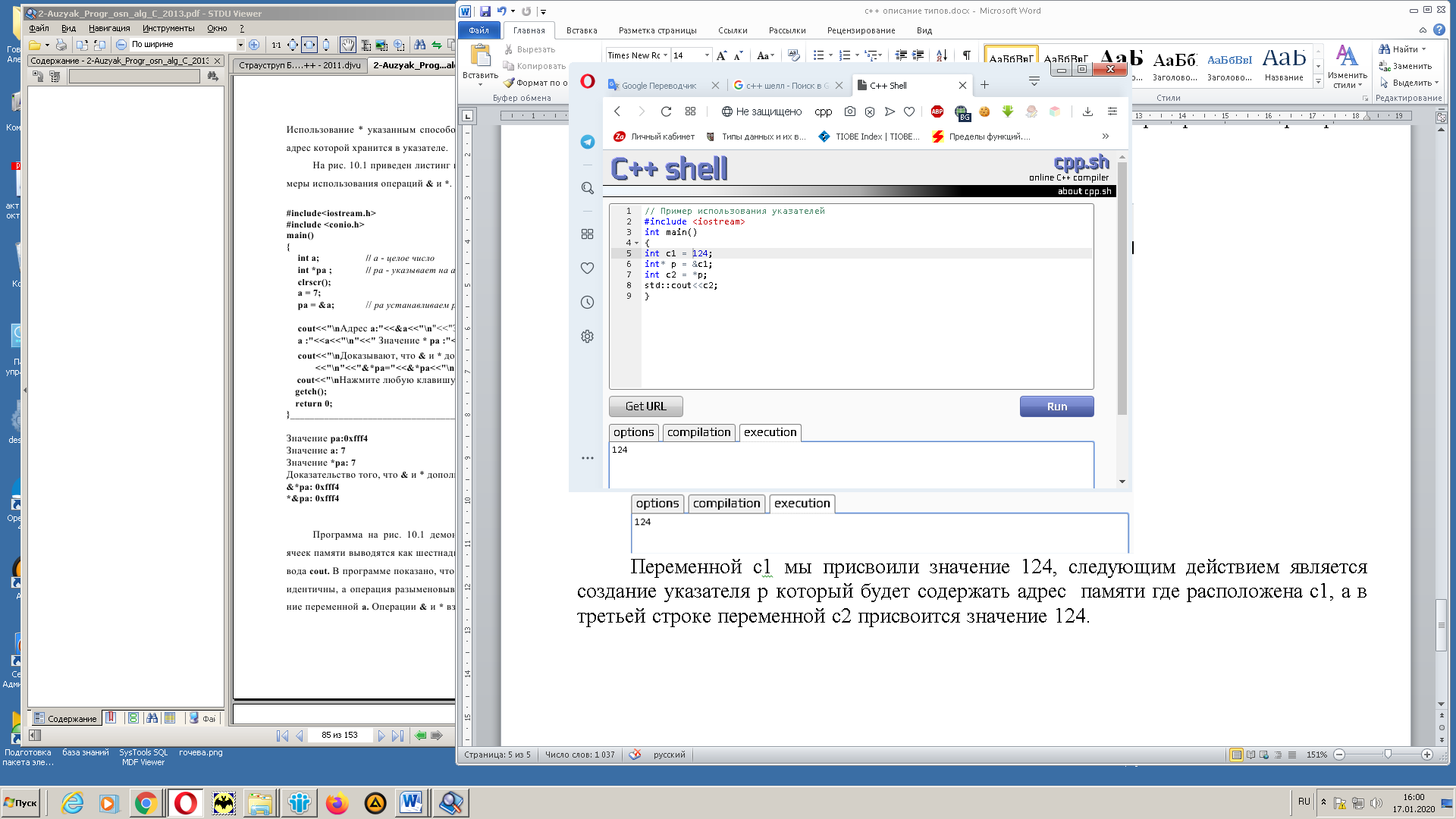
Рис. 8. Пример использования указателей в С++
Указатели возможно использовать как операнды в арифметических выражениях (с ограничениями), выражениях сравнения и присваивания.[12]
Пример использования указателей с массивами и арифметических операций на рисунке 9.
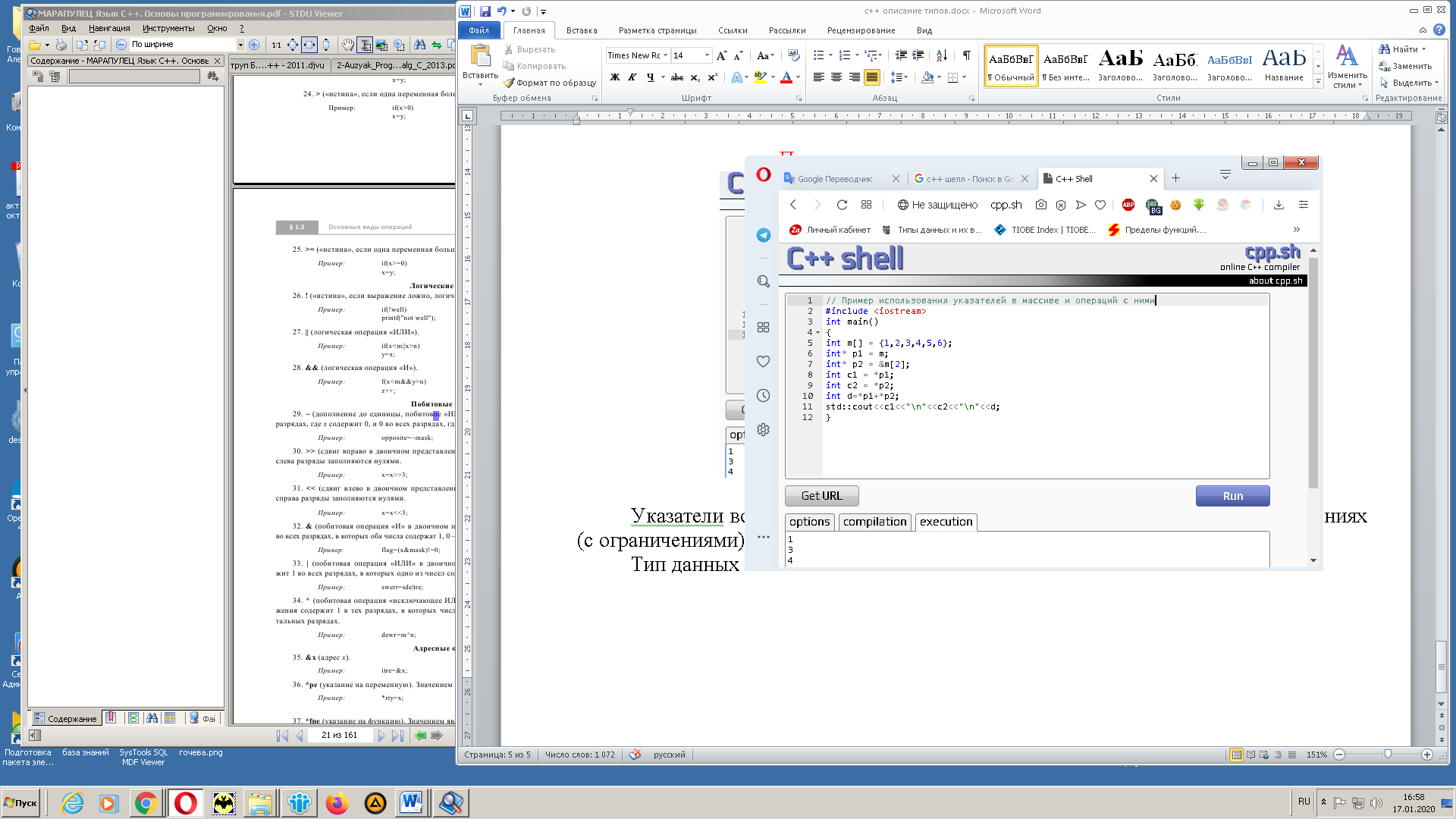
Рис. 9. Использование указателей как операндов
Задан массив m состоящий из 6 значений. В первом случае указание на массив используется как указатель на его первый элемент, во втором случае на конкретный элемент массива под порядковым номером 2 (при этом необходимо учитывать что нумерация начинается с 0) и в конце «складывает» два указателя (на самом деле складываются значения на которые указывают указатели).
