
Способы представления данных в информационных системах(ИНФОРМАЦИОННАЯ СИСТЕМА. ПОНЯТИЕ И КЛАССИФИКАЦИЯ)
Содержание:

ВВЕДЕНИЕ
Информационная система это взаимосвязанная совокупность концепций, методов, технологий, технических и программных средств, используемых для сбора, обработки, хранения и выдачи информации потребителю в интересах достижения поставленной цели.
Исторически первыми видами информационных систем являются архивы и библиотеки. Им присущи все атрибуты информационной системы. Они обеспечивают в какой-либо предметной области сбор данных, их представление (систематизацию) и хранение в определенной форме. В них определяется порядок использования информационных фондов.
Информационные системы, в которых представление, хранение и обработка информации осуществляются с использованием компьютерных технологий, называются автоматизированными. Автоматизированные информационные системы в настоящее время являются неотъемлемой частью инструментов информационных технологий в широком спектре видов деятельности.
Особенно важным в контексте понятия информационных технологий является понятие «данных».
В информатике «данные» понимаются как информация, представленная в формализованном виде, что обеспечивает возможность ее хранения, обработки и передачи. Данные характеризуются конкретной формой (способом) представления и неразрывно связаны с обработкой, хранением и передачей информации. Например, информация о сотруднике организации с точки зрения ее хранения, обработки и транспортировки представлена в виде учетной карточки подразделения персонала с формализованной структурой (поля с определенными правилами заполнения).
Таким образом, информация на стадии данных характеризуется определенной формой представления и дополнительной характеристикой, выражаемой термином «структура».
Актуальность темы объясняется разнообразием способов представления данных в современных информационных системах, которые определяют их форму и структуру.
Цель курсовой работы - рассмотрение аспекта способов представления данных в информационных системах.
Для достижения поставленной цели необходимо решить ряд задач, а именно:
- изучить этапы жизненного цикла информационной системы;
- рассмотреть модели информационных систем;
- рассмотреть понятие информационных систем, и способов представления информации.
Объектом исследования являются способы представления данных в информационных системах.
Предметом исследования — совокупность методов обработки и хранения данных.
Структурно курсовая работа состоит из введения, двух глав, заключения и списка использованной литературы.
1 ИНФОРМАЦИОННАЯ СИСТЕМА. ПОНЯТИЕ И КЛАССИФИКАЦИЯ
1.1 Понятие информационной системы
Информационная система имеет сложную структуру и использует различные технологии. К понятию техническое устройство относятся: компьютеры, устройства для сбора, накопления, обработки и вывода информационных данных, устройства передачи данных и каналы связи, техническую документацию, в которой определяются правила эксплуатации и использования технического устройства. Информационное обеспечение составляют значения параметров, характеризующих объекты информационной системы, данные о формах входящих и исходящих документов.
Совокупность математических методов, алгоритмов, моделей и программ, реализующих функции информационной системы, представляют собой математические и программные средства. Организационно-правовое обеспечение представляет собой совокупность документов, регламентирующих деятельность людей в информационной системе: законы, нормативные акты, инструкции и т.д. К другим средствам можно отнести, например, например, лингвистику, которая определяет интерфейс, представление данных в базе данных и тому подобное.
Данные в информационной системе могут храниться в неструктурированном или структурированном виде [1]. Неструктурированные — это обычные текстовые документы (иногда иллюстрированные): статьи, рефераты, журналы и книги. Системы, в которых хранят неструктурированные данные, не всегда дают конкретный ответ на вопрос пользователя, но могут предоставить текст документа или список документов, в которых необходимо искать ответ.
Структурирование данных включает в себя установку правил, которые определяют их форму, тип, размер, значение и тому подобное. В информационную систему данные поступают из источника. Данные отправляются для хранения или специальной обработки в системе, а затем передаются потребителю. Потребителем может быть человек, устройство или другая информационная система.
Между потребителем и собственно информационной системой может быть установлена обратная связь (от потребителя к блоку приема информации).
В информационной системе происходят следующие процессы:
- ввод данных, полученных из различных источников;
- обработки (преобразования) данных;
- хранения входящих и обработанных данных;
- вывода информационных данных, пользовательских;
- отправка / получение данных сети.
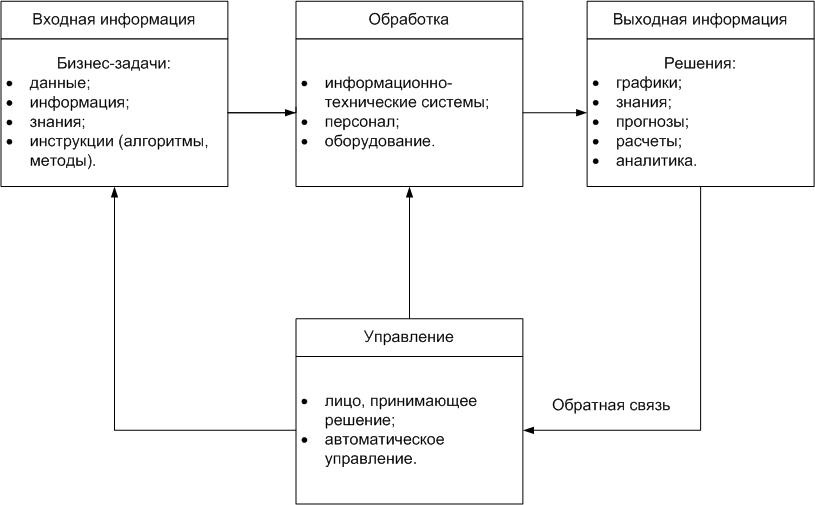
Рисунок 1- Структурная схема информационной системы
Разработка информационной системы предполагает решение двух задач: наполнения системы данными определенной предметной области; создание интерфейса пользователя (желательно графического) для получения необходимых информационных данных [2].Между источником и потребителем информационной системы может быть организовано взаимодействие: произвольное взаимодействие, которое предусматривает обязательное участие операторов и на стороне приема, и на стороне передачи.
Возможен обмен в произвольном, но заранее оговоренном формате; интерактивный удаленный доступ, в которой оператор находится на передающем стороне, обрабатываются принятые документы автоматически; контролируемая потоковая обработка. Например, принятый по электронной почте файл содержит HTML форму, запуск которой начинает процесс обработки документа или прием оператором электронной почте документов в обусловленном формате и далее — запуск программы обработки. Требует обязательного контроля оператора на стороне приема; полностью автоматизированный процесс приема и обработки электронных документов в оговоренном формате, участие операторов не нужна.
1.2 Классификация информационных систем
Принципы построения информационных систем является относительно постоянными. Но разнообразие сфер и форм применения современных информационных технологий порождает большое разнообразие способов классификации информационных систем [3].
Информационные системы классифицируют:
1. по степени автоматизации: ручные, в которых обработку информационных данных выполняет человек; автоматизированные, в которых часть функций (подсистем) управления или обработки данных осуществляют автоматически, а часть — выполняет человек; автоматические, которых все функции управления и обработки данных осуществляется с помощью технических средств без участия человека.
2. по масштабу использования: одиночные, которые реализованы, как правило, на автономном персональном компьютере без обязательного подключения к компьютерной сети и содержащие несколько простых составляющих с общим информационным фондом; групповые, которые ориентированы на коллективное использование информационных данных и зачастую построены на основе локальной компьютерной сети; корпоративные, которые ориентированы на крупные компании с поддержкой территориально удаленных компьютерных информационных узлов и сетей.
Как правило, они имеют иерархическую клиент-серверную структуру со специализацией серверов; глобальные, охватывающие территорию государства или континента (например, Интернет) [4].
3. по сфере назначения (предметной области, указаны лишь некоторые):
- экономическая (функция управления на предприятии);
- медицинская;
- географическая;
- административная;
- производственная;
- учебная;
- экологическая;
- криминалистическая; военная.
4. по месту деятельности:
- научные, предназначенные для автоматизации деятельности ученых, анализа статистических данных, управления экспериментом;
- автоматизированного проектирования, предназначенные для автоматизации труда инженеров-проектировщиков и разработчиков новой техники или технологий. Они помогают осуществлять:
- разработку новых изделий и технологий их производства;
- различные инженерные расчеты: определение технических параметров изделий;
- расходных норм — трудовых, материальных, финансовых;
- создание графической документации (чертежей, схем, планировок) моделирования проектируемых объектов;
- создание программ для станков с числовым программным управлением.