В Pascal для объявления указателей используется значок - ^.
Правила объявления аналогичны уже выше рассматриваемым:
p: ^char;
Для объявления переменных не связывая их, с каким либо типом данных можно использовать указатель без типа (pointer).[14]
p:pointer;
Для присваивания значения адреса используется оператор @ или адрес объекта с помощью функции ADDR.
p:= @X
Для работы с указателями в Pascal применяются различные функции и процедуры: ADDR(X) - результат POINTER, X –имя любой переменной, процедуры или функции; OFS(X):WORD - возвращает значение смещения адреса объекта X; SEG(X):WORD - возвращает значение сегмента адреса объекта X; CSEG(X):WORD, DSEG(X):WORD, SSEG(X):WORD, SPRT(X):WORD - возвращает текущее значение соответствующего регистра;
PRT(SEG,OFS) - преобразует отдельно заданные значение сегмента и смещения к типу указателя; MAXAVAIL:LONGINT - возвращает размер наибольшего непрерывного участка кучи; MEMXAVAIL:LONGINT - возвращает размер общего свободного пространства кучи.
Процедуры так же используются для работы с памятью – резервирования, уничтожения динамических переменных и возвращения в общую кучу фрагментов памяти зарезервированных указателями и т.п.[17]
2.8. Логические типы
Логический тип данных имеется в языках С++[16] и Pascal.[14]
Так как значение относится к типу целые, в памяти занимает 1 байт и его диапазон допустимых значений 256 знаков, для значения false определено число 0, а остальные от единицы до 255 это значение true. Таким образом выполняется false < true.
Для Pascal при объявлении логического типа используется boolean, для С++ bool. Правила объявления переменных такие же как и для остальных типов. Пример присвоения в Pascal:
x:=true;
y:=5>3;
В Pascal помимо операция отношения рассмотренных ранее имеются следующие логические операции: NOT – отрицание; OR – логическое объединение; AND – логическое пересечение; XOR – исключающее ИЛИ.[5]
В С++ данного типа используются следующие операции: && - логическое И, || - логическое ИЛИ, ! – логическое НЕ, а также возможны следующие операции отношения: > (больше), < (меньше), == (равно) следует обратить внимание что именно 2 символа = , >= (больше или равно), <= (меньше или равно) и != (не равно). [12]
Отсутствие в С++ логической операции ИЛИ в случае необходимости можно заменить использованием операции отношения !=.
При составлении сложных логических выражений имеющих своим значение тип boolean либо bool надо учитывать приоритет выполнения логических операций.[16], [17] Продемонстрируем это примером. Так как приоритет логического оператора (!)НЕ выше чем у отношения равенства, то в первом примере допущена ошибка, во втором же случае приоритет выполнения логического выражения правильно задан скобками. На рисунке 10 приведен пример неправильного и правильного составления логического выражения.
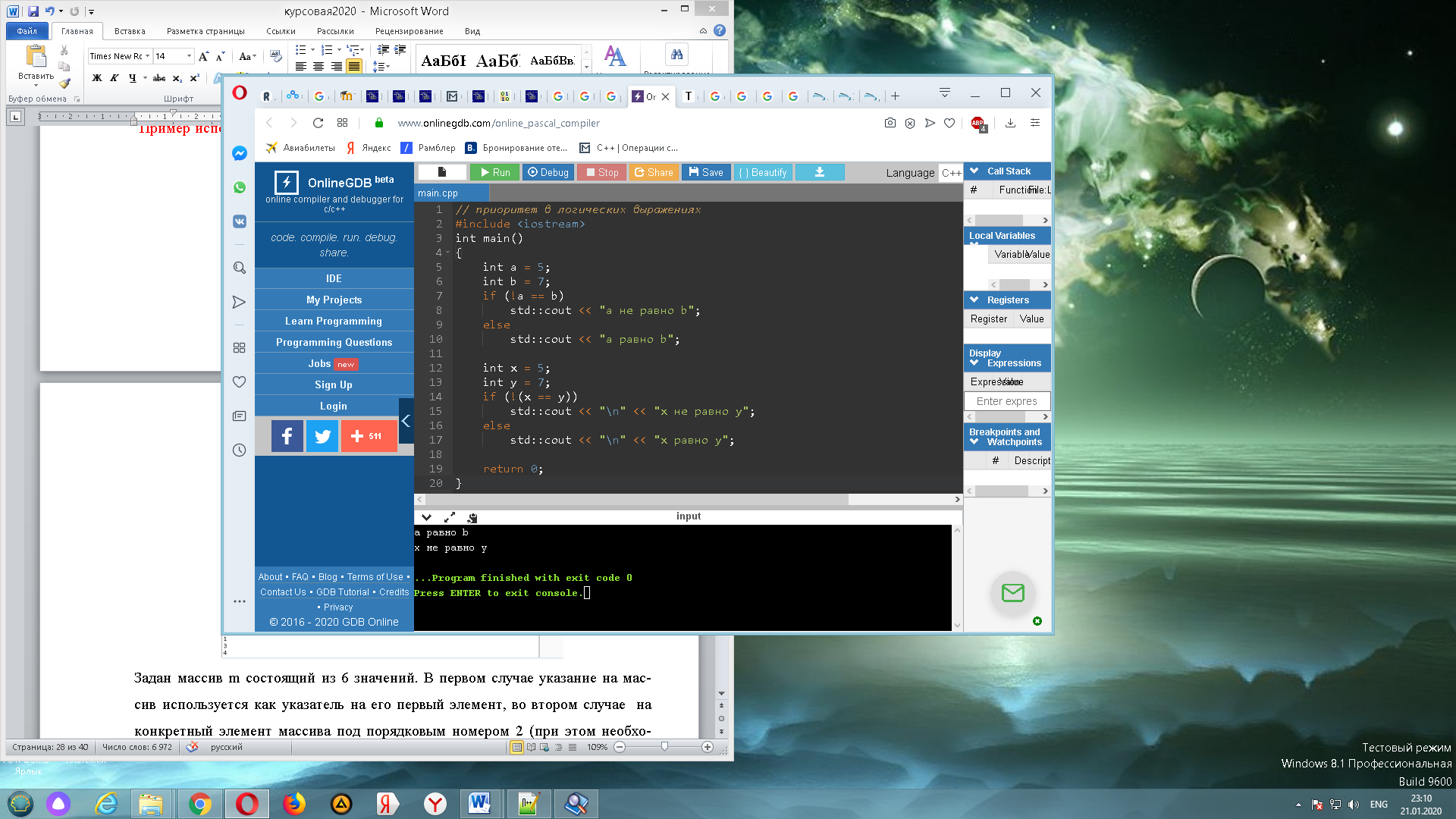
Рис. 10. Демонстрация приоритета в логических выражениях
Приоритет и правила в логических выражения в общих случаях таковы:
Если логический оператор НЕ (NOT, !) должен работать с результатами работы других операторов, то эти операторы и их операнды должны находиться в круглых скобках.
Логические операции одного приоритетного уровня выполняются слева направо.[17] Порядок операций можно изменить, воспользовавшись круглыми скобками. Обязательно следует учитывать тот факт, что в разных языках программирования логические операции могут иметь разный приоритет по отношению к другим операциям – арифметическим и сравнения. Например, в QBasic приоритет логических операций ниже, чем операций сравнения. В Pascal наоборот, а приоритет оператора NOT выше, чем у арифметических операций. В Pascalоператор OR (логическое ИЛИ) имеет высший приоритет над оператором =, а в С++ оператор == имеет приоритет выше чем || (логическое ИЛИ). [14], [16]
2.9. Тип массивы
Общее правило для типов данных массивы в языках это то, что все элементы массива должны иметь одинаковый тип.
Массивы могут быть как одномерными (вектор) так и многомерными. Двумерный массив можно рассматривать как массив из двух одномерных массивов, примером двумерного массива может являться матрица (таблица),
а трехмерный массив как массив с элементами из двумерных. [13] Каждый элемент массива имеет свой индекс - в одномерных массивах (векторах) это порядковый номер элемента, в двумерных индексы обозначает номер строки и столбца.
1 3 4 6
9 8 7 5
В приведенной матрице элемент соответствующий числу 7 имеет индекс [2,3]
Для массивов в объявлении соблюдается общее правило, что массив должен иметь уникальное имя, заданную размерность (максимальное значение индекса массива) и указание на тип данных элементов массива. Ценность массивов заключается в том, что существует только лишь одно имя переменной связанной с массивом, а обращение к конкретной ячейке содержащей данные происходит по ее индексу и нет необходимости объявлять огромное количество однотипных переменных.
Массив может быть фиксированного размера и его размер может задаваться динамически.
Элементы массива размещаются в памяти в последовательных ячейках. Массив занимает количество байт, равное произведению количества элементов массива на размер одного элемента, а адрес первого элемента массива является адресом массива.
В Qbasic для объявления массивов и одновременного отведения памяти под хранение их элементов используется оператор DIM. [10]
Пример:
DIM NAMES$(9)
Задан одномерный массив из 10 элементов (с 0 по 9) каждый элемент массива имеет строковый тип (String). После создания массива значения элементов массива равны 0, а в нашем случае пустой строке. [6]
Для двумерного массива правила те же DIM CEL (3, 4) - здесь мы указали двумерного массива чисел.
Ввод данных может осуществляться с клавиатуры с помощью оператора INPUT и PRINT, READ, DATA.
Обращение к элементу массива происходит по индексу элемента А$ = NAMES$(5) где 5 это индекс массива.
С элементами массива возможны любые операции соотносящиеся с типом данных массива.
В Pascal процедура объявление массива используется «array» [11], массив можно задать несколькими способами:
Через объявление типа
type
massiv = array[ 1..10 ] of string;
- где massiv это имя типа, в квадратных скобках список одного или нескольких индексных типов, разделенных запятыми, string – задание типа данных массива.
Индекс массива может быть задан любым перечислимыми типом кроме типа longint.
Вторым способом объявления является непосредственное задание переменной указанного типа в разделе объявления переменных[7]
var
x,y,z: array[1..10] of integer;
a : array [byte] of integer;
В случает такого описания переменные x,y,z считаются массивами одного типа, но вот в случае такого объявления:
var
с = array[1..10] of char;
d = array[1..10] of char;
переменные c и d будут считаются переменными разных типов.
Наиболее удачным в таком случае будет объявление через предварительное описание типа. При этом надо учитывать то, что часто возникает необходимость чтобы значения переменных одного массива были присвоены другому массиву и при одинаковых типах не возникает проблем совместимости. [17]
Еще один интересный момент заключается в тоv, что тип в объявлении массива «of» может быть любым типом имеющимся в Pascal, то он может быть и в том числе массивом. Это дает возможность создания многомерных массивов:
type
massiv = array[1..10] of array[1..15] of integer;[17]
или то же, но в более удобным виде
type
massiv = array[1..10, 1..15] of integer;
Глубина вложенности массивов может быть произвольной, единственное ограничение это размер в адресации, который зависит от реализации, т.к. адреса в массиве это беззнаковые целые числа. [17]
Если мы имеем массив с заранее известными данными, то при объявлении можно сразу же «заполнить» массив значениями, например:
const
massiv:array[1..4] of integer = (1, 3, 2, 5);
Массив, как и в QBasic, можно заполнить различными способами и в том числе случайными значениями с использованием функции random: - рисунок 11.
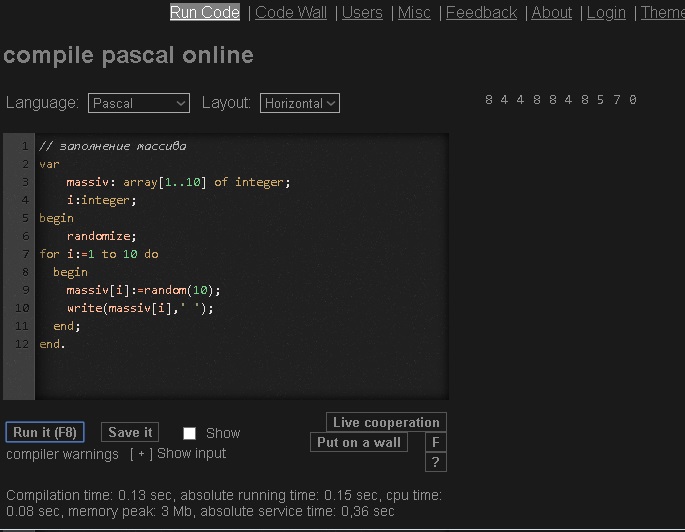
Рис. 11. Присваивание элементам массива значений функцией random
Обращение к элементам массива отличается от Qbasic тем, в для Pascal индекс элемента заключается в квадратные скобки: [7],[10],
Massiv[5]:= 66; (элементу с индексом 5 присвоено значение 66).