- организационного управления, предназначенные для автоматизации функции административного (управленческого) персонала промышленных предприятий и непромышленных объектов (банков, бирж, страховых компаний, гостиниц и т.д.) и отдельных офисов (филиалов);
- управления технологическими процессами, предназначенные для автоматизации различных технологических процессов (гибкие производственные процессы, металлургия, энергетика и т.д.).
Основные задачи информационных систем - IP:
- Поиск, обработка и хранение информации, которая накапливается в течение длительного времени. Компьютеризированные ИС предназначены для более быстрой и надежной обработки информации, благодаря чему люди не теряют время, избегая случайных ошибок, присущих им, экономя затраты и делая жизнь более комфортной.
- Хранение данных различной структуры. Не существует разработанного IP, работающего с одним однородным файлом данных. Кроме того, разумным требованием к информационной системе является ее развитие. Могут появиться новые функции, которые требуют дополнительных данных с новой структурой. Кроме того, вся ранее накопленная информация должна оставаться сохранной. Теоретически эту проблему можно решить с помощью нескольких файлов внешней памяти, в каждом из которых хранятся данные с фиксированной структурой. В зависимости от организации используемой системы управления файлами, структура может быть структурой записи файлов или поддерживаться отдельной библиотечной функцией, написанной специально для IP. Есть хорошо известные примеры реально работающих IP-адресов, в которых хранение данных планировалось на основе файлов. В результате разработки большинства систем в них был определен отдельный компонент, который является своего рода системой управления базами данных (СУБД).
- Анализировать и прогнозировать информационные потоки различных типов и типов, движущихся в обществе. Эти потоки изучаются с целью минимизации, стандартизации и адаптации их для эффективной обработки на компьютерах, а также особенностей потоков информации, проходящих через различные каналы распространения информации.
- Исследования способов по представлению и хранению информации, создание специальных языков для формального описания информации различного характера, разработка специальных методов сжатия и кодирования информации, аннотирование объемных документов и их обобщение. В этой области ведется работа по созданию больших банков данных, которые хранят информацию из различных областей знаний в форме, доступной для компьютеров.
- Построение процедур и технических мер для их реализации, которые могут автоматизировать процесс извлечения информации из документов, которые не предназначены для компьютеров, но ориентированы на восприятие их человеком.
- Создание информационно-поисковых систем, способных распознавать вопросы о хранении информации, сформулированные на естественном языке, а также специальный язык запросов для систем этого типа.
- Создание сетей хранения, обработки и передачи информации, в которые входят банки информации, терминалы, процессинговые центры и средства связи. Конкретные задачи, решаемые информационной системой, зависят от области применения, для которой предназначена система. Область применения информационных приложений разнообразна: банковское дело, управление производством, медицина, транспорт, образование и т. д.
1.3 Этапы жизненного цикла информационной системы
Жизненный цикл ИС – совокупность этапов, которые проходит ИС в своем развитии от момента принятия решения о ее создании до прекращения функционирования [5].
Жизненный цикл информационной системы включает следующие этапы:
1) предпроектный;
2) проектирование логическое и техническое;
3) проектирование рабочее (физическое);
4) внедрение;
5) эксплуатацию;
6) изъятие.
Предпроектный этап включает в себя исследование и анализ системы управления компанией, выявляющие имеющихся информационных потребителей. Целью данного этапа является формирование требований к ИС, корректно и точно отражающих цели и задачи организации-заказчика. Чтобы специфицировать процесс создания ИС, отвечающей потребностям организации, нужно выяснить и четко сформулировать, в чем заключаются эти потребности. Для этого необходимо определить требования заказчиков к ИС и отобразить их на языке моделей в требования к разработке проекта ИС так, чтобы обеспечить соответствие будущей ИС целям и задачам организации.
Задача формирования требований к ИС является одной из наиболее ответственных, трудно формализуемых и наиболее дорогих и тяжелых для исправления в случае ошибки [6].
Современные инструментальные средства и программные продукты позволяют достаточно быстро создавать ИС по готовым требованиям. Но зачастую эти системы не удовлетворяют заказчиков, требуют многочисленных доработок, что приводит к резкому удорожанию фактической стоимости ИС. Основной причиной такого положения является неправильное, неточное или неполное определение требований к ИС на этапе анализа.
На этом этапе должны решаться проблемы, связанные с разработкой технического задания, плана мероприятий по подготовке объекта, включая подготовку персонала и финансирования. На данном этапе также осуществляется анализ осуществимости ИС, а именно рассматривается:
- эксплуатационная осуществимость – возможно ли создание данной ИС, насколько она будет удобно в эксплуатации и отвечать заданным требованиям;
- экономическая осуществимость – стоимость, эффективность с точки зрения пользователя;
Проектирование логическое и техническое – это разработка в соответствии со сформулированными требованиями и выявленными информационными потребностями системной и функциональной архитектуры ИС.
На этапе проектирования, прежде всего, формируются модели данных. Проектировщики в качестве исходной информации получают результаты анализа. Построение логической и физической моделей данных является основной частью проектирования базы данных [7]. Полученная в процессе анализа информационная модель сначала преобразуется в логическую, а затем в физическую модель данных.
Параллельно с проектированием схемы базы данных выполняется проектирование процессов, чтобы получить спецификации (описания) всех модулей ИС. Оба эти процесса проектирования тесно связаны, поскольку часть бизнес-логики обычно реализуется в базе данных (ограничения, триггеры, хранимые процедуры). Главная цель проектирования процессов заключается в отображении функций, полученных на этапе анализа, в модули информационной системы. При проектировании модулей определяют интерфейсы программ: разметку меню, вид окон, горячие клавиши и связанные с ними вызовы.
Кроме того, на этапе проектирования осуществляется также разработка архитектуры ИС, включающая в себя выбор платформы (платформ) и операционной системы (операционных систем). В неоднородной ИС могут работать несколько компьютеров на разных аппаратных платформах и под управлением различных операционных систем.
Кроме выбора платформы, на этапе проектирования определяются виды архитектуры:
- архитектура «файл-сервер» или «клиент-сервер»;
- база данных централизованная или распределенная. Если база данных будет распределенной, то какие механизмы поддержки согласованности и актуальности данных будут использоваться;
- серверы, параллельные или одиночные для баз данных (в целях достижения необходимой производительности) и т.д.
Этап проектирования завершается разработкой технического проекта ИС.
Проектирование рабочее (физическое) включает создание и настройку программ, наполнение баз данных, создание рабочих инструкций для персонала. Проектирование заканчивается созданием рабочего проекта [8].
Рабочий проект – это техническая документация, утвержденная в установленном порядке, содержащая уточненные данные и детализированные общесистемные проектные решения, программы и инструкции по решению задач, а также уточненную оценку экономической эффективности автоматизированной системы управления и уточненный перечень мероприятий по подготовке объекта к внедрению.
В ходе опытного и промышленного внедрения осуществляется комплексная отводка системы и обучение персонала.
Внедрение системы – это процесс постепенного перехода от существующей ИС к новой, предусмотренной документацией рабочего проекта на всю систему. Внедрение отдельных задач и подсистем может проводиться параллельно с разработкой рабочего проекта на всю систему.
Основными этапами внедрения системы являются:
- подготовка объекта к внедрению системы;
- сдача задач и подсистем в опытную эксплуатацию;
- проведение опытной эксплуатации;
- сдача задач, подсистем, системы в целом в промышленную эксплуатацию.
Опытная эксплуатация ИС заключается в проверке алгоритмов, программ и звеньев технологического процесса обработки данных в реальных условиях. Она проводится для следующего:
- окончательной отладки программ и отработки технологического процесса решения задач;
- проверки подготовленности информационной базы;
- отработки взаимосвязи задач системы;
- приобретения навыков работы персоналом предприятия;
- настройки всей системы в целом и устранения выявленных недочетов.
После окончания опытной эксплуатации системы составляется отчет о внедрении. При положительных результатах опытной эксплуатации система сдается в промышленную эксплуатацию.
Эксплуатация ИС – ее использование в реальных условиях. В ходе эксплуатации также осуществляется сопровождение, анализ работы системы, исправление ошибок и недоработок, оформление требований и разработка планов по модернизации и расширению системы [9].
Изъятием ИС из эксплуатации называется полное изъятие ИС из эксплуатации или существенная модернизация, позволяющая говорить о создании принципиально новой информационной системы.
Существующие модели жизненного цикла определяют порядок исполнения этапов в ходе разработки, а также критерии перехода от этапа к этапу. В соответствии с этим наибольшее распространение получили три следующие модели жизненного цикла:
1) каскадная модель, предполагающая переход на следующий этап после полного окончания работ по предыдущему этапу;
2) поэтапная модель с промежуточным контролем, т.е. итерационная модель разработки с циклами обратной связи между этапами. Преимущество такой модели заключается в том, что межэтапные корректировки обеспечивают меньшую трудоемкость по сравнению с каскадной моделью, однако время жизни каждого из этапов растягивается на весь период разработки;
3) спиральная модель делает упор на начальные этапы ЖЦ: анализ требований, проектирование спецификаций, предварительное и детальное проектирование. На этих этапах проверяется и обосновывается реализуемость технических решений путем создания прототипов. Каждый виток спирали соответствует поэтапной модели создания фрагмента или версии программного изделия, на нем уточняются цели и характеристики проекта, определяется его качество, планируются работы следующего витка спирали [10]. Таким образом, углубляются и последовательно конкретизируются детали проекта, и в результате выбирается обоснованный вариант, который доводится до реализации.
Исследования последних лет показали, что повышение производительности за счет использования информационных технологий достигается очень редко. Главная причина в том, что новые информационные технологии часто являются зеркальным отображением предыдущих методов и процессов.
2 СПОСОБЫ ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
При работе с СУБД разные люди и разные программы, запущенные людьми, видят СУБД по-разному. Конечный пользователь работает в некоторых приложениях и, вероятно, ничего не знает о внутренней структуре. Программа, которую использует пользователь и, соответственно, программист, написавший программу, видит и использует ту часть базы данных, которую ему разрешено видеть [11]. Администратор, позволяющий определенным пользователям просматривать определенные данные, видит полную схему базы данных. Группа программистов, которая разработала ядро исполнителя запросов (SQL-сервер) и предоставила администратору возможность создавать схему базы данных, реализовала сопоставление базы данных с внешними устройствами и памятью.
В соответствии с этим выделяют три уровня представления данных.
Уровень конечного пользователя - прикладной (пользовательский) уровень. В определенном смысле это самый важный уровень, именно на том уровне, на котором работает пользователь, то есть человек, для которого написана программа. Пользователь рассматривает базу данных как набор нескольких взаимосвязанных полей в форме, как набор меню и команд, выполняя их, решая собственные задачи, например, резервируя два билета в Сочи 20 июля этого года.
Уровень программиста и администратора - концептуальный уровень. На этом уровне есть программист, который создает прикладные программы, и администратор, который разрабатывает структуру базы данных (схему). Администратор видит всю схему, ему доступна вся информация. По сути, его видение является подмножеством того, что видит администратор.
Уровень реализации - физический уровень [12]. На физическом уровне определяется, как хранятся данные и как осуществляется доступ к ним. Например, сервер СУБД реализует в внутри себя именно этот уровень. Как правило, физическое представление не только скрыто от посторонних глаз, но и является частной, закрытой информацией фирмы производителя СУБД.
Значительная часть пользователей, приобретая компьютер или приобретая его, сначала осваивают операции с текстовыми файлами. На первом этапе компьютер обычно используется как удобная и «интеллектуальная» пишущая машинка (для подготовки, хранения, изменения и печати всех типов писем, статей, статей, объявлений, статей и т. д.).
Маловероятно, что многие люди думают, что на данном этапе они уже используют примитивную информационную систему, которая в данном случае состоит из следующих элементов:
- Текстовый редактор как инструмент для манипулирования текстами;
- Группы текстовых файлов (баз данных) как объект обработки.
На следующем этапе многие люди думают об использовании текстового файла в качестве своего рода записной книжки, где можно легко ввести различную информацию «списком», такую как: рецепты, номера телефонов, каталоги видеотеки, музыкальной библиотеки, адреса и названия организаций и т. д. Способ представления и размещения информации в таких «хранилищах» обычно придумывается самим пользователем. Например, адвокат может поместить карточки своих клиентов в текстовый файл с указанием его фамилии, имени и отчества, адреса места жительства, предмета юридической консультации и других данных, например: «Иванов П.И., Тула, ул. Сафонова, 12, Наследство», «Сидоров П.Т., Москва, ул. Тверская, 34, кв. 25, автомобильная авария »и др. [13].
Каковы недостатки этого подхода? Создавая базы данных, мы стремимся предоставить возможность, во-первых, сортировать информацию по различным критериям (например, по теме консультаций), а во-вторых, быстро извлекать выборку с произвольной комбинацией характеристик (например, клиенты обращавшихся по вопросу наследства). Организация данных, описанная выше, не позволит ни того, ни другого, потому что размещение информации в текстовом файле намного сложнее, чем даже в картонной коробке. Кроме того, компьютер может даже не иметь возможности выбирать клиентов с одинаковой темой консультации, если одна и та же тема записана по-разному в записи о разных клиентах (например, «Наследование», «Наел» и т. д.).
Для того чтобы компьютер мог осуществлять точный поиск и систематизацию данных, в первую очередь необходимо разработать и соблюдать определенные правила (соглашения) о том, как представлять информацию при записи данных. В связи с приведенной выше примером записей адвоката, это означает, что тема консультации должна быть указана одинаково во всех случаях записи. Все записи о клиентах должны иметь одинаковую длину (например, две строки на клиента), позиция описания определенных атрибутов данных в каждой записи должна быть одинаковой (например, запись начинается с фамилии, темы юридических консультаций записывается с начала второй строки). Такой процесс адаптации форматов данных и значений к возможностям компьютера, например, устранение произвольности в исполнении длины и (или) значений называется -структурирование информации. Другими словами, структурирование - это введение соглашений о том, как представлены данные. Тогда информационная система представляет собой комбинацию структурированных данных (баз данных) тем или иным образом и комплекса аппаратного и программного обеспечения для хранения данных и манипулирования ими.
2.1 Иерархическая модель данных
Основой информационной системы, объектом ее обработки является база данных (БД). База данных - это набор информации о конкретных объектах реального мира в любой предметной области или разделе предметной области. Например, база данных университетов (высшее образование), база данных лекарств (медицина), база данных автомобилей (автосалон), база данных строительных материалов (склад) и т. д. Синоним термина «база данных» - «банк данных».
В основе любой базы данных лежит модель данных, которая представляет собой структуру данных, соглашения о том, как их представлять и как ими манипулировать. Другими словами, это формализованное описание доменных объектов и их взаимосвязи [14].
Различают три основных типа моделей данных: иерархическую, сетевую и реляционную.
Иерархическая модель данных - это представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) разных уровней.
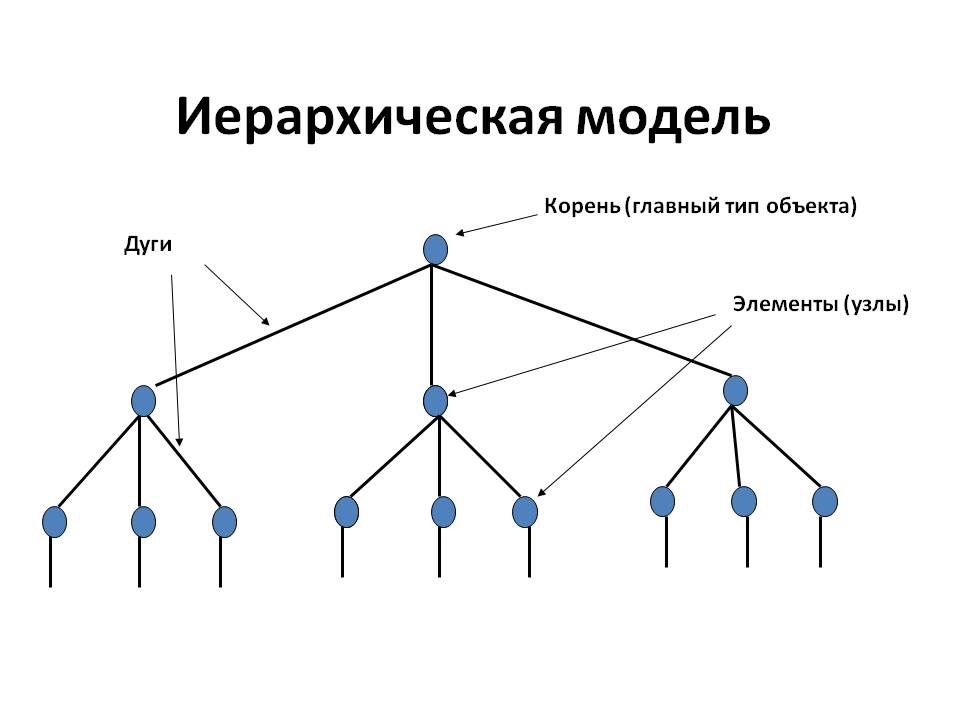
Рисунок 2 – Иерархическая структура.