Массивы в С++ организуются по тем же основным признакам, что и в предыдущих языках. Массив объявляется в следующем виде:
int massiv[10] - создан одномерный массив с именем М состоящий из 10 целых чисел. Он может быть также объявлен без инициализации либо его создании можно сразу указать значения всех элементов массива int massiv [10] = {10,5,3,2,8,8,6,0,1,4}.[8]
Как и в случае с Pascal объявление int mas[10], a[16]; задаст нам два массива одного типа.
int a[]={5,-12,-12,9,10,0,-9,-12,-1,23,65,64,11,43,39,-15};
Инициализация массива таким образом позволит компилятору самому определить размерность массива при создании, но надо учитывать, что такой подход возможен только при его инициализации, при обычном объявлении размерность массива необходимо указывать.
При инициализации двумерного массива можно воспользоваться следующим способом:
int a[4][3] = { {0, 7, 9}, {9, 63, -1}, {4, 9, 0}, {3, -3, 30}}; - четыре строки по три значения.[8]
Правила обращения к элементу по индексу был продемонстрирован на рисунке 9.
Исходя из того что, по сути дела массивы, во всех рассматриваемых языках используются для одной и той же цели, то и основные действия производимые с массивами имеют схожие черты. Ими могут быть суммирование элементов массива, поиск элемента в массиве, нахождение максимально и минимального значения, операций сдвига, так называемая «пузырьковая сортировка» и множество других.
В связи с этим работа с массивами почти всегда связана с организацией циклов обрабатывающих массив данных.[15],[17]
Работая с массивами данных нередко возникает вопрос о том какие размеры необходимы для размещения массива в памяти, сколько элементов должен содержать массив и т.п. Эти вопросы можно решать различными способами: можно задавать размеры массива «жестко», но тогда, если вдруг случиться ситуация что количество элементов массива необходимо увеличить, то придется перекомпилировать программу, можно задать максимально возможные размеры, а использовать только необходимое количество задаваемое пользователем значений, но в этом случае нерационально расходуется память, а можно память выделять динамически – по мере необходимости, а в случае ненадобности освобождать ее.
Для этого служат динамические массивы.[4] Их реализация чрезвычайно сильно зависит от языка программирования и даже в семействе Pascal она довольно сильно различается. В Классическом Турбо Паскале способов заключается в использовании указателей и процедуры getmem [14] которая создает новую динамическую переменную заданного размера и помещает ее адрес в указателя. Для освобождения памяти используется процедура freemem, в PascalABC процедура SetLength и т.д.
Для С++ пример задания динамического массива приведен на рисунке 12.
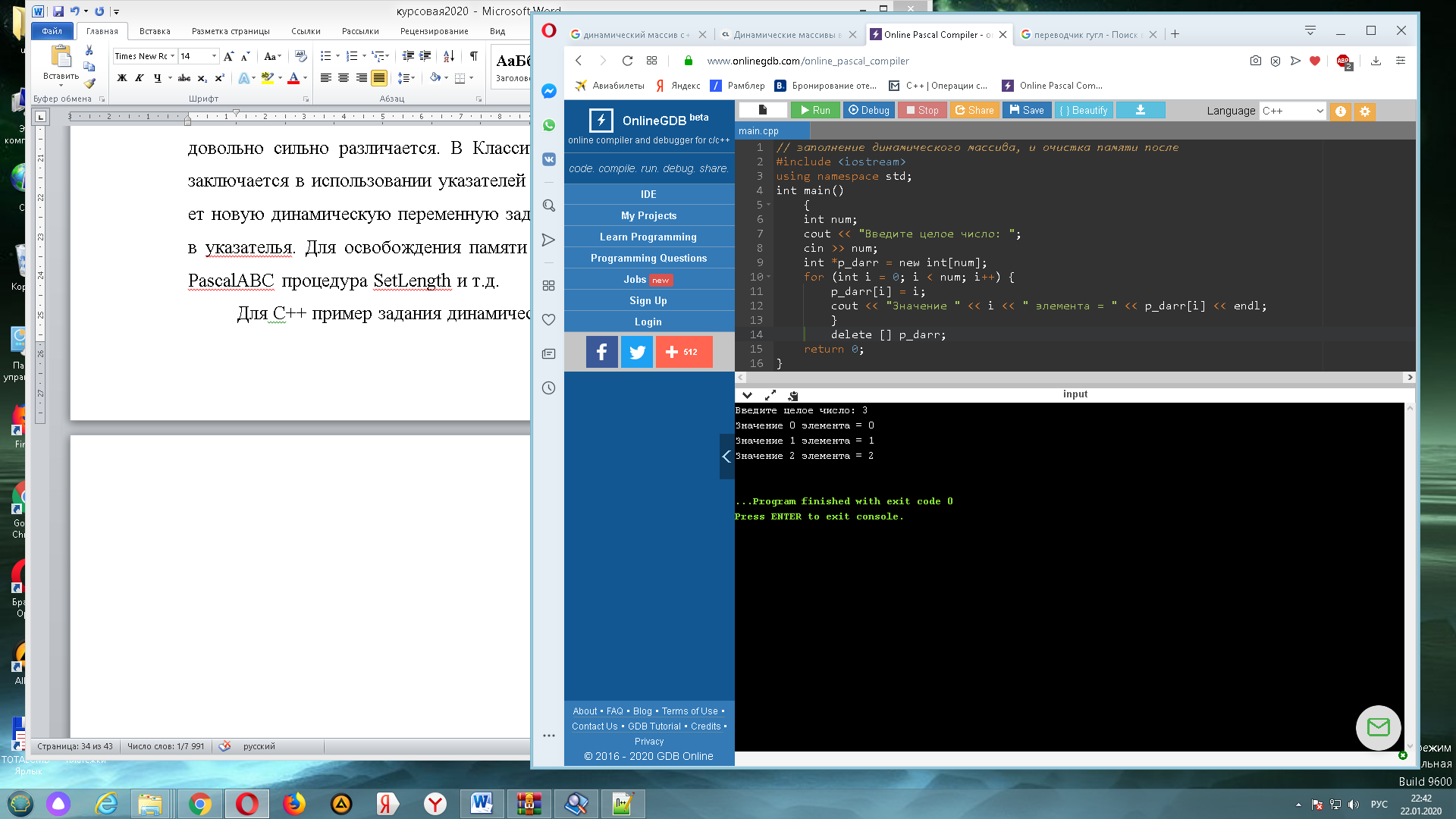
Рис. 12. Пример создания динамического массива С++
2.10. Тип диапазон
Тип диапазон (он же интервальный тип) применяется в Pascal в качестве производного типа от своего базового в качестве которого может выступать любой порядковый тип.[17] Тип диапазон задается границами внутри базового типа. В основном применяется при создании массивов. При этом необходимо помнить что левая граница не должна превышать правую границу и что тип-диапазон наследует все свойства базового типа. При объявлении ему надо задать минимальное и максимальное значение.
type
bukva = ‘A’ .. ‘Я’
var
diap:0..100; (переменная diap может принимать значение от 0 до 100)
В Pascal имеются две основных функции работающие с диапазонами high(x) - максимальное значение диапазона, к которому принадлежит переменная x; и соответственно low(x) для минимального.