Иерархические или древовидные структуры данных разрабатывались и использовались в течение длительного времени. Например, большинство методов индексации основаны на древовидных структурах данных. Иерархическая модель данных близка по своей концепции с иерархической структурой данных. Однако модель описывает не конкретные методы работы и манипулирования ссылками, а метод логического представления данных, который использует разработчик структуры базы данных при отражении реальных зависимостей с использованием механизмов, доступных в СУБД.
Между объектами существуют связи, каждый объект верхнего уровня может иметь ссылки на несколько объектов более низкого уровня. Объект верхнего уровня (предок) может иметь несколько подчиненных объектов на нижнем уровне (потомки). Но у каждого потомка есть только один предок. Объекты, имеющие общих предков, называются близнецами.
В некотором смысле иерархическая база данных - это файловая система, которая состоит из корневого каталога, в котором существует иерархия подкаталогов и файлов.
Пример. Иерархическая база данных содержит информацию о покупателях и их заказах. Объект «покупатель» – предок. Объект «заказ» – потомок. Объект «покупатель» будет иметь указатели от каждого заказчика к заказам данного покупателя (объекты «заказ»). В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не иерархические данные при использовании этой модели.
При условии, если потомок может иметь более одного предка, то невозможно или очень сложно использовать иерархическую модель данных.
У иерархических СУБД есть достоинства и недостатки. К достоинствам относится возможность реализовать фантастически быстрый поиск нужных значений, когда условия запроса соответствуют иерархии в схеме базе данных. Например, приведенный выше запрос обработает очень быстро. С другой стороны, если запрос не соответствует имеющейся иерархии, то и его программирование, и его исполнение, потребуют значительных усилий. Например, попытки реализовать запрос типа “в скольких сборниках статей опубликовал свои статьи господин Плагиаторов" может оказаться весьма трудной задачей (мы можем искать в направлении от статьи к автору, но не наоборот).
Недостатком иерархической модели является сложность внесения изменений. Если по какой-то причине условия задачи изменились и модель предметной области перестает быть иерархической (например, в нашем примере мы хотим иметь зависимость не только авторов от статьи, но и статей от автора), то приведение схемы базы данных в соответствие предметной области становится нетривиальной задачей.
Также, недостатком иерархической модели является тот факт, что модель слишком жесткая. Иерархическая модель очень хорошо подходит для устоявшихся предметных областей с четкими отношениями “родитель-потомок", то есть к моделям, в которых существует четкое подчинение между понятиями. Там, где выполняются условия, проявляются преимущества иерархической модели - очень высокая скорость поиска.
2.2 Сетевая модель данных
Модель сетевых данных заменяет более простую и понятную иерархическую модель. По своей сути сетевая модель очень похожа на иерархическую модель, она также имеет узлы, то есть корневые элементы, в которые вводится наиболее важная информация [15]. Между собой узлы объединены посредством связей. И узлы лежат на том же расстоянии от формы корневого узла, что и в иерархической модели, образуя уровни. Особенность иерархической модели заключается в том, что от одного элемента до другого возможен только один маршрут, в сетевой напротив -есть несколько маршрутов. Модель сетевых данных предоставляет возможность строить более сложные структуры данных. В этом основное отличие двух моделей
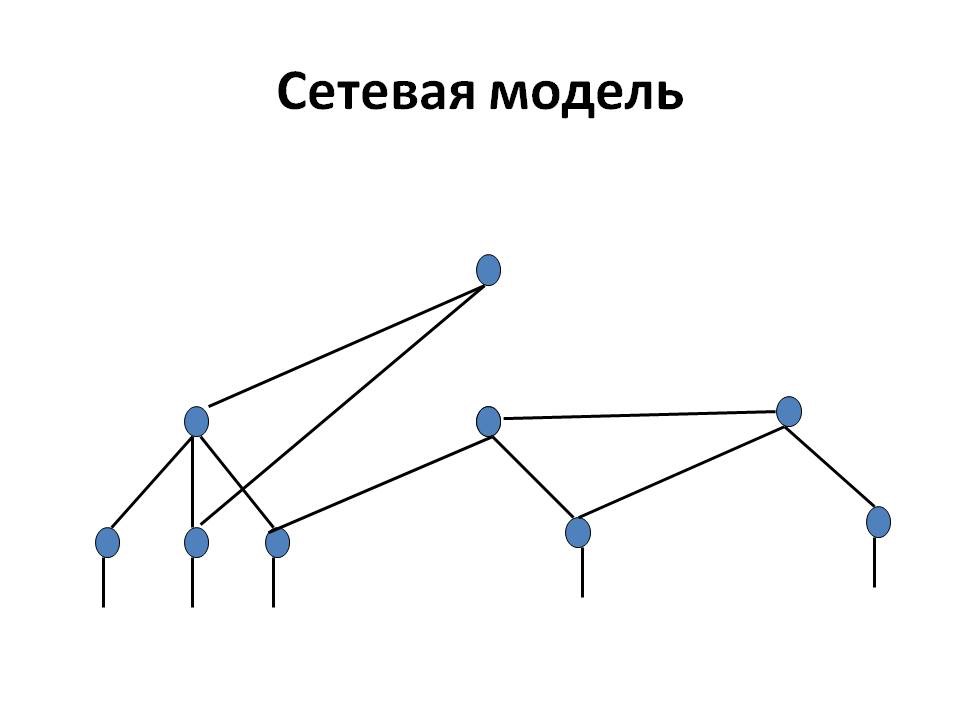
Рисунок 3- Сетевая структура
Целью создания такой модели данных было внедрение отношений «многие ко многим» с одновременным исправлением всех недостатков в иерархической модели, выявленных с течением времени. Модель сетевых данных основана на применении теории графов. С этой точки зрения ей соответствует произвольный граф.
В этой модели каждый потомок может иметь произвольное количество предков. Сетевая база данных состоит из определенного набора записей, а также определенного набора связей между записями. Два типа записей, предок и потомок, определяют типы отношений. Экземпляр типа связи обычно является одним экземпляром типа записи предка, включая упорядоченный набор элементов, связанных с типом записи потомка. Под набором обычно подразумевается именованный набор записей, где записи одного типа объявляются как владельцы набора, а остальные записи объявляются членами набора.
Сетевая модель данных обладает некоторыми особенностями. Все типы используемых связей в обязательном порядке должны быть функциональными, то есть "многие к одному", "один к множеству" или "один к одному". В этой модели такое внутреннее ограничение выражается утверждением, что для этого типа связи обязательно должны выполняться определенные условия с определенным типом наследственных записей и типом записи-потомка. Для того чтобы определить связь "многие ко многим", был введен особый тип записей, а также пара функциональных связей вида "один к множеству" и "множество к одному". Если есть необходимость, то в запись, исполняющую роль связки, может быть добавлена дополнительная информация.
В сетевой модели групповые отношения обычно описывают связь вида "один к множеству", то есть владелец один, а у него много подчиненных. Можно привести в пример такое отношение, как «работать». Тут подразумевается, что каждый сотрудник работает в каком-то определенном отделе, но в каждом отделе вполне может работать несколько сотрудников. В сетевой модели вида "один к множеству" отношения между различными объектами реализуются с помощью групповых отношений.
2.3 Реляционная модель данных
История реляционных СУБД ведет свое начало с конца 60-х, когда одновременно несколькими авторами были выдвинуты предложения об использовании теоретико-множественных операторов для организации доступа к данным. Затем была экспериментальная система управления базами данных System R и использованный в ней язык SEQUEL, который можно считать непосредственным предшественником языка SQL. В настоящее время именно язык SQL является стандартом для работы с реляционными СУБД. Например, семейство серверов реляционных баз данных Informix Dynamic Server поддерживают все эти стандарты и, кроме того, обеспечивают дополнительные возможности [16].
В настоящее время наиболее развитой теоретической и широко применяемой практикой является метод организации информационных систем в виде реляционных баз данных. Методология занимала и продолжает занимать лидирующие позиции на рынке информационных услуг из-за неизменности предметных областей. Она незаменима в системах обработки транзакций, в системах принятия решений, в информационно-справочных и офисных системах. Применение такого способа при хранении и обработке данных востребовано в различных пользовательских средах от автоматизированных информационных систем до современных адаптивных информационных систем. Организация данных виде таблицы проста и понятна, что обеспечивает ясность при воплощении теоретических положений в разработки для пользователей информационных систем.

Рисунок 4- Реляционная структура
Табличная организация данных может быть использована в информационных системах любой архитектуры. Она применима в системах, основанных на архитектурах файловый сервер и клиент-сервер, а также в многоуровневой архитектуре, в системах, использующих интернет-технологии.
Таблица служит универсальным средством представления информации. В реляционных базах данных это основной объект, на котором фактически строятся все операции между элементами в системе, а также внешнее взаимодействие с пользователем. В базах данных другого типа, например, иерархических, также используется табличная форма данных, но только как важный вспомогательный элемент. Первая роль в них включает иерархические отношения, которые могут быть эффективно реализованы с помощью методологии теории графов. Здесь, в свою очередь, она выступает в качестве сервисного инструмента при определении взаимосвязи между элементами разных таблиц в реляционных базах данных.
Информационные системы, представленные в виде реляционной базы данных, можно разделить на однотабличные и многотабличные. Спрос на базы данных с одной таблицей относительно невелик. Такие разработки применимы в случае информационной системы с относительно небольшим количеством полей или в случае, когда разделение на отдельные таблицы приводит к чрезмерной детализации данных. В подавляющем большинстве случаев реляционная база данных действует как система с несколькими таблицами [17]. При проектировании таких информационных систем они руководствуются принципами нормализации данных. Принципы стандартизации определяют такое разделение базы данных на таблицы, чтобы исключить дублирование информации об одном и том же объекте. Это позволяет избежать потери памяти при хранении и потери времени при обработке информации в системе.
Многотабличная база данных представляет собой систему взаимосвязанных таблиц. Ни одна таблица в среде информационной системы не изолирована от других таблиц. В этом случае ее данные должны быть включены в другую таблицу базы данных. Межтабличные связи выражают прямые логические или косвенные причинно-следственные связи между объектами информационной системы. Они позволяют исследовать объекты информационной системы не сами по себе, а изучать степень влияния элементов или групп элементов одной таблицы на элементы или группы элементов другой таблицы. Следует подчеркнуть, что такой качественный анализ существенно отличается от простого статистического анализа данных. Он требует применения для анализа связей иных инструментов, например, методологии функционального анализа данных. Однако, заметим, что другой инструментарий не означает, что он проще или, наоборот, более сложен в использовании. Он качественно иной, изучая скрытые параметры информационной системы в виде взаимосвязей между элементами, позволяет прогнозировать и моделировать характер окружающей среды.
Одной из основных функций любой информационной среды, помимо хранения самой информации, является поиск данных, соответствующих критериям пользователя. Пользователь формулирует критерии в форме запроса. Ответ - это часть данных из информационной системы, которая соответствует указанным параметрам. Результат запроса также является таблицей. Он может быть частью существующей таблицы базы данных или генерироваться по запросу на основе данных из разных таблиц. В этом случае сгенерированная таблица хранится отдельно от основных данных информационной системы.
Основным достоинством реляционных СУБД, обеспечившим таким СУБД высокую популярность, является не функциональность языка запросов - языка SQL. Это означает, что формулируется не то, как необходимо найти данные, а то, что необходимо найти.
Еще одним преимуществом реляционных СУБД является высокая стандартизация. Существует несколько стандартов, определяющих синтаксис и семантику операторов SQL. Почти все производители систем управления реляционными базами данных поддерживают стандарты. В результате программисты и разработчики получили возможность разрабатывать легко переносимые, надежные приложения, которые могут работать на самых разных аппаратных средствах. К преимуществам реляционных СУБД относится тот факт, что существует очень четкая математическая основа для работы с данными.
Недостатком реляционной модели является ограниченность, предопределенность набора возможных типов данных атрибутов, их атомарность, что затрудняет использование реляционной модели для некоторых современных приложений. Частично эта проблема решается за счет введения больших двоичных объектов, но более полное и аккуратное решение используется в расширении реляционной модели - в объектно-реляционных СУБД.
3 РАЗРАБОТКА И ПРОЕКТИРОВАНИЕ БД ИС НА ПРЕДПРИЯТИИ ГП «АЛУШТАЛИФТ»
3.1 Проектирование БД ИС «Вызов»
Проектирование баз данных - процесс решения задач, связанных с созданием баз данных.
При выполнении этого процесса решаются следующие основные задачи:
- обеспечение базы данных всей необходимой информацией;
- обеспечить возможность представления данных по всем необходимым запросам;
- сокращение избыточности данных и дублирования;
- обеспечение целостности данных (правильность их содержимого): устранение несоответствий в содержимом данных, устранение их потери и т. д.
В процессе написания использовался язык SQL, поскольку основным требованием к реляционной СУБД является наличие сильного и в то же время простого языка, который позволяет выполнять все операции, которые нужны пользователю. В последние время таким повсеместно принятым языком стал язык реляционных БД SQL - Structured Query Language [18].
На основе описания предметной области во втором разделе, описанном в первом разделе, мы разработаем модель базы данных разработанного IP.
Необходимо разработать базу данных для автоматизации приема заявок на ремонт лифта. Для этого рассмотрим основные этапы, через которые проходит приложение: лифт выходит из строя, заявка приходит к диспетчеру, диспетчер ищет нужный лифт, вызывает лифтера и сообщает о заявке.
Для каждой заявки заводится отдельная строка в таблице базы данных, в которой указываются:
- Номер вызова;
- Дата вызова;
- № лифта;
- Вид работы;
- Лифтер.
При занесении данных о новой заявке, необходимо заполнить форму «Вызов», в открывающемся окне будет расположено несколько полей для заполнения:
- «Выбор лифтера», где будет отображаться список лифтеров и их допуск к работе с возможностью добавления нового лифтера;
- «Вид ремонта», где будет показано его описание, какова цена и нужный допуск работника;
- «Выбор лифта», где будет список из лифтов с указанием точного адреса и номера подъезда;
- «Календарь», где надо будет выбрать дату получения заявки;
Данные в таблице можно редактировать по мере необходимости. Их можно отсортировать по дате, сотруднику, городу и т. д. Программа «Вызов» будет способствовать работе диспетчера предприятий. Наиболее рутинными и в то же время наиболее ответственными процессами являются: найти правильный лифт, заполнить анкету.
Согласно ER – методу проектирования на первом этапе определяем сущности и их атрибуты. При проектировании БД ИС ГП «Алушталифт» выделены следующие сущности:
- Дом;
- Вызов;
- Лифт;
- Ремонтные работы;
- Лифтер.
Вся информация для хранения в базе данных делится на сущности и атрибуты по определенным характеристикам. У каждого объекта есть набор атрибутов. Для каждой из этих сущностей мы определяем атрибуты сущностей:
- Сущность «дом» включает в себя следующие атрибуты: код дома, город и адрес. Ключевое поле «Рег. № дома»;
- Сущность «вызов» включает в себя следующие атрибуты: код вызова, код работы, код лифтера, код лифта и дату вызова. Ключевое поле «номер вызова»;
- Сущность «лифт» включает в себя следующие атрибуты: код лифта, имя, тип лифта, тип дверей, подъезд и код дома. Ключевое поле «С/№ лифта»;
- Сущность «ремонтные работы» включает в себя следующие атрибуты: код работы, тип работы, цена, описание и допуск работника. Ключевое поле «Код рем. Работы»;
- Сущность «лифтер» включает в себя следующие атрибуты: код лифтера, ФИО, адрес лифтера, допуск и дату приема на работу. Ключевое поле «Рег. № лифтера»
На втором этапе проектирования мы определяем степень взаимосвязи между сущностями и классом аксессуаров. Предположим, что в вызове может быть много ремонтов, в то время как ремонт может быть только в одном вызове. Вызов включает в себя ремонтные работы, и ремонтные работы необходимы, чтобы подать заявку на вызов. Таким образом, степень связи между отношениями «ремонтные работы» и «вызов» составляет один ко многим (1: N), и класс членства N ассоциированного объекта является обязательным. Следовательно, согласно правилу 4 генерации предварительных отношений достаточно иметь два отношения, по одному для каждого объекта, при условии, что ключ объекта служит в качестве первичного ключа для соответствующего отношения. Дополнительно ключ 1-связной сущности должен быть добавлен в качестве атрибута в отношение, отводимое N-связной сущности.
Точно так же в вызове может быть много лифтов, в то время как лифт относится только к одному вызову. Для вызова требуется лифт, а в вызове должен быть указан лифт. Таким образом, степень связи между отношением «лифт» и «вызов» составляет один ко многим (1: N), членство в классе является обязательным. Следовательно, согласно правилу 4 генерации предварительных отношений достаточно иметь два отношения, по одному для каждого объекта, при условии, что ключ объекта служит в качестве первичного ключа для соответствующего отношения. Кроме того, ключ 1-связного объекта должен быть добавлен в качестве атрибута к отношению, назначенному для N-связанного объекта.