2.11. Тип множество
Множество — это структурированный тип данных имеющийся в языках Pascal [14], он является набором каких либо элементов взаимосвязанных между собой по каком-либо признакам и этот набор можно рассматривать как некое единое целое.
В Pascal элементы множества должны принадлежать одному из порядковых типов, количество элементов множества может меняться от 0 (пустое множество) до 256 значений. Отличительно чертой множества от массива является именно непостоянное количество элементов. Для объявления множества используются зарезервированные слова set of.
type
DandC = set of ‘0’.. ‘9’;
var
s1,s2 : DandC;
Переменная получит свое значение только в результате выполнения оператора присваивания:
s1: = [‘5’, ‘1’, ‘6’, ‘0’];
Базовым типом для множества могут быть любые порядковые типы кроме word, longint и integer.
С множествами возможны стандартные те же операции что и в математическом понимании. * - пересечение множеств, + объединение, - разность, = проверка эквивалентности, проверки вхождения <= и > = (первое во второе и второе в первое), IN – проверка принадлежности и т.д.[17] Имеется также две процедуры ориентированные на увеличение скорости работы с одиночными элементами – INCLUDE для включения элемента во множество и EXCLUDE для исключения.
INCLUDE (s1, ‘9’) - во множество s1 включен символ ‘9’.
В операциях со множествами возвращаемым значением является true или false, при этом как в сложных выражениях операции имеют свой приоритет выполнения.[17]
В С++ ситуация со множествами такая же как и, например, со строками, отдельного типа множество нет, но для работы с ними необходимо подключить библиотеку в заголовочным файлом #include <set> и объявить множество.[16]
На рисунке 13 показаны правила объявления множества и работы с ним.
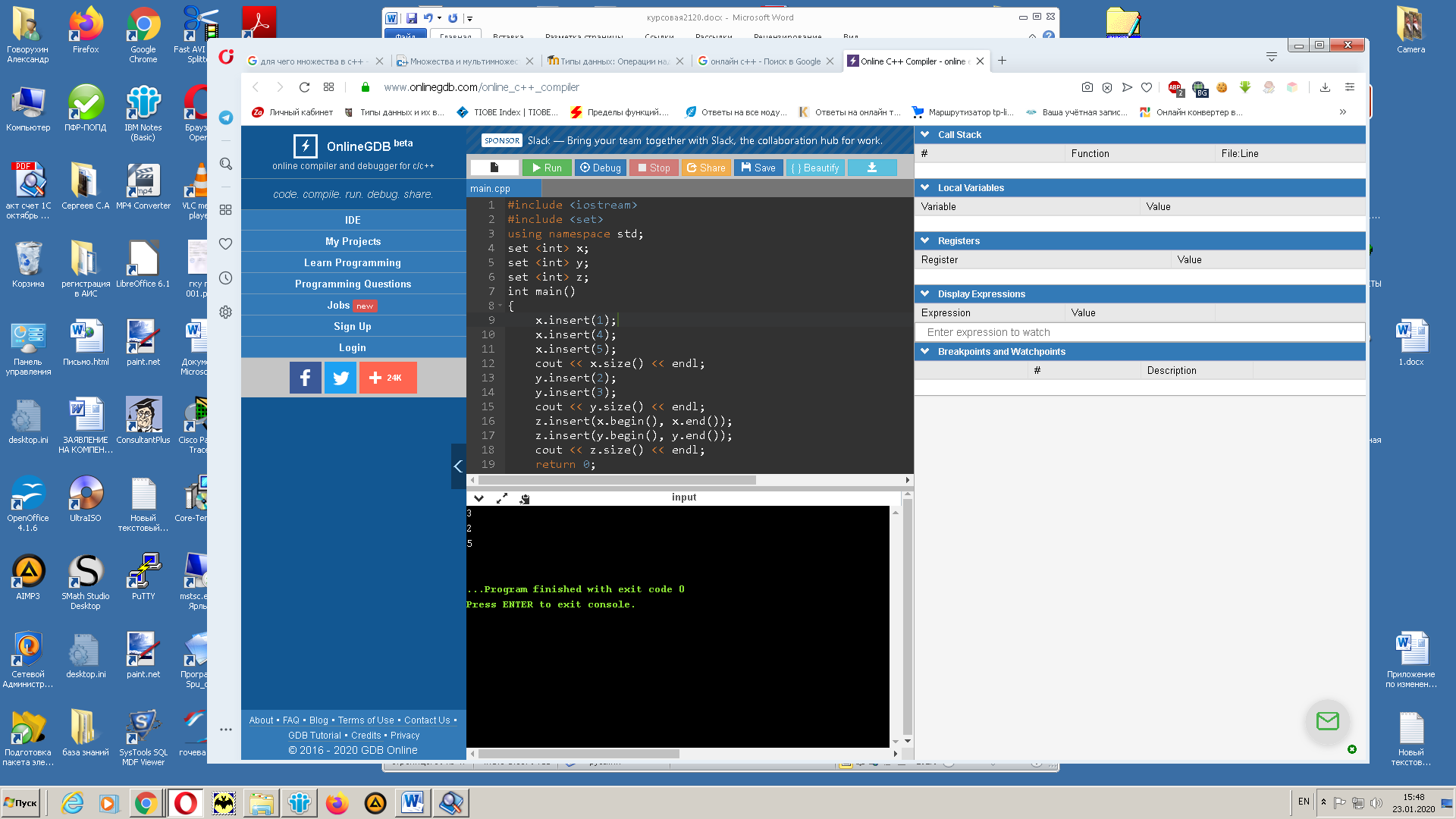
Рис. 13. Пример объявления и работы со множеством в С++
2.12. Тип записи
Тип записи необходим для объединения различных типов данных в единую структуру. Например, описывая звезду мы можем указать ее имя, которое будет являться текстовым типом, расстояние до нее в километрах и это будет целое положительное число (применять иное нету смысла), а звездная величина как положительным так и отрицательным вещественным. В этом главное отличие запись от массива, т.к. в массиве могут присутствовать только данные одного типа.[8]
В языке Паскаль запись определяется путем указания служебного слова record и перечисления входящих в запись элементов с указанием типов этих элементов.[14]
type star=record
sname: string;
sras: longint;
svel: single;
end;
Присваивание переменной типа запись происходит стандартным методом zvezda1: star;. Единственная операция, которую можно произвести над однотипными записями это присваивание. Все другие операции производятся над отдельными полями записи zvezda1.sname := ‘Sun’.[17]
С++ тип записи называется структурой. Он относится к типу структуры данных и классы. Для объявления используется ключевое слово struct.[12]
stuct star {
char sname
long sras
float svel };
Присваивание значений производится следующим образом: имя переменной.имя члена структуры значение: star.svel= 25;
В обоих случаях наблюдается единый подход к обращению элементу структуры через оператор выбора члена записи/структуры (.) Записи и структуры широко используются для организации более сложных структур динамических данных как стек, дерево и т.д.