В вызове может находится множество лифтеров, но лифтер может относится только к одному вызову. Лифтер обязан относится к вызову, а вызов должен включать в себя лифтера. Таким образом, степень связи между отношениями «лифтер» и «вызов» - один ко многим (1:N), класс принадлежности – обязательный. Следовательно, по правилу 4 генерации предварительных отношений достаточным является наличие двух отношений, по одному на каждую сущность, при условии, что ключ сущности служит в качестве первичного ключа для соответствующего отношения. Дополнительно ключ 1-связной сущности должен быть добавлен в качестве атрибута в отношение, отводимое N-связной сущности.
Лифт может содержать много домов, но дом может содержать только один лифт. Дом должен принадлежать лифту, а лифт должен включать в себя дом. Из этого следует, что степень связи между отношениями «дом» и «лифт» составляет один ко многим (1: N), принадлежность к классу является обязательной. Следовательно, согласно правилу 4 генерации предварительных отношений достаточно иметь два отношения, по одному для каждого объекта, при условии, что ключ объекта служит в качестве первичного ключа для соответствующего отношения. Кроме того, ключ 1-связного объекта должен быть добавлен в качестве атрибута к отношению, назначенному для N-связанного объекта.
В результате мы получили инфологическую модель БД ИС «Вызов» в виде ER – диаграммы (Рис. 5)
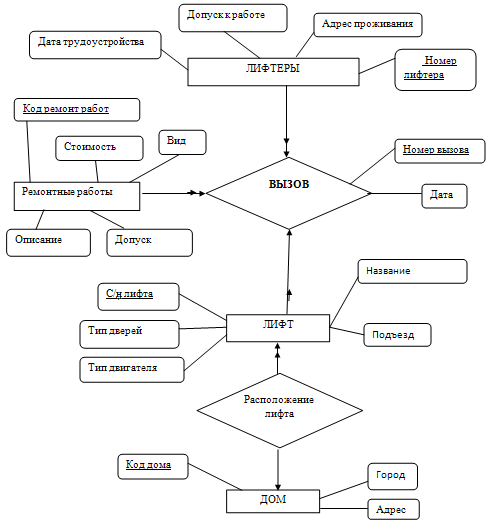
Рисунок 5 - ER – диаграмма БД ИС «Вызов»
На основе полученной инфологической модели построим даталогическю модель в виде просто сети (Рис. 6).
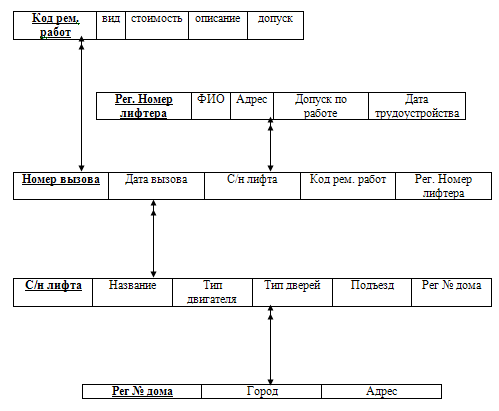
Рисунок 6 - Даталогическая модель БД ИС «Вызов»
Теперь мы можем на основе даталогической модели построить физическую модель БД ИС «Вызов» в нотации СУБД Paradox.
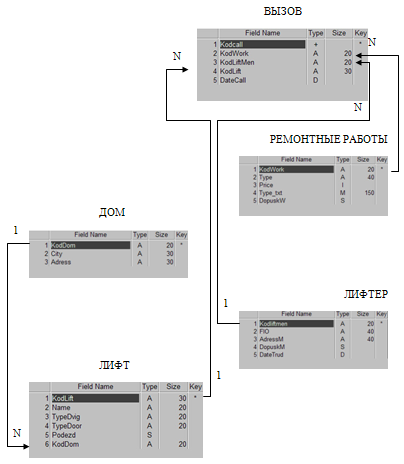
Рисунок 7- Физическая модель БД ИС «Вызов»
После того как мы создали все таблицы и обеспечили целостность данных, можно приступить к разработке интерфейса приложения.
3.2 Разработка БД ИС «Вызов» в среде Delphi 7
Для обеспечения доступа к данным из таблиц при создании приложения использовался модуль данных (DM), в котором были расположены компоненты таблицы и источники данных. Для этих компонентов была выбрана база данных ware (созданный alias). Модуль данных изображен на рисунке 8.
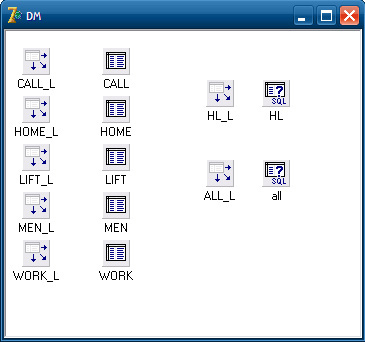
Рисунок 8 - Модуль данных
Для реализации SQL запросов, которые используются приложением, в модуль данных были добавлены еще несколько компонентов TQuery и DataSource [19]. Добавив все необходимые фреймы и обеспечив им доступ к данным, мы получили готовый программный продукт.
Рассмотрим интерфейс приложения. Создание и просмотр заявок происходит в главном окне «Вызов» (см. рис.9). В правом окне окна мы видим уже полученные заявки с полной информацией о них: код вызова, код лифта, код лифта, код задания и данные вызова. В центре окна находятся выпадающие меню, в которых лифт выбран с его уникальным номером, ниже находится кнопка для добавления нового лифта в базу данных. Слева находится список лифтов и их доступ, чуть ниже кнопка добавления нового сотрудника. В левом нижнем углу раскрываются меню с типом ремонтных работ и их описанием с возможностью добавления нового ремонта. В программе также есть календарь для выбора даты получения заявки.
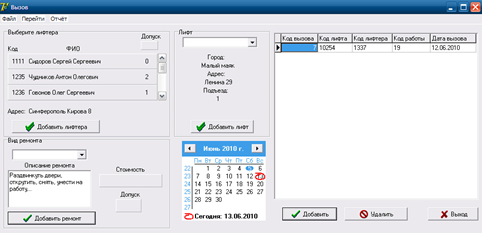
Рисунок -9 Главное окно программы «Вызов»
Новая заявка была создана при помощи формы «Вызова». Здесь необходимо выбрать номер дома, вид ремонта, лифт, дату подачи заявки. Если допуск лифтера не соответствует типу работ, система сообщит об этом. Для удобства ввода информации поля «Тип ремонта» и «Лифт» создаются с помощью элемента DBLookupComboBox. Для того чтобы не вводить каждый раз эту информацию вручную, её можно выбрать из выпадающего списка.
При нажатии на кнопку «добавить» добавление заявки будет происходить при следующей обработки события OnClick для формы «Вызов»:
If dm.MENDopuskM.Value>=DM.WORKDopuskW.Value then
dm.CALL.Append
else MessageBox(0, PChar('Не соответствует допуск работника!!'), PChar('Внимание'), mb_Right);
If dm.MENDopuskM.Value>=DM.WORKDopuskW.Value then
DM.call['KodLift']:=DM.HLKodLift.Value
else dm.CALL.Append;
If dm.MENDopuskM.Value>=DM.WORKDopuskW.Value then
DM.call['KodLiftMen']:=DM.MENKodLiftMen.Value
else dm.CALL.Append;
If dm.MENDopuskM.Value>=DM.WORKDopuskW.Value then
DM.call['KodWork']:=DM.WORKKodWork.Value
else dm.CALL.Append;
If dm.MENDopuskM.Value>=DM.WORKDopuskW.Value then
DM.call['DateCall']:=monthcalendar1.Date
else dm.CALL.Append;
If dm.MENDopuskM.Value>=DM.WORKDopuskW.Value then
DM.CALL.Post
else DM.CALL.Delete;
Для того что бы добавить нового лифтера нам надо открыть форму «Лифтеры» нажав в главном окне кнопку «Добавить лифтера» (рис. 10).
Сверху будут показаны текущие работники, ниже будет возможность добавить нового. Для добавления нового сотрудника необходимо ввести: регистрационный номер, имя, адрес места жительства, приема и дату приема на работу.