2.13. Процедурные типы
Эти типы используются в Pascal. Функции с процедурами рассматриваются как некоторые параметры которые могут принимать переменные. Процедурные тип указывает вид процедуры или функции который можно использовать в качестве параметра и с какими параметрами должны они должны быть.
type
ProcА = procedure;
ProcB = procedure(var х,y: integer);
FuncF= function(x: real): real;
В первом случае объявлена процедура без параметров, во втором с двумя переменными целого типа и функция вещественного типа с одним параметром.[14] Затем следует ввести переменные для этих типов:
var
a: ProcА;
f: FuncF;
Следует соблюдать правило что переменная и подпрограмма совпадали по типам и числу формальных параметров для присваивания, а функции должны иметь одинаковый тип. В памяти процедурная переменная занимает 4 байта в которых размещен полный адрес подпрограммы. Процедурные переменные используются как переменные в выражения (в случае если переменная функция), может использоваться в виде оператора (если она процедура), как составная часть (компонента) других более сложных переменных или как параметр передаваемый в подпрограмму.[17] Эта идея единства подпрограммы и данных получила развитие в концепции объектно-ориентированного программирования.
Для Qbasic можно привести некое подобие процедурного типа в виде использования подпрограмм [10] на рисунке 14.
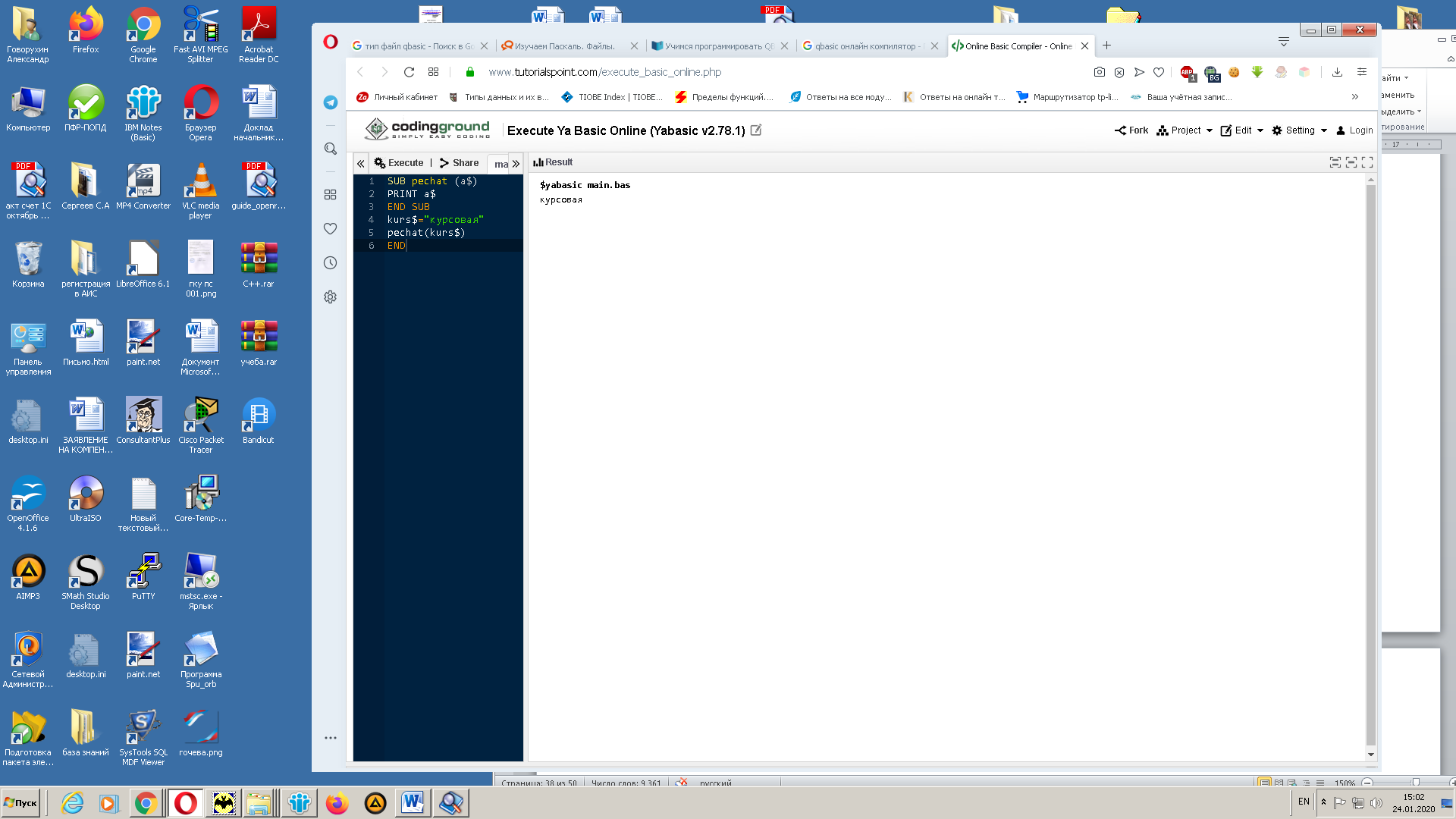
Рис. 14. Использование подпрограмм
2.14. Тип класс.