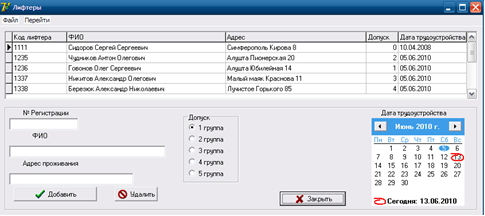
Рисунок 10- Форма «Лифтеры»
При нажатии на кнопку «добавить» происходит событие OnClick для формы «Лифтеры»:
DM.MEN.Append;
DM.MEN['KodLiftMen']:=edit1.Text;
DM.MEN['FIO']:=edit2.Text;
DM.MEN['AdressM']:=edit3.Text;
DM.MEN['DopuskM']:=radiogroup1.ItemIndex;
DM.MEN['DateTrud']:=monthcalendar1.Date;
dm.MEN.Post;
edit1.Text:='';
edit2.Text:='';
edit3.Text:='';
Вся необходимая информация о ремонтных работах содержится в форме «Ремонт» (рис.11). При появлении новых видов работ, их можно добавить в базу при помощи той же формы.
Информация о новых ремонтных работах вносится при помощи формы «Ремонт» с вкладки «Вызов».
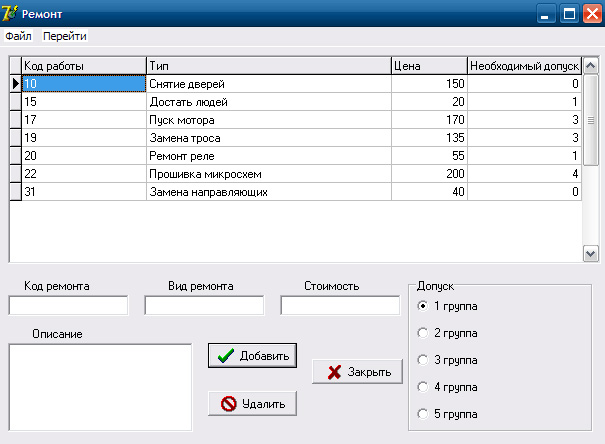
Рисунок 11- Форма «Ремонт»
Для того что бы добавить новый вид ремонта надо заполнить следующие поля: код ремонта, вид ремонта, стоимость, его описание и требуемый допуск лифтера для выполнения работы. Нажимая кнопку «Добавить» происходит следующие событие OnClick для формы «Ремонт»:
DM.WORK.Append;
DM.WORK['KodWork']:=edit1.Text;
DM.WORK['Type']:=edit2.Text;
DM.WORK['Price']:=edit3.Text;
DM.WORK['Type_txt']:=memo1.Text;
DM.WORK['DopuskW']:=radiogroup1.ItemIndex;
DM.WORK.Post;
edit1.Text:='';
edit2.Text:='';
edit3.Text:='';
memo1.Text:='';
Аналогичным способом выполнена форма «Лифт» (рис.12).
Здесь можно увидеть список текущих лифтов с описанием их характеристик, таких как: код лифта, имя, тип лифта, тип дверей. Номер подъезда и код дома.
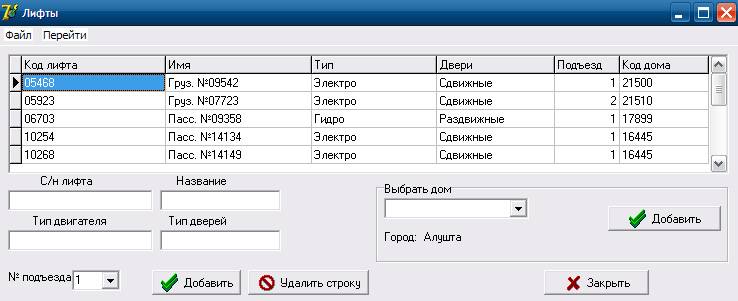
Рисунок 12- Форма «Лифты»
Для добавления нового лифта мы заполняем следующие поля: С/н лифта, название, тип двигателя, тип дверей, номер подъезда и дом. Для удобства ввода данных поля «номер подъезда» и «Дом» выполнены с помощью элемента DBLookupComboBox. Для того чтобы не вводить каждый раз эту информацию вручную, её можно выбрать из выпадающего списка. Эта форма очень удобно для добавления новых лифтов которое предприятие будет обслуживать в будущем.
При нажатии на кнопку «Добавить» происходит следующие событие OnClick для формы «Лифты»:
DM.Lift.Append;
DM.Lift['KodLift']:=edit1.Text;
DM.Lift['Name']:=edit2.Text;
DM.Lift['TypeDvig']:=edit3.Text;
DM.Lift['TypeDoor']:=edit4.Text;
DM.Lift['Podezd']:=ComboBox1.text;
DM.Lift['KodDom']:=DM.HomeKodDom.Value;
DM.Lift.Post;
edit1.Text:='';
edit2.Text:='';
edit3.Text:='';
edit4.Text:='';
При необходимости добавления нового дома в форме «Лифты» нужно нажать на кнопку добавить дом. При этом откроется форма «Дом» (см. рис.13).
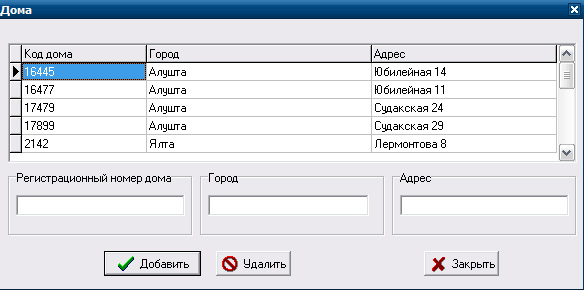
Рисунок 13- Форма «Дома»
Чтобы добавить новый дом, необходимо заполнить только три поля: регистрационный номер дома, город и его адрес.
При нажатии на кнопку «Добавить» происходит следующие событие OnClick для формы «Дом»:
DM.HOME.Append;
DM.HOME['KodDom']:=edit1.Text;
DM.HOME['City']:=edit2.Text;
DM.HOME['Adress']:=edit3.Text;
DM.HOME.Post;
edit1.Text:='';
edit2.Text:='';
edit3.Text:='';
В БД ИС "Вызов" предоставляет систему отчетности для удобного просмотра выполненных работ, при необходимости их можно распечатать, передать другим органам или выставить счет заказчику. Чтобы просмотреть отчет в форме «Позвонить», щелкните меню «Отчет», и откроется форма «Отчет», в которой есть три вкладки: отчет по дате, отчет по сотруднику, отчет по городу.
В отчете по дате можно просмотреть, сколько было заявок в определенный день (рис.14).
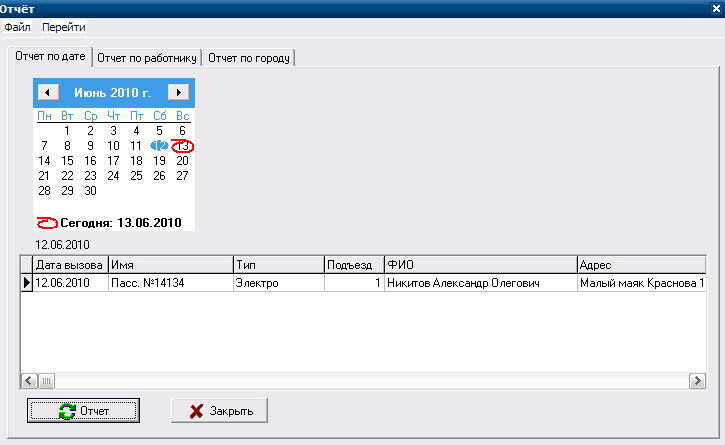
Рисунок 14- Отчет по дате
В отчете по работнику можно увидеть, сколько тот или иной сотрудник выполнил заявок (рис.15).
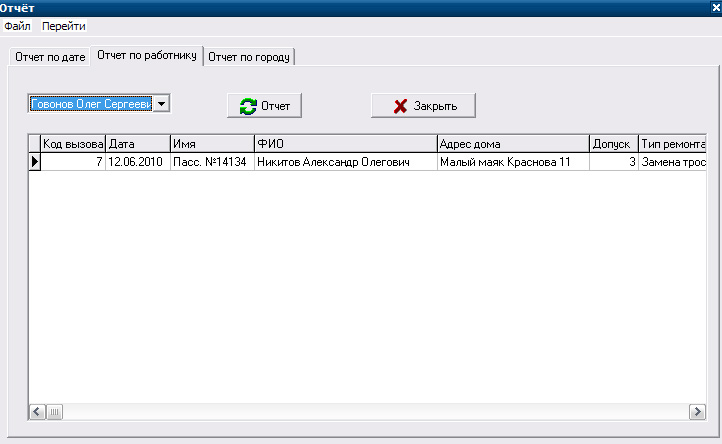
Рисунок 15- Отчет по работнику
В отчете по городу можно просмотреть информацию о выполненных заявках в определенном городе (рис.16).
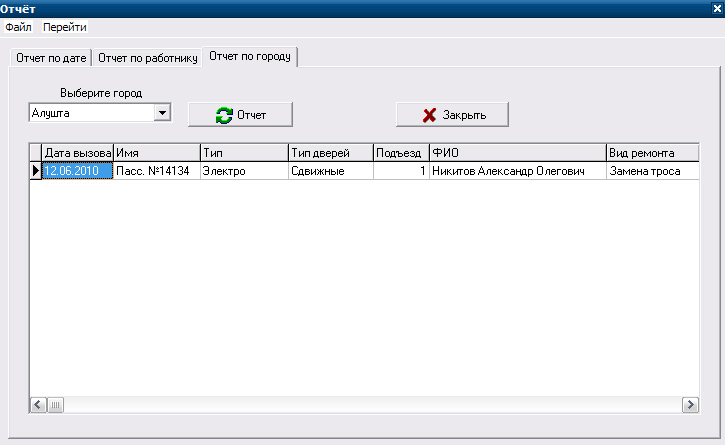
Рисунок 16 - Отчет по городу
В результате можно отметить, что на основе моделей бизнес-процессов можно разработать приложение (в качестве примера «вызова») за относительно короткое время, которое может автоматизировать процессы и значительно сократить затрачиваемое время. Внедрение программных продуктов исключает (насколько это возможно) ошибки в ведении документации или расчетов. Создание баз данных позволяет получить своевременный и полный доступ ко всей представленной информации наиболее удобным способом.
ЗАКЛЮЧЕНИЕ
Подведем итог. В модернизированном мире человеку все время приходится сталкиваться с большим объемом знаний и данных, запоминать их, анализировать и исследовать. Ежедневно, их количество только возрастает, и делается все труднее и труднее обрабатывать информацию. Справиться с таким объемом достаточно сложно, поэтому используют информационные системы. Однако, как правильно предоставить данные в информационных системах вопрос проблематичный, поэтому рассмотрение данной темы будет актуально.
На сегодняшний день системы управления базами данных являются наиболее устоявшейся областью информационных технологий.
В те годы, когда создавалось понятие «база данных», в ней действительно хранились только данные. В современных системах управления базами данных возможно не только хранить структурированные данные, но также хранить программный код, например, Методы через взаимодействие с потребителем или со сложным программным и аппаратным обеспечением.
Таким образом, можно утверждать, что современные базы данных хранят не только данные, но и информацию.
Базы данных имеют две основные функции. Они группируют данные по информационным объектам и их отношениям и предоставляют данные пользователям.
Данные - это формализованное представление информации, доступной для обработки, интерпретации и обмена между людьми или автоматически.
Информация может храниться в неструктурированной форме, например в форме текстового документа, где данные об объектах предметной области записываются в произвольной форме.
Структурированный тип хранения информации предполагает введение соглашений о способах представления данных. Это означает, что данные определенного типа, формата и содержимого могут находиться в определенном месте в хранилище.
Автоматизировать обработку данных, хранящихся в неструктурированной форме, сложно, а иногда просто невозможно. Поэтому они разрабатывают определенные соглашения о методах представления данных. Обычно это делается разработчиком базы данных. В результате все детали имеют одинаковый тип и тип данных, что делает их структурированными и позволяет создавать базу данных.
База данных - это именованная коллекция структурированных данных, относящихся к конкретной предметной области.
СПИСОК ЛИТЕРАТУРЫ
- Архангельский А. Н. Программирование в Delphi / А. Н. Архангельский. - 7 М.: Библио-Пресс, 2003. – 256 с.
- Баженов Р. И., Лопатин Д. К. О применении современных технологий в разработке интеллектуальных систем // Журнал научных публикаций аспирантов и докторантов. – 2014. – № 3 (93). – С. 263-264.
- Бобровский С. В. Delphi 7. Учебный курс / С. В. Бобровский Информ-Пресс: Питер, 2003. – 362 с.
- Емельченков Е. П., Киселева О. М. О представлении предметных областей с помощью семантических сетей // NovaInfo.Ru. – 2016. – Т. 2. № 42. – С. 17-23.
- Избачков Ю. С., Петров В. Н., Васильев А. А., Телина И. С. Информационные системы: Учебник для вузов. – СПб.: Питер, 2011. – 544 с.
- Козлов С. В. Применение методов функционального анализа при формировании оптимальных стратегий обучения школьников // Международный журнал экспериментального образования. – 2016. – № 3-2. – С. 182-185; URL: http://www.expeducation.ru/ru/article/view?id=9696 (дата обращения: 21.04.2016).
- Козлов С. В. Теория графов и соответствия Галуа как инструменты проектирования информационных систем // NovaInfo.Ru. – 2016. – Т. 3. – № 48. – С. 144-149.
- Козлов С. В. Функциональные назначения и возможности информационно-образовательного ресурса «Advanced Tester» // Горизонты науки. – 2011. – №2 (6). – С. 9-12.
- Кон П. М. Универсальная алгебра / П. М. Кон; пер. с англ. Т. М. Баранович; под ред. А. Г. Куроша. – М.: Мир, 1968. – 351 с.
- Киселева О. М. Пример применения методов математического моделирования // NovaInfo.Ru. – 2016. – Т. 1. – № 42. – С. 67-70.
- Максимова Н. А. Сервис-ориентированная архитектура: от концепции к применению // NovaInfo.Ru. – 2016. – Т. 4. – № 44. – С. 19-22.
- Могилев А. В., Пак Н. И., Хеннер Е. К. Информатика: учеб. пособие для студ. пед. вузов / под ред. Е. К. Хеннера. – М., 2012. – 848 с.
- Максимова Н. А., Бояринов Д. А. Электронный образовательный портал личностного развития учащихся // Хроники объединенного фонда электронных ресурсов Наука и образование. – 2015. – № 12 (79). – С. 1.
- Максимова Н. А. Проектирование региональных образовательных порталов // NovaInfo.Ru. – 2016. – Т. 3. – № 48. – С. 438-442.
- Моисеев В. В., Баженов Р. И. Разработка информационной системы по учету средств криптографической защиты информации // Постулат. – 2016. – № 3. – С. 22.
- Парватов Н. Г. Соответствие Галуа для замкнутых классов дискретных функций // Прикладная дискретная математика. – 2010. – №2(8). – С. 10-15.
- Размахнина А. Н., Баженов Р. И. О применении экспертных систем в различных областях // Постулат. – 2017. – № 1 (15). – С. 38.
- Саймон А. Р. Стратегические технологии баз данных / А. Р. Саймон. – М.: Финансы и статистика, 1999. 457 с.
- Харрингтон Д. Л Проектирование реляционных баз данных. Просто и доступно / Д. Л. Харрингтон. – М.: ЛОРИ, 2000. – 277 с.

- Разработка регламента выполнения процесса «Управление информационными ресурсами (Описание бизнес-процессов «AS-IS»)
- Личностные деформации стрессового типа (Эмоциональное выгорание)
- Биологическая обратная связь как психотерапевтический метод (Виды биологической обратной связи в психотерапии)
- Налоговый учет по налогу на имущество организаций (Освобождение от обязанностей налогоплательщика)
- Бренд как конкурентное преимущество компании(ПРОЦЕСС УПРАВЛЕНИЯ БРЕНДАМИ В ИНТЕРНЕТЕ)
- Учет наличных денежных средств в кассе предприятия"
- Документирование и инвентаризация (Документирование и инвентаризация как компоненты метода бухгалтерского учёта)
- Понятие и значение приватизации(Порядок оформления приватизации жилья)
- Интернет-маркетинговые решения для салона красоты (Комплексное продвижение сайта в интернете)
- Средства разработки клиентских программ.(ИССЛЕДОВАНИЕ СОСТОЯНИЯ СРЕДСТВ ВЫЯВЛЕНИЯ ПРОБЛЕМ ВОПРОСАХ ОКАЗАНИЯ ЖИЛИЩНО-КОММУНАЛЬНЫХ УСЛУГ И БОРЬБЫ С ВЫЯВЛЕННЫМИ НАРУШЕНИЯМИ ПО ИНИЦИАТИВЕ ПОТРЕБИТЕЛЕЙ ТАКИХ УСЛУГ)
- История развития программирования в РоссиИСТОрические аспекты развития программирования)и(
- Разработка регламента выполнения процесса «Разработка бюджетов