В С++ класс используется как элемент объектно-ориентированного программирования.[15] В уже описанных выше типе перечисления и типе структура они использовались как объекты для хранения неких данных заданных программистом. При внешнем сходстве с типом структура основным отличием класса является то, что он может не только содержать данные, но и некие функции (методы) которые будут работать с этими данными.[8]
В языке С++ все члены класса относятся к одной из областей доступа - public (доступный любым функциям), protected (доступный только собственным методам и методам производных классов), private (доступный только собственным методам).[16]
Приведем на рисунке 15 пример создания класса PrintKurs где он доступен любым функциям (public), kurs это метод (функция печати), PrintK Kurs будет объектом, а вызовом функции класса является Kurs.kurs
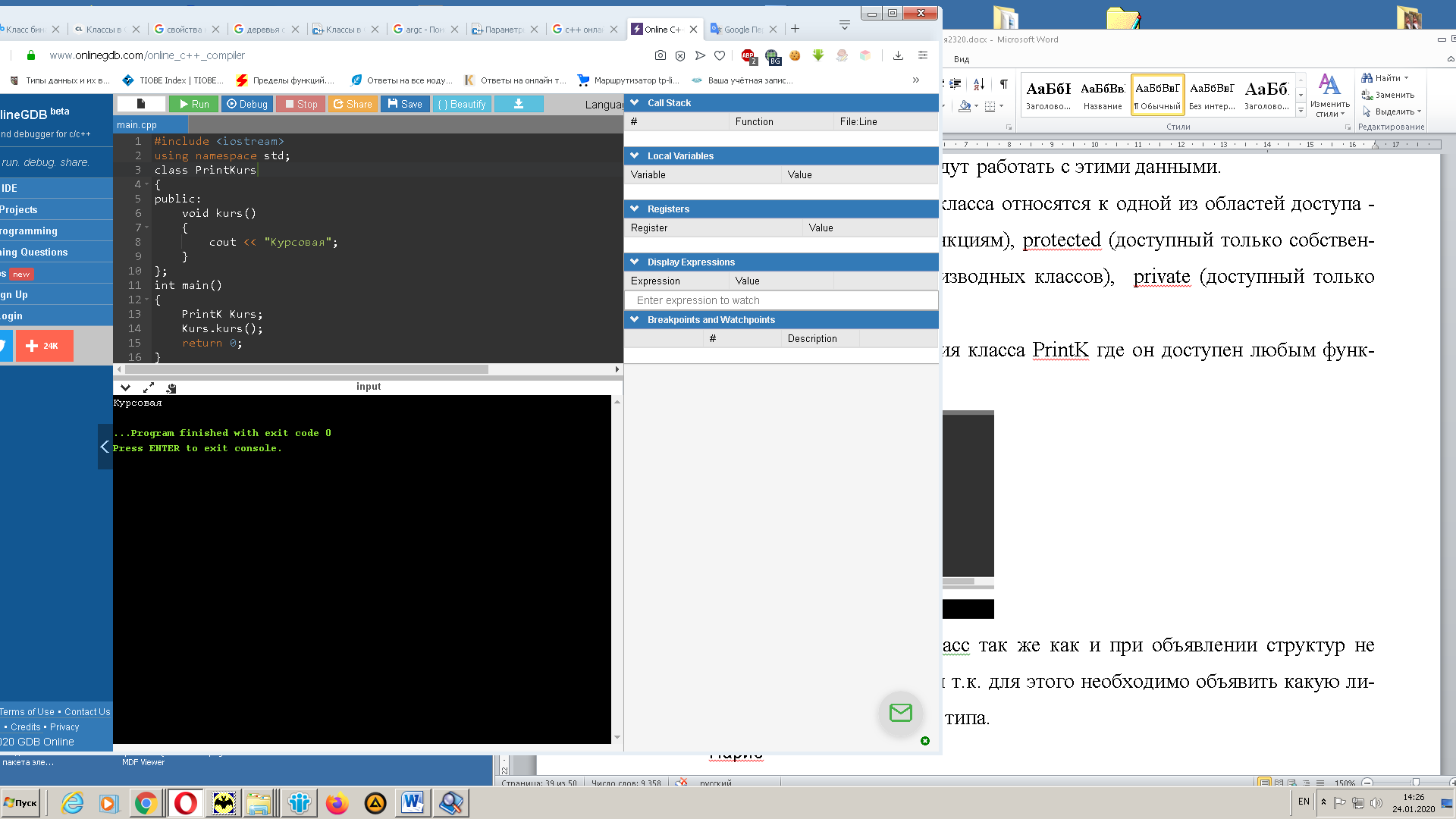
Рис. 15. Создание класса
При объявлении типа класс так же как и при объявлении структур не происходит выделение памяти т.к. для этого необходимо объявить какую либо переменную (объект) этого типа.
2.15. Тип файл
Само понятие типа файл несколько отличается от привычного представления обычного физического файла, например картинки на флешке. Это может быть область в памяти, сами физические файлы, логические устройства.
Например, зная размерность массива и тип его данных можно заранее выделить область памяти где он будет храниться. Если же это невозможно определить или необходимый объем будет меняться, то можно выделить некий тип, где все эти значения будут храниться последовательно не определять величину этой последовательности – это и будет файловый тип данных.[14]
Доступ к элементам этой последовательности может осуществляться последовательно (от первого ко второму и т.д.) и произвольно (для этого доступ осуществляется по номеру элемента).[2]
Рассмотрим работу с физическими файлами.
Pascal различает текстовые файлы, типизированные (последовательность элементов единого) типа и нетипизированные (последовательность элементов произвольного типа) файлы.[17] Доступ к ним происходит с помощью переменных файлового типа:
var
f1: file of char; (типизированный файл)
f3: file; (нетипизированный файл)
t: text; (текстовый файл)
Так же можно задать файловый тип в описании типов аналогичным образом как и в описании других уже рассмотренных типов.
Доступ к физическим файлам появляется только после того как переменная ассоциирована с файлом Assign (f, ‘C:\file.txt’) – при этом надо иметь ввиду что имя файла это не только его имя, но и путь к нему и он является строковым типом. При этом надо иметь ввиду правила наименования файлов (правило 8.3 для DOS, ограничение длины пути и т.п.). Вместо имени на диске можно указать имя логического устройства.
Для работы с файлами используются различные процедуры - reset() открыть файл для чтения (переместится на первый элемент и в случае типизированного файла откроет его и для чтения и для записи) и в случае отсутствия файла сообщит об ошибке, close - закроет файл(это надо делать обязательно после завершения работы с файлом чтобы сохранить все что с ним делали, erase уничтожит, filesize(): longint возвратит количество элементов, seek(f, n); - сместит указатель на позицию n и т.д.
Особенностью работы с нетипизированными файлами заключается в том, что надо указать число байт которое будет считано или записано за 1 раз reset(f, size); – size это количество байт, blockread (f, x, size); - х количество блоков, size соответственно размер. Имеются некоторые различия при работе с разными типами файлов, например процедура открытия для записи APPEND применима только к текстовым файлам.[17] Помимо этого имеется множество тонкостей и особенностей, описание которых займет большой объем.
В Qbasic нетипизированный файл называется бинарным. Открытие файлов и создание (в сочетании APPEND) выполняется командой OPEN.[10]
OPEN "C:\text.txt" FOR INTPUT AS #1 - INPUT для открытия в режиме ввода, #1 – порядковый номер канала который работает с файлом. После завершения как и в Pascal файл надо закрыть командой CLOSE #1. Чтение осуществляется командой INPUT, а запись PRINT. Если файл объявлен двоичным - BINARY, то необходимо указывать длину записи в байтах. Для записи в конец файла используется APPEND. Помимо этого есть множество других команд для работы с типом файл.
Основной отличительной особенностью работы с файлами в С++ является то, что в нем нет операторов которые работают с файлами. Все действия с ними выполняются с использованием функций включенных в стандартные библиотеки.[16] Они оперируют не только с физическими файлами. Чтобы осуществлять действия с файлами имеются классы ifstream для файлового вывода, ofstream для ввода которые определены в fstream. Для реализации файлового ввода-вывода нужно включить в программу заголовочный файл include# <fstream>. Пример на рисунке 16. При этом надо помнить, что для
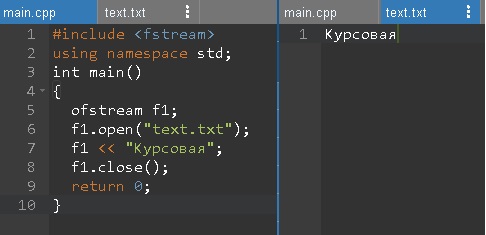
Рис. 16. Создание файла С++
Файлы можно открывать в различных режимах ios::in - для чтения, ios::out - для записи, ios::trunc - очистить файл и др. f1.open("text.txt", ios::app); и при этом режимы открытия файлов можно комбинировать с помощью поразрядной логической операции ИЛИ ( | ).
Произвольный доступ к файлу осуществляется с использованием методов seekg() и seekp() - ifstream &seekg(смещение, позиция); также имеются указатели определяющие в каком месте именно будет производиться следующая операция и многое другое.[15].
Все описанные методы и некоторые возможности работы с типом файл лишь малая часть возможностей.
Рассмотрев, описав и проанализировав типы файлов различных языков программирования и выяснены общие закономерности и различия. Приведены сравнительные характеристики базовых типов данных.
Приведены практические примеры некоторых методов работы с разными типами данных.
ЗАКЛЮЧЕНИЕ
Глубокий подход в изучении и понимание концепции типов данных используемых в языках программирования помогает отбирать из имеющихся возможных вариантов решения конкретных поставленных задач наиболее эффективные решения с применением современных методов работы с данными, реализации заложенных методов и возможностей. Уверенное знание функций, процедур, имеющихся приемов по работе с разными типами данными позволяет сформулировать и претворить в жизнь решения нестандартных задач при программированию. Рассматривая и сравнивая типы данных вплотную подошли к типам используемым в объектно-ориентированном программировании.
Идеологически ООП - подход к программированию как к моделированию информационных объектов, решающий на новом уровне основную задачу структурного программирования, позволяющий в полной мере соответствовать актуальным требованиям, предъявляемым к разработке программного обеспечения в целях развития цифровой экономики.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Белов М. П. Основы алгоритмизации в информационных системах: Учеб.пособие. - СПб.: СЗТУ, 2003. - 85 с.
- Введение в язык паскаль: учебное пособие. / В.Г. Абрамов, Н.П. Трифонов, Г.Н. Трифонова. – М.: КНОРУС, 2011. – 384 с.
- Волкова Т.И. Введение в программирование: учебное пособие. – М.; Берлин: Директ-Медиа, 2018. -138 с.
- Вылиток А.А., Матвеева Т.К. Динамические структуры данных. Задание практикума. Язык Паскаль: Учебно-методическое пособие. (издание второе, переработанное и дополненное). - М.: Издательский отдел Факультета ВМиК МГУ им. М.В. Ломоносова, 2015. – 54 с.
- Гусева А.И. Учимся программировать: PASCAL 7.0. задачи и методы их решения.– 2-е изд., испр. и дополн. – М.: Диалог-МИФИ, 2011. – 216 с.
- Жданова Т.А., Бузыкова Ю.С. Основы алгоритмизации и программирования: учеб. пособие.– Хабаровск: Изд-во Тихоокеан. гос. ун-та, 2011. – 56 с.
- Кадырова Г. Р. Основы алгоритмизации и программирования: Учебное пособие. – Ульяновск: УлГТУ, 2014. – 95 с.
- Макаров В.Л. Программирование и основы алгоритмизации. Учеб. пособие. - СПб.: СЗТУ, 2003. – 110 с.
- Марапулец Ю. В. Язык С++. Основы программирования. Издание второе, исправленное и дополненное. - Петропавловск-Камчатский: КамГУ им. Витуса Беринга, 2019. - 158 с.
- Мельникова О.И., Бонюшкина А.Ю. Начала программирования на языке QBasic: Учебное пособие. – М.: Издательство ЭКОМ, 2002. – 304 с.
- Основы алгоритмизации и программирования: Метод. указ. / Сост.: И.П. Рак, А.В. Терехов, А.В.Селезнев. - Тамбов: Изд-во Тамб. гос. техн. ун-та, 2004. - 24 с.
- Программирование и основы алгоритмизации: Для инженерных специальностей технических университетов и вузов. / А.Г. Аузяк, Ю.А. Богомолов, А.И. Маликов и др.: - Казань: Изд-во Казанского национального исследовательского технического ун-та - КАИ, 2013. - 153 с.
- Рейзлин В.И. Язык С++ и программирование на нём: учебное пособие 2-е изд., переработанное Томский политехнический университет. – Томск: Издательство Томского политехнического университета, 2015. – 212 с.
- Рапаков Г. Г., Ржеуцкая С. Ю. Программирование на языке Pascal. - СПб.: БХВ-Петербург, 2004. — 480 с.
- Страуструп Б. Программирование: принципы и практика с использованием С++, 2-е изд.: Пер. с анг. – М.: ООО «И.Д. Вильямс», 2016. – 1328 с.
- Страуструп Б. Язык программирования C++. Специальное издание. Пер. с англ. - М.: Издательство Бином, 2011. -1136 с.
- Фаронов В.В. Турбо Паскаль 7.0 Начальный курс. Учебное пособие. – М.: Издательство «ОМД Групп», 2003. – 616 с.
- ISO/IEC 14882:2017 [ISO/IEC 14882:2017] Programming languages — C++ // International Organization for Standardization URL: https://www.iso.org/standard/68564.html (дата обращения: 22.12.2019).
- ISO/IEC/IEEE 24765:2017 [ISO/IEC/IEEE 24765:2017,ISO/IEC/IEEE 24765:2017] Systems and software engineering — Vocabulary // International Organization for Standardization URL: https://www.iso.org/standard/71952.html (дата обращения: 19.12.2019).
- TIOBE Programming Community Index Definition // TIOBE Software BV URL: https://www.tiobe.com/tiobe-index/programming-languages-definition (дата обращения: 19.12.2019).

- Художественно-конструкторский проект настенных часов с простой функцией (с упаковкой и комплексом тиражной печатной продукции)
- Особенности управления организациями в современных условиях и пути его совершенствования (Разработка мероприятий по основным направлениям совершенствования управления)
- Тема 5: Статус нотариуса
- Нотариат в РФ (Понятие, сущность, особенности нотариата)
- Роль мотивации в поведении организации (Современные технологии мотивации персонала и их использование в практике управления сотрудниками)
- Оперативно-розыскная деятельность и права граждан
- Эффективность менеджмента организации
- Направления совершенствования межбюджетных отношений в Российской Федерации
- Национальная безопасность Российской Федерации: региональный аспект (Теоретические аспекты организации экономической безопасности субъектов российской федерации)
- Менеджмент человеческих ресурсов (Сущность человеческих ресурсов и технологии управления ими в условиях рыночной экономики)
- Бюджетный федерализм в Российской Федерации
- Структура органов местного самоуправления и критерии оценки их деятельности (на конкретном примере